
Prvních několik služeb je snadných. Jedna rotace, jeden kanál a pak záloha.
Jakmile však vaše společnost dosáhne desítek mikroslužeb, více regionů a vrstveného vlastnictví, ruční eskalace přestanou být pracovním postupem a stanou se přítěží.
Tato příručka vysvětluje, jak automatizovat postupy eskalace incidentů, které se přizpůsobují vaší technické organizaci, aniž by docházelo k mezerám ve vašem systému pohotovostních služeb.
A také se podíváme, jak ClickUp zapadá do vytváření eskalačního systému, kterému mohou vaše technické týmy důvěřovat. 🎯
⭐ Doporučená šablona
Reagujte rychle a efektivně v nouzových situacích, od přírodních katastrof po narušení bezpečnosti dat, pomocí šablony ClickUp Incident Action Plan (IAP).

Šablona obsahuje předdefinované sekce pro:
- Definujte cíle incidentů a priority reakcí
- Vytvořte jasnou strukturu velení
- Koordinujte akce napříč týmy v reálném čase
- Zaznamenávejte rozhodnutí, časové osy a klíčové aktualizace v okamžiku, kdy k nim dojde.
- Zůstaňte v kontaktu s eskalací a sledujte její průběh
A protože je součástí ClickUp, funguje jako živý dokument pro řízení incidentů, nikoli jako statický kontrolní seznam.
Proč automatizovat postupy eskalace incidentů
Pokud váš tým spravuje složité systémy s přísnými smlouvami o úrovni služeb (SLA), ruční eskalace vás pouze zpomaluje. Automatizovaná eskalace činí proces reakce předvídatelným a méně stresujícím, a to i při incidentech s vysokým tlakem.
Zde je důvod, proč musíte automatizovat eskalační cesty ve vaší organizaci. 👇
Riziko manuální eskalace
Jakmile máte co do činění s desítkami služeb, několika směnami pohotovostních služeb a neustále se měnícími vlastníky, lidské zásahy se rychle stanou problémem.
Mezi běžné úskalí patří:
- Zmeškaná nebo zpožděná oznámení, když někdo přehlédne e-mail, SMS nebo chatovou zprávu
- Zmatek při předávání, zejména pokud nejsou cesty eskalace jasně zdokumentovány
- Eskalace na nesprávný tým z důvodu neaktualizované mapy odpovědností
- Úzká místa způsobená spoléháním se na jednu osobu, která „posouvá výstrahu dál“
📖 Přečtěte si také: Jak napsat zprávu o incidentu
Výhody automatizace
Automatizace ITSM dává vašim eskalačním cestám strukturu a dynamiku. Místo toho, abyste doufali, že někdo upozornění uvidí, váš systém okamžitě a konzistentně provede předem definovanou sekvenci.
Toto získají týmy, když používají AI k automatizaci úkolů:
- Rychlejší reakční doby, protože výstrahy se během několika sekund dostanou k správné osobě nebo týmu.
- Konzistentní provádění eskalačních kroků, i ve 3 hodiny ráno, kdy je rozhodování pomalejší.
- Integrovaná redundance zajišťuje, že záložní pracovníci budou informováni, pokud primární pracovník na pohotovosti zmešká výstrahu.
- Jasná viditelnost napříč týmy, protože všichni chápou, jak eskalace probíhají.
- Méně hašení požárů a více předvídatelných pohotovostních služeb
📖 Přečtěte si také: Příklady plánů kontinuity podnikání
Snížení únavy z výstrah a lidských přehlédnutí
Únava z výstrah ničí efektivitu pohotovostních služeb. Když je váš tým příliš často nebo z nesprávných důvodů upozorňován, přestane reagovat s naléhavostí. Automatizace pomáhá filtrovat a eskalovat pouze to, co skutečně vyžaduje lidskou pozornost.
Díky automatizované logice eskalace:
- Výstrahy se slabým signálem nebo duplicitní výstrahy jsou potlačeny, než se dostanou k pracovníkovi v pohotovosti.
- Pravidla založená na závažnosti zajišťují, že drobné problémy nebudou zbytečně budit někoho ze spánku.
- Výstrahy se eskalují pouze v případě, že systém zaznamená nedostatečnou odezvu v rámci definovaného časového rámce.
- Týmy tráví méně času tříděním šumu a více času řešením skutečných problémů.
Podpora dodržování SLA a zásad pohotovostních služeb
Automatizovaná eskalace usnadňuje dodržování předpisů bez nutnosti neustálého manuálního dohledu. Pro vedoucí pracovníky v oblasti IT, kteří spravují přísné SLA nebo interní závazky spolehlivosti, slouží AI jako ochranná bariéra, která vynucuje očekávané chování. Pomáhá vám:
- Zajistěte, aby oznámení o incidentech dodržovala předem definovaná pravidla pro směrování.
- Automaticky dodržujte lhůty pro reakci stanovené ve smlouvě SLA díky časově naplánovaným eskalacím.
- Prosazujte rozpisy pohotovostních služeb bez nutnosti spoléhat se na zastaralé tabulky.
- Vytvářejte auditní stopy pro každé upozornění, eskalaci a potvrzení.
🎥 Chcete spustit celý pracovní postup eskalační cesty bez použití rukou? Super agenti vám pomohou . 👇🏼
🔍 Věděli jste? Řízení misí NASA v podstatě funguje na automatizované eskalační logice. Pokud telemetrie překročí povolený rozsah, systém okamžitě odešle automatické výstrahy specialistům podle dané oblasti.
Co je to eskalační politika v rámci správy incidentů?
Eskalační politika je předem definovaný soubor pravidel, který určuje, kdo bude informován, kdy bude informován a jak bude odpovědnost předána výše nebo mezi týmy.
Představte si to jako strukturovaný plán, který zabraňuje zpoždění incidentů, zajišťuje, že se ve správný čas zapojí ti správní odborníci, a pomáhá týmům plnit SLA.
Dobře strukturovaná politika řízení eskalace obvykle zahrnuje:
- Směrování založené na pravidlech, které definuje, kdo je na řadě, když někdo nepotvrdí nebo není schopen vyřešit incident.
- Časované spouštěče, které automaticky eskalují po 5, 15 nebo 30 minutách v závislosti na závažnosti.
- Způsoby oznamování, jako jsou telefonní hovory, SMS, chat nebo e-mail
- Úrovně eskalačního plánu od úrovně 1 (primární pohotovost) > úroveň 2 (seniorní inženýři/SME) > úroveň 3 (vedení)
- Očekávání ohledně dokumentace, aby noví respondenti mohli převzít úkoly bez ztráty důležitého kontextu
📖 Přečtěte si také: Jak prioritizovat úkoly jako P0, P1, P2, P3 a P4
Typy eskalačních zásad
Zde jsou základní typy zásad, které by váš tým měl znát:
1. Hierarchická eskalace (vertikální)
Výstrahy se posouvají nahoru v hierarchii, od juniorních inženýrů přes seniorní specialisty až po vedení. Tuto funkci použijte, když situace vyžaduje hlubší odborné znalosti, rozhodovací pravomoc nebo viditelnost vedení.
2. Funkční eskalace (horizontální)
Místo směrem nahoru se výstraha šíří napříč týmy k té funkci, která vlastní dotčený systém. To je ideální pro incidenty spojené s konkrétní doménou, jako jsou databáze, sítě, platby nebo API.
3. Eskalace na základě času
Toto je základ většiny automatizovaných systémů. V tomto typu se výstraha po uplynutí určitého časového období, často přímo vázaného na SLA, přesune na další úroveň. Je to zvláště důležité, když potřebujete zaručenou odezvu mimo pracovní dobu.
4. Eskalace na základě dopadu
Eskalace založená na dopadu závisí na závažnosti nebo dopadu na podnikání, nikoli na hierarchii nebo čase. Je užitečná v případě výpadků, selhání plateb, problémů s klienty nebo narušení bezpečnosti.
5. Paralelní eskalace
V tomto případě je současně informováno více osob nebo týmů. Paralelní eskalace se používá u závažných problémů, které vyžadují více specializací, nebo v situacích, kdy je jakékoli zpoždění nepřijatelné.
🔍 Věděli jste? Nedávná studie o výstražných signálech zjistila, že extrémně výrazné nebo „hlasité/jasné“ výstrahy mohou zpomalit reakční dobu, zejména pokud jsou neočekávané. Jakmile se však typ výstrahy stane očekávaným (tj. součástí předem navrženého systému eskalace/oznamování), reakční doba se zlepší. To naznačuje, že při automatizaci eskalačních cest byste neměli lidi zaplavovat výstrahami s vysokou prioritou.
Kdy spustit automatickou eskalaci
Nyní, když víte, jak jsou eskalační cesty strukturovány, je dalším krokem rozhodnutí, kdy by se tato pravidla měla automaticky spouštět.
Níže jsou uvedeny základní situace, které spouštějí automatickou eskalaci a tvoří logickou vrstvu vašich zásad. 💁
Eskalace podle závažnosti
Automatická eskalace se spustí, když závažnost nebo dopad incidentu překročí určitou hranici. Incidenty s vysokou závažností vyžadují okamžitou pozornost vedoucích pracovníků a automatická eskalace obchází překážky a během několika sekund zapojí do řešení odborníky.
📌 Příklad: Úplný výpadek služeb, selhání platební brány nebo závažné zhoršení kvality služeb, které má dopad na mnoho uživatelů nebo klíčové systémy, vyžaduje automatickou eskalaci.
Eskalace na základě času
Pokud nikdo incident v definovaném časovém okně nepotvrdí ani nevyřeší, upozornění se automaticky eskaluje na další úroveň. Tím se zabrání stagnaci ticketů, zejména mimo běžnou pracovní dobu nebo v případě, že první respondent není k dispozici nebo je přetížený.
📌 Příklad: Po 10–15 minutách bez potvrzení dojde k eskalaci od prvního respondenta k seniornímu inženýrovi; po dalších 30–60 minutách bez řešení dojde k další eskalaci.
Kontextová eskalace
Tato logika eskalace zohledňuje kontextové atributy incidentu, jako je dotčená služba nebo systém, vlastník služby, ovlivněný segment zákazníků (interní vs. externí, VIP vs. běžní) nebo funkční doména (databáze, síť, integrace). Na základě tohoto kontextu jsou výstrahy směrovány k nejrelevantnějšímu respondentu nebo týmu.
Zde se vyhnete přetížení týmů irelevantními incidenty, zkrátíte dobu reakce a zajistíte, že problémy ve své oblasti budou řešit odborníci.
📌 Příklady: Náhlý nárůst latence v platební službě by měl přímo upozornit platební tým, nebo chyba backendu v mikro službě fakturace by měla upozornit fakturační tým.
Eskalace na základě metadat
Moderní nástroje pro výstrahy a incidenty zachycují metadata, jako je zdroj původu (který monitorovací nástroj nebo pravidlo výstrahy se spustilo), identita uživatele/zákazníka, umístění, historická četnost podobných incidentů nebo štítky. To vám pomůže aplikovat podrobnější a inteligentnější logiku, místo aby se spoléhalo na hrubá pravidla založená na závažnosti nebo čase.
📌 Příklady: Opakující se výstrahy ze stejného subsystému mohou naznačovat hlubší systémový problém, který vyžaduje rychlejší eskalaci. Nebo výstrahy pro VIP zákazníky mohou spustit další oznámení.
Kombinace spouštěčů pro vytváření chytřejších, adaptivních zásad eskalace
V praxi se mnoho týmů nespoléhá pouze na jeden typ spouštěče. Místo toho vytvářejí hybridní zásady eskalace, které kombinují pravidla závažnosti, času, kontextu a metadat.
Tento vrstvený přístup umožňuje týmům vytvářet eskalační zásady, které jsou jak responzivní (rychlé, když je to potřeba), tak inteligentní (selektivní, aby minimalizovaly šum), což vede k lepším výsledkům při řešení incidentů a efektivnějšímu přidělování zdrojů.
🔍 Věděli jste, že... V 18. století používali námořníci v nouzových situacích přísný eskalační řetězec. Pokud námořník nižší hodnosti zaznamenal nebezpečí, zazvonil na zvonek a předal zprávu výše v hierarchii, až ji nakonec obdržel kapitán, který učinil konečné rozhodnutí.
Jak navrhnout efektivní postupy eskalace
Návrh eskalačních cest spočívá ve vytvoření systému, který spolehlivě směruje správné výstrahy správným osobám s minimálními potížemi.
Zde je praktický podrobný rámec, který můžete použít v komplexních distribuovaných prostředích.
P. S. Prozkoumáme také, jak vám v tomto ohledu mohou pomoci některé funkce ClickUp! 🤩
Krok č. 1: Definujte jasná kritéria, úrovně a odpovědnosti pro eskalaci
Začněte tím, že definujete, co představuje incident, který vyžaduje eskalaci. Zaznamenejte objektivní kritéria, aby každý technik v pohotovosti, ať už se jedná o nového respondenta L1 nebo zkušeného SRE, interpretoval závažnost incidentu stejným způsobem.
To zajistí jasný eskalační pracovní postup, odstraní nejednoznačnosti a zajistí, že automatizace se spustí pouze v případě, kdy je to skutečně nutné.
Zahrňte kritéria, jako jsou:
- Prahové hodnoty závažnosti: výpadek služby, selhání platby, problémy s ověřením, poškození dat a bezpečnostní výstrahy
- Dopad: Výpadky ovlivňující zákazníky, zhoršení interních služeb, selhání API partnerů, rizika v oblasti dodržování předpisů nebo bezpečnosti
- Kontext kritický pro podnikání: Vysoký dopad na zákazníky, toky ovlivňující příjmy, vysoce rizikové systémy (např. platby, fakturace)
Jakmile jsou definována kritéria a spouštěče, zmapujte, kdo bude upozorněn a jaké jsou jeho povinnosti v každém bodě eskalace.
Jasně definujte úrovně:
- Úroveň jedna (primární manažer incidentů v pohotovosti): Působí jako první respondent a je odpovědný za potvrzení, počáteční třídění a pokusy o zmírnění následků.
- Úroveň dvě (zálohování/specialista/SME): Poskytuje hluboké technické znalosti a řeší složité systémové problémy.
- Úroveň tři (technický manažer/vedoucí): Dohlíží na závažné incidenty, schvaluje významná opatření, koordinuje komunikaci mezi týmy a v případě potřeby spouští eskalaci k dodavateli.
🚀 Výhoda ClickUp: Pomocí ClickUp Docs udržujte jediný zdroj pravdivých informací o kritériích, úrovních a odpovědnostech eskalace a dokumentujte role a odpovědnosti, včetně toho, kdo:
- Potvrzuje a zmírňuje
- Komunikuje se zainteresovanými stranami
- Zpracovává eskalace dodavatelů nebo externích partnerů
- Vede velení při incidentech
Tyto konkrétní role můžete také propojit s příslušnými úkoly ClickUp, aby byl zachován kontext.
Vytvořte si vlastní znalostní databázi:
Jakmile jsou definována kritéria eskalace a odpovědnost, týmy potřebují konzistentní způsob, jak zaznamenávat, sledovat a analyzovat technické incidenty. Šablona ClickUp Incident Report Template poskytuje strukturovaný, snadno přístupný systém pro dokumentaci IT a provozních incidentů na jednom místě.
Tato funkce, zabudovaná do ClickUp Docs, pomáhá týmům reagujícím na incidenty zaznamenávat důležité podrobnosti, jako je závažnost incidentu, ovlivněné služby, časové osy, shrnutí příčin, kroky k zmírnění dopadů a následné akce.
Krok č. 2: Standardizujte vytváření incidentů
Ještě před aktivací eskalačních cest potřebuje váš tým spolehlivý způsob, jak zachytit, normalizovat a obohatit data o incidentech. Pokud je počáteční záznam o incidentu neúplný nebo nekonzistentní, selže i ta nejsofistikovanější eskalační logika.
Standardizace by měla:
- Třídění příchozích upozornění: Převádějte upozornění do jednotných vlastních polí, jako je závažnost, kategorie, ovlivněná služba, typ incidentu a stav potvrzení.
- Automaticky obohacujte incidenty: Načtěte metadata, včetně clusteru, ID nasazení, vlastníků služeb nebo závislostí.
- Zajistěte, aby každá událost zachycovala kontext: Zaznamenejte, kdo ji nahlásil, jak byla detekována, prostředí (produkční/testovací) a všechny relevantní protokoly nebo snímky obrazovky.
Vytvořte formulář ClickUp přímo ze seznamu, kde jsou incidenty sledovány, a navrhněte jej tak, aby odrážel vaši provozní realitu a relevantní data, na kterých závisí vaše logika eskalace. Tímto způsobem, namísto roztříštěných zpráv v chatu, e-mailech nebo na dashboardu, každý incident vstupuje do vašeho systému v jednotném formátu, na který může automatizace spolehlivě reagovat.

Záměrně seskupujte pole, aby každý incident byl plně kontextualizován:
- Identifikace (název, shrnutí)
- Klasifikace (závažnost, typ, ovlivněná služba)
- Zdroj (monitorování, uživatel, API)
- Důkazy (protokoly, snímky obrazovky)
- Obchodní kontext (úroveň SLA, dopad na zákazníky)
Každé odeslání formuláře automaticky vytvoří nový úkol ClickUp, přičemž všechny odpovědi jsou přiřazeny k vlastním polím ClickUp. Tím je zajištěno, že incidenty jsou při vytvoření normalizovány, což odstraňuje nejednoznačnost a eliminuje potřebu ruční reakce na incidenty.
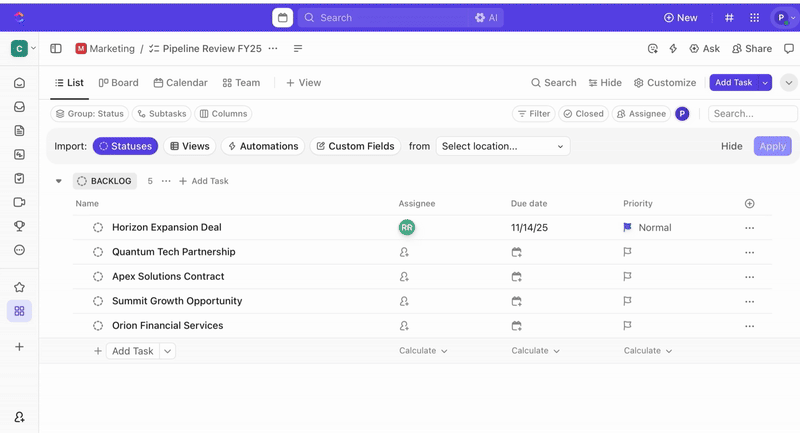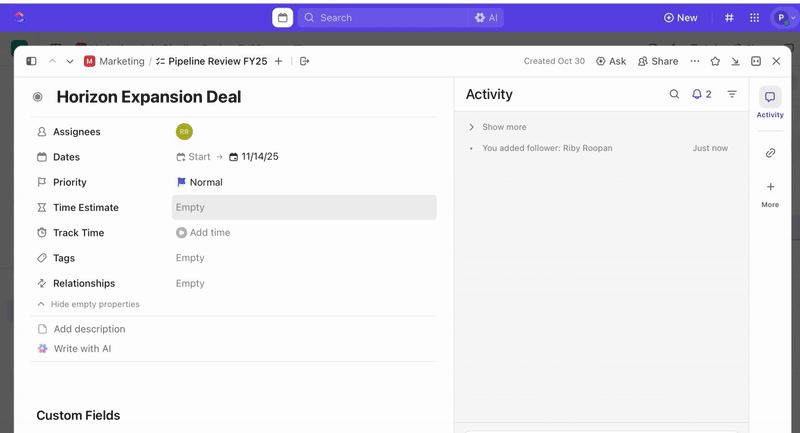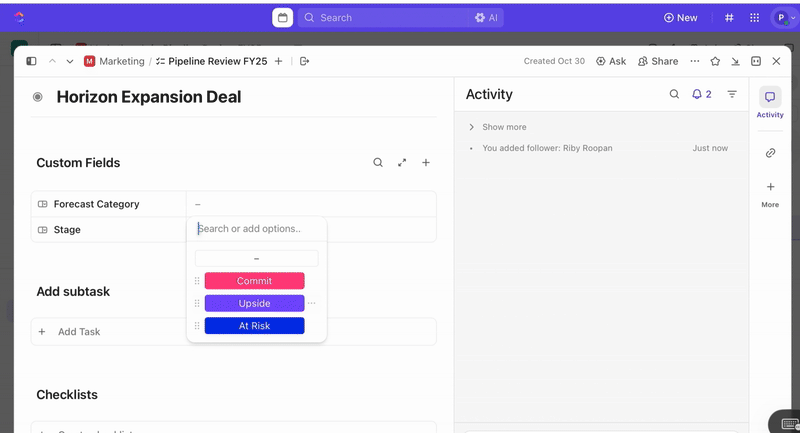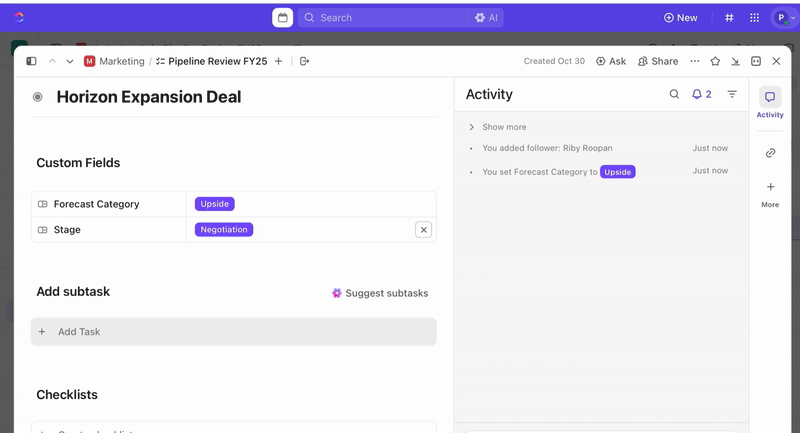
Jakmile jsou úkoly vytvořeny, můžete pomocí vlastních polí řídit třídění a stanovení priorit (např. závažnost, dopad, skupina respondentů) a definovat vlastní stavy ClickUp, které odrážejí fáze incidentu (Nový > Třídění > Vyšetřování > Zmírňování > Vyřešeno).
Krok č. 3: Vytvořte eskalační cestu (tj. pořadí + načasování + kanály)
To je jádro cesty. Rozvrhněte cestu do fází, kde každá fáze definuje, kdo je informován, prostřednictvím jakého kanálu (kanálů) a po jaké době bez potvrzení nebo řešení.
- Definujte „časový limit potvrzení“ a „časový limit řešení“.
Zde je příklad pracovního postupu:
- Fáze jedna: První osoba v pohotovosti, která byla okamžitě informována prostřednictvím SMS/chatového kanálu, musí potvrdit přijetí zprávy do 5–10 minut.
- Fáze dvě: Pokud během následujících 15–20 minut nedojde k potvrzení nebo k žádné akci, eskalujte incident na záložní/SRE tým + senior inženýra prostřednictvím SMS/chatového kanálu/e-mailu.
- Fáze tři: Pokud se problém po dalších 30–60 minutách stále nepodaří vyřešit, eskalujte jej na technického manažera/vedení a případně spusťte kanál „závažný incident“.
- Rozhodněte se, zda by se postup eskalace měl „opakovat“ (znovu upozornit stejnou úroveň) nebo „pokračovat dále“.
- U kritických incidentů nastavte opakovaná oznámení, dokud někdo neodpoví. U incidentů s nižší prioritou můžete zvolit jediný eskalační tok.
- Zajistěte, aby byla cesta zdokumentována pomocí šablony reakce zákaznického servisu a byla přístupná všem příslušným zaměstnancům.
❗️ Poznámka: „Časový limit pro potvrzení“ je doba, během které musí první respondent potvrdit, že viděl výstrahu, zatímco „časový limit pro vyřešení“ je doba, během které musí tým problém vyřešit nebo zmírnit, než dojde k další eskalaci.
Krok č. 4: Začlenění automatizace a podpory nástrojů
Jakmile máte stanovená kritéria, proces třídění a standardy obohacování, dalším krokem je umožnit eskalaci bez nutnosti spoléhat se na to, že si lidé budou pamatovat, kdy a komu eskalovat. Právě zde se ClickUp Automations stává klíčovou součástí vašeho pracovního postupu.

Můžete nastavit možnosti automatizace, které reagují na stejné signály, jaké váš tým používá během incidentů. Zde je několik příkladů:
- Pokud se závažnost aktualizuje na SEV-1 ➡️ Okamžitě přiřaďte seniorního SRE + informujte chatový kanál pohotovostní služby.
- Pokud stav zůstane nezměněn po dobu X minut ➡️ Spusťte eskalaci na další úroveň
- Pokud uplyne termín (např. termín potvrzení) ➡️ Eskalujte na L2
A právě v tomto ohledu jde ClickUp Brain ještě dál. Využívá kontext z vašeho pracovního prostoru k poskytování okamžitých odpovědí, automatickému generování aktualizací a podpoře přístupu k znalostem.
Použijte nástroje jako AI Prioritize k automatickému vyhodnocení incidentů a nastavení správné priority podle vaší vlastní logiky. Příkladové výzvy:
- Pokud incident ovlivňuje produkci a má dopad na zákazníky, nastavte prioritu: Naléhavé.
- Pokud je přiřazeným týmem tým SRE a protokoly zmiňují „latence“, nastavte prioritu: Vysoká.
- Pokud popis obsahuje bezpečnostní klíčová slova, jako je „porušení“, nastavte prioritu: urgentní.
A jakmile je nastavena priorita, převezme kontrolu AI Assign a automaticky přiřadí incidenty na základě podmínek, které definujete.
Můžete vytvořit výzvy jako:
- Pokud je priorita urgentní a dotčená služba obsahuje „platby“, přiřaďte ji seniornímu SRE.
- Pokud je typ incidentu databáze a region je US-East, přiřaďte jej DB On-Call.
- Pokud název úkolu obsahuje slovo „bezpečnost“, přiřaďte jej vedoucímu SecOps.
Vyzkoušejte tyto pokyny na prvních třech úkolech, než je použijete na celý seznam.
🚀 Výhoda ClickUp: Nasazujte inteligentní automatizační boty, které jsou součástí vašeho pracovního prostoru a reagují na aktivity v reálném čase pomocí ClickUp Super Agents.
Jsou plně informováni o vašich úkolech, dokumentech, chatech a procesech, takže každá automatizovaná akce je kontextová.
Například můžete umístit Team StandUp Agent do složky „Production Incidents Folder“ (Složka incidentů ve výrobě), aby každé ráno automaticky zveřejňoval denní souhrn. Váš tým obdrží okamžitý přehled s počtem otevřených incidentů, těch, které zůstávají nevyřešené, a změn, ke kterým došlo za posledních 24 hodin.
Nyní to spojte s agentem Ambient Answers ve vašem kanálu „#incident-room“. Když respondenti položí otázky jako „Kde je runbook SEV-1?“ nebo „Selhalo toto API již dříve?“, agent čerpá z vašich pracovních znalostí a poskytuje okamžité a přesné odpovědi.

Krok č. 5: Standardizujte komunikační kanály
Při eskalaci incidentů je stejně důležité, jak a kde týmy komunikují, jako to, kdo je o nich informován. Bez standardizovaných kanálů se aktualizace ztrácejí, rozhodnutí se duplicitují a zúčastněné strany dostávají protichůdné informace.
Definujte jasné eskalační kanály pro každou fázi životního cyklu incidentu a používejte je konzistentně napříč týmy:
| Kritéria | Název kanálu | Účel |
| Zjištěna úroveň SEV-1 nebo SEV-2 | #incident-critical | Centrální prostor pro výstrahy s vysokou závažností a okamžité třídění |
| Probíhá aktivní řešení problému | #incident-warroom | Centrum pro spolupráci v reálném čase pro inženýry, produktové manažery, pracovníky kontroly kvality a podporu |
| Vyžadována viditelnost vedení | #incident-leadership | Aktualizace s vysokou prioritou pro manažery a vedoucí pracovníky |
| Je nutná komunikace se zákazníky | #incident-comms | Prostor pro návrh, kontrolu a sladění externí komunikace se zákazníky |
| Zahájena revize po incidentu | #incident-retro | Strukturovaná diskuse o retrospektivních poznámkách, poznatcích a akčních bodech |
Každý kanál má definované publikum a účel, což týmům pomáhá omezit rušivé vlivy a zároveň informovat příslušné týmy.
🚀 Výhoda ClickUp: Sladěte svou strategii kanálů s integrovanou komunikační vrstvou pomocí ClickUp Chat. Každé upozornění, aktualizace a rozhodnutí zůstává přímo spojeno s úkolem, seznamem nebo prostorem incidentu, kde se práce odehrává.
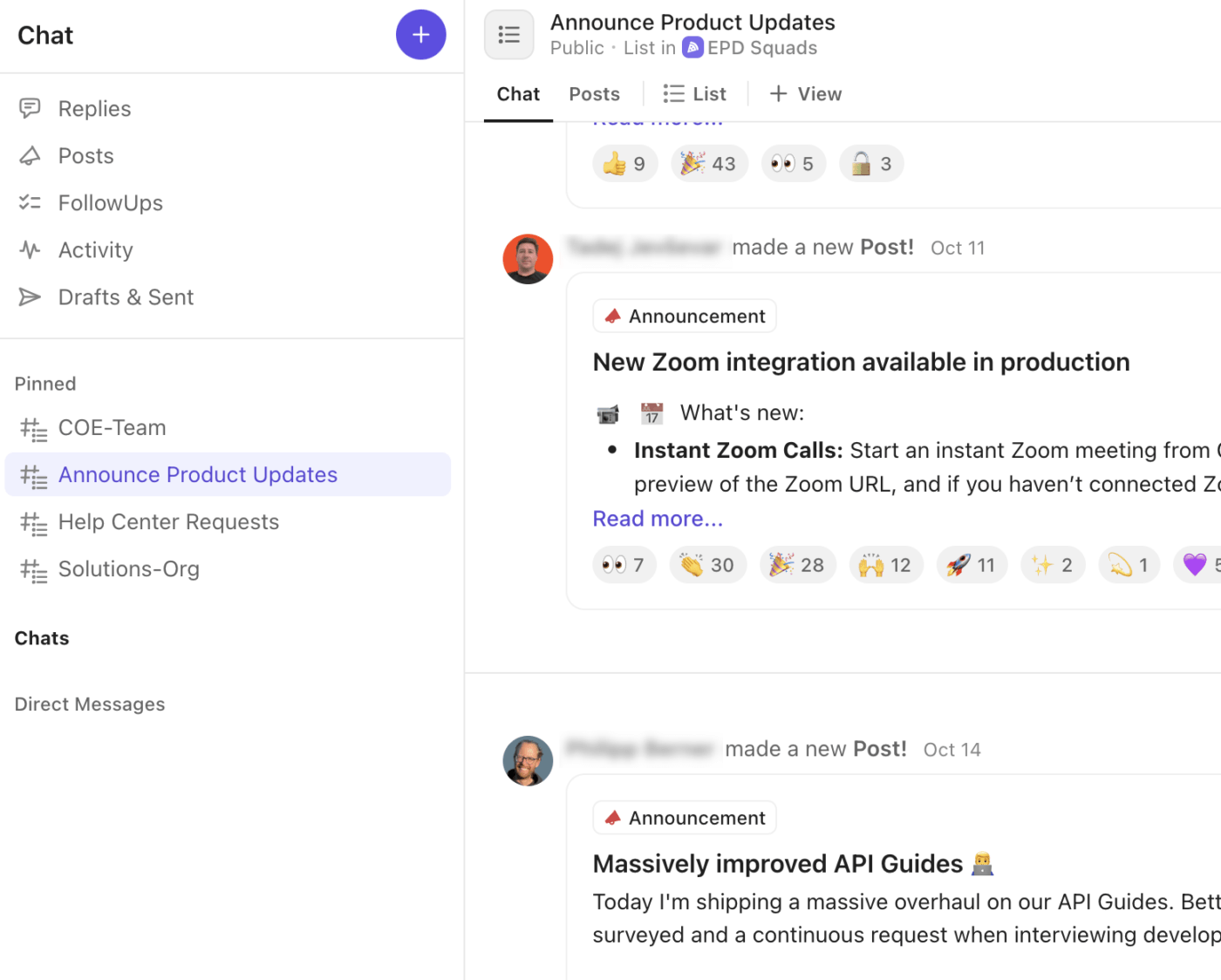
Takto ClickUp Chat vylepšuje váš pracovní postup při řešení incidentů:
- Vytvořte speciální chatové vlákna pro kritické diskuse, porady, vedení nebo komunikaci se zákazníky.
- Proměňte chatové zprávy na úkoly ClickUp okamžitě a zajistěte, že se rozhodnutí a následné kroky neztratí v konverzaci.
- Připojte se k rychlým audio nebo video hovorům pomocí ClickUp SyncUps pro živou koordinaci incidentů nebo briefingy vedení.
- Zveřejňujte „oznámení“ nebo aktualizace , abyste informovali celou společnost o stavu incidentů na vysoké úrovni.
- Označujte členy týmu, vkládejte screenshoty a připojujte protokoly přímo v chatu, abyste měli technický kontext vždy po ruce.
Krok č. 6: Otestujte, zkontrolujte a vylepšete svou eskalační cestu
Zásady eskalace se musí vyvíjet spolu s vašimi systémy. Zde je několik věcí, které musíte pravidelně provádět:
| Aktivita | Co testovat nebo kontrolovat | Proč je to důležité |
| Požární cvičení v pohotovosti (čtvrtletně) | Simulujte incidenty P1 a P2, ověřte načasování eskalace a směrování. | Zajišťuje, že automatizace a eskalační cesty fungují i pod tlakem. |
| Ověření eskalační cesty | Zkontrolujte, zda nedochází k eskalaci do slepé uličky nebo zda nechybí vlastníci. | Zabraňuje zablokování incidentů bez viditelnosti |
| Časovače procesu potvrzení a řešení | Porovnejte nakonfigurované časovače se skutečnými hodnotami MTTA a MTTR. | Zajišťuje realistické a efektivní načasování eskalace |
| Hodnocení únavy z výstrah | Identifikujte respondenty, kteří dostávají nadměrné nebo opakované výstrahy. | Snižuje vyhoření a počet zmeškaných kritických výstrah |
| Závažnost a přesnost stanovení priorit | Zkontrolujte, zda byly incidenty správně klasifikovány. | Zlepšuje směrování, rychlost reakce a přesnost eskalace |
| Následná kontrola po incidentu | Zajistěte, aby byly úkoly z retrospektivy splněny. | Zabraňuje opakovaným incidentům a systémovým selháním |
Nástroje a integrace pro automatizaci eskalace
V této části se seznámíte se softwarem pro správu incidentů, který vám pomůže rychleji detekovat incidenty, okamžitě je směrovat a udržovat všechny týmy v obraze bez nutnosti ručního sledování.
1. ClickUp (nejlepší pro sjednocení mezifunkčních eskalací do jednoho propojeného pracovního prostoru pro incidenty)
Tradiční metody eskalace nutí týmy žonglovat s e-maily, tabulkami, chatovými vlákny a roztroušenými poznámkami, což téměř znemožňuje získat jasný přehled o tom, co se děje, v reálném čase.
Software ClickUp Task Management Software for Escalation Management eliminuje rušivé vlivy tím, že konsoliduje všechny podrobnosti eskalace do jediného organizovaného pracovního prostoru.
Podívejme se na některé funkce softwaru pro správu IT aktiv, díky nimž je ClickUp nejlepší volbou pro týmy, které spravují velké množství eskalací a složité pracovní postupy při řešení incidentů.
Pracujte podle svých představ
Zobrazte si své úkoly z různých úhlů pohledu, aby odpovídaly vašim provozním potřebám, pomocí zobrazení ClickUp:
- Zobrazení seznamu ClickUp, aby vedoucí SRE mohli třídit incidenty podle závažnosti, zbývajícího času SLA nebo pohotovostních skupin pro rychlé třídění.
- ClickUp Board View umožňuje technickým manažerům vizualizovat předávání úkolů a odpovědnost týmů během eskalací.
- ClickUp Gantt View pro vedoucí programů k mapování milníků řešení a závislostí napříč službami
- ClickUp Workload View pro plánovače pohotovostních služeb, kteří zajišťují, aby inženýři nebyli přetíženi během období s vysokým počtem incidentů.
Proměňte diskuse na schůzkách v konkrétní kroky
Během eskalací a přezkoumávání incidentů může být spolehlivé zaznamenávání diskusí a akčních položek náročné. ClickUp AI Notetaker se automaticky připojuje k schůzkám naplánovaným v Google Kalendáři, Outlooku, Zoomu nebo Teams, zaznamenává a přepisuje konverzaci.
Po schůzce:
- Přístup k prohledávatelným přepisem a shrnutím akčních položek
- Zajistěte přehlednost pomocí poznámek uložených v ClickUp Docs. Díky tomu můžete snadno odkazovat na úkoly související s incidenty nebo retrospektivní zprávy.
- Ptejte se ClickUp AI na obsah schůzek, abyste si ujasnili rozhodnutí nebo odhalili opomenuté následné kroky.
Propojte se se stávajícími nástroji ve vašem technologickém stacku
V pozadí zajišťují integrace ClickUp a ekosystém Webhooks plynulé propojení s ostatními částmi vašeho stacku.
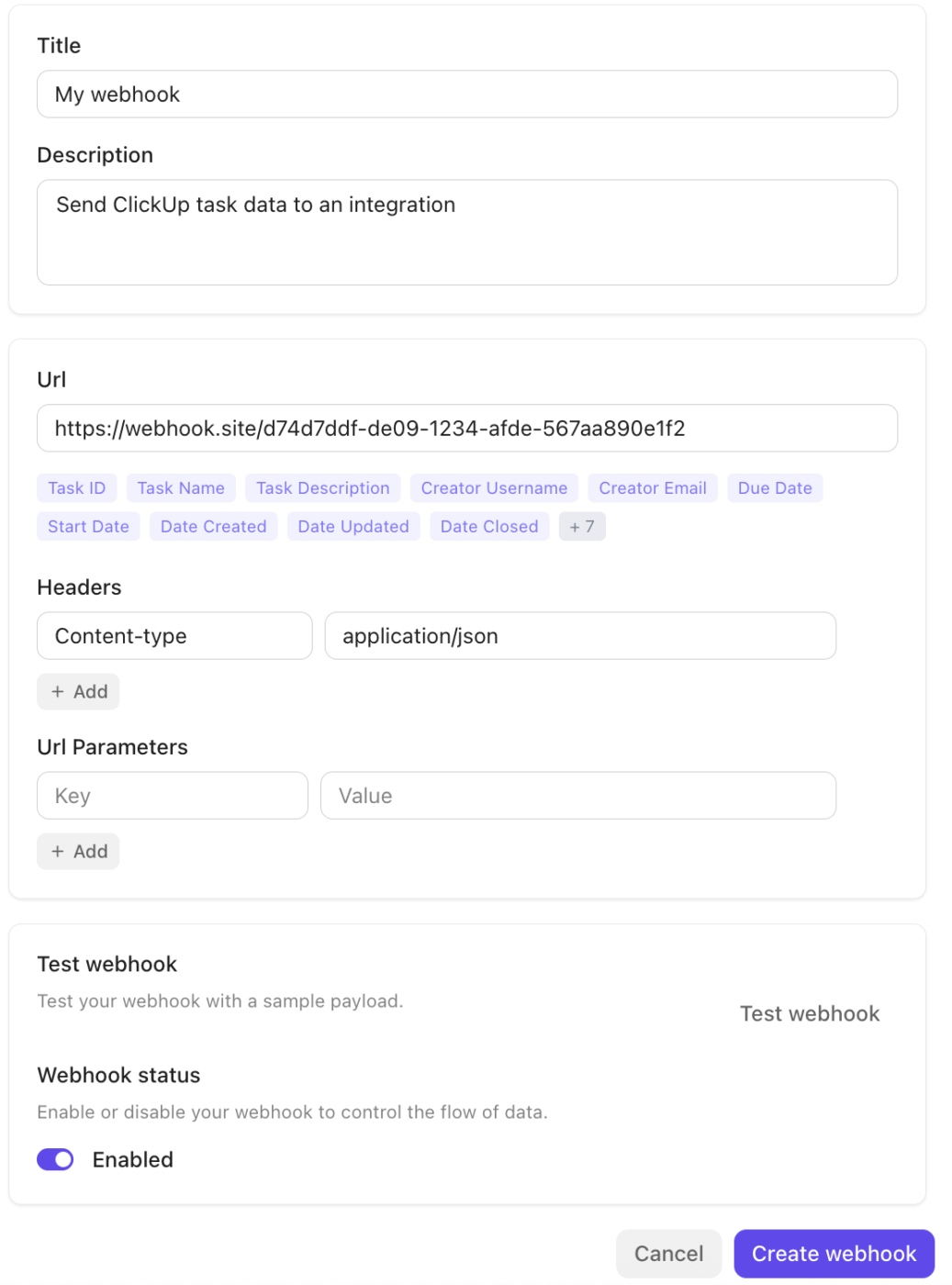
Platforma se nativně integruje s nástroji jako Slack, GitHub, Zoom a dalšími a podporuje Webhooks prostřednictvím své veřejné API pro vysílání událostí (aktualizace úkolů a změny stavu) do externích služeb nebo automatizačních pipeline. To usnadňuje spouštění pracovních postupů, synchronizaci dat nebo eskalaci incidentů napříč systémy bez ručního předávání.
Spojte všechny své nástroje umělé inteligence
Aby se automatizace a kontext dostaly na další úroveň, ClickUp BrainGPT přináší kontextovou AI do vašich eskalačních pracovních postupů. Jedná se o kontextovou super AI aplikaci, která rozumí vašim úkolům, dokumentům a historickému kontextu.
Díky funkcím Enterprise Search a Connected Apps můžete okamžitě načíst informace ze svého pracovního prostoru, Slacku, Google Drive, GitHubu a dalších zdrojů. Během živých hovorů o incidentech vám funkce Talk-to-Text v ClickUp umožňuje diktovat poznámky nebo pokyny k eskalaci bez použití rukou, takže vám nic neunikne.
Opakující se úkoly můžete také standardizovat pomocí vlastních AI výzev a uložených výzev, například: „Shrňte všechny nevyřešené incidenty a doporučte eskalační opatření.“
Nejlepší funkce ClickUp
- Upřednostněte kritické problémy: Použijte ClickUp Task Priorities k označení urgentních nebo významných eskalací.
- Organizujte složité eskalační sekvence: Nastavte závislosti úkolů ClickUp tak, aby propojovaly související úkoly (např. „Čeká se na“ nebo „Blokuje se“), aby eskalační kroky zabránily předčasným akcím nebo vzniku úzkých míst.
- Rozdělte incidenty na proveditelné části: Rozdělte eskalace na podrobné akční položky a přiřaďte je týmům pomocí vnořených podúkolů.
- Přesně sledujte rychlost řešení: Zaznamenávejte a sledujte, jak dlouho trvá potvrzení a vyřešení eskalačních úkolů pomocí nástroje Project Time Tracking od ClickUp.
Omezení ClickUp
- S tolika funkcemi, zobrazeními a možnostmi přizpůsobení se týmy často potýkají s určitou náročností na zaučení, než se vše stane intuitivním.
Ceny ClickUp
[Ceník]
Hodnocení a recenze ClickUp
- G2: 4,7/5 (více než 10 300 recenzí)
- Capterra: 4,6/5 (více než 4 400 recenzí)
Co říkají skuteční uživatelé o ClickUp?
Tato recenze opravdu říká vše:
ClickUp shromažďuje všechny mé úkoly, projekty a komunikaci na jednom místě, což mi neuvěřitelně usnadňuje organizaci. Líbí se mi, jak je vše přizpůsobitelné – od zobrazení a pracovních postupů až po řídicí panely –, takže si mohu svůj pracovní prostor strukturovat přesně podle svých potřeb. Schopnost spolupracovat v reálném čase, přidělovat úkoly a sledovat pokrok bez nutnosti přepínat mezi nástroji je obrovskou výhodou.
ClickUp shromažďuje všechny mé úkoly, projekty a komunikaci na jednom místě, což mi neuvěřitelně usnadňuje organizaci. Líbí se mi, jak je vše přizpůsobitelné – od zobrazení a pracovních postupů až po řídicí panely –, takže si mohu svůj pracovní prostor strukturovat přesně podle svých potřeb. Schopnost spolupracovat v reálném čase, přidělovat úkoly a sledovat pokrok bez nutnosti přepínat mezi nástroji je obrovskou výhodou.
📮 ClickUp Insight: 21 % lidí uvádí, že více než 80 % svého pracovního dne tráví opakujícími se úkoly. Dalších 20 % uvádí, že opakující se úkoly zabírají alespoň 40 % jejich dne.
To je téměř polovina pracovního týdne (41 %) věnovaná úkolům, které nevyžadují mnoho strategického myšlení nebo kreativity (jako například následné e-maily 👀).
Super agenti ClickUp vám pomohou tuto rutinu eliminovat. Myslete na vytváření úkolů, připomenutí, aktualizace, poznámky ze schůzek, psaní e-mailů a dokonce i vytváření komplexních pracovních postupů! To vše (a ještě více) lze automatizovat během chvilky pomocí ClickUp, vaší aplikace pro vše, co souvisí s prací.
💫 Skutečné výsledky: Společnost Lulu Press ušetří díky automatizaci ClickUp 1 hodinu denně na každého zaměstnance, což vede k 12% zvýšení efektivity práce.
2. PagerDuty (nejlepší pro upozornění v reálném čase a inteligentní reakci na pohotovost)
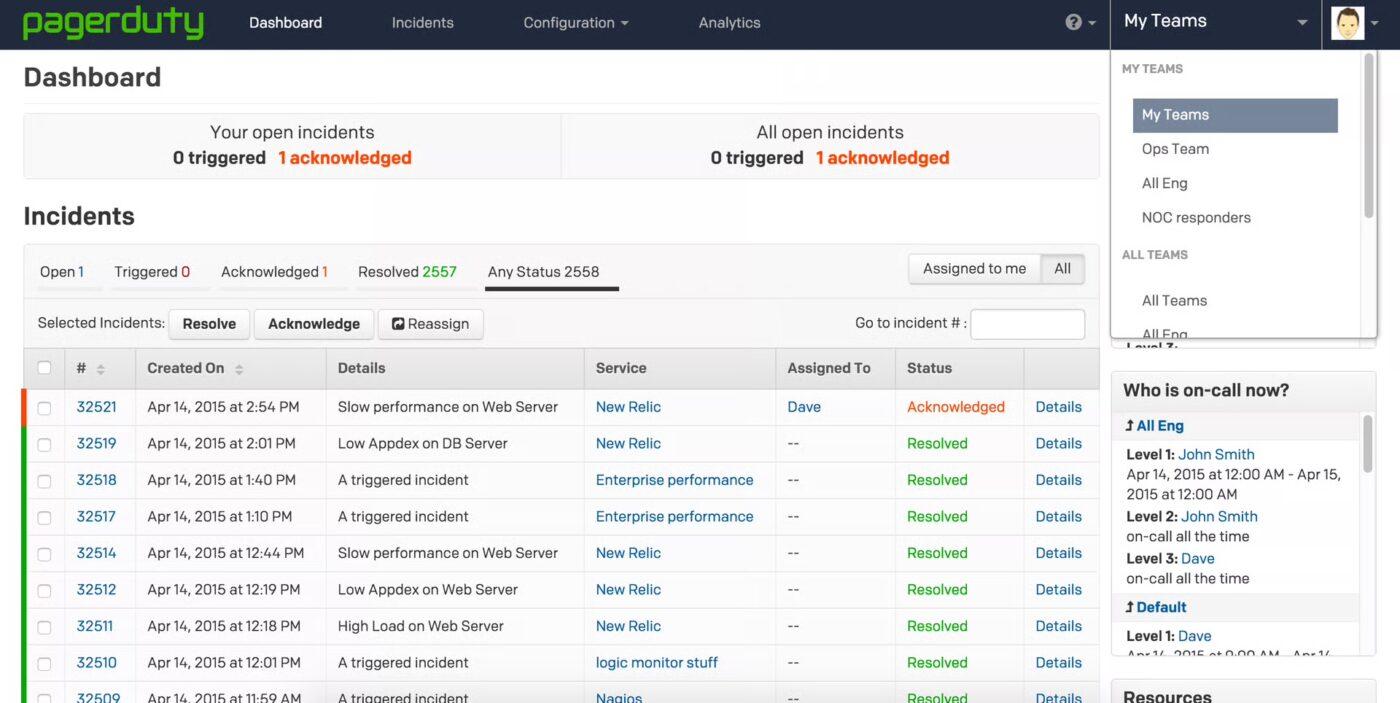
PagerDuty je cloudová platforma pro správu IT incidentů a digitální operace, která týmům pomáhá rychle detekovat, reagovat a řešit kritické incidenty, jako jsou výpadky nebo bezpečnostní hrozby. Poskytuje vedoucím pracovníkům v oblastech SRE, DevOps a podpory jasnou cestu od signálu k řešení, podporovanou automatizací, tříděním založeným na umělé inteligenci a hluboce integrovanými pracovními postupy.
Funkce jako Jeli Incident Analysis, PagerDuty Analytics a Runbook Automation pomáhají týmům zkrátit prostoje, eliminovat rutinní úkoly a poučit se z každé události.
Nejlepší funkce PagerDuty
- Automatizujte směrování incidentů pomocí integrované funkce On-Call Management a dynamických Escalation Policies.
- Zrychlete třídění pomocí AIOps, které filtruje rušivé výstrahy, koreluje události a zvýrazňuje skutečné signály.
- Udržujte interní a externí zainteresované strany v souladu pomocí komunikace se zainteresovanými stranami, šablon pro aktualizaci stavu a stránek se stavem.
- Sjednoťte své nástroje pomocí více než 700 integrací a rozšiřitelných API pomocí monitorování, protokolování, CI/CD a systémů podpory.
Omezení PagerDuty
- Vysoký objem výstrah, pokud nejsou integrované systémy a inteligentní prahové hodnoty správně nastaveny, což vede k rušení a únavě.
- Během špiček může docházet k duplicitním nebo opakovaným výstrahám, což ztěžuje potvrzení pod tlakem.
Ceny PagerDuty
- Zdarma
- Profesionální: 25 $/měsíc na uživatele
- Podnikání: 49 $/měsíc na uživatele
- Podnik: ceny na míru
Hodnocení a recenze PagerDuty
- G2: 4,5/5 (více než 900 recenzí)
- Capterra: 4,6/5 (více než 200 recenzí)
Co říkají skuteční uživatelé o PagerDuty?
Slovy skutečného uživatele:
PagerDuty zajišťuje rychlé a spolehlivé upozornění na incidenty. Posílá správná oznámení ve správný čas a udržuje náš tým organizovaný. […] PagerDuty může být někdy hlučný, když nejsou upozornění dobře filtrována. Některá nastavení jsou pro nové uživatele trochu složitá.
PagerDuty zajišťuje rychlé a spolehlivé upozornění na incidenty. Posílá správná oznámení ve správný čas a udržuje náš tým organizovaný. […] PagerDuty může být někdy hlučný, když nejsou upozornění dobře filtrována. Některá nastavení jsou pro nové uživatele trochu složitá.
💡 Tip pro profesionály: Vytvořte výjimky, i když máte jasnou eskalační cestu. Nechte kritické výpadky, bezpečnostní výstrahy nebo incidenty v regulovaném prostředí přeskakovat přímo na vyšší nebo specializované respondenty.
3. GLPi (nejlepší pro komplexní správu aktiv a provoz služeb v souladu s ITIL)
Gestionnaire Libre de Parc Informatique (GLPi) je komplexní open-source platforma pro správu IT služeb (ITSM) a správu IT aktiv (ITAM). Týmy získávají komplexní přehled o své infrastruktuře (hardware, software, licence a síťová zařízení) a mohou spravovat incidenty, požadavky na služby a změny pomocí procesů v souladu s ITIL.
Všechny vaše smlouvy a dokumentace, včetně záruk a servisních smluv, zůstávají přehledně uspořádány, což zabraňuje jejich ztrátě v různých systémech. Pokud spravujete datová centra, GLPi vám dokonce umožňuje vizualizovat rozvržení, trasy kabeláže a spotřebu energie, takže vždy víte, co se děje v zákulisí.
Nejlepší funkce GLPi
- Pomocí pluginů GLPI Inventory, OCS Inventory nebo FusionInventory můžete automaticky detekovat a katalogizovat nové IT prostředky.
- Automatizujte opakující se úkoly, přiřazování ticketů, oznámení a opakující se události, abyste snížili manuální práci.
- Vytvořte znalostní databázi pro často kladené otázky, dokumentaci a články propojené s tikety pro samoobslužnou podporu a podporu techniků.
- Propojte se s Azure/Entra, Centreon, Google, OAuth2 a webhooky, abyste synchronizovali data, spouštěli pracovní postupy a vylepšili svou CMDB.
Omezení GLPi
- Kompatibilita pluginů se může mezi verzemi lišit, což způsobuje zvýšené náklady na údržbu.
- Funkce pro vytváření zpráv, analýzy a export se jeví jako omezené a vyžadují vylepšení.
Ceny GLPi
- Ceny na míru
Hodnocení a recenze GLPi
- G2: 4,6/5 (více než 30 recenzí)
- Capterra: 4,5/5 (více než 40 recenzí)
Co říkají skuteční uživatelé o GLPi?
Zde je názor jednoho uživatele:
Velmi přizpůsobitelný open-source systém pro správu IT aktiv a podporu ticketů s velkou komunitou uživatelů. Uživatelské rozhraní je pro začátečníky trochu komplikované. Pluginy nejsou vždy podporovány ze starých verzí do nových.
Velmi přizpůsobitelný open-source systém pro správu IT aktiv a podporu ticketů s velkou komunitou uživatelů. Uživatelské rozhraní je pro začátečníky trochu komplikované. Pluginy nejsou vždy podporovány ze starých verzí do nových.
4. Splunk On-Call (nejlepší pro směrování monitorovacích výstrah přímo k technikům)
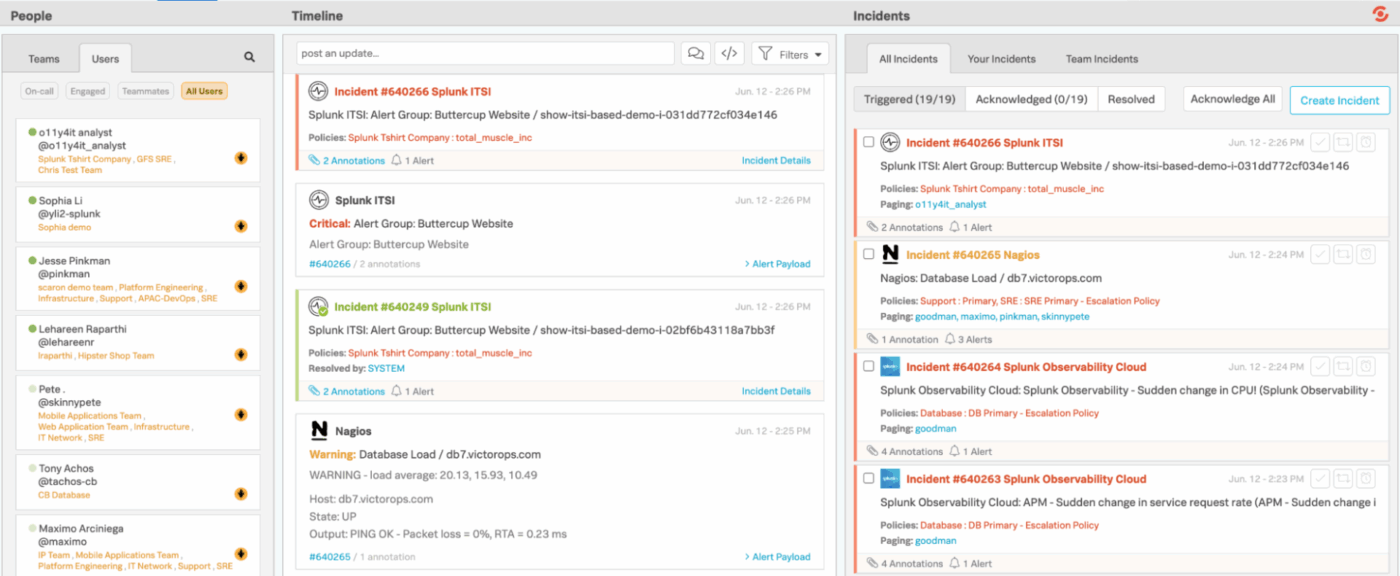
Splunk On-Call poskytuje technickým a pohotovostním týmům rychlejší a přehlednější způsob správy incidentů, který eliminuje potřebu pomalých tradičních workflow pro vytváření ticketů. Namísto zasílání upozornění do obecné fronty se integruje přímo do vašeho monitorovacího a pozorovacího stacku a okamžitě směruje problémy správným osobám na základě plánů, pravidel a kontextu.
Díky integraci mobilních zařízení a chatu je snadné potvrzovat, přesměrovávat nebo řešit incidenty odkudkoli. A v pozadí Splunk On-Call vede podrobný záznam trendů, osvědčených vzorců a eskalačního chování.
Nejlepší funkce Splunk On-Call
- Rozšiřte možnosti platformy pomocí více než 1 000 prověřených integrací a doplňků od společnosti Splunk a širší komunity.
- Vytvářejte vlastní panely a vizuální přehledy pro sledování objemu výstrah, stavu incidentů, výkonu respondentů a pracovní zátěže týmu.
- Rychle filtrujte incidenty podle vaší vlastní činnosti, incidentů týmu nebo všeho, co se děje v celé organizaci.
- Přepínejte mezi zobrazeními Spuštěno, Potvrzeno a Vyřešeno, abyste viděli, v jakém stavu se každá událost nachází.
Omezení služby Splunk On-Call
- Plánování směn napříč více týmy může být komplikované, pokud nejsou předem definována pravidla.
- Omezená schopnost generovat podrobné zprávy o incidentech podle data
Ceny služby Splunk On-Call
- Ceny na míru
Hodnocení a recenze Splunk On-Call
- G2: 4,6/5 (více než 40 recenzí)
- Capterra: 4,5/5 (více než 30 recenzí)
Co říkají skuteční uživatelé o Splunk On-Call?
Jeden uživatel to shrnul takto:
Možnost řešit incidenty, eskalace a přebírat povinnosti svých kolegů z mobilní aplikace je úžasná. […] Rád bych mohl z mobilní aplikace plánovat přepsání a měnit běžné plánování v případě nouzových změn v rozvrhu.
Možnost řešit incidenty, eskalace a přebírat povinnosti svých kolegů z mobilní aplikace je úžasná. […] Rád bych mohl z mobilní aplikace plánovat přepsání a měnit běžné plánování v případě nouzových změn v rozvrhu.
🔍 Věděli jste? Logika „přesměrování na správnou osobu, pokud selže první úroveň“ má kořeny v raných telefonních ústřednách: když ruční operátoři nemohli spojit hovor, systém jej přesměroval (nebo eskaloval) na jiného operátora nebo ústřednu.
5. ServiceNow (nejlepší pro koordinaci na podnikové úrovni s automatizací podporovanou umělou inteligencí)
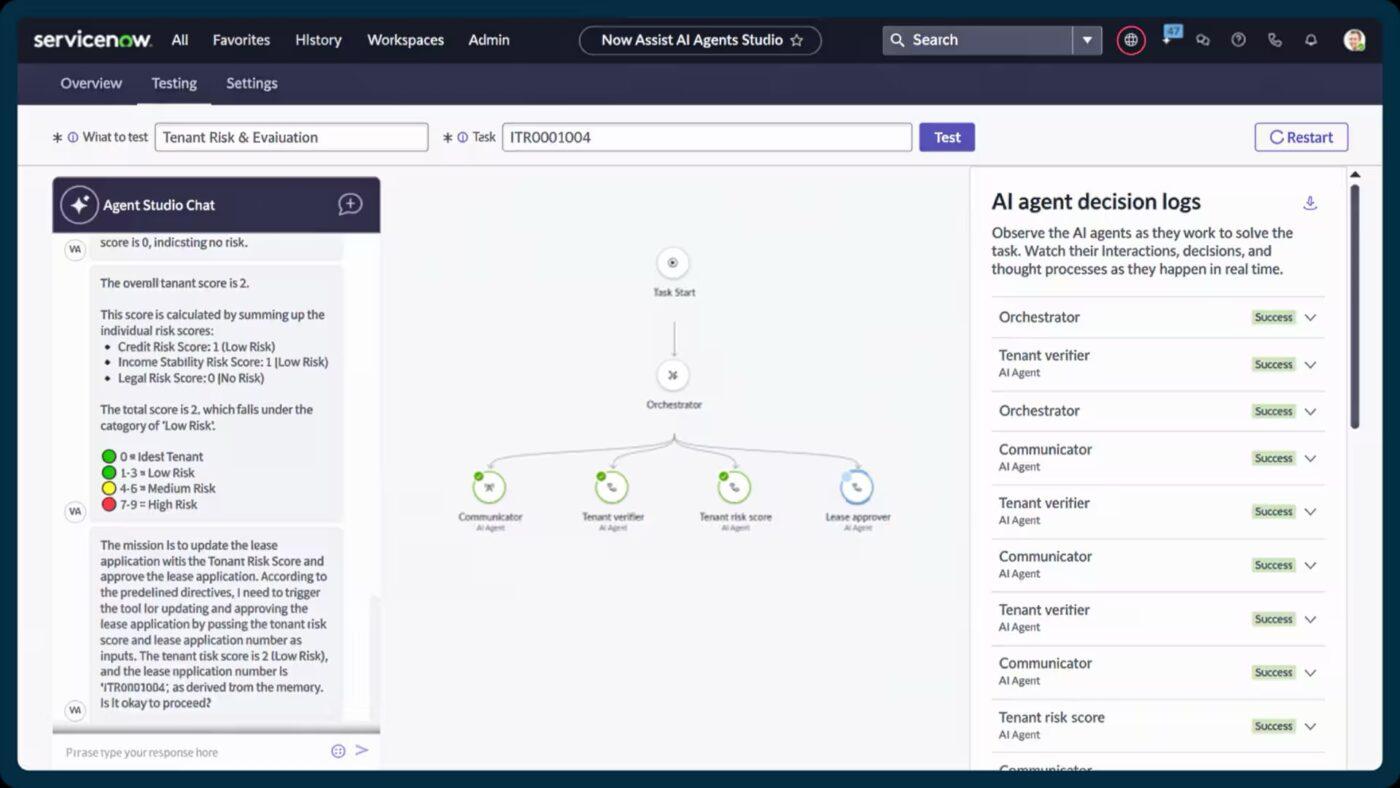
ServiceNow automaticky klasifikuje, prioritizuje a směruje incidenty v okamžiku jejich zaznamenání. Díky funkcím jako Now Assist pro automatizovaná doporučení incidentových ticketů a inteligentní generování obsahu mohou respondenti řešit problémy rychleji a s větším kontextem.
Spojuje správu incidentů, změn a aktiv. Tímto způsobem získáte přehled v reálném čase o tom, jak jsou služby propojeny, kde se objevují úzká místa a které komponenty mohou přispívat k opakovaným výpadkům.
Nejlepší funkce ServiceNow
- Přiřazujte, směrujte a sledujte úkoly v terénu pomocí Field Service Management a Dispatcher Workspace.
- Poskytněte zaměstnancům a zákazníkům samoobslužný portál založený na AI Search a virtuálních agentech.
- Pomocí integrovaných pracovních postupů a nástrojů s nízkými požadavky na kódování v App Engine můžete rozšířit nebo přizpůsobit servisní procesy.
- Automatizujte opakující se úkoly a pracovní postupy napříč týmy pomocí nástrojů Flow Designer a Automation Engine.
Omezení ServiceNow
- Možnosti přizpůsobení uživatelského rozhraní a portálu působí zastarale nebo omezujícím dojmem.
- Vysoká závislost na kvalifikovaném personálu nebo konzultantech při implementaci
Ceny ServiceNow
- Ceny na míru
Hodnocení a recenze ServiceNow
- G2: 4,4/5 (více než 3 300 recenzí)
- Capterra: 4,5/5 (více než 300 recenzí)
Co říkají skuteční uživatelé o ServiceNow?
Jeden uživatel to vyjádřil takto:
[…] Předem připravené toky jsou pro mě dalším významným prvkem, protože zefektivňují procesy a šetří značné množství času, minimalizují potřebu vlastních konfigurací a umožňují plynulejší a efektivnější pracovní postupy. […] Navíc jsem měl potíže s přizpůsobením svého vlastního řešení systému správy zákaznických služeb, což vyžadovalo poměrně mnoho opakování.
[…] Předem připravené toky jsou pro mě dalším významným prvkem, protože zefektivňují procesy a šetří značné množství času, minimalizují potřebu vlastních konfigurací a umožňují plynulejší a efektivnější pracovní postupy. […] Navíc jsem měl potíže s přizpůsobením svého vlastního řešení systému správy zákaznických služeb, což vyžadovalo poměrně mnoho opakování.
Osvědčené postupy a správa
Zde je několik osvědčených postupů, které zajistí, že automatizace zůstane přesná, zabrání únavě z výstrah a bude v souladu s obchodními a regulačními očekáváními.
- Definujte nekompromisní kritéria eskalace: Propojte spouštěče s měřitelnými signály, jako jsou porušení SLO, výkyvy v anomáliích, dopad na úroveň zákazníků nebo citlivost z hlediska předpisů.
- Stanovte jasné role na každé úrovni: Použijte jednoduchou mapu RACI pro každou úroveň eskalace, aby během incidentů s vysokým tlakem nikdy nedocházelo k nejasnostem ohledně odpovědností.
- Prosazujte dynamické řízení pohotovostních služeb: Automaticky upravujte eskalační cesty v závislosti na víkendech, svátcích, kapacitních limitech a předáváních, abyste snížili únavu a zabránili tichým stránkám.
- Zaveďte lidské kontrolní body pro scénáře s vysokým rizikem: I při automatizaci vyžadujte ruční potvrzení incidentů týkajících se odhalení údajů o zákaznících, plateb nebo regulovaných pracovních postupů.
- Udržujte úplné auditní stopy: Uchovávejte neměnné záznamy o tom, komu byla zaslána zpráva, kdy ji potvrdil, jaké automatizované kroky byly spuštěny a jaká rozhodnutí byla přijata.
🧠 Zajímavost: Nejstarší známá písemná stížnost na světě byla vyryta na hliněné tabulce kolem roku 1750 př. n. l. Jednalo se v podstatě o ranou formu eskalace stavu projektu. Zákazník jménem Nanni napsal obchodníkovi Ea-nāṣirovi, rozhořčený tím, že měď, kterou obdržel, byla nižší kvality, než bylo slíbeno, a že jeho posel byl špatně zacházen.
Časté výzvy a jak je překonat
I přes jasnou eskalační politiku se týmy často potýkají s provozními překážkami, které zpomalují reakci na incidenty nebo způsobují zmatek.
Tato tabulka zdůrazňuje běžné výzvy, které přesahují základní kroky nastavení, a poskytuje praktické strategie k jejich překonání.
| Výzvy ❌ | Řešení ✅ |
| Nekonzistentní kontext při předávání | Pomocí propojení úkolů a šablon hlášení incidentů v ClickUp můžete udržovat úplnou auditní stopu podrobností incidentu, ovlivněných systémů a předchozích akcí na každé úrovni eskalace. |
| Přetížení respondentů upozorněními s nízkou prioritou | Implementujte dynamické stanovení priorit pomocí vlastních polí ClickUp a AI Prioritize, abyste filtrovali incidenty na základě závažnosti, dopadu a prahových hodnot SLA. |
| Nedostatečná viditelnost napříč týmy | Nastavte sdílené pracovní prostory, přidávejte komentáře a vytvářejte vizuální tabule ClickUp, abyste zainteresovaným stranám mohli prezentovat aktualizace v reálném čase. |
| Zpožděné rozhodování během kritických incidentů | Automatizujte oznámení pomocí funkce Doporučené akce v ClickUp Brain Max, která okamžitě upozorní příslušné pracovníky na základě typu incidentu, jeho závažnosti a historických vzorců. |
| Obtížné sledování opakujících se problémů | Využijte vlastní reporty a šablony opakujících se úkolů ClickUp k identifikaci vzorců, příčin a opakujících se incidentů pro proaktivní prevenci. |
| Fragmentované znalosti během eskalace | Udržujte centralizované SOP, runbooky a dokumentaci incidentů v ClickUp Docs a propojte je s příslušnými úkoly, abyste je měli okamžitě k dispozici během živých eskalací. |
| Nesoulad odpovědností mezi směnami | Pomocí zobrazení pracovní zátěže a časové osy v ClickUp můžete vizualizovat úkoly a zajistit, aby při změnách směn nebo předáváních nedocházelo k překrývání nebo mezerám. |
| Ruční sledování dodržování předpisů a mezery v auditu | Automatizujte souhrny připravené pro audit pomocí ClickUp Brain, abyste zaznamenali všechny akce, oznámení a řešení incidentů. |
Měření dopadu automatizované eskalace
Sledování účinnosti automatizované eskalace vyžaduje zaměření se na klíčové metriky v oblasti objemu, efektivity a kvality. Tyto ukazatele odhalí, zda jsou vaše eskalační procesy rychlejší, přesnější a méně frustrující jak pro týmy, tak pro zákazníky.
Sledujte tyto metriky:
- Míra eskalace (objem): Procento problémů eskalovaných nad první úroveň. Vysoká míra může naznačovat mezery v počátečním třídění nebo znalostních bázích.
- Míra opakované eskalace (objem): Četnost, s jakou je stejný problém eskalován vícekrát. Signalizuje neúplné řešení nebo ztrátu kontextu.
- Doba eskalace (efektivita): Doba od detekce po eskalaci. Kratší doba trvání jednotlivých fází znamená rychlejší automatické rozpoznání kritických problémů.
- Doba zpoždění předání (efektivita): Rozdíl mezi eskalací a okamžikem, kdy další tým začne pracovat, aby se zdůraznilo tření při směrování nebo oznamování.
- Doba řešení eskalovaných případů (efektivita): Celková doba od eskalace po vyřešení. Rychlejší řešení ukazuje účinnost automatizace.
- Skóre spokojenosti zákazníků (CSAT) (kvalita): Zpětná vazba k eskalovaným interakcím za účelem měření plynulosti postupu.
- Přenášení kontextu (kvalita): Zda agenti dostávají kompletní historii incidentu, aby se zajistilo, že zákazníci neopakují informace.
- Řešení při prvním kontaktu (FCR) (kvalita): Procento problémů vyřešených při jediném kontaktu.
🚀 Výhoda ClickUp: Získejte v reálném čase vizuální a AI poháněné přehledy o všech metrikách eskalace pomocí ClickUp Dashboards.
Pomocí karet Tabulka, Koláč, Sloupec, Čára, Výpočet a Časové hlášení můžete sledovat trendy eskalace, úzká místa a výkon. Sledujte míru eskalace, opakovanou eskalaci a dobu eskalace pomocí karet propojených s úkoly, vlastními poli a stavy.
Chcete-li jít ještě dál, použijte karty AI, jako jsou AI Executive Summary, AI Project Update a AI StandUp, abyste zdůraznili trendy, zpoždění a výsledky řešení.
Spravujte své incidenty rychleji s ClickUp
Mnozí si myslí, že eskalace incidentů spočívá pouze v předání tiketu další osobě, ale je to mnohem víc než to. Jedná se o strukturovaný systém, ve kterém každý krok, od třídění až po řešení, funguje v harmonii.
ClickUp vám nabízí dokonalý jednotný pracovní prostor. S ClickUp Automations můžete automaticky spouštět upozornění, směrovat úkoly a aktualizovat stavy. A ClickUp Brain pomáhá prioritizovat incidenty, generovat souhrny a navrhovat další kroky.
Agenti ClickUp AI fungují jako inteligentní asistenti ve vašem pracovním prostoru, zatímco panely ClickUp poskytují živý přehled o vašich eskalacích.
Zaregistrujte se do ClickUp ještě dnes zdarma!
Často kladené otázky (FAQ)
Cesta eskalace incidentů je předem definovaná sekvence kroků, která určuje, jak jsou problémy směrovány ke správnému týmu nebo jednotlivci na základě závažnosti, dopadu a načasování. Zajišťuje, že incidenty jsou řešeny efektivně a odpovědnost je jasná. TEXT
Automatizaci použijte pro jasně definované incidenty s vysokou prioritou a jasnými kritérii (např. výpadky služeb, narušení bezpečnosti). Ruční eskalaci si ponechte pro nejednoznačné nebo kritické situace, které vyžadují lidský úsudek nebo další kontext.
Platformy jako ClickUp, PagerDuty, Jira Service Management a ServiceNow umožňují automatické směrování, oznámení a aktualizace. Pomáhají týmům snižovat zpoždění a udržovat strukturované pracovní postupy při řešení incidentů.
Nastavte jasné prahové hodnoty pro výstrahy, stanovte priority podle závažnosti a využívejte inteligentní oznámení. Omezte opakovaná oznámení na kritické incidenty a využijte dashboardy nebo nástroje umělé inteligence k sumarizaci aktualizací, místo abyste zasílali každou drobnou změnu.
Pravidelně, alespoň jednou za čtvrt roku nebo po závažných incidentech, kontrolujte zásady eskalace. Tím zajistíte, že kritéria, odpovědnosti a pravidla automatizace odrážejí aktuální pracovní postupy, struktury týmů a obchodní priority.