
Първите няколко услуги са лесни. Една ротация, един канал и след това резервно копие.
Въпреки това, когато вашата компания достигне десетки микроуслуги, множество региони и многослойна собственост, ръчното ескалиране престава да бъде работен процес и се превръща в пречка.
Това ръководство обяснява как да автоматизирате пътищата за ескалиране на инциденти, които се мащабират според вашата инженерна организация, без да създават пропуски във вашата система за дежурства.
Ще видим и как ClickUp се вписва в създаването на система за ескалация, на която вашите инженерни екипи могат да се доверят. 🎯
⭐ Представен шаблон
Реагирайте бързо и ефективно при извънредни ситуации, от природни бедствия до нарушения на сигурността на данните, като използвате шаблона на ClickUp за план за действие при инциденти (IAP).

Шаблонът ви предоставя предварително дефинирани секции за:
- Определете целите на инцидентите и приоритетите за реакция
- Създайте ясна командна структура
- Координирайте действията между екипите в реално време
- Записвайте решения, срокове и ключови актуализации в момента, в който се случват.
- Останете свързани с ескалацията и проследявайте развитието
И тъй като се намира в ClickUp, той функционира като документ за управление на инциденти в реално време, а не като статичен списък за проверка.
Защо да автоматизирате процесите по ескалиране на инциденти
Когато екипът ви разполага със сложни системи с строги SLA, ръчното ескалиране само ви забавя. Автоматизираното ескалиране прави процеса на реагиране предсказуем и безстресен, дори при инциденти с голямо напрежение.
Ето защо трябва да автоматизирате ескалационните пътища на вашата организация. 👇
Рискът от ръчно ескалиране
Когато имате работа с десетки услуги, множество дежурства и постоянно променяща се отговорност, стъпките, зависещи от човешкия фактор, бързо се превръщат в проблем.
Често срещани капани включват:
- Пропуснати или забавени известия, когато някой пропусне имейл, SMS или чат съобщение
- Объркване при предаването на задачи, особено когато пътищата за ескалация не са ясно документирани
- Ескалиране към грешния екип, защото картата на отговорностите не е актуализирана
- Пречки, причинени от разчитането на един човек да „препрати сигнал за тревога“
📖 Прочетете също: Как да напишете доклад за инцидент
Предимства на автоматизацията
Автоматизацията на ITSM придава структура и динамика на вашите пътища за ескалация. Вместо да се надявате, че някой ще види предупреждението, вашата система изпълнява предварително определена последователност незабавно и последователно.
Ето какво печелят екипите, когато използват изкуствен интелект за автоматизиране на задачите:
- По-бързо време за реакция, защото сигналите достигат до правилния човек или екип в рамките на секунди.
- Последователно изпълнение на стъпките за ескалация, дори в 3 часа сутринта, когато вземането на решения е по-бавно.
- Вградена резервираност, която гарантира, че резервните отговарящи лица получават уведомление, ако основният дежурен пропусне сигнализацията.
- Ясна видимост между екипите, защото всички разбират как протича ескалацията
- По-малко гасене на пожари и по-предвидими дежурства
📖 Прочетете също: Примери за планове за непрекъснатост на дейността
Намаляване на умората от аларми и човешките пропуски
Умората от алармите унищожава ефективността на дежурните. Когато екипът ви получава прекалено често сигнали или по неправилни причини, той спира да реагира спешно. Автоматизацията помага да се филтрират и ескалират само случаите, които наистина изискват човешко внимание.
С автоматизирана логика за ескалация:
- Сигналите с ниска интензивност или дублиращите се сигнали се потискат, преди да достигнат дежурния.
- Правилата, базирани на степента на сериозност, гарантират, че незначителни проблеми няма да събудят някого без необходимост.
- Сигналите се ескалират само ако системата открие липса на отговор в рамките на определен период от време.
- Екипите прекарват по-малко време в сортиране на шума и повече време в решаване на реални проблеми.
Подкрепа за спазването на SLA и политиката за дежурство
Автоматизираното ескалиране улеснява спазването на изискванията без постоянен ръчен надзор. За ръководителите на ИТ операции, които управляват строги SLA или вътрешни ангажименти за надеждност, AI служи като предпазна бариера, която налага очакваното поведение. Тя ви помага да:
- Уверете се, че уведомленията за инциденти следват предварително определени правила за маршрутизиране.
- Поддържайте автоматично сроковете за реакция по SLA с ескалации по график.
- Прилагайте графици за дежурства, без да разчитате на остарели таблици.
- Създайте одитни следи за всяко предупреждение, ескалация и потвърждение.
🎥 Искате да управлявате целия си работен процес по ескалация без да се налага да правите нищо? Super Agents ви помага . 👇🏼
🔍 Знаете ли, че... Контролният център на НАСА работи основно на базата на автоматизирана логика за ескалация. Ако телеметрията излезе извън обхвата, системата незабавно изпраща автоматизирани сигнали до специалистите по области.
Какво е политика за ескалация в управлението на инциденти?
Политиката за ескалация е предварително определен набор от правила, който определя кои лица се уведомяват, кога се уведомяват и как отговорността се прехвърля нагоре или между екипите.
Представете си го като структуриран план, който предотвратява забавянето на инцидентите, гарантира, че подходящите експерти се включват в подходящия момент, и помага на екипите да спазват SLA.
Една добре структурирана политика за управление на ескалацията обикновено включва:
- Маршрутизиране на базата на правила, което определя кой е следващият в реда, когато някой не потвърди или не може да разреши инцидента.
- Времеви тригери, които автоматично ескалират след 5, 15 или 30 минути в зависимост от сериозността
- Методи за уведомяване като телефонни обаждания, SMS, чат или имейл
- Нива на плана за ескалация от ниво 1 (първоначален дежурен) > ниво 2 (старши инженери/SME) > ниво 3 (ръководство)
- Очаквания за документацията, така че новите реагиращи лица да могат да поемат без да губят важен контекст
📖 Прочетете също: Как да приоритизирате задачите като P0, P1, P2, P3 и P4
Видове политики за ескалация
Ето основните видове политики, които вашият екип трябва да разбере:
1. Йерархично ескалиране (вертикално)
Сигналите се прехвърлят нагоре по веригата на командване, от младши инженери към старши специалисти и ръководство. Използвайте това, когато ситуацията изисква по-задълбочени експертни познания, правомощия за вземане на решения или видимост на ръководството.
2. Функционално ескалиране (хоризонтално)
Вместо да се предава нагоре, сигналът се предава между екипите до функцията, която отговаря за засегнатата система. Това е идеално за инциденти, свързани с конкретна област, като бази данни, мрежи, плащания или API.
3. Ескалация въз основа на време
Това е основата на повечето автоматизирани системи. При този тип сигналът преминава към следващото ниво след определен период от време, често пряко свързан с SLA. Това е особено важно, когато се нуждаете от гарантирана реакция извън работното време.
4. Ескалация въз основа на въздействието
Ескалацията въз основа на въздействието зависи от сериозността или въздействието върху бизнеса, а не от йерархията или времето. Тя е полезна при прекъсвания, неуспешни плащания, проблеми с клиенти или нарушения на сигурността.
5. Паралелно ескалиране
В този случай няколко души или екипа се уведомяват едновременно. Паралелното ескалиране се използва за проблеми с висока степен на сериозност, които изискват няколко специалисти, или за ситуации, в които всяко забавяне е неприемливо.
🔍 Знаете ли? Неотдавнашно проучване на сигналите за предупреждение установи, че изключително ярките или „шумни/ярки“ предупреждения могат да забавят времето за реакция, особено ако предупреждението е неочаквано. Но след като типът предупреждение стане очакван (т.е. част от предварително проектирана система за ескалация/уведомяване), времето за реакция се подобрява. Това предполага, че когато автоматизирате пътищата за ескалация, не трябва просто да засипвате хората с аларми с висок приоритет.
Кога да задействате автоматично ескалиране
Сега, когато знаете как са структурирани пътищата за ескалация, следващата стъпка е да решите кога тези правила трябва да се изпълняват автоматично.
По-долу са посочени основните ситуации, които предизвикват автоматично ескалиране, формирайки логическия слой зад вашите политики. 💁
Ескалация въз основа на сериозността
Автоматичното ескалиране се задейства, когато сериозността или въздействието на инцидента превиши определен праг. Инцидентите с висока сериозност изискват незабавно внимание от висшестоящите, а автоматичното ескалиране заобикаля пречките и включва експертите в процеса за секунди.
📌 Пример: Пълно прекъсване на услугата, отказ на платежния портал или сериозно влошаване, засягащо много потребители или основни системи, изисква автоматично ескалиране.
Ескалация на базата на време
Ако никой не потвърди или не разреши инцидента в рамките на определено време, сигналът автоматично се ескалира до следващото ниво. Това предотвратява забавянето на билетите, особено извън нормалното работно време или когато първият отговарящ не е на разположение или е претоварен.
📌 Пример: След 10-15 минути без потвърждение, се извършва ескалация от първия реагиращ към старши инженер; след още 30-60 минути без решение, се извършва по-нататъшна ескалация.
Контекстуално ескалиране
Тази логика на ескалация взема предвид контекстуалните характеристики на инцидента, като засегнатата услуга или система, собственика на услугата, засегнатия сегмент клиенти (вътрешни срещу външни, VIP срещу обикновени) или функционалната област (база данни, мрежа, интеграция). Въз основа на този контекст сигналите се препращат към най-подходящия отговорник или екип.
По този начин избягвате претоварването на екипите с нерелевантни инциденти, намалявате времето за реакция и гарантирате, че специалистите се занимават с проблеми в тяхната област.
📌 Примери: Скок в латентността на платежната услуга трябва да сигнализира директно на екипа по плащанията, а грешка в бекенда на микроуслугата за фактуриране трябва да уведоми екипа по фактурирането.
Ескалация на базата на метаданни
Съвременните инструменти за предупреждение и инциденти записват метаданни като източника (кой инструмент за мониторинг или правило за предупреждение е задействано), самоличността на потребителя/клиента, местоположението, честотата на подобни инциденти в миналото или етикети. Това ви помага да прилагате по-подробна и интелигентна логика, вместо да разчитате на груби правила, основани на тежестта или времето.
📌 Примери: Повтарящи се предупреждения от една и съща подсистема могат да indicar по-дълбок, системен проблем, който изисква по-бързо ескалиране. Или предупрежденията за VIP клиенти могат да предизвикат допълнителни уведомления.
Комбиниране на тригери за създаване на по-интелигентни, адаптивни политики за ескалация
На практика много екипи не разчитат само на един тип тригер. Вместо това те създават хибридни политики за ескалация, които комбинират правила за тежест, време, контекст и метаданни.
Този многопластов подход позволява на екипите да създават политики за ескалация, които са едновременно отзивчиви (бързи, когато е необходимо) и интелигентни (селективни, за да се сведе до минимум шума), което води до по-добри резултати при инциденти и по-ефективно разпределение на ресурсите.
🔍 Знаете ли, че... През 18-ти век екипажите на военните кораби са използвали строга верига за ескалация при извънредни ситуации. Ако моряк с по-нисък ранг забележеше опасност, той звънеше с камбана и предаваше съобщението нагоре по йерархията, докато капитанът вземеше окончателното решение.
Как да проектирате ефективни пътища за ескалация
Проектирането на пътища за ескалация означава изграждането на система, която надеждно препраща правилните сигнали към правилните хора с минимални затруднения.
Ето една практична, стъпка по стъпка рамка, която можете да използвате в сложни, разпределени среди.
П.С. Ще разгледаме и как някои функции на ClickUp могат да ви помогнат в това! 🤩
Стъпка № 1: Определете ясни критерии, нива и отговорности за ескалация
Започнете с определяне на това, което представлява инцидент, който изисква ескалация. Документирайте обективни критерии, така че всеки дежурен инженер, независимо дали е нов L1 реагиращ или опитен SRE, да интерпретира сериозността на инцидента по един и същи начин.
Това осигурява ясен работен процес за ескалация, премахва неяснотите и гарантира, че автоматизацията се задейства само когато е наистина необходимо.
Включете критерии като:
- Прагове за сериозност: прекъсване на услугата, проблеми с плащанията, проблеми с удостоверяването, повреждане на данни и предупреждения за сигурността
- Въздействие: Прекъсвания в обслужването на клиенти, влошаване на вътрешните услуги, грешки в API на партньори, съответствие или риск за безопасността
- Контекст, критичен за бизнеса: въздействие върху клиенти с висока стойност, потоци, засягащи приходите, системи с висок риск (напр. плащания, фактуриране)
След като критериите и тригерите са определени, начертайте кой получава сигнал и какви са неговите отговорности на всеки етап от ескалацията.
Определете ясно нивата:
- Ниво едно (първичен дежурен мениджър по инциденти): Действа като първи реагиращ и отговаря за потвърждаване, първоначална сортировка и опити за смекчаване на последиците.
- Ниво две (резервен/специалист/SME): Осигурява дълбока техническа експертиза и решава сложни системни проблеми.
- Ниво три (инженер-мениджър/ръководство): Наблюдава сериозни инциденти, одобрява важни действия, координира комуникацията между екипите и при необходимост задейства ескалация към доставчика.
🚀 Предимство на ClickUp: Използвайте ClickUp Docs, за да поддържате единен източник на информация за критериите, нивата и отговорностите за ескалация, както и да документирате ролите и отговорностите, включително кой:
- Потвърждава и смекчава
- Комуникира със заинтересованите страни
- Обработва ескалации от доставчици или външни партньори
- Ръководи командването при инциденти
Можете също да свържете тези конкретни роли с съответните задачи в ClickUp, за да поддържате контекста свързан.
Създайте своя собствена база от знания:
След като критериите за ескалация и отговорността са определени, екипите се нуждаят от последователен начин за записване, проследяване и анализиране на техническите инциденти. Шаблонът за доклад за инциденти на ClickUp предоставя структурирана, леснодостъпна система за документиране на ИТ и оперативни инциденти на едно място.
Вграден в ClickUp Docs, той помага на екипите за реагиране при инциденти да записват важни подробности като тежестта на инцидента, засегнатите услуги, времевата рамка, обобщения на основните причини, стъпки за смекчаване на последиците и последващи действия.
Стъпка 2: Стандартизирайте създаването на инциденти
Преди пътеките за ескалация да се активират, екипът ви се нуждае от надежден начин за събиране, нормализиране и обогатяване на данните за инцидентите. Ако първоначалният запис на инцидента е непълен или непоследователен, дори и най-сложната логика за ескалация ще се провали.
Стандартизацията трябва:
- Сортиране на входящите сигнали: Преобразувайте сигналите в последователни потребителски полета като сериозност, категория, засегната услуга, тип инцидент и статус на потвърждение.
- Обогатете инцидента автоматично: Въведете метаданни, включително клъстер, идентификационен номер на разгръщането, собственици на услуги или зависимости.
- Уверете се, че всеки инцидент отразява контекста: Запишете кой го е докладвал, как е бил открит, средата (производствена/тестова) и всички съответни логове или екранни снимки.
Създайте формуляр ClickUp директно от списъка, в който се проследяват инцидентите, и го проектирайте така, че да отразява вашата оперативна реалност и съответните данни, от които зависи вашата логика за ескалация. По този начин, вместо фрагментирани съобщения в чата, имейла или таблото, всеки инцидент влиза в системата ви в единен формат, по който автоматизацията може да действа надеждно.

Групирайте полетата целенасочено, така че всеки инцидент да бъде напълно контекстуализиран:
- Идентификация (заглавие, резюме)
- Класификация (тежест, тип, засегната услуга)
- Източник (мониторинг, потребител, API)
- Доказателства (регистри, екранни снимки)
- Бизнес контекст (ниво SLA, въздействие върху клиентите)
Всяко подаване на формуляр автоматично създава нова задача в ClickUp, като всички отговори се отразяват в персонализираните полета на ClickUp. Това гарантира, че инцидентите се нормализират в момента на създаването им, като се премахва двусмислието и се елиминира необходимостта от ръчно реагиране на инциденти.
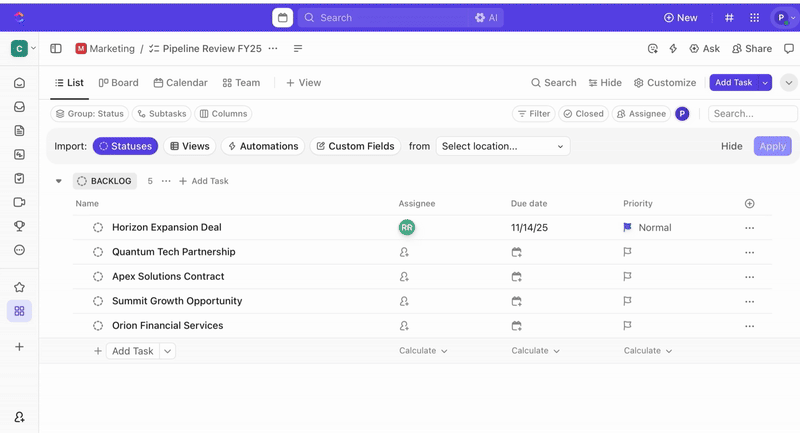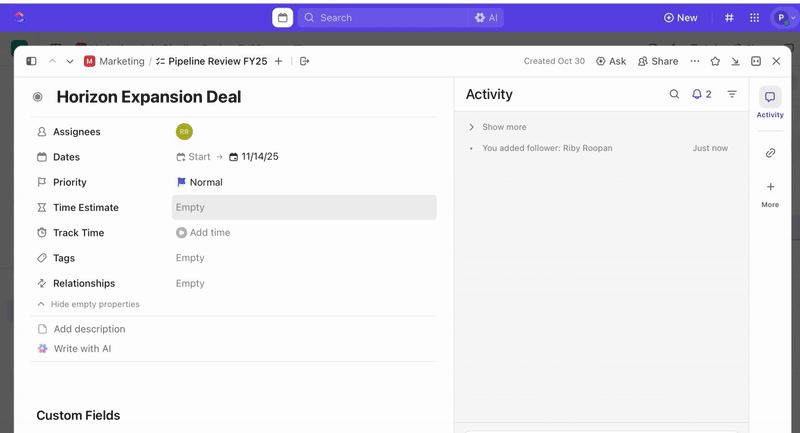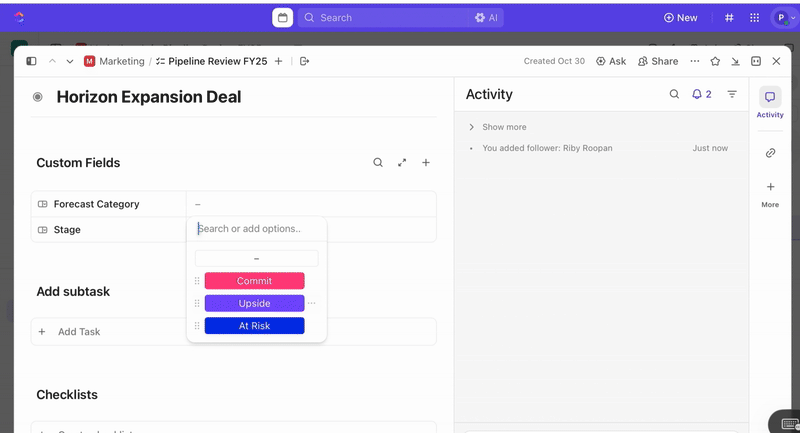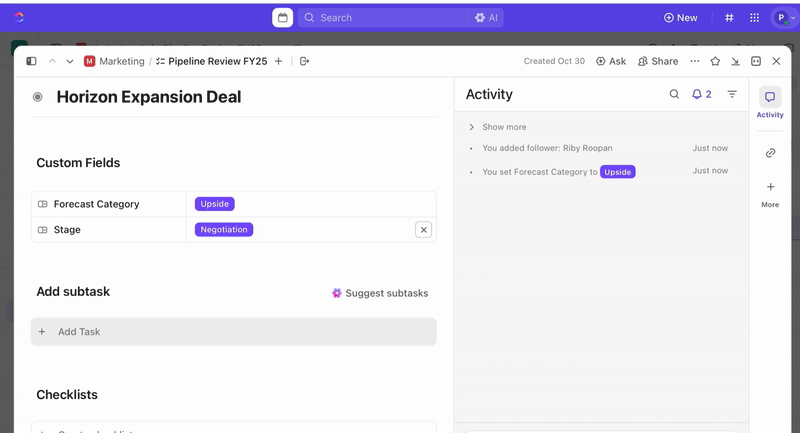
След като задачите са създадени, можете да използвате персонализирани полета, за да управлявате сортирането и приоритизирането (например сериозност, въздействие, група отговарящи) и да дефинирате персонализирани статуси в ClickUp, които отразяват етапите на инцидента (Нов > Сортиране > Разследване > Омекотяване > Решен).
Стъпка 3: Изградете пътя за ескалация (т.е. последователност + време + канали)
Това е същността на пътя. Разпределете пътя на етапи, като всеки етап определя кой се уведомява, по какъв канал (канали) и след колко време без потвърждение или разрешаване.
- Определете „време за потвърждение“ и „време за разрешаване“.
Ето един пример за работен процес:
- Етап едно: Първият дежурен, уведомен незабавно чрез SMS/чат канал, трябва да потвърди в рамките на 5-10 минути.
- Втора фаза: Ако в следващите 15-20 минути няма потвърждение или действие, ескалирайте към екипа за поддръжка/SRE + старши инженер чрез SMS/чат канал/имейл.
- Етап три: Ако след още 30-60 минути проблемът все още не е решен, ескалирайте го до инженерния мениджър/ръководството и по желание задействайте канал за „сериозни инциденти“.
- Решете дали пътят за ескалация трябва да се „повтори“ (да се уведоми отново същото ниво) или да „продължи напред“.
- За критични инциденти настройте повтарящи се известия, докато някой не отговори. За инциденти с по-ниска приоритетност може да предпочетете единствен ескалационен поток.
- Уверете се, че пътят е документиран с помощта на шаблон за реакция на обслужване на клиенти и е достъпен за всички съответни служители.
❗️ Забележка: „Време за потвърждение“ е времето, в което първият реагиращ трябва да потвърди, че е видял предупреждението, докато „време за разрешаване“ е времето, в което екипът трябва да отстрани или смекчи проблема, преди да се задейства следващата ескалация.
Стъпка 4: Вградете автоматизация и поддръжка на инструменти
След като критериите, процесът на сортиране и стандартите за обогатяване са въведени, следващата стъпка е да се активира ескалацията, без да се разчита на хората да помнят кога и към кого да ескалират. Тук ClickUp Automations се превръща в основна част от вашия работен процес.

Можете да настроите възможности за автоматизация, които реагират на същите сигнали, които вашият екип използва по време на инциденти. Ето няколко примера:
- Ако степента на сериозност се актуализира до SEV-1 ➡️ Незабавно назначете старши SRE + уведомете дежурния чат канал
- Ако състоянието остане непроменено в продължение на X минути ➡️ Задействайте ескалация до следващото ниво
- Ако крайният срок изтече (напр. краен срок за потвърждение) ➡️ Ескалирайте до L2
И тук ClickUp Brain отива още по-далеч. Той използва контекста от вашето работно пространство, за да предоставя незабавни отговори, автоматично да генерира актуализации и да поддържа достъпа до знания.
Използвайте инструменти като AI Prioritize, за да оценявате автоматично инцидентите и да задавате правилната приоритетност, използвайки собствената си логика. Примери за подсказки:
- Ако инцидентът засяга производството и оказва влияние върху клиентите, задайте приоритет: Спешно
- Ако отговорникът е екипът на SRE и в логовете се споменава „латентност“, задайте приоритет: Висок
- Ако описанието включва ключови думи, свързани със сигурността, като „нарушение“, задайте приоритет: спешно.
И след като приоритетът е зададен, AI Assign поема контрола и автоматично разпределя инцидентите въз основа на зададените от вас условия.
Можете да създадете подсказки като:
- Ако приоритетът е спешен и засегнатата услуга включва „плащания“, възложете задачата на старши SRE.
- Ако типът инцидент е база данни и регионът е US-East, възложете на DB On-Call.
- Ако името на задачата включва „сигурност“, възложете я на ръководителя на SecOps.
Тествайте тези подсказки върху първите три задачи, преди да ги приложите към целия списък.
🚀 Предимство на ClickUp: Внедрете интелигентни ботове за автоматизация, които се намират във вашето работно пространство и реагират на дейностите в реално време с ClickUp Super Agents.
Те са напълно запознати с вашите задачи, документи, чатове и процеси, така че всяко автоматизирано действие е контекстуално.
Например, можете да поставите Team StandUp Agent във вашата „Папка с инциденти в производството“, така че той автоматично да публикува ежедневно обобщение всяка сутрин. Вашият екип получава незабавен обзор, показващ броя на отворените инциденти, кои от тях остават нерешени и какви промени са настъпили през последните 24 часа.
Сега съчетайте това с Ambient Answers Agent във вашия канал „#incident-room“. Когато отговарящите задават въпроси като „Къде е ръководството за SEV-1?“ или „Имало ли е предишни проблеми с този API?“, той ще извлече информация от знанията във вашето работно пространство, за да даде незабавни и точни отговори.

Стъпка 5: Стандартизирайте каналите за комуникация
Когато инцидентите ескалират, начинът и мястото, където екипите комуникират, са също толкова важни, колкото и това кой получава уведомление. Без стандартизирани канали актуализациите се губят, решенията се дублират и заинтересованите страни получават противоречива информация.
Определете ясни канали за ескалация за всеки етап от жизнения цикъл на инцидента и ги използвайте последователно във всички екипи:
| Критерии | Име на канала | Цел |
| SEV-1 или SEV-2 открити | #incident-critical | Централно място за сигнали с висока степен на сериозност и незабавно сортиране |
| Активно отстраняване на проблеми в ход | #incident-warroom | Център за сътрудничество в реално време за инженери, продуктови специалисти, специалисти по качество и поддръжка |
| Необходима е видимост на ръководството | #incident-leadership | Актуализации с висока значимост за мениджъри и ръководители |
| Необходима е комуникация с клиенти | #incident-comms | Пространство за изготвяне, преглед и съгласуване на комуникациите с външни клиенти |
| Започна преглед след инцидента | #incident-retro | Структурирана дискусия за ретроспективни бележки, изводи и действия |
Всеки канал има определена аудитория и цел, което помага на екипите да намалят шума, като същевременно информират подходящите екипи.
🚀 Предимство на ClickUp: Съчетайте стратегията си за канали с вграден слой за комуникация, използвайки ClickUp Chat. Всяко предупреждение, актуализация и решение остава пряко свързано с задачата, списъка или пространството, където се извършва работата.
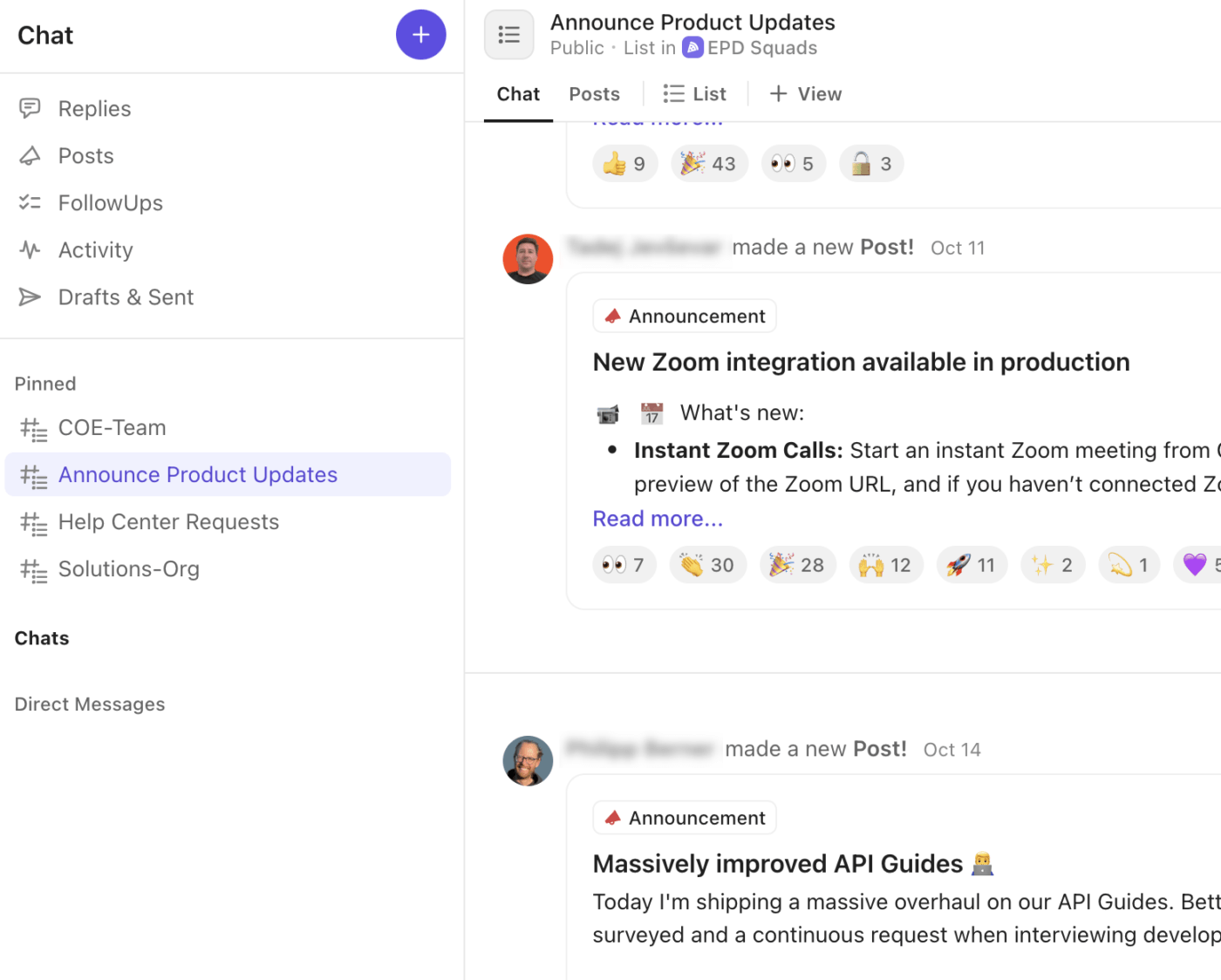
Ето как ClickUp Chat подобрява работния процес при инциденти:
- Създайте специални чат низове за критични дискусии, дискусии в кризисен център, дискусии на ръководството или дискусии с клиенти.
- Превърнете чат съобщенията в задачи в ClickUp мигновено, като се уверите, че решенията и последващите действия не се губят в разговора.
- Включете се в бързи аудио или видео разговори с ClickUp SyncUps за координация на инциденти на живо или брифинги на ръководството.
- Публикувайте „обявления“ или актуализации, за да разпространите информация за състоянието на инцидентите на високо ниво в цялата компания.
- Маркирайте колеги, добавяйте скрийншотове и прикачайте логове директно в чата, за да запазите техническия контекст наблизо.
Стъпка 6: Тествайте, проверете и усъвършенствайте пътя за ескалиране
Политиките за ескалация трябва да се развиват заедно с вашите системи. Ето какво трябва да правите редовно:
| Дейност | Какво да тествате или прегледате | Защо е важно |
| Учения за пожарна безопасност (на тримесечие) | Симулирайте инциденти P1 и P2, проверете времето за ескалация и маршрутизирането. | Гарантира, че автоматизацията и ескалационните пътища работят под натиск |
| Валидиране на пътя за ескалация | Проверете за ескалации в задънена улица или липсващи собственици. | Предотвратява забавянето на инцидентите без видимост |
| Таймери за потвърждаване и разрешаване на процеси | Сравнете конфигурираните таймери с действителните MTTA и MTTR | Поддържа ескалацията реалистична и ефективна |
| Оценка на умората от аларми | Идентифицирайте отговарящите лица, които получават прекалено много или повтарящи се сигнали | Намалява изтощението и пропуснатите критични предупреждения |
| Точност на тежестта и приоритизирането | Проверете дали инцидентите са класифицирани правилно. | Подобрява маршрутизирането, скоростта на реакция и точността на ескалацията |
| Проследяване след инцидент | Уверете се, че действията от ретроспективите са изпълнени. | Предотвратява повтарящи се инциденти и системни откази |
Инструменти и интеграции за автоматизация на ескалацията
В тази секция ще ви запознаем със софтуера за управление на инциденти, който ви помага да откривате инциденти по-бързо, да ги препращате незабавно и да държите всеки екип в течение без ръчно проследяване.
1. ClickUp (Най-доброто решение за обединяване на междуфункционалните ескалации в едно свързано работно пространство за инциденти)
Традиционните методи за ескалация принуждават екипите да се справят с имейли, таблици, чат низове и разпръснати бележки, което прави почти невъзможно да се получи ясна представа в реално време за това, което се случва.
Софтуерът за управление на задачи ClickUp за управление на ескалацията елиминира шума, като консолидира всички подробности за ескалацията в едно единно, организирано работно пространство.
Нека разгледаме някои функции на софтуера за управление на ИТ активи, които позиционират ClickUp като най-добрият избор за екипи, управляващи ескалации с голям обем и сложни работни потоци при инциденти.
Работете по свой начин
Визуализирайте задачите си от различни ъгли, за да отговарят на вашите оперативни нужди с ClickUp Views:
- ClickUp List View, така че ръководителите на SRE да могат да сортират инцидентите по тежест, оставащо време по SLA или дежурни групи за бързо сортиране.
- ClickUp Board View позволява на инженерните мениджъри да визуализират предаването на задачи и отговорностите на екипа по време на ескалации.
- ClickUp Gantt View за ръководители на програми, за да картографират етапите на разрешаване и зависимостите между услугите
- ClickUp Workload View за дежурни планиращи, които гарантират, че инженерите не са претоварени по време на периоди с голям брой инциденти.
Превърнете дискусиите от срещите в действия
По време на ескалации и прегледи на инциденти, надеждното записване на дискусиите и действията може да бъде предизвикателство. ClickUp AI Notetaker автоматично се присъединява към срещите, насрочени в Google Calendar, Outlook, Zoom или Teams, като записва и транскрибира разговора.
След срещата:
- Достъп до транскрипти с възможност за търсене и обобщения на действията
- Осигурете яснота, като използвате бележките, запазени в ClickUp Docs. Това улеснява връзката с задачите по инцидента или ретроспективните доклади.
- Задавайте въпроси на ClickUp AI относно съдържанието на срещите, за да изясните решенията или да откриете пропуснати последващи действия.
Свържете се със съществуващите инструменти във вашия технологичен набор
Зад кулисите, ClickUp Integrations и екосистемата Webhooks осигуряват безпроблемна свързаност с останалата част от вашия стек.
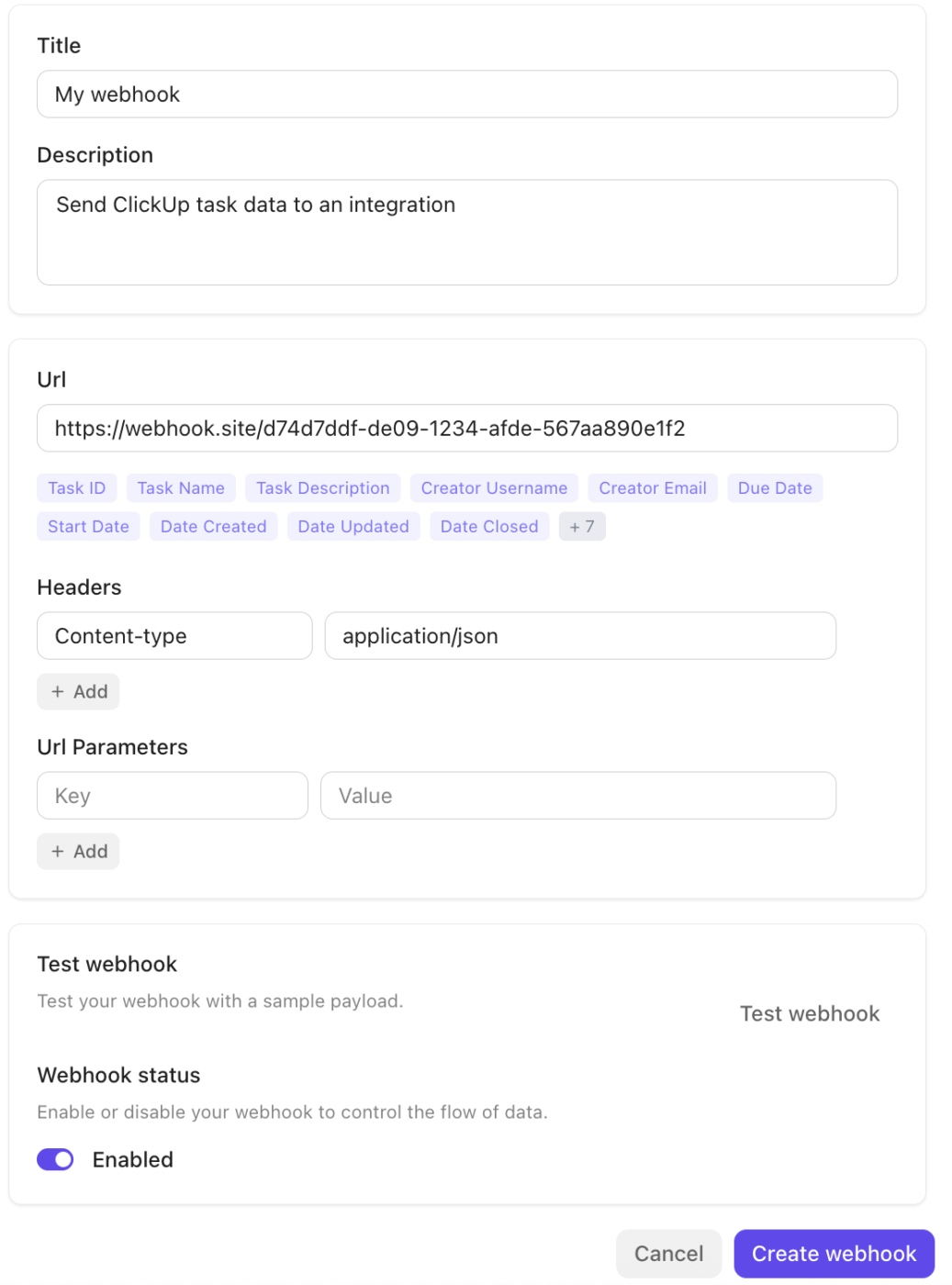
Платформата се интегрира по подразбиране с инструменти като Slack, GitHub, Zoom и други и поддържа Webhooks чрез своя публичен API за разпространяване на събития (актуализации на задачи и промени в състоянието) към външни услуги или автоматизирани процеси. Това улеснява задействането на работни потоци, синхронизирането на данни или ескалирането на инциденти в различни системи без ръчно прехвърляне.
Обединете всичките си AI инструменти
За да пренесете автоматизацията и контекста на следващото ниво, ClickUp BrainGPT въвежда контекстуална изкуствена интелигентност във вашите ескалационни работни процеси. Това е контекстуално супер AI приложение, което разбира вашите задачи, документи и исторически контекст.
С Enterprise Search и Connected Apps можете незабавно да извличате информация от работното си пространство, Slack, Google Drive, GitHub и др. По време на разговори на живо за инциденти, Talk-to-Text в ClickUp ви позволява да диктувате бележки или инструкции за ескалация без да използвате ръцете си, като по този начин се гарантира, че нищо няма да бъде пропуснато.
Можете също да стандартизирате повтарящи се задачи с персонализирани AI подсказки и запазени подсказки, като например: „Обобщете всички нерешени инциденти и препоръчайте действия за ескалация“.
Най-добрите функции на ClickUp
- Приоритизирайте критичните проблеми: Използвайте ClickUp Task Priorities, за да подчертаете спешните или високоприоритетни ескалации.
- Организирайте сложни последователности за ескалация: Настройте зависимостите на задачите в ClickUp, за да свържете свързани задачи (например „В очакване“ или „Блокиране“), така че стъпките за ескалация да избягват преждевременни действия или затруднения.
- Разделете инцидентите на изпълними части: Разделете ескалациите на подробни действия и ги разпределете между екипите с вложени подзадачи.
- Проследявайте точно скоростта на разрешаване: Записвайте и наблюдавайте колко време отнема потвърждаването и разрешаването на ескалираните задачи с функцията за проследяване на времето по проекти на ClickUp.
Ограничения на ClickUp
- С толкова много функции, изгледи и опции за персонализиране, екипите често се сблъскват с крива на обучение, преди всичко да им се струва интуитивно.
Цени на ClickUp
[Ценова таблица]
Оценки и рецензии за ClickUp
- G2: 4,7/5 (над 10 300 отзива)
- Capterra: 4,6/5 (над 4400 отзива)
Какво казват реалните потребители за ClickUp?
Този отзив наистина казва всичко:
ClickUp събира всичките ми задачи, проекти и комуникация на едно място, което прави организирането изключително лесно. Обичам това, че всичко може да се персонализира – от изгледите и работните процеси до таблата – така че мога да структурирам работното си пространство точно по начина, по който ми е необходимо. Възможността да сътруднича в реално време, да възлагам задачи и да проследявам напредъка, без да сменям инструментите, е огромно предимство.
ClickUp обединява всичките ми задачи, проекти и комуникация на едно място, което прави поддържането на организация изключително лесно. Обичам това, че всичко може да се персонализира – от изгледите и работните процеси до таблата – така че мога да структурирам работното си пространство точно по начина, по който ми е необходимо. Възможността да сътруднича в реално време, да възлагам задачи и да проследявам напредъка, без да сменям инструменти, е огромно предимство.
📮 ClickUp Insight: 21% от хората казват, че повече от 80% от работния си ден прекарват в повтарящи се задачи. А други 20% казват, че повтарящите се задачи отнемат поне 40% от деня им.
Това е почти половината от работната седмица (41%), посветена на задачи, които не изискват много стратегическо мислене или креативност (като последващи имейли 👀).
Супер агентите на ClickUp помагат да се елиминира тази тежка работа. Помислете за създаване на задачи, напомняния, актуализации, бележки от срещи, изготвяне на имейли и дори създаване на цялостни работни процеси! Всичко това (и още много други неща) може да бъде автоматизирано за нула време с ClickUp, вашето приложение за всичко, свързано с работата.
💫 Реални резултати: Lulu Press спестява 1 час на ден на всеки служител, използвайки ClickUp Automations, което води до 12% увеличение на ефективността на работата.
2. PagerDuty (най-доброто решение за сигнализиране в реално време и интелигентна реакция при повикване)
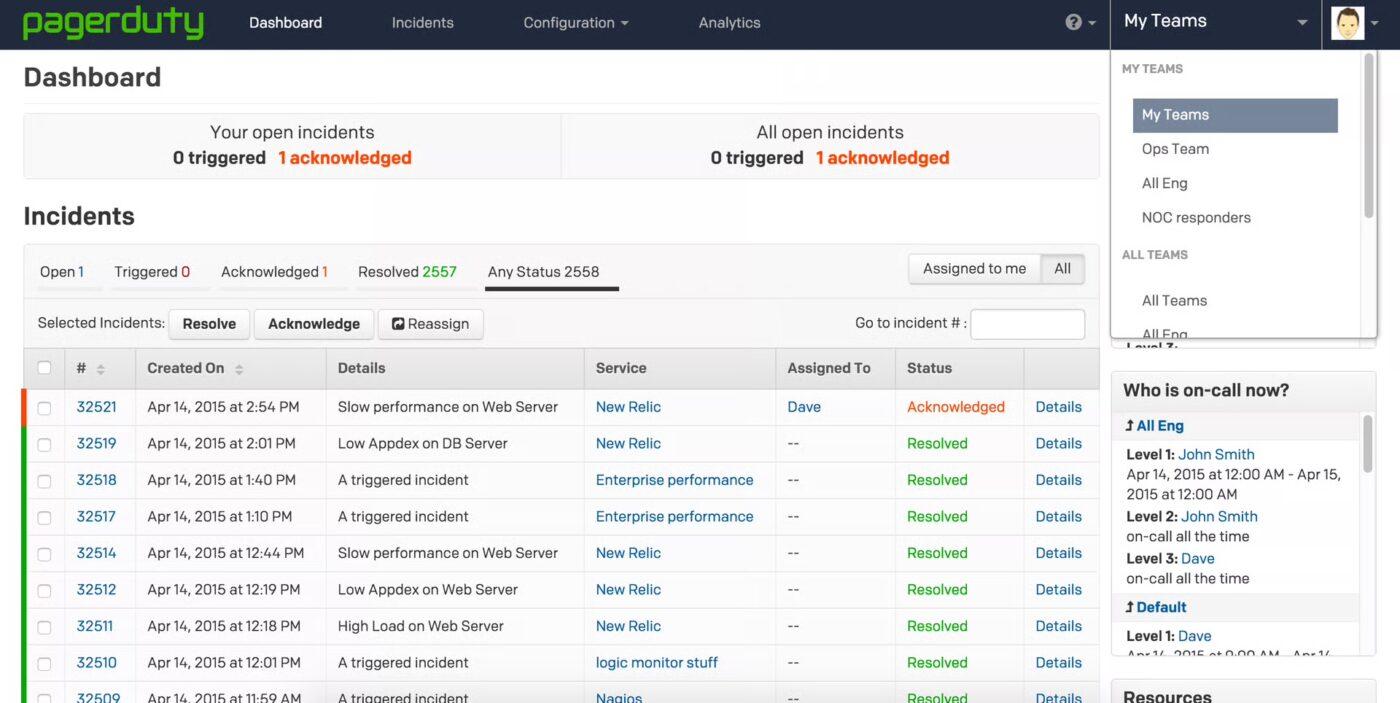
PagerDuty е облачна платформа за управление на ИТ инциденти и цифрови операции, която помага на екипите бързо да откриват, реагират и разрешават критични инциденти като прекъсвания или заплахи за сигурността. Тя предоставя на SRE, DevOps и ръководителите на поддръжката ясен път от сигнал до разрешаване, подкрепен от автоматизация, сортиране, задвижвано от изкуствен интелект, и дълбоко интегрирани работни потоци.
Функции като Jeli Incident Analysis, PagerDuty Analytics и Runbook Automation помагат на екипите да намалят прекъсванията, да елиминират рутинните задачи и да се учат от всеки инцидент.
Най-добрите функции на PagerDuty
- Автоматизирайте маршрутизирането на инциденти с вграденото управление на дежурствата и динамичните политики за ескалация.
- Ускорете сортирането с помощта на AIOps, което филтрира шума от предупрежденията, корелира събитията и подчертава истинските сигнали.
- Поддържайте вътрешните и външните заинтересовани страни в синхрон с Stakeholder Comms, Status Update Templates и Status Pages.
- Обединете набора си от инструменти с над 700 интеграции и разширяеми API чрез системи за мониторинг, регистриране, CI/CD и поддръжка.
Ограничения на PagerDuty
- Висок брой сигнали за тревога, ако интеграциите и интелигентните прагове не са настроени, което води до шум и умора
- По време на пикови натоварвания може да се появят дублирани или повтарящи се сигнали, което затруднява потвърждаването под натиск.
Цени на PagerDuty
- Безплатно
- Професионална версия: 25 USD/месец на потребител
- Бизнес: 49 $/месец на потребител
- Предприятие: персонализирано ценообразуване
Оценки и рецензии за PagerDuty
- G2: 4,5/5 (над 900 отзива)
- Capterra: 4,6/5 (над 200 отзива)
Какво казват реалните потребители за PagerDuty?
По думите на един реален потребител:
PagerDuty прави сигналите за инциденти бързи и надеждни. Изпраща правилните уведомления в точното време и поддържа екипа ни организиран. […] PagerDuty може да бъде шумно понякога, когато сигналите не са добре филтрирани. Някои настройки са малко сложни за нови потребители.
PagerDuty прави сигналите за инциденти бързи и надеждни. Изпраща правилните уведомления в точното време и поддържа екипа ни организиран. […] PagerDuty може да бъде шумно понякога, когато сигналите не са добре филтрирани. Някои настройки са малко сложни за нови потребители.
💡 Съвет от професионалист: Създайте изключения, дори и при ясен път за ескалация. Нека критичните прекъсвания, сигналите за сигурност или инцидентите в регулирана среда да се препращат директно към старши или специализирани отговарящи лица.
3. GLPi (Най-доброто решение за цялостно управление на активи и ITIL-съобразени сервизни операции)
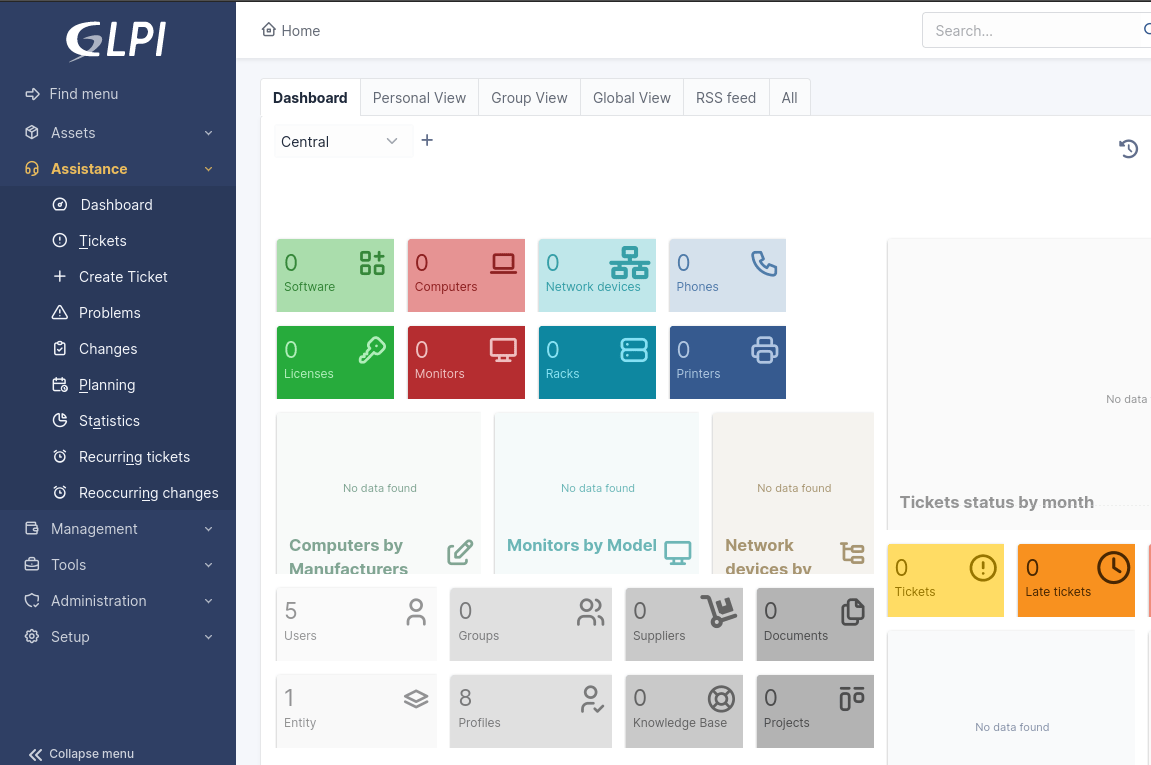
Gestionnaire Libre de Parc Informatique (GLPi) е пълномащабна платформа с отворен код за управление на ИТ услуги (ITSM) и ИТ активи (ITAM). Екипите получават цялостен поглед върху инфраструктурата си (хардуер, софтуер, лицензи и мрежови устройства) и могат да управляват инциденти, заявки за услуги и промени, използвайки процеси, съобразени с ITIL.
Всички ваши договори и документация, включително гаранции и сервизни споразумения, остават добре организирани, което предотвратява загубата им в различни системи. Ако управлявате центрове за данни, GLPi ви позволява дори да визуализирате разположения, кабелни трасета и енергопотребление, за да знаете винаги какво се случва зад кулисите.
Най-добрите функции на GLPi
- Използвайте приставки GLPI Inventory, OCS Inventory или FusionInventory, за да откривате и каталогизирате автоматично нови ИТ активи.
- Автоматизирайте повтарящи се задачи, задания за билети, известия и повтарящи се събития, за да намалите ръчната работа.
- Създайте база от знания за често задавани въпроси, документация и статии, свързани с билетите за самообслужване и техническа поддръжка.
- Свържете се с Azure/Entra, Centreon, Google, OAuth2 и уебхукове, за да синхронизирате данни, да задействате работни потоци и да подобрите вашата CMDB.
Ограничения на GLPi
- Съвместимостта на приставките може да се наруши между версиите, което води до допълнителни разходи за поддръжка.
- Възможностите за отчитане, анализи и експортиране изглеждат ограничени и се нуждаят от подобрение.
Цени на GLPi
- Персонализирани цени
Оценки и рецензии за GLPi
- G2: 4,6/5 (над 30 отзива)
- Capterra: 4,5/5 (над 40 отзива)
Какво казват реалните потребители за GLPi?
Ето какво споделя един от потребителите:
Много адаптивна система за управление на ИТ активи и поддръжка с отворен код, с голяма поддържаща общност. Потребителският интерфейс е малко сложен за начинаещи. Плъгините не винаги се поддържат от старите версии към новите.
Много адаптивна система за управление на ИТ активи и поддръжка с отворен код, с голяма поддържаща общност. Потребителският интерфейс е малко сложен за начинаещи. Плъгините не винаги се поддържат от старите версии към новите.
4. Splunk On-Call (най-подходящ за препращане на сигнали за мониторинг директно към инженерите)
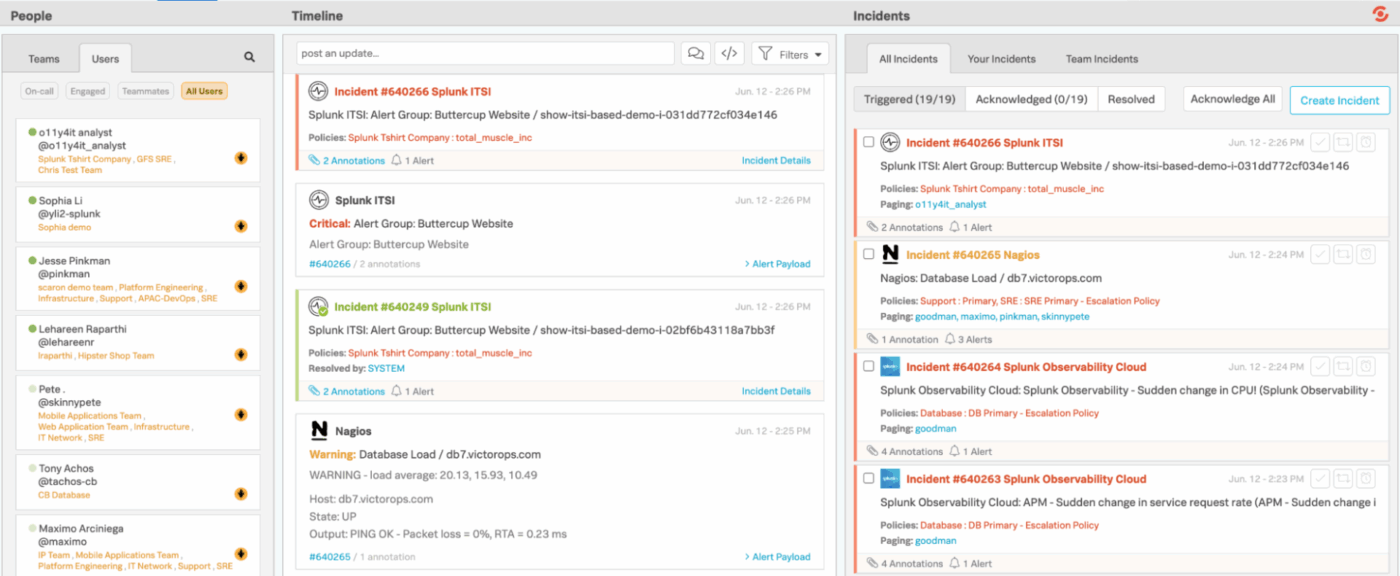
Splunk On-Call предоставя на инженерните и дежурните екипи по-бърз и по-ясен начин за управление на инциденти, като елиминира необходимостта от бавни, традиционни работни процеси за издаване на билети. Вместо да изпраща сигнали в обща опашка, той се интегрира директно с вашия стек за мониторинг и наблюдение, като незабавно препраща проблемите към подходящите лица въз основа на графици, правила и контекст.
Интеграциите с мобилни устройства и чат улесняват потвърждаването, пренасочването или разрешаването на инциденти отвсякъде. А зад кулисите Splunk On-Call поддържа подробен архив на тенденциите, доказаните модели и поведението при ескалация.
Най-добрите функции на Splunk On-Call
- Разширете възможностите на платформата, като използвате над 1000 проверени интеграции и добавки от Splunk и по-широката общност.
- Създавайте персонализирани табла и визуални отчети, за да следите обема на сигналите, състоянието на инцидентите, ефективността на отговарящите и натоварването на екипа.
- Бързо филтрирайте инциденти според вашата собствена дейност, инциденти на екипа или всичко, което се случва в организацията.
- Превключвайте между Triggered, Acknowledged и Resolved Views, за да видите в какъв етап се намира всеки инцидент.
Ограничения на Splunk On-Call
- Планирането на смени в няколко екипа може да се усложни, ако правилата не са предварително определени.
- Ограничена възможност за генериране на подробни отчети за инциденти по дати
Цени на Splunk On-Call
- Персонализирани цени
Оценки и рецензии за Splunk On-Call
- G2: 4. 6/5 (40+ отзива)
- Capterra: 4,5/5 (над 30 отзива)
Какво казват реалните потребители за Splunk On-Call?
Един потребител го обобщи по следния начин:
Възможността да се справям с инциденти, ескалации и да поемам задълженията на колегите си от мобилното приложение е страхотна. […] Бих искал да мога да планирам преопределяния и да променям редовния график от мобилното приложение за спешни промени в графика.
Възможността да се справям с инциденти, ескалации и да поемам задълженията на колегите си от мобилното приложение е страхотна. […] Бих искал да мога да планирам преодолявания и да променям редовния график от мобилното приложение за спешни промени в графика.
🔍 Знаете ли, че... Логиката „пренасочване към подходящия човек, ако първото ниво се провали“ има корени в ранните телефонни централи: когато операторите не можеха да свържат обаждането, системата я пренасочваше (или ескалираше) към друг оператор или централа.
5. ServiceNow (най-подходящ за координиране на корпоративно ниво с автоматизация, подпомагана от изкуствен интелект)
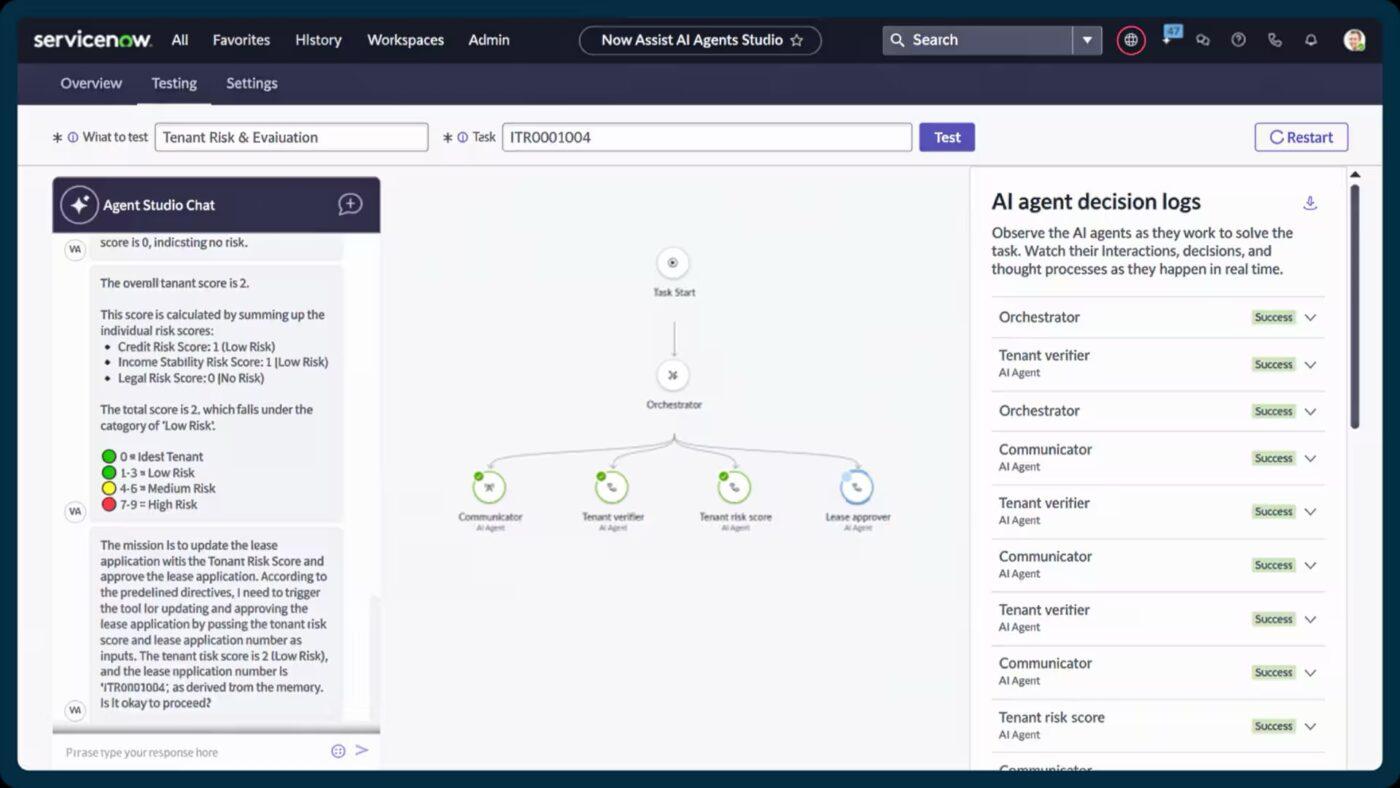
ServiceNow автоматично класифицира, приоритизира и насочва инцидентите в момента, в който бъдат регистрирани. С функции като Now Assist за автоматизирани препоръки за билети за инциденти и интелигентно генериране на съдържание, отговарящите могат да разрешават проблемите по-бързо и с повече контекст.
Той обединява управлението на инциденти, промени и активи. По този начин получавате реална представа за това как са свързани услугите, къде се появяват затруднения и кои компоненти могат да допринасят за повтарящи се прекъсвания.
Най-добрите функции на ServiceNow
- Разпределяйте, насочвайте и наблюдавайте задачите на място чрез Управление на услугите на място и Работно пространство на диспечера.
- Дайте възможност на служителите и клиентите да използват портал за самообслужване, базиран на AI Search и виртуални агенти.
- Използвайте вградените работни потоци и инструменти с ниско ниво на кодиране в App Engine, за да разширите или персонализирате сервизните процеси.
- Автоматизирайте повтарящите се задачи и работни процеси в екипите с Flow Designer и Automation Engine.
Ограничения на ServiceNow
- Опциите за персонализиране на потребителския интерфейс и портала изглеждат остарели или ограничаващи.
- Висока зависимост от квалифициран персонал или консултанти за внедряване
Цени на ServiceNow
- Персонализирани цени
Оценки и рецензии за ServiceNow
- G2: 4. 4/5 (3300+ отзива)
- Capterra: 4,5/5 (над 300 отзива)
Какво казват реалните потребители за ServiceNow?
Ето как го формулира един потребител:
[…] Предварително създадените потоци са друго важно предимство за мен, тъй като те рационализират процесите и спестяват значително време, като намаляват необходимостта от персонализирани конфигурации и позволяват по-гладък и по-ефективен работен процес. […] Освен това имах затруднения да приспособя моето персонализирано решение към системата за управление на обслужването на клиенти, което изискваше доста много повторения.
[…] Предварително създадените потоци са друго важно предимство за мен, тъй като те рационализират процесите и спестяват значително време, като намаляват необходимостта от персонализирани конфигурации и позволяват по-гладък и по-ефективен работен процес. […] Освен това имах затруднения да приспособя моето персонализирано решение към системата за управление на обслужването на клиенти, което изискваше доста много повторения.
Най-добри практики и управление
Ето някои най-добри практики, които гарантират, че автоматизацията остава точна, избягва преумората от сигнали и е в съответствие с бизнес и регулаторните очаквания.
- Определете критерии за ескалация, които не подлежат на договаряне: Свържете тригерите с измерими сигнали като нарушения на SLO, пикове на аномалии, въздействие върху нивото на клиентите или регулаторна чувствителност.
- Уточнете ролите на всеки етап: Използвайте проста RACI карта за всеки етап на ескалация, за да няма неясноти относно отговорностите по време на инциденти с висока степен на напрежение.
- Прилагайте динамично управление на дежурствата: Автоматично коригирайте пътищата за ескалация около уикендите, празниците, ограниченията на капацитета и предаването на дежурствата, за да намалите изтощението и да предотвратите мълчаливите страници.
- Въведете човешки контролни точки за сценарии с висок риск: Дори при автоматизация, изисквайте ръчно потвърждение за инциденти, свързани с излагане на клиентски данни, плащания или регулирани работни процеси.
- Поддържайте пълни одитни следи: Съхранявайте неизменни записи за това кой е бил извикан, кога е потвърдил, какви автоматизирани стъпки са били предприети и какви решения са били взети.
🧠 Интересен факт: Най-старата известна писмена жалба в света е издълбана на глинена плочка около 1750 г. пр.н.е. По същество това е ранен пример за ескалация на статуса на проект. Клиент на име Нани пише на търговеца Еа-насир, ядосан, че полученият от него мед е с по-ниско качество от обещаното и че неговият пратеник е бил третиран зле.
Често срещани предизвикателства и как да ги преодолеете
Дори и при наличието на ясна политика за ескалация, екипите често се сблъскват с оперативни пречки, които забавят реакцията при инциденти или създават объркване.
Тази таблица подчертава често срещаните предизвикателства, които надхвърлят основните стъпки за настройка, и предоставя практически стратегии за преодоляването им.
| Предизвикателства ❌ | Решения ✅ |
| Непоследователен контекст по време на предаването | Използвайте шаблоните за свързване на задачи и доклади за инциденти на ClickUp, за да поддържате пълен одит на подробностите за инцидентите, засегнатите системи и предишните действия на всяко ниво на ескалация. |
| Претоварване на отговарящите с аларми с ниска приоритетност | Въведете динамично приоритизиране с ClickUp Custom Fields и AI Prioritize, за да филтрирате инцидентите въз основа на тежестта, въздействието и праговете на SLA. |
| Липса на видимост между екипите | Настройте споделени работни пространства, добавяйте коментари и създавайте визуални ClickUp Whiteboards, за да представяте актуализации в реално време за заинтересованите страни. |
| Забавено вземане на решения по време на критични инциденти | Автоматизирайте уведомленията, като използвате Предложените действия на ClickUp Brain Max, за да предупредите незабавно подходящия персонал въз основа на типа, тежестта и историческите модели на инцидента. |
| Трудности при проследяването на повтарящи се проблеми | Използвайте персонализираните отчети и шаблони за повтарящи се задачи на ClickUp, за да идентифицирате модели, основни причини и повтарящи се инциденти за проактивна превенция. |
| Фрагментирани знания по време на ескалацията | Поддържайте централизирани SOP, ръководства и документация за инциденти в ClickUp Docs, като ги свържете с съответните задачи за незабавна справка по време на ескалации на живо. |
| Несъгласувани отговорности между смени | Използвайте изгледите „Работна натовареност“ и „Времева линия“ на ClickUp, за да визуализирате задачите и да се уверите, че няма припокривания или пропуски по време на смяна на смени или предаване на задачи. |
| Ръчно проследяване на съответствието и пропуски в одита | Автоматизирайте готовите за одит обобщения с ClickUp Brain, за да регистрирате всички действия, уведомления и решения по инциденти. |
Измерване на въздействието на автоматизираното ескалиране
Проследяването на ефективността на автоматизираното ескалиране изисква фокусиране върху ключови показатели за обем, ефективност и качество. Тези показатели разкриват дали вашите процеси на ескалиране са по-бързи, по-точни и по-малко фрустриращи както за екипите, така и за клиентите.
Проследявайте следните показатели:
- Процент на ескалация (обем): Процент на проблемите, ескалирани отвъд първото ниво. Високите проценти могат да показват пропуски в първоначалната сортировка или в базите от знания.
- Честота на ескалация (обем): Честотата, с която един и същ проблем се ескалира многократно. Показва непълни решения или загубен контекст.
- Време за ескалация (ефективност): Продължителност от откриването до ескалацията. По-кратките етапи означават по-бързо автоматично разпознаване на критични проблеми.
- Време за забавяне на предаването (ефективност): Разлика между ескалацията и момента, в който следващият екип започва работа, за да се подчертае конфликтът при маршрутизирането или уведомяването.
- Време за разрешаване на ескалираните случаи (ефективност): Общо време от ескалацията до разрешаването. По-бързото разрешаване показва ефективността на автоматизацията.
- Оценка на удовлетвореността на клиентите (CSAT) (качество): обратна връзка за ескалираните взаимодействия, за да се измери гладкостта на пътя
- Предаване на контекста (качество): Дали агентите получават пълната история на инцидента, за да се гарантира, че клиентите не повтарят информацията
- Решаване при първия контакт (FCR) (качество): Процент на проблемите, решени при еднократно взаимодействие
🚀 Предимство на ClickUp: Получавайте в реално време визуални и базирани на изкуствен интелект анализи за всички показатели за ескалация с таблата за управление на ClickUp.
Можете да проследявате тенденциите при ескалацията, пречките и производителността с таблични, кръгови, бар, линейни, изчислителни и карти за отчитане на времето. Наблюдавайте честотата на ескалацията, повтарящата се ескалация и времето до ескалация с карти, свързани с задачи, персонализирани полета и статуси.
За да стигнете още по-далеч, използвайте AI карти като AI Executive Summary, AI Project Update и AI StandUp, за да подчертаете тенденции, забавяния и резултати от разрешаването на проблеми.
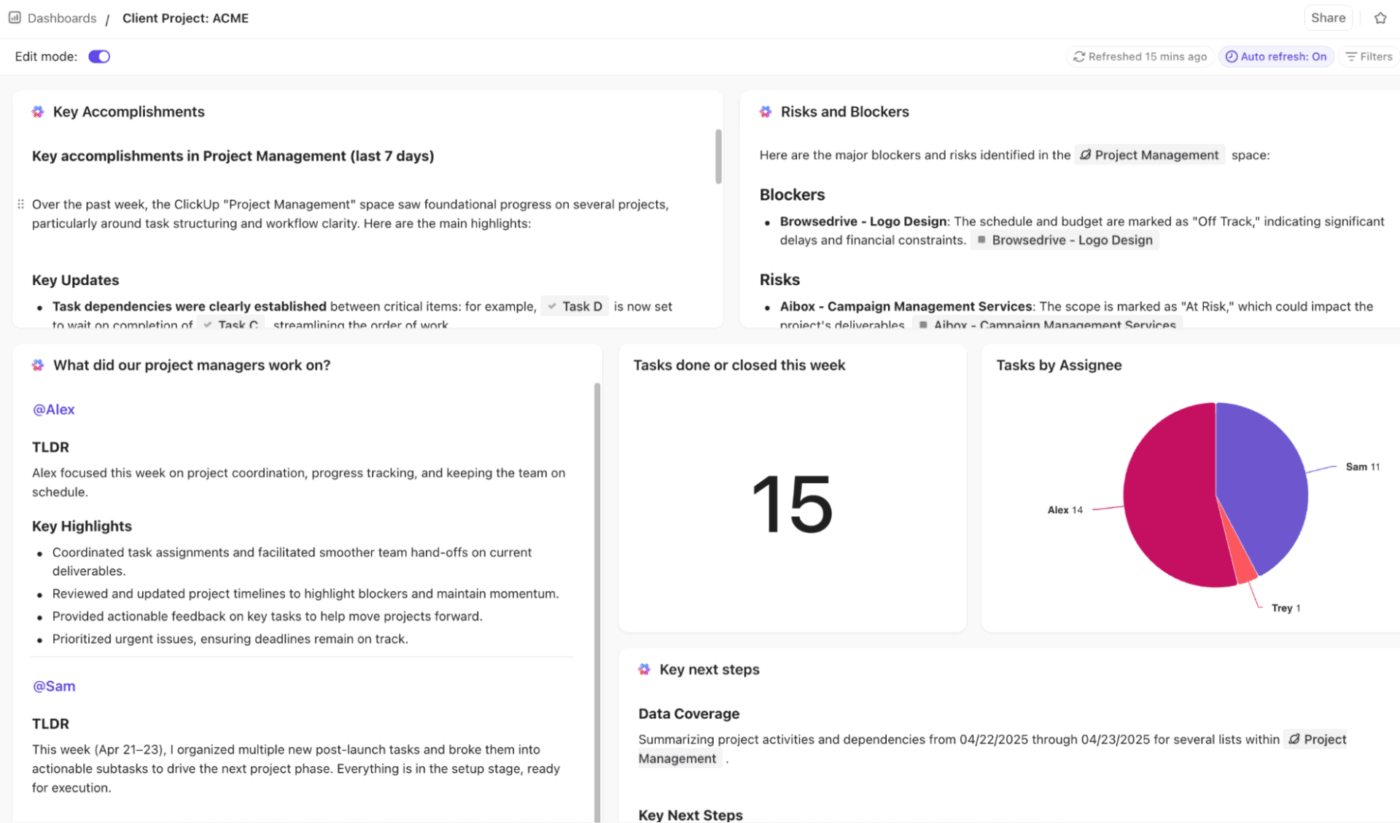
Управлявайте инцидентите си по-бързо с ClickUp
Мнозина смятат, че ескалацията на инциденти се състои само в предаването на билет на следващия човек, но всъщност е много повече от това. Това е структурирана система, в която всяка стъпка, от сортирането до разрешаването, работи в хармония.
ClickUp ви предоставя идеалното унифицирано работно пространство. С ClickUp Automations можете да задействате предупреждения, да пренасочвате задачи и да актуализирате статуси автоматично. А ClickUp Brain помага да се приоритизират инцидентите, да се генерират обобщения и да се предложат следващи стъпки.
AI агентите на ClickUp действат като интелигентни асистенти във вашето работно пространство, а таблата на ClickUp предоставят актуална информация за вашите ескалации.
Регистрирайте се безплатно в ClickUp още днес!
Често задавани въпроси (FAQ)
Пътят за ескалиране на инциденти е предварително определена поредица от стъпки, която определя как проблемите се насочват към подходящия екип или лице въз основа на тежестта, въздействието и времето. Тя гарантира, че инцидентите се разглеждат ефективно и отговорността е ясна. ТЕКСТ
Използвайте автоматизацията за добре дефинирани инциденти с висок приоритет и ясни критерии (например прекъсвания на услугите, нарушения на сигурността). Запазете ръчното ескалиране за неясни или критични ситуации, които изискват човешка преценка или допълнителен контекст.
Платформи като ClickUp, PagerDuty, Jira Service Management и ServiceNow позволяват автоматизирано маршрутизиране, известия и актуализации. Те помагат на екипите да намалят закъсненията и да поддържат структурирани работни потоци при инциденти.
Задайте ясни прагове за предупреждения, приоритизирайте според сериозността и използвайте интелигентни известия. Ограничете повтарящите се известия до критични инциденти и използвайте табла или AI инструменти, за да обобщавате актуализациите, вместо да изпращате всяка малка промяна.
Редовно преглеждайте политиките за ескалация, най-малко веднъж на тримесечие или след сериозни инциденти. Това гарантира, че критериите, отговорностите и правилата за автоматизация отразяват текущите работни процеси, структурата на екипа и бизнес приоритетите.