

Pense em um banco de dados relacional como um arquivo bem organizado, onde cada gaveta e pasta é etiquetada e classificada para facilitar o acesso. Sem ele, encontrar o documento certo pode ser um pesadelo.
Um sistema robusto de gerenciamento de banco de dados relacional [RDBMS] é crucial para qualquer aplicativo de sucesso. Ao organizar e gerenciar dados de forma eficiente, os bancos de dados relacionais tornam o gerenciamento de dados intuitivo e poderoso.
Bancos de dados relacionais bem projetados:
- Adapte-se às metas de negócios sem interromper o sistema.
- Permita uma fácil recuperação de dados
- Não tenha redundância de dados
- Capture todos os dados necessários
Mas o que torna um sistema de gerenciamento de banco de dados relacional “relacional” e por que ele é tão essencial? Esta publicação no blog explorará os conceitos por trás de um sistema de banco de dados relacional e fornecerá as ferramentas necessárias para criar um.
Entendendo bancos de dados relacionais
Um banco de dados relacional armazena dados em um formato estruturado usando linhas e colunas. É como um banco de dados Excel bem organizado, onde os dados são organizados em tabelas. Cada tabela representa um tipo diferente de dados, e as relações entre as tabelas são estabelecidas por meio de identificadores exclusivos conhecidos como chaves.
Isso permite que você recupere e manipule informações com eficiência no mesmo banco de dados ou em vários bancos de dados.
Antigamente, eram principalmente os desenvolvedores que usavam bancos de dados. Eles extraíam informações dos bancos de dados com SQL ou Structured Query Language, uma linguagem de programação. Na verdade, um RDMBS também é chamado de banco de dados SQL.
Um banco de dados não relacional, em contraste, ou um banco de dados NoSQL, armazena dados, mas sem as tabelas, linhas ou chaves que caracterizam um banco de dados relacional. Em vez disso, os bancos de dados não relacionais otimizam seu armazenamento com base no tipo de dados que estão sendo armazenados.
Componentes de um banco de dados relacional
É necessário compreender os componentes fundamentais de um banco de dados relacional para gerenciar e usar dados de maneira eficaz. Juntos, esses componentes estruturam, armazenam e vinculam dados para garantir precisão e eficiência.
1. Tabelas
Imagine as tabelas como a base dos seus dados, onde cada tabela contém informações sobre uma entidade específica. Por exemplo, você pode ter uma tabela Projetos com colunas para ID do projeto, nome, data de início e status. Cada linha dessa tabela representa um projeto diferente, organizado de forma clara para facilitar o acesso.
— Crie a tabela do projeto
CREATE TABLE Projetos (
ProjectID INT PRIMARY KEY,
ProjectName VARCHAR(100),
StartDate DATE,
Status VARCHAR(50)
);
2. Chave primária
Chaves primárias são identificadores ou marcadores exclusivos para cada registro que não podem ser deixados em branco. Elas garantem que uma consulta possa identificar distintamente cada linha em uma tabela, e uma tabela pode ter apenas uma chave primária. Por exemplo, em uma tabela de tarefas, o ID da tarefa pode ser a chave primária, distinguindo cada tarefa das demais.
— Crie a tabela de tarefas
Tarefas CREATE TABLE (
TaskID INT PRIMARY KEY,
TaskName VARCHAR(100),
Data de vencimento DATA
);
3. Chave estrangeira
Uma chave estrangeira é como uma conexão lógica que liga uma tabela a outra. É um campo em uma tabela que cria um link para outra, referenciando uma chave primária nessa tabela. Por exemplo, digamos que você queira identificar os comentários associados a uma tarefa. Assim, em uma tabela Comentários, o ID da tarefa se torna uma chave estrangeira que se liga ao ID da tarefa na tabela Tarefas [acima], mostrando a qual tarefa cada comentário está relacionado.
— Crie a tabela de comentários
CREATE TABLE Comentários (
CommentID INT PRIMARY KEY,
TaskID INT,
ComentárioTexto TEXTO,
CHAVE ESTRANGEIRA (TaskID) REFERÊNCIAS Tarefas(TaskID)
);
4. Índices
Os índices melhoram o desempenho das consultas, permitindo acesso rápido às linhas com base nos valores das colunas. Por exemplo, criar um índice na coluna StartDate na tabela Projects acelera as consultas que filtram por datas de início de projetos.
— Crie um índice na coluna StartDate
CREATE INDEX idx_startdate ON Projects(StartDate);
5. Visualizações
As visualizações são tabelas virtuais criadas por meio da consulta de dados de uma ou mais tabelas. Elas simplificam consultas complexas, apresentando os dados em um formato mais acessível. Por exemplo, uma visualização pode mostrar um resumo dos status dos projetos e das tarefas associadas.
— Crie uma visualização para resumir as tarefas do projeto
CREATE VIEW ProjectTaskSummary AS
SELECT p. ProjectName, t. TaskName
FROM Projects p
JOIN Tasks t ON p. ProjectID = t. ProjectID;
Diferentes tipos de relações em bancos de dados relacionais
Estabelecer como diferentes tabelas interagem em bancos de dados relacionais é crucial para manter a integridade dos dados e otimizar as consultas. Essas interações são definidas por meio de várias relações, cada uma com uma finalidade específica para organizar e vincular dados de maneira eficaz.
Compreender essas relações ajuda a projetar um esquema de banco de dados robusto que reflete com precisão as conexões do mundo real entre diferentes entidades.
1. Relacionamento um-para-um
Imagine um cenário em que cada funcionário [um] tem exatamente um crachá de identificação de funcionário [um]. Assim, nos registros da tabela Funcionários, cada registro corresponderá a um único registro na tabela Crachás de identificação de funcionários. É uma relação um-para-um entre tabelas, em que uma entrada corresponde exatamente à outra.
Aqui está um exemplo de código para ilustrar uma relação um-para-um:
— Crie a tabela dos funcionários
CREATE TABLE Funcionários (
EmployeeID INT PRIMARY KEY,
Nome VARCHAR(100)
);
— Crie a tabela IDBadges
CREATE TABLE IDBadges (
BadgeID INT PRIMARY KEY,
EmployeeID INT UNIQUE,
FOREIGN KEY (EmployeeID) REFERÊNCIAS Employees(EmployeeID)
);
O EmployeeID na tabela IDBadges corresponde exclusivamente [UNIQUE é um comando SQL que não permite dados duplicados ou entradas repetitivas nos registros sob o atributo] a uma entrada no campo EmployeeID na tabela Employees.
2. Relacionamento um-para-muitos
Pense em um gerente de projetos de uma grande organização que supervisiona vários projetos.
Neste caso, a tabela Gerentes de Projeto tem uma relação um-para-muitos com a tabela Projetos. O Gerente de Projeto lida com muitos projetos, mas cada projeto pertence a apenas um Gerente de Projeto.
— Crie a tabela do gerente de projetos
CREATE TABLE Gerentes de Projeto (
ManagerID INT PRIMARY KEY,
ManagerName VARCHAR(100)
);
— Crie a tabela do projeto
CREATE TABLE Projetos (
ProjectID INT PRIMARY KEY,
ProjectName VARCHAR(100),
ManagerID INT,
CHAVE ESTRANGEIRA (ManagerID) REFERÊNCIAS ProjectManagers(ManagerID)
);
O campo ManagerID é a referência que conecta as duas tabelas. No entanto, ele não é exclusivo na segunda tabela, o que significa que pode haver vários registros de um único ManagerID na tabela, ou um gerente pode ter vários projetos.
3. Relacionamento muitos-para-muitos
Imagine um cenário em que vários funcionários [muitos] estão trabalhando em vários projetos [muitos].
Para acompanhar isso, você usaria uma tabela de junção, como Employee_Project_Assignments, que conecta os funcionários aos projetos em que estão trabalhando. Essa tabela terá chaves estrangeiras ligando a tabela Employees e a tabela Projects.
— Crie a tabela dos funcionários
CREATE TABLE Funcionários (
EmployeeID INT PRIMARY KEY,
NomeDoFuncionário VARCHAR(100)
);
— Crie a tabela do projeto
CREATE TABLE Projetos (
ProjectID INT PRIMARY KEY,
NomeDoProjeto VARCHAR(100)
);
— Crie a tabela de atribuições de projetos dos funcionários
CREATE TABLE Employee_Project_Assignments (
EmployeeID INT,
ProjectID INT,
CHAVE PRIMÁRIA (ID do funcionário, ID do projeto),
FOREIGN KEY (EmployeeID) REFERÊNCIAS Employees(EmployeeID),
FOREIGN KEY (ProjectID) REFERÊNCIAS Projects(ProjectID)
);
Aqui, Employee_Project_Assignments é a tabela de junção que vincula funcionários e projetos.
Benefícios dos bancos de dados relacionais
Os bancos de dados relacionais mudaram a abordagem ao gerenciamento de dados. Seus benefícios os tornam a solução ideal para quem trabalha com grandes conjuntos de dados interconectados.
1. Consistência
Imagine tentar entender um conjunto de dados desconexo, em que as tabelas e os campos não seguem regras de nomenclatura e estão espalhados por toda parte — confuso, não é?
Os bancos de dados relacionais se destacam porque se concentram na consistência. Eles aplicam regras de integridade de dados que organizam as informações para manter tudo preciso e confiável.
Por exemplo, se você estiver criando um banco de dados de clientes, os bancos de dados relacionais garantem que os detalhes de contato dos clientes sejam vinculados corretamente aos seus pedidos, evitando incompatibilidades ou erros.
— Crie a tabela do cliente
CREATE TABLE clientes (
customer_id INT PRIMARY KEY,
nome VARCHAR(100),
e-mail VARCHAR(100)
);
— Crie a tabela de pedidos com uma restrição de chave estrangeira
CREATE TABLE pedidos (
order_id INT PRIMARY KEY,
customer_id INT,
order_date DATE,
FOREIGN KEY (customer_id) REFERÊNCIAS clientes(customer_id)
);
Este código impede que os pedidos sejam vinculados a clientes inexistentes, garantindo a consistência dos dados. Assim, usando o modelo relacional, você sempre trabalha com pontos de dados confiáveis, tornando sua análise e seus relatórios descomplicados!
2. Normalização
É cansativo lidar com vários servidores e planilhas e lidar com informações duplicadas de clientes. Os bancos de dados relacionais são uma grande mudança nesse sentido.
A normalização organiza suas estruturas de dados em tabelas perfeitamente relacionadas, que reduzem a redundância e otimizam o armazenamento dos dados usando o modelo relacional.
Imagine um sistema de CRM (Gerenciamento de Relacionamento com o Cliente). A normalização ajuda a separar os detalhes do cliente de suas interações e compras. Se um cliente atualizar suas informações de contato, você só precisará atualizá-las uma vez.
Veja como você pode configurá-lo:
— Crie uma tabela de clientes
CREATE TABLE clientes (
customer_id INT PRIMARY KEY,
nome VARCHAR(100),
e-mail VARCHAR(100),
telefone VARCHAR(20)
);
— Crie uma tabela de pedidos
CREATE TABLE pedidos (
order_id INT PRIMARY KEY,
customer_id INT,
order_date DATE,
total_amount DECIMAL(10, 2),
FOREIGN KEY (customer_id) REFERÊNCIAS clientes(customer_id)
);
— Crie uma tabela de interações com o cliente:
CREATE TABLE interações_com_clientes (
interaction_id INT PRIMARY KEY,
customer_id INT,
interaction_date DATE,
interaction_type VARCHAR(50),
notas TEXTO,
FOREIGN KEY (customer_id) REFERÊNCIAS clientes(customer_id)
);
Com essa configuração, atualizar o e-mail de um cliente é muito fácil — basta fazer a alteração na tabela Clientes, e isso não afeta as consultas ou outras tabelas em nenhum outro lugar. Isso torna o gerenciamento, a consulta e o armazenamento de dados mais eficientes e menos propensos a erros.
3. Escalabilidade
À medida que sua empresa cresce, o mesmo ocorre com o banco de dados de funcionários e o banco de dados de clientes. Os desenvolvedores de sistemas de software de banco de dados relacional projetam bancos de dados relacionais para lidar com grandes volumes de dados.
Quer você esteja gerenciando os registros de vendas de uma startup ou os múltiplos usuários de uma gigante da tecnologia, os bancos de dados relacionais se adaptam facilmente à medida que sua empresa cresce. Eles indexam o modelo de dados e otimizam os conjuntos de dados para manter o desempenho estável à medida que seus dados aumentam.
Por exemplo, para melhorar o desempenho da consulta em uma tabela grande de pedidos, você pode criar um índice na coluna order_date:
— Crie um índice na coluna order_date
CREATE INDEX idx_order_date ON orders(order_date);
Este índice cria um conjunto de dados separado que armazena a localização da coluna order_date e pode ser consultado rapidamente.
A criação de um índice acelera a execução da consulta quando você executa um filtro ou classifica por ordem de data, tornando as transações do seu banco de dados relacional mais rápidas.
Isso também ajuda seus sistemas de gerenciamento de banco de dados relacional a se adaptarem à medida que os pedidos aumentam.
4. Flexibilidade
A flexibilidade é fundamental quando se trabalha com necessidades de dados em constante evolução, e os bancos de dados relacionais oferecem exatamente isso.
Precisa adicionar novos campos ou tabelas? Vá em frente!
Por exemplo, se você precisar rastrear os pontos de fidelidade dos clientes na tabela de clientes do seu banco de dados de Gerenciamento de Recursos do Cliente [CRM], você pode adicionar uma nova coluna:
— Adicione uma nova coluna para pontos de fidelidade
ALTER TABLE clientes ADD pontos_de_fidelidade INT DEFAULT 0;
Essa adaptabilidade garante que seu modelo de gerenciamento de banco de dados relacional possa crescer e mudar de acordo com as necessidades do seu projeto, sem afetar o modelo de dados relacional existente, as estruturas de armazenamento físico, o modelo de armazenamento físico de dados ou as operações do banco de dados.
À medida que exploramos os sistemas de bancos de dados relacionais, o ClickUp se destaca como uma ferramenta versátil de gerenciamento de projetos, oferecendo poderosas funcionalidades de CRM e banco de dados relacional.

O software de gerenciamento de projetos CRM da ClickUp transforma a forma como você gerencia o relacionamento com os clientes e otimiza os processos de vendas. Você pode personalizar o modelo de banco de dados relacional do cliente de acordo com suas preferências, vinculando tarefas, documentos e negócios, e usar automação e formulários para otimizar fluxos de trabalho, automatizar atribuições de tarefas e acionar atualizações de status.
Você pode explorar as informações sobre seus clientes com painéis de desempenho para visualizar métricas críticas, como o valor da vida útil do cliente e o tamanho médio dos negócios.
Além disso, o ClickUp CRM pode ajudá-lo a simplificar o gerenciamento de contas, organizar clientes, gerenciar pipelines, rastrear pedidos e até mesmo adicionar dados geográficos — tudo projetado para aumentar a eficiência e a produtividade do seu CRM.
5. Recursos poderosos de consulta
Para revelar insights em seu banco de dados relacional, você pode usar SQL para realizar pesquisas complexas, unir várias tabelas e agregar dados.
Por exemplo, digamos que você esteja analisando o desempenho das vendas, encontrando o número total de pedidos e seu valor por cliente. Essa consulta une as tabelas de clientes e pedidos para fornecer um resumo do desempenho das vendas por cliente.
Um procedimento armazenado é como um atalho em um banco de dados. Procedimentos armazenados são blocos pré-escritos de código SQL que você pode executar sempre que precisar realizar consultas complexas, automatizar tarefas ou lidar com processos repetitivos.
Ao usar procedimentos armazenados, você otimiza as operações, aumenta a eficiência e garante que as ações do banco de dados sejam consistentes e rápidas. Os procedimentos armazenados são perfeitos para validação de dados e atualização de registros.
O SQL permite reunir dados de diferentes tabelas para criar relatórios detalhados e visualizações. Essa capacidade de gerar insights significativos torna os bancos de dados relacionais uma ferramenta vital para administradores de bancos de dados, analistas de dados ou desenvolvedores de dados.
Etapas para criar um banco de dados relacional
Agora que exploramos e compreendemos os componentes e os diferentes tipos de relações em bancos de dados relacionais, é hora de aplicar o que aprendemos. Aqui está um guia passo a passo para construir um banco de dados relacional. Para entender melhor, criaremos um banco de dados de gerenciamento de projetos.
Etapa 1: Defina o objetivo
Comece esclarecendo o que seu sistema de banco de dados relacional fará.
Em nosso exemplo, estamos construindo um modelo de banco de dados relacional para rastrear propriedades de gerenciamento de projetos, como tarefas, membros da equipe e prazos.
Você deseja que o banco de dados relacional:
- Gerencie vários projetos simultaneamente
- Atribua tarefas aos membros da equipe e acompanhe o progresso deles.
- Monitore os prazos das tarefas e os status de conclusão
- Gere relatórios sobre o andamento do projeto e o desempenho da equipe.
Etapa 2: Projete o esquema
Em seguida, esboce a estrutura do seu banco de dados relacional.
Identifique as entidades principais [tabelas], seus atributos de dados [colunas] e como eles interagem. Essa etapa envolve planejar como seus dados estruturados serão organizados e relacionados.
Entidades para gerenciamento de projetos:
- Projetos: Contém detalhes sobre cada projeto
- Tarefas: Inclui informações sobre tarefas individuais.
- Membros da equipe: Armazena detalhes sobre a equipe
- Atribuições de tarefas: vincula tarefas aos membros da equipe
Aqui está um exemplo de esquema:
| Nome da tabela | Atributos | Descrição |
| Projetos | project_id (INT, PK)project_name (VARCHAR(100))start_date (DATE)end_date (DATE) | A tabela armazena informações sobre cada projeto. |
| Tarefas | task_id (INT, PK)project_id (INT, FK)task_name (VARCHAR(100))status (VARCHAR(50))due_date (DATE) | A tabela contém detalhes das tarefas associadas aos projetos. |
| Membros da equipe | member_id (INT, PK)name (VARCHAR(100))role (VARCHAR(50)) | A tabela contém informações sobre os membros da equipe. |
| TarefasAtribuições | task_id (INT, FK)member_id (INT, FK)assignment_date (DATE) | A tabela vincula tarefas aos membros da equipe com datas de atribuição. |
As relações entre essas estruturas lógicas de dados e tabelas de dados podem, às vezes, ser confusas, pois a maioria dos sistemas de gerenciamento de bancos de dados relacionais se tornam cada vez mais complexos.
Muitos preferem uma representação visual das relações, geralmente por meio de mapas mentais e ferramentas de design de bancos de dados relacionais .
Abordaremos mapas mentais e ferramentas de design de bancos de dados relacionais mais adiante neste artigo.
Etapa 3: Estabeleça relações
Discutimos os tipos de relações anteriormente, e o esquema da tabela ajuda a definir as relações entre as tabelas.
A chave estrangeira é fundamental para garantir a consistência dos dados e permitir consultas complexas.
Eles vinculam pontos de dados relacionados entre tabelas e mantêm a integridade dos dados referenciais em todo o processo, garantindo que cada registro esteja conectado corretamente aos outros.
Mas você precisa compartilhá-lo para facilitar a consulta, como no exemplo abaixo:
- As tarefas estão relacionadas aos projetos por meio do project_id.
- As atribuições de tarefas vinculam tarefas e membros da equipe usando task_id e member_id.
Etapa 4: Criar tabelas
Já discutimos o processo de criação de tabelas, definindo chaves primárias e estrangeiras em profundidade. Você pode consultar essas seções conforme necessário. No entanto, você pode encontrar as consultas SQL abaixo para criar um pequeno banco de dados relacional de gerenciamento de projetos como parte do guia.
— Crie uma tabela de projetos
CREATE TABLE Projetos (
project_id INT PRIMARY KEY,
project_name VARCHAR(100),
start_date DATE,
end_date DATE
);
— Crie uma tabela de tarefas
Tarefas CREATE TABLE (
task_id INT PRIMARY KEY,
project_id INT,
task_name VARCHAR(100),
status VARCHAR(50),
data_vencimento DATA,
FOREIGN KEY (project_id) REFERÊNCIAS Projetos(project_id)
);
— Crie uma tabela de membros da equipe
CREATE TABLE TeamMembers (
member_id INT PRIMARY KEY,
nome VARCHAR(100),
função VARCHAR(50)
);
— Criar tabela de atribuições de tarefas
CREATE TABLE TarefasAtribuídas (
task_id INT,
member_id INT,
assignment_date DATE,
FOREIGN KEY (task_id) REFERÊNCIAS Tasks(task_id),
FOREIGN KEY (member_id) REFERENCES TeamMembers(member_id),
CHAVE PRIMÁRIA (task_id, member_id)
);
Etapa 5: Preencha os dados
Adicione alguns dados reais às suas tabelas para ver como tudo funciona.
Esta etapa envolve testar sua configuração para garantir que seus bancos de dados relacionais funcionem conforme o esperado. Isso inclui inserir detalhes do projeto, descrições de tarefas, membros da equipe e atribuições no banco de dados SQL.
Exemplo de código SQL
— Inserir na tabela Projetos
INSERT INTO Projetos (id_projeto, nome_projeto, data_início, data_término) VALUES
(1, “Redesenho do site”, “2024-01-01”, “2024-06-30”),
(2, “Desenvolvimento de aplicativos móveis”, “2024-03-01”, “2024-12-31”);
— Insira na tabela Tarefas
INSERT INTO Tarefas (id_tarefa, id_projeto, nome_tarefa, status, data_vence) VALUES
(1, 1, “Maquetes de design”, “Em andamento”, “15/02/2024”),
(2, 1, “Desenvolvimento Front-end”, “Não iniciado”, “30/04/2024”);
— Insira na tabela Membros da equipe
INSERT INTO TeamMembers (member_id, name, role) VALUES
(1, “Alice Johnson”, “Designer”),
(2, “Bob Smith”, “Desenvolvedor”);
— Insira na tabela Atribuições de tarefas
INSERT INTO Tarefas (id_tarefa, id_membro, data_atribuição) VALORES
(1, 1, ‘2024-01-10’),
(2, 2, ‘2024-03-01’);
Etapa 6: Consultar dados
Por fim, depois que os dados estiverem armazenados em seu banco de dados relacional, use consultas SQL para recuperá-los e analisá-los. As consultas podem ajudá-lo a acompanhar o andamento do projeto, monitorar as atribuições de tarefas e gerar relatórios valiosos.
Exemplo de consulta SQL
— Consulta para encontrar todas as tarefas de um projeto específico
SELECT t. nome_da_tarefa, t. status, t. data_de_vencimento, tm. nome
DE Tarefas t
JOIN TaskAssignments ta ON t. task_id = ta. task_id
JOIN TeamMembers tm ON ta. member_id = tm. member_id
WHERE t. project_id = 1;
Criando sistemas de gerenciamento de bancos de dados relacionais com a visualização de tabelas do ClickUp
O ClickUp se destaca na criação de bancos de dados relacionais e planilhas organizadas, colaborativas e com visualização clara, usando sua visualização de tabela.
A visualização de tabela do ClickUp suporta mais de 15 tipos de dados, desde fórmulas e progresso de tarefas até custos e classificações, e permite anexar documentos e links diretamente às suas tabelas. Ela oferece uma maneira visual e intuitiva de gerenciar seu banco de dados relacional e a estrutura de dados relacional dentro dos projetos.

Um guia passo a passo para criar um sistema de gerenciamento de banco de dados relacional usando a visualização de tabela do ClickUp.
Etapa 1: Defina o banco de dados
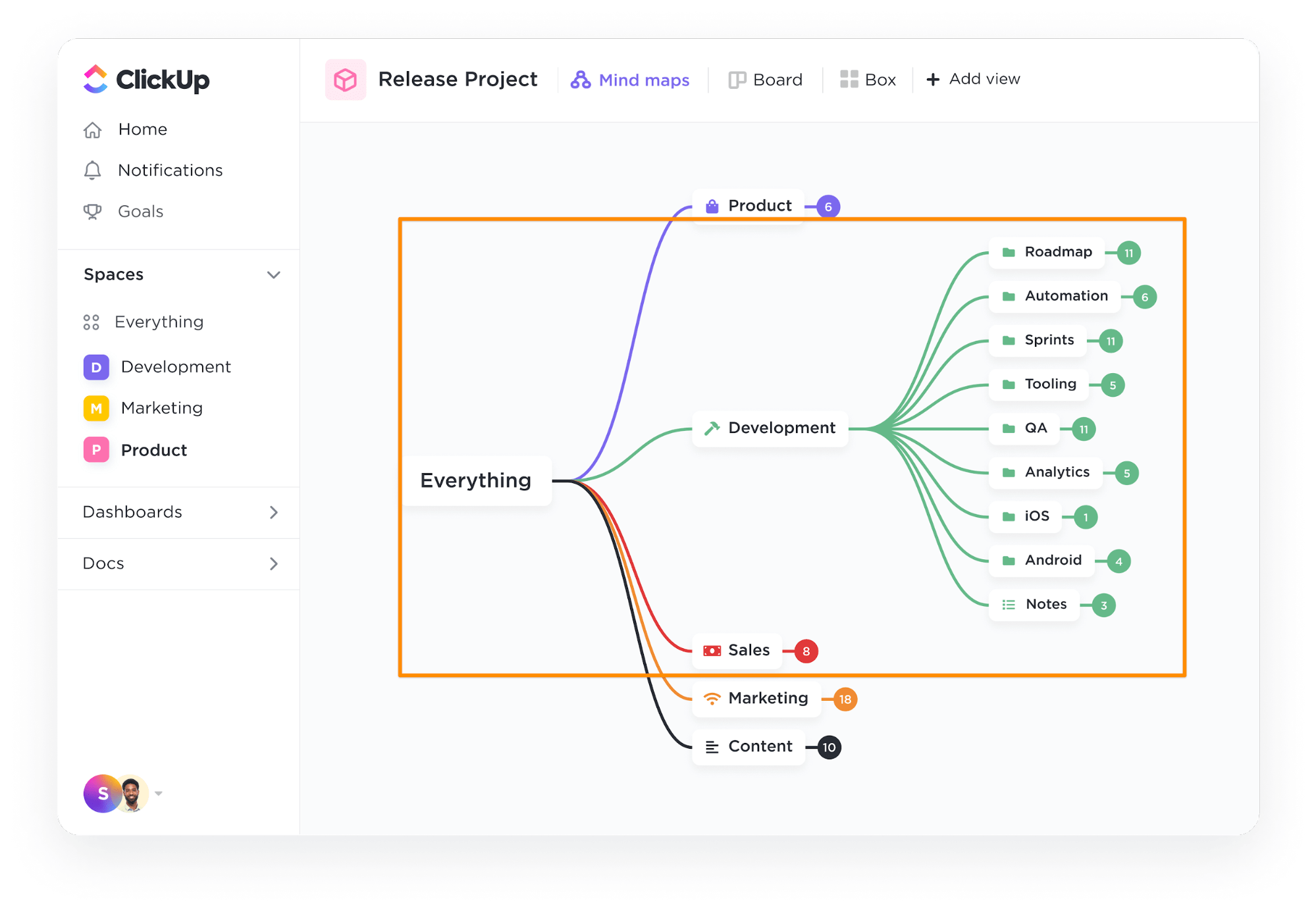
Use a ferramenta ClickUp Mind Maps para preencher e definir o esquema do seu banco de dados, ou seja, quais tabelas criar e suas relações entre si.
Etapa 2: Configure uma exibição de tabela
Navegue até o projeto ou espaço de trabalho desejado no ClickUp.

Adicione uma nova visualização e selecione a visualização Tabela.
Etapa 3: Criar tabelas
Use tarefas e campos personalizados para representar tabelas e colunas.

Organize os principais pontos de dados na visualização Tabela.
Etapa 4: Estabeleça relações
Use campos personalizados para vincular tarefas relacionadas [por exemplo, usando campos suspensos para referenciar outras tarefas].

Mantenha a integridade dos dados, garantindo que os links estejam corretos.
Etapa 5: Gerenciar dados
Adicione, edite e exclua entradas de dados diretamente na visualização Tabela.

Use filtros e opções de classificação para gerenciar e analisar dados.
Etapa 6: Consulta e relatório
Use os recursos avançados de filtragem e relatórios do ClickUp para gerar insights a partir de seus dados relacionais.

Os modelos de banco de dados gratuitos e prontos para uso do ClickUp podem acelerar o processo de criação do seu banco de dados relacional e simplificar as coisas.

O modelo de planilha do ClickUp reúne informações cruciais sobre os clientes para o seu negócio. É um modelo em nível de lista que usa um banco de dados de arquivo simples.
Basta adicionar o modelo ao seu espaço e usá-lo diretamente.
Esses modelos de planilha ajudam você a capturar e gerenciar com eficiência detalhes importantes dos clientes. Você pode armazenar dados com segurança e criar bancos de dados relacionais altamente eficientes que podem ajudar a equipe de vendas da sua organização.
O modelo de planilha editável do ClickUp é o modelo mais facilmente personalizável para gerenciar dados financeiros complexos. Esse modelo simplifica o acompanhamento do orçamento e o planejamento de projetos.
Recursos como importação automatizada de dados, fórmulas financeiras personalizadas, visuais intuitivos para acompanhar o progresso e status, campos e visualizações personalizados para organizar e gerenciar registros financeiros com eficiência tornam-no ideal para especialistas e gerentes de dados financeiros.
Com o ClickUp, você pode automatizar tarefas, configurar atualizações recorrentes e revisar sua estrutura de dados de maneira integrada, garantindo precisão e consistência em todos os seus documentos.
A criação de conteúdo pode rapidamente se tornar algo exaustivo devido à quantidade de conteúdo gerado. Para gerenciar isso, um banco de dados de conteúdo ajuda a organizar e rastrear o conteúdo de forma eficiente, facilitando o dimensionamento à medida que suas necessidades aumentam. Ele consolida todas as informações relacionadas ao conteúdo, como status e métricas, em um sistema padronizado, economizando tempo e evitando a duplicação de esforços.
O modelo de banco de dados do blog da ClickUp é sua ferramenta ideal para gerenciar com eficiência o conteúdo do blog. Ao contrário de outras planilhas de gerenciamento de projetos do Excel, ele é altamente intuitivo e pode ajudá-lo a organizar postagens, otimizar a criação e acompanhar o progresso desde o rascunho até a publicação.

Você pode usar este modelo para:
- Categorize e subcategorize as postagens do blog para facilitar o acesso e a recuperação.
- Monitore o status de cada postagem, desde a concepção até a publicação, com status personalizados.
- Use várias visualizações, como Tabela, Rastreador de status e Hub de banco de dados, para visualizar os dados.
- Use listas de verificação e campos pré-preenchidos para otimizar o processo de criação de postagens no blog.
- Analise o desempenho do blog e gerencie análises para otimizar a estratégia de conteúdo.
Com controle de tempo integrado, tags e avisos de dependência, gerenciar o conteúdo do seu blog nunca foi tão fácil.
Construa uma base sólida com bancos de dados relacionais
Um sistema de gerenciamento de banco de dados relacional é mais do que apenas uma ferramenta para um administrador de banco de dados — é a espinha dorsal do gerenciamento de dados escalável e eficiente. Dominar as complexidades das tabelas, chaves primárias e estrangeiras e relações de banco de dados permite que você projete sistemas robustos e flexíveis.
Ao aproveitar esses princípios e o ClickUp, você pode melhorar a integridade dos dados, otimizar o acesso e impulsionar soluções inovadoras.
Pronto para elevar seu gerenciamento de dados? Inscreva-se hoje mesmo no ClickUp e descubra como ele pode transformar seu gerenciamento de banco de dados relacional e sua produtividade!