

産業が拡大し、新たな競合が市場に参入する中、カスタマーの要求に応えることはますます難しくなっている。このような競争の激化は、顧客離れにつながる可能性があり、中小企業(SMB)では次のようなレポートが作成されています。
/を報告している。 https://www.forbes.com/advisor/business/churn-rate/。 10 から 15 /と報告されている。
.
カスタマーサクセスマネージャーであれ、ライフサイクルマーケティングのプロフェッショナルであれ、解約予測モデルは、顧客離脱の特定と対処方法に革命をもたらすことができます。この技術満載のソリューションを効果的に導入するには、CRMアプリケーションとデータ分析への深い理解が必要です。
この詳細なガイドでは、効果的な解約予測モデルの構築について知っておくべきことをすべて説明します。
解約予測モデルとは?
解約予測モデルとは、カスタムデータを分析する統計的または機械学習モデルです。その目的は、顧客がビジネスとの関係を絶つ可能性を予測するためのインサイトを生成することです。
解約のタイプは以下の通りです:
- 契約解約:*これは、顧客が契約またはサブスクリプション期間の終了時にビジネスとの関係を終了することです。
- 自主的解約:* これは、顧客が契約終了前にビジネスから離れることを選択した場合に起こります。
これらのタイプはどちらも、主に不満や、より良い代替品を見つけることに基づいている。
顧客離れを予測することがビジネスにとって重要である理由をいくつか挙げてみよう:
- 顧客維持戦略の焦点:リスクのある顧客を特定することで、ビジネスは顧客維持の努力を彼らの特定のニーズに合わせて調整し、解約を防ぐことができます。
- Improvesカスタマー・エクスペリエンス ### データの前処理:品質と精度の基礎
情報は刻一刻とスペースに溢れています。ビジネスには、最も適切な洞察を得るために質の高いデータが必要です。
データ前処理は、このような大量の解約予測データを収集し、フィルタリングするデータサイエンスの要素です。ここでは、解約予測におけるデータ前処理の鍵となる2つの要素を紹介します。
データ収集は最初のステップです。顧客情報、請求記録、アンケート回答、市場データの収集が含まれます。 データのクリーニングは、エラーや不整合を特定し修正することで、データの正確性を確保します。インスタンスンスでは、CRMからデータを取り出しますが、データ・クリーニングの段階では、データセット内の重複エントリーや欠落情報を発見するのに役立ちます。
データ分析:解約予測モデルの原動力
データ分析とは、収集したデータをレビューし、ビジネスに役立つ実用的な洞察に変換することです。このデータサイエンスの要素は、ステークホルダーに情報を提供し 顧客維持 戦略を策定し、重要な意思決定に影響を与える。
ここでは、データ分析がどのように解約予測を促進するかをご紹介します:
- パターン、トレンド、関係を特定し、顧客の行動に関する洞察を明らかにします。また、ビジネス戦略の進捗状況を明らかにします。
- 複雑なデータを理解しやすくするために、視覚的な表現を通じて洞察を伝えます。また、チャート、グラフ、ダッシュボードを活用することで、洞察が実行可能なものになります。
- 統計分析の助けを借りて、顧客離れに影響を与える要因間の関係を明らかにします。
こちらもお読みください
/参考文献 https://clickup.com/ja/blog/148859/undefined/ カスタマーサクセスとマーケティング戦略を強化するための製品分析データの活用 /%href/
機械学習:予測力の柱
機械学習は、データから学習し、時間の経過とともにパフォーマンスを向上させるアルゴリズムの開発に焦点を当てている。ここでは、機械学習が正確な解約予測にどのような役割を果たしているかを紹介する:
- 新しいデータから継続的に学習することで、予測精度を向上させます。これにより、顧客のニーズが変化しても正確な解約予測モデルを維持できる。
- 解約リスクの高いカスタマーを特定し、その顧客にリテンション努力を集中させることで、リソース配分を最適化します。
- 解約リスクの増加を示す可能性のある、カスタマーの行動における微妙な変化を検出します。これにより、問題に対処するための積極的なステップを促進する解約予測モデルの能力が強化されます。
このような影響を念頭に置いて、2つの一般的な機械学習のフォームを紹介しよう:
- ロジスティック回帰:このアルゴリズムは、統計分析アプローチを使って複数の変数からデータを見直す。そして、カスタマーの解約の可能性を評価し、イエスかノーのフォーマットで結果を返す。通信、銀行、小売などの生産性やサービスを扱うビジネスに非常に効果的である。
- 意思決定ツリー学習:このモデルは、意思決定とその潜在的な結果を視覚的に表現し、顧客をより細かいセグメントに分類する。決定木は、ビジネスが個々の顧客または特定のグループに戦略を調整することを可能にする。関連するアルゴリズムであるランダムフォレストは、複数の決定木を採用して精度を高め、複雑なデータセットを効果的に処理する。
解約予測モデルの構築方法:ステップ・バイ・ステップの内訳
ここでは、解約予測モデルを構築するためのステップ・バイ・ステップの内訳を示します。
ステップ1:データの収集とレビュー
最初のステップは、質の高いデータを入手することです。
関連するデータソースを特定する。
顧客の属性、履歴データ、購入履歴、利用パターン、カスタマーサポートとのやり取りなど、どのデータソースに解約に関連する情報が含まれているかを特定する。
ここでは、最も効果的なデータソースを紹介します:
- CRMシステム: 履歴データ、デモグラフィック、購入履歴、カスタマーサポートなど、豊富なカスタマー情報を保存しているこれらのシステムを活用する。
- 顧客アンケート:顧客からの直接的なフィードバックを利用して、満足度や解約の理由を把握する。
- ウェブサイトやアプリの分析:ユーザーの行動を追跡し、解約につながる可能性のある傾向や潜在的な問題を特定する。
- ソーシャルメディアのモニタリング:オンライン会話を分析し、顧客の感情を測定し、潜在的な問題を特定する。
- カスタマーサポートのログ: 過去のカスタマーとのやり取りやサポートチケットを確認し、彼らの懸念を理解し、共通の問題点を特定する。
データの収集とクリーニング
選択したソースから必要なデータを収集し、不整合、欠損値、異常値を除去するためにクリーニングと前処理を行い、その品質を確保する。
以下は、チャーン関連データの例である:
- 顧客の属性:年齢、性別、場所など。
- 購買履歴: 購買の頻度、頻度、価値。
- エンゲージメント・メトリクス:ウェブサイト訪問、アプリ利用、カスタマーサポートとのやりとり
- 解約ステータス: 顧客がサービスの利用をやめたかどうか
データを処理することは、効果的な解約予測モデルを開発する上で非常に重要であるが、拡張機能である。精度と構造のプレッシャーの中で、適切なツールは処理時間とリソースを削減することができます。
ClickUpの多彩な機能は、ここに最適です。主にタスク管理とプロジェクト・コラボレーションのために設計されていますが、解約予測プロジェクトのデータ収集、分析、モデリングの各フェーズを即座に強化します。
ClickUpは、すぐに使えるテンプレートとソリューションで、チームのあらゆるオペレーションタスクの効率化を支援します。インスタンスンス
/参照 http://www.clickup.com/teams/crm クリックアップCRM /%href/
連絡先情報の保存から購入履歴の追跡まで、すべてのカスタマー・トランザクションをシームレスに管理。
/イメージ https://clickup.com/blog/wp-content/uploads/2024/08/ClickUp-CRM-Solution.png クリックアップCRMソリューション /クリックアップ
クリックアップCRMソリューションで、すべての顧客データを一元管理し、顧客とのコミュニケーションを改善します。
クリックアップCRMの主な機能は以下の通りです:
- リアルタイムのデータ更新により、最新の顧客フィードバックや製品の使用状況を常に把握できます。これにより、解約予測の精度が向上します。
- コンタクト情報、購入履歴、カスタマーサポート、フィードバックなど、幅広い範囲のカスタマーデータを保存できます。ClickUpの15以上のビュー.これにより、顧客エンゲージメントの包括的なビューが提供され、潜在的な解約指標の特定が容易になります。
- でデータ収集プロセスをカスタムできます。 /でデータ収集プロセスをカスタマイズできます。 https://clickup.com/integrations ClickUp API /%href/ .また、手動によるデータ収集の負担を軽減するために、ビジネスに特化した自動化を構築することもできます。
- /を利用することもできます。 https://clickup.com/integrations 1,000以上のツールを統合 /を統合します。 を統合することで、すべてのプラットフォームにおけるカスタマー・インタラクションの一貫したビューを確保することができます。また、複数の予測モデリングソフトウェアを統合し、解約予測の信頼性を高めます。
- 使用方法 /を使用してください。 https://clickup.com/features/custom-fields ClickUpのカスタムフィールド /を使用します。 とステータスを使用して、解約確率を可視化できます。インスタンスンスでは、「顧客の健康状態」というあらかじめデザインされたデータフィールドを追加することができます。
ClickUp CRMに加えて、このプラットフォーム上のカスタマーサポートデータのためのもう一つの効果的なデータソース機能は以下の通りです。
/参照 https://clickup.com/teams/customer-service です。 クリックアップカスタマーサービス /%href/
.

クリックアップのカスタマーサービスマネジメントを利用して、カスタマーサービスチームに質の高い解決策を迅速に提供できるようにしましょう。
クリックアップカスタマーサービスは、信頼関係を構築し、フィードバックを可視化し、カスタマーの喜びを促進します。また、顧客からのフィードバックを測定するための理想的なデータソースであり、顧客データの収集を容易にします。
このソフトウェアの3つの機能をご紹介します:
- アンケート、サポートチケットログを含む様々なチャネルからのフィードバックを収集・整理し、適切な統合により、ソーシャルメディアとの相互作用も実現します。
- [カスタマーのフィードバックを分析する。](https://clickup.com/blog/how-to-analyze-customer-feedback//) これらとは別に、ClickUpはカスタムテンプレートも提供しており、解約予測モデルのための顧客インサイトを追跡・整理するプロセスの構築に役立ちます。
クリックアップ顧客満足度アンケートテンプレート

顧客満足度アンケートテンプレート
満足度は解約の決め手であり ClickUp 顧客満足度アンケートテンプレート は、顧客満足度を可視化するのに最適な評価フレームワークです。
ここでは、解約予測モデルのためのデータ収集に欠かせない機能をいくつかご紹介します:
- アンケートの作成プロセスを効率化テンプレートの拡張機能と魅力的なプリフィルデータフィールドを使用します。
- 解約ステータスや提案など、より具体的な質問を含むようにデータフィールドをカスタム化する。
- プラットフォーム内蔵の階層ビューで、すべての回答を1つのスペースに集め、整理する。
- ボードビュー、リストビュー、カレンダービューなど、ClickUpのカスタムビューを使って、顧客満足度や改善点を簡単に可視化できます。これらは、解約予測モデルのために収集したいデータを反映させるために簡単にカスタムできます。
💡 Pro Tip:クリックアップカスタムフィールドを使用して、デモグラフィック、購買行動、製品の使用状況など、さまざまな基準に基づいて顧客を分類します。
クリックアップ顧客ニーズ分析テンプレート
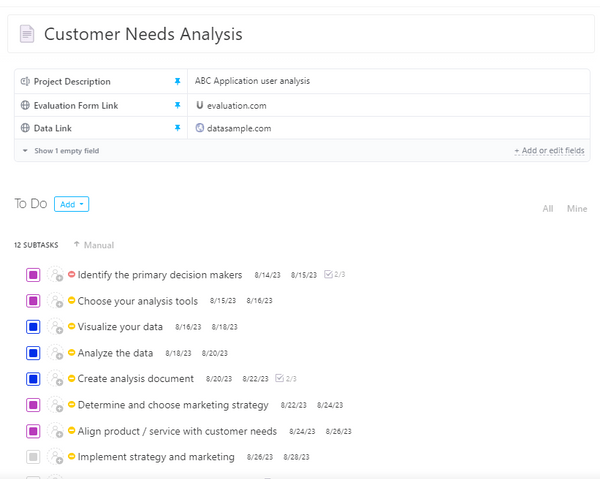
ClickUp顧客ニーズ分析テンプレート
**ClickUp 顧客ニーズ分析テンプレート は、カスタマーのフィードバックを収集、整理、分析するための完璧なフレームワークです。
ここでは、解約に影響する顧客データを特定するのに理想的な、このテンプレートの主な機能をご紹介します:
- 解約に関連するパターンを特定するために、関連する要因に基づいてカスタマーをグループ化します。
- 顧客と製品やサービスとのやり取りをマップし、苦痛のポイントや摩擦の領域を特定する。
- カスタマージャーニーの中で、解約が起こりやすいフェーズを特定します。
これらのテンプレートとクリックアップの包括的なCRMシステムにより、必要な顧客データの収集と処理がシームレスになります。
ステップ2:データ分析におけるオーバーサンプリングとアンダーサンプリングを理解する。
第2のステップは、予測モデルのバイアスを取り除くことです。
データセットはしばしばアンバランスで、解約した顧客よりも解約していない顧客の方が多くなります。これは、リアルタイムの顧客満足度や今後の解約率の可能性に関する不正確な洞察につながります。
このようなバイアスを取り除くために、データサイエンティストやアナリストはデータセットを正規化する必要があります。やることを2つ紹介しよう:
オーバーサンプリング
解約された顧客のインスタンス数を増やして、クラスのバランスを取ります。オーバーサンプリングには主に2つの方法があります:
- ランダム・オーバーサンプリング:* 既存の解約顧客データ・ポイントをランダムに複製します。
- Synthetic minority oversampling:この方法は、重複の繰り返しを避けるために、既存のデータポイントに基づいて新しい合成解約顧客データポイントを作成します。
オーバーサンプリング
アンダースサンプリングは、解約していない顧客のインスタンス数のバランスをとることに重点を置く。これは貴重なデータを失うリスクがあるため、小規模な顧客データプールとは相性が悪い。
以下はアンダーサンプリングの3つの方法である:
- ランダムアンダーサンプリング:マジョリティクラスからインスタンスをランダムに取り除く。
- トメックリンク: これは類似したインスタンスを識別し、除去することを含む。
- クラスタベースのアンダーサンプリング: ここでは、非解約顧客を類似性に基づいてグループ化し、最も一般的なグループから顧客を削除します。これにより、解約していない顧客の多様性を維持しながら、全体の番号を減らすことができます。
バイアスを取り除いた後、変数のエンコードを開始します。
ステップ3:カテゴリ変数のエンコード。
ほとんどの機械学習アルゴリズムは数値データを使って仕事をします。しかし、実世界のデータセットの変数の多くは、テキストやラベルのフォームです。これらはカテゴリー変数と呼ばれる。
テキストやラベルはアルゴリズムとは相容れないので、数値フォーマットでエンコードしなければならない。
以下に2つのエンコード方法を示す:
**1.ワンホット・エンコーディング
ワンホットエンコーディングのステップを以下に示す:
- カテゴリ変数の各カテゴリに新しいバイナリ列を作成する。
- 各行は、そのカテゴリに対応する列に1を持ち、他の列には0を持つ。
例:の場合
- データフィールド: "SubscriptionType"
- カテゴリー: "ベーシック"、"スタンダード"、"プレミアム"
結果:。
エンコードされた結果は、3つの新しい列である:
- SubscriptionType_Basic
- SubscriptionType_Standard
- SubscriptionType_Premium
カスタムデータに基づいて、これらの列には1または0が割り当てられる。
2.ラベルのエンコーディング。
このテクニックは、カテゴリ変数内の各カテゴリにユニークな数値を割り当てることを含む。これは、"Low"、"Medium"、"High "のような自然な注文を持つカテゴリに最適である。
例:.
- データフィールド: 顧客満足度
- カテゴリー:「非常に不満」、「不満」、「どちらでもない」、「満足」、「非常に満足
* 結果:
ラベルエンコーディングでは、各カテゴリーに値1、2、3、4、5が割り当てられる。
解約予測用語集 (英語)
解約予測におけるオーバーフィットとは、モデルがトレーニングデータを学習しすぎてしまい、基本的なパターンを捉えるのではなく、ノイズや癖を記憶してしまうことです。これは、トレーニングデータ上では非常に優れたパフォーマンスを発揮するものの、新しい未知のデータへの汎化に苦労するモデルにつながります。解約予測では、これはモデルがトレーニングセットの顧客の解約を正確に予測しても、将来解約しそうな顧客を正しく識別できないことを意味します。
正則化は、解約モデルが個々の機能に過度な重みを割り当てないようにする手法で、オーバーフィッティングを引き起こす可能性があります。要するに、正則化はモデルが最も重要な機能に集中し、単一の機能に過度に依存することを避けることで、新しい未知のデータに対してより良く汎化することを助けます。
ステップ4:予測モデルの構築
このフェーズでは、準備したデータに対して機械学習アルゴリズムを学習させ、顧客離反を予測するモデルを作成します。
予測モデルを構築するための4つのパートをご紹介します:
正しいアルゴリズムの選択
データの性質と問題によって選択するアルゴリズムが決まります。前のセクションでは、解約予測に最適な機械学習アルゴリズムをいくつか取り上げました。
モデルのトレーニング
アルゴリズムを選択したら、準備したデータセットを使って学習させます。これは、モデルに機能(独立変数)と対応するターゲット変数(解約ステータス)*を与えることを含みます。モデルは、解約を予測できるデータのパターンとリレーションシップを識別するために学習します。
モデルチューニング
モデルをトレーニングしたとはいえ、それが提供できる状態であることを確認する必要があります。モデルのチューニングに最適なアプローチは実験です。
モデルのパフォーマンスを最適化するためには、アルゴリズム内の異なる設定を実験する必要があるかもしれません。このプロセスは、ハイパーパラメータまたはモデルチューニングとして知られています。
以下は、解約予測モデルにおける設定の例です:
- 正則化: オーバーフィッティングを防ぐためにモデルの複雑さを制御します。
- L1正則化: 最も重要な機能を特定します。
- L2正則化:係数の大きさを減らし、オーバーフィッティングを防ぐ。
- 学習率: 学習プロセス中のステップサイズを決定します。
- ランダムフォレストまたは勾配ブースティング・アンサンブルにおける決定木の数を制御する。
最適な組み合わせを見つけるためのアルゴリズムとテクニックをいくつか紹介しよう:
- グリッド探索: 指定されたグリッド内でハイパーパラメータのすべての組み合わせを試す。
- ベイズ最適化:アルゴリズム設定を探索するために確率的機械学習モデルを使用する。
可視化
モデルの学習とチューニングが完了したら、そのパフォーマンスと洞察を視覚化する必要があります。
統合ダッシュボードは、モデルの予測、主要メトリクス、機能の重要性の概要をインタラクティブに提供します。これにより、利害関係者はモデルの動作を理解し、改善のための領域を特定することができます。また、予測に基づいて情報に基づいた意思決定を行う上で重要な役割を果たします。

ClickUp Brainで解約予測インサイトを統合、自動化、管理する。
を使用して、解約予測モデルの構築と開発方法を変革します。
/参照 https://www.clickup.com/ai。 ClickUpブレイン /を使用します。
-時間と努力を節約する強力なAIツール。インサイト(洞察)から自動化まで、必要なものを効率化するように設計されています。
ここでは、生産性と効率性を促進するBrainの機能をいくつかご紹介します:
- **AIを活用したプロジェクト要約で進捗レポートを即座に作成。ClickUp Brainはプロジェクトデータを分析し、数回クリックするだけで包括的なレポートを作成します。
- Brainの高度なアルゴリズムとテクニックでデータ準備タスクを自動化します。品質を損なうことなく、収集からクリーニングまでのデータ前処理タスクを加速します。
- 予測モデルに対応し、予測を自動化します。ClickUp Brainには、データの収集と可視化を簡素化するClickUp CRMとダッシュボードも付属しています。
💡 プロヒント:ナレッジベースをClickUp Brainと統合することで、カスタマーサポートチームが顧客の質問に迅速かつ正確に回答できるようになり、業務が効率化されます。
/を効率化します。 https://clickup.com/ja/blog/110567/undefined/ カスタマーコミュニケーション /ナレッジベース
プロセスがある。
クリックアップで解約率を抑制し、継続性をセキュリティで確保する。
どのカスタマが満足していないのか、あるいはサービスの利用をやめる可能性があるのかを見出し、それを把握することは大きなメリットです。とはいえ、解約予測モデルは単に顧客を失うといった潜在的な問題を解決するだけではありません。 カスタムサービスの改善にも役立つ。 .
それはビジネスの継続と顧客の喜びにつながる。
ClickUpが提供する包括的なステップとプラクティスがあれば、解約予測モデルまであと一歩です。あとは、ClickUpがCRM、カスタマーサービス、テンプレートなどで提供するAIとデータサイエンスの力を活用するだけです。
それでは
/参照 https://clickup.com/signup 今すぐClickUpに登録しよう /%href/
解約率を抑え、永続的なリレーションシップを築くために!