
De flesta AI-implementeringsprojekt misslyckas inte för att teamen valde fel modell, utan för att ingen tre månader senare kan komma ihåg varför de valde den eller hur man replikerar installationen. 46 % av AI-projekten skrotas mellan proof-of-concept och bred implementering.
Den här guiden visar dig hur du använder Hugging Face för AI-implementering – från val och testning av modeller till hantering av implementeringsprocessen – så att ditt team kan leverera snabbare utan att förlora viktiga beslut i Slack-trådar och spridda kalkylblad.
Vad är Hugging Face?
Hugging Face är en öppen källkodsplattform och communityhub som tillhandahåller förtränade AI-modeller, datamängder och verktyg för att bygga och distribuera maskininlärningsapplikationer.
Tänk på det som ett enormt digitalt bibliotek där du kan hitta färdiga AI-modeller istället för att spendera månader och betydande resurser på att bygga dem från grunden.
Det är utformat för maskininlärningsingenjörer och datavetare, men dess verktyg används i allt högre grad av tvärfunktionella produkt-, design- och ingenjörsteam för att integrera AI i sina arbetsflöden.
Visste du att: 63 % av organisationerna saknar adekvata rutiner för datahantering för AI. Detta leder ofta till att projekt fastnar och resurser går till spillo.
Den största utmaningen för många team är den enorma komplexiteten i att implementera AI. Processen innebär att välja rätt modell bland tusentals alternativ, hantera den underliggande infrastrukturen, versionera experiment och säkerställa att tekniska och icke-tekniska intressenter är samordnade.
Hugging Face förenklar detta genom att tillhandahålla Model Hub, ett centralt arkiv med över 2 miljoner modeller. Plattformens transformers-bibliotek är nyckeln som låser upp dessa modeller, så att du kan ladda och använda dem med bara några rader Python-kod.
Men även med dessa kraftfulla verktyg förblir AI-implementering en utmaning för projektledningen, som kräver noggrann uppföljning av modellval, testning och lansering för att säkerställa framgång.
📮ClickUp Insight: 92 % av kunskapsarbetare riskerar att förlora viktiga beslut som är utspridda i chattar, e-postmeddelanden och kalkylblad. Utan ett enhetligt system för att registrera och spåra beslut går viktiga affärsinsikter förlorade i det digitala bruset.
Med ClickUps funktioner för uppgiftshantering behöver du aldrig oroa dig för detta. Skapa uppgifter från chatt, uppgiftskommentarer, dokument och e-postmeddelanden med ett enda klick!
Hugging Face-modeller som du kan distribuera
Det kan kännas överväldigande att navigera i Hugging Face Hub när du är nybörjare. Med hundratusentals modeller är det viktigt att förstå de huvudsakliga kategorierna för att hitta den som passar bäst för ditt projekt. Modellerna sträcker sig från små, effektiva alternativ som är utformade för ett enda syfte till stora, allmänna modeller som kan hantera komplexa resonemang.
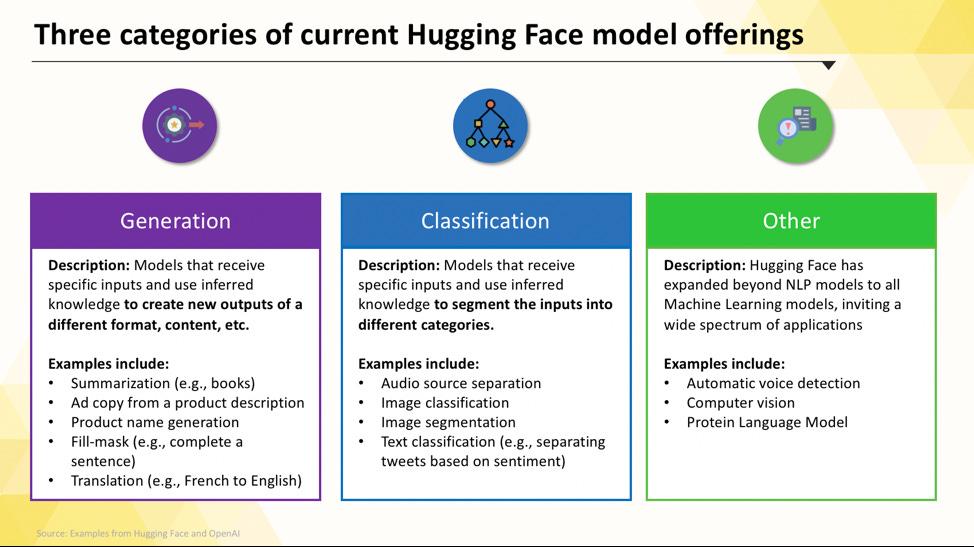
Uppgiftsspecifika språkmodeller
När ditt team behöver lösa ett enda, väl definierat problem behöver du ofta inte en omfattande, allmän modell. Tiden och kostnaden för att köra en sådan modell kan vara oöverkomlig, särskilt när ett mindre, mer fokuserat AI-verktyg skulle fungera bättre. Det är här uppgiftsspecifika modeller kommer in.
Dessa är modeller som har tränats och optimerats för en viss funktion. Eftersom de är specialiserade är de vanligtvis mindre, snabbare och mer resurseffektiva än sina större motsvarigheter.
Detta gör dem idealiska för produktionsmiljöer där hastighet och kostnad är viktiga faktorer. Många kan till och med köras på standard-CPU-hårdvara, vilket gör dem tillgängliga utan dyra GPU:er.
Vanliga typer av uppgiftsspecifika modeller inkluderar:
- Textklassificering: Använd detta för att kategorisera text i fördefinierade etiketter, till exempel sortera kundfeedback i ”positiva” eller ”negativa” kategorier eller tagga supportärenden efter ämne.
- Sentimentanalys: Detta hjälper dig att avgöra den emotionella tonen i en text, vilket är användbart för varumärkesövervakning på sociala medier.
- Namngiven enhetsigenkänning: Extrahera specifika enheter som personer, platser och organisationer från dokument för att strukturera ostrukturerade data.
- Sammanfattning: Kondensera långa artiklar eller rapporter till koncisa sammanfattningar och spara värdefull läsningstid för ditt team.
- Översättning: Konvertera text från ett språk till ett annat automatiskt
📚 Läs också: Hur man använder Hugging Face för textsammanfattning
Stora språkmodeller
Ibland kräver ditt projekt mer än bara enkel klassificering eller sammanfattning. Du kanske behöver en AI som kan generera kreativa marknadsföringstexter, skriva kod eller svara på komplexa användarfrågor på ett konversationsliknande sätt. För dessa scenarier kommer du sannolikt att vända dig till en stor språkmodell (LLM).
LLM är modeller med miljarder parametrar som tränats på enorma mängder text och data från internet. Denna omfattande träning gör att de kan förstå nyanser, sammanhang och komplexa resonemang. Populära open source-LLM som finns tillgängliga på Hugging Face inkluderar modeller från Llama-, Mistral- och Falcon-familjerna.
Nackdelen med denna kraft är de betydande beräkningsresurser som krävs. Implementering av dessa modeller kräver nästan alltid kraftfulla GPU:er med mycket minne (VRAM).
För att göra dem mer tillgängliga kan du använda tekniker som kvantisering, vilket minskar modellens storlek till en liten kostnad i prestanda, så att den kan köras på mindre kraftfull hårdvara.
📚 Läs också: Vad är LLM-agenter inom AI och hur fungerar de?
Text-till-bild- och multimodala modeller
Dina data består inte alltid bara av text. Ditt team kan behöva generera bilder för en marknadsföringskampanj, transkribera ljud från ett möte eller förstå innehållet i en video. Det är här multimodala modeller, som är utformade för att fungera med olika typer av data, blir viktiga.
Den mest populära typen av multimodal modell är text-till-bild-modellen, som genererar bilder från en textbeskrivning. Modeller som Stable Diffusion använder en teknik som kallas diffusion för att skapa fantastiska bilder från enkla uppmaningar. Men möjligheterna sträcker sig långt bortom bildgenerering.
Andra vanliga multimodala modeller som du kan distribuera från Hugging Face inkluderar:
- Bildtext: Generera automatiskt beskrivande text för bilder, vilket är utmärkt för tillgänglighet och innehållshantering.
- Taligenkänning: Transkribera talat ljud till skriftlig text med modeller som OpenAI:s Whisper.
- Visuell frågesvar: Ställ frågor om en bild och få ett textbaserat svar, till exempel ”Vilken färg har bilen på den här bilden?”
Precis som LLM är dessa modeller beräkningsintensiva och kräver vanligtvis en GPU för att fungera effektivt.
📚 Läs också: 50+ AI-bildprompter för att skapa fantastiska bilder
För att se hur dessa olika typer av AI-modeller översätts till praktiska affärsapplikationer, titta på denna översikt över verkliga AI-användningsfall inom olika branscher och funktioner.
Hur mogen är din organisation när det gäller AI?
Vår undersökning av 316 yrkesverksamma visar att en verklig AI-transformation kräver mer än bara att införa AI-funktioner. Gör AI-mognadsbedömningen för att se var din organisation står och vad du kan göra för att förbättra ditt resultat.
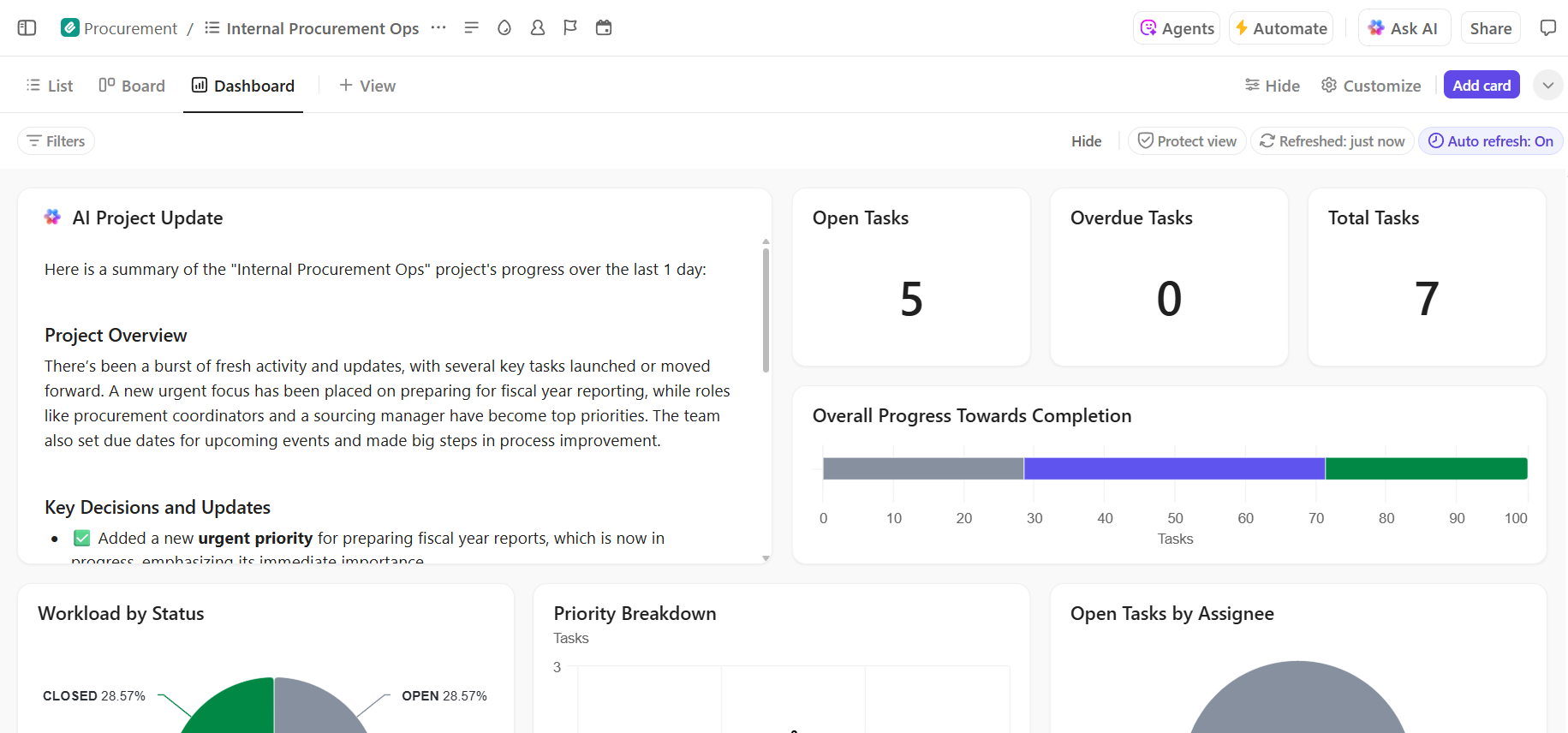
Hur man konfigurerar Hugging Face för AI-implementering
Innan du kan distribuera din första modell måste du se till att din lokala miljö och ditt Hugging Face-konto är korrekt konfigurerade. Det är vanligt att team blir frustrerade när olika medlemmar har inkonsekventa inställningar, vilket leder till det klassiska problemet ”det fungerar på min dator”. Att ta några minuter för att standardisera denna process sparar timmar av felsökning senare.
- Skapa ett Hugging Face-konto och generera en åtkomsttoken. Registrera först ett gratis konto på Hugging Face-webbplatsen. När du har loggat in navigerar du till din profil, klickar på "Inställningar" och går sedan till fliken "Åtkomsttoken". Generera en ny token med minst "läsbehörighet"; du behöver den för att ladda ner modeller.
- Installera de nödvändiga Python-biblioteken. Öppna din terminal och installera de kärnbibliotek du behöver. De två viktigaste är transformers och huggingface_hub. Du kan installera dem med pip: pip install transformers huggingface_hub
- Konfigurera autentisering. För att använda din åtkomsttoken kan du antingen logga in via kommandoraden genom att köra huggingface-cli login och klistra in din token när du blir ombedd, eller så kan du ställa in den som en miljövariabel i ditt system. Inloggning via kommandoraden är ofta det enklaste sättet att komma igång.
- Verifiera installationen. Det bästa sättet att bekräfta att allt fungerar är att köra en enkel kod. Prova att ladda en grundläggande modell med hjälp av pipeline-funktionen från transformers-biblioteket. Om den körs utan fel är du redo att sätta igång.
Tänk på att vissa modeller på Hub är ”gated”, vilket innebär att du måste godkänna licensvillkoren på modellens sida innan du kan komma åt dem med din token.
Kom också ihåg att det är en projektledningsuppgift i sig att hålla reda på vem som har vilka behörigheter och vilka miljökonfigurationer som används, och det blir ännu viktigare ju större ditt team blir.
🌟 Om du integrerar Hugging Face-modeller i bredare mjukvarusystem hjälper ClickUps mjukvaruintegrationsmall dig att visualisera arbetsflöden och spåra tekniska integrationer i flera steg.
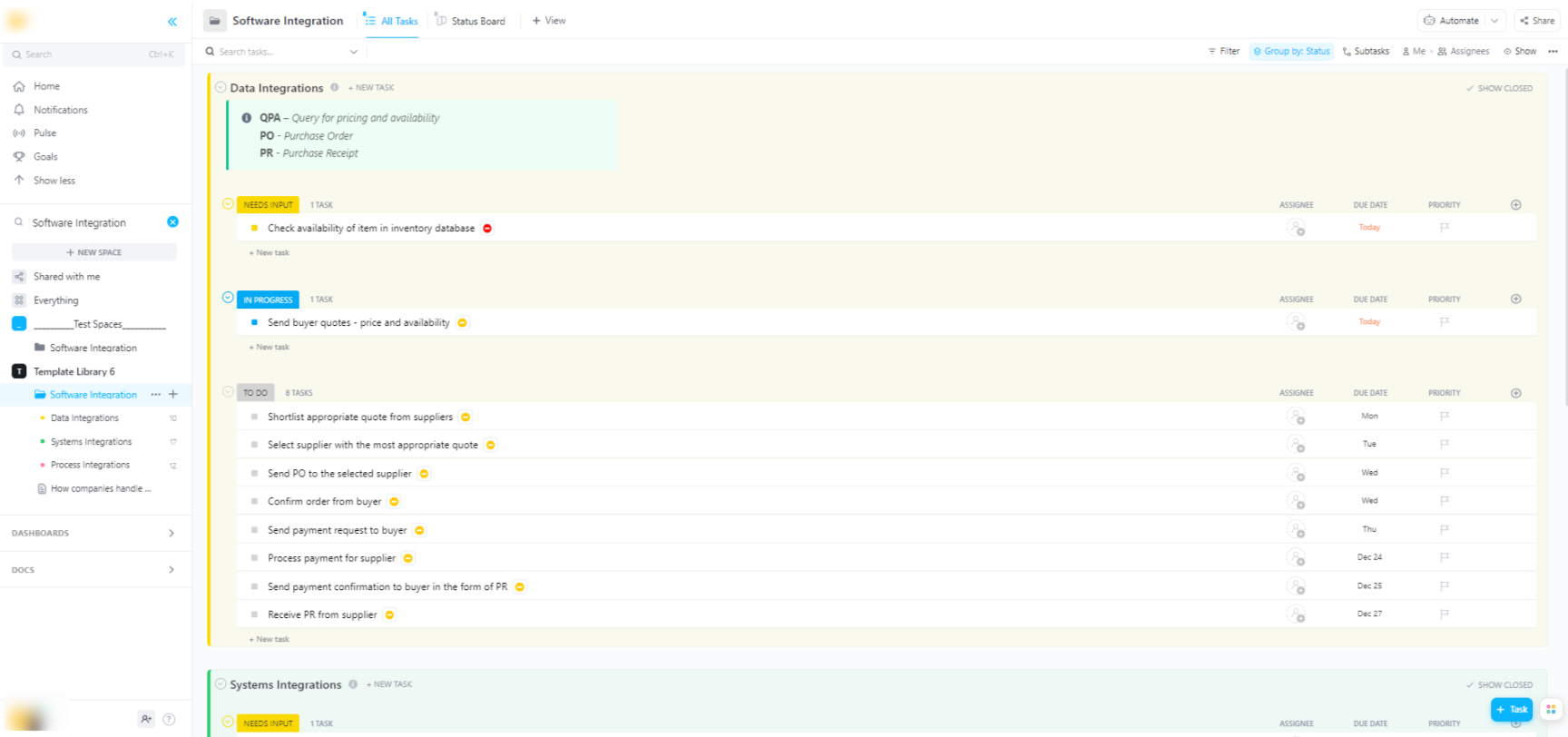
Mallen ger dig ett lättanvänt system där du kan:
- Visualisera kopplingarna mellan olika mjukvarulösningar
- Skapa och tilldela uppgifter till teammedlemmar för smidigare samarbete
- Organisera alla uppgifter relaterade till integration på ett och samma ställe.
Distributionsalternativ för Hugging Face-modeller
När du har testat en modell lokalt är nästa fråga: var ska den placeras? Att distribuera en modell till en produktionsmiljö där den kan användas av andra är ett viktigt steg, men alternativen kan vara förvirrande. Att välja fel väg kan leda till långsam prestanda, höga kostnader eller oförmåga att hantera användartrafik.
Ditt val beror på dina specifika behov, såsom förväntad trafik, budget och om du bygger en snabb prototyp eller en skalbar, produktionsklar applikation.
Hugging Face Spaces
Om du behöver skapa en demo eller ett internt verktyg snabbt är Hugging Face Spaces ofta det bästa valet. Spaces är en gratis plattform för att hosta maskininlärningsapplikationer och är perfekt för att bygga prototyper som du kan dela med ditt team eller dina intressenter.
Du kan bygga din apps användargränssnitt med hjälp av populära ramverk som Gradio eller Streamlit, vilket gör det enkelt att skapa interaktiva demos med bara några rader Python.
Att skapa ett Space är lika enkelt som att välja ditt föredragna SDK, ansluta ett Git-arkiv med din kod och välja din hårdvara. Spaces erbjuder en gratis CPU-nivå för grundläggande appar, men du kan uppgradera till betald GPU-hårdvara för mer krävande modeller.
Tänk på begränsningarna:
- Inte för API:er med hög trafik: Spaces är utformat för demonstrationer, inte för att hantera tusentals samtidiga API-förfrågningar.
- Kallstart: Om ditt Space är inaktivt kan det gå i viloläge för att spara resurser, vilket orsakar en fördröjning för den första användaren som öppnar det igen.
- Git-baserat arbetsflöde: All din applikationskod hanteras via ett Git-arkiv, vilket är utmärkt för versionshantering.
Hugging Face Inference API
När du behöver integrera en modell i en befintlig applikation vill du troligen använda ett API. Hugging Face Inference API låter dig köra modeller utan att behöva hantera någon av den underliggande infrastrukturen själv. Du skickar helt enkelt en HTTP-förfrågan med dina data och får tillbaka en förutsägelse.
Denna metod är idealisk när du inte vill hantera servrar, skalning eller underhåll. Hugging Face erbjuder två huvudnivåer för denna tjänst:
- Gratis inferens-API: Detta är ett hastighetsbegränsat, delat infrastrukturalternativ som är utmärkt för utveckling och testning. Det är perfekt för användningsfall med låg trafik eller när du just har kommit igång.
- Inference Endpoints: För produktionsapplikationer bör du använda Inference Endpoints. Detta är en betaltjänst som ger dig dedikerad, autoskalande infrastruktur, vilket säkerställer att din applikation är snabb och pålitlig även under tung belastning.
Användningen av API:et innebär att du skickar en JSON-payload till modellens slutpunkts-URL med din autentiseringstoken i begäranhuvudet.
Distribution på molnplattform
För team som redan har en betydande närvaro hos en stor molnleverantör som Amazon Web Services (AWS), Google Cloud Platform (GCP) eller Microsoft Azure kan det vara det mest logiska valet att distribuera där. Denna metod ger dig mest kontroll och gör det möjligt att integrera modellen med dina befintliga molntjänster och säkerhetsprotokoll.
Det allmänna arbetsflödet innebär att du ”containeriserar” din modell och dess beroenden med hjälp av Docker och sedan distribuerar den containern till en molnbaserad datortjänst. Varje molnleverantör har tjänster och integrationer som förenklar denna process:
- AWS SageMaker: Erbjuder inbyggd integration för träning och distribution av Hugging Face-modeller.
- Google Cloud Vertex AI: Gör det möjligt att distribuera modeller från Hub till hanterade slutpunkter.
- Azure Machine Learning: Tillhandahåller verktyg för att importera och använda Hugging Face-modeller.
Även om denna metod kräver mer konfiguration och DevOps-expertis är den ofta det bästa alternativet för storskaliga implementeringar på företagsnivå där du behöver full kontroll över miljön.
Hur man kör Hugging Face-modeller för inferens
När du använder Hugging Face för AI-distribution är ”running inference” processen att använda din tränade modell för att göra förutsägelser om nya, osedda data. Det är i det ögonblicket som din modell utför det arbete du distribuerade den för. Att få detta steg rätt är avgörande för att bygga en responsiv och effektiv applikation.
Det mest frustrerande för team är att skriva inferenskod som är långsam eller ineffektiv, vilket kan leda till en dålig användarupplevelse och höga driftskostnader. Lyckligtvis erbjuder transformers-biblioteket flera sätt att köra inferens, var och en med sina egna avvägningar mellan enkelhet och kontroll.
- Pipeline API: Detta är det enklaste och vanligaste sättet att komma igång. Funktionen pipeline() abstraherar bort det mesta av komplexiteten och hanterar förbehandling av data, vidarebefordran av modeller och efterbehandling åt dig. För många standarduppgifter, såsom sentimentanalys, kan du få en förutsägelse med bara en rad kod.
- AutoModel + AutoTokenizer: När du behöver mer kontroll över inferensprocessen kan du använda klasserna AutoModel och AutoTokenizer direkt. Detta gör att du manuellt kan hantera hur din text tokeniseras och hur modellens råa utdata konverteras till en läsbar förutsägelse. Denna metod är användbar när du arbetar med en anpassad uppgift eller behöver implementera specifik logik för för- eller efterbearbetning.
- Batchbearbetning: För att maximera effektiviteten, särskilt på en GPU, bör du bearbeta indata i batcher istället för en i taget. Att skicka en batch med indata genom modellen i ett enda framåtpass är betydligt snabbare än att skicka varje indata individuellt.
Att övervaka prestandan hos din inferenskod är en viktig del av distributionscykeln. Att spåra mätvärden som latens (hur lång tid en förutsägelse tar) och genomströmning (hur många förutsägelser du kan göra per sekund) kräver samordning och tydlig dokumentation, särskilt när olika teammedlemmar experimenterar med nya modellversioner.
📚 Läs också: De bästa verktygen för samarbete i AI-team
Steg-för-steg-exempel: Distribuera en Hugging Face-modell
Låt oss gå igenom ett komplett exempel på implementering av en enkel modell för sentimentanalys. Genom att följa dessa steg kommer du från att välja en modell till att ha en live, testbar slutpunkt.
- Välj din modell: Gå till Hugging Face Hub och använd filtren till vänster för att söka efter modeller som utför ”Textklassificering”. En bra utgångspunkt är distilbert-base-uncased-finetuned-sst-2-english. Läs modellkortet för att förstå dess prestanda och hur du använder den.
- Installera beroenden: Se till att du har de nödvändiga biblioteken installerade i din lokala Python-miljö. För den här modellen behöver du bara transformers och torch. Kör pip install transformers torch
- Testa lokalt: Innan du distribuerar, se alltid till att modellen fungerar som förväntat på din maskin. Skriv ett litet Python-skript för att ladda modellen med hjälp av pipelinen och testa den med ett exempel på en mening. Till exempel: classifier = pipeline("sentiment-analysis", model="distilbert-base-uncased-finetuned-sst-2-english") följt av classifier("ClickUp är den bästa produktivitetsplattformen!")
- Skapa distribution: I det här exemplet använder vi Hugging Face Spaces för en snabb och enkel distribution. Skapa ett nytt Space, välj Gradio SDK och skapa en app.py-fil som laddar din modell och definierar ett enkelt Gradio-gränssnitt för att interagera med den.
- Verifiera distribution: När ditt Space är igång kan du använda det interaktiva gränssnittet för att testa det. Du kan också göra en direkt API-förfrågan till Space-slutpunkten för att få ett JSON-svar, vilket bekräftar att det fungerar programmatiskt.
Efter dessa steg har du en live-modell. Nästa fas i projektet skulle innebära att övervaka dess användning, planera för uppdateringar och eventuellt skala upp infrastrukturen om den blir populär.
För team som hanterar komplexa AI-implementeringsprojekt med flera faser – från datapreparering till produktionsimplementering – erbjuder Software Project Management Advanced Template från ClickUp en omfattande struktur.
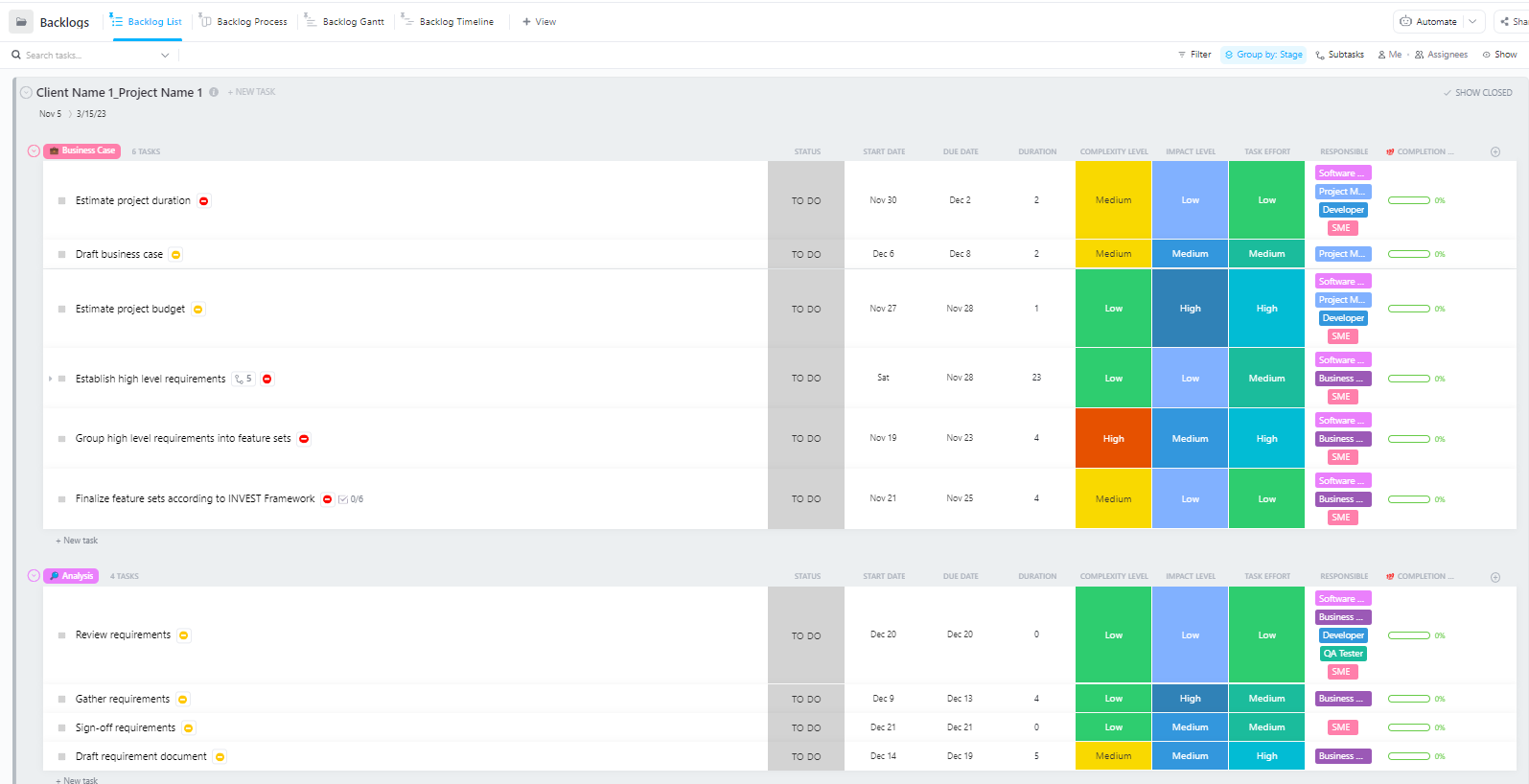
Denna mall hjälper team att:
- Hantera projekt med flera milstolpar, uppgifter, resurser och beroenden
- Visualisera projektets framsteg med Gantt-diagram och tidslinjer.
- Samarbeta smidigt med teammedlemmarna för att säkerställa ett framgångsrikt slutförande.
Vanliga utmaningar vid Hugging Face-implementering och hur man löser dem
Även med en tydlig plan är det troligt att du stöter på några hinder under implementeringen. Att stirra på ett kryptiskt felmeddelande kan vara otroligt frustrerande och kan stoppa ditt teams framsteg. Här är några av de vanligaste utmaningarna och hur du löser dem. 🛠️
🚨Problem: ”Modellen kräver autentisering”
- Orsak: Du försöker komma åt en "gated" modell som kräver att du accepterar dess licensvillkor.
- Lösning: Gå till modellens sida på Hub, läs och acceptera licensavtalet. Se till att åtkomsttoken du använder har "läsbehörighet".
🚨Problem: ”CUDA out of memory”
- Orsak: Modellen du försöker ladda är för stor för ditt grafikkorts minne (VRAM).
- Lösning: Den snabbaste lösningen är att använda en mindre version av modellen eller en kvantiserad version. Du kan också försöka minska batchstorleken under inferensen.
🚨Problem: ”trust_remote_code error”
- Orsak: Vissa modeller på Hub kräver anpassad kod för att köras, och av säkerhetsskäl kör biblioteket inte den som standard.
- Lösning: Du kan kringgå detta genom att lägga till trust_remote_code=True när du laddar modellen. Du bör dock alltid granska källkoden först för att säkerställa att den är säker.
🚨Problem: ”Tokenizer mismatch”
- Orsak: Den tokenizer du använder är inte exakt samma som den som modellen tränades med, vilket leder till felaktiga inmatningar och dålig prestanda.
- Lösning: Ladda alltid tokenizer från samma modellcheckpoint som modellen själv. Till exempel AutoTokenizer. from_pretrained("modellnamn")
🚨Problem: ”Rate limit exceeded”
- Orsak: Du har gjort för många förfrågningar till det kostnadsfria Inference API under en kort period.
- Lösning: För produktionsanvändning, uppgradera till en dedikerad inferensändpunkt. För utveckling kan du implementera caching för att undvika att skicka samma begäran flera gånger.
Det är avgörande att spåra vilka lösningar som fungerar för vilka problem. Utan en central plats för att dokumentera dessa resultat hamnar teamen ofta i en situation där de löser samma problem om och om igen.
📮 ClickUp Insight: 1 av 4 anställda använder fyra eller fler verktyg bara för att skapa sammanhang på jobbet. En viktig detalj kan vara gömd i ett e-postmeddelande, utvidgad i en Slack-tråd och dokumenterad i ett separat verktyg, vilket tvingar teamen att slösa tid på att leta efter information istället för att få jobbet gjort.
ClickUp samlar hela ditt arbetsflöde på en enda plattform. Med funktioner som ClickUp Email Project Management, ClickUp Chat, ClickUp Docs och ClickUp Brain hålls allt sammankopplat, synkroniserat och omedelbart tillgängligt. Säg adjö till ”arbete om arbete” och återta din produktiva tid.
💫 Verkliga resultat: Team kan spara mer än 5 timmar varje vecka med ClickUp – det är över 250 timmar per person och år – genom att eliminera föråldrade processer för kunskapshantering. Tänk vad ditt team skulle kunna åstadkomma med en extra produktiv vecka varje kvartal!
Hur man hanterar AI-implementeringsprojekt i ClickUp
Att använda Hugging Face för AI-distribution gör det enklare att paketera, hosta och leverera modeller – men det eliminerar inte koordineringstiden för distribution i verkligheten. Team måste fortfarande spåra vilka modeller som testas, samordna konfigurationer, dokumentera beslut och se till att alla – från ML-ingenjörer till produkt- och driftspersonal – är på samma sida.
När ditt teknikteam testar olika modeller, ditt produktteam definierar krav och intressenterna ber om uppdateringar, sprids informationen över Slack, e-post, kalkylblad och olika dokument.
Denna arbetsutbredning – fragmenteringen av arbetsaktiviteter över flera, icke sammankopplade verktyg som inte kommunicerar med varandra – skapar förvirring och saktar ner alla.
Det är här ClickUp, världens första konvergerade AI-arbetsyta, spelar en viktig roll genom att samla projektledning, dokumentation och teamkommunikation i en enda arbetsyta.
Denna konvergens är särskilt värdefull för AI-implementeringsprojekt, där tekniska och icke-tekniska intressenter behöver delad synlighet utan att behöva använda fem olika verktyg.
Istället för att sprida uppdateringar över biljetter, dokument och chattrådar kan teamen hantera hela distributionscykeln på ett och samma ställe.
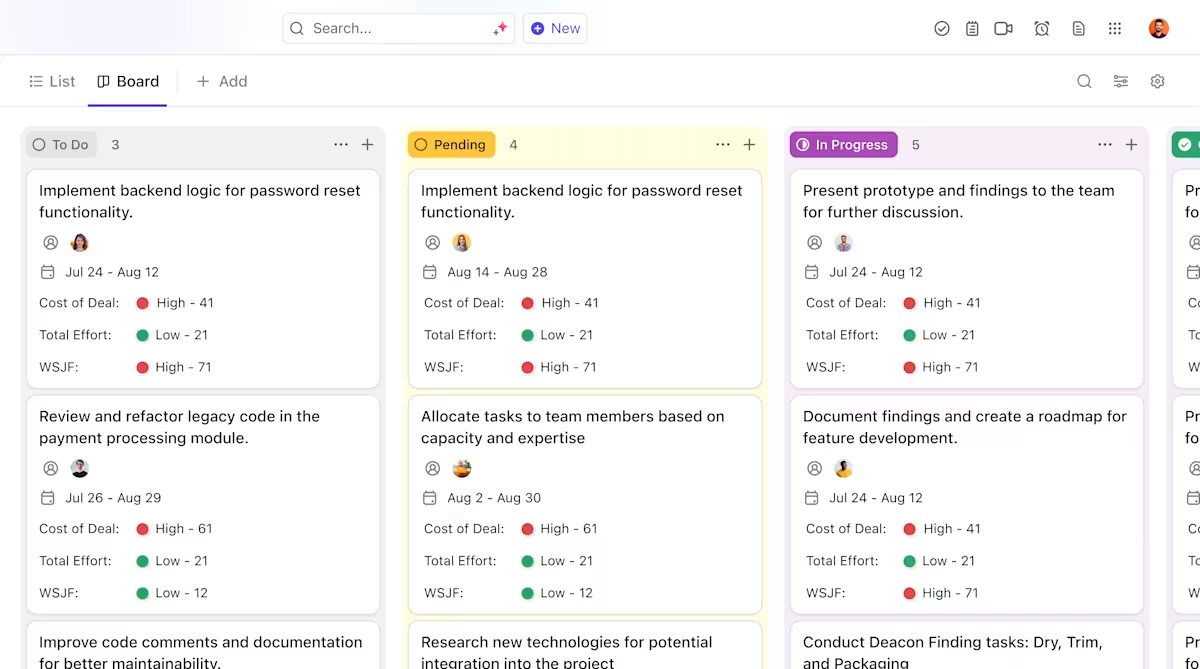
Så här kan ClickUp stödja ditt AI-implementeringsprojekt:
- Tydlig ägarskap och spårning genom modellens livscykel: Använd ClickUp Tasks för att spåra Hugging Face-modeller genom utvärdering, testning, staging och produktion, med anpassade statusar, ägare och blockerare som är synliga för hela teamet.
- Centraliserad, levande dokumentation om implementering: Underhåll implementeringsmanualer, miljökonfigurationer och felsökningsguider i ClickUp Docs, så att dokumentationen utvecklas tillsammans med dina modeller och förblir lätt att söka och referera till. Eftersom Docs är kopplade till uppgifter finns din dokumentation precis bredvid det arbete den avser.
- Samarbete i sitt sammanhang utan arbetsbelastning: Håll diskussioner, beslut och uppdateringar direkt kopplade till uppgifter och dokument, vilket minskar beroendet av spridda Slack-trådar, e-postmeddelanden och osammanhängande projektverktyg.
- Fullständig insyn i implementeringsprocessen: Övervaka implementeringsprocessen, identifiera risker i ett tidigt skede och balansera teamets kapacitet med hjälp av ClickUp Dashboards som visar framsteg och flaskhalsar i realtid.
- Snabbare onboarding och beslutsåterkallande med inbyggd AI: Använd ClickUp Brain för att sammanfatta långa distributionsdokument, ta fram relevanta insikter från tidigare distributioner och hjälpa nya teammedlemmar att komma igång utan att behöva gräva i historiska sammanhang.
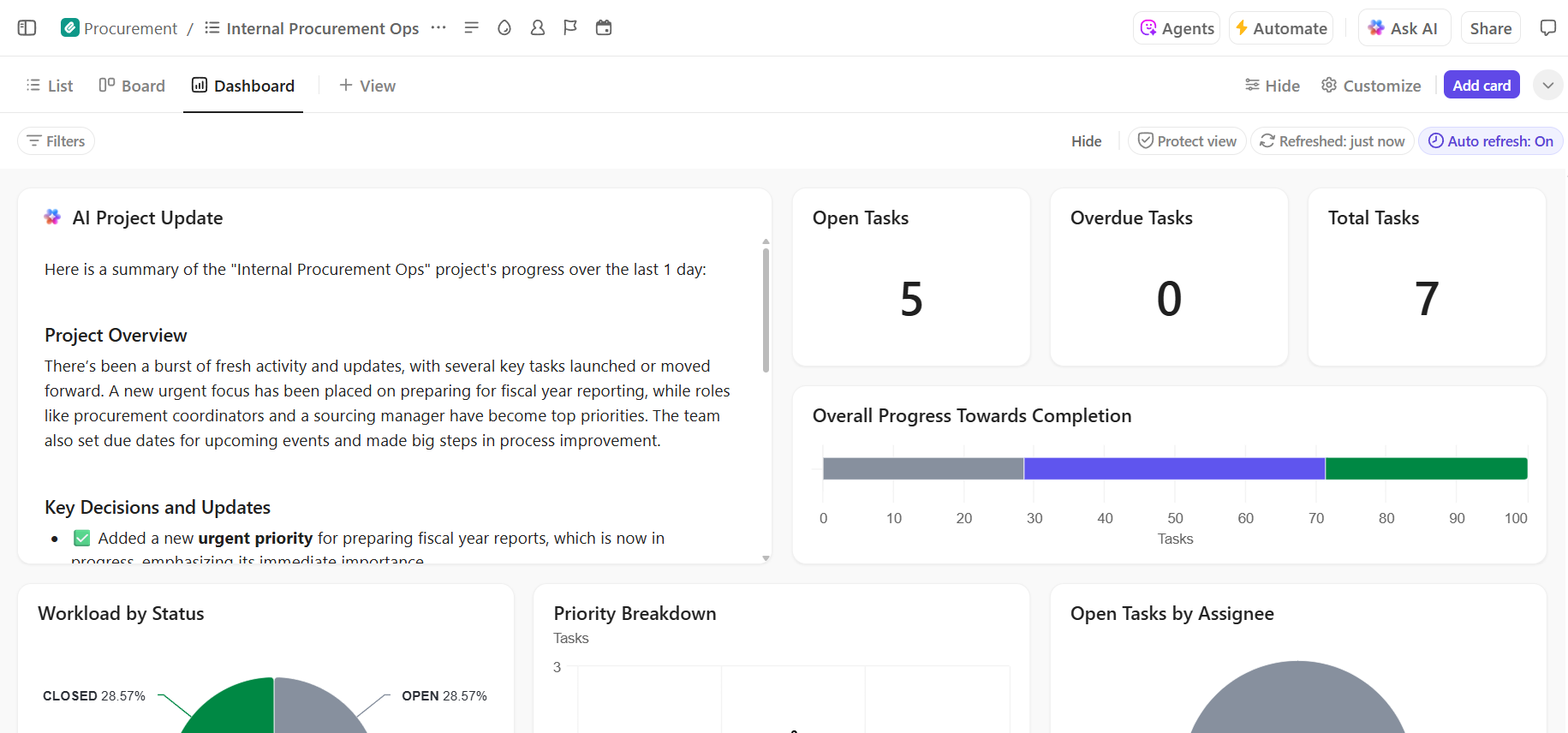
Hantera ditt AI-implementeringsprojekt smidigt i ClickUp
En framgångsrik Hugging Face-implementering kräver en solid teknisk grund och tydlig, organiserad projektledning. De tekniska utmaningarna är lösbara, men det är ofta brister i samordning och kommunikation som gör att projekt misslyckas.
Genom att etablera ett tydligt arbetsflöde på en enda plattform kan ditt team leverera snabbare och undvika frustrationen med kontextförlust – när team slösar timmar på att söka efter information, växla mellan appar och upprepa uppdateringar på flera plattformar.
ClickUp, appen som innehåller allt du behöver för arbetet, samlar din projektledning, dokumentation och teamkommunikation på ett ställe så att du får en enda källa till information för hela livscykeln för din AI-implementering.
Samla dina AI-implementeringsprojekt och eliminera verktygsröran. Kom igång gratis med ClickUp idag.
Vanliga frågor (FAQ)
Ja, Hugging Face erbjuder ett generöst gratispaket som inkluderar tillgång till Model Hub, CPU-drivna Spaces för demonstrationer och ett hastighetsbegränsat Inference API för testning. För produktionsbehov som kräver dedikerad hårdvara eller högre gränser finns betalda abonnemang tillgängliga.
Spaces är utformat för att vara värd för interaktiva applikationer med ett visuellt frontend, vilket gör det idealiskt för demonstrationer och interna verktyg. Inference API ger programmatisk åtkomst till modeller, så att du kan integrera dem i dina applikationer via enkla HTTP-förfrågningar.
Absolut. Genom interaktiva demonstrationer på Hugging Face Spaces kan icke-tekniska teammedlemmar experimentera med och ge feedback på modeller utan att skriva en enda rad kod.
De främsta begränsningarna för den kostnadsfria nivån är hastighetsbegränsningar för Inference API, användningen av delad CPU-hårdvara för Spaces, vilket kan vara långsamt, och ”kallstart” där inaktiva appar tar en stund att starta. /