
De flesta utvecklare som bygger ett Hugging Face-sammanfattningsskript stöter på samma problem: sammanfattningen fungerar perfekt i deras terminal. Men den kopplas sällan till det faktiska arbete den ska stödja.
Den här guiden visar dig hur du bygger en textsammanfattare med Hugging Faces Transformers-bibliotek och visar sedan varför även en felfri implementering kan skapa fler problem än den löser när ditt team behöver sammanfattningar som faktiskt kopplas till uppgifter, projekt och beslut.
Vad är textsammanfattning?
Team drunknar i information. Du står inför långa dokument, oändliga mötesprotokoll, komplicerade forskningsrapporter och kvartalsrapporter som tar timmar att bearbeta manuellt. Denna ständiga informationsöverbelastning bromsar beslutsfattandet och dödar produktiviteten.
Text sammanfattning är processen att använda Natural Language Processing (NLP) för att kondensera innehållet till en kort, sammanhängande version som bevarar den viktigaste informationen. Tänk på det som en omedelbar sammanfattning för alla dokument. Denna NLP-sammanfattningsteknik använder vanligtvis en av två metoder:
Extraktiv sammanfattning: Denna metod fungerar genom att identifiera och plocka ut de viktigaste meningarna direkt från källtexten. Det är som att ha en markeringspenna som automatiskt plockar ut de viktigaste punkterna åt dig. Den slutliga sammanfattningen är en samling av originalmeningar.
Abstrakt sammanfattning: Denna mer avancerade metod genererar helt nya meningar för att fånga källtextens kärnbudskap. Den parafraserar informationen, vilket resulterar i en mer flytande och människoliknande sammanfattning, ungefär som när en person skulle förklara en lång historia med egna ord.
Du ser resultaten av detta överallt. Det används för att kondensera mötesanteckningar till åtgärdspunkter, destillera kundfeedback till trender och skapa snabba översikter av projektdokumentation. Målet är alltid detsamma: att få den väsentliga informationen utan att läsa varje enskilt ord.
📮 ClickUp Insight: Den genomsnittliga yrkesverksamma spenderar mer än 30 minuter om dagen på att söka efter arbetsrelaterad information. Det är över 120 timmar om året som går förlorade på att söka igenom e-postmeddelanden, Slack-trådar och spridda filer. En intelligent AI-assistent inbyggd i din arbetsyta kan ändra på det. ClickUp Brain levererar omedelbara insikter och svar genom att visa rätt dokument, konversationer och uppgiftsdetaljer på några sekunder, så att du kan sluta söka och börja arbeta.
💫 Verkliga resultat: Team som QubicaAMF har sparat över 5 timmar per vecka med hjälp av ClickUp, över 250 timmar per person och år, genom att eliminera föråldrade processer för kunskapshantering.
Varför använda Hugging Face för textsammanfattning?
Att bygga en anpassad text sammanfattningsmodell från grunden är ett enormt arbete. Det kräver enorma datamängder för träning, kraftfulla och dyra beräkningsresurser och ett team av experter på maskininlärning. Denna höga inträdesbarriär hindrar de flesta teknik- och produktteam från att ens komma igång.
Hugging Face är plattformen som löser detta problem. Det är en öppen källkodsgemenskap och datavetenskapsplattform som ger dig tillgång till tusentals förtränade modeller, vilket effektivt demokratiserar LLM-sammanfattning för utvecklare. Istället för att bygga från grunden kan du börja med en kraftfull modell som redan är 99 % färdig.
Här är anledningen till att så många utvecklare vänder sig till Hugging Face: 🛠️
Tillgång till förtränade modeller: Hugging Face Hub är ett enormt arkiv med över 2 miljoner offentliga modeller som tränats av företag som Google, Meta och OpenAI. Du kan ladda ner och använda dessa toppmoderna checkpoints för dina egna projekt.
Förenklad pipeline-API: Pipeline-funktionen är en högnivå-API som hanterar alla komplexa steg, såsom textförbehandling, modellinferens och utdataformatering, med bara några få rader kod.
Modellvariation: Du är inte begränsad till ett enda alternativ. Du kan välja mellan ett brett utbud av arkitekturer som BART, T5 och Pegasus, var och en med olika styrkor, storlekar och prestandaegenskaper.
Flexibilitet i ramverket: Transformers-biblioteket fungerar sömlöst med de två mest populära ramverken för djupinlärning, PyTorch och TensorFlow. Du kan använda det som ditt team redan är bekvämt med.
Community-support: Med omfattande dokumentation, officiella kurser och en aktiv community av utvecklare är det enkelt att hitta tutorials och få hjälp när du stöter på problem.
Hugging Face är otroligt kraftfullt för utvecklare, men det är viktigt att komma ihåg att det är en kodbaserad lösning. Det krävs teknisk expertis för att implementera och underhålla den. Detta är inte alltid rätt lösning för icke-tekniska team som bara behöver sammanfatta sitt arbete.
🧐 Visste du att? Hugging Faces Transformers-bibliotek gjorde det vanligt att använda avancerade NLP-modeller med några få rader kod, vilket är anledningen till att prototyper för sammanfattningar ofta börjar där.
Vad är Hugging Face Transformers?
Du har alltså bestämt dig för att använda Hugging Face, men hur fungerar egentligen tekniken? Kärnteknologin är en arkitektur som kallas Transformer. När den introducerades i en artikel från 2017 med titeln ”Attention Is All You Need” förändrade den helt området NLP.
Innan Transformers hade modeller svårt att förstå sammanhanget i långa meningar. Transformers viktigaste innovation är uppmärksamhetsmekanismen, som gör det möjligt för modellen att väga betydelsen av olika ord i ingångstexten när den bearbetar ett specifikt ord. Detta hjälper den att fånga långväga beroenden och förstå sammanhanget, vilket är avgörande för att skapa sammanhängande sammanfattningar.
Hugging Face Transformers-biblioteket är ett Python-paket som gör det otroligt enkelt för dig att använda dessa komplexa modeller. Du behöver inte ha en doktorsexamen i maskininlärning. Biblioteket abstraherar bort det tunga arbetet.
De tre viktigaste komponenterna du behöver känna till
- Tokenizers: Modeller förstår inte ord, de förstår siffror. En tokenizer tar din inmatade text och omvandlar den till en sekvens av numeriska tokens – en process som kallas tokenisering – som modellen kan bearbeta.
- Modeller: Dessa är de förtränade neurala nätverken själva. För sammanfattning är dessa vanligtvis sekvens-till-sekvens-modeller med en kodare-avkodare-struktur. Kodaren läser inmatad text för att skapa en numerisk representation, och avkodaren använder den representationen för att generera sammanfattningen.
- Pipelines: Detta är det enklaste sättet att använda en modell. En pipeline binder samman en förtränad modell med motsvarande tokenizer och hanterar alla steg i förbearbetningen av indata och efterbearbetningen av utdata åt dig.
Två av de mest populära modellerna för sammanfattning är BART och T5. BART (Bidirectional and Auto-Regressive Transformer) är särskilt bra på abstrakt sammanfattning och producerar sammanfattningar som låter mycket naturliga. T5 (Text-to-Text Transfer Transformer) är en mångsidig modell som ramar in varje NLP-uppgift som ett text-till-text-problem, vilket gör den till en kraftfull allroundmodell.
🎥 Titta på den här videon för att se en jämförelse av de bästa AI-PDF-sammanfattarna – och lär dig vilka verktyg som levererar de snabbaste och mest exakta sammanfattningarna utan att förlora sammanhanget.
Hur man bygger en textsammanfattare med Hugging Face
Är du redo att bygga ditt eget exempel på en sammanfattare? Allt du behöver är grundläggande kunskaper i Python, en kodredigerare som VS Code och en internetanslutning. Hela processen består av bara fyra steg. På några minuter har du en fungerande sammanfattare.
Steg 1: Installera nödvändiga bibliotek
Först måste du installera de nödvändiga biblioteken. Det viktigaste är transformers. Du behöver också ett ramverk för djupinlärning som PyTorch eller TensorFlow. Vi använder PyTorch i det här exemplet.
Öppna din terminal eller kommandotolk och kör följande kommando:

Vissa modeller, som T5, kräver också biblioteket sentencepiece för sin tokenizer. Det är en bra idé att installera det också.

💡 Proffstips: Skapa en virtuell Python-miljö innan du installerar dessa paket. Detta håller dina projektberoenden isolerade och förhindrar konflikter med andra projekt på din dator.
Steg 2: Ladda modellen och tokenizer
Det enklaste sättet att komma igång är att använda pipeline-funktionen. Den hanterar automatiskt laddningen av rätt modell och tokenizer för sammanfattningsuppgiften.
I ditt Python-skript importerar du pipelinen och initialiserar den så här:

Här specificerar vi två saker:
Uppgiften: Vi talar om för pipelinen att vi vill utföra en ”sammanfattning”.
Modellen: Vi väljer en specifik förtränad modellcheckpoint från Hugging Face Hub. facebook/bart-large-cnn är ett populärt val som är tränat på nyhetsartiklar och fungerar bra för allmän sammanfattning. För snabbare testning kan du använda en mindre modell som t5-small.
Första gången du kör den här koden kommer den att ladda ner modellvikterna från Hub, vilket kan ta några minuter. Därefter kommer modellen att cachelagras på din lokala dator för omedelbar laddning.
Steg 3: Skapa sammanfattningsfunktionen
För att göra din kod ren och återanvändbar är det bäst att lägga sammanfattningslogiken i en funktion. Detta gör det också enkelt att experimentera med olika parametrar.
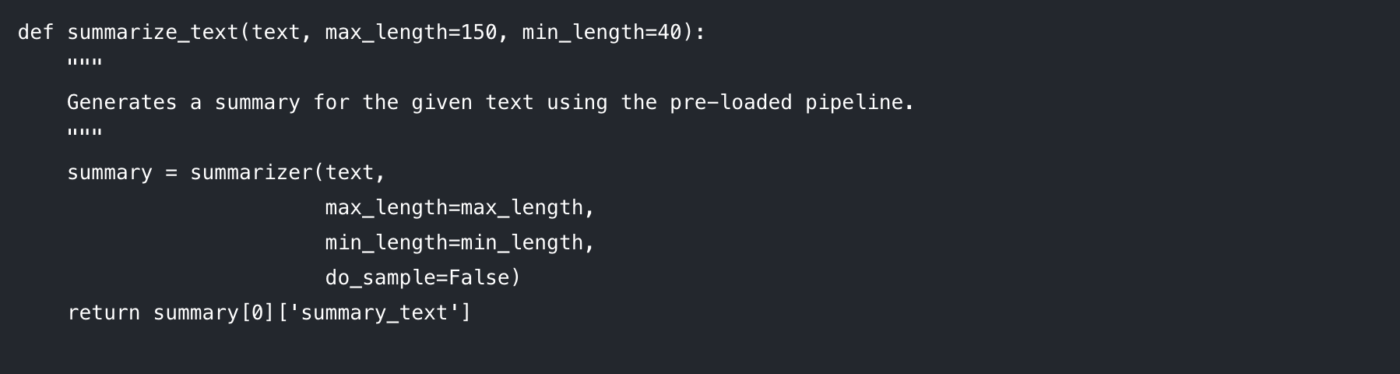
Låt oss bryta ner de parametrar du kan kontrollera:
max_length: Detta anger det maximala antalet token (ungefär ord) för den sammanfattande utdata.
min_length: Detta anger det minsta antalet token för att förhindra att modellen genererar alltför korta eller tomma sammanfattningar.
do_sample: När inställningen är False använder modellen en deterministisk metod (som beam search) för att generera den mest sannolika sammanfattningen. Om inställningen är True introduceras slumpmässighet, vilket kan ge mer kreativa men mindre förutsägbara resultat.
Att justera dessa parametrar är nyckeln till att få den utskriftskvalitet du önskar.
Steg 4: Skapa din sammanfattning
Nu kommer det roliga. Skicka din text till funktionen och skriv ut resultatet. 🤩

Du bör se en kondenserad version av artikeln utskriven på din konsol. Om du stöter på problem finns här några snabba lösningar:
Inmatningstexten är för lång: Modellen kan ge ett felmeddelande om din inmatning överskrider den maximala längden (ofta 512 eller 1024 token). Lägg till truncation=True i summarizer()-anropet för att automatiskt klippa av långa inmatningar.
Sammanfattningen är för allmän: Försök att öka parametern num_beams (t.ex. num_beams=4). Detta gör att modellen söker mer noggrant efter en bättre sammanfattning, men kan vara något långsammare.
Denna kodbaserade metod är fantastisk för utvecklare som bygger anpassade appar. Men vad händer när du behöver integrera detta i ett teams dagliga arbete? Det är där begränsningarna börjar visa sig.
Begränsningar hos Hugging Face för textsammanfattning
Hugging Face är ett utmärkt val när du vill ha flexibilitet och kontroll. Men när du försöker använda det för riktiga teamarbetsflöden (inte bara en demobok) dyker det snabbt upp några förutsägbara utmaningar.
Tokenbegränsningar och huvudvärk med långa dokument
De flesta sammanfattningsmodeller har en fast maximal inmatningslängd. Till exempel är facebook/bart-large-cnn konfigurerad med max_position_embeddings = 1024. Det innebär att längre dokument ofta måste trunkeras eller delas upp i mindre delar.
Om du bara behöver en snabb baslinje kan du aktivera trunkering i pipelinen och gå vidare. Men om du behöver trogna sammanfattningar av långa dokument hamnar du vanligtvis i att bygga upp en chunking-logik och sedan göra en andra genomgång, en ”sammanfattning av sammanfattningar”, för att sammanfoga resultaten. Det är extra arbete, och det är lätt att få inkonsekventa resultat.
Risken för hallucinationer (och verifieringskostnaden)
Abstraktiva modeller kan ibland hallucinera och generera text som låter trovärdig men som faktiskt är felaktig. För affärskritisk användning skapar det ett problem: varje sammanfattning måste verifieras manuellt. I det läget sparar du inte egentligen tid, utan flyttar bara arbetet till en annan del av processen.
Bristande kontextmedvetenhet
En Hugging Face-modell känner bara till den text du matar in i den. Den har ingen förståelse för ditt projekts mål, de personer som är involverade eller hur ett dokument relaterar till ett annat, eftersom den saknar den kontextuella intelligensen hos moderna system. Den kan inte tala om för dig om en sammanfattning från ett kundsamtal strider mot projektkravsdokumentet, eftersom den lever isolerat.
Integrationskostnader (problemet med den sista sträckan)
Att skapa en sammanfattning är oftast den enkla delen. Det svåra är det som kommer efteråt.
Vart tar sammanfattningen vägen? Vem ser den? Hur omvandlas den till en åtgärdsbar uppgift? Hur kopplar du den till det arbete som utlöste den?
Att lösa den "sista biten" innebär att bygga anpassade integrationer och limkod. Det innebär extra arbete för utvecklarna i förväg och skapar ofta ett klumpigt arbetsflöde för alla andra.
Tekniska hinder och löpande underhåll
En Python-baserad metod är främst tillgänglig för personer som kan koda. Det skapar ett praktiskt hinder för marknadsförings-, försäljnings- och driftsteam, vilket innebär att användningen förblir begränsad.
Det ingår även löpande underhåll: hantering av beroenden, uppdatering av bibliotek och att se till att allt fungerar när API:er och modeller utvecklas. Det som börjar som en snabb vinst kan i tysthet bli ännu ett system att sköta.
📮 ClickUp Insight: 42 % av störningarna på jobbet beror på att man måste jonglera mellan olika plattformar, hantera e-post och hoppa mellan möten. Tänk om du kunde eliminera dessa kostsamma avbrott? ClickUp förenar dina arbetsflöden (och chatt) under en enda, strömlinjeformad plattform. Starta och hantera dina uppgifter från chatt, dokument, whiteboards och mer, medan AI-drivna funktioner håller sammanhanget sammankopplat, sökbart och hanterbart.
Det större problemet: Kontextens spridning
Även om ditt sammanfattningsskript fungerar perfekt kan ditt team fortfarande förlora tid eftersom resultatet är kopplat från den plats där arbetet faktiskt utförs.
Det är kontextutbredning, när team slösar timmar på att söka efter information, växla mellan appar och leta efter filer på olika plattformar.
Det är här en konvergerad arbetsyta förändrar spelplanen. Istället för att generera sammanfattningar på ett ställe och försöka "flytta dem till arbetet" senare, håller ett konvergerat system projekt, dokument och konversationer tillsammans, med ClickUp Brain inbäddat som intelligenslager. Dina sammanfattningar förblir kopplade till uppgifter och dokument, så nästa steg är uppenbart och överlämningen sker omedelbart.
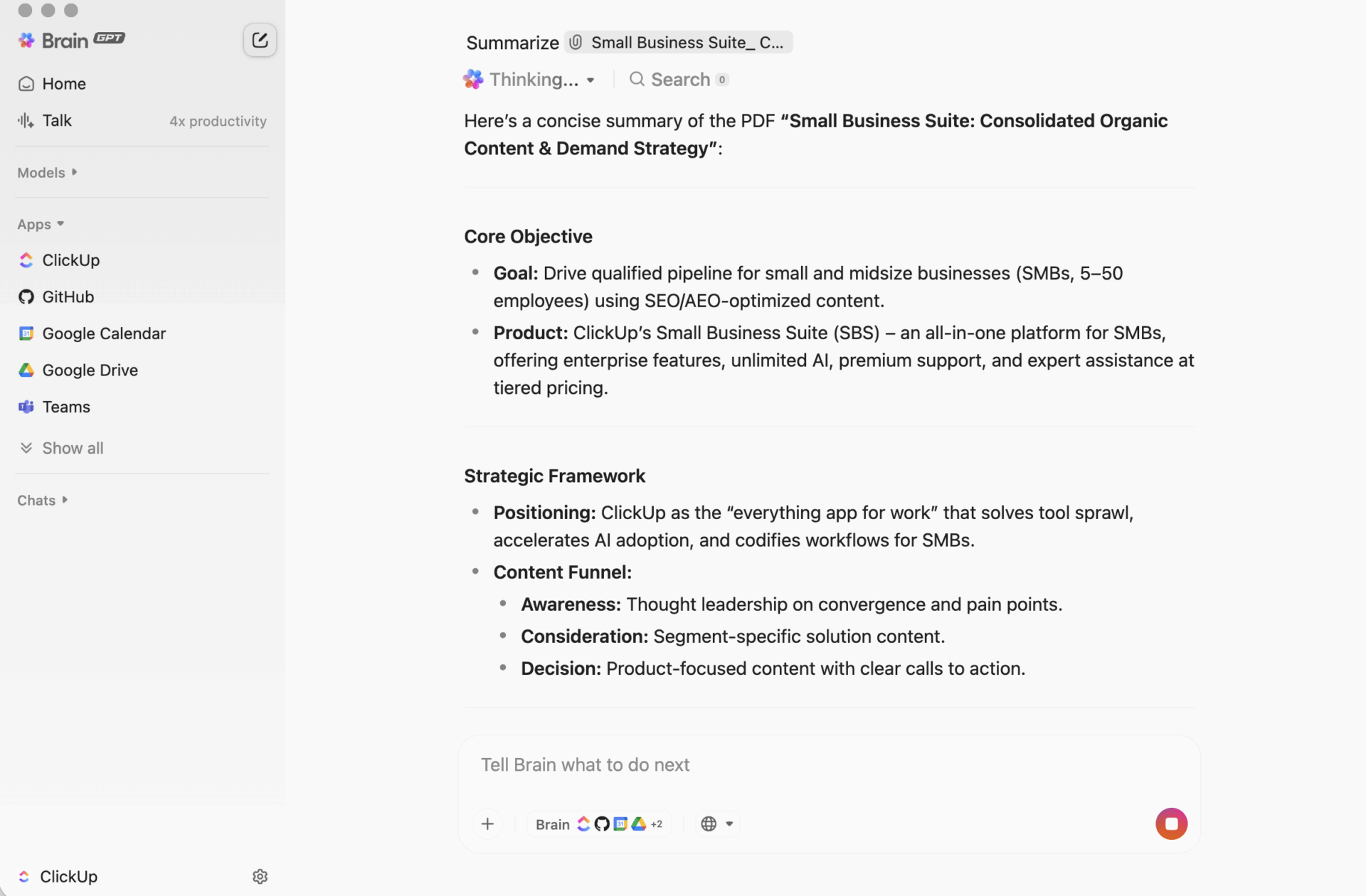
Sammanfattningar som omvandlas till handling med ClickUp
Ett sammanfattningsskript kan fungera perfekt och ändå misslyckas på ett irriterande sätt: sammanfattningen hamnar någonstans separat från arbetet.
Denna lucka skapar kontextförvirring, där informationen är utspridd över dokument, chattråd, uppgifter och ”snabba anteckningar” i verktyg som inte är kopplade till varandra. Människor lägger mer tid på att hitta sammanfattningen än på att använda den. Den verkliga vinsten är inte bara att generera en sammanfattning. Det är att hålla sammanfattningen kopplad till beslut, ansvariga och nästa steg där arbetet faktiskt utförs.
Det är vad ClickUp Brain gör annorlunda. Det sammanfattar uppgifter, dokument och konversationer inom samma arbetsyta där dina projekt finns, så att ditt team kan förstå något och agera på det utan att byta verktyg.

ClickUp BrainGPT: interagera med sammanfattningar med hjälp av naturligt språk
På datorn är BrainGPT det konversationsgränssnittet för ClickUp Brain. Istället för att öppna skript, anteckningsböcker eller externa AI-verktyg kan ditt team fråga efter vad de behöver i klartext, direkt i ClickUp.
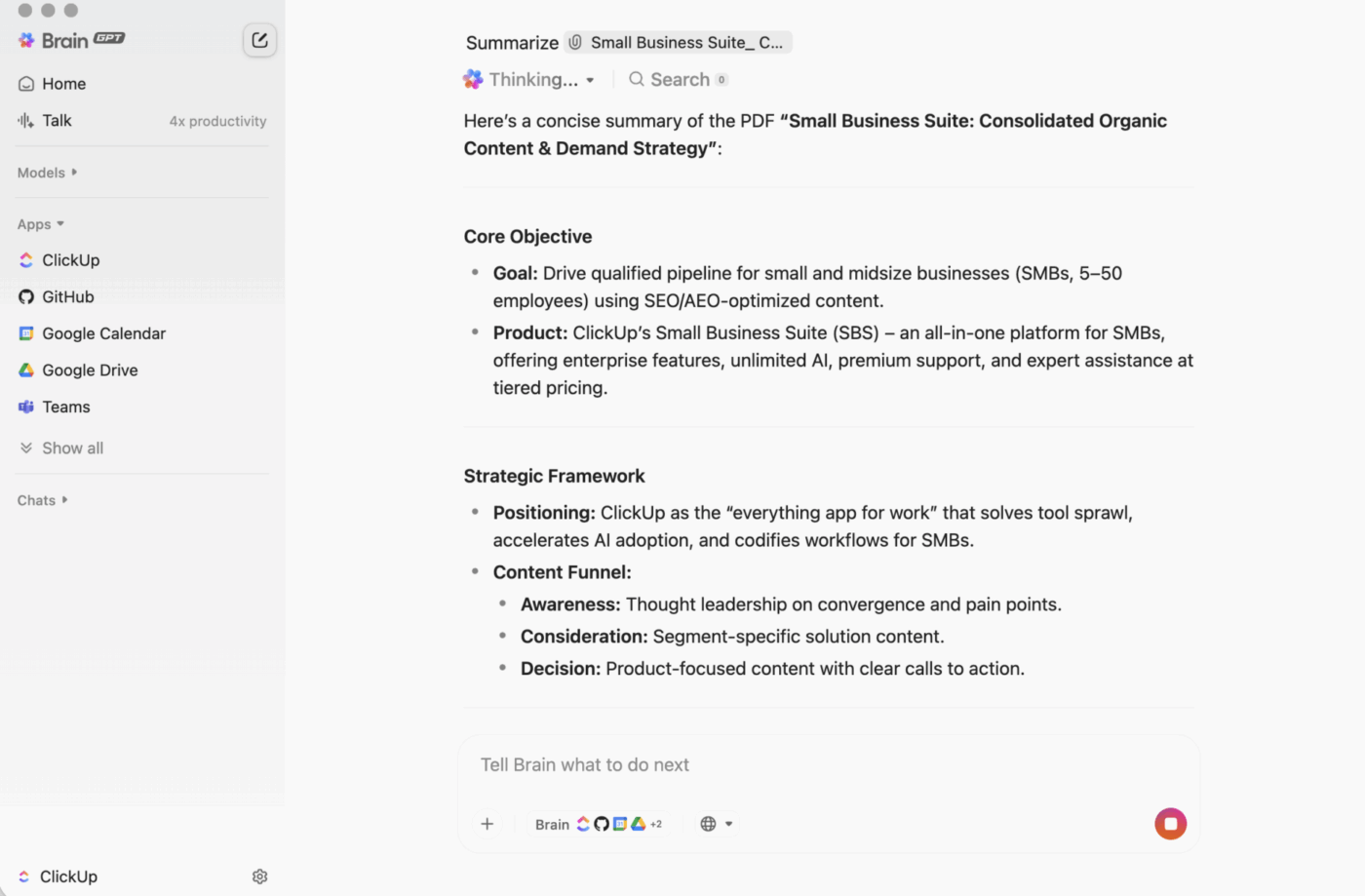
Du kan skriva (eller använda röst-till-text) för att:
- Sammanfatta en lång uppgiftsbeskrivning, kommentartråd eller dokument.
- Följ upp med frågor som "Vilka är nästa steg?" eller "Vem ansvarar för detta?"
- Omvandla en sammanfattning till handling genom att skapa uppgifter utifrån den, med ansvariga och förfallodatum.
Eftersom ClickUp Brain fungerar inuti din arbetsyta baseras resultatet på livekontext: uppgiftsbeskrivningar, kommentarer, deluppgifter, länkade dokument och projektstruktur. Du klistrar inte in text i ett separat verktyg och hoppas att inget viktigt går förlorat.
Varför detta är bättre än ett kodbaserat sammanfattningsflöde för de flesta team
Ett arbetsflöde som skapats av utvecklare kan generera starka sammanfattningar. Friktionen uppstår efter det, när någon måste kopiera resultatet till den plats där arbetet utförs, sedan översätta det till uppgifter och sedan följa upp genomförandet.
ClickUp Brain sluter cirkeln:
Ingen kodning krävsAlla i teamet kan sammanfatta ett dokument, en uppgiftstråd eller en rörig uppsättning kommentarer utan att installera något eller skriva kod.
Kontextmedvetna sammanfattningarClickUp Brain kan inkludera de delar som människor vanligtvis glömmer: beslut som begravts i kommentarer, hinder som nämns i svar, deluppgifter som förändrar innebörden av ”klart”.
Sammanfattningar finns där arbetet finnsDu kan komma ikapp inom en uppgift, lägga till en sammanfattning högst upp i ClickUp Docs eller snabbt sammanfatta en diskussion utan att skapa ytterligare ett ”sammanfattningsdokument” som ingen läser.
Mindre verktygsspridningDu behöver inte separata skript, Jupyter-anteckningsböcker, API-nycklar eller ett arbetsflöde som bara en person förstår. Dina dokument, uppgifter och sammanfattningar finns alla i samma system.
Detta är den praktiska fördelen med en samlad arbetsyta: sammanfattning, handling och samarbete sker samtidigt istället för att sammanfogas i efterhand.
Detta är den praktiska fördelen med en samlad arbetsyta: sammanfattning, handling och samarbete sker samtidigt istället för att sammanfogas i efterhand.
Hur det fungerar i verkligheten
Här är några vanliga mönster som team använder:
- Sammanfatta en kommentartråd: öppna en uppgift med en lång diskussion, klicka på AI-alternativet och få en snabb sammanfattning av vad som har ändrats och vad som är viktigt.
- Sammanfatta ett dokument: öppna ett ClickUp-dokument och använd "Ask AI" för att generera en sammanfattning av sidan så att alla snabbt kan orientera sig.
- Extrahera åtgärdspunkter: ta sammanfattningen och omvandla omedelbart nästa steg till uppgifter med ansvariga och förfallodatum, så att momentum inte går förlorat i överlämningen.
| Kapacitet | Hugging Face (kodbaserad) | ClickUp Brain |
|---|---|---|
| Installation krävs | Python-miljö, bibliotek, kodning | Ingen, inbyggd |
| Kontextmedvetenhet | Endast text (det du matar in) | Fullständigt arbetsutrymmeskontext (uppgifter, dokument, kommentarer, deluppgifter) |
| Arbetsflödesintegration | Manuell export/import | Native: sammanfattningar kan bli uppgifter och uppdateringar |
| Tekniska färdigheter som krävs | Utvecklingsnivå | Alla i teamet |
| Underhåll | Löpande underhåll av modeller och kod | Automatiska uppdateringar |
Från sammanfattningar till genomförande med Super Agents
Sammanfattningar är användbara. Det svåra är att se till att de konsekvent omsätts i handling, särskilt när volymen ökar.
Det är här ClickUp Super Agents kommer in. De kan använda sammanfattad information och driva arbetet framåt baserat på triggers och villkor, inom samma arbetsyta.
Med Super Agents kan teamen:
- Sammanfatta förändringar enligt ett schema (veckovis projektöversikt, dagliga statusrapporter)
- Extrahera åtgärdspunkter och tilldela ägare automatiskt
- Markera fastnat arbete (uppgifter som fastnat i granskning, obesvarade trådar, försenade nästa steg)
- Håll ledarskapets synlighet hög utan manuell rapportering
Istället för en sammanfattning i form av statisk text hjälper agenterna till att se till att sammanfattningen blir en plan och att planen blir framsteg.
Sammanfattningar som finns där arbetet utförs
Hugging Face Transformers är utmärkta när du behöver en anpassad app, en skräddarsydd pipeline eller full kontroll över modellens beteende.
Men för de flesta team är det största problemet inte ”Kan vi sammanfatta detta?” utan ”Kan vi sammanfatta detta och omedelbart omvandla det till arbete, med ansvariga, deadlines och synlighet?”
Om ditt mål är teamproduktivitet och snabb genomförande, ger ClickUp Brain dig sammanfattningar i sammanhang, precis där arbetet utförs, med en tydlig väg från "här är det viktigaste" till "här är vad vi gör härnäst".
Är du redo att hoppa över installationen och börja sammanfatta där ditt arbete faktiskt utförs? Kom igång gratis med ClickUp och låt Brain sköta det tunga arbetet.