

Stora språkmodeller (LLM) har öppnat upp spännande nya möjligheter för programvaruapplikationer. De möjliggör mer intelligenta och dynamiska system än någonsin tidigare.
Experter förutspår att appar som drivs av dessa modeller kommer att kunna automatisera nästan hälften av allt digitalt arbete år 2025.
Men när vi låser upp dessa funktioner dyker en utmaning upp: hur kan vi på ett tillförlitligt sätt mäta kvaliteten på deras resultat i stor skala? En liten justering i inställningarna, och plötsligt ser du ett märkbart annorlunda resultat. Denna variabilitet kan göra det svårt att mäta deras prestanda, vilket är avgörande när man förbereder en modell för användning i verkligheten.
Denna artikel ger insikter om de bästa metoderna för utvärdering av LLM-system, från testning före driftsättning till produktion. Så, låt oss börja!
Vad är en LLM-utvärdering?
LLM-utvärderingsmått är ett sätt att se om dina uppmaningar, modellinställningar eller arbetsflöden uppfyller de mål du har satt upp. Dessa mått ger dig insikt i hur väl din stora språkmodell presterar och om den verkligen är redo för användning i verkligheten.
Idag mäter några av de vanligaste mätvärdena kontextåterkallande i RAG-uppgifter (retrieval-augmented generation), exakta matchningar för klassificeringar, JSON-validering för strukturerade utdata och semantisk likhet för mer kreativa uppgifter.
Var och en av dessa mätvärden säkerställer på ett unikt sätt att LLM uppfyller standarderna för ditt specifika användningsfall.
Varför behöver du utvärdera en LLM?
Stora språkmodeller (LLM) används nu i ett brett spektrum av applikationer. Det är viktigt att utvärdera modellernas prestanda för att säkerställa att de uppfyller förväntade standarder och effektivt tjänar sina avsedda syften.
Tänk på det så här: LLM driver allt från chatbots för kundsupport till kreativa verktyg, och ju mer avancerade de blir, desto fler ställen dyker de upp.
Det innebär att vi behöver bättre sätt att övervaka och utvärdera dem – traditionella metoder klarar helt enkelt inte av alla uppgifter som dessa modeller hanterar.
Bra utvärderingsmått är som en kvalitetskontroll för LLM. De visar om modellen är tillräckligt tillförlitlig, korrekt och effektiv för användning i verkligheten. Utan dessa kontroller kan misstag smyga sig in, vilket kan leda till frustrerande eller till och med vilseledande användarupplevelser.
När du har starka utvärderingsmått är det lättare att upptäcka problem, förbättra modellen och se till att den är redo att möta användarnas specifika behov. På så sätt vet du att den AI-plattform du arbetar med håller standard och kan leverera de resultat du behöver.
📖 Läs mer: LLM vs. generativ AI: En detaljerad guide
Typer av LLM-utvärderingar
Utvärderingar ger en unik inblick i modellens kapacitet. Varje typ behandlar olika kvalitetsaspekter, vilket bidrar till att skapa en pålitlig, säker och effektiv distributionsmodell.
Här är de olika typerna av LLM-utvärderingsmetoder:
- Intrinsisk utvärdering fokuserar på modellens interna prestanda i specifika språkliga eller förståelseuppgifter utan att involvera verkliga tillämpningar. Den utförs vanligtvis under modellens utvecklingsfas för att förstå dess kärnfunktioner.
- Extrinsisk utvärdering bedömer modellens prestanda i verkliga tillämpningar. Denna typ av utvärdering undersöker hur väl modellen uppfyller specifika mål inom ett sammanhang.
- Robusthetsutvärdering testar modellens stabilitet och tillförlitlighet i olika scenarier, inklusive oväntade indata och ogynnsamma förhållanden. Den identifierar potentiella svagheter och säkerställer att modellen beter sig förutsägbart.
- Effektivitets- och latensprovning undersöker modellens resursanvändning, hastighet och latens. Det säkerställer att modellen kan utföra uppgifter snabbt och till en rimlig beräkningskostnad, vilket är viktigt för skalbarheten.
- Etik- och säkerhetsutvärdering säkerställer att modellen överensstämmer med etiska standarder och säkerhetsriktlinjer, vilket är avgörande i känsliga tillämpningar.
LLM-modellutvärderingar jämfört med LLM-systemutvärderingar
Utvärdering av stora språkmodeller (LLM) innefattar två huvudsakliga tillvägagångssätt: modellutvärderingar och systemutvärderingar. Var och en fokuserar på olika aspekter av LLM:s prestanda, och det är viktigt att känna till skillnaden för att maximera dessa modellers potential.
🧠 Modellutvärderingar tittar på LLM:s allmänna färdigheter. Denna typ av utvärdering testar modellens förmåga att förstå, generera och arbeta med språk på ett korrekt sätt i olika sammanhang. Det är som att se hur väl modellen kan hantera olika uppgifter, nästan som ett allmänt intelligensprov.
Modellutvärderingar kan till exempel ställa frågan: ”Hur mångsidig är den här modellen?”
🎯 LLM systemutvärderingar mäter hur LLM presterar inom en specifik konfiguration eller ett specifikt syfte, till exempel i en chattbot för kundtjänst. Här handlar det mindre om modellens breda förmågor och mer om hur den utför specifika uppgifter för att förbättra användarupplevelsen.
Systemutvärderingar fokuserar dock på frågor som ”Hur väl hanterar modellen denna specifika uppgift för användarna?”
Modellutvärderingar hjälper utvecklare att förstå LLM:s övergripande förmågor och begränsningar, vilket leder till förbättringar. Systemutvärderingar fokuserar på hur väl LLM uppfyller användarnas behov i specifika sammanhang, vilket säkerställer en smidigare användarupplevelse.
Tillsammans ger dessa utvärderingar en fullständig bild av LLM:s styrkor och förbättringsområden, vilket gör den mer kraftfull och användarvänlig i verkliga tillämpningar.
Låt oss nu utforska de specifika mätvärdena för LLM-utvärdering.
Mätvärden för LLM-utvärdering
Några tillförlitliga och populära utvärderingsmått är:
1. Förvirring
Perplexitet mäter hur väl en språkmodell kan förutsäga en sekvens av ord. I grund och botten indikerar det modellens osäkerhet om nästa ord i en mening. En lägre perplexitetspoäng innebär att modellen är mer säker i sina förutsägelser, vilket leder till bättre prestanda.
📌 Exempel: Tänk dig att en modell genererar text utifrån prompten ”Katten satt på...”. Om den förutsäger en hög sannolikhet för ord som ”matta” och ”golv” förstår den sammanhanget väl, vilket resulterar i en låg perplexitetspoäng.
Å andra sidan, om den föreslår ett orelaterat ord som "rymdskepp", skulle förvirringspoängen bli högre, vilket indikerar att modellen har svårt att förutsäga meningsfull text.
2. BLEU-poäng
BLEU-poängen (Bilingual Evaluation Understudy) används främst för att utvärdera maskinöversättning och bedöma textgenerering.
Den mäter hur många n-gram (sammanhängande sekvenser av n element från ett givet textprov) i utdata överlappar med dem i en eller flera referenstexter. Poängen varierar mellan 0 och 1, där högre poäng indikerar bättre prestanda.
📌 Exempel: Om din modell genererar meningen ”Den snabba bruna räven hoppar över den lata hunden” och referenstexten är ”En snabb brun räv hoppar över en lat hund”, kommer BLEU att jämföra de gemensamma n-grammen.
Ett högt betyg indikerar att den genererade meningen stämmer väl överens med referensen, medan ett lägre betyg kan tyda på att det genererade resultatet inte stämmer överens.
3. F1-poäng
LLM-utvärderingsmåttet F1-poäng används främst för klassificeringsuppgifter. Det mäter balansen mellan precision (noggrannheten i de positiva förutsägelserna) och återkallelse (förmågan att identifiera alla relevanta fall).
Skalan går från 0 till 1, där 1 innebär perfekt noggrannhet.
📌 Exempel: I en frågesport, om modellen får frågan ”Vilken färg har himlen?” och svarar ”Himlen är blå” (sant positivt) men också inkluderar ”Himlen är grön” (falskt positivt), kommer F1-poängen att ta hänsyn till både relevansen av det rätta svaret och det felaktiga.
Denna mätvärde hjälper till att säkerställa en balanserad utvärdering av modellens prestanda.
4. METEOR
METEOR (Metric for Evaluation of Translation with Explicit ORdering) går längre än exakt ordmatchning. Den tar hänsyn till synonymer, stamord och parafraser för att utvärdera likheten mellan genererad text och referenstext. Denna mätmetod syftar till att bättre överensstämma med mänskligt omdöme.
📌 Exempel: Om din modell genererar ”Katten vilade på mattan” och referensen är ”Katten låg på mattan”, skulle METEOR ge detta ett högre betyg än BLEU eftersom det känner igen att ”katt” är en synonym för ”katt” och att ”matta” och ”golvmatta” har liknande betydelser.
Detta gör METEOR särskilt användbart för att fånga nyanserna i språket.
5. BERTScore
BERTScore utvärderar textlikhet baserat på kontextuella inbäddningar som härrör från modeller som BERT (Bidirectional Encoder Representations from Transformers). Det fokuserar mer på betydelse än exakta ordmatchningar, vilket möjliggör en bättre semantisk likhetsbedömning.
📌 Exempel: När man jämför meningarna ”Bilen rusade fram på vägen” och ”Fordonet körde fort längs gatan” analyserar BERTScore de underliggande betydelserna snarare än bara ordvalet.
Även om orden skiljer sig åt är de övergripande idéerna likartade, vilket leder till ett högt BERTScore-värde som återspeglar effektiviteten hos det genererade innehållet.
6. Mänsklig utvärdering
Mänsklig utvärdering är fortfarande en viktig del av LLM-bedömningen. Det innebär att mänskliga bedömare betygsätter kvaliteten på modellresultaten utifrån olika kriterier, såsom flyt och relevans. Tekniker som Likert-skalor och A/B-testning kan användas för att samla in feedback.
📌 Exempel: Efter att ha genererat svar från en chattbot för kundtjänst kan mänskliga utvärderare betygsätta varje svar på en skala från 1 till 5. Om chattboten till exempel ger ett tydligt och hjälpsamt svar på en kundförfrågan kan den få betyget 5, medan ett vagt eller förvirrande svar kan få betyget 2.
7. Uppgiftsspecifika mätvärden
Olika LLM-uppgifter kräver skräddarsydda utvärderingsmått.
För dialogsystem kan mätvärdena bedöma användarengagemang eller uppgiftsgenomförandegrad. För kodgenerering kan framgång mätas utifrån hur ofta den genererade koden kompileras eller klarar tester.
📌 Exempel: I en chatbot för kundsupport kan engagemangsnivån mätas utifrån hur länge användarna stannar kvar i en konversation eller hur många uppföljningsfrågor de ställer.
Om användarna ofta ber om ytterligare information tyder det på att modellen lyckas engagera dem och effektivt besvara deras frågor.
8. Robusthet och rättvisa
För att bedöma en modells robusthet måste man testa hur väl den reagerar på oväntade eller ovanliga indata. Rättvisemätvärden hjälper till att identifiera partiskhet i modellens utdata, vilket säkerställer att den fungerar rättvist i olika demografiska grupper och scenarier.
📌 Exempel: När du testar en modell med en nyckfull fråga som ”Vad tycker du om enhörningar?” bör den hantera frågan på ett elegant sätt och ge ett relevant svar. Om den istället ger ett meningslöst eller olämpligt svar indikerar det en brist på robusthet.
Rättvisetestning säkerställer att modellen inte producerar partiska eller skadliga resultat, vilket främjar ett mer inkluderande AI-system.
9. Effektivitetsmått
I takt med att språkmodellerna blir allt mer komplexa blir det allt viktigare att mäta deras effektivitet när det gäller hastighet, minnesanvändning och energiförbrukning. Effektivitetsmått hjälper till att utvärdera hur resurskrävande en modell är när den genererar svar.
📌 Exempel: För en stor språkmodell kan mätning av effektivitet innebära att man spårar hur snabbt den genererar svar på användarnas frågor och hur mycket minne den använder under denna process.
Om det tar för lång tid att svara eller förbrukar för mycket resurser kan det vara ett problem för applikationer som kräver realtidsprestanda, såsom chattbottar eller översättningstjänster.
Nu vet du hur man utvärderar en LLM-modell. Men vilka verktyg kan du använda för att mäta detta? Låt oss utforska det.
Hur ClickUp Brain kan förbättra LLM-utvärderingen
ClickUp är en app för allt som rör arbete med en inbyggd personlig assistent som heter ClickUp Brain.
ClickUp Brain är en game changer för LLM-prestandautvärdering. Så vad gör det?
Den organiserar och lyfter fram de mest relevanta uppgifterna, så att ditt team kan hålla sig på rätt spår. Med sina AI-drivna funktioner är ClickUp Brain en av de bästa programvarorna för neurala nätverk som finns på marknaden. Den gör hela processen smidigare, effektivare och mer samarbetsinriktad än någonsin. Låt oss utforska dess möjligheter tillsammans.
Intelligent kunskapshantering
När man utvärderar stora språkmodeller (LLM) kan hanteringen av stora datamängder vara överväldigande.

ClickUp Brain kan organisera och lyfta fram viktiga mätvärden och resurser som är skräddarsydda för LLM-utvärdering. Istället för att leta igenom spridda kalkylblad och komplicerade rapporter samlar ClickUp Brain allt på ett ställe. Prestandamätvärden, benchmarkingdata och testresultat är alla tillgängliga i ett tydligt och användarvänligt gränssnitt.
Denna organisation hjälper ditt team att sålla bort ovidkommande information och fokusera på de insikter som verkligen betyder något, vilket gör det enklare att tolka trender och prestationsmönster.
Med allt du behöver på ett och samma ställe kan du gå från ren datainsamling till effektivt, datadrivet beslutsfattande och omvandla informationsöverflödet till användbar information.
Projektplanering och arbetsflödeshantering
LLM-utvärderingar kräver noggrann planering och samarbete, och ClickUp gör det enkelt att hantera denna process.
Du kan enkelt delegera ansvar som datainsamling, modellträning och prestandatestning samtidigt som du anger prioriteringar för att säkerställa att de viktigaste uppgifterna får uppmärksamhet först. Dessutom kan du med hjälp av anpassade fält skräddarsy arbetsflöden efter de specifika behoven i ditt projekt.

Med ClickUp kan alla se vem som gör vad och när, vilket hjälper till att undvika förseningar och säkerställer att uppgifterna flyter smidigt inom teamet. Det är ett utmärkt sätt att hålla allt organiserat och på rätt spår från början till slut.
Mätning av statistik via anpassade instrumentpaneler
Vill du hålla ett öga på hur dina LLM-system presterar?
ClickUp Dashboards visualiserar prestationsindikatorerna i realtid. Det gör att du kan övervaka din modells framsteg direkt. Dessa dashboards är mycket anpassningsbara, så att du kan skapa grafer och diagram som visar exakt vad du behöver när du behöver det.
Du kan se hur din modells noggrannhet utvecklas genom utvärderingsstadierna eller bryta ner resursförbrukningen i varje fas. Med denna information kan du snabbt upptäcka trender, identifiera områden som kan förbättras och göra justeringar direkt.
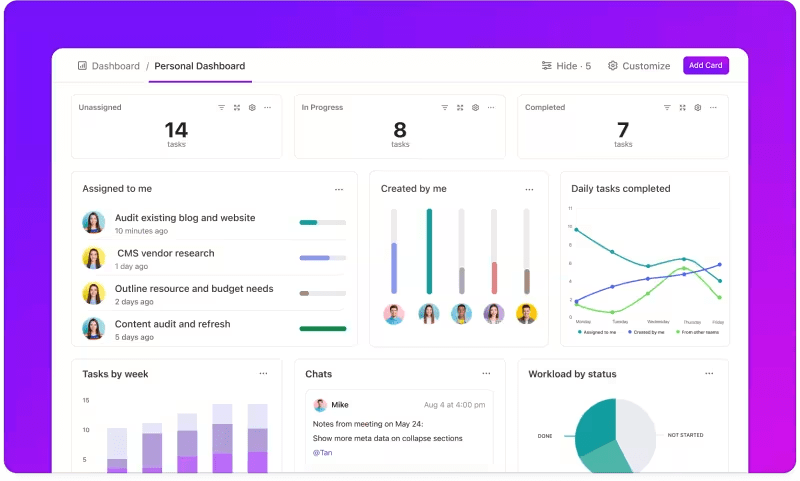
Istället för att vänta på nästa detaljerade rapport kan du med ClickUp Dashboards hålla dig informerad och responsiv, vilket gör det möjligt för ditt team att fatta datadrivna beslut utan dröjsmål.
Automatiserade insikter
Dataanalys kan vara tidskrävande, men ClickUp Brain-funktionerna underlättar arbetet genom att ge värdefulla insikter. De lyfter fram viktiga trender och ger till och med rekommendationer baserade på data, vilket gör det enklare att dra meningsfulla slutsatser.
Med ClickUp Brains automatiserade insikter behöver du inte manuellt gå igenom rådata för att hitta mönster – programmet hittar dem åt dig. Denna automatisering frigör tid för ditt team att fokusera på att förfina modellens prestanda istället för att fastna i repetitiva dataanalyser.
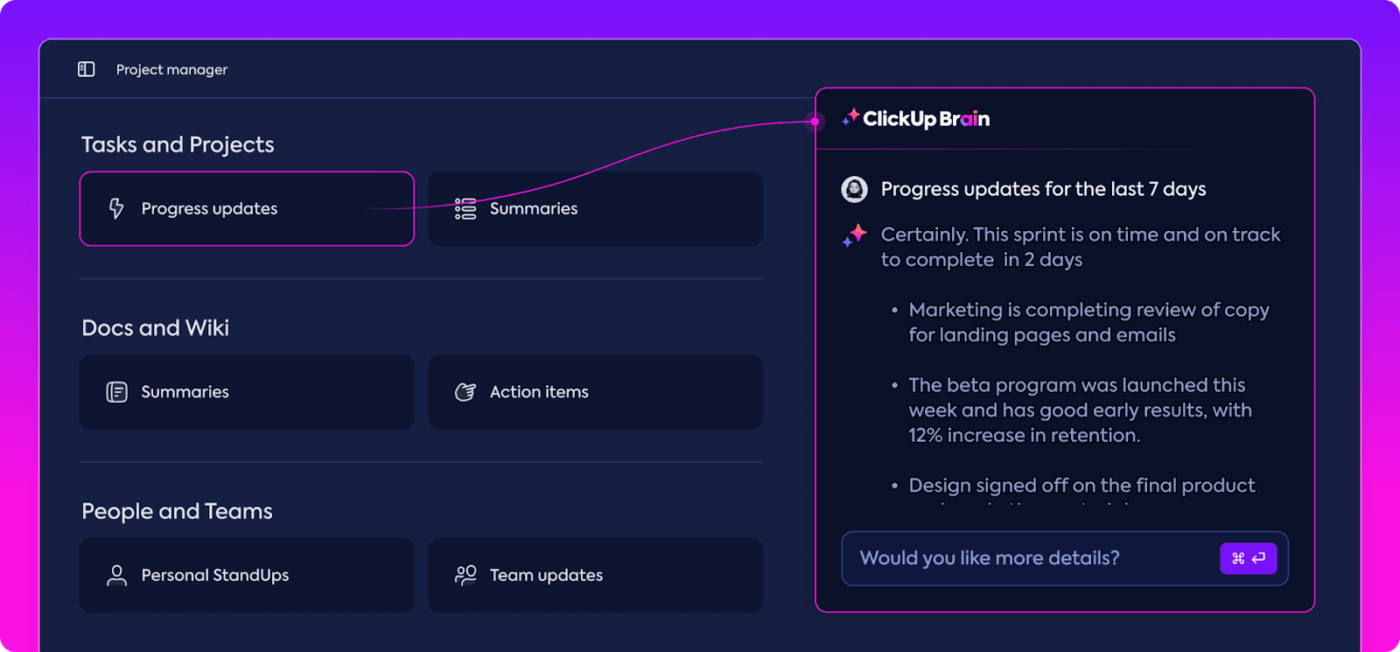
De insikter som genereras är färdiga att användas, så att ditt team omedelbart kan se vad som fungerar och var förändringar kan behövas. Genom att minska tiden som läggs på analys hjälper ClickUp ditt team att påskynda utvärderingsprocessen och fokusera på implementeringen.
Dokumentation och samarbete
Du behöver inte längre söka igenom e-postmeddelanden eller flera plattformar för att hitta det du behöver – allt finns där, redo när du är det.
ClickUp Docs är en central hubb som samlar allt ditt team behöver för en smidig LLM-utvärdering. Den organiserar viktig projektdokumentation – som benchmarkingkriterier, testresultat och prestandaloggar – på ett enda tillgängligt ställe så att alla snabbt kan komma åt den senaste informationen.
Det som verkligen skiljer ClickUp Docs från andra är dess funktioner för samarbete i realtid. Den integrerade ClickUp Chat och Comments gör det möjligt för teammedlemmar att diskutera insikter, ge feedback och föreslå ändringar direkt i dokumenten.
Det innebär att ditt team kan diskutera resultaten och göra justeringar direkt på plattformen, så att alla diskussioner förblir relevanta och fokuserade.

Allt från dokumentation till teamarbete sker inom ClickUp Docs, vilket skapar en strömlinjeformad utvärderingsprocess där alla kan se, dela och agera på de senaste utvecklingen.
Resultatet? Ett smidigt, enhetligt arbetsflöde som gör att ditt team kan arbeta mot sina mål med fullständig tydlighet.
Är du redo att prova ClickUp? Innan dess ska vi diskutera några tips och tricks för att få ut det mesta av din LLM-utvärdering.
Bästa praxis för LLM-utvärdering
En välstrukturerad strategi för LLM-utvärdering säkerställer att modellen uppfyller dina behov, överensstämmer med användarnas förväntningar och levererar meningsfulla resultat.
Att sätta upp tydliga mål, ta hänsyn till slutanvändarna och använda olika mätvärden hjälper dig att utforma en grundlig utvärdering som visar styrkor och förbättringsområden. Nedan följer några bästa praxis som kan vägleda dig i processen.
🎯 Definiera tydliga mål
Innan du påbörjar utvärderingsprocessen är det viktigt att veta exakt vad du vill att din stora språkmodell (LLM) ska uppnå. Ta dig tid att beskriva de specifika uppgifterna eller målen för modellen.
📌 Exempel: Om du vill förbättra maskinöversättningens prestanda, klargör vilka kvalitetsnivåer du vill uppnå. Att ha tydliga mål hjälper dig att fokusera på de mest relevanta mätvärdena, vilket säkerställer att din utvärdering förblir i linje med dessa mål och mäter framgången på ett korrekt sätt.
👥 Tänk på din målgrupp
Fundera över vem som kommer att använda LLM och vilka behov de har. Det är viktigt att anpassa utvärderingen efter dina tänkta användare.
📌 Exempel: Om din modell är avsedd att generera engagerande innehåll bör du vara särskilt uppmärksam på mått som flyt och sammanhang. Att förstå din målgrupp hjälper dig att förfina dina utvärderingskriterier och säkerställa att modellen levererar verkligt värde i praktiska tillämpningar.
📊 Använd olika mätvärden
Förlita dig inte på en enda mätparameter för att utvärdera din LLM; en kombination av mätparametrar ger dig en mer fullständig bild av dess prestanda. Varje mätparameter fångar upp olika aspekter, så genom att använda flera kan du identifiera både styrkor och svagheter.
📌 Exempel: BLEU-poäng är utmärkta för att mäta översättningskvalitet, men de täcker kanske inte alla nyanser i kreativt skrivande. Genom att införliva mått som perplexitet för prediktiv noggrannhet och till och med mänskliga utvärderingar för sammanhang kan du få en mycket mer välrundad förståelse för hur väl din modell presterar.
LLM-riktmärken och verktyg
Utvärdering av stora språkmodeller (LLM) baseras ofta på branschstandardiserade riktmärken och specialiserade verktyg som hjälper till att mäta modellens prestanda i olika uppgifter.
Här är en översikt över några vanliga riktmärken och verktyg som ger struktur och tydlighet åt utvärderingsprocessen.
Viktiga riktmärken
- GLUE (General Language Understanding Evaluation): GLUE utvärderar modellens kapacitet inom flera språkuppgifter, inklusive meningsklassificering, likhet och inferens. Det är ett viktigt riktmärke för modeller som behöver hantera allmän språkkunskap.
- SQuAD (Stanford Question Answering Dataset): SQuAD-utvärderingsramverket är idealiskt för läsförståelse och mäter hur väl en modell svarar på frågor baserade på en textpassage. Det används vanligtvis för uppgifter som kundsupport och kunskapsbaserad informationshämtning, där precisa svar är avgörande.
- SuperGLUE: SuperGLUE är en förbättrad version av GLUE som utvärderar modeller utifrån mer komplexa resonemang och kontextuella förståelseuppgifter. Det ger djupare insikter, särskilt för applikationer som kräver avancerad språkförståelse.
Viktiga utvärderingsverktyg
- Hugging Face : Det är mycket populärt för sitt omfattande modellbibliotek, sina datamängder och utvärderingsfunktioner. Dess mycket intuitiva gränssnitt gör det enkelt för användarna att välja riktmärken, anpassa utvärderingar och spåra modellprestanda, vilket gör det mångsidigt för många LLM-applikationer.
- SuperAnnotate: Specialiserat på hantering och annotering av data, vilket är avgörande för övervakade inlärningsuppgifter. Det är särskilt användbart för att förfina modellens noggrannhet, eftersom det underlättar högkvalitativa, mänskligt annoterade data som förbättrar modellens prestanda vid komplexa uppgifter.
- AllenNLP: AllenNLP har utvecklats av Allen Institute for AI och riktar sig till forskare och utvecklare som arbetar med anpassade NLP-modeller. Det stöder en rad olika benchmarktest och tillhandahåller verktyg för att träna, testa och utvärdera språkmodeller, vilket ger flexibilitet för olika NLP-applikationer.
Genom att kombinera dessa riktmärken och verktyg får du en heltäckande metod för LLM-utvärdering. Riktmärken kan sätta standarder för olika uppgifter, medan verktygen ger den struktur och flexibilitet som behövs för att effektivt spåra, förfina och förbättra modellens prestanda.
Tillsammans säkerställer de att LLM uppfyller både tekniska standarder och praktiska tillämpningsbehov.
Utmaningar vid utvärdering av LLM-modeller
Utvärdering av stora språkmodeller (LLM) kräver en nyanserad approach. Den fokuserar på kvaliteten på svaren och förståelsen för modellens anpassningsförmåga och begränsningar i olika scenarier.
Eftersom dessa modeller är tränade på omfattande datamängder påverkas deras beteende av en rad faktorer, vilket gör det viktigt att utvärdera mer än bara noggrannheten.
En riktig utvärdering innebär att man undersöker modellens tillförlitlighet, motståndskraft mot ovanliga uppmaningar och övergripande responskonsistens. Denna process hjälper till att ge en tydligare bild av modellens styrkor och svagheter och avslöjar områden som behöver förbättras.
Här är en närmare titt på några vanliga utmaningar som uppstår under LLM-utvärdering.
1. Överlappning av träningsdata
Det är svårt att veta om modellen redan har sett några av testuppgifterna. Eftersom LLM tränas på enorma datamängder finns det en risk att vissa testfrågor överlappar träningsexemplen. Detta kan få modellen att se bättre ut än den egentligen är, eftersom den kanske bara upprepar vad den redan vet istället för att visa verklig förståelse.
2. Inkonsekvent prestanda
LLM kan ge oförutsägbara svar. Ena stunden levererar de imponerande insikter, och nästa stund gör de konstiga fel eller presenterar påhittad information som fakta (så kallade ”hallucinationer”).
Denna inkonsekvens innebär att även om LLM-resultaten kan vara utmärkta inom vissa områden, kan de vara bristfälliga inom andra, vilket gör det svårt att korrekt bedöma dess övergripande tillförlitlighet och kvalitet.
3. Motstridiga sårbarheter
LLM kan vara känsliga för fientliga attacker, där skickligt utformade uppmaningar lurar dem att producera felaktiga eller skadliga svar. Denna sårbarhet avslöjar svagheter i modellen och kan leda till oväntade eller partiska resultat. Att testa dessa fientliga svagheter är avgörande för att förstå var modellens gränser ligger.
Praktiska användningsfall för LLM-utvärdering
Slutligen följer här några vanliga situationer där LLM-utvärdering verkligen gör skillnad:
Chatbots för kundsupport
LLM används ofta i chattbottar för att hantera kundfrågor. Genom att utvärdera hur väl modellen svarar kan du säkerställa att den ger korrekta, hjälpsamma och kontextuellt relevanta svar.
Det är viktigt att mäta dess förmåga att förstå kundens avsikt, hantera olika frågor och ge mänskliga svar. Detta gör det möjligt för företag att säkerställa en smidig kundupplevelse och samtidigt minimera frustrationen.
Innehållsgenerering
Många företag använder LLM för att generera blogginnehåll, sociala medier och produktbeskrivningar. Genom att utvärdera kvaliteten på det genererade innehållet kan du säkerställa att det är grammatiskt korrekt, engagerande och relevant för målgruppen. Mått som kreativitet, sammanhang och relevans för ämnet är viktiga för att upprätthålla en hög standard på innehållet.
Sentimentanalys
LLM kan analysera känslan i kundfeedback, inlägg på sociala medier eller produktrecensioner. Det är viktigt att utvärdera hur noggrant modellen identifierar om en text är positiv, negativ eller neutral. Detta hjälper företag att förstå kundernas känslor, förfina produkter eller tjänster, öka användarnas tillfredsställelse och förbättra marknadsföringsstrategier.
Kodgenerering
Utvecklare använder ofta LLM för att generera kod. Det är viktigt att utvärdera modellens förmåga att producera funktionell och effektiv kod.
Det är viktigt att kontrollera om den genererade koden är logiskt korrekt, felfri och uppfyller uppgiftskraven. Detta bidrar till att minska mängden manuell kodning som behövs och förbättrar produktiviteten.
Optimera din LLM-utvärdering med ClickUp
Att utvärdera LLM handlar om att välja rätt mätvärden som stämmer överens med dina mål. Nyckeln är att förstå dina specifika mål, oavsett om det handlar om att förbättra översättningskvaliteten, förbättra innehållsgenereringen eller finjustera för specialiserade uppgifter.
Att välja rätt mått för prestationsbedömning, såsom RAG eller finjusteringsmått, utgör grunden för en korrekt och meningsfull utvärdering. Samtidigt ger avancerade poängsättare som G-Eval, Prometheus, SelfCheckGPT och QAG precisa insikter tack vare sina starka resonemangsförmågor.
Det betyder dock inte att dessa poäng är perfekta – det är fortfarande viktigt att se till att de är tillförlitliga.
När du går vidare med din LLM-applikationsutvärdering kan du anpassa processen efter ditt specifika användningsfall. Det finns ingen universell mätmetod som fungerar i alla scenarier. En kombination av mätmetoder, tillsammans med fokus på sammanhanget, ger dig en mer exakt bild av din modells prestanda.
För att effektivisera din LLM-utvärdering och förbättra teamsamarbetet är ClickUp den perfekta lösningen för att hantera arbetsflöden och spåra viktiga mätvärden.
Vill du öka ditt teams produktivitet? Registrera dig för ClickUp idag och upplev hur det kan förändra ditt arbetsflöde!