チームがたった1つのAIエージェントをデプロイするためだけに、プロンプト作成やモデル調整、データパイプライン構築に何時間も費やすと、生産性は完全に停滞してしまいます。
Databricksは、企業データにおけるビルドと最適化のワークフロー全体を自動化することで、このボトルネックを解決するAgent Bricksを導入しました。
本ガイドでは、提供される機能、仕事原理、そしてご自身のスタックに適合するかどうかを順を追って解説します。
主な鍵
- Databricks Agent Bricksは合成データとベンチマークを用いてエージェント作成を自動化します
- 手動でのプロンプト調整を不要にし、Unity Catalogと直接連携します
- 早期導入者からは、最適化コストは高いものの、大規模環境では強力なパフォーマンスを発揮すると報告されています
- 地域ごとのアクセス制限とカスタム機能のリミットは、ベータ期間中も主要なリスク要因です
Databricksはエージェント型AIを提供していますか?
はい、Databricksは2025年6月11日、サンフランシスコで開催されたData+AI SummitにおいてAgent Bricksを発表しました。
このプラットフォームは、ドメイン固有の合成データとタスク特化型ベンチマークを生成し、手動のプロンプトエンジニアリングなしでコストと品質を最適化するモデルを自動生成することで、AIエージェントの作成を自動化します。
2023年にDatabricksがMosaicMLを買収したことを基盤に構築された本製品は、Databricksをデータレイクハウスプロバイダーかつエージェント型AIプラットフォームとしてポジションするものです。
大量の社内文書、トランザクション記録、非構造化コンテンツを管理し、セキュリティに知見を抽出、質問に回答、または複数ステップのワークフローを調整できるエージェントを必要とするチームをターゲットとしています。
Agent Bricksは2025年半ばにパブリックベータ版として提供開始され、当初は米国地域のAWSで利用可能となり、年末までに欧州への拡大がプランされています。
実際の仕事とは?
Agent Bricksは従来の試行錯誤のループをガイド付きパイプラインに集約します。タスクを平易な言語で記述し、Unity Catalogを通じてデータソースを接続するだけで、システムがドメインを反映した合成トレーニング例を自動生成します。
これらの例はベンチマークスイートに組み込まれ、候補モデルの精度・レイテンシー・コストを評価します。プラットフォームはその後、推論あたりのコストが最低でありながら品質バーを満たす構成を選択します。
このワークフローにより、チームが通常数週間かけて行っていたデータのラベル付け、プロンプトの調整、A/Bテストの実行が不要になります。
MLflow 3.0はバックエンドで評価実行をすべて記録するため、モデルの決定を基盤となるデータやパラメーターまで遡って追跡できます。エージェントがDatabricks Lakehouseの境界外にデータを抽出しないため、セキュリティは完全に維持されます。
そのアーキテクチャ概要は、実際の問題解決に役立つのを目にした時にこそ真価を発揮します。
実際の運用ではどのような形になるのか?
アストラゼネカのデータチームは、規制当局への提出のために構造化抽出が必要な40万件の臨床試験PDFのバックログに直面していました。手作業でのレビューには数か月を要したでしょう。
彼らはAgent Bricksで情報抽出エージェントを設定し、文書リポジトリを指定して、試用プロトコルスキーマに基づく合成サンプルを生成させました。このエージェントはコードを一切書かずに、わずか60分未満で40万ファイル全てを解析しました。
- チームはデータ抽出のボトルネックと規制上の期限を特定した。
- Unity Catalogを介してAgent Bricksを内部ドキュメントレイクに接続します。
- プラットフォームは最適化を実行し、タスク固有のベンチマークを生成し、微調整されたモデルを選択します。
- エージェントを本番環境にデプロイし、数週間かかっていた手仕事を1時間未満に短縮します。
ハワイアン・エレクトリック社も、脆弱なLangChainベースのソリューションをAgentBricksに置き換えたことで、法的文書クエリにおいて同様の効果を実感しました。
新エージェントは自動化評価と人間評価の両方で、回答精度において従来のツールを大幅に上回り、従業員がコンプライアンス照会に安心して依存できる信頼性を提供しました。
統合とエコシステム適合性
Agent BricksはDatabricksの統合レイヤーを継承しているため、データチームや機械学習チームが既に使用しているプラットフォームに直接接続できます。
Unity Catalogは中央管理のhubとして機能し、単一のポリシーフレームワークでデータレイク、データウェアハウス、ベクトルストアへのアクセスを一元管理します。
エージェントは、データを外部サービスにコピーすることなく、レイクハウスに保存されたDeltaテーブル、Parquetファイル、またはドキュメントをクエリします。
| プラットフォーム/パートナー | 統合の本質 |
|---|---|
| Unity Catalog | データ、モデル、エージェント出力に対する統一されたガバナンス |
| Neon | トランザクション処理エージェントワークフロー向けサーバーレスPostgres |
| Tecton | 100ミリ秒未満のレイテンシを実現するリアルタイム機能提供 |
| OpenAI | 企業データ上でのGPT-5へのネイティブアクセス |
開発者は標準のDatabricks APIおよびSDKを通じてAgent Bricksとやり取りします。ai_query SQL機能によりアナリストはクエリ内で直接LLMを呼び出せ、RESTエンドポイントはModel Servingインフラストラクチャを介してエージェントを提供します。
IDE統合はCI/CDパイプラインをサポートするため、エンジニアはアプリケーションコードと共にエージェント設定のバージョン管理が可能です。
今後のTecton買収により、オンライン機能ストアがAgent Bricksに組み込まれ、10ミリ秒未満の遅延でエージェントにストリーミングデータを提供します。
この機能により、最新情報を依存関係とする不正検知、パーソナライゼーション、その他のユースケースがロック解除されます。
現時点では、チームはバッチ機能でプロトタイプを作成でき、2026年半ばに統合が稼働次第、リアルタイムデータへの切り替えをプランしています。
コミュニティの反響と初期ユーザーの感想
初期のフィードバックは、使いやすさへの熱狂とベータリミットへの警戒心が入り混じっています。
あるRedditユーザーは、ノーコードのエージェントビルダーとUnity Catalogとの緊密な連携を称賛し、エージェントが自動的にデータ許可を継承する点をメモしました。
同じユーザーが指摘したように、完全な最適化実行には通常1時間以上かかり、100ドル以上のコンピューティングコストが発生します。これは実験を重ねるうちに累積していく可能性があります。
- 「ワークフローを大幅に簡素化し、手動調整を削減してくれます。」Reddit
- 「ベータ版では最適化実行あたりのコストが高くなる可能性があります。」Reddit
- 「内部コンテンツへのセキュリティを確保したアクセスは、プラットフォームへの信頼を築きます。」Databricks Community
地域ごとの提供状況が欧州チームの摩擦を生じさせた。Databricksのアカウント担当者は2025年半ば、Agent Bricksが初期プレビュー段階では米国限定であることを確認。これにより一部顧客は米国リージョンにサンドボックスワークスペースを立ち上げて製品テストを実施した(プロンプト)。
フォーラム投稿ではプレビュー版の不安定性や頻繁な機能変更もメンションされています。これはベータソフトウェアでは一般的な現象ですが、高稼働率が求められるユースケースではプランに沿って対応すべき点です。
総合的に見て、ベータ版の特異性と計算コストを吸収できる早期導入者は、Agent Bricksが提供する自動化の価値を認識しています。アストラゼネカの40万文書解析やハワイアン・エレクトリックの精度向上は、同プラットフォームが本番規模のタスクを処理できる証拠として業界全体に共感を呼んでいます。
エンジニアリングリソースを今すぐ投入するか、製品が成熟するまで待つかを判断する際、実世界の検証が重要である。
ロードマップとエコシステムOutlook
Databricksは今後18か月でAgent Bricksの地域的・機能的拡大を進めます。2025年第4四半期までに、プレビュー版が欧州地域へ展開され、西ヨーロッパにおけるAzureデプロイメントから開始されます。
フェーズ導入により、企業は多様なユーザーフィードバックを収集し、地域ごとのデータ規制への準拠を確認した上で、一般提供を開始できます。
2026年半ばに予定されているTecton統合により、エージェントはストリーム、API、データウェアハウスからリアルタイム機能を99.99%の稼働率で取得可能になります。これにより、秒単位の最新データを必要とする不正検知やパーソナライゼーションといったユースケースを実現します。
NeonとMooncakeはマージされ、統一された「Lakehouse DB」体験を提供します。これによりエージェントはETLパイプラインなしで、ACID準拠の書き込みと瞬時の分析読み取りが可能になります。
「Agent Bricksは企業AIにおける大きな転換点を示す」とVentureBeatのアナリストはメモし、従来型データパイプラインの排除による10倍から100倍のパフォーマンス向上を強調した。
初期の4種類(情報抽出、ナレッジアシスタント、マルチエージェントスーパーバイザー、カスタムLLMエージェント)を超える新たなエージェントテンプレートが登場予定です。
Databricksの研究チームは、コードアシスタント、プランエージェント、外部APIコネクタの開発を進めています。OpenAIとの提携により、OpenAIがGPT-5や将来のモデルをリリースする際には、Agent Bricksでネイティブに利用可能となり、ファーストパーティによるサポートとガバナンスが提供されます。
長期的に、Databricksはエージェント型AIをプラットフォーム上の新たなユーザーペルソナとして位置付け、データエンジニアやアナリストと並列に存在させることを構想しています。このビジョンには、規制産業におけるエージェント導入の拡大に伴い、監査ログ、バイアス検出、きめ細かいポリシー制御といった責任あるAI機能への継続的な投資も含まれます。
Databricks Agentic AIの費用はいくらですか?
Agent BricksはDatabricksの使用量ベースの料金体系のフォロワーであり、初期ライセンス費用は不要です。コンピューティングとモデル推論の秒単位で課金され、Databricks Units(DBU)で請求されます。
モデルサービングおよび機能サービングの作業負荷は、基盤となるクラウドインスタンスのコストを含むプレミアムプランで、DBU秒あたり約0.07ドルで実行されます。ファウンデーションモデル向けのGPU加速推論も、DBU秒あたり約0.07ドルで提供されます。
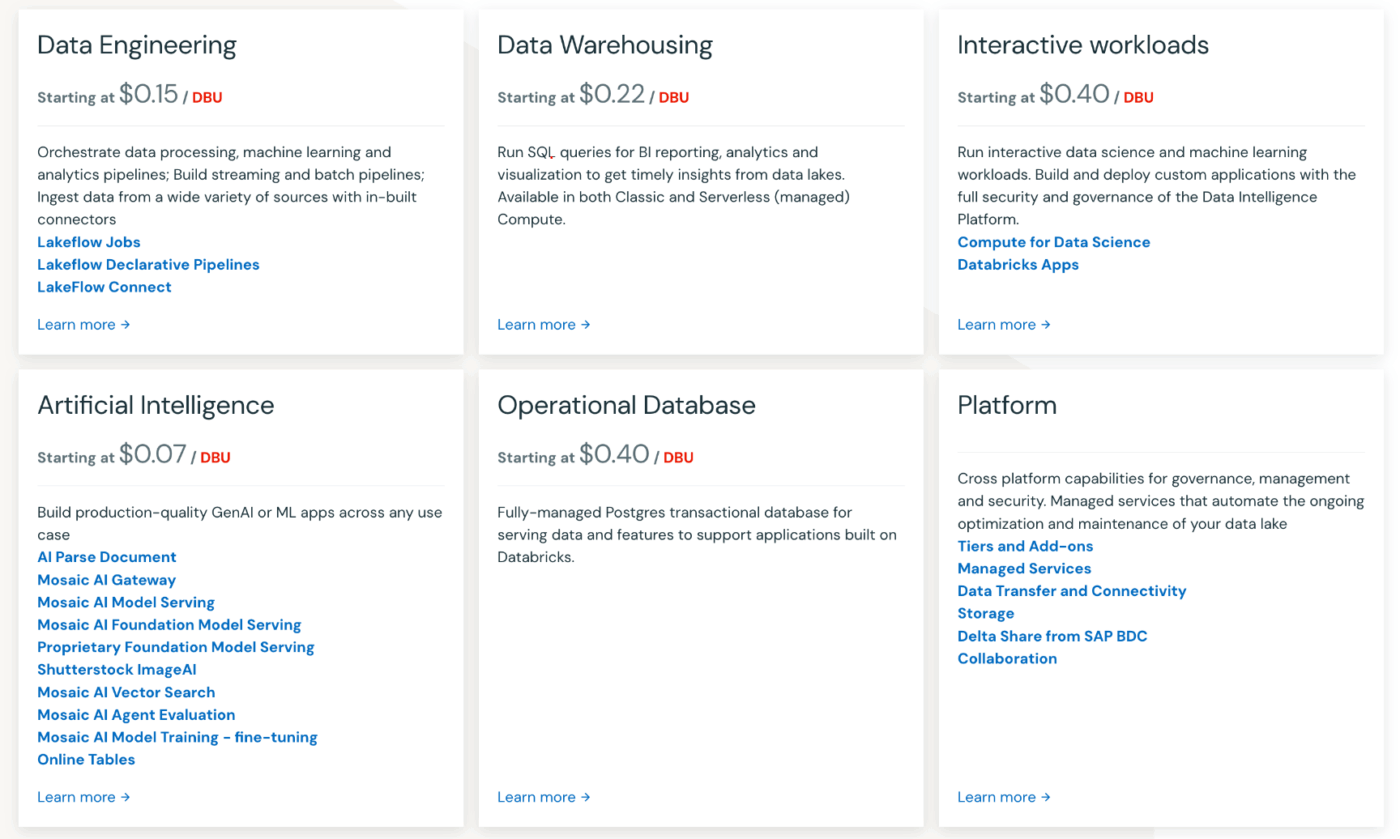
最も負荷がかかるのは初期の最適化実行です。初期ユーザーの一人は、合成データを生成しエージェントを調整する1時間のトレーニングサイクルで、クラウドコンピューティングに100ドル以上を費やしたと報告しています。
最適化後、エージェントの提供コストは大幅に削減されます。システムがクエリあたりのトークンを削減しながら品質を維持する、コスト効率の高いモデル構成を特定したためです。チームはDatabricksの予算ポリシーを通じて予算リミットを設定し、実験中の支出を制限できます。
企業顧客はコミットメントパック(前払いDBU時間)を購入することでボリューム割引を確保でき、オンデマンド課金と比較して実質的な秒単価の削減が可能です。正確な価格はクラウドプロバイダー(AWS、Azure、GCP)とリージョンによって変動し、一部のリージョンでは米国東部または西部よりも若干高くなります。
注意すべき隠れたコストには、ベクトル検索の演算処理、データ取り込み、データ配布の変化に伴う定期的な再トレーニングが含まれます。総所有権コストを算出する際には、手動のプロンプト調整やデータラベルを省略することで節約できるエンジニアリング時間を考慮に入れましょう。
早期導入者からは、Agent Bricksが削減する数週間の仕事が、特にエージェント導入遅延による機会損失を考慮すると、計算コストを相殺することが多いとの報告があります。