![Cara Melatih Gemini Menggunakan Data Anda Sendiri pada [tahun]](https://clickup.com/blog/wp-content/uploads/2025/12/ClickUp-Brain-Contextual-QA-Feature-1.gif)

Menurut studi terbaru tentang perusahaan, 73% organisasi melaporkan bahwa model AI mereka gagal memahami terminologi dan konteks spesifik perusahaan, yang mengakibatkan output yang memerlukan koreksi manual yang ekstensif. Hal ini menjadi salah satu tantangan terbesar dalam adopsi AI.
Model bahasa besar seperti Google Gemini sudah dilatih menggunakan dataset publik yang sangat besar. Yang sebenarnya dibutuhkan kebanyakan perusahaan bukanlah melatih model baru, tetapi mengajarkan Gemini konteks bisnis Anda: dokumen, alur kerja, pelanggan, dan pengetahuan internal Anda.
Panduan ini akan memandu Anda melalui seluruh proses melatih model Gemini Google menggunakan data Anda sendiri. Kami akan membahas segala hal mulai dari menyiapkan dataset dalam format JSONL yang benar hingga menjalankan tugas penyesuaian di Google AI Studio.
Kami juga akan membahas apakah ruang kerja terintegrasi dengan konteks AI bawaan dapat menghemat waktu pengaturan Anda selama berminggu-minggu.
Apa Itu Penyesuaian Gemini dan Mengapa Hal Ini Penting?
Penyesuaian Gemini adalah proses melatih model dasar Google menggunakan data Anda sendiri.
Anda ingin AI yang memahami bisnis Anda, tetapi model siap pakai memberikan respons generik yang tidak sesuai. Ini berarti Anda membuang waktu untuk terus-menerus memperbaiki output, menjelaskan ulang terminologi perusahaan Anda, dan merasa frustrasi ketika AI tidak memahami hal tersebut.
Pergantian yang terus-menerus ini memperlambat tim Anda dan mengganggu janji produktivitas AI.
Penyesuaian Gemini menciptakan model Gemini kustom yang mempelajari pola, nada, dan pengetahuan domain spesifik Anda, sehingga dapat merespons dengan lebih akurat pada kasus penggunaan unik Anda. Pendekatan ini paling efektif untuk tugas-tugas yang konsisten dan dapat diulang, di mana model dasar seringkali gagal.
Perbedaan antara fine-tuning dan prompt engineering
Prompt engineering melibatkan pemberian instruksi sementara dan berbasis sesi kepada model setiap kali Anda berinteraksi dengannya. Setelah percakapan berakhir, model akan melupakan konteks Anda.
Pendekatan ini mencapai batasnya ketika kasus penggunaan Anda memerlukan pengetahuan khusus yang tidak dimiliki oleh model dasar. Anda hanya dapat memberikan begitu banyak instruksi sebelum model perlu benar-benar belajar pola Anda.
Di sisi lain, penyetelan (fine-tuning) secara permanen mengubah perilaku model dengan memodifikasi bobot internalnya berdasarkan contoh pelatihan Anda, sehingga perubahan tersebut tetap berlaku di semua sesi mendatang.
Penyesuaian model (fine-tuning) bukanlah solusi cepat untuk frustrasi sesekali dalam penggunaan AI; ini merupakan investasi waktu dan data yang signifikan. Penyesuaian model paling masuk akal dalam skenario spesifik di mana model dasar secara konsisten tidak memadai, dan Anda membutuhkan solusi permanen.
Pertimbangkan untuk melakukan fine-tuning ketika Anda membutuhkan AI untuk menguasai:
- Istilah khusus: Industri Anda menggunakan istilah teknis yang seringkali salah diinterpretasikan atau tidak digunakan dengan benar oleh model.
- Format output yang konsisten: Anda memerlukan respons dalam struktur yang sangat spesifik setiap kali, seperti menghasilkan laporan atau potongan kode.
- Keahlian domain: Model ini tidak memiliki pengetahuan tentang produk niche Anda, proses internal, atau alur kerja eksklusif.
- Suara merek: Anda ingin semua output yang dihasilkan AI sepenuhnya sesuai dengan suara merek, gaya, dan kepribadian perusahaan Anda yang tepat.
| Aspek | Prompt engineering | Penyesuaian halus |
| Apa itu | Membuat instruksi yang lebih baik dalam prompt untuk mengarahkan perilaku model | Melatih model lebih lanjut menggunakan contoh-contoh Anda sendiri |
| Perubahan apa yang terjadi? | Data masukan yang Anda kirimkan ke model | Bobot internal model |
| Kecepatan implementasi | Segera — berfungsi secara instan | Lambat — memerlukan persiapan dataset dan waktu pelatihan |
| Kompleksitas teknis | Rendah — tidak memerlukan keahlian ML | Sedang hingga tinggi — memerlukan pipeline ML |
| Data yang diperlukan | Beberapa contoh bagus di dalam prompt | Ratusan hingga ribuan contoh yang dilabeli |
| Konsistensi output | Medium — bervariasi tergantung pada prompt | Tinggi — perilaku sudah terintegrasi ke dalam model |
| Terbaik untuk | Tugas satu kali, eksperimen, iterasi cepat | Tugas-tugas berulang yang memerlukan output yang konsisten |
Prompt engineering menentukan apa yang Anda katakan kepada model. Fine-tuning menentukan cara model berpikir.
Meskipun artikel ini berfokus pada Gemini, memahami pendekatan alternatif dalam penyesuaian AI dapat memberikan wawasan berharga tentang metode berbeda untuk mencapai tujuan serupa.
Video ini menunjukkan cara membuat GPT kustom, pendekatan populer lainnya untuk menyesuaikan AI dengan kasus penggunaan spesifik:
📖 Baca Juga: Cara Menjadi Prompt Engineer
Cara Menyiapkan Data Pelatihan Anda untuk Gemini
Sebagian besar proyek penyempurnaan model gagal sebelum dimulai karena tim meremehkan proses persiapan data. Gartner memprediksi 60% proyek AI akan ditinggalkan karena data yang tidak siap untuk AI.
Anda bisa menghabiskan berminggu-minggu mengumpulkan dan memformat data dengan salah, hanya untuk melihat proses pelatihan gagal atau menghasilkan model yang tidak berguna. Ini seringkali merupakan bagian paling memakan waktu dari seluruh proses, tetapi melakukannya dengan benar adalah faktor paling penting untuk kesuksesan.
Prinsip "sampah masuk, sampah keluar" sangat berlaku di sini. Kualitas model kustom Anda akan menjadi cerminan langsung dari kualitas data yang Anda gunakan untuk melatihnya.
Persyaratan format dataset
Gemini memerlukan data pelatihan Anda dalam format khusus yang disebut JSONL, singkatan dari JSON Lines. Dalam file JSONL, setiap baris merupakan objek JSON lengkap dan mandiri yang mewakili satu contoh pelatihan. Struktur ini memudahkan sistem untuk memproses dataset besar secara berurutan, baris demi baris.
Setiap contoh pelatihan harus mengandung dua bidang kunci:
- text_input: Ini adalah prompt atau pertanyaan yang akan Anda ajukan kepada model.
- output: Ini adalah respons ideal dan sempurna yang ingin Anda ajarkan kepada model untuk dihasilkan.
Untuk kemudahan, Google AI Studio juga menerima unggahan dalam format CSV dan akan mengonversinya menjadi struktur JSONL yang diperlukan untuk Anda.
Hal ini dapat memudahkan proses penginputan data awal jika tim Anda lebih nyaman bekerja dengan spreadsheet.
Rekomendasi ukuran dataset
Meskipun kualitas lebih penting daripada kuantitas, Anda tetap memerlukan jumlah contoh minimum agar model dapat mengenali dan belajar pola. Memulai dengan terlalu sedikit contoh akan menghasilkan model yang tidak dapat generalisasi atau berkinerja andal.
Berikut adalah beberapa pedoman umum untuk ukuran dataset:
- Minimum yang diperlukan: Untuk tugas-tugas sederhana dan sangat spesifik, Anda dapat mulai melihat hasil dengan sekitar 100 hingga 500 contoh berkualitas tinggi.
- Hasil yang lebih baik: Untuk output yang lebih kompleks atau nuansa, menargetkan 500 hingga 1.000 contoh akan menghasilkan model yang lebih tangguh dan andal.
- Pengembalian yang berkurang: Pada titik tertentu, menambahkan lebih banyak data yang berulang tidak akan secara signifikan meningkatkan kinerja. Fokuslah pada keragaman dan kualitas daripada volume yang besar.
Mengumpulkan ratusan contoh berkualitas tinggi merupakan tantangan besar bagi sebagian besar tim. Rencanakan fase pengumpulan data ini dengan matang sebelum Anda memutuskan untuk melanjutkan ke proses penyempurnaan model.
📮 ClickUp Insight: Seorang profesional rata-rata menghabiskan lebih dari 30 menit sehari untuk mencari informasi terkait pekerjaan—itu berarti lebih dari 120 jam setahun terbuang untuk menggali email, obrolan Slack, dan file yang tersebar.
Asisten AI cerdas yang terintegrasi dalam ruang kerja Anda dapat mengubah hal itu. Kenalkan ClickUp Brain. Ia memberikan wawasan dan jawaban instan dengan menampilkan dokumen, percakapan, dan detail tugas yang tepat dalam hitungan detik—sehingga Anda dapat berhenti mencari dan mulai bekerja.
💫 Hasil Nyata: Tim seperti QubicaAMF menghemat lebih dari 5 jam per minggu dengan menggunakan ClickUp—itu setara dengan lebih dari 250 jam per tahun per orang—dengan menghilangkan proses manajemen pengetahuan yang usang. Bayangkan apa yang dapat diciptakan tim Anda dengan tambahan satu minggu produktivitas setiap kuartal!
Praktik terbaik untuk kualitas data
Contoh yang tidak konsisten atau bertentangan akan membingungkan model, menyebabkan output yang tidak dapat diandalkan dan tidak terduga. Untuk menghindari hal ini, data pelatihan Anda perlu dikurasi dan dibersihkan dengan teliti. Satu contoh yang buruk dapat menghilangkan pembelajaran dari banyak contoh yang baik.
Ikuti panduan ini untuk memastikan kualitas data yang tinggi:
- Konsistensi: Semua contoh harus mengikuti format, gaya, dan nada yang sama. Jika Anda ingin AI bersikap formal, semua contoh output Anda harus formal.
- Keragaman: Data set Anda harus mencakup seluruh rentang masukan yang kemungkinan akan dihadapi model dalam penggunaan dunia nyata. Jangan hanya melatihnya pada kasus-kasus yang mudah.
- Akurasi: Setiap contoh output harus sempurna. Harus menjadi respons yang tepat yang Anda inginkan model menghasilkan, bebas dari kesalahan atau typo.
- Kebersihan Data: Sebelum melatih model, Anda harus menghapus contoh data yang duplikat, memperbaiki semua kesalahan ejaan dan tata bahasa, serta menyelesaikan semua kontradiksi dalam data.
Sangat disarankan untuk melibatkan beberapa orang dalam meninjau dan memvalidasi contoh pelatihan. Mata yang segar seringkali dapat mendeteksi kesalahan atau ketidakkonsistenan yang mungkin terlewatkan.
Cara Menyesuaikan Gemini Langkah demi Langkah
Proses penyetelan Gemini melibatkan beberapa langkah teknis di platform Google. Satu kesalahan konfigurasi dapat membuang-buang waktu pelatihan yang berharga dan sumber daya komputasi, memaksa Anda untuk memulai dari awal. Panduan praktis ini dirancang untuk mengurangi trial-and-error, membimbing Anda melalui proses dari awal hingga akhir. 🛠️
Sebelum memulai, Anda memerlukan akun Google Cloud dengan fitur penagihan yang diaktifkan dan akses ke Google AI Studio. Siapkan setidaknya beberapa jam untuk pengaturan awal dan tugas pelatihan pertama Anda, ditambah waktu tambahan untuk pengujian dan penyempurnaan model Anda.
Langkah 1: Siapkan Google AI Studio
Google AI Studio adalah antarmuka berbasis web tempat Anda akan mengelola seluruh proses penyempurnaan model. Platform ini menyediakan cara yang ramah pengguna untuk mengunggah data, mengonfigurasi pelatihan, dan menguji model kustom Anda tanpa perlu menulis kode.
Pertama, kunjungi ai.google.dev dan masuk menggunakan akun Google Anda.
Anda perlu menyetujui syarat dan ketentuan layanan serta membuat proyek baru di Google Cloud Console jika belum memilikinya. Pastikan Anda mengaktifkan API yang diperlukan sesuai petunjuk platform.
Langkah 2: Unggah dataset pelatihan Anda
Setelah pengaturan selesai, navigasikan ke bagian penyesuaian di Google AI Studio. Di sini, Anda akan memulai proses pembuatan model kustom Anda.
Pilih opsi "Buat model yang disesuaikan" dan pilih model dasar Anda. Gemini 1.5 Flash adalah pilihan umum dan hemat biaya untuk penyempurnaan.
Selanjutnya, unggah berkas JSONL atau CSV yang berisi dataset pelatihan yang telah Anda siapkan. Platform akan memvalidasi berkas Anda untuk memastikan memenuhi persyaratan format, dan menandai kesalahan umum seperti bidang yang hilang atau struktur yang tidak sesuai.
Langkah 3: Konfigurasikan pengaturan penyempurnaan Anda
Setelah data Anda diunggah dan diverifikasi, Anda akan mengonfigurasi parameter pelatihan. Pengaturan ini, yang dikenal sebagai hiperparameter, mengontrol cara model belajar dari data Anda.
Opsi utama yang akan Anda lihat adalah:
- Epochs: Ini menentukan berapa kali model akan dilatih pada seluruh dataset Anda. Lebih banyak epochs dapat menghasilkan pembelajaran yang lebih baik, tetapi juga berisiko menyebabkan overfitting.
- Laju pembelajaran: Ini mengontrol seberapa agresif model menyesuaikan bobotnya berdasarkan contoh-contoh Anda.
- Ukuran batch: Ini menentukan berapa banyak contoh pelatihan yang diproses bersama dalam satu grup.
Untuk percobaan pertama Anda, disarankan untuk memulai dengan pengaturan default yang direkomendasikan oleh Google AI Studio. Platform ini menyederhanakan keputusan-keputusan kompleks tersebut, sehingga dapat diakses bahkan jika Anda bukan ahli machine learning.
Langkah 4: Jalankan tugas penyesuaian
Setelah pengaturan Anda dikonfigurasi, Anda dapat memulai proses penyesuaian. Server Google akan mulai memproses data Anda dan menyesuaikan parameter model. Proses pelatihan ini dapat memakan waktu mulai dari beberapa menit hingga beberapa jam, tergantung pada ukuran dataset Anda dan model yang Anda pilih.
Anda dapat memantau kemajuan pekerjaan langsung melalui dashboard Google AI Studio. Karena pekerjaan dijalankan di server Google, Anda dapat menutup browser dengan aman dan kembali nanti untuk memeriksa statusnya. Jika pekerjaan gagal, hal itu hampir selalu disebabkan oleh masalah kualitas atau format data pelatihan Anda.
Langkah 5: Uji model kustom Anda
Setelah proses pelatihan selesai, model kustom Anda siap untuk diuji. ✨
Anda dapat mengaksesnya melalui antarmuka playground di Google AI Studio.
Mulailah dengan mengirimkan prompt uji yang mirip dengan contoh pelatihan Anda untuk memverifikasi akurasinya. Kemudian, uji model tersebut pada kasus ekstrem dan variasi baru yang belum pernah dilihat sebelumnya untuk mengevaluasi kemampuannya dalam generalisasi.
- Akurasi: Apakah model tersebut menghasilkan output yang tepat sesuai dengan yang Anda latih?
- Generalisasi: Apakah model tersebut dapat menangani masukan baru yang serupa tetapi tidak identik dengan data pelatihan Anda dengan benar?
- Konsistensi: Apakah responsnya dapat diandalkan dan dapat diprediksi dalam beberapa upaya dengan prompt yang sama?
Jika hasilnya tidak memuaskan, Anda mungkin perlu kembali, memperbaiki data pelatihan dengan menambahkan contoh tambahan atau memperbaiki ketidakkonsistenan, lalu melatih ulang model tersebut.
Praktik Terbaik untuk Melatih Gemini pada Data Kustom
Hanya mengikuti langkah-langkah teknis tidak menjamin model yang bagus. Banyak tim menyelesaikan proses ini namun kecewa dengan hasilnya karena mereka melewatkan strategi optimasi yang digunakan oleh praktisi berpengalaman. Inilah yang membedakan model yang berfungsi dengan model yang berkinerja tinggi.
Tidak mengherankan, laporan Deloitte tentang "State of Generative AI in the Enterprise" menemukan bahwa dua pertiga perusahaan melaporkan bahwa 30% atau kurang dari eksperimen AI generatif mereka akan sepenuhnya diimplementasikan dalam enam bulan.
Mengadopsi praktik terbaik ini akan menghemat waktu Anda dan menghasilkan hasil yang jauh lebih baik.
- Mulailah dari skala kecil, lalu skalakan: Sebelum melakukan pelatihan penuh, uji pendekatan Anda dengan subset kecil data Anda (misalnya, 100 contoh). Ini memungkinkan Anda memvalidasi format data dan mendapatkan gambaran cepat tentang kinerja tanpa membuang waktu berjam-jam.
- Versi data Anda: Saat Anda menambahkan, menghapus, atau mengedit contoh pelatihan, simpan setiap versi dataset Anda. Hal ini memungkinkan Anda melacak perubahan, mereproduksi hasil, dan kembali ke versi sebelumnya jika versi baru berkinerja lebih buruk.
- Uji sebelum dan setelah: Sebelum memulai penyempurnaan, tetapkan titik acuan dengan mengevaluasi kinerja model dasar pada tugas-tugas utama Anda. Hal ini memungkinkan Anda untuk mengukur secara objektif seberapa besar peningkatan yang dicapai melalui upaya penyempurnaan Anda.
- Ulangi pada kegagalan: Ketika model kustom Anda menghasilkan jawaban yang salah atau tidak terformat dengan baik, jangan hanya merasa frustrasi. Tambahkan kasus kegagalan spesifik tersebut sebagai contoh baru yang telah diperbaiki dalam data pelatihan Anda untuk iterasi berikutnya.
- Dokumentasikan proses Anda: Catat setiap sesi pelatihan, termasuk versi dataset yang digunakan, hiperparameter, dan hasilnya. Dokumentasi ini sangat berharga untuk memahami apa yang berhasil dan apa yang tidak seiring waktu.
Mengelola iterasi, versi dataset, dan dokumentasi ini memerlukan manajemen proyek yang kuat. Memusatkan pekerjaan ini dalam platform yang dirancang untuk alur kerja terstruktur dapat mencegah proses menjadi kacau.
Tantangan Umum Saat Melatih Gemini
Tim sering menginvestasikan waktu dan sumber daya yang signifikan dalam penyempurnaan model, namun sering menemui hambatan yang dapat diprediksi, yang mengakibatkan upaya sia-sia dan frustrasi. Mengetahui hambatan umum ini sebelumnya dapat membantu Anda menjalani proses dengan lebih lancar.
Berikut adalah beberapa tantangan yang paling sering muncul dan cara mengatasinya:
- Overfitting: Hal ini terjadi ketika model menghafal contoh pelatihan dengan sempurna tetapi gagal generalisasi ke input baru yang belum pernah dilihat. Untuk memperbaikinya, Anda dapat menambah keragaman pada data pelatihan, mempertimbangkan untuk mengurangi jumlah epoch, atau menjelajahi metode alternatif seperti retrieval-augmented generation.
- Hasil yang tidak konsisten: Jika model memberikan jawaban yang berbeda untuk pertanyaan yang sangat mirip, kemungkinan besar hal ini disebabkan oleh data pelatihan yang mengandung contoh-contoh yang bertentangan atau tidak konsisten. Diperlukan proses pembersihan data yang menyeluruh untuk menyelesaikan konflik-konflik ini.
- Pergeseran format: Terkadang model akan mulai mengikuti struktur output yang diinginkan, tetapi kemudian "bergeser" dari struktur tersebut seiring waktu. Solusinya adalah menyertakan instruksi format secara eksplisit dalam output contoh pelatihan Anda, bukan hanya kontennya.
- siklus iterasi lambat: Ketika setiap sesi pelatihan memakan waktu berjam-jam, hal ini secara drastis memperlambat kemampuan Anda untuk bereksperimen dan meningkatkan model. Uji ide Anda pada dataset yang lebih kecil terlebih dahulu untuk mendapatkan umpan balik lebih cepat sebelum meluncurkan tugas pelatihan penuh.
- Hambatan pengumpulan data: Seringkali, bagian tersulit adalah hambatan pengumpulan data dalam mengumpulkan cukup contoh berkualitas tinggi. Mulailah dengan memanfaatkan konten terbaik yang sudah ada—seperti tiket dukungan, salinan pemasaran, atau dokumen teknis—dan kembangkan dari sana.
Tantangan-tantangan ini merupakan alasan utama mengapa banyak tim akhirnya mencari alternatif untuk proses penyetelan manual.
📮ClickUp Insight: 88% responden survei kami menggunakan AI untuk tugas pribadi mereka, namun lebih dari 50% enggan menggunakannya di tempat kerja. Tiga hambatan utama? Kurangnya integrasi yang mulus, kesenjangan pengetahuan, atau kekhawatiran keamanan. Tapi bagaimana jika AI sudah terintegrasi ke dalam ruang kerja Anda dan sudah aman? ClickUp Brain, asisten AI bawaan ClickUp, menjadikan hal ini kenyataan. Ia memahami perintah dalam bahasa sehari-hari, mengatasi ketiga hambatan adopsi AI sambil menghubungkan obrolan, tugas, dokumen, dan pengetahuan Anda di seluruh ruang kerja. Temukan jawaban dan wawasan dengan satu klik!
Mengapa ClickUp Adalah Alternatif yang Lebih Cerdas
Penyesuaian Gemini sangat powerful—tetapi juga merupakan solusi sementara.
Selama artikel ini, kita telah melihat bahwa penyempurnaan model pada dasarnya berfokus pada satu hal: mengajarkan AI untuk memahami konteks bisnis Anda. Masalahnya, penyempurnaan model melakukannya secara tidak langsung. Anda menyiapkan dataset, merancang contoh, melatih ulang model, dan memelihara pipeline, semua agar AI dapat meniru cara tim Anda bekerja.
Hal itu masuk akal untuk kasus penggunaan khusus. Namun, bagi kebanyakan tim, tujuan sebenarnya bukanlah personalisasi Gemini demi personalisasi itu sendiri. Tujuannya lebih sederhana:
Anda ingin AI yang memahami pekerjaan Anda.
Di sinilah ClickUp mengambil pendekatan yang secara fundamental berbeda—dan lebih cerdas.
ClickUp’s Converged AI Workspace memberikan tim Anda AI yang langsung memahami konteks kerja Anda—tanpa perlu usaha ekstra. Alih-alih melatih AI untuk belajar konteks Anda nanti, Anda bekerja dengan ClickUp Brain, asisten AI terintegrasi, di mana konteks Anda sudah ada.
Tugas, dokumen, komentar, riwayat proyek, dan keputusan Anda terhubung secara native. Tidak perlu melatih AI pada data Anda karena AI tersebut sudah ada di tempat Anda bekerja, memanfaatkan ekosistem manajemen pengetahuan yang sudah ada.
| Aspek | Penyesuaian Gemini | ClickUp Brain |
|---|---|---|
| Waktu penyiapan | Hari hingga minggu untuk persiapan data | Segera—berfungsi dengan data yang sudah ada di ruang kerja Anda |
| Sumber konteks | Contoh pelatihan yang dikurasi secara manual | Akses otomatis ke semua pekerjaan yang terhubung |
| Pemeliharaan | Lakukan pelatihan ulang saat kebutuhan Anda berubah. | Dibaharui secara berkala seiring perkembangan ruang kerja Anda. |
| Keterampilan teknis diperlukan | Sedang hingga tinggi | Tidak ada |
Karena ClickUp adalah sistem kerja Anda, ClickUp Brain beroperasi di dalam grafik data terhubung Anda. Tidak ada penyebaran AI di alat-alat yang terputus, tidak ada alur pelatihan yang rapuh, dan tidak ada risiko model menjadi tidak sinkron dengan cara tim Anda sebenarnya bekerja.
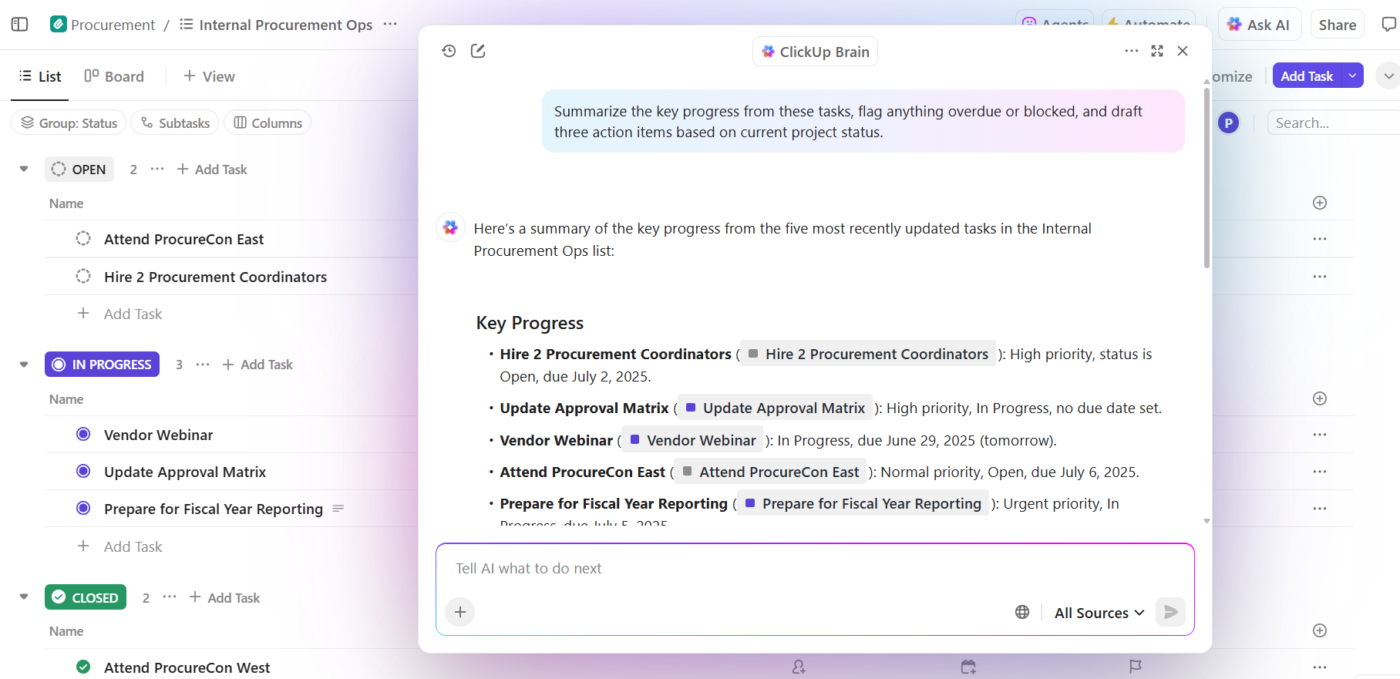
Inilah contohnya dalam praktik:
- Ajukan pertanyaan tentang proyek Anda: ClickUp Brain melakukan pencarian di seluruh ruang kerja, termasuk tugas, dokumen, komentar, dan pembaruan, untuk menjawab pertanyaan menggunakan data proyek nyata Anda—bukan pengetahuan pelatihan generik.
- Generate konten dengan konteks: ClickUp Brain sudah memiliki akses aman ke tugas, file, komentar, dan riwayat proyek Anda. Ia dapat membuat dokumen, ringkasan, dan pembaruan status yang merujuk pada pekerjaan aktual, jadwal, dan prioritas Anda. Tidak lagi ada penyebaran konteks, di mana tim membuang waktu berjam-jam mencari informasi di berbagai aplikasi dan file.
- Otomatisasi dengan pemahaman: Dengan ClickUp Automations, Anda dapat membangun otomatisasi yang merespons secara cerdas terhadap konteks proyek, seperti tenggat waktu, kepemilikan, dan perubahan status, bukan hanya aturan statis. AI bahkan dapat membangun ini untuk Anda, tanpa perlu kode.
💡Tips Pro: Manfaatkan kekuatan sejati AI di ruang kerja Anda dengan ClickUp Super Agents.
Super Agents adalah rekan kerja AI ClickUp—dikonfigurasi sebagai pengguna AI yang bekerja bersama tim Anda di dalam ruang kerja. Mereka bersifat ambient dan kontekstual, dan dapat ditugaskan ke tugas, disebutkan dalam komentar, dipicu melalui peristiwa atau jadwal, atau diarahkan melalui obrolan—sama seperti rekan kerja manusia.
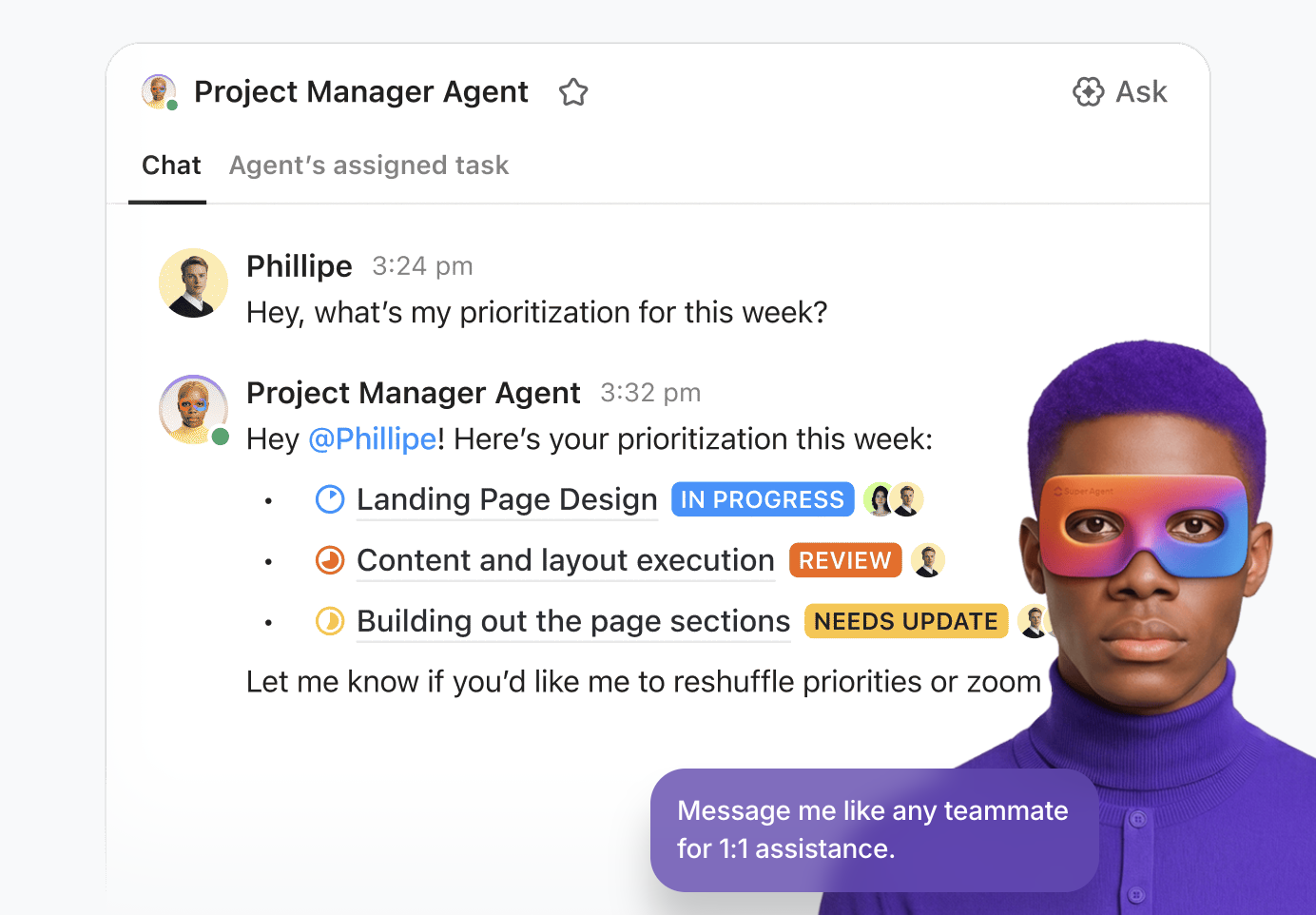
Anda dapat membangun dan mengimplementasikan model tersebut menggunakan pembuat visual tanpa kode yang memungkinkan Anda:
- Identifikasi peristiwa awal, seperti pesan atau perubahan status tugas.
- Tentukan aturan operasional, termasuk cara merangkum data, mendelegasikan tugas, atau menyesuaikan prioritas.
- Lakukan tindakan eksternal melalui alat dan ekstensi terintegrasi.
- Sediakan data pendukung dengan menghubungkan agen ke basis pengetahuan yang relevan.
Pelajari lebih lanjut tentang Super Agents dalam video di bawah ini.
Sesuaikan Strategi AI Anda: Dapatkan ClickUp
Fine-tuning mengajarkan AI pola-pola Anda melalui contoh statis, tetapi menggunakan perangkat lunak yang terintegrasi di ruang kerja seperti ClickUp menghilangkan penyebaran konteks dengan memberikan AI Anda konteks langsung dan otomatis.
Inilah inti dari transformasi AI yang sukses: tim yang mengonsolidasikan pekerjaan mereka di platform terintegrasi menghabiskan lebih sedikit waktu untuk melatih AI dan lebih banyak waktu untuk memanfaatkannya. Seiring perkembangan ruang kerja Anda, AI Anda akan berkembang secara otomatis—tanpa perlu siklus pelatihan ulang.
Siap untuk melewati proses pelatihan dan langsung menggunakan AI yang sudah memahami pekerjaan Anda? Mulailah secara gratis dengan ClickUp dan rasakan manfaat dari ruang kerja terintegrasi.
Pertanyaan yang Sering Diajukan (FAQ)
Model yang telah disesuaikan Anda belajar dari contoh pelatihan Anda, tetapi model dasar Gemini Google tidak menyimpan atau belajar dari data percakapan Anda secara default. Model kustom Anda terpisah dari model dasar yang melayani pengguna lain.
Meskipun proses pelatihan itu sendiri mungkin hanya memakan waktu beberapa jam, investasi waktu yang lebih besar terletak pada persiapan data pelatihan berkualitas tinggi. Fase persiapan data ini seringkali membutuhkan waktu berhari-hari atau bahkan berminggu-minggu untuk diselesaikan dengan baik.
Ya, Anda dapat menyesuaikan model tanpa menulis kode menggunakan Google AI Studio. Platform ini menyediakan antarmuka visual yang menangani sebagian besar kompleksitas teknis, meskipun Anda tetap perlu memahami persyaratan format data.
Instruksi kustom adalah prompt sementara berbasis sesi yang mengarahkan perilaku model untuk percakapan tunggal. Penyesuaian model, bagaimanapun, secara permanen menyesuaikan parameter internal model berdasarkan contoh pelatihan Anda, menciptakan perubahan permanen pada perilakunya.