

Anda adalah seorang kepala departemen yang sedang mencari orang yang tepat untuk menangani tugas tertentu. Dengan data perusahaan yang sangat banyak, menemukan orang yang paling cocok hampir tidak mungkin, terutama jika tugas Anda sangat sensitif terhadap waktu.
Ditambah lagi, siapa yang memiliki bandwidth untuk bertanya kepada semua orang apakah mereka memiliki pengetahuan yang cukup tentang area tertentu?
Namun, bagaimana jika Anda dapat dengan mudah bertanya kepada sistem, 'Siapa yang paling sering ditugaskan untuk melakukan [tugas]?' dan mendapatkan jawaban yang instan dan akurat berdasarkan data yang sebenarnya? Itulah yang dilakukan oleh Sistem Temu Kembali Informasi.
Sistem ini menyaring tumpukan data untuk menemukan apa yang Anda butuhkan.
Sekarang, skala ide tersebut ke database global-sistem IR mengatur data dalam jumlah besar, membantu Anda menemukan jawaban yang paling relevan dalam hitungan detik. Panduan ini akan membahas berbagai model pencarian informasi, cara kerjanya, dan peran teknologi AI dalam sistem IR.
⏰ Ringkasan 60 Detik
📌 Sistem Information Retrieval (IR) membantu menemukan informasi yang relevan dari koleksi data yang besar, berfungsi seperti asisten virtual yang menyaring data untuk menemukan apa yang Anda butuhkan
📌 Sistem IR memiliki komponen-komponen utama: basis data, pengindeks, antarmuka pencarian, pemroses kueri, model pencarian, dan mekanisme pemeringkatan/penilaian
📌 Empat model IR utama digunakan: Boolean (menggunakan operator AND/OR/NOT), Ruang Vektor (merepresentasikan dokumen sebagai vektor), Probabilistik (menggunakan pendekatan statistik), dan Saling Ketergantungan Istilah (menganalisis hubungan antar istilah)
📌 Pembelajaran Mesin dan Pemrosesan Bahasa Alami meningkatkan sistem IR dengan meningkatkan pengenalan pola, pemeringkatan hasil, dan pemahaman konteks
📌 Tantangan utama termasuk privasi data, skalabilitas, dan menjaga kualitas data saat memproses kumpulan data yang besar
Apa itu Pencarian Informasi (IR)?
Temu Kembali Informasi (IR) secara sederhana berarti menemukan informasi yang tepat dari koleksi data yang besar, seperti perpustakaan digital, database, atau Arsip Internet.
Ini seperti memiliki asisten virtual yang menyaring tumpukan data untuk memberikan apa yang Anda butuhkan
Di permukaan, pengguna memasukkan kueri, sering kali menggunakan kata kunci atau frasa, untuk mencari informasi tertentu. Di balik layar, teknik dan algoritme canggih menganalisis string pencarian dan mencocokkannya dengan data yang relevan
Alih-alih hanya mengidentifikasi satu jawaban, sistem IR menyediakan beberapa objek - masing-masing dengan tingkat relevansi yang berbeda dengan kueri Anda. Ditambah lagi, sistem ini digunakan di mana-mana dan memiliki banyak aplikasi (akan dibahas lebih lanjut segera 🔔).
💡Tip Profesional: Perlu menemukan orang yang paling ahli untuk suatu tugas? Masukkan istilah spesifik seperti 'analisis laporan penjualan tugas Q1 dan Q2 yang ditugaskan kepada' ke dalam sistem pencarian informasi. Dengan begitu, sistem ini dengan cepat menyaring data yang tidak relevan dan menunjukkan dengan tepat siapa yang paling sering menanganinya.
Aplikasi IR di berbagai bidang
Dari perawatan kesehatan hingga e-commerce, sistem IR digunakan di berbagai bidang untuk mengelola dan mengelompokkan data. Berikut adalah beberapa contohnya 👇
Kesehatan
Dalam bidang kesehatan, sistem IR memindai basis data rekam medis dan makalah penelitian untuk membantu dokter dan peneliti menemukan informasi yang paling relevan. Hasilnya, sistem ini mempercepat diagnosis penyakit, mengidentifikasi pilihan pengobatan, dan menemukan penelitian yang paling relevan dengan menggunakan umpan balik yang relevan.
Layanan pelanggan
Teknik pencarian informasi membuat dukungan pelanggan menjadi lebih cepat dan akurat. Sebagai contoh, agen dapat mengetikkan pertanyaan pengguna seperti 'kebijakan pengembalian dana' ke dalam sistem perusahaan untuk mendapatkan jawaban yang cepat.
Chatbot AI dan meja bantuan yang didukung oleh pencarian informasi melangkah lebih jauh, menawarkan solusi waktu nyata tanpa keterlibatan manusia. Itulah mengapa pertanyaan Anda sering kali dijawab dalam hitungan detik!
Platform e-commerce
Sistem IR membuat belanja online menjadi mudah. Mereka menganalisis basis data dan mencocokkan perilaku pelanggan untuk merekomendasikan produk yang Anda sukai.
Sebagai contoh, Amazon menggunakan IR untuk menyarankan barang berdasarkan riwayat pencarian Anda dan pembelian sebelumnya, sehingga membantu Anda menemukan apa yang Anda butuhkan.
Komponen Sistem Temu Kembali Informasi
Sekarang kita telah mengetahui apa itu temu kembali informasi dan bagaimana cara kerjanya. Mari kita uraikan blok-blok bangunan utama sistem IR. →
1. Database
Semuanya dimulai dari basis data. Database adalah kumpulan titik data yang saling terkait, seperti dokumen teks, email, halaman web, gambar, dan video. Ketika Anda memasukkan query, sistem IR akan mencari melalui pencocokan database untuk mengambil informasi yang paling relevan untuk kebutuhan Anda.
2. Pengindeks
Sebelum sistem dapat mengambil apa pun, pengindeks mengatur data. Ini seperti menyiapkan katalog perpustakaan untuk membuat pencarian lebih cepat. Pengindeks memproses dokumen dengan:
- Tokenisasi: Memecah konten menjadi bagian-bagian yang lebih kecil, seperti memecah kalimat menjadi kata atau frasa (disebut token)
- Stemming: Menyederhanakan kata menjadi bentuk dasarnya (misalnya, 'running' menjadi 'run')
- Penghapusan kata: Melewatkan kata pengisi seperti 'dan', 'atau', dan 'yang' untuk fokus pada kueri utama
- Ekstraksi kata kunci: Mengidentifikasi kata kunci utama dalam teks
- Ekstraksi metadata: Menarik detail tambahan seperti penulis, tanggal publikasi, atau judul
3. Antarmuka pencarian
Antarmuka pencarian bertindak sebagai pintu gerbang Anda ke sistem IR. Di sinilah Anda mengetikkan kueri Anda menggunakan kata kunci sederhana atau filter yang lebih rinci. Didesain agar mudah digunakan, antarmuka ini memastikan Anda dapat dengan mudah menyampaikan kebutuhan akses informasi Anda dan mendapatkan hasil yang relevan yang Anda cari.
4. Pemroses kueri
Setelah Anda menekan 'cari', pengolah kueri akan mengambil alih. Pengolah kueri menyempurnakan masukan Anda dengan menerapkan teknik-teknik yang tercantum di bagian pengindeks. Selain itu, ia juga menangani **operator Boolean seperti 'AND', 'OR', dan 'NOT' untuk membuat kueri Anda lebih cerdas.
5. Model pengambilan
Di sinilah keajaiban terjadi. Sistem membandingkan kueri yang Anda berikan dengan dokumen yang diindeks menggunakan model pengambilan. Metode-metode ini memutuskan bagaimana mencocokkan kueri Anda dengan data yang tersimpan. Beberapa nama yang umum termasuk:
- Model Boolean
- Model ruang vektor
- Model probabilistik
- Dan, masih banyak lagi... (akan dibahas nanti)
6. Pemeringkatan dan penilaian
Setelah kecocokan potensial ditemukan, sistem memberi peringkat berdasarkan relevansi. **Setiap dokumen mendapat nilai menggunakan metode seperti TF-IDF (Term Frequency-Inverse Document Frequency) atau algoritme lainnya. Hal ini memastikan hasil yang paling relevan muncul di bagian atas.
7. Presentasi atau tampilan
Terakhir, hasilnya disajikan kepada Anda. Biasanya, sistem menampilkan daftar peringkat dokumen teks dengan fitur tambahan seperti cuplikan, filter, atau opsi pengurutan, sehingga memudahkan Anda memilih dokumen yang paling relevan. Namun, jumlah hasil yang ditampilkan dapat bervariasi berdasarkan preferensi, kueri, atau pengaturan sistem Anda.
🔍Tahukah Anda?: Sistem pencarian informasi tradisional sangat bergantung pada basis data terstruktur dan pencocokan kata kunci dasar. Hasilnya? Masalah relevansi dan personalisasi yang besar.
Saat itulah teknologi AI modern mengubah pengambilan teks:
- Machine Learning (ML): Membantu sistem IR belajar dari pola perilaku pengguna dan meningkatkan hasil pencarian dari waktu ke waktu
- Deep Neural Networks (DNN): Algoritme yang dapat memproses data yang tidak terstruktur (seperti gambar atau video) dan mengungkap hubungan yang kompleks
- Pemrosesan Bahasa Alami (NLP): Memungkinkan sistem untuk memahami makna dan konteks kueri untuk mendukung pengenalan gambar dan analisis sentimen, sehingga akses informasi menjadi lebih fleksibel
Model-model Pencarian Informasi
Ada beberapa sistem IR yang berbeda yang menyederhanakan proses menemukan dokumen yang relevan. Mari kita lihat yang paling banyak digunakan:
1. Teori Himpunan dan Model Boolean
Model Boolean adalah salah satu teknik pengambilan informasi yang paling sederhana. Berikut cara kerjanya:
- AND: Mengambil dokumen yang mengandung semua istilah dalam kueri. Sebagai contoh, pencarian untuk 'kucing DAN anjing' akan mengembalikan dokumen yang menyebutkan keduanya di mesin pencari
- OR: Menemukan dokumen yang mengandung salah satu istilah dalam kueri. Untuk 'kucing ATAU anjing', ini mengambil dokumen yang menyebutkan kucing, anjing, atau keduanya
- NOT: Mengecualikan dokumen yang mengandung istilah tertentu. Sebagai contoh, 'kucing DAN BUKAN anjing' mengembalikan dokumen yang menyebutkan kucing tapi bukan anjing
Model ini menggunakan konsep 'kantong kata', di mana matriks 2D dibuat. Dalam matriks ini:
- Kolom mewakili dokumen
- Baris mewakili istilah dari kueri
Setiap sel diberi nilai 1 (jika istilah tersebut ada) atau 0 (jika tidak ada).

melalui AIML.com ✅ Pro
- Mudah dipahami dan diterapkan
- Mengambil dokumen yang sama persis dengan istilah kueri
❌ Kekurangan
- Model Boolean tidak mengurutkan dokumen berdasarkan relevansi, sehingga semua hasil dianggap sama pentingnya
- Berfokus pada pencocokan istilah yang tepat, sehingga hasilnya dapat bervariasi dalam arti atau konteks kueri
2. Model Ruang Vektor
Model Ruang Vektor adalah model aljabar yang merepresentasikan dokumen dan kueri sebagai vektor dalam ruang multi-dimensi. Beginilah cara kerjanya:
1. Matriks term-dokumen dibuat, di mana baris adalah istilah dan kolom adalah dokumen
2. Sebuah vektor kueri dibentuk berdasarkan istilah pencarian pengguna
3. Sistem menghitung skor numerik menggunakan ukuran yang disebut kesamaan kosinus, yang menentukan seberapa dekat vektor kueri cocok dengan vektor dokumen

melalui Pusat Ilmu Data Sebagai sistem pencarian informasi, dokumen kemudian diberi peringkat berdasarkan skor ini, dengan peringkat tertinggi adalah yang paling relevan.
✅ Kelebihan
- Mengambil item meskipun hanya beberapa istilah yang cocok
- Variasi penggunaan istilah dan panjang dokumen, mengakomodasi beragam jenis dokumen
kekurangan * Kontra
- Kosakata dan koleksi dokumen yang lebih besar membuat penghitungan kemiripan menjadi sumber daya yang intensif
3. Model Probabilistik
Model ini menggunakan pendekatan statistik, menggunakan probabilitas untuk memperkirakan seberapa relevan sebuah dokumen dengan kueri. Ini mempertimbangkan:
- Frekuensi istilah dalam dokumen
- Seberapa sering istilah muncul bersama (co-occurrence)
- Panjang dokumen dan jumlah total istilah kueri
Sistem memperlakukan proses pencarian sebagai peristiwa probabilistik, memberi peringkat pada dokumen yang disimpan berdasarkan kemungkinan relevansinya. Pendekatan ini menambah kedalaman dengan mengevaluasi objek data di luar keberadaan istilah dasar.
✅ Kelebihan
- Beradaptasi dengan baik untuk berbagai aplikasi, termasuk analisis keandalan dan penilaian aliran-aliran
❌ Kekurangan
- Bergantung pada asumsi tentang hubungan data, yang dapat menyebabkan hasil yang menyesatkan
4. Model Saling Ketergantungan Istilah
Tidak seperti model yang lebih sederhana, Model Ketergantungan Istilah berfokus pada hubungan antar istilah, bukan hanya frekuensinya. Model-model ini menganalisis bagaimana kata dan frasa berhubungan satu sama lain untuk meningkatkan akurasi hasil.
Model ini menggunakan salah satu dari dua pendekatan:
- Mode Immanen: Mengeksplorasi hubungan di dalam teks itu sendiri
- Mode transenden: Mempertimbangkan data eksternal atau konteks untuk menyimpulkan hubungan
Metode ini terutama berguna untuk menangkap nuansa makna, seperti sinonim atau frasa yang sesuai dengan konteks.
✅ Kelebihan
- Menangkap nuansa dalam bahasa dengan mempertimbangkan hubungan istilah
- Meningkatkan kinerja pencarian dengan memahami ketergantungan istilah dan konteks
❌ Kontra
- Membutuhkan data yang luas untuk memodelkan hubungan istilah secara akurat, yang mungkin tidak selalu tersedia
Itu dia! Ini adalah beberapa sistem temu balik informasi yang umum digunakan, dengan pro dan kontranya masing-masing.
➡️ Baca Lebih Lanjut: 4 Alternatif Pencarian Spotlight dan Pesaing
Pencarian Informasi vs Kueri Data
Meskipun kedua istilah ini terlihat hampir sama, keduanya beroperasi secara berbeda. Jadi, mari kita letakkan IR dan Data Querying secara berdampingan untuk melihat bagaimana keduanya dapat dibandingkan dalam hal tujuan, kasus penggunaan, dan contoh:
| Aspek | Pencarian Informasi (IR) | Pengujian Data |
|---|---|---|
| Definisi | Bertindak seperti mesin pencari yang menelusuri banyak data untuk memberikan hasil yang paling relevan | Anggap saja seperti mengajukan pertanyaan spesifik kepada database dalam bahasa yang dimengerti (seperti SQL) |
| Tujuan/Sasaran** | Membantu Anda menemukan informasi atau sumber daya yang akurat dan relevan di mesin pencari dengan cepat dan mudah | Mengambil data yang tepat sehingga Anda dapat menganalisis, memperbarui, atau menghitung angka |
| Kasus Penggunaan | Digunakan untuk pencarian web, rekomendasi eCommerce, perpustakaan digital, wawasan perawatan kesehatan, dan banyak lagi | Sangat cocok untuk tugas-tugas seperti mengelola stok di eCommerce, menganalisis keuangan, dan mengoptimalkan rantai pasokan |
| Contoh | Mencari 'Laptop terbaik antara $ 800 dan $ 1000' di Google untuk mendapatkan hasil peringkat | Mengajukan pertanyaan ke sistem inventaris Anda untuk 'SELECT * FROM Laptop WHERE Price >= 800 AND Price <= 1000' untuk menemukan apa yang tersedia |
Peran Pembelajaran Mesin dan NLP dalam Pencarian Informasi
Sistem IR seperti pemburu harta karun untuk data-mereka menyaring informasi dalam jumlah besar untuk menemukan apa yang Anda cari. Namun, ketika ML dan NLP bergabung, sistem ini menjadi lebih pintar, lebih cepat, dan jauh lebih akurat.
Bayangkan ML sebagai otak di balik sistem IR. 🧠
ML membantu sistem untuk belajar, beradaptasi, dan meningkatkan hasil setiap kali Anda mencari informasi. Begini cara kerjanya:
- Menemukan pola: ML mempelajari apa yang diklik pengguna, apa yang mereka abaikan, dan apa yang paling sering mereka baca. Kemudian menggunakan pengetahuan ini untuk menampilkan hasil yang paling relevan di lain waktu
- Hasil pemeringkatan: ML mengambil informasi dan juga memberi peringkat. Itu berarti hasil terbaik dan paling berguna muncul di bagian atas pencarian Anda
- Beradaptasi dengan waktu: Dengan setiap kueri, ML menjadi lebih baik. Ia menangkap tren, menyempurnakan pemahamannya, dan menangani pertanyaan yang paling sulit sekalipun dengan mudah
Misalnya, jika Anda mencari 'laptop murah terbaik' hari ini dan berinteraksi dengan hasil yang spesifik, ML akan tahu untuk memprioritaskan pilihan yang serupa ketika Anda mencari 'notebook terjangkau' nanti. Dengan menggabungkan AI dan ML, mesin pencari web bahkan dapat memprediksi apa yang Anda butuhkan selanjutnya.
Sekarang mari kita bahas tentang NLP. NLP membantu sistem IR memahami apa yang Anda maksud, bukan hanya kata-kata yang Anda ketik. Dengan kata-kata sederhana:
- Memahami konteks: NLP tahu bahwa ketika Anda mengatakan 'jaguar,' Anda bisa berarti hewan atau mobil - dan NLP mengetahuinya berdasarkan permintaan Anda yang lain
- Menangani bahasa yang kompleks: Apakah pertanyaan Anda sederhana ('penerbangan murah') atau terperinci ('penerbangan langsung ke Tokyo di bawah $500'), NLP memastikan sistem memahami dan memberikan hasil yang tepat
Bersama-sama, NLP dan IR membuat pencarian terasa intuitif, seperti berbicara dengan seseorang yang langsung mengerti Anda. Ini berarti lebih sedikit scrolling, lebih sedikit frustrasi, dan lebih banyak momen "wow, ini yang saya butuhkan!".
Peran ClickUp dalam Pencarian Informasi ClickUp yang merupakan 'aplikasi segalanya untuk bekerja,' meningkatkan manajemen data dengan model IR.
Its aI bawaan secara unik mengidentifikasi dan mencocokkan hasil dengan permintaan pengguna, membawa teknologi cerdas ke tingkat berikutnya.
Dan untuk mempermanis kesepakatan, Penelusuran Terhubung dari ClickUp memudahkan Anda untuk mendapatkan semua yang Anda butuhkan 'dengan segera' di ujung jari Anda. Itu artinya:
- Cari apa saja: Yang suka mengacak-acak email dansistem manajemen pengetahuan untuk menemukan file penting? Temukan file apa pun dalam hitungan detik menggunakan opsi Pencarian Terhubung. Lebih baik lagi, cari file di seluruh aplikasi Anda yang terhubung dan akses semuanya di satu tempat
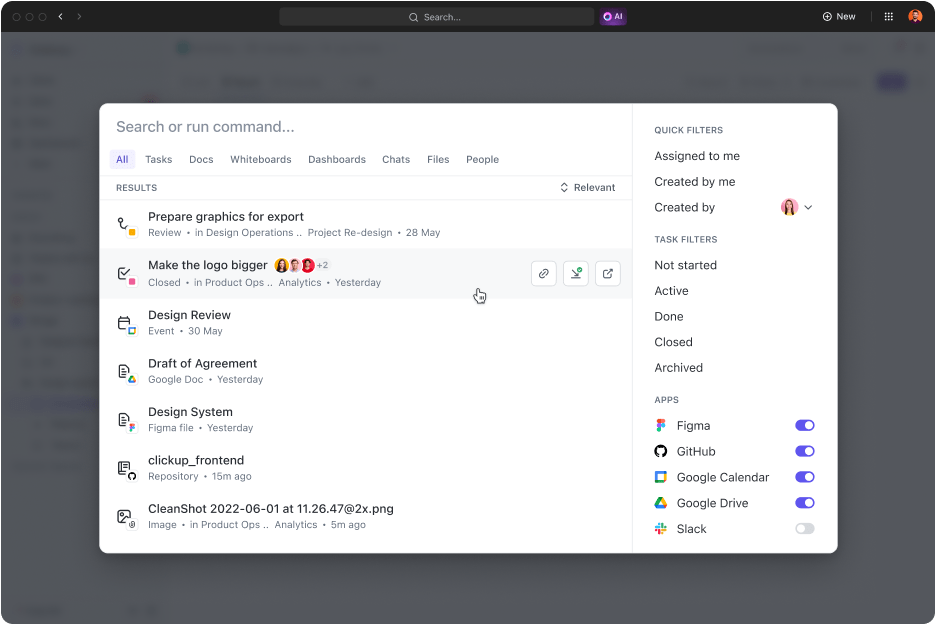
Cari apa saja dan temukan file apa saja dalam hitungan detik menggunakan Pencarian Terhubung ClickUp
- Hubungkan aplikasi favorit Anda:ClickUp memiliki beberapa integrasi terbaik yang memperluas kemampuan pencariannya ke aplikasi pihak ketiga seperti Google Drive, Slack, Dropbox, Figma, dan banyak lagi

Integrasikan aplikasi favorit Anda dan akses serta kelola file dengan mudah
- Tentukan hasil: Semakin sering Anda menggunakannya, semakin baik dalam memahami apa yang Anda cari, memberikan hasil yang dirancang khusus untuk Anda
- Cari dengan cara Anda: Akses Pencarian Terhubung danmencari file PDF dengan cepat dari mana saja di ruang kerja Anda. Misalnya, Anda dapat memulai pencarian dari Command Center, Bilah Tindakan Global, atau desktop Anda
- Buat perintah pencarian khusus: Tambahkan perintah pencarian khusus seperti pintasan ke tautan, menyimpan teks untuk nanti, dan banyak lagi untuk merampingkan alur kerja Anda
Sebagai tambahan, bagaimana jika ada cara untuk mengotomatiskan tugas-tugas yang membosankan, bekerja lebih cepat, dan menyelesaikan lebih banyak hal dalam waktu singkat? ClickUp Brain asisten AI bawaan, membuat hal ini menjadi kenyataan bagi Anda. Ini adalah asisten terbaik untuk manajemen data-pintar, cepat, dan selalu siap membantu.
Singkatnya 👇
- Pusat pengetahuan lengkap: Tidak perlu lagi mengandalkan email dan pesan untuk mendapatkan pembaruan. Tanyakan apa pun tentang Tugas, Dokumen, atau Orang Anda dan duduklah dengan tenang sementara ClickUp Brain memetakan jawaban berdasarkan konteks dari dalam dan aplikasi yang terhubung

Tanyakan apa pun tentang pekerjaan Anda kepada ClickUp Brain dan dapatkan wawasan instan
- Temukan apa yang Anda butuhkan dengan lebih cepat: ClickUp Brain mengurutkan hasil dengan cerdas seperti sistem IR yang canggih. Sistem ini memprioritaskan file yang relevan, menyarankan tugas yang terkait, dan bahkan membantu Anda menemukan beban kerja yang tersembunyi dalam data Anda
- Automasi tugas: Brain mengotomatiskan pembuatan laporan atau melacak tenggat waktu melalui fiturAlat-alat AI. Ini adalah asisten pribadi yang membebaskan waktu Anda untuk mengambil keputusan yang lebih besar sambil menjaga semuanya tetap pada jalurnya
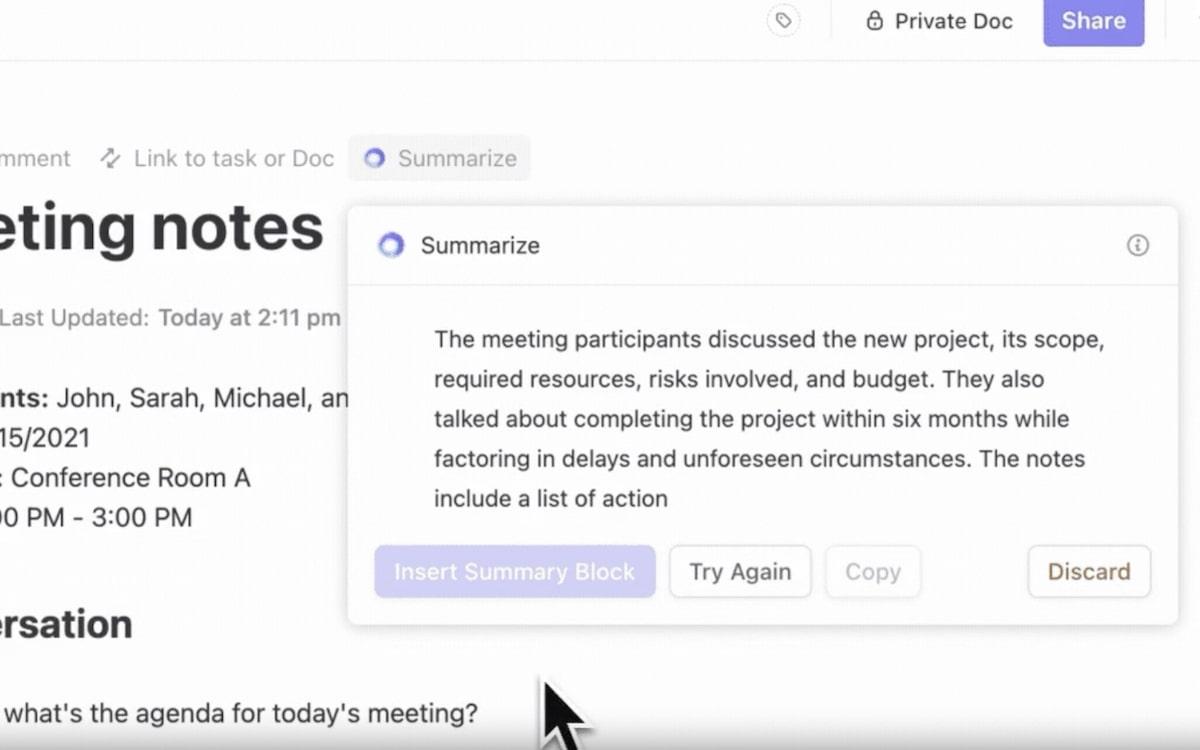
Mengotomatiskan alur kerja, meringkas laporan, dan menyederhanakan tugas dengan mudah dengan ClickUp
- Pencarian yang memahami konteks: Dengan NLP, NLP memahami pertanyaan Anda-bahkan jika kueri Anda rumit atau tidak jelas. Misalnya, mencari 'laporan penjualan Q1' memberi Anda laporan yang tepat terkait dengan tugas Anda
➡️ Baca Lebih Lanjut: Apa yang dimaksud dengan Sistem Manajemen Kerja dan Bagaimana Menerapkannya?
Tantangan dan Arah Masa Depan dalam Pencarian Informasi
Dunia pencarian informasi adalah tentang memahami data dalam jumlah yang sangat besar, namun sistem IR yang paling canggih sekalipun menghadapi beberapa kendala di sepanjang perjalanannya.
Mari kita jelajahi tantangan umum dan tren menarik yang membentuk masa depan disiplin ilmiah yang penting ini:
- Privasi dan keamanan data: Agar model IR dapat memberikan hasil yang faktual, model ini sering kali membutuhkan akses ke data yang sensitif. Namun, melindungi data pengguna bukanlah hal yang mudah untuk sumber daya pencarian informasi
- Skalabilitas dan kinerja: Saat pengguna mencari melalui kumpulan data yang besar, penanganan koleksi konten yang meningkat dapat membebani model pencarian yang paling kuat sekalipun. Tantangannya adalah memastikan pengambilan yang efisien tanpa mengorbankan relevansi hasil pencarian
- Kualitas data dan pemahaman kontekstual: Kueri yang ambigu atau metadata yang tidak terorganisir dengan baik dapat menyebabkan ketidaksesuaian, sehingga menyulitkan sistem untuk mengidentifikasi maksud pengguna secara unik
Tren dan kemajuan yang muncul dalam teknologi IR
Meskipun terdapat banyak rintangan, kemajuan teknologi baru-baru ini telah memungkinkan kita untuk membangun sistem yang lebih cerdas dan lebih efisien.
Sistem pencarian informasi modern sekarang menggunakan metode canggih seperti analisis berbasis grafik untuk menginterpretasikan angka dan teks serta konteksnya, metadata, dan hubungan di antara titik-titik data.
**Apa artinya ini bagi pengguna? Ini memungkinkan pengambilan teks yang lebih tepat dan analisis yang terperinci, terutama di bidang-bidang seperti penelitian dan industri yang padat data.
Dikombinasikan dengan teknologi web semantik, sistem ini berfokus pada string pencarian dan maksud pengguna. Sistem ini dapat melampaui pencocokan literal dan mengambil dokumen yang sangat relevan, bahkan untuk pertanyaan pengguna yang rumit dalam proses pencarian informasi.
Misalnya, pencarian 'manfaat kerja jarak jauh' dapat memberikan hasil yang berkaitan dengan produktivitas, kesehatan mental, dan keseimbangan kehidupan kerja-semuanya karena sistem memahami hubungannya.
Mengambil Dokumen dengan Cepat Dengan Manajemen Data ClickUp
Menggali file, aplikasi, dan alat yang tak ada habisnya untuk menemukan satu dokumen penting memang melelahkan. Bayangkan jika Anda mencoba menganalisis dokumen yang diambil sebagai seorang peneliti, mahasiswa, profesional TI, atau ilmuwan data-dan itu hanya akan membuat Anda kewalahan dengan informasi yang berlebihan.
Namun dengan ClickUp, Anda tidak akan pernah membuang waktu untuk berburu informasi lagi.
Ini adalah solusi lengkap yang menyatukan pekerjaan Anda di satu tempat. Dengan fitur-fitur seperti Connected Search dan ClickUp Brain, tidak masalah di mana pun data Anda berada - ClickUp memudahkan untuk menemukan, mengelola, dan menindaklanjutinya.
Mengapa harus puas dengan 'biasa saja' jika Anda bisa mendapatkan yang 'luar biasa'? Coba ClickUp secara gratis dan lihat bagaimana aplikasi ini mengubah alur kerja Anda menjadi sesuatu yang berani, efisien, dan benar-benar tak terbendung!