

Model Bahasa Besar (LLM) telah membuka kemungkinan-kemungkinan baru yang menarik untuk aplikasi perangkat lunak. LLM memungkinkan sistem yang lebih cerdas dan dinamis daripada sebelumnya.
Para ahli memperkirakan bahwa pada tahun 2025, aplikasi yang didukung oleh model ini dapat mengotomatiskan hampir setengah dari semua pekerjaan digital .
Namun demikian, saat kita membuka kemampuan ini, ada tantangan yang membayangi: bagaimana cara kita mengukur kualitas outputnya secara andal pada skala besar? Sedikit perubahan kecil dalam pengaturan, dan tiba-tiba, Anda akan melihat hasil foto yang sangat berbeda. Keragaman ini bisa menyulitkan untuk mengukur performanya, yang sangat penting apabila menyiapkan model untuk penggunaan di dunia nyata.
Artikel ini akan berbagi wawasan tentang praktik evaluasi sistem LLM terbaik, mulai dari pengujian pra-penerapan hingga produksi. Jadi, mari kita mulai!
Apa yang dimaksud dengan Evaluasi LLM?
Metrik evaluasi LLM adalah cara untuk melihat apakah perintah, pengaturan model, atau alur kerja Anda mencapai tujuan yang telah Anda tetapkan. Metrik ini memberi Anda wawasan tentang seberapa baik Model Bahasa Besar yang dilakukan dan apakah benar-benar siap untuk digunakan di dunia nyata.
Saat ini, beberapa metrik yang paling umum mengukur penarikan konteks dalam tugas-tugas retrieval-augmented generation (RAG), pencocokan yang sama persis untuk klasifikasi, validasi JSON untuk keluaran terstruktur, dan kesamaan semantik untuk tugas-tugas yang lebih kreatif.
Masing-masing metrik ini secara unik memastikan LLM memenuhi standar untuk kasus penggunaan spesifik Anda.
Mengapa Anda perlu mengevaluasi LLM?
Model bahasa besar (LLM) sekarang digunakan di berbagai aplikasi. Sangatlah penting untuk mengevaluasi kinerja model untuk memastikan bahwa model tersebut memenuhi standar yang diharapkan dan secara efektif melayani tujuan yang dimaksudkan.
Pikirkanlah seperti ini: LLM memberdayakan segala sesuatu mulai dari chatbot dukungan pelanggan hingga alat bantu kreatif, dan seiring perkembangannya, LLM muncul di lebih banyak tempat.
Ini berarti kita membutuhkan cara yang lebih baik untuk memantau dan menilai mereka-metode tradisional tidak dapat mengikuti semua tugas yang ditangani oleh model-model ini.
Metrik evaluasi yang baik seperti pemeriksaan kualitas untuk LLM. Metrik tersebut menunjukkan apakah model tersebut dapat diandalkan, akurat, dan cukup efisien untuk penggunaan di dunia nyata. Tanpa pemeriksaan ini, kesalahan dapat terjadi, yang menyebabkan pengalaman pengguna yang membuat frustrasi atau bahkan menyesatkan.
Ketika Anda memiliki metrik evaluasi yang kuat, akan lebih mudah untuk menemukan masalah, meningkatkan model, dan memastikan model siap untuk memenuhi kebutuhan spesifik penggunanya. Dengan cara ini, Anda mengetahui Platform AI yang Anda gunakan sudah memenuhi standar dan dapat memberikan hasil yang Anda butuhkan.
📖 Baca Lebih Lanjut: LLM vs AI Generatif: Panduan Rinci
Jenis Evaluasi LLM
Evaluasi memberikan lensa yang unik untuk memeriksa kemampuan model. Setiap jenis membahas berbagai aspek kualitas, membantu membangun model penerapan yang andal, aman, dan efisien.
Berikut adalah berbagai jenis metode evaluasi LLM:
- Evaluasi intrinsik berfokus pada kinerja internal model pada tugas-tugas linguistik atau pemahaman tertentu tanpa melibatkan aplikasi dunia nyata. Biasanya dilakukan selama tahap pengembangan model untuk memahami kemampuan inti
- Evaluasi ekstrinsik menilai kinerja model dalam aplikasi dunia nyata. Jenis evaluasi ini menguji seberapa baik model memenuhi tujuan tertentu dalam suatu konteks
- Evaluasi ketahanan menguji stabilitas dan keandalan model dalam berbagai skenario, termasuk input yang tidak terduga dan kondisi yang tidak menguntungkan. Evaluasi ini mengidentifikasi potensi kelemahan, memastikan model berperilaku sesuai dengan yang diharapkan
- Pengujian efisiensi dan latensi menguji penggunaan sumber daya, kecepatan, dan latensi model. Ini memastikan bahwa model dapat melakukan tugas dengan cepat dan dengan biaya komputasi yang wajar, yang penting untuk skalabilitas
- Evaluasi etika dan keamanan memastikan bahwa model sesuai dengan standar etika dan pedoman keamanan, yang sangat penting dalam aplikasi yang sensitif
Evaluasi model LLM vs. evaluasi sistem LLM
Mengevaluasi model bahasa besar (LLM) melibatkan dua pendekatan utama: evaluasi model dan evaluasi sistem. Masing-masing berfokus pada aspek yang berbeda dari kinerja LLM, dan mengetahui perbedaannya sangat penting untuk memaksimalkan potensi model-model ini.
🧠 Evaluasi model melihat keterampilan umum LLM. Jenis evaluasi ini menguji model berdasarkan kemampuannya untuk memahami, menghasilkan, dan bekerja dengan bahasa secara akurat di berbagai konteks. Ini seperti melihat seberapa baik model dapat menangani tugas yang berbeda, hampir seperti tes kecerdasan umum.
Sebagai contoh, evaluasi model mungkin bertanya, "Seberapa fleksibelkah model ini? "
evaluasi sistem LLM mengukur bagaimana kinerja LLM dalam pengaturan atau tujuan tertentu, seperti dalam chatbot layanan pelanggan. Di sini, ini bukan tentang kemampuan model yang luas dan lebih banyak tentang bagaimana model tersebut melakukan tugas-tugas tertentu untuk meningkatkan pengalaman pengguna.
Namun, evaluasi sistem berfokus pada pertanyaan seperti, "Seberapa baik model menangani tugas spesifik ini untuk pengguna? "
Evaluasi model membantu pengembang memahami kemampuan dan keterbatasan LLM secara keseluruhan, sehingga dapat memandu perbaikan. Evaluasi sistem difokuskan pada seberapa baik LLM memenuhi kebutuhan pengguna dalam konteks tertentu, memastikan pengalaman pengguna yang lebih lancar.
Bersama-sama, evaluasi ini memberikan gambaran lengkap tentang kekuatan LLM dan area untuk perbaikan, membuatnya lebih kuat dan ramah pengguna dalam aplikasi nyata.
Sekarang, mari kita jelajahi metrik spesifik untuk Evaluasi LLM.
Metrik untuk Evaluasi LLM
Beberapa metrik evaluasi yang dapat diandalkan dan menjadi tren antara lain:
1. Kebingungan
Perplexity mengukur seberapa baik model bahasa memprediksi urutan kata. Pada dasarnya, ini menunjukkan ketidakpastian model tentang kata berikutnya dalam sebuah kalimat. Nilai perplexity yang lebih rendah berarti model lebih percaya diri dalam prediksinya, sehingga menghasilkan kinerja yang lebih baik.
📌 Contoh: Bayangkan sebuah model menghasilkan teks dari perintah "Kucing itu duduk di atas." Jika model memprediksi probabilitas yang tinggi untuk kata-kata seperti "tikar" dan "lantai", maka model tersebut memahami konteksnya dengan baik, sehingga menghasilkan skor kebingungan yang rendah.
Di sisi lain, jika model menyarankan kata yang tidak terkait seperti "pesawat luar angkasa", skor kebingungan akan lebih tinggi, yang mengindikasikan bahwa model tersebut kesulitan untuk memprediksi teks yang masuk akal.
2. Skor BLEU
Skor BLEU (Bilingual Evaluation Understudy) terutama digunakan untuk mengevaluasi terjemahan mesin dan menilai pembuatan teks.
Skor ini mengukur berapa banyak n-gram (urutan yang berdekatan dari n item dari sampel teks yang diberikan) dalam output yang tumpang tindih dengan yang ada dalam satu atau lebih teks referensi. Skor berkisar antara 0 hingga 1, dengan skor yang lebih tinggi menunjukkan kinerja yang lebih baik.
📌 Contoh: Jika model Anda menghasilkan kalimat "Rubah coklat yang cepat melompati anjing yang malas" dan teks referensinya adalah "Rubah coklat yang cepat melompati anjing yang malas," BLEU akan membandingkan n-gram yang sama.
Nilai yang tinggi menunjukkan bahwa kalimat yang dihasilkan sangat cocok dengan referensi, sementara nilai yang lebih rendah mungkin menunjukkan bahwa hasil yang dihasilkan tidak selaras dengan baik.
3. Skor F1
Metrik evaluasi LLM skor F1 terutama untuk tugas klasifikasi. Metrik ini mengukur keseimbangan antara presisi (keakuratan prediksi positif) dan recall (kemampuan untuk mengidentifikasi semua contoh yang relevan)
Nilai ini berkisar antara 0 hingga 1, di mana nilai 1 menunjukkan akurasi yang sempurna.
📌 Contoh: Dalam tugas menjawab pertanyaan, jika model ditanya, "Apa warna langit?" dan merespons dengan "Langit berwarna biru" (positif sejati) tetapi juga menyertakan "Langit berwarna hijau" (positif palsu), skor F1 akan mempertimbangkan relevansi jawaban yang benar dan jawaban yang salah.
Metrik ini membantu memastikan evaluasi yang seimbang terhadap kinerja model.
4. METEOR
METEOR (Metrik untuk Evaluasi Terjemahan dengan Pemesanan Eksplisit) lebih dari sekadar pencocokan kata yang tepat. Metrik ini mempertimbangkan sinonim, stemming, dan parafrase untuk mengevaluasi kemiripan antara teks yang dihasilkan dengan teks referensi. Metrik ini bertujuan untuk menyelaraskan lebih dekat dengan penilaian manusia.
📌 Contoh: Jika model Anda menghasilkan "Kucing itu berbaring di atas karpet" dan referensinya adalah "Kucing itu berbaring di atas karpet," METEOR akan memberikan nilai yang lebih tinggi daripada BLEU karena METEOR menyadari bahwa "kucing" adalah sinonim dari "kucing", sedangkan "karpet" dan "kucing" memiliki arti yang sama.
Hal ini membuat METEOR sangat berguna untuk menangkap nuansa bahasa.
5. BERTSkor
BERTScore mengevaluasi kemiripan teks berdasarkan penyematan kontekstual yang berasal dari model seperti BERT (Representasi Encoder Dua Arah dari Transformers). Ini lebih berfokus pada makna daripada pencocokan kata yang tepat, memungkinkan penilaian kemiripan semantik yang lebih baik.
📌 Contoh: Saat membandingkan kalimat "Mobil itu melaju di jalan" dan "Kendaraan itu melaju di jalan," BERTScore menganalisis makna yang mendasarinya, bukan hanya pilihan kata.
Meskipun kata-katanya berbeda, namun keseluruhan gagasannya serupa, sehingga menghasilkan BERTScore yang tinggi yang mencerminkan keefektifan konten yang dihasilkan.
6. Evaluasi Manusia
Evaluasi manusia tetap menjadi aspek penting dalam penilaian LLM. Ini melibatkan juri manusia yang menilai kualitas dari keluaran model berdasarkan berbagai kriteria seperti kefasihan dan relevansi. Teknik seperti skala Likert dan pengujian A/B dapat digunakan untuk mengumpulkan umpan balik.
📌 Contoh: Setelah menghasilkan tanggapan dari chatbot layanan pelanggan, evaluator manusia dapat menilai setiap tanggapan pada skala 1 hingga 5. Misalnya, jika chatbot memberikan jawaban yang jelas dan bermanfaat untuk pertanyaan pelanggan, itu mungkin menerima nilai 5, sementara respons yang tidak jelas atau membingungkan bisa mendapatkan nilai 2.
7. Metrik khusus tugas
Tugas LLM yang berbeda memerlukan metrik evaluasi yang disesuaikan.
Untuk sistem dialog, metrik dapat menilai keterlibatan pengguna atau tingkat penyelesaian tugas. Untuk pembuatan kode, keberhasilan dapat diukur dari seberapa sering kode yang dibuat dapat dikompilasi atau lulus uji coba.
📌 Contoh: Dalam chatbot dukungan pelanggan, tingkat keterlibatan dapat diukur dari berapa lama pengguna bertahan dalam percakapan atau berapa banyak pertanyaan lanjutan yang mereka ajukan.
Jika pengguna sering meminta informasi tambahan, ini menunjukkan bahwa model tersebut berhasil melibatkan mereka dan secara efektif menjawab pertanyaan mereka.
8. Kekokohan dan keadilan
Menilai ketahanan model melibatkan pengujian seberapa baik model tersebut merespons input yang tidak terduga atau tidak biasa Metrik keadilan membantu mengidentifikasi bias dalam output model, memastikan kinerjanya adil di berbagai demografi dan skenario.
📌 Contoh: Saat menguji model dengan pertanyaan aneh seperti, "Apa pendapat Anda tentang unicorn?", model tersebut harus menangani pertanyaan tersebut dengan anggun dan memberikan respons yang relevan. Jika model memberikan jawaban yang tidak masuk akal atau tidak sesuai, hal ini mengindikasikan kurangnya ketangguhan.
Pengujian keadilan memastikan bahwa model tidak menghasilkan output yang bias atau berbahaya, mempromosikan model yang lebih inklusif Sistem AI .
📖 Baca Lebih Lanjut: Perbedaan Antara Pembelajaran Mesin & Kecerdasan Buatan
9. Metrik efisiensi
Seiring dengan bertambahnya kompleksitas model bahasa, menjadi semakin penting untuk mengukur efisiensinya terkait kecepatan, penggunaan memori, dan konsumsi energi. Metrik efisiensi membantu mengevaluasi seberapa intensif sumber daya yang digunakan oleh sebuah model ketika menghasilkan respons.
📌 Contoh: Untuk model bahasa yang besar, mengukur efisiensi dapat melibatkan pelacakan seberapa cepat model tersebut menghasilkan jawaban atas pertanyaan pengguna dan berapa banyak memori yang digunakan selama proses ini.
Jika terlalu lama untuk merespons atau menghabiskan sumber daya yang berlebihan, hal ini dapat menjadi masalah bagi aplikasi yang membutuhkan kinerja waktu nyata, seperti chatbot atau layanan terjemahan.
Sekarang, Anda telah mengetahui cara mengevaluasi model LLM. Namun, alat apa yang dapat Anda gunakan untuk mengukurnya? Mari kita jelajahi.
Bagaimana ClickUp Brain Dapat Meningkatkan Evaluasi LLM
ClickUp adalah aplikasi yang bisa digunakan untuk segala hal dengan asisten pribadi yang disebut ClickUp Brain. ClickUp Brain adalah pengubah permainan untuk evaluasi kinerja LLM. Jadi apa yang dilakukannya?
Aplikasi ini mengatur dan menyoroti data yang paling relevan, menjaga tim Anda tetap berada di jalurnya. Dengan fitur-fiturnya yang didukung oleh AI, ClickUp Brain adalah salah satu yang terbaik perangkat lunak jaringan saraf di luar sana. Ini membuat seluruh proses menjadi lebih lancar, lebih efisien, dan lebih kolaboratif dari sebelumnya. Mari kita jelajahi kemampuannya bersama-sama.
Manajemen pengetahuan yang cerdas
Ketika mengevaluasi Model Bahasa Besar (LLM), mengelola data dalam jumlah yang sangat besar bisa menjadi hal yang luar biasa.

meringkas data dan menyederhanakan pelacakan metrik kinerja dengan ClickUp Brain ClickUp Brain dapat mengatur dan menyoroti metrik dan sumber daya penting yang dirancang khusus untuk evaluasi LLM. Daripada mencari-cari di spreadsheet yang tersebar dan laporan yang padat, ClickUp Brain menyatukan semuanya di satu tempat. Metrik kinerja, data pembandingan, dan hasil pengujian semuanya dapat diakses dalam antarmuka yang jelas dan mudah digunakan.
Pengaturan ini membantu tim Anda mengurangi kebisingan dan fokus pada wawasan yang benar-benar penting, membuatnya lebih mudah untuk menafsirkan tren dan pola kinerja.
Dengan semua yang Anda butuhkan di satu tempat, Anda dapat beralih dari sekadar pengumpulan data menjadi pengambilan keputusan yang berdampak dan berbasis data, mengubah informasi yang berlebihan menjadi kecerdasan yang dapat ditindaklanjuti.
Perencanaan proyek dan manajemen alur kerja
Evaluasi LLM membutuhkan perencanaan dan kolaborasi yang cermat, dan ClickUp memudahkan pengelolaan proses ini.
Anda dapat dengan mudah mendelegasikan tanggung jawab seperti pengumpulan data, pelatihan model, dan pengujian kinerja sekaligus menetapkan prioritas untuk memastikan tugas-tugas yang paling penting mendapatkan perhatian terlebih dahulu. Selain itu, Custom Fields memungkinkan Anda untuk menyesuaikan alur kerja dengan kebutuhan spesifik proyek Anda.

buat dan tetapkan tugas serta sederhanakan alur kerja menggunakan AI di ClickUp_
Dengan ClickUp, semua orang bisa melihat siapa yang melakukan apa dan kapan, membantu menghindari penundaan dan memastikan tugas-tugas berjalan dengan lancar di seluruh tim. Ini adalah cara terbaik untuk menjaga semuanya tetap teratur dan berada di jalur yang benar dari awal hingga akhir.
Pelacakan metrik melalui dasbor khusus
Ingin terus memantau kinerja sistem LLM Anda? Dasbor ClickUp memvisualisasikan indikator kinerja secara real time. Hal ini memungkinkan Anda untuk memantau kemajuan model Anda secara instan. Dasbor ini sangat mudah disesuaikan, memungkinkan Anda membuat grafik dan bagan yang menyajikan apa yang Anda butuhkan saat Anda membutuhkannya.
Anda dapat melihat akurasi model Anda berevolusi di seluruh tahap evaluasi atau merinci konsumsi sumber daya pada setiap fase. Informasi ini memungkinkan Anda untuk melihat tren dengan cepat, mengidentifikasi area yang perlu ditingkatkan, dan membuat penyesuaian dengan cepat.
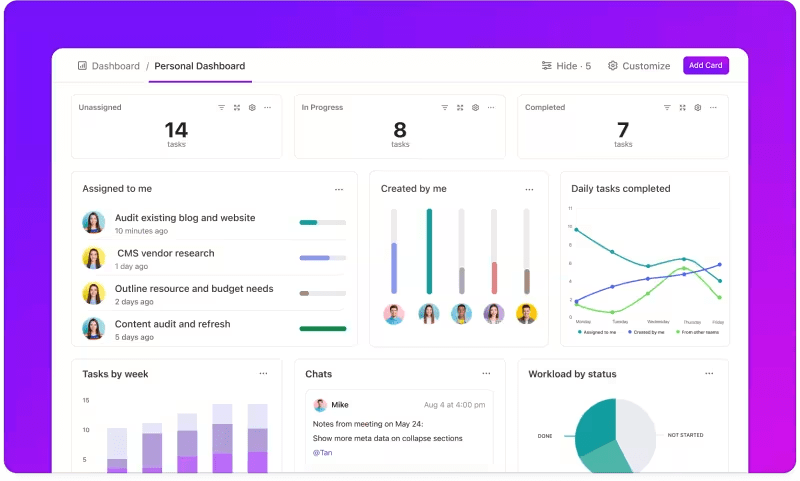
lihat kemajuan evaluasi Anda dalam satu pandangan di Dasbor ClickUp
Daripada menunggu laporan rinci berikutnya, Dasbor ClickUp memungkinkan Anda tetap mendapat informasi dan responsif, memberdayakan tim Anda untuk membuat keputusan berdasarkan data tanpa penundaan.
Wawasan otomatis
Analisis data dapat memakan waktu, namun Fitur ClickUp Brain meringankan beban dengan memberikan wawasan yang berharga. Fitur ini menyoroti tren-tren penting dan bahkan menyarankan rekomendasi berdasarkan data, sehingga lebih mudah untuk menarik kesimpulan yang berarti.
Dengan wawasan otomatis ClickUp Brain, Anda tidak perlu menyisir data mentah untuk mencari pola secara manual - ClickUp Brain akan menemukannya untuk Anda. Otomatisasi ini membebaskan tim Anda untuk fokus pada penyempurnaan kinerja model daripada terjebak dalam analisis data yang berulang-ulang.
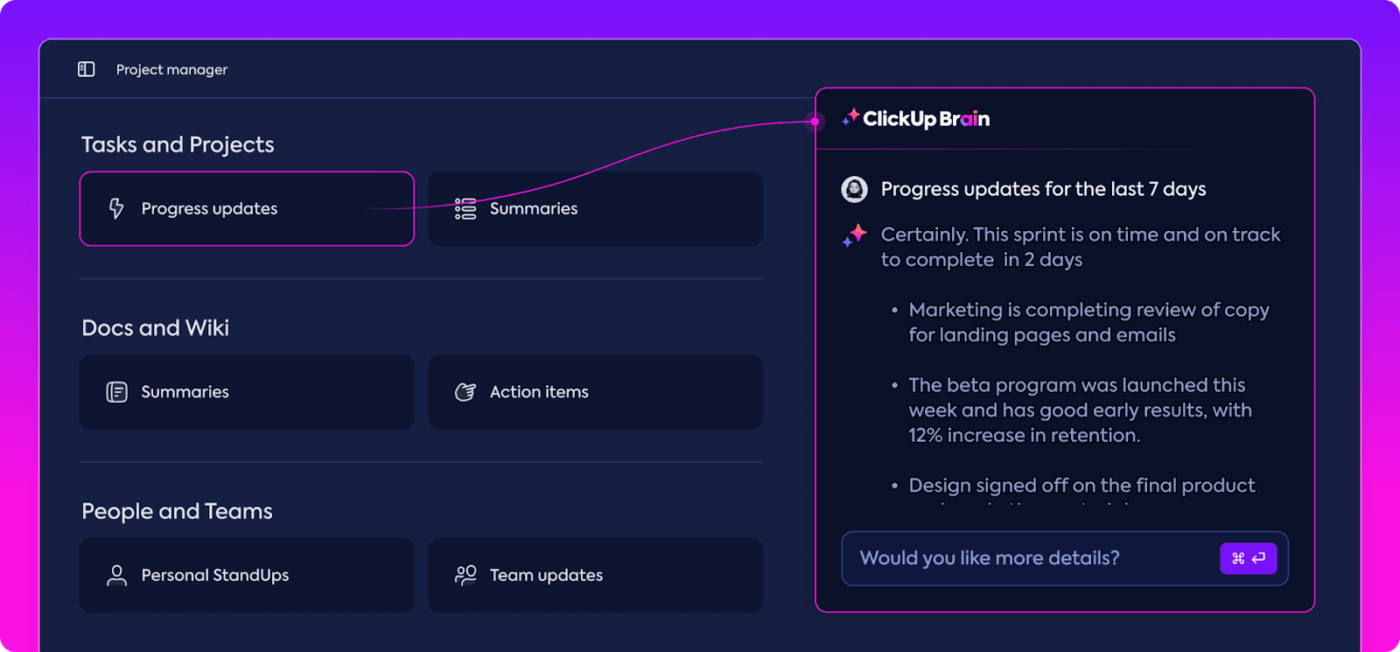
dapatkan wawasan yang dapat ditindaklanjuti dengan ClickUp Brain_
Wawasan yang dihasilkan siap digunakan, memungkinkan tim Anda untuk segera melihat apa yang berhasil dan di mana perubahan mungkin diperlukan. Dengan mengurangi waktu yang dihabiskan untuk analisis, ClickUp membantu tim Anda mempercepat proses evaluasi dan fokus pada implementasi.
Dokumentasi dan kolaborasi
Tidak perlu lagi mencari-cari di berbagai email atau platform untuk menemukan apa yang Anda butuhkan; semuanya ada di sana, siap saat Anda membutuhkannya. Dokumen ClickUp adalah pusat pusat yang menyatukan semua yang dibutuhkan tim Anda untuk evaluasi LLM yang lancar. Ini mengatur dokumentasi proyek utama-seperti kriteria tolok ukur, hasil pengujian, dan catatan kinerja-ke dalam satu tempat yang dapat diakses sehingga semua orang dapat dengan cepat mengakses informasi terbaru.
Yang membedakan ClickUp Docs dengan yang lain adalah fitur kolaborasi real-time. Terintegrasi ClickUp Chat dan Komentar memungkinkan anggota tim untuk mendiskusikan wawasan, memberikan umpan balik, dan menyarankan perubahan secara langsung di dalam dokumen.
Ini berarti tim Anda dapat membahas temuan dan melakukan penyesuaian langsung di platform, menjaga semua diskusi tetap relevan dan tepat sasaran.

berkolaborasi dan mengedit dokumen ClickUp dengan tim Anda secara real time_
Segala sesuatu mulai dari dokumentasi hingga kerja sama tim dilakukan di dalam ClickUp Docs, menciptakan proses evaluasi yang efisien di mana semua orang dapat melihat, berbagi, dan bertindak berdasarkan perkembangan terbaru.
Hasilnya? Alur kerja yang lancar dan terpadu yang memungkinkan tim Anda bergerak menuju tujuan mereka dengan kejelasan yang lengkap.
Apakah Anda siap untuk mencoba ClickUp? Sebelum itu, mari kita bahas beberapa tips dan trik untuk mendapatkan hasil maksimal dari Evaluasi LLM Anda.
Praktik Terbaik dalam Evaluasi LLM
Pendekatan yang terstruktur dengan baik untuk evaluasi LLM memastikan bahwa model tersebut memenuhi kebutuhan Anda, selaras dengan ekspektasi pengguna, dan memberikan hasil yang berarti.
Menetapkan tujuan yang jelas, mempertimbangkan pengguna akhir, dan menggunakan berbagai metrik membantu membentuk evaluasi menyeluruh yang mengungkapkan kekuatan dan area untuk perbaikan. Di bawah ini adalah beberapa praktik terbaik untuk memandu proses Anda.
🎯 Tentukan tujuan yang jelas
Sebelum memulai proses evaluasi, penting untuk mengetahui secara pasti apa yang ingin dicapai oleh model bahasa besar (LLM) Anda. Luangkan waktu untuk menguraikan tugas atau tujuan spesifik untuk model tersebut.
📌 Contoh: Jika Anda ingin meningkatkan kinerja penerjemahan mesin, perjelas tingkat kualitas yang ingin Anda capai. Memiliki tujuan yang jelas akan membantu Anda berfokus pada metrik yang paling relevan, memastikan bahwa evaluasi Anda tetap selaras dengan tujuan tersebut dan mengukur keberhasilan secara akurat.
👥 Pertimbangkan audiens Anda
Pikirkan tentang siapa yang akan menggunakan LLM dan apa kebutuhan mereka. Menyesuaikan evaluasi dengan pengguna yang Anda tuju sangatlah penting.
📌 Contoh: Jika model Anda dimaksudkan untuk menghasilkan konten yang menarik, Anda perlu memperhatikan metrik seperti kefasihan dan koherensi. Memahami audiens Anda membantu menyempurnakan kriteria evaluasi Anda, memastikan model memberikan nilai nyata dalam aplikasi praktis
📊 Memanfaatkan metrik yang beragam
Jangan hanya mengandalkan satu metrik untuk mengevaluasi LLM Anda; campuran metrik memberikan gambaran yang lebih lengkap tentang kinerjanya. Setiap metrik menangkap aspek yang berbeda, sehingga menggunakan beberapa metrik dapat membantu Anda mengidentifikasi kekuatan dan kelemahan.
📌 Contoh: Meskipun skor BLEU sangat bagus untuk mengukur kualitas terjemahan, skor tersebut mungkin tidak mencakup semua nuansa penulisan kreatif. Memasukkan metrik seperti kebingungan untuk akurasi prediksi dan bahkan evaluasi manusia untuk konteks dapat menghasilkan pemahaman yang lebih menyeluruh tentang seberapa baik kinerja model Anda
Tolok Ukur dan Alat LLM
Mengevaluasi model bahasa besar (LLM) sering kali bergantung pada tolok ukur standar industri dan alat khusus yang membantu mengukur kinerja model di berbagai tugas.
Berikut ini adalah rincian beberapa tolok ukur dan alat bantu yang banyak digunakan yang memberikan struktur dan kejelasan pada proses evaluasi.
Tolok Ukur Utama
- GLUE (General Language Understanding Evaluation): GLUE menilai kemampuan model di berbagai tugas bahasa, termasuk klasifikasi kalimat, kemiripan, dan kesimpulan. Ini adalah tolok ukur utama untuk model yang perlu menangani pemahaman bahasa untuk tujuan umum
- SQuAD (Stanford Question Answering Dataset): Kerangka kerja evaluasi SQuAD sangat ideal untuk pemahaman bacaan dan mengukur seberapa baik model menjawab pertanyaan berdasarkan bacaan. Biasanya digunakan untuk tugas-tugas seperti dukungan pelanggan dan pencarian berbasis pengetahuan, di mana jawaban yang tepat sangat penting
- SuperGLUE: Sebagai versi GLUE yang disempurnakan, SuperGLUE mengevaluasi model pada tugas-tugas penalaran dan pemahaman kontekstual yang lebih kompleks. Ini memberikan wawasan yang lebih dalam, terutama untuk aplikasi yang membutuhkan pemahaman bahasa tingkat lanjut
Alat Evaluasi Penting
- Memeluk Wajah : Ini sangat populer karena perpustakaan model, kumpulan data, dan fitur evaluasinya yang luas. Antarmukanya yang sangat intuitif memungkinkan pengguna untuk dengan mudah memilih tolok ukur, menyesuaikan evaluasi, dan melacak kinerja model, membuatnya serbaguna untuk banyak aplikasi LLM
- SuperAnnotate : Ini mengkhususkan diri dalam mengelola dan membuat anotasi data, yang sangat penting untuk tugas-tugas pembelajaran yang diawasi. Ini sangat berguna untuk menyempurnakan akurasi model, karena memfasilitasi data berkualitas tinggi yang dianotasi oleh manusia yang meningkatkan kinerja model pada tugas-tugas yang kompleks
- AllenNLP **Dikembangkan oleh Allen Institute for AI, AllenNLP ditujukan untuk para peneliti dan pengembang yang bekerja pada model NLP khusus. Ini mendukung berbagai tolok ukur dan menyediakan alat untuk melatih, menguji, dan mengevaluasi model bahasa, menawarkan fleksibilitas untuk aplikasi NLP yang beragam
Menggunakan kombinasi tolok ukur dan alat bantu ini menawarkan pendekatan yang komprehensif untuk evaluasi LLM. Tolok ukur dapat menetapkan standar di seluruh tugas, sementara alat menyediakan struktur dan fleksibilitas yang diperlukan untuk melacak, menyempurnakan, dan meningkatkan kinerja model secara efektif.
Bersama-sama, keduanya memastikan LLM memenuhi standar teknis dan kebutuhan aplikasi praktis.
Tantangan Evaluasi Model LLM
Mengevaluasi model bahasa besar (LLM) membutuhkan pendekatan yang berbeda. Pendekatan ini berfokus pada kualitas respons dan pemahaman tentang kemampuan adaptasi dan keterbatasan model di berbagai skenario.
Karena model-model ini dilatih pada kumpulan data yang luas, perilaku mereka dipengaruhi oleh berbagai faktor, sehingga penting untuk menilai lebih dari sekadar keakuratan.
Evaluasi yang benar berarti memeriksa keandalan model, ketahanan terhadap kondisi yang tidak biasa meminta dan konsistensi respons secara keseluruhan. Proses ini membantu memberikan gambaran yang lebih jelas mengenai kekuatan dan kelemahan model, dan mengungkap area yang perlu disempurnakan.
Berikut ini adalah beberapa tantangan umum yang muncul selama evaluasi LLM.
1. Data pelatihan yang tumpang tindih
Sulit untuk mengetahui apakah model telah melihat beberapa data uji. Karena LLM dilatih pada set data yang sangat besar, ada kemungkinan beberapa pertanyaan tes tumpang tindih dengan contoh pelatihan. Hal ini dapat membuat model terlihat lebih baik daripada yang sebenarnya, karena mungkin saja model tersebut hanya mengulangi apa yang sudah diketahui alih-alih menunjukkan pemahaman yang sebenarnya.
2. Kinerja yang tidak konsisten
LLM dapat memberikan respons yang tidak terduga. Satu saat, mereka memberikan wawasan yang mengesankan, dan di saat berikutnya, mereka membuat kesalahan yang aneh atau menyajikan informasi imajiner sebagai fakta (dikenal sebagai 'halusinasi').
Ketidakkonsistenan ini berarti bahwa meskipun hasil LLM mungkin bersinar di beberapa area, namun di area lain bisa saja gagal, sehingga sulit untuk menilai keandalan dan kualitasnya secara keseluruhan secara akurat.
3. Kerentanan terhadap pihak lawan
LLM dapat rentan terhadap serangan lawan, di mana permintaan yang dibuat dengan cerdik mengelabui mereka untuk menghasilkan respons yang cacat atau berbahaya. Kerentanan ini mengekspos kelemahan dalam model dan dapat menyebabkan keluaran yang tidak terduga atau bias. Menguji kelemahan-kelemahan ini sangat penting untuk memahami di mana batas-batas model berada.
Kasus Penggunaan Evaluasi LLM Praktis
Terakhir, berikut ini adalah beberapa situasi umum di mana evaluasi LLM benar-benar membuat perbedaan:
Chatbot dukungan pelanggan
LLM banyak digunakan dalam chatbot untuk menangani pertanyaan pelanggan. Mengevaluasi seberapa baik model merespons memastikan model tersebut memberikan jawaban yang akurat, bermanfaat, dan relevan secara kontekstual.
Sangat penting untuk mengukur kemampuannya dalam memahami maksud pelanggan, menangani beragam pertanyaan, dan memberikan tanggapan seperti manusia. Hal ini akan memungkinkan bisnis untuk memastikan pengalaman pelanggan yang lancar sekaligus meminimalkan frustrasi.
Pembuatan konten
Banyak bisnis menggunakan LLM untuk menghasilkan konten blog, media sosial, dan deskripsi produk. Mengevaluasi kualitas konten yang dihasilkan membantu memastikan bahwa konten tersebut benar secara tata bahasa, menarik, dan relevan dengan audiens target. Metrik seperti kreativitas, koherensi, dan relevansi dengan topik sangat penting di sini untuk mempertahankan standar konten yang tinggi.
Analisis sentimen
LLM dapat menganalisis sentimen umpan balik pelanggan, unggahan media sosial, atau ulasan produk. Sangat penting untuk mengevaluasi seberapa akurat model mengidentifikasi apakah sebuah teks positif, negatif, atau netral. Hal ini membantu bisnis memahami emosi pelanggan, menyempurnakan produk atau layanan, meningkatkan kepuasan pengguna, dan meningkatkan strategi pemasaran.
Pembuatan kode
Pengembang sering menggunakan LLM untuk membantu menghasilkan kode. Mengevaluasi kemampuan model untuk menghasilkan kode yang fungsional dan efisien sangat penting.
Penting untuk memeriksa apakah kode yang dihasilkan secara logis baik, bebas dari kesalahan, dan memenuhi persyaratan tugas. Hal ini membantu mengurangi jumlah pengkodean manual yang diperlukan dan meningkatkan produktivitas.
Optimalkan Evaluasi LLM Anda Dengan ClickUp
Mengevaluasi LLM adalah tentang memilih metrik yang tepat yang sesuai dengan tujuan Anda. Kuncinya adalah memahami tujuan spesifik Anda, apakah itu meningkatkan kualitas terjemahan, meningkatkan pembuatan konten, atau menyempurnakan untuk tugas-tugas khusus.
Memilih metrik yang tepat untuk penilaian kinerja, seperti RAG atau metrik penyempurnaan, merupakan dasar dari evaluasi yang akurat dan bermakna. Sementara itu, penilai tingkat lanjut seperti G-Eval, Prometheus, SelfCheckGPT, dan QAG memberikan wawasan yang tepat berkat kemampuan penalarannya yang kuat.
Namun, bukan berarti skor-skor ini sempurna-tetap penting untuk memastikan bahwa skor tersebut dapat diandalkan.
Saat Anda melanjutkan evaluasi aplikasi LLM, sesuaikan prosesnya agar sesuai dengan kasus penggunaan spesifik Anda. Tidak ada metrik universal yang dapat digunakan untuk semua skenario. Kombinasi metrik, bersama dengan fokus pada konteks, akan memberikan gambaran yang lebih akurat tentang kinerja model Anda.
Untuk menyederhanakan evaluasi LLM Anda dan meningkatkan kolaborasi tim, ClickUp adalah solusi ideal untuk mengelola alur kerja dan melacak metrik penting.
Ingin meningkatkan produktivitas tim Anda? Daftar ke ClickUp hari ini dan rasakan bagaimana ClickUp dapat mengubah alur kerja Anda!