
เคยไหมที่กำลังทานอาหารเย็นอยู่ดีๆ แล้วโทรศัพท์ก็สั่นเตือนด้วย "การแจ้งเตือนวิกฤต" ที่สุดท้ายกลับกลายเป็นแค่บันทึกประจำวันธรรมดา? มันน่าหงุดหงิดไม่น้อย แต่อย่างน้อยคุณก็รู้ว่า Opsgenie คอยดูแลคุณอยู่
ตอนนี้คือความท้าทายที่แท้จริง: Atlassian ได้หยุดขาย Opsgenie แล้ว และในไม่ช้า การสนับสนุนเต็มรูปแบบจะสิ้นสุดลง สำหรับทีมที่พึ่งพา Opsgenie ในการจัดตารางเวร, การยกระดับปัญหา, และการแจ้งเตือน นั่นคือสัญญาณเตือนที่ไม่มีใครต้องการ
สิ่งที่ดีคือ คุณไม่จำเป็นต้องรอจนถึงนาทีสุดท้าย การให้เวลาตัวเองในการสำรวจตัวเลือกอื่นๆ ตอนนี้ หมายความว่าทีมของคุณสามารถปรับตัวเข้ากับกิจวัตรใหม่ได้โดยไม่มีความเครียดจากการตัดสินใจอย่างเร่งรีบ
ในบทความนี้ เราจะพาคุณไปดูทางเลือกที่ดีที่สุดสำหรับ Opsgenie เปรียบเทียบจุดเด่นของแต่ละตัวเลือก และแสดงให้เห็นว่าทำไมClickUpจึงมอบวิธีการทำงานที่ราบรื่นและเชื่อมโยงกันมากขึ้นให้กับทีมของคุณ
⭐ เทมเพลตแนะนำ
ให้ทีมไอทีของคุณบันทึกเหตุการณ์ได้อย่างถูกต้องและเผยให้เห็นแนวโน้มที่ช่วยในการปรับปรุงระยะยาว.เทมเพลตรายงานเหตุการณ์ไอทีของ ClickUpช่วยให้คุณบันทึกข้อมูลเหตุการณ์ในรูปแบบที่สม่ำเสมอและน่าเชื่อถือ.

ทางเลือกของ Opsgenie ในพริบตา
นี่คือการเปรียบเทียบอย่างรวดเร็วของตัวเลือกทางเลือกที่ดีที่สุดสำหรับ Opsgenie เพื่อช่วยคุณเลือกสิ่งที่เหมาะกับคุณตามคุณสมบัติหลัก, ราคา, และคะแนนผู้ใช้.
| เครื่องมือ | เหมาะที่สุดสำหรับ | คุณสมบัติเด่น | ราคา* | การจัดอันดับ |
| ClickUp | การจัดการงานแบบครบวงจรพร้อมเวิร์กโฟลว์สำหรับเหตุการณ์ การวางแผนทรัพยากร และการทำงานอัตโนมัติสำหรับทีมทุกขนาด | การแจ้งเตือนที่ปรับแต่งได้, ระบบอัตโนมัติสำหรับการยกระดับปัญหา, งานและรายการสำหรับเหตุการณ์, สถานะที่กำหนดเอง, แชทแบบเรียลไทม์, แดชบอร์ดสำหรับการทบทวนหลังเหตุการณ์, การเชื่อมต่อกับระบบอื่นกว่า 1,000 ระบบ | มีแผนฟรีให้บริการ; ปรับแต่งได้สำหรับองค์กร | G2: 4. 7/5 (10,500+) Capterra: 4. 6/5 (4,500+) |
| เพจเจอร์ดัทตี้ | การแจ้งเตือนเหตุการณ์แบบเรียลไทม์และการทำงานอัตโนมัติในระดับองค์กรขนาดใหญ่ | การแจ้งเตือนหลายช่องทาง, นโยบายการยกระดับ, การจัดตารางเวร, AIOps เพื่อลดสัญญาณรบกวน, การผสานรวมกับเครื่องมือมากกว่า 600 รายการ | แผนฟรี; แผนชำระเงินเริ่มต้นที่ $25/เดือนต่อผู้ใช้ | G2: 4. 5/5 (900+) Capterra: 4. 6/5 (200+) |
| xMatters | การจัดการเหตุการณ์และการทำงานอัตโนมัติที่คุ้มค่าสำหรับทีมที่กำลังเติบโต | ระบบการทำงานอัตโนมัติ, การจัดการเหตุการณ์แบบปรับตัว, การจัดตารางเวร, ข้อมูลสัญญาณ, การผสานรวมมากกว่า 200 ระบบ | แผนฟรี; แผนชำระเงินเริ่มต้นที่ $9/เดือนต่อผู้ใช้ | G2: 4. 5/5 (670+) Capterra: 4. 6/5 (140+) |
| AlertOps | การลดเสียงรบกวนด้วยปัญญาประดิษฐ์และการตอบสนองอย่างรวดเร็วสำหรับทีมขนาดเล็กถึงขนาดกลาง | AI OpsIQ ลดเสียงรบกวน, การยกระดับที่ยืดหยุ่น, การครอบคลุมการเรียกใช้งาน, การทำงานอัตโนมัติของเวิร์กโฟลว์แบบไม่ต้องเขียนโค้ด, การผสานรวมมากกว่า 200 รายการ | แผนฟรี; แผนชำระเงินเริ่มต้นที่ $10/เดือนต่อผู้ใช้ | G2: 4. 7/5 (150+) Capterra: 4. 7/5 (20+) |
| สปลังค์ ออนคอล | การทำให้การจัดตารางเวรยามง่ายขึ้นและลดความเหนื่อยล้าสำหรับทีมขนาดใหญ่ | การยกระดับปัญหาโดยอัตโนมัติ, แอปพลิเคชันบนมือถือ, การปรับสมดุลปริมาณงาน, คำแนะนำจากปัญญาประดิษฐ์, บันทึกการตรวจสอบ | ราคาตามความต้องการ | G2: 4. 6/5 (50+) Capterra: 4. 5/5 (30+) |
| ดาต้าดอก | การสังเกตการณ์แบบครบวงจรพร้อมการตรวจสอบความปลอดภัยสำหรับองค์กร | การตรวจสอบโครงสร้างพื้นฐาน + บันทึก + แอปพลิเคชัน, ความปลอดภัยบนคลาวด์, การตรวจจับความผิดปกติด้วย AI, การผสานรวมมากกว่า 900 รายการ | แผนฟรี; แผนชำระเงินเริ่มต้นที่ $15/เดือนต่อผู้ใช้ | G2: 4. 4/5 (660+) Capterra: 4. 6/5 (320+) |
| สควอดแคสต์ | การตอบสนองต่อการเรียกและเหตุการณ์แบบรวมเป็นหนึ่ง พร้อมราคาที่คุ้มค่าสำหรับทีมขนาดกลาง | ตารางเวลาอัตโนมัติ, การลบข้อมูลซ้ำ, หนังสือคู่มือการปฏิบัติงาน, หน้าสถานะ, การวิเคราะห์หลังเหตุการณ์ | แผนฟรี; แผนชำระเงินเริ่มต้นที่ $12/เดือนต่อผู้ใช้ | G2: 4. 4/5 (300+) Capterra: รีวิวไม่เพียงพอ |
| จุดดับเพลิง | ระบบคู่มือการทำงานอัตโนมัติและการเป็นเจ้าของบริการสำหรับองค์กร | Runbooks, การจัดตารางเวรสัญญาณ, แคตตาล็อกบริการ, การทำงานร่วมกันผ่าน Slack/Teams, การทบทวนงานที่เสริมด้วย AI | แผนฟรี; แผนชำระเงินเริ่มต้นที่ $9,600/ปี ต่อผู้ใช้ | G2: 4. 5/5 (130+) Capterra: ไม่มีการรีวิวเพียงพอ |
| งานโทร | การจัดการเหตุการณ์ที่มีราคาย่อมเยาพร้อมระบบอัตโนมัติสำหรับทีมขนาดกลางถึงขนาดใหญ่ | การจัดตารางเวรแบบไดนามิก, การกำหนดเส้นทางด้วย AI, การแจ้งเตือนหลายช่องทาง, การครอบคลุม DevOps + BizOps | แผนฟรี; แผนชำระเงินเริ่มต้นที่ $9/เดือนต่อผู้ใช้ | G2: รีวิวไม่เพียงพอ Capterra: รีวิวไม่เพียงพอ |
| แจ้งเตือน | การจัดการเหตุการณ์แบบ AI-first ที่เน้นความเป็นส่วนตัวสำหรับทีมที่กำลังขยายตัว | การแจ้งเตือนหลายช่องทาง, ผู้ช่วยตอบกลับด้วย AI, การจัดตารางเวร, หน้าสถานะอัตโนมัติ, การผสานรวมกับ ITSM และเครื่องมือตรวจสอบ | แผนฟรี; แผนชำระเงินเริ่มต้นที่ $24/เดือนต่อผู้ใช้ | G2: รีวิวไม่เพียงพอ Capterra: 4. 7/5 (60+) |
| เซนดูตี้ | การตอบสนองต่อเหตุการณ์ที่ขับเคลื่อนด้วย AI ในระดับองค์กรสำหรับทีมขนาดเล็กถึงขนาดใหญ่ | การจัดการเหตุการณ์ของ ZenAI, การจัดตารางเวรเรียกใช้งานขั้นสูง, คู่มือการปฏิบัติงานอัตโนมัติ, การเชื่อมต่อมากกว่า 150 ระบบ | แผนฟรี; แผนชำระเงินเริ่มต้นที่ $6/เดือนต่อผู้ใช้ | G2: 4. 6/5 (135+) Capterra: รีวิวไม่เพียงพอ |
| เหตุการณ์. io | การตอบสนองต่อเหตุการณ์บน Slack สำหรับบริษัทขนาดกลางถึงขนาดใหญ่ | เหตุการณ์แบบครบวงจรใน Slack, AI SRE, การจัดตารางเวร, หน้าสถานะอัตโนมัติ, แดชบอร์ดข้อมูลเชิงลึก | แผนฟรี; แผนชำระเงินเริ่มต้นที่ $19/เดือนต่อผู้ใช้ | G2: 4. 8/5 (180+) Capterra: รีวิวไม่เพียงพอ |
เกณฑ์สำคัญในการประเมินทางเลือกของ Opsgenie
ฉันรู้ว่าเรามีเวลาเกือบ 2 ปีก่อนที่พวกเขาจะเลิกใช้มันอย่างสมบูรณ์ แต่ฉันไม่เห็นเหตุผลที่จะรอ 😛
ฉันรู้ว่าเรามีเวลาเกือบ 2 ปีก่อนที่พวกเขาจะเลิกใช้มันอย่างสมบูรณ์ แต่ฉันไม่เห็นเหตุผลที่จะต้องรอ 😛
ความคิดเห็นของผู้ใช้ Redditคนนั้นสะท้อนความเป็นจริงที่ทีม PMO ด้านไอทีหลายทีมกำลังเผชิญอยู่ ใช่แล้ว Opsgenie เคยเป็นเครื่องมือคู่ใจที่ดีมาหลายปี แต่การพึ่งพาเพียงเพราะคุ้นเคยเท่านั้นจะไม่ช่วยอะไรเมื่อการสนับสนุนสิ้นสุดลง
สิ่งที่ควรทำอย่างรอบคอบในตอนนี้คือพิจารณาว่าอะไรที่ทำให้ Opsgenie มีประโยชน์ตั้งแต่แรกเริ่ม และใช้คุณสมบัติเหล่านั้นเป็นแนวทางในการเลือกแพลตฟอร์มการจัดการเหตุการณ์ถัดไปของคุณ
นี่คือลักษณะบางประการที่ควรให้ความสนใจ:
- ส่งการแจ้งเตือนอย่างทันท่วงทีผ่านช่องทางต่าง ๆ เช่น โทรศัพท์, อีเมล, SMS หรือการแจ้งเตือนแบบพุช
- รักษาการแจ้งเตือนให้ตรงเป้าหมาย เพื่อให้บุคคลที่เหมาะสมได้รับข้อมูลโดยไม่รบกวนสมาชิกคนอื่นๆ ในทีม
- นำนโยบายการยกระดับการจัดการ มาใช้เพื่อให้แน่ใจว่าเหตุการณ์สำคัญจะไม่ถูกมองข้าม
- รวมศูนย์การอัปเดตเหตุการณ์ เพื่อให้ทีมสามารถเห็นภาพรวมทั้งหมดในขณะที่จัดการเหตุการณ์
- จัดทำบททบทวนหลังเกิดเหตุ เพื่อเรียนรู้จากเหตุการณ์ที่คล้ายคลึงกันและปรับปรุงอย่างต่อเนื่อง
- ความสามารถในการผสานรวมข้อเสนอ กับเครื่องมือที่ทีมไอทีของคุณใช้งานอยู่แล้ว
Opsgenie สร้างชื่อเสียงจากการช่วยเหลือทีม DevOps ในการลดความเหนื่อยล้าจากการแจ้งเตือน รักษาความชัดเจนในตารางเวร และแก้ไขปัญหาโดยไม่เกิดความสับสน เมื่อคุณสำรวจทางเลือกอื่นของ Opsgenie โปรดยึดถือคุณค่าเหล่านี้ไว้เสมอ
📖 อ่านเพิ่มเติม: เครื่องมือซอฟต์แวร์การจัดการเหตุการณ์ที่ดีที่สุดสำหรับทีมไอที
ทางเลือกที่ดีที่สุด 12 อันดับของ Opsgenie
แม้ว่า Opsgenie อาจกำลังจะยุติการให้บริการ แต่ไม่ได้หมายความว่าทีมของคุณจะต้องสูญเสียแรงผลักดันไป นี่คือตัวเลือกที่เหมาะสมซึ่งจะช่วยให้ทีมปฏิบัติการของคุณมีความมั่นใจในช่วงเวลาสำคัญ
วิธีที่เราตรวจสอบซอฟต์แวร์ที่ ClickUp
ทีมบรรณาธิการของเราปฏิบัติตามกระบวนการที่โปร่งใส มีหลักฐานการวิจัยรองรับ และเป็นกลางต่อผู้ขาย เพื่อให้คุณสามารถไว้วางใจได้ว่าคำแนะนำของเราอยู่บนพื้นฐานของคุณค่าที่แท้จริงของผลิตภัณฑ์
นี่คือรายละเอียดโดยละเอียดเกี่ยวกับวิธีการที่เราตรวจสอบซอฟต์แวร์ที่ ClickUp
1. ClickUp (เหมาะที่สุดสำหรับการจัดการกระบวนการทำงานของเหตุการณ์ควบคู่ไปกับการบริหารโครงการที่กว้างขวาง)
เมื่อออกจาก Opsgenie ทีมต่างๆ จะกังวลน้อยลงเกี่ยวกับการสูญเสียการแจ้งเตือน และกังวลมากขึ้นเกี่ยวกับการปรับตัวให้เข้ากับกระบวนการจัดการเหตุการณ์ใหม่
ปัญหาหลักคือการขยายตัวของงาน (Work Sprawl) ซึ่งการอัปเดต, ตารางเวลา, และนโยบายต่าง ๆ ถูกกระจายอยู่ในแอปพลิเคชัน, อีเมล, และเอกสารต่าง ๆ ที่แตกต่างกัน การกระจายตัวเช่นนี้ทำให้พลังงานถูกใช้ไปอย่างสิ้นเปลือง และบังคับให้ทีมต้องเริ่มต้นจากศูนย์ทุกครั้งที่มีเหตุการณ์เกิดขึ้น
การวิจัยแสดงให้เห็นว่าพนักงานใช้เวลา 117 นาทีในการค้นหาอีเมล และใช้เวลา 153 นาทีในการอ่านข้อความใน Microsoft Teams ในวันทำงานแต่ละวัน โดยมีการขัดจังหวะทุกสองสามนาที
ClickUp เข้ามาเป็นทางเลือกแทน Opsgenie โดยการดึงงานที่แยกออกจากกันทั้งหมดมาไว้ในพื้นที่ทำงานที่รวมกันเพียงแห่งเดียว นี่คือวิธีที่ฟีเจอร์ของมันตอบสนองต่อความท้าทายเหล่านั้นอย่างลึกซึ้ง
กระบวนการทำงานอัตโนมัติ
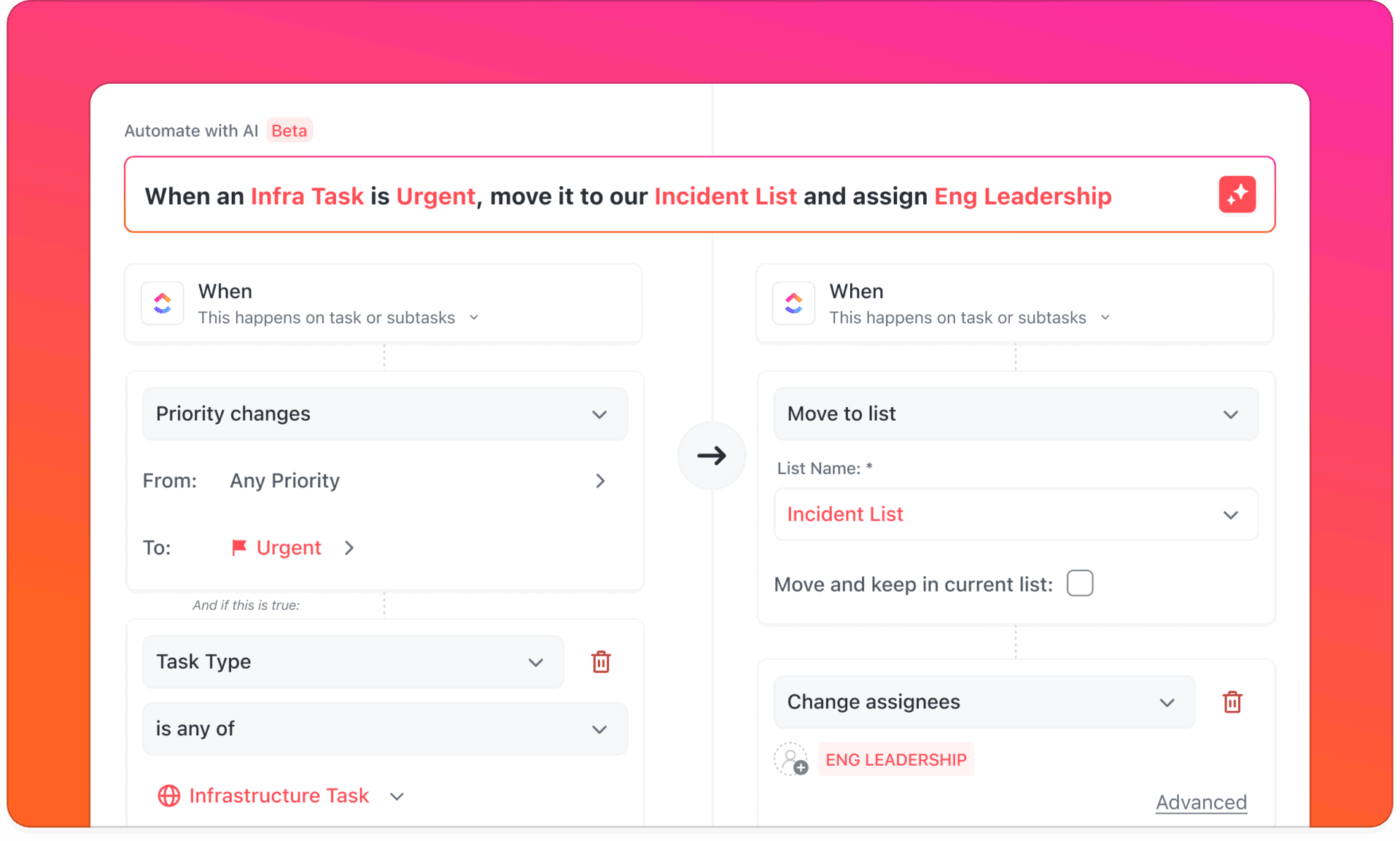
เมื่อมีการแจ้งเตือนจากเครื่องมือติดตาม, เครื่องมือแชท, และอีเมล, ยากที่จะบอกว่าอะไรสำคัญและใครควรตอบสนอง.
ด้วยClickUp AutomationsและAI Agents การแจ้งเตือนจะกลายเป็นกิจกรรมที่มีความหมาย การแจ้งเตือนที่เข้ามาสามารถสร้างและมอบหมายงานให้กับวิศวกรที่อยู่ในสถานะพร้อมให้บริการได้โดยอัตโนมัติ แจ้งเตือนบุคคลที่เหมาะสมโดยไม่รบกวนสมาชิกทีมคนอื่นๆ
หากไม่มีการตอบกลับภายในระยะเวลาที่กำหนด ระบบจะดำเนินการส่งต่อปัญหาไปยังขั้นตอนต่อไปตามขั้นตอนมาตรฐานของคุณโดยอัตโนมัติ
📌 ตัวอย่าง: มีการรายงานการหยุดทำงานของเซิร์ฟเวอร์ที่มีความสำคัญสูง ClickUp Automations จะสร้างงานใหม่ในรายการเหตุการณ์ของคุณ ทำเครื่องหมายว่าเร่งด่วน มอบหมายให้กับวิศวกรที่อยู่ในเวร และส่งการแจ้งเตือนแบบพุชบนมือถือ ในเวลาเดียวกัน ตัวแทน AI ที่คุณกำหนดเองจะโพสต์ข้อความสั้นๆ ในช่องเหตุการณ์ในClickUp Chatเพื่อให้ทีมทราบแต่ไม่รู้สึกว่ามีข้อมูลมากเกินไป
ความชัดเจนและความรับผิดชอบในงาน
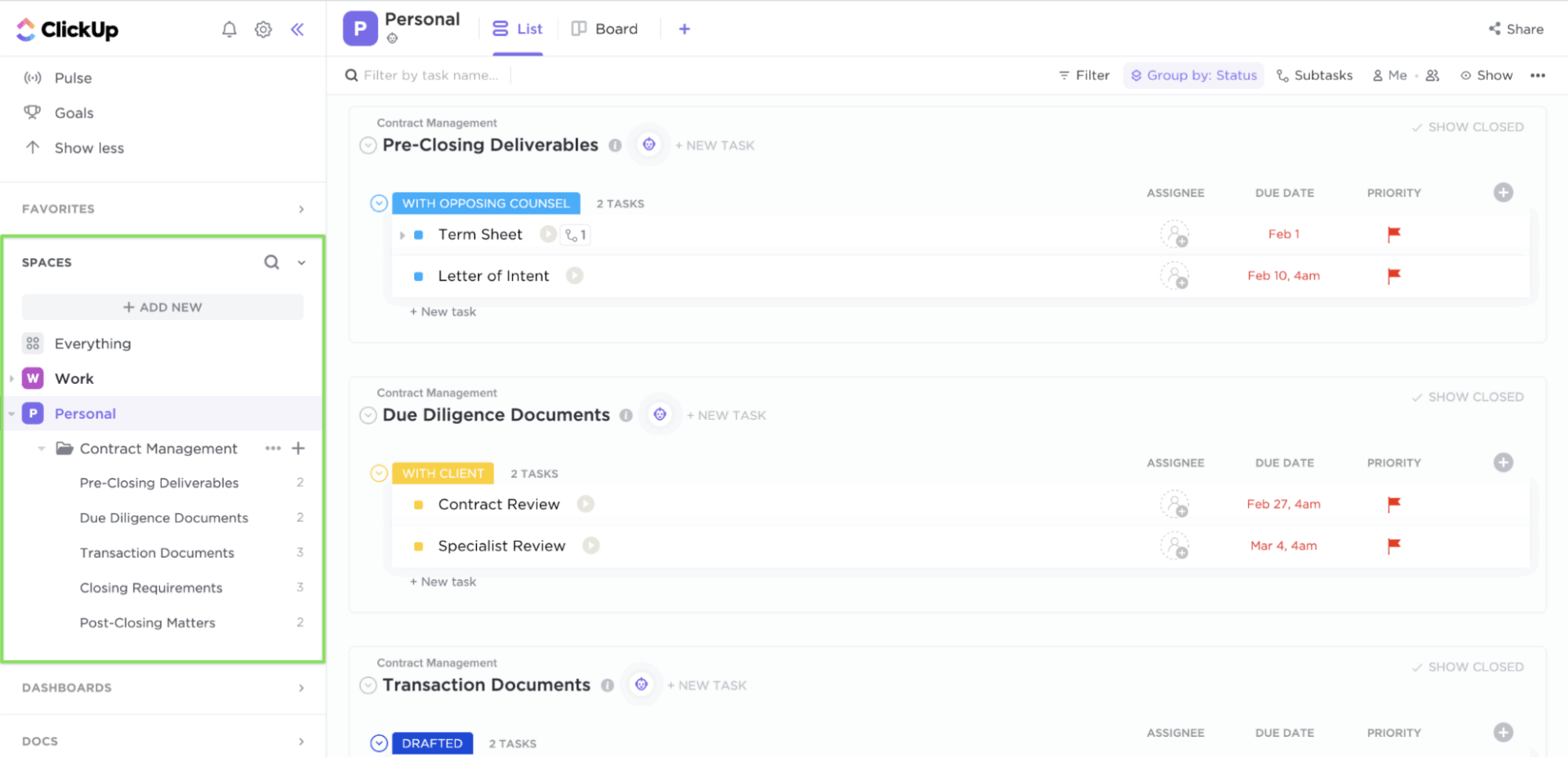
เมื่อเกิดเหตุการณ์ขึ้น ทีมมักจะเสียเวลาไปกับการคิดว่าจะทำอะไรและขั้นตอนต่อไปคืออะไรClickUp Tasksช่วยเพิ่มความชัดเจนให้กับกระบวนการจัดการเหตุการณ์ของคุณ
แต่ละงานสามารถมีเจ้าของที่ชัดเจน, ลำดับความสำคัญ, และกำหนดเวลาส่งมอบได้ ภายในแต่ละงาน คุณสามารถเพิ่มรายการตรวจสอบ, ลิงก์ runbook, และภาพหน้าจอได้ ฟิลด์ที่กำหนดเองสามารถบันทึกความรุนแรง, บริการที่ได้รับผลกระทบ, หรือขั้นตอนของการยกระดับปัญหา ในขณะที่สถานะงานที่กำหนดเองและรายการใน ClickUpช่วยขจัดความไม่แน่นอนโดยการกำหนดกระบวนการตอบสนองให้เป็นลำดับที่ชัดเจน
📌 ตัวอย่าง: เหตุการณ์ที่ 'รายงานแล้ว' จะย้ายไปยังสถานะ 'กำลังตรวจสอบ' เมื่อวิศวกรเปิดงานนั้น ขั้นตอนการแก้ไขจะถูกติดตามในรายการตรวจสอบ พร้อมบันทึกและบันทึกเหตุการณ์ที่เพิ่มในคำอธิบาย การเปลี่ยนแปลงสถานะแต่ละครั้งจะแจ้งเตือนเฉพาะผู้ที่เกี่ยวข้องเท่านั้น เพื่อให้วิศวกรสามารถทำงานต่อไปได้ ในขณะที่ผู้นำยังคงได้รับข้อมูลอย่างต่อเนื่อง
การอัปเดตที่ไม่ทำให้การทำงานสะดุด
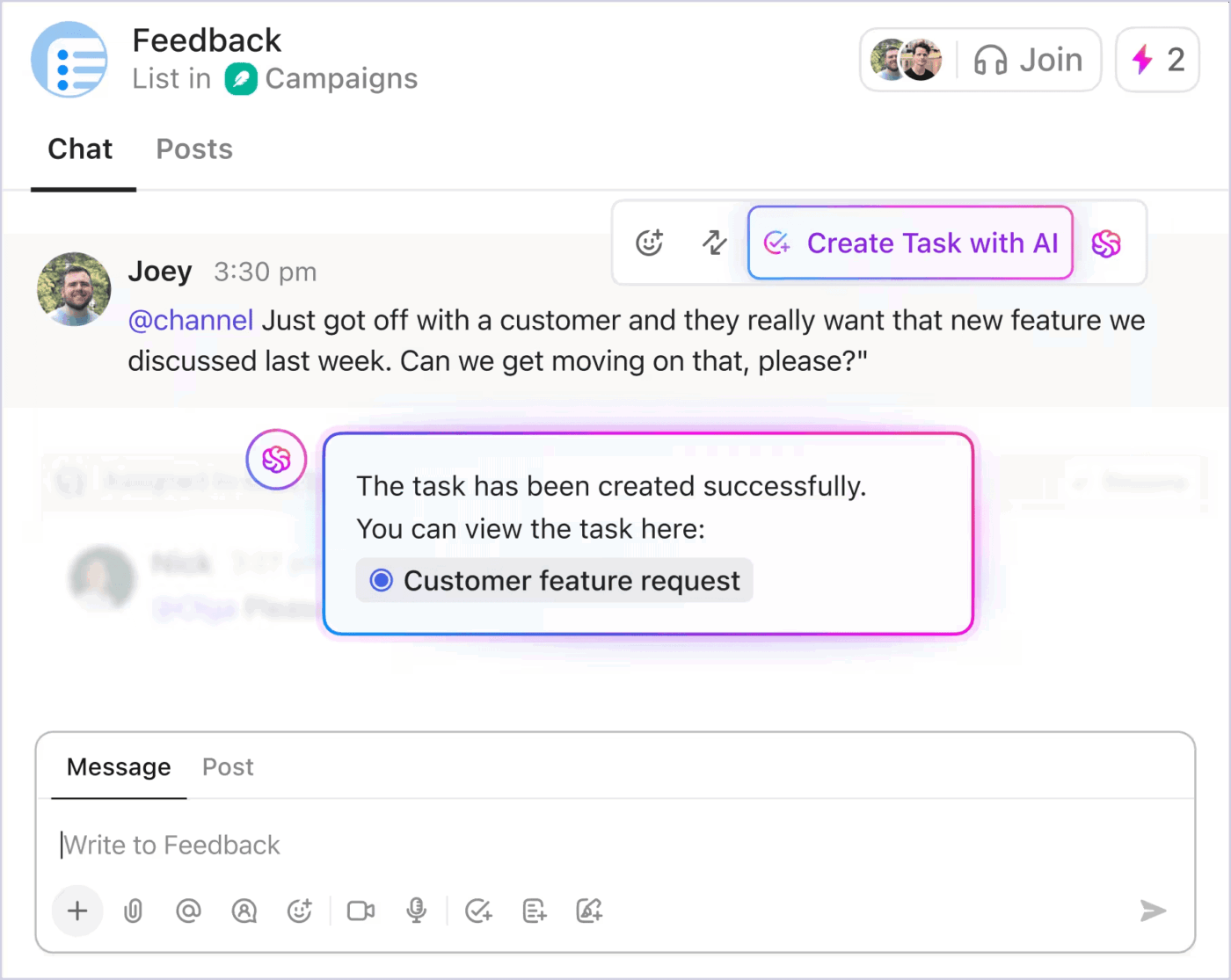
ในระหว่างเหตุการณ์วิกฤต การอัปเดตข้อมูลแก่ผู้มีส่วนได้ส่วนเสียไม่ควรขัดขวางความพยายามในการตอบสนองClickUp Chatแก้ไขปัญหานี้โดยการแนบการสนทนาไว้กับงานของเหตุการณ์โดยตรง สมาชิกในทีมและผู้นำสามารถติดตามการสนทนา เห็นการตัดสินใจที่ทำ และเพิ่มความคิดเห็นได้แบบเรียลไทม์
ClickUp ยังสามารถเชื่อมต่อกับ Slack และ Microsoft Teams ได้ด้วย ทำให้การอัปเดตปรากฏในช่องทางที่ผู้คนติดตามอยู่แล้ว
กำลังมองหาเคล็ดลับที่ดีที่สุดสำหรับการทำงานร่วมกันแบบเรียลไทม์อยู่ใช่ไหม? นี่คือคู่มือสำหรับคุณ:
การทบทวนหลังเหตุการณ์ที่นำไปสู่การเปลี่ยนแปลงที่ยั่งยืน
บ่อยครั้งที่การทบทวนหลังเหตุการณ์ถูกเขียนขึ้นแต่กลับถูกลืมClickUp Docsช่วยให้การทบทวนเหล่านี้มีชีวิตอยู่ต่อไปโดยการเก็บการวิเคราะห์หลังเหตุการณ์มาตรฐานไว้เคียงข้างกับงานที่เกี่ยวข้องกับเหตุการณ์นั้นโดยตรง
ในขณะเดียวกันแดชบอร์ดของ ClickUpจะแสดงเมตริกต่างๆ เช่น เวลาเฉลี่ยในการแก้ไขปัญหา ความถี่ของเหตุการณ์ และรูปแบบที่เกิดขึ้นซ้ำ ความชัดเจนนี้ช่วยให้ทีมไอทีและทีม DevOps เปลี่ยนจากการแก้ไขปัญหาแบบรับมือเป็นรายครั้งไปสู่การปรับปรุงเชิงรุก
💡 เคล็ดลับมืออาชีพ: การทบทวนหลังเหตุการณ์อาจใช้เวลาหลายชั่วโมงในการเขียน แก้ไข และค้นหาบริบทClickUp Brainช่วยเปลี่ยนแปลงกระบวนการนี้โดยรวบรวมบันทึก ไทม์ไลน์ และรายการที่ต้องดำเนินการโดยอัตโนมัติ สามารถสรุปงานที่เกี่ยวข้องกับเหตุการณ์ ร่างรายงานบทเรียนใน ClickUp Docs และแนะนำขั้นตอนถัดไปโดยอ้างอิงจากเหตุการณ์ที่คล้ายคลึงกัน
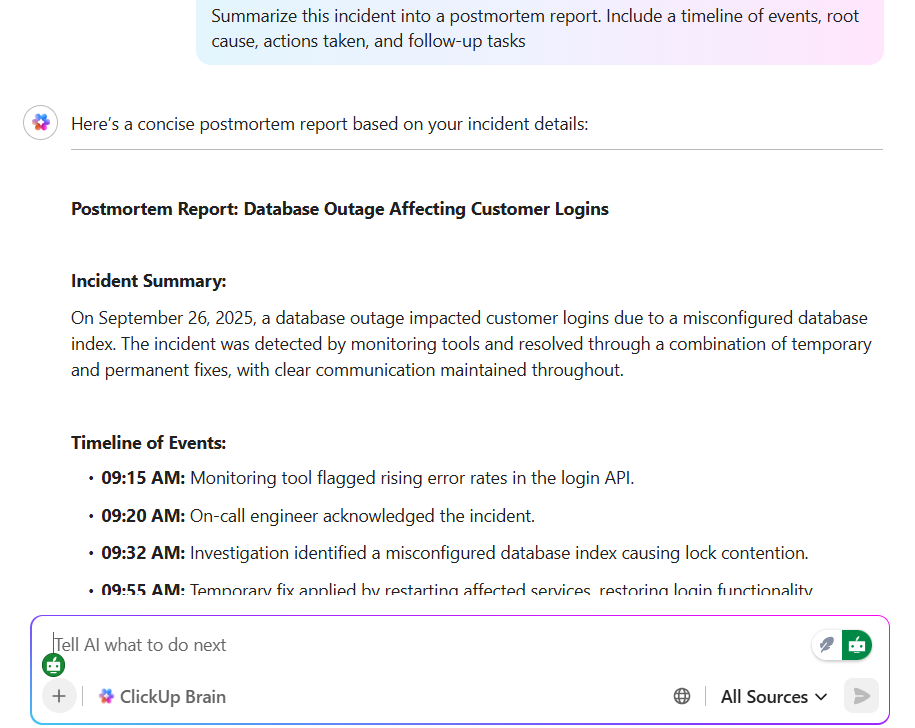
ด้วยClickUp Brain Max คุณจะได้รับความเร็วที่เพิ่มขึ้นจากฟีเจอร์ Talk to Text ของ ClickUp— พูดความคิดของคุณแบบเรียลไทม์และดูมันกลายเป็นบันทึกที่เรียบร้อยพร้อมแชร์ได้ทันที ทั้งสองฟีเจอร์นี้ช่วยให้ ทีมประหยัดเวลาได้เกือบหนึ่งวันเต็มในแต่ละสัปดาห์ ด้วยการตัดงานเขียนและการค้นหาที่ไม่จำเป็นออกไป ทำให้คุณสามารถมุ่งเน้นไปที่การป้องกันเหตุการณ์ถัดไปแทนที่จะต้องเล่าเหตุการณ์ที่ผ่านมาซ้ำ
เพิ่มโครงสร้างและประหยัดเวลาด้วยเทมเพลต

ในกรณีฉุกเฉิน คุณจะเรียนรู้อย่างแท้จริงถึงคุณค่าของกระบวนการที่ชัดเจนและเป็นขั้นตอน
เทมเพลตแผนปฏิบัติการกรณีเหตุการณ์ของ ClickUpเป็นเช่นนั้นจริง ๆ เอกสารนี้ระบุอย่างชัดเจนว่าต้องทำอะไร ใครต้องทำ และทำตามลำดับอย่างไร ช่วยให้ทุกคนทำงานสอดคล้องกัน ลดความเสี่ยง และมั่นใจได้ว่าไม่มีขั้นตอนใดถูกมองข้าม
อีกหนึ่งความท้าทายในสายงานไอทีคือการบันทึกเหตุการณ์อย่างมีประสิทธิภาพ เพื่อให้สามารถสังเกตเห็นรูปแบบและป้องกันปัญหาในอนาคตได้แม่แบบรายงานเหตุการณ์ไอทีของ ClickUpช่วยให้การรายงานเป็นเรื่องง่าย เปลี่ยนทุกปัญหาให้กลายเป็นข้อมูลที่มีคุณค่า
คุณสมบัติที่ดีที่สุดของ ClickUp
- ลดความเหนื่อยล้าจากการแจ้งเตือนด้วยClickUp Notificationsที่สามารถปรับแต่งได้ เพื่อให้มั่นใจว่าเฉพาะบุคคลที่เกี่ยวข้องเท่านั้นที่จะได้รับการแจ้งเตือน
- สร้างงาน กำหนดงาน และรายงานเหตุการณ์โดยอัตโนมัติด้วย ClickUp Automations และ AI Agents
- สร้างขั้นตอนการทำงานสำหรับเหตุการณ์ที่ชัดเจนด้วย ClickUp Tasks, Lists, และ Statusesพร้อมเทมเพลตรายงานเหตุการณ์เพื่อเป็นแนวทางในทุกขั้นตอนของการตอบสนอง
- เปิดใช้งานการทำงานร่วมกันของทีมด้วย ClickUp Chat และ ClickUp Docs เพื่อให้การสนทนา การอัปเดต และข้อสรุปต่างๆ อยู่ในเหตุการณ์เดียวกัน
- ติดตามสถานะงานและรายงานเหตุการณ์ผ่านแดชบอร์ด ClickUp
- สร้างข้อมูลเชิงลึกจากเหตุการณ์และงานที่ปิดแล้ว และสร้างหรือปรับปรุง SOP สำหรับการปรับปรุงในอนาคตด้วย ClickUp Brain
ข้อจำกัดของ ClickUp
- ความยืดหยุ่นของแพลตฟอร์มอาจรู้สึกท่วมท้นสำหรับทีมขนาดเล็กที่ต้องการเพียงการแจ้งเตือนพื้นฐานและการจัดการการเข้าเวร
ราคาของ ClickUp
คะแนนและรีวิว ClickUp
- G2: 4. 7/5 (10,500+ รีวิว)
- Capterra: 4. 6/5 (4,500+ รีวิว)
ผู้ใช้พูดถึง ClickUp อย่างไร
ผู้ใช้ G2รายนี้รายงานว่า:
การทำงานร่วมกันในโครงการกลายเป็นเรื่องง่ายขึ้นมากตั้งแต่การนำมาใช้ของคลิกอัพ เนื่องจากสามารถมอบหมายงานให้กับสมาชิกได้อย่างง่ายดาย และคุณสามารถติดตามความคืบหน้าได้ผ่านการแชท นอกจากนี้ยังมีการแจ้งเตือนทางอีเมลและแจ้งเตือนเมื่อมีงานที่ไม่ได้ทำเสร็จในกรณีที่มีงานที่ไม่ได้ทำเสร็จ
การทำงานร่วมกันในโครงการกลายเป็นเรื่องง่ายขึ้นมากตั้งแต่การนำมาใช้ของคลิกอัพ เนื่องจากสามารถมอบหมายงานให้สมาชิกได้อย่างง่ายดาย และคุณสามารถติดตามความคืบหน้าผ่านการแชทได้ นอกจากนี้ยังมีการแจ้งเตือนทางอีเมลและแจ้งเตือนเมื่อมีงานที่ไม่ได้ทำเสร็จในกรณีที่มีงานที่ไม่ได้ทำเสร็จ
📖 อ่านเพิ่มเติม: วิธีเขียนรายงานเหตุการณ์ในที่ทำงาน
2. PagerDuty (เหมาะที่สุดสำหรับการแจ้งเตือนเหตุการณ์แบบเรียลไทม์และการทำงานอัตโนมัติในระดับองค์กร)
หากคุณกำลังจะออกจาก Opsgenie ความกังวลแรกของคุณนั้นง่ายมาก คือ จะมีคนที่เหมาะสมได้รับการแจ้งเตือน ในเวลาที่เหมาะสม ผ่านช่องทางที่ถูกต้องหรือไม่?
PagerDuty ถูกสร้างขึ้นเพื่อขจัดความเครียดนั้นออกไป คุณกำหนดบริการ ตารางเวลา และนโยบายการยกระดับปัญหาที่ชัดเจน เพื่อให้มั่นใจว่าความรับผิดชอบไม่เคยคลุมเครือ สัญญาณแจ้งเตือนจาก CloudWatch, Prometheus, Datadog, Jira, ServiceNow, Slack, Zoom และอื่นๆ จะถูกรวบรวมไว้ในที่เดียวและจัดกลุ่มเป็นเหตุการณ์เดียว ไม่ใช่การแจ้งเตือนแยกกัน 15 ครั้ง
ข้อมูลเชิงลึกของเหตุการณ์ ช่วยลดการซ้ำซ้อนและเชื่อมโยงปัญหาที่เกี่ยวข้อง ซึ่งช่วยลดความเหนื่อยล้าจากการแจ้งเตือนโดยไม่ปิดเสียงปัญหาที่แท้จริง ผู้ตอบสนองสามารถรับทราบหรือยกระดับปัญหาได้จากแอปมือถือหรือโดยตรงจาก Slack หรือ Teams พร้อมการสร้างห้องเหตุการณ์และสะพานเชื่อมต่อโดยอัตโนมัติ
หลังจากการแก้ไข ปัญหาจะแสดงเวลาที่ใช้ในการรับรู้ เวลาที่ใช้ในการแก้ไข และจุดปัญหาที่เกิดขึ้นซ้ำ เพื่อให้คุณสามารถแก้ไขสาเหตุที่แท้จริงได้แทนที่จะไล่ตามอาการ
คุณสมบัติที่ดีที่สุดของ PagerDuty
- อนุญาตให้บุคคลปรับแต่งการแจ้งเตือนผ่าน SMS, โทรศัพท์, อีเมล, การแจ้งเตือนแบบพุช และ Slack เพื่อลดการรบกวนโดยไม่พลาดเหตุการณ์สำคัญ
- ทำให้การตั้งค่าเป็นเรื่องง่ายด้วยการแจ้งเตือนทดสอบ การผสานรวมบริการ และการออกแบบนโยบายการยกระดับปัญหาที่ชัดเจน
- ให้การสนับสนุนเกี่ยวกับตารางการโทรและขั้นตอนการแจ้งเตือนที่เหมาะสม เพื่อให้บุคคลที่เกี่ยวข้องได้รับทราบและดำเนินการต่อไปจนกว่าจะได้รับการยืนยัน
- เปิดใช้งานการดำเนินการเกี่ยวกับเหตุการณ์ผ่าน Slack เช่น ยืนยัน รับทราบ แก้ไข และส่งต่อปัญหาโดยตรงในแชท
- ลดความเหนื่อยล้าจากการแจ้งเตือนด้วย AIOps ที่จัดกลุ่มข้อมูลซ้ำและเน้นเหตุการณ์เร่งด่วน
ข้อจำกัดของ PagerDuty
- หัวหน้าทีมไม่สามารถปรับแต่งวิธีการส่งการแจ้งเตือนได้อย่างเต็มที่ในระดับทีม ซึ่งจำกัดความยืดหยุ่นเมื่อผู้จัดการต้องการกฎการยกระดับที่สอดคล้องกัน
- การแจ้งเตือนทางอีเมลไม่มีฟังก์ชันการตอบกลับเพื่อดำเนินการ ทำให้ผู้ตอบต้องคลิกผ่านไปยังแพลตฟอร์มแทนที่จะจัดการโดยตรงจากกล่องจดหมาย
- คุณสมบัติขั้นสูง เช่น AIOps และใบอนุญาตการสื่อสารกับผู้มีส่วนได้ส่วนเสีย มีค่าใช้จ่ายเพิ่มเติมที่สูงมาก
ราคาของ PagerDuty
- ฟรี
- มืออาชีพ: $25/เดือน ต่อผู้ใช้
- ธุรกิจ: $49/เดือน ต่อผู้ใช้
- องค์กร: ราคาที่กำหนดเอง
คะแนนและรีวิวของ PagerDuty
- G2: 4. 5/5 (รีวิวมากกว่า 900+)
- Capterra: 4. 6/5 (รีวิวมากกว่า 200 รายการ)
ผู้ใช้พูดถึง PagerDuty ว่าอย่างไร
ผู้ใช้ G2คนนี้กล่าวว่า:
ฉันชอบที่หน้าที่ดูแลเพจเจอร์มีเสียงแจ้งเตือนหลายแบบ บางเสียงก็ตลกมาก ตั้งแต่ได้รับหน้าที่ดูแลเพจเจอร์ ฉันสามารถตอบสนองต่อเหตุการณ์และประสานงานกับทีมได้อย่างมีประสิทธิภาพมากขึ้น
ฉันชอบที่หน้าที่รับสัญญาณเรียกตัวมีเสียงแจ้งเตือนหลายแบบ บางเสียงก็ตลกมาก ตั้งแต่ได้รับหน้าที่นี้ ฉันสามารถตอบสนองต่อเหตุการณ์และประสานงานกับทีมได้อย่างมีประสิทธิภาพมากขึ้น
📖 อ่านเพิ่มเติม: แผนสำรองคืออะไร & วิธีการพัฒนาแผนสำรอง?
3. xMatters (เหมาะที่สุดสำหรับการจัดการเหตุการณ์และการทำงานอัตโนมัติที่คุ้มค่า)
ผู้ใช้ Redditคนหนึ่งสรุปได้ดีที่สุดว่า:
คุณได้ในสิ่งที่คุณจ่าย แต่คุณจ่ายน้อยกว่า มีทุกสิ่งที่คุณต้องการ แต่แน่นอนว่ามันไม่หรูหราเหมือน PagerDuty
คุณได้ในสิ่งที่คุณจ่าย แต่จ่ายน้อยกว่า มีทุกสิ่งที่คุณต้องการ แต่แน่นอนว่าไม่หรูหราเท่า PagerDuty
ประโยคนั้นสะท้อนตำแหน่งของ xMatters ได้อย่างชัดเจน—ราคาไม่แพง, เชื่อถือได้, และแข็งแกร่งในด้านที่สำคัญที่สุด
หากคุณกำลังจะออกจาก Opsgenie ปัญหาของคุณมักมีอยู่สองประการ คือ มีข้อมูลแจ้งเตือนมากเกินไปจนรบกวนคนที่ใช่ และไม่แน่ใจว่าจะต้องดำเนินการต่อไปอย่างไร xMatters ช่วยแก้ไขทั้งสองประเด็นนี้ด้วยการให้คุณสามารถวางแผนบริการและตารางเวรได้อย่างเป็นระบบ จากนั้นจึงส่งการแจ้งเตือนพร้อมบริบทที่ชัดเจนไปยังบุคคลที่เหมาะสมผ่านช่องทางที่ถูกต้อง
ผู้ใช้ชื่นชมการแจ้งเตือนที่ตรงเป้าหมายพร้อมรายละเอียดที่เป็นประโยชน์ รวมถึงเส้นทางการตรวจสอบที่สมบูรณ์ซึ่งแสดงว่าใครได้รับการแจ้งเตือน ใครตอบรับ และเมื่อใด บันทึกดังกล่าวทำให้การตรวจสอบหลังเหตุการณ์และการตรวจสอบการปฏิบัติตามข้อกำหนดเป็นเรื่องง่าย
เครื่องมือสร้างเวิร์กโฟลว์แบบโลว์โค้ดจะเปลี่ยนสัญญาณจาก Datadog, Prometheus หรือ ServiceNow ให้กลายเป็นลำดับขั้นตอนที่ชัดเจน
ด้วยการทำงานอัตโนมัติของกระบวนการและการจัดการโครงการ DevOpsที่ปรับตัวได้เป็นแกนหลัก xMatters ช่วยให้ทีมทำงานได้เร็วขึ้นและลดเสียงรบกวนจากการแจ้งเตือน
คุณสมบัติเด่นของ xMatters
- ทำให้กระบวนการทำงานของเหตุการณ์เป็นอัตโนมัติด้วยการผสานระบบแบบไม่ต้องเขียนโค้ดและแบบเขียนโค้ดน้อยที่ช่วยเร่งการแก้ไขและลดงานที่ต้องทำด้วยตนเอง
- จัดการตารางเวรและขั้นตอนการส่งต่อได้อย่างราบรื่น เพื่อให้บุคคลที่เหมาะสมได้รับการแจ้งเตือนในเวลาที่เหมาะสมเสมอ
- นำการจัดการเหตุการณ์แบบปรับตัวได้มาใช้เพื่อลดผลกระทบต่อลูกค้าและรวบรวมบทเรียนจากทุกเหตุการณ์
- กรองเสียงรบกวนด้วยสัญญาณอัจฉริยะ การแจ้งเตือนที่สัมพันธ์กัน และการแจ้งเตือนที่สมบูรณ์เพื่อบริบทที่ชัดเจนยิ่งขึ้น
- เข้าถึงการวิเคราะห์เชิงปฏิบัติได้เพื่อระบุความไม่มีประสิทธิภาพและปรับปรุงการร่วมมือระหว่างทีม
ข้อจำกัดของ xMatters
- อินเตอร์เฟซและประสบการณ์ผู้ใช้รู้สึกไม่ได้รับการปรับปรุงอย่างละเอียดเมื่อเทียบกับคู่แข่ง
- การรายงานขั้นสูงและการวิเคราะห์มีข้อจำกัดในแผนระดับล่าง
- การครอบคลุมการสนับสนุนทั่วโลกอาจแตกต่างกันขึ้นอยู่กับแผนที่เลือก
ราคาของ xMatters
- ฟรี
- เริ่มต้น (สิ่งจำเป็น): $9/เดือน ต่อผู้ใช้
- ฐาน (มาตรฐาน): $39/เดือน ต่อผู้ใช้
- ขั้นสูง: การกำหนดราคาแบบกำหนดเอง
คะแนนและรีวิวของ xMatters
- G2: 4. 5/5 (670+ รีวิว)
- Capterra: 4. 6/5 (140+ รีวิว)
ผู้ใช้พูดถึง xMatters
รีวิวนี้จากCapterraประกอบด้วย:
เมื่อเกิดเหตุการณ์ด้านความปลอดภัยของข้อมูลในบริษัท Xmatters จะเปิดใช้งานโปรโตคอลการตอบสนองทันที: จัดระเบียบโปรโตคอลการดำเนินการของทีมตามหน้าที่ของพวกเขา การแจ้งเตือนจะถูกส่งผ่านช่องทางต่างๆ
เมื่อเกิดเหตุการณ์ด้านความปลอดภัยของข้อมูลในบริษัท Xmatters จะเปิดใช้งานโปรโตคอลการตอบสนองทันที: จัดระเบียบโปรโตคอลการดำเนินการของทีมตามหน้าที่ของพวกเขา การแจ้งเตือนจะถูกส่งผ่านช่องทางต่างๆ
📮 ClickUp Insight: 28% ของพนักงานกล่าวว่างานตามติดพวกเขาหลังเวลาทำงาน และอีกแปดเปอร์เซ็นต์มักมีปัญหาในการหยุดพัก นั่นหมายถึงมากกว่าหนึ่งในสามที่นำความเครียดกลับบ้าน
ใช้ClickUp Remindersเพื่อปกป้องกิจวัตรยามเย็นของคุณ ตั้งการแจ้งเตือนสรุปประจำวัน การแจ้งเตือนแบบเงียบนอกเวลาทำงาน และสำรองเวลาส่วนตัวไว้ในปฏิทินของคุณ การหยุดพักควรเป็นทางเลือกที่คุณตัดสินใจได้
💫 ผลลัพธ์ที่แท้จริง:Lulu Pressประหยัดเวลาได้ประมาณหนึ่งชั่วโมงต่อคนต่อวันด้วยระบบอัตโนมัติของ ClickUp ส่งผลให้ประสิทธิภาพเพิ่มขึ้น 12%
4. AlertOps (เหมาะที่สุดสำหรับการลดเสียงรบกวนด้วย AI และการตอบสนองต่อเหตุการณ์อย่างรวดเร็ว)
ปริมาณการแจ้งเตือนยังคงเพิ่มขึ้นอย่างต่อเนื่อง โดย88% ของทีมรายงานว่ามีการเพิ่มขึ้นในปีที่ผ่านมา และเกือบครึ่งหนึ่งระบุว่าอัตราการเพิ่มขึ้นนั้นเกิน 25% เสียงรบกวนอย่างต่อเนื่องเช่นนี้นำไปสู่ความเหนื่อยล้าจากการแจ้งเตือน ซึ่ง 76% ของศูนย์ปฏิบัติการด้านความปลอดภัย (SOC) ระบุว่าเป็นความท้าทายอันดับหนึ่งของพวกเขาในปัจจุบัน
นั่นคือความเป็นจริงที่คุณนำมาสู่การแทนที่ Opsgenie ทุกครั้ง เครื่องมือถัดไปที่คุณเลือกต้องสามารถตัดสินได้ว่าการแจ้งเตือนใดสมควรได้รับการดำเนินการ AlertOps มุ่งเน้นไปที่จุดนี้ด้วย OpsIQ ซึ่งเป็นแกนกลาง AI ที่กรองการแจ้งเตือนซ้ำ, เชื่อมโยงสัญญาณที่เกี่ยวข้อง, สรุปบริบท, และแนะนำขั้นตอนถัดไป เพื่อให้ผู้ตอบสนองเห็นเหตุการณ์เดียวที่ชัดเจนแทนที่จะเป็นฟีดที่ต้องเลื่อนดู
คุณสามารถเริ่มต้นด้วยตารางเวรเรียกเข้าเริ่มต้นหรือสร้างตารางของคุณเอง จากนั้นกำหนดเส้นทางผ่านการโทรศัพท์, SMS, แอปมือถือ, แชท, หรืออีเมล พร้อมกฎการยกระดับที่ทำงานจนกว่าจะมีคนรับผิดชอบปัญหา การกำหนดเส้นทางสายเรียกเข้าแบบเรียลไทม์จะส่งลูกค้าไปยังเจ้าหน้าที่เวรปัจจุบันตามตารางเวลาแบบเรียลไทม์ และนโยบายตาม SLA จะยกระดับก่อนการละเมิดแทนที่จะเป็นหลังจากนั้น
นอกจากนี้ แพลตฟอร์มยังผสานการทำงานกับเครื่องมือมากกว่า 200 รายการ ตั้งแต่การตรวจสอบและระบบแจ้งปัญหา ไปจนถึง O365 และ Slack เพื่อให้การคัดแยกปัญหาไม่สะดุดเนื่องจากขาดบริบท
คุณสมบัติที่ดีที่สุดของ AlertOps
- กรองและระงับการแจ้งเตือนซ้ำด้วยระบบลดสัญญาณรบกวนที่ขับเคลื่อนด้วย AI ซึ่งใช้ OpsIQ™ ในการสรุปการแจ้งเตือนและแนะนำวิธีแก้ไขโดยอัตโนมัติ
- จัดการตารางเวรตามความต้องการพร้อมกฎการยกระดับที่ยืดหยุ่น การให้บริการตามเวลาท้องถิ่นทั่วโลก และการจัดเส้นทางสายด่วนแบบเรียลไทม์สำหรับปัญหาสำคัญของลูกค้า
- อัตโนมัติการคัดแยกและการทำงานโดยใช้เทมเพลต ITแบบไม่ต้องเขียนโค้ด เพื่อเร่งการตอบสนองและรับรองว่าเหตุการณ์ต่างๆ ได้รับการจัดการอย่างสม่ำเสมอ
- ผสานการทำงานกับเครื่องมือมากกว่า 200 รายการได้ทันที รวมถึง Slack, O365, Jira, Dynatrace และ ConnectWise พร้อมรองรับการเชื่อมต่อแบบกำหนดเองสำหรับแอปพลิเคชันภายในองค์กร
ข้อจำกัดของ AlertOps
- การตั้งค่าตารางเวลาอาจดูไม่ตรงตามสัญชาตญาณในตอนแรกและอาจต้องอาศัยการลองผิดลองถูก
- UI อาจมีข้อบกพร่องเล็กน้อยในบางครั้ง โดยมีฟีเจอร์ขั้นสูงบางรายการที่ต้องใช้ขั้นตอนเพิ่มเติมในการตั้งค่า
- มีการรายงานความล่าช้าในการซิงค์ปฏิทินกับระบบภายนอก เช่น Outlook
ราคาของ AlertOps
- เริ่มต้น: ฟรี
- มาตรฐาน: $10/เดือน ต่อผู้ใช้
- พรีเมียม: $22/เดือน ต่อผู้ใช้
- องค์กรธุรกิจ: $34/เดือน ต่อผู้ใช้
AlertOps คะแนนและรีวิว
- G2: 4. 7/5 (150+ รีวิว)
- Capterra: 4. 7/5 (รีวิวมากกว่า 20 รายการ)
สิ่งที่ผู้ใช้พูดถึง AlertOps
บทวิจารณ์ G2นี้ชี้ให้เห็นอย่างชัดเจนว่า:
เราใช้เวลาส่วนใหญ่ในไตรมาสที่ 3 ของปีที่แล้วในการทดสอบเครื่องมือสำหรับตารางเวลาและการแจ้งเตือนสำหรับทีม IT หนึ่งทีมของเรา หลังจากพบ AlertOps ฉันก็หยุดมองหาทันที เพราะมันมีราคาที่เข้าถึงได้ ทีมงานของพวกเขาช่วยเหลือและอดทนอย่างมากในกระบวนการตั้งค่าและการใช้งาน และตั้งแต่ที่เราตั้งค่าทุกอย่างให้สมบูรณ์และใช้งานได้ เราก็ไม่มีปัญหาเลย!
เราใช้เวลาส่วนใหญ่ในไตรมาสที่ 3 ของปีที่แล้วในการทดสอบเครื่องมือสำหรับตารางเวลาและการแจ้งเตือนสำหรับทีม IT หนึ่งในทีมของเรา หลังจากพบ AlertOps ฉันก็หยุดมองหาเครื่องมืออื่น ๆ ไปเลย เพราะมันมีราคาที่เอื้อมถึงได้ ทีมของพวกเขามีความช่วยเหลือและอดทนอย่างมากในกระบวนการติดตั้งและนำไปใช้ และตั้งแต่เราติดตั้งและใช้งานอย่างเต็มรูปแบบแล้ว เราไม่มีปัญหาเลย!
📖 อ่านเพิ่มเติม: ตัวอย่าง SOP: แนวทางปฏิบัติที่ดีที่สุดเพื่อเพิ่มประสิทธิภาพและการปฏิบัติตามข้อกำหนด
5. Splunk On-Call (เหมาะที่สุดสำหรับการทำให้การจัดตารางเวรง่ายขึ้นและลดความเหนื่อยล้า)
หากคุณเคยดูการแสดงคลาสสิกของ Abbott และ Costello เรื่อง "Who's on First?" คุณจะเข้าใจความสับสนในการพยายามหาว่าใครเป็นคนรับผิดชอบอะไรอยู่ การหมุนเวียนเวรเรียกตัวสามารถรู้สึกเหมือนกันได้เมื่อไม่มีระบบที่ชัดเจน
นั่นคือจุดที่ Splunk On-Call เข้ามาช่วย ✨
คุณกำหนดแผนทีมและตารางเวลาเพียงครั้งเดียว จากนั้น การแจ้งเตือนจะมาถึงพร้อมบริบท บนทุกอุปกรณ์ ผู้ตอบสนองสามารถรับทราบ เปลี่ยนเส้นทาง หรือเลื่อนการแจ้งเตือนได้จากแอป iOS หรือ Android และแพลตฟอร์มยังสามารถเปิดห้องสำหรับการทำงานร่วมกันและเริ่มการทบทวนหลังเหตุการณ์โดยไม่ต้องมีขั้นตอนเพิ่มเติม
เครื่องมือจัดการกฎจะแนบคู่มือการปฏิบัติงานและแดชบอร์ดเข้ากับเหตุการณ์ เพื่อให้บุคคลแรกที่ได้รับแจ้งไม่ต้องเริ่มต้นจากศูนย์ ระบบการเรียนรู้ของเครื่องจะแนะนำผู้ตอบสนองที่เหมาะสมโดยอิงจากเหตุการณ์ที่คล้ายกัน ซึ่งช่วยลดเวลาในการรับรู้และแก้ไขปัญหา
คุณสมบัติที่ดีที่สุดของ Splunk On-Call
- ทำให้การยกระดับปัญหาและการตอบสนองต่อเหตุการณ์เป็นอัตโนมัติเพื่อรับทราบและแก้ไขปัญหาได้รวดเร็วขึ้น
- ใช้แอป iOS และ Android เพื่อรับ, ระงับ, เปลี่ยนเส้นทาง, หรือแก้ไขการแจ้งเตือนได้โดยตรงจากอุปกรณ์มือถือ
- ทำให้การจัดตารางเวลาเป็นเรื่องง่ายด้วยการหมุนเวียนงาน การแทนที่ และการกำหนดนโยบายการยกระดับที่ออกแบบมาเพื่อปรับสมดุลภาระงานอย่างยุติธรรม
- รับบริบทเหตุการณ์ที่เกิดขึ้นและเส้นทางการตรวจสอบย้อนหลังเพื่อสนับสนุนการประเมินสถานการณ์เบื้องต้นที่รวดเร็วขึ้นและการวิเคราะห์หลังเกิดเหตุ
- นำคำแนะนำจากการเรียนรู้ของเครื่องมาใช้เพื่อระบุผู้ตอบสนองที่เหมาะสมโดยอิงจากข้อมูลการแก้ไขปัญหาในอดีต
ข้อจำกัดของ Splunk On-Call
- อินเทอร์เฟซอาจดูซับซ้อนในตอนแรก และการนำทางต้องใช้เวลาปรับตัวบ้าง
- การล่าช้าเป็นครั้งคราวในช่วงที่มีการเข้าใช้งานสูงส่งผลต่อความรวดเร็วในการตอบสนองแบบเรียลไทม์
- ตัวเลือกการออกใบอนุญาตและการจัดการผู้ใช้มีจำกัดมากกว่าเมื่อเทียบกับคู่แข่งบางราย
ราคา Splunk On-Call
- ราคาตามความต้องการ
Splunk On-Call คะแนนและรีวิว
- G2: 4. 6/5 (50+ รีวิว)
- Capterra: 4. 5/5 (รีวิวมากกว่า 30 รายการ)
ผู้ใช้พูดถึง Splunk On-Call
บทวิจารณ์ G2นี้ระบุว่า:
ความสามารถในการสร้างทีมและกำหนดกะงานระหว่างทีมต่างๆ เป็นหนึ่งในทรัพยากรที่มีประโยชน์มากที่สุดบนแพลตฟอร์มนี้ Splunk On-Call มีการผสานรวมกับเครื่องมือหลายประเภทอย่างง่ายดาย ทำให้การตั้งค่าและการกำหนดค่าต่างๆ เป็นเรื่องที่สะดวกและรวดเร็ว
ความสามารถในการสร้างทีมและกำหนดกะงานระหว่างทีมต่างๆ เป็นหนึ่งในทรัพยากรที่มีประโยชน์มากที่สุดบนแพลตฟอร์มนี้ Splunk On-Call มีการผสานรวมกับเครื่องมือหลายอย่างอย่างง่ายดาย ทำให้การตั้งค่าและการกำหนดค่าต่างๆ เป็นเรื่องที่ง่ายมาก
📝อ่านเพิ่มเติม:การขจัดปัญหาการขยายตัวของ AI: วิธีที่ AI เชิงบริบทเปลี่ยนแปลงประสิทธิภาพการทำงานในที่ทำงาน
6. Datadog (เหมาะที่สุดสำหรับการสังเกตการณ์แบบครบวงจรพร้อมการตรวจสอบความปลอดภัยแบบบูรณาการ)
สำหรับผู้ใช้ Opsgenie ปัญหาคือเรื่องบริบท เมื่อมีการแจ้งเตือนเกิดขึ้น คุณยังคงต้องค้นหาบันทึกข้อมูล ร่องรอย เมตริก และสัญญาณด้านความปลอดภัยต่าง ๆ เพื่อทำความเข้าใจว่าอะไรกันแน่ที่กำลังมีปัญหาอยู่
Datadog ดึงมุมมองเหล่านั้นมารวมไว้ในไทม์ไลน์เดียว โครงสร้างพื้นฐาน, คอนเทนเนอร์, เซิร์ฟเวอร์เลส, ฐานข้อมูล, และแอปพลิเคชันจะอยู่เคียงข้างกับล็อก, เทรซ, และ RUM เพื่อให้ผู้ตอบสนองไม่ต้องเดา
ระบบเฝ้าระวังและศักยภาพ AI ใหม่ช่วยเน้นความผิดปกติ, จัดกลุ่มสัญญาณที่เกี่ยวข้อง, และสรุปผลกระทบที่อาจเกิดขึ้น ซึ่งช่วยลดการสื่อสารซ้ำซ้อนในระหว่างการคัดแยกปัญหา หากคุณมีเครื่องมือแจ้งเตือนอยู่แล้ว คุณสามารถส่งการแจ้งเตือนจาก Datadog เข้าไปในเครื่องมือนั้นได้
หากคุณต้องการทำงานภายใน Datadog ระบบการจัดการเหตุการณ์จะให้เจ้าของเหตุการณ์, ระยะเวลา, การอัปเดตสำหรับผู้มีส่วนได้ส่วนเสีย, และการติดตามผล โดยไม่ต้องออกจากแพลตฟอร์ม
ประโยชน์ในทางปฏิบัติปรากฏให้เห็นอย่างรวดเร็ว การแจ้งเตือนที่รบกวนน้อยลงเนื่องจากมีการรวมข้อมูลที่ซ้ำกัน การวิเคราะห์สาเหตุที่แท้จริงทำได้เร็วขึ้นเพราะแต่ละการแจ้งเตือนมีเมตริกและบันทึกที่อธิบายไว้อย่างชัดเจน ท่าทีด้านความปลอดภัยที่แข็งแกร่งขึ้นเพราะการตั้งค่าที่ผิดพลาดและช่องโหว่จะปรากฏขึ้นพร้อมกับข้อมูลประสิทธิภาพ
ด้วยการผสานรวมมากกว่า 900 รายการ, SLOs (เป้าหมายระดับการให้บริการ) ที่ชัดเจน และแดชบอร์ด ทีมของคุณสามารถดำเนินการตั้งแต่การตรวจพบสัญญาณไปจนถึงการแก้ไขปัญหาได้ในที่เดียวโดยไม่ต้องสลับแท็บไปมา นี่เป็นตัวเลือกที่ดีสำหรับการย้ายระบบจาก Opsgenie ที่ต้องการปิดช่องว่างด้านการสังเกตการณ์ด้วย
คุณสมบัติที่ดีที่สุดของ Datadog
- ตรวจสอบโครงสร้างพื้นฐาน, บันทึก, แอปพลิเคชัน, ฐานข้อมูล, และงานที่ไม่มีเซิร์ฟเวอร์จากแพลตฟอร์มเดียว
- สภาพแวดล้อมคลาวด์ที่ปลอดภัยพร้อมการจัดการช่องโหว่ในตัว การทำแผนที่การปฏิบัติตามข้อกำหนด และการจัดการสิทธิ์
- ใช้การตรวจสอบแบบสังเคราะห์และการตรวจสอบจากผู้ใช้จริงเพื่อตรวจจับปัญหา ก่อนที่ลูกค้าจะสังเกตเห็น
- อัตโนมัติกระบวนการทำงานด้วยการผสานรวมกว่า 900 รายการและแดชบอร์ดที่สร้างไว้ล่วงหน้า
- นำคุณสมบัติของ AI และการเรียนรู้ของเครื่อง เช่น Watchdog และ LLM Observability มาใช้เพื่อการตรวจจับความผิดปกติและการให้ข้อมูลเชิงลึกอย่างชาญฉลาด
ข้อจำกัดของ Datadog
- การกำหนดราคาสามารถปรับเพิ่มได้อย่างรวดเร็วเมื่อมีจำนวนโฮสต์สูงและมีการเพิ่มบริการเสริม
- อินเทอร์เฟซและแดชบอร์ดอาจดูซับซ้อนสำหรับผู้ใช้ใหม่
- คุณสมบัติด้านความปลอดภัยขั้นสูงบางอย่างถูกจำกัดไว้เฉพาะแผนระดับที่สูงกว่า
ราคาของ Datadog
- ฟรี
- ข้อดี: $15 ต่อเดือนต่อโฮสต์
- องค์กร: $23/เดือน ต่อโฮสต์
- DevSecOps Pro: $22/เดือน ต่อโฮสต์
- DevSecOps สำหรับองค์กร: $34/เดือน ต่อโฮสต์
คะแนนและรีวิวของ Datadog
- G2: 4. 4/5 (660+ รีวิว)
- Capterra: 4. 6/5 (รีวิว 320+ รายการ)
ผู้ใช้พูดถึง Datadog
โดยรวมแล้ว หลังจากผ่านขึ้นบ้างลงบ้าง พวกเขาก็เป็นคู่ค้าที่ดี เครื่องมือของพวกเขามีพลังมาก และสามารถช่วยให้เกิดการปฏิบัติที่ยอดเยี่ยมเกี่ยวกับการสังเกตได้ แต่คุณต้องจ่ายเงินเพื่อใช้มัน
โดยรวมแล้ว หลังจากผ่านขึ้นลงบ้าง พวกเขาก็เป็นคู่ค้าที่ดี เครื่องมือของพวกเขามีพลังมาก และสามารถช่วยให้เกิดการปฏิบัติที่ยอดเยี่ยมเกี่ยวกับการสังเกตได้ แต่คุณต้องจ่ายเงินเพื่อใช้มัน
📖 อ่านเพิ่มเติม: วิธีลดความเสี่ยงด้านความปลอดภัยทางไซเบอร์ในการบริหารโครงการ
7. Squadcast (เหมาะที่สุดสำหรับการรวมการตอบสนองต่อการเรียกและเหตุการณ์เข้าด้วยกัน พร้อมคุณค่าที่แข็งแกร่ง)
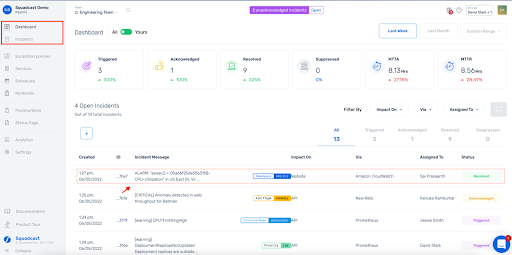
เมื่อคุณต้องจัดการกับตารางงานหลายชุดและกฎเฉพาะของลูกค้าหลังเวลาทำการ คุณต้องการการแจ้งเตือนที่เคารพกฎเหล่านั้นโดยไม่ต้องคอยดูแล
นั่นคือช่องว่างที่ Squadcast ได้รับความไว้วางใจ 🌟
ผู้ใช้ได้สังเกตเห็นว่าตารางเวรและการยกเว้นสามารถสร้างแบบจำลองได้ง่าย และแอปพลิเคชันมือถือจะยังคงส่งต่อหากผู้ตอบสนองคนแรกไม่ตอบ ดังนั้นปัญหาที่สำคัญจะไม่ถูกมองข้าม
สำหรับ MSP และทีมที่มีลูกค้าจำนวนมาก คุณสามารถตั้งค่าการให้บริการตลอด 24 ชั่วโมงทุกวันสำหรับลูกค้าบางราย ในขณะที่ลูกค้าอื่น ๆ จะได้รับการแจ้งเตือนนอกเวลาทำการเฉพาะในกรณีฉุกเฉินเท่านั้น ส่วนติดต่อผู้ใช้ (UI) ช่วยให้คุณมองเห็นเหตุการณ์ที่กำลังเกิดขึ้นและผู้ที่รับผิดชอบได้อย่างง่ายดาย
มีมากกว่าการสลับหน้าเพจอยู่เบื้องหลัง ระบบอัตโนมัติด้านความน่าเชื่อถือจะขับเคลื่อนเหตุการณ์ต่าง ๆ ผ่านขั้นตอนการทำงานที่สม่ำเสมอด้วยรันบุ๊คและการอัปเดตสถานะ การติดตาม SLO และไทม์ไลน์ที่แสดงรูปแบบปัญหาซึ่งคุณสามารถดำเนินการได้จริง อีกทั้งการกำหนดราคายังโปร่งใสเพียงพอที่ทีมขนาดเล็กจะไม่รู้สึกว่าถูกกีดกัน
คุณสมบัติที่ดีที่สุดของ Squadcast
- ระบบอัตโนมัติสำหรับการจัดตารางเวรเฝ้าระวัง พร้อมการยกระดับและการยกเลิกคำสั่งที่ยืดหยุ่น
- ลดความเหนื่อยล้าจากการแจ้งเตือนโดยการรวมและกำจัดข้อมูลแจ้งเตือนที่ซ้ำซ้อน
- แก้ไขปัญหาได้รวดเร็วขึ้นด้วยรันบุ๊คและเวิร์กโฟลว์
- ให้ผู้มีส่วนได้ส่วนเสียทราบข้อมูลผ่านหน้าสถานะที่สามารถปรับแต่งได้
- บันทึกการวิเคราะห์หลังเหตุการณ์และข้อมูลเชิงลึกเพื่อสร้างวัฒนธรรมการเรียนรู้
ข้อจำกัดของ Squadcast
- มุมมองตารางเวลาอาจดูแออัดเมื่อมีตารางการทำงานหลายรายการเปิดใช้งานอยู่ ซึ่งทำให้ยากต่อการตรวจสอบว่าใครกำลังอยู่ในสถานะพร้อมปฏิบัติงานได้อย่างรวดเร็ว
- มีการรายงานว่าอาจเกิดความล่าช้าเป็นครั้งคราวในการซิงค์การแจ้งเตือนจากการเชื่อมต่อบางรายการ
- แผนฟรีมีข้อจำกัดสำหรับทีมที่ต้องการหน้าสถานะและการวิเคราะห์เชิงลึก
ราคา Squadcast
- ข้อดี: $12/เดือน ต่อผู้ใช้
- พรีเมียม: $19/เดือน ต่อผู้ใช้
- องค์กร: ราคาตามความต้องการ
คะแนนและรีวิว Squadcast
- G2: 4. 4/5 (รีวิวมากกว่า 300+)
- Capterra: ไม่มีการรีวิวเพียงพอ
ผู้ใช้พูดถึง Squadcast ว่าอย่างไร
บทวิจารณ์ G2นี้กล่าวว่า:
Squadcast สามารถรับข้อมูลจากเครื่องมือติดตามหลากหลายประเภทที่เรามีอยู่ และยังสามารถตั้งค่าตารางเวรและสิทธิ์การยกเลิกการแจ้งเตือนสำหรับผู้ที่จะได้รับการแจ้งเตือนสำหรับปัญหาแต่ละประเภทได้อย่างง่ายดาย
Squadcast สามารถรับข้อมูลจากเครื่องมือตรวจสอบต่าง ๆ ที่เรามีได้อย่างง่ายดาย และสามารถตั้งค่าตารางเวรและสิทธิ์การ override สำหรับผู้ที่ควรได้รับการแจ้งเตือนสำหรับปัญหาแต่ละประเภทได้อย่างสะดวก
📖 อ่านเพิ่มเติม: การจัดการความเสี่ยงด้านความปลอดภัยทางไซเบอร์
8. FireHydrant (เหมาะที่สุดสำหรับการทำงานอัตโนมัติของ runbooks และการเป็นเจ้าของบริการ)
ซอฟต์แวร์การจัดการเหตุการณ์นี้มอบกระบวนการที่มีโครงสร้างดีซึ่งช่วยให้บริการดำเนินไปอย่างราบรื่น
FireHydrant ให้การตอบสนองโดยใช้รันบุ๊ค, แคตตาล็อกบริการ, และพื้นที่ทำงานร่วมกัน. ประกาศเหตุการณ์ และแพลตฟอร์มจะสร้างช่องทางใน Slack หรือ Teams, แนบรันบุ๊คที่เหมาะสม, ดึงการเป็นเจ้าของจากแคตตาล็อกบริการ, และเริ่มไทม์ไลน์ที่สามารถตรวจสอบได้.
ในขณะเดียวกัน ระบบ AI ของมันช่วยลดค่าใช้จ่ายโดยสรุปเหตุการณ์ที่เกิดขึ้นทันที แนะนำการอัปเดตสำหรับผู้มีส่วนได้ส่วนเสีย และบันทึกการประชุมแบบเรียลไทม์ เพื่อให้ทีมสามารถมุ่งเน้นไปที่การแก้ไขปัญหาแทนการจดบันทึก
ทีมยังเน้นย้ำถึงการสนับสนุนที่ตอบสนองอย่างรวดเร็วและแนวทางที่ให้ความสำคัญกับ API เป็นอันดับแรกด้วย Terraform ซึ่งช่วยให้ผู้นำฝ่ายปฏิบัติการสามารถเชื่อมต่อ FireHydrant เข้ากับกระบวนการทำงานที่มีอยู่เดิมได้อย่างราบรื่นไร้รอยต่อ
คุณสมบัติเด่นของ FireHydrant
- ทำให้การตอบสนองต่อเหตุการณ์เป็นอัตโนมัติด้วยคู่มือปฏิบัติการที่รวบรวมแนวปฏิบัติที่ดีที่สุด
- จัดการตารางเวรและแจ้งเตือนด้วย Signals พร้อมด้วยนโยบายการยกระดับปัญหา
- รวมศูนย์ความเป็นเจ้าของผ่านแคตตาล็อกบริการเพื่อให้วิศวกรที่เหมาะสมตอบสนองทันที
- ทำงานร่วมกันโดยตรงใน Slack หรือ Teams ด้วยช่องและการอัปเดตที่สร้างขึ้นโดยอัตโนมัติ
- ใช้การทบทวนย้อนหลังและการวิเคราะห์ที่เสริมด้วย AI เพื่อรวบรวมข้อมูลเชิงลึกและเพิ่มความน่าเชื่อถืออย่างต่อเนื่อง
ข้อจำกัดของ FireHydrant
- คุณสมบัติการอัตโนมัติขั้นสูงต้องการแผนระดับสูงกว่า
- เส้นทางการเรียนรู้สำหรับการตั้งค่าเวิร์กโฟลว์และการผสานรวมที่กำหนดเอง
- ผู้ตอบแบบจำกัดและคู่มือการดำเนินการในแผนระดับเริ่มต้น
ราคาของ FireHydrant
- ฟรี: ทดลองใช้สองสัปดาห์
- แพลตฟอร์มโปร: $9,600/ปี ต่อผู้ใช้
- องค์กร: ราคาตามตกลง
การให้คะแนนและรีวิว FireHydrant
- G2: 4. 5/5 (รีวิวมากกว่า 130 รายการ)
- Capterra: ไม่มีการรีวิวเพียงพอ
สิ่งที่ผู้ใช้พูดถึง FireHydrant
ผู้ใช้ G2คนนี้บันทึกไว้:
ทำงานอย่างเต็มรูปแบบผ่าน Slack หรือเครื่องมือแชท/การทำงานร่วมกันอื่น ๆ FireHydrant สามารถผสานการทำงานและให้คุณเปิด/อัปเดต/แก้ไขเหตุการณ์ได้โดยไม่ต้องออกจากที่ที่คุณกำลังดำเนินการตอบสนองต่อเหตุการณ์นั้นอยู่
ทำงานอย่างเต็มรูปแบบผ่าน Slack หรือเครื่องมือแชท/การทำงานร่วมกันอื่น ๆ FireHydrant สามารถผสานการทำงานและให้คุณเปิด/อัปเดต/แก้ไขเหตุการณ์ได้โดยไม่ต้องออกจากที่ที่คุณกำลังดำเนินการตอบสนองต่อเหตุการณ์นั้นอยู่
9. TaskCall (เหมาะที่สุดสำหรับการจัดการเหตุการณ์ที่มีราคาไม่แพงพร้อมระบบอัตโนมัติ)
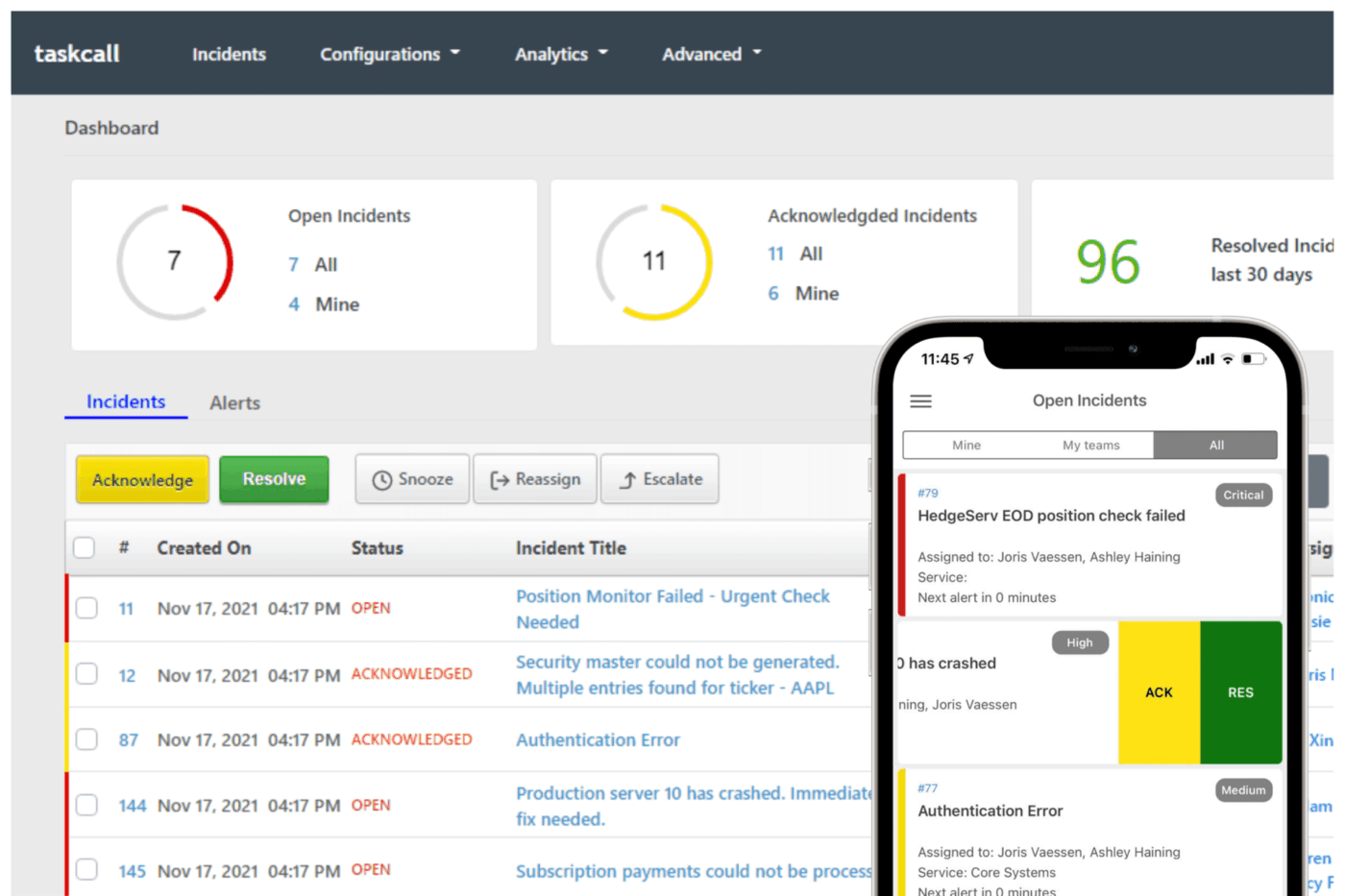
ในการศึกษาความเสี่ยงทางไซเบอร์ล่าสุด การตอบสนองต่อเหตุการณ์ถูกระบุว่าเป็นหนึ่งในมาตรการควบคุมหลักที่องค์กรต้องเสริมสร้างเพื่อลดความเสี่ยง
นั่นเน้นย้ำให้เห็นถึงความสำคัญอย่างยิ่งของกระบวนการทำงานที่รวดเร็วและเชื่อถือได้ในการจัดการเหตุการณ์
ทีมมักจะสะดุดไม่ใช่ที่การแจ้งเตือนเอง แต่เป็นการวุ่นวายที่ตามมา ใครคือคนที่รับผิดชอบในขณะนี้? การแจ้งเตือนนี้เกี่ยวข้องกับแอป โครงสร้างพื้นฐาน หรือการดำเนินงานของลูกค้า? คุณจะแจ้งให้ผู้นำทราบได้อย่างไรโดยไม่ขัดขวางการแก้ไขปัญหา?
TaskCall จัดการกับช่วงเวลาเหล่านั้นโดยตรง การเรียกเข้าเวรจะถูกกำหนดจากเนื้อหาของเหตุการณ์ ทำให้การส่งต่อถึงผู้ตอบสนองที่เหมาะสมโดยอัตโนมัติ และการยกระดับอัตโนมัติจะครอบคลุมช่องว่าง การแจ้งเตือนจะส่งถึงผู้ใช้ทางโทรศัพท์, SMS, การแจ้งเตือนแบบพุช, อีเมล หรือแชท
เพื่อลดเสียงรบกวน ข้อมูลเชิงลึกของเหตุการณ์จะเชื่อมโยงข้อมูลซ้ำกันและระงับการแจ้งเตือนที่มีคุณค่าต่ำ บริบทจะถูกเชื่อมโยงเข้าด้วยกันโดยการดึงสัญญาณจากเครื่องมือต่างๆ เช่น AWS, Datadog, Slack, Jira และ Zendesk ซึ่งหมายความว่าวิศวกรจะเห็นผลกระทบและความรับผิดชอบแทนที่จะเป็นเพียงกระแสการแจ้งเตือนดิบๆ
คุณสมบัติเด่นของ TaskCall
- ระบบอัตโนมัติสำหรับการจัดตารางเวรเฝ้าระบบด้วยการหมุนเวียนแบบไดนามิกและการส่งต่อหลายระดับ
- ลดเสียงรบกวนด้วยข้อมูลเชิงลึกจากเหตุการณ์ที่ขับเคลื่อนด้วย AI และการกำหนดเส้นทางแบบมีเงื่อนไข
- จัดการเหตุการณ์ต่างๆ ใน DevOps, IT-Ops และ BizOps ในแพลตฟอร์มเดียวที่รวมศูนย์
- ผสานรวมกับเครื่องมือการตรวจสอบ, การบันทึก, และการสนับสนุน เช่น AWS, Jira, Zendesk, และ Slack
- ให้บริการครอบคลุมอย่างเต็มที่ผ่านแอปพลิเคชันมือถือ, การแจ้งเตือนแบบพุช, SMS, และการแจ้งเตือนทางเสียง
ข้อจำกัดของ TaskCall
- แผนฟรีจำกัดผู้ใช้สูงสุดห้าคน ซึ่งอาจไม่รองรับการขยายทีมในอนาคต
- การวิเคราะห์และแดชบอร์ดส่วนใหญ่ถูกจำกัดไว้เฉพาะแผนที่มีราคาสูงกว่า
ราคาของ TaskCall
- ฟรี
- เริ่มต้น: $9/เดือน ต่อผู้ใช้
- ธุรกิจ: $19/เดือน ต่อผู้ใช้
- การดำเนินงานดิจิทัล: $29/เดือน ต่อผู้ใช้
คะแนนและรีวิวของ TaskCall
- G2: ไม่มีการรีวิวเพียงพอ
- Capterra: ไม่มีการรีวิวเพียงพอ
10. ilert (เหมาะที่สุดสำหรับการจัดการเหตุการณ์ที่เน้น AI เป็นอันดับแรกพร้อมการปกป้องความเป็นส่วนตัว)
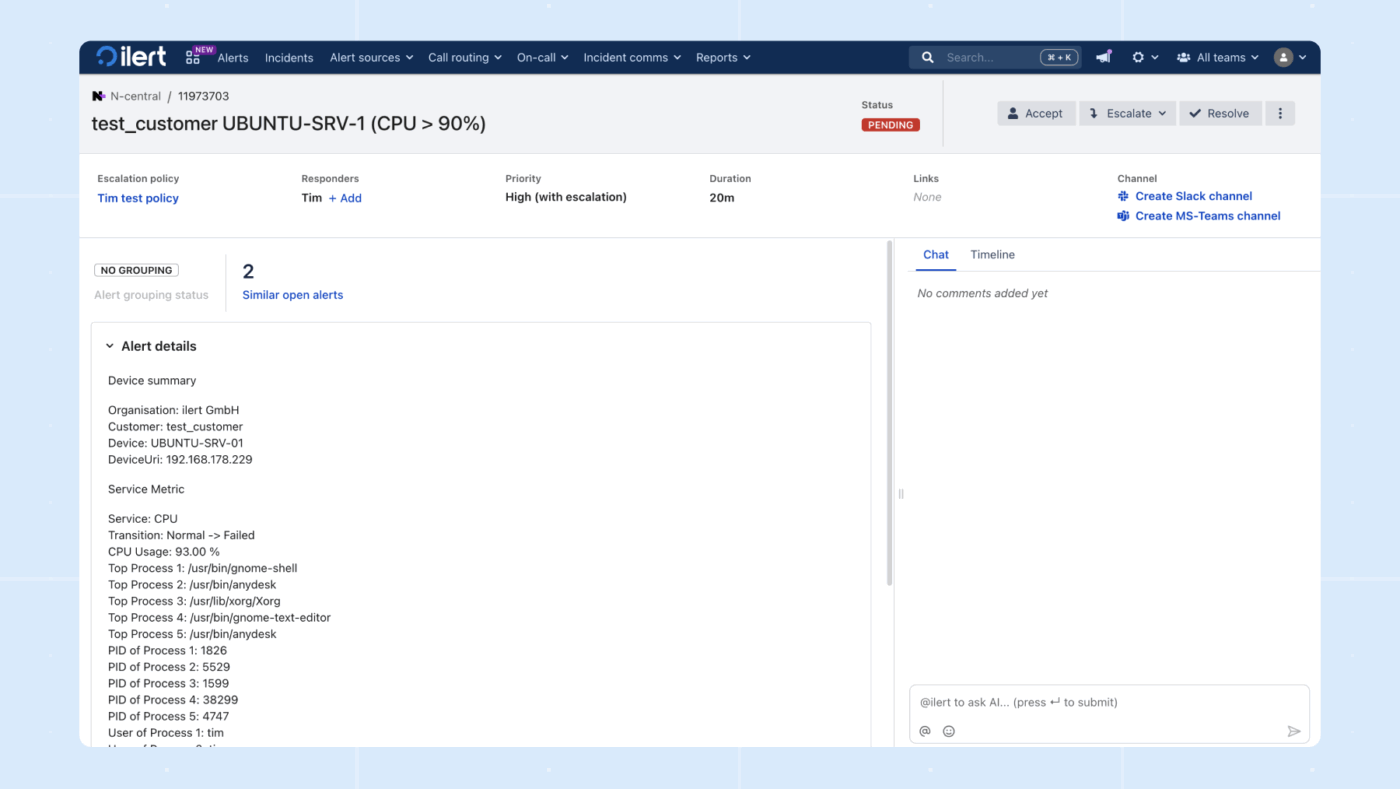
ilert เป็นแพลตฟอร์มการจัดการการเรียกใช้งานและการแจ้งเตือนเหตุการณ์ที่เน้นความน่าเชื่อถือและความเป็นส่วนตัวของข้อมูลเป็นอย่างมาก ช่วยให้ทีมมั่นใจได้ว่าการแจ้งเตือนที่สำคัญจากระบบตรวจสอบจะถึงวิศวกรที่รับผิดชอบในเวลาที่เหมาะสม
แพลตฟอร์มนี้มีการจัดตารางการทำงานแบบยืดหยุ่นตามความต้องการ นโยบายการส่งต่อปัญหาหลายระดับ และการแจ้งเตือนผ่านช่องทางหลากหลาย รวมถึงการแจ้งเตือนแบบพุช SMS และการโทรเสียง
การจัดเส้นทางที่เคารพตารางเวลาปัจจุบันและเส้นทางการส่งต่อที่เหมาะสม หมายถึงการโทรจากลูกค้าจะถึงบุคคลที่ถูกต้องแทนที่จะถูกส่งต่อไปมาในระบบโทรศัพท์
ใน Slack หรือ Teams ผู้ตอบสนองจะทำงานเกี่ยวกับเหตุการณ์ในแชทในขณะที่ Ilert บันทึกบริบท ระยะเวลา และติดตามผล
ตัวแทนเสียง AI ตอบรับสายด่วนของคุณ รวบรวมข้อมูลที่ถูกต้อง และแจ้งวิศวกรที่อยู่ในเวรทันที ผู้ตอบสนองวิเคราะห์เมตริก บันทึก และการเปลี่ยนแปลงล่าสุดทั่วทั้งระบบของคุณ แสดงสาเหตุที่เป็นไปได้ แจ้งเตือนบุคคลที่ควรดึงเข้ามา และแม้กระทั่งเสนอเส้นทางย้อนกลับเพื่อการแก้ไขที่รวดเร็วขึ้น
คุณยังคงควบคุมได้ในทุกขั้นตอน
คุณสมบัติที่ดีที่สุดของ ilert
- แจ้งเตือนหลายช่องทางที่เชื่อถือได้ผ่านเสียง, SMS, การแจ้งเตือนแบบพุช, และแชท
- อัตโนมัติการจัดการการเฝ้าระวังด้วยการจัดตารางเวลาและเส้นทางการส่งต่อ
- ส่งมอบการอัปเดตอย่างรวดเร็วผ่านหน้าสถานะที่ขับเคลื่อนด้วย AI และการสื่อสารกับผู้มีส่วนได้ส่วนเสีย
- ใช้ ilert Responder AI เพื่อวิเคราะห์เหตุการณ์ เปิดเผยสาเหตุที่แท้จริง และแนะนำการดำเนินการ
- ผสานการทำงานกับเครื่องมือการตรวจสอบและ ITSM เช่น Prometheus, Datadog, Jira และ Slack
ข้อจำกัดการแจ้งเตือน
- ราคาอาจดูสูงสำหรับทีมขนาดเล็ก
- การผสานรวมบางอย่างต้องใช้ความพยายามในการตั้งค่าเพิ่มเติม
- แอปพลิเคชันมือถืออาจได้รับประโยชน์จากคุณสมบัติที่ทันสมัยมากขึ้น
แจ้งเตือนราคา
- ฟรี
- ข้อดี: $24 ต่อเดือนต่อผู้ใช้
- ขนาด: $49/เดือน ต่อผู้ใช้
- องค์กร: ราคาตามตกลง
การแจ้งเตือนและรีวิว
- G2: ไม่มีการรีวิวเพียงพอ
- Capterra: 4. 7/5 (รีวิวมากกว่า 60 รายการ)
ผู้ใช้พูดถึง ilert
ฉันพบว่าเครื่องมือนี้ใช้งานง่ายและมีประสิทธิภาพมากสำหรับการจัดการกะสแตนด์บายภายในทีมไอที มันให้ความยืดหยุ่นโดยอนุญาตให้ตอบกลับได้โดยตรงผ่านแอป, SMS หรือการโทรศัพท์ ซึ่งทำให้มันใช้งานได้จริงในสถานการณ์จริง
ฉันพบว่าเครื่องมือนี้ใช้งานง่ายและมีประสิทธิภาพมากสำหรับการจัดการกะสแตนด์บายภายในทีมไอที มันให้ความยืดหยุ่นโดยอนุญาตให้ตอบกลับได้โดยตรงผ่านแอป, SMS หรือการโทรศัพท์ ซึ่งทำให้มันใช้งานได้จริงในสถานการณ์จริง
11. Zenduty (ดีที่สุดสำหรับการตอบสนองต่อเหตุการณ์ที่ขับเคลื่อนด้วย AI ในระดับใหญ่)
Zenduty ช่วยให้ทีมวิศวกรรมและ DevOps มุ่งเน้นไปที่สัญญาณที่สำคัญ ลด MTTR (เวลาเฉลี่ยในการแก้ไขปัญหา) และมอบแพลตฟอร์มเดียวที่เชื่อถือได้ให้กับองค์กรในการจัดการเหตุการณ์ต่างๆ
ผู้ใช้ต่างชื่นชมการแจ้งเตือนที่รวดเร็วและเชื่อถือได้อย่างต่อเนื่อง โดยมีการแจ้งเตือนแบบพุช, โทรศัพท์, และ SMS มาถึงโดยไม่มีสะดุด ทำให้วิศวกรที่อยู่ในระบบสามารถรับทราบการแจ้งเตือนได้จากการแจ้งเตือนและกลับไปทำงานต่อได้ ทีมยังชอบที่สามารถปรับแต่งการแจ้งเตือนตามความรุนแรง, บริการ, หรือประเภทของเหตุการณ์ได้ ทำให้บุคคลที่เหมาะสมได้รับการติดต่อในเวลาที่เหมาะสมแทนที่จะติดต่อทุกคนพร้อมกัน
แพลตฟอร์มนี้รองรับการตอบสนองต่อเหตุการณ์ร่วมกัน โดยมีบทบาทของเหตุการณ์, แม่แบบงาน, และช่องทางการสื่อสารที่ผสานรวมไว้ด้วยกัน คุณสมบัติที่สำคัญคือแนวทางที่อิงตามระบบบัญชาการเหตุการณ์ (ICS) ซึ่งให้กรอบโครงสร้างที่เป็นระบบสำหรับการจัดการเหตุการณ์ขนาดใหญ่
หากคุณกำลังมองหาการย้ายจาก Opsgenie, Zenduty เป็นตัวเลือกที่ดี ด้วยการสนับสนุนการย้ายข้อมูลที่ได้รับรีวิวเชิงบวก
คุณสมบัติที่ดีที่สุดของ Zenduty
- ให้บริการการจัดการเหตุการณ์ด้วยระบบ AI ผ่าน ZenAI
- สนับสนุนการจัดตารางเวรเรียกตัวขั้นสูงด้วยการหมุนเวียนและการยกระดับการแจ้งเตือนที่ปรับแต่งได้
- ทำให้คู่มือการจัดการเหตุการณ์เป็นอัตโนมัติเพื่อให้งานและการติดตามผลถูกติดตามอย่างสม่ำเสมอ
- ผสานการทำงานอย่างไร้รอยต่อกับเครื่องมือมากกว่า 150 รายการ เช่น Slack, Teams, Jira, Datadog และ Grafana
- ส่งการแจ้งเตือนบนมือถือแบบเรียลไทม์บน iOS, Android และแม้แต่สมาร์ทวอทช์
ข้อจำกัดของ Zenduty
- ฟังก์ชันการค้นหาสามารถรวมเหตุการณ์หลายเหตุการณ์เข้าด้วยกัน ทำให้การติดตามยากขึ้น
- คุณสมบัติขั้นสูงบางอย่างถูกจำกัดไว้สำหรับแผนระดับที่สูงกว่า
- การแจ้งเตือนซ้อนทับกันในการตั้งค่าที่ซับซ้อนอาจทำให้เกิดการแจ้งเตือนซ้ำ
ราคาของ Zenduty
- ฟรี
- เริ่มต้น: $6/เดือน ต่อผู้ใช้
- การเติบโต: $16/เดือน ต่อผู้ใช้
- องค์กรธุรกิจ: $25/เดือน ต่อผู้ใช้
คะแนนและรีวิวของ Zenduty
- G2: 4. 6/5 (135+ รีวิว)
- Capterra: ไม่มีการรีวิวเพียงพอ
สิ่งที่ผู้ใช้พูดถึง Zenduty
บทวิจารณ์ G2นี้ระบุว่า:
สิ่งที่ฉันชอบมากที่สุดเกี่ยวกับ Zenduty คือการให้ข้อมูลเชิงลึกที่ขับเคลื่อนด้วยการวิเคราะห์ข้อมูลเชิงลึก ด้วยการวิเคราะห์เหตุการณ์ต่าง ๆ เราสามารถติดตามแนวโน้มได้ – เช่น วันใด บริการใด หรือกะใดที่มีปัญหาเกิดขึ้นมากกว่ากัน ระบุสิ่งที่ผิดพลาด และกำหนดพื้นที่ที่ต้องปรับปรุง
สิ่งที่ฉันชอบมากที่สุดเกี่ยวกับ Zenduty คือการให้ข้อมูลเชิงลึกที่ขับเคลื่อนด้วยการวิเคราะห์ข้อมูลเชิงลึก ด้วยการวิเคราะห์เหตุการณ์ต่าง ๆ เราสามารถติดตามแนวโน้มได้ – เช่น วัน, บริการ, หรือกะที่มีปัญหาเกิดขึ้นมากกว่า, ระบุสิ่งที่ผิดพลาด, และกำหนดพื้นที่ที่ต้องปรับปรุง
📖 อ่านเพิ่มเติม: ซอฟต์แวร์การจัดการปฏิบัติการด้านไอทีที่ดีที่สุด
12. Incident.io (เหมาะที่สุดสำหรับการตอบสนองต่อเหตุการณ์บน Slack โดยตรง)
สมมติว่าเรากำลังอยู่ในเหตุการณ์ฉุกเฉินกันสักครู่ เครื่องเพจเจอร์ดังขึ้น ทุกคนตื่นตัว ใน Opsgenie คุณต้องรับทราบเหตุการณ์ จากนั้นค้นหาห้องที่เหมาะสม แล้วคัดลอกบริบทไปยังอีกที่หนึ่งเพื่อให้ทุกคนเห็นว่ามีอะไรเกิดขึ้น
จังหวะนั้นคือช่วงเวลาที่ทีมส่วนใหญ่ต้องการแก้ไข นี่คือจุดที่ incident. io แตกต่างออกไป
คุณสามารถประกาศได้โดยตรงใน Slack และพื้นที่ที่สะอาดจะปรากฏขึ้นพร้อมกับบทบาท, ไทม์ไลน์, และขั้นตอนต่อไปสองหรือสามขั้นตอนที่ได้จัดเตรียมไว้แล้ว คุณสามารถโทร, ส่งข้อความ, ส่งอีเมล, หรือเพียงแค่แตะเพื่อรับทราบได้ งานจะเริ่มต้นทันที และยังคงมองเห็นได้
ผู้ใช้ยังคงอธิบายจังหวะเดิมซ้ำ ๆ เมื่อพวกเขาเปลี่ยนมาใช้ ระบบจะเปิดช่องทางขึ้นมาโดยมีเพียงสัญญาณที่คุณต้องการเท่านั้น แอปจะส่งการติดตามผลและร่างสรุปที่ชัดเจนในขณะที่คุณยังคงแก้ไขปัญหาอยู่ การอัปเดตสถานะสำหรับลูกค้าพร้อมส่งได้ทันทีโดยไม่ต้องออกจากหัวข้อสนทนา เพียงเท่านี้ก็ช่วยลดการพูดคุยที่มักวนเวียนอยู่ในห้องแชทและข้อความส่วนตัวอื่น ๆ ได้อย่างมาก
การนำไปใช้ของทีมที่มีขนาดแตกต่างกันมากเป็นเรื่องง่าย กลุ่มเล็ก ๆ พูดถึงการเชื่อมต่อกับ Linear และ New Relic ภายในสองสามสัปดาห์และได้รับคุณค่าจริงตั้งแต่วันแรก องค์กรขนาดใหญ่แบ่งปันว่าพวกเขาได้ขยายการใช้งานไปยังหลายทีมภายในประมาณหนึ่งเดือนและไม่ได้หยุดงานในแผนงานเพื่อทำสิ่งนี้
Incident. io คุณสมบัติที่ดีที่สุด
- ดำเนินการแก้ไขเหตุการณ์ตั้งแต่ต้นจนจบโดยตรงใน Slack หรือ Microsoft Teams
- ใช้ AI SRE เพื่อแนะนำการแก้ไขปัญหา, ตรวจสอบปัญหา, และร่างการสื่อสาร
- จัดการตารางเวรเฝ้าระวังด้วยระบบลดเสียงรบกวนที่ขับเคลื่อนด้วย AI
- ระบบอัตโนมัติการอัปเดตหน้าสถานะสำหรับลูกค้าและผู้มีส่วนได้ส่วนเสีย
- รับข้อมูลเชิงลึกเกี่ยวกับแนวโน้ม ระยะเวลา และตัวชี้วัด MTTx ด้วยแดชบอร์ด
ข้อจำกัดของ incident. io
- อินเทอร์เฟซอาจรู้สึกแออัดด้วยหลายการแจ้งเตือนจาก Slack
- การกำหนดค่าขั้นสูง (เช่น เส้นทางการส่งต่อ) อาจต้องมีการปรับแต่งอย่างละเอียด
- ฟีเจอร์ AI บางอย่างรองรับเฉพาะภาษาอังกฤษเท่านั้น
ราคาของ incident. io
- พื้นฐาน: ฟรี
- ทีม: $19/เดือน ต่อผู้ใช้
- ข้อดี: $25/เดือน ต่อผู้ใช้
- องค์กร: ราคาตามตกลง
การให้คะแนนและรีวิวของ incident.io
- G2: 4. 8/5 (180+ รีวิว)
- Capterra: ไม่มีการรีวิวเพียงพอ
ผู้ใช้พูดถึง Incident.io ว่าอย่างไร
บทวิจารณ์ G2นี้แบ่งปันว่า:
สำหรับผม incident.io มีความสมดุลที่ลงตัวระหว่างไม่รบกวนการทำงานในขณะที่ยังคงให้โครงสร้าง กระบวนการ และการรวบรวมข้อมูลที่จำเป็นสำหรับการจัดการเหตุการณ์ได้อย่างครบถ้วน
สำหรับฉัน incident.io สร้างสมดุลได้อย่างลงตัวระหว่างไม่รบกวนการทำงาน ในขณะที่ยังคงให้โครงสร้าง กระบวนการ และการรวบรวมข้อมูลที่จำเป็นสำหรับการจัดการเหตุการณ์
💡เคล็ดลับมืออาชีพ:ใช้ตัวแทนที่สร้างไว้ล่วงหน้าเพื่อตอบคำถามของทีมหรือแชร์การอัปเดต หรือกำหนดค่าตัวแทน AI ของ ClickUpที่กำหนดเองเพื่อตรวจสอบสถานะงานและวันที่ครบกำหนด ส่งการแจ้งเตือน ยกระดับปัญหา หรืออัปเดตสถานะตามความจำเป็น เพื่อขับเคลื่อนงานให้ดำเนินไป
วิดีโอนี้จะแสดงให้คุณเห็นวิธี:
สิ่งที่คาดหวังระหว่างและหลังการย้ายข้อมูลจาก Opsgenie
การย้ายออกจาก Opsgenie อาจรู้สึกเหมือนกับการเก็บข้าวของออกจากบ้านที่คุณอาศัยอยู่มาหลายปี ทุกตารางเวลา กฎการยกระดับปัญหา และการเชื่อมต่อต่าง ๆ ล้วนมีที่ของมัน และการคิดถึงการย้ายทุกอย่างไปยังบ้านใหม่ก็อาจดูเป็นเรื่องที่น่าหวั่นใจ
Atlassian มีเครื่องมือการย้ายข้อมูลในแอปสำหรับการย้ายไปยัง Jira Service Management หรือ Compass กระบวนการนี้มีการจัดโครงสร้างที่ชัดเจน สามารถคาดการณ์ได้ และออกแบบมาเพื่อลดการหยุดชะงักให้น้อยที่สุด
หากคุณตัดสินใจเลือกหนึ่งในสองตัวเลือกนี้ คุณสามารถตรวจสอบแผนของคุณ ตั้งวันที่จะย้ายข้อมูล และให้เครื่องมือทำงานหนักแทนคุณได้เลย มาดูกันว่ามันทำงานอย่างไร และประเมินว่านี่เป็นตัวเลือกที่ดีสำหรับองค์กรของคุณหรือไม่
การไหลของการย้ายถิ่นในภาพรวม
ขั้นตอนที่ 1 → ทบทวนและเลือกเส้นทางของคุณ
ประเมินแผน Opsgenie ของคุณและตัดสินใจว่า Jira Service Management (เน้นด้าน ITSM) หรือ Compass (เน้นด้านนักพัฒนา) เหมาะสมกับความต้องการของคุณ
ขั้นตอนที่ 2 → กำหนดวันย้ายข้อมูลของคุณ
เลือกช่วงเวลาที่เหมาะสมกับรอบการเรียกเก็บเงินและความพร้อมของทีมคุณ
ขั้นตอนที่ 3 → อนุมัติการเรียกเก็บเงิน
ผู้ดูแลระบบเรียกเก็บเงินของ Atlassian ของคุณยืนยันแผนเพื่อให้สามารถจัดเตรียมผลิตภัณฑ์ใหม่ได้
ขั้นตอนที่ 4 → การย้ายข้อมูลในเบื้องหลัง
ข้อมูลของ Opsgenie จะเริ่มซิงค์ในขณะที่ทีมของคุณยังคงทำงานตามปกติ
ขั้นตอนที่ 5 → การเปลี่ยนผ่านและการปิดระบบ
คุณมีเวลา 120 วันในการดำเนินการย้ายให้เสร็จสมบูรณ์ก่อนที่ Opsgenie จะถูกปิดใช้งาน
โดยสรุป นี่คือสิ่งที่คุณคาดหวังได้:
- ใช้เครื่องมือการย้ายข้อมูลแบบมีคำแนะนำเพื่อทำให้งานหนักเป็นอัตโนมัติ
- รักษาการเข้าถึง Opsgenie อย่างเต็มที่ในระหว่างและหลังการย้ายข้อมูลจนกว่าจะปิดระบบ
- ทำตามคู่มือการย้ายข้อมูลที่ปรับให้เหมาะกับคุณใน Jira Service Management หรือ Compass
- ปรับกระบวนการทำงานและกำหนดค่าใหม่ในช่วงระยะเวลาเปลี่ยนผ่าน 120 วัน
- รับประกันความต่อเนื่องของการแจ้งเตือน, ตารางเวลา, และการผสานรวมโดยไม่มีการขัดจังหวะ
ข้อดีและข้อเสียของการย้ายจาก Opsgenie ไปยัง Jira Service Management
ข้อดี:
- สามารถสร้างกระบวนการทำงานที่ราบรื่นและเป็นหนึ่งเดียว
- สำหรับทีมที่ได้ลงทุนในระบบนิเวศของ Atlassian ไปมากแล้ว การตัดสินใจนี้อาจเป็นทางเลือกที่สะดวกและคุ้มค่า
- การวิเคราะห์หลังเหตุการณ์ที่มีประสิทธิภาพของ Jira ช่วยให้กระบวนการติดตามการดำเนินการตามมีความง่ายขึ้น
- การรวบรวมข้อมูลเหตุการณ์ไว้ใน JSM ช่วยให้สามารถรายงานได้ทรงพลังและครอบคลุมมากขึ้น
ข้อเสีย:
- ฟังก์ชันขั้นสูงบางอย่างของ Opsgenie แบบสแตนด์อโลนอาจไม่สามารถใช้งานได้ทันทีใน JSM
- การย้ายเข้าสู่สภาพแวดล้อม JSM ที่กว้างขึ้นอาจเพิ่มความซับซ้อนและเสียงรบกวน
- ทีมจะต้องได้รับการฝึกอบรมใหม่เกี่ยวกับอินเทอร์เฟซใหม่และกระบวนการทำงานภายใน JSM
นี่คือความคิดเห็นจากผู้ใช้ Reddit เกี่ยวกับเรื่องนี้
ผู้ใช้ Redditคนนี้รู้สึกว่าโดยรวมแล้วการย้ายครั้งนี้ได้ผลสำหรับพวกเขา:
มันไม่ได้แย่เกินไปสำหรับเรา ฉันต้องดูเรื่องการตั้งค่าบทบาทและสิทธิ์อีกครั้ง แต่ทุกอย่างดูเหมือนจะเปลี่ยนผ่านไปได้ค่อนข้างดี ยกเว้นในกรณีที่คุณมีชื่อทีม Jira ที่เหมือนกับของ OpsGenies ทุกตัวเลย มันไม่รวมกันได้ดีและทำให้บางตัวเสียหายไป แนะนำให้คุณเปลี่ยนชื่อทีมเหล่านั้นหากคุณมีเหมือนกัน
มันไม่ได้แย่เกินไปสำหรับเรา ฉันต้องดูเรื่องการตั้งค่าบทบาทและสิทธิ์อีกครั้ง แต่ทุกอย่างดูเหมือนจะเปลี่ยนผ่านไปได้ค่อนข้างดี ยกเว้นในกรณีที่คุณมีชื่อทีม Jira ที่เหมือนกับของ OpsGenies ทุกตัวเลย มันไม่รวมกันได้ดีและทำให้บางส่วนเสียหายไปสองสามตัว แนะนำให้แน่ใจว่าคุณได้เปลี่ยนชื่อเหล่านั้นแล้วหากคุณมีเหมือนกัน
นี่คืออีกคนหนึ่งที่มีประสบการณ์ไม่ดีอย่างชัดเจน:
ในกรณีที่มีใครกำลังพิจารณาตัวเลือกนี้: เราได้เปลี่ยนไปใช้ Jira Service Management ซึ่งเป็นส่วนหนึ่งของแพ็กเกจที่เราจ่ายไปแล้ว (บริษัทกำลังประหยัดอย่างจริงจัง) มันแย่มากจนฉันไม่สามารถอธิบายได้ อย่าพิจารณาเป็นตัวเลือกเลย
ในกรณีที่มีใครกำลังพิจารณาตัวเลือกนี้: เราได้เปลี่ยนไปใช้ Jira Service Management แล้ว ซึ่งเป็นส่วนหนึ่งของแพ็กเกจที่เราได้ชำระเงินไปแล้ว (บริษัทกำลังประหยัดอย่างหนัก) มันแย่มากจนไม่สามารถอธิบายได้ อย่าพิจารณาเป็นตัวเลือกเลย
และอีกคนหนึ่งที่กำลังมองหาการเปลี่ยนอีกครั้งหลังจากอยู่กับ JSM มาเพียงหกเดือน:
JSM แย่มาก ไม่สามารถเปรียบเทียบกับ PagerDuty, Rootly หรือ Incident.io ได้เลย เราเปลี่ยนมาใช้มันเมื่อประมาณ 6 เดือนที่แล้วที่ทำงาน และตอนนี้เรากำลังมองหาทางเลือกอื่น ๆ อยู่ มันไม่ยืดหยุ่นเลย แทบไม่มีการเชื่อมต่อ (integration) ที่ดี ไม่มีระบบสนับสนุน Slack ที่ดี และการแจ้งเตือนเมื่อต้องเข้าเวร (on-call alerts) และหน้าเพจ (pages) ถูกพลาดโดยวิศวกรในอัตราที่สูงมาก (เราไม่เคยมีปัญหานี้เลยตอนใช้ OpeGenie)
JSM แย่มาก ไม่สามารถเทียบกับ PagerDuty, Rootly หรือ Incident.io ได้เลย เราเปลี่ยนมาใช้มันเมื่อประมาณ 6 เดือนที่แล้วในที่ทำงาน และตอนนี้เรากำลังมองหาทางเลือกอื่นแล้ว มันไม่ยืดหยุ่นเลย แทบไม่มีการเชื่อมต่อกับระบบอื่น ๆ ไม่มีระบบสนับสนุน Slack ที่ดี และการแจ้งเตือนและเพจสำหรับวิศวกรที่อยู่ในเวรกำลังถูกพลาดบ่อยมาก (เราไม่เคยมีปัญหานี้เลยตอนใช้ OpeGenie)
ทางเลือกอื่นที่ Atlassian นำเสนอคือ Compass ซึ่งไม่ใช่ทางเลือกโดยตรงของ Opsgenie แต่เป็นแพลตฟอร์มประสบการณ์สำหรับนักพัฒนาที่ออกแบบมาเพื่อทำแผนที่และจัดการส่วนประกอบ บริการ และความพึ่งพาของสถาปัตยกรรมซอฟต์แวร์ที่ซับซ้อน
เราขอแนะนำให้พิจารณาปัจจัยเหล่านี้ก่อนตัดสินใจเลือกทางเลือกของ Opsgenie ที่เหมาะสมที่สุดสำหรับทีมของคุณ
Opsgenie โทร, ClickUp เลือก
การเปลี่ยนจาก Opsgenie อาจรู้สึกเหมือนเป็นก้าวใหญ่ แต่ให้มองว่าเป็นโอกาสที่จะทำให้ชีวิตของทีมคุณง่ายขึ้น
คุณได้เห็นแล้วว่าเครื่องมืออื่น ๆ เปรียบเทียบกันอย่างไร แต่ละอย่างมีจุดแข็งของตัวเอง แต่ก็ยังมีข้อจำกัดเช่นกัน
อย่างไรก็ตาม ClickUp ชนะใจผู้คนอย่างเงียบๆ 🤗
นี่คือเหตุผล: มันรวมงาน การสื่อสาร และกระบวนการทำงานของคุณไว้ในที่เดียว คุณไม่ต้องสลับหน้าจอหรือรวบรวมเครื่องมือแยกกันอีกต่อไป ทีมของคุณจะเชื่อมต่อกันอยู่เสมอ เข้าใจลำดับความสำคัญอย่างชัดเจน และมั่นใจในสิ่งที่ต้องดำเนินการต่อไป
การเลือกโซลูชันการจัดการเหตุการณ์ที่เหมาะสมไม่ใช่แค่เรื่องของการแจ้งเตือนเท่านั้น—แต่คือการสร้างกรอบการจัดการเหตุการณ์ที่แข็งแกร่งซึ่งสนับสนุนประสิทธิภาพการดำเนินงานในระยะยาว ด้วย ClickUp ทีมงานของคุณสามารถจัดการเหตุการณ์ได้อย่างเชิงรุก ลดสัญญาณรบกวน และสร้างความสม่ำเสมอในทุกการตอบสนอง 😌
หากคุณพร้อมที่จะลดความปวดหัวและเพิ่มความชัดเจน ตอนนี้คือเวลาที่เหมาะที่สุดในการลงทะเบียนใช้ ClickUp!
คำถามที่พบบ่อย (FAQ)
การย้ายข้อมูลของ Opsgenie ต้องถูกกำหนดเวลาไว้ก่อนวันที่ 2027 เมษายน. หลังจากวันที่ดังกล่าว ข้อมูลของ Opsgenie จะไม่สามารถเข้าถึงได้.
ทางเลือกที่แข็งแกร่งที่สุดบางตัว ได้แก่ Jira Service Management, PagerDuty, FireHydrant, TaskCall, ilert, Zenduty และ incident.io แต่ละตัวมีความสมดุลที่แตกต่างกันในด้านการจัดการการเรียกใช้งาน, การทำงานอัตโนมัติ และการผสานรวม อย่างไรก็ตาม หากคุณต้องการแพลตฟอร์มที่ครบวงจรและขับเคลื่อนด้วย AI ที่รวมการทำงาน, การสื่อสาร และเอกสารของคุณไว้ในที่เดียว ให้เลือก ClickUp
Jira Service Management ประกอบด้วยคุณสมบัติหลักส่วนใหญ่ของ Opsgenie เช่น การแจ้งเตือน การจัดตารางเวร และการจัดการขั้นตอนการทำงานของเหตุการณ์ แต่ฟังก์ชันขั้นสูงบางอย่างอาจแตกต่างกัน Compass เป็นตัวเลือกสำหรับทีมพัฒนาที่มุ่งเน้นไปที่แคตตาล็อกบริการและการติดตามส่วนประกอบ
ใช่. Atlassian มีเครื่องมือการโยกย้ายข้อมูลในแอปที่ช่วยย้ายการแจ้งเตือน, ตารางเวลา, และนโยบายการเลื่อนขั้นโดยอัตโนมัติ. คุณสามารถทดสอบการโยกย้ายในบัญชีทดลองก่อนที่จะดำเนินการจริงได้.
ใช่ เครื่องมือเช่น Cabot, OpenDuty และ Alertmanager สามารถปรับแต่งได้เป็นทางเลือกแบบโอเพนซอร์ส แม้ว่าจะต้องมีการตั้งค่าและการบำรุงรักษามากกว่า
ค่าใช้จ่ายขึ้นอยู่กับแพลตฟอร์มที่คุณเลือก Jira Service Management, Compass และทางเลือกอื่น ๆ มีระบบราคาแบบแบ่งชั้น ซึ่งมักคิดตามจำนวนผู้ใช้ต่อเดือน บางเครื่องมือโอเพนซอร์สสามารถใช้ได้ฟรี แต่ต้องเสียค่าใช้จ่ายด้านโครงสร้างพื้นฐานและการสนับสนุน
ใช่ ทีมของคุณสามารถใช้ Opsgenie ต่อไปได้ในช่วงระยะเวลาการย้ายข้อมูล และการเชื่อมต่อจะยังคงใช้งานได้จนกว่าจะปิด Opsgenie อย่างถาวร หลังจากนั้นจะต้องกำหนดค่าใหม่ในแพลตฟอร์มใหม่ของคุณ