
Har du någonsin varit mitt i middagen när din telefon vibrerar med en ”kritisk varning” som visar sig vara inget mer än rutinloggar? Det är frustrerande, men åtminstone visste du att Opsgenie hade din rygg.
Nu kommer den verkliga utmaningen: Atlassian har slutat sälja Opsgenie, och snart kommer det fullständiga stödet att upphöra. För team som förlitar sig på det för jourplanering, eskaleringar och varningar är det en väckarklocka som ingen ville ha.
Det positiva är att du inte behöver vänta till sista minuten. Om du ger dig själv tid att utforska andra alternativ nu kan ditt team anpassa sig till en ny rutin utan stressen av hastiga beslut.
I den här artikeln går vi igenom de bästa alternativen till Opsgenie, jämför deras styrkor och visar varför ClickUp erbjuder ditt team ett lugnare och mer sammanhängande sätt att arbeta på.
⭐ Utvalda mallar
Låt dina IT-team logga incidenter korrekt och upptäck trender som kan leda till långsiktiga förbättringar. ClickUps mall för IT-incidentrapporter hjälper dig att registrera incidentdetaljer i ett konsekvent och tillförlitligt format.

Opsgenie-alternativ i korthet
Här är en snabb jämförelse av de bästa alternativen till Opsgenie som hjälper dig att välja rätt lösning baserat på viktiga funktioner, priser och användarbetyg.
| Verktyg | Bäst för | Viktiga funktioner | Priser* | Betyg |
| ClickUp | Allt-i-ett-arbetshantering med incidentarbetsflöden, resursplanering och automatisering för team av alla storlekar. | Anpassningsbara aviseringar, automatisering för eskaleringar, incidentuppgifter och listor, anpassade statusar, chatt i realtid, instrumentpaneler för granskning efter incidenter, över 1 000 integrationer | Gratis plan tillgänglig; anpassningar för företag | G2: 4,7/5 (10 500+) Capterra: 4,6/5 (4 500+) |
| PagerDuty | Realtidslarm vid incidenter och automatisering i stor skala för stora företag | Varningar via flera kanaler, eskaleringspolicyer, jourplanering, AIOps för brusreducering, integrationer med över 600 verktyg | Gratis plan; Betalda planer från 25 $/månad per användare | G2: 4,5/5 (900+) Capterra: 4,6/5 (200+) |
| xMatters | Kostnadseffektiv incidenthantering och automatisering av arbetsflöden för växande team | Automatiserade arbetsflöden, adaptiv incidenthantering, jourplanering, signalinformation, över 200 integrationer | Gratis plan; Betalda planer från 9 $/månad per användare | G2: 4,5/5 (670+) Capterra: 4,6/5 (140+) |
| AlertOps | AI-driven brusreducering och snabb respons för små till medelstora team | AI OpsIQ brusreducering, flexibla eskaleringar, jourtjänstgöring, automatisering av arbetsflöden utan kod, över 200 integrationer | Gratis plan; Betalda planer från 10 $/månad per användare | G2: 4,7/5 (150+) Capterra: 4,7/5 (20+) |
| Splunk On-Call | Förenkla jourplanering och minska utbrändhet för stora team | Automatiserade eskaleringar, mobilappar, arbetsbelastningsbalansering, ML-rekommendationer, revisionsspår | Anpassad prissättning | G2: 4,6/5 (50+) Capterra: 4,5/5 (30+) |
| Datadog | Fullständig övervakning med säkerhetsövervakning för företag | Infra + logg + appövervakning, molnsäkerhet, avvikelsedetektering med AI, över 900 integrationer | Gratis plan; Betalda planer från 15 $/månad per användare | G2: 4,4/5 (660+) Capterra: 4,6/5 (320+) |
| Squadcast | Enhetlig jourtjänst och incidenthantering med prisvärda lösningar för medelstora team | Automatiserade scheman, deduplicering, runbooks, statussidor, efteranalyser | Gratis plan; Betalda planer från 12 $/månad per användare | G2: 4,4/5 (300+) Capterra: Otillräckligt med recensioner |
| FireHydrant | Automatiserade runbooks och serviceägande för företag | Runbooks, Signals jourplanering, servicekatalog, Slack/Teams-samarbete, AI-berikade retrospektiv | Gratis plan; Betalda planer från 9 600 $/år per användare | G2: 4,5/5 (130+) Capterra: Otillräckligt med recensioner |
| TaskCall | Prisvärd incidenthantering med automatisering för medelstora till stora team | Dynamisk jourplanering, AI-driven dirigering, flerkanaliga varningar, DevOps + BizOps-täckning | Gratis plan; Betalda planer från 9 $/månad per användare | G2: Otillräckligt antal recensioner Capterra: Otillräckligt antal recensioner |
| ilert | AI-baserad incidenthantering med fokus på integritet för skalbara team | Varningar via flera kanaler, AI Responder-assistent, jourplanering, automatiserade statussidor, integrationer med ITSM + övervakningsverktyg | Gratis plan; Betalda planer från 24 $/månad per användare | G2: Inte tillräckligt med recensioner Capterra: 4,7/5 (60+) |
| Zenduty | AI-driven incidenthantering i stor skala för små till stora team | ZenAI incidenthantering, avancerad jourplanering, automatiserade playbooks, över 150 integrationer | Gratis plan; Betalda planer från 6 $/månad per användare | G2: 4,6/5 (135+) Capterra: Inte tillräckligt med recensioner |
| Incident. io | Slack-integrerad incidenthantering för medelstora till stora företag | Hela incidenthanteringen i Slack, AI SRE, jourplanering, automatiserade statussidor, insiktsdashboards | Gratis plan; Betalda planer från 19 $/månad per användare | G2: 4,8/5 (180+) Capterra: Inte tillräckligt med recensioner |
Viktiga kriterier för att utvärdera alternativ till Opsgenie
Jag vet att vi har nästan två år på oss innan de helt fasar ut det, men jag ser ingen anledning att vänta 😛
Jag vet att vi har nästan två år på oss innan de helt fasar ut det, men jag ser ingen anledning att vänta 😛
Den kommentaren från en Reddit-användare fångar den verklighet som många IT-PMO-team står inför. Ja, Opsgenie har varit en bra följeslagare i många år, men att förlita sig på det bara för att det är bekant hjälper inte när supporten upphör.
Det kloka att göra nu är att titta på vad som gjorde Opsgenie användbart från början och använda samma egenskaper som vägledning när du väljer din nästa plattform för incidenthantering.
Här är några av de egenskaper som är värda att uppmärksamma:
- Skicka varningar i rätt tid via flera kanaler, såsom telefon, e-post, SMS eller push-meddelanden.
- Håll aviseringarna riktade så att rätt person informeras utan att överbelasta resten av teamet.
- Inför eskaleringspolicyer som säkerställer att kritiska incidenter aldrig ignoreras.
- Centralisera incidentuppdateringar så att teamen kan se helheten samtidigt som de hanterar incidenter.
- Gör utvärderingar efter incidenter för att lära av liknande incidenter och förbättra rutinerna över tid.
- Erbjud integrationsmöjligheter med verktyg som dina IT-team redan förlitar sig på.
Opsgenie har byggt upp sitt rykte genom att hjälpa DevOps-team att minska larmtrötthet, hålla ordning på jourscheman och lösa incidenter utan förvirring. När du utforskar varje alternativ till Opsgenie, håll fast vid samma värderingar.
📖 Läs också: De bästa verktygen för incidenthantering för IT-team
De 12 bästa alternativen till Opsgenie
Opsgenie kanske är på väg att avvecklas, men det betyder inte att ditt team måste tappa fart. Här är några lämpliga ersättare som ger dina driftteam självförtroende i kritiska situationer.
Hur vi granskar programvara på ClickUp
Vår redaktion följer en transparent, forskningsbaserad och leverantörsneutral process, så du kan lita på att våra rekommendationer baseras på produkternas verkliga värde.
Här är en detaljerad beskrivning av hur vi granskar programvara på ClickUp.
1. ClickUp (bäst för hantering av incidentarbetsflöden tillsammans med bredare projektledning)
När team lämnar Opsgenie oroar de sig mindre för att förlora larm och mer för att anpassa sig till ett nytt arbetsflöde för incidenthantering.
Det centrala problemet är Work Sprawl, där uppdateringar, scheman och policyer är utspridda över olika appar, e-postmeddelanden och dokument. Denna fragmentering dränerar energi och tvingar teamen att börja om från början vid varje incident.
Undersökningar visar att anställda lägger 117 minuter på att gå igenom e-post och 153 minuter på Microsoft Teams-meddelanden per vardag, med avbrott varannan minut.
ClickUp träder in som ett alternativ till Opsgenie genom att samla allt det osammanhängande arbetet i en enda samlad arbetsyta. Här är en djupgående beskrivning av hur dess funktioner möter dessa utmaningar.
Automatiserade arbetsflöden för incidenthantering
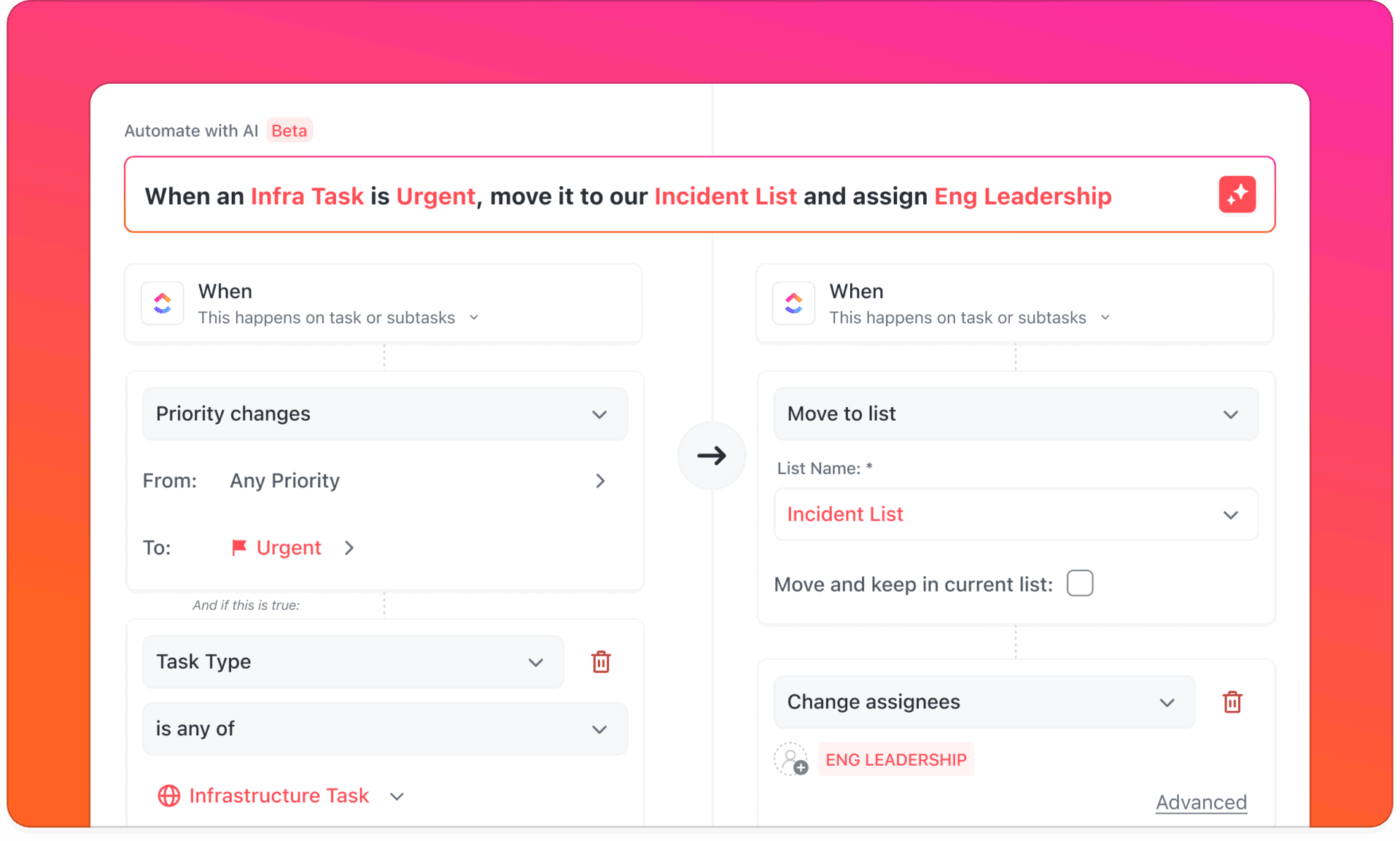
Med varningar från övervakningsverktyg, chattverktyg och e-post är det svårt att avgöra vad som är viktigt och vem som ska reagera.
Med ClickUp Automations och AI Agents blir varningar meningsfulla åtgärder. Inkommande varningar kan automatiskt skapa och tilldela uppgifter till jourhavande tekniker, vilket meddelar rätt person utan att distrahera resten av teamet.
Om det inte kommer något svar inom en viss tid eskalerar systemet automatiskt ärendet enligt dina standardprocedurer.
📌 Exempel: Ett serveravbrott med hög prioritet rapporteras. ClickUp Automations skapar en ny uppgift i din incidentlista, markerar den som brådskande, tilldelar den till jourhavande tekniker och skickar en push-avisering till mobilen. Samtidigt publicerar din anpassade AI-agent ett kort meddelande i incidentkanalen i ClickUp Chat så att teamet informeras utan att överväldigas.
Tydlighet och ansvarsskyldighet kring uppgifter
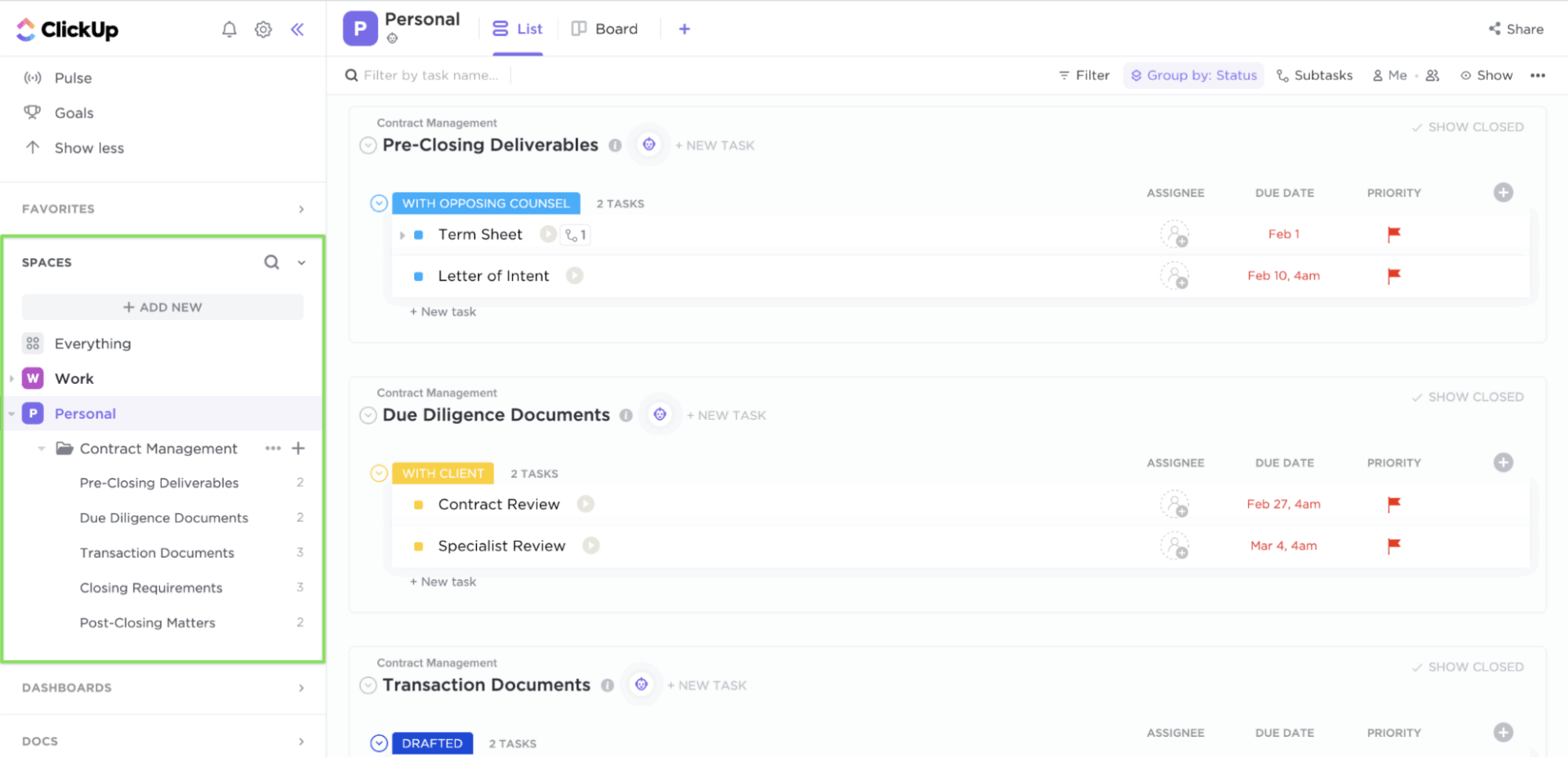
När en incident inträffar slösar team ofta tid på att fundera över vad de ska göra och vad som ska hända härnäst. ClickUp Tasks skapar klarhet i dina incidenthanteringsprocesser.
Varje uppgift kan ha en tydlig ägare, prioritet och deadline. Inom varje uppgift kan du lägga till checklistor, länkar till runbooks och skärmdumpar. Anpassade fält registrerar allvarlighetsgrad, berörda tjänster eller eskaleringsstadium, medan ClickUps anpassade uppgiftsstatusar och listor eliminerar osäkerhet genom att kartlägga hanteringsprocessen i en tydlig sekvens.
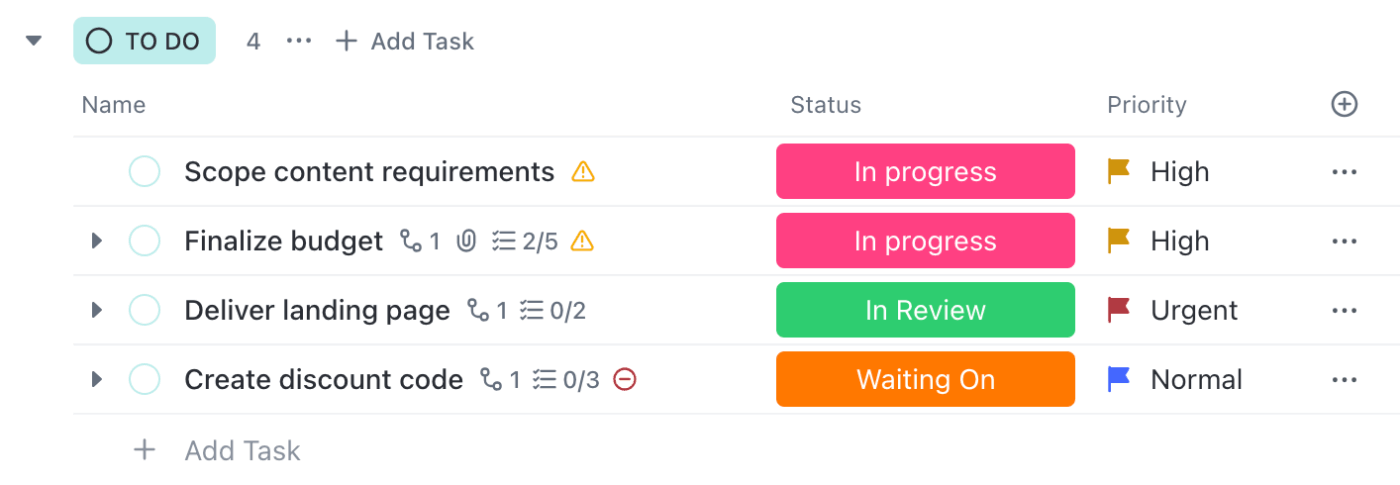
📌 Exempel: En incident som har rapporterats flyttas till statusen ”Undersöker” när teknikern öppnar uppgiften. Åtgärder för att minska risken spåras i en checklista, med anteckningar och loggar som läggs till i beskrivningen. Varje statusändring meddelas endast till berörda personer, så att teknikerna kan arbeta medan ledarna hålls informerade.
Uppdateringar som inte stör arbetsflödet
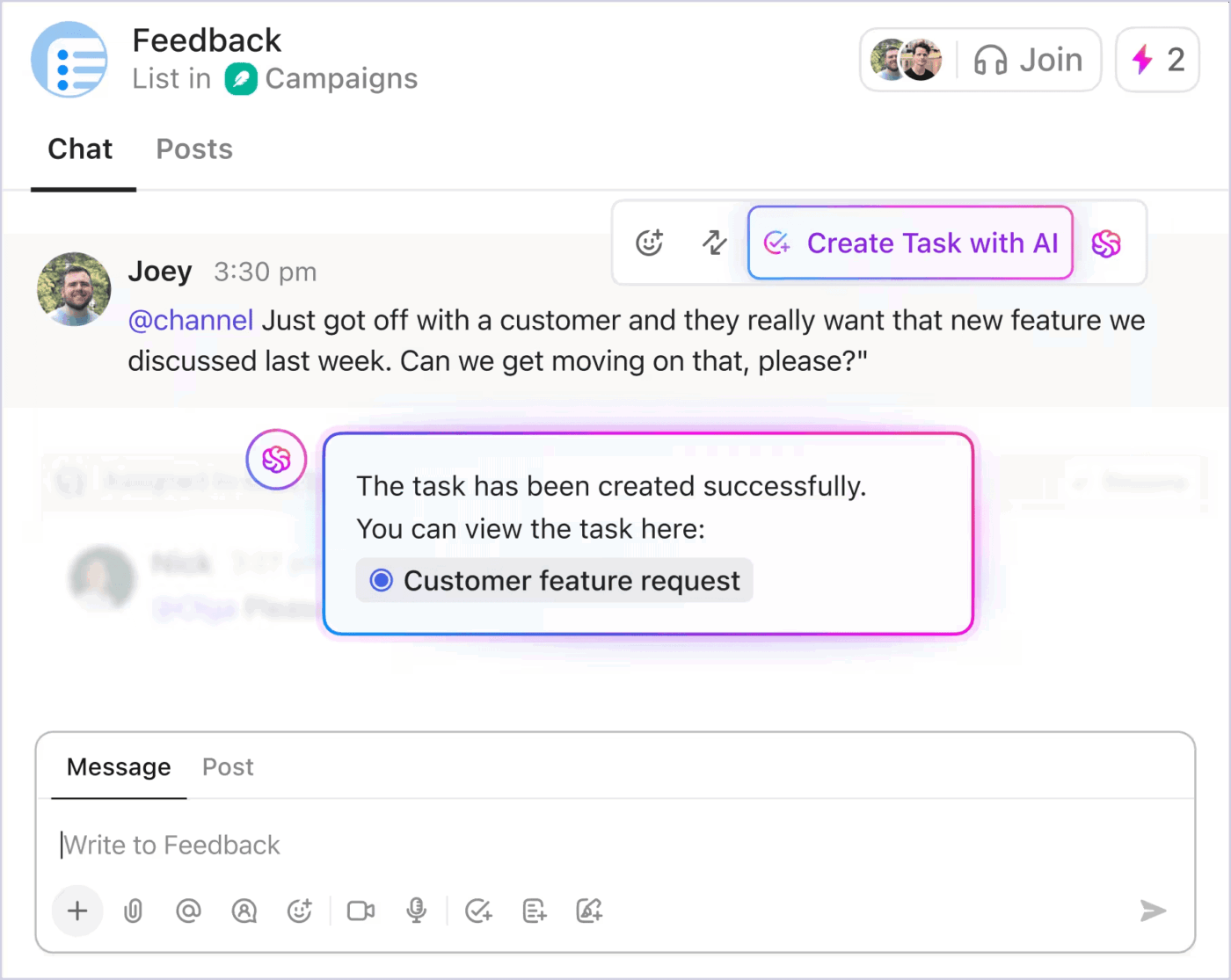
Under kritiska incidenter bör uppdateringar till intressenter inte störa hanteringen. ClickUp Chat löser detta genom att koppla konversationen direkt till incidentuppgiften. Teammedlemmar och ledare kan följa tråden, se beslut som fattats och lägga till kommentarer i realtid.
ClickUp integreras också med Slack och Microsoft Teams, vilket gör att uppdateringar visas i de kanaler som användarna redan följer.
Letar du efter de bästa tipsen när det gäller realtidssamarbete? Här är en guide:
Granskningar efter incidenter som leder till varaktiga förändringar
Alltför ofta skrivs incidentrapporter, men glöms sedan bort. ClickUp Docs håller dem levande genom att lagra standardiserade efteranalyser direkt tillsammans med incidentuppgifterna.
Samtidigt visar ClickUp Dashboards mätvärden som genomsnittlig tid till lösning, incidentfrekvens och återkommande mönster. Denna synlighet hjälper IT-team och DevOps-team att gå från reaktiv brandbekämpning till proaktiv förbättring.
💡 Proffstips: Efterhandsgranskningar av incidenter kan ta timmar att skriva, redigera och gräva fram sammanhanget. ClickUp Brain förändrar det genom att automatiskt samla anteckningar, tidslinjer och åtgärdspunkter. Det kan sammanfatta en incidentuppgift, utarbeta en efterhandsanalys i ClickUp Docs och till och med föreslå nästa steg baserat på liknande incidenter.
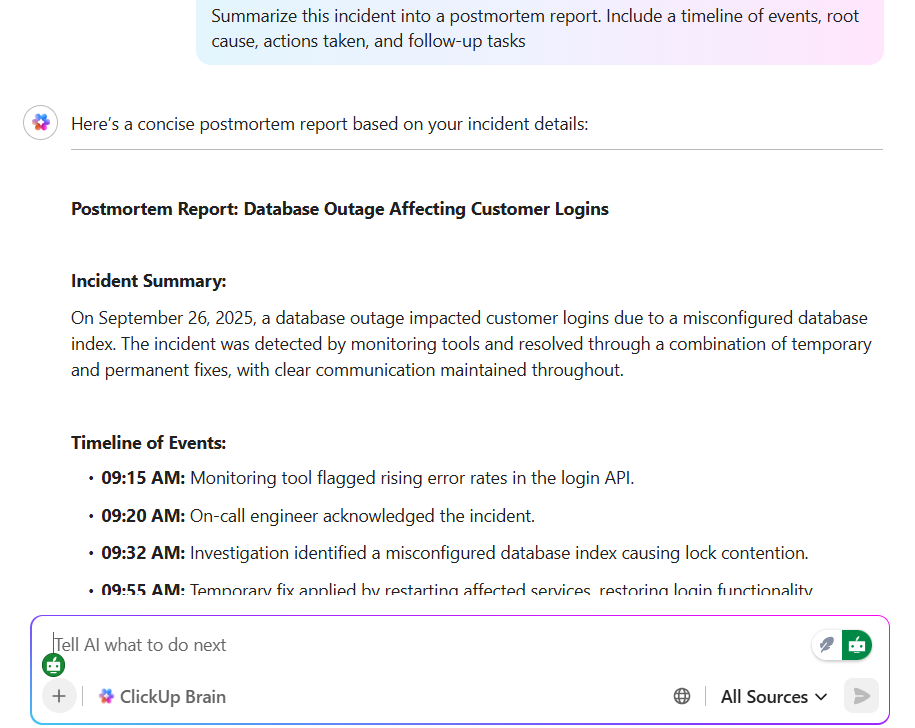
Med ClickUp Brain Max får du den extra hastigheten i ClickUps Talk to Text – diktera dina tankar i realtid och se dem förvandlas till polerade anteckningar som är redo att delas. Tillsammans hjälper de team att spara nästan en hel dag varje vecka genom att eliminera det tidskrävande arbetet med att skriva och söka, så att du kan fokusera på att förebygga nästa incident istället för att återberätta den senaste.
Skapa struktur och spara tid med mallar

I en nödsituation lär man sig verkligen uppskatta värdet av en tydlig, stegvis process.
ClickUps mall för incidentåtgärdsplan är precis det. Den anger exakt vad som behöver göras, vem som behöver göra det och i vilken ordning. Den håller alla samordnade, minskar riskerna och säkerställer att inga steg förbises.
En annan utmaning inom IT är att dokumentera incidenter på ett effektivt sätt så att mönster kan upptäckas och förebyggas i framtiden. ClickUps mall för IT-incidentrapporter gör rapporteringen enkel och förvandlar varje problem till en värdefull datapunkt.
ClickUps bästa funktioner
- Minska varningsutmattningen med anpassningsbara ClickUp-meddelanden som säkerställer att endast rätt personer varnas.
- Automatisera skapandet, tilldelningen och rapporteringen av incidentuppgifter med ClickUp Automations och AI Agents.
- Skapa tydliga arbetsflöden för incidenter med ClickUps uppgifter, listor och statusar samt mallar för incidentrapporter som guidar dig genom varje steg i hanteringen.
- Möjliggör teamsamarbete med ClickUp Chat och ClickUp Docs, så att konversationer, uppdateringar och slutsatser lever med incidenten.
- Spåra uppgiftsstatus och incidentrapporter via ClickUp Dashboards
- Generera insikter från incidenter och avslutade uppgifter, och skapa eller uppdatera SOP:er för framtida förbättringar med ClickUp Brain.
Begränsningar för ClickUp
- Plattformens flexibilitet kan kännas överväldigande för mindre team som bara vill ha grundläggande larmfunktioner och jourhantering.
Priser för ClickUp
Betyg och recensioner för ClickUp
- G2: 4,7/5 (över 10 500 recensioner)
- Capterra: 4,6/5 (över 4 500 recensioner)
Vad användarna säger om ClickUp
Denna G2-användare rapporterade:
Att arbeta tillsammans på ett projekt har blivit mycket enklare sedan ClickUp implementerades, eftersom uppgifter enkelt kan tilldelas medlemmar och man kan följa framstegen via chatt. Det går till och med att skicka e-postmeddelanden och förseningsvarningar om en uppgift inte har utförts.
Att arbeta tillsammans på ett projekt har blivit mycket enklare sedan ClickUp implementerades, eftersom uppgifter enkelt kan tilldelas medlemmar och man kan följa framstegen via chatt. Det går till och med att skicka e-postmeddelanden och förseningsvarningar om en uppgift inte har utförts.
📖 Läs också: Hur man skriver en incidentrapport på jobbet
2. PagerDuty (bäst för realtidslarm vid incidenter och automatisering i stor skala)
Om du lämnar Opsgenie är din första oro enkel. Kommer rätt person att få varningen, vid rätt tidpunkt, på rätt kanal?
PagerDuty är utformat för att eliminera den stressen. Du definierar tjänster, scheman och tydliga eskaleringspolicyer så att ansvaret aldrig är oklart. Signaler från CloudWatch, Prometheus, Datadog, Jira, ServiceNow, Slack, Zoom och andra hamnar på ett ställe och grupperas i en enda incident, inte 15 separata pingar.
Event Intelligence minskar dubbletter och korrelerar relaterade problem, vilket minskar varningsutmattning utan att dämpa verkliga problem. Responsen kan bekräfta eller eskalera från mobilappen eller direkt från Slack eller Teams, med incidentrum och bryggor som skapas automatiskt.
Efter lösningen visas analyser av tid för bekräftelse, tid för lösning och återkommande problemområden så att du kan åtgärda orsakerna istället för att jaga symptomen.
PagerDuty bästa funktioner
- Låt individer anpassa varningar via SMS, telefon, e-post, push-meddelanden och Slack för att minska störningar utan att missa kritiska incidenter.
- Gör installationen enkel med testvarningar, tjänsteintegrationer och enkel utformning av eskaleringspolicyer.
- Stöd för jourplaner och eskaleringar som meddelar rätt person och fortsätter tills de bekräftas.
- Aktivera Slack-baserade incidentåtgärder som bekräfta, lösa och eskalera direkt i chatten.
- Minska varningsutmattningen med AIOps som grupperar dubbletter och markerar brådskande incidenter.
Begränsningar med PagerDuty
- Teamledare kan inte helt anpassa metoderna för varningstillförsel på teamnivå, vilket begränsar flexibiliteten när chefer vill ha konsekventa eskaleringsregler.
- E-postvarningar saknar möjlighet att svara direkt, vilket tvingar responspersonalen att klicka sig vidare till plattformen istället för att hantera ärendet direkt från inkorgen.
- Avancerade funktioner som AIOps och licenser för kommunikation med intressenter medför höga extra kostnader.
PagerDuty-priser
- Gratis
- Professional: 25 $/månad per användare
- Företag: 49 $/månad per användare
- Företag: Anpassad prissättning
Betyg och recensioner av PagerDuty
- G2: 4,5/5 (över 900 recensioner)
- Capterra: 4,6/5 (över 200 recensioner)
Vad användarna säger om PagerDuty
Denna G2-användare nämnde:
Jag älskar att personsökaren har flera olika ljudsignaler, några av dem är riktigt roliga. Sedan jag började använda personsökaren har jag kunnat hantera incidenter och engagera teamen på ett mer effektivt sätt.
Jag älskar att personsökaren har flera olika ljudsignaler, några av dem är riktigt roliga. Sedan jag började använda personsökaren har jag kunnat hantera incidenter och engagera teamen på ett mer effektivt sätt.
📖 Läs också: Vad är en beredskapsplan och hur utarbetar man en?
3. xMatters (Bäst för kostnadseffektiv incidenthantering och automatisering)
En Reddit-användare sammanfattade det bäst:
Du får vad du betalar för, men du betalar mindre. Har allt du vill ha, men är definitivt inte lika avancerat som PagerDuty.
Du får vad du betalar för, men du betalar mindre. Har allt du vill ha, men är definitivt inte lika avancerat som PagerDuty.
Den meningen sammanfattar xMatters positionering – prisvärt, pålitligt och starkt inom de områden som är viktigast.
Om du lämnar Opsgenie har du oftast två problem. För mycket buller som väcker fel personer och osäkerhet om vem som ansvarar för nästa steg. xMatters löser båda problemen genom att låta dig kartlägga tjänster och jourplaner och sedan vidarebefordra varningar med exakt kontext så att rätt person nås på rätt kanal.
Användarna uppskattar riktade aviseringar med användbar information, samt en fullständig revisionsspår som visar vem som blev uppringd, vem som bekräftade och när. Denna dokumentation gör det enkelt att granska incidenter i efterhand och kontrollera efterlevnaden.
Den lågkodade arbetsflödesbyggaren omvandlar en signal från Datadog, Prometheus eller ServiceNow till en tydlig sekvens av åtgärder.
Med automatisering av arbetsflöden och adaptiv DevOps-projektledning i centrum hjälper xMatters team att arbeta snabbare och minska antalet onödiga varningar.
xMatters bästa funktioner
- Automatisera incidentarbetsflöden med kodfria och kodfattiga integrationer som påskyndar lösningen och minskar manuella uppgifter.
- Hantera jourplaner och eskaleringar smidigt så att rätt person alltid varnas vid rätt tidpunkt.
- Använd adaptiv incidenthantering för att minimera påverkan på kunderna och dra lärdom av varje händelse.
- Filtrera bort brus med signalinformation, korrelation av varningar och förbättrade aviseringar för tydligare sammanhang.
- Få tillgång till användbar analys för att identifiera ineffektiviteter och förbättra samarbetet mellan teamen.
Begränsningar med xMatters
- Gränssnittet och användarupplevelsen känns mindre raffinerade jämfört med konkurrenterna.
- Avancerad rapportering och analys är begränsad i lägre prisnivåer.
- Den globala supporttäckningen varierar beroende på vilken plan du väljer.
Priser för xMatters
- Gratis
- Starter (Essentials): 9 $/månad per användare
- Base (Standard): 39 $/månad per användare
- Avancerat: Anpassad prissättning
xMatters betyg och recensioner
- G2: 4,5/5 (över 670 recensioner)
- Capterra: 4,6/5 (över 140 recensioner)
Vad användarna säger om xMatters
Denna Capterra-recension innehöll:
När vi har en datasäkerhetsincident i företaget aktiverar Xmatters omedelbart hanteringsprotokollen: det organiserar teamets åtgärdsprotokoll enligt deras funktioner. Meddelanden skickas via olika kanaler.
När vi har en datasäkerhetsincident i företaget aktiverar Xmatters omedelbart hanteringsprotokollen: det organiserar teamets åtgärdsprotokoll enligt deras funktioner. Meddelanden skickas via olika kanaler.
📮 ClickUp Insight: 28 % av de anställda säger att arbetet följer med dem efter arbetstidens slut, och ytterligare 8 % har ofta svårt att koppla bort jobbet. Det innebär att mer än en tredjedel tar med sig stressen hem.
Använd ClickUp Reminders för att skydda din kvällsrutin. Ställ in en daglig sammanfattningspåminnelse, tysta aviseringar utanför arbetstid och reservera personlig tid i din kalender. Att koppla av ska vara ett val du själv gör.
💫 Verkliga resultat: Lulu Press sparar ungefär en timme per person och dag med ClickUp Automations, vilket leder till en effektivitetsökning på 12 %.
4. AlertOps (bäst för AI-driven brusreducering och snabb incidenthantering)
Antalet larm fortsätter att öka, med 88 % av teamen som rapporterar en ökning under det senaste året och nästan hälften som säger att dessa ökningar var över 25 %. Denna typ av konstant störning leder till larmtrötthet, vilket 76 % av SOC:er (Security Operations Centers) nu anger som sin största utmaning.
Det är den verkligheten du tar med dig till alla ersättare för Opsgenie. Nästa verktyg du väljer måste kunna bedöma vilka larm som kräver åtgärder. AlertOps tar fasta på det med OpsIQ, en AI-kärna som filtrerar dubbletter, korrelerar relaterade signaler, sammanfattar sammanhanget och föreslår nästa steg så att responspersonalen ser en tydlig incident istället för en rullande feed.
Du kan börja med standardjourplanen eller skapa en egen, och sedan vidarebefordra via telefon, SMS, mobilapp, chatt eller e-post med eskaleringsregler som fortsätter att fungera tills någon tar ansvar för problemet. Live-vidarebefordran av samtal skickar kunderna till den aktuella jourhavande personalen baserat på realtidsscheman, och SLA-baserade policyer eskaleras före ett brott snarare än efter.
Dessutom integreras plattformen med mer än 200 verktyg, från övervakning och ärendehantering till O365 och Slack, så att triageringen inte fastnar på grund av saknad kontext.
AlertOps bästa funktioner
- Filtrera och undertryck dubbla varningar med AI-driven brusreducering från OpsIQ™, som sammanfattar varningar och föreslår lösningar automatiskt.
- Hantera jourplaner med flexibla eskaleringsregler, dygnet-runt-täckning och live-samtalsdirigering för kritiska kundärenden.
- Automatisera triage och arbetsflöden med hjälp av kodfria IT-mallar för att påskynda hanteringen och säkerställa att incidenter hanteras på ett konsekvent sätt.
- Integrera med över 200 verktyg direkt, inklusive Slack, O365, Jira, Dynatrace och ConnectWise, plus anpassade integrationer för interna appar.
Begränsningar för AlertOps
- Schemaläggningen kan kännas ointuitiv i början och kan kräva lite trial and error.
- Användargränssnittet har ibland brister, och vissa avancerade funktioner kräver extra steg för att konfigureras.
- Förseningar i kalendersynkronisering har rapporterats med externa system som Outlook.
Priser för AlertOps
- Starter: Gratis
- Standard: 10 USD/månad per användare
- Premium: 22 $/månad per användare
- Enterprise: 34 $/månad per användare
AlertOps betyg och recensioner
- G2: 4,7/5 (över 150 recensioner)
- Capterra: 4,7/5 (över 20 recensioner)
Vad användarna säger om AlertOps
Denna G2-recension gör det tydligt:
Vi tillbringade större delen av tredje kvartalet förra året med att testa schemaläggnings- och varningsverktyg för ett av våra IT-team. Efter att ha hittat AlertOps slutade jag leta. Det är prisvärt, teamet är otroligt hjälpsamt och tålmodigt under installationsprocessen och implementeringen, och sedan vi fick allt installerat och igång har vi inte haft några problem alls!
Vi tillbringade större delen av tredje kvartalet förra året med att testa schemaläggnings- och varningsverktyg för ett av våra IT-team. Efter att ha hittat AlertOps slutade jag leta. Det är prisvärt, teamet är otroligt hjälpsamt och tålmodigt under installationsprocessen och implementeringen, och sedan vi fick allt installerat och igång har vi inte haft några problem alls!
5. Splunk On-Call (Bäst för att förenkla jourplanering och minska utbrändhet)
Om du någonsin har sett den klassiska sketchen Abbott and Costello "Who's on First?" vet du hur förvirrande det kan vara att försöka lista ut vem som egentligen är ansvarig för vad. Jourtjänstgöring kan kännas på samma sätt när det inte finns något tydligt system på plats.
Det är där Splunk On-Call kommer in i bilden. ✨
Du kartlägger team och scheman en gång, sedan kommer varningarna med kontext till valfri enhet. Responsen kan bekräfta, omdirigera eller snooza från iOS- eller Android-appen, och plattformen kan öppna ett rum för samarbete och starta granskningen efter incidenten utan extra steg.
En regelmotor kopplar runbooks och dashboards till incidenter så att den första personen som larmas aldrig börjar från noll. Maskininlärning föreslår rätt responspersonal baserat på liknande incidenter, vilket hjälper till att minska tiden för bekräftelse och lösning.
Splunk On-Call bästa funktioner
- Automatisera eskaleringar och incidenthanteringsarbetsflöden för snabbare bekräftelse och lösning.
- Använd iOS- och Android-appar för att ta emot, snooza, omdirigera eller lösa varningar direkt från en mobil enhet.
- Förenkla schemaläggningen med rotationer, överstyrningar och eskaleringspolicyer som är utformade för att balansera arbetsbelastningen på ett rättvist sätt.
- Få information om incidentens sammanhang och historiska revisionsspår för att underlätta snabbare prioritering och analys efter incidenten.
- Använd rekommendationer från maskininlärning för att identifiera rätt responspersonal baserat på tidigare lösningsdata.
Begränsningar för Splunk On-Call
- Gränssnittet kan kännas komplicerat i början, och navigeringen kräver viss anpassning.
- Tillfälliga fördröjningar under perioder med hög trafik påverkar responsen i realtid.
- Licensierings- och användarhanteringsalternativen är mer begränsade jämfört med vissa konkurrenter.
Priser för Splunk On-Call
- Anpassad prissättning
Splunk On-Call betyg och recensioner
- G2: 4,6/5 (över 50 recensioner)
- Capterra: 4,5/5 (över 30 recensioner)
Vad användarna säger om Splunk On-Call
Denna G2-recension konstaterar:
Möjligheten att skapa team och konfigurera skift mellan dem är en av de mest användbara funktionerna på denna plattform. Splunk On-Call erbjuder enkel integration med flera verktyg, vilket gör konfigurationen mycket enkel att ställa in.
Möjligheten att skapa team och konfigurera skift mellan dem är en av de mest användbara funktionerna på denna plattform. Splunk On-Call erbjuder enkel integration med flera verktyg, vilket gör konfigurationen mycket enkel att ställa in.
6. Datadog (Bäst för fullständig övervakning med integrerad säkerhetsövervakning)
För Opsgenie-användare är kontexten ett problem. En varning utlöses, men du måste fortfarande leta efter loggar, spår, mätvärden och säkerhetssignaler för att ta reda på vad som faktiskt är fel.
Datadog samlar dessa vyer i en enda tidslinje. Infrastruktur, containrar, serverlösa lösningar, databaser och appar finns bredvid loggar, spårningar och RUM så att responspersonalen inte behöver gissa.
Watchdog och de nya AI-funktionerna lyfter fram avvikelser, grupperar relaterade signaler och sammanfattar sannolika konsekvenser, vilket minskar behovet av fram- och återkommande kommunikation under triageringen. Om du redan har ett personsökningsverktyg kan du mata in Datadog-varningar i det.
Om du vill stanna kvar i Datadog ger Incident Management dig ägare, tidslinjer, uppdateringar för intressenter och uppföljningar utan att du behöver lämna plattformen.
De praktiska fördelarna märks snabbt. Färre störande ping-meddelanden eftersom dubbletter samlas ihop. Snabbare analys av grundorsaker eftersom varje larm innehåller de mätvärden och loggar som förklarar det. Starkare säkerhet eftersom felkonfigurationer och sårbarheter syns tillsammans med prestandadata.
Med över 900 integrationer, tydliga SLO:er (Service Level Objectives) och instrumentpaneler kan ditt team gå från signal till åtgärd på ett och samma ställe istället för att hoppa mellan olika flikar. Detta är ett bra val för Opsgenie-migreringar som också vill täppa till luckor i övervakningen.
Datadogs bästa funktioner
- Övervaka infrastruktur, loggar, applikationer, databaser och serverlösa arbetsbelastningar från en enda plattform.
- Säkra molnmiljöer med inbyggd sårbarhetshantering, kartläggning av efterlevnad och behörighetshantering
- Använd syntetisk övervakning och övervakning av verkliga användare för att upptäcka problem innan kunderna märker dem.
- Automatisera arbetsflöden med över 900 integrationer och förkonfigurerade instrumentpaneler.
- Använd AI- och maskininlärningsfunktioner som Watchdog och LLM Observability för att upptäcka avvikelser och få intelligenta insikter.
Datadogs begränsningar
- Priserna kan snabbt stiga vid ett stort antal värdar och tillägg.
- Gränssnittet och instrumentpanelerna kan kännas överväldigande för nya användare.
- Vissa avancerade säkerhetsfunktioner är endast tillgängliga i högre prisnivåer.
Datadogs prissättning
- Gratis
- Pro: 15 USD/månad per värd
- Enterprise: 23 $/månad per värd
- DevSecOps Pro: 22 $/månad per värd
- DevSecOps Enterprise: 34 $/månad per värd
Datadog-betyg och recensioner
- G2: 4,4/5 (över 660 recensioner)
- Capterra: 4,6/5 (320+ recensioner)
Vad användarna säger om Datadog
Denna recension från Capterra citerar:
Sammantaget har de, efter några upp- och nedgångar, varit en bra partner. Deras verktyg är extremt kraftfullt och möjliggör många utmärkta metoder kring observerbarhet, men man måste betala för det.
Sammantaget har de, efter några upp- och nedgångar, varit en bra partner. Deras verktyg är extremt kraftfullt och möjliggör många utmärkta metoder kring observerbarhet, men man måste betala för det.
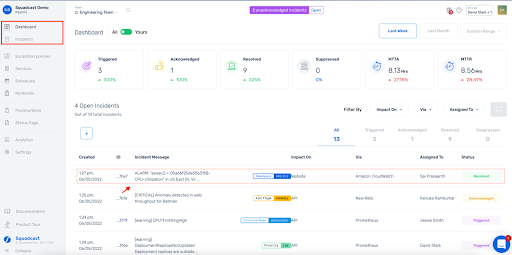
7. Squadcast (Bäst för enhetlig jourtjänst och incidenthantering med stort mervärde)
När du hanterar flera scheman och kundspecifika regler för arbetstid utanför kontorstid behöver du varningar för att följa dessa regler utan att behöva hålla koll på dem manuellt.
Det är inom denna nisch som Squadcast har vunnit förtroende. 🌟
Användare har noterat att scheman och undantag är lätta att modellera och att mobilappen fortsätter att eskalera om den första respondenten inte svarar, så att kritiska problem inte glöms bort.
För MSP:er och team med många kunder uppskattar man att man kan ställa in 24/7-täckning för vissa kunder, medan andra endast får larm utanför kontorstid för kritiska incidenter. Gränssnittet gör det enkelt att se aktiva incidenter och vem som är ansvarig.
Det finns mer än bara personsökning under huven. Pålitlig automatisering hanterar incidenter genom konsekventa arbetsflöden med runbooks och statusuppdateringar, SLO-spårning och tidslinjer som visar mönster som du faktiskt kan agera på, och prissättningen är tillräckligt transparent för att mindre team inte ska känna sig utestängda.
Squadcasts bästa funktioner
- Automatisera jourplanering med flexibla eskaleringar och överstyrningar
- Minska varningsutmattningen genom att konsolidera och deduplicera aviseringar
- Lös incidenter snabbare med runbooks och arbetsflöden
- Håll intressenterna informerade genom anpassningsbara statussidor
- Samla in efteranalyser och insikter för att skapa en lärandekultur
Begränsningar för Squadcast
- Schema-vyerna kan bli överfulla när många scheman är aktiva, vilket gör det svårare att snabbt se vem som har jour.
- Det har rapporterats om tillfälliga fördröjningar i synkroniseringen av varningar från vissa integrationer.
- Gratisplanen är begränsad för team som vill ha statussidor och mer djupgående analyser.
Priser för Squadcast
- Pro: 12 $/månad per användare
- Premium: 19 $/månad per användare
- Enterprise: Anpassad prissättning
Squadcast-betyg och recensioner
- G2: 4,4/5 (över 300 recensioner)
- Capterra: Inte tillräckligt med recensioner
Vad användarna säger om Squadcast
Denna G2-recension nämnde:
Squadcast kan ta emot information från olika övervakningsverktyg som vi har och det är enkelt att ställa in scheman och överstyrningar för vem som ska varnas för olika typer av problem.
Squadcast kan ta emot information från olika övervakningsverktyg som vi har och det är enkelt att ställa in scheman och överstyrningar för vem som ska varnas för olika typer av problem.
📖 Läs också: Riskhantering inom cybersäkerhet
8. FireHydrant (bäst för automatiserade runbooks och tjänsteägande)
Denna programvara för incidenthantering erbjuder en välstrukturerad process som håller tjänsterna igång utan problem.
FireHydrant fokuserar på responser kring runbooks, en servicekatalog och en delad arbetsyta. Anmäl en incident så skapar plattformen en kanal i Slack eller Teams, bifogar rätt runbook, hämtar ägarskap från servicekatalogen och startar en granskbar tidslinje.
Samtidigt håller dess AI omkostnaderna nere med omedelbara incidentöversikter, förslag på uppdateringar till intressenter och live-transkriptioner av möten, så att teamet kan fokusera på att hantera incidenten istället för att ta anteckningar.
Teamen lyfter också fram responsiv support och en API-först-strategi med Terraform som gör det möjligt för driftschefer att integrera FireHydrant i befintliga arbetsflöden utan problem.
FireHydrants bästa funktioner
- Automatisera incidenthantering med runbooks som kodifierar bästa praxis
- Hantera jourplaner och larm med Signals, komplett med eskaleringspolicyer.
- Centralisera ägarskapet genom servicekatalogen så att rätt tekniker kan reagera omedelbart.
- Samarbeta direkt i Slack eller Teams med automatiskt genererade kanaler och uppdateringar.
- Använd AI-berikade retrospektiver och analyser för att få insikter och öka tillförlitligheten över tid.
FireHydrants begränsningar
- Avancerade automatiseringsfunktioner kräver högre prisnivåer.
- Inlärningskurva för att konfigurera anpassade arbetsflöden och integrationer
- Begränsat antal responspersonal och runbooks i startpaketet
Priser för FireHydrant
- Gratis: Två veckors provperiod
- Platform Pro: 9 600 USD/år per användare
- Enterprise: Anpassad prissättning
FireHydrant-betyg och recensioner
- G2: 4,5/5 (över 130 recensioner)
- Capterra: Inte tillräckligt med recensioner
Vad användarna säger om FireHydrant
Denna G2-användare skrev:
FireHydrant fungerar helt utanför Slack eller andra chatt-/samarbetsverktyg och integreras så att du kan öppna/uppdatera/lösa incidenter utan att behöva lämna den plats där incidenthanteringen sker.
FireHydrant fungerar helt utanför Slack eller andra chatt-/samarbetsverktyg och integreras så att du kan öppna/uppdatera/lösa incidenter utan att behöva lämna den plats där incidenthanteringen sker.
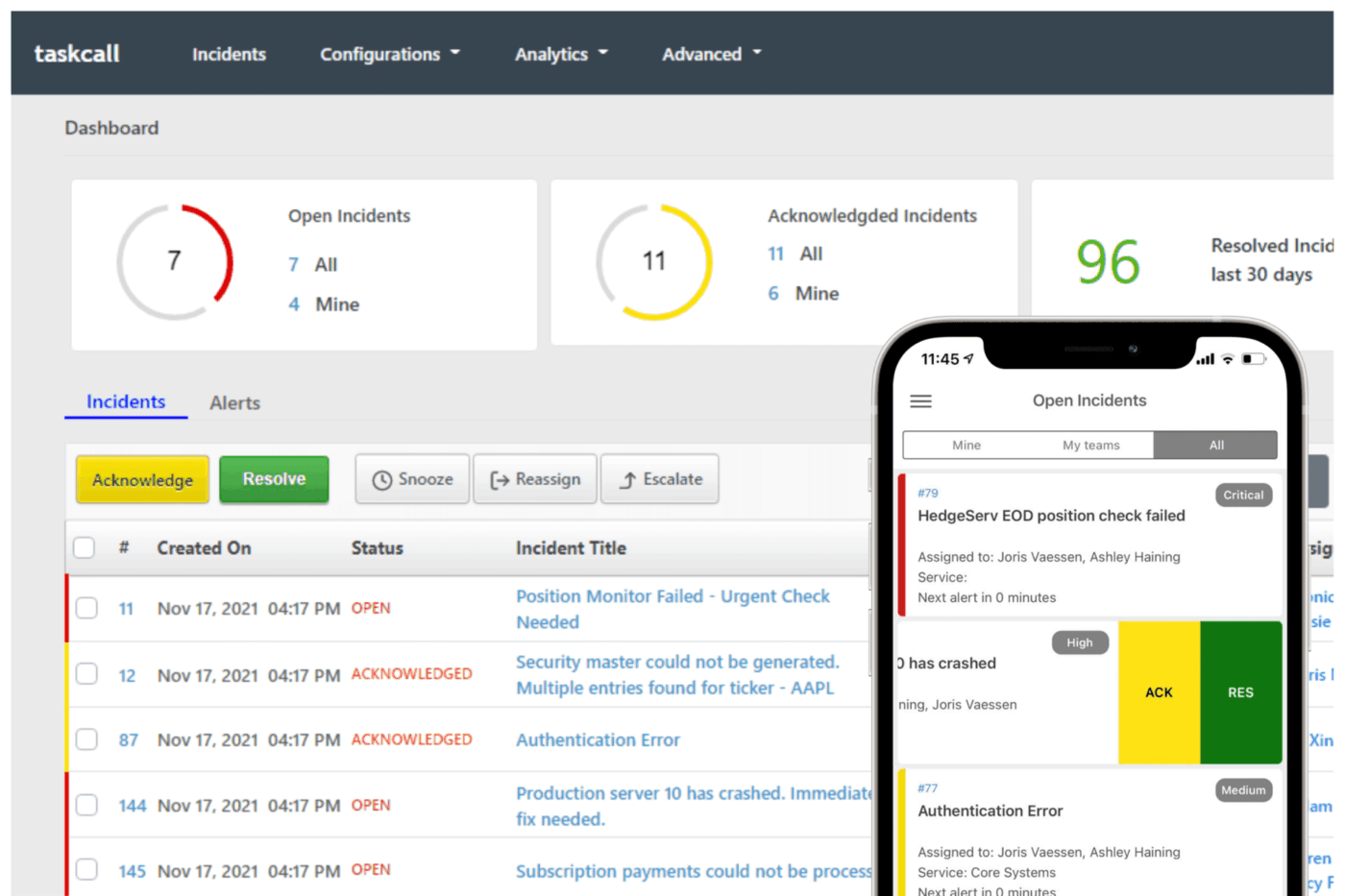
9. TaskCall (Bäst för prisvärd incidenthantering med automatisering)
I en nyligen genomförd studie om cyberrisker identifierades incidenthantering som en av de viktigaste kontrollerna som organisationer måste stärka för att minska exponeringen.
Det understryker hur viktigt det har blivit med snabba och tillförlitliga arbetsflöden för incidenthantering.
Team snubblar vanligtvis inte på själva larmet utan på den kaos som följer. Vem är verkligen på plats just nu? Tillhör larmet appen, infrastrukturen eller kundtjänsten? Hur håller du ledarna informerade utan att ta över åtgärden?
TaskCall hanterar dessa situationer direkt. Jourtjänstgöringen bestäms utifrån incidentens innehåll, så att ärendet hamnar hos rätt person och automatisk eskalering täcker luckor. Meddelanden skickas via telefon, SMS, push-meddelanden, e-post eller chatt.
För att minska bruset korrelerar händelseinformationen dubbletter och undertrycker pingar med lågt värde. Kontexten sammanfogas genom att hämta signaler från verktyg som AWS, Datadog, Slack, Jira och Zendesk, vilket innebär att ingenjörerna ser effekten och ansvaret istället för en rå ström av varningar.
TaskCalls bästa funktioner
- Automatisera jourplanering med dynamiska rotationer och eskaleringar på flera nivåer
- Minska störningarna med AI-driven händelseinformation och villkorlig dirigering.
- Hantera incidenter inom DevOps, IT-Ops och BizOps på en enda plattform.
- Integrera med övervaknings-, loggnings- och supportverktyg som AWS, Jira, Zendesk och Slack.
- Ge full täckning med mobilappar, push-meddelanden, SMS och röstvarningar.
Begränsningar för TaskCall
- Gratisplan begränsad till fem användare, vilket kanske inte räcker för växande team
- De flesta analysverktyg och instrumentpaneler är begränsade till de dyrare abonnemangen.
Priser för TaskCall
- Gratis
- Starter: 9 $/månad per användare
- Företag: 19 $/månad per användare
- Digitala operationer: 29 $/månad per användare
TaskCall-betyg och recensioner
- G2: Inte tillräckligt med recensioner
- Capterra: Inte tillräckligt med recensioner
10. ilert (Bäst för AI-baserad incidenthantering med fokus på integritet)
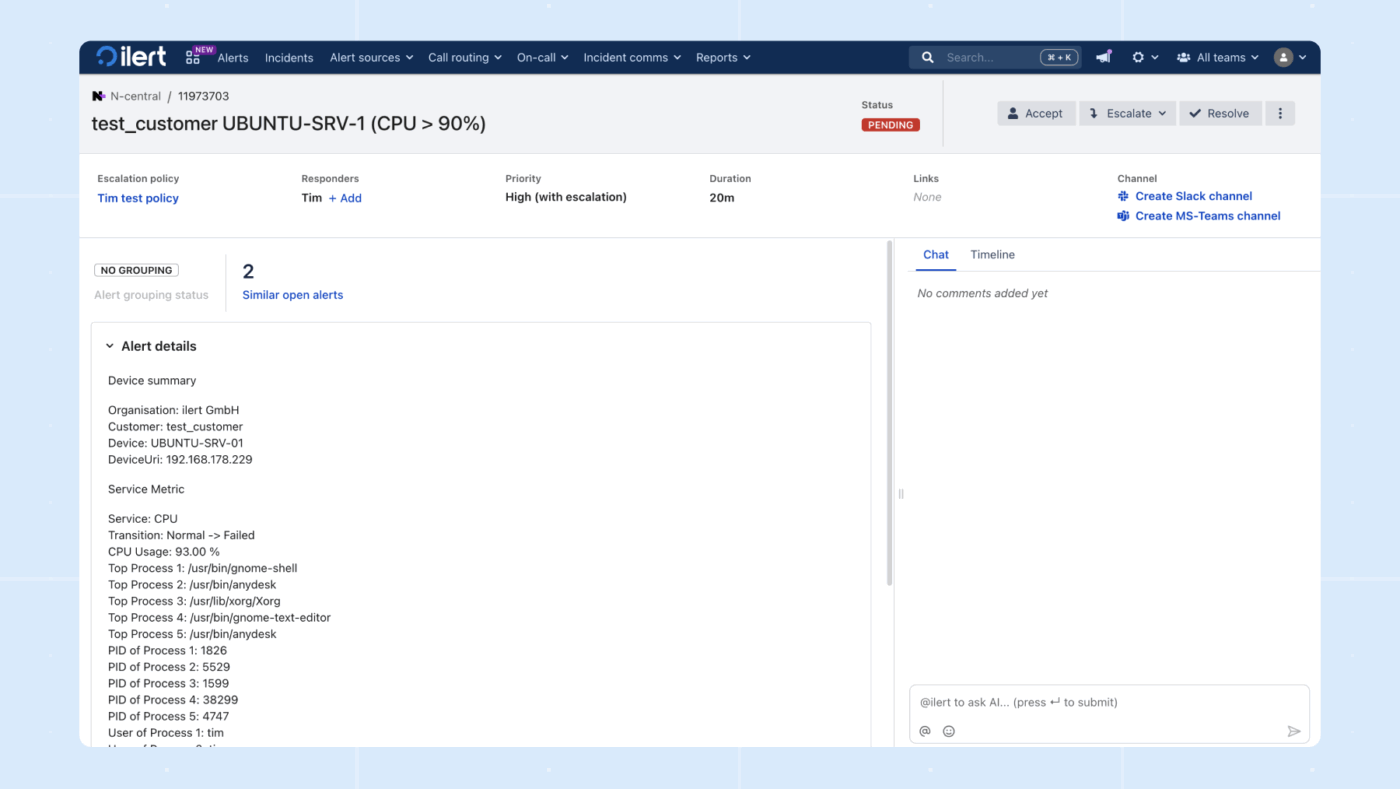
ilert är en plattform för jourhantering och incidentvarningar med starkt fokus på tillförlitlighet och dataintegritet. Den hjälper team att säkerställa att kritiska varningar från övervakningssystem når rätt jourhavande tekniker omedelbart.
Plattformen erbjuder flexibel jourplanering, flerlagriga eskaleringspolicyer och aviseringar via flera kanaler, inklusive push-meddelanden, SMS och röstsamtal.
Vidarebefordran som respekterar det aktuella schemat och eskaleringsvägen innebär att kundsamtal når rätt person istället för att studsa runt i ett telefonnätverk.
I Slack eller Teams arbetar responspersonalen med incidenten i chatten medan Ilert registrerar sammanhang, tidslinjer och uppföljningar.
AI Voice Agent svarar på din hotline, samlar in rätt information och meddelar jourhavande tekniker omedelbart. Responder analyserar mätvärden, loggar och senaste ändringar i hela din stack, identifierar troliga orsaker, föreslår vem som bör kopplas in och föreslår till och med en återställningsväg för snabbare avhjälpande.
Du har kontroll över varje steg.
ilert bästa funktioner
- Tillhandahåll tillförlitliga varningar via flera kanaler, såsom röstmeddelanden, SMS, push-meddelanden och chatt.
- Automatisera jourhanteringen med schemaläggning och eskaleringsvägar
- Leverera snabba uppdateringar via AI-drivna statussidor och kommunikation med intressenter.
- Använd ilert Responder AI för att analysera incidenter, hitta grundorsaker och föreslå åtgärder.
- Integrera med övervaknings- och ITSM-verktyg som Prometheus, Datadog, Jira och Slack.
ilert-begränsningar
- Priserna kan kännas höga för mindre team.
- Vissa integrationer kräver extra installationsarbete.
- Mobilappen skulle kunna dra nytta av mer avancerade funktioner
ilert-priser
- Gratis
- Pro: 24 $/månad per användare
- Skala: 49 $/månad per användare
- Enterprise: Anpassad prissättning
ilert-betyg och recensioner
- G2: Inte tillräckligt med recensioner
- Capterra: 4,7/5 (över 60 recensioner)
Vad användarna säger om ilert
Denna Capterra-recension rapporterade:
Jag tycker att detta verktyg är mycket intuitivt och effektivt för att hantera jourtjänstgöring inom IT-team. Det erbjuder flexibilitet genom att möjliggöra svar direkt via appen, SMS eller telefonsamtal, vilket gör det särskilt praktiskt i verkliga situationer.
Jag tycker att detta verktyg är mycket intuitivt och effektivt för att hantera jourtjänstgöring inom IT-team. Det erbjuder flexibilitet genom att möjliggöra svar direkt via appen, SMS eller telefonsamtal, vilket gör det särskilt praktiskt i verkliga situationer.
11. Zenduty (Bäst för AI-driven incidenthantering i stor skala)
Zenduty hjälper teknik- och DevOps-team att fokusera på de signaler som är viktiga, vilket minskar MTTR (Mean Time To Resolution) och ger organisationer en enda, pålitlig plattform för att hantera incidenter.
Användarna berömmer konsekvent de snabba och pålitliga varningarna, med push-meddelanden, samtal och SMS som kommer fram utan fördröjning, så att jourhavande tekniker kan bekräfta från meddelandet och återgå till arbetet. Teamen uppskattar också att de kan anpassa meddelanden efter allvarlighetsgrad, tjänst eller incidenttyp, så att rätt person kontaktas vid rätt tillfälle istället för alla på en gång.
Plattformen stöder samarbetsbaserad incidenthantering med incidentroller, uppgiftsmallar och integrerade kommunikationskanaler. En viktig funktion är dess Incident Command System (ICS)-baserade tillvägagångssätt, som ger ett strukturerat ramverk för hantering av storskaliga incidenter.
Om du vill byta från Opsgenie är Zenduty ett bra alternativ, med migreringssupport som fått positiva recensioner.
Zendutys bästa funktioner
- Erbjud AI-driven incidenthantering med ZenAI
- Stöd avancerad jourplanering med anpassningsbara rotationer och eskaleringar
- Automatisera incidenthanteringsmanualer så att uppgifter och uppföljningar spåras konsekvent.
- Integrera smidigt med över 150 verktyg som Slack, Teams, Jira, Datadog och Grafana.
- Leverera mobilvarningar i realtid på iOS, Android och till och med smartklockor
Zendutys begränsningar
- Sökfunktionen kan blanda flera incidenter, vilket gör spårningen svårare.
- Vissa avancerade funktioner är begränsade till högre prisnivåer.
- Överlappande aviseringar i komplexa konfigurationer kan leda till dubbla larm.
Priser för Zenduty
- Gratis
- Starter: 6 $/månad per användare
- Tillväxt: 16 $/månad per användare
- Enterprise: 25 USD/månad per användare
Zenduty-betyg och recensioner
- G2: 4,6/5 (över 135 recensioner)
- Capterra: Inte tillräckligt med recensioner
Vad användarna säger om Zenduty
I denna G2-recension står det:
Det jag gillar mest med Zenduty är dess analysdrivna insikter. Genom att analysera incidenter kan vi spåra trender – till exempel vilka dagar, tjänster eller skift som upplevt fler problem, identifiera vad som gått fel och fastställa vilka områden som behöver förbättras.
Det jag gillar mest med Zenduty är dess analysdrivna insikter. Genom att analysera incidenter kan vi spåra trender – till exempel vilka dagar, tjänster eller skift som upplevt fler problem, identifiera vad som gått fel och fastställa vilka områden som behöver förbättras.
📖 Läs också: Bästa programvaran för IT-driftshantering
12. Incident. io (Bäst för incidenthantering i Slack)
Låt oss för ett ögonblick låtsas att vi befinner oss mitt i en incident. Personsökaren går igång. Folk vaknar. I Opsgenie bekräftar du, letar sedan efter rätt rum och kopierar sedan kontexten till ännu en plats så att alla kan se vad som händer.
Det är just det här steget som de flesta team vill förbättra. Det är här incident.io skiljer sig från mängden.
Du gör din anmälan direkt i Slack, och ett överskådligt fönster visas med roller, tidsplan och de två eller tre nästa stegen redan utstakade. Du kan ringa, skicka sms, mejla eller bara trycka för att bekräfta. Arbetet påbörjas omedelbart och förblir synligt.
Användarna beskriver samma rytm när de byter. En kanal startar med endast den signal du behöver. Appen påminner om uppföljningar och skapar en tydlig sammanfattning medan du fortfarande felsöker. Statusuppdateringar för kunder är redo att skickas utan att du behöver lämna tråden. Det i sig minskar det prat som vanligtvis virvlar runt i sidorum och DM:er.
Införandet har varit enkelt för team av mycket olika storlek. Mindre grupper talar om att koppla det till Linear och New Relic på ett par veckor och få verkligt värde redan från dag ett. Större organisationer berättar att de rullade ut det över flera team på ungefär en månad och inte behövde skjuta upp arbetet med roadmapen för att göra det.
Incident. io bästa funktioner
- Hantera incidenter från början till slut direkt i Slack eller Microsoft Teams
- Använd AI SRE för att föreslå lösningar, undersöka problem och utarbeta kommunikation
- Hantera jourplaner med AI-driven brusreducering
- Automatisera uppdateringar av statussidan för kunder och intressenter
- Få insikter om trender, tidslinjer och MTTx-mått med hjälp av dashboards.
Begränsningar för Incident.io
- Gränssnittet kan kännas överbelastat med många Slack-meddelanden.
- Avancerad konfiguration (som eskaleringsvägar) kan kräva finjustering.
- Vissa AI-funktioner är begränsade till engelska.
Priser för Incident.io
- Basic: Gratis
- Team: 19 $/månad per användare
- Pro: 25 $/månad per användare
- Enterprise: Anpassad prissättning
Incident. io betyg och recensioner
- G2: 4,8/5 (över 180 recensioner)
- Capterra: Inte tillräckligt med recensioner
Vad användarna säger om Incident. io
Denna G2-recension delade:
För mig har incident.io hittat den perfekta balansen mellan att inte vara i vägen och samtidigt tillhandahålla struktur, processer och datainsamling för incidenthantering.
För mig har incident.io hittat den perfekta balansen mellan att inte vara i vägen och samtidigt tillhandahålla struktur, processer och datainsamling för incidenthantering.
💡Proffstips: Använd fördefinierade agenter för att svara på teamets frågor eller dela uppdateringar, eller konfigurera en anpassad ClickUp AI-agent för att övervaka uppgiftsstatus och förfallodatum och skicka påminnelser, eskalera problem eller uppdatera status efter behov för att driva arbetet framåt.
Den här videon visar hur:
Vad du kan förvänta dig under och efter migreringen från Opsgenie
Att byta från Opsgenie kan kännas som att packa ihop ett hus som du har bott i i flera år. Varje schema, eskaleringsregel och integration har sin plats, och tanken på att flytta allt till ett nytt hem kan kännas överväldigande.
Atlassian erbjuder ett migreringsverktyg i appen för övergång till Jira Service Management eller Compass. Processen är strukturerad, förutsägbar och utformad för att minimera störningar.
Om du bestämmer dig för att använda något av dessa verktyg kan du bara granska din plan, ange migreringsdatum och låta verktyget sköta det tunga arbetet. Låt oss se hur det fungerar och bedöma om det är ett bra val för din organisation.
Migreringsflödet i korthet
Steg 1 → Granska och välj din väg
Utvärdera din Opsgenie-plan och bestäm om Jira Service Management (ITSM-fokuserat) eller Compass (utvecklingsfokuserat) är rätt val.
Steg 2 → Planera din migreringsdag
Välj en tidsplan som passar din faktureringscykel och ditt teams beredskap.
Steg 3 → Godkänn fakturering
Din faktureringsadministratör hos Atlassian bekräftar planen så att den nya produkten kan levereras.
Steg 4 → Datamigrering i bakgrunden
Opsgenie-data börjar synkroniseras medan ditt team fortsätter att arbeta som vanligt.
Steg 5 → Övergång och avstängning
Du har 120 dagar på dig att slutföra flytten innan Opsgenie stängs av.
Kortfattat kan du förvänta dig följande:
- Använd det guidade migreringsverktyget för att automatisera det tunga arbetet.
- Behåll full tillgång till Opsgenie under och efter migreringen fram till avstängningen.
- Följ personliga migreringsguider i Jira Service Management eller Compass.
- Justera arbetsflöden och konfigurera om inställningar under den 120 dagar långa övergångsperioden.
- Säkerställ kontinuiteten i varningar, scheman och integrationer utan avbrott.
För- och nackdelar med att migrera från Opsgenie till Jira Service Management
Fördelar:
- Det kan skapa ett smidigt, enhetligt arbetsflöde.
- För team som redan har investerat mycket i Atlassians ekosystem kan det vara ett bekvämt och kostnadseffektivt beslut.
- Jiras effektiva analys efter incidenter förenklar processen för att spåra uppföljningsåtgärder.
- Genom att samla incidentdata i JSM får du mer kraftfull och holistisk rapportering.
Nackdelar:
- Vissa av de avancerade funktionerna i fristående Opsgenie kanske inte är omedelbart tillgängliga i JSM.
- Att flytta till en bredare JSM-miljö kan öka komplexiteten och störningarna.
- Teamen kommer att behöva omskolas i det nya gränssnittet och arbetsflödena inom JSM.
Här är några tankar från Redditors om ämnet
Denna Redditor ansåg att flytten hade fungerat bra för dem överlag:
Det gick inte så dåligt för oss. Jag måste se över rollerna och behörigheterna igen, men allt verkade fungera ganska bra, förutom om du har exakt samma Jira-teamnamn som OpsGenies motsvarighet. De gick inte att slå samman och några av dem gick sönder. Jag rekommenderar att du ändrar dem om du har det.
Det gick inte så dåligt för oss. Jag måste se över rollerna och behörigheterna igen, men allt verkade fungera ganska bra, förutom om du har exakt samma Jira-teamnamn som OpsGenies motsvarighet. De gick inte att slå samman och några av dem gick sönder. Jag rekommenderar att du ändrar dem om du har det.
Här är en annan person som uppenbarligen inte har haft den bästa upplevelsen:
Om någon överväger detta alternativ: vi bytte till Jira Service Management, det ingår i vårt paket som vi redan har betalat för (företaget sparar aggressivt). Det är så dåligt att jag inte ens kan förklara. Överväg det inte som ett alternativ.
Om någon överväger detta alternativ: vi bytte till Jira Service Management, det ingår i vårt paket som vi redan har betalat för (företaget sparar aggressivt). Det är så dåligt att jag inte ens kan förklara. Överväg det inte som ett alternativ.
Och en annan som redan efter sex månader med JSM funderar på att byta igen:
JSM är hemskt. Det är inte alls jämförbart med PagerDuty, Rootly eller Incident. io. Vi bytte också till det för ungefär sex månader sedan på jobbet och letar redan efter alternativ. Det är så oflexibelt, har nästan inga integrationer, har inte bra Slack-stöd och jourlarmen och sidorna missas av ingenjörerna med ganska hög frekvens (vi hade aldrig detta problem med OpeGenie).
JSM är hemskt. Det är inte alls jämförbart med PagerDuty, Rootly eller Incident. io. Vi bytte också till det för ungefär sex månader sedan på jobbet och letar redan efter alternativ. Det är så oflexibelt, har nästan inga integrationer, har inte bra Slack-stöd och jourlarmen och sidorna missas av ingenjörerna med ganska hög frekvens (vi hade aldrig detta problem med OpeGenie).
Det andra alternativet som Atlassian erbjuder, Compass, är inte ett direkt alternativ till Opsgenie. Det är istället en plattform för utvecklare som är utformad för att kartlägga och hantera komponenter, tjänster och beroenden i en komplex programvaruarkitektur.
Vi rekommenderar att du väger dessa faktorer innan du bestämmer dig för det Opsgenie-alternativ som passar bäst för ditt team.
Opsgenie ringer, ClickUp svarar
Att byta från Opsgenie kan kännas som ett stort steg, men se det som en möjlighet att göra livet enklare för ditt team.
Du har sett hur de andra verktygen står sig, var och ett med sina egna styrkor, men också med sina begränsningar.
ClickUp vinner dock tyst och stilla hjärtan. 🤗
Här är varför: Det samlar dina uppgifter, din kommunikation och dina arbetsflöden på ett och samma ställe. Du behöver inte hoppa mellan olika skärmar eller lappa ihop separata verktyg. Istället håller ditt team kontakten, har tydliga prioriteringar och är säkra på vad som behöver göras härnäst.
Att välja rätt lösning för incidenthantering handlar inte bara om varningar – det handlar om att skapa ett robust ramverk för incidenthantering som stöder långsiktig operativ effektivitet. Med ClickUp kan ditt team proaktivt hantera incidenter samtidigt som det minskar störningar och skapar konsekvens i alla insatser. 😌
Om du är redo för mindre huvudvärk och mer tydlighet är det dags att registrera dig för ClickUp!
Vanliga frågor (FAQ)
Opsgenie-migreringar måste schemaläggas före april 2027. Efter det datumet kommer Opsgenie-data inte längre att vara tillgängliga.
Några av de starkaste alternativen är Jira Service Management, PagerDuty, FireHydrant, TaskCall, ilert, Zenduty och incident.io. Var och en erbjuder en olika balans mellan jourhantering, automatisering och integrationer. Men om du vill ha en allt-i-ett-plattform med AI-stöd som samlar dina arbetsflöden, din kommunikation och din dokumentation på ett ställe, välj ClickUp.
Jira Service Management innehåller de flesta av Opsgenies kärnfunktioner, såsom larm, jourplanering och incidentarbetsflöden, men vissa avancerade funktioner kan skilja sig åt. Compass är ett alternativ för utvecklingsteam som fokuserar på servicekataloger och komponentuppföljning.
Ja. Atlassian tillhandahåller ett migreringsverktyg i appen som automatiskt flyttar varningar, scheman och eskaleringspolicyer. Du kan till och med testa migreringen i ett demokonto innan du bestämmer dig.
Ja. Verktyg som Cabot, OpenDuty och Alertmanager kan anpassas som ersättare för öppen källkod, men de kan kräva mer installation och underhåll.
Kostnaderna beror på vilken plattform du väljer. Jira Service Management, Compass och andra alternativ erbjuder differentierade priser, ofta per användare och månad. Vissa open source-verktyg är gratis att använda men kräver infrastruktur- och supportkostnader.
Ja. Ditt team kan fortsätta använda Opsgenie under migreringsperioden, och integrationerna förblir aktiva tills Opsgenie stängs av permanent. Därefter måste de konfigureras om i din nya plattform.