
Били ли сте някога по време на вечеря, когато телефонът ви зазвъни с „критично предупреждение“, което в крайна сметка се оказва нищо повече от рутинни записи? Това е досадно, но поне знаете, че Opsgenie ви пази гърба.
Сега идва истинското предизвикателство: Atlassian спря да продава Opsgenie и скоро пълната поддръжка ще приключи. За екипите, които разчитат на него за планиране на дежурства, ескалации и сигнали, това е тревожен сигнал, който никой не е искал.
Хубавото е, че не е нужно да чакате до последния момент. Ако си отделите време да разгледате другите опции сега, вашият екип ще може да се приспособи към новата рутина без стреса от прибързани решения.
В тази статия ще разгледаме най-добрите алтернативи на Opsgenie, ще сравним техните предимства и ще покажем защо ClickUp предлага на вашия екип по-спокоен и по-свързан начин на работа.
⭐ Представен шаблон
Позволете на вашите ИТ екипи да регистрират инциденти точно и да откриват тенденции, които водят до дългосрочни подобрения. Шаблонът за доклад за ИТ инциденти на ClickUp ви помага да записвате подробностите за инцидентите в последователен и надежден формат.

Opsgenie алтернативи на един поглед
Ето едно бързо сравнение на най-добрите алтернативи на Opsgenie, което ще ви помогне да изберете най-подходящия вариант въз основа на ключови функции, цени и потребителски оценки.
| Инструмент | Най-подходящ за | Основни функции | Цени* | Оценки |
| ClickUp | Цялостно управление на работата с работни потоци за инциденти, планиране на ресурсите и автоматизация за екипи от всякакъв размер. | Персонализирани известия, автоматизация за ескалации, задачи и списъци за инциденти, персонализирани статуси, чат в реално време, табла за преглед след инцидент, над 1000 интеграции | Наличен е безплатен план; персонализиране за предприятия | G2: 4,7/5 (10 500+) Capterra: 4,6/5 (4500+) |
| PagerDuty | Сигнализиране за инциденти в реално време и автоматизация в мащаб за големи компании | Многоканални сигнали, политики за ескалация, планиране на дежурства, AIOps за намаляване на шума, интеграции с над 600 инструмента | Безплатен план; Платени планове от 25 $/месец на потребител | G2: 4,5/5 (900+) Capterra: 4,6/5 (200+) |
| xMatters | Икономично управление на инциденти и автоматизация на работния процес за разрастващи се екипи | Автоматизирани работни процеси, адаптивно управление на инциденти, планиране на дежурства, сигнална информация, над 200 интеграции | Безплатен план; Платени планове от 9 $/месец на потребител | G2: 4,5/5 (670+) Capterra: 4,6/5 (140+) |
| AlertOps | Намаляване на шума и бърза реакция с помощта на изкуствен интелект за малки и средни екипи | AI OpsIQ за намаляване на шума, гъвкави ескалации, покритие на дежурства, автоматизация на работния процес без код, над 200 интеграции | Безплатен план; Платени планове от 10 $/месец на потребител | G2: 4,7/5 (150+) Capterra: 4,7/5 (20+) |
| Splunk On-Call | Опростяване на графиците за дежурства и намаляване на изтощението при големи екипи | Автоматизирани ескалации, мобилни приложения, балансиране на натоварването, ML препоръки, одитни следи | Персонализирани цени | G2: 4,6/5 (50+) Capterra: 4,5/5 (30+) |
| Datadog | Пълна наблюдаемост с мониторинг на сигурността за предприятия | Мониторинг на инфраструктура + логове + приложения, облачна сигурност, откриване на аномалии с AI, над 900 интеграции | Безплатен план; Платени планове от 15 $/месец на потребител | G2: 4,4/5 (660+) Capterra: 4,6/5 (320+) |
| Squadcast | Унифицирани дежурства и реагиране на инциденти с изгодна цена за средни по размер екипи | Автоматизирани графици, дедупликация, ръководства, страници със статус, постмортеми | Безплатен план; Платени планове от 12 $/месец на потребител | G2: 4. 4/5 (300+) Capterra: Недостатъчно отзиви |
| FireHydrant | Автоматизирани ръководства и собственост върху услугите за предприятия | Runbooks, Signals планиране на дежурства, Service Catalog, Slack/Teams сътрудничество, AI-обогатени ретроспективи | Безплатен план; Платени планове от 9600 $/година на потребител | G2: 4,5/5 (130+) Capterra: Недостатъчно отзиви |
| TaskCall | Достъпно управление на инциденти с автоматизация за средни и големи екипи | Динамично планиране на дежурства, маршрутизиране с изкуствен интелект, многоканални сигнали, покритие DevOps + BizOps | Безплатен план; Платени планове от 9 $/месец на потребител | G2: Недостатъчно рецензии Capterra: Недостатъчно рецензии |
| ilert | Управление на инциденти с приоритет на изкуствения интелект и фокус върху поверителността за разрастващи се екипи | Многоканални сигнали, AI Responder асистент, график за дежурства, автоматизирани страници за състоянието, интеграции с ITSM + инструменти за мониторинг | Безплатен план; Платени планове от 24 $/месец на потребител | G2: Недостатъчно рецензии Capterra: 4,7/5 (60+) |
| Zenduty | Реагиране на инциденти с помощта на изкуствен интелект в мащаб за малки и големи екипи | Управление на инциденти ZenAI, разширено планиране на дежурства, автоматизирани наръчници, над 150 интеграции | Безплатен план; Платени планове от 6 $/месец на потребител | G2: 4,6/5 (135+) Capterra: Недостатъчно отзиви |
| Incident. io | Реагиране на инциденти в Slack за средни и големи компании | Цялостни инциденти в Slack, AI SRE, график за дежурства, автоматизирани страници за състоянието, табла с информация | Безплатен план; Платени планове от 19 $/месец на потребител | G2: 4,8/5 (180+) Capterra: Недостатъчно отзиви |
Ключови критерии за оценка на алтернативите на Opsgenie
Знам, че имаме почти 2 години, преди да го изтеглят напълно, но не виждам причина да чакам 😛
Знам, че имаме почти 2 години, преди да го изтеглят напълно, но не виждам причина да чакам 😛
Този коментар на потребител на Reddit отразява реалността, с която се сблъскват много IT PMO екипи. Да, Opsgenie беше добър спътник в продължение на години, но разчитането само на него, защото е познат, няма да помогне, след като поддръжката приключи.
Разумното решение в момента е да разгледате какво е направило Opsgenie полезен и да използвате същите качества като ориентир при избора на следващата си платформа за управление на инциденти.
Ето някои от характеристиките, на които си заслужава да обърнете внимание:
- Изпращайте навременни сигнали чрез различни канали като телефон, имейл, SMS или push известия.
- Поддържайте целенасочени известия, така че правилният човек да бъде информиран, без да се претоварва останалата част от екипа.
- Въведете политики за ескалация, които гарантират, че критичните инциденти никога няма да бъдат пренебрегнати.
- Централизирайте актуализациите за инциденти, за да могат екипите да виждат цялостната картина, докато управляват инцидентите.
- Предоставяйте прегледи след инциденти, за да се поучите от подобни инциденти и да се подобрите с времето.
- Предлагайте възможности за интеграция с инструменти, на които вашите ИТ екипи вече разчитат.
Opsgenie е изградил репутацията си, помагайки на DevOps екипите да намалят умората от сигналите, да поддържат ясни графици за дежурства и да разрешават инциденти без объркване. Докато разглеждате всяка алтернатива на Opsgenie, дръжте се на същите ценности.
📖 Прочетете също: Най-добрите софтуерни инструменти за управление на инциденти за ИТ екипи
12-те най-добри алтернативи на Opsgenie
Opsgenie може и да се изчерпва, но това не означава, че вашият екип трябва да загуби инерция. Ето някои подходящи заместители, които ще дадат увереност на вашите оперативни екипи в критични моменти.
Как оценяваме софтуера в ClickUp
Нашият редакционен екип следва прозрачен, подкрепен с проучвания и независим от доставчиците процес, така че можете да сте сигурни, че нашите препоръки се основават на реалната стойност на продуктите.
Ето подробно описание на това как преглеждаме софтуера в ClickUp.
1. ClickUp (най-добър за обработка на работни потоци при инциденти, заедно с по-широко управление на проекти)
Когато напускат Opsgenie, екипите се притесняват по-малко за загубата на сигнали и повече за адаптирането към нов работен процес за управление на инциденти.
Основният проблем е разпръскването на работата, при което актуализациите, графиците и политиките са разпръснати в различни приложения, имейли и документи. Тази фрагментация отнема енергия и принуждава екипите да започват от нулата при всеки инцидент.
Проучвания показват, че служителите прекарват 117 минути в преглеждане на имейли и 153 минути в съобщения в Microsoft Teams всеки делничен ден, с прекъсвания на всеки няколко минути.
ClickUp се явява като алтернатива на Opsgenie, като обединява цялата тази разкъсана работа в едно конвергентно работно пространство. Ето как неговите функции отговарят на тези предизвикателства в дълбочина.
Автоматизирани работни процеси за реагиране
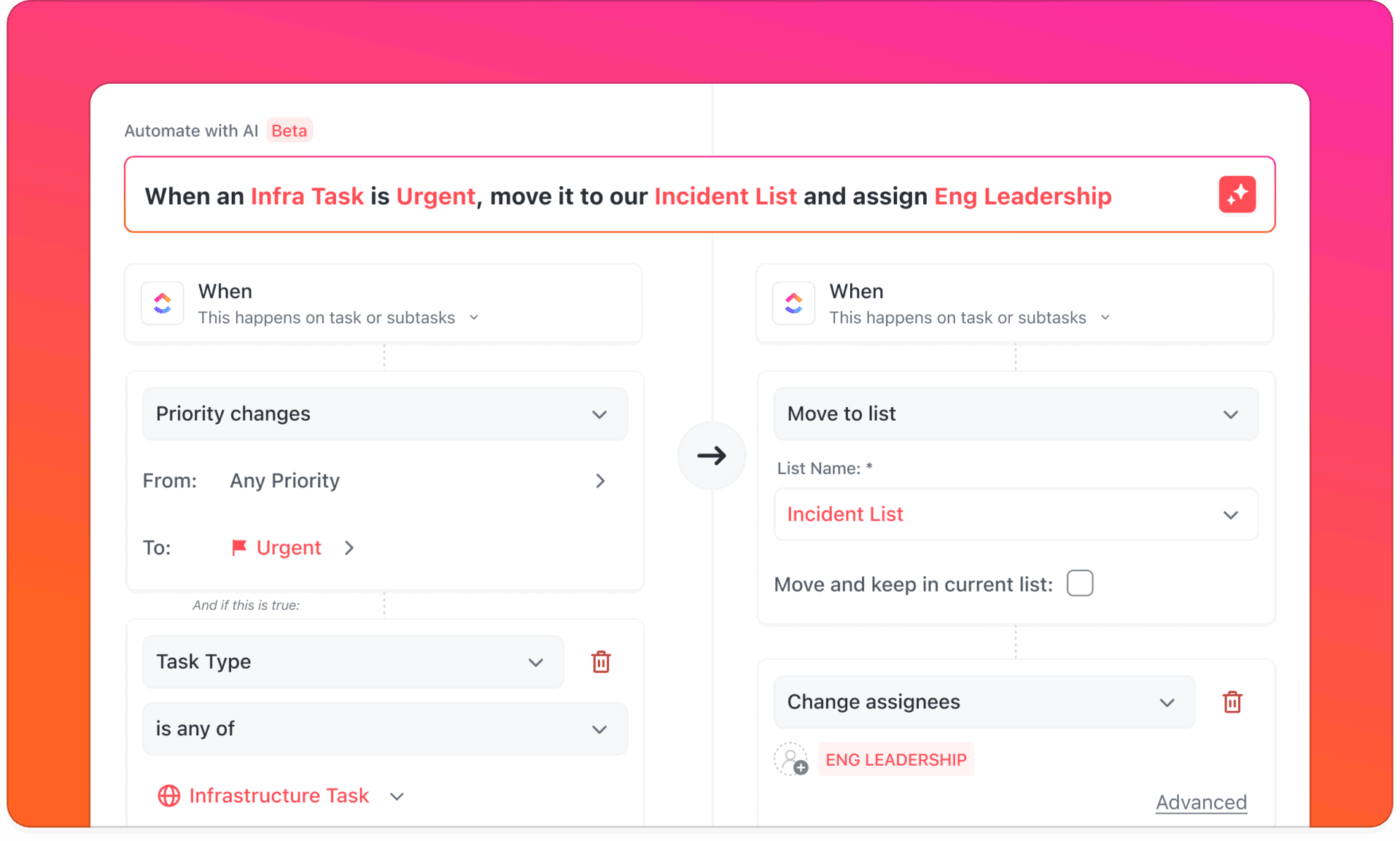
С сигналите, идващи от инструменти за мониторинг, чат инструменти и имейл, е трудно да се прецени какво е важно и кой трябва да реагира.
С ClickUp Automations и AI Agents сигналите се превръщат в значими действия. Получените сигнали могат автоматично да създават и възлагат задачи на дежурния инженер, като уведомяват правилния човек, без да разсейват останалата част от екипа.
Ако няма отговор в рамките на определено време, системата автоматично ескалира проблема според вашите стандартни процедури.
📌 Пример: Съобщава се за прекъсване на сървъра с висок приоритет. ClickUp Automations създава нова задача в списъка ви с инциденти, маркира я като спешна, възлага я на дежурния инженер и изпраща мобилно push известие. В същото време вашият персонализиран AI Agent публикува кратко съобщение в канала за инциденти в ClickUp Chat, така че екипът да бъде информиран, но не и претоварен.
Яснота и отговорност по отношение на задачите
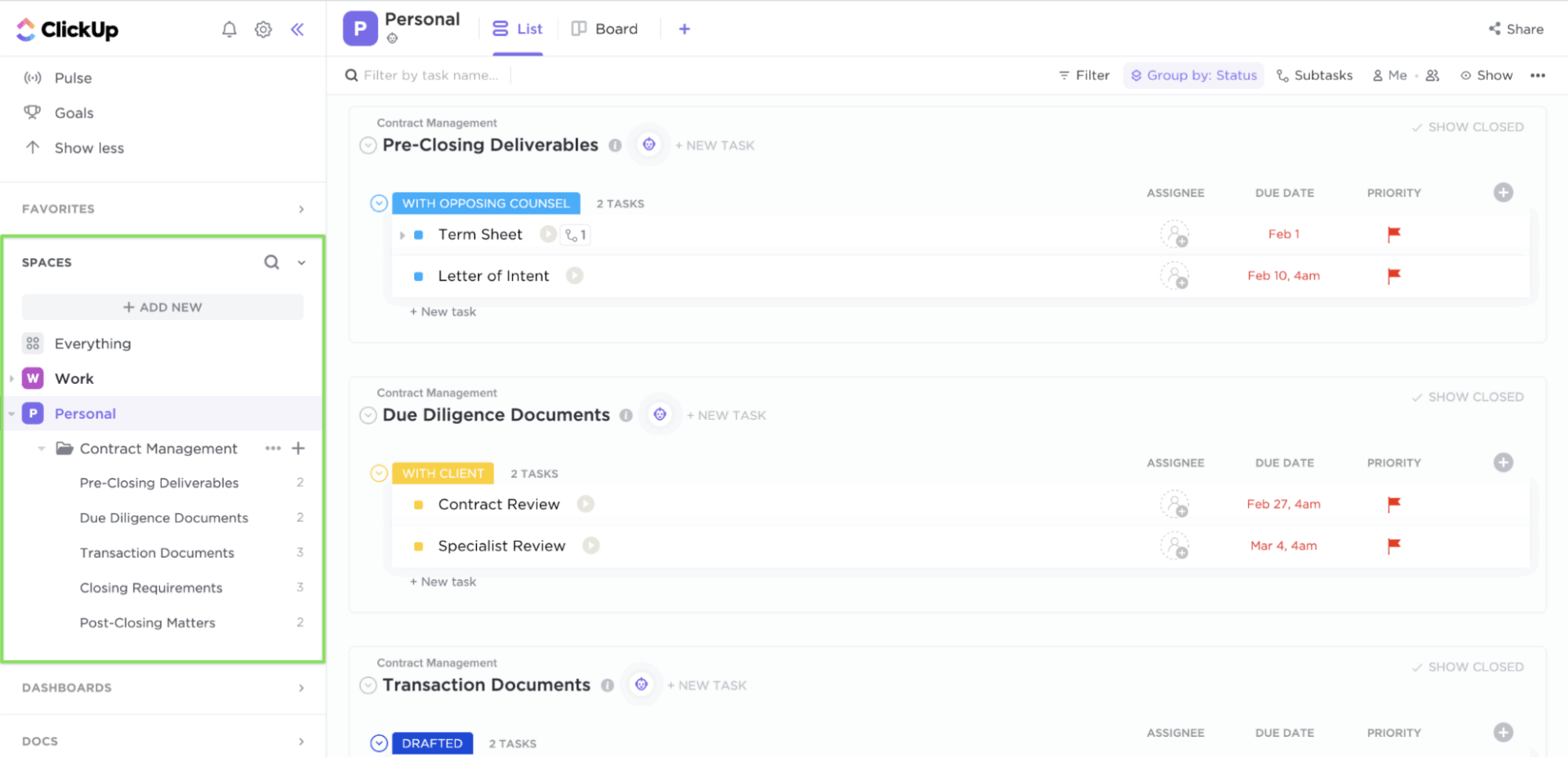
Когато възникне инцидент, екипите често губят време, за да разберат какво да правят и какво следва да се направи. ClickUp Tasks внася яснота в процесите ви за управление на инциденти.
Всяка задача може да има ясен собственик, приоритет и краен срок. В рамките на всяка задача можете да добавяте списъци за проверка, връзки към ръководства и екранни снимки. Потребителските полета записват степента на сериозност, засегнатите услуги или етапа на ескалация, докато потребителските статуси и списъци на задачите в ClickUp премахват несигурността, като представят процеса на реагиране в ясна последователност.
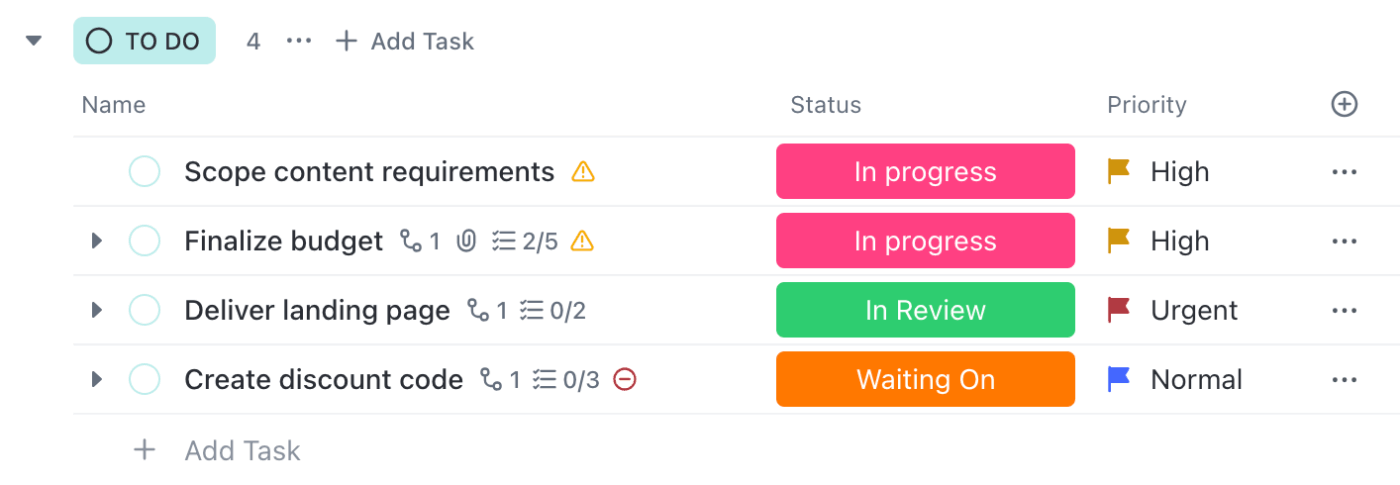
📌 Пример: „Докладван“ инцидент преминава в „Разследване“, след като инженерът отвори задачата. Мерките за смекчаване на последиците се проследяват в списък за проверка, като в описанието се добавят бележки и записи. Всяка промяна в статуса уведомява само съответните лица, така че инженерите могат да работят, а ръководителите да остават информирани.
Актуализации, които не прекъсват работния процес
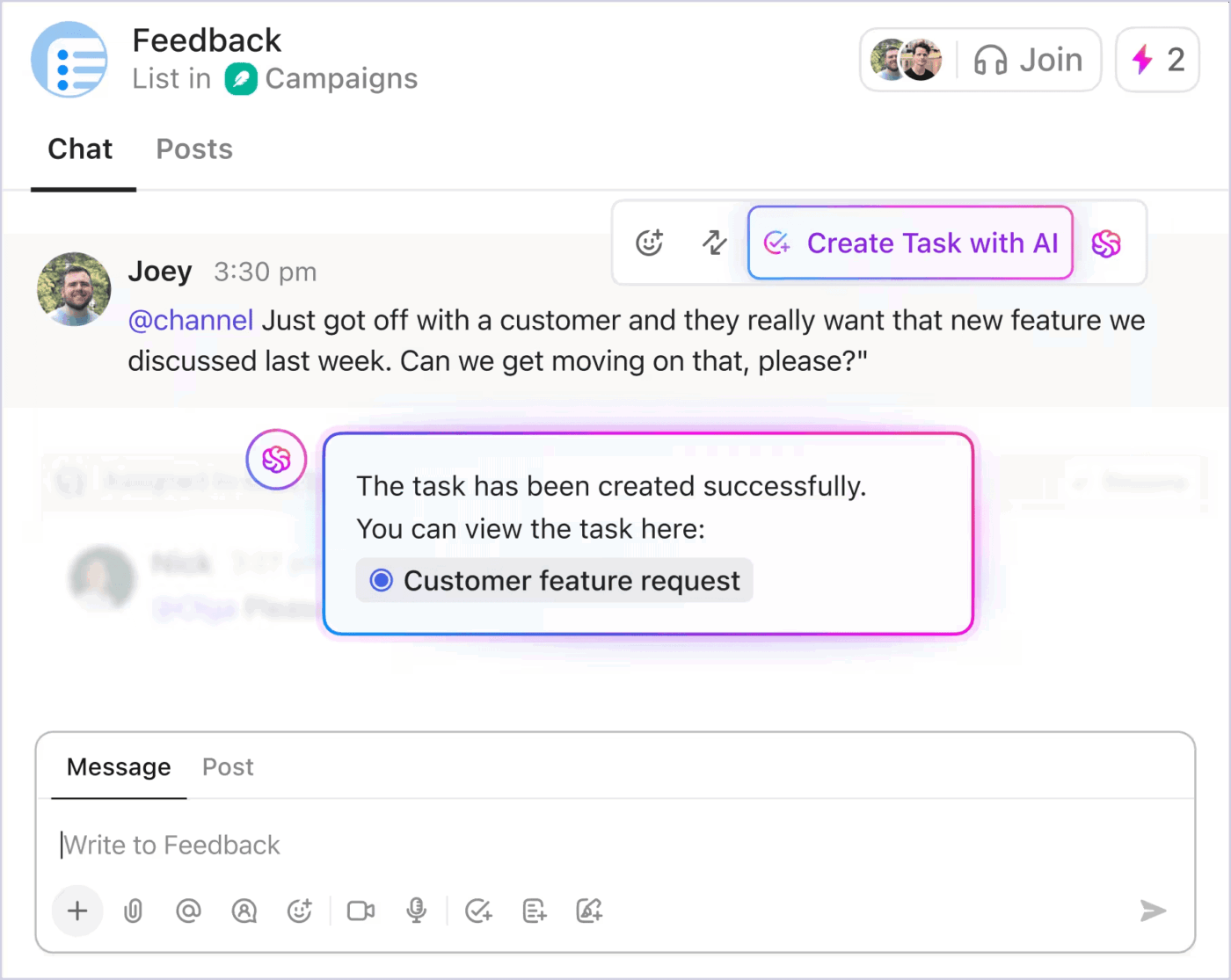
По време на критични инциденти актуализациите на заинтересованите страни не трябва да прекъсват усилията за реагиране. ClickUp Chat решава този проблем, като прикачва разговора директно към задачата за инцидента. Членовете на екипа и ръководителите могат да следят нишката, да виждат взетите решения и да добавят коментари в реално време.
ClickUp се интегрира и със Slack и Microsoft Teams, което позволява актуализациите да се появяват в каналите, които хората вече следят.
Търсите най-добрите съвети за сътрудничество в реално време? Ето един наръчник:
Прегледи след инциденти, които водят до трайни промени
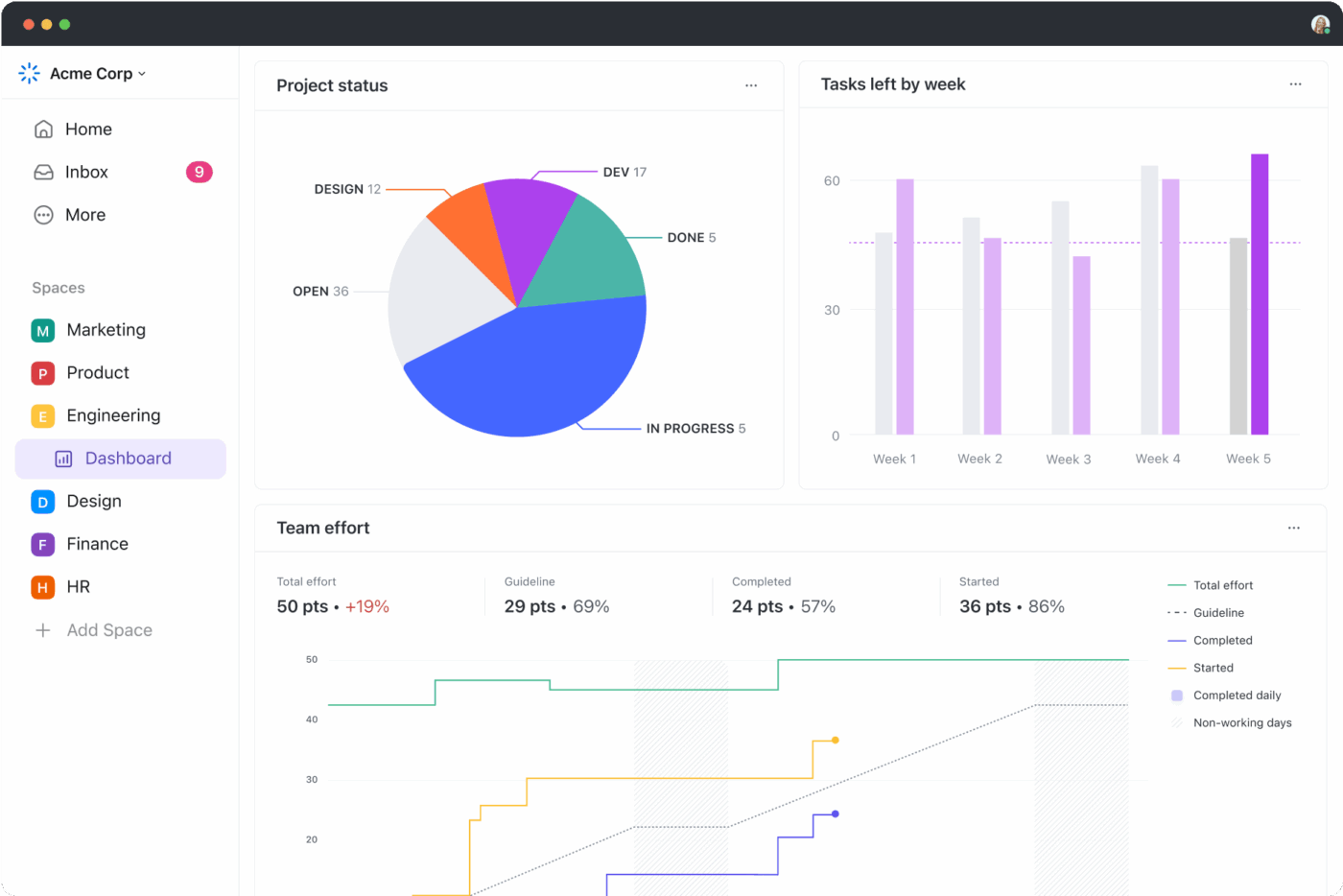
Твърде често се случва прегледите след инциденти да се пишат, но да се забравят. ClickUp Docs ги запазва, като съхранява стандартизирани постмортеми директно заедно със задачите по инцидентите.
Междувременно таблата на ClickUp показват показатели като средно време за разрешаване, честота на инциденти и повтарящи се модели. Тази видимост помага на ИТ екипите и DevOps екипите да преминат от реактивно гасене на пожари към проактивно подобрение.
💡 Професионален съвет: Прегледите след инциденти могат да отнемат часове на писане, редактиране и търсене на контекст. ClickUp Brain променя това, като автоматично събира бележки, времеви линии и действия. Може да обобщи задачата по инцидента, да изготви постмортем в ClickUp Docs и дори да предложи следващи стъпки въз основа на подобни инциденти.
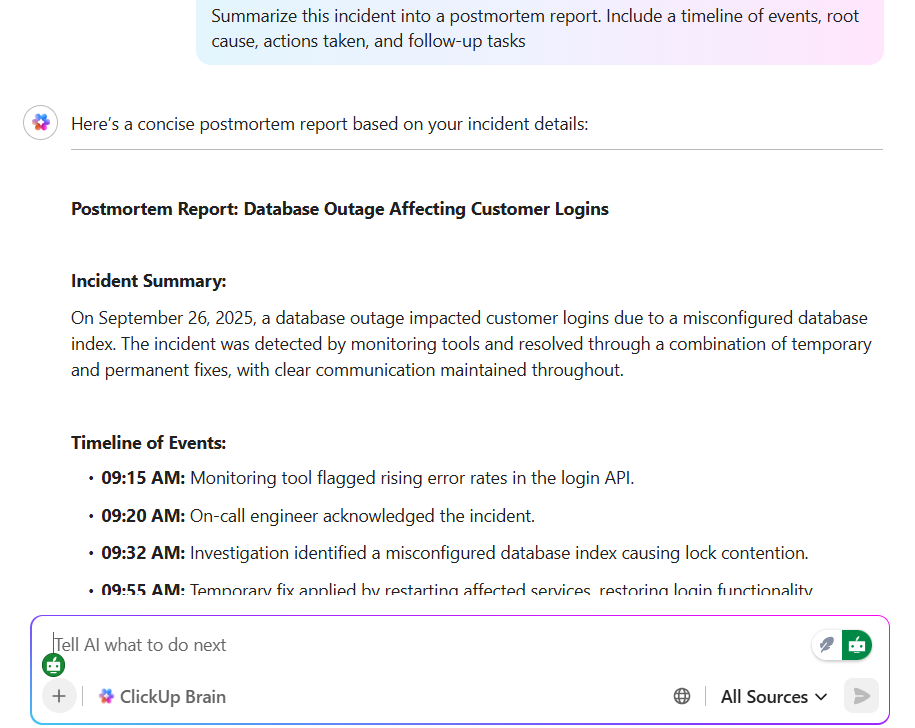
С ClickUp Brain Max получавате допълнителната скорост на Talk to Text на ClickUp – диктувайте мислите си в реално време и гледайте как се превръщат в изпипани бележки, готови за споделяне. Заедно те помагат на екипите да спестят почти цял ден всяка седмица, като премахват натоварената работа по писане и търсене, така че можете да се съсредоточите върху предотвратяването на следващия инцидент, вместо да разказвате отново за последния.
Въведете структура и спестете време с шаблони

В спешни ситуации наистина се научавате да цените стойността на ясен, поетапен процес.
Шаблонът за план за действие при инциденти на ClickUp е точно това. Той определя точно какво трябва да се направи, кой трябва да го направи и в какъв ред. Той поддържа всички в синхрон, намалява рисковете и гарантира, че нито една стъпка не се пропуска.
Друго предизвикателство в ИТ е ефективното документиране на инциденти, за да могат да се откриват модели и да се предотвратяват в бъдеще. Шаблонът за докладване на ИТ инциденти на ClickUp улеснява докладването, превръщайки всеки проблем в ценна точка от данните.
Най-добрите функции на ClickUp
- Намалете умората от сигналите с персонализирани известия в ClickUp, които гарантират, че само подходящите хора получават сигнали.
- Автоматизирайте създаването, разпределянето и отчитането на задачи при инциденти с ClickUp Automations и AI Agents.
- Създайте ясни работни процеси за инциденти с ClickUp Tasks, Lists и Statuses, както и шаблони за доклади за инциденти, които да ви насочват на всеки етап от реагирането.
- Улеснете сътрудничеството в екипа с ClickUp Chat и ClickUp Docs, за да може разговорите, актуализациите и изводите да се отразяват в реално време при инциденти.
- Проследявайте статуса на задачите и докладите за инциденти чрез таблата на ClickUp.
- Извличайте информация от инциденти и приключени задачи и създавайте или актуализирайте стандартни оперативни процедури за бъдещи подобрения с ClickUp Brain.
Ограничения на ClickUp
- Гъвкавостта на платформата може да се окаже прекалено голяма за по-малки екипи, които се нуждаят само от основни функции за предупреждения и управление на дежурствата.
Цени на ClickUp
Оценки и рецензии за ClickUp
- G2: 4,7/5 (над 10 500 отзива)
- Capterra: 4,6/5 (над 4500 отзива)
Какво казват потребителите за ClickUp
Този потребител на G2 споделя:
Работата по проект стана много по-лесна след внедряването на ClickUp, тъй като задачите могат лесно да се разпределят между членовете на екипа и можете да следите напредъка чрез чат. То дори изпраща имейл уведомления и предупреждения за просрочени задачи в случай на неизпълнена задача.
Работата по проект стана много по-лесна след внедряването на ClickUp, тъй като задачите могат лесно да се разпределят между членовете на екипа, а напредъкът може да се проследява чрез чат. При неизпълнена задача се изпращат дори имейл уведомления и предупреждения за просрочване.
📖 Прочетете също: Как да напишете доклад за инцидент на работното място
2. PagerDuty (Най-добър за сигнализиране на инциденти в реално време и автоматизация в голям мащаб)
Ако напускате Opsgenie, първата ви грижа е проста. Ще получи ли правилният човек сигналите в правилния момент и по правилния канал?
PagerDuty е създаден, за да премахне този стрес. Вие определяте услугите, графиците и ясните политики за ескалация, така че отговорността никога не е под въпрос. Сигналите от CloudWatch, Prometheus, Datadog, Jira, ServiceNow, Slack, Zoom и други се събират на едно място и се групират в един инцидент, а не в 15 отделни сигнали.
Event Intelligence намалява дублирането и свързва свързани проблеми, което намалява умората от сигналите, без да заглушава реалните проблеми. Отговарящите могат да потвърждават или ескалират от мобилното приложение или директно от Slack или Teams, като инцидентните стаи и мостове се създават автоматично.
След разрешаването на проблема, аналитиката показва времето за потвърждение, времето за разрешаване и повтарящите се проблемни точки, така че да можете да отстраните основните причини, вместо да се занимавате с симптомите.
Най-добрите функции на PagerDuty
- Позволете на потребителите да персонализират сигналите чрез SMS, телефон, имейл, push и Slack, за да намалите шума, без да пропускате критични инциденти.
- Опростете настройката с тестови сигнали, интеграции на услуги и ясен дизайн на политиката за ескалация.
- Поддръжка на графици за дежурства и ескалации, които уведомяват правилния човек и продължават, докато не получат потвърждение.
- Активирайте действия при инциденти, базирани на Slack, като потвърждаване, разрешаване и ескалиране директно в чата.
- Намалете умората от сигналите с AIOps, който групира дублиращите се сигнали и подчертава спешните инциденти.
Ограничения на PagerDuty
- Ръководителите на екипи не могат напълно да персонализират методите за доставка на сигнали на ниво екип, което ограничава гъвкавостта, когато мениджърите искат последователни правила за ескалиране.
- Имейл сигналите не предлагат възможност за действие чрез отговор, което принуждава отговарящите да кликват върху платформата, вместо да управляват директно от пощенската си кутия.
- Разширените функции като AIOps и лицензи за комуникация със заинтересованите страни са свързани с високи допълнителни разходи.
Цени на PagerDuty
- Безплатно
- Професионална версия: 25 $/месец на потребител
- Бизнес: 49 $/месец на потребител
- Enterprise: Персонализирани цени
Оценки и рецензии за PagerDuty
- G2: 4,5/5 (над 900 отзива)
- Capterra: 4,6/5 (над 200 отзива)
Какво казват потребителите за PagerDuty
Този потребител на G2 споделя:
Обичам, че pager duty има няколко различни звукови сигнали, някои от които са много забавни. Откакто започнах да използвам pager duty, успявам да реагирам на инциденти и да ангажирам екипите по-ефективно.
Обичам, че pager duty има няколко различни звукови сигнали, някои от които са много забавни. Откакто започнах да използвам pager duty, успявам да реагирам на инциденти и да ангажирам екипите по-ефективно.
3. xMatters (Най-доброто решение за рентабилно управление на инциденти и автоматизация)
Един потребител на Reddit го обобщи най-добре:
Получавате това, за което плащате, но плащате по-малко. Има всичко, което искате, макар че определено не е толкова луксозен като PagerDuty.
Получавате това, за което плащате, но плащате по-малко. Има всичко, което искате, макар че определено не е толкова луксозен като PagerDuty.
Тази фраза отразява позиционирането на xMatters – достъпна, надеждна и силна в областите, които са най-важни.
Ако напускате Opsgenie, обикновено имате два проблема. Прекалено много шум, който буди неподходящите хора, и несигурност относно това кой е отговорен за следващата стъпка. xMatters решава и двата проблема, като ви позволява да картографирате услугите и графиците за дежурства, а след това да насочвате сигналите с точен контекст, така че да се свържете с правилния човек по правилния канал.
Потребителите оценяват целевите известия с полезна информация, както и пълния одит, който показва кой е бил уведомен, кой е потвърдил и кога. Този запис улеснява прегледа след инцидента и проверката за съответствие.
Нискокодовият инструмент за създаване на работни потоци превръща сигнал от Datadog, Prometheus или ServiceNow в ясна поредица от действия.
С автоматизация на работния процес и адаптивно управление на DevOps проекти в основата си, xMatters помага на екипите да работят по-бързо и да се справят с излишните сигнали.
Най-добрите функции на xMatters
- Автоматизирайте работните процеси при инциденти с интеграции без код и с малко код, които ускоряват разрешаването и намаляват ръчните задачи.
- Управлявайте графиците за дежурства и ескалациите безпроблемно, така че винаги да се предупреждава правилният човек в точното време.
- Приложете адаптивно управление на инциденти, за да минимизирате въздействието върху клиентите и да извлечете поуки от всяко събитие.
- Филтрирайте шума с интелигентни сигнали, корелация на сигналите и обогатени известия за по-ясен контекст.
- Достъп до полезни анализи за идентифициране на неефективности и подобряване на сътрудничеството между екипите
Ограничения на xMatters
- Интерфейсът и потребителското изживяване са по-малко усъвършенствани в сравнение с конкурентите.
- Разширените функции за отчитане и анализи са ограничени в плановете от по-ниско ниво.
- Глобалното покритие на поддръжката варира в зависимост от избрания план.
Цени на xMatters
- Безплатно
- Starter (Essentials): 9 $/месец на потребител
- Базов (стандартен): 39 $/месец на потребител
- Разширено: Персонализирани цени
Оценки и рецензии за xMatters
- G2: 4,5/5 (над 670 отзива)
- Capterra: 4,6/5 (над 140 отзива)
Какво казват потребителите за xMatters
В тази рецензия на Capterra се представят:
Когато в компанията възникне инцидент, свързан с сигурността на данните, Xmatters незабавно активира протоколите за реагиране: организира протоколите за действие на екипа според техните функции. Уведомленията се изпращат по различни начини.
Когато в компанията възникне инцидент, свързан с сигурността на данните, Xmatters незабавно активира протоколите за реагиране: организира протоколите за действие на екипа според техните функции. Уведомленията се изпращат по различни начини.
📮 ClickUp Insight: 28% от служителите казват, че работата ги преследва и след работно време, а други 8% често се борят да се откъснат от нея. Това означава, че повече от една трета от тях носят стреса у дома.
Използвайте напомнянията на ClickUp, за да защитите вечерната си рутина. Задайте ежедневно напомняне за приключване на работния ден, тихи известия извън работното време и запазете лично време в календара си. Изключването трябва да бъде ваш избор.
💫 Реални резултати: Lulu Press спестява около един час на човек на ден с ClickUp Automations, което води до 12% повишение на ефективността.
4. AlertOps (най-добър за намаляване на шума с помощта на изкуствен интелект и бързо реагиране при инциденти)
Обемът на сигналите продължава да нараства, като 88% от екипите отчитат увеличение през последната година, а почти половината казват, че тези пикове са над 25%. Този вид постоянен шум води до умора от сигналите, която 76% от SOC (центровете за операции по сигурността) сега посочват като най-голямото си предизвикателство.
Това е реалността, която въвеждате във всеки заместител на Opsgenie. Следващият инструмент, който изберете, трябва да може да прецени кои сигнали заслужават действие. AlertOps се опира на това с OpsIQ, AI ядро, което филтрира дублиращите се сигнали, корелира свързаните сигнали, обобщава контекста и предлага следващи стъпки, така че отговарящите да виждат един ясен инцидент, вместо да превъртат фийда.
Можете да започнете с подразбиращото се графика за дежурства или да създадете свой собствен, след което да пренасочвате обажданията по телефон, SMS, мобилно приложение, чат или имейл с правила за ескалация, които продължават да работят, докато някой не поеме отговорността за проблема. Пренасочването на обажданията в реално време препраща клиентите към текущия дежурен персонал въз основа на графици в реално време, а политиките, базирани на SLA, ескалират преди нарушението, а не след него.
Освен това платформата се интегрира с повече от 200 инструмента, от мониторинг и издаване на билети до O365 и Slack, така че сортирането не се забавя поради липса на контекст.
Най-добрите функции на AlertOps
- Филтрирайте и потискайте дублиращите се сигнали с AI-базирано намаляване на шума, задвижвано от OpsIQ™, което обобщава сигналите и предлага решения автоматично.
- Управлявайте графиците за дежурства с гъвкави правила за ескалация, денонощно покритие и маршрутизиране на живо на обажданията за критични проблеми на клиенти.
- Автоматизирайте сортирането и работните процеси, като използвате IT шаблони без код, за да ускорите реакцията и да гарантирате, че инцидентите се обработват последователно.
- Интегрирайте с над 200 инструмента, включително Slack, O365, Jira, Dynatrace и ConnectWise, както и персонализирани интеграции за вътрешни приложения.
Ограничения на AlertOps
- Настройката на графика може да ви се стори неинтуитивна в началото и може да изисква проби и грешки.
- Потребителският интерфейс понякога е несъвършен, като някои разширени функции изискват допълнителни стъпки за конфигуриране.
- Съобщава се за забавяния при синхронизирането на календара с външни системи като Outlook.
Цени на AlertOps
- Starter: Безплатно
- Стандартен: 10 $/месец на потребител
- Премиум: 22 $/месец на потребител
- Enterprise: 34 $/месец на потребител
Оценки и рецензии за AlertOps
- G2: 4,7/5 (над 150 отзива)
- Capterra: 4,7/5 (над 20 отзива)
Какво казват потребителите за AlertOps
Това ревю в G2 го показва ясно:
Прекарахме по-голямата част от третото тримесечие на миналата година в тестване на инструменти за планиране/алармиране за един от нашите ИТ екипи. След като открих AlertOps, спрях да търся, защото е достъпен, екипът е изключително полезен и търпелив в процеса на настройка и внедряване, а откакто всичко е напълно настроено и работи, нямаме никакви проблеми!
Прекарахме по-голямата част от третото тримесечие на миналата година в тестване на инструменти за планиране/алармиране за един от нашите ИТ екипи. След като открих AlertOps, спрях да търся, защото е достъпен, екипът е изключително полезен и търпелив в процеса на настройка и внедряване, а откакто всичко е напълно настроено и работи, нямаме никакви проблеми!
📖 Прочетете също: Примери за SOP: Най-добри практики за производителност и съответствие
5. Splunk On-Call (най-доброто решение за опростяване на графиците за дежурства и намаляване на изтощението)
Ако някога сте гледали класическата сценка на Абът и Костело „Кой е първи?“*, знаете колко объркващо е да се опитвате да разберете кой всъщност е отговорен за какво. Ротацията на дежурствата може да предизвика същото усещане, когато няма ясна система.
Тук на помощ идва Splunk On-Call. ✨
Картографирате екипите и графиците веднъж, след което алармите пристигат с контекст на всяко устройство. Отговарящите могат да потвърждават, пренасочват или отлагат от приложението за iOS или Android, а платформата може да отвори стая за сътрудничество и да започне преглед след инцидента без допълнителни стъпки.
Двигател за правила прикачва ръководства и табла към инциденти, така че първият човек, който получава сигнал, никога не започва напълно неподготвен. Машинното обучение предлага подходящите лица за реагиране въз основа на подобни инциденти, което помага да се съкрати времето за потвърждаване и разрешаване.
Най-добрите функции на Splunk On-Call
- Автоматизирайте ескалациите и работните процеси за реагиране на инциденти за по-бързо потвърждаване и разрешаване.
- Използвайте приложенията за iOS и Android, за да получавате, отлагате, пренасочвате или разрешавате сигнали директно от мобилно устройство.
- Опростете планирането с ротации, преодолявания и политики за ескалация, предназначени да балансират справедливо натоварването.
- Получете контекст на инцидентите и исторически одитни следи, за да подпомогнете по-бързото сортиране и анализ след инцидента.
- Приложете препоръки за машинно обучение, за да идентифицирате подходящите реагиращи лица въз основа на данни за разрешени инциденти в миналото.
Ограничения на Splunk On-Call
- Интерфейсът може да ви се стори сложен в началото, а навигацията изисква известно приспособяване.
- Случайното забавяне по време на периоди с висок трафик влияе на реакцията в реално време.
- Опциите за лицензиране и управление на потребителите са по-ограничени в сравнение с някои конкуренти.
Цени на Splunk On-Call
- Персонализирани цени
Оценки и рецензии за Splunk On-Call
- G2: 4,6/5 (над 50 отзива)
- Capterra: 4,5/5 (над 30 отзива)
Какво казват потребителите за Splunk On-Call
В тази рецензия на G2 се отбелязва:
Възможността да създавате екипи и да конфигурирате смени между тях е един от най-полезните ресурси, налични на тази платформа. Splunk On-Call осигурява лесна интеграция с няколко инструмента, което прави конфигурацията му много лесна за настройка.
Възможността да създавате екипи и да конфигурирате смени между тях е един от най-полезните ресурси, налични на тази платформа. Splunk On-Call осигурява лесна интеграция с няколко инструмента, което прави конфигурацията му много лесна за настройка.
📝Прочетете също: Елиминиране на разрастването на изкуствения интелект: как контекстуалният изкуствен интелект променя производителността на работното място
6. Datadog (Най-добър за пълна наблюдаемост с интегрирано наблюдение на сигурността)
За потребителите на Opsgenie проблемът е контекстът. Алармата се задейства, но вие все пак трябва да търсите логове, следи, метрики и сигнали за сигурност, за да разберете какво всъщност не работи.
Datadog обединява тези изгледи в една времева линия. Инфраструктурата, контейнерите, безсервърните технологии, базите данни и приложенията са разположени до логовете, следите и RUM, така че отговарящите не трябва да гадаят.
Watchdog и новите AI възможности подчертават аномалии, групират свързани сигнали и обобщават вероятното въздействие, което намалява необходимостта от многократни проверки по време на сортирането. Ако вече разполагате с инструмент за пейджинг, можете да въведете в него предупрежденията от Datadog.
Ако искате да останете в Datadog, Incident Management ви предоставя собственици, графици, актуализации за заинтересованите страни и последващи действия, без да напускате платформата.
Практическите ползи се проявяват бързо. По-малко шумни сигнали, защото дублиращите се се обединяват. По-бърз анализ на основните причини, защото всяко предупреждение съдържа показателите и логовете, които го обясняват. По-силна сигурност, защото грешките в конфигурацията и уязвимостите се проявяват заедно с данните за производителността.
С над 900 интеграции, ясни SLO (цели за ниво на обслужване) и табла, вашият екип може да премине от сигнал към поправка на едно място, вместо да преминава от един раздел в друг. Това е добър избор за миграции от Opsgenie, които също искат да запълнят пропуските в наблюдаемостта.
Най-добрите функции на Datadog
- Наблюдавайте инфраструктурата, логовете, приложенията, базите данни и безсервърните работни натоварвания от една платформа.
- Сигурни облачни среди с вградено управление на уязвимостите, картографиране на съответствието и управление на правата
- Използвайте синтетично наблюдение и наблюдение на реални потребители, за да откривате проблеми, преди клиентите да ги забележат.
- Автоматизирайте работните процеси с над 900 интеграции и предварително създадени табла.
- Приложете функции за изкуствен интелект и машинно обучение като Watchdog и LLM Observability за откриване на аномалии и интелигентни анализи.
Ограничения на Datadog
- Цените могат да се променят бързо при голям брой хостове и добавки.
- Интерфейсът и таблото за управление могат да се сторят прекалено сложни за новите потребители.
- Някои разширени функции за сигурност са достъпни само в плановете от по-висок клас.
Цени на Datadog
- Безплатно
- Pro: 15 $/месец на хост
- Enterprise: 23 $/месец на хост
- DevSecOps Pro: 22 $/месец на хост
- DevSecOps Enterprise: 34 $/месец на хост
Оценки и рецензии за Datadog
- G2: 4,4/5 (над 660 отзива)
- Capterra: 4,6/5 (над 320 отзива)
Какво казват потребителите за Datadog
В тази рецензия на Capterra се цитира:
Като цяло, след някои възходи и падения, те се оказаха добър партньор. Техният инструмент е изключително мощен и позволява много отлични практики в областта на наблюдаемостта, но трябва да платите за него.
Като цяло, след някои възходи и падения, те се оказаха добър партньор. Техният инструмент е изключително мощен и позволява много добри практики в областта на наблюдаемостта, но трябва да се плати за него.
7. Squadcast (Най-доброто решение за обединени дежурства и реагиране при инциденти с висока стойност)
Когато работите с множество графици и специфични за клиента правила за извънработно време, се нуждаете от сигнали, за да спазвате тези правила без да се налага да ги следите ръчно.
Това е нишата, в която Squadcast печели доверие. 🌟
Потребителите отбелязват, че графиците и преопределянията са лесни за моделиране и че мобилното приложение продължава да ескалира, ако първият отзовал се не отговори, така че критичните проблеми не се пропускат.
За MSP и екипи с много клиенти е удобно, че можете да настроите 24/7 покритие за определени клиенти, докато другите могат да получават сигнали извън работно време само за критични инциденти. Потребителският интерфейс улеснява прегледа на активните инциденти и кои лица са отговорни за тях.
Има много повече от просто пейджинг. Автоматизацията на надеждността премества инцидентите през последователни работни потоци с runbooks и актуализации на статуса, проследяване на SLO и графики, които можете да използвате, а ценообразуването е достатъчно прозрачно, за да не се чувстват по-малките екипи изключени.
Най-добрите функции на Squadcast
- Автоматизирайте графиците за дежурства с гъвкави ескалации и преодолявания
- Намалете умората от сигналите чрез консолидиране и дедублиране на уведомленията.
- Решавайте инциденти по-бързо с помощта на ръководства и работни процеси
- Дръжте заинтересованите страни информирани чрез персонализирани страници за състоянието
- Записвайте постмортеми и прозрения, за да изградите култура на учене
Ограничения на Squadcast
- Графикът може да стане претрупан, когато има много активни графици, което затруднява бързото преглеждане на дежурните.
- Съобщава се за периодично забавяне при синхронизирането на сигнали от определени интеграции.
- Безплатният план е ограничен за екипи, които искат страници със статус и по-задълбочени анализи.
Цени на Squadcast
- Pro: 12 $/месец на потребител
- Премиум: 19 $/месец на потребител
- Enterprise: Персонализирани цени
Оценки и рецензии за Squadcast
- G2: 4,4/5 (над 300 отзива)
- Capterra: Недостатъчно отзиви
Какво казват потребителите за Squadcast
В тази рецензия на G2 се споменава:
Squadcast може да приема данни от различни инструменти за мониторинг, с които разполагаме, и е лесно да се настроят графици и преопределяния за това кой трябва да бъде предупреждаван за различни видове проблеми.
Squadcast може да приема данни от различни инструменти за мониторинг, с които разполагаме, и е лесно да се настроят графици и преопределяния за това кой трябва да бъде предупреждаван за различни видове проблеми.
📖 Прочетете също: Управление на рисковете за киберсигурността
8. FireHydrant (най-добър за автоматизирани ръководства и собственост върху услугите)
Този софтуер за управление на инциденти предлага добре структуриран процес, който поддържа безпроблемното функциониране на услугите.
FireHydrant фокусира отговорите около ръководства за работа, каталог с услуги и споделено работно пространство. Декларирайте инцидент и платформата създава канал в Slack или Teams, прикачва подходящото ръководство за работа, извлича собствеността от каталога с услуги и започва контролируема времева линия.
Междувременно, неговата изкуствена интелигентност поддържа ниски разходи с незабавни обобщения на инциденти, предложени актуализации за заинтересованите страни и транскрипти на срещи на живо, така че екипът да може да се съсредоточи върху смекчаването на последиците, а не върху воденето на бележки.
Екипите също така подчертават отзивчивата поддръжка и подходът „API first“ с Terraform, който позволява на оперативните ръководители да интегрират FireHydrant в съществуващите работни процеси без проблеми.
Най-добрите функции на FireHydrant
- Автоматизирайте реагирането при инциденти с ръководства, които кодифицират най-добрите практики.
- Управлявайте графиците за дежурства и сигнализирането с Signals, допълнени с политики за ескалация.
- Централизирайте собствеността чрез каталога на услугите, за да могат подходящите инженери да реагират незабавно.
- Сътрудничество директно в Slack или Teams с автоматично генерирани канали и актуализации
- Използвайте обогатени с изкуствен интелект ретроспективи и анализи, за да събирате информация и да повишавате надеждността с течение на времето.
Ограничения на FireHydrant
- Разширените функции за автоматизация изискват планове от по-високо ниво.
- Крива на обучение за настройка на персонализирани работни процеси и интеграции
- Ограничен брой отговарящи и ръководства в плана за начинаещи
Цени на FireHydrant
- Безплатно: Двуседмичен пробен период
- Platform Pro: 9600 USD/година на потребител
- Enterprise: Персонализирани цени
Оценки и рецензии за FireHydrant
- G2: 4,5/5 (над 130 отзива)
- Capterra: Недостатъчно рецензии
Какво казват потребителите за FireHydrant
Този потребител на G2 споделя:
Работейки изцяло от Slack или друг чат/инструмент за сътрудничество, FireHydrant се интегрира и ви позволява да отваряте/актуализирате/решавате инциденти, без да се налага да напускате мястото, където се извършва действието за реагиране на инциденти.
Работейки изцяло от Slack или друг чат/инструмент за сътрудничество, FireHydrant се интегрира и ви позволява да отваряте/актуализирате/решавате инциденти, без да се налага да напускате мястото, където се извършва действието за реагиране на инциденти.
9. TaskCall (Най-доброто решение за достъпно управление на инциденти с автоматизация)
В скорошно проучване на киберрисковете реагирането на инциденти беше определено като един от основните контролни механизми, които организациите трябва да укрепят, за да намалят експозицията си.
Това подчертава колко важни са станали бързите и надеждни работни процеси при инциденти.
Екипите обикновено се спъват не в самото предупреждение, а в последващата суматоха. Кой е наистина на линия в момента? Предупреждението принадлежи ли на приложението, инфраструктурата или операциите с клиенти? Как да държите лидерите информирани, без да прекъсвате процеса на отстраняване на проблема?
TaskCall се справя директно с тези моменти. Дежурството се определя от съдържанието на инцидента, така че маршрутизирането достига до правилния отговорник, а автоматичното ескалиране покрива пропуските. Уведомленията пристигат по телефон, SMS, push, имейл или чат.
За да се намали шума, интелигентната система за събития съпоставя дублиращите се сигнали и потиска сигналите с ниска стойност. Контекстът се съставя чрез събиране на сигнали от инструменти като AWS, Datadog, Slack, Jira и Zendesk, което означава, че инженерите виждат въздействието и отговорността, вместо суров поток от сигнали.
Най-добрите функции на TaskCall
- Автоматизирайте графика за дежурства с динамични ротации и ескалации на няколко нива.
- Намалете шума с помощта на AI-базирана информация за събития и условно маршрутизиране.
- Управлявайте инциденти в DevOps, IT-Ops и BizOps в една унифицирана платформа
- Интегрирайте с инструменти за мониторинг, регистриране и поддръжка като AWS, Jira, Zendesk и Slack.
- Осигурете пълно покритие с мобилни приложения, известия, SMS и гласови сигнали.
Ограничения на TaskCall
- Безплатният план е ограничен до пет потребители, което може да не е достатъчно за растящи екипи.
- Повечето анализи и табла са ограничени до по-скъпите планове.
Цени на TaskCall
- Безплатно
- Стартово ниво: 9 $/месец на потребител
- Бизнес: 19 $/месец на потребител
- Цифрови операции: 29 $/месец на потребител
Оценки и рецензии за TaskCall
- G2: Недостатъчно отзиви
- Capterra: Недостатъчно рецензии
10. ilert (Най-добър за управление на инциденти с приоритет на изкуствения интелект и фокус върху поверителността)
ilert е платформа за управление на дежурства и сигнализиране за инциденти, която поставя силен акцент върху надеждността и поверителността на данните. Тя помага на екипите да гарантират, че критичните сигнали от системите за мониторинг достигат своевременно до правилните дежурни инженери.
Платформата предлага гъвкаво планиране на дежурства, многослойни политики за ескалация и известия чрез множество канали, включително push, SMS и гласови повиквания.
Маршрутизирането, което спазва текущия график и пътя на ескалация, означава, че обажданията на клиентите достигат до правилния човек, вместо да се прехвърлят от един оператор на друг.
В Slack или Teams отговарящите работят по инцидента в чата, докато Ilert записва контекста, времевата линия и последващите действия.
AI Voice Agent отговаря на горещата линия, събира необходимата информация и незабавно уведомява дежурния инженер. Responder анализира показателите, логовете и последните промени в цялата ви система, открива вероятните основни причини, предлага кои други лица да бъдат включени и дори предлага начин за връщане назад за по-бързо разрешаване на проблема.
Вие запазвате контрола на всеки етап.
Най-добрите функции на ilert
- Осигурете надеждни многоканални сигнали чрез глас, SMS, push и чат.
- Автоматизирайте управлението на дежурствата с планиране и ескалационни пътища
- Предоставяйте бързи актуализации чрез страници за състоянието, задвижвани от изкуствен интелект, и комуникации със заинтересованите страни.
- Използвайте ilert Responder AI, за да анализирате инциденти, да откриете основните причини и да предложите действия.
- Интегрирайте с инструменти за мониторинг и ITSM като Prometheus, Datadog, Jira и Slack.
Ограничения на ilert
- Цените може да се сторят високи за по-малките екипи.
- Някои интеграции изискват допълнителни усилия за настройка.
- Мобилното приложение може да се възползва от по-разширени функции
Цени на ilert
- Безплатно
- Pro: 24 $/месец на потребител
- Мащаб: 49 $/месец на потребител
- Enterprise: Персонализирани цени
ilert оценки и рецензии
- G2: Недостатъчно рецензии
- Capterra: 4,7/5 (над 60 отзива)
Какво казват потребителите за ilert
В тази рецензия на Capterra се посочва:
Намирам този инструмент за много интуитивен и ефективен за управление на дежурствата в ИТ екипите. Той предлага гъвкавост, като позволява отговори директно чрез приложението, SMS или телефонно обаждане, което го прави особено практичен в реални ситуации.
Намирам този инструмент за много интуитивен и ефективен за управление на дежурствата в ИТ екипите. Той предлага гъвкавост, като позволява отговори директно чрез приложението, SMS или телефонно обаждане, което го прави особено практичен в реални ситуации.
11. Zenduty (Най-доброто решение за реагиране на инциденти в голям мащаб, базирано на изкуствен интелект)
Zenduty помага на инженерните и DevOps екипи да се фокусират върху важните сигнали, като намалява MTTR (средното време за разрешаване) и предоставя на организациите единна и надеждна платформа за управление на инциденти.
Потребителите постоянно хвалят бързите и надеждни сигнали, като push, обаждания и SMS, които пристигат без закъснение, така че дежурните инженери могат да потвърдят от уведомлението и да се върнат на работа. Екипите също харесват факта, че могат да персонализират уведомленията според сериозността, услугата или типа инцидент, така че да се свърже с правилния човек в правилния момент, а не с всички наведнъж.
Платформата поддържа съвместно реагиране при инциденти, с роли при инциденти, шаблони за задачи и интегрирани канали за комуникация. Важна характеристика е подходът, базиран на Incident Command System (ICS), който осигурява структурирана рамка за управление на инциденти от голям мащаб.
Ако искате да преминете от Opsgenie, Zenduty е добър вариант, като поддръжката му за миграция получава положителни отзиви.
Най-добрите функции на Zenduty
- Осигурете управление на инциденти, базирано на изкуствен интелект, с ZenAI
- Поддържайте разширено планиране на дежурствата с персонализирани ротации и ескалации.
- Автоматизирайте сценариите за инциденти, за да се проследяват последователно задачите и последващите действия.
- Интегрирайте безпроблемно с над 150 инструмента като Slack, Teams, Jira, Datadog и Grafana.
- Изпращайте мобилни сигнали в реално време на iOS, Android и дори на смарт часовници.
Ограничения на Zenduty
- Функцията за търсене може да смесва няколко инцидента, което затруднява проследяването
- Някои разширени функции са ограничени до планове от по-висок клас.
- При сложни настройки припокриването на уведомленията може да доведе до дублиране на сигналите.
Цени на Zenduty
- Безплатно
- Стартово ниво: 6 $/месец на потребител
- Растеж: 16 $/месец на потребител
- Enterprise: 25 $/месец на потребител
Оценки и рецензии за Zenduty
- G2: 4,6/5 (над 135 отзива)
- Capterra: Недостатъчно отзиви
Какво казват потребителите за Zenduty
В тази рецензия на G2 се отбелязва:
Това, което най-много ми харесва в Zenduty, са аналитичните му прозрения. Чрез анализиране на инцидентите можем да проследяваме тенденции – например кои дни, услуги или смени са имали повече проблеми, да идентифицираме какво е пошло нередно и да определим областите, които се нуждаят от подобрение.
Това, което най-много ми харесва в Zenduty, са аналитичните му прозрения. Чрез анализиране на инцидентите можем да проследяваме тенденциите – например кои дни, услуги или смени са имали повече проблеми, да идентифицираме какво е пошло нередно и да определим областите, които се нуждаят от подобрение.
📖 Прочетете също: Най-добрият софтуер за управление на ИТ операции
12. Incident. io (Най-доброто решение за реагиране при инциденти в Slack)
Да си представим за момент, че сме в разгара на инцидент. Пейджърът звъни. Хората се събуждат. В Opsgenie потвърждавате, след това търсите подходящата стая, а след това копирате контекста на друго място, за да може всеки да види какво се случва.
Този скок е моментът, който повечето екипи искат да поправят. Тук incident.io се различава.
Декларирате директно в Slack и се появява чисто пространство с роли, времева линия и следващите две или три стъпки, които вече са определени. Можете да се обадите, да изпратите SMS, имейл или просто да натиснете, за да потвърдите. Работата започва веднага и остава видима.
Потребителите продължават да описват същия ритъм, след като преминат към него. Каналът се задейства само със сигнала, от който се нуждаете. Приложението подсказва последващи действия и изготвя кратко резюме, докато вие все още отстранявате проблема. Актуализациите на състоянието за клиентите са готови за изпращане, без да напускате нишката. Само това намалява разговорите, които обикновено се водят в странични стаи и директни съобщения.
Приемането беше лесно за екипи с много различни размери. По-малките групи споделят, че са го свързали с Linear и New Relic за няколко седмици и са получили реална полза още от първия ден. По-големите организации споделят, че са го внедрили в няколко екипа за около месец и не са забавили работата по пътната карта, за да го направят.
Най-добрите функции на Incident.io
- Управлявайте инциденти от начало до край директно в Slack или Microsoft Teams
- Използвайте AI SRE, за да предлагате решения, разследвате проблеми и изготвяте комуникации.
- Управлявайте графиците за дежурства с AI-базирано намаляване на шума
- Автоматизирайте актуализациите на статуса на страницата за клиенти и заинтересовани страни
- Получете информация за тенденциите, времевите графици и показателите MTTx с помощта на табла за управление.
Ограничения на Incident.io
- Интерфейсът може да изглежда претрупан с много известия от Slack.
- Разширената конфигурация (като пътища за ескалация) може да изисква фина настройка.
- Някои AI функции са ограничени само до английски език.
Цени на Incident.io
- Основен: Безплатен
- Екип: 19 $/месец на потребител
- Pro: 25 $/месец на потребител
- Enterprise: Персонализирани цени
Incident. io оценки и рецензии
- G2: 4,8/5 (над 180 отзива)
- Capterra: Недостатъчно рецензии
Какво казват потребителите за Incident. io
Това е споделено в рецензията на G2:
За мен incident. io постига точното равновесие между това да не пречи, като в същото време осигурява структура, процес и събиране на данни за управлението на инциденти.
За мен incident. io постига точното равновесие между това да не пречи, като в същото време осигурява структура, процес и събиране на данни за управление на инциденти.
💡Съвет от професионалист: Използвайте предварително създадени агенти, за да отговаряте на въпроси на екипа или да споделяте актуална информация, или конфигурирайте персонализиран AI агент на ClickUp, за да следите статуса на задачите и крайните срокове, да изпращате напомняния, да ескалирате проблеми или да актуализирате статуса според нуждите, за да напредвате.
Това видео ви показва как:
Какво да очаквате по време и след миграцията от Opsgenie
Преминаването от Opsgenie може да ви се стори като опаковане на вещи от къща, в която сте живели години наред. Всяка програма, правило за ескалация и интеграция има своето място и мисълта да пренесете всичко това в нов дом може да ви се стори обезкуражаваща.
Atlassian предлага вграден в приложението инструмент за миграция към Jira Service Management или Compass. Процесът е структуриран, предвидим и проектиран така, че да сведе до минимум прекъсванията.
Ако решите да използвате някой от тях, просто прегледайте плана си, определете датата на миграцията и оставете инструментът да свърши тежка работа. Нека да видим как ще работи и да преценим дали това е добър избор за вашата организация.
Преглед на миграционния поток
Стъпка 1 → Прегледайте и изберете своя път
Оценете плана си за Opsgenie и решете дали Jira Service Management (фокусиран върху ITSM) или Compass (фокусиран върху разработчиците) е по-подходящ за вас.
Стъпка 2 → Насрочете датата на миграцията
Изберете график, който отговаря на вашия цикъл на фактуриране и готовността на екипа ви.
Стъпка 3 → Одобрение на фактуриране
Вашият администратор по фактуриране на Atlassian потвърждава плана, за да може новият продукт да бъде предоставен.
Стъпка 4 → Миграция на данни във фонов режим
Данните от Opsgenie започват да се синхронизират, докато екипът ви продължава да работи както обикновено.
Стъпка 5 → Преход и изключване
Имате 120 дни, за да финализирате преминаването, преди Opsgenie да бъде изключен.
Накратко, ето какво можете да очаквате:
- Използвайте инструмента за миграция с помощта на ръководство, за да автоматизирате тежките задачи.
- Поддържайте пълен достъп до Opsgenie по време и след миграцията, докато не бъде изключен.
- Следвайте персонализираните ръководства за миграция в Jira Service Management или Compass.
- Настройте работните процеси и преконфигурирайте настройките по време на 120-дневния преходен период.
- Осигурете непрекъснатост на сигналите, графиците и интеграциите без прекъсвания.
Предимства и недостатъци на миграцията от Opsgenie към Jira Service Management
Предимства:
- Той може да създаде безпроблемен, унифициран работен процес.
- За екипи, които вече са инвестирали значително в екосистемата на Atlassian, това може да бъде удобно и рентабилно решение.
- Ефективният анализ след инцидент на Jira опростява процеса на проследяване на последващите действия.
- Консолидирането на данните за инциденти в JSM позволява по-мощно и цялостно отчитане.
Недостатъци:
- Някои от разширените функции на самостоятелния Opsgenie може да не са веднага достъпни в JSM.
- Преминаването към по-широка JSM среда може да увеличи сложността и шума
- Екипите ще трябва да бъдат преквалифицирани за новия интерфейс и работни процеси в JSM.
Ето някои мнения на потребители на Reddit по темата
Този потребител на Reddit смята, че промяната като цяло е била полезна за тях:
За нас не се получи толкова зле. Трябва да преразгледам настройките на ролите и разрешенията, но всичко изглеждаше да преминава доста добре, освен ако имате същите имена на Jira екипи като тези в OpsGenies. Те не се обединиха добре и няколко от тях се повредиха. Препоръчвам да ги промените, ако имате такива.
За нас не се получи толкова зле. Трябва да преразгледам настройките на ролите и разрешенията, но всичко изглеждаше да преминава доста добре, освен ако имате точно същите имена на Jira екипи като тези в OpsGenies. Те не се обединиха добре и няколко от тях се повредиха. Препоръчвам да ги промените, ако имате такива.
Ето още един, който явно не е имал най-доброто преживяване:
В случай, че някой обмисля тази опция: ние преминахме към Jira Service Management, която е част от пакета, за който вече сме платили (компанията пести агресивно). Толкова е лошо, че дори не мога да го обясня. Не го считайте за опция.
В случай, че някой обмисля тази опция: ние преминахме към Jira Service Management, която е част от пакета, за който вече сме платили (компанията пести агресивно). Толкова е лошо, че дори не мога да го обясня. Не го считайте за опция.
И още един, който вече иска да смени отново след шест месеца с JSM:
JSM е ужасен. Той по никакъв начин не може да се сравни с PagerDuty, Rootly или Incident. io. Ние също преминахме към него преди около 6 месеца на работа и вече търсим алтернативи. Той е толкова негъвкав, почти няма интеграции, няма добра поддръжка за Slack, а сигналите за дежурства и страниците се пропускат от инженерите с доста висока успеваемост (никога не сме имали този проблем с OpeGenie).
JSM е ужасен. Той по никакъв начин не може да се сравни с PagerDuty, Rootly или Incident. io. Ние също преминахме към него преди около 6 месеца на работа и вече търсим алтернативи. Той е толкова негъвкав, почти няма интеграции, няма добра поддръжка за Slack, а сигналите за дежурства и страниците се пропускат от инженерите с доста висока успеваемост (никога не сме имали този проблем с OpeGenie).
Другата алтернатива, предлагана от Atlassian, Compass, не е пряка алтернатива на Opsgenie. Вместо това, тя е платформа за разработчици, предназначена за картографиране и управление на компонентите, услугите и зависимостите на сложна софтуерна архитектура.
Препоръчваме да прецените тези фактори, преди да изберете най-подходящата алтернатива на Opsgenie за вашия екип.
Opsgenie звъни, ClickUp отговаря
Преминаването от Opsgenie може да изглежда като голяма крачка, но погледнете на това като възможност да улесните живота на вашия екип.
Видяхте как се представят другите инструменти, всеки със своите силни страни, но и със своите ограничения.
Въпреки това, ClickUp тихо печели сърцата. 🤗
Ето защо: Той обединява вашите задачи, комуникация и работни процеси на едно място. Не се налага да преминавате от един екран на друг или да комбинирате отделни инструменти. Вместо това, вашият екип остава свързан, с ясни приоритети и уверен в това, което трябва да се случи по-нататък.
Изборът на подходящо решение за управление на инциденти не се отнася само до сигналите – става въпрос за създаване на стабилна рамка за управление на инциденти, която поддържа дългосрочна оперативна ефективност. С ClickUp вашият екип може да управлява инцидентите проактивно, като същевременно намалява шума и изгражда последователност във всеки отговор. 😌
Ако сте готови за по-малко главоболия и повече яснота, сега е моментът да се регистрирате в ClickUp!
Често задавани въпроси (FAQ)
Миграциите от Opsgenie трябва да бъдат планирани преди април 2027 г. След тази дата данните от Opsgenie вече няма да бъдат достъпни.
Някои от най-силните алтернативи включват Jira Service Management, PagerDuty, FireHydrant, TaskCall, ilert, Zenduty и incident.io. Всяка от тях предлага различен баланс между управление на дежурства, автоматизация и интеграции. Ако обаче искате всеобхватна платформа, задвижвана от изкуствен интелект, която съхранява вашите работни потоци, комуникации и документация на едно място, изберете ClickUp.
Jira Service Management включва повечето от основните функции на Opsgenie, като предупреждения, график за дежурства и работни потоци при инциденти, но някои разширени функции могат да се различават. Compass е опция за екипи за разработка, фокусирани върху каталози с услуги и проследяване на компоненти.
Да. Atlassian предоставя вграден в приложението инструмент за миграция, който автоматично прехвърля сигнали, графици и политики за ескалация. Можете дори да тествате миграцията в демо акаунт, преди да се ангажирате.
Да. Инструменти като Cabot, OpenDuty и Alertmanager могат да бъдат персонализирани като заместители с отворен код, въпреки че може да изискват повече настройки и поддръжка.
Разходите зависят от избраната платформа. Jira Service Management, Compass и други алтернативи предлагат цени на нива, често на базата на брой потребители на месец. Някои инструменти с отворен код са безплатни, но изискват разходи за инфраструктура и поддръжка.
Да. Вашият екип може да продължи да използва Opsgenie по време на миграционния период, а интеграциите остават активни, докато Opsgenie не бъде окончателно изключен. След това те трябва да бъдат преконфигурирани във вашата нова платформа.