
คุณปล่อยอัปเดตซอฟต์แวร์ล่าสุดออกมา และรายงานก็เริ่มหลั่งไหลเข้ามา
ทันใดนั้น ตัวชี้วัดเดียวก็กลายเป็นตัวกำหนดทุกอย่าง ตั้งแต่ CSAT/NPS ไปจนถึงการล่าช้าของโร้ดแมป: เวลาในการแก้ไขบั๊ก
ผู้บริหารมองว่านี่คือตัวชี้วัดการรักษาสัญญา—เราสามารถส่งมอบงาน เรียนรู้ และปกป้องรายได้ตามกำหนดเวลาได้หรือไม่? ผู้ปฏิบัติงานรู้สึกถึงความยากลำบากในแนวรบ—ตั๋วงานซ้ำซ้อน ความรับผิดชอบไม่ชัดเจน การยกระดับปัญหาที่วุ่นวาย และบริบทที่กระจัดกระจายอยู่ใน Slack, สเปรดชีต และเครื่องมือแยกต่างหาก
การแตกแยกนั้นยืดระยะเวลาของวงจร, ซ่อนสาเหตุที่แท้จริง, และเปลี่ยนการจัดลำดับความสำคัญให้กลายเป็นการคาดเดา
ผลลัพธ์คืออะไร? การเรียนรู้ช้าลง, การไม่ทำตามสัญญา, และงานที่ค้างคาซึ่งค่อยๆ ก่อให้เกิดภาระในทุกๆ สปรินต์
คู่มือนี้เป็นคู่มือฉบับสมบูรณ์สำหรับคุณในการวัดผล, เปรียบเทียบมาตรฐาน, และลดเวลาการแก้ไขข้อบกพร่อง พร้อมทั้งแสดงให้เห็นอย่างชัดเจนว่า AI เปลี่ยนกระบวนการทำงานอย่างไรเมื่อเทียบกับกระบวนการแบบดั้งเดิมที่ทำด้วยมือ
เวลาการแก้ไขข้อบกพร่องคืออะไร?
เวลาในการแก้ไขบั๊กคือระยะเวลาที่ใช้ในการแก้ไขบั๊ก โดยเริ่มนับตั้งแต่เวลาที่บั๊กถูกรายงานจนกระทั่งบั๊กได้รับการแก้ไขอย่างสมบูรณ์
ในทางปฏิบัติ นาฬิกาจะเริ่มทำงานเมื่อมีการรายงานหรือตรวจพบปัญหา (ผ่านทางผู้ใช้, QA, หรือการตรวจสอบ) และจะหยุดเมื่อการแก้ไขถูกนำไปใช้และผสานรวมแล้ว พร้อมสำหรับการตรวจสอบหรือการปล่อย—ขึ้นอยู่กับว่าทีมของคุณนิยามคำว่า "เสร็จ" ไว้อย่างไร
ตัวอย่าง: การเกิดข้อผิดพลาดระดับ P1 รายงานเมื่อเวลา 10:00 น. วันจันทร์ และมีการแก้ไขรวมเข้าไปเมื่อเวลา 15:00 น. วันอังคาร จะมีเวลาแก้ไขรวมประมาณ 29 ชั่วโมง
มันไม่เหมือนกับเวลาการตรวจจับข้อบกพร่อง. เวลาการตรวจจับวัดว่าคุณสามารถรับรู้ข้อบกพร่องได้รวดเร็วเพียงใดหลังจากที่มันเกิดขึ้น (การแจ้งเตือน,เครื่องมือทดสอบคุณภาพพบ, ลูกค้าแจ้ง).
เวลาในการแก้ไขปัญหาวัดความเร็วที่คุณเคลื่อนจากขั้นตอนการรับรู้ไปสู่การแก้ไข—การแยกประเภท, การทำซ้ำ, การวินิจฉัย, การดำเนินการ, การตรวจสอบ, การทดสอบ, และการเตรียมการปล่อย. คิดถึงการตรวจจับว่า "เรารู้ว่ามันเสีย" และการแก้ไขว่า "มันถูกแก้ไขและพร้อมแล้ว."
ทีมต่างๆ ใช้ขอบเขตที่แตกต่างกันเล็กน้อย; เลือกหนึ่งและใช้ให้สม่ำเสมอเพื่อให้แนวโน้มของคุณเป็นของจริง:
- รายงาน → แก้ไขแล้ว: สิ้นสุดเมื่อการแก้ไขโค้ดถูกรวมและพร้อมสำหรับการตรวจสอบคุณภาพ (QA) เหมาะสำหรับประสิทธิภาพการทำงานของทีมวิศวกรรม
- รายงาน → ปิด: รวมถึงการตรวจสอบคุณภาพและการปล่อย. เหมาะสำหรับ SLA ที่มีผลกระทบต่อผู้ใช้
- ตรวจพบ → แก้ไขแล้ว: เริ่มต้นเมื่อการตรวจสอบ/QA ตรวจพบปัญหา แม้ก่อนที่ตั๋วจะเกิดขึ้น มีประโยชน์สำหรับทีมที่มีการใช้งานหนักในสภาพแวดล้อมการผลิต
🧠 เกร็ดความรู้: ข้อผิดพลาดที่แปลกแต่ตลกในFinal Fantasy XIV ได้รับ คำชมเชยว่า มีความเฉพาะเจาะจงมากจนผู้อ่านตั้งชื่อให้ว่า "การแก้ไขข้อผิดพลาดที่เฉพาะเจาะจงที่สุดใน MMO ปี 2025" มันเกิดขึ้นเมื่อผู้เล่นตั้งราคาไอเท็มระหว่าง 44,442 กิล และ 49,087 กิล ในโซนกิจกรรมเฉพาะ—ทำให้การเชื่อมต่อหลุดเนื่องจากอาจเป็นข้อผิดพลาดจากการล้นของจำนวนเต็ม
เหตุใดจึงสำคัญ
ระยะเวลาในการแก้ไขปัญหาเป็นเครื่องมือในการกำหนดจังหวะการปล่อยเวอร์ชัน ระยะเวลาที่ยาวนานหรือไม่สามารถคาดการณ์ได้จะบังคับให้ต้องลดขอบเขตงาน แก้ไขปัญหาเฉพาะหน้า และระงับการปล่อยเวอร์ชัน นอกจากนี้ยังก่อให้เกิดหนี้สินในการวางแผน เนื่องจากส่วนหางยาว (ค่าผิดปกติ) ส่งผลกระทบต่อสปรินต์มากกว่าค่าเฉลี่ยที่คาดการณ์ไว้
นอกจากนี้ยังเชื่อมโยงโดยตรงกับความพึงพอใจของลูกค้า ลูกค้าจะยอมรับปัญหาได้เมื่อได้รับการยอมรับอย่างรวดเร็วและแก้ไขได้อย่างคาดเดาได้ การแก้ไขที่ล่าช้า—หรือแย่กว่านั้นคือการแก้ไขที่ไม่แน่นอน—จะนำไปสู่การยกระดับปัญหา ส่งผลให้คะแนน CSAT/NPS ลดลง และทำให้การต่ออายุสัญญาตกอยู่ในความเสี่ยง
โดยสรุป หากคุณวัดเวลาการแก้ไขข้อบกพร่องอย่างชัดเจนและลดมันอย่างเป็นระบบ แผนงานและความสัมพันธ์ของคุณจะดีขึ้น
📖 อ่านเพิ่มเติม: วิธีจัดลำดับความสำคัญของบั๊กเพื่อการแก้ไขปัญหาอย่างมีประสิทธิภาพ
วิธีวัดเวลาการแก้ไขปัญหาบั๊ก?
ก่อนอื่น ตัดสินใจว่าจุดเริ่มต้นและจุดสิ้นสุดของนาฬิกาของคุณคือตรงไหน
ทีมส่วนใหญ่เลือก รายงาน → แก้ไขแล้ว (การแก้ไขได้ถูกรวมและพร้อมสำหรับการตรวจสอบ) หรือ รายงาน → ปิด (QA ได้ตรวจสอบแล้วและการเปลี่ยนแปลงได้ถูกปล่อยหรือปิดด้วยวิธีอื่น)
เลือกหนึ่งคำจำกัดความและใช้มันอย่างสม่ำเสมอเพื่อให้แนวโน้มของคุณมีความหมาย
ตอนนี้คุณต้องการตัวชี้วัดที่สามารถสังเกตได้ มาดูกันว่ามีอะไรบ้าง:
ตัวชี้วัดการติดตามข้อบกพร่องที่สำคัญที่ควรระวัง:
| 📊 เมตริก | 📌 สิ่งที่มันหมายถึง | 💡 วิธีช่วยเหลือ | 🧮 สูตร (ถ้ามี) |
|---|---|---|---|
| จำนวนข้อบกพร่อง 🐞 | จำนวนรวมของบั๊กที่รายงาน | ให้ภาพรวมของสุขภาพระบบในมุมสูง จำนวนสูง? ถึงเวลาตรวจสอบแล้ว | จำนวนข้อบกพร่องทั้งหมด = ข้อบกพร่องทั้งหมดที่บันทึกในระบบ {เปิด + ปิด} |
| ข้อบกพร่องที่เปิดอยู่ 🚧 | บั๊กที่ยังไม่ได้แก้ไข | แสดงปริมาณงานปัจจุบัน ช่วยในการจัดลำดับความสำคัญ | ข้อบกพร่องที่เปิดอยู่ = ข้อบกพร่องทั้งหมด - ข้อบกพร่องที่ปิดแล้ว |
| ข้อบกพร่องที่แก้ไขแล้ว ✅ | บั๊กที่ได้รับการแก้ไขและตรวจสอบแล้ว | ติดตามความก้าวหน้าและงานที่ดำเนินการแล้ว | ข้อบกพร่องที่ปิดแล้ว = จำนวนข้อบกพร่องที่มีสถานะ "ปิด" หรือ "แก้ไขแล้ว" |
| ความรุนแรงของข้อบกพร่อง 🔥 | ความรุนแรงของบั๊ก (เช่น รุนแรง, ใหญ่, เล็ก) | ช่วยในการคัดแยกตามระดับความรุนแรง | ติดตามเป็น ฟิลด์ประเภทหมวดหมู่ ไม่มีสูตร ใช้ตัวกรอง/การจัดกลุ่ม |
| ลำดับความสำคัญของข้อบกพร่อง 📅 | ความเร่งด่วนในการแก้ไขข้อบกพร่อง | ช่วยในการวางแผนการสปรินต์และการปล่อย | นอกจากนี้ยังเป็น ฟิลด์เชิงหมวดหมู่ ซึ่งโดยทั่วไปจะมีการจัดอันดับ (เช่น P0, P1, P2) |
| เวลาในการแก้ไข ⏱️ | เวลาตั้งแต่รายงานบั๊กจนถึงการแก้ไข | วัดการตอบสนอง | เวลาที่ใช้ในการแก้ไข = วันที่ปิด - วันที่รายงาน |
| อัตราการเปิดใหม่ 🔄 | ร้อยละของข้อบกพร่องที่ถูกเปิดใหม่หลังจากปิดแล้ว | สะท้อนปัญหาคุณภาพการแก้ไขหรือปัญหาการถดถอย | อัตราการเปิดใหม่ (%) = {ข้อบกพร่องที่เปิดใหม่ ÷ ข้อบกพร่องที่ปิดทั้งหมด} × 100 |
| การรั่วไหลของข้อบกพร่อง 🕳️ | บั๊กที่หลุดเข้าไปในขั้นตอนการผลิต | บ่งชี้ถึงประสิทธิภาพของการทดสอบคุณภาพ/ซอฟต์แวร์ | อัตราการรั่วไหล (%) = {จำนวนข้อบกพร่องที่ผลิตได้ ÷ จำนวนข้อบกพร่องทั้งหมด} × 100 |
| ความหนาแน่นของข้อบกพร่อง 🧮 | จำนวนข้อบกพร่องต่อหน่วยขนาดของโค้ด | เน้นพื้นที่โค้ดที่มีความเสี่ยงสูง | ความหนาแน่นของข้อบกพร่อง = จำนวนข้อบกพร่อง ÷ KLOC {Kilo Lines of Code} |
| บั๊กที่ได้รับมอบหมาย vs บั๊กที่ยังไม่ได้มอบหมาย 👥 | การแจกแจงข้อบกพร่องตามเจ้าของ | ตรวจสอบให้แน่ใจว่าไม่มีสิ่งใดตกหล่นหรือถูกมองข้าม | ใช้ ฟิลเตอร์: ยังไม่มีการกำหนด = ข้อบกพร่องที่ "ผู้รับผิดชอบ" เป็นค่าว่าง |
| อายุของบั๊กที่เปิดอยู่ 🧓 | ระยะเวลาที่ข้อบกพร่องยังไม่ได้รับการแก้ไข | ระบุจุดที่หยุดนิ่งและความเสี่ยงของงานค้างสะสม | อายุของข้อบกพร่อง = วันที่ปัจจุบัน - วันที่รายงาน |
| ข้อบกพร่องซ้ำ 🧬 | จำนวนรายงานซ้ำ | เน้นข้อผิดพลาดในกระบวนการรับข้อมูล | อัตราซ้ำซ้อน = จำนวนซ้ำ ÷ จำนวนข้อบกพร่องทั้งหมด × 100 |
| MTTD (ระยะเวลาเฉลี่ยก่อนตรวจพบ) 🔎 | เวลาเฉลี่ยที่ใช้ในการตรวจพบข้อบกพร่องหรือเหตุการณ์ | มาตรการที่ติดตามและประเมินประสิทธิภาพการรับรู้ | MTTD = Σ(เวลาที่ตรวจพบ - เวลาที่เริ่ม) ÷ จำนวนบั๊ก |
| MTTR (เวลาเฉลี่ยในการแก้ไขปัญหา) 🔧 | เวลาเฉลี่ยในการแก้ไขข้อบกพร่องให้สมบูรณ์หลังจากการตรวจพบ | ติดตามการตอบสนองของวิศวกรและระยะเวลาในการแก้ไข | MTTR = Σ(เวลาที่แก้ไข - เวลาที่ตรวจพบ) ÷ จำนวนข้อบกพร่องที่แก้ไข |
| MTTA (เวลาเฉลี่ยในการตอบรับ) 📬 | เวลาตั้งแต่ตรวจพบจนถึงเวลาที่มีคนเริ่มแก้ไขข้อบกพร่อง | แสดงการตอบสนองของทีมและความตื่นตัวในการตอบสนองต่อเหตุการณ์ | MTTA = Σ(เวลาตอบรับ - เวลาตรวจพบ) ÷ จำนวนข้อบกพร่อง |
| MTBF (ค่าเฉลี่ยเวลาที่เครื่องทำงานได้ก่อนเกิดการล้มเหลว) 🔁 | ระยะเวลาตั้งแต่ความล้มเหลวหนึ่งได้รับการแก้ไขจนเกิดความล้มเหลวครั้งต่อไป | บ่งชี้ถึงความเสถียรภาพตลอดเวลา | MTBF = เวลาทำงานทั้งหมด ÷ จำนวนครั้งที่ล้มเหลว |
⚡️ แหล่งเก็บแม่แบบ: 15 แม่แบบและแบบฟอร์มรายงานข้อบกพร่องฟรีสำหรับการติดตามข้อบกพร่อง
ปัจจัยที่มีผลต่อเวลาการแก้ไขปัญหาของบัก
เวลาในการแก้ไขปัญหา มักถูกเปรียบเทียบกับ "ความเร็วในการเขียนโค้ดของวิศวกร"
แต่นั่นเป็นเพียงส่วนหนึ่งของกระบวนการเท่านั้น
เวลาในการแก้ไขบั๊กคือผลรวมของคุณภาพเมื่อรับเข้า ประสิทธิภาพการไหลผ่านระบบของคุณ และความเสี่ยงจากความพึ่งพา เมื่อใดก็ตามที่ปัจจัยใดปัจจัยหนึ่งเหล่านี้ล้มเหลว วงจรเวลาจะยืดออก ความสามารถในการคาดการณ์จะลดลง และการยกระดับปัญหาจะทวีความรุนแรงขึ้น
คุณภาพของข้อมูลที่รับเข้าเป็นตัวกำหนดทิศทาง
รายงานที่ส่งมาโดยไม่มีขั้นตอนการทำซ้ำที่ชัดเจน รายละเอียดสภาพแวดล้อม บันทึก หรือข้อมูลเวอร์ชัน/บิลด์ จะทำให้ต้องมีการติดต่อกลับไปกลับมาเพิ่มเติม รายงานซ้ำจากหลายช่องทาง (ฝ่ายสนับสนุน, QA, การตรวจสอบ, Slack) จะเพิ่มเสียงรบกวนและทำให้การรับผิดชอบแยกส่วน
ยิ่งคุณจับบริบทที่ถูกต้องและกำจัดข้อมูลซ้ำได้เร็วเท่าไร คุณก็จะยิ่งลดการส่งต่อและการสอบถามเพื่อชี้แจงในภายหลังได้มากขึ้นเท่านั้น
การจัดลำดับความสำคัญและการกำหนดเส้นทางเป็นตัวกำหนดว่าใครจะแก้ไขบั๊กและเมื่อใด
ป้ายกำกับความรุนแรงที่ไม่สอดคล้องกับผลกระทบต่อลูกค้า/ธุรกิจ (หรือที่เปลี่ยนแปลงไปตามกาลเวลา) ก่อให้เกิดการสลับคิว: ตั๋วที่มีเสียงดังที่สุดจะข้ามคิวไปก่อน ในขณะที่ข้อบกพร่องที่มีผลกระทบสูงยังคงค้างอยู่
กฎการกำหนดเส้นทางที่ชัดเจนตามส่วนประกอบ/เจ้าของ และคิวเดียวที่เป็นแหล่งข้อมูลหลักช่วยให้งาน P0/P1 ไม่ถูกฝังอยู่ใต้ "งานล่าสุดและเสียงรบกวน"
การเป็นเจ้าของงานและการส่งต่อที่ไม่ชัดเจนคือตัวการเงียบ
หากไม่ชัดเจนว่าบั๊กนั้นเกี่ยวข้องกับมือถือ, ระบบยืนยันตัวตน, หรือทีมแพลตฟอร์ม, บั๊กนั้นจะถูกส่งกลับ. การส่งกลับแต่ละครั้งจะทำให้บริบทถูกรีเซ็ต.
เขตเวลาทำให้ปัญหานี้ซับซ้อนยิ่งขึ้น: บั๊กที่ถูกรายงานในช่วงท้ายของวันโดยไม่มีผู้รับผิดชอบที่ระบุชื่อ อาจสูญหายไป 12–24 ชั่วโมงก่อนที่ใครจะเริ่มตรวจสอบและทำซ้ำปัญหาได้ การกำหนดขอบเขตความรับผิดชอบอย่างชัดเจนว่า "ใครรับผิดชอบอะไร" พร้อมการกำหนดผู้รับผิดชอบประจำหรือรายสัปดาห์ จะช่วยขจัดปัญหาการล่าช้านี้
ความสามารถในการทำซ้ำได้ขึ้นอยู่กับความสามารถในการสังเกต
บันทึกข้อมูลที่ขาดหาย รหัสความสัมพันธ์ที่หายไป หรือการขาดข้อมูลการเกิดข้อผิดพลาดทำให้การวินิจฉัยกลายเป็นเพียงการคาดเดา ข้อบกพร่องที่ปรากฏเฉพาะเมื่อใช้แฟล็ก ผู้เช่า หรือรูปแบบข้อมูลเฉพาะนั้นยากที่จะทำซ้ำในสภาพแวดล้อมการพัฒนา
หากวิศวกรไม่สามารถเข้าถึงข้อมูลที่ผ่านการฆ่าเชื้อซึ่งใกล้เคียงกับการผลิตจริงได้อย่างปลอดภัย พวกเขาจะต้องติดตั้งอุปกรณ์ใหม่, ทำการปรับใช้ใหม่, และรอคอย—ซึ่งอาจใช้เวลาหลายวันแทนที่จะเป็นเพียงไม่กี่ชั่วโมง
สิ่งแวดล้อมและความเท่าเทียมของข้อมูลช่วยให้คุณซื่อสัตย์
"ทำงานบนเครื่องของฉัน" มักหมายถึง "ข้อมูลการผลิตแตกต่าง" ยิ่งการพัฒนา/การทดสอบของคุณแตกต่างจากระบบจริง (การตั้งค่า, บริการ, เวอร์ชันของบุคคลที่สาม) มากเท่าไร คุณก็จะเสียเวลาในการแก้ไขปัญหาที่ไม่มีอยู่จริงมากขึ้นเท่านั้น การสร้างภาพข้อมูลที่ปลอดภัย, สคริปต์เริ่มต้น, และการตรวจสอบความถูกต้องช่วยลดช่องว่างนั้นได้
งานที่อยู่ระหว่างดำเนินการ (WIP) และการมุ่งเน้นเป็นตัวขับเคลื่อนปริมาณงานที่เสร็จสิ้นจริง
ทีมที่ทำงานหนักเกินไปจะดึงบั๊กมากเกินไปในคราวเดียว ทำให้ความสนใจกระจัดกระจาย และสลับไปมาระหว่างงานและการประชุม การสลับบริบทเพิ่มชั่วโมงที่มองไม่เห็น
การจำกัดจำนวนงานที่อยู่ในระหว่างดำเนินการ (WIP) ให้เห็นได้ชัดเจน และให้ความสำคัญกับการทำงานที่เริ่มต้นไว้ให้เสร็จก่อนที่จะเริ่มงานใหม่ จะช่วยยกระดับค่ากลางของผลงานให้สูงขึ้นได้เร็วกว่าความพยายามของบุคคลใดบุคคลหนึ่งเพียงคนเดียว
การตรวจสอบโค้ด, CI, และความเร็วในการควบคุมคุณภาพเป็นปัญหาคอขวดที่พบได้บ่อย
เวลาในการสร้างที่ช้า, การทดสอบที่ไม่เสถียร, และข้อตกลงการให้บริการการตรวจสอบที่ไม่ชัดเจนทำให้การแก้ไขปัญหาที่รวดเร็วหยุดชะงัก แพทช์ที่ใช้เวลาเพียง 10 นาทีอาจต้องใช้เวลาสองวันในการรอผู้ตรวจสอบหรือการวางในกระบวนการที่ใช้เวลาหลายชั่วโมง
ในทำนองเดียวกัน คิว QA ที่ทำการทดสอบแบบกลุ่มหรือพึ่งพาการทดสอบเบื้องต้นด้วยมือ (smoke pass) อาจเพิ่มระยะเวลาเต็มวันให้กับขั้นตอน "รายงาน → ปิด" แม้ว่าขั้นตอน "รายงาน → แก้ไข" จะรวดเร็วก็ตาม
การพึ่งพาขยายคิวให้ยาวขึ้น
การเปลี่ยนแปลงข้ามทีม (เช่น การเปลี่ยนแปลงโครงสร้างข้อมูล การย้ายแพลตฟอร์ม การอัปเดต SDK) ข้อผิดพลาดจากผู้ให้บริการ หรือการตรวจสอบจากร้านค้าแอป (สำหรับมือถือ) ล้วนทำให้เกิดสถานะรอโดยไม่ตั้งใจ หากไม่มีการติดตามสถานะ "ถูกบล็อก/หยุดชั่วคราว" อย่างชัดเจน ช่วงเวลาที่รอเหล่านี้จะไปเพิ่มค่าเฉลี่ยโดยที่มองไม่เห็น และซ่อนจุดคอขวดที่แท้จริงเอาไว้
รุ่นการปล่อยและการย้อนกลับมีความสำคัญ
หากคุณจัดส่งซอฟต์แวร์ในรูปแบบของ release train ที่มีขนาดใหญ่และต้องผ่านการตรวจสอบด้วยมือ แม้แต่บั๊กที่แก้ไขแล้วก็จะยังค้างอยู่จนกว่า train ขบวนถัดไปจะออกเดินทาง ฟีเจอร์แฟล็ก, การปล่อยเวอร์ชันแบบ canary, และช่องทางสำหรับแก้ไขปัญหาเร่งด่วน (hotfix lane) จะช่วยลดระยะเวลาที่ฟีเจอร์หรือการแก้ไขค้างอยู่ในระบบ—โดยเฉพาะในกรณีเหตุการณ์วิกฤตระดับ P0/P1—โดยช่วยให้คุณแยกการปล่อยการแก้ไขออกจากวงจรการปล่อยเวอร์ชันเต็มได้
สถาปัตยกรรมและหนี้ทางเทคโนโลยีกำหนดเพดานของคุณ
การเชื่อมโยงที่แน่นเกินไป การขาดรอยต่อสำหรับการทดสอบ และโมดูลเก่าที่ไม่โปร่งใส ทำให้การแก้ไขปัญหาเล็กน้อยกลายเป็นความเสี่ยง ทีมจึงต้องชดเชยด้วยการทดสอบเพิ่มเติมและการตรวจสอบที่ยาวนานขึ้น ซึ่งส่งผลให้วงจรการพัฒนาใช้เวลานานขึ้น ในทางตรงกันข้าม โค้ดที่แบ่งเป็นโมดูลพร้อมกับการทดสอบสัญญาที่ดี จะช่วยให้คุณสามารถเปลี่ยนแปลงได้อย่างรวดเร็วโดยไม่กระทบต่อระบบที่เกี่ยวข้อง
การสื่อสารและการรักษาความสะอาดสถานะมีอิทธิพลต่อความสามารถในการคาดการณ์
การอัปเดตที่คลุมเครือ ("กำลังตรวจสอบอยู่") ก่อให้เกิดงานที่ต้องทำซ้ำเมื่อผู้มีส่วนได้ส่วนเสียสอบถามกำหนดเวลา การสนับสนุนต้องเปิดตั๋วใหม่ หรือผลิตภัณฑ์ถูกยกระดับ ปัญหาเหล่านี้สามารถลดลงได้ด้วยการเปลี่ยนแปลงสถานะที่ชัดเจน บันทึกเกี่ยวกับการทำซ้ำและสาเหตุที่แท้จริง รวมถึงการแจ้งกำหนดเวลาที่ชัดเจน ซึ่งจะช่วยลดการรบกวนและปกป้องสมาธิของทีมวิศวกรรมของคุณ
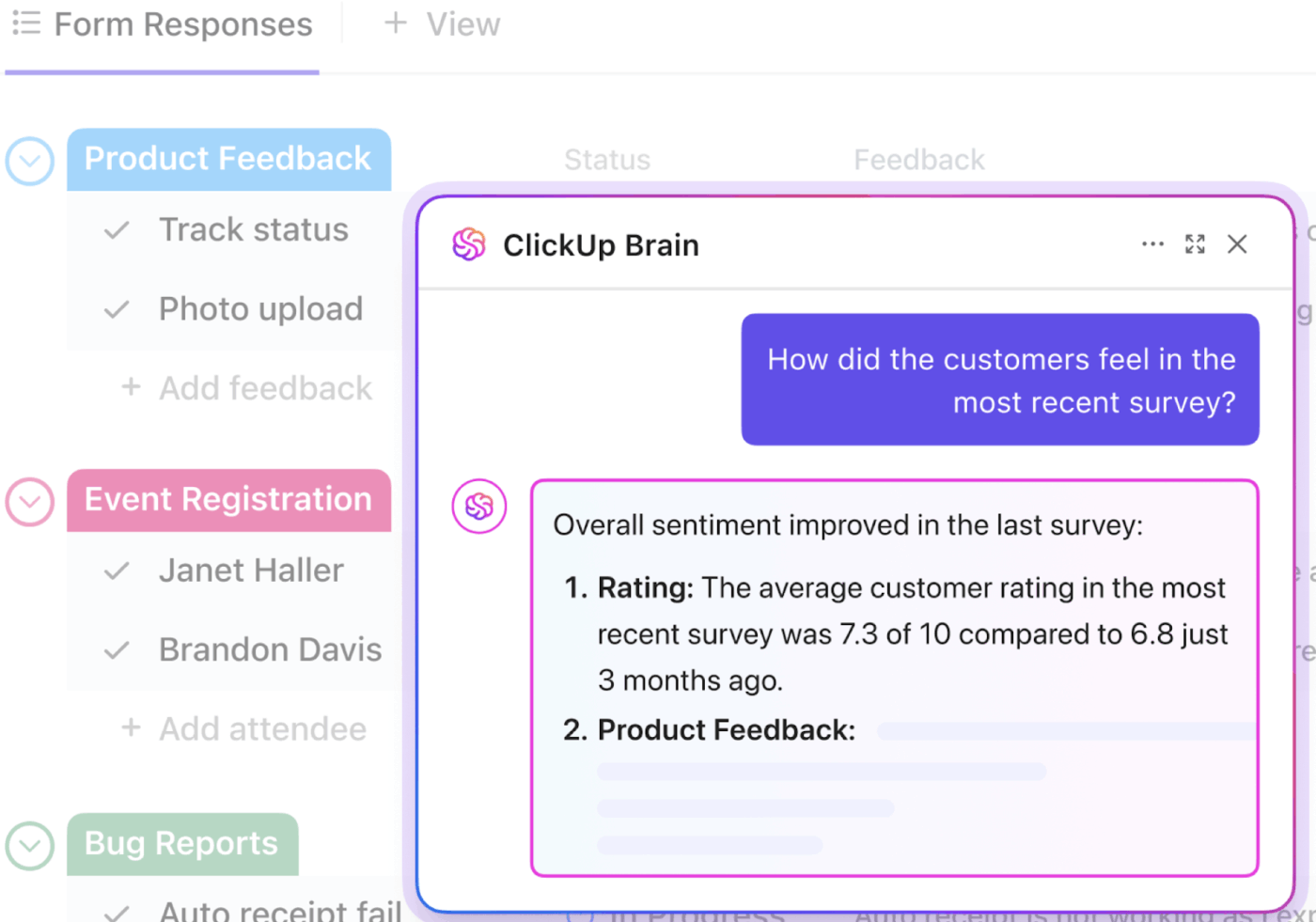
📮ClickUp Insight: มืออาชีพโดยเฉลี่ยใช้เวลา 30 นาทีขึ้นไปต่อวันในการค้นหาข้อมูลที่เกี่ยวข้องกับงาน—นั่นคือมากกว่า 120 ชั่วโมงต่อปีที่สูญเสียไปกับการค้นหาอีเมล, กระทู้ใน Slack และไฟล์ที่กระจัดกระจาย
ผู้ช่วย AI ที่ชาญฉลาดฝังอยู่ในที่ทำงานของคุณสามารถเปลี่ยนแปลงสิ่งนั้นได้ ขอแนะนำClickUp Brain ที่มอบข้อมูลเชิงลึกและคำตอบทันทีด้วยการแสดงเอกสาร การสนทนา และรายละเอียดงานที่เหมาะสมภายในไม่กี่วินาที—เพื่อให้คุณหยุดค้นหาและเริ่มทำงานได้ทันที
💫 ผลลัพธ์ที่แท้จริง: ทีมอย่าง QubicaAMF สามารถประหยัดเวลาได้มากกว่า 5 ชั่วโมงต่อสัปดาห์โดยใช้ ClickUp—นั่นคือมากกว่า 250 ชั่วโมงต่อปีต่อคน—ด้วยการกำจัดกระบวนการจัดการความรู้ที่ล้าสมัย ลองนึกภาพว่าทีมของคุณจะสามารถสร้างอะไรได้บ้างหากมีเวลาเพิ่มอีกหนึ่งสัปดาห์ในแต่ละไตรมาส!
ตัวชี้วัดสำคัญที่บ่งชี้ว่าเวลาในการแก้ไขปัญหาของคุณอาจล่าช้า
❗️จำนวน "เวลาที่ต้องยอมรับ" ที่เพิ่มขึ้น และตั๋วจำนวนมากที่ไม่มีเจ้าของเป็นเวลา >12 ชั่วโมง
❗️การเพิ่มขึ้นของ "เวลาในการตรวจสอบ/CI" และการทดสอบที่ล้มเหลวบ่อยครั้ง
❗️อัตราการซ้ำซ้อนสูงในข้อมูลที่รับเข้าและป้ายกำกับความรุนแรงที่ไม่สอดคล้องกันระหว่างทีม
❗️มีบั๊กหลายรายการอยู่ในสถานะ "ถูกบล็อก" โดยไม่มีแหล่งที่มาภายนอกที่ระบุชื่อ
❗️อัตราการเปิดใหม่ค่อยๆ เพิ่มขึ้น (การแก้ไขไม่สามารถทำซ้ำได้หรือคำจำกัดความของการเสร็จสิ้นไม่ชัดเจน)
องค์กรต่างๆ รู้สึกถึงปัจจัยเหล่านี้แตกต่างกัน ผู้บริหารมองว่าเป็นวงจรการเรียนรู้ที่พลาดไปและโอกาสทางรายได้ที่สูญเสียไป ผู้ปฏิบัติงานรู้สึกว่าเป็นเสียงรบกวนจากการจัดลำดับความสำคัญและขาดความชัดเจนในการรับผิดชอบ
การปรับแต่งการรับเข้า, การไหล, และการพึ่งพาเป็นวิธีที่คุณดึงทั้งเส้นโค้ง—ค่ามัธยฐานและ P90—ลงมา
ต้องการเรียนรู้เพิ่มเติมเกี่ยวกับการเขียนรายงานข้อผิดพลาดให้ดีขึ้นหรือไม่? เริ่มต้นที่นี่ 👇🏼
📖 อ่านเพิ่มเติม: วงจรชีวิตการทดสอบซอฟต์แวร์ (STLC): ภาพรวมและขั้นตอนต่างๆ
มาตรฐานอุตสาหกรรมสำหรับเวลาในการแก้ไขข้อบกพร่อง
เกณฑ์มาตรฐานในการแก้ไขข้อบกพร่องจะเปลี่ยนแปลงไปตามระดับความเสี่ยงที่ยอมรับได้ รูปแบบการปล่อยเวอร์ชัน และความเร็วในการนำการเปลี่ยนแปลงออกสู่ระบบ
นี่คือจุดที่คุณสามารถใช้ค่ากลาง (P50) เพื่อทำความเข้าใจการไหลปกติของคุณ และใช้ P90 เพื่อกำหนดคำมั่นสัญญาและ SLA—โดยแบ่งตามความรุนแรงและแหล่งที่มา (ลูกค้า, QA, การตรวจสอบ)
มาดูกันว่ามันหมายความว่าอย่างไร:
| 🔑 คำศัพท์ | 📝 คำอธิบาย | 💡 ทำไมมันถึงสำคัญ |
|---|---|---|
| P50 (ค่ามัธยฐาน) | ค่ากลาง—50% ของการแก้ไขบั๊กทำได้เร็วกว่านี้ และอีก 50% ทำได้ช้ากว่า | 👉 สะท้อนเวลาการแก้ไขปัญหาโดยทั่วไปหรือที่พบบ่อยที่สุดของคุณ เหมาะสำหรับการทำความเข้าใจประสิทธิภาพการทำงานปกติ |
| P90 (เปอร์เซ็นไทล์ที่ 90) | 90% ของบั๊กได้รับการแก้ไขภายในเวลานี้ มีเพียง 10% เท่านั้นที่ใช้เวลานานกว่า | 👉 แสดงถึงขอบเขตที่เลวร้ายที่สุด (แต่ยังคงเป็นไปได้ในทางปฏิบัติ) มีประโยชน์สำหรับการกำหนดคำมั่นสัญญาภายนอก |
| SLA (ข้อตกลงระดับการให้บริการ) | ข้อผูกพันที่คุณทำ—ทั้งภายในองค์กรหรือกับลูกค้า—เกี่ยวกับความรวดเร็วในการแก้ไขปัญหา | 👉 ตัวอย่าง: "เราแก้ไขบั๊ก P1 ภายใน 48 ชั่วโมง 90% ของเวลา" ช่วยสร้างความไว้วางใจและความรับผิดชอบ |
| ตามความรุนแรงและแหล่งที่มา | การแบ่งกลุ่มตัวชี้วัดของคุณตามสองมิติหลัก: • ความรุนแรง (เช่น P0, P1, P2)• แหล่งที่มา (เช่น ลูกค้า, QA, การตรวจสอบ) | 👉 ช่วยให้การติดตามและการจัดลำดับความสำคัญมีความแม่นยำมากขึ้น เพื่อให้ข้อบกพร่องที่สำคัญได้รับความสนใจอย่างรวดเร็ว |
ด้านล่างนี้คือช่วงทิศทางที่อิงตามอุตสาหกรรมที่ทีมที่มีประสบการณ์มักจะมุ่งเป้า; ให้ถือว่าเป็นช่วงเริ่มต้น แล้วปรับให้เข้ากับบริบทของคุณ
SaaS
พร้อมใช้งานตลอดเวลาและรองรับ CI/CD อย่างเต็มรูปแบบ ทำให้การแก้ไขปัญหาเฉพาะหน้าเป็นเรื่องปกติ ปัญหาวิกฤต (P0/P1) มักจะตั้งเป้าให้แก้ไขภายในระยะเวลาเฉลี่ยไม่เกินหนึ่งวันทำการ โดย P90 จะแก้ไขภายใน 24–48 ชั่วโมง ปัญหาที่ไม่วิกฤต (P2+) มักใช้เวลาเฉลี่ย 3–7 วัน โดย P90 จะแก้ไขภายใน 10–14 วัน ทีมงานที่มีฟีเจอร์แฟล็กที่แข็งแกร่งและการทดสอบอัตโนมัติจะมีแนวโน้มแก้ไขปัญหาได้รวดเร็วกว่า
แพลตฟอร์มอีคอมเมิร์ซ
เนื่องจากกระบวนการแปลงและตะกร้าสินค้าเป็นปัจจัยสำคัญต่อรายได้ มาตรฐานจึงสูงขึ้น ปัญหา P0/P1 มักจะได้รับการแก้ไขภายในไม่กี่ชั่วโมง (ย้อนกลับ, แจ้งเตือน, หรือกำหนดค่า) และแก้ไขเสร็จสมบูรณ์ในวันเดียวกัน; P90 มักจะแก้ไขภายในสิ้นวันหรือภายใน 12 ชั่วโมงในช่วงฤดูสูงสุด ปัญหา P2+ มักจะใช้เวลาแก้ไข 2–5 วัน โดย P90 จะแก้ไขภายใน 10 วัน
ซอฟต์แวร์สำหรับองค์กร
การตรวจสอบที่เข้มงวดขึ้นและช่วงเวลาการเปลี่ยนแปลงของลูกค้าที่นานขึ้นทำให้จังหวะการทำงานช้าลง สำหรับ P0/P1 ทีมจะตั้งเป้าหมายในการหาวิธีแก้ไขชั่วคราวภายใน 4–24 ชั่วโมง และแก้ไขปัญหาภายใน 1–3 วันทำการ; สำหรับ P90 ภายใน 5 วันทำการ ส่วนรายการ P2+ มักจะถูกจัดกลุ่มรวมกันในรถไฟการปล่อย (release trains) โดยมีค่ามัธยฐานอยู่ที่ 2–4 สัปดาห์ ขึ้นอยู่กับตารางการเปิดตัวของลูกค้า
เกมและแอปพลิเคชันมือถือ
ระบบแบ็กเอนด์ที่ให้บริการแบบเรียลไทม์จะทำงานคล้ายกับ SaaS (การตั้งค่าและย้อนกลับภายในไม่กี่นาทีถึงไม่กี่ชั่วโมง; P90 ภายในวันเดียวกัน) การอัปเดตฝั่งลูกค้าจะถูกจำกัดด้วยการตรวจสอบของร้านค้า: P0/P1 มักใช้มาตรการฝั่งเซิร์ฟเวอร์ทันทีและส่งแพตช์อัปเดตให้ลูกค้าภายใน 1–3 วัน; P90 ภายในหนึ่งสัปดาห์หากได้รับการตรวจสอบเร่งด่วน การแก้ไข P2+ มักจะถูกจัดตารางไว้ในสปรินต์ถัดไปหรือการปล่อยคอนเทนต์ครั้งถัดไป
ธนาคาร/ฟินเทค
ประตูความเสี่ยงและการปฏิบัติตามข้อกำหนดขับเคลื่อนรูปแบบ "บรรเทาอย่างรวดเร็ว เปลี่ยนแปลงอย่างระมัดระวัง" P0/P1 จะได้รับการบรรเทาอย่างรวดเร็ว (การแจ้งเตือน การย้อนกลับ การเปลี่ยนเส้นทางภายในไม่กี่นาทีถึงไม่กี่ชั่วโมง) และแก้ไขอย่างสมบูรณ์ภายใน 1–3 วัน; P90 ภายในหนึ่งสัปดาห์ โดยคำนึงถึงการควบคุมการเปลี่ยนแปลง P2+ มักใช้เวลา 2–6 สัปดาห์เพื่อให้ผ่านการตรวจสอบด้านความปลอดภัย การตรวจสอบภายใน และการอนุมัติจากคณะกรรมการบริหาร
หากตัวเลขของคุณอยู่นอกช่วงที่กำหนดไว้ ให้ตรวจสอบคุณภาพของข้อมูลที่รับเข้า, การจัดเส้นทาง/การเป็นเจ้าของ, การตรวจสอบโค้ด, ปริมาณงาน QA และการอนุมัติการพึ่งพา ก่อนที่จะสรุปว่า "ความเร็วของวิศวกรรม" คือปัญหาหลัก
🌼 คุณรู้หรือไม่:จากการสำรวจของ Stack Overflow ในปี 2024 พบว่านักพัฒนามากขึ้นเรื่อย ๆ ใช้ AI เป็นผู้ช่วยคู่ใจตลอดเส้นทางการเขียนโค้ด 82% ใช้ AI ในการเขียนโค้ดจริง ๆ—เรียกได้ว่าเป็นผู้ร่วมงานที่สร้างสรรค์อย่างแท้จริง! เมื่อติดขัดหรือกำลังหาวิธีแก้ปัญหา 67.5% พึ่งพา AI ในการค้นหาคำตอบ และมากกว่าครึ่ง (56.7%) ใช้อำนาจของ AI ในการแก้ไขข้อผิดพลาดและขอความช่วยเหลือ
สำหรับบางคน เครื่องมือ AI ยังพิสูจน์ว่ามีประโยชน์ในการบันทึกโครงการ (40.1%) และแม้กระทั่งการสร้างข้อมูลหรือเนื้อหาสังเคราะห์ (34.8%) สงสัยเกี่ยวกับโค้ดเบสใหม่หรือไม่? เกือบหนึ่งในสาม (30.9%) ใช้ AI เพื่อทำความคุ้นเคย การทดสอบโค้ดยังคงเป็นงานที่ต้องทำด้วยมือสำหรับหลายคน แต่ 27.2% ก็ยอมรับการใช้ AI ในขั้นตอนนี้เช่นกัน ส่วนอื่นๆ เช่น การตรวจสอบโค้ด การวางแผนโครงการ และการวิเคราะห์เชิงคาดการณ์ มีการนำ AI มาใช้ในระดับที่ต่ำกว่า แต่เห็นได้ชัดว่า AI กำลังค่อยๆ แทรกซึมเข้าไปในทุกขั้นตอนของการพัฒนาซอฟต์แวร์
📖 อ่านเพิ่มเติม: วิธีใช้ AI เพื่อการประกันคุณภาพ
วิธีลดเวลาในการแก้ไขปัญหาบั๊ก
ความเร็วในการแก้ไขข้อบกพร่องขึ้นอยู่กับการขจัดอุปสรรคในทุกขั้นตอนของการส่งต่อ ตั้งแต่การรับเรื่องไปจนถึงการปล่อยงาน
การได้ประโยชน์มากที่สุดมาจากการทำให้ 30 นาทีแรกฉลาดขึ้น (การรับเข้าที่สะอาด, เจ้าของที่ถูกต้อง, ความสำคัญที่ถูกต้อง), จากนั้นบีบอัดลูปที่ตามมา (ผลิตซ้ำ, ทบทวน, ตรวจสอบ)
นี่คือกลยุทธ์เก้าประการที่ทำงานร่วมกันเป็นระบบ AI ช่วยเร่งแต่ละขั้นตอน และกระบวนการทำงานจะดำเนินไปอย่างราบรื่นในที่เดียว ทำให้ผู้บริหารสามารถคาดการณ์ได้ และผู้ปฏิบัติงานได้รับประสบการณ์การทำงานที่ลื่นไหล
1. รวบรวมข้อมูลและจับบริบทจากแหล่งที่มา
ระยะเวลาในการแก้ไขข้อบกพร่องจะยาวนานขึ้นเมื่อคุณต้องสร้างบริบทใหม่จากเธรดใน Slack, ตั๋วสนับสนุน และสเปรดชีต ให้รวบรวมรายงานทั้งหมด—ทั้งฝ่ายสนับสนุน, QA, การตรวจสอบ—เข้าสู่คิวเดียวด้วยเทมเพลตที่มีโครงสร้างซึ่งรวบรวมข้อมูลเกี่ยวกับส่วนประกอบ, ความรุนแรง, สภาพแวดล้อม, เวอร์ชัน/บิลด์ของแอป, ขั้นตอนในการทำซ้ำ, ผลที่คาดหวังเทียบกับที่เกิดขึ้นจริง และไฟล์แนบ (ล็อก/HAR/หน้าจอ)
ระบบ AI สามารถสรุปรายงานยาวได้โดยอัตโนมัติ, สกัดขั้นตอนการทำซ้ำและรายละเอียดของสภาพแวดล้อมจากไฟล์แนบ, และทำเครื่องหมายเอกสารที่อาจซ้ำซ้อนเพื่อให้การคัดกรองเริ่มต้นด้วยบันทึกที่สอดคล้องและสมบูรณ์
ตัวชี้วัดที่ควรติดตาม: MTTA (ตอบรับภายในไม่กี่นาที ไม่ใช่หลายชั่วโมง), อัตราการทำซ้ำ, เวลา "ต้องการข้อมูลเพิ่มเติม"

📖 อ่านเพิ่มเติม: พลังของแบบฟอร์ม ClickUp: เพิ่มประสิทธิภาพการทำงานสำหรับทีมซอฟต์แวร์
2. การคัดแยกผู้ป่วยและจัดเส้นทางด้วยระบบ AI เพื่อลด MTTA อย่างมีประสิทธิภาพ
การแก้ไขที่เร็วที่สุดคือสิ่งที่ไปถึงโต๊ะที่ถูกต้องทันที
ใช้กฎง่าย ๆ ร่วมกับ AI เพื่อจัดหมวดหมู่ความรุนแรง ระบุเจ้าของที่น่าจะเป็นตามชิ้นส่วน/พื้นที่รหัส และมอบหมายโดยอัตโนมัติพร้อมนาฬิกา SLA กำหนดช่องทางที่ชัดเจนสำหรับ P0/P1 กับทุกสิ่งอื่น ๆ และทำให้ "ใครเป็นเจ้าของสิ่งนี้" ชัดเจนไม่คลุมเครือ
ระบบอัตโนมัติสามารถกำหนดลำดับความสำคัญจากฟิลด์ต่างๆ, ส่งต่อตามส่วนประกอบไปยังทีม, เริ่มจับเวลา SLA, และแจ้งเตือนวิศวกรที่อยู่ในเวร; AI สามารถเสนอระดับความรุนแรงและเจ้าของงานตามรูปแบบในอดีต เมื่อการคัดกรองกลายเป็นกระบวนการที่ใช้เวลา 2–5 นาทีแทนที่จะเป็นการถกเถียง 30 นาที, MTTA ของคุณจะลดลงและ MTTR ของคุณจะตามมา
เมตริกที่ควรติดตาม: MTTA, คุณภาพการตอบกลับครั้งแรก (ความคิดเห็นแรกขอข้อมูลถูกต้องหรือไม่?), จำนวนการส่งต่อต่อบัก
นี่คือสิ่งที่เกิดขึ้นจริง:
3. จัดลำดับความสำคัญตามผลกระทบทางธุรกิจโดยใช้ระดับ SLA ที่ชัดเจน
"เสียงดังที่สุดชนะ" ทำให้คิวไม่แน่นอนและทำลายความไว้วางใจกับผู้บริหารที่ติดตาม CSAT/NPS และการต่ออายุ
แทนที่ด้วยคะแนนที่ผสมผสานความรุนแรง ความถี่ ARR ที่ได้รับผลกระทบ ความสำคัญของคุณลักษณะ และความใกล้ชิดกับการต่ออายุ/การเปิดตัว และสนับสนุนด้วยระดับ SLA (เช่น P0: แก้ไขภายใน 1–2 ชั่วโมง แก้ไขภายในหนึ่งวัน; P1: ภายในวันเดียวกัน; P2: ภายในสปรินต์)
รักษาช่องทาง P0/P1 ที่มองเห็นได้พร้อมขีดจำกัดงานที่กำลังดำเนินการอยู่ (WIP) เพื่อไม่ให้งานใดขาดแคลนทรัพยากร
เมตริกที่ควรติดตาม: ความละเอียด P50/P90 ตามระดับชั้น, อัตราการละเมิด SLA, ความสัมพันธ์กับ CSAT/NPS
💡เคล็ดลับจากผู้เชี่ยวชาญ:ฟีเจอร์ลำดับความสำคัญของงาน,ฟิลด์ที่กำหนดเอง และฟิลด์การพึ่งพาของ ClickUp ช่วยให้คุณสามารถคำนวณคะแนนผลกระทบและเชื่อมโยงข้อบกพร่องกับบัญชี, ข้อเสนอแนะ หรือรายการในแผนงานได้ นอกจากนี้ ฟีเจอร์เป้าหมายใน ClickUpยังช่วยให้คุณเชื่อมโยงการปฏิบัติตาม SLA กับวัตถุประสงค์ระดับบริษัท ซึ่งตรงกับความกังวลของผู้บริหารเกี่ยวกับการสอดคล้องกัน
4. ทำให้การสืบพันธุ์และการวินิจฉัยเป็นกิจกรรมที่ทำเพียงครั้งเดียว
ทุกครั้งที่มีการเพิ่มข้อความ "ช่วยส่งล็อกได้ไหม?" จะทำให้เวลาในการแก้ไขปัญหาเพิ่มขึ้น
กำหนดมาตรฐานว่า "ดี" ควรเป็นอย่างไร: กำหนดช่องข้อมูลที่จำเป็นสำหรับการสร้าง/การคอมมิต, สภาพแวดล้อม, ขั้นตอนการทำซ้ำ, ผลที่คาดหวังเทียบกับผลลัพธ์จริง รวมถึงไฟล์แนบสำหรับบันทึก, ไฟล์ดัมพ์ข้อมูลที่เกิดข้อผิดพลาด และไฟล์ HAR ติดตั้งเครื่องมือวัดข้อมูลจากฝั่งลูกค้าและเซิร์ฟเวอร์ เพื่อให้สามารถเชื่อมโยงรหัสข้อผิดพลาดและรหัสคำขอกับข้อมูลการติดตามได้
นำ Sentry (หรือที่คล้ายกัน) มาใช้เพื่อดู stack trace และเชื่อมโยงปัญหานั้นกับบั๊กโดยตรง AI สามารถอ่านบันทึกและ trace เพื่อเสนอขอบเขตความผิดพลาดที่น่าจะเป็นไปได้และสร้างตัวอย่างการเกิดปัญหาที่น้อยที่สุด ทำให้การตรวจสอบด้วยสายตาเป็นเวลาหนึ่งชั่วโมงกลายเป็นงานที่มุ่งเน้นเพียงไม่กี่นาที
จัดเก็บ runbooks สำหรับประเภทของบั๊กที่พบบ่อย เพื่อให้วิศวกรไม่ต้องเริ่มต้นใหม่ตั้งแต่ต้น
เมตริกที่ควรติดตาม: เวลาที่ใช้ในการ "รอข้อมูล," เปอร์เซ็นต์ที่สามารถทำซ้ำได้ในการตรวจสอบครั้งแรก, อัตราการเปิดใหม่ที่เกี่ยวข้องกับข้อมูลที่ขาดหายไป
📖 เรียนรู้เพิ่มเติม: วิธีใช้ AI ในการพัฒนาซอฟต์แวร์ (กรณีศึกษาและเครื่องมือ)
5. ย่นระยะเวลาการตรวจสอบโค้ดและรอบการทดสอบ
การปรับปรุงใหญ่หยุดชะงัก ให้มุ่งเน้นการแก้ไขเฉพาะจุด การพัฒนาโดยใช้ฐานหลัก และการเปิดใช้งานฟีเจอร์ผ่านฟีเจอร์แฟล็ก เพื่อให้สามารถส่งการแก้ไขได้อย่างปลอดภัย กำหนดผู้ตรวจสอบล่วงหน้าตามเจ้าของโค้ดเพื่อลดเวลาว่าง และใช้เช็กลิสต์ (เช่น ทดสอบแล้ว เพิ่มข้อมูลจากเทเลเมทริกซ์ เปิดใช้งานแฟล็กผ่านคิลสวิตช์) เพื่อให้คุณภาพถูกฝังไว้ตั้งแต่ต้น
ระบบอัตโนมัติควรย้ายบั๊กไปยังสถานะ "อยู่ระหว่างการตรวจสอบ" เมื่อเปิด PR และไปยังสถานะ "แก้ไขแล้ว" เมื่อมีการผสาน; AI สามารถแนะนำการทดสอบหน่วยหรือเน้นความแตกต่างที่มีความเสี่ยงเพื่อให้การตรวจสอบมีประสิทธิภาพมากขึ้น
เมตริกที่ควรติดตาม: เวลาที่อยู่ในสถานะ "กำลังตรวจสอบ" อัตราการเปลี่ยนแปลงความล้มเหลวสำหรับ PR ที่แก้ไขบั๊ก และระยะเวลาการล่าช้าในการตรวจสอบ P90
คุณสามารถใช้การเชื่อมต่อGitHub/GitLabใน ClickUpเพื่อรักษาสถานะการตัดสินใจของคุณให้สอดคล้องกัน;ระบบอัตโนมัติสามารถบังคับใช้ "คำจำกัดความของการเสร็จสิ้น" ได้
📖 อ่านเพิ่มเติม: วิธีใช้ AI เพื่อทำงานอัตโนมัติ
6. ทำให้การตรวจสอบขนานกันและทำให้สภาพแวดล้อม QA มีความเท่าเทียมกันจริง
การตรวจสอบไม่ควรเริ่มต้นในอีกหลายวันต่อมาหรือในสภาพแวดล้อมที่ไม่มีลูกค้าของคุณใช้งาน
รักษา "พร้อมสำหรับ QA" ให้เข้มงวด: การแก้ไขปัญหาเฉพาะจุดที่ขับเคลื่อนด้วยธงต้องได้รับการตรวจสอบในสภาพแวดล้อมที่คล้ายกับการผลิตโดยใช้ข้อมูลเริ่มต้นที่ตรงกับกรณีที่มีการรายงาน
หากเป็นไปได้ ให้ตั้งค่าสภาพแวดล้อมชั่วคราวจากสาขาที่มีบั๊กเพื่อให้ทีม QA สามารถตรวจสอบได้ทันที จากนั้น AI สามารถสร้างกรณีทดสอบจากคำอธิบายบั๊กและการทดสอบย้อนหลังในอดีตได้
ตัวชี้วัดที่ควรติดตาม: เวลาที่ใช้ใน "QA/การตรวจสอบ," อัตราการตีกลับจาก QA กลับไปยัง dev, เวลาเฉลี่ยในการปิดหลังจากรวม.

📖 อ่านเพิ่มเติม: วิธีเขียนกรณีทดสอบอย่างมีประสิทธิภาพ
7. สื่อสารสถานะอย่างชัดเจนเพื่อลดภาระการประสานงาน
การอัปเดตที่ดีช่วยป้องกันการแจ้งเตือนสถานะสามครั้งและการยกระดับปัญหาหนึ่งครั้ง
จัดการการอัปเดตเหมือนผลิตภัณฑ์: สั้น กระชับ เฉพาะเจาะจง และคำนึงถึงกลุ่มเป้าหมาย (ฝ่ายสนับสนุน ผู้บริหาร ลูกค้า) กำหนดจังหวะการแจ้งสำหรับ P0/P1 (เช่น ทุกชั่วโมงจนกว่าจะแก้ไขได้ จากนั้นทุกสี่ชั่วโมง) และรักษาแหล่งข้อมูลเดียวที่เป็นความจริง
AI สามารถร่างการอัปเดตที่ปลอดภัยสำหรับลูกค้าและสรุปภายในจากประวัติการทำงาน รวมถึงสถานะสดตามความรุนแรงและทีม สำหรับผู้บริหารเช่นผู้อำนวยการฝ่ายผลิตภัณฑ์ของคุณ สามารถรวบรวมข้อบกพร่องขึ้นไปยังโครงการเพื่อให้พวกเขาเห็นว่างานคุณภาพที่สำคัญกำลังคุกคามคำมั่นสัญญาในการส่งมอบหรือไม่
ตัวชี้วัดที่ควรติดตาม: ระยะเวลาในการอัปเดตสถานะบน P0/P1, ความพึงพอใจของผู้มีส่วนได้ส่วนเสียต่อการสื่อสาร
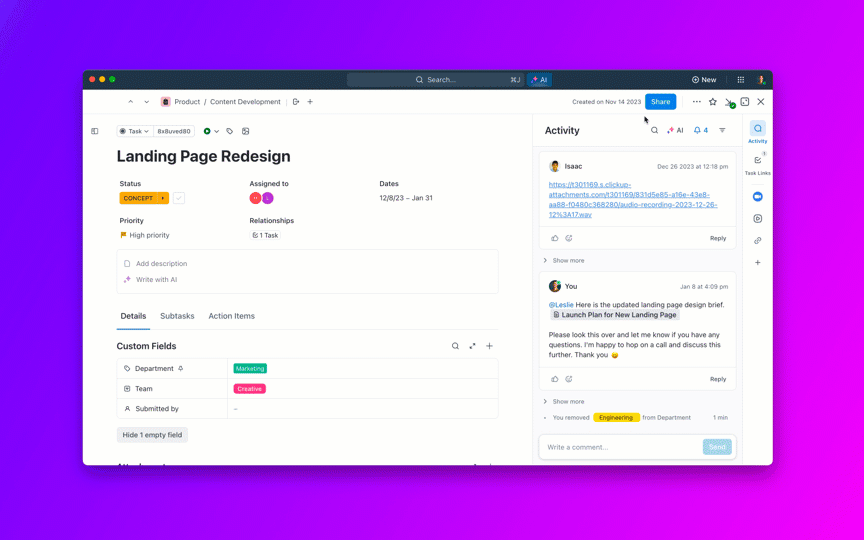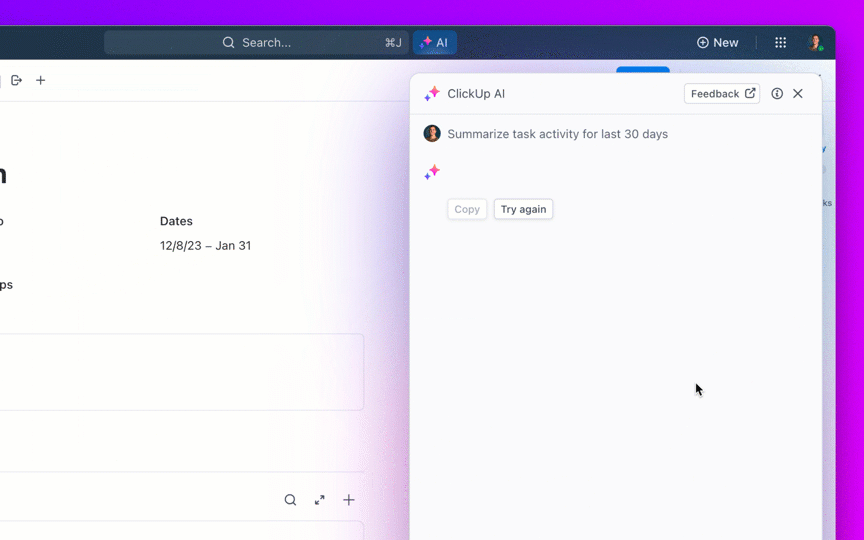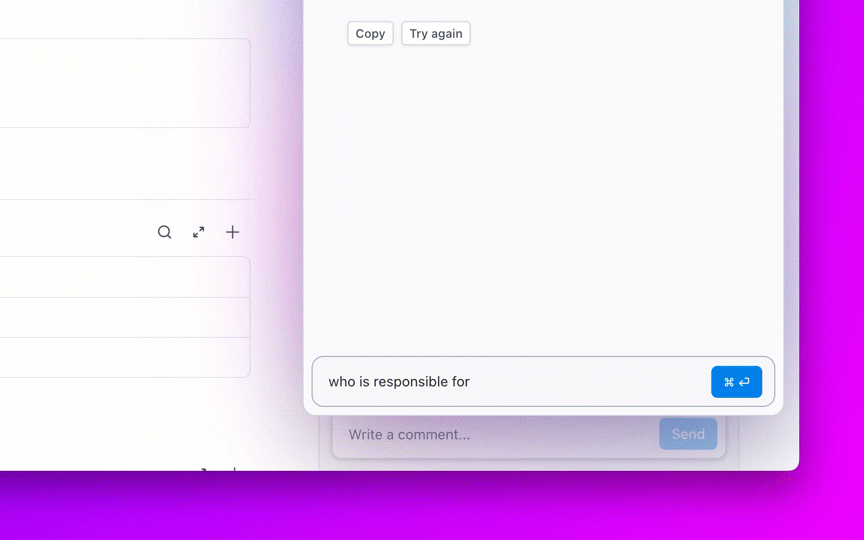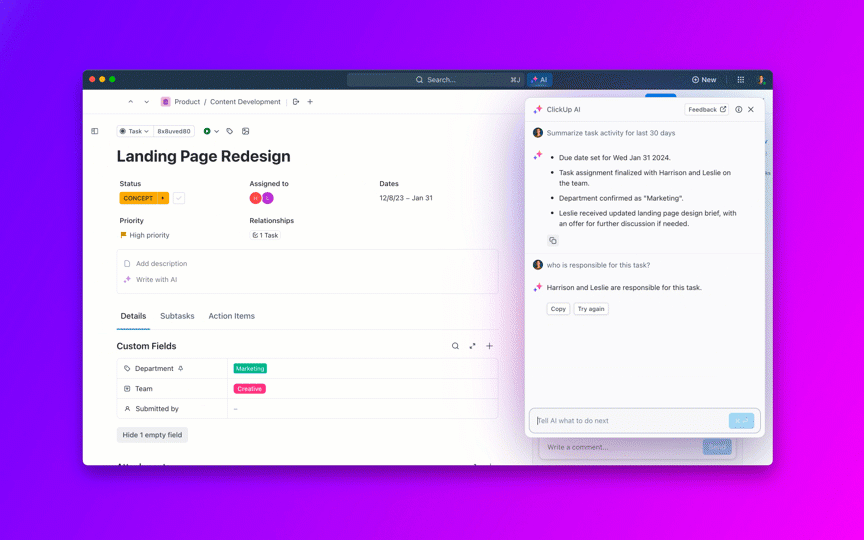
8. ควบคุมอายุของงานค้างและป้องกันไม่ให้ "เปิดค้างตลอดไป"
งานค้างที่สะสมและล้าสมัยที่เพิ่มขึ้นค่อยๆ กดดันทุกสปรินต์อย่างเงียบๆ
กำหนดนโยบายการติดตามอายุงาน (เช่น P2 > 30 วัน ให้ดำเนินการทบทวน, P3 > 90 วัน ต้องมีเหตุผลประกอบ) และจัดตารางการตรวจสอบสถานะงานค้างรายสัปดาห์เพื่อรวมรายการที่ซ้ำกัน ปิดรายงานที่ไม่ใช้งานแล้ว และเปลี่ยนบั๊กที่มีมูลค่าต่ำให้เป็นรายการในแบ็คล็อกของผลิตภัณฑ์
ใช้ AI เพื่อจัดกลุ่มงานค้างตามธีม (เช่น "หมดอายุโทเค็นการยืนยันตัวตน", "การอัปโหลดภาพไม่เสถียร") เพื่อให้คุณสามารถกำหนดเวลาสัปดาห์สำหรับการแก้ไขตามธีมและกำจัดข้อบกพร่องประเภทเดียวกันได้ในคราวเดียว
เมตริกที่ควรติดตาม: จำนวนงานค้างตามช่วงอายุของงาน, เปอร์เซ็นต์ของปัญหาที่ปิดเนื่องจากซ้ำ/ล้าสมัย, อัตราการลดจำนวนงานตามธีม.
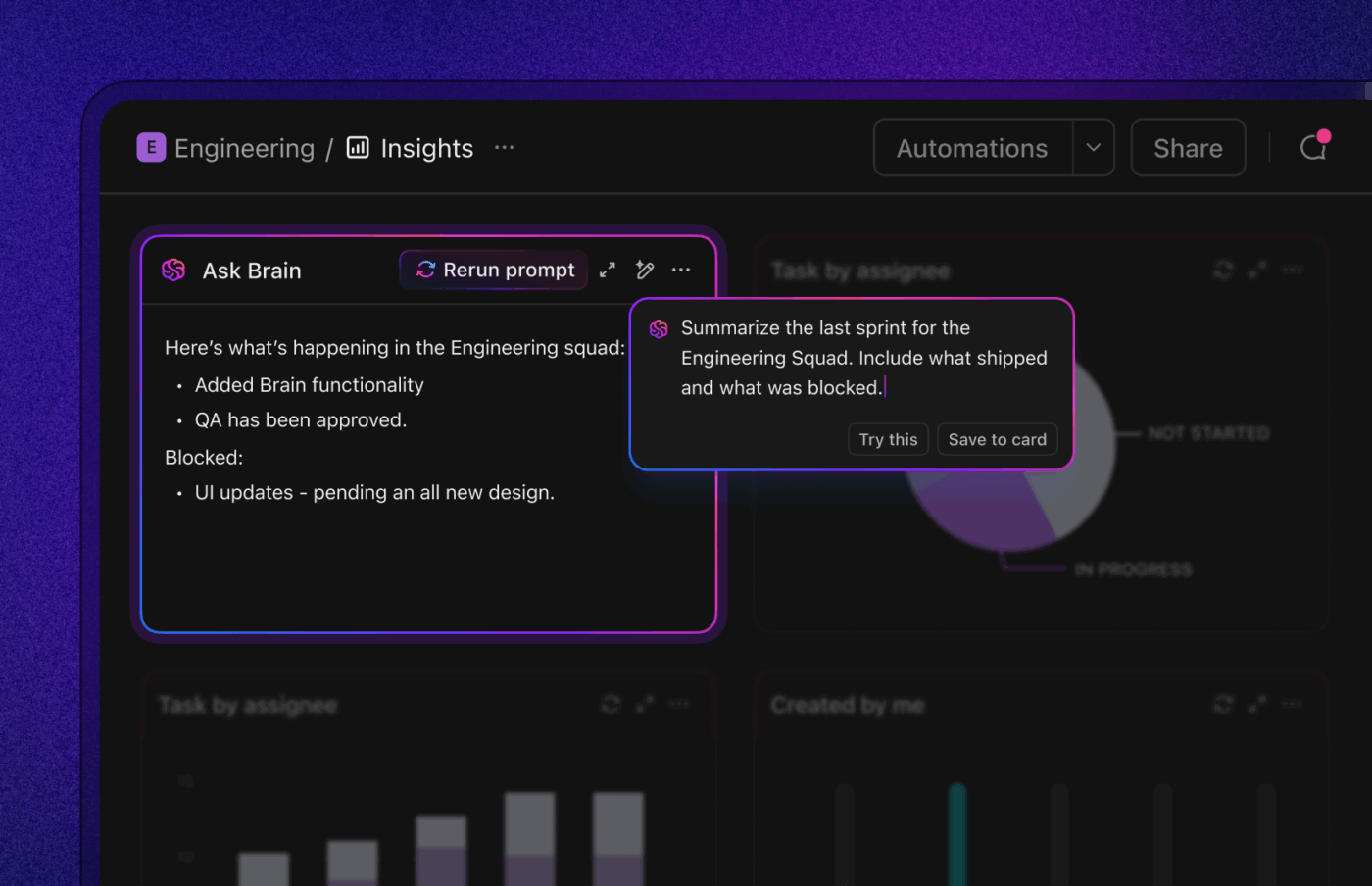
9. ปิดวงจรด้วยสาเหตุที่แท้จริงและการป้องกัน
หากข้อบกพร่องประเภทเดียวกันเกิดขึ้นซ้ำๆ การปรับปรุง MTTR ของคุณกำลังปกปิดปัญหาที่ใหญ่กว่า
ทำการวิเคราะห์หาสาเหตุที่แท้จริงอย่างรวดเร็วและปราศจากข้อผิดพลาดสำหรับ P0/P1 และ P2 ที่มีความถี่สูง; ติดแท็กสาเหตุที่แท้จริง (ช่องว่างของสเปก, ช่องว่างของการทดสอบ, ช่องว่างของเครื่องมือ, ความไม่เสถียรของการรวมระบบ), เชื่อมโยงไปยังส่วนประกอบและเหตุการณ์ที่ได้รับผลกระทบ, และติดตามงานติดตามผล (การป้องกัน, การทดสอบ, กฎการตรวจสอบ) จนเสร็จสมบูรณ์
AI สามารถร่างสรุป RCA และเสนอการทดสอบป้องกันหรือกฎการตรวจสอบเบื้องต้นตามประวัติการเปลี่ยนแปลงได้ และนี่คือวิธีที่คุณเปลี่ยนจากการแก้ปัญหาเฉพาะหน้าไปสู่การเกิดปัญหาน้อยลง
ตัวชี้วัดที่ควรติดตาม: อัตราการเปิดใหม่, อัตราการถดถอย, ระยะเวลาห่างระหว่างการเกิดซ้ำ, และเปอร์เซ็นต์ของ RCA ที่มีการดำเนินการป้องกันเสร็จสมบูรณ์

เมื่อรวมการเปลี่ยนแปลงเหล่านี้เข้าด้วยกัน จะช่วยลดระยะเวลาของกระบวนการตั้งแต่ต้นจนจบ: การยืนยันที่รวดเร็วขึ้น การคัดแยกที่ชัดเจนขึ้น การจัดลำดับความสำคัญที่ชาญฉลาดขึ้น การหยุดชะงักในการตรวจสอบและ QA ที่น้อยลง และการสื่อสารที่ชัดเจนขึ้น ผู้บริหารจะได้รับข้อมูลที่คาดการณ์ได้ซึ่งเชื่อมโยงกับ CSAT/NPS และรายได้ ส่วนผู้ปฏิบัติงานจะได้รับคิวที่สงบขึ้นพร้อมกับการสลับบริบทที่น้อยลง
📖 อ่านเพิ่มเติม: วิธีดำเนินการวิเคราะห์หาสาเหตุที่แท้จริง
เครื่องมือ AI ที่ช่วยลดเวลาในการแก้ไขข้อบกพร่อง
AI สามารถลดเวลาในการแก้ไขปัญหาได้ในทุกขั้นตอน—การรับเรื่อง, การคัดกรอง, การจัดส่ง, การแก้ไข, และการตรวจสอบ.
อย่างไรก็ตาม ประโยชน์ที่แท้จริงจะเกิดขึ้นเมื่อเครื่องมือเข้าใจบริบทและช่วยให้งานดำเนินต่อไปได้โดยไม่ต้องคอยช่วยเหลือตลอดเวลา
มองหา ระบบที่เพิ่มข้อมูลให้รายงานโดยอัตโนมัติ (ขั้นตอนการทำซ้ำ, สภาพแวดล้อม, การซ้ำซ้อน), จัดลำดับความสำคัญตามผลกระทบ, ส่งต่อไปยังเจ้าของที่เหมาะสม, ร่างการอัปเดตที่ชัดเจน, และผสานการทำงานอย่างแน่นแฟ้นกับโค้ด, CI, และการสังเกตการณ์ของคุณ
เครื่องมือที่ดีที่สุดในกลุ่มนี้ยังรองรับเวิร์กโฟลว์แบบตัวแทน: บอทที่เฝ้าดู SLA, กระตุ้นผู้ตรวจสอบ, ยกระดับปัญหาที่ติดขัด, และสรุปผลลัพธ์สำหรับผู้มีส่วนได้ส่วนเสีย นี่คือเครื่องมือ AI ของเราสำหรับการแก้ไขข้อบกพร่องที่ดีขึ้น:
1. ClickUp (ดีที่สุดสำหรับ AI เชิงบริบท, ระบบอัตโนมัติ, และกระบวนการทำงานแบบตัวแทน)
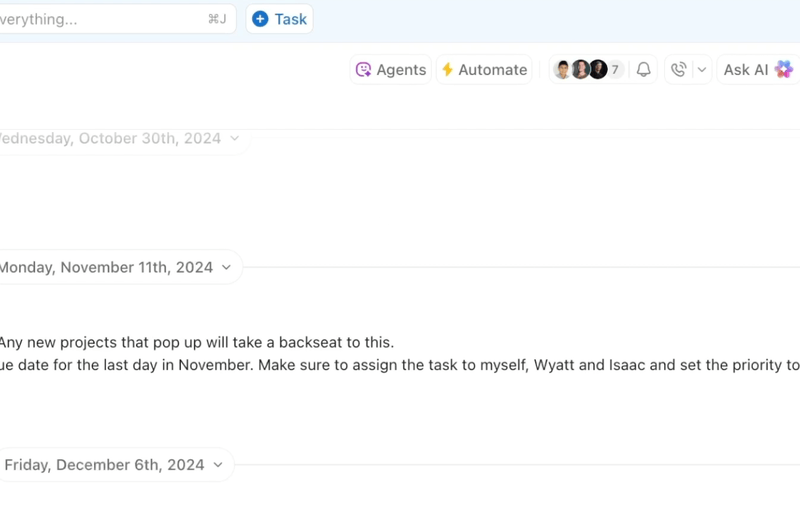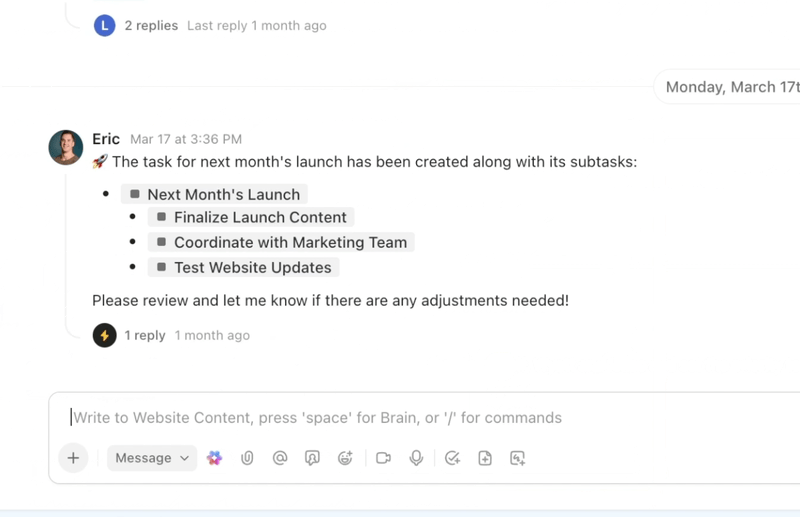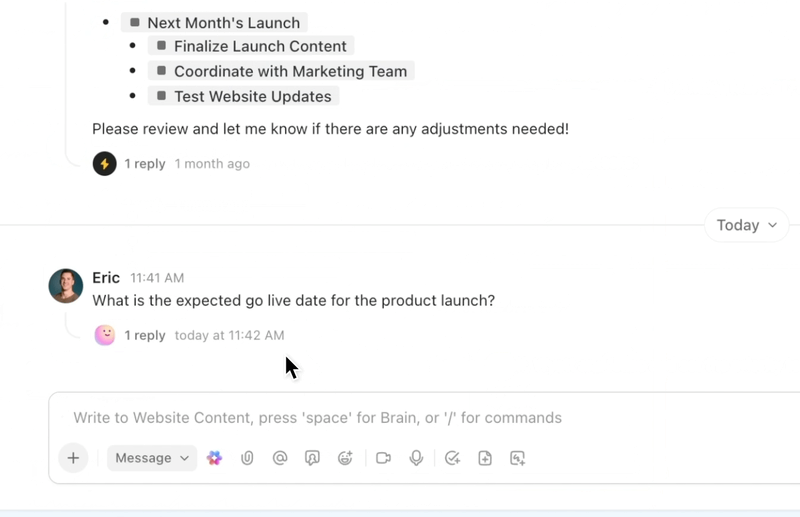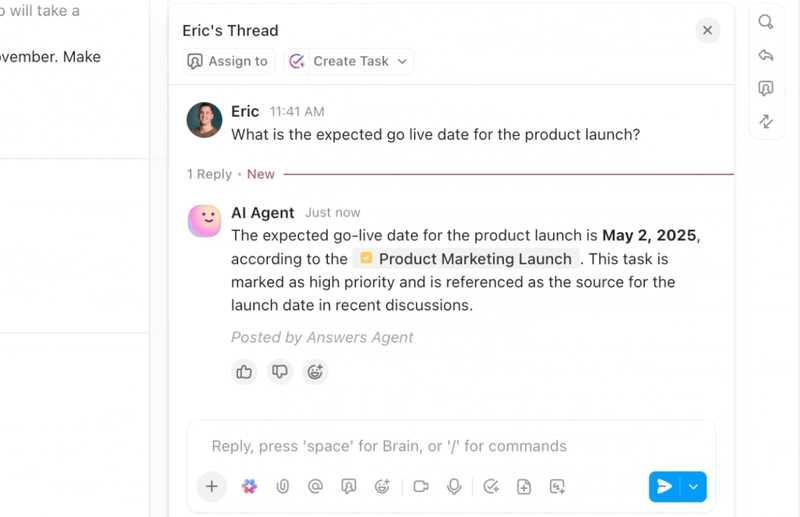
หากคุณต้องการกระบวนการแก้ไขข้อผิดพลาดที่มีประสิทธิภาพและชาญฉลาด ClickUp แอปครบวงจรสำหรับการทำงาน นำ AI, ระบบอัตโนมัติ และการช่วยเหลือกระบวนการทำงานแบบเอเจนต์ มาไว้ในที่เดียว
ClickUp Brainแสดงบริบทที่ถูกต้องทันที—สรุปหัวข้อปัญหาที่ยาว, แยกขั้นตอนในการทำซ้ำและรายละเอียดสภาพแวดล้อมจากไฟล์แนบ, แจ้งเตือนสิ่งที่อาจซ้ำซ้อน, และแนะนำการดำเนินการถัดไป แทนที่จะต้องค้นหาผ่าน Slack, ตั๋วงาน, และบันทึก, ทีมจะได้รับบันทึกที่สะอาดและสมบูรณ์ซึ่งสามารถดำเนินการได้ทันที
ระบบอัตโนมัติและตัวแทนอัตโนมัติใน ClickUpช่วยให้งานดำเนินไปอย่างต่อเนื่องโดยไม่ต้องคอยดูแลตลอดเวลา ข้อผิดพลาดจะถูกส่งไปยังทีมที่เหมาะสมโดยอัตโนมัติ มีการมอบหมายเจ้าของงาน มีการกำหนด SLA และกำหนดเวลาส่งงาน สถานะจะอัปเดตตามความคืบหน้าของงาน และผู้มีส่วนได้ส่วนเสียจะได้รับการแจ้งเตือนอย่างทันท่วงที

ตัวแทนเหล่านี้สามารถจัดลำดับความสำคัญและจำแนกประเภทของปัญหาได้ จัดกลุ่มรายงานที่คล้ายกัน อ้างอิงการแก้ไขในอดีตเพื่อแนะนำแนวทางที่เป็นไปได้ และยกระดับรายการเร่งด่วน—ทำให้ MTTA และ MTTR ลดลงแม้ในช่วงที่มีปริมาณงานเพิ่มขึ้น
🛠️ ต้องการชุดเครื่องมือพร้อมใช้งานหรือไม่?แม่แบบการติดตามข้อบกพร่องและปัญหาของ ClickUpเป็นโซลูชันอันทรงพลังจากClickUp สำหรับซอฟต์แวร์ ที่ออกแบบมาเพื่อช่วยให้ ทีมสนับสนุน วิศวกรรม และผลิตภัณฑ์สามารถจัดการข้อบกพร่องและปัญหาของซอฟต์แวร์ได้อย่างง่ายดาย ด้วยมุมมองที่ปรับแต่งได้ เช่น รายการ กระดาน ปริมาณงาน แบบฟอร์ม และไทม์ไลน์ ทีมต่างๆ สามารถมองเห็นและจัดการกระบวนการติดตามข้อบกพร่องในรูปแบบที่เหมาะสมที่สุดสำหรับพวกเขา
เทมเพลตนี้มีสถานะที่กำหนดเอง 20 สถานะ และฟิลด์ที่กำหนดเอง 7 ฟิลด์ ช่วยให้สามารถปรับแต่งกระบวนการทำงานได้ตามความต้องการ เพื่อให้ทุกปัญหาได้รับการติดตามตั้งแต่การค้นพบจนถึงการแก้ไข ระบบอัตโนมัติที่ติดตั้งไว้ล่วงหน้าจะดูแลงานที่ทำซ้ำๆ ช่วยให้มีเวลาว่างมากขึ้นและลดความพยายามในการทำงานด้วยตนเอง
💟 โบนัส: Brain MAX คือ ผู้ช่วยบนเดสก์ท็อปที่ขับเคลื่อนด้วย AI ของคุณ ออกแบบมาเพื่อเร่งการแก้ไขข้อบกพร่องด้วยฟีเจอร์ที่ชาญฉลาดและใช้งานได้จริง
เมื่อคุณพบข้อผิดพลาด ให้ใช้ฟีเจอร์พูดเป็นข้อความของ Brain MAX เพื่อบันทึกปัญหา—บันทึกเสียงของคุณจะถูกถอดความเป็นข้อความทันทีและสามารถแนบกับบิลต์ใหม่หรือบิลต์ที่มีอยู่แล้วได้ ฟีเจอร์ค้นหาแบบองค์กรจะค้นหาผ่านเครื่องมือที่คุณเชื่อมต่อไว้ทั้งหมด เช่น ClickUp, GitHub, Google Drive, และ Slack เพื่อค้นหาบิลต์ที่เกี่ยวข้อง, บันทึกข้อผิดพลาด, ชิ้นส่วนโค้ด, และเอกสารประกอบ ทำให้คุณมีข้อมูลครบถ้วนโดยไม่ต้องสลับแอปพลิเคชัน
ต้องการประสานงานการแก้ไขหรือไม่? Brain MAX ช่วยให้คุณมอบหมายบั๊กให้กับนักพัฒนาที่เหมาะสม ตั้งค่าการแจ้งเตือนอัตโนมัติสำหรับการอัปเดตสถานะ และติดตามความคืบหน้า—ทั้งหมดนี้จากเดสก์ท็อปของคุณ!
2. เซนทรี (เหมาะที่สุดสำหรับการจับข้อผิดพลาด)
Sentry ช่วยลด MTTD และเวลาในการสร้างใหม่โดยการจับข้อผิดพลาด, บันทึก, และเซสชันของผู้ใช้ไว้ในที่เดียว การจัดกลุ่มปัญหาที่ขับเคลื่อนด้วย AI ช่วยลดสัญญาณรบกวน; "การแก้ไขที่น่าสงสัย" และกฎการเป็นเจ้าของระบุเจ้าของโค้ดที่น่าจะเป็น ทำให้การส่งต่อเป็นไปอย่างทันที การเล่นซ้ำเซสชันให้วิศวกรเห็นเส้นทางผู้ใช้และรายละเอียดของคอนโซล/เครือข่ายที่แน่นอนเพื่อสร้างใหม่โดยไม่ต้องกลับไปกลับมาอย่างไม่มีที่สิ้นสุด
คุณสมบัติของ Sentry AI สามารถสรุปบริบทของปัญหาและในบางสแต็กสามารถเสนอแพตช์ Autofix ที่อ้างอิงถึงโค้ดที่เป็นปัญหาได้ ผลกระทบในทางปฏิบัติ: ลดจำนวนตั๋วที่ซ้ำซ้อน การมอบหมายงานที่รวดเร็วขึ้น และเส้นทางที่สั้นลงจากการรายงานไปยังแพตช์ที่ใช้งานได้
3. GitHub Copilot (เหมาะที่สุดสำหรับการตรวจสอบโค้ดอย่างรวดเร็ว)
Copilot ช่วยเร่ง กระบวนการแก้ไขภายในตัวแก้ไข โดยอธิบายเส้นทางของสแต็ก เสนอการแก้ไขที่ตรงจุด เขียนการทดสอบหน่วยเพื่อยืนยันการแก้ไข และสร้างโครงสร้างพื้นฐานสำหรับสคริปต์การจำลองปัญหา
Copilot Chat สามารถช่วยวิเคราะห์โค้ดที่มีข้อผิดพลาด แนะนำการปรับปรุงโค้ดให้ปลอดภัยยิ่งขึ้น และสร้างความคิดเห็นหรือคำอธิบายสำหรับ PR ที่ช่วยให้การตรวจสอบโค้ดรวดเร็วขึ้น เมื่อใช้ร่วมกับกระบวนการตรวจสอบที่จำเป็นและ CI จะช่วยลดเวลาจาก "วินิจฉัย → ดำเนินการ → ทดสอบ" ลงได้หลายชั่วโมง โดยเฉพาะอย่างยิ่งสำหรับบั๊กที่มีขอบเขตชัดเจนและสามารถทำซ้ำได้
4. Snyk โดย DeepCode AI (เหมาะที่สุดสำหรับการค้นหาแบบแผน)
DeepCode'sAI-powered static analysis ค้นหาข้อบกพร่องและรูปแบบที่ไม่ปลอดภัยขณะที่คุณเขียนโค้ดและใน PRs มันเน้นให้เห็นถึงกระบวนการที่มีปัญหา อธิบายว่าทำไมจึงเกิดขึ้น และเสนอการแก้ไขที่ปลอดภัยซึ่งเหมาะกับสไตล์โค้ดของคุณ
โดยการตรวจจับการถดถอยก่อนการรวมและการแนะนำนักพัฒนาให้ใช้รูปแบบที่ปลอดภัยยิ่งขึ้น คุณจะลดอัตราการเกิดข้อผิดพลาดใหม่และเร่งการแก้ไขข้อผิดพลาดทางตรรกะที่ซับซ้อนซึ่งยากต่อการตรวจพบในระหว่างการตรวจสอบ การผสานรวมกับ IDE และ PR ทำให้กระบวนการนี้อยู่ใกล้กับจุดที่งานเกิดขึ้น
5. Watchdog และ AIOps ของ Datadog (เหมาะที่สุดสำหรับการวิเคราะห์บันทึก)
Watchdog ของ Datadogใช้ ML เพื่อตรวจจับความผิดปกติในบันทึกข้อมูล เมตริก การติดตามการติดตาม และผู้ใช้จริง มันเชื่อมโยงการเพิ่มขึ้นอย่างรวดเร็วกับเครื่องหมายการปรับใช้ การเปลี่ยนแปลงโครงสร้างพื้นฐาน และโทโพโลยีเพื่อแนะนำสาเหตุที่เป็นไปได้
สำหรับข้อบกพร่องที่ส่งผลกระทบต่อลูกค้า หมายถึงการตรวจจับภายในไม่กี่นาที การจัดกลุ่มโดยอัตโนมัติเพื่อลดสัญญาณเตือนรบกวน และข้อมูลที่ชัดเจนสำหรับจุดที่ควรตรวจสอบ เวลาในการคัดแยกปัญหาลดลงเพราะคุณเริ่มต้นด้วย "การปรับใช้ครั้งนี้ส่งผลต่อบริการเหล่านี้และอัตราข้อผิดพลาดเพิ่มขึ้นที่จุดสิ้นสุดนี้" แทนที่จะเริ่มต้นจากศูนย์
⚡️ แหล่งเก็บแม่แบบ: แม่แบบการติดตามปัญหาและการบันทึกฟรีใน Excel & ClickUp
6. New Relic AI (เหมาะที่สุดสำหรับการระบุและสรุปแนวโน้ม)
กล่องจดหมายข้อผิดพลาดของ New Relicจัดกลุ่มข้อผิดพลาดที่คล้ายกันข้ามบริการและเวอร์ชัน ในขณะที่ผู้ช่วย AI ของมันสรุปผลกระทบ ไฮไลต์สาเหตุที่เป็นไปได้ และเชื่อมโยงไปยังการติดตาม/ธุรกรรมที่เกี่ยวข้อง
ความสัมพันธ์ของการปรับใช้และข้อมูลเชิงลึกเกี่ยวกับการเปลี่ยนแปลงของเอนทิตีทำให้เห็นได้ชัดเจนว่าเมื่อใดที่การปล่อยเวอร์ชันล่าสุดเป็นสาเหตุ สำหรับระบบแบบกระจาย การมีบริบทนี้จะช่วยลดเวลาในการติดต่อข้ามทีมหลายชั่วโมง และส่งบั๊กไปยังเจ้าของที่ถูกต้องพร้อมสมมติฐานที่ชัดเจนแล้ว
7. โรลบาร์ (เหมาะที่สุดสำหรับกระบวนการทำงานอัตโนมัติ)
Rollbarเชี่ยวชาญด้านการตรวจสอบข้อผิดพลาดแบบเรียลไทม์ด้วยระบบลายนิ้วมืออัจฉริยะที่ช่วยจัดกลุ่มข้อผิดพลาดซ้ำและติดตามแนวโน้มการเกิดขึ้นของปัญหา รายงานสรุปที่ขับเคลื่อนด้วย AI และคำแนะนำในการหาสาเหตุที่แท้จริงช่วยให้ทีมเข้าใจขอบเขตของปัญหา (ผู้ใช้ที่ได้รับผลกระทบ เวอร์ชันที่ได้รับผลกระทบ) ในขณะที่ข้อมูลเทเลเมทริกซ์และสแต็กเทรซช่วยให้ค้นหาสาเหตุและแก้ไขปัญหาได้อย่างรวดเร็ว
กฎการทำงานของ Rollbar สามารถสร้างงานโดยอัตโนมัติ ติดแท็กความรุนแรง และส่งต่อไปยังเจ้าของ ทำให้กระแสข้อผิดพลาดที่รบกวนกลายเป็นคิวที่มีการจัดลำดับความสำคัญพร้อมบริบทที่แนบมา
8. PagerDuty AIOps และการทำงานอัตโนมัติของรันบุ๊ค (การวินิจฉัยที่ดีที่สุดแบบใช้การสัมผัสต่ำ)
PagerDutyใช้การเชื่อมโยงเหตุการณ์และการลดสัญญาณรบกวนด้วย ML เพื่อรวมการแจ้งเตือนจำนวนมากให้กลายเป็นเหตุการณ์ที่สามารถดำเนินการได้
การกำหนดเส้นทางแบบไดนามิกจะส่งปัญหาไปยังผู้ที่รับผิดชอบในทันที ในขณะที่ระบบอัตโนมัติตามคู่มือการทำงานสามารถเริ่มการวินิจฉัยหรือการแก้ไขเบื้องต้น (เช่น รีสตาร์ทบริการ, รีโรลการปรับใช้, เปิด/ปิดฟีเจอร์) ได้ก่อนที่มนุษย์จะเข้ามาเกี่ยวข้อง สำหรับเวลาในการแก้ไขบั๊ก นั่นหมายถึง MTTA ที่สั้นลง การแก้ไขปัญหา P0 ที่รวดเร็วยิ่งขึ้น และชั่วโมงการทำงานที่สูญเสียไปกับความเหนื่อยล้าจากการแจ้งเตือนที่น้อยลง
เส้นเรื่องหลักคือระบบอัตโนมัติร่วมกับ AI ในทุกขั้นตอน คุณสามารถตรวจจับได้เร็วขึ้น จัดเส้นทางได้อย่างชาญฉลาดยิ่งขึ้น เข้าถึงโค้ดได้เร็วขึ้น และสื่อสารสถานะโดยไม่ต้องรบกวนวิศวกร—ทั้งหมดนี้รวมกันเป็นการลดเวลาในการแก้ไขข้อบกพร่องอย่างมีนัยสำคัญ
📖 อ่านเพิ่มเติม: วิธีใช้ AI ใน DevOps
ตัวอย่างจากโลกจริงของการใช้ AI ในการแก้ไขข้อบกพร่อง
ดังนั้น ปัญญาประดิษฐ์ (AI) ได้ออกจากห้องปฏิบัติการอย่างเป็นทางการแล้ว มันกำลังลดเวลาในการแก้ไขข้อผิดพลาดในโลกแห่งความเป็นจริง
มาดูกันว่าทำอย่างไร!
| โดเมน / องค์กร | วิธีการใช้ปัญญาประดิษฐ์ | ผลกระทบ / ประโยชน์ |
|---|---|---|
| ยูบิซอฟต์ | พัฒนา Commit Assistant, เครื่องมือ AI ที่ได้รับการฝึกฝนจากโค้ดภายในองค์กรเป็นเวลาสิบปี ซึ่งสามารถทำนายและป้องกันข้อผิดพลาดในขั้นตอนการเขียนโค้ดได้ | มุ่งลดเวลาและค่าใช้จ่ายอย่างมาก—ค่าใช้จ่ายในการพัฒนาเกมถึง 70% มักถูกใช้ไปกับการแก้ไขข้อบกพร่องตามปกติ |
| Razer (แพลตฟอร์ม Wyvrn) | เปิดตัว QA Copilotที่ขับเคลื่อนด้วย AI (ผสานรวมกับ Unreal และ Unity)เพื่ออัตโนมัติการตรวจจับข้อบกพร่องและสร้างรายงาน QA | เพิ่มประสิทธิภาพการตรวจจับข้อผิดพลาดได้สูงสุด 25% และลดเวลาการตรวจสอบคุณภาพลงครึ่งหนึ่ง |
| Google / DeepMind และ Project Zero | แนะนำBig Sleep, เครื่องมือ AI ที่สามารถตรวจจับช่องโหว่ด้านความปลอดภัยในซอฟต์แวร์โอเพนซอร์ส เช่น FFmpeg และ ImageMagick ได้โดยอัตโนมัติ | ตรวจพบข้อบกพร่อง 20 รายการ ซึ่งได้รับการตรวจสอบโดยผู้เชี่ยวชาญมนุษย์แล้วทั้งหมด และกำหนดให้แก้ไขในแพตช์ต่อไป |
| นักวิจัยจากมหาวิทยาลัยแคลิฟอร์เนีย เบิร์กลีย์ | โดยใช้เกณฑ์มาตรฐานที่ชื่อว่าCyberGymโมเดล AI ได้วิเคราะห์โครงการโอเพนซอร์สจำนวน 188 โครงการ ค้นพบช่องโหว่ 17 รายการ ซึ่งรวมถึงบั๊กที่ไม่เคยถูกค้นพบมาก่อน (zero-day) จำนวน 15 รายการ และสร้างการโจมตีแบบ proof-of-concept ขึ้นมา | แสดงให้เห็นถึงความสามารถที่พัฒนาอย่างต่อเนื่องของ AI ในการตรวจจับช่องโหว่และการพิสูจน์การโจมตีอัตโนมัติ |
| Spur (สตาร์ทอัพเยล) | พัฒนาตัวแทนปัญญาประดิษฐ์ที่สามารถแปลคำอธิบายกรณีทดสอบที่เขียนด้วยภาษาทั่วไปให้เป็นขั้นตอนการทดสอบเว็บไซต์แบบอัตโนมัติได้อย่างมีประสิทธิภาพ— ซึ่งเปรียบเสมือนกระบวนการทำงานด้านคุณภาพ (QA) ที่เขียนขึ้นเองโดยอัตโนมัติ | เปิดใช้งานการทดสอบอัตโนมัติโดยมีการแทรกแซงจากมนุษย์น้อยที่สุด |
| รายงานข้อบกพร่องของ Android ที่สร้างขึ้นโดยอัตโนมัติ | ใช้ NLP ร่วมกับระบบการเรียนรู้แบบเสริมแรงเพื่อแปลความหมายของภาษาในรายงานข้อบกพร่อง และสร้างขั้นตอนเพื่อจำลองข้อบกพร่องบนระบบ Android | บรรลุความแม่นยำ 67% ความครอบคลุม 77% และสามารถทำซ้ำรายงานข้อบกพร่องได้ 74% ซึ่งดีกว่าวิธีการแบบดั้งเดิม |
ข้อผิดพลาดทั่วไปในการวัดเวลาการแก้ไขบั๊ก
หากการวัดของคุณผิดพลาด แผนการปรับปรุงของคุณก็จะผิดพลาดเช่นกัน
ตัวเลข "ไม่ดี" ส่วนใหญ่ในกระบวนการแก้ไขข้อบกพร่องมาจากคำจำกัดความที่ไม่ชัดเจน, กระบวนการทำงานที่ไม่สม่ำเสมอ, และการวิเคราะห์ที่ไม่ลึกซึ้ง.
ดังนั้นเริ่มต้นด้วยพื้นฐานก่อน—อะไรที่ถือว่าเป็นการเริ่มต้น/หยุด, วิธีจัดการกับการรอและการเปิดใหม่—จากนั้นอ่านข้อมูลในแบบที่ลูกค้าของคุณได้รับประสบการณ์ ซึ่งรวมถึง:
❌ ขอบเขตที่ไม่ชัดเจน: การรวมสถานะ Reported→Resolved และ Reported→Closed ไว้ในแดชบอร์ดเดียวกัน (หรือสลับเดือนไปมา) จะทำให้แนวโน้มไม่มีความหมาย เลือกขอบเขตเพียงหนึ่งอย่าง บันทึกไว้ และบังคับใช้กับทุกทีม หากคุณต้องการทั้งสองแบบ ให้เผยแพร่เป็นเมตริกแยกกันโดยมีป้ายกำกับที่ชัดเจน
❌ วิธีการใช้ค่าเฉลี่ยเพียงอย่างเดียว: การพึ่งพาค่าเฉลี่ยจะซ่อนความเป็นจริงของคิวที่มีค่าผิดปกติซึ่งใช้เวลานาน ให้ใช้ค่ามัธยฐาน (P50) สำหรับเวลา "ทั่วไป" ของคุณ, P90 สำหรับความสามารถในการคาดการณ์/SLA และเก็บค่าเฉลี่ยไว้สำหรับการวางแผนความจุเท่านั้น ควรดูการกระจายตัวเสมอ ไม่ใช่แค่ตัวเลขเดียว
❌ ไม่มีการแบ่งกลุ่ม: การรวมบั๊กทั้งหมดเข้าด้วยกันทำให้เหตุการณ์ P0 ผสมกับปัญหาเล็กน้อย P3 การแบ่งตามความรุนแรง แหล่งที่มา (ลูกค้า vs. QA vs. การตรวจสอบ) ส่วนประกอบ/ทีม และ "ใหม่ vs. การย้อนกลับ" เป็นสิ่งสำคัญ P0/P1 P90 คือสิ่งที่ผู้มีส่วนได้ส่วนเสียรู้สึก; ส่วนค่ามัธยฐานของ P2+ คือสิ่งที่ทีมวิศวกรรมวางแผนไว้
❌ การเพิกเฉยต่อเวลาที่ "หยุดชั่วคราว": กำลังรอข้อมูลจากลูกค้า ผู้ให้บริการภายนอก หรือช่วงเวลาการปล่อยงานอยู่หรือไม่? หากคุณไม่ติดตามสถานะที่ถูกบล็อก/หยุดชั่วคราวเป็นสถานะหลัก เวลาที่ใช้ในการแก้ไขจะกลายเป็นประเด็นถกเถียง รายงานทั้งเวลาปฏิทินและเวลาที่ใช้งานจริงเพื่อให้เห็นจุดคอขวดและยุติการโต้แย้ง
❌ ช่องว่างการปรับเวลาให้สม่ำเสมอ: การผสมผสานเขตเวลาหรือการสลับระหว่างเวลาทำการและเวลาปฏิทินระหว่างกระบวนการทำให้การเปรียบเทียบเสียหาย ปรับเวลาให้สอดคล้องกันในเขตเวลาเดียว (หรือ UTC) และตัดสินใจครั้งเดียวว่า SLA จะวัดเป็นเวลาทำการหรือเวลาปฏิทิน จากนั้นใช้อย่างสม่ำเสมอ
❌ ข้อมูลนำเข้าที่ไม่สะอาดและซ้ำซ้อน: ข้อมูลสภาพแวดล้อม/ข้อมูลการสร้างที่ขาดหายไปและตั๋วที่ซ้ำซ้อนทำให้เวลาเพิ่มขึ้นและสร้างความสับสนในความเป็นเจ้าของ ควรกำหนดมาตรฐานข้อมูลที่จำเป็นตั้งแต่ขั้นตอนการรับข้อมูล เพิ่มเติมข้อมูลโดยอัตโนมัติ (บันทึก, เวอร์ชัน, อุปกรณ์) และกำจัดข้อมูลซ้ำโดยไม่รีเซ็ตเวลา—ปิดตั๋วที่ซ้ำกันโดยเชื่อมโยงเป็นปัญหาเดียวกัน ไม่ใช่ปัญหา "ใหม่"
❌ โมเดลสถานะที่ไม่สอดคล้องกัน: สถานะที่กำหนดเอง ("QA Ready-ish," "Pending Review 2") ทำให้ไม่สามารถทราบระยะเวลาที่อยู่ในสถานะนั้น ๆ และการเปลี่ยนสถานะไม่น่าเชื่อถือ กำหนดขั้นตอนการทำงานมาตรฐาน (New → Triaged → In Progress → In Review → Resolved → Closed) และตรวจสอบสถานะที่อยู่นอกเส้นทาง
❌ มองไม่เห็นเวลาในแต่ละสถานะ: ตัวเลข "เวลาทั้งหมด" เพียงตัวเดียวไม่สามารถบอกได้ว่างานติดขัดตรงไหน ควรบันทึกและตรวจสอบเวลาที่ใช้ในแต่ละสถานะ เช่น รอการตรวจสอบ (Triaged), อยู่ระหว่างการตรวจสอบ (In Review), ถูกบล็อก (Blocked) และตรวจสอบคุณภาพ (QA) หากเวลาที่ใช้ในการตรวจสอบโค้ด (P90) มีมากกว่าเวลาในการพัฒนา (Implementation) มาก แสดงว่าการแก้ไขของคุณไม่ใช่ "การเขียนโค้ดให้เร็วขึ้น" แต่เป็นการปลดล็อกขีดจำกัดของความสามารถในการตรวจสอบต่างหาก
🧠 ข้อเท็จจริงที่น่าสนใจ: การแข่งขัน AI Cyber Challenge ล่าสุดของ DARPAได้แสดงให้เห็นถึงความก้าวหน้าครั้งสำคัญในด้านการอัตโนมัติของความปลอดภัยทางไซเบอร์ การแข่งขันนี้ได้นำเสนอระบบ AI ที่ถูกออกแบบมาเพื่อตรวจจับ, ใช้ประโยชน์, และแก้ไขช่องโหว่ในซอฟต์แวร์ได้โดยอัตโนมัติ—โดยไม่ต้องมีการแทรกแซงจากมนุษย์ ทีมชนะเลิศ "ทีมแอตแลนตา" ได้ค้นพบ 77% ของบั๊กที่ถูกฉีดเข้าไป อย่างน่าประทับใจ และสามารถแก้ไขได้ถึง 61% ของบั๊กเหล่านั้น แสดงให้เห็นถึงพลังของ AI ที่ไม่เพียงแต่ค้นหาข้อบกพร่องเท่านั้น แต่ยังแก้ไขได้อย่างมีประสิทธิภาพอีกด้วย
❌ ภาวะตาบอดจากการเปิดใหม่: การมองว่าการเปิดใหม่เป็นบั๊กใหม่จะเป็นการรีเซ็ตนาฬิกาและทำให้ MTTR ดูดีขึ้น ติดตามอัตราการเปิดใหม่และ "เวลาที่ใช้ในการปิดให้เสถียร" (จากรายงานครั้งแรกจนถึงปิดครั้งสุดท้ายในทุกวงจร) การเปิดใหม่ที่เพิ่มขึ้นมักบ่งชี้ถึงการจำลองที่อ่อนแอ ช่องว่างในการทดสอบ หรือคำจำกัดความของ "เสร็จสมบูรณ์" ที่ไม่ชัดเจน
❌ ไม่มี MTTA: ทีมหมกมุ่นกับ MTTR และละเลย MTTA (เวลาการรับรู้/ความเป็นเจ้าของ) MTTA ที่สูงเป็นสัญญาณเตือนล่วงหน้าสำหรับการแก้ไขปัญหาที่ยาวนาน วัดค่านี้ ตั้งค่า SLA ตามความรุนแรง และทำให้การกำหนดเส้นทาง/การยกระดับเป็นอัตโนมัติเพื่อลดค่านี้ลง
❌ AI/ระบบอัตโนมัติโดยไม่มีมาตรการควบคุม: การปล่อยให้ AI กำหนดความรุนแรงหรือปิดกรณีซ้ำโดยปราศจากการตรวจสอบ อาจทำให้จัดประเภทกรณีขอบเขตผิดพลาดและบิดเบือนตัวชี้วัดโดยไม่รู้ตัว ใช้ AI สำหรับข้อเสนอแนะเท่านั้น ต้องให้มนุษย์ยืนยันในกรณี P0/P1 และตรวจสอบประสิทธิภาพของโมเดลทุกเดือนเพื่อให้ข้อมูลของคุณเชื่อถือได้
ขันตะเข็บเหล่านี้ให้แน่น และแผนภูมิเวลาการแก้ไขปัญหาของคุณจะสะท้อนความเป็นจริงในที่สุด จากนั้น การปรับปรุงจะทวีคูณขึ้น: การรับข้อมูลที่ดีขึ้นจะลด MTTA สถานะที่ชัดเจนจะเผยให้เห็นคอขวดที่แท้จริง และ P90 ที่แบ่งส่วนจะให้คำมั่นสัญญาแก่ผู้นำที่คุณสามารถรักษาได้
⚡️ แหล่งเก็บแม่แบบ: 10 แม่แบบกรณีทดสอบสำหรับการทดสอบซอฟต์แวร์
แนวทางปฏิบัติที่ดีที่สุดสำหรับการแก้ไขข้อบกพร่องอย่างมีประสิทธิภาพ
สรุปแล้ว นี่คือจุดสำคัญที่ควรจำไว้!
| 🧩 แนวทางปฏิบัติที่ดีที่สุด | 💡 หมายความว่า | 🚀 ทำไมมันถึงสำคัญ |
| ใช้ระบบติดตามข้อบกพร่องที่แข็งแกร่ง | ติดตามข้อบกพร่องที่รายงานทั้งหมดโดยใช้ระบบติดตามข้อบกพร่องแบบรวมศูนย์ | รับประกันว่าไม่มีบั๊กสูญหายและช่วยให้สามารถมองเห็นสถานะของบั๊กได้ทั่วทั้งทีม |
| เขียนรายงานข้อบกพร่องอย่างละเอียด | รวมบริบททางภาพ ข้อมูลระบบปฏิบัติการ ขั้นตอนในการทำซ้ำ และระดับความรุนแรง | ช่วยให้นักพัฒนาแก้ไขข้อบกพร่องได้เร็วขึ้นด้วยข้อมูลที่จำเป็นทั้งหมดตั้งแต่แรก |
| จัดหมวดหมู่และจัดลำดับความสำคัญของข้อบกพร่อง | ใช้เมทริกซ์ลำดับความสำคัญเพื่อจัดลำดับความสำคัญของบั๊กตามความเร่งด่วนและผลกระทบ | มุ่งเน้นให้ทีมให้ความสำคัญกับบั๊กที่สำคัญและปัญหาที่เร่งด่วนเป็นอันดับแรก |
| ใช้ประโยชน์จากการทดสอบอัตโนมัติ | ทดสอบโดยอัตโนมัติใน CI/CD pipeline ของคุณ | สนับสนุนการตรวจพบในระยะแรกและป้องกันการถดถอย |
| กำหนดแนวทางการรายงานที่ชัดเจน | จัดเตรียมแม่แบบและฝึกอบรมวิธีการรายงานข้อบกพร่อง | นำไปสู่ข้อมูลที่ถูกต้องและการสื่อสารที่ราบรื่นยิ่งขึ้น |
| ติดตามตัวชี้วัดสำคัญ | วัดเวลาในการแก้ไขปัญหา, เวลาที่ผ่านไป, และเวลาในการตอบสนอง | ช่วยให้สามารถติดตามและปรับปรุงประสิทธิภาพโดยใช้ข้อมูลย้อนหลัง |
| ใช้แนวทางเชิงรุก | อย่ารอให้ผู้ใช้บ่น—ทดสอบเชิงรุก | เพิ่มประสิทธิภาพความพึงพอใจของลูกค้าและลดภาระงานสนับสนุน |
| ใช้ประโยชน์จากเครื่องมืออัจฉริยะและ ML | ใช้การเรียนรู้ของเครื่องเพื่อทำนายข้อบกพร่องและแนะนำการแก้ไข | ปรับปรุงประสิทธิภาพในการระบุสาเหตุที่แท้จริงและแก้ไขข้อบกพร่อง |
| สอดคล้องกับ SLA | ปฏิบัติตามข้อตกลงระดับการให้บริการที่ตกลงกันไว้สำหรับการแก้ไขปัญหา | สร้างความไว้วางใจและตอบสนองความคาดหวังของลูกค้าอย่างทันท่วงที |
| ทบทวนและปรับปรุงอย่างต่อเนื่อง | วิเคราะห์บั๊กที่เปิดใหม่, รวบรวมความคิดเห็น, และปรับปรุงกระบวนการ. | ส่งเสริมการพัฒนาอย่างต่อเนื่องของกระบวนการพัฒนาและการจัดการข้อบกพร่องของคุณ |
การแก้ไขข้อบกพร่องให้ง่ายขึ้นด้วย AI ที่เข้าใจบริบท
ทีมแก้ไขบั๊กที่เร็วที่สุดไม่ได้พึ่งพาการแก้ปัญหาแบบฮีโร่ พวกเขาออกแบบระบบ: การกำหนดจุดเริ่มต้น/สิ้นสุดที่ชัดเจน, การรับข้อมูลที่สะอาด, การจัดลำดับความสำคัญตามผลกระทบทางธุรกิจ, ความรับผิดชอบที่ชัดเจน, และวงจรการให้ข้อมูลย้อนกลับที่กระชับระหว่างฝ่ายสนับสนุน, QA, วิศวกรรม, และการปล่อยเวอร์ชัน
ClickUp สามารถเป็นศูนย์บัญชาการขับเคลื่อนด้วย AI สำหรับระบบการแก้ไขข้อบกพร่องของคุณได้ รวบรวมรายงานทั้งหมดไว้ในคิวเดียว มาตรฐานบริบทด้วยฟิลด์ที่มีโครงสร้าง และให้ AI ของ ClickUp คัดกรอง สรุป และจัดลำดับความสำคัญ ในขณะที่การทำงานอัตโนมัติบังคับใช้ SLA ยกระดับเมื่อเวลาผ่านไป และรักษาความสอดคล้องของผู้มีส่วนได้ส่วนเสีย เชื่อมโยงข้อบกพร่องกับลูกค้า โค้ด และการปล่อย เพื่อให้ผู้บริหารเห็นผลกระทบและนักปฏิบัติอยู่ในกระบวนการทำงาน
หากคุณพร้อมที่จะลดเวลาในการแก้ไขปัญหาและทำให้แผนงานของคุณคาดการณ์ได้มากขึ้นลงทะเบียนใช้ ClickUpและเริ่มวัดผลลัพธ์ได้ในไม่กี่วัน—ไม่ใช่หลายไตรมาส
คำถามที่พบบ่อย
เวลาแก้ไขข้อบกพร่องที่ดีควรเป็นเท่าไร?
ไม่มีตัวเลข "ดี" เพียงตัวเดียว—มันขึ้นอยู่กับระดับความรุนแรง, รูปแบบการปล่อย, และความทนต่อความเสี่ยง ใช้ค่ามัธยฐาน (P50) สำหรับประสิทธิภาพ "ทั่วไป" และ P90 สำหรับคำมั่นสัญญา/SLA และแบ่งตามระดับความรุนแรงและแหล่งที่มา
อะไรคือความแตกต่างระหว่างการแก้ไขข้อบกพร่องกับการปิดข้อบกพร่อง?
การแก้ไข (Resolution) คือเมื่อการแก้ไขได้ถูกนำไปใช้จริง (เช่น โค้ดถูกผสานรวม, การตั้งค่าถูกนำไปใช้) และทีมพิจารณาว่าข้อบกพร่องได้รับการแก้ไขแล้ว การปิดงาน (Closure) คือเมื่อปัญหาได้รับการตรวจสอบและเสร็จสิ้นอย่างเป็นทางการ (เช่น ผ่านการตรวจสอบคุณภาพในสภาพแวดล้อมเป้าหมาย, ถูกปล่อยออกไป, หรือถูกทำเครื่องหมายว่าไม่แก้ไข/ซ้ำพร้อมเหตุผล) หลายทีมวัดทั้งสองอย่าง: รายงาน→แก้ไข สะท้อนความเร็วของฝ่ายวิศวกรรม; รายงาน→ปิดงาน สะท้อนคุณภาพโดยรวมตั้งแต่ต้นจนจบ ใช้คำจำกัดความที่สอดคล้องกันเพื่อไม่ให้แดชบอร์ดผสมปนเประหว่างขั้นตอนต่างๆ
อะไรคือความแตกต่างระหว่างเวลาการแก้ไขข้อบกพร่องกับเวลาการตรวจพบข้อบกพร่อง?
เวลาในการตรวจพบ (MTTD) คือระยะเวลาที่ใช้ในการค้นพบข้อบกพร่องหลังจากเกิดขึ้นหรือถูกส่งออกไปแล้ว—ผ่านการตรวจสอบ, QA, หรือผู้ใช้ เวลาในการแก้ไขคือระยะเวลาที่ใช้ตั้งแต่การตรวจพบ/รายงานจนถึงการแก้ไขถูกนำไปใช้ (และหากต้องการ, ได้รับการตรวจสอบ/ปล่อย) เมื่อรวมกันแล้ว, ทั้งสองจะกำหนดหน้าต่างผลกระทบต่อลูกค้า: ตรวจพบเร็ว, ยอมรับเร็ว, แก้ไขเร็ว, และปล่อยอย่างปลอดภัย คุณยังสามารถติดตาม MTTA (เวลาในการรับทราบ/มอบหมาย) เพื่อตรวจจับความล่าช้าในการคัดแยกผู้ป่วย ซึ่งมักเป็นสัญญาณบ่งชี้ว่าอาจใช้เวลาแก้ไขปัญหานานขึ้น
AI ช่วยในการแก้ไขข้อบกพร่องอย่างไร?
AI ย่อขั้นตอนที่มักใช้เวลานาน: การรับเข้า การคัดแยก การวินิจฉัย การแก้ไข และการตรวจสอบ
- การรับข้อมูลและการคัดกรอง: สรุปโดยอัตโนมัติจากรายงานยาว, แยกขั้นตอนการทดสอบ/สภาพแวดล้อม, ระบุข้อมูลซ้ำ, และแนะนำระดับความรุนแรง/ลำดับความสำคัญ เพื่อให้วิศวกรเริ่มต้นด้วยบริบทที่ชัดเจน (เช่น ClickUp AI, Sentry AI)
- การกำหนดเส้นทางและ SLA: ทำนายส่วนประกอบ/เจ้าของที่น่าจะเป็น, ตั้งเวลา, และยกระดับเมื่อ MTTA หรือการรอการทบทวนล่าช้า—ลด "เวลาที่อยู่ในสถานะ" ที่ไม่ได้ใช้งาน (ClickUp Automations และเวิร์กโฟลว์แบบตัวแทน).
- การวินิจฉัย: กลุ่มข้อผิดพลาดที่คล้ายกัน, สัมพันธ์กับการเพิ่มขึ้นของข้อผิดพลาดกับการคอมมิต/การปล่อยล่าสุด, และชี้ไปยังสาเหตุที่เป็นไปได้ด้วย stack traces และบริบทของโค้ด (Sentry AI และเครื่องมือที่คล้ายกัน)
- การนำไปใช้: แนะนำการเปลี่ยนแปลงโค้ดและการทดสอบตามรูปแบบจากรีโพสิตอรีของคุณ ช่วยเร่งกระบวนการ "เขียน/แก้ไข" ให้รวดเร็วขึ้น (GitHub Copilot; Snyk Code AI โดย DeepCode)
- การตรวจสอบและการสื่อสาร: เขียนกรณีทดสอบจากขั้นตอนการทำซ้ำ, ร่างบันทึกการปล่อยและการอัปเดตสำหรับผู้มีส่วนได้ส่วนเสีย, และสรุปสถานะสำหรับผู้บริหารและลูกค้า (ClickUp AI) เมื่อใช้ร่วมกัน—ClickUp เป็นศูนย์บัญชาการพร้อมกับ Sentry/Copilot/DeepCode ในระบบ—ทีมสามารถลดเวลา MTTA/P90 โดยไม่ต้องพึ่งพาการทำงานแบบฮีโร่