
Du släpper den senaste programuppdateringen och rapporterna börjar strömma in.
Plötsligt styr en enda mätparameter allt från CSAT/NPS till avvikelser från roadmap: tiden för att lösa buggar.
Chefer ser det som ett mått på huruvida vi kan leverera, lära oss och skydda intäkterna enligt plan. Praktikerna känner smärtan i skyttegravarna – dubbla ärenden, otydligt ansvar, bullriga eskaleringar och kontext som är utspridd över Slack, kalkylblad och separata verktyg.
Denna fragmentering förlänger cyklerna, döljer de bakomliggande orsakerna och gör prioriteringen till en gissningslek.
Resultatet? Långsammare inlärning, missade åtaganden och en eftersläpning som tyst belastar varje sprint.
Den här guiden är din kompletta handbok för att mäta, jämföra och minska tiden för buggfixning och visar konkret hur AI förändrar arbetsflödet jämfört med traditionella, manuella processer.
Vad är buggresolversningstid?
Bugfixningstid är den tid det tar att åtgärda en bugg, mätt från det ögonblick buggen rapporteras till dess att den är helt åtgärdad.
I praktiken startar klockan när ett problem rapporteras eller upptäcks (via användare, kvalitetssäkring eller övervakning) och stannar när åtgärden har implementerats och sammanfogats, redo för verifiering eller release – beroende på hur ditt team definierar ”klart”.
Exempel: en P1-krasch rapporterad kl. 10:00 på måndagen, med en korrigering sammanfogad kl. 15:00 på tisdagen, har en lösningstid på cirka 29 timmar.
Det är inte samma sak som tiden för att upptäcka buggar. Upptäcktstiden mäter hur snabbt du upptäcker ett fel efter att det har uppstått (larm utlöses, QA-testverktyg hittar det, kunder rapporterar det).
Lösningstiden mäter hur snabbt du går från att upptäcka felet till att åtgärda det – triagering, reproducering, diagnostisering, implementering, granskning, testning och förberedelse för release. Tänk på upptäckten som ”vi vet att det är trasigt” och lösningen som ”det är fixat och klart”.
Team använder något olika gränser; välj en och var konsekvent så att dina trender blir verkliga:
- Rapporterad → Löst: Avslutas när kodkorrigeringen har sammanfogats och är klar för kvalitetssäkring. Bra för ingenjörsgenomströmning
- Rapporterad → Stängd: Inkluderar QA-validering och release. Bäst för SLA:er som påverkar kunderna
- Upptäckt → Löst: Startar när övervakning/QA upptäcker problemet, även innan ett ärende finns. Användbart för produktionsintensiva team.
🧠 Rolig fakta: En udda men rolig bugg i Final Fantasy XIV fick beröm för att den var så specifik att läsarna kallade den för ”den mest specifika buggfixen i ett MMO 2025”. Den uppstod när spelare prissatte föremål mellan exakt 44 442 gil och 49 087 gil i en viss evenemangszon, vilket orsakade avbrott på grund av vad som kan ha varit ett heltalsoverflödsfel.
Varför det är viktigt
Lösningstiden är en påverkande faktor för releasekadensen. Långa eller oförutsägbara tider tvingar fram omfattande nedskärningar, snabbkorrigeringar och releasefrysningar. De skapar planeringsskulder eftersom långsvansen (avvikelserna) stör sprints mer än genomsnittet antyder.
Det är också direkt kopplat till kundnöjdhet. Kunderna tolererar problem när de erkänns snabbt och löses på ett förutsägbart sätt. Långsamma lösningar – eller ännu värre, varierande lösningar – leder till eskaleringar, försämrar CSAT/NPS och äventyrar förnyelser.
Kort sagt, om du mäter tiden för buggfixning på ett tydligt sätt och systematiskt minskar den, kommer dina roadmaps och relationer att förbättras.
Hur mäter man tiden för buggfixning?
Bestäm först var din klocka startar och stannar.
De flesta team väljer antingen Rapporterad → Löst (korrigeringen är sammanfogad och redo för verifiering) eller Rapporterad → Stängd (QA har validerat och ändringen är släppt eller på annat sätt stängd).
Välj en definition och använd den konsekvent så att dina trender blir meningsfulla.
Nu behöver du några observerbara mätvärden. Låt oss sammanfatta dem:
Viktiga mått för felspårning att hålla utkik efter:
| 📊 Mätvärde | 📌 Vad det står för | 💡 Hur det hjälper | 🧮 Formel (om tillämpligt) |
|---|---|---|---|
| Antal buggar 🐞 | Totalt antal rapporterade buggar | Ger en översikt över systemets hälsa. Högt antal? Dags att undersöka saken. | Totalt antal buggar = Alla buggar som loggats i systemet {Öppna + Stängda} |
| Öppna buggar 🚧 | Buggar som ännu inte har åtgärdats | Visar aktuell arbetsbelastning. Hjälper till med prioritering. | Öppna buggar = Totalt antal buggar - Stängda buggar |
| Stängda buggar ✅ | Buggar som har lösts och verifierats | Spårar framsteg och utfört arbete. | Stängda buggar = Antal buggar med statusen "Stängd" eller "Löst" |
| Buggens allvarlighetsgrad 🔥 | Buggens kritikalitet (t.ex. kritisk, större, mindre) | Hjälper till med triage baserat på påverkan. | Spåras som kategorifält, ingen formel. Använd filter/gruppering. |
| Felprioritet 📅 | Hur brådskande är det att åtgärda ett fel? | Hjälper till med sprint- och releaseplanering. | Även ett kategoriskt fält, vanligtvis rangordnat (t.ex. P0, P1, P2). |
| Tid till lösning ⏱️ | Tid från felrapport till åtgärd | Mäter responsivitet. | Tid till lösning = datum för avslutande – datum för rapportering |
| Återöppningsfrekvens 🔄 | Procentandel buggar som återöppnats efter att ha stängts | Återspeglar kvaliteten på korrigeringar eller regressionsproblem. | Återöppningsfrekvens (%) = {Återöppnade buggar ÷ Totalt antal stängda buggar} × 100 |
| Buggläckage 🕳️ | Buggar som smugit sig in i produktionen | Indikerar effektiviteten hos kvalitetssäkring/programvarutestning. | Läckagefrekvens (%) = {Produktfel ÷ Totalt antal fel} × 100 |
| Felkoncentration 🧮 | Buggar per storleksenhet i koden | Markerar riskbenägna kodområden. | Felkoncentration = Antal buggar ÷ KLOC {Kilo Lines of Code} |
| Tilldelade vs otilldelade buggar 👥 | Fördelning av buggar efter ägarskap | Säkerställer att inget faller mellan stolarna. | Använd ett filter: Otilldelade = Buggar där "Tilldelad till" är tomt |
| Ålder på öppna buggar 🧓 | Hur länge ett fel förblir olöst | Upptäck risker för stagnation och eftersläpning. | Bug Age = Aktuellt datum - Datum då felet rapporterades |
| Duplicerade buggar 🧬 | Antal dubbla rapporter | Markerar fel i intagsprocesserna. | Duplikatfrekvens = Duplikater ÷ Totalt antal buggar × 100 |
| MTTD (genomsnittlig tid till upptäckt) 🔎 | Genomsnittlig tid för att upptäcka buggar eller incidenter | Mäter övervaknings- och medvetenhetseffektivitet. | MTTD = Σ(tid för upptäckt – tid för introduktion) ÷ antal buggar |
| MTTR (genomsnittlig tid för att lösa) 🔧 | Genomsnittlig tid för att helt åtgärda ett fel efter upptäckt | Spårar teknikernas responsivitet och åtgärdstid. | MTTR = Σ(tid för lösning – tid för upptäckt) ÷ antal lösta buggar |
| MTTA (medel tid till bekräftelse) 📬 | Tiden från upptäckt till dess att någon börjar arbeta med felet | Visar teamets reaktionsförmåga och respons på larm. | MTTA = Σ(bekräftad tid – upptäckt tid) ÷ antal buggar |
| MTBF (medelvärde för tid mellan fel) 🔁 | Tiden mellan ett löst fel och nästa fel som uppstår | Indikerar stabilitet över tid. | MTBF = Total drifttid ÷ Antal fel |
Faktorer som påverkar tiden för att lösa buggar
Lösningstiden likställs ofta med ”hur snabbt ingenjörerna kodar”.
Men det är bara en del av processen.
Tiden för att lösa buggar är summan av kvaliteten vid intag, flödeseffektiviteten genom ditt system och beroenderisken. När någon av dessa faktorer sviktar förlängs cykeltiden, förutsägbarheten minskar och eskaleringarna blir mer påtagliga.
Intagskvaliteten sätter tonen
Rapporter som kommer in utan tydliga reproduktionssteg, miljöinformation, loggar eller versions-/bygginformation tvingar fram extra fram- och återkommande kommunikation. Dubbletter av rapporter från flera kanaler (support, kvalitetssäkring, övervakning, Slack) skapar extra brus och splittrar ansvaret.
Ju tidigare du fångar upp rätt sammanhang – och deduplicerar – desto färre överlämningar och förtydliganden behöver du senare.
Prioritering och vidarebefordran avgör vem som hanterar felet och när.
Allvarlighetsgrader som inte motsvarar kundens/verksamhetens påverkan (eller som förändras över tid) orsakar köfluktuationer: de mest uppmärksammade ärendena hoppar över kön medan fel med stor påverkan hamnar i bakgrunden.
Tydliga regler för vidarebefordran efter komponent/ägare och en enda kö med sanningsenlig information förhindrar att P0/P1-arbete begravs under ”nyligen och bullrigt”.
Ägarskap och överlämningar är tysta mördare
Om det är oklart om ett fel hör till mobil-, backend-autentiserings- eller plattformsteamet, studsar det tillbaka. Varje studs återställer kontexten.
Tidszoner förvärrar detta: en bugg som rapporteras sent på dagen utan namngiven ägare kan förlora 12–24 timmar innan någon ens börjar reproducera den. Tydliga definitioner av ”vem som äger vad”, med jourhavande eller veckovis DRI, eliminerar denna fördröjning.
Reproducerbarhet beror på observerbarhet
Glesa loggar, saknade korrelations-ID:n eller brist på kraschspår gör diagnosen till gissningslek. Buggar som endast uppträder med specifika flaggor, hyresgäster eller datastrukturer är svåra att återskapa i utvecklingsmiljön.
Om ingenjörer inte kan få säker tillgång till sanerade produktionsliknande data, slutar de med att instrumentera, omplacera och vänta – i dagar istället för timmar.
Miljö och dataparitet håller dig ärlig
”Fungerar på min maskin” betyder oftast ”produktionsdata är annorlunda”. Ju mer din utveckling/staging skiljer sig från produktionen (konfiguration, tjänster, tredjepartsversioner), desto mer tid kommer du att spendera på att jaga spöken. Säkra datamomentbilder, seed-skript och paritetskontroller minskar den klyftan.
Pågående arbete (WIP) och fokus driver den faktiska genomströmningen
Överbelastade team tar sig an för många buggar samtidigt, splittrar sin uppmärksamhet och sliter mellan uppgifter och möten. Kontextväxlingar lägger till osynliga timmar.
En synlig WIP-gräns och en tendens att avsluta det som påbörjats innan nytt arbete påbörjas kommer att sänka din median snabbare än någon enskild hjältes insats.
Kodgranskning, CI och QA-hastighet är klassiska flaskhalsar.
Långsamma byggtider, opålitliga tester och otydliga SLA:er för granskning fördröjer annars snabba korrigeringar. En 10-minuters patch kan ta två dagar att vänta på en granskare eller att få plats i en flera timmar lång pipeline.
På samma sätt kan QA-köer som batchtestar eller förlitar sig på manuella rökprov lägga till hela dagar till "Rapporterad → Stängd", även när "Rapporterad → Löst" går snabbt.
Beroenden förlänger köerna
Förändringar som berör flera team (schema, plattformsövergångar, SDK-uppdateringar), leverantörsfel eller appbutiksgranskningar (mobil) skapar väntetider. Utan explicit spårning av ”blockerade/pausade” ärenden blåser dessa väntetider upp dina genomsnitt på ett osynligt sätt och döljer var den verkliga flaskhalsen finns.
Release-modell och återställningsstrategi är viktiga
Om du levererar i stora releasetåg med manuella grindar, får även lösta buggar vänta tills nästa tåg avgår. Funktionsflaggor, kanariefrigivningar och hotfix-banor förkortar svansen – särskilt för P0/P1-incidenter – genom att du kan koppla bort fixdistributionen från hela releasecykler.
Arkitektur och teknisk skuld sätter din övre gräns
Tät koppling, brist på testskarvar och ogenomskinliga äldre moduler gör enkla korrigeringar riskabla. Team kompenserar med extra testning och längre granskningar, vilket förlänger cyklerna. Omvänt gör modulär kod med bra kontraktstester att du kan gå snabbt framåt utan att störa angränsande system.
Kommunikation och statushygien påverkar förutsägbarheten
Vaga uppdateringar ("undersöker saken") skapar omarbete när intressenter frågar efter beräknad tid för färdigställande, support öppnar ärenden på nytt eller produkten eskaleras. Tydliga statusövergångar, anteckningar om reproduktion och grundorsak samt en publicerad beräknad tid för färdigställande minskar avhopp och skyddar ditt teknikteams fokus.
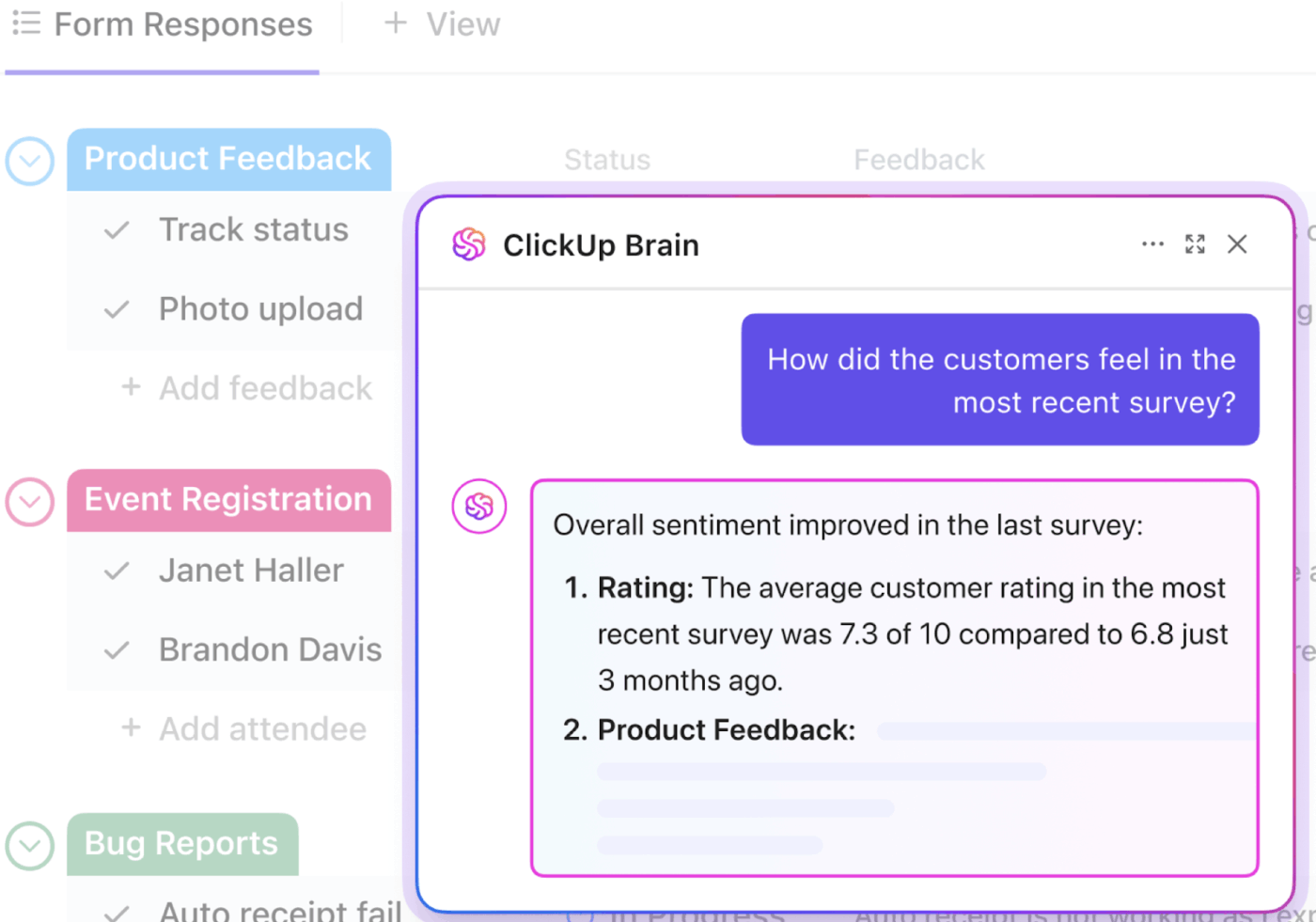
📮ClickUp Insight: Den genomsnittliga yrkesverksamma person spenderar mer än 30 minuter om dagen på att söka efter arbetsrelaterad information – det är över 120 timmar om året som går förlorade på att leta igenom e-postmeddelanden, Slack-trådar och spridda filer.
En intelligent AI-assistent inbyggd i din arbetsyta kan ändra på det. Presentera ClickUp Brain. Den ger omedelbara insikter och svar genom att visa rätt dokument, konversationer och uppgiftsdetaljer på några sekunder – så att du kan sluta söka och börja arbeta.
💫 Verkliga resultat: Team som QubicaAMF har sparat över 5 timmar per vecka med hjälp av ClickUp – det är över 250 timmar per person och år – genom att eliminera föråldrade processer för kunskapshantering. Tänk vad ditt team skulle kunna åstadkomma med en extra produktiv vecka varje kvartal!
Ledande indikatorer på att din lösningstid kommer att förlängas
❗️Ökande ”tid till bekräftelse” och många ärenden utan ägare i mer än 12 timmar
❗️Ökande "Time in Review/CI"-segment och frekventa testfel
❗️Hög dupliceringsgrad vid intag och inkonsekventa allvarlighetsgrader mellan teamen
❗️Flera buggar som ligger i "Blocked" utan namngiven extern beroende
❗️Återöppningsfrekvensen ökar (korrigeringarna är inte reproducerbara eller definitionerna av färdigt är otydliga)
Olika organisationer upplever dessa faktorer på olika sätt. Ledande befattningshavare upplever dem som förlorade inlärningscykler och förlorade intäktsmöjligheter, medan operatörer upplever dem som triagestörningar och otydliga ansvarsfördelningar.
Genom att justera intag, flöde och beroenden kan du dra ner hela kurvan – median och P90.
Vill du lära dig mer om hur du skriver bättre felrapporter? Börja här. 👇🏼
Branschstandarder för tid för buggfixning
Benchmarking av buggfixning varierar beroende på risktolerans, releasemodell och hur snabbt du kan leverera ändringar.
Här kan du använda medianvärden (P50) för att förstå ditt typiska flöde och P90 för att fastställa löften och SLA:er – efter allvarlighetsgrad och källa (kund, kvalitetssäkring, övervakning).
Låt oss bryta ner vad det innebär:
| 🔑 Term | 📝 Beskrivning | 💡 Varför det är viktigt |
|---|---|---|
| P50 (median) | Medelvärdet – 50 % av buggfixarna är snabbare än detta och 50 % är långsammare. | 👉 Återspeglar din typiska eller vanligaste lösningstid. Bra för att förstå normal prestanda. |
| P90 (90:e percentilen) | 90 % av buggarna åtgärdas inom denna tid. Endast 10 % tar längre tid. | 👉 Representerar ett värsta fall (men fortfarande realistiskt). Användbart för att fastställa externa löften. |
| SLA (servicenivåavtal) | Åtaganden du gör – internt eller gentemot kunder – om hur snabbt problem ska åtgärdas | 👉 Exempel: ”Vi löser P1-buggar inom 48 timmar i 90 % av fallen. ” Hjälper till att bygga förtroende och ansvarstagande |
| Efter allvarlighetsgrad och källa | Segmentera dina mätvärden efter två viktiga dimensioner: • Allvarlighetsgrad (t.ex. P0, P1, P2)• Källa (t.ex. kund, kvalitetssäkring, övervakning) | 👉 Möjliggör mer exakt spårning och prioritering, så att kritiska buggar får uppmärksamhet snabbare. |
Nedan finns riktlinjer baserade på branscher som erfarna team ofta riktar in sig på. Betrakta dem som utgångspunkter och anpassa dem sedan efter din situation.
SaaS
Alltid tillgängligt och CI/CD-vänligt, så snabbkorrigeringar är vanliga. Kritiska problem (P0/P1) strävar ofta efter en median på under en arbetsdag, med P90 inom 24–48 timmar. Icke-kritiska problem (P2+) hamnar vanligtvis på en median på 3–7 dagar, med P90 inom 10–14 dagar. Team med robusta funktionsflaggor och automatiserade tester tenderar att vara snabbare.
E-handelsplattformar
Eftersom konvertering och kundvagnsflöden är avgörande för intäkterna är ribban högre. P0/P1-problem åtgärdas vanligtvis inom några timmar (återställning, flaggning eller konfiguration) och löses helt samma dag. P90 före slutet av dagen eller <12 timmar är vanligt under högsäsong. P2+-problem löses ofta inom 2–5 dagar, med P90 inom 10 dagar.
Företagsprogramvara
Krävande validering och kundförändringsfönster saktar ner takten. För P0/P1 siktar teamen på en tillfällig lösning inom 4–24 timmar och en permanent lösning inom 1–3 arbetsdagar; P90 inom 5 arbetsdagar. P2+-ärenden samlas ofta i release-tåg, med en median på 2–4 veckor beroende på kundernas lanseringsscheman.
Spel och mobilappar
Live-service-backends fungerar som SaaS (flaggor och återställningar på några minuter till timmar; P90 samma dag). Klientuppdateringar begränsas av butiksgranskningar: P0/P1 använder ofta server-sidan omedelbart och skickar en klientpatch inom 1–3 dagar; P90 inom en vecka med påskyndad granskning. P2+-korrigeringar schemaläggs vanligtvis till nästa sprint eller innehållsleverans.
Bank/Fintech
Risk- och efterlevnadskontroller driver ett mönster av ”snabb avhjälpning, försiktig förändring”. P0/P1 avhjälps snabbt (flaggor, återställningar, trafikförändringar inom några minuter till timmar) och åtgärdas helt inom 1–3 dagar; P90 inom en vecka, med hänsyn till förändringskontroll. P2+ tar ofta 2–6 veckor att godkänna säkerhets-, revisions- och CAB-granskningar.
Om dina siffror ligger utanför dessa intervall, titta på intagskvalitet, dirigering/ägande, kodgranskning och QA-genomströmning samt godkännanden av beroenden innan du antar att ”teknikhastigheten” är kärnproblemet.
🌼 Visste du att: Enligt en undersökning från Stack Overflow från 2024 använde utvecklare i allt högre grad AI som sin trogna hjälpreda under kodningsprocessen. Hela 82 % använde AI för att skriva kod – snacka om en kreativ medarbetare! När de fastnade eller letade efter lösningar förlitade sig 67,5 % på AI för att söka efter svar, och över hälften (56,7 %) förlitade sig på AI för att felsöka och få hjälp.
För vissa har AI-verktyg också visat sig vara praktiska för att dokumentera projekt (40,1 %) och till och med skapa syntetiska data eller innehåll (34,8 %). Nyfiken på en ny kodbas? Nästan en tredjedel (30,9 %) använder AI för att komma igång. Att testa kod är fortfarande ett manuellt slit för många, men 27,2 % har även här tagit till sig AI. Andra områden som kodgranskning, projektplanering och prediktiv analys har en lägre AI-användning, men det är tydligt att AI stadigt väver in sig i alla stadier av mjukvaruutvecklingen.
📖 Läs mer: Hur man använder AI för kvalitetssäkring
Hur man minskar tiden för buggfixning
Snabb buggfixning handlar om att eliminera friktion vid varje överlämning, från intag till release.
De största vinsterna uppnås genom att göra de första 30 minuterna smartare (ren inmatning, rätt ägare, rätt prioritet) och sedan komprimera de efterföljande stegen (reproducera, granska, verifiera).
Här är nio strategier som fungerar tillsammans som ett system. AI påskyndar varje steg och arbetsflödet sker på ett överskådligt sätt på ett och samma ställe, så att chefer får förutsägbarhet och praktiker får flyt.
1. Centralisera intag och fånga kontext vid källan
Feltiden förlängs när du rekonstruerar sammanhanget från Slack-trådar, supportärenden och kalkylblad. Samla alla rapporter – support, kvalitetssäkring, övervakning – i en enda kö med en strukturerad mall som samlar in information om komponenter, allvarlighetsgrad, miljö, appversion/build, steg för att reproducera, förväntat kontra faktiskt och bilagor (loggar/HAR/skärmbilder).
AI kan automatiskt sammanfatta långa rapporter, extrahera reproduceringssteg och miljöinformation från bilagor samt markera troliga dubbletter så att triageringen kan börja med en sammanhängande, berikad dokumentation.
Mätvärden att hålla koll på: MTTA (bekräftelse inom några minuter, inte timmar), dupliceringsfrekvens, tid för ”Behöver information”.

2. AI-assisterad triage och dirigering för att minska MTTA
De snabbaste lösningarna är de som hamnar på rätt skrivbord omedelbart.
Använd enkla regler och AI för att klassificera allvarlighetsgrad, identifiera troliga ägare efter komponent/kodområde och automatiskt tilldela med en SLA-klocka. Ställ in tydliga swimlanes för P0/P1 jämfört med allt annat och gör det tydligt vem som är ansvarig.
Automatiseringar kan ställa in prioritet från fält, dirigera efter komponent till en grupp, starta en SLA-timer och meddela en jourhavande tekniker. AI kan föreslå allvarlighetsgrad och ansvarig baserat på tidigare mönster. När triagering tar 2–5 minuter istället för 30 minuters diskussioner minskar din MTTA och din MTTR följer efter.
Mätvärden att hålla koll på: MTTA, kvaliteten på första svaret (begär den första kommentaren rätt information?), antal överlämningar per bugg.
Så här ser det ut i praktiken:
3. Prioritera efter affärspåverkan med tydliga SLA-nivåer
”Den som ropar högst vinner” gör köerna oförutsägbara och undergräver förtroendet hos chefer som övervakar CSAT/NPS och förnyelser.
Ersätt det med ett betyg som kombinerar allvarlighetsgrad, frekvens, påverkat ARR, funktionens kritikalitet och närhet till förnyelser/lanseringar – och stöd det med SLA-nivåer (t.ex. P0: mildra inom 1–2 timmar, lösa inom en dag; P1: samma dag; P2: inom en sprint).
Håll en synlig P0/P1-fil med WIP-gränser så att inget hamnar i bakgrunden.
Mätvärden att bevaka: P50/P90-lösning per nivå, SLA-överträdelsegrad, korrelation med CSAT/NPS.
💡Proffstips: Med ClickUps fält för uppgiftsprioriteringar, anpassade fält och beroenden kan du beräkna en påverkanpoäng och koppla buggar till konton, feedback eller roadmap-objekt. Dessutom hjälper målen i ClickUp dig att koppla SLA-efterlevnad till målen på företagsnivå, vilket direkt tilltalar ledningens oro över samordning.
4. Gör reproduktion och diagnos till en engångsaktivitet
Varje extra loop med "kan du skicka loggar?" förlänger tiden för att lösa problemet.
Standardisera vad som är ”bra”: obligatoriska fält för build/commit, miljö, reproduceringssteg, förväntat kontra faktiskt, plus bilagor för loggar, kraschdumps och HAR-filer. Instrumentera klient-/servertelemetri så att krasch-ID:n och förfrågnings-ID:n kan länkas till spår.
Använd Sentry (eller liknande) för stacktraces och länka det problemet direkt till buggen. AI kan läsa loggar och spår för att föreslå en trolig felfunktion och generera en minimal reproduktion, vilket förvandlar en timmes ögonträning till några minuters fokuserat arbete.
Spara runbooks för vanliga typer av buggar så att teknikerna inte behöver börja från scratch.
Mätvärden att hålla koll på: Tid som spenderas på att "vänta på information", procentandel som reproduceras vid första försöket, återöppningsfrekvens kopplad till saknad reproduktion.
5. Förkorta kodgranskningen och testcykeln
Stora PR-projekt fastnar. Satsa på kirurgiska patchar, trunkbaserad utveckling och funktionsflaggor så att korrigeringar kan levereras på ett säkert sätt. Fördela granskare i förväg efter kodägande för att undvika ledig tid, och använd checklistor (uppdaterade tester, telemetri tillagd, flagga bakom en kill switch) så att kvaliteten blir inbyggd.
Automatiseringen bör flytta felet till "Under granskning" vid PR-öppning och till "Löst" vid sammanslagning. AI kan föreslå enhetstester eller markera riskfyllda skillnader för att fokusera granskningen.
Mätvärden att hålla koll på: Tid i "Under granskning", förändringsfelprocent för buggfix-PR:er och P90-granskningsfördröjning.
Du kan använda GitHub/GitLab -integrationer i ClickUp för att hålla din lösningsstatus synkroniserad. Automatiseringar kan genomdriva ”definitionen av färdig”.
6. Parallellisera verifieringen och gör QA-miljön verklig
Verifieringen bör inte påbörjas flera dagar senare eller i en miljö som ingen av dina kunder använder.
Håll "redo för QA" strikt: flaggstyrda snabbkorrigeringar validerade i produktionsliknande miljöer med seed-data som matchar rapporterade fall.
Om möjligt, skapa tillfälliga miljöer från buggrenen så att QA kan validera omedelbart. AI kan sedan generera testfall från bugbeskrivningen och tidigare regressioner.
Mätvärden att hålla koll på: Tid i ”QA/verifiering”, avvisningsfrekvens från QA tillbaka till utveckling, median tid till avslut efter sammanslagning.

📖 Läs mer: Hur man skriver effektiva testfall
7. Kommunicera status tydligt för att minska samordningskostnaderna
En bra uppdatering förhindrar tre statusuppdateringar och en eskalering.
Behandla uppdateringar som en produkt: korta, specifika och anpassade efter målgruppen (support, chefer, kunder). Fastställ en rytm för P0/P1 (t.ex. varje timme tills problemet är löst, sedan var fjärde timme) och ha en enda källa till information.
AI kan skapa kundsäkra uppdateringar och interna sammanfattningar från uppgiftshistoriken, inklusive live-status efter allvarlighetsgrad och team. För chefer som din produktchef kan buggar rullas upp till initiativ så att de kan se om kritiskt kvalitetsarbete hotar leveranslöften.
Mätvärden att bevaka: Tid mellan statusuppdateringar på P0/P1, intressenternas CSAT för kommunikation.
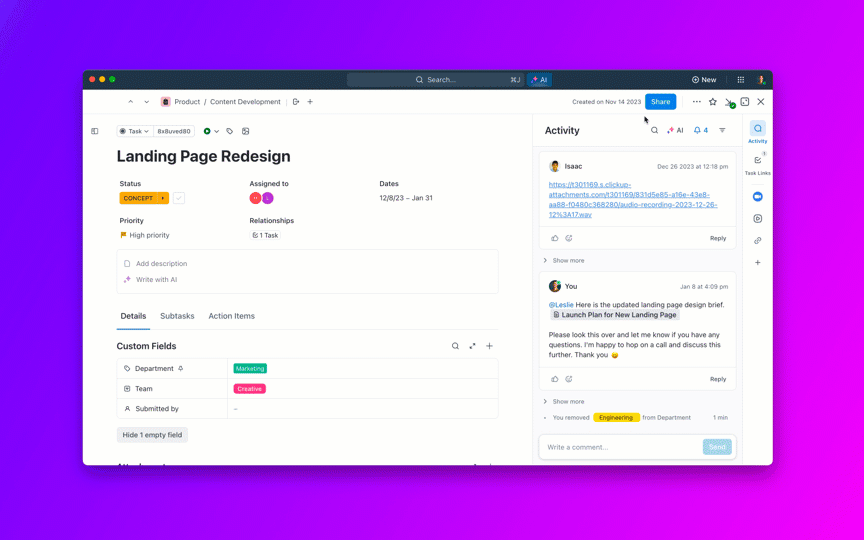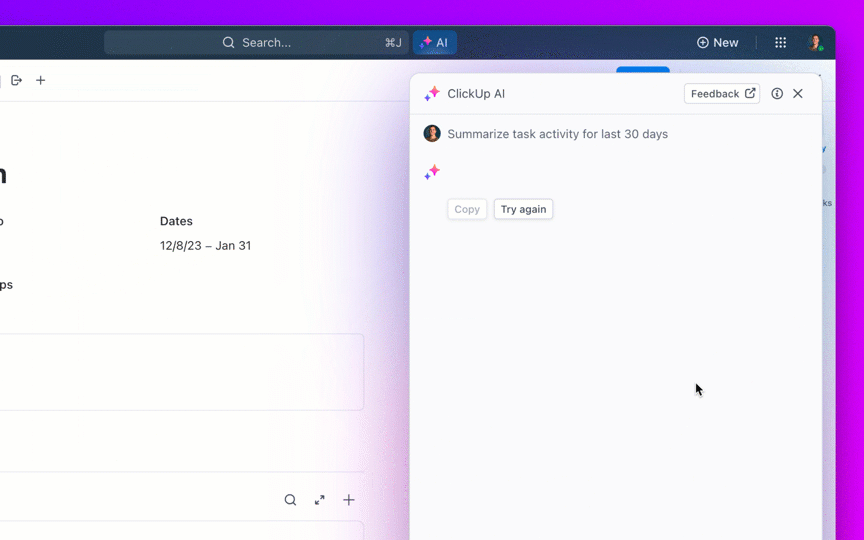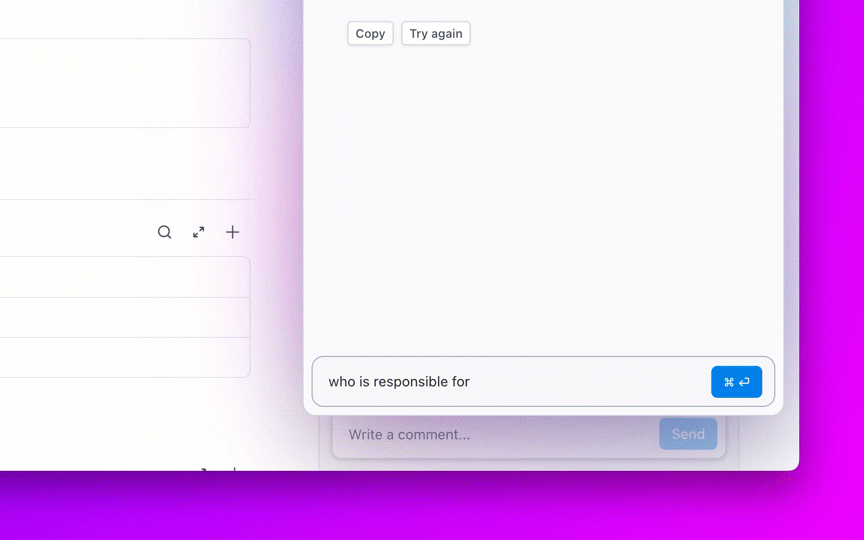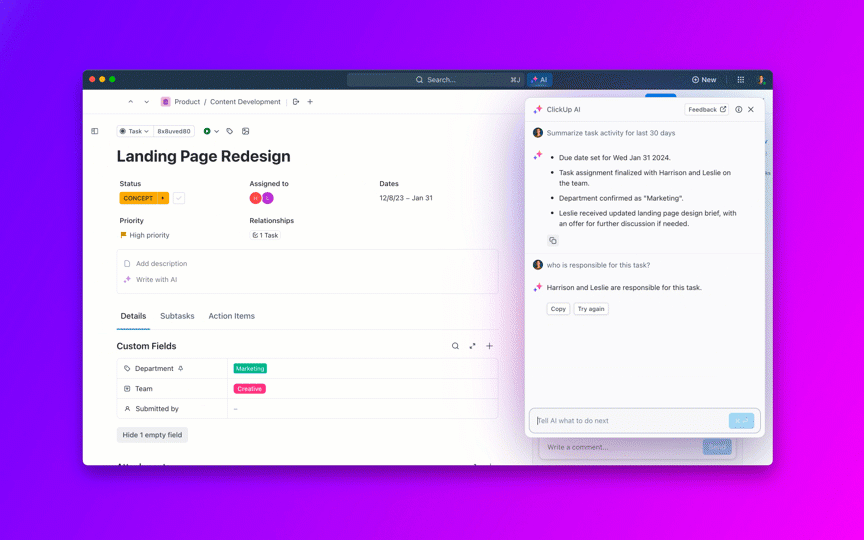
8. Kontrollera åldern på backloggen och förhindra att ärenden förblir öppna i evighet
En växande, föråldrad backlog belastar tyst varje sprint.
Ställ in åldringspolicyer (t.ex. P2 > 30 dagar utlöser granskning, P3 > 90 dagar kräver motivering) och schemalägg en veckovis "åldringstriage" för att slå samman dubbletter, stänga föråldrade rapporter och konvertera buggar med lågt värde till produktbackloggposter.
Använd AI för att gruppera backloggen efter tema (t.ex. "autentiseringstoken har gått ut", "bilduppladdningsproblem") så att du kan planera tematiska fixveckor och ta bort en hel klass av fel på en gång.
Mätvärden att hålla koll på: antalet eftersläpningar per åldersgrupp, procentandel av ärenden som avslutats som dubbletter/föråldrade, tematisk burn-down-hastighet.
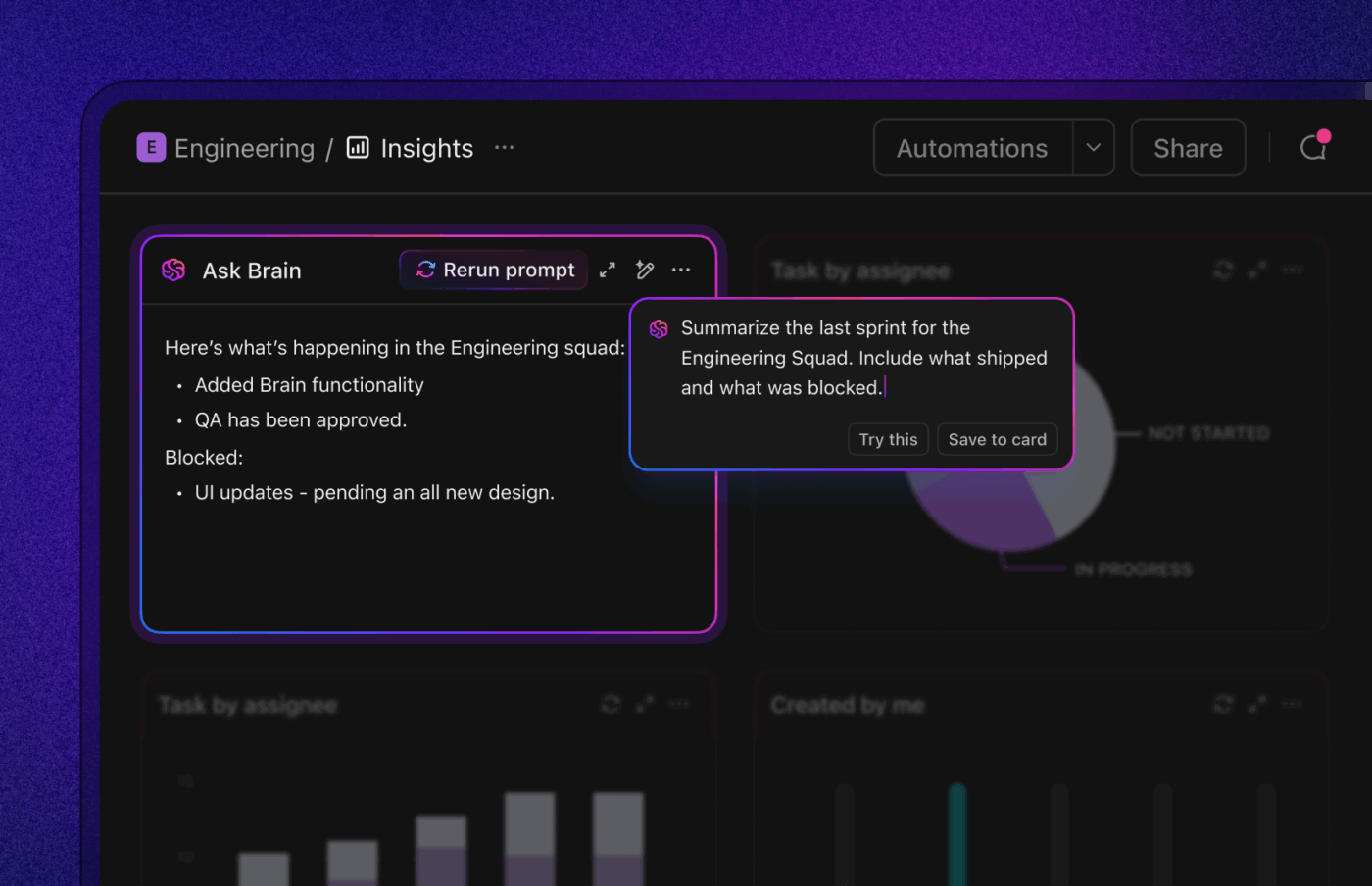
9. Slut cirkeln med grundorsaken och förebyggande åtgärder
Om samma typ av fel återkommer gång på gång, döljer dina MTTR-förbättringar ett större problem.
Gör snabba, felfria grundorsaksanalyser på P0/P1 och högfrekventa P2:or; märk grundorsaker (specifikationsbrister, testbrister, verktygsbrister, integrationsinstabilitet), länka till berörda komponenter och incidenter och spåra uppföljningsuppgifter (skydd, tester, lint-regler) till slutförandet.
AI kan utarbeta RCA-sammanfattningar och föreslå förebyggande tester eller lint-regler baserat på ändringshistoriken. Och det är så du går från att släcka bränder till att få färre bränder.
Mätvärden att hålla koll på: Återöppningsfrekvens, regressionsfrekvens, tid mellan återkommande fel och procentandel av RCA:er med genomförda förebyggande åtgärder.

Sammantaget komprimerar dessa förändringar hela processen: snabbare bekräftelse, renare triage, smartare prioritering, färre avbrott i granskning och kvalitetssäkring samt tydligare kommunikation. Chefer får förutsägbarhet kopplad till CSAT/NPS och intäkter, medan praktiker får en lugnare kö med mindre kontextväxling.
📖 Läs mer: Hur man utför en grundorsaksanalys
AI-verktyg som hjälper till att minska tiden för buggfixning
AI kan minska tiden för att lösa problem i varje steg – intag, triage, vidarebefordran, åtgärd och verifiering.
De verkliga vinsterna uppnås dock när verktygen förstår sammanhanget och håller arbetet igång utan att behöva någon hjälp.
Leta efter system som automatiskt berikar rapporter (reproducerbara steg, miljö, dubbletter), prioriterar efter påverkan, vidarebefordrar till rätt ägare, utformar tydliga uppdateringar och integreras tätt med din kod, CI och observabilitet.
De bästa av dem stöder även agentliknande arbetsflöden: bots som övervakar SLA:er, påminner granskare, eskalerar fastnade ärenden och sammanfattar resultaten för intressenter. Här är vår sammanställning av AI-verktyg för bättre buggfixning:
1. ClickUp (Bäst för kontextuell AI, automatiseringar och agentiska arbetsflöden)
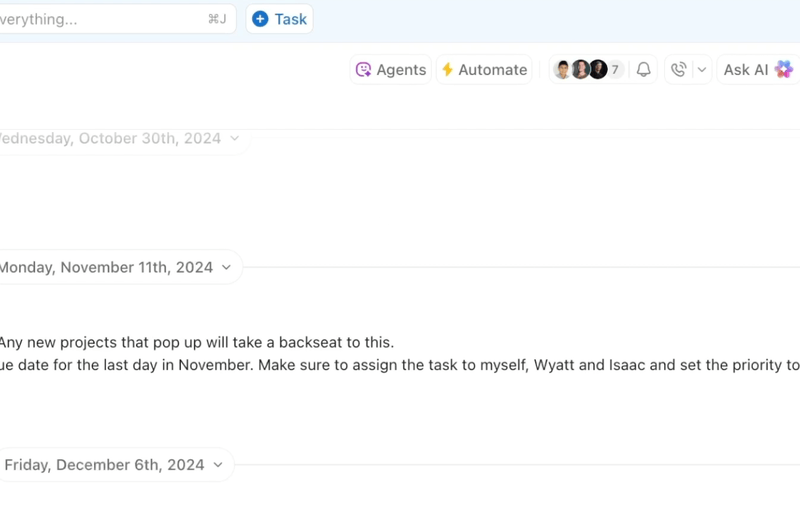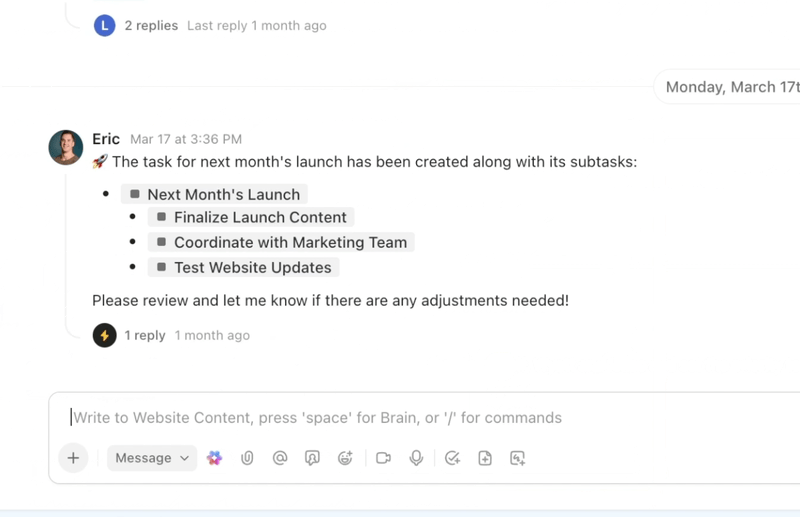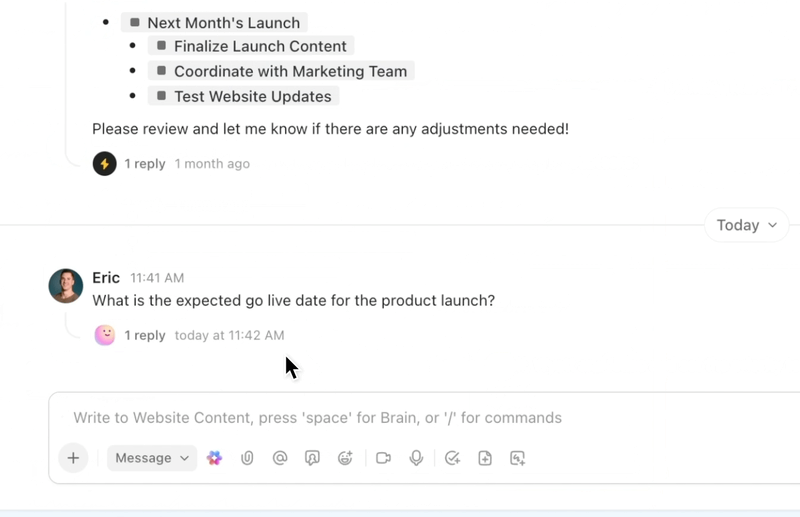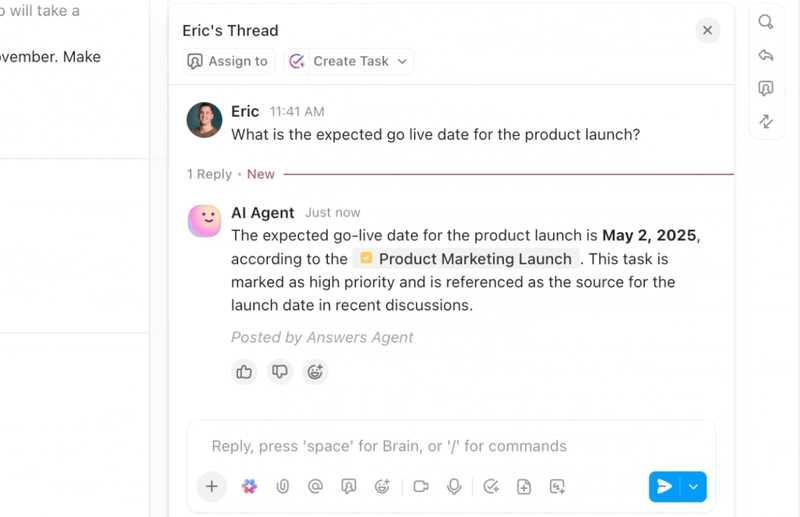
Om du vill ha ett strömlinjeformat, intelligent arbetsflöde för felsökning erbjuder ClickUp, appen för allt som har med arbete att göra, AI, automatiseringar och agentbaserad arbetsflödesassistans på ett och samma ställe.
ClickUp Brain visar rätt sammanhang direkt – sammanfattar långa buggtrådar, extraherar steg för att reproducera och miljödetaljer från bilagor, flaggar troliga dubbletter och föreslår nästa åtgärder. Istället för att bläddra igenom Slack, biljetter och loggar får teamen en ren, berikad rapport som de kan agera på omedelbart.
Automatiseringar och Autopilot Agents i ClickUp håller arbetet igång utan ständig övervakning. Buggar dirigeras automatiskt till rätt team, ägare tilldelas, SLA:er och förfallodatum fastställs, status uppdateras i takt med att arbetet fortskrider och intressenter får meddelanden i rätt tid.

Dessa agenter kan till och med triagera och kategorisera problem, gruppera liknande rapporter, hänvisa till tidigare lösningar för att föreslå möjliga vägar framåt och eskalera brådskande ärenden – så att MTTA och MTTR minskar även när volymen ökar.
🛠️ Vill du ha ett färdigt verktyg? ClickUp Bug & Issue Tracking Template är en kraftfull lösning från ClickUp for Software som är utformad för att hjälpa support-, teknik- och produktteam att enkelt hålla koll på programvarufel och problem. Med anpassningsbara vyer som lista, tavla, arbetsbelastning, formulär och tidslinje kan teamen visualisera och hantera sin felspårningsprocess på det sätt som passar dem bäst.
Mallens 20 anpassade statusar och 7 anpassade fält möjliggör ett skräddarsytt arbetsflöde, vilket säkerställer att varje problem spåras från upptäckt till lösning. Inbyggda automatiseringar tar hand om repetitiva uppgifter, vilket frigör värdefull tid och minskar manuellt arbete.
💟 Bonus: Brain MAX är din AI-drivna desktop-kompanjon, utformad för att påskynda buggfixningen med smarta, praktiska funktioner.
När du stöter på ett fel använder du helt enkelt Brain MAX:s talk-to-text för att diktera problemet – dina talade anteckningar transkriberas omedelbart och kan bifogas till ett nytt eller befintligt felärende. Enterprise Search söker igenom alla dina anslutna verktyg – som ClickUp, GitHub, Google Drive och Slack – för att hitta relaterade felrapporter, felloggar, kodsnuttar och dokumentation, så att du har all information du behöver utan att behöva byta app.
Behöver du samordna en korrigering? Med Brain MAX kan du tilldela felet till rätt utvecklare, ställa in automatiska påminnelser för statusuppdateringar och spåra framsteg – allt från din dator!
2. Sentry (bäst för att fånga upp fel)
Sentry minskar MTTD och reproduktionstiden genom att samla fel, spårningar och användarsessioner på ett ställe. AI-driven problemgruppering minskar bruset; regler för ”Suspect Commit” och ägarskap identifierar den troliga kodägaren, så vidarebefordran sker omedelbart. Session Replay ger ingenjörerna den exakta användarvägen och konsol-/nätverksdetaljerna för att reproducera utan ändlösa fram- och återgångar.
Sentry AI-funktionerna kan sammanfatta problemets sammanhang och, i vissa stackar, föreslå Autofix-patchar som refererar till den felaktiga koden. Den praktiska effekten: färre dubbla ärenden, snabbare tilldelning och en kortare väg från rapport till fungerande patch.
3. GitHub Copilot (bäst för snabbare granskning av kod)
Copilot påskyndar fixningsprocessen i redigeraren. Det förklarar stacktraces, föreslår riktade patchar, skriver enhetstester för att låsa fixen och skapar reproducerbara skript.
Copilot Chat kan gå igenom felaktig kod, föreslå säkrare omstruktureringar och generera kommentarer eller PR-beskrivningar som gör kodgranskningen snabbare. I kombination med nödvändiga granskningar och CI minskar det tiden för ”diagnostisera → implementera → testa”, särskilt för buggar med tydlig reproduktion och väl avgränsad omfattning.
4. Snyk av DeepCode AI (bäst för att upptäcka mönster)
DeepCodes AI-drivna statiska analys hittar fel och osäkra mönster när du kodar och i PR:er. Den markerar problematiska flöden, förklarar varför de uppstår och föreslår säkra korrigeringar som passar din kodbas.
Genom att upptäcka regressioner före sammanslagningen och guida utvecklare till säkrare mönster minskar du förekomsten av nya buggar och påskyndar åtgärdandet av knepiga logiska fel som är svåra att upptäcka vid granskning. IDE- och PR-integrationer håller detta nära där arbetet utförs.
5. Datadogs Watchdog och AIOps (bäst för logganalys)
Datadogs Watchdog använder ML för att upptäcka avvikelser i loggar, mätvärden, spårningar och övervakning av verkliga användare. Det korrelerar toppar med driftsmarkörer, infrastrukturförändringar och topologi för att föreslå troliga orsaker.
För fel som påverkar kunderna innebär det att det tar bara några minuter att upptäcka dem, automatisk gruppering för att minska antalet falska larm och konkreta ledtrådar om var man ska leta. Triage-tiden minskar eftersom du börjar med "denna distribution påverkade dessa tjänster och felfrekvensen ökade på denna slutpunkt" istället för att börja från noll.
6. New Relic AI (Bäst för att identifiera och sammanfatta trender)
New Relics Errors Inbox grupperar liknande fel över tjänster och versioner, medan dess AI-assistent sammanfattar påverkan, lyfter fram troliga orsaker och länkar till de spår/transaktioner som är inblandade.
Korrelationer mellan distributioner och information om ändringar i enheter gör det uppenbart när en ny release är orsaken till problemet. För distribuerade system sparar det sammanhanget timmar av pingande mellan team och leder felet till rätt ansvarig med en redan utformad, solid hypotes.
7. Rollbar (bäst för automatiserade arbetsflöden)
Rollbar specialiserar sig på realtidsövervakning av fel med intelligent fingeravtrycksidentifiering för att gruppera dubbletter och spåra förekomsttrender. Dess AI-drivna sammanfattningar och tips om grundorsaker hjälper team att förstå omfattningen (berörda användare, påverkade versioner), medan telemetri och stacktraces ger snabba ledtrådar för reproduktion.
Rollbars arbetsflödesregler kan automatiskt skapa uppgifter, märka allvarlighetsgrad och vidarebefordra till ägare, vilket förvandlar bullriga felströmmar till prioriterade köer med bifogad kontext.
8. PagerDuty AIOps och automatisering av runbooks (bäst inom lågkontaktdiagnostik)
PagerDuty använder händelsekorrelation och ML-baserad brusreducering för att omvandla larmstormar till hanterbara incidenter.
Dynamisk dirigering skickar problemet direkt till rätt jourhavande, medan automatisering av runbooks kan starta diagnostik eller åtgärder (starta om tjänster, återställa en distribution, växla en funktionsflagga) innan en människa kopplas in. För buggresolversningstiden innebär det kortare MTTA, snabbare åtgärder för P0:or och färre timmar som går förlorade på grund av alarmtrötthet.
Den röda tråden är automatisering plus AI i varje steg. Du upptäcker tidigare, dirigerar smartare, kommer fram till koden snabbare och kommunicerar status utan att bromsa ingenjörerna – allt detta bidrar till en betydande minskning av tiden för att lösa buggar.
📖 Läs mer: Hur man använder AI i DevOps
Verkliga exempel på användning av AI för buggfixning
Så nu är AI officiellt ute ur laboratoriet. Det minskar tiden för att lösa buggar i verkligheten.
Låt oss titta på hur!
| Domän/organisation | Hur AI användes | Effekt/fördel |
|---|---|---|
| Ubisoft | Utvecklat Commit Assistant, ett AI-verktyg som tränats på ett decenniums interna kodning och som förutsäger och förebygger buggar redan i kodningsstadiet. | Syftet är att dramatiskt minska tid och kostnader – upp till 70 % av kostnaderna för spelutveckling går traditionellt till buggfixar. |
| Razer (Wyvrn-plattformen) | Lanserade AI-drivna QA Copilot (integrerat med Unreal och Unity) för att automatisera buggdetektering och generera QA-rapporter. | Ökar buggdetekteringen med upp till 25 % och halverar QA-tiden. |
| Google / DeepMind & Project Zero | Vi introducerade Big Sleep, ett AI-verktyg som självständigt upptäcker säkerhetsbrister i öppen källkodsprogramvara som FFmpeg och ImageMagick. | Identifierade 20 buggar, alla verifierade av mänskliga experter och planerade för patchning. |
| Forskare vid UC Berkeley | Med hjälp av ett benchmarktest vid namn CyberGym analyserade AI-modeller 188 open source-projekt , upptäckte 17 sårbarheter – däribland 15 okända ”zero-day”-buggar – och genererade proof-of-concept-exploits. | Visar AI:s växande förmåga inom sårbarhetsdetektering och automatiserad exploateringsskydd. |
| Spur (Yale Startup) | Utvecklat en AI-agent som översätter testbeskrivningar i klartext till automatiserade webbplatstestrutiner – i praktiken ett självskrivande QA-arbetsflöde. | Möjliggör autonom testning med minimal mänsklig inblandning |
| Automatisk reproduktion av Android-felrapporter | Använde NLP + förstärkningsinlärning för att tolka språket i felrapporter och generera steg för att reproducera Android-fel. | Uppnådde 67 % precision, 77 % återkallelse och reproducerade 74 % av felrapporterna, vilket överträffade traditionella metoder. |
Vanliga misstag vid mätning av tid för buggfixning
Om dina mätningar är felaktiga blir även din förbättringsplan felaktig.
De flesta ”dåliga siffror” i arbetsflöden för buggfixning kommer från vaga definitioner, inkonsekventa arbetsflöden och ytlig analys.
Börja med grunderna – vad som räknas som start/stopp, hur du hanterar väntetider och återupptagningar – och läs sedan av data utifrån hur dina kunder upplever dem. Det innefattar:
❌ Otydliga gränser: Att blanda Rapporterade→Lösta och Rapporterade→Stängda i samma instrumentpanel (eller växla mellan månader) gör trenderna meningslösa. Välj en gräns, dokumentera den och tillämpa den i alla team. Om du behöver båda, publicera dem som separata mätvärden med tydliga etiketter.
❌ Enbart genomsnittsbaserad metod: Att förlita sig på medelvärdet döljer verkligheten med några få långvariga avvikelser i köerna. Använd medianvärdet (P50) för din ”typiska” tid, P90 för förutsägbarhet/SLA och behåll medelvärdet för kapacitetsplanering. Titta alltid på fördelningen, inte bara på ett enda tal.
❌ Ingen segmentering: Att slå ihop alla buggar blandar P0-incidenter med kosmetiska P3-incidenter. Segmentera efter allvarlighetsgrad, källa (kund vs. QA vs. övervakning), komponent/team och ”nytt vs. regression”. Din P0/P1 P90 är vad intressenterna upplever; din P2+ median är vad teknikavdelningen planerar utifrån.
❌ Ignorera "pausad" tid: Väntar du på kundloggar, en extern leverantör eller ett releasefönster? Om du inte spårar Blockerad/Pausad som en förstklassig status blir din lösningstid ett argument. Rapportera både kalendertid och aktiv tid så att flaskhalsar blir synliga och debatterna upphör.
❌ Gap i tidsnormalisering: Att blanda tidszoner eller växla mellan kontorstid och kalenderdagar mitt i processen förstör jämförelserna. Normalisera tidsstämplar till en zon (eller UTC) och bestäm en gång för alla om SLA:er ska mätas i kontorstid eller kalenderdagar. Tillämpa detta konsekvent.
❌ Felaktig registrering och dubbletter: Saknad miljö-/bygginformation och dubbla ärenden förlänger handläggningstiden och skapar förvirring kring ansvaret. Standardisera obligatoriska fält vid registrering, berika automatiskt (loggar, version, enhet) och ta bort dubbletter utan att återställa klockan – stäng dubbletter som länkade, inte som ”nya” ärenden.
❌ Inkonsekventa statusmodeller: Skräddarsydda statusar (”QA Ready-ish”, ”Pending Review 2”) döljer tiden i status och gör statusövergångar opålitliga. Definiera ett kanoniskt arbetsflöde (Ny → Triage → Pågående → Under granskning → Löst → Stängd) och granska avvikande statusar.
❌ Blind för tid i status: En enda siffra för ”total tid” kan inte visa var arbetet fastnar. Registrera och granska tiden som spenderas i Triaged, In Review, Blocked och QA. Om kodgranskning P90 överskuggar implementeringen är din lösning inte att ”koda snabbare” – utan att frigöra granskningskapacitet.
🧠 Rolig fakta: DARPA:s senaste AI Cyber Challenge visade upp ett banbrytande framsteg inom automatisering av cybersäkerhet. Tävlingen presenterade AI-system som är utformade för att självständigt upptäcka, utnyttja och åtgärda sårbarheter i programvara – utan mänsklig inblandning. Det vinnande laget, ”Team Atlanta”, upptäckte imponerande nog 77 % av de injicerade buggarna och lyckades åtgärda 61 % av dem, vilket visar på AI:s förmåga att inte bara hitta brister utan också aktivt åtgärda dem.
❌ Blindhet för återöppningar: Att behandla återöppningar som nya buggar återställer klockan och smickrar MTTR. Spåra återöppningsfrekvensen och ”tiden till stabil stängning” (från första rapporten till slutlig stängning över alla cykler). Ökande återöppningar pekar vanligtvis på svag reproduktion, testluckor eller en vag definition av färdig.
❌ Ingen MTTA: Team är fixerade vid MTTR och ignorerar MTTA (bekräftelse-/ansvarstid). Hög MTTA är ett tidigt varningstecken på lång lösningstid. Mät den, ställ in SLA:er efter allvarlighetsgrad och automatisera vidarebefordran/eskalering för att hålla den nere.
❌ AI/automatisering utan skyddsräcken: Att låta AI fastställa allvarlighetsgrad eller stänga dubbletter utan granskning kan leda till felklassificering av gränsfall och tyst snedvrida mätvärden. Använd AI för förslag, kräv mänsklig bekräftelse på P0/P1 och granska modellens prestanda varje månad så att dina data förblir tillförlitliga.
Stram upp dessa sömmar så kommer dina diagram över lösningstider äntligen att spegla verkligheten. Därifrån kommer förbättringarna att ackumuleras: bättre intag minskar MTTA, renare tillstånd avslöjar verkliga flaskhalsar och segmenterade P90 ger ledare löften som du kan hålla.
⚡️ Mallarkiv: 10 testfallmallar för mjukvarutestning
Bästa praxis för bättre buggfixning
Sammanfattningsvis är här de viktigaste punkterna att tänka på!
| 🧩 Bästa praxis | 💡 Vad det innebär | 🚀 Varför det är viktigt |
| Använd ett robust system för felspårning | Spåra alla rapporterade buggar med hjälp av ett centraliserat buggspårningssystem. | Säkerställer att inga buggar går förlorade och ger insyn i buggstatusen för alla team. |
| Skriv detaljerade felrapporter | Inkludera visuell kontext, OS-information, steg för att reproducera och allvarlighetsgrad. | Hjälper utvecklare att åtgärda buggar snabbare med all viktig information tillgänglig från början. |
| Kategorisera och prioritera buggar | Använd en prioritetsmatris för att sortera buggar efter brådskandehet och påverkan. | Fokuserar teamet på kritiska buggar och brådskande problem först. |
| Utnyttja automatiserad testning | Kör tester automatiskt i din CI/CD-pipeline. | Stöder tidig upptäckt och förhindrar regressioner. |
| Definiera tydliga riktlinjer för rapportering | Tillhandahåll mallar och utbildning om hur man rapporterar buggar. | Resulterar i korrekt information och smidigare kommunikation. |
| Spåra viktiga mätvärden | Mät lösningstid, förfluten tid och svarstid. | Möjliggör prestandaspårning och förbättring med hjälp av historiska data. |
| Använd en proaktiv strategi | Vänta inte på att användarna ska klaga – testa proaktivt. | Ökar kundnöjdheten och minskar supportbelastningen. |
| Utnyttja smarta verktyg och ML | Använd maskininlärning för att förutsäga buggar och föreslå korrigeringar. | Förbättrar effektiviteten när det gäller att identifiera grundorsaker och åtgärda buggar. |
| Anpassa efter SLA | Uppfyll överenskomna servicenivåavtal för lösning. | Skapar förtroende och uppfyller kundernas förväntningar i rätt tid. |
| Granska och förbättra kontinuerligt | Analysera återupptagna buggar, samla in feedback och justera processer. | Främjar kontinuerlig förbättring av din utvecklingsprocess och bugghantering. |
Enkel buggfixning med kontextuell AI
De snabbaste buggfixningsteamen förlitar sig inte på hjältedåd. De utformar ett system: tydliga start-/stoppdefinitioner, ren intagning, prioritering av affärspåverkan, tydligt ägarskap och täta feedbackloopar mellan support, kvalitetssäkring, teknik och release.
ClickUp kan vara det AI-drivna kommandocentret för ditt system för buggfixning. Centralisera alla rapporter i en kö, standardisera sammanhanget med strukturerade fält och låt ClickUp AI triagera, sammanfatta och prioritera medan automatiseringar upprätthåller SLA:er, eskalerar när tidsgränser överskrids och håller intressenterna samordnade. Koppla buggar till kunder, kod och releaser så att chefer ser effekten och praktikerna kan fortsätta arbeta.
Om du är redo att minska tiden för buggfixning och göra din roadmap mer förutsägbar, registrera dig för ClickUp och börja mäta förbättringen i dagar – inte kvartal.
Vanliga frågor
Vad är en bra tid för att lösa buggar?
Det finns inte ett enda ”bra” tal – det beror på allvarlighetsgrad, releasemodell och risktolerans. Använd medianvärden (P50) för ”typisk” prestanda och P90 för löften/SLA, och segmentera efter allvarlighetsgrad och källa.
Vad är skillnaden mellan buggfixning och buggstängning?
Lösning innebär att åtgärden har implementerats (t.ex. kod sammanslagen, konfiguration tillämpad) och teamet anser att felet är åtgärdat. Avslutning innebär att problemet har verifierats och formellt avslutats (t.ex. QA validerat i målmiljön, släppt eller markerat som kommer inte att åtgärdas/dupliceras med motivering). Många team mäter båda: Rapporterat→Löst återspeglar teknikhastigheten; Rapporterat→Avslutat återspeglar kvalitetsflödet från början till slut. Använd konsekventa definitioner så att dashboards inte blandar olika stadier.
Vad är skillnaden mellan tid för buggfixning och tid för buggdetektering?
Detektionstid (MTTD) är hur lång tid det tar att upptäcka ett fel efter att det har uppstått eller levererats – via övervakning, kvalitetssäkring eller användare. Lösningstid är hur lång tid det tar från detektion/rapportering till att åtgärden implementeras (och, om du föredrar det, valideras/släpps). Tillsammans definierar de kundpåverkansfönstret: upptäck snabbt, bekräfta snabbt, lös snabbt och släpp säkert. Du kan också spåra MTTA (tid till bekräftelse/tilldelning) för att upptäcka fördröjningar i triageringen som ofta förutsäger en längre lösningstid.
Hur hjälper AI till vid felsökning?
AI komprimerar de steg som vanligtvis tar lång tid: intag, triage, diagnos, åtgärd och verifiering.
- Intag och triage: Sammanfattar automatiskt långa rapporter, extraherar reproduceringssteg/miljö, markerar dubbletter och föreslår allvarlighetsgrad/prioritet så att ingenjörerna kan börja med ett tydligt sammanhang (t.ex. ClickUp AI, Sentry AI).
- Routing och SLA: Förutspår sannolika komponenter/ägare, ställer in timers och eskalerar när MTTA eller granskningsväntetider överskrids, vilket minskar inaktiv "tid i status" (ClickUp Automations och agentliknande arbetsflöden).
- Diagnos: Grupperar liknande fel, korrelerar toppar med senaste commit/releaser och pekar på troliga grundorsaker med stacktraces och kodkontext (Sentry AI och liknande).
- Implementering: Föreslår kodändringar och tester baserat på mönster från ditt repo, vilket påskyndar "skriv/fixa"-cykeln (GitHub Copilot; Snyk Code AI av DeepCode).
- Verifiering och kommunikation: skriver testfall från reproduceringssteg, utkast till release notes och uppdateringar till intressenter, samt sammanfattar status för chefer och kunder (ClickUp AI). Genom att använda ClickUp som kommandocentral tillsammans med Sentry/Copilot/DeepCode i stacken kan teamen minska MTTA/P90-tiderna utan att behöva förlita sig på hjältedåd.