
Vydáte nejnovější aktualizaci softwaru a začnou se hromadit zprávy.
Najednou vše od CSAT/NPS po zpoždění roadmapy řídí jedna metrika: doba řešení chyb.
Vedení to vnímá jako metriku plnění slibů – dokážeme dodávat, učit se a chránit příjmy podle plánu? Praktici pociťují bolest v zákopech – duplicitní tikety, nejasné vlastnictví, hlučné eskalace a kontext roztříštěný mezi Slack, tabulky a samostatné nástroje.
Tato fragmentace prodlužuje cykly, zakrývá příčiny problémů a mění stanovení priorit v hádání.
Výsledek? Pomalejší učení, nesplněné závazky a nevyřízené úkoly, které tiše zatěžují každý sprint.
Tato příručka je komplexním návodem pro měření, porovnávání a zkracování doby řešení chyb a konkrétně ukazuje, jak umělá inteligence mění pracovní postupy ve srovnání s tradičními manuálními procesy.
Co je doba řešení chyb?
Doba řešení chyb je doba potřebná k opravě chyby, měřená od okamžiku nahlášení chyby až do jejího úplného vyřešení.
V praxi se čas začíná měřit v okamžiku, kdy je problém nahlášen nebo detekován (uživateli, oddělením QA nebo monitorovacím systémem), a končí v okamžiku, kdy je oprava implementována a sloučena, připravena k ověření nebo vydání – v závislosti na tom, jak váš tým definuje „hotovo“.
Příklad: P1 selhání nahlášené v pondělí v 10:00, s opravou sloučenou v úterý v 15:00, má dobu řešení ~29 hodin.
Není to totéž jako doba detekce chyb. Doba detekce měří, jak rychle rozpoznáte vadu po jejím vzniku (spuštění alarmů, nalezení pomocí nástrojů pro testování kvality, nahlášení zákazníky).
Doba řešení měří, jak rychle přejdete od zjištění k nápravě – třídění, reprodukci, diagnostice, implementaci, kontrole, testování a přípravě k vydání. Detekci si představte jako „víme, že je to rozbité“ a řešení jako „je to opravené a připravené“.
Týmy používají mírně odlišné hranice; vyberte si jednu a buďte konzistentní, aby vaše trendy byly reálné:
- Nahlášeno → Vyřešeno: Končí, když je oprava kódu sloučena a připravena pro kontrolu kvality. Vhodné pro propustnost inženýrství.
- Nahlášeno → Uzavřeno: Zahrnuje ověření kvality a vydání. Nejvhodnější pro SLA s dopadem na zákazníky.
- Detekováno → Vyřešeno: Začíná, když monitorování/QA detekuje problém, ještě předtím, než existuje ticket. Užitečné pro týmy s velkým objemem produkce.
🧠 Zajímavost: Podivná, ale zábavná chyba ve hře Final Fantasy XIV si vysloužila chválu za to, že byla tak specifická, že ji čtenáři nazvali „nejspecifičtější opravou chyby v MMO 2025“. Projevila se, když hráči ocenili položky přesně na 44 442 gilů a 49 087 gilů v určité zóně události, což způsobilo odpojení kvůli možné chybě přetečení celých čísel.
Proč je to důležité
Doba řešení je pákou pro kadenci vydávání verzí. Dlouhá nebo nepředvídatelná doba nutí k omezení rozsahu, hotfixům a zmrazení vydávání verzí; vytváří plánovací dluh, protože dlouhý ocas (odlehlé hodnoty) narušuje sprinty více, než naznačuje průměr.
To také přímo souvisí se spokojeností zákazníků. Zákazníci tolerují problémy, pokud jsou rychle rozpoznány a předvídatelně vyřešeny. Pomalé opravy – nebo ještě hůře, proměnlivé opravy – vedou k eskalaci, snižují CSAT/NPS a ohrožují obnovení smluv.
Stručně řečeno, pokud budete měřit dobu řešení chyb přehledně a systematicky ji zkracovat, zlepší se vaše plány a vztahy.
📖 Další informace: Jak stanovit priority chyb pro efektivní řešení problémů
Jak měřit dobu potřebnou k odstranění chyb?
Nejprve se rozhodněte, kde se začne a skončí měření času.
Většina týmů volí buď možnost Nahlášeno → Vyřešeno (oprava je sloučena a připravena k ověření) nebo Nahlášeno → Uzavřeno (QA ověřilo a změna je vydána nebo jinak uzavřena).
Vyberte si jednu definici a používejte ji důsledně, aby vaše trendy byly smysluplné.
Nyní potřebujete některé pozorovatelné metriky. Pojďme si je nastínit:
Klíčové metriky pro sledování chyb, na které je třeba se zaměřit:
| 📊 Metrika | 📌 Co to znamená | 💡 Jak to pomáhá | 🧮 Vzorec (pokud je použitelný) |
|---|---|---|---|
| Počet chyb 🐞 | Celkový počet nahlášených chyb | Poskytuje přehled o stavu systému. Vysoké číslo? Je čas to prošetřit. | Celkový počet chyb = všechny chyby zaznamenané v systému {otevřené + uzavřené} |
| Otevřené chyby 🚧 | Chyby, které ještě nebyly opraveny | Zobrazuje aktuální pracovní zátěž. Pomáhá s určováním priorit. | Otevřené chyby = celkový počet chyb – uzavřené chyby |
| Uzavřené chyby ✅ | Chyby, které jsou vyřešeny a ověřeny | Sleduje pokrok a provedenou práci. | Uzavřené chyby = počet chyb se stavem „Uzavřeno“ nebo „Vyřešeno“ |
| Závažnost chyby 🔥 | Kritičnost chyby (např. kritická, závažná, méně závažná) | Pomáhá třídit podle dopadu. | Sledováno jako kategorické pole, bez vzorce. Použijte filtry/seskupení. |
| Priorita chyb 📅 | Jak naléhavě je třeba chybu opravit | Pomáhá při plánování sprintů a vydání. | Také kategorické pole, obvykle seřazené (např. P0, P1, P2). |
| Doba řešení ⏱️ | Čas od nahlášení chyby po její opravu | Měří schopnost reagovat. | Doba řešení = datum uzavření – datum nahlášení |
| Míra opětovného otevření 🔄 | Procento chyb, které byly po uzavření znovu otevřeny | Odráží kvalitu oprav nebo problémy s regresí. | Míra opětovného otevření (%) = {Opětovně otevřené chyby ÷ Celkový počet uzavřených chyb} × 100 |
| Únik chyb 🕳️ | Chyby, které se dostaly do produkce | Ukazuje účinnost kontroly kvality/testování softwaru. | Míra úniku (%) = {Chyby produktu ÷ Celkový počet chyb} × 100 |
| Hustota vad 🧮 | Chyby na jednotku velikosti kódu | Zvýrazňuje oblasti kódu náchylné k rizikům. | Hustota chyb = počet chyb ÷ KLOC {tisíc řádků kódu} |
| Přiřazené vs. nepřidělené chyby 👥 | Rozložení chyb podle vlastnictví | Zajistí, že nic neunikne vaší pozornosti. | Použijte filtr: Nepřiřazené = Chyby, u kterých je pole „Přiřazeno“ prázdné. |
| Věk otevřených chyb 🧓 | Jak dlouho zůstává chyba nevyřešena | Odhaluje rizika stagnace a hromadění nevyřízených úkolů. | Stáří chyby = aktuální datum – datum nahlášení |
| Duplicitní chyby 🧬 | Počet duplicitních hlášení | Zvýrazňuje chyby v procesech přijímání. | Míra duplicit = duplikáty ÷ celkový počet chyb × 100 |
| MTTD (průměrná doba detekce) 🔎 | Průměrná doba potřebná k detekci chyb nebo incidentů | Měří efektivitu monitorování a informovanosti. | MTTD = Σ(čas detekce – čas zavedení) ÷ počet chyb |
| MTTR (průměrná doba řešení) 🔧 | Průměrná doba potřebná k úplnému odstranění chyby po jejím zjištění | Sleduje reakční schopnost techniků a dobu opravy. | MTTR = Σ(čas vyřešení – čas detekce) ÷ počet vyřešených chyb |
| MTTA (průměrná doba potvrzení) 📬 | Čas od detekce chyby do okamžiku, kdy někdo začne na její opravě pracovat | Zobrazuje reaktivitu týmu a schopnost reagovat na výstrahy. | MTTA = Σ(čas potvrzení – čas detekce) ÷ počet chyb |
| MTBF (průměrná doba mezi poruchami) 🔁 | Čas mezi vyřešením jedné poruchy a výskytem další poruchy | Ukazuje stabilitu v průběhu času. | MTBF = celková doba provozuschopnosti ÷ počet poruch |
⚡️ Archiv šablon: 15 bezplatných šablon a formulářů pro hlášení chyb a sledování chyb
Faktory, které ovlivňují dobu řešení chyb
Doba řešení se často rovná „rychlosti, s jakou inženýři programují“.
Ale to je jen jedna část procesu.
Doba řešení chyb je součtem kvality při přijetí, efektivity toku vaším systémem a rizika závislosti. Pokud některý z těchto faktorů selže, prodlužuje se cyklus, klesá předvídatelnost a eskalace se stávají hlasitějšími.
Kvalita přijatých požadavků udává tón
Hlášení, která přicházejí bez jasných kroků k reprodukci, podrobností o prostředí, protokolů nebo informací o verzi/sestavení, vyžadují další komunikaci. Duplicitní hlášení z více kanálů (podpora, kontrola kvality, monitorování, Slack) zvyšují zátěž a rozdělují odpovědnost.
Čím dříve zachytíte správný kontext – a odstraníte duplicity – tím méně předávání a vyjasňování budete později potřebovat.
Prioritizace a směrování určují, kdo se bude chybou zabývat a kdy.
Štítky závažnosti, které neodpovídají dopadu na zákazníky/podnikání (nebo se v průběhu času mění), způsobují fluktuaci fronty: nejhlasitější ticket přeskočí frontu, zatímco chyby s velkým dopadem zůstávají nevyřešeny.
Jasná pravidla směrování podle komponenty/vlastníka a jediná fronta pravdy zabraňují tomu, aby práce P0/P1 byla pohřbena pod „nedávnými a hlučnými“ úkoly.
Vlastnictví a předávání úkolů jsou tichými zabijáky
Pokud není jasné, zda chyba patří do mobilního, backendového ověřovacího nebo platformového týmu, je odražena. Každé odražení resetuje kontext.
Časová pásma tuto situaci ještě zhoršují: chyba nahlášená pozdě večer bez určení odpovědné osoby může způsobit ztrátu 12–24 hodin, než se někdo vůbec začne zabývat její reprodukcí. Přesné definice „kdo za co odpovídá“ s pohotovostním nebo týdenním DRI tento problém odstraňují.
Reprodukovatelnost závisí na pozorovatelnosti
Řídké protokoly, chybějící korelační ID nebo nedostatek stop po selhání mění diagnostiku v hádání. Chyby, které se objevují pouze s konkrétními příznaky, nájemci nebo datovými tvary, je obtížné reprodukovat ve vývoji.
Pokud inženýři nemají bezpečný přístup k očištěným datům podobným produkčním, skončí tím, že budou provádět instrumentaci, opětovné nasazení a čekání – a to celé dny místo hodin.
Parita prostředí a dat vám pomáhá zachovat poctivost
„Funguje to na mém počítači“ obvykle znamená „produkční data jsou odlišná“. Čím více se vaše vývojové/testovací prostředí liší od produkčního (konfigurace, služby, verze třetích stran), tím více času strávíte honbou za duchy. Bezpečné snímky dat, seed skripty a kontroly parity tuto mezeru zmenšují.
Probíhající práce (WIP) a zaměření určují skutečný výkon
Přetížené týmy řeší příliš mnoho chyb najednou, rozptylují svou pozornost a přeskakují mezi úkoly a schůzkami. Přepínání mezi úkoly přidává neviditelné hodiny práce.
Viditelný limit rozpracovaných úkolů a tendence dokončit započaté úkoly před přijetím nových zakázek sníží vaši mediánovou hodnotu rychleji než jakékoli individuální hrdinské úsilí.
Kontrola kódu, CI a rychlost QA jsou klasickými úzkými místy.
Pomalé sestavování, nespolehlivé testy a nejasné SLA pro kontrolu brzdí jinak rychlé opravy. Oprava, která trvá 10 minut, může strávit dva dny čekáním na recenzenta nebo zařazením do několikahodinového procesu.
Podobně fronty QA, které testují dávkově nebo se spoléhají na manuální kouřové testy, mohou přidat celé dny k procesu „Nahlášeno → Uzavřeno“, i když proces „Nahlášeno → Vyřešeno“ je rychlý.
Závislosti prodlužují fronty
Změny napříč týmy (schéma, migrace platforem, aktualizace SDK), chyby dodavatelů nebo recenze v obchodech s aplikacemi (mobilní) způsobují stavy čekání. Bez explicitního sledování „Blokováno/Pozastaveno“ tyto čekací doby neviditelně zvyšují vaše průměry a skrývají skutečné úzké hrdlo.
Důležitost modelu vydávání a strategie vrácení zpět
Pokud dodáváte v rozsáhlých release vlacích s manuálními bránami, i vyřešené chyby čekají až do odjezdu dalšího vlaku. Funkce feature flags, canary releases a hotfix lanes zkracují dobu řešení, zejména u incidentů P0/P1, tím, že vám umožňují oddělit nasazení oprav od úplných release cyklů.
Architektura a technologický dluh určují vaše limity
Těsné propojení, nedostatek testovacích spojů a neprůhledné starší moduly činí jednoduché opravy riskantními. Týmy to kompenzují dodatečným testováním a delšími revizemi, což prodlužuje cykly. Naopak modulární kód s dobrými kontraktovými testy vám umožňuje postupovat rychle, aniž byste narušili sousední systémy.
Komunikace a stavová hygiena ovlivňují předvídatelnost
Nejasné aktualizace („prověřujeme to“) vedou k opakované práci, když se zainteresované strany ptají na předpokládaný čas vyřešení, podpora znovu otevírá tikety nebo se problém eskaluje na vyšší úroveň. Jasné změny stavu, poznámky k reprodukci a příčině problému a zveřejněný předpokládaný čas vyřešení snižují fluktuaci a chrání soustředění vašeho technického týmu.
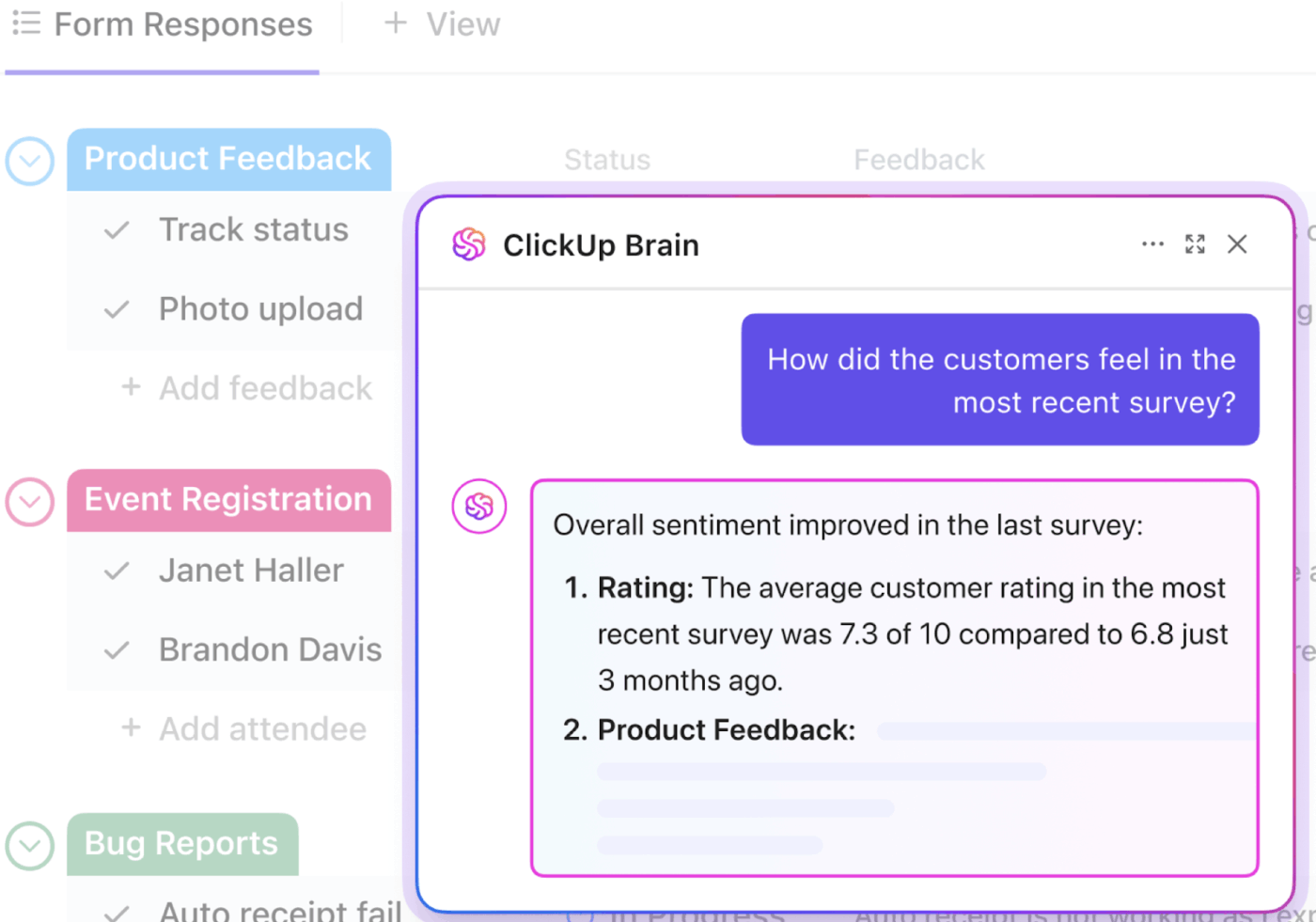
📮ClickUp Insight: Průměrný profesionál stráví více než 30 minut denně hledáním informací souvisejících s prací – to je více než 120 hodin ročně ztracených prohledáváním e-mailů, vláken ve Slacku a roztroušených souborů.
Inteligentní asistent AI zabudovaný do vašeho pracovního prostoru to může změnit. Představujeme ClickUp Brain. Poskytuje okamžité informace a odpovědi tím, že během několika sekund vyhledá správné dokumenty, konverzace a podrobnosti úkolů, takže můžete přestat hledat a začít pracovat.
💫 Skutečné výsledky: Týmy jako QubicaAMF ušetřily díky ClickUp více než 5 hodin týdně, což představuje přes 250 hodin ročně na osobu, a to díky odstranění zastaralých procesů správy znalostí. Představte si, co by váš tým mohl vytvořit s extra týdnem produktivity každý čtvrtrok!
Hlavní ukazatele, že se váš čas potřebný k řešení problémů prodlouží
❗️Rostoucí „doba potvrzení“ a velké množství ticketů bez vlastníka po dobu delší než 12 hodin
❗️Rostoucí segmenty „Time in Review/CI“ a častá nestabilita testů
❗️Vysoká míra duplicit při přijímání a nekonzistentní označení závažnosti mezi týmy
❗️Několik chyb se nachází ve stavu „Blokováno“ bez pojmenované externí závislosti.
❗️Míra opětovného otevření se zvyšuje (opravy nejsou reprodukovatelné nebo definice dokončení jsou nejasné)
Různé organizace vnímají tyto faktory odlišně. Vedoucí pracovníci je vnímají jako zmeškané vzdělávací cykly a ztrátu příjmů; operátoři je vnímají jako rušivý faktor při třídění a nejasné rozdělení odpovědnosti.
Vyladěním příjmu, toku a závislostí můžete snížit celou křivku – medián i P90.
Chcete se dozvědět více o tom, jak psát lepší zprávy o chybách? Začněte zde. 👇🏼
📖 Další informace: Životní cyklus testování softwaru (STLC): přehled a fáze
Průmyslové benchmarky pro dobu řešení chyb
Benchmarky řešení chyb se mění v závislosti na toleranci rizika, modelu vydávání a rychlosti, s jakou můžete změny dodávat.
Zde můžete použít mediány (P50) k pochopení typického toku a P90 k nastavení slibů a SLA – podle závažnosti a zdroje (zákazník, QA, monitorování).
Pojďme si vysvětlit, co to znamená:
| 🔑 Termín | 📝 Popis | 💡 Proč je to důležité |
|---|---|---|
| P50 (medián) | Střední hodnota – 50 % oprav chyb je rychlejších než tato hodnota a 50 % je pomalejších. | 👉 Odráží vaši typickou nebo nejčastější dobu řešení. Vhodné pro pochopení běžného výkonu. |
| P90 (90. percentil) | 90 % chyb je opraveno v tomto čase. Pouze 10 % trvá déle. | 👉 Představuje nejhorší (ale stále realistický) případ. Užitečné pro stanovení externích slibů. |
| SLA (smlouvy o úrovni služeb) | Závazky, které přijímáte – interně nebo vůči zákazníkům – ohledně rychlosti řešení problémů | 👉 Příklad: „Chyby P1 řešíme do 48 hodin v 90 % případů. “ Pomáhá budovat důvěru a odpovědnost |
| Podle závažnosti a zdroje | Segmentujte své metriky podle dvou klíčových dimenzí: • Závažnost (např. P0, P1, P2)• Zdroj (např. zákazník, kontrola kvality, monitorování) | 👉 Umožňuje přesnější sledování a stanovení priorit, takže kritické chyby jsou řešeny rychleji. |
Níže jsou uvedeny orientační rozsahy založené na odvětvích, na která se často zaměřují zkušené týmy. Berte je jako výchozí hodnoty a poté je přizpůsobte vašemu kontextu.
SaaS
Vždy v provozu a kompatibilní s CI/CD, takže opravy jsou běžné. Kritické problémy (P0/P1) se často snaží dosáhnout mediánu pod jeden pracovní den, s P90 do 24–48 hodin. Nekritické problémy (P2+) se obvykle řeší v mediánu 3–7 dní, s P90 do 10–14 dnů. Týmy s robustními funkčními příznaky a automatizovanými testy mají tendenci k rychlejšímu řešení.
E-commerce platformy
Protože konverze a toky v košíku jsou klíčové pro výnosy, laťka je nastavena výše. Problémy P0/P1 se obvykle zmírňují během několika hodin (rollback, označení nebo konfigurace) a jsou plně vyřešeny ještě týž den; P90 do konce dne nebo <12 hodin je běžné v období špičky. Problémy P2+ se často řeší za 2–5 dní, P90 do 10 dnů.
Podnikový software
Náročnější validace a okna pro změny ze strany zákazníků zpomalují tempo. U P0/P1 se týmy snaží najít řešení do 4–24 hodin a opravu do 1–3 pracovních dnů; u P90 do 5 pracovních dnů. Položky P2+ se často sdružují do release trainů s mediánem 2–4 týdny v závislosti na harmonogramech zavádění u zákazníků.
Hry a mobilní aplikace
Backendy živých služeb se chovají jako SaaS (označení a vrácení změn během několika minut až hodin; P90 ve stejný den). Aktualizace klientů jsou omezeny recenzemi obchodů: P0/P1 často okamžitě používají páky na straně serveru a dodávají opravu klienta během 1–3 dnů; P90 do týdne s urychlenou recenzí. Opravy P2+ jsou obvykle naplánovány do dalšího sprintu nebo vydání obsahu.
Bankovnictví/Fintech
Brány rizik a dodržování předpisů vedou k modelu „rychlé zmírnění, opatrná změna“. P0/P1 jsou rychle zmírněny (označení, vrácení, přesměrování provozu během několika minut až hodin) a plně opraveny za 1–3 dny; P90 do týdne, s přihlédnutím ke kontrole změn. P2+ často trvá 2–6 týdnů, než projde bezpečnostními, auditními a CAB kontrolami.
Pokud vaše čísla leží mimo tyto rozsahy, podívejte se na kvalitu přijímání, směrování/vlastnictví, kontrolu kódu a propustnost QA a schvalování závislostí, než budete předpokládat, že jádrem problému je „rychlost vývoje“.
🌼 Věděli jste, že: Podle průzkumu Stack Overflow z roku 2024 vývojáři stále častěji využívají AI jako svého spolehlivého pomocníka při programování. Až 82 % z nich používá AI k psaní kódu – to je opravdu kreativní spolupracovník! Když narazí na problém nebo hledají řešení, 67,5 % se spoléhá na AI při hledání odpovědí a více než polovina (56,7 %) ji využívá k ladění a získávání pomoci.
Pro některé se nástroje umělé inteligence osvědčily také při dokumentaci projektů (40,1 %) a dokonce i při vytváření syntetických dat nebo obsahu (34,8 %). Zajímá vás nová kódová základna? Téměř třetina (30,9 %) používá AI k tomu, aby se rychle zorientovala. Testování kódu je pro mnohé stále ruční prací, ale 27,2 % zde také přijalo AI. V jiných oblastech, jako je revize kódu, plánování projektů a prediktivní analytika, je přijetí AI nižší, ale je zřejmé, že se AI postupně prosazuje ve všech fázích vývoje softwaru.
📖 Další informace: Jak používat umělou inteligenci pro zajištění kvality
Jak zkrátit dobu potřebnou k odstranění chyb
Rychlost řešení chyb spočívá v odstranění překážek při každém předání od přijetí po vydání.
Největší zisky přináší chytřejší využití prvních 30 minut (čistý příjem, správný vlastník, správná priorita) a následné zkrácení smyček (reprodukce, kontrola, ověření).
Zde je devět strategií, které fungují společně jako jeden systém. Umělá inteligence urychluje každý krok a pracovní postupy jsou přehledně uspořádány na jednom místě, takže vedoucí pracovníci získávají předvídatelnost a odborníci plynulost.
1. Centralizujte příjem a zachycujte kontext u zdroje
Doba řešení chyb se prodlužuje, když rekonstruujete kontext ze Slackových vláken, ticketů podpory a tabulek. Sdružte všechny zprávy – podporu, kontrolu kvality, monitorování – do jedné fronty pomocí strukturované šablony, která shromažďuje komponenty, závažnost, prostředí, verzi/build aplikace, kroky k reprodukci, očekávané vs. skutečné hodnoty a přílohy (protokoly/HAR/obrazovky).
Umělá inteligence dokáže automaticky shrnout dlouhé zprávy, extrahovat kroky k reprodukci a podrobnosti o prostředí z příloh a označit pravděpodobné duplikáty, takže třídění začíná s koherentním a obohaceným záznamem.
Metriky, které je třeba sledovat: MTTA (potvrzení během několika minut, nikoli hodin), míra duplicit, doba „Potřeba informací“.

📖 Další informace: Síla formulářů ClickUp: Zefektivnění práce softwarových týmů
2. Třídění a směrování s podporou umělé inteligence pro výrazné zkrácení MTTA
Nejrychlejší opravy jsou ty, které se okamžitě dostanou na správný stůl.
Pomocí jednoduchých pravidel a umělé inteligence klasifikujte závažnost, identifikujte pravděpodobné vlastníky podle komponenty/oblasti kódu a automaticky přiřazujte pomocí SLA hodin. Nastavte jasné rozdělení pro P0/P1 oproti všem ostatním a jednoznačně určete, „kdo je za to zodpovědný“.
Automatizace může nastavit prioritu z polí, směrovat podle komponenty do týmu, spustit časovač SLA a upozornit technika v pohotovosti; umělá inteligence může navrhnout závažnost a vlastníka na základě minulých vzorců. Když se třídění stane 2–5minutovým procesem namísto 30minutové debaty, vaše MTTA klesne a vaše MTTR následuje.
Metriky, které je třeba sledovat: MTTA, kvalita první reakce (žádá první komentář správné informace?), počet předání na chybu.
Takto to vypadá v praxi:
3. Stanovte priority podle dopadu na podnikání pomocí explicitních úrovní SLA
„Nejhlasitější hlas vyhrává“ činí fronty nepředvídatelnými a narušuje důvěru vedoucích pracovníků, kteří sledují CSAT/NPS a obnovení.
Nahraďte to skóre, které kombinuje závažnost, frekvenci, ovlivněný ARR, kritičnost funkce a blízkost obnovení/spuštění – a podpořte jej úrovněmi SLA (např. P0: zmírnit do 1–2 hodin, vyřešit do jednoho dne; P1: ve stejný den; P2: do jednoho sprintu).
Udržujte viditelnou dráhu P0/P1 s limity WIP, aby nic nezůstalo opomenuto.
Metriky, které je třeba sledovat: řešení P50/P90 podle úrovně, míra porušení SLA, korelace s CSAT/NPS.
💡Tip pro profesionály: Pole Task Priorities (Priority úkolů), Custom Fields(Vlastní pole) a Dependencies (Závislosti) v ClickUp vám umožňují vypočítat skóre dopadu a propojit chyby s účty, zpětnou vazbou nebo položkami roadmapy. Navíc vám Goals (Cíle) v ClickUp pomohou propojit dodržování SLA s cíli na úrovni společnosti, což přímo odpovídá obavám vedení ohledně sladění.
4. Zredukování reprodukce a diagnostiky na jeden krok
Každá další smyčka s otázkou „můžete poslat protokoly?“ prodlužuje dobu řešení.
Standardizujte, co znamená „dobrý“: povinná pole pro sestavení/commit, prostředí, kroky reprodukce, očekávané vs. skutečné, plus přílohy pro protokoly, výpisy paměti a soubory HAR. Nastavte telemetrii klienta/serveru tak, aby ID selhání a ID požadavků bylo možné propojit se stopami.
Využijte Sentry (nebo podobný nástroj) pro sledování zásobníku a propojte tento problém přímo s chybou. Umělá inteligence dokáže číst protokoly a trasy, aby navrhla pravděpodobnou oblast poruchy a vygenerovala minimální reprodukci, čímž se hodina prohlížení změní na několik minut soustředěné práce.
Ukládejte runbooky pro běžné typy chyb, aby inženýři nemuseli začínat od nuly.
Metriky, které je třeba sledovat: Čas strávený „čekáním na informace“, procento reprodukovatelnosti při prvním pokusu, míra opětovného otevření související s chybějící reprodukovatelností.
5. Zkraťte cyklus kontroly kódu a testování
Velké PR se zdržují. Zaměřte se na chirurgické opravy, vývoj založený na kmeni a příznaky funkcí, aby opravy mohly být bezpečně dodány. Předem přiřaďte recenzenty podle vlastnictví kódu, abyste se vyhnuli prostojům, a použijte kontrolní seznamy (aktualizované testy, přidaná telemetrie, příznak za kill switch), aby byla zajištěna kvalita.
Automatizace by měla přesunout chybu do stavu „V kontrole“ při otevření PR a do stavu „Vyřešeno“ při sloučení; umělá inteligence může navrhnout jednotkové testy nebo zvýraznit rizikové rozdíly, na které se má kontrola zaměřit.
Metriky, které je třeba sledovat: Doba strávená v „In Review“ (V kontrole), míra selhání změn u PR oprav chyb a latence kontroly P90.
V ClickUp můžete použít integrace GitHub/GitLab, abyste udrželi synchronizaci stavu řešení; automatizace mohou vynutit „definici dokončení“.
📖 Další informace: Jak používat AI k automatizaci úkolů
6. Paralelizujte ověřování a zajistěte skutečnou paritu prostředí QA
Ověřování by nemělo začínat o několik dní později nebo v prostředí, které žádný z vašich zákazníků nepoužívá.
Udržujte „připravenost pro QA“ na vysoké úrovni: hotfixy založené na vlajkách ověřené v prostředí podobném produkčnímu s počátečními daty, která odpovídají nahlášeným případům.
Pokud je to možné, nastavte dočasná prostředí z větve chyb, aby QA mohla okamžitě provést ověření; AI pak může generovat testovací případy z popisu chyby a minulých regresí.
Metriky, které je třeba sledovat: Doba strávená v „QA/ověřování“, míra odchodu z QA zpět do vývoje, medián doby do uzavření po sloučení.

📖 Další informace: Jak psát efektivní testovací případy
7. Jasně komunikujte stav, abyste snížili náklady na koordinaci
Dobrá aktualizace zabrání třem stavovým pingům a jedné eskalaci.
Považujte aktualizace za produkt: krátké, konkrétní a přizpůsobené cílovému publiku (podpora, vedení, zákazníci). Stanovte frekvenci pro P0/P1 (např. každou hodinu, dokud není problém vyřešen, poté každé čtyři hodiny) a udržujte jediný zdroj pravdivých informací.
Umělá inteligence dokáže na základě historie úkolů, včetně aktuálního stavu podle závažnosti a týmu, vytvářet návrhy aktualizací bezpečných pro zákazníky a interní souhrny. Pro vedoucí pracovníky, jako je váš ředitel produktového oddělení, lze chyby shrnout do iniciativ, aby mohli posoudit, zda kritická práce na kvalitě ohrožuje sliby dodání.
Metriky, které je třeba sledovat: Čas mezi aktualizacemi stavu P0/P1, spokojenost zainteresovaných stran s komunikací.
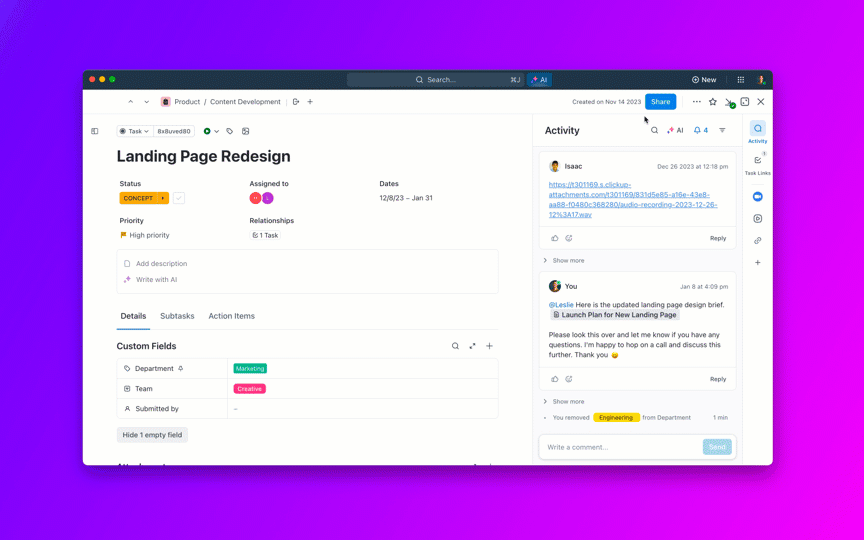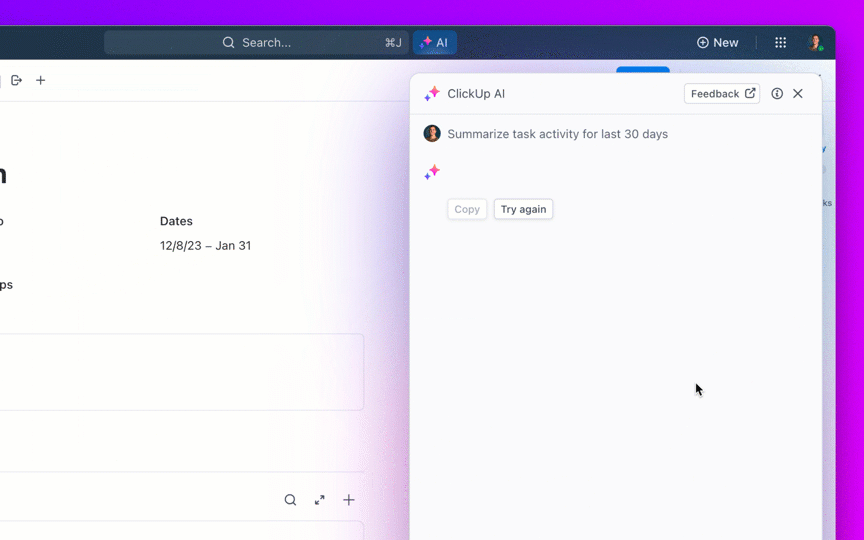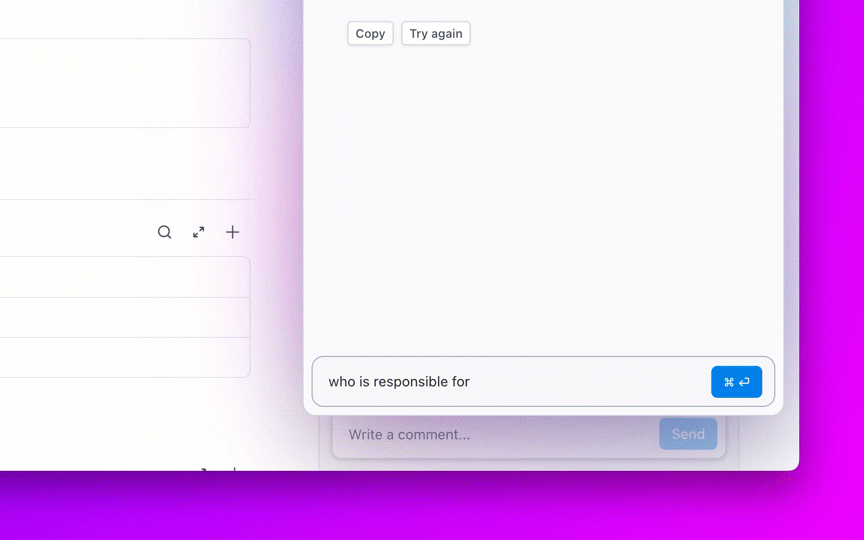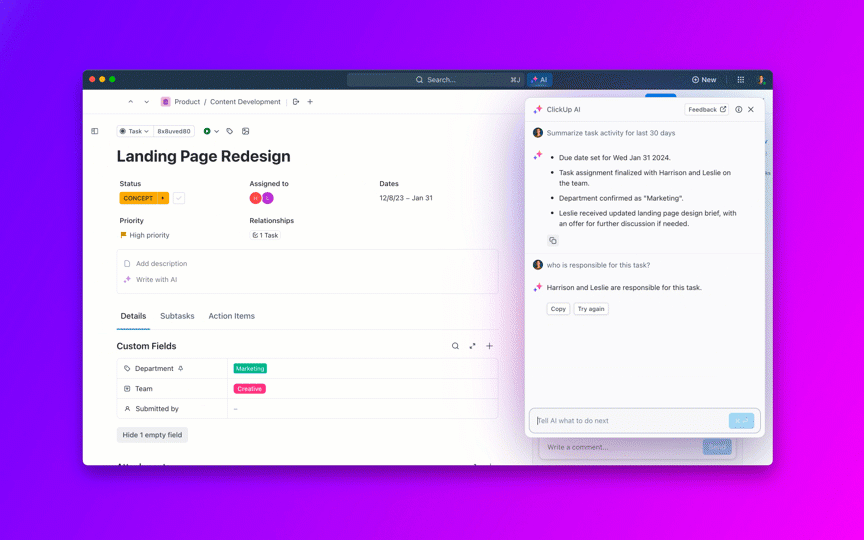
8. Kontrolujte stárnutí nevyřízených úkolů a zabraňte jejich „věčnému otevření“
Rostoucí počet nevyřízených úkolů tiše zatěžuje každý sprint.
Nastavte zásady stárnutí (např. P2 > 30 dní spustí kontrolu, P3 > 90 dní vyžaduje odůvodnění) a naplánujte týdenní „třídění podle stáří“, abyste sloučili duplicity, uzavřeli zastaralé zprávy a převedli chyby s nízkou hodnotou na položky produktového backlogu.
Pomocí umělé inteligence seskupte nevyřízené úkoly podle témat (např. „vypršení platnosti autentizačního tokenu“, „nestabilita nahrávání obrázků“), abyste mohli naplánovat tematické opravné týdny a odstranit celou třídu chyb najednou.
Metriky, které je třeba sledovat: počet nevyřízených úkolů podle stáří, % uzavřených úkolů jako duplicitních/zastaralých, tematická rychlost vyřizování úkolů.
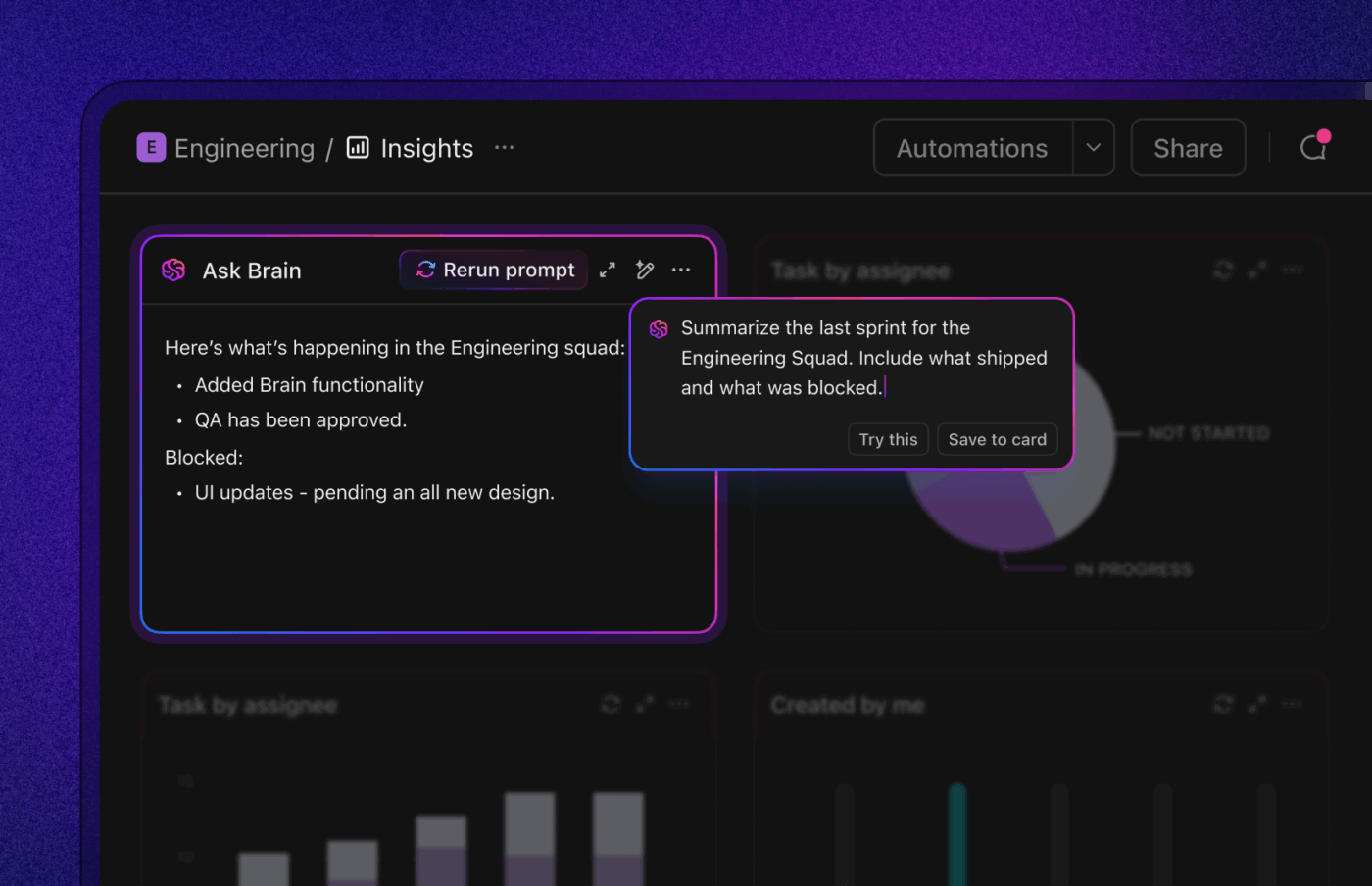
9. Uzavřete smyčku pomocí identifikace příčiny a prevence
Pokud se stejný typ závady opakuje, zlepšení MTTR zakrývá větší problém.
Provádějte rychlou a bezchybnou analýzu příčin u P0/P1 a vysokofrekvenčních P2; označujte příčiny (nedostatky ve specifikacích, nedostatky v testování, nedostatky v nástrojích, nestabilita integrace), propojujte je s ovlivněnými komponenty a incidenty a sledujte následné úkoly (ochrany, testy, pravidla lint) až do jejich dokončení.
Umělá inteligence může vytvářet souhrny RCA a navrhovat preventivní testy nebo pravidla lint na základě historie změn. A tak se dostanete od hašení požárů k menšímu počtu požárů.
Metriky, které je třeba sledovat: Míra opětovného otevření, míra regrese, doba mezi opakováním a procento RCA s dokončenými preventivními opatřeními.

Dohromady tyto změny zkracují celou cestu: rychlejší potvrzení, přehlednější třídění, chytřejší stanovení priorit, méně zdržení při kontrole a kontrole kvality a jasnější komunikace. Vedoucí pracovníci získávají předvídatelnost spojenou s CSAT/NPS a výnosy; odborníci získávají klidnější frontu s méně přepínáním kontextu.
📖 Další informace: Jak provést analýzu příčin
Nástroje umělé inteligence, které pomáhají zkrátit dobu řešení chyb
Umělá inteligence může zkrátit dobu řešení v každém kroku – přijetí, třídění, směrování, opravu a ověření.
Skutečné výhody však přicházejí, když nástroje rozumějí kontextu a udržují práci v chodu bez nutnosti ručního zásahu.
Hledejte systémy, které automaticky obohacují zprávy (reprodukční kroky, prostředí, duplikáty), stanovují priority podle dopadu, směrují je správnému vlastníkovi, vytvářejí jasné aktualizace a úzce se integrují s vaším kódem, CI a pozorovatelností.
Nejlepší z nich podporují také pracovní postupy podobné agentům: boty, které sledují SLA, upozorňují recenzenty, eskalují zaseknuté položky a shrnují výsledky pro zúčastněné strany. Zde je náš výběr nástrojů AI pro lepší řešení chyb:
1. ClickUp (nejlepší pro kontextovou AI, automatizaci a agentické pracovní postupy)
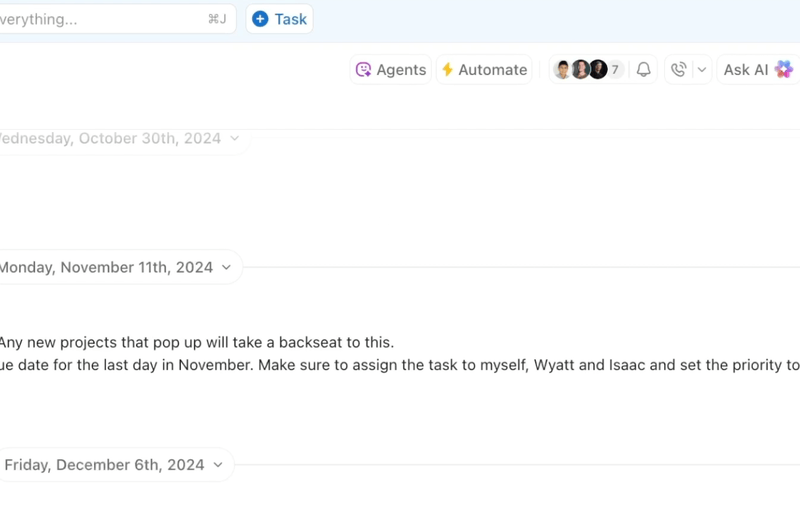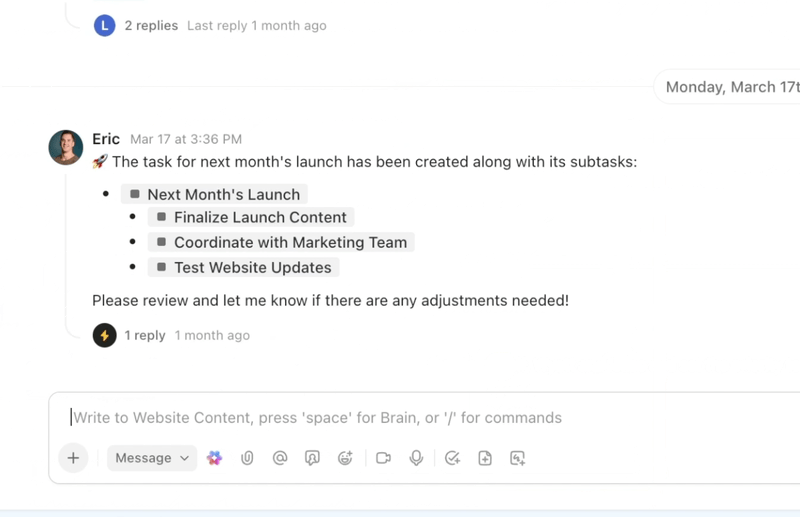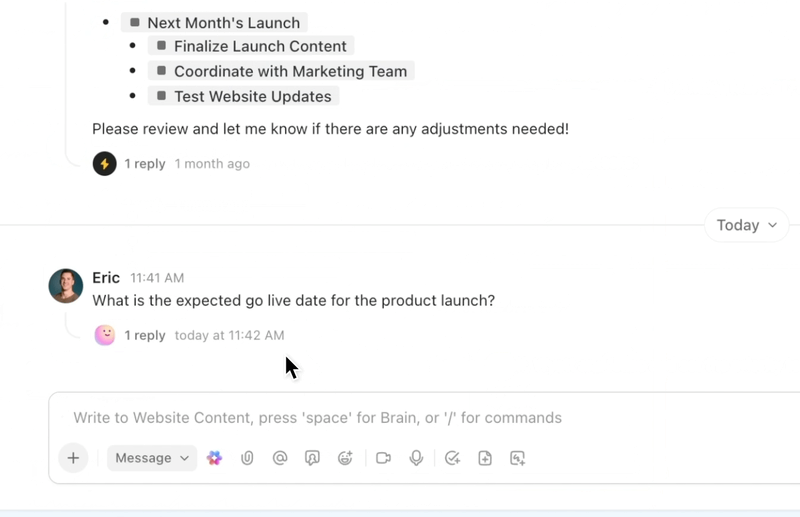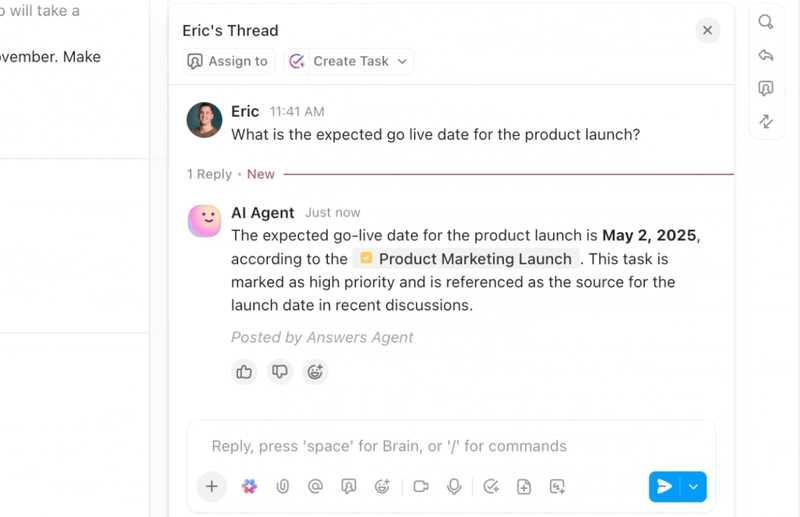
Pokud chcete efektivní a inteligentní pracovní postup pro řešení chyb, ClickUp, aplikace pro vše, co souvisí s prací, spojuje umělou inteligenci, automatizaci a asistenci při pracovních postupech na jednom místě.
ClickUp Brain okamžitě zobrazí správný kontext – shrne dlouhé vlákna chyb, extrahuje kroky k reprodukci a podrobnosti o prostředí z příloh, označí pravděpodobné duplikáty a navrhne další kroky. Místo procházení Slackem, tikety a protokoly získají týmy přehledný a obohacený záznam, na základě kterého mohou okamžitě jednat.
Automatizace a agenti Autopilot v ClickUp udržují práci v chodu bez neustálého dohledu. Chyby jsou automaticky směrovány správnému týmu, jsou přiřazeni vlastníci, nastaveny SLA a termíny, stavy se aktualizují podle postupu práce a zúčastněné strany dostávají včasná oznámení.

Tito agenti mohou dokonce třídit a kategorizovat problémy, seskupovat podobné zprávy, odkazovat na historické opravy, aby navrhli pravděpodobné cesty vpřed, a eskalovat urgentní položky – takže MTTA a MTTR klesají i při náhlém nárůstu objemu.
🛠️ Chcete hotovou sadu nástrojů? Šablona ClickUp Bug & Issue Tracking Template je výkonné řešení od ClickUp for Software, které bylo navrženo tak , aby pomáhalo týmům podpory, vývoje a produktového oddělení snadno zvládat chyby a problémy v softwaru. Díky přizpůsobitelným zobrazením, jako jsou Seznam, Tabule, Pracovní vytížení, Formulář a Časová osa, mohou týmy vizualizovat a spravovat proces sledování chyb způsobem, který jim nejlépe vyhovuje.
20 vlastních stavů a 7 vlastních polí šablony umožňují přizpůsobený pracovní postup, který zajišťuje sledování každého problému od jeho zjištění až po vyřešení. Integrované automatizace se postarají o opakující se úkoly, čímž ušetříte drahocenný čas a snížíte manuální úsilí.
💟 Bonus: Brain MAX je váš desktopový pomocník poháněný umělou inteligencí, který je navržen tak, aby urychlil řešení chyb pomocí chytrých a praktických funkcí.
Když narazíte na chybu, stačí použít funkci Brain MAX „talk-to-text“ a nadiktovat problém – vaše mluvené poznámky se okamžitě přepíší a lze je připojit k novému nebo existujícímu ticketu s chybou. Funkce Enterprise Search prohledává všechny vaše připojené nástroje, jako jsou ClickUp, GitHub, Google Drive a Slack, a vyhledává související hlášení o chybách, protokoly chyb, úryvky kódu a dokumentaci, takže máte k dispozici veškerý potřebný kontext, aniž byste museli přepínat mezi aplikacemi.
Potřebujete koordinovat opravu? Brain MAX vám umožní přiřadit chybu správnému vývojáři, nastavit automatické připomenutí pro aktualizace stavu a sledovat pokrok – to vše z vašeho počítače!
2. Sentry (nejlepší pro zachycování chyb)
Sentry zmenšuje MTTD a čas reprodukce tím, že zachycuje chyby, stopy a uživatelské relace na jednom místě. Seskupování problémů pomocí umělé inteligence snižuje šum; pravidla „Suspect Commit“ a vlastnictví identifikují pravděpodobného vlastníka kódu, takže směrování je okamžité. Session Replay poskytuje inženýrům přesnou uživatelskou cestu a podrobnosti o konzoli/síti, které lze reprodukovat bez nekonečného přecházení sem a tam.
Funkce Sentry AI dokážou shrnout kontext problému a v některých případech navrhnout opravy Autofix, které odkazují na problematický kód. Praktický dopad: méně duplicitních ticketů, rychlejší přiřazování a kratší cesta od nahlášení k funkční opravě.
3. GitHub Copilot (nejlepší pro rychlejší kontrolu kódu)
Copilot urychluje cyklus oprav v editoru. Vysvětluje záznamy o stavu zásobníku, navrhuje cílené opravy, píše jednotkové testy k zajištění opravy a vytváří skripty pro reprodukci.
Copilot Chat dokáže projít nefunkční kód, navrhnout bezpečnější refaktoring a generovat komentáře nebo popisy PR, které urychlují revizi kódu. V kombinaci s povinnými revizemi a CI zkracuje čas potřebný pro „diagnostiku → implementaci → testování“, zejména u chyb s jasným rozsahem a jasnou reprodukcí.
4. Snyk od DeepCode AI (nejlepší pro rozpoznávání vzorců)
Statická analýza DeepCode založená na umělé inteligenci vyhledává chyby a nezabezpečené vzorce při psaní kódu a v PR. Zvýrazňuje problematické toky, vysvětluje, proč k nim dochází, a navrhuje bezpečné opravy, které odpovídají idiomům vaší kódové základny.
Díky zachycení regresí před sloučením a nasměrování vývojářů k bezpečnějším vzorcům snížíte počet nových chyb a urychlíte opravu složitých logických chyb, které je při kontrole obtížné odhalit. Integrace IDE a PR zajišťuje, že vše probíhá v těsné blízkosti místa, kde se práce vykonává.
5. Datadog’s Watchdog a AIOps (nejlepší pro analýzu protokolů)
Watchdog od Datadogu využívá strojové učení k odhalování anomálií v protokolech, metrikách, trasách a monitorování reálných uživatelů. Koreluje výkyvy s ukazateli nasazení, změnami infrastruktury a topologií, aby navrhl pravděpodobné příčiny.
U chyb, které mají dopad na zákazníky, to znamená minutové detekce, automatické seskupování pro snížení počtu falešných poplachů a konkrétní vodítka, kde hledat. Doba třídění se zkracuje, protože začínáte s informacemi „toto nasazení ovlivnilo tyto služby a míra chybovosti vzrostla na tomto koncovém bodě“ namísto prázdného listu.
6. New Relic AI (nejlepší pro identifikaci a shrnutí trendů)
Errors Inbox od New Relic seskupuje podobné chyby napříč službami a verzemi, zatímco jeho asistent AI shrnuje dopady, zdůrazňuje pravděpodobné příčiny a odkazuje na příslušné trasy/transakce.
Korelace nasazení a informace o změnách entit jasně ukazují, kdy je na vině nedávná aktualizace. U distribuovaných systémů tento kontext zkracuje hodiny vzájemné komunikace mezi týmy a předává chybu správnému vlastníkovi s již vytvořenou spolehlivou hypotézou.
7. Rollbar (nejlepší pro automatizované pracovní postupy)
Rollbar se specializuje na monitorování chyb v reálném čase pomocí inteligentního otiskování, které seskupuje duplicity a sleduje trendy výskytu. Jeho souhrny založené na umělé inteligenci a nápovědy k příčinám pomáhají týmům pochopit rozsah (počet postižených uživatelů, ovlivněné verze), zatímco telemetrie a trasování zásobníku poskytují rychlé vodítko k reprodukci.
Pravidla pracovního postupu Rollbar mohou automaticky vytvářet úkoly, označovat závažnost a směrovat je k vlastníkům, čímž se hlučné proudy chyb mění na prioritní fronty s připojeným kontextem.
8. PagerDuty AIOps a automatizace runbooků (nejlepší z diagnostiky s minimálními zásahy)
PagerDuty využívá korelaci událostí a redukci šumu založenou na strojovém učení, aby zredukoval záplavu výstrah na řešitelné incidenty.
Dynamické směrování okamžitě předá problém správnému pracovníkovi v pohotovosti, zatímco automatizace runbooků může spustit diagnostiku nebo nápravná opatření (restartovat služby, vrátit nasazení zpět, přepnout příznak funkce) ještě předtím, než se do věci zapojí člověk. Pro dobu řešení chyb to znamená kratší MTTA, rychlejší nápravná opatření pro P0 a méně hodin ztracených kvůli únavě z výstrah.
Hlavním prvkem je automatizace a umělá inteligence v každém kroku. Chyby detekujete dříve, směrujete je chytřeji, dostanete se k kódu rychleji a komunikujete stav, aniž byste zpomalovali práci inženýrů – to vše přispívá k významnému zkrácení doby potřebné k řešení chyb.
📖 Další informace: Jak používat AI v DevOps
Praktické příklady využití umělé inteligence při řešení chyb
Umělá inteligence tedy oficiálně opustila laboratoře. Ve skutečném světě zkracuje dobu potřebnou k řešení chyb.
Podívejme se, jak na to!
| Doména / Organizace | Jak byla použita umělá inteligence | Dopad / přínos |
|---|---|---|
| Ubisoft | Vyvinuli jsme Commit Assistant, nástroj umělé inteligence, který byl vycvičen na základě desetiletí interního kódu a který předpovídá a předchází chybám již ve fázi kódování. | Cílem je výrazně snížit čas a náklady – až 70 % výdajů na vývoj her se tradičně vynakládá na opravy chyb. |
| Razer (platforma Wyvrn) | Spustili jsme AI-řízený QA Copilot (integrovaný s Unreal a Unity) pro automatizaci detekce chyb a generování QA reportů. | Zvyšuje detekci chyb až o 25 % a zkracuje dobu kontroly kvality na polovinu. |
| Google / DeepMind & Project Zero | Představili jsme Big Sleep, nástroj umělé inteligence, který autonomně detekuje bezpečnostní zranitelnosti v open-source softwaru, jako jsou FFmpeg a ImageMagick. | Bylo identifikováno 20 chyb, které byly ověřeny lidskými odborníky a jsou určeny k opravě. |
| Výzkumníci z UC Berkeley | Pomocí benchmarku s názvem CyberGym analyzovaly modely umělé inteligence 188 open-source projektů , odhalily 17 zranitelností – včetně 15 neznámých chyb typu „zero-day“ – a vygenerovaly exploity typu proof-of-concept. | Demonstruje rostoucí schopnosti umělé inteligence v oblasti detekce zranitelností a automatizovaného testování zranitelností. |
| Spur (startup z Yale) | Vyvinuli jsme AI agenta, který překládá popisy testovacích případů v běžném jazyce do automatizovaných rutin pro testování webových stránek – v podstatě se jedná o samopíšící pracovní postup QA. | Umožňuje autonomní testování s minimálním lidským zásahem. |
| Automatické reprodukování zpráv o chybách v systému Android | Používali jsme NLP + posilující učení k interpretaci jazyka hlášení chyb a generování kroků k reprodukci chyb Androidu. | Dosáhli jsme 67% přesnosti, 77% spolehlivosti a reprodukovali jsme 74% hlášení chyb, čímž jsme překonali tradiční metody. |
Časté chyby při měření doby řešení chyb
Pokud vaše měření není přesné, nebude přesný ani váš plán zlepšení.
Většina „špatných čísel“ v pracovních postupech řešení chyb pochází z nejasných definic, nekonzistentních pracovních postupů a povrchní analýzy.
Začněte tedy nejprve se základy – co se počítá jako start/stop, jak zacházet s čekáním a opětovným otevřením – a poté si přečtěte data tak, jak je vnímají vaši zákazníci. To zahrnuje:
❌ Nejasné hranice: Smíchání položek Nahlášeno→Vyřešeno a Nahlášeno→Uzavřeno v jednom dashboardu (nebo jejich střídání každý měsíc) činí trendy bezvýznamnými. Vyberte jednu hranici, zdokumentujte ji a prosazujte ji ve všech týmech. Pokud potřebujete obě, zveřejněte je jako samostatné metriky s jasnými popisky.
❌ Přístup založený pouze na průměrech: Spoléhání se na průměr zakrývá realitu front s několika dlouhodobými výjimkami. Pro „typický“ čas použijte medián (P50), pro předvídatelnost/SLA použijte P90 a průměr si ponechte pro plánování kapacity. Vždy se dívejte na rozložení, ne jen na jedno číslo.
❌ Žádná segmentace: Sloučením všech chyb dohromady se incidenty P0 mísí s kosmetickými incidenty P3. Segmentujte podle závažnosti, zdroje (zákazník vs. QA vs. monitorování), komponenty/týmu a „nové vs. regrese“. Vaše P0/P1 P90 je to, co vnímají zainteresované strany; vaše medián P2+ je to, podle čeho se řídí plánování inženýrů.
❌ Ignorování „pozastaveného“ času: Čekáte na záznamy zákazníků, externího dodavatele nebo termín vydání? Pokud nesledujete stav „Blokováno/Pozastaveno“ jako stav první třídy, doba řešení se stane předmětem sporů. Nahlaste jak kalendářní čas, tak aktivní čas, aby byly viditelné překážky a debaty ustaly.
❌ Rozdíly v normalizaci času: Smíchání časových pásem nebo přepínání mezi pracovními hodinami a kalendářními hodinami uprostřed procesu narušuje srovnání. Normalizujte časová razítka do jednoho pásma (nebo UTC) a jednou se rozhodněte, zda se SLA měří v pracovních nebo kalendářních hodinách; aplikujte to důsledně.
❌ Nečisté přijetí a duplikáty: Chybějící informace o prostředí/sestavení a duplicitní tikety prodlužují čas a způsobují zmatek ohledně vlastnictví. Standardizujte povinná pole při přijetí, automaticky je obohacujte (protokoly, verze, zařízení) a odstraňujte duplikáty bez resetování času – uzavřete duplicity jako propojené, nikoli jako „nové“ problémy.
❌ Nekonzistentní modely stavu: Individuální stavy („QA Ready-ish“, „Pending Review 2“) skrývají dobu trvání stavu a činí přechody mezi stavy nespolehlivými. Definujte kanonický pracovní postup (Nový → Třídění → Probíhá → V revizi → Vyřešeno → Uzavřeno) a provádějte audit stavů mimo cestu.
❌ Slepota vůči času ve stavu: Jediné číslo „celkového času“ vám neřekne, kde se práce zastavila. Zachyťte a zkontrolujte čas strávený v triáži, kontrole, blokování a kontrole kvality. Pokud kontrola kódu P90 převyšuje implementaci, vaším řešením není „rychlejší kódování“, ale uvolnění kapacity pro kontrolu.
🧠 Zajímavost: Poslední soutěž DARPA AI Cyber Challenge představila průlomový pokrok v automatizaci kybernetické bezpečnosti. Soutěž představila systémy umělé inteligence navržené tak, aby autonomně detekovaly, využívaly a opravovaly zranitelnosti v softwaru – bez lidského zásahu. Vítězný tým „Team Atlanta“ odhalil 77 % vložených chyb a úspěšně opravil 61 % z nich, čímž demonstroval sílu umělé inteligence nejen při hledání chyb, ale i při jejich aktivním opravování.
❌ Slepota k opětovnému otevření: Považování opětovného otevření za novou chybu resetuje čas a zkresluje MTTR. Sledujte míru opětovného otevření a „čas do stabilního uzavření“ (od prvního nahlášení po konečné uzavření ve všech cyklech). Rostoucí počet opětovných otevření obvykle poukazuje na slabou reprodukovatelnost, mezery v testování nebo nejasnou definici dokončení.
❌ Žádné MTTA: Týmy se soustředí na MTTR a ignorují MTTA (doba potvrzení/převzetí odpovědnosti). Vysoká hodnota MTTA je varovným signálem pro dlouhé řešení. Změřte ji, nastavte SLA podle závažnosti a automatizujte směrování/eskalaci, abyste ji udrželi na nízké úrovni.
❌ AI/automatizace bez bezpečnostních opatření: Pokud necháte AI nastavit závažnost nebo uzavřít duplikáty bez kontroly, může dojít k nesprávné klasifikaci okrajových případů a tichému zkreslení metrik. Používejte AI pro návrhy, vyžadujte lidské potvrzení u P0/P1 a každý měsíc provádějte audit výkonu modelu, aby vaše data zůstala důvěryhodná.
Zlepšete tyto procesy a vaše grafy doby řešení konečně budou odrážet realitu. Odtud se zlepšení znásobí: lepší příjem zmenší MTTA, čistší stavy odhalí skutečné překážky a segmentované P90 poskytnou vedoucím pracovníkům sliby, které můžete dodržet.
⚡️ Archiv šablon: 10 šablon testovacích případů pro testování softwaru
Osvědčené postupy pro lepší řešení chyb
Zde je shrnutí nejdůležitějších bodů, které je třeba mít na paměti!
| 🧩 Osvědčené postupy | 💡 Co to znamená | 🚀 Proč je to důležité |
| Používejte robustní systém sledování chyb | Sledujte všechny nahlášené chyby pomocí centralizovaného systému sledování chyb. | Zajišťuje, že žádná chyba nezůstane opomenuta, a umožňuje přehled o stavu chyb napříč týmy. |
| Pište podrobné zprávy o chybách | Zahrňte vizuální kontext, informace o operačním systému, kroky k reprodukci a závažnost. | Pomáhá vývojářům opravovat chyby rychleji díky všem podstatným informacím, které mají k dispozici předem. |
| Kategorizujte a upřednostňujte chyby | Pomocí matice priorit tříděte chyby podle naléhavosti a dopadu. | Zaměřte tým nejprve na kritické chyby a naléhavé problémy. |
| Využijte automatizované testování | Spouštějte testy automaticky ve vašem CI/CD pipeline. | Podporuje včasnou detekci a zabraňuje regresím. |
| Definujte jasné pokyny pro podávání zpráv | Poskytněte šablony a školení o tom, jak hlásit chyby. | Výsledkem jsou přesné informace a plynulejší komunikace. |
| Sledujte klíčové metriky | Měřte dobu řešení, uplynulý čas a dobu odezvy. | Umožňuje sledování a zlepšování výkonu pomocí historických dat. |
| Používejte proaktivní přístup | Nečekejte, až si uživatelé začnou stěžovat – testujte proaktivně. | Zvyšuje spokojenost zákazníků a snižuje zátěž podpory. |
| Využijte chytré nástroje a strojové učení | Využijte strojové učení k předpovídání chyb a navrhování oprav. | Zvyšuje efektivitu při identifikaci příčin a opravě chyb. |
| Sladění se smlouvami o úrovni služeb (SLA) | Dodržujte dohodnuté smlouvy o úrovni služeb pro řešení problémů. | Buduje důvěru a včas splňuje očekávání klientů. |
| Průběžně kontrolujte a vylepšujte | Analyzujte znovu otevřené chyby, sbírejte zpětnou vazbu a vylepšujte procesy. | Podporuje neustálé zlepšování vašeho vývojového procesu a správy chyb. |
Jednoduché řešení chyb díky kontextové umělé inteligenci
Nejrychlejší týmy pro řešení chyb se nespoléhají na hrdinské činy. Navrhují systém: jasné definice začátku/konce, čistý příjem, prioritizace podle dopadu na podnikání, jasné vlastnictví a těsné zpětné vazby mezi podporou, QA, inženýrstvím a vydáváním.
ClickUp může být tímto řídicím centrem poháněným umělou inteligencí pro váš systém řešení chyb. Centralizujte všechny zprávy do jedné fronty, standardizujte kontext pomocí strukturovaných polí a nechte ClickUp AI třídit, sumarizovat a stanovovat priority, zatímco automatizace prosazuje SLA, eskaluje při překročení lhůt a udržuje zainteresované strany v souladu. Propojte chyby se zákazníky, kódem a verzemi, aby vedoucí pracovníci viděli dopad a odborníci zůstali v proudu.
Pokud jste připraveni zkrátit dobu řešení chyb a zvýšit předvídatelnost svého plánu, zaregistrujte se do ClickUp a začněte měřit zlepšení v řádu dnů, nikoli čtvrtletí.
Často kladené otázky
Jaká je vhodná doba řešení chyb?
Neexistuje jediná „správná“ hodnota – záleží na závažnosti, modelu vydání a toleranci rizika. Použijte mediány (P50) pro „typický“ výkon a P90 pro sliby/SLA a segmentujte podle závažnosti a zdroje.
Jaký je rozdíl mezi řešením chyb a uzavřením chyb?
Řešení nastává, když je oprava implementována (např. sloučení kódu, aplikace konfigurace) a tým považuje chybu za vyřešenou. Uzavření nastává, když je problém ověřen a formálně dokončen (např. validace QA v cílovém prostředí, vydání nebo označení jako „nebude opraveno/duplikát“ s odůvodněním). Mnoho týmů měří obojí: Nahlášeno→Vyřešeno odráží rychlost vývoje; Nahlášeno→Uzavřeno odráží celkový tok kvality. Používejte konzistentní definice, aby se na panelech nezaměňovaly jednotlivé fáze.
Jaký je rozdíl mezi časem potřebným k odstranění chyby a časem potřebným k jejímu odhalení?
Doba detekce (MTTD) je doba, za kterou je chyba odhalena po jejím vzniku nebo dodání – prostřednictvím monitorování, kontroly kvality nebo uživatelů. Doba řešení je doba, za kterou se od detekce/nahlášení dostanete k implementaci opravy (a pokud chcete, také k ověření/uvolnění). Společně definují okno dopadu na zákazníka: rychlá detekce, rychlé potvrzení, rychlé řešení a bezpečné uvolnění. Můžete také sledovat MTTA (čas na potvrzení/přiřazení), abyste odhalili zpoždění při třídění, která často předpovídají delší řešení.
Jak umělá inteligence pomáhá při řešení chyb?
Umělá inteligence zkracuje cykly, které obvykle trvají dlouho: přijetí, třídění, diagnostika, oprava a ověření.
- Příjem a třídění: Automaticky shrnuje dlouhé zprávy, extrahuje kroky/prostředí pro reprodukci, označuje duplikáty a navrhuje závažnost/prioritu, aby inženýři mohli začít s čistým kontextem (např. ClickUp AI, Sentry AI).
- Směrování a SLA: Předpovídá pravděpodobnou komponentu/vlastníka, nastavuje časovače a eskaluje, když dojde k prodloužení MTTA nebo čekání na kontrolu, čímž se zkracuje nečinný „čas ve stavu“ (automatizace ClickUp a pracovní postupy podobné agentům).
- Diagnostika: Seskupuje podobné chyby, koreluje špičky s nedávnými commitem/vydáním a poukazuje na pravděpodobné příčiny pomocí stack trace a kontextu kódu (Sentry AI a podobné).
- Implementace: Navrhuje změny kódu a testy na základě vzorů z vašeho repozitáře, čímž urychluje cyklus „psaní/opravování“ (GitHub Copilot; Snyk Code AI od DeepCode).
- Ověřování a komunikace: píše testovací případy z reprodukčních kroků, navrhuje poznámky k vydání a aktualizace pro zúčastněné strany a shrnuje stav pro vedoucí pracovníky a zákazníky (ClickUp AI). Při společném použití – ClickUp jako velitelské centrum se Sentry/Copilot/DeepCode ve stacku – týmy zkracují časy MTTA/P90, aniž by se spoléhaly na hrdinské výkony.