
Пускате най-новата актуализация на софтуера и започват да пристигат доклади.
Изведнъж един показател определя всичко – от CSAT/NPS до отклонения от плана: времето за отстраняване на грешки.
Ръководителите го разглеждат като показател за спазване на обещанията – можем ли да доставяме, да се учим и да защитаваме приходите си по график? Практикуващите изпитват трудности в ежедневната си работа – дублирани билети, неясна отговорност, шумни ескалации и контекст, разпръснат в Slack, електронни таблици и отделни инструменти.
Тази фрагментация удължава циклите, затрупва основните причини и превръща приоритизирането в гадаене.
Резултатът? По-бавно учене, пропуснати ангажименти и натрупана работа, която тихо тежи на всеки спринт.
Това ръководство е вашият пълен наръчник за измерване, сравняване и намаляване на времето за отстраняване на грешки и показва конкретно как изкуственият интелект променя работния процес в сравнение с традиционните ръчни процеси.
Какво е време за отстраняване на бъгове?
Времето за отстраняване на грешки е времето, необходимо за отстраняване на дадена грешка, измерено от момента на нейното докладване до пълното й отстраняване.
На практика часовникът започва да тиктака, когато проблемът бъде докладван или открит (от потребители, QA или мониторинг), и спира, когато поправката бъде приложена и обединена, готова за проверка или пускане – в зависимост от това как вашият екип дефинира „завършено“.
Пример: срив P1, докладван в 10:00 ч. в понеделник, с поправка, приложена в 15:00 ч. във вторник, има време за разрешаване от ~29 часа.
Това не е същото като времето за откриване на бъгове. Времето за откриване измерва колко бързо разпознавате дефект, след като той се е появил (задействане на аларми, откриване от инструменти за QA тестване, сигнализиране от клиенти).
Времето за отстраняване измерва колко бързо преминавате от осъзнаване към отстраняване – сортиране, възпроизвеждане, диагностициране, внедряване, преглед, тестване и подготовка за пускане. Мислете за откриването като „знаем, че има проблем“ и за отстраняването като „проблемът е отстранен и всичко е готово“.
Екипите използват леко различни граници; изберете една и бъдете последователни, за да са реални вашите тенденции:
- Докладвано → Решено: Приключва, когато поправката на кода е обединена и готова за QA. Подходящо за инженерна производителност
- Докладвано → Затворено: Включва QA валидиране и пускане. Най-подходящо за SLA, които оказват влияние върху клиентите.
- Открит → Решен: Започва, когато мониторингът/QA открие проблема, дори преди да има билет. Полезно за екипи с голям обем на производство.
🧠 Интересен факт: Една странна, но забавна грешка в Final Fantasy XIV спечели похвали за това, че беше толкова специфична, че читателите я нарекоха „Най-специфичната поправка на грешка в MMO 2025“. Тя се проявяваше, когато играчите определяха цени на предмети между точно 44 442 и 49 087 гил в определена зона на събитието, което водеше до прекъсване на връзката поради грешка, вероятно свързана с препълване на цялото число.
Защо е важно
Времето за отстраняване на грешки е фактор, който влияе върху честотата на пускането на нови версии. Дългите или непредвидими срокове налагат съкращаване на обхвата, бързи поправки и замразяване на пускането на нови версии; те създават планировъчен дълг, защото дългите опашки (изключенията) пречат на спринтовете повече, отколкото показва средната стойност.
Това е пряко свързано и с удовлетвореността на клиентите. Клиентите толерират проблемите, когато те се признават бързо и се разрешават предвидимо. Бавните поправки – или по-лошо, променливите поправки – водят до ескалации, понижават CSAT/NPS и излагат на риск подновяването на договорите.
Накратко, ако измервате времето за отстраняване на бъгове по ясен и систематичен начин и го намалявате, вашите пътни карти и взаимоотношения ще се подобрят.
📖 Прочетете още: Как да приоритизирате бъговете за ефективно разрешаване на проблеми
Как да измервате времето за отстраняване на бъгове?
Първо, решете откъде да започне и да спре часовникът ви.
Повечето екипи избират или „Докладвано → Решено“ (поправката е обединена и готова за проверка) или „Докладвано → Затворено“ (QA е потвърдило и промяната е пусната или по друг начин затворена).
Изберете едно определение и го използвайте последователно, за да бъдат тенденциите ви значими.
Сега ви трябват някои наблюдаеми показатели. Нека ги очертаем:
Ключови показатели за проследяване на бъгове, на които да обърнете внимание:
| 📊 Метрика | 📌 Какво означава това | 💡 Как помага | 🧮 Формула (ако е приложимо) |
|---|---|---|---|
| Брой бъгове 🐞 | Общ брой на докладваните бъгове | Предоставя обща представа за състоянието на системата. Висока стойност? Време е за разследване. | Общо бъгове = Всички бъгове, регистрирани в системата {Отворени + Затворени} |
| Отворени бъгове 🚧 | Бъгове, които все още не са отстранени | Показва текущата работна натовареност. Помага при определянето на приоритетите. | Отворени бъгове = Общо бъгове - Затворени бъгове |
| Затворени бъгове ✅ | Отстранени и проверени бъгове | Проследява напредъка и свършената работа. | Затворени бъгове = Брой бъгове със статус „Затворен” или „Решен” |
| Тежест на бъга 🔥 | Критичност на грешката (например критична, сериозна, незначителна) | Помага за сортиране въз основа на въздействието. | Проследява се като категорично поле, без формула. Използвайте филтри/групиране. |
| Приоритет на бъговете 📅 | Колко спешно трябва да бъде отстранена дадена грешка | Помага при планирането на спринтове и пускането на версии. | Също така категорично поле, обикновено класифицирано (напр. P0, P1, P2). |
| Време за разрешаване ⏱️ | Време от докладването на грешката до отстраняването й | Измерва реактивността. | Време за разрешаване = Дата на затваряне - Дата на докладване |
| Процент на повторно отваряне 🔄 | % от бъговете, които са отворени отново след затваряне | Отразява качеството на поправките или проблемите с регресията. | Процент на повторно отваряне (%) = {Повторно отворени бъгове ÷ Общо затворени бъгове} × 100 |
| Изтичане на бъгове 🕳️ | Бъгове, които са се промъкнали в производството | Показва ефективността на QA/тестването на софтуера. | Процент на изтичане (%) = {Производствени бъгове ÷ Общо бъгове} × 100 |
| Плътност на дефектите 🧮 | Бъгове на единица размер на кода | Подчертава областите в кода, които са изложени на риск. | Плътност на дефектите = Брой бъгове ÷ KLOC {килобайтове код} |
| Присвоени срещу неприсвоени бъгове 👥 | Разпределение на бъговете по собственост | Гарантира, че нищо няма да бъде пропуснато. | Използвайте филтър: Неприсвоени = Грешки, при които „Присвоено на“ е празно |
| Възраст на отворените бъгове 🧓 | Колко дълго остава неотстранен един бъг | Открива рискове от стагнация и забавяне. | Възраст на грешката = текуща дата – дата на докладване |
| Дублирани бъгове 🧬 | Брой дублирани доклади | Посочва грешките в процесите на приемане. | Процент на дублиране = Дубликати ÷ Общ брой бъгове × 100 |
| MTTD (средно време за откриване) 🔎 | Средно време, необходимо за откриване на бъгове или инциденти | Измерва ефективността на мониторинга и осведомеността. | MTTD = Σ(Време на откриване - Време на въвеждане) ÷ Брой бъгове |
| MTTR (средно време за отстраняване) 🔧 | Средно време за пълно отстраняване на бъг след откриването му | Проследява реактивността на инженерите и времето за отстраняване на грешки. | MTTR = Σ(Време за отстраняване - Време за откриване) ÷ Брой отстранени бъгове |
| MTTA (средно време за потвърждение) 📬 | Времето от откриването до момента, в който някой започне да работи по отстраняването на грешката | Показва реактивността на екипа и бързината на реакция при сигнали. | MTTA = Σ(Време за потвърждение - Време за откриване) ÷ Брой бъгове |
| MTBF (средно време между откази) 🔁 | Времето между отстраняването на една повреда и появата на следващата | Показва стабилност във времето. | MTBF = Общо време на работа ÷ Брой повреди |
⚡️ Архив с шаблони: 15 безплатни шаблона и формуляри за докладване на бъгове за проследяване на бъгове
Фактори, които влияят върху времето за отстраняване на грешки
Времето за отстраняване на грешки често се равнява на „колко бързо кодират инженерите“.
Но това е само една част от процеса.
Времето за отстраняване на бъгове е сбор от качеството при приемане, ефективността на потока през системата и риска от зависимост. Когато някое от тези три неща се провали, цикълът се удължава, предсказуемостта спада и ескалациите стават по-силни.
Качеството на приемането определя тона
Докладите, които пристигат без ясни стъпки за възпроизвеждане, подробности за средата, логове или информация за версията/създаването, налагат допълнителни размени на информация. Дублираните доклади от различни канали (поддръжка, QA, мониторинг, Slack) създават шум и раздробяват отговорността.
Колкото по-рано уловите правилния контекст и премахнете дублиращата се информация, толкова по-малко прехвърляния и изяснявания ще са ви необходими по-късно.
Приоритизирането и маршрутизирането определят кой се занимава с грешката и кога.
Етикетите за сериозност, които не отразяват въздействието върху клиентите/бизнеса (или които се променят с времето), водят до пренареждане на опашката: най-шумните билети прескачат на преден план, докато дефектите с голямо въздействие остават на заден план.
Ясните правила за маршрутизиране по компонент/собственик и единна опашка от истини не позволяват работата по P0/P1 да бъде затрупана от „скорошни и шумни“ задачи.
Отговорността и предаването на задачи са тихи убийци
Ако не е ясно дали даден бъг принадлежи на мобилния, бекенд автентификационния или платформения екип, той се отхвърля. Всяко отхвърляне нулира контекста.
Часовите зони усложняват нещата: бъг, докладван късно през деня, без посочен отговорник, може да загуби 12–24 часа, преди някой да започне да го възпроизвежда. Точните дефиниции на „кой за какво отговаря“ с дежурен или седмичен DRI премахват тази забава.
Възпроизводимостта зависи от наблюдаемостта
Оскъдните логове, липсващите идентификатори за корелация или липсата на следи от сривове превръщат диагностиката в догадки. Грешките, които се появяват само с определени флагове, наематели или форми на данни, са трудни за възпроизвеждане в разработката.
Ако инженерите не могат да получат безопасен достъп до пречистени данни, подобни на производствени, те се налага да инструментират, преразпределят и чакат – дни, вместо часове.
Равнопоставеността на средата и данните ви гарантира честност
„Работи на моя компютър“ обикновено означава „продуктовите данни са различни“. Колкото повече вашата разработка/тестване се различава от производството (конфигурация, услуги, версии на трети страни), толкова повече време ще прекарате в преследване на призраци. Сигурните снимки на данни, скриптове за семена и проверки за паритет намаляват тази разлика.
Работата в процес (WIP) и фокусът определят реалната производителност
Претоварените екипи се занимават с твърде много бъгове едновременно, раздробяват вниманието си и се разкъсват между задачи и срещи. Смяната на контекста добавя невидими часове.
Видимото ограничение на текущата работа и склонността да завършвате започнатото, преди да започнете нова работа, ще понижат средната ви стойност по-бързо от всеки индивидуален героичен подвиг.
Прегледът на кода, CI и QA скоростта са класически пречки.
Бавните времена за изграждане, нестабилните тестове и неясните SLA за преглед забавят иначе бързите поправки. Един 10-минутен пач може да отнеме два дни в очакване на прегледащ или да се вмъкне в часове наредба.
По същия начин, QA опашките, които тестват на партиди или разчитат на ръчни тестове, могат да добавят цели дни към „Докладвано → Затворено“, дори когато „Докладвано → Решено“ е бързо.
Зависимостите удължават опашките
Промените между екипите (схема, миграции на платформи, актуализации на SDK), бъгове на доставчици или прегледи в магазини за приложения (мобилни) предизвикват състояния на изчакване. Без изрично проследяване на „Блокирани/Паузирани“, тези изчаквания невидимо увеличават средните ви стойности и скриват къде се намира истинското затруднение.
Моделът на пускане и стратегията за връщане назад са от значение
Ако доставяте в големи релийз влакове с ръчни контролни точки, дори разрешените бъгове остават нерешени до отпътуването на следващия влак. Функционалните флагове, канарските релийзи и лентите за бързи поправки съкращават опашката – особено за инциденти P0/P1 – като ви позволяват да разделите внедряването на поправките от пълните цикли на релийз.
Архитектурата и технологичният дълг определят вашия таван
Тясното свързване, липсата на тестови шевове и непрозрачните стари модули правят простите поправки рисковани. Екипите компенсират с допълнителни тестове и по-дълги прегледи, което удължава циклите. От друга страна, модулният код с добри тестове на договори ви позволява да се движите бързо, без да нарушавате съседните системи.
Комуникацията и поддържането на статуса влияят върху предвидимостта
Неясните актуализации („разглеждаме въпроса“) водят до преработване, когато заинтересованите страни питат за очакваното време за разрешаване, поддръжката отваря отново билетите или продуктът ескалира. Ясните преходи в статуса, бележките за възпроизвеждане и основната причина, както и публикуваното очаквано време за разрешаване намаляват отлива и предпазват фокуса на инженерния ви екип.
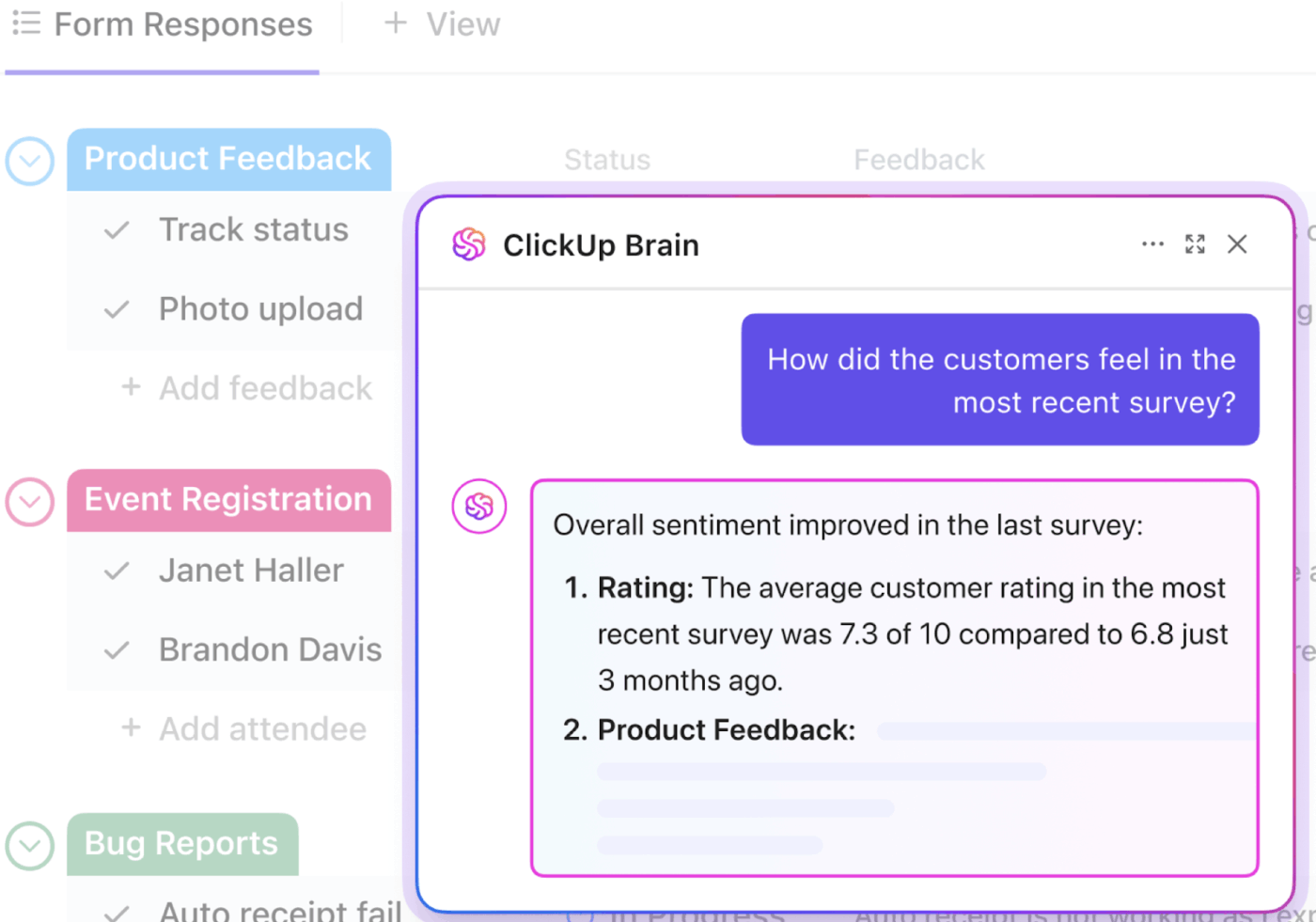
📮ClickUp Insight: Средностатистическият професионалист прекарва над 30 минути на ден в търсене на информация, свързана с работата си – това са над 120 часа годишно, загубени в претърсване на имейли, Slack низове и разпръснати файлове.
Интелигентен AI асистент, вграден в работното ви пространство, може да промени това. Запознайте се с ClickUp Brain. Той предоставя незабавни прозрения и отговори, като извежда на преден план подходящите документи, разговори и подробности за задачите за секунди – така че можете да спрете да търсите и да започнете да работите.
💫 Реални резултати: Екипи като QubicaAMF спестиха над 5 часа седмично с помощта на ClickUp – това са над 250 часа годишно на човек – като премахнаха остарелите процеси за управление на знанията. Представете си какво би могъл да създаде вашият екип с една допълнителна седмица продуктивност на тримесечие!
Водещи индикатори, че времето за разрешаване на проблеми ще се удължи
❗️Увеличаващо се „време за потвърждение“ и много билети без собственик за >12 часа
❗️Нарастващи сегменти „Време за преглед/CI“ и чести проблеми с тестовете
❗️Висок процент на дублиране при приемането и несъответствия в етикетите за сериозност между екипите
❗️Няколко бъга, които са в състояние „Блокирани“ без посочена външна зависимост
❗️Процентът на повторно отваряне се увеличава (поправките не са възпроизводими или дефинициите за „завършено“ са неясни)
Различните организации възприемат тези фактори по различен начин. Ръководителите ги възприемат като пропуснати цикли на обучение и загуба на приходи, а операторите – като шум при сортирането и неясно разпределение на отговорностите.
Чрез настройване на приемането, потока и зависимостите можете да понижите цялата крива – медиана и P90.
Искате да научите повече за писането на по-добри доклади за бъгове? Започнете оттук. 👇🏼
Стандарти в индустрията за времето за отстраняване на грешки
Сравнителните показатели за отстраняване на бъгове се променят в зависимост от толерантността към риска, модела на пускане на пазара и скоростта, с която можете да внедрите промените.
Тук можете да използвате медиани (P50), за да разберете типичния си поток, и P90, за да зададете обещания и SLA – по тежест и източник (клиент, QA, мониторинг).
Нека разгледаме какво означава това:
| 🔑 Термин | 📝 Описание | 💡 Защо е важно |
|---|---|---|
| P50 (медиана) | Средната стойност – 50% от отстраняванията на бъгове са по-бързи от това, а 50% са по-бавни. | 👉 Отразява типичното или най-често срещаното време за разрешаване. Подходящо за разбиране на нормалната производителност. |
| P90 (90-ти процентил) | 90% от бъговете се отстраняват в рамките на това време. Само 10% отнемат повече време. | 👉 Представлява най-лошия (но все пак реалистичен) вариант. Полезно за определяне на външни обещания. |
| SLA (споразумения за ниво на обслужване) | Ангажименти, които поемате – вътрешно или към клиенти – относно това колко бързо ще бъдат разрешени проблемите | 👉 Пример: „Ние разрешаваме P1 бъгове в рамките на 48 часа в 90% от случаите. ” Помага за изграждането на доверие и отговорност |
| По тежест и източник | Сегментирайте показателите си по две ключови измерения: • Сериозност (напр. P0, P1, P2)• Източник (напр. клиент, QA, мониторинг) | 👉 Позволява по-точно проследяване и приоритизиране, така че критичните бъгове получават по-бързо внимание. |
По-долу са посочени насоки, базирани на индустрии, към които често се ориентират зрелите екипи; третирайте ги като начални диапазони, след което ги адаптирайте към вашия контекст.
SaaS
Винаги активни и съвместими с CI/CD, така че бързите поправки са често срещани. Критичните проблеми (P0/P1) често се целят в средна стойност под един работен ден, с P90 в рамките на 24–48 часа. Некритичните (P2+) обикновено се решават в рамките на 3–7 дни, с P90 в рамките на 10–14 дни. Екипите с надеждни функционални флагове и автоматизирани тестове са склонни да работят по-бързо.
Платформи за електронна търговия
Тъй като конверсията и потоците в количката са от решаващо значение за приходите, летвата е по-висока. Проблемите P0/P1 обикновено се разрешават в рамките на няколко часа (отмяна, маркиране или конфигуриране) и се решават напълно в същия ден; P90 до края на деня или <12 часа е обичайно през пиковите сезони. Проблемите P2+ често се решават в рамките на 2–5 дни, а P90 – в рамките на 10 дни.
Софтуер за предприятия
По-тежката валидация и прозорците за промени от страна на клиентите забавят темпото. За P0/P1 екипите се стремят да намерят временно решение в рамките на 4–24 часа и да го отстранят в рамките на 1–3 работни дни; P90 в рамките на 5 работни дни. Елементите P2+ често се групират в релийз влакове, със средна продължителност от 2–4 седмици, в зависимост от графиците за внедряване на клиентите.
Игри и мобилни приложения
Бакендът на услугите на живо се държи като SaaS (флагове и отмятания в рамките на минути до часове; P90 в същия ден). Актуализациите на клиента са ограничени от прегледите на магазина: P0/P1 често използват незабавно лостове от страна на сървъра и изпращат клиентски пач в рамките на 1–3 дни; P90 в рамките на една седмица с ускорен преглед. Поправките P2+ обикновено се планират в следващия спринт или пускане на съдържание.
Банково дело/финансови технологии
Рисковете и изискванията за съответствие водят до модел „бързо смекчаване, внимателни промени“. P0/P1 се смекчават бързо (маркиране, връщане назад, промени в трафика в рамките на минути до часове) и се отстраняват напълно в рамките на 1–3 дни; P90 – в рамките на една седмица, като се отчита контролът на промените. P2+ често отнема 2–6 седмици, за да премине през проверки за сигурност, одит и CAB.
Ако вашите цифри са извън тези граници, проверете качеството на приемането, маршрутизирането/собствеността, прегледа на кода и производителността на QA, както и одобренията на зависимостите, преди да приемете, че „скоростта на инженеринга“ е основният проблем.
🌼 Знаете ли, че: Според проучване на Stack Overflow от 2024 г., разработчиците все по-често използват изкуствен интелект като свой надежден помощник в процеса на кодиране. Огромните 82% използват изкуствен интелект, за да пишат код – това е истински творчески сътрудник! Когато се затрудняват или търсят решения, 67,5% разчитат на изкуствен интелект, за да търсят отговори, а над половината (56,7%) разчитат на него, за да отстраняват грешки и да получават помощ.
За някои AI инструментите се оказаха полезни и за документиране на проекти (40,1%) и дори за създаване на синтетични данни или съдържание (34,8%). Любопитни ли сте за нова кодова база? Почти една трета (30,9%) използват изкуствен интелект, за да се запознаят с нея. Тестването на код все още е ръчна работа за мнозина, но 27,2% са приели изкуствения интелект и в тази област. В други области, като преглед на код, планиране на проекти и предсказуема аналитика, използването на изкуствен интелект е по-ниско, но е ясно, че изкуственият интелект постепенно се вписва във всеки етап от разработката на софтуер.
📖 Прочетете още: Как да използвате изкуствен интелект за осигуряване на качеството
Как да намалите времето за отстраняване на грешки
Бързината при отстраняването на бъгове се свежда до премахване на пречките при всяко предаване от приемането до пускането.
Най-големите ползи се постигат, като се оптимизират първите 30 минути (чисто приемане, подходящ собственик, подходящ приоритет), а след това се компресират следващите цикли (възпроизвеждане, преглед, проверка).
Ето девет стратегии, които работят заедно като система. Изкуственият интелект ускорява всяка стъпка, а работният процес се осъществява на едно място, така че мениджърите получават предвидимост, а практиците – плавен работен поток.
1. Централизирайте приемането и записвайте контекста при източника
Времето за отстраняване на бъгове се удължава, когато възстановявате контекста от Slack низове, билети за поддръжка и електронни таблици. Съберете всички доклади – поддръжка, QA, мониторинг – в една опашка с структуриран шаблон, който събира компоненти, сериозност, среда, версия/изграждане на приложението, стъпки за възпроизвеждане, очаквани срещу действителни резултати и прикачени файлове (регистри/HAR/екрани).
Изкуственият интелект може автоматично да обобщава дълги доклади, да извлича стъпки за възпроизвеждане и подробности за средата от прикачените файлове и да маркира вероятни дубликати, така че сортирането да започва с кохерентен и обогатен запис.
Показатели, които трябва да следите: MTTA (потвърждение в рамките на минути, а не часове), процент на дублиране, време за „Необходима информация“.

2. Сортиране и маршрутизиране с помощта на изкуствен интелект за значително намаляване на MTTA
Най-бързите решения са тези, които веднага попадат на правилното бюро.
Използвайте прости правила и изкуствен интелект, за да класифицирате сериозността, да идентифицирате вероятните собственици по компонент/код и да присвоите автоматично SLA часовник. Задайте ясни граници за P0/P1 спрямо всичко останало и направете „кой е собственикът“ недвусмислен.
Автоматизацията може да задава приоритет от полета, да насочва по компоненти към екип, да стартира таймер за SLA и да уведомява дежурния инженер; изкуственият интелект може да предложи степен на сериозност и отговорно лице въз основа на минали модели. Когато сортирането отнема 2–5 минути вместо 30-минутна дискусия, MTTA се понижава, а MTTR следва.
Показатели, които трябва да следите: MTTA, качество на първия отговор (първият коментар изисква ли правилната информация?), брой предавания на бъг.
Ето как изглежда това на практика:
3. Приоритизирайте според бизнес въздействието с ясни нива на SLA
Принципът „най-силният глас печели“ прави опашките непредсказуеми и подкопава доверието на мениджърите, които следят CSAT/NPS и подновяванията.
Заменете това с оценка, която съчетава тежестта, честотата, засегнатия ARR, критичността на функцията и близостта до подновявания/стартирания – и я подкрепете с нива на SLA (например P0: смекчаване в рамките на 1–2 часа, разрешаване в рамките на един ден; P1: в същия ден; P2: в рамките на спринт).
Поддържайте видима P0/P1 лента с WIP ограничения, за да не остане нищо незавършено.
Показатели, които трябва да следите: P50/P90 разрешаване по нива, процент на нарушения на SLA, корелация с CSAT/NPS.
💡Съвет от професионалист: Полетата „Приоритети на задачите“, „Персонализирани полета“ и „Зависимости“ в ClickUp ви позволяват да изчислите оценка на въздействието и да свържете бъговете с акаунти, обратна връзка или елементи от пътната карта. Освен това, „Целите“ в ClickUp ви помагат да обвържете спазването на SLA с целите на ниво компания, което отговаря директно на загрижеността на ръководството относно съгласуваността.
4. Превърнете възпроизвеждането и диагностиката в еднократна дейност
Всяка допълнителна циклична проверка с въпроса „Можете ли да изпратите логове?“ удължава времето за разрешаване на проблема.
Стандартизирайте какво означава „добро“: задължителни полета за изграждане/потвърждаване, среда, стъпки за възпроизвеждане, очаквани срещу действителни, плюс прикачени файлове за логове, дъмпове при срив и HAR файлове. Инструментирайте телеметрията на клиент/сървър, така че идентификаторите на сривове и идентификаторите на заявки да могат да се свързват с трасиранията.
Въведете Sentry (или подобен софтуер) за проследяване на стека и свържете проблема директно с грешката. Изкуственият интелект може да чете логове и проследявания, за да предложи вероятна област на грешка и да генерира минимално възпроизвеждане, превръщайки един час наблюдение в няколко минути целенасочена работа.
Съхранявайте ръководства за често срещани видове бъгове, за да не се налага инженерите да започват от нулата.
Показатели, които трябва да следите: време, прекарано в „очакване на информация“, процент на възпроизвеждане при първия опит, процент на повторно отваряне, свързан с липсващо възпроизвеждане.
📖 Научете повече: Как да използвате изкуствен интелект в разработката на софтуер (примери за употреба и инструменти)
5. Съкратете цикъла на преглед и тестване на кода
Големите PR се забавят. Целете се в хирургични кръпки, разработка на базата на trunk и функционални флагове, за да може поправките да бъдат изпратени безопасно. Предварително назначете рецензенти според собствеността на кода, за да избегнете празен ход, и използвайте списъци за проверка (актуализирани тестове, добавена телеметрия, флаг зад kill switch), за да се гарантира качеството.
Автоматизацията трябва да премести грешката в „В процес на преглед“ при отваряне на PR и в „Решена“ при сливане; изкуственият интелект може да предложи единични тестове или да подчертае рискови разлики, за да се фокусира прегледът.
Показатели, които трябва да следите: Време в „В процес на преглед“, процент на неуспешни промени за PR за отстраняване на бъгове и латентност на преглед P90.
Можете да използвате интеграциите GitHub/GitLab в ClickUp, за да синхронизирате статуса на разрешаването; Автоматизацията може да наложи „дефиницията за завършено“.
📖 Прочетете още: Как да използвате изкуствен интелект за автоматизиране на задачи
6. Паралелизирайте верификацията и постигнете реална паритет в QA средата
Проверката не трябва да започва дни по-късно или в среда, която никой от вашите клиенти не използва.
Поддържайте „готовност за QA“: отбелязани с флаг корекции, валидирани в производствени среди с начални данни, които съответстват на докладваните случаи.
Когато е възможно, създайте временни среди от клона на грешката, за да може QA да ги валидира незабавно; след това изкуственият интелект може да генерира тестови случаи от описанието на грешката и минали регресии.
Показатели, които трябва да следите: Време в „QA/Проверка“, процент на отпадане от QA обратно към разработка, средно време за приключване след сливане.

📖 Прочетете още: Как да напишете ефективни тестови случаи
7. Комуникирайте ясно статуса, за да намалите разходите за координация
Една добра актуализация предотвратява три проверки на състоянието и едно ескалиране.
Третирайте актуализациите като продукт: кратки, конкретни и съобразени с аудиторията (поддръжка, ръководители, клиенти). Установете ритъм за P0/P1 (например, на всеки час, докато проблемът не бъде разрешен, след това на всеки четири часа) и поддържайте единен източник на информация.
Изкуственият интелект може да изготвя безопасни за клиентите актуализации и вътрешни обобщения от историята на задачите, включително актуален статус по тежест и екип. За мениджъри като вашия директор по продуктите, прехвърлете бъговете към инициативи, за да могат да видят дали критичната работа по качеството заплашва обещанията за доставка.
Показатели, които трябва да следите: Време между актуализациите на статуса на P0/P1, CSAT на заинтересованите страни по отношение на комуникациите.
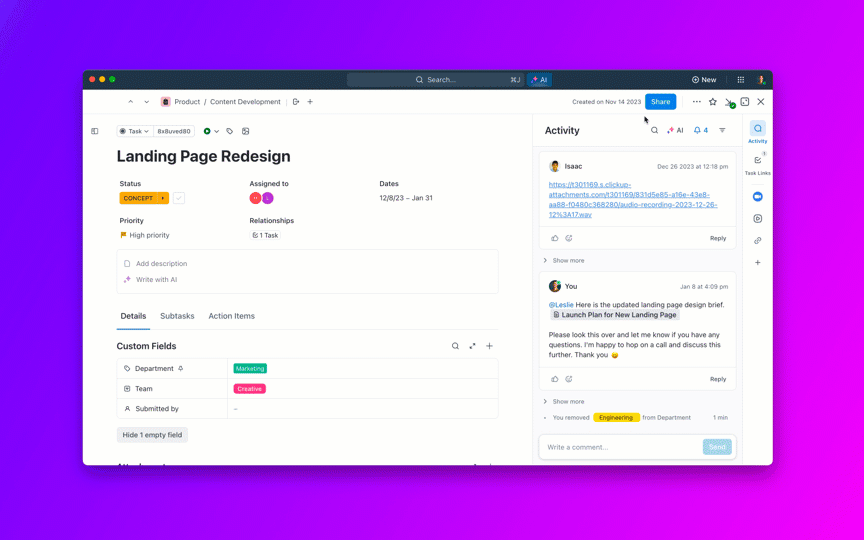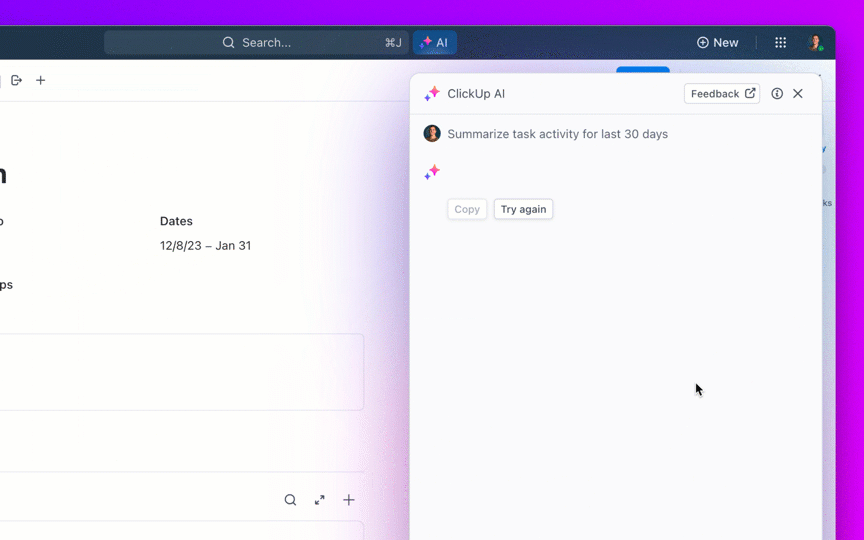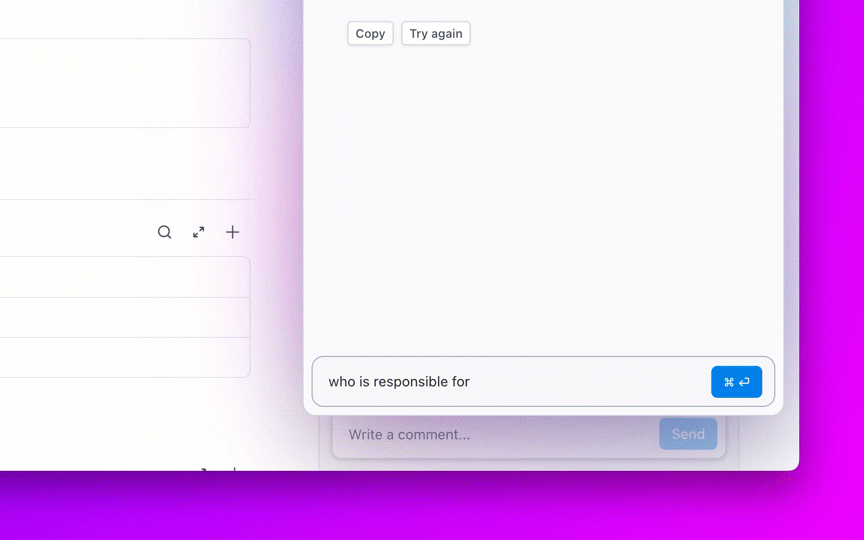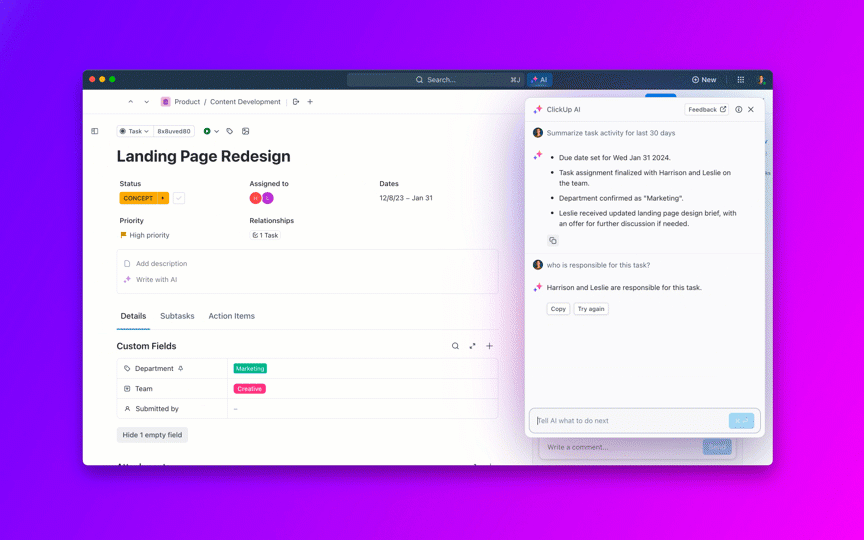
8. Контролирайте забавянето на натрупаните задачи и предотвратявайте „вечно отворените“ задачи
Нарастващото забавяне тихо обременява всеки спринт.
Задайте политики за стареене (например, P2 > 30 дни предизвиква преразглеждане, P3 > 90 дни изисква обосновка) и планирайте седмична „сортировка по стареене“, за да обедините дублиращите се елементи, да затворите остарелите доклади и да превърнете бъговете с ниска стойност в елементи от продуктовия беклог.
Използвайте изкуствен интелект, за да групирате натрупаните задачи по теми (например „изтичане на валидността на токена за удостоверяване“, „нестабилност при качването на изображения“), така че да можете да планирате тематични седмици за отстраняване на грешки и да премахнете цяла категория дефекти наведнъж.
Показатели, които трябва да следите: брой на забавените задачи по възраст, % на затворени проблеми като дубликати/остарели, тематична скорост на изчерпване.
9. Затворете цикъла с основната причина и превенция
Ако един и същ вид дефект продължава да се повтаря, подобренията в MTTR прикриват по-голям проблем.
Извършвайте бърз и безпроблемен анализ на основните причини за P0/P1 и високочестотни P2; маркирайте основните причини (пропуски в спецификациите, пропуски в тестовете, пропуски в инструментите, нестабилност на интеграцията), свържете ги с засегнатите компоненти и инциденти и проследявайте последващите задачи (предпазни мерки, тестове, правила за линт) до тяхното завършване.
Изкуственият интелект може да изготвя обобщения на RCA и да предлага превантивни тестове или правила за проверка въз основа на историята на промените. И така преминавате от гасене на пожари към по-малко пожари.
Показатели, които трябва да следите: процент на повторно отваряне, процент на регресия, време между повторенията и процент на RCA с изпълнени превантивни действия.

Взети заедно, тези промени съкращават целия процес: по-бързо потвърждаване, по-ясна сортировка, по-интелигентно приоритизиране, по-малко забавяния при прегледа и QA и по-ясна комуникация. Ръководителите получават предвидимост, свързана с CSAT/NPS и приходите; практикуващите получават по-спокойна опашка с по-малко превключване на контекста.
📖 Прочетете още: Как да извършите анализ на основните причини
AI инструменти, които помагат за намаляване на времето за отстраняване на грешки
Изкуственият интелект може да съкрати времето за разрешаване на проблеми на всеки етап – приемане, сортиране, насочване, отстраняване и проверка.
Въпреки това, истинските ползи се постигат, когато инструментите разбират контекста и поддържат работата без ръчно управление.
Потърсете системи, които автоматично обогатяват отчетите (стъпки за възпроизвеждане, среда, дубликати), приоритизират по въздействие, насочват към правилния собственик, изготвят ясни актуализации и се интегрират плътно с вашия код, CI и наблюдаемост.
Най-добрите от тях поддържат и работни процеси, подобни на тези на агентите: ботове, които следят SLA, подканват рецензентите, ескалират заседналите елементи и обобщават резултатите за заинтересованите страни. Ето нашите AI инструменти за по-добро отстраняване на бъгове:
1. ClickUp (Най-доброто за контекстуална изкуствена интелигентност, автоматизация и агентни работни процеси)
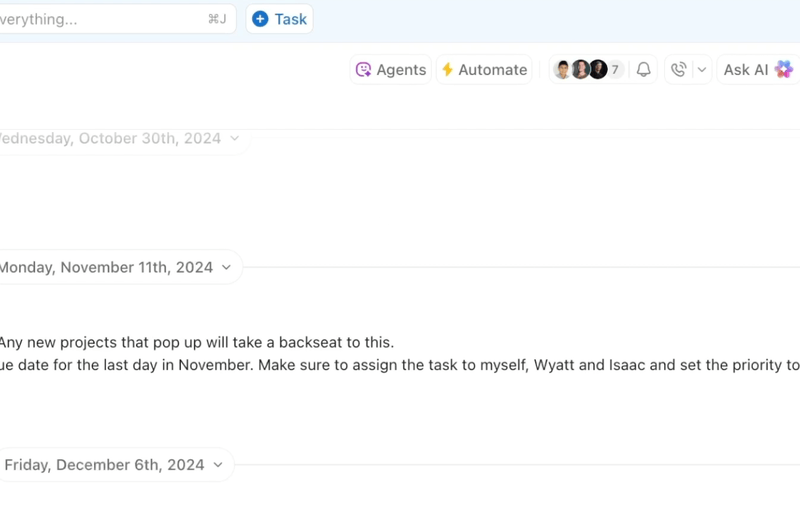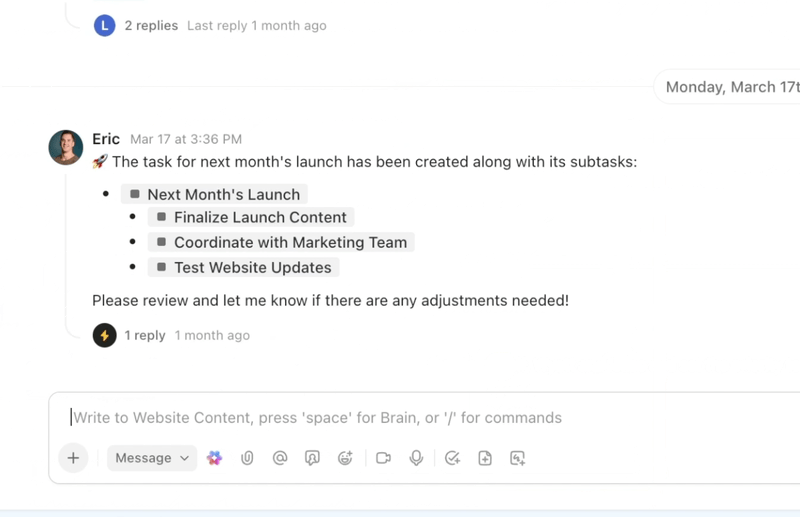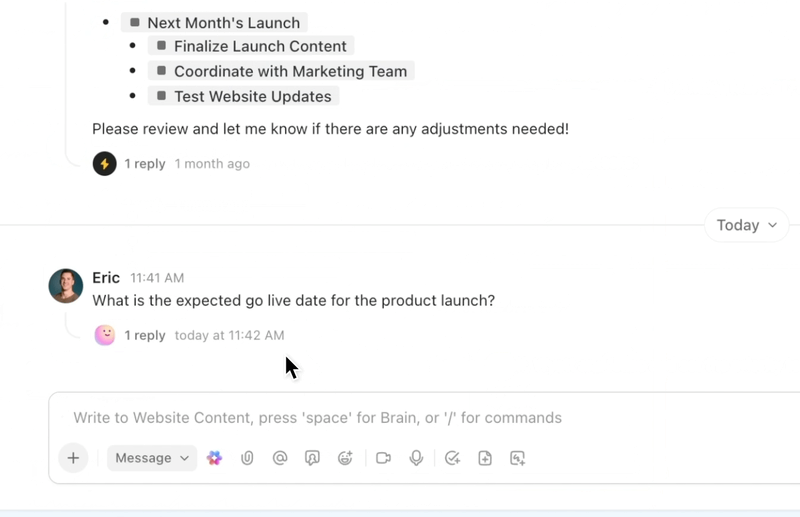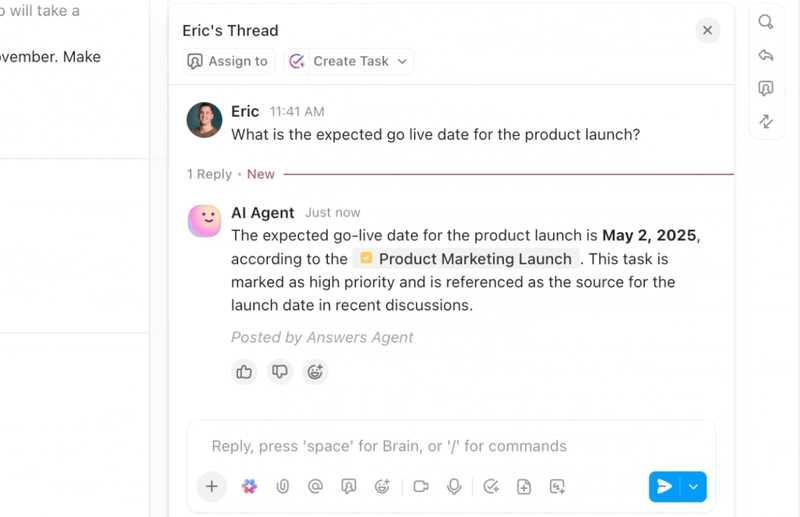
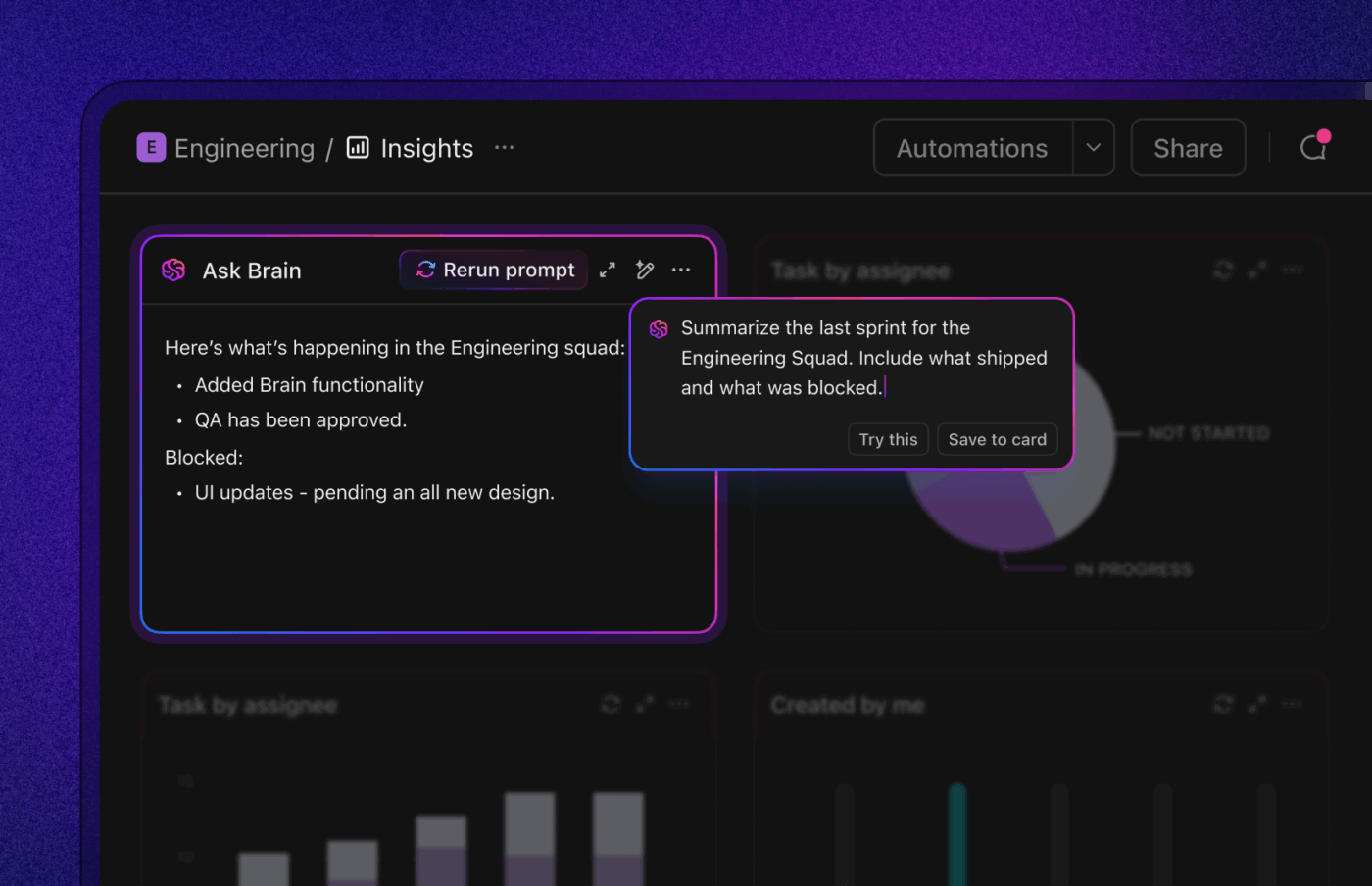
Ако искате оптимизиран, интелигентен работен процес за отстраняване на бъгове, ClickUp, приложението за всичко, свързано с работата, събира на едно място изкуствен интелект, автоматизация и помощ за работния процес.
ClickUp Brain незабавно извежда на преден план правилния контекст – обобщава дългите низове от бъгове, извлича стъпки за възпроизвеждане и подробности за средата от прикачените файлове, маркира вероятни дубликати и предлага следващи действия. Вместо да претърсват Slack, билетите и логовете, екипите получават чист, обогатен запис, по който могат да действат незабавно.
Автоматизацията и агентите на Autopilot в ClickUp поддържат работата без постоянна намеса. Грешките се препращат автоматично към подходящия екип, определят се отговорни лица, задават се SLA и крайни срокове, статусите се актуализират с напредъка на работата, а заинтересованите страни получават навременни известия.

Тези агенти могат дори да сортират и категоризират проблеми, да групират сходни доклади, да се позовават на исторически поправки, за да предложат вероятни начини за действие, и да ескалират спешни въпроси – така че MTTA и MTTR да намалеят дори при пикове в обема.
🛠️ Искате готов за употреба набор от инструменти? Шаблонът за проследяване на бъгове и проблеми на ClickUp е мощно решение от ClickUp for Software, създадено да помогне на екипите за поддръжка, инженеринг и продукти да се справят лесно с бъговете и проблемите в софтуера. С персонализирани изгледи като Списък, Табло, Натоварване, Формуляр и Времева линия, екипите могат да визуализират и управляват процеса на проследяване на бъгове по начин, който им подхожда най-добре.
20-те персонализирани статуса и 7-те персонализирани полета на шаблона позволяват създаването на персонализиран работен процес, който гарантира, че всеки проблем се проследява от откриването до разрешаването му. Вградените автоматизации се грижат за повтарящите се задачи, което освобождава ценно време и намалява ръчния труд.
💟 Бонус: Brain MAX е вашият AI-базиран спътник на работния плот, създаден да ускори разрешаването на бъгове с интелигентни и практични функции.
Когато срещнете бъг, просто използвайте функцията „говори към текст“ на Brain MAX, за да диктувате проблема – вашите гласови бележки се транскрибират незабавно и могат да бъдат прикачени към нов или съществуващ билет за бъг. Функцията „Enterprise Search“ претърсва всички ваши свързани инструменти – като ClickUp, GitHub, Google Drive и Slack – за да открие свързани доклади за бъгове, регистри за грешки, фрагменти от код и документация, така че да имате цялата необходима информация, без да превключвате между приложенията.
Имате нужда да координирате поправка? Brain MAX ви позволява да възложите грешката на подходящия разработчик, да зададете автоматични напомняния за актуализации на статуса и да проследявате напредъка – всичко това от вашия десктоп!
2. Sentry (най-доброто решение за засичане на грешки)
Sentry намалява MTTD и времето за възпроизвеждане, като записва грешки, следи и потребителски сесии на едно място. Групирането на проблеми, задвижвано от изкуствен интелект, намалява шума; правилата за „подозрителни ангажименти“ и собственост идентифицират вероятния собственик на кода, така че маршрутизирането е незабавно. Session Replay предоставя на инженерите точния път на потребителя и подробности за конзолата/мрежата, за да могат да възпроизведат проблема без безкрайни обсъждания.
Функциите на Sentry AI могат да обобщят контекста на проблема и, в някои случаи, да предложат Autofix пачове, които се позовават на проблемния код. Практическото въздействие: по-малко дублирани билети, по-бързо задаване и по-кратък път от доклада до работещия пач.
3. GitHub Copilot (най-подходящ за по-бързо преглеждане на код)
Copilot ускорява цикъла на отстраняване на грешки в редактора. Той обяснява следите на стека, предлага целеви кръпки, пише единични тестове, за да фиксира поправката, и създава скелети на скриптове за възпроизвеждане.
Copilot Chat може да прегледа проблемния код, да предложи по-безопасни рефактори и да генерира коментари или PR описания, които ускоряват прегледа на кода. В комбинация с необходимите прегледи и CI, той спестява часове от „диагностика → имплементиране → тестване“, особено за бъгове с ясен обхват и ясно възпроизвеждане.
4. Snyk от DeepCode AI (най-подходящ за откриване на модели)
Статичният анализ на DeepCode, задвижван от изкуствен интелект, открива дефекти и несигурни модели, докато пишете код и в PR. Той подчертава проблемните потоци, обяснява защо се появяват и предлага сигурни корекции, които пасват на вашите кодови идиоми.
Като откривате регресиите преди сливането и насочвате разработчиците към по-безопасни модели, вие намалявате честотата на появата на нови бъгове и ускорявате отстраняването на сложни логически грешки, които са трудни за откриване при преглед. Интеграциите на IDE и PR поддържат това близо до мястото, където се извършва работата.
5. Watchdog и AIOps на Datadog (най-подходящи за анализ на логове)
Watchdog на Datadog използва ML, за да открива аномалии в логовете, метриките, следите и мониторинга на реални потребители. Той съпоставя пиковете с маркери за внедряване, промени в инфраструктурата и топология, за да предложи вероятни основни причини.
За дефекти, които оказват влияние върху клиентите, това означава откриване за минути, автоматично групиране за намаляване на шума от предупрежденията и конкретни насоки за това къде да търсите. Времето за сортиране се намалява, защото започвате с „това внедряване засегна тези услуги и процентът на грешки се повиши на този крайни пункт“, вместо да започвате от нулата.
⚡️ Архив с шаблони: Безплатни шаблони за проследяване на проблеми и регистриране в Excel и ClickUp
6. New Relic AI (Най-доброто решение за идентифициране и обобщаване на тенденции)
Errors Inbox на New Relic групира сходни грешки в различните услуги и версии, а AI асистентът обобщава въздействието, подчертава вероятните причини и предоставя връзки към съответните следи/транзакции.
Корелациите при внедряването и интелигентната промяна на обектите правят очевидно кога вината е на скорошно пускане. За разпределените системи този контекст спестява часове на общуване между екипите и насочва грешката към правилния собственик с вече формирана солидна хипотеза.
7. Rollbar (Най-доброто за автоматизирани работни процеси)
Rollbar е специализирана в наблюдение на грешки в реално време с интелигентно отпечатване, за да групира дублиращите се грешки и да проследява тенденциите в появата им. Нейните AI-базирани обобщения и подсказки за основните причини помагат на екипите да разберат обхвата (засегнати потребители, засегнати версии), докато телеметрията и следите от стека дават бързи улики за възпроизвеждане.
Правилата за работния процес на Rollbar могат автоматично да създават задачи, да маркират сериозността и да ги препращат към собствениците, превръщайки шумните потоци от грешки в приоритетни опашки с прикачен контекст.
8. PagerDuty AIOps и автоматизация на runbook (Най-доброто от диагностиката с минимална намеса)
PagerDuty използва корелация на събития и ML-базирано намаляване на шума, за да превърне потока от сигнали в инциденти, които могат да бъдат разрешени.
Динамичното маршрутизиране незабавно препраща проблема към подходящия дежурен специалист, а автоматизацията на runbook може да стартира диагностика или мерки за смекчаване на последиците (рестартиране на услуги, отмяна на внедряване, превключване на функционален флаг) преди да се намеси човек. По отношение на времето за отстраняване на грешки, това означава по-кратко MTTA, по-бързи мерки за смекчаване на последиците за P0 и по-малко часове, загубени поради умора от аларми.
Основната идея е автоматизация и изкуствен интелект на всеки етап. Откривате по-рано, насочвате по-умно, стигате по-бързо до кода и съобщавате статуса, без да забавяте инженерите – всичко това води до значително намаляване на времето за отстраняване на грешки.
📖 Прочетете още: Как да използвате изкуствен интелект в DevOps
Реални примери за използване на изкуствен интелект за отстраняване на бъгове
Така че изкуственият интелект официално излезе от лабораторията. Той намалява времето за отстраняване на грешки в реалния свят.
Нека да видим как!
| Домейн / Организация | Как беше използвана изкуствената интелигентност | Въздействие/полза |
|---|---|---|
| Ubisoft | Разработихме Commit Assistant, AI инструмент, обучен на базата на десет години вътрешен код, който предвижда и предотвратява бъгове на етапа на кодиране. | Целта е да се намалят значително времето и разходите – традиционно до 70% от разходите за разработване на игри се изразходват за отстраняване на бъгове. |
| Razer (платформа Wyvrn) | Стартирахме QA Copilot (интегриран с Unreal и Unity), задвижван от изкуствен интелект, за автоматизиране на откриването на бъгове и генериране на QA отчети. | Повишава откриването на бъгове с до 25% и намалява времето за QA наполовина. |
| Google / DeepMind & Project Zero | Представихме Big Sleep, AI инструмент, който автономно открива уязвимости в сигурността на софтуер с отворен код като FFmpeg и ImageMagick. | Идентифицирани са 20 бъга, всички проверени от експерти и планирани за поправка. |
| Изследователи от Калифорнийския университет в Бъркли | Използвайки бенчмарк, наречен CyberGym, моделите на изкуствен интелект анализираха 188 проекта с отворен код, откривайки 17 уязвимости, включително 15 неизвестни „нулеви“ бъгове, и генерирайки експлойти за доказване на концепцията. | Демонстрира развиващите се възможности на изкуствения интелект в откриването на уязвимости и автоматизираното тестване за експлойти. |
| Spur (стартъп от Йейл) | Разработен е AI агент, който превежда описанията на тестовите случаи на обикновен език в автоматизирани процедури за тестване на уебсайтове – ефективно самописващ се QA работен процес. | Позволява автономно тестване с минимално човешко участие. |
| Автоматично възпроизвеждане на доклади за грешки в Android | Използвахме NLP + подсилващо обучение, за да интерпретираме езика на докладите за бъгове и да генерираме стъпки за възпроизвеждане на бъгове в Android. | Постигната е 67% точност, 77% възстановяване и възпроизвеждане на 74% от докладите за грешки, което надминава традиционните методи. |
Чести грешки при измерване на времето за отстраняване на бъгове
Ако измерването ви е неточно, планът ви за подобрение също ще бъде неточен.
Повечето „лоши резултати“ в работните процеси за отстраняване на грешки се дължат на неясни дефиниции, непоследователни работни процеси и повърхностен анализ.
Започнете с основите – какво се счита за стартиране/спиране, как се справяте с изчакванията и повторно отваряне – след това прочетете данните така, както ги възприемат вашите клиенти. Това включва:
❌ Неясни граници: Смесването на „Докладвани→Решени“ и „Докладвани→Затворени“ в един и същ табло (или преминаването от месец на месец) прави тенденциите безсмислени. Изберете една граница, документирайте я и я прилагайте във всички екипи. Ако имате нужда и от двете, публикувайте ги като отделни показатели с ясни етикети.
❌ Подход, основан само на средни стойности: Разчитането на средната стойност скрива реалността на опашките с няколко дълготрайни изключения. Използвайте медианата (P50) за „типичното“ време, P90 за предсказуемост/SLA и запазете средната стойност за планиране на капацитета. Винаги гледайте разпределението, а не само едно число.
❌ Без сегментиране: Обединяването на всички бъгове смесва инциденти P0 с козметични P3. Сегментирайте по тежест, източник (клиент срещу QA срещу мониторинг), компонент/екип и „ново срещу регресия“. Вашият P0/P1 P90 е това, което усещат заинтересованите страни; вашата медиана P2+ е това, около което инженерите планират.
❌ Пренебрегване на „паузираното“ време: Чакате ли клиентски логове, външен доставчик или прозорец за пускане? Ако не проследявате „Блокирано/Паузирано“ като първокласен статус, времето за разрешаване се превръща в спор. Докладвайте както календарното време, така и активното време, за да са видими пречките и да се прекратят споровете.
❌ Разлики в нормализирането на времето: Смесването на часови зони или преминаването от работно време към календарно време по време на процеса нарушава сравненията. Нормализирайте времевите отметки до една зона (или UTC) и решете веднъж дали SLA се измерват в работни или календарни часове; прилагайте това последователно.
❌ Неправилно въвеждане и дубликати: Липсваща информация за средата/създаването и дублиращи се билети удължават времето и объркват собствеността. Стандартизирайте задължителните полета при въвеждането, обогатявайте автоматично (регистри, версия, устройство) и премахвайте дублиращите се данни, без да нулирате часовника – затваряйте дублиращите се данни като свързани, а не като „нови“ проблеми.
❌ Несъвместими модели на състояния: Персонализираните състояния („QA Ready-ish“, „Pending Review 2“) скриват времето в състоянието и правят преходите между състоянията ненадеждни. Дефинирайте каноничен работен процес (Нов → Триаж → В процес → В преглед → Решен → Затворен) и проверете за състояния, които се отклоняват от пътя.
❌ Независимост от времето в статуса: Единствената цифра за „общо време“ не може да ви покаже къде се забавя работата. Записвайте и преглеждайте времето, прекарано в сортиране, преглед, блокиране и QA. Ако прегледът на кода P90 засенчва имплементацията, решението ви не е „по-бързо кодиране“, а деблокиране на капацитета за преглед.
🧠 Интересен факт: Последният AI Cyber Challenge на DARPA показа революционен скок в автоматизацията на киберсигурността. В състезанието участваха AI системи, проектирани да откриват, експлоатират и поправят уязвимости в софтуера автономно, без човешка намеса. Победителният отбор „Team Atlanta“ впечатляващо откри 77% от вкараните бъгове и успешно поправи 61% от тях, демонстрирайки силата на изкуствения интелект не само да намира недостатъци, но и активно да ги отстранява.
❌ Слепота към повторно отваряне: Третирането на повторно отваряне като нов бъг нулира часовника и завишава MTTR. Проследявайте честотата на повторно отваряне и „времето до стабилно затваряне“ (от първото съобщение до окончателното затваряне през всички цикли). Увеличаването на повторно отваряне обикновено сочи към слабо възпроизвеждане, пропуски в тестовете или неясна дефиниция на „завършено“.
❌ Без MTTA: Екипите са обсебени от MTTR и пренебрегват MTTA (време за потвърждаване/приемане на отговорност). Високото MTTA е ранен сигнал за дълго разрешаване. Измервайте го, задавайте SLA според сериозността и автоматизирайте маршрутизирането/ескалацията, за да го поддържате ниско.
❌ Изкуствен интелект/автоматизация без предпазни мерки: Ако оставите изкуственият интелект да определя степента на сериозност или да затваря дубликати без преглед, това може да доведе до неправилна класификация на крайни случаи и незабележимо изкривяване на показателите. Използвайте изкуствения интелект за предложения, изисквайте потвърждение от човек за P0/P1 и проверявайте месечно ефективността на модела, за да запазите надеждността на данните си.
Подобряване на тези процеси ще доведе до това, че графиките за времето за разрешаване на проблеми най-накрая ще отразяват реалността. Оттам нататък подобренията се натрупват: по-доброто приемане намалява MTTA, по-ясните състояния разкриват истинските пречки, а сегментираните P90 дават на лидерите обещания, които можете да спазите.
⚡️ Архив с шаблони: 10 шаблона за тестови случаи за тестване на софтуер
Най-добри практики за по-добро отстраняване на грешки
В обобщение, ето най-важните съвети, които трябва да имате предвид!
| 🧩 Най-добри практики | 💡 Какво означава това | 🚀 Защо е важно |
| Използвайте надеждна система за проследяване на грешки | Проследявайте всички докладвани грешки с помощта на централизирана система за проследяване на грешки. | Гарантира, че нито една грешка няма да бъде пропусната, и позволява видимост на състоянието на грешките в различните екипи. |
| Напишете подробни доклади за грешките | Включете визуален контекст, информация за операционната система, стъпки за възпроизвеждане и степен на сериозност. | Помага на разработчиците да отстраняват бъговете по-бързо, като им предоставя цялата необходима информация предварително. |
| Категоризирайте и приоритизирайте бъговете | Използвайте матрица за приоритети, за да сортирате бъговете според спешността и въздействието им. | Фокусира екипа върху критичните бъгове и спешните проблеми. |
| Използвайте автоматизираното тестване | Извършвайте тестове автоматично във вашия CI/CD пайплайн. | Поддържа ранното откриване и предотвратява регресиите. |
| Определете ясни указания за отчитане | Предоставяйте шаблони и обучение за това как да се докладват бъгове. | Това води до точна информация и по-гладка комуникация. |
| Проследявайте ключови показатели | Измервайте времето за разрешаване, изминалото време и времето за реакция. | Позволява проследяване и подобряване на производителността чрез използване на исторически данни. |
| Използвайте проактивен подход | Не чакайте потребителите да се оплакват – тествайте проактивно. | Повишава удовлетвореността на клиентите и намалява натоварването на поддръжката. |
| Използвайте интелигентни инструменти и машинно обучение | Използвайте машинно обучение, за да предвиждате бъгове и да предлагате решения. | Подобрява ефективността при идентифицирането на основните причини и отстраняването на бъгове. |
| Съгласувайте се със SLA | Спазвайте договорените споразумения за ниво на обслужване за отстраняване на грешки. | Изгражда доверие и отговаря на очакванията на клиентите в срок. |
| Преглеждайте и подобрявайте непрекъснато | Анализирайте повторно отворени бъгове, събирайте обратна връзка и оптимизирайте процесите. | Насърчава непрекъснатото усъвършенстване на процеса на разработка и управлението на грешки. |
Опростено отстраняване на грешки с контекстуална изкуствена интелигентност
Най-бързите екипи за отстраняване на грешки не разчитат на героични действия. Те проектират система: ясни дефиниции за стартиране/спиране, чисто приемане, приоритизиране на въздействието върху бизнеса, ясно разпределение на отговорностите и строги цикли на обратна връзка между поддръжката, QA, инженеринга и пускането на продукта.
ClickUp може да бъде този AI-базиран команден център за вашата система за отстраняване на бъгове. Централизирайте всеки доклад в една опашка, стандартизирайте контекста със структурирани полета и оставете ClickUp AI да сортира, обобщава и приоритизира, докато автоматизацията налага SLA, ескалира при закъснения и поддържа заинтересованите страни в синхрон. Свържете бъговете с клиенти, код и версии, така че мениджърите да виждат въздействието, а практиците да останат в потока.
Ако сте готови да намалите времето за отстраняване на бъгове и да направите плана си за действие по-предсказуем, регистрирайте се в ClickUp и започнете да измервате подобрението в дни, а не в тримесечия.
Често задавани въпроси
Какво е добро време за отстраняване на бъгове?
Няма едно единствено „добро“ число – то зависи от сериозността, модела на пускане и толерантността към риска. Използвайте медиани (P50) за „типична“ производителност и P90 за обещания/SLA, и сегментирайте по сериозност и източник.
Каква е разликата между отстраняване на бъгове и затваряне на бъгове?
Решаването е, когато поправката е приложена (например, кодът е обединен, конфигурацията е приложена) и екипът счита, че дефектът е отстранен. Закриването е, когато проблемът е проверен и официално приключен (например, QA е валидиран в целевата среда, пуснат или маркиран като „няма да се поправя/дублира“ с обосновка). Много екипи измерват и двете: „Докладвано→Решено“ отразява скоростта на инженеринга; „Докладвано→Закрито“ отразява цялостния поток на качеството. Използвайте последователни дефиниции, за да не се смесват етапите в таблото.
Каква е разликата между времето за отстраняване на бъгове и времето за откриване на бъгове?
Времето за откриване (MTTD) е времето, необходимо за откриване на дефект след възникването или доставката му – чрез мониторинг, QA или потребители. Времето за отстраняване е времето, необходимо от откриването/докладването до прилагането на корекцията (и, ако предпочитате, валидирането/освобождаването). Заедно те определят прозореца на въздействие върху клиента: бързо откриване, бързо потвърждаване, бързо отстраняване и безопасно освобождаване. Можете също да проследите MTTA (време за потвърждаване/разпределяне), за да откриете забавяния в сортирането, които често предсказват по-дълго разрешаване.
Как изкуственият интелект помага при отстраняването на бъгове?
Изкуственият интелект съкращава циклите, които обикновено отнемат много време: приемане, сортиране, диагностика, отстраняване и проверка.
- Приемане и сортиране: Автоматично обобщава дълги доклади, извлича стъпки/среда за възпроизвеждане, маркира дубликати и предлага степен на сериозност/приоритет, така че инженерите да започнат с ясен контекст (напр. ClickUp AI, Sentry AI).
- Маршрутизиране и SLA: Предсказва вероятния компонент/собственик, задава таймери и ескалира, когато MTTA или чакането за преглед се забавят, като по този начин намалява празното „време в статус“ (ClickUp Automations и работни процеси, подобни на тези на агентите).
- Диагностика: Групира сходни грешки, свързва пиковете с последните комити/релийзи и посочва вероятните основни причини с трасиране на стека и контекста на кода (Sentry AI и подобни).
- Приложение: Предлага промени в кода и тестове въз основа на модели от вашето хранилище, ускорявайки цикъла „написване/поправяне“ (GitHub Copilot; Snyk Code AI от DeepCode).
- Проверка и комуникация: пише тестови случаи от стъпки за възпроизвеждане, изготвя бележки за пускане и актуализации за заинтересованите страни и обобщава състоянието за ръководители и клиенти (ClickUp AI). Използвани заедно – ClickUp като командно център с Sentry/Copilot/DeepCode в стека – екипите намаляват времето за MTTA/P90, без да разчитат на героични усилия.