
De flesta tror att de måste välja mellan att använda kraftfulla AI-verktyg eller att hålla sina data privata. Men du kan faktiskt få båda delarna. Att köra AI lokalt innebär att data aldrig lämnar din hårdvara. Du behåller full kontroll över din information samtidigt som du automatiserar dina mest repetitiva uppgifter.
Den här guiden visar hur du använder lokal AI för säkra arbetsflöden med hjälp av verktyg som Ollama. Du lär dig hur du väljer open source-modeller som passar just din hårdvaruspecifikation. Och hur du bygger automatiserade arbetsflöden som bearbetar privata dokument lokalt.
Vi kommer också att titta på hur man centraliserar arbetsflöden i en samlad plattform som ClickUp. 😎
Vad är lokal AI?
Lokal AI innebär att du kör stora språkmodeller (LLM) helt och hållet på din egen hårdvara – till exempel din bärbara dator eller en lokal server – istället för att skicka dina data till externa molntjänster. Detta passar alla team som hanterar känslig information, från teknik- och produktdesign till juridik- och ekonomiavdelningar.
Med de flesta molnbaserade AI-verktyg skickas dina kommandon, dokument och data till tredjepartsservrar. Du förlorar kontrollen över hur den informationen bearbetas, lagras eller används.
Däremot håller lokal AI dina data inom din egen miljö. Du behåller fullständig kontroll över säkerheten och dataskyddet för dina arbetsflöden.
Naturligtvis finns det en avvägning. Att sätta upp lokal AI kräver mer tekniskt arbete och en initial investering i hårdvara. Men det eliminerar helt ditt beroende av externa leverantörer. Med inferens på enheten stannar din information precis där du vill ha den.
Varför lokal AI är viktigt för säkra arbetsflöden i team
🔎 Visste du att? Endast 1 av 10 konsumenter är villiga att dela känslig information, såsom finansiella uppgifter, kommunikationsdata eller biometriska data, med AI-drivna system.
Denna tveksamhet speglar en växande verklighet för B2B-team. Med molnbaserad AI överlämnar du i praktiken ditt företags immateriella rättigheter till en tredje part. För juridik-, ekonomi- eller HR-team innebär detta ett enormt ansvar.
Lokal AI förändrar denna dynamik genom att flytta AI till din egen hårdvara. Här är varför det är viktigt för din dagliga verksamhet:
- Eliminera dataläckage: Förhindra att proprietär kod eller privata kundavtal används för att träna en offentlig modell som dina konkurrenter kan komma att använda
- Upprätthåll regelefterlevnad: Håll dig inom ramarna för GDPR eller HIPAA eftersom känslig data aldrig passerar internationella gränser eller hamnar på en tredjepartsserver
- Bli oberoende av internet: Utför komplexa dataanalyser eller ritningsuppgifter under strömavbrott eller i miljöer med hög säkerhet där åtkomsten till molnet är begränsad
- Hantera kostnaderna på ett förutsägbart sätt: Undvik stigande API-avgifter när ditt team växer, eftersom din enda kostnad är den hårdvara du redan äger
Genom att integrera lokal AI med dina befintliga verktyg kan du automatisera ditt arbete utan att kompromissa med säkerheten.
⚠️ Det är dock viktigt att komma ihåg att detta problem kan förvärras. Ditt team kanske vill införa flera AI-verktyg, vilket kan leda till AI-spridning – en okontrollerad ökning av AI-verktyg utan överblick eller strategi. Detta kan leda till slöseri med pengar, dubbelarbete och säkerhetsrisker.
I slutändan breddar det din säkerhetshotmodell och gör arbetet svårare att spåra.
📮ClickUp Insight: Lågpresterande team är fyra gånger mer benägna att jonglera med 15 eller fler verktyg, medan högpresterande team upprätthåller effektiviteten genom att begränsa sin verktygslåda till nio eller färre plattformar. Men vad sägs om att använda en enda plattform? Som den allomfattande appen för arbete samlar ClickUp dina uppgifter, projekt, dokument, wikis, chattar och samtal på en enda plattform, komplett med AI-drivna arbetsflöden. Redo att arbeta smartare? ClickUp fungerar för alla team, gör arbetet synligt och låter dig fokusera på det som är viktigt medan AI sköter resten.
Vad behöver du för att köra lokal AI?
Du behöver ingen specialiserad superdator för att köra AI lokalt. De senaste förändringarna i hur modeller byggs gör att du kan komma igång med den hårdvara du redan har. Den behöver bara uppfylla några specifika kriterier.
Hårdvarukrav
Din hårdvara avgör storleken och hastigheten på de AI-modeller du kan använda. Medan en kraftfull maskin låter dig köra mer komplexa resonemangsmodeller har mindre modeller blivit förvånansvärt kapabla.
- GPU med VRAM: Ett dedikerat NVIDIA-kort med minst 12 GB VRAM är det bästa valet för de flesta team just nu. Det gör att du kan köra medelstora modeller som Llama 3.3 (8B) eller Mistral Small i hög hastighet
- System-RAM: Om du inte har ett avancerat grafikkort hanterar datorns RAM-minne belastningen. 32 GB ger dig tillräckligt med utrymme för att köra en modell samtidigt som du har webbläsaren och projektledningsverktygen öppna
- Unified memory (för Mac-användare): Om du använder en Mac med ett chip i M-serien (M2, M3 eller M4) delas ditt RAM-minne och GPU-minne. Detta gör Mac-datorer särskilt effektiva för lokal AI eftersom modellen kan komma åt hela minnespoolen
- Snabb lagring: Modeller är stora filer, ofta mellan 5 GB och 50 GB. Det är viktigt att använda en NVMe SSD för att undvika långa väntetider när du laddar en ny modell
🔎 Visste du att? Att bygga en PC är betydligt dyrare än för bara några månader sedan. Tidigare kostade ett 32 GB DDR5-minneskit under 130 dollar, men nu har priset på samma kit stigit till över 400 dollar. Denna förändring har gjort 32 GB till det nya absoluta minimumet för allt seriöst lokalt AI-arbete, eftersom du behöver tillräckligt med utrymme för att köra modeller utan att systemets prestanda kollapsar.
Programvarukrav
Programvaran fungerar som en bro mellan din hårdvara och AI:n. Du behöver inte längre vara utvecklare för att få detta att fungera.
- Operativsystem: Även om Linux är AI:s naturliga hemvist är Windows och macOS numera lika kapabla. Windows-användare kan använda WSL2 för en Linux-liknande miljö, även om många verktyg numera körs direkt på Windows
- Modellhanterare: Verktyg som Ollama eller LM Studio är den enklaste utgångspunkten. De sköter kvantiseringen – det vill säga komprimerar modellen så att den automatiskt passar på din hårdvara
- Drivrutiner: Du behöver de senaste drivrutinerna för din hårdvara, till exempel den senaste CUDA-drivrutinen för NVIDIA-kort. De flesta moderna installationsprogram kontrollerar detta åt dig under installationen
Alternativ för LLM med öppen källkod
Vi ser en explosion av öppna modeller som du kan ladda ner gratis. Dessa utvecklas av företag som Meta (Llama), Mistral och Alibaba (Qwen). Till skillnad från slutna system låter dessa modeller dig se exakt hur de fungerar och vart dina data tar vägen.
När du väljer en stor språkmodell bör du titta på programvarulicensen. De flesta använder Apache 2.0 eller MIT, vilket gör att du kan använda dem för affärsverksamhet utan månatlig abonnemangsavgift. Eftersom dessa modeller finns på din egen hårdvara integreras de direkt i dina privata arbetsflöden.
Du kan till exempel använda en lokal modell för att skriva utkast till interna e-postmeddelanden, sammanfatta mötesprotokoll eller analysera egna datamängder. På så sätt förblir dina mest känsliga projektdetaljer och strategiska anteckningar på din egen dator.
🧠 Rolig fakta: Apples chip i M-serien erbjuder en unik arkitektonisk fördel för team som fokuserar på integritet. Macs Unified Memory gör det möjligt för AI att använda hela systemets RAM-minne som om det vore dedikerat grafikkortminne.
Det innebär att en MacBook med 128 GB RAM kan köra stora, mycket avancerade modeller som normalt skulle kräva specialiserad företagshårdvara som kostar över 10 000 dollar.
De bästa lokala AI-modellerna för teamarbetsflöden
För att hitta rätt modell bör du matcha modellens styrkor med ditt teams uppgifter och hårdvarukapacitet.
Allmänna modeller
Dessa är arbetshästarna i din lokala installation. Använd dem för att skriva utkast till e-postmeddelanden, sammanfatta projektuppdateringar eller brainstorma kreativa idéer.
- Llama 4 Scout (17B): Har ett kontextfönster på 10 miljoner token, vilket gör att du kan bearbeta tusentals sidor text på en gång
- Mistral Small 4: Använder en arkitektur med en blandning av experter, vilket innebär att den endast aktiverar en bråkdel av sina parametrar för varje uppgift
- Qwen 3.5 (7B): Presterar konsekvent bättre om ditt team hanterar teknisk dokumentation på flera språk
Modeller för resonemang och verktygsanvändning
Använd dessa när du behöver LLM-agenterna för att lösa flerstegsproblem, följa komplex logik eller agera som en autonom agent inom dina arbetsflöden.
- Llama 4 Maverick: Den är multimodal från grunden. Detta gör den idealisk för team som behöver analysera komplexa diagram eller finansiella kalkylblad, där det visuella sammanhanget är lika viktigt som texten
- Phi-4 (14B): Anpassad för STEM och logiskt resonemang. Använd den för datavalidering eller komplexa matematiska uppgifter som vanligtvis kräver mycket större och dyrare modeller
- DeepSeek-R1: Visar sin interna tankekedja, vilket hjälper dig att verifiera dess logik för analyser med höga insatser. Perfekt för djupgående forskning och strategisk planering
Uppgiftsspecifika modeller
Ibland är ett specialiserat verktyg effektivare än en allmän assistent. Dessa modeller är optimerade för en specifik del av ditt arbetsflöde.
- Qwen 3-Coder-Next: Förstår logik på repositorienivå, vilket gör att den kan föreslå buggfixar eller omstrukturera kod över flera filer. Allt detta samtidigt som den följer ditt teams specifika stilguider
- Voxtral Mini: Identifierar olika talare i en inspelning och omvandlar inspelningar från privata möten till sökbar text. Fungerar helt offline, vilket är bra för att undvika dataläckage
- Nomic Embed v1.5: Omvandlar dina privata dokument till matematiska data för semantisk sökning. Detta gör att du kan söka i ditt teams interna kunskapsbas efter betydelse istället för bara nyckelord
📚 Läs även: LLM-sökmotorer: AI-driven informationssökning
Populära verktyg för att köra lokal AI
Du behöver inte längre vara mjukvaruutvecklare för att köra modeller på din egen dator. Flera användarvänliga program sköter nu den tekniska installationen åt dig på några minuter.
Ollama och OpenWebUI
Ollama är lämpligt om du vill ha snabbhet och flexibilitet. Det körs i bakgrunden och hanterar ditt modellbibliotek via ett enkelt gränssnitt.
Även om det börjar som ett grundläggande verktyg, kombinerar de flesta det med OpenWebUI. Detta ger en smidig chattupplevelse i din webbläsare som ser ut och känns som de molnbaserade verktyg du redan känner till. Det skapar också en lokal brygga för andra appar på din dator så att de kan kommunicera säkert med dina AI-modeller.
LM Studio
Om du föredrar en traditionell datorapplikation är LM Studio ett utmärkt alternativ. Det fungerar som en appbutik för AI. Du kan använda det för att söka efter, ladda ner och chatta med en ny modell med bara några få klick.
Appen har inbyggd hårdvaruidentifiering, så den konfigurerar automatiskt inställningarna efter just din GPU eller ditt RAM-minne. Det gör den till en utmärkt utgångspunkt om du vill experimentera med olika modeller utan att behöva skriva en enda rad kod.
GPT4All
För team som enbart fokuserar på integritet och dokumentanalys är GPT4All en pålitlig och enkel lösning. Den fungerar på nästan vilken dator som helst, inklusive äldre bärbara datorer som kanske inte har ett dedikerat grafikkort.
Den mest användbara funktionen är möjligheten att chatta direkt med dina lokala filer. Du kan peka ut en mapp på din hårddisk i appen, och AI:n kommer att svara på frågor om just de dokumenten. Allt utan att någonsin ladda upp dem till en tredjepartsserver.
Så här konfigurerar du lokal AI för säkra arbetsflöden
Denna genomgång använder Ollama eftersom det är ett verktyg med bred stöd för att bygga säkra, lokala AI-arbetsflöden.
Steg 1: Installera Ollama
Ladda ner installationsprogrammet från den officiella webbplatsen för ditt specifika operativsystem. Medan tidigare Windows-versioner krävde manuell installation av Linux-subsystemet, installeras den aktuella versionen som en inbyggd applikation.
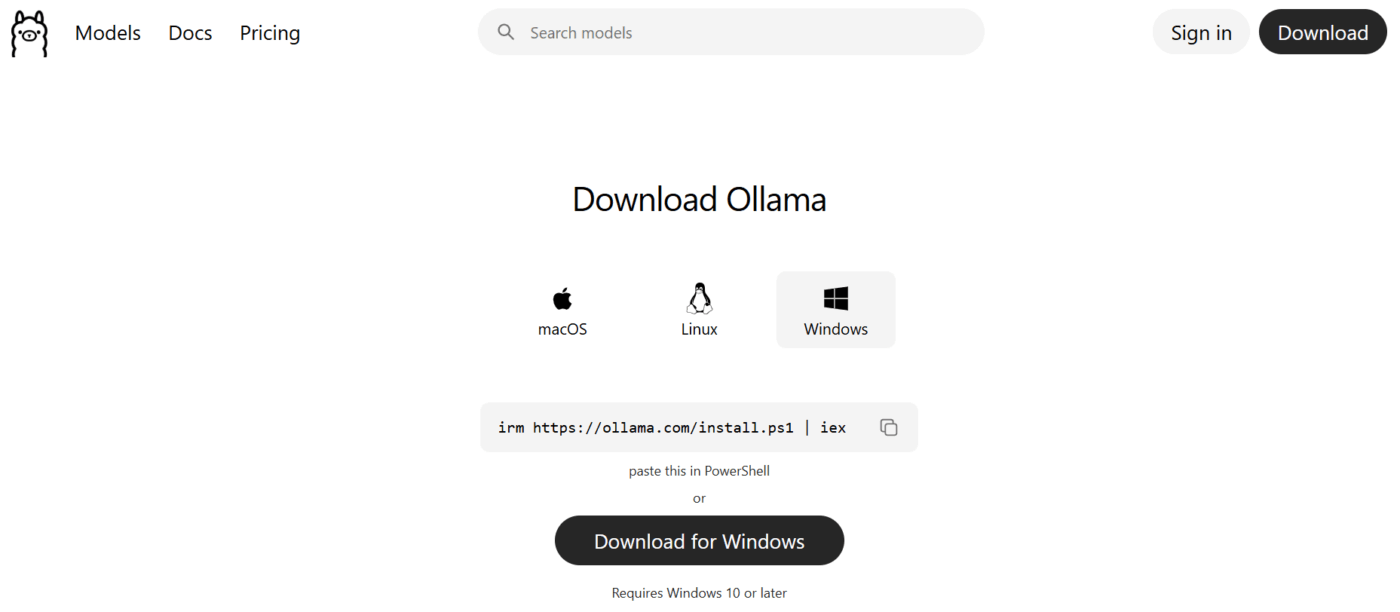
Installationen bör bara ta några minuter. När installationen är klar öppnar du terminalen eller kommandotolken och skriver ollama --version för att bekräfta att den är klar att användas.
Steg 2: Ladda ner och kör en modell
För att börja använda en AI måste du hämta dess vikter till din maskin. För ditt första test kan du prova en kompakt men kraftfull modell som Llama 3.2 (3B) eller den senaste Mistral.
Använd kommandot ollama run llama3.2 för att starta nedladdningen.
Beroende på din internethastighet tar detta vanligtvis några minuter. När nedladdningen är klar kan du skriva en kommando direkt i terminalen för att få ett omedelbart svar från modellen på din hårddisk.
Steg 3: Anslut till ditt arbetsflödesverktyg
Det verkliga värdet av lokal AI ligger i att integrera den i dina dagliga arbetsuppgifter. När Ollama körs startar det automatiskt en lokal server på http://localhost:11434. Detta skapar en säker bro som gör det möjligt för andra applikationer att kommunicera med din modell.
Eftersom denna server är kompatibel med standardprotokoll från OpenAI kan du ansluta den till automatiseringsplattformar eller interna skript genom att helt enkelt byta ut API-adressen. Du kan till exempel peka ett lokalt dokumentsökverktyg mot denna adress. Detta gör att det kan sammanfatta privata filer utan att någonsin skicka texten till molnet.
Bästa praxis för säkerhet i lokala AI-arbetsflöden
Att köra AI lokalt är ett stort steg framåt för integriteten. Att lagra data lokalt innebär dock att du nu är ansvarig för att skydda dem. Även om du har eliminerat risken för ett molnintrång från tredje part måste du fortfarande säkra din hårdvara och hur ditt team interagerar med modellerna.
Följ dessa bästa praxis:
- Nätverksisolering: Begränsa API-åtkomsten till betrodda interna nätverk så att din AI-server förblir oåtkomlig från det offentliga internet
- Validering av indata: Rensa all data innan den skickas till modellen. Detta blockerar dolda skadliga instruktioner i dokument eller e-postmeddelanden
- Åtkomstkontroll: Implementera autentisering på din AI-ändpunkt för att säkerställa att endast behöriga användare kan utlösa modellåtgärder
- Revisionsloggning: För register över alla modellinteraktioner för att underlätta efterlevnads- och säkerhetsutredningar
- Containerisolering: Kör dina modeller i sandboxade miljöer som Docker. Detta förhindrar att en potentiell säkerhetsöverträdelse når dina centrala systemfiler
- Regelbundna uppdateringar: Installera de senaste uppdateringarna för verktyg som Ollama för att skydda dig mot nyupptäckta sårbarheter
- Hastighetsbegränsning: För att förhindra att en enskild användare eller ett skript överbelastar din server med förfrågningar bör du implementera hastighetsbegränsning för att kontrollera hur många förfrågningar som kan göras under en viss tidsperiod
🔎 Visste du att? Promptbaserade manipulationer är inte längre ett teoretiskt hot. En färsk undersökning från Gartner visade att 32 % av organisationerna utsattes för en skadlig promptattack mot AI-applikationer under det senaste året. Dessa attacker kan manipulera din lokala modell så att den genererar partiska eller obehöriga resultat.
Hur du skapar säkra AI-arbetsflöden för ditt team
När din lokala server är igång kan du integrera den i ditt dagliga arbete. Detta förvandlar ett enkelt verktyg till en privat produktivitetsmotor. Det mest effektiva sättet att göra detta är genom Retrieval-Augmented Generation (RAG).
Denna process kopplar samman din lokala AI med en privat databas med dina egna filer. Du kan besvara frågor utifrån just ditt företags sammanhang utan att någonsin ladda upp en enda byte till molnet.
Du kan också utforma arbetsflöden med mänsklig inblandning där AI:ns arbete granskas av mänskliga teammedlemmar. Detta säkerställer noggrannhet samtidigt som det avsevärt påskyndar din produktion.
Här är några praktiska exempel:
- Dokumentanalys: Sammanfatta interna rapporter eller kundfeedback för att omedelbart få fram viktiga insikter
- Utkastgenerering: Skapa första versioner av e-postmeddelanden eller projektuppdateringar som teammedlemmarna kan finjustera
- Dataklassificering: Kategorisera inkommande uppgifter automatiskt utifrån det specifika innehållet i förfrågan
- Förberedelser inför mötet: Skapa diskussionspunkter genom att analysera relaterade projektfiler som är lagrade på din lokala hårddisk
- Kodgranskning: Få feedback på egenutvecklad källkod utan att exponera din immateriella egendom för tredje part
📮ClickUp Insight: Vår undersökning om AI-mognad visar att tillgången till AI på arbetsplatsen fortfarande är begränsad – 36 % av de tillfrågade har ingen tillgång alls, och endast 14 % uppger att de flesta anställda faktiskt kan experimentera med det. När AI kräver behörigheter, extra verktyg eller komplicerade installationer får teamen inte ens chansen att testa det i det verkliga, dagliga arbetet.
ClickUp Brain eliminerar alla dessa hinder genom att integrera AI direkt i det arbetsutrymme du redan använder. Du kan utnyttja flera AI-modeller, generera bilder, skriva eller felsöka kod, söka på webben, sammanfatta dokument och mycket mer – utan att byta verktyg eller tappa fokus.
Det är din AI-partner i din omgivning, enkel att använda och tillgänglig för alla i teamet.
Begränsningar vid användning av lokal AI för AI-arbetsflöden
Lokal AI är ett kraftfullt verktyg, men det är ingen mirakelkur för alla problem. Att förstå dess begränsningar hjälper dig att avgöra när du ska behålla en uppgift på din egen hårdvara och när du ska använda molnet. För vissa team kan de tekniska och ekonomiska avvägningarna överväga fördelarna med integriteten.
- Prestandagräns: De bästa proprietära modellerna har fortfarande en liten fördel när det gäller komplexa resonemang och kreativa nyanser jämfört med open source-versionerna
- Hårdvaruinvestering: Snabb prestanda för stora modeller kräver dyra GPU:er med betydande VRAM. Detta kan innebära höga initialkostnader för små team
- Underhållskostnader: Du ansvarar själv för alla programuppdateringar, felsökning av hårdvara och säkerhetsuppdateringar utan stöd från leverantörens supportteam
- Teknisk expertis: För att optimera en lokal miljö krävs praktisk kunskap om modellkvantisering och serverkonfiguration
- Säkerhetshantering: Till skillnad från molntjänster har lokala modeller inte inbyggd moderering. Du måste implementera egna innehållsfilter och skyddsmekanismer
- Strömförbrukning: Att köra storskaliga AI-modeller på dina egna servrar eller arbetsstationer kan avsevärt öka din elförbrukning och dina kylbehov
Många team använder en hybridstrategi: lokal AI för känslig data och molnbaserad AI för mindre känsliga uppgifter som kräver maximal kapacitet. Här är en snabb översikt över jämförelsen mellan de två:
| Faktor | Lokal AI | Moln-AI |
|---|---|---|
| Dataskydd | Full kontroll | Data som skickas till leverantören |
| Komplexitet vid installation | Högre | Sänk |
| Löpande kostnader | Hårdvara + el | Avgifter per token |
| Modellfunktioner | Bra, förbättras | Toppmodern |
| Underhåll | Självhanterad | Leverantörshanterat |
Hur ClickUp stöder säkra AI-drivna arbetsflöden
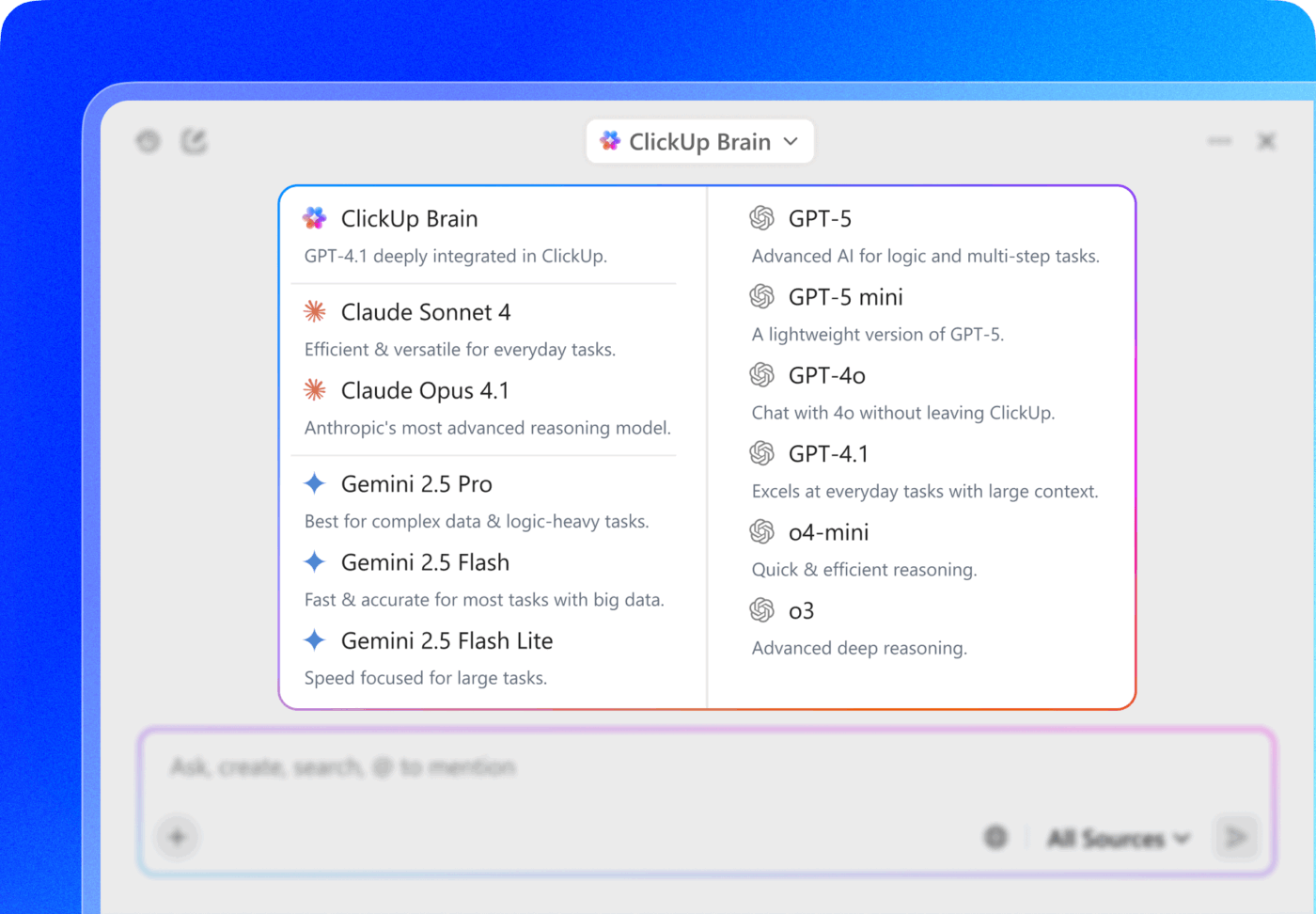
De flesta team står idag inför ett val: använda kraftfull molnbaserad AI och oroa sig för vart data tar vägen, eller sätta upp lokala modeller och hantera löpande kostnader. ClickUp kringgår detta dilemma genom att fungera som en konvergerad AI-arbetsyta – där AI:n redan finns inbyggd i det system där ditt arbete utförs.
ClickUp Brain är AI-lagret som är inbyggt direkt i ClickUps arbetsyta, utformat för att förstå dina uppgifter, dokument och teamkommunikation på ett och samma ställe. Det ger AI-stöd med full kontext – inga separata verktyg, inga bräckliga integrationer.
För team som vill bygga säkra AI-arbetsflöden är den kombinationen av sammanhang och kontroll skillnaden mellan experiment och verklig implementering.
🌟 ClickUp är dessutom SOC 2-certifierat och följer ISO 42001-standarderna för ansvarsfull AI-hantering. Detta säkerställer att dina data aldrig används för att träna tredjepartsmodeller, vilket gör att du kan automatisera ditt arbete med samma trygghet som i en lokal installation.
Få tillgång till sökfunktioner och autonoma arbetsflöden med ClickUp Brain
När dina data väl är säkra inom arbetsytan extraherar ClickUp Brain värde från dina uppgifter och dokument i realtid.
Eftersom AI:n är inbyggd undviker den den kontextklyfta som saktar ner lokala installationer. Du kan ställa frågor som kräver en fullständig överblick över din projekthistorik för att kunna besvaras korrekt:
- Identifiera de slutgiltiga besluten i en lång teknisk sammanfattning utan att behöva bläddra igenom olika versioner
- Skapa utkast till uppdateringar för intressenter utifrån kommentarer till uppgifter och statusändringar
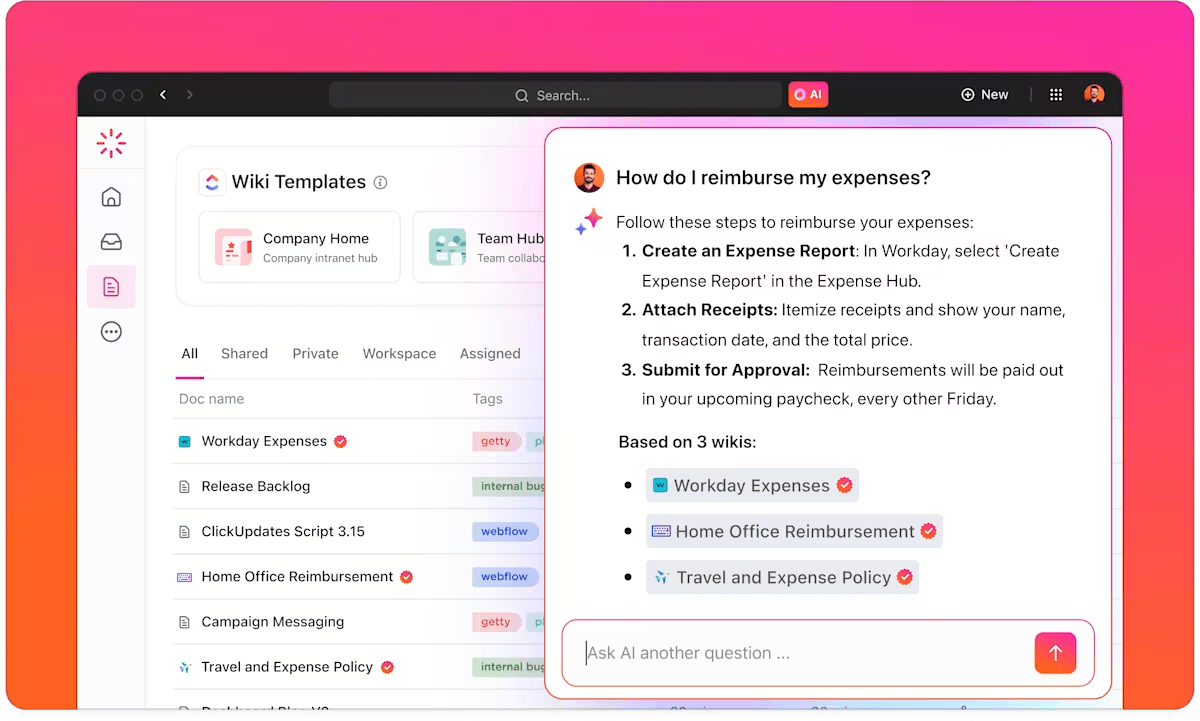
ClickUp Brain genererar svar baserade på data från din arbetsyta genom att analysera det specifika innehållet i dina dokument, uppgifter och chattar. Detta säkerställer att AI:n alltid har den senaste kontexten när ditt projekt utvecklas.
Detta gör det möjligt för ditt team att bygga vidare på insikter utan att manuellt behöva förklara projektets historik på nytt eller flytta data mellan verktyg som inte är sammankopplade.
💡Proffstips: Du kan utöka kontexten i din arbetsyta ännu mer genom att använda Enterprise AI Search för att hämta information från alla dina externa verktyg.
Ställ till exempel en djupgående fråga som ”Visa alla öppna affärer i pipelinen”, så söker ClickUp Brain igenom dina anslutna appar, inklusive Slack, Google Drive och Gmail, för att leverera ett pålitligt svar i realtid med källhänvisningar.
Detta omvandlar fragmenterade data på flera plattformar till ett enda, sökbart informationslager där du kan hitta vilken fil, vilket meddelande eller vilken uppgift som helst utan att någonsin behöva lämna din arbetsyta.
Hantera uppgifter på ett smart sätt med automatisering och AI
ClickUp Brain hjälper inte bara passivt – det arbetar aktivt inom ditt uppgiftssystem. Det kan:
- Skapa uppgifter från mötesanteckningar eller Docs
- Dela upp stora leveranser i deluppgifter
- Föreslå uppgiftsansvariga baserat på tidigare aktivitet
- Rekommendera deadlines baserat på projektets sammanhang
Det kan också uppdatera uppgiftsstatus, sammanfatta långa kommentartrådar till tydliga nästa steg och flagga hinder innan de bromsar upp utförandet.

I kombination med ClickUp Automation blir detta ett slutet system: AI kan utlösa arbetsflöden (som att tilldela uppgifter, meddela intressenter eller uppdatera prioriteringar) baserat på förändringar i ditt arbetsutrymme.
När ett dokument till exempel är färdigställt kan uppgifter skapas och tilldelas automatiskt utan att någon manuellt behöver flytta data mellan verktygen.
💟 Bonus: Gör ClickUp Brain MAX till ditt ”beslutsminne”.
Använd det för att:
- Sammanfatta långa kommentartrådar till tydliga beslut och nästa steg
- Uppdatera dokumentationen med ”vad som har ändrats och varför” efter viktiga milstolpar
- Skapa veckovisa beslutsloggar från uppgifter, möten och uppdateringar
Med tiden skapar detta ett levande lager av institutionell kunskap som Brain MAX kan hänvisa till. Istället för att svara på frågor isolerat börjar det alltså svara med medvetenhet om tidigare beslut, prioriteringar och mönster.
Det är då AI går från att vara hjälpsamt till att bli pålitligt – särskilt i säkra AI-arbetsflöden där sammanhang och spårbarhet är viktigt.
Få säker, kontextmedveten körning i stor skala med Super Agents
ClickUps Super Agents tar ClickUp Brain ett steg längre – från att assistera i arbetet till att aktivt driva det. Dessa agenter kan konfigureras för att övervaka arbetsflöden, vidta åtgärder och samordna uppgifter i hela ditt arbetsutrymme baserat på fördefinierade regler och realtidssammanhang.
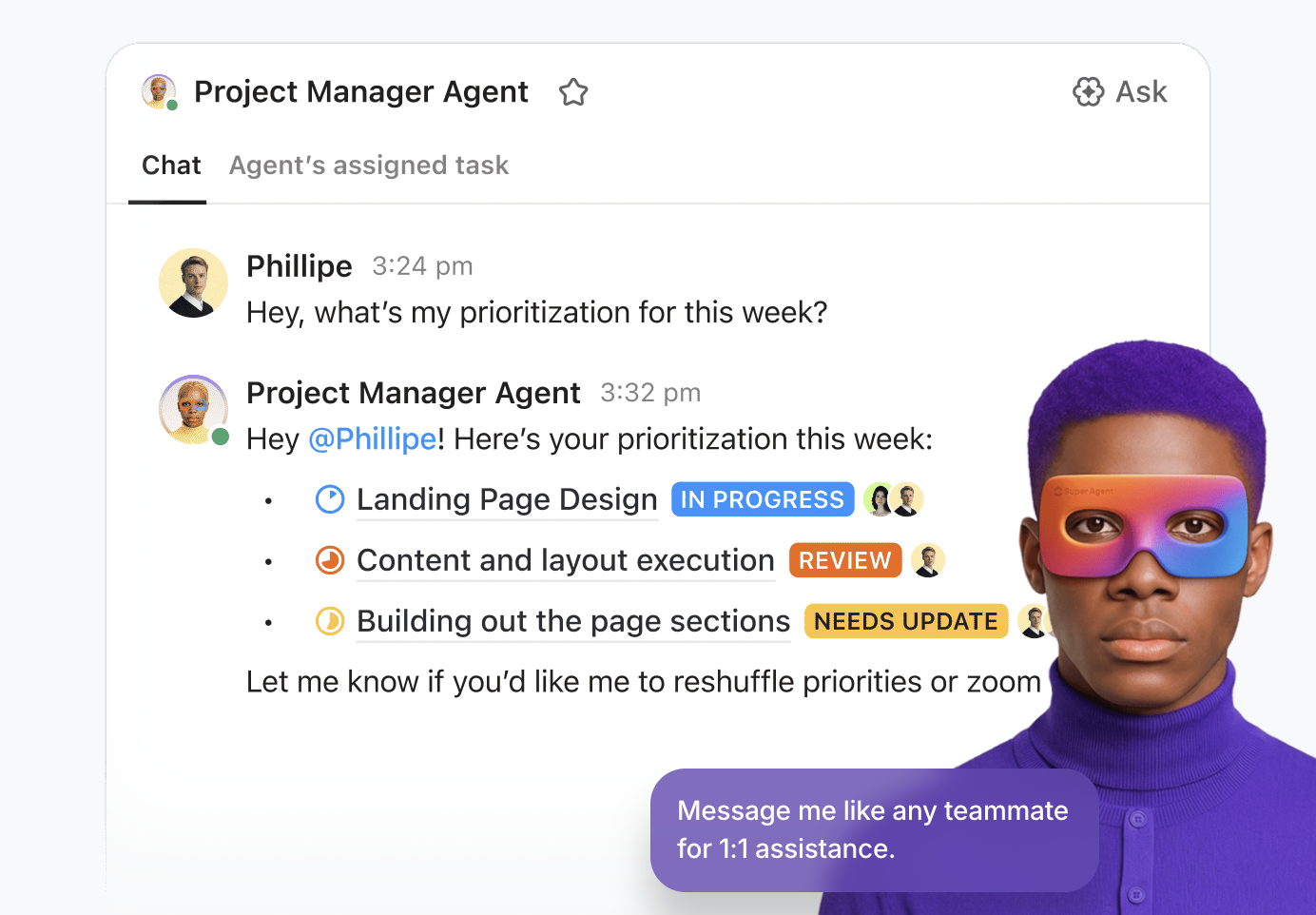
En Super Agent kan till exempel:
- Övervaka inkommande förfrågningar eller dokument och konvertera dem automatiskt till strukturerade uppgifter med ansvariga och deadlines
- Följ projektets framsteg och flagga risker eller förseningar innan de eskalerar
- Aktivera automatiseringar i flera steg när villkoren är uppfyllda – till exempel att meddela intressenter, uppdatera prioriteringar eller skapa uppföljningsuppgifter
Dessa agenter körs helt och hållet inom ClickUps enhetliga arbetsyta, med fullständig insyn i dina uppgifter, dokument och behörighetsstruktur. Det innebär:
- Du behöver inte exportera data till externa AI-system eller orkestreringsverktyg
- De får endast tillgång till data som de har behörighet att se
- De agerar inom samma behörighetsgränser som ditt team
Läs mer om hur du arbetar med Super Agents:
Dra nytta av AI-stöd i dina dokument
Med ClickUp Docs är AI-assistansen inbyggd direkt i dina dokumentationsarbetsflöden. Team kan utarbeta projektbeskrivningar, sammanfatta långa rapporter, extrahera åtgärdspunkter eller skriva om innehåll för olika målgrupper – allt utan att lämna plattformen.
Detta är viktigt för säkra AI-arbetsflöden eftersom en av de största riskerna uppstår när känslig information kopieras och klistras in i externa verktyg. I ClickUp minimerar du dataförflyttningen och behåller full kontroll över åtkomsten genom behörigheter.
Slutgiltigt omdöme: Bygga din egen privata AI-stack
Lokal AI utnyttjar artificiell intelligens samtidigt som du behåller full kontroll över dataintegritet och efterlevnad. Denna väg kräver dock betydande investeringar i hårdvara, teknisk installation och löpande underhåll.
Säkerhetsrutiner är fortfarande avgörande oavsett om du använder lokal eller molnbaserad AI. Den mest effektiva strategin innebär ofta en hybridlösning: att använda lokal AI för de mest känsliga operationerna samtidigt som du utnyttjar hanterade, säkra lösningar för den dagliga produktiviteten.
Det är viktigt att väga för- och nackdelar mot varandra – för många team är kanske inte den extra kostnaden för en egenbyggd lösning det rätta valet.
För dem som vill ha kraftfull AI-produktivitet utan infrastrukturbördan erbjuder hanterade lösningar som ClickUp Brain en övertygande medelväg. Det ger säkerhet i företagsklass utan någon komplexitet vid installationen.
Kom igång med ClickUp gratis och utforska säkra, kontextuella AI-drivna arbetsflöden för ditt team.
Vanliga frågor
Vad är skillnaden mellan lokal AI och molnbaserad AI för teamarbetsflöden?
Lokal AI körs helt och hållet på din egen hårdvara, vilket säkerställer att data aldrig lämnar ditt interna nätverk, medan molnbaserad AI skickar förfrågningar till tredjepartsservrar för bearbetning. Lokala installationer ger fullständig datasuveränitet och offlineåtkomst, medan molntjänster erbjuder högre datorkraft och användarvänlighet på bekostnad av direkt datakontroll.
Hur kan team använda lokala AI-modeller med konfidentiella projektdata?
Team kan använda lokal AI för att bearbeta känsliga dokument, proprietär kod och finansiella register genom att peka modellen mot privata lokala kataloger. Eftersom inferensen sker på enheten kan du utföra uppgifter som automatiserad sammanfattning, dataextrahering och interna kunskapssökningar utan att riskera exponering mot offentliga LLM-träningsuppsättningar.
Är lokala AI-modeller lika kapabla som ChatGPT när det gäller arbetsuppgifter?
Många lokala modeller med öppen källkod, såsom Llama 3 och Mistral, är nu mycket kapabla att hantera rutinmässiga arbetsuppgifter som utkast, kodning och sammanfattning. Medan molnmodeller i toppklass som GPT-4o fortfarande är ledande när det gäller extremt komplexa resonemang, erbjuder lokala modeller jämförbar prestanda för 90 % av den dagliga verksamheten med betydligt bättre integritet.
Vilka är för- och nackdelarna med att köra AI lokalt jämfört med att använda molnbaserade AI-tjänster?
Den främsta avvägningen är valet mellan fullständig dataintegritet med lokal AI och den underhållsfria skalbarheten hos molnbaserad AI. Att köra AI lokalt kräver en initial investering i hårdvara och teknisk expertis, men eliminerar återkommande API-avgifter och risker för dataläckage. Molnbaserad AI går snabbare att driftsätta men medför löpande abonnemangskostnader och beroende av data från tredje part.