

Det finns två typer av AI-assistenter: en som vet allt fram till förra veckan och en som vet vad som hände för en minut sedan.
Om du frågade den första AI-assistenten ”Är mitt flyg fortfarande försenat?” skulle den kanske svara utifrån gårdagens schema och kunna ha fel. Den andra assistenten, som drivs av uppdaterade data, kontrollerar liveuppdateringar och ger dig rätt svar.
Den andra assistenten är vad vi kallar live-kunskap, sett i praktiken.
Och det utgör grunden för agentiska AI-system – sådana som inte bara svarar på frågor, utan agerar, beslutar, samordnar och anpassar sig. Här ligger fokus på autonomi, anpassningsförmåga och målinriktat resonemang .
I den här bloggen utforskar vi vad live-kunskap innebär i AI-sammanhang, varför det är viktigt, hur det fungerar och hur du kan använda det i verkliga arbetsflöden.
Oavsett om du arbetar med drift, produkt, support eller ledarskap ger den här artikeln dig grunderna för att ställa rätt frågor, utvärdera system och förstå hur live-kunskap kan förändra din teknik och dina affärsresultat. Låt oss dyka in i ämnet.
Vad är live-kunskap i agentbaserad AI?
Live-kunskap avser information som är realtidsbaserad, uppdaterad och tillgänglig för ett AI-system i det ögonblick det behöver agera.
Det är en term som vanligtvis används i sammanhanget med agentisk och omgivande AI – AI-agenter som känner dina medarbetare, din kunskap, ditt arbete och dina processer så väl att de kan arbeta smidigt och proaktivt i bakgrunden.
Live-kunskap innebär att AI inte bara förlitar sig på den dataset den tränats på eller den ögonblicksbild av kunskap som fanns vid implementeringen. Istället fortsätter den att lära sig, kopplar upp sig mot aktuella dataflöden och anpassar sina åtgärder utifrån vad som faktiskt händer just nu.
När vi diskuterar detta i sammanhanget med AI-agenter (dvs. system som agerar eller fattar beslut) gör live-kunskap det möjligt för dem att uppfatta förändringar i sin omgivning, integrera ny information och välja efterföljande steg därefter.
Hur det skiljer sig från statiska träningsdata och traditionella kunskapsbaser
De flesta traditionella AI-system tränas på en fast dataset – såsom text, bilder eller loggar – och distribueras sedan. Och deras kunskap förändras inte om du inte tränar om eller uppdaterar dem.
Det är som att läsa en bok om datorer som publicerades på 90-talet och försöka använda en MacBook från 2025.
Traditionella kunskapsbaser (till exempel ditt företags FAQ-arkiv eller en statisk databas med produktspecifikationer) kan uppdateras regelbundet, men är inte utformade för att kontinuerligt strömma ny information och anpassa sig.
Live-kunskap skiljer sig åt eftersom den är kontinuerlig och dynamisk – din agent arbetar utifrån en live-feed istället för att förlita sig på en cachad kopia.
Kort sagt:
- Statisk träning = ”vad modellen visste när den byggdes”
- Live-kunskap = ”vad modellen vet när världen förändras, i realtid”
Förhållandet mellan live-kunskap och agenters autonomi
Agentiska AI-system är byggda för att göra mer än bara svara på frågor.
De kan:
- Samordna åtgärder
- Planera arbetsflöden i flera steg
- Arbeta med minimal mänsklig inblandning
För att göra detta effektivt behöver de en djup förståelse för det aktuella läget, inklusive systemstatus, de senaste affärsmätvärdena, kundkontexten och externa händelser. Det är precis vad live-kunskap ger.
Med hjälp av detta kan agenten känna av när förhållandena förändras, anpassa sitt beslutsförfarande och agera på ett sätt som överensstämmer med den aktuella verkligheten i verksamheten eller miljön.
Hur live-kunskap löser problem med spridda arbetsplatser och osammanhängande arbetsflöden
Live-kunskap – att ha realtidsåtkomst till information över alla dina verktyg – löser direkt vardagsproblem som orsakas av spridning på arbetsplatsen. Men vad är det egentligen?
Tänk dig att du arbetar med ett projekt och behöver den senaste feedbacken från kunden, men den är begravd i en e-posttråd medan projektplanen finns i ett separat verktyg och designfilerna finns i ännu en annan app. Utan live-kunskap slösar du tid på att växla mellan plattformar, be teammedlemmar om uppdateringar eller till och med missa viktiga detaljer.
Live-kunskap ger dig det bästa scenariot där du omedelbart kan söka och hitta feedback, se den senaste projektstatusen och få tillgång till de senaste designerna – allt på ett ställe, oavsett var data finns.
En marknadsföringschef kan till exempel samtidigt få tillgång till kampanjresultat från analysverktyg, granska kreativa tillgångar från en designplattform och kontrollera teamdiskussioner från chattappar. En supportagent kan se en kunds hela historik – e-postmeddelanden, ärenden och chattloggar – utan att behöva växla mellan olika system.
Det innebär mindre tid för att leta efter information, färre missade uppdateringar och snabbare, säkrare beslut. Kort sagt, live-kunskap kopplar samman din splittrade digitala värld, vilket gör det dagliga arbetet smidigare och mer produktivt.
Som världens första konvergerade AI-arbetsplats levererar ClickUps Live Intelligence AI Agent allt detta och ännu mer. Se hur det fungerar här. 👇🏼
Viktiga komponenter som möjliggör livekunskapssystem
Bakom varje livekunskapssystem ligger ett osynligt nätverk av rörliga delar: kontinuerlig inhämtning av data, koppling av källor och lärande från resultat. Dessa komponenter samverkar för att säkerställa att informationen inte bara lagras, utan flödar, uppdateras och anpassas i takt med att arbetet fortskrider.
I praktiken bygger live-kunskap på en blandning av dataförflyttning, integrationsintelligens, kontextuellt minne och feedbackdriven inlärning. Varje del har en specifik roll i att hålla din arbetsplats informerad och proaktiv snarare än reaktiv.
En av de största utmaningarna i dynamiska organisationer är arbetsutbredning. När teamen inför nya verktyg och processer kan kunskapen snabbt fragmenteras över plattformar, kanaler och format. Utan ett system som samlar och synliggör denna spridda information går värdefulla insikter förlorade och teamen slösar tid på att söka eller duplicera arbete. Live-kunskap hanterar direkt arbetsutbredning genom att kontinuerligt integrera och koppla samman information från alla källor, vilket säkerställer att kunskapen förblir tillgänglig, uppdaterad och användbar – oavsett dess ursprung. Detta enhetliga tillvägagångssätt förhindrar fragmentering och gör det möjligt för teamen att arbeta smartare, inte hårdare.
Här är en översikt över de centrala byggstenarna som gör detta möjligt och hur de används i praktiken:
| Komponent | Vad det gör | Så fungerar det |
|---|---|---|
| Datapipelines | Föra in nya data i systemet kontinuerligt | Datapipelines använder API:er, händelseströmmar och webhooks för att hämta eller skicka ny information från flera verktyg och miljöer. |
| Integrationslager | Koppla samman data från olika interna och externa system i en enhetlig vy. | Integrationslager synkroniserar information mellan appar som CRM-system, databaser och IoT-sensorer, vilket eliminerar silos och dubbelarbete. |
| Kontext- och minnessystem | Hjälp AI att komma ihåg vad som är relevant och glömma vad som inte är det. | Dessa system skapar ett ”arbetsminne” för agenterna, vilket gör att de kan behålla sammanhanget från senaste konversationer, åtgärder eller arbetsflöden samtidigt som de rensar bort föråldrade data. |
| Mekanismer för hämtning och uppdatering | Låt systemen få tillgång till den senaste informationen när den behövs. | Hämtningsverktyg hämtar data precis innan ett svar eller beslut fattas, vilket säkerställer att de senaste uppdateringarna används. Interna lagringsplatser uppdateras automatiskt med nya insikter. |
| Feedbackloopar | Möjliggör kontinuerligt lärande och förbättring utifrån resultat | Feedbackmekanismer granskar tidigare åtgärder med nya data, jämför förväntade resultat med faktiska resultat och justerar interna modeller därefter. |
Tillsammans förvandlar dessa komponenter AI från ”kunskap vid en viss tidpunkt” till ”kontinuerlig förståelse i realtid”.
Varför livekunskap är viktigt för AI-agenter
AI-system är bara så bra som den kunskap de agerar utifrån.
I moderna arbetsflöden förändras den kunskapen varje minut. Oavsett om det handlar om skiftande kundsentiment, föränderliga produktdata eller operativ prestanda i realtid, förlorar statisk information snabbt sin relevans.
Det är där live-kunskap blir avgörande.
Live-kunskap gör det möjligt för AI-agenter att övergå från passiva respondenter till anpassningsbara problemlösare. Dessa agenter synkroniseras kontinuerligt med verkliga förhållanden, känner av förändringar när de inträffar och anpassar sitt resonemang i realtid. Denna förmåga gör AI säkrare, mer tillförlitlig och mer anpassad till mänskliga mål i komplexa, dynamiska system.
Begränsningar med statisk kunskap i dynamiska miljöer
När AI-system endast använder statiska data (dvs. vad de visste vid tidpunkten för träningen eller senaste uppdateringen) riskerar de att fatta beslut som inte längre stämmer överens med verkligheten. Till exempel kan marknadspriserna ha förändrats, serverns prestanda ha försämrats eller produktens tillgänglighet ha förändrats.
Om en agent inte uppmärksammar och tar hänsyn till dessa förändringar kan det leda till felaktiga svar, olämpliga åtgärder eller, ännu värre, risker.
Forskning visar att i takt med att systemen blir allt mer autonoma blir beroendet av föråldrade data en betydande sårbarhet. AI-kunskapsbaser kan hjälpa till att överbrygga denna klyfta. Titta på den här videon för att lära dig mer om dem. 👇🏼
🌏 När chatbots inte har rätt live-kunskap:
Air Canadas AI-drivna virtuella assistent gav en kund felaktig information om flygbolagets policy för resor vid dödsfall. Kunden, Jake Moffatt, sörjde sin mormors död och använde chatboten för att fråga om rabatterade biljettpriser.
Chatboten informerade honom felaktigt om att han kunde köpa en biljett till fullt pris och ansöka om återbetalning av sorgrabatten inom 90 dagar. Moffatt litade på detta råd och bokade dyra flygbiljetter. Air Canadas faktiska policy krävde dock att en rabatterad sorgrabatt skulle begäras före resan och kunde inte tillämpas retroaktivt.
Verkliga scenarier där live-kunskap är avgörande
Air Canada är bara ett exempel. Här är fler scenarier där live-kunskap kan göra skillnad:
- Kundtjänstmedarbetare: En AI-assistent som inte kan kontrollera den senaste leveransstatusen eller lagernivån kommer att ge dåliga svar eller missa möjligheter att följa upp.
- Finansiella agenter: Aktiekurser, valutakurser eller ekonomiska indikatorer förändras varje sekund. En modell utan live-data kommer att ligga efter marknadens verklighet.
- Agenter inom hälso- och sjukvården: Patientövervakningsdata (hjärtfrekvens, blodtryck, laboratorieresultat) kan förändras snabbt. Agenter som inte har tillgång till färsk data kan missa varningssignaler.
- DevOps eller driftsagenter : Systemmetrik, incidenter, användarbeteende – förändringar här kan eskalera snabbt. Agenter behöver live-medvetenhet för att kunna meddela, åtgärda eller eskalera vid rätt tidpunkt.
Zillow stängde sin verksamhet inom fastighetsförmedling (Zillow Offers) efter att dess AI-modell för prissättning av bostäder misslyckades med att korrekt förutsäga den snabbt föränderliga bostadsmarknaden under pandemin, vilket ledde till stora ekonomiska förluster på grund av överbetalning för fastigheter. Detta belyser risken för modellavvikelser när ekonomiska indikatorer förändras snabbt.
Inverkan på agenters beslutsfattande och noggrannhet
När live-kunskap integreras blir agenterna mer tillförlitliga, exakta och snabba. De kan undvika ”föråldrade” beslut, minska fördröjningen vid upptäckt av förändringar och reagera på lämpligt sätt.
De bygger också förtroende: användarna vet att agenten "vet vad som pågår".
Ur ett beslutsfattarperspektiv säkerställer live-kunskap att "input" till agentens planering och åtgärder är giltiga för tillfället. Detta leder till bättre resultat, färre fel och mer flexibla processer.
Affärsvärde och konkurrensfördelar
För organisationer innebär övergången från statisk till live-kunskap i AI-agenter flera fördelar:
- Snabbare respons på förändringar: När din AI vet vad som händer just nu kan du agera snabbare.
- Personlig och uppdaterad interaktion: Kundupplevelsen förbättras när svaren återspeglar den senaste kontexten.
- Operativ motståndskraft: System som snabbt upptäcker avvikelser eller förändringar kan minska riskerna.
- Konkurrensfördel: Om dina agenter kan anpassa sig i realtid och andra inte kan det, får du en fördel i form av snabbhet och insikt.
Sammanfattningsvis är live-kunskap en strategisk förmåga för organisationer som vill ligga steget före förändringar.
Hur livekunskap fungerar: Kärnkomponenter
Live-kunskap står för live-arbetsflöden, medvetenhet och anpassningsförmåga.
När kunskap flödar i realtid hjälper det teamen att fatta snabbare och smartare beslut.
Så här fungerar livekunskapssystem bakom kulisserna, med hjälp av tre viktiga lager: realtidsdatakällor, integrationsmetoder och agentarkitektur.
Komponent 1: Realtidsdatakällor
Varje livekunskapssystem börjar med sina indata: data som kontinuerligt strömmar in från dina verktyg, appar och dagliga arbetsflöden. Dessa indata kan komma från praktiskt taget var som helst där ditt arbete utförs: en kund som skickar in ett supportärende i Zendesk, en säljare som uppdaterar affärsanteckningar i Salesforce eller en utvecklare som lägger upp ny kod på GitHub.
Även automatiserade system bidrar med signaler: IoT-sensorer rapporterar utrustningens prestanda, marknadsföringsdashboards tillhandahåller livekampanjstatistik och finansplattformar uppdaterar intäktssiffror i realtid.
Tillsammans bildar dessa olika dataströmmar grunden för live-kunskap: ett kontinuerligt, sammankopplat informationsflöde som speglar vad som händer just nu i ditt affärsekosystem. När ett AI-system kan komma åt och tolka dessa indata direkt går det bortom passiv datainsamling och blir en realtidssamarbetspartner som hjälper team att agera, anpassa sig och fatta beslut snabbare.
API:er och webhooks
API:er och webhooks är bindväven i den moderna arbetsplatsen. API:er möjliggör strukturerad datadelning på begäran.
ClickUp Integrations hjälper dig till exempel att hämta uppdateringar från Slack eller Salesforce på några sekunder. Webhooks går ett steg längre genom att automatiskt skicka uppdateringar när något ändras, vilket håller dina data uppdaterade utan att du behöver synkronisera manuellt. Tillsammans eliminerar de ”informationsfördröjningar” och säkerställer att ditt system alltid speglar vad som händer just nu.
Databasanslutningar
Realtidsanslutningar till databaser gör det möjligt för modeller att övervaka och reagera på operativa data allteftersom de utvecklas. Oavsett om det handlar om kundinsikter från ett CRM-system eller uppdateringar om framsteg från ditt projektledningsverktyg, säkerställer denna direkta pipeline att dina AI-beslut baseras på liveinformation som är korrekt.
Strömbehandlingssystem
Strömbehandlingssystem som Kafka och Flink omvandlar råa händelsedata till omedelbara insikter. Det kan innebära realtidsvarningar när ett projekt stannar upp, automatisk arbetsbelastningsbalansering eller identifiering av flaskhalsar i arbetsflödet innan de blir hinder. Dessa system ger teamen en pulskontroll på sina verksamheter medan de pågår.
Externa kunskapsbaser
Inget system kan fungera isolerat. Genom att ansluta till externa kunskapskällor – produktdokumentation, forskningsbibliotek eller offentliga datamängder – får live-system ett globalt sammanhang.
Det innebär att din AI-assistent inte bara förstår vad som händer på din arbetsplats, utan också varför det är viktigt i det större sammanhanget.
Komponent 2: Metoder för kunskapsintegration
När data väl flödar är nästa steg att integrera den i ett levande, dynamiskt kunskapslager som utvecklas kontinuerligt.
Dynamisk kontextinjektion
Kontext är den hemliga ingrediensen som förvandlar rådata till meningsfull insikt. Dynamisk kontextinjektion gör det möjligt för AI-system att införliva den mest relevanta och aktuella informationen – såsom senaste projektuppdateringar eller teamets prioriteringar – precis när beslut fattas. Det är som att ha en assistent som minns exakt vad du behöver i rätt ögonblick.
Se hur Brain Agent gör det inom ClickUp:
Mekanismer för hämtning i realtid
Traditionell AI-sökning bygger på lagrad information. Realtidsåtervinning går längre genom att kontinuerligt skanna och uppdatera anslutna källor och endast visa det mest aktuella och relevanta innehållet.
När du till exempel ber ClickUp Brain om en projektsammanfattning söker den inte igenom gamla filer – den hämtar istället nya insikter från de senaste live-uppgifterna.
Uppdateringar av kunskapsgrafen
Kunskapsgrafer kartlägger relationer mellan människor, uppgifter, mål och idéer. Genom att hålla dessa grafer uppdaterade i realtid säkerställer du att beroenden utvecklas i takt med dina arbetsflöden. När prioriteringar förändras eller nya uppgifter läggs till balanseras grafen automatiskt om, vilket ger teamen en tydlig och alltid korrekt bild av hur arbetet hänger ihop.
Kontinuerliga inlärningsmetoder
Kontinuerligt lärande gör det möjligt för AI-modeller att anpassa sig utifrån användarfeedback och förändrade mönster. Varje kommentar, korrigering och beslut blir träningsdata, vilket hjälper systemet att bli smartare när det gäller hur ditt team faktiskt arbetar.
Komponent 3: Agentarkitektur för live-kunskap
Det sista lagret, och ofta det mest komplexa, är hur AI-agenter hanterar, lagrar och prioriterar kunskap för att upprätthålla sammanhang och responsivitet.
Minneshanteringssystem
Precis som människor behöver AI veta vad den ska komma ihåg och vad den ska glömma. Minnesystem balanserar korttidsminne med långtidslagring, bevarar viktig kontext (som pågående mål eller kundpreferenser) och filtrerar bort irrelevant information. Detta håller systemet skarpt och förhindrar överbelastning.
Optimering av kontextfönster
Kontextfönster definierar hur mycket information en AI kan "se" samtidigt. När dessa fönster är optimerade kan agenter hantera långa, komplexa interaktioner utan att tappa bort viktiga detaljer. I praktiken innebär detta att din AI kan återkalla hela projekthistoriker och konversationer – inte bara de senaste meddelandena – vilket möjliggör mer exakta och relevanta svar.
Men när organisationer börjar använda fler AI-verktyg och agenter uppstår en ny utmaning: AI-spridning. Kunskap, åtgärder och sammanhang kan fragmenteras mellan olika bots och plattformar, vilket leder till inkonsekventa svar, dubbelarbete och förlorade insikter. Live knowledge löser detta genom att samla information och optimera sammanhangsfönster i alla AI-system, så att varje agent hämtar information från en enda, uppdaterad källa. Detta tillvägagångssätt förhindrar fragmentering och gör det möjligt för din AI att leverera konsekvent och omfattande support.
Prioritering av information
All kunskap förtjänar inte samma uppmärksamhet. Intelligent prioritering säkerställer att AI fokuserar på det som verkligen är viktigt: brådskande uppgifter, förändrade beroenden eller större prestandaförändringar. Genom att filtrera efter påverkan förhindrar systemet överbelastning av data och ökar tydligheten.
Cachestrategier
Hastighet driver adoption. Genom att cacha information som används ofta, såsom senaste kommentarer, uppdateringar av uppgifter eller prestationsmått, möjliggörs omedelbar åtkomst samtidigt som systembelastningen minskas. Detta innebär att ditt team får en smidig samverkan i realtid utan fördröjning mellan handling och insikt.
Live-kunskap förvandlar arbetet från reaktivt till proaktivt. När realtidsdata, kontinuerligt lärande och intelligent agentarkitektur samverkar slutar dina system att hamna på efterkälken.
Det är grunden för snabbare beslut, färre blinda fläckar och ett mer sammankopplat AI-ekosystem.
📮ClickUp Insight: 18 % av våra undersökningsdeltagare vill använda AI för att organisera sina liv genom kalendrar, uppgifter och påminnelser. Ytterligare 15 % vill att AI ska hantera rutinuppgifter och administrativt arbete.
För att göra detta måste en AI kunna: förstå prioritetsnivåerna för varje uppgift i ett arbetsflöde, utföra nödvändiga steg för att skapa eller justera uppgifter och konfigurera automatiserade arbetsflöden.
De flesta verktyg har ett eller två av dessa steg utarbetade. ClickUp har dock hjälpt användare att konsolidera upp till 5+ appar med hjälp av vår plattform med ClickUp Brain MAX!
Typer av livekunskapssystem
I det här avsnittet kommer vi att fördjupa oss i de olika arkitektoniska mönstren för att leverera live-kunskap till AI-agenter – hur data flödar, när agenten får uppdateringar och vilka avvägningar som måste göras.
Pull-baserade system
I en pull-baserad modell begär agenten data när den behöver det. Tänk på det som en elev som räcker upp handen mitt i en lektion: ”Hur är vädret just nu?” eller ”Hur ser det senaste lagerläget ut?” Agenten skickar en förfrågan till en livekälla (API, databas) och använder resultatet i nästa steg i sitt resonemang.
👉🏽 Varför använda pull-baserat? Det är effektivt när agenten inte alltid behöver live-data i varje ögonblick. Du slipper att kontinuerligt strömma in all data, vilket kan vara kostsamt eller onödigt. Det ger också mer kontroll: du bestämmer exakt vad som ska hämtas och när.
👉🏽 Nackdelar: Det kan medföra fördröjningar – om dataförfrågan tar tid kan agenten vänta och svara långsammare. Du riskerar också att missa uppdateringar mellan omröstningarna (om du bara kontrollerar periodiskt). Till exempel kan en kundsupportagent bara hämta API:et för leveransstatus när en kund frågar "Var är min beställning?" istället för att upprätthålla en konstant livefeed av leveranshändelser.
Push-baserade system
Här, istället för att vänta på att agenten ska fråga, skickar systemet uppdateringar till agenten så fort något förändras. Det är som att prenumerera på nyhetsnotiser: när något händer får du omedelbart ett meddelande. För en AI-agent som använder live-kunskap innebär detta att den alltid har uppdaterad kontext när händelserna utvecklas.
👉🏽 Varför använda push-baserat? Det ger minimal latens och hög responsivitet eftersom agenten är medveten om förändringar när de inträffar. Detta är värdefullt i höghastighets- eller högriskkontexter (t.ex. finansiell handel, systemhälsoövervakning).
👉🏽 Nackdelar: Det kan vara dyrare och mer komplicerat att underhålla. Agenten kan få många uppdateringar som är irrelevanta, vilket kräver filtrering och prioritering. Du behöver också en robust infrastruktur för att hantera kontinuerliga strömmar. Till exempel får en DevOps AI-agent webhook-varningar när serverns CPU-användning överskrider ett tröskelvärde och initierar en skalningsåtgärd.
Hybridmetoder
I praktiken kombinerar de mest robusta live-kunskapssystemen både pull- och push-metoder. Agenten prenumererar på kritiska händelser (push) och hämtar ibland bredare kontextuell data när det behövs (pull).
Denna hybridmodell hjälper till att skapa en balans mellan responsivitet och kostnad/komplexitet. I ett scenario med försäljningsagenter kan AI till exempel få push-meddelanden när en potentiell kund öppnar ett förslag, samtidigt som den hämtar CRM-data om kundens historik när den utformar sin nästa kontakt.
Händelsestyrda arkitekturer
Både push- och hybridsystem bygger på konceptet händelsestyrd arkitektur.
Här är systemet uppbyggt kring händelser (affärstransaktioner, sensoravläsningar, användarinteraktioner) som utlöser logikflöden, beslut eller statusuppdateringar.
Enligt branschanalyser håller streamingplattformar och ”streaming lakehouses” på att bli exekveringslager för agentbaserad AI, vilket suddar ut gränsen mellan historiska data och live-data.
I sådana system sprids händelser genom pipelines, berikas med kontext och matas in i agenter som resonerar, agerar och sedan eventuellt avger nya händelser.
Live-kunskapsagenten blir därmed en nod i en realtidsfeedbackslinga: uppfatta → resonera → agera → uppdatera.
👉🏽 Varför detta är viktigt: Med händelsestyrda system är live-kunskap inte bara ett tillägg – det blir en integrerad del av hur agenten uppfattar och påverkar verkligheten. När en händelse inträffar uppdaterar agenten sin världsmodell och reagerar därefter.
👉🏽 Avvägningar: Det kräver design för samtidighet, latens, händelseordning, felhantering (vad händer om en händelse går förlorad eller försenas?) och ”vad händer om”-logik för scenarier som inte förutsetts.
Implementering av live-kunskap: Tekniska tillvägagångssätt
Att bygga live-kunskap innebär att utveckla intelligens som ständigt utvecklas. Bakom kulisserna väver organisationer samman API:er, streamingarkitekturer, kontextmotorer och anpassningsbara inlärningsmodeller för att hålla informationen aktuell och användbar.
I det här avsnittet undersöker vi hur dessa system fungerar: teknikerna som möjliggör realtidsmedvetenhet, arkitekturmönstren som gör det skalbart och de praktiska steg som teamen tar för att övergå från statisk kunskap till kontinuerlig, live-intelligens.
Retrieval-Augmented Generation (RAG) med live-datakällor
En vanlig metod är att kombinera en stor språkmodell (LLM) med ett live-hämtningssystem, ofta kallat RAG.
I RAG-användningsfall, när agenten behöver svara, utför den först ett hämtningssteg: den söker i uppdaterade externa källor (vektordatabaser, API:er, dokument). Därefter använder LLM den hämtade datan (i sin prompt eller sitt sammanhang) för att generera resultatet.
För live-kunskap är hämtningskällorna inte statiska arkiv – de är kontinuerligt uppdaterade, live-flöden. Detta säkerställer att modellens resultat återspeglar den aktuella situationen i världen.
Implementeringssteg:
- Identifiera livekällor (API:er, strömmar, databaser)
- Indexera eller gör dem sökbara (vektordatabas, kunskapsgraf, relationsdatabas)
- Vid varje agentaktivering: hämta relevanta poster från den senaste tiden och infoga dem i prompten/kontexten.
- Generera svar
- Uppdatera valfritt minne eller kunskapslager med nya upptäckta fakta.
MCP-servrar och realtidsprotokoll
Nyare standarder, såsom Model Context Protocol (MCP), syftar till att definiera hur modeller interagerar med live-system: dataändpunkter, AI-verktyg, samtal och kontextuellt minne.
Enligt en vitbok kan MCP spela samma roll för AI som HTTP en gång gjorde för webben (koppla samman modeller med verktyg och data).
I praktiken innebär detta att din agentarkitektur kan ha:
- En MCP-server som hanterar inkommande förfrågningar från modell- eller agentlagret
- Ett servicelager som kopplar samman interna/externa verktyg, API:er och live-dataströmmar.
- Ett kontextstyrningslager som upprätthåller status, minne och relevant aktuell data.
Genom att standardisera gränssnittet gör du systemet modulärt – agenter kan ansluta olika datakällor, verktyg och minnesdiagram.
Uppdateringar av vektordatabasen
När det gäller live-kunskap har många system en vektordatabas (inbäddningar) vars innehåll uppdateras kontinuerligt.
Inbäddningar representerar nya dokument, live-datapunkter och entitetstillstånd. Så återhämtningen är aktuell. När till exempel nya sensordata anländer konverterar du dem till en inbäddning och infogar dem i vektorlagret, så att efterföljande frågor tar hänsyn till dem.
Implementeringsöverväganden:
- Hur ofta bäddar du in live-data på nytt?
- Hur raderar du föråldrade inbäddningar?
- Hur undviker du överbelastning av vektorlagret och säkerställer snabb sökning?
API-orkestreringsmönster
Agenter anropar sällan en enda API; de anropar ofta flera slutpunkter i sekvens eller parallellt. Implementeringar av live-kunskap kräver samordning. Till exempel:
- Steg 1: Kontrollera API:et för live-inventering
- Steg 2: Om lagret är lågt, kontrollera leverantörens ETA API
- Steg 3: Skapa kundmeddelanden baserat på kombinerade resultat
Detta samordningslager kan inkludera caching, omförsökslogik, hastighetsbegränsning, fallbacks och dataaggregering. Utformningen av detta lager är avgörande för stabilitet och prestanda.
Verktygsanvändning och funktionsanrop
I de flesta AI-ramverk använder agenter verktyg för att vidta åtgärder.
Ett verktyg är helt enkelt en fördefinierad funktion som agenten kan anropa, till exempel get_stock_price(), check_server_status() eller fetch_customer_order().
Moderna LLM-ramverk gör detta möjligt genom funktionsanrop, där modellen bestämmer vilket verktyg som ska användas, skickar rätt parametrar och får ett strukturerat svar som den kan resonera över.
Live-kunskapsagenter tar detta ett steg längre. Istället för statiska eller simulerade data ansluter deras verktyg direkt till realtidskällor – live-databaser, API:er och händelseströmmar. Agenten kan hämta aktuella resultat, tolka dem i sitt sammanhang och agera eller svara omedelbart. Denna bro mellan resonemang och verkliga data är det som förvandlar en passiv modell till ett anpassningsbart, kontinuerligt medvetet system.
Implementeringssteg:
- Definiera verktygsfunktioner som omfattar live-datakällor (API:er, databaser)
- Se till att agenten kan välja vilket verktyg som ska anropas och ta fram argument.
- Fånga upp verktygsutdata och integrera dem i resonemangskontexten.
- Säkerställ loggning, felhantering och fallback (vad händer om verktyget slutar fungera?).
📖 Läs mer: MCP vs. RAG vs. AI-agenter
Användningsfall och tillämpningar
Live-kunskap går snabbt från att vara ett koncept till att bli en konkurrensfördel.
Från projektkoordinering i realtid till anpassningsbar kundsupport och prediktivt underhåll – organisationer ser redan konkreta vinster i form av snabbhet, noggrannhet och framsynthet.
Nedan följer några av de mest intressanta sätten som live-kunskap används på idag och hur det omdefinierar vad ”intelligent arbete” egentligen innebär i praktiken.
Kundtjänstmedarbetare med live-produktlager
Inom detaljhandeln kan en supportchattbot kopplad till live-lager- och leveranssystem svara på frågor som "Finns det i lager?", "När levereras det?" eller "Kan jag få expressleverans?".
Istället för att förlita sig på statiska FAQ-data (som kan visa "slut i lager" även när varor just har kommit in) frågar agenten realtidslager och leverans-API:er.
Finansiella agenter med marknadsdataflöden
Finansiella arbetsflöden kräver omedelbar informationshämtning.
En AI-agent som är ansluten till marknadsdata-API:er (aktiekurser, valutakurser, ekonomiska indikatorer) kan övervaka förändringar i realtid och antingen varna mänskliga handlare eller agera autonomt inom definierade parametrar.
Live-kunskapslagret är det som skiljer en enkel analytisk instrumentpanel (statiska rapporter) från en autonom agent som känner av en plötslig värdeminskning och utlöser en säkring eller handel.
Bank of Americas virtuella assistent, ”Erica”, visar framgångsrikt värdet av att använda realtidsdata för AI-agenter inom finanssektorn. Den hanterar hundratals miljoner kundinteraktioner varje år genom att få tillgång till aktuell kontoinformation, ge personlig och omedelbar vägledning om ekonomi, hjälpa till med transaktioner och hantera budgetar.
Hälso- och sjukvårdsagenter med patientövervakning
Inom hälso- och sjukvården innebär live-kunskap att man ansluter till patientsensorer, medicinsk utrustning, elektroniska patientjournaler (EHR) och strömmar vitala tecken.
En AI-agent kan övervaka en patients hjärtfrekvens, syrenivå och laboratorieresultat i realtid, jämföra dem med tröskelvärden eller mönster och varna läkare eller vidta rekommenderade åtgärder (t.ex. eskalera tillståndet). Varningssystem som drivs av live-dataanalys hjälper redan till att identifiera sepsis eller hjärtsvikt betydligt tidigare än traditionella metoder.
Nvidia utvecklar till exempel en AI-agentplattform för företag som driver uppgiftsspecifika agenter – inklusive en som är utformad för Ottawa Hospital för att hjälpa patienter dygnet runt. Agenten guidar patienterna genom förberedelserna inför operationen, återhämtningen efter operationen och rehabiliteringsstegen.
Som Kimberly Powell, vice vd och chef för hälso- och sjukvårdsavdelningen på Nvidia, förklarar är målet att frigöra tid för klinikerna och samtidigt förbättra patientupplevelsen.
DevOps-agenter med systemmetrik
Inom IT-drift övervakar live-kunskapsagenter loggar, telemetri, infrastrukturhändelser och API:er för servicestatus. När latensen ökar, fel uppstår eller resurser tar slut kan agenten utlösa åtgärder – starta om en tjänst, öka kapaciteten eller omdirigera trafiken. Eftersom agenten hela tiden är medveten om systemets aktuella status kan den agera mer effektivt och minska driftstopp.
Säljagenter med CRM-integration
Inom försäljning innebär live-kunskap att koppla en agent till CRM, kommunikationsplattformar och senaste lead-aktivitet.
Föreställ dig en säljassistent som övervakar när en potentiell kund öppnar ett förslag och sedan uppmanar säljaren: ”Ditt förslag har just visats. Vill du boka en uppföljning nu?” Agenten kan hämta live-engagemangsdata, leadkontext, historiska vinstprocent – allt dynamiskt – för att ta fram aktuella, personliga förslag. Detta höjer kontakten från generisk till kontextmedveten handling.
JPMorgan Chase utnyttjade AI-agenter under en nyligen inträffad marknadsomvälvning för att ge råd snabbare, betjäna fler kunder och öka försäljningen. Deras AI-drivna assistent "Coach" hjälpte finansiella rådgivare att få fram insikter upp till 95 % snabbare, vilket gjorde det möjligt för företaget att öka bruttoförsäljningen med cirka 20 % mellan 2023 och 2024 och sätta upp ett mål om att öka antalet kunder med 50 % under de kommande 3–5 åren.
Lås upp live-intelligens för din organisation med ClickUp
Dagens team behöver mer än statiska verktyg. De behöver en arbetsplats som aktivt förstår, kopplar samman och påskyndar arbetet. ClickUp är den första konvergerade AI-arbetsplatsen, utvecklad för att leverera live-intelligens genom att integrera kunskap, automatisering och samarbete i en enda, enhetlig plattform.
Enhetlig företagssökning: Realtidskunskap inom räckhåll
Hitta svar direkt, oavsett var informationen finns. ClickUps Enterprise Search kopplar samman uppgifter, dokument, chatt och integrerade verktyg från tredje part i en enda AI-driven sökfält. Sökningar med naturligt språk ger kontextrika resultat och sammanställer strukturerade och ostrukturerade data så att du kan fatta beslut snabbare.
- Sök bland uppgifter, dokument, chattar och integrerade verktyg från tredje part med hjälp av en enda AI-driven sökfält.
- Använd frågor i naturligt språk för att hämta strukturerade och ostrukturerade data från alla anslutna tredjepartskällor.
- Få omedelbar tillgång till policyer, projektuppdateringar, filer och ämnesexpertis med kontextrika resultat.
- Indexera och koppla samman information från Google Drive, Slack och andra plattformar för en helhetsbild.
Automatisera, samordna och resonera över arbetsflöden med AI-agenter
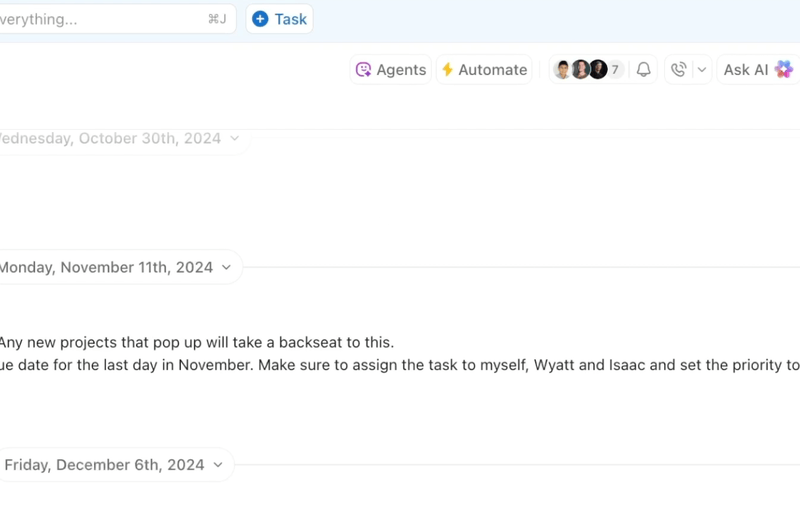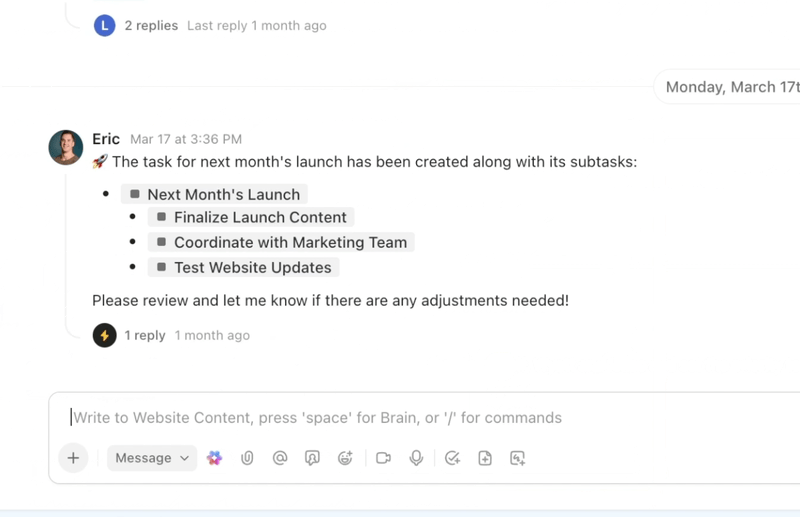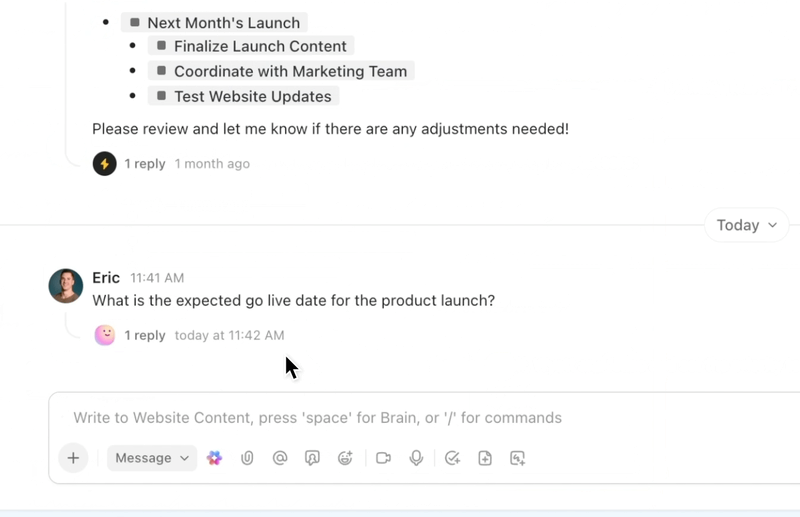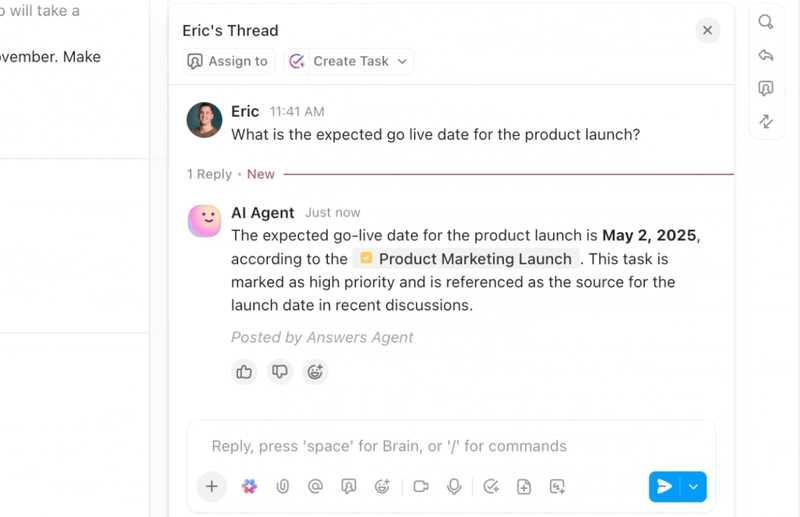
Automatisera repetitiva uppgifter och samordna komplexa processer med intelligenta AI-agenter som fungerar som digitala teammedlemmar. ClickUps AI-agenter utnyttjar realtidsdata och kontext från arbetsytan, vilket gör det möjligt för dem att resonera, vidta åtgärder och anpassa sig till föränderliga affärsbehov.
- Implementera anpassningsbara AI-agenter som automatiserar uppgifter, prioriterar förfrågningar och utför arbetsflöden i flera steg.
- Sammanfatta möten, skapa innehåll, uppdatera uppgifter och utlösa automatiseringar baserat på realtidsdata.
- Anpassa åtgärder baserat på sammanhang, beroenden och affärslogik med hjälp av avancerade resonemangsfunktioner.
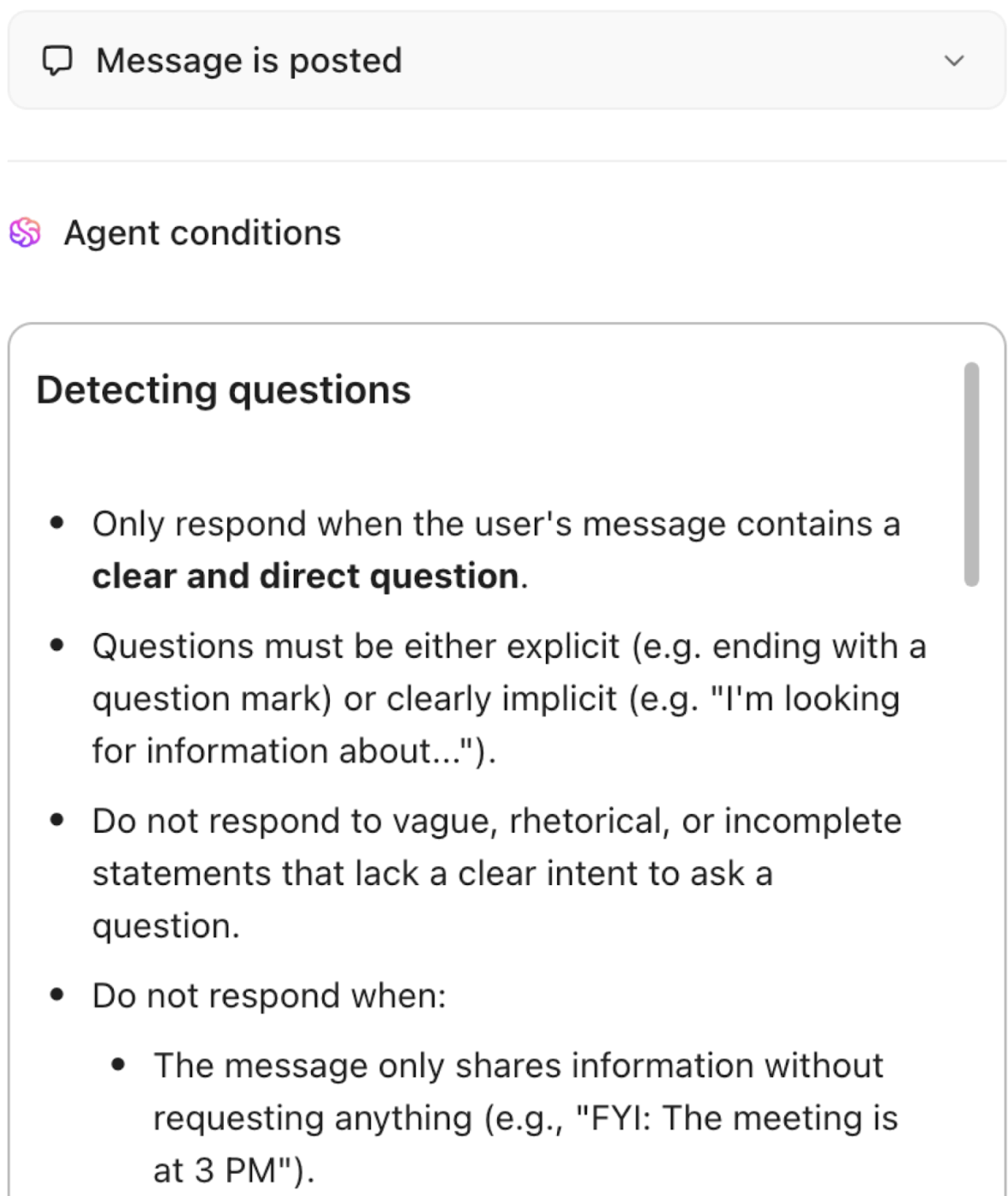
Live-kunskapshantering: Dynamisk, kontextuell och alltid uppdaterad
Förvandla statisk dokumentation till en levande kunskapsbas. ClickUp Knowledge Management indexerar och länkar automatiskt information från uppgifter, dokument och konversationer, vilket säkerställer att kunskapen alltid är aktuell och tillgänglig. AI-drivna förslag visar relevant innehåll medan du arbetar, samtidigt som smart organisation och behörigheter håller känslig data säker.
- Indexera och länka automatiskt information från ClickUp Tasks, ClickUp Docs och konversationer för en levande kunskapsbas.
- Hitta relevant innehåll med AI-drivna förslag medan du arbetar.
- Organisera kunskap med detaljerade behörigheter för säker och sökbar delning.
- Håll dokumentation, introduktionsguider och institutionell kunskap alltid uppdaterad och tillgänglig.
Konvergerat samarbete: Kontextuellt, uppkopplat och handlingsbart
Samarbetet i ClickUp är djupt integrerat med ditt arbete.
Redigering i realtid, AI-drivna sammanfattningar och kontextuella rekommendationer säkerställer att varje konversation är användbar. ClickUp Chat, Whiteboards, Docs och Tasks är sammankopplade, så att brainstorming, planering och genomförande sker i ett enda flöde.
Det hjälper dig att:
- Samarbeta i realtid med integrerade dokument, whiteboards och uppgifter, som alla är länkade för smidiga arbetsflöden.
- Omvandla konversationer till praktiska nästa steg med AI-drivna sammanfattningar och rekommendationer.
- Visualisera beroenden, hinder och projektstatus med liveuppdateringar och smarta aviseringar.
- Gör det möjligt för tvärfunktionella team att brainstorma, planera och genomföra i en enhetlig miljö.
ClickUp är inte bara en arbetsplats. Det är en live-intelligensplattform som förenar din organisations kunskap, automatiserar arbetet och ger teamen praktiska insikter, allt i realtid.
Vi har jämfört de bästa sökprogrammen för företag, och här är resultaten:
Utmaningar och bästa praxis
Live-kunskap erbjuder stora fördelar, men medför också risker och komplexitet.
Nedan följer de viktigaste AI-utmaningarna som organisationer står inför, tillsammans med metoder för att mildra dem.
| Utmaning | Beskrivning | Bästa praxis |
|---|---|---|
| Optimering av latens och prestanda | Anslutning till live-data medför fördröjningar från API-anrop, strömbehandling och hämtning. Om svaren fördröjs påverkas användarupplevelsen och förtroendet negativt. | ✅ Cache mindre kritiska data för att undvika redundanta hämtningar✅ Prioritera kritiska, tidskänsliga flöden; uppdatera andra mindre ofta✅ Optimera hämtning och kontextinjektion för att minska modellens väntetid✅ Övervaka kontinuerligt latensmått och ställ in prestandatrösklar |
| Datakvalitet kontra beräkningskostnad | Att upprätthålla realtidsdata för alla källor kan vara kostsamt och ineffektivt. All information behöver inte uppdateras varje sekund. | ✅ Klassificera data efter kritikalitet (måste vara live vs. kan vara periodisk)✅ Använd differentierade uppdateringsfrekvenser✅ Balansera värde mot kostnad – uppdatera endast så ofta som det påverkar beslut |
| Säkerhet och åtkomstkontroll | Live-system är ofta kopplade till känslig intern eller extern data (CRM, EHR, finansiella system), vilket skapar risker för obehörig åtkomst eller läckage. | ✅ Tillämpa åtkomst med minsta möjliga behörighet för API:er och begränsa agenternas behörigheter✅ Granska alla dataanrop som agenten gör✅ Tillämpa kryptering, säkra kanaler, autentisering och aktivitetsloggning ✅ Använd avvikelsedetektering för att flagga ovanligt åtkomstbeteende |
| Felhantering och reservstrategier | Live-datakällor kan sluta fungera på grund av API-driftstopp, latensspikar eller felaktiga data. Agenter måste hantera dessa störningar på ett smidigt sätt. | ✅ Implementera omförsök, timeouts och fallback-mekanismer (t.ex. cachade data, eskalering till mänsklig hantering)✅ Logga och övervaka felmetriker som saknade data eller latensavvikelser✅ Säkerställ graciös nedgradering istället för tysta fel |
| Efterlevnad och datastyrning | Live-kunskap involverar ofta reglerad eller personlig information, vilket kräver strikt övervakning och spårbarhet. | ✅ Klassificera data efter känslighet och tillämpa lagringspolicyer✅ Bevara datans ursprung – spåra källor, uppdateringar och användning✅ Upprätta styrning för agentutbildning, minne och datauppdateringar✅ Involvera juridiska team och compliance-team tidigt, särskilt i reglerade sektorer |
Framtiden för live-kunskap inom AI
I framtiden kommer live-kunskap att fortsätta utvecklas och forma hur AI-agenter fungerar – från reaktion till förväntan, från isolerade agenter till nätverk av samarbetande agenter och från centraliserade moln till distribuerade arkitekturer.
Prediktiv kunskapscaching
I stället för att vänta på förfrågningar hämtar agenterna proaktivt och cachar data som de sannolikt kommer att behöva. Prediktiva cachningsmodeller analyserar historiska åtkomstmönster, tidsmässiga sammanhang (t.ex. marknadens öppettider) och användarnas avsikter för att förladda dokument, nyhetsflöden eller telemetri i snabba lokala lagringsutrymmen, vilket gör att agenten kan svara med en latens på mindre än en sekund.
Användningsfall: en investeringsagent laddar ner resultatrapporter och likviditetsöversikter innan marknaden öppnar; en kundsupportagent hämtar senast inkomna ärenden och produktdokument innan ett schemalagt supportbesök. Forskning visar att AI-driven prediktiv förhämtning och cacheplacering avsevärt förbättrar träfffrekvensen och minskar latensen i edge- och innehållsleveransscenarier.
Nya standarder och protokoll
Interoperabilitet kommer att påskynda utvecklingen. Protokoll som Model Context Protocol (MCP) och leverantörsinitiativ (t.ex. Algolias MCP Server) skapar standardiserade sätt för agenter att begära, infoga och uppdatera livekontext från externa system. Standarder minskar behovet av skräddarsydd limkod, förbättrar säkerhetskontroller (tydliga gränssnitt och autentisering) och gör det enklare att kombinera och matcha hämtningslager, minneslager och resonemangsmotorer mellan olika leverantörer. I praktiken innebär införandet av MCP-liknande gränssnitt att teamen kan byta ut hämtningstjänster eller lägga till nya dataflöden med minimalt omarbete för agenterna.
Integration med edge- och distribuerade system
Live-kunskap i utkanten erbjuder två betydande fördelar: minskad latens och förbättrad integritet/kontroll. Enheter och lokala gateways kommer att vara värdar för kompakta agenter som känner av, resonerar och agerar lokalt, och synkroniserar selektivt med molnlagringsplatser när nätverket eller policyn tillåter det.
Detta mönster passar tillverkning (där fabriksmaskiner fattar lokala kontrollbeslut), fordon (ombordagenter som reagerar på sensorfusion) och reglerade områden där data måste förbli lokala. Branschundersökningar och rapporter om edge-AI förutspår snabbare beslutsfattande och lägre molnberoende i takt med att distribuerat lärande och federerade tekniker mognar.
För team som bygger live-kunskapsstackar innebär detta att man utformar skiktade arkitekturer där kritiska, latenskänsliga inferenser körs lokalt medan långsiktigt lärande och tunga modelluppdateringar sker centralt.
Kunskapsdelning mellan flera agenter
Modellen med en enda agent ersätts av ekosystem med samverkande agenter.
Multiagentramverk gör det möjligt för flera specialiserade agenter att dela situationsmedvetenhet, uppdatera delade kunskapsgrafer och samordna åtgärder, vilket gör dem särskilt användbara inom flottförvaltning, leveranskedjor och storskaliga verksamheter.
Ny forskning om LLM-baserade multiagent-system visar metoder för distribuerad planering, rollspecialisering och konsensusbyggande mellan agenter. I praktiken behöver teamen delade scheman (gemensamma ontologier), effektiva pub/sub-kanaler för statusuppdateringar och logik för konfliktlösning (vem som åsidosätter vad och när).
Kontinuerligt lärande och självförbättring
Live-kunskap kommer att förena återvinning, resonemang, minne, handling och kontinuerligt lärande i slutna loopar. Agenterna kommer att observera resultat, införliva korrigerande signaler och uppdatera minnen eller kunskapsgrafer för att förbättra framtida beteenden.
De största tekniska utmaningarna är att förhindra katastrofal glömska, bevara ursprunget och säkerställa säkerheten för onlineuppdateringar. Nya undersökningar inom kontinuerligt onlineinlärning och agentanpassning beskriver praktiska tillvägagångssätt (episodiska minnesbuffertar, återuppspelningsstrategier och begränsad finjustering) som gör det möjligt att ständigt förbättra modellerna samtidigt som avvikelser begränsas. För produktteam innebär detta att investera i märkta feedbackpipelines, säkra uppdateringspolicyer och övervakning som kopplar modellbeteendet tillbaka till verkliga KPI:er.
Använd live-kunskap i arbetet med ClickUp
Nästa steg för AI på arbetsplatsen är inte bara smartare modeller.
Live-kunskap är det som förbinder statisk intelligens och anpassningsbar handling, vilket gör det möjligt för AI-agenter att arbeta med en realtidsförståelse av projekt, prioriteringar och framsteg. Organisationer som kan mata sina AI-system med färsk, kontextuell och tillförlitlig data kommer att kunna utnyttja den verkliga potentialen hos omgivande intelligens: sömlös samordning, snabbare genomförande och bättre beslut i alla team.
ClickUp är byggt för denna förändring. Genom att samla uppgifter, dokument, mål, chatt och insikter i ett sammankopplat system ger ClickUp AI-agenter en levande, dynamisk källa till sanning – inte en statisk databas. Dess kontextuella och omgivande AI-funktioner gör att informationen förblir aktuell i alla arbetsflöden, vilket säkerställer att automatiseringen baseras på verkligheten, inte på föråldrade ögonblicksbilder.
I takt med att arbetet blir allt mer dynamiskt kommer verktyg som förstår sammanhanget i rörelse att definiera produktivitetens nästa fördel. ClickUps mission är att göra det möjligt – där varje åtgärd, uppdatering och idé omedelbart informerar nästa, och där teamen äntligen får uppleva vad AI kan göra när kunskapen förblir levande.
Vanliga frågor
Live-kunskap ökar prestandan genom att tillhandahålla aktuell kontext: beslut baseras på uppdaterade fakta snarare än föråldrade data. Det leder till mer exakta svar, snabbare reaktionstider och ökat förtroende hos användarna.
Många kan göra det, men alla behöver inte. Agenter som arbetar i stabila sammanhang med få förändringar kanske inte har lika stor nytta av det. Men för alla agenter som arbetar i dynamiska miljöer (marknader, kunder, system) är live-kunskap en kraftfull möjliggörare.
Testningen innebär att man simulerar förändringar i den verkliga världen: variera live-inmatningarna, infoga händelser, mäta latens, verifiera agenternas utdata och kontrollera om det finns fel eller föråldrade svar. Övervaka hela arbetsflöden, användarresultat och systemets robusthet under live-förhållanden.