

Du är avdelningschef och letar efter den perfekta personen för att hantera en viss uppgift. Med enorma mängder företagsdata är det nästan omöjligt att hitta den bästa kandidaten, särskilt om uppgiften är tidsbegränsad.
Dessutom, vem har tid att fråga alla om de har tillräcklig kunskap om ett specifikt område?
Men tänk om du helt enkelt kunde fråga ett system: ”Vem har tilldelats [uppgiften] flest gånger?” och få ett omedelbart, korrekt svar baserat på verkliga data? Det är vad informationshämtningssystem gör.
Dessa system söker igenom berg av data för att hitta exakt det du behöver.
Nu kan du skala upp den idén till en global databas – ett IR-system organiserar stora mängder data och hjälper dig att hitta de mest relevanta svaren på några sekunder. Den här guiden utforskar olika modeller för informationshämtning, hur de fungerar och AI-teknikens roll i ett IR-system.
⏰ 60-sekunders sammanfattning
📌 Informationshämtningssystem (IR) hjälper dig att hitta relevant information i stora datamängder och fungerar som en virtuell assistent som söker igenom data för att hitta det du behöver.
📌 IR-system har följande nyckelkomponenter: databas, indexerare, sökgränssnitt, sökprocessor, informationshämtningsmodeller och ranknings-/poängsättningsmekanismer.
📌 Fyra huvudsakliga IR-modeller används: Boolesk (använder AND/OR/NOT-operatorer), vektorrum (representerar dokument som vektorer), probabilistisk (använder statistiska metoder) och termberoende (analyserar relationer mellan termer).
📌 Maskininlärning och naturlig språkbehandling förbättrar IR-system genom att förbättra mönsterigenkänning, resultatrankning och förståelse av sammanhang.
📌 De största utmaningarna är dataintegritet, skalbarhet och att upprätthålla datakvaliteten vid bearbetning av stora datamängder.
Vad är informationshämtning (IR)?
Informationshämtning (IR) innebär helt enkelt att hitta rätt information i stora datamängder, såsom digitala bibliotek, databaser eller internetarkiv.
Det är som att ha en virtuell assistent som går igenom berg av data för att ge dig exakt det du behöver.
På ytan anger användaren en sökfråga, ofta med hjälp av nyckelord eller fraser, för att söka efter specifik information. Bakom kulisserna analyserar avancerade tekniker och algoritmer söksträngarna och matchar dem med relevant data.
I stället för att bara identifiera ett enda svar ger IR-system flera objekt – var och ett med olika grad av relevans för din sökning. Dessutom används de överallt och har flera tillämpningar (mer om det snart 🔔).
💡Proffstips: Behöver du hitta den mest kompetenta personen för en uppgift? Ange specifika termer som "försäljningsrapportanalys Q1 och Q2 uppgifter tilldelade till" i informationshämtningssystemet. På så sätt filtreras snabbt bort irrelevant data och systemet identifierar vem som har hanterat det mest.
Tillämpningar av IR inom olika områden
Från hälso- och sjukvård till e-handel används IR-system inom många olika områden för att hantera och kategorisera data. Här är några exempel 👇
Hälso- och sjukvård
Inom hälso- och sjukvården skannar IR-system databaser med medicinska journaler och forskningsrapporter för att hjälpa läkare och forskare att hitta den mest relevanta informationen. På så sätt påskyndar de diagnosen av sjukdomar, identifierar behandlingsalternativ och hittar de mest relevanta studierna med hjälp av relevant feedback.
Kundservice
Tekniker för informationshämtning gör kundsupporten snabbare och mer precis. Till exempel kan agenter skriva in användarfrågor som ”återbetalningspolicy” i företagets system för att få omedelbara svar.
AI-chattbottar och helpdeskar som drivs av informationshämtning går ett steg längre och erbjuder lösningar i realtid utan mänsklig inblandning. Det är därför dina frågor ofta besvaras på några sekunder!
E-handelsplattformar
IR-system gör online-shopping till en barnlek. De analyserar databaser och matchar kundbeteenden för att rekommendera produkter som du kommer att älska.
Amazon använder till exempel IR för att föreslå artiklar baserat på din sökhistorik och tidigare köp, vilket hjälper dig att hitta exakt det du behöver.
Komponenter i ett informationshämtningssystem
Nu vet vi vad informationshämtning är och hur det fungerar. Låt oss bryta ner de viktigaste byggstenarna i ett IR-system. →
1. Databas
Allt börjar med databasen. Det är en samling av sammanhängande datapunkter, såsom textdokument, e-postmeddelanden, webbsidor, bilder och videor. När du anger en given sökfråga söker IR-systemet igenom dessa databasmatchningar för att hämta den information som är mest relevant för dina behov.
2. Indexerare
Innan systemet kan hämta något organiserar indexeraren data. Det är som att förbereda en bibliotekskatalog för att göra sökningen snabbare. Indexeraren bearbetar dokument genom att:
- Tokenisering: Att dela upp innehåll i mindre bitar, till exempel att dela upp meningar i ord eller fraser (kallade tokens).
- Stemming: Förenkla ord till deras grundform (t.ex. "running" blir "run").
- Borttagning av stoppord: Hoppa över fyllnadsord som "och", "eller" och "den" för att fokusera på den primära sökfrågan.
- Nyckelordsutvinning: Identifiera de viktigaste nyckelorden i texten
- Metadataextraktion: Hämta extra information som författare, publiceringsdatum eller titel.
3. Sökgränssnitt
Sökgränssnittet fungerar som din inkörsport till IR-systemet. Här skriver du in din sökfråga med hjälp av enkla nyckelord eller mer detaljerade filter. Gränssnittet är utformat för att vara användarvänligt och säkerställer att du enkelt kan kommunicera dina behov av information och få de relevanta resultat du söker.
4. Frågeprocessor
När du klickar på "sök" tar sökprocessorn över. Den förfinar din inmatning genom att tillämpa tekniker som anges i indexeringsavsnittet. Dessutom hanterar den booleska operatorer som "AND", "OR" och "NOT" för att göra din sökning smartare.
5. Hämtningsmodeller
Det är här magin sker. Systemet jämför din sökfråga med de indexerade dokumenten med hjälp av informationshämtningsmodeller. Dessa metoder avgör hur din sökfråga ska matchas med den lagrade informationen. Några vanliga namn är:
- Booleska modeller
- Vektorrumsmodeller
- Probabilistiska modeller
- Och mycket mer... (diskuteras senare)
6. Rankning och poängsättning
När potentiella träffar har hittats rangordnar systemet dem efter relevans. Varje dokument får en poäng med hjälp av metoder som TF-IDF (Term Frequency-Inverse Document Frequency) eller andra algoritmer. Detta säkerställer att det mest relevanta resultatet visas högst upp.
7. Presentation eller visning
Slutligen presenteras resultaten för dig. Vanligtvis visar systemet en rangordnad lista över textdokument med extra funktioner som utdrag, filter eller sorteringsalternativ. Detta gör det enklare att välja det mest relevanta dokumentet. Antalet visade resultat kan dock variera beroende på dina preferenser, sökfråga eller systeminställningar.
🔍Visste du att?: Traditionella informationshämtningssystem var starkt beroende av strukturerade databaser och grundläggande sökordsmatchning. Resultatet? Stora problem med relevans och personalisering.
Det var då moderna AI-tekniker förändrade textåtervinning genom:
- Maskininlärning (ML): Hjälper IR-system att lära sig av mönster i användarnas beteende och förbättra sökresultaten över tid.
- Djupa neurala nätverk: Algoritmer som kan bearbeta ostrukturerade data (som bilder eller videor) och avslöja komplexa relationer.
- Naturlig språkbehandling (NLP): Gör det möjligt för system att förstå betydelsen och sammanhanget i sökfrågor för att stödja bildigenkänning och sentimentanalys, vilket gör informationsåtkomsten mer mångsidig.
Modeller för informationshämtning
Det finns olika IR-system som effektiviserar processen att hitta relevanta dokument. Låt oss titta på de mest använda:
1. Mängdlära och booleska modeller
Den booleska modellen är en av de enklaste teknikerna för informationshämtning. Så här fungerar den:
- OCH: Hämtar dokument som innehåller alla termerna i sökfrågan. Om du till exempel söker efter ”katt OCH hund” kommer sökmotorn att visa dokument som nämner båda termerna.
- ELLER: Hittar dokument som innehåller någon av termerna i sökfrågan. För ”katt ELLER hund” hämtar den dokument som nämner antingen katt, hund eller båda.
- NOT: Exkluderar dokument som innehåller ett specifikt begrepp. Till exempel ger "katt AND NOT hund" dokument som nämner katt men inte hund.
Denna modell använder ett ”bag of words”-koncept, där en 2D-matris skapas. I denna matris:
- Kolumnerna representerar dokument
- Raderna representerar termer från sökfrågan.
Varje cell tilldelas värdet 1 (om termen finns) eller 0 (om den inte finns).

✅ Fördelar
- Lätt att förstå och implementera
- Hämtar dokument som exakt matchar söktermerna
❌ Nackdelar
- Booleska modeller rangordnar inte dokument efter relevans, så alla resultat behandlas som lika viktiga.
- Fokuserar på exakta termmatchningar, så resultaten kan variera beroende på sökfrågans innebörd eller sammanhang.
2. Vektorrumsmodeller
En vektorrumsmodell är en algebraisk modell som representerar både dokument och sökfrågor som vektorer i ett flerdimensionellt rum. Så här fungerar det:
1. En term-dokumentmatris skapas, där raderna är termer och kolumnerna är dokument.
2. En frågevektor bildas baserat på användarens söktermer.
3. Systemet beräknar ett numeriskt betyg med hjälp av ett mått som kallas kosinuslikhet, som avgör hur väl sökvektorn matchar dokumentvektorerna.

Som ett informationshämtningssystem rankas dokumenten sedan utifrån dessa poäng, där de högst rankade är de mest relevanta.
✅ Fördelar
- Hämtar objekt även om endast vissa termer matchar
- Variationer i termer och dokumentlängd, anpassning till olika dokumenttyper
❌ Nackdelar
- Större ordförråd och dokumentsamlingar gör likhetsberäkningar resurskrävande.
3. Probabilistiska modeller
Denna modell använder en statistisk metod och utgår från sannolikheten för att uppskatta hur relevant ett dokument är för sökfrågan. Den tar hänsyn till:
- Frekvensen av termer i dokumentet
- Hur ofta förekommer termer tillsammans (samförekomst)
- Dokumentets längd och det totala antalet söktermer
Systemet behandlar hämtningsprocessen som en probabilistisk händelse och rangordnar lagrade dokument utifrån deras relevans. Denna metod ger ytterligare djup genom att utvärdera dataobjekt utöver grundläggande termförekomst.
✅ Fördelar
- Anpassar sig väl till olika tillämpningar, inklusive tillförlitlighetsanalys och belastningsflödesbedömningar.
❌ Nackdelar
- Baseras på antaganden om datarelationer, vilket kan leda till missvisande resultat.
4. Modeller för termers ömsesidiga beroende
Till skillnad från enklare modeller fokuserar termberoendemodeller på relationer mellan termer snarare än bara deras frekvens. Dessa modeller analyserar hur ord och fraser relaterar till varandra för att förbättra resultatens noggrannhet.
De använder en av två metoder:
- Immanent läge: Utforskar relationer inom själva texten
- Transcendent läge: Beaktar extern data eller sammanhang för att dra slutsatser om relationer.
Denna metod är särskilt användbar för att fånga nyanser i betydelsen, såsom synonymer eller kontextspecifika fraser.
✅ Fördelar
- Fångar upp nyanser i språket genom att beakta relationer mellan termer
- Förbättrar sökprestandan genom att förstå termberoenden och sammanhang
❌ Nackdelar
- Kräver omfattande data för att korrekt modellera termrelationer, vilket inte alltid är tillgängligt.
Det var allt! Det här är några av de vanligaste informationshämtningssystemen, med sina egna för- och nackdelar.
Informationshämtning kontra datakonsultation
Även om dessa två termer verkar nästan identiska, fungerar de på olika sätt. Låt oss därför jämföra IR och datakonsultation för att se hur de skiljer sig åt när det gäller syfte, användningsfall och exempel:
| Aspekt | Informationshämtning (IR) | Datakonsultation |
| Definition | Fungerar som en sökmotor som söker igenom massor av data för att ge dig de mest relevanta resultaten. | Tänk på det som att ställa en specifik fråga till en databas på ett språk som den förstår (som SQL). |
| Mål/syfte | Hjälper dig att hitta korrekt och relevant information eller resurser på sökmotorer – snabbt och enkelt. | Hämtar exakta data så att du kan analysera, uppdatera eller bearbeta siffror. |
| Användningsfall | Används för webbsökningar, e-handelsrekommendationer, digitala bibliotek, insikter inom hälso- och sjukvård och mycket mer. | Perfekt för uppgifter som lagerhantering inom e-handel, finansanalys och optimering av leveranskedjor. |
| Exempel | Sök på "Bästa bärbara datorer mellan 800 och 1000 dollar" på Google för att få rankade resultat. | Sök i ditt lagersystem efter "SELECT * FROM Laptops WHERE Price >= 800 AND Price <= 1000" för att se vad som finns i lager. |
Maskininlärningens och NLP:s roll i informationshämtning
IR-system är som skattjägare för data – de söker igenom enorma mängder information för att hitta exakt det du letar efter. Men när ML och NLP slår sig samman blir dessa system smartare, snabbare och mycket mer exakta.
Tänk på ML som hjärnan bakom IR-system. 🧠
Det hjälper systemet att lära sig, anpassa sig och förbättra resultaten varje gång du söker efter information. Så här fungerar det:
- Upptäcka mönster: ML studerar vad användarna klickar på, vad de ignorerar och vad de lägger mest tid på att läsa. Den använder sedan denna kunskap för att visa dig de mest relevanta resultaten nästa gång.
- Rankningsresultat: ML hämtar information och rankar den också. Det innebär att de bästa och mest användbara resultaten visas högst upp i sökresultaten.
- Anpassning över tid: Med varje sökning blir ML bättre. Det plockar upp trender, förfinar sin förståelse och hanterar även de svåraste frågorna med lätthet.
Om du till exempel söker efter ”bästa budgetlaptops” idag och interagerar med specifika resultat, kommer ML att prioritera liknande alternativ när du senare söker efter ”prisvärda bärbara datorer”. Genom att kombinera AI med ML kan webbsökmotorer till och med förutsäga vad du kan behöva härnäst.
Nu ska vi prata om NLP. Det hjälper IR-system att förstå vad du menar, inte bara de ord du skriver. Enkelt uttryckt:
- Det förstår sammanhanget: NLP vet att när du säger "jaguar" kan du mena djuret eller bilen – och det räknar ut det utifrån resten av din fråga.
- Det hanterar komplexa språk: Oavsett om din sökning är enkel ("billiga flyg") eller detaljerad ("direktflyg till Tokyo under 500 dollar") ser NLP till att systemet förstår och levererar rätt resultat.
Tillsammans gör NLP och IR sökningen intuitiv, som att prata med någon som verkligen förstår dig. Det innebär mindre scrollande, mindre frustration och fler ”wow, det här är precis vad jag behövde!”-ögonblick.
ClickUps roll i informationshämtning
ClickUp, ”allt-i-ett-appen för arbete”, förbättrar datahanteringen med IR-modeller.
Den inbyggda AI-tekniken identifierar och matchar resultaten med användarens sökfråga på ett unikt sätt, vilket tar intelligent teknik till en helt ny nivå.
Och för att göra det ännu bättre gör ClickUps Connected Search det enkelt att få allt du behöver "omedelbart" till hands. Det betyder:
- Sök efter vad som helst: Vem gillar att bläddra igenom e-postmeddelanden och kunskapshanteringssystem för att hitta viktiga filer? Hitta vilken fil som helst på några sekunder med hjälp av alternativet Connected Search. Ännu bättre, sök efter filer i dina anslutna appar och få tillgång till allt på ett och samma ställe.
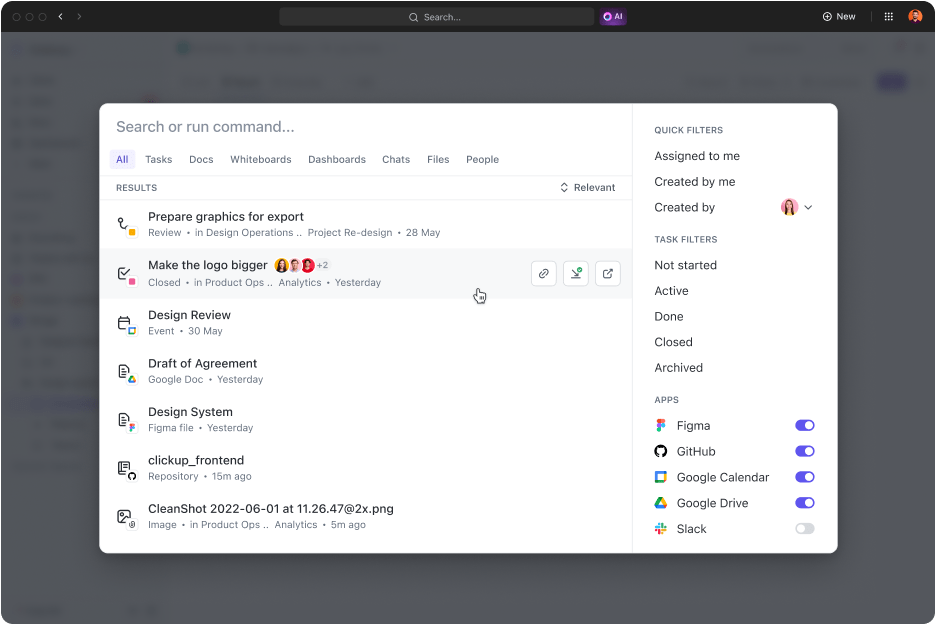
- Anslut dina favoritappar: ClickUp har några av de bästa integrationerna som utökar dess sökfunktioner till tredjepartsappar som Google Drive, Slack, Dropbox, Figma och många fler.

- Förfina resultaten: Ju mer du använder det, desto bättre blir det på att förstå vad du letar efter och leverera resultat som är skräddarsydda just för dig.
- Sök på ditt sätt: Få tillgång till Connected Search och sök snabbt i PDF-filer var som helst i ditt arbetsområde. Du kan till exempel starta en sökning från Command Center, Global Action Bar eller din skrivbord.
- Skapa anpassade sökkommandon: Lägg till anpassade sökkommandon som genvägar till länkar, spara text för senare användning och mycket mer för att effektivisera ditt arbetsflöde.
Och vad skulle du säga om det fanns ett sätt att automatisera tråkiga uppgifter, arbeta snabbare och få mer gjort på nolltid?
ClickUp Brain, den inbyggda AI-assistenten, gör detta möjligt för dig. Det är den ultimata assistenten för datahantering – smart, snabb och alltid redo att hjälpa till.
I korthet 👇
- Allt-i-ett-kunskapshubb: Du behöver aldrig mer förlita dig på e-post och meddelanden för uppdateringar. Fråga vad som helst om dina uppgifter, dokument eller personer och luta dig tillbaka medan ClickUp Brain kartlägger svar baserat på sammanhanget från interna och anslutna appar.

- Hitta det du behöver snabbare: ClickUp Brain rangordnar resultaten på ett intelligent sätt, precis som ett avancerat IR-system. Det prioriterar relevanta filer, föreslår relaterade uppgifter och hjälper dig till och med att upptäcka dolda arbetsbelastningar i dina data.
- Automatisera uppgifter: Brain automatiserar generering av rapporter eller spårning av deadlines med hjälp av sina AI-verktyg. Det är en personlig assistent som frigör tid för viktigare beslut samtidigt som allt hålls på rätt spår.
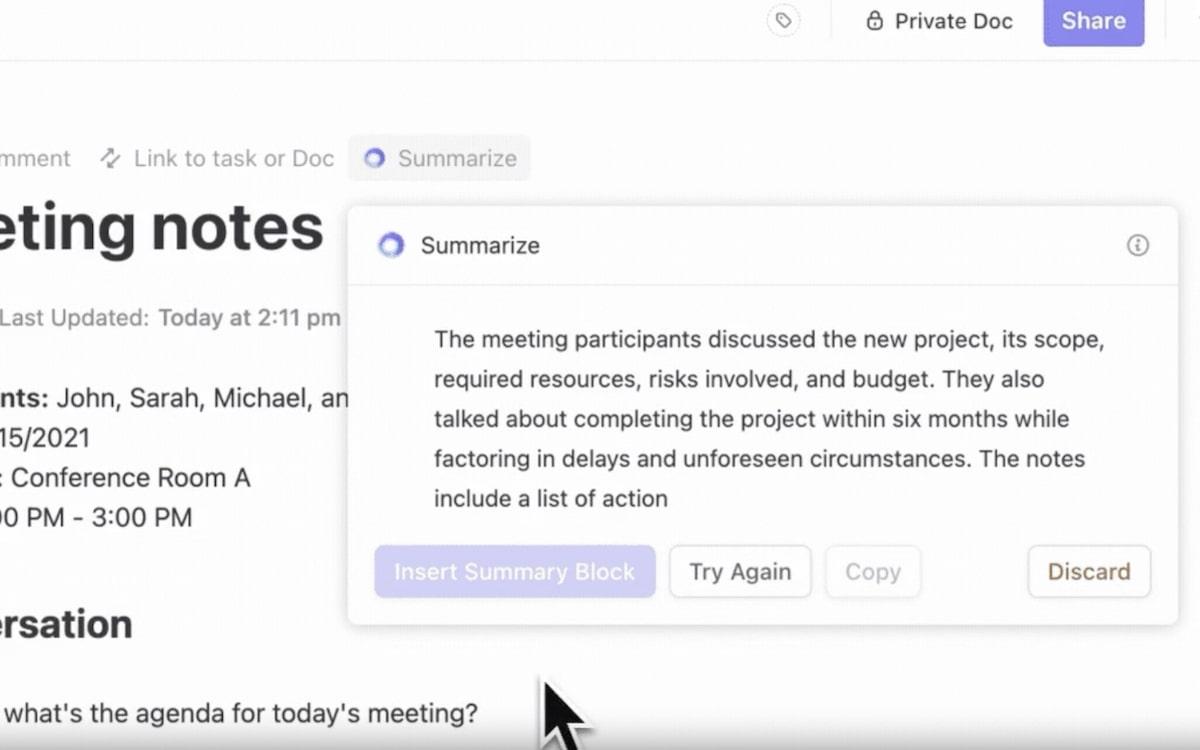
- Kontextmedveten sökning: Med NLP förstår den din fråga – även om din sökning är komplex eller vag. Om du till exempel söker efter ”rapport om försäljningen under första kvartalet” får du den exakta rapporten som är kopplad till din uppgift.
Utmaningar och framtida riktningar inom informationshämtning
Informationshämtning handlar om att förstå stora mängder data, men även de mest avancerade IR-systemen stöter på några hinder längs vägen.
Låt oss utforska de vanliga utmaningarna och de spännande trenderna som formar framtiden för denna viktiga vetenskapliga disciplin:
- Dataskydd och säkerhet: För att en IR-modell ska kunna ge faktabaserade resultat behöver den ofta tillgång till känslig data. Att skydda användardata är dock inte helt enkelt för informationshämtningsresurser.
- Skalbarhet och prestanda: När användare söker i stora datamängder kan hanteringen av växande innehållssamlingar överbelasta även de mest robusta sökmodellerna. Utmaningen är att säkerställa effektiv sökning utan att kompromissa med sökresultatens relevans.
- Datakvalitet och kontextuell förståelse: Tvetydiga sökfrågor eller dåligt organiserade metadata kan leda till felmatchningar, vilket gör det svårt för systemet att entydigt identifiera användarens avsikt.
Nya trender och framsteg inom IR-teknik
Trots många hinder har de senaste tekniska framstegen gjort det möjligt för oss att bygga smartare och effektivare system.
Moderna informationshämtningssystem använder nu avancerade metoder som grafbaserad analys för att tolka siffror, text, sammanhang, metadata och relationer mellan datapunkterna.
Vad betyder detta för användarna? Det möjliggör mer precis textsökning och detaljerad analys, särskilt inom områden som forskning och datatunga branscher.
I kombination med semantiska webbtekniker fokuserar det på söksträngar och användarens avsikt. Dessa system kan gå utöver bokstavliga matchningar och hämta mycket relevanta dokument, även för komplicerade användarfrågor i informationshämtningsprocessen.
Om du till exempel söker på ”fördelar med distansarbete” kan du få resultat relaterade till produktivitet, mental hälsa och balans mellan arbete och privatliv – allt tack vare att systemet förstår sambanden.
Hämta dokument snabbt med ClickUps datahantering
Att gräva igenom oändliga filer, appar och verktyg för att hitta det där enda viktiga dokumentet är utmattande. Tänk dig att försöka analysera hämtade dokument som forskare, student, IT-proffs eller datavetare – det blir bara en röra av informationsöverflöd.
Men med ClickUp kommer du aldrig mer att slösa tid på att leta efter information.
Det är en allt-i-ett-lösning som samlar allt ditt arbete på ett ställe. Med funktioner som Connected Search och ClickUp Brain spelar det ingen roll var dina data finns – ClickUp gör det enkelt att hitta, hantera och agera på dem.
Varför nöja sig med "bara okej" när du kan få "fantastiskt"? Prova ClickUp gratis och se hur det förvandlar ditt arbetsflöde till något djärvt, effektivt och helt enkelt ohejdbart!