

Големите езикови модели (LLM) отвориха вълнуващи нови възможности за софтуерните приложения. Те позволяват създаването на по-интелигентни и динамични системи от всякога.
Експертите прогнозират, че до 2025 г. приложенията, базирани на тези модели, ще могат да автоматизират почти половината от цялата цифрова работа.
Но докато отключваме тези възможности, се появява едно предизвикателство: как да измерим надеждно качеството на резултатите им в голям мащаб? Малка промяна в настройките и изведнъж получавате значително различен резултат. Тази променливост може да затрудни оценяването на тяхната ефективност, което е от решаващо значение при подготовката на модел за реално използване.
В тази статия ще споделим информация за най-добрите практики за оценка на LLM системата, от тестване преди внедряване до производство. Да започнем!
Какво е LLM оценка?
Показателите за оценка на LLM са начин да видите дали вашите подсказки, настройки на модела или работни процеси отговарят на поставените от вас цели. Тези показатели ви дават представа за това колко добре функционира вашият голям езиков модел и дали той е наистина готов за използване в реалния свят.
Днес някои от най-често използваните показатели измерват възстановяването на контекста в задачи за генериране с подпомагано извличане (RAG), точните съвпадения за класификации, JSON валидиране за структурирани резултати и семантична прилика за по-творчески задачи.
Всяка от тези метрики гарантира, че LLM отговаря на стандартите за вашия конкретен случай на употреба.
Защо е необходимо да оценявате LLM?
Големите езикови модели (LLM) се използват в широк спектър от приложения. От съществено значение е да се оцени ефективността на моделите, за да се гарантира, че отговарят на очакваните стандарти и ефективно служат на предвидените цели.
Помислете по следния начин: LLM захранват всичко – от чатботове за обслужване на клиенти до творчески инструменти, и с напредъка си се появяват на все повече места.
Това означава, че се нуждаем от по-добри начини за наблюдение и оценка – традиционните методи просто не могат да се справят с всички задачи, които тези модели изпълняват.
Добрите показатели за оценка са като проверка на качеството за LLM. Те показват дали моделът е достатъчно надежден, точен и ефективен за използване в реалния свят. Без тези проверки може да се пропуснат грешки, което да доведе до разочароващи или дори подвеждащи потребителски преживявания.
Когато разполагате с надеждни показатели за оценка, е по-лесно да откриете проблеми, да подобрите модела и да се уверите, че той е готов да отговори на конкретните нужди на потребителите. По този начин знаете, че AI платформата, с която работите, отговаря на стандартите и може да ви предостави необходимите резултати.
📖 Прочетете още: LLM срещу генеративна AI: подробно ръководство
Видове LLM оценки
Оценките предоставят уникална перспектива за разглеждане на възможностите на модела. Всеки тип се отнася до различни аспекти на качеството, като помага за изграждането на надежден, безопасен и ефективен модел за внедряване.
Ето различните видове методи за оценка на LLM:
- Вътрешната оценка се фокусира върху вътрешната производителност на модела при конкретни езикови или задачи за разбиране, без да включва приложения в реалния свят. Обикновено се провежда по време на етапа на разработване на модела, за да се разберат основните му възможности.
- Външната оценка оценява ефективността на модела в реални приложения. Този тип оценка проверява доколко добре моделът отговаря на конкретни цели в даден контекст.
- Оценката на устойчивостта тества стабилността и надеждността на модела в различни сценарии, включително неочаквани входни данни и неблагоприятни условия. Тя идентифицира потенциални слабости, гарантирайки, че моделът се държи предвидимо.
- Тестването на ефективността и латентността проверява използването на ресурсите, скоростта и латентността на модела. То гарантира, че моделът може да изпълнява задачи бързо и с разумни изчислителни разходи, което е от съществено значение за мащабируемостта.
- Оценката на етиката и безопасността гарантира, че моделът е в съответствие с етичните стандарти и насоките за безопасност, което е от жизненоважно значение при чувствителни приложения.
Оценки на LLM модели срещу оценки на LLM системи
Оценяването на големи езикови модели (LLM) включва два основни подхода: оценки на модели и оценки на системи. Всеки от тях се фокусира върху различни аспекти от представянето на LLM, а познаването на разликите е от съществено значение за максимизиране на потенциала на тези модели.
🧠 Оценките на моделите разглеждат общите умения на LLM. Този тип оценка тества способността на модела да разбира, генерира и работи с езика точно в различни контексти. Това е като да се види колко добре моделът може да се справи с различни задачи, почти като тест за обща интелигентност.
Например, оценките на моделите могат да задават въпроса: „Колко гъвкав е този модел?“
🎯 Оценките на LLM системата измерват как LLM се представя в рамките на конкретна настройка или цел, като например в чатбот за обслужване на клиенти. Тук не става въпрос толкова за широките възможности на модела, колкото за това как той изпълнява конкретни задачи, за да подобри потребителското преживяване.
Системните оценки обаче се фокусират върху въпроси като: „Колко добре моделът се справя с тази конкретна задача за потребителите?“
Оценките на моделите помагат на разработчиците да разберат общите възможности и ограничения на LLM, като насочват подобренията. Оценките на системата са фокусирани върху това колко добре LLM отговаря на нуждите на потребителите в конкретни контексти, като осигурява по-гладко потребителско преживяване.
Заедно тези оценки предоставят пълна картина на силните страни и областите за подобрение на LLM, което го прави по-мощен и лесен за използване в реални приложения.
Сега нека разгледаме конкретните показатели за LLM оценката.
Показатели за оценка на LLM
Някои надеждни и актуални показатели за оценка включват:
1. Объркване
Perplexity измерва колко добре езиковият модел предсказва последователността от думи. По същество, той показва несигурността на модела относно следващата дума в изречението. По-нисък резултат за perplexity означава, че моделът е по-уверен в своите предсказания, което води до по-добра производителност.
📌 Пример: Представете си, че моделът генерира текст от подсказката „Котката седна на...“. Ако той предскаже висока вероятност за думи като „постелка“ и „под“, това означава, че разбира добре контекста, което води до ниска степен на объркване.
От друга страна, ако предложи несвързана дума като „космически кораб“, оценката за объркване ще бъде по-висока, което показва, че моделът се затруднява да предскаже смислен текст.
2. BLEU Score
Резултатът BLEU (Bilingual Evaluation Understudy) се използва предимно за оценка на машинен превод и генериране на текст.
Тя измерва колко n-грами (последователни последователности от n елемента от даден текстов образец) в изхода се припокриват с тези в един или повече референтни текстове. Резултатът варира от 0 до 1, като по-високите резултати показват по-добра производителност.
📌 Пример: Ако вашият модел генерира изречението „Бързата кафява лисица скача над мързеливото куче“ и референтен текст е „Бърза кафява лисица скача над мързеливото куче“, BLEU ще сравни общите n-грами.
Високият резултат показва, че генерираното изречение съответства в голяма степен на референцията, докато по-ниският резултат може да означава, че генерираният резултат не съответства добре.
3. F1 Score
Показателят за оценка на LLM F1 score се използва предимно за задачи по класифициране. Той измерва баланса между прецизност (точността на положителните прогнози) и възстановяване (способността да се идентифицират всички релевантни случаи).
Скалата варира от 0 до 1, като резултат 1 означава перфектна точност.
📌 Пример: В задача за отговаряне на въпроси, ако на модела бъде зададен въпросът „Какъв цвят е небето?“ и той отговори „Небето е синьо“ (вярно положително), но включи и „Небето е зелено“ (фалшиво положително), F1 резултатът ще вземе предвид както релевантността на верния отговор, така и на неверния.
Този показател помага да се гарантира балансирана оценка на ефективността на модела.
4. METEOR
METEOR (Metric for Evaluation of Translation with Explicit ORdering) отива отвъд точното съвпадение на думите. Той взема предвид синоними, коренни думи и перифрази, за да оцени сходството между генерирания текст и референтен текст. Тази метрика има за цел да се доближи повече до човешката преценка.
📌 Пример: Ако вашият модел генерира „Котката почиваше на килима“, а референцията е „Котката лежеше на килима“, METEOR ще даде по-висока оценка от BLEU, защото разпознава, че „котка“ е синоним на „котка“, а „килим“ и „килим“ имат сходно значение.
Това прави METEOR особено полезен за улавяне на нюансите на езика.
5. BERTScore
BERTScore оценява сходството на текстове въз основа на контекстуални вграждания, извлечени от модели като BERT (Bidirectional Encoder Representations from Transformers). Той се фокусира повече върху значението, отколкото върху точното съвпадение на думите, което позволява по-добра оценка на семантичното сходство.
📌 Пример: Когато сравнява изреченията „Колата се носеше по пътя“ и „Превозното средство се движеше с висока скорост по улицата“, BERTScore анализира основните значения, а не само избора на думи.
Въпреки че думите са различни, общите идеи са сходни, което води до висок BERTScore, който отразява ефективността на генерираното съдържание.
6. Човешка оценка
Човешката оценка остава ключов аспект от оценяването на LLM. Тя включва човешки съдии, които оценяват качеството на резултатите от модела въз основа на различни критерии, като например плавност и релевантност. Техники като скалата на Ликерт и A/B тестовете могат да се използват за събиране на обратна връзка.
📌 Пример: След генериране на отговори от чатбот за обслужване на клиенти, човешките оценители могат да оценят всеки отговор по скала от 1 до 5. Например, ако чатботът даде ясен и полезен отговор на запитване на клиент, той може да получи 5, докато неясен или объркващ отговор може да получи 2.
7. Показатели, специфични за задачите
Различните задачи на LLM изискват специално адаптирани показатели за оценка.
За диалоговите системи показателите могат да оценяват ангажираността на потребителите или степента на изпълнение на задачите. За генерирането на код успехът може да се измерва по това колко често генерираният код се компилира или преминава тестове.
📌 Пример: В чатбот за обслужване на клиенти нивото на ангажираност може да се измерва по това колко дълго потребителите остават в разговора или колко последващи въпроси задават.
Ако потребителите често искат допълнителна информация, това показва, че моделът успешно ги ангажира и ефективно отговаря на техните запитвания.
8. Стабилност и справедливост
Оценяването на стабилността на модела включва тестване на това колко добре реагира той на неочаквани или необичайни входни данни. Показателите за справедливост помагат да се идентифицират пристрастия в резултатите на модела, като се гарантира, че той работи справедливо в различни демографски групи и сценарии.
📌 Пример: Когато тествате модел с необичаен въпрос като „Какво мислите за еднорозите?“, той трябва да се справи с въпроса с лекота и да даде подходящ отговор. Ако вместо това даде безсмислен или неподходящ отговор, това показва липса на стабилност.
Тестването за справедливост гарантира, че моделът не генерира пристрастни или вредни резултати, като по този начин насърчава по-инклузивна AI система.
📖 Прочетете още: Разликата между машинно обучение и изкуствен интелект
9. Показатели за ефективност
С нарастващата сложност на езиковите модели става все по-важно да се измерва тяхната ефективност по отношение на скоростта, използването на паметта и консумацията на енергия. Показателите за ефективност помагат да се оцени колко ресурсоемък е даден модел при генерирането на отговори.
📌 Пример: При голям езиков модел измерването на ефективността може да включва проследяване на скоростта, с която той генерира отговори на запитвания на потребители, и количеството памет, което използва по време на този процес.
Ако отговарянето отнема прекалено много време или консумира прекалено много ресурси, това може да бъде проблем за приложения, които изискват работа в реално време, като чатботове или преводачески услуги.
Сега вече знаете как да оцените LLM модел. Но какви инструменти можете да използвате, за да го измерите? Нека разгледаме.
Как ClickUp Brain може да подобри LLM оценката
ClickUp е приложение за всичко, свързано с работата, с вграден личен асистент, наречен ClickUp Brain.
ClickUp Brain променя изцяло оценяването на LLM. Какво прави то?
Той организира и подчертава най-релевантните данни, като поддържа екипа ви в правилната посока. С функциите си, задвижвани от изкуствен интелект, ClickUp Brain е един от най-добрите софтуери за невронни мрежи на пазара. Той прави целия процес по-гладък, по-ефективен и по-съвместен от всякога. Нека заедно разгледаме неговите възможности.
Интелигентно управление на знанията
При оценяването на големи езикови модели (LLM) управлението на огромни количества данни може да бъде прекалено обременяващо.

ClickUp Brain може да организира и да изтъкне важни показатели и ресурси, специално пригодени за LLM оценката. Вместо да ровите в разпръснати таблици и плътни доклади, ClickUp Brain събира всичко на едно място. Показателите за производителност, данните за сравнителен анализ и резултатите от тестовете са достъпни в ясен и лесен за ползване интерфейс.
Тази организация помага на вашия екип да преодолее шума и да се фокусира върху наистина важните прозрения, което улеснява интерпретирането на тенденциите и моделите на представяне.
С всичко необходимо на едно място, можете да преминете от просто събиране на данни към вземане на решения, основани на данни, които оказват влияние, превръщайки информационното претоварване в полезна информация.
Планиране на проекти и управление на работния процес
Оценките на LLM изискват внимателно планиране и сътрудничество, а ClickUp улеснява управлението на този процес.
Можете лесно да делегирате отговорности като събиране на данни, обучение на модели и тестване на производителността, като същевременно задавате приоритети, за да сте сигурни, че най-важните задачи получават внимание на първо място. Освен това, персонализираните полета ви позволяват да адаптирате работните процеси към специфичните нужди на вашия проект.

С ClickUp всеки може да види кой какво прави и кога, което помага да се избегнат забавяния и да се гарантира, че задачите се изпълняват гладко в целия екип. Това е чудесен начин да поддържате всичко организирано и в ред от начало до край.
Проследяване на показателите чрез персонализирани табла
Искате да следите отблизо как се представят вашите LLM системи?
ClickUp Dashboards визуализира показателите за ефективност в реално време. Това ви позволява да следите напредъка на вашия модел незабавно. Тези табла са силно персонализирани, което ви позволява да създавате графики и диаграми, които представят точно това, от което се нуждаете, когато се нуждаете от него.
Можете да наблюдавате как точността на вашия модел се развива през различните етапи на оценката или да разделите потреблението на ресурси на всяка фаза. Тази информация ви позволява бързо да забележите тенденции, да идентифицирате области за подобрение и да правите корекции в движение.
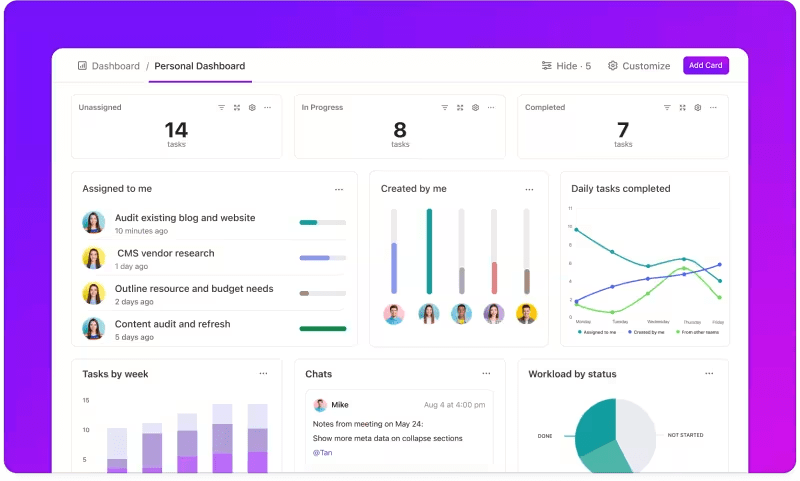
Вместо да чакате следващия подробен доклад, таблата на ClickUp ви позволяват да сте информирани и да реагирате бързо, като дават възможност на вашия екип да взема решения въз основа на данни без забавяне.
Автоматизирани анализи
Анализът на данни може да отнеме много време, но функциите на ClickUp Brain облекчават задачата, като предоставят ценна информация. Той подчертава важни тенденции и дори предлага препоръки въз основа на данните, което улеснява извеждането на значими заключения.
С автоматизираните анализи на ClickUp Brain няма нужда да претърсвате ръчно суровите данни за модели – той ги открива за вас. Тази автоматизация освобождава екипа ви, за да се съсредоточи върху усъвършенстването на производителността на модела, вместо да се затрупва с повтарящи се анализи на данни.
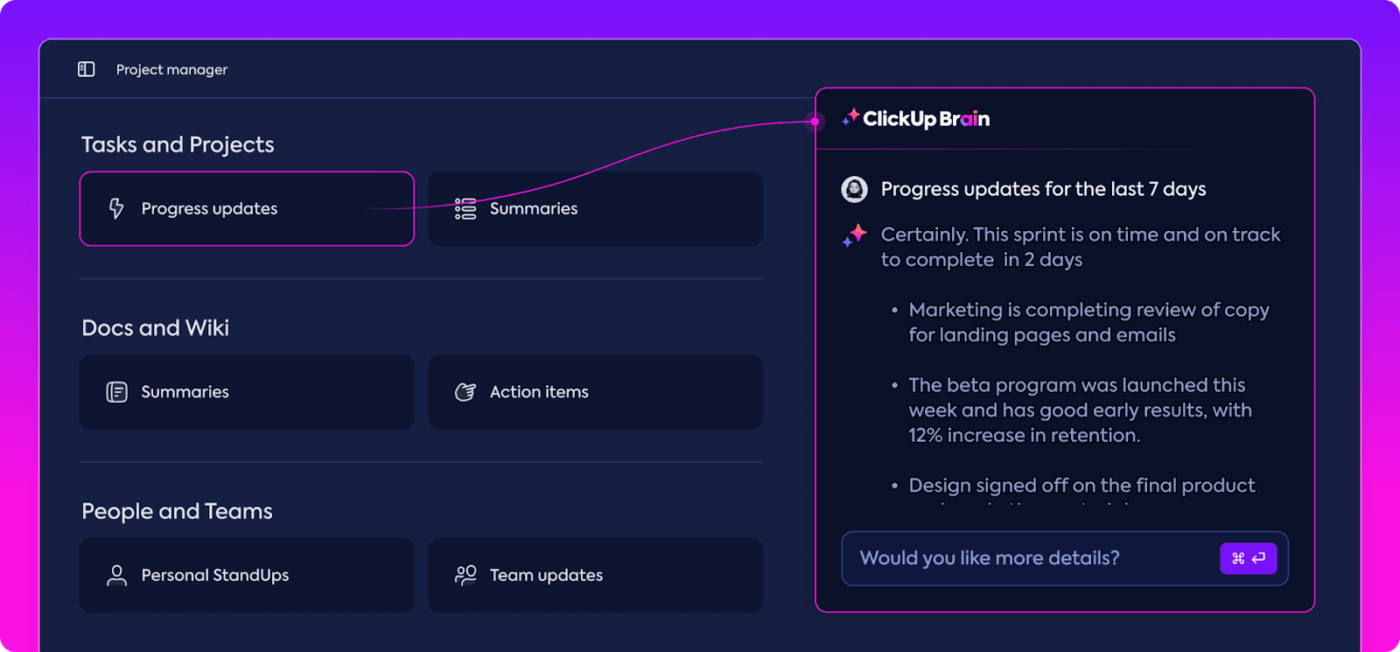
Получените данни са готови за употреба, което позволява на вашия екип да види веднага какво работи и къде може да са необходими промени. Чрез намаляване на времето, прекарано в анализ, ClickUp помага на вашия екип да ускори процеса на оценка и да се съсредоточи върху внедряването.
Документация и сътрудничество
Вече не е нужно да претърсвате имейли или множество платформи, за да намерите това, от което се нуждаете; всичко е на мястото си, готово, когато сте готови.
ClickUp Docs е централен хъб, който обединява всичко, от което вашият екип се нуждае за безпроблемна LLM оценка. Той организира ключовата документация по проекта – като критерии за сравнение, резултати от тестове и регистри за производителност – на едно достъпно място, така че всеки да може бързо да получи достъп до най-новата информация.
Това, което наистина отличава ClickUp Docs, са функциите за сътрудничество в реално време. Интегрираните ClickUp Chat и Comments позволяват на членовете на екипа да обсъждат идеи, да дават обратна връзка и да предлагат промени директно в документите.
Това означава, че вашият екип може да обсъжда резултатите и да прави корекции директно на платформата, като всички дискусии остават уместни и по темата.

Всичко, от документацията до работата в екип, се случва в ClickUp Docs, създавайки опростен процес на оценка, в който всеки може да вижда, споделя и реагира на най-новите разработки.
Резултатът? Гладък, унифициран работен процес, който позволява на вашия екип да се движи към целите си с пълна яснота.
Готови ли сте да опитате ClickUp? Преди това нека обсъдим някои съвети и трикове, за да извлечете максимална полза от LLM оценката си.
Най-добри практики в оценката на LLM
Добре структурираният подход към LLM оценката гарантира, че моделът отговаря на вашите нужди, съответства на очакванията на потребителите и предоставя значими резултати.
Поставянето на ясни цели, отчитането на крайните потребители и използването на различни показатели помагат за изготвянето на задълбочена оценка, която разкрива силните страни и областите, които се нуждаят от подобрение. По-долу са представени някои най-добри практики, които да ви насочат в процеса.
🎯 Определете ясни цели
Преди да започнете процеса на оценка, е важно да знаете точно какво искате да постигне вашият голям езиков модел (LLM). Отделете време, за да очертаете конкретните задачи или цели на модела.
📌 Пример: Ако искате да подобрите ефективността на машината за превод, уточнете нивата на качество, които искате да постигнете. Ясните цели ви помагат да се съсредоточите върху най-релевантните показатели, като гарантирате, че вашата оценка остава съобразена с тези цели и точно измерва успеха.
👥 Обърнете внимание на аудиторията си
Помислете кои лица ще използват LLM и какви са техните нужди. Изключително важно е оценката да бъде съобразена с целевите потребители.
📌 Пример: Ако вашият модел е предназначен да генерира ангажиращо съдържание, ще искате да обърнете специално внимание на показатели като плавност и съгласуваност. Разбирането на вашата аудитория помага да усъвършенствате критериите си за оценка, като се уверявате, че моделът предоставя реална стойност в практическото приложение.
📊 Използвайте разнообразни показатели
Не разчитайте само на един показател за оценка на LLM; комбинацията от показатели ви дава по-пълна представа за неговата ефективност. Всеки показател отразява различни аспекти, така че използването на няколко от тях може да ви помогне да идентифицирате както силните, така и слабите страни.
📌 Пример: Въпреки че BLEU резултатите са отлични за измерване на качеството на превода, те може да не обхващат всички нюанси на творческото писане. Включването на показатели като перплексност за предсказуема точност и дори човешки оценки за контекста може да доведе до много по-пълно разбиране за това колко добре се представя вашият модел.
LLM бенчмаркове и инструменти
Оценяването на големи езикови модели (LLM) често се основава на стандартни за индустрията критерии и специализирани инструменти, които помагат да се измери ефективността на модела при различни задачи.
Ето разбивка на някои широко използвани критерии и инструменти, които придават структура и яснота на процеса на оценяване.
Ключови показатели
- GLUE (General Language Understanding Evaluation): GLUE оценява възможностите на модела в множество езикови задачи, включително класифициране на изречения, сходство и изводи. Това е основен еталон за модели, които трябва да се справят с разбирането на езика за общи цели.
- SQuAD (Stanford Question Answering Dataset): Рамката за оценка SQuAD е идеална за четене с разбиране и измерва колко добре даден модел отговаря на въпроси въз основа на текстов пасаж. Тя се използва често за задачи като обслужване на клиенти и извличане на информация въз основа на знания, където точните отговори са от решаващо значение.
- SuperGLUE: Като подобрена версия на GLUE, SuperGLUE оценява моделите по по-сложни задачи за разсъждение и контекстуално разбиране. Тя предоставя по-задълбочени прозрения, особено за приложения, изискващи напреднало езиково разбиране.
Основни инструменти за оценка
- Hugging Face : Той е широко популярен с обширната си библиотека от модели, набори от данни и функции за оценка. Неговият интуитивен интерфейс позволява на потребителите лесно да избират бенчмаркове, да персонализират оценките и да проследяват производителността на моделите, което го прави универсален за много LLM приложения.
- SuperAnnotate: Специализирано е в управлението и анотирането на данни, което е от решаващо значение за задачите по надзиравано обучение. То е особено полезно за усъвършенстване на точността на моделите, тъй като улеснява получаването на висококачествени, анотирани от хора данни, които подобряват производителността на моделите при сложни задачи.
- AllenNLP: Разработен от Allen Institute for AI, AllenNLP е предназначен за изследователи и разработчици, които работят върху персонализирани NLP модели. Той поддържа редица бенчмаркове и предоставя инструменти за обучение, тестване и оценка на езикови модели, като предлага гъвкавост за различни NLP приложения.
Използването на комбинация от тези критерии и инструменти предлага цялостен подход към оценката на LLM. Критериите могат да определят стандарти за различните задачи, докато инструментите осигуряват структурата и гъвкавостта, необходими за ефективно проследяване, усъвършенстване и подобряване на производителността на модела.
Заедно те гарантират, че LLM отговарят както на техническите стандарти, така и на нуждите на практическото приложение.
Предизвикателства при оценката на LLM модели
Оценяването на големи езикови модели (LLM) изисква деликатен подход. То се фокусира върху качеството на отговорите и разбирането на адаптивността и ограниченията на модела в различни сценарии.
Тъй като тези модели са обучени на базата на обширни набори от данни, тяхното поведение се влияе от редица фактори, което прави необходимо да се оценява не само точността.
Истинската оценка означава да се провери надеждността на модела, устойчивостта му на необичайни команди и цялостната последователност на отговорите. Този процес помага да се получи по-ясна представа за силните и слабите страни на модела и разкрива областите, които се нуждаят от усъвършенстване.
Ето по-подробен поглед върху някои често срещани предизвикателства, които възникват по време на LLM оценката.
1. Припокриване на данните за обучение
Трудно е да се прецени дали моделът вече е „виждал“ някои от тестовите данни. Тъй като LLM се обучават на базата на огромни масиви от данни, има вероятност някои тестови въпроси да се припокриват с примерите от обучението. Това може да направи модела да изглежда по-добър, отколкото е в действителност, тъй като той може просто да повтаря това, което вече знае, вместо да демонстрира истинско разбиране.
2. Непостоянни резултати
LLM могат да дават непредсказуеми отговори. В един момент те предоставят впечатляващи прозрения, а в следващия правят странни грешки или представят въображаема информация като факти (известни като „халюцинации“).
Тази несъответствие означава, че макар LLM да дава отлични резултати в някои области, в други може да не е толкова успешен, което затруднява точната оценка на цялостната му надеждност и качество.
3. Уязвимости, свързани с противопоставянето
LLM могат да бъдат податливи на враждебни атаки, при които умело изработени команди ги подмамват да дават погрешни или вредни отговори. Тази уязвимост разкрива слабости в модела и може да доведе до неочаквани или пристрастни резултати. Тестването за тези враждебни слабости е от решаващо значение за разбирането на границите на модела.
Практически примери за LLM оценка
Накрая, ето няколко често срещани ситуации, в които оценката на LLM наистина има значение:
Чатботове за обслужване на клиенти
LLM се използват широко в чатботовете за обработка на запитвания от клиенти. Оценката на ефективността на модела гарантира, че той предоставя точни, полезни и контекстуално подходящи отговори.
От решаващо значение е да се измери способността му да разбира намеренията на клиентите, да се справя с разнообразни въпроси и да дава отговори, подобни на човешките. Това ще позволи на бизнеса да осигури гладко обслужване на клиентите, като същевременно сведе до минимум неудовлетвореността.
Създаване на съдържание
Много компании използват LLM за генериране на съдържание за блогове, социални медии и описания на продукти. Оценяването на качеството на генерираното съдържание помага да се гарантира, че то е граматически правилно, интересно и подходящо за целевата аудитория. Показатели като креативност, съгласуваност и релевантност към темата са важни за поддържането на високи стандарти на съдържанието.
Анализ на настроенията
LLM могат да анализират настроенията в обратната връзка от клиентите, публикациите в социалните медии или рецензиите за продукти. Важно е да се оцени колко точно моделът идентифицира дали даден текст е положителен, отрицателен или неутрален. Това помага на бизнеса да разбере емоциите на клиентите, да усъвършенства продуктите или услугите, да повиши удовлетвореността на потребителите и да подобри маркетинговите стратегии.
Генериране на код
Разработчиците често използват LLM, за да подпомогнат генерирането на код. Оценяването на способността на модела да произвежда функционален и ефективен код е от решаващо значение.
Важно е да проверите дали генерираният код е логически правилен, без грешки и отговаря на изискванията на задачата. Това помага да се намали количеството ръчно кодиране и подобрява производителността.
Оптимизирайте вашата LLM оценка с ClickUp
Оценяването на LLM се състои в избора на подходящи показатели, които съответстват на вашите цели. Ключът е да разберете конкретните си цели, независимо дали става въпрос за подобряване на качеството на превода, усъвършенстване на генерирането на съдържание или фина настройка за специализирани задачи.
Изборът на подходящи показатели за оценка на ефективността, като RAG или показатели за фина настройка, е в основата на точната и значима оценка. Междувременно, усъвършенствани системи за оценяване като G-Eval, Prometheus, SelfCheckGPT и QAG предоставят точни данни благодарение на своите силни способности за разсъждение.
Това обаче не означава, че тези резултати са перфектни – все пак е важно да се уверите, че са надеждни.
Докато напредвате с оценката на LLM приложението си, адаптирайте процеса, за да отговаря на вашия конкретен случай на употреба. Няма универсална метрика, която да работи за всеки сценарий. Комбинацията от метрики, заедно с фокуса върху контекста, ще ви даде по-точна представа за производителността на вашия модел.
За да оптимизирате LLM оценката си и да подобрите сътрудничеството в екипа, ClickUp е идеалното решение за управление на работните процеси и проследяване на важни показатели.
Искате да подобрите производителността на вашия екип? Регистрирайте се в ClickUp още днес и вижте как той може да промени вашия работен процес!