

บอทบริการลูกค้าที่เรียนรู้จากการโต้ตอบทุกครั้ง ผู้ช่วยขายที่ปรับกลยุทธ์ตามข้อมูลเชิงลึกแบบเรียลไทม์ สิ่งเหล่านี้ไม่ใช่แค่แนวคิด—แต่เป็นความจริงแล้ว ด้วย ตัวแทนการเรียนรู้ AI
แต่สิ่งที่ทำให้ตัวแทนเหล่านี้มีความพิเศษคืออะไร และตัวแทนที่เรียนรู้ทำงานอย่างไรเพื่อให้เกิดความยืดหยุ่นนี้?
ต่างจากระบบ AI แบบดั้งเดิมที่ทำงานด้วยการโปรแกรมที่ตายตัว ตัวแทนการเรียนรู้สามารถพัฒนาได้
พวกเขาปรับตัว ปรับปรุง และปรับปรุงการกระทำของตนตลอดเวลา ทำให้พวกเขาไม่สามารถขาดได้ในอุตสาหกรรมเช่นยานพาหนะอัตโนมัติและระบบการแพทย์ ที่ความยืดหยุ่นและความแม่นยำไม่สามารถต่อรองได้
คิดถึงพวกเขาเหมือนกับ AI ที่ฉลาดขึ้นด้วยประสบการณ์ เหมือนกับมนุษย์
ในบล็อกนี้ เราจะสำรวจองค์ประกอบหลัก กระบวนการ ประเภท และการประยุกต์ใช้ของตัวแทนการเรียนรู้ในปัญญาประดิษฐ์ 🤖
⏰ สรุป 60 วินาที
นี่คือบทนำสั้นๆ เกี่ยวกับการเรียนรู้ตัวแทนในปัญญาประดิษฐ์:
สิ่งที่พวกเขาทำ: ปรับตัวผ่านการมีปฏิสัมพันธ์ เช่น บอทบริการลูกค้าปรับปรุงการตอบสนอง
การใช้งานหลัก: หุ่นยนต์, บริการส่วนบุคคล, และระบบอัจฉริยะ เช่น อุปกรณ์ภายในบ้าน
องค์ประกอบหลัก:
- องค์ประกอบแห่งการเรียนรู้: รวบรวมความรู้เพื่อพัฒนาประสิทธิภาพ
- องค์ประกอบด้านประสิทธิภาพ: ปฏิบัติงานตามความรู้ที่ได้เรียนรู้
- นักวิจารณ์: ประเมินการกระทำและให้ข้อเสนอแนะ
- เครื่องสร้างปัญหา: ระบุโอกาสในการเรียนรู้เพิ่มเติม
วิธีการเรียนรู้:
- การเรียนรู้แบบมีผู้สอน: รู้จักรูปแบบโดยใช้ข้อมูลที่มีป้ายกำกับ
- การเรียนรู้แบบไม่มีผู้ควบคุม: ระบุโครงสร้างในข้อมูลที่ไม่มีป้ายกำกับ
- การเรียนรู้แบบเสริมแรง: เรียนรู้ผ่านการลองผิดลองถูก
ผลกระทบในโลกจริง: เพิ่มความสามารถในการปรับตัว ประสิทธิภาพ และการตัดสินใจในหลากหลายอุตสาหกรรม
⚙️ โบนัส: รู้สึกสับสนกับศัพท์เฉพาะของ AI หรือไม่?ลองดูอภิธานศัพท์ AIของเราที่ครอบคลุมเพื่อทำความเข้าใจแนวคิดพื้นฐานและคำศัพท์ขั้นสูงได้อย่างง่ายดาย
ตัวแทนการเรียนรู้ในปัญญาประดิษฐ์คืออะไร?
ตัวแทนการเรียนรู้ในปัญญาประดิษฐ์คือระบบที่พัฒนาขึ้นตามกาลเวลาโดยการเรียนรู้จากสภาพแวดล้อมของตน พวกเขาปรับตัว, ตัดสินใจอย่างชาญฉลาดขึ้น, และปรับปรุงการกระทำให้เหมาะสมที่สุดตามคำแนะนำและข้อมูล
ต่างจากระบบ AI แบบดั้งเดิมที่คงที่ ตัวแทนการเรียนรู้จะพัฒนาอย่างต่อเนื่อง ซึ่งทำให้พวกมันมีความสำคัญอย่างยิ่งสำหรับหุ่นยนต์และคำแนะนำที่ปรับให้เหมาะกับบุคคล ซึ่งสภาพแวดล้อมไม่สามารถคาดการณ์ได้และเปลี่ยนแปลงอยู่เสมอ
🔍 คุณรู้หรือไม่? ตัวแทนการเรียนรู้ทำงานในลักษณะของวงจรป้อนกลับ—รับรู้สภาพแวดล้อม เรียนรู้จากข้อมูลที่ได้รับ และปรับปรุงการกระทำของตน สิ่งนี้ได้รับแรงบันดาลใจจากวิธีที่มนุษย์เรียนรู้จากประสบการณ์
องค์ประกอบหลักของตัวแทนการเรียนรู้
ตัวแทนการเรียนรู้มักประกอบด้วยส่วนประกอบหลายส่วนที่เชื่อมต่อกันและทำงานร่วมกันเพื่อให้มั่นใจถึงความสามารถในการปรับตัวและการปรับปรุงอย่างต่อเนื่องเมื่อเวลาผ่านไป
นี่คือองค์ประกอบที่สำคัญของกระบวนการเรียนรู้ 📋
องค์ประกอบแห่งการเรียนรู้
หน้าที่หลักของตัวแทนคือการได้รับความรู้และปรับปรุงประสิทธิภาพโดยการวิเคราะห์ข้อมูล, การโต้ตอบ, และคำแนะนำ.
การใช้เทคนิค AIเช่น การเรียนรู้แบบมีผู้สอน การเรียนรู้แบบเสริมแรง และการเรียนรู้แบบไม่มีผู้สอน ตัวแทนจะปรับตัวและปรับปรุงพฤติกรรมของตนเพื่อเพิ่มประสิทธิภาพการทำงาน
📌 ตัวอย่าง: ผู้ช่วยเสมือนจริงอย่าง Siri จะเรียนรู้ความชอบของผู้ใช้เมื่อเวลาผ่านไป เช่น คำสั่งที่ใช้บ่อยหรือสำเนียงเฉพาะ เพื่อตอบสนองได้อย่างแม่นยำและเป็นส่วนตัวมากขึ้น
องค์ประกอบด้านประสิทธิภาพ
ส่วนประกอบนี้ดำเนินการงานโดยมีปฏิสัมพันธ์กับสภาพแวดล้อมและตัดสินใจโดยอิงจากข้อมูลที่มีอยู่ โดยพื้นฐานแล้วเป็นส่วน 'แขนปฏิบัติการ' ของตัวแทน
📌 ตัวอย่าง: ในรถยนต์ขับเคลื่อนอัตโนมัติ องค์ประกอบด้านประสิทธิภาพจะประมวลผลข้อมูลการจราจรและสภาพแวดล้อมเพื่อตัดสินใจแบบเรียลไทม์ เช่น การหยุดรถเมื่อเจอสัญญาณไฟแดงหรือการหลีกเลี่ยงสิ่งกีดขวาง
นักวิจารณ์
นักวิจารณ์ประเมินการกระทำที่ดำเนินการโดยองค์ประกอบของการปฏิบัติงานและให้ข้อเสนอแนะ ข้อเสนอแนะนี้ช่วยให้องค์ประกอบของการเรียนรู้ระบุสิ่งที่ทำได้ดีและสิ่งที่ต้องปรับปรุง
📌 ตัวอย่าง: ในระบบแนะนำ ระบบจะวิเคราะห์การโต้ตอบของผู้ใช้ (เช่น การคลิกหรือการข้าม) เพื่อกำหนดว่าข้อเสนอแนะใดประสบความสำเร็จ และช่วยองค์ประกอบที่เรียนรู้ปรับปรุงคำแนะนำในอนาคต
เครื่องสร้างปัญหา
ส่วนประกอบนี้ส่งเสริมการสำรวจโดยการแนะนำสถานการณ์หรือการกระทำใหม่ ๆ ให้ตัวแทนทดสอบ
มันผลักดันให้ตัวแทนก้าวข้ามขอบเขตความสบายของตน เพื่อให้เกิดการพัฒนาอย่างต่อเนื่อง ตัวแทนยังช่วยป้องกันผลลัพธ์ที่ไม่เหมาะสมที่สุดโดยการขยายขอบเขตประสบการณ์ของตัวแทน
📌 ตัวอย่าง: ในระบบปัญญาประดิษฐ์สำหรับอีคอมเมิร์ซ ตัวสร้างปัญหาอาจแนะนำกลยุทธ์การตลาดที่ปรับให้เหมาะกับบุคคลหรือจำลองรูปแบบพฤติกรรมของลูกค้าได้ ซึ่งช่วยให้ระบบปัญญาประดิษฐ์ปรับปรุงแนวทางของตนเพื่อให้คำแนะนำที่เหมาะกับผู้ใช้แต่ละคนตามความชอบที่แตกต่างกัน
กระบวนการเรียนรู้ในตัวแทนการเรียนรู้
ตัวแทนการเรียนรู้พึ่งพาหลักสามประเภทหลักในการปรับตัวและปรับปรุง ประเภทเหล่านี้ได้ถูกสรุปไว้ด้านล่าง 👇
1. การเรียนรู้แบบมีผู้ควบคุม
ตัวแทนเรียนรู้จากชุดข้อมูลที่มีป้ายกำกับไว้ ซึ่งแต่ละอินพุตจะสอดคล้องกับเอาต์พุตที่เฉพาะเจาะจง
วิธีนี้ต้องการปริมาณข้อมูลจำนวนมากที่มีการระบุอย่างถูกต้องสำหรับการฝึกอบรม และถูกนำมาใช้อย่างแพร่หลายในแอปพลิเคชันเช่นการจดจำภาพ, การแปลภาษา, และการตรวจจับการฉ้อโกง
📌 ตัวอย่าง: ระบบกรองอีเมลเรียนรู้ที่จะจำแนกอีเมลว่าเป็นสแปมหรือไม่โดยอิงจากข้อมูลในอดีต องค์ประกอบที่เรียนรู้จะระบุรูปแบบระหว่างข้อมูลนำเข้า (เนื้อหาอีเมล) และข้อมูลส่งออก (ป้ายกำกับการจำแนกประเภท) เพื่อทำการคาดการณ์ที่แม่นยำ
2. การเรียนรู้แบบไม่มีผู้ควบคุม
รูปแบบหรือความสัมพันธ์ที่ซ่อนอยู่ในข้อมูลจะปรากฏขึ้นเมื่อตัวแทนวิเคราะห์ข้อมูลโดยไม่มีป้ายกำกับที่ชัดเจน วิธีการนี้เหมาะสำหรับการตรวจจับความผิดปกติ การสร้างระบบแนะนำ และการเพิ่มประสิทธิภาพการบีบอัดข้อมูล
นอกจากนี้ยังช่วยระบุข้อมูลเชิงลึกที่อาจไม่ปรากฏให้เห็นทันทีจากข้อมูลที่มีป้ายกำกับ
📌 ตัวอย่าง: การแบ่งกลุ่มลูกค้าในการตลาดสามารถจัดกลุ่มผู้ใช้ตามพฤติกรรมของพวกเขาเพื่อออกแบบแคมเปญที่ตรงเป้าหมาย การเน้นคือการทำความเข้าใจโครงสร้างและการสร้างกลุ่มหรือความสัมพันธ์
3. การเรียนรู้แบบเสริมแรง
ต่างจากข้างต้น การเรียนรู้แบบเสริมแรง (RL) เกี่ยวข้องกับตัวแทนที่ดำเนินการในสภาพแวดล้อมเพื่อเพิ่มรางวัลสะสมให้สูงสุดเมื่อเวลาผ่านไป
ตัวแทนเรียนรู้ผ่านการลองผิดลองถูก โดยได้รับข้อมูลย้อนกลับผ่านรางวัลหรือบทลงโทษ
🔔 โปรดจำไว้: การเลือกวิธีการเรียนรู้ขึ้นอยู่กับปัญหา ความพร้อมของข้อมูล และความซับซ้อนของสภาพแวดล้อม การเรียนรู้แบบเสริมกำลังมีความสำคัญอย่างยิ่งสำหรับงานที่ไม่มีการกำกับดูแลโดยตรง เนื่องจากใช้การวนซ้ำของข้อมูลป้อนกลับเพื่อปรับการกระทำ
เทคนิคการเรียนรู้แบบเสริมแรง
- การวนซ้ำนโยบาย: ปรับปรุงความคาดหวังของรางวัลโดยการเรียนรู้โดยตรงนโยบายที่แปลงสถานะเป็นการกระทำ
- การวนค่า: กำหนดการกระทำที่เหมาะสมที่สุดโดยการคำนวณค่าของแต่ละคู่สถานะ-การกระทำ
- วิธีการมอนติคาร์โล: จำลองสถานการณ์ในอนาคตหลายรูปแบบเพื่อทำนายผลตอบแทนจากการกระทำ โดยเฉพาะอย่างยิ่งในสภาพแวดล้อมที่มีความเปลี่ยนแปลงและอาศัยความน่าจะเป็น
ตัวอย่างการประยุกต์ใช้ RL ในโลกจริง
- การขับขี่อัตโนมัติ: อัลกอริทึม RL ฝึกฝนยานพาหนะให้สามารถนำทางได้อย่างปลอดภัย ปรับเส้นทางให้เหมาะสม และปรับตัวเข้ากับสภาพการจราจรโดยการเรียนรู้อย่างต่อเนื่องจากสภาพแวดล้อมจำลอง
- AlphaGo และปัญญาประดิษฐ์ในเกม: การเรียนรู้แบบเสริมกำลังขับเคลื่อน AlphaGo ของ Google ให้เอาชนะแชมป์มนุษย์ได้ด้วยการเรียนรู้กลยุทธ์ที่เหมาะสมที่สุดสำหรับเกมซับซ้อนเช่นโก
- การกำหนดราคาแบบไดนามิก: แพลตฟอร์มอีคอมเมิร์ซใช้ RL เพื่อปรับกลยุทธ์การกำหนดราคาตามรูปแบบความต้องการและการกระทำของคู่แข่งเพื่อเพิ่มรายได้สูงสุด
🧠 ข้อเท็จจริงสนุกๆ: ตัวแทนการเรียนรู้สามารถเอาชนะแชมป์เปี้ยนมนุษย์ในเกมอย่างหมากรุกและสตาร์คราฟท์ได้ แสดงให้เห็นถึงความสามารถในการปรับตัวและความฉลาดของพวกเขา
การเรียนรู้แบบ Q-learning และวิธีการเครือข่ายประสาทเทียม
Q-learning เป็นอัลกอริทึม RL ที่ใช้กันอย่างแพร่หลาย ซึ่งตัวแทนจะเรียนรู้ค่าของแต่ละคู่สถานะ-การกระทำผ่านการสำรวจและข้อมูลย้อนกลับ ตัวแทนจะสร้างตาราง Q ซึ่งเป็นเมทริกซ์ที่กำหนดรางวัลที่คาดหวังให้กับคู่สถานะ-การกระทำ
มันเลือกการกระทำที่มีค่า Q สูงสุด และปรับปรุงตารางของมันอย่างต่อเนื่องเพื่อเพิ่มความถูกต้อง
📌 ตัวอย่าง: โดรนที่ใช้ปัญญาประดิษฐ์ในการเรียนรู้เพื่อส่งมอบพัสดุอย่างมีประสิทธิภาพ ใช้การเรียนรู้แบบ Q-learning ในการประเมินเส้นทาง โดยจะกำหนดรางวัลสำหรับการส่งมอบตรงเวลาและบทลงโทษสำหรับการล่าช้าหรือการชนกัน เมื่อเวลาผ่านไป โดรนจะปรับปรุงตาราง Q ของมันเพื่อเลือกเส้นทางส่งมอบที่มีประสิทธิภาพและปลอดภัยที่สุด
อย่างไรก็ตาม ตาราง Q จะไม่สามารถใช้งานได้จริงในสภาพแวดล้อมที่ซับซ้อนซึ่งมีพื้นที่สถานะที่มีมิติสูง
เครือข่ายประสาทเทียมเข้ามาช่วยตรงนี้ โดยประมาณค่า Q แทนที่จะเก็บค่าไว้โดยตรง การเปลี่ยนแปลงนี้ช่วยให้การเรียนรู้แบบเสริมแรงสามารถแก้ไขปัญหาที่ซับซ้อนมากขึ้นได้
เครือข่าย Q ลึก (DQNs) พัฒนาไปอีกขั้น โดยใช้การเรียนรู้เชิงลึกเพื่อประมวลผลข้อมูลดิบที่ไม่มีโครงสร้าง เช่น ภาพหรือข้อมูลจากเซ็นเซอร์ เครือข่ายเหล่านี้สามารถจับคู่ข้อมูลจากประสาทสัมผัสกับการกระทำได้โดยตรง โดยไม่จำเป็นต้องมีการสร้างคุณลักษณะที่ซับซ้อน
📌 ตัวอย่าง: ในรถยนต์ขับเคลื่อนอัตโนมัติ DQNs จะประมวลผลข้อมูลจากเซ็นเซอร์แบบเรียลไทม์เพื่อเรียนรู้กลยุทธ์การขับขี่ เช่น การเปลี่ยนเลนหรือการหลีกเลี่ยงสิ่งกีดขวาง โดยไม่ต้องมีกฎเกณฑ์ที่ตั้งไว้ล่วงหน้า
วิธีการขั้นสูงเหล่านี้ช่วยให้ตัวแทนสามารถขยายขีดความสามารถในการเรียนรู้ของตนให้เหมาะสมกับงานที่ต้องการพลังการคำนวณสูงและความสามารถในการปรับตัว
⚙️ โบนัส: เรียนรู้วิธีสร้างและปรับปรุงฐานความรู้ AIที่ช่วยเพิ่มประสิทธิภาพการจัดการข้อมูล ปรับปรุงการตัดสินใจ และเพิ่มผลผลิตของทีม
กระบวนการเรียนรู้สำหรับตัวแทนให้ความสำคัญกับการสร้างกลยุทธ์เพื่อการตัดสินใจอย่างชาญฉลาดในเวลาจริง. นี่คือแง่มุมที่สำคัญที่ช่วยในการตัดสินใจ:
- การสำรวจกับการใช้ประโยชน์: ตัวแทนจะสร้างสมดุลระหว่างการสำรวจการกระทำใหม่เพื่อค้นหาวิธีที่ดีกว่ากับการใช้ประโยชน์จากการกระทำที่รู้จักแล้วเพื่อเพิ่มรางวัลให้สูงสุด
- การตัดสินใจแบบหลายตัวแทน: ในสภาพแวดล้อมที่ร่วมมือกันหรือแข่งขันกัน ตัวแทนจะโต้ตอบและปรับกลยุทธ์ตามเป้าหมายร่วมกันหรือกลยุทธ์ที่เป็นปฏิปักษ์
- การแลกเปลี่ยนเชิงกลยุทธ์: ตัวแทนยังเรียนรู้ที่จะจัดลำดับความสำคัญของเป้าหมายตามบริบท เช่น การสร้างสมดุลระหว่างความเร็วและความแม่นยำในระบบจัดส่ง
🎤 ประกาศพอดแคสต์: สำรวจรายการพอดแคสต์ AIที่คัดสรรมาอย่างดีของเรา เพื่อเพิ่มพูนความเข้าใจเกี่ยวกับการทำงานของตัวแทนการเรียนรู้
ประเภทของตัวแทนปัญญาประดิษฐ์
ตัวแทนการเรียนรู้ในปัญญาประดิษฐ์มีหลากหลายรูปแบบ แต่ละรูปแบบถูกออกแบบมาเพื่อตอบสนองงานและความท้าทายเฉพาะด้าน
มาสำรวจกลไกการทำงาน ลักษณะเฉพาะตัว และตัวอย่างจากโลกจริงของพวกเขากันเถอะ 👀
สารกระตุ้นปฏิกิริยาสะท้อนกลับอย่างง่าย
ตัวแทนเหล่านี้ตอบสนองต่อสิ่งกระตุ้นโดยตรงตามกฎที่กำหนดไว้ล่วงหน้า พวกเขาใช้กลไกเงื่อนไข-การกระทำ (if-then) เพื่อเลือกการกระทำตามสภาพแวดล้อมปัจจุบันโดยไม่คำนึงถึงประวัติหรืออนาคต
ลักษณะ
- ทำงานบนระบบเงื่อนไข-การกระทำที่อิงตามตรรกะ
- ไม่ปรับตัวต่อการเปลี่ยนแปลงหรือเรียนรู้จากประสบการณ์ที่ผ่านมา
- ทำงานได้ดีที่สุดในสภาพแวดล้อมที่โปร่งใสและคาดการณ์ได้
ตัวอย่าง
เทอร์โมสตัททำหน้าที่เป็นตัวกระตุ้นแบบสะท้อนกลับอย่างง่าย โดยจะเปิดระบบทำความร้อนเมื่ออุณหภูมิลดลงต่ำกว่าค่าที่กำหนดไว้ และจะปิดระบบเมื่ออุณหภูมิสูงขึ้น เทอร์โมสตัทตัดสินใจโดยอาศัยข้อมูลอุณหภูมิปัจจุบันเพียงอย่างเดียว
🧠 ข้อเท็จจริงสนุกๆ: การทดลองบางประเภทกำหนดความต้องการจำลองให้กับตัวแทนการเรียนรู้ เช่น ความหิวหรือความกระหาย เพื่อกระตุ้นให้พวกเขาพัฒนาพฤติกรรมที่มีเป้าหมายและเรียนรู้วิธีตอบสนองต่อ "ความต้องการ" เหล่านี้อย่างมีประสิทธิภาพ
ตัวแทนปฏิกิริยาแบบจำลอง
ตัวแทนเหล่านี้รักษาแบบจำลองภายในของโลกที่ช่วยให้พวกเขาสามารถพิจารณาผลกระทบของการกระทำของตนได้ พวกเขายังสามารถอนุมานสภาพของสิ่งแวดล้อมที่อยู่นอกเหนือสิ่งที่พวกเขาสามารถรับรู้ได้ในทันที
ลักษณะ
- ใช้แบบจำลองที่จัดเก็บไว้ของสภาพแวดล้อมเพื่อการตัดสินใจ
- ประมาณสถานะปัจจุบันเพื่อจัดการกับสภาพแวดล้อมที่สังเกตได้บางส่วน
- มีความยืดหยุ่นและปรับตัวได้มากกว่าเมื่อเทียบกับสารกระตุ้นแบบตอบสนองอัตโนมัติ
ตัวอย่าง
รถยนต์ขับเคลื่อนอัตโนมัติของเทสลาใช้เอเจนต์ที่อิงตามแบบจำลองในการนำทางบนท้องถนน มันตรวจจับสิ่งกีดขวางที่มองเห็นได้และคาดการณ์การเคลื่อนไหวของยานพาหนะที่อยู่ใกล้เคียง รวมถึงยานพาหนะที่อยู่ในจุดบอด โดยใช้เซ็นเซอร์ขั้นสูงและข้อมูลแบบเรียลไทม์ สิ่งนี้ช่วยให้รถสามารถตัดสินใจในการขับขี่ได้อย่างแม่นยำและมีข้อมูลครบถ้วน เพิ่มความปลอดภัยและประสิทธิภาพในการขับขี่
🔍 คุณรู้หรือไม่? แนวคิดของตัวแทนการเรียนรู้มักเลียนแบบพฤติกรรมที่สังเกตได้ในสัตว์ เช่น การเรียนรู้จากการลองผิดลองถูก หรือการเรียนรู้โดยใช้รางวัลเป็นแรงจูงใจ
ฟังก์ชันตัวแทนซอฟต์แวร์และผู้ช่วยเสมือน
ตัวแทนเหล่านี้ดำเนินการในสภาพแวดล้อมดิจิทัลและทำงานเฉพาะทางโดยอัตโนมัติ
ผู้ช่วยเสมือนจริงเช่น Siri หรือ Alexa ดำเนินการตามคำสั่งของผู้ใช้โดยใช้การประมวลผลภาษาธรรมชาติ (NLP) และดำเนินการตามคำสั่ง เช่น การตอบคำถามหรือควบคุมอุปกรณ์อัจฉริยะ
ลักษณะ
- ทำให้งานประจำวันง่ายขึ้น เช่น การจัดตารางเวลา การตั้งการแจ้งเตือน หรือการควบคุมอุปกรณ์
- ปรับปรุงอย่างต่อเนื่องโดยใช้การเรียนรู้ของอัลกอริทึมและข้อมูลการโต้ตอบของผู้ใช้
- ทำงานแบบอะซิงโครนัส ตอบสนองแบบเรียลไทม์หรือเมื่อถูกกระตุ้น
ตัวอย่าง
อเล็กซ่าสามารถเล่นเพลง ตั้งการแจ้งเตือน และควบคุมอุปกรณ์สมาร์ทโฮมได้โดยการแปลคำสั่งเสียง เชื่อมต่อกับระบบบนคลาวด์ และดำเนินการที่เหมาะสม
🔍 คุณรู้หรือไม่? ตัวแทนที่เน้นประโยชน์ใช้สอย ซึ่งมุ่งเน้นการเพิ่มผลลัพธ์สูงสุดโดยการประเมินการกระทำที่แตกต่างกัน มักทำงานร่วมกับตัวแทนที่เน้นการเรียนรู้ใน AI ตัวแทนที่เน้นการเรียนรู้จะปรับกลยุทธ์ของตนให้ดีขึ้นตามประสบการณ์ และสามารถใช้การตัดสินใจที่เน้นประโยชน์ใช้สอยเพื่อทำการเลือกที่ชาญฉลาดยิ่งขึ้น
ระบบหลายตัวแทนและการประยุกต์ใช้ทฤษฎีเกม
ระบบเหล่านี้ประกอบด้วยตัวแทนหลายตัวที่ทำงานร่วมกัน, แข่งขันกัน, หรือทำงานอย่างอิสระเพื่อให้บรรลุเป้าหมายส่วนตัวหรือเป้าหมายร่วมกัน
นอกจากนี้ หลักการทางทฤษฎีเกมมักชี้นำพฤติกรรมของพวกเขาในสถานการณ์การแข่งขัน
ลักษณะ
- ต้องการการประสานงานหรือการเจรจาต่อรองระหว่างตัวแทน
- ทำงานได้ดีในสภาพแวดล้อมที่มีการเปลี่ยนแปลงและกระจายตัว
- จำลองหรือจัดการระบบที่ซับซ้อน เช่น ห่วงโซ่อุปทานหรือการจราจรในเมือง
ตัวอย่าง
ในระบบอัตโนมัติคลังสินค้าของ Amazon หุ่นยนต์ (ตัวแทน) ทำงานร่วมกันเพื่อหยิบ จัดเรียง และขนส่งสินค้า หุ่นยนต์เหล่านี้สื่อสารกันเพื่อหลีกเลี่ยงการชนกันและเพื่อให้การทำงานเป็นไปอย่างราบรื่น หลักการทางทฤษฎีเกมช่วยในการจัดการลำดับความสำคัญที่แข่งขันกัน เช่น การรักษาสมดุลระหว่างความเร็วและทรัพยากร เพื่อให้ระบบทำงานได้อย่างมีประสิทธิภาพ
การประยุกต์ใช้ตัวแทนการเรียนรู้
ตัวแทนการเรียนรู้ได้เปลี่ยนแปลงอุตสาหกรรมมากมายโดยการปรับปรุงประสิทธิภาพและการตัดสินใจ
นี่คือตัวอย่างการใช้งานที่สำคัญ 📚
หุ่นยนต์และระบบอัตโนมัติ
ตัวแทนการเรียนรู้เป็นแกนหลักของหุ่นยนต์สมัยใหม่ ช่วยให้หุ่นยนต์สามารถทำงานได้อย่างอัตโนมัติและปรับตัวได้ในสภาพแวดล้อมที่เปลี่ยนแปลง
ต่างจากระบบแบบดั้งเดิมที่ต้องการการโปรแกรมอย่างละเอียดสำหรับแต่ละงาน ตัวแทนการเรียนรู้ช่วยให้หุ่นยนต์สามารถปรับปรุงตัวเองได้ผ่านการโต้ตอบและการให้คำแนะนำ
วิธีการทำงาน
หุ่นยนต์ที่ติดตั้งตัวแทนการเรียนรู้ใช้เทคนิคเช่นการเรียนรู้แบบเสริมกำลังเพื่อโต้ตอบกับสิ่งแวดล้อมและประเมินผลลัพธ์ของการกระทำของพวกเขา พวกมันปรับปรุงพฤติกรรมของตนตลอดเวลา โดยมุ่งเน้นไปที่การเพิ่มรางวัลให้สูงสุดและหลีกเลี่ยงการลงโทษ
โครงข่ายประสาทเทียมได้พัฒนาไปอีกขั้น โดยช่วยให้หุ่นยนต์สามารถประมวลผลข้อมูลที่ซับซ้อน เช่น ข้อมูลภาพหรือการจัดวางเชิงพื้นที่ ซึ่งช่วยส่งเสริมการตัดสินใจที่ซับซ้อน
ตัวอย่าง
- ยานพาหนะอัตโนมัติ: ในภาคเกษตรกรรม ตัวแทนการเรียนรู้ขับเคลื่อนรถแทรกเตอร์อัตโนมัติเพื่อนำทางในทุ่งนา ปรับตัวกับสภาพดินที่หลากหลาย และเพิ่มประสิทธิภาพกระบวนการปลูกหรือเก็บเกี่ยว พวกเขาใช้ข้อมูลแบบเรียลไทม์เพื่อปรับปรุงประสิทธิภาพและลดการสูญเสีย
- หุ่นยนต์อุตสาหกรรม: ในการผลิต แขนกลหุ่นยนต์ที่ติดตั้งเอเจนต์การเรียนรู้จะปรับแต่งการเคลื่อนไหวของตนเพื่อเพิ่มความแม่นยำ ประสิทธิภาพ และความปลอดภัย เช่น ในสายการประกอบรถยนต์
📖 อ่านเพิ่มเติม: เคล็ดลับ AI ที่ทำให้คุณเร็วขึ้น ฉลาดขึ้น และเก่งขึ้น
การจำลองแบบและแบบจำลองที่ใช้ตัวแทน
ตัวแทนการเรียนรู้ขับเคลื่อนการจำลองที่เสนอวิธีการที่มีประสิทธิภาพด้านต้นทุนและปราศจากความเสี่ยงในการศึกษาเกี่ยวกับระบบที่ซับซ้อน
ระบบเหล่านี้จำลองพลวัตของโลกจริง ทำนายผลลัพธ์ และปรับกลยุทธ์ให้เหมาะสมที่สุดโดยการจำลองตัวแทนที่มีพฤติกรรมและความสามารถในการปรับตัวที่แตกต่างกัน
วิธีการทำงาน
ตัวแทนการเรียนรู้ในแบบจำลองสังเกตสภาพแวดล้อมของตน ทดสอบการกระทำ และปรับกลยุทธ์ของตนเพื่อเพิ่มประสิทธิภาพให้สูงสุด พวกมันเรียนรู้และปรับปรุงอย่างต่อเนื่องตลอดเวลา ทำให้สามารถปรับให้ผลลัพธ์ดีที่สุดได้
การจำลองสถานการณ์มีประสิทธิภาพสูงในการจัดการห่วงโซ่อุปทาน การวางผังเมือง และการพัฒนาหุ่นยนต์
ตัวอย่าง
- การจัดการจราจร: ตัวแทนจำลองแบบจำลองการไหลของจราจรในเมือง ซึ่งช่วยให้ผู้วิจัยสามารถทดสอบการแทรกแซง เช่น ถนนใหม่หรือการกำหนดราคาตามปริมาณการจราจร ก่อนการนำไปใช้จริง
- ระบาดวิทยา: ในการจำลองสถานการณ์การระบาดใหญ่ ตัวแทนการเรียนรู้จะเลียนแบบพฤติกรรมของมนุษย์เพื่อประเมินการแพร่กระจายของโรค นอกจากนี้ยังช่วยประเมินประสิทธิภาพของมาตรการควบคุม เช่น การเว้นระยะห่างทางสังคม
💡 เคล็ดลับจากผู้เชี่ยวชาญ: ปรับปรุงการเตรียมข้อมูลก่อนการเรียนรู้ของเครื่องในAIเพื่อเพิ่มความแม่นยำและประสิทธิภาพของตัวแทนการเรียนรู้ การป้อนข้อมูลคุณภาพสูงจะช่วยให้การตัดสินใจมีความน่าเชื่อถือมากขึ้น
ระบบอัจฉริยะ
ตัวแทนการเรียนรู้ขับเคลื่อนระบบอัจฉริยะโดยการทำให้การประมวลผลข้อมูลแบบเรียลไทม์และการปรับตัวให้เข้ากับพฤติกรรมและความชอบของผู้ใช้เป็นไปได้
จากเครื่องใช้ไฟฟ้าอัจฉริยะไปจนถึงอุปกรณ์ทำความสะอาดอัตโนมัติ ระบบเหล่านี้เปลี่ยนแปลงวิธีที่ผู้ใช้มีปฏิสัมพันธ์กับเทคโนโลยี ทำให้การทำงานประจำวันมีประสิทธิภาพและปรับให้เข้ากับความต้องการส่วนบุคคลมากขึ้น
วิธีการทำงาน
อุปกรณ์อย่าง Roomba ใช้เซ็นเซอร์ในตัวและตัวแทนการเรียนรู้เพื่อทำแผนที่รูปแบบบ้าน หลีกเลี่ยงสิ่งกีดขวาง และปรับเส้นทางการทำความสะอาดให้เหมาะสมที่สุด อุปกรณ์เหล่านี้จะรวบรวมและวิเคราะห์ข้อมูลอย่างต่อเนื่อง เช่น พื้นที่ที่ต้องการทำความสะอาดบ่อยหรือตำแหน่งของเฟอร์นิเจอร์ ซึ่งช่วยเพิ่มประสิทธิภาพการทำงานในแต่ละครั้งที่ใช้
ตัวอย่าง
- อุปกรณ์สมาร์ทโฮม: เทอร์โมสตัทอย่าง Nest เรียนรู้ตารางเวลาและความชอบอุณหภูมิของผู้ใช้ โดยจะปรับการตั้งค่าโดยอัตโนมัติเพื่อประหยัดพลังงานในขณะที่ยังคงความสบาย
- หุ่นยนต์ดูดฝุ่น: Roomba รวบรวมข้อมูลหลายจุดต่อวินาที ซึ่งช่วยให้มันเรียนรู้การเคลื่อนที่รอบเฟอร์นิเจอร์และระบุพื้นที่ที่มีการสัญจรสูงเพื่อการทำความสะอาดที่มีประสิทธิภาพ
ระบบอัจฉริยะเหล่านี้เน้นย้ำถึงการประยุกต์ใช้จริงของตัวแทนการเรียนรู้ในชีวิตประจำวัน เช่น การปรับปรุงกระบวนการทำงานให้มีประสิทธิภาพมากขึ้นและการทำงานซ้ำๆ โดยอัตโนมัติเพื่อเพิ่มประสิทธิภาพ
🔍 คุณรู้หรือไม่? Roomba รวบรวมข้อมูลมากกว่า 230,400 จุดต่อวินาทีเพื่อสร้างแผนที่บ้านของคุณ
ฟอรัมออนไลน์และผู้ช่วยเสมือน
ตัวแทนการเรียนรู้มีบทบาทสำคัญในการเพิ่มประสิทธิภาพการโต้ตอบออนไลน์และความช่วยเหลือดิจิทัล พวกเขาช่วยให้ฟอรัมและผู้ช่วยเสมือนสามารถมอบประสบการณ์ที่ปรับให้เหมาะกับแต่ละบุคคลได้
วิธีการทำงาน
ตัวแทนการเรียนรู้ทำหน้าที่ควบคุมการอภิปรายในฟอรัม และระบุและลบสแปมหรือเนื้อหาที่เป็นอันตราย. อย่างน่าสนใจ พวกเขายังแนะนำหัวข้อที่เกี่ยวข้องให้กับผู้ใช้ตามประวัติการท่องเว็บของพวกเขา.
ผู้ช่วยเสมือนจริง AIเช่น Alexa และ Google Assistant ใช้ตัวแทนการเรียนรู้เพื่อประมวลผลข้อมูลภาษาธรรมชาติ ปรับปรุงความเข้าใจตามบริบทของพวกเขาตลอดเวลา
ตัวอย่าง
- ฟอรัมอินเทอร์เน็ต: บอทผู้ดูแลของ Reddit ใช้ตัวแทนการเรียนรู้เพื่อสแกนโพสต์เพื่อหาการละเมิดกฎหรือภาษาที่เป็นพิษ การดูแลรักษาด้วย AI ดังกล่าวช่วยให้ชุมชนออนไลน์ปลอดภัยและน่าดึงดูด
- ผู้ช่วยเสมือน: อเล็กซ่าเรียนรู้ความชอบของผู้ใช้ เช่น เพลย์ลิสต์โปรดหรือคำสั่งสมาร์ทโฮมที่ใช้บ่อย เพื่อมอบความช่วยเหลือที่ปรับให้เหมาะกับแต่ละบุคคลและเชิงรุก
⚙️ โบนัส:เรียนรู้วิธีใช้ AI ในที่ทำงานของคุณเพื่อเพิ่มประสิทธิภาพการทำงานและทำให้งานต่างๆ เป็นระบบด้วยตัวแทนอัจฉริยะ
ความท้าทายในการพัฒนาตัวแทนการเรียนรู้
การพัฒนาตัวแทนการเรียนรู้เกี่ยวข้องกับความท้าทายทางเทคนิค, จริยธรรม, และการปฏิบัติจริง, รวมถึงการออกแบบอัลกอริทึม, ความต้องการทางคอมพิวเตอร์, และการนำไปใช้ในโลกจริง.
มาดูความท้าทายสำคัญบางประการที่การพัฒนา AI ต้องเผชิญในขณะที่มันพัฒนาไป 🚧
การบาลานซ์ระหว่างการค้นหาและการใช้ประโยชน์
ตัวแทนการเรียนรู้เผชิญกับปัญหาในการบาลานซ์ระหว่างการค้นหาและการใช้ประโยชน์
แม้ว่าอัลกอริทึมอย่าง epsilon-greedy จะสามารถช่วยได้ แต่การบรรลุสมดุลที่เหมาะสมนั้นขึ้นอยู่กับบริบทอย่างมาก นอกจากนี้ การสำรวจมากเกินไปอาจส่งผลให้เกิดความไม่มีประสิทธิภาพ ในขณะที่การพึ่งพาการใช้ประโยชน์มากเกินไปอาจนำไปสู่การแก้ปัญหาที่ไม่เหมาะสมที่สุด
การจัดการค่าใช้จ่ายในการคำนวณสูง
การฝึกฝนตัวแทนการเรียนรู้ที่มีความซับซ้อนมักต้องการทรัพยากรการคำนวณที่มากมาย. สิ่งนี้มีความเกี่ยวข้องมากขึ้นในสภาพแวดล้อมที่มีพลวัตที่ซับซ้อนหรือมีพื้นที่สถานะ-การกระทำที่ใหญ่.
โปรดจำไว้ว่าอัลกอริทึมเช่นการเรียนรู้เชิงเสริมแรงด้วยโครงข่ายประสาทเทียม เช่น Deep Q-Learning ต้องการพลังการประมวลผลและหน่วยความจำอย่างมาก คุณจะต้องได้รับความช่วยเหลือในการทำให้การเรียนรู้แบบเรียลไทม์เป็นไปได้ในแอปพลิเคชันที่มีทรัพยากรจำกัด
การเอาชนะปัญหาการขยายขนาดและการเรียนรู้แบบถ่ายโอน
การปรับขนาดตัวแทนการเรียนรู้ให้ทำงานได้อย่างมีประสิทธิภาพในสภาพแวดล้อมขนาดใหญ่และหลายมิติยังคงเป็นความท้าทาย การเรียนรู้แบบถ่ายโอน ซึ่งตัวแทนนำความรู้จากโดเมนหนึ่งไปใช้กับอีกโดเมนหนึ่ง ยังคงอยู่ในช่วงเริ่มต้น
สิ่งนี้ได้จำกัดความสามารถของพวกเขาในการประยุกต์ใช้ความรู้หรือทักษะไปยังงานหรือสภาพแวดล้อมอื่น ๆ
📌 ตัวอย่าง: ตัวแทนปัญญาประดิษฐ์ที่ฝึกฝนสำหรับหมากรุกจะประสบปัญหาในการเล่นโก เนื่องจากกฎและวัตถุประสงค์ที่แตกต่างกันอย่างมาก ซึ่งเน้นย้ำถึงความท้าทายในการถ่ายโอนความรู้ข้ามโดเมน
คุณภาพและความพร้อมใช้งานของข้อมูล
ประสิทธิภาพของตัวแทนการเรียนรู้ขึ้นอยู่กับคุณภาพและความหลากหลายของข้อมูลการฝึกอบรมเป็นอย่างมาก
ข้อมูลที่ไม่เพียงพอหรือมีอคติสามารถนำไปสู่การเรียนรู้ที่ไม่สมบูรณ์หรือผิดพลาด และส่งผลให้เกิดการตัดสินใจที่ไม่เหมาะสมหรือผิดจรรยาบรรณ นอกจากนี้ การเก็บข้อมูลจากโลกจริงเพื่อใช้ในการฝึกอบรมอาจมีค่าใช้จ่ายสูงและใช้เวลานาน
เครื่องมือและทรัพยากรสำหรับตัวแทนการเรียนรู้
นักพัฒนาและนักวิจัยพึ่งพาเครื่องมือต่าง ๆ ในการสร้างและฝึกฝนตัวแทนการเรียนรู้ เฟรมเวิร์กเช่น TensorFlow, PyTorch, และ OpenAI Gym มอบโครงสร้างพื้นฐานพื้นฐานสำหรับการนำไปใช้ของอัลกอริทึมการเรียนรู้ของเครื่อง
เครื่องมือเหล่านี้ยังช่วยสร้างสภาพแวดล้อมจำลองได้อีกด้วยแอปพลิเคชัน AIบางตัวยังช่วยให้กระบวนการนี้ง่ายขึ้นและดีขึ้น
สำหรับวิธีการเรียนรู้ของเครื่องแบบดั้งเดิม เครื่องมือเช่น Scikit-learn ยังคงเชื่อถือได้และมีประสิทธิภาพ
สำหรับการบริหารโครงการวิจัยและพัฒนาด้านปัญญาประดิษฐ์ClickUpมอบมากกว่าการจัดการงาน— มันทำหน้าที่เป็นศูนย์กลางที่รวมทุกอย่างไว้เพื่อจัดระเบียบงาน ติดตามความคืบหน้า และส่งเสริมการทำงานร่วมกันอย่างราบรื่นระหว่างทีมต่างๆ
ClickUp สำหรับการจัดการโครงการด้วย AIช่วยลดความพยายามในการประเมินสถานะงานและการจัดสรรหน้าที่ด้วยตนเอง
แทนที่จะต้องตรวจสอบงานแต่ละอย่างด้วยตนเองหรือคอยหาว่าใครว่างอยู่ AI จะเป็นผู้จัดการงานหนักเหล่านี้ให้โดยอัตโนมัติ สามารถอัปเดตความคืบหน้าโดยทันที ระบุจุดติดขัด และแนะนำบุคคลที่เหมาะสมที่สุดสำหรับแต่ละงานตามปริมาณงานและทักษะของแต่ละคน
ด้วยวิธีนี้ คุณจะใช้เวลาในการจัดการเอกสารที่น่าเบื่อน้อยลง และมีเวลาเพิ่มขึ้นสำหรับสิ่งที่สำคัญ—การขับเคลื่อนโครงการของคุณให้ก้าวหน้า
นี่คือคุณสมบัติที่โดดเด่นซึ่งขับเคลื่อนด้วย AI 🤩
คลิกอัพ เบรน
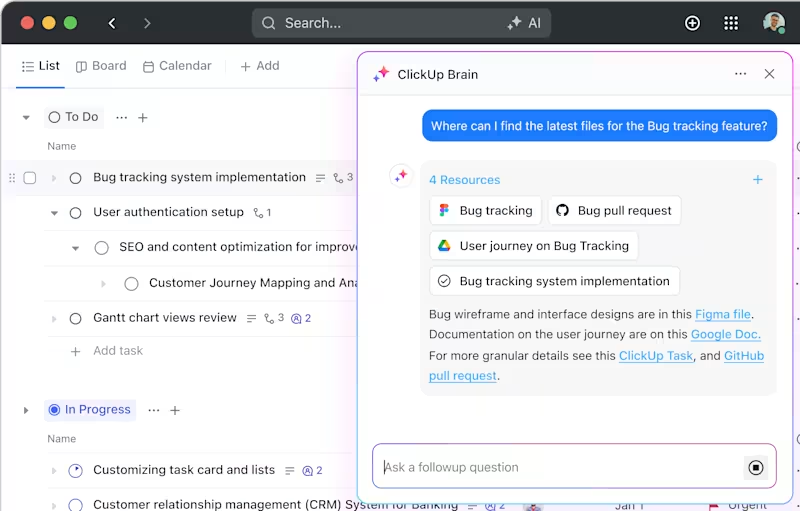
ClickUp Brain ผู้ช่วยอัจฉริยะที่ขับเคลื่อนด้วย AI ซึ่งถูกผสานเข้ากับแพลตฟอร์ม ช่วยทำให้โครงการที่ซับซ้อนที่สุดกลายเป็นเรื่องง่าย มันจะแบ่งการศึกษาที่กว้างขวางออกเป็นงานและงานย่อยที่จัดการได้ ช่วยให้คุณสามารถจัดระเบียบและติดตามความคืบหน้าได้อย่างมีประสิทธิภาพ
ต้องการเข้าถึงผลการทดลองหรือเอกสารอย่างรวดเร็วใช่ไหม? เพียงพิมพ์คำถาม แล้ว ClickUp Brain จะค้นหาทุกสิ่งที่คุณต้องการภายในไม่กี่วินาที นอกจากนี้ยังสามารถถามคำถามเพิ่มเติมตามข้อมูลที่มีอยู่ได้อีกด้วย ราวกับมีผู้ช่วยส่วนตัวคอยดูแลคุณ
นอกจากนี้ ยังเชื่อมโยงงานกับทรัพยากรที่เกี่ยวข้องโดยอัตโนมัติ ช่วยประหยัดเวลาและความพยายามของคุณ
สมมติว่าคุณกำลังทำการศึกษาเกี่ยวกับวิธีที่ตัวแทนการเรียนรู้แบบเสริมแรงพัฒนาขึ้นตามเวลา
คุณมีหลายขั้นตอน—การทบทวนวรรณกรรม, การเก็บรวบรวมข้อมูล, การทดลอง, และการวิเคราะห์. ด้วย ClickUp Brain, คุณสามารถถามว่า, 'แยกการศึกษานี้เป็นงานย่อย,' และมันจะสร้างงานย่อยสำหรับแต่ละขั้นตอนโดยอัตโนมัติ.
จากนั้นคุณสามารถขอให้มันดึงเอกสารที่เกี่ยวข้องกับการเรียนรู้แบบ Q-learning หรือดึงชุดข้อมูลเกี่ยวกับประสิทธิภาพของตัวแทน ซึ่งมันจะทำได้ทันที ขณะที่คุณทำงานผ่านภารกิจต่าง ๆ ClickUp Brain สามารถเชื่อมโยงบทความวิจัยหรือผลการทดลองเฉพาะไปยังภารกิจนั้น ๆ ได้โดยตรง ทำให้ทุกอย่างเป็นระเบียบ
ไม่ว่าจะเป็นการจัดการกรอบงานวิจัยหรือโครงการประจำวัน ClickUp Brain ช่วยให้คุณสามารถทำงานได้อย่างชาญฉลาด ไม่เหนื่อยหนัก
การทำงานอัตโนมัติของ ClickUp
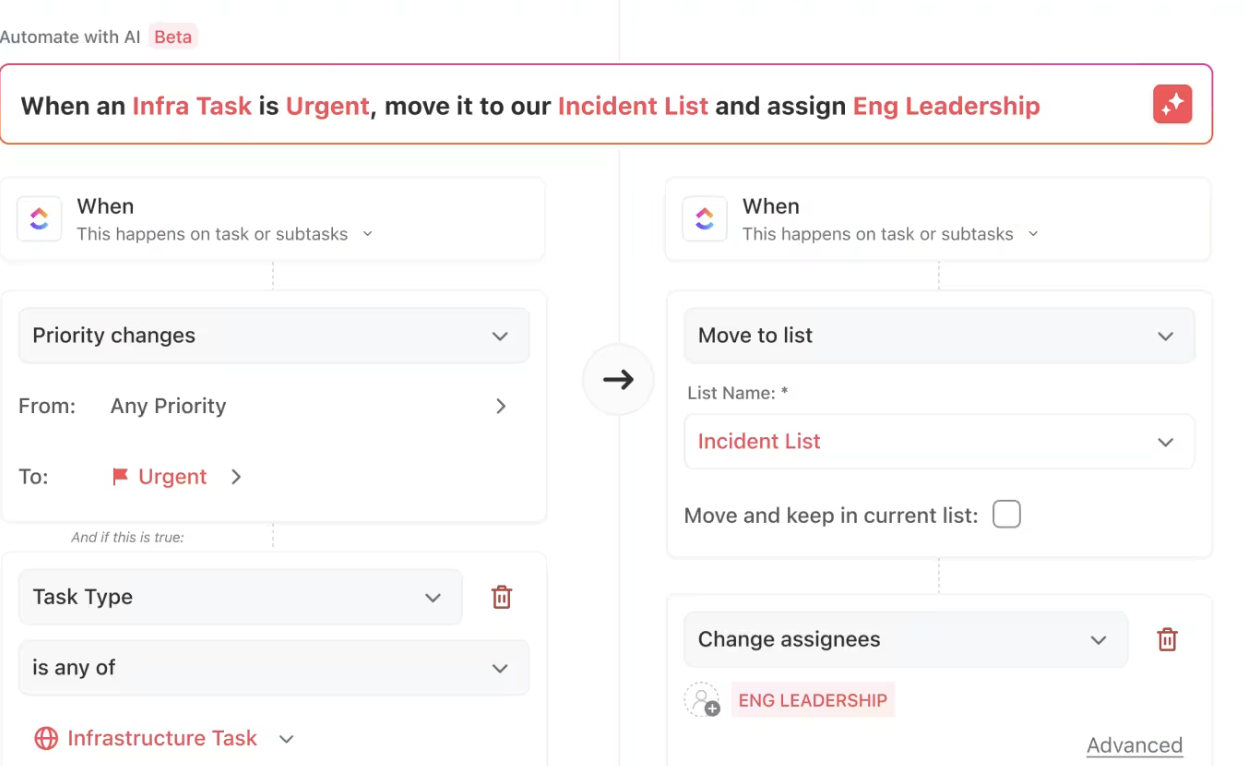
ClickUp Automationsเป็นวิธีที่ง่ายแต่ทรงพลังในการปรับปรุงกระบวนการทำงานของคุณให้มีประสิทธิภาพยิ่งขึ้น
มันช่วยให้สามารถมอบหมายงานได้ทันทีเมื่อข้อกำหนดเบื้องต้นเสร็จสมบูรณ์ แจ้งเตือนผู้มีส่วนได้ส่วนเสียเกี่ยวกับความคืบหน้าของงาน และแจ้งเตือนความล่าช้า—ทั้งหมดนี้โดยไม่ต้องมีการแทรกแซงด้วยตนเอง
คุณยังสามารถใช้คำสั่งในภาษาธรรมชาติได้ ทำให้การจัดการเวิร์กโฟลง่ายขึ้นไปอีก ไม่จำเป็นต้องเข้าไปในตั้งค่าที่ซับซ้อนหรือคำเทคนิค—เพียงแค่บอก ClickUp ว่าคุณต้องการอะไร และมันจะสร้างระบบอัตโนมัติให้คุณ
ไม่ว่าจะเป็น 'ย้ายงานไปยังขั้นตอนถัดไปเมื่อถูกทำเครื่องหมายว่าเสร็จสิ้น' หรือ 'มอบหมายงานให้กับ Sarah เมื่อความสำคัญสูง' ClickUp เข้าใจคำขอของคุณและตั้งค่าให้โดยอัตโนมัติ
📖 อ่านเพิ่มเติม: วิธีใช้ AI เพื่อเพิ่มประสิทธิภาพการทำงาน (กรณีศึกษาและเครื่องมือ)
พัฒนาตัวแทนการเรียนรู้อย่างมืออาชีพด้วย ClickUp
ในการสร้างตัวแทนการเรียนรู้ของ AI คุณจะต้องมีการผสมผสานอย่างเชี่ยวชาญระหว่างกระบวนการทำงานที่มีโครงสร้างและเครื่องมือที่ปรับตัวได้ ความต้องการที่เพิ่มขึ้นในด้านความเชี่ยวชาญทางเทคนิคทำให้มันท้าทายยิ่งขึ้น โดยเฉพาะเมื่อพิจารณาถึงลักษณะของงานที่ต้องอาศัยข้อมูลเชิงสถิติและข้อมูลสนับสนุน
พิจารณาใช้ ClickUp เพื่อทำให้โครงการเหล่านี้มีประสิทธิภาพมากขึ้น นอกเหนือจากการจัดระเบียบแล้ว เครื่องมือนี้ยังสนับสนุนนวัตกรรมของทีมคุณโดยการกำจัดความไม่มีประสิทธิภาพที่สามารถหลีกเลี่ยงได้
ClickUp Brain ช่วยแยกงานที่ซับซ้อนออกเป็นส่วนย่อย ค้นหาทรัพยากรที่เกี่ยวข้องได้ทันที และให้ข้อมูลเชิงลึกที่ขับเคลื่อนด้วย AI เพื่อช่วยให้โครงการของคุณเป็นระเบียบและดำเนินไปตามแผน ในขณะเดียวกัน ClickUp Automations จะจัดการงานที่ทำซ้ำ เช่น การอัปเดตสถานะหรือการมอบหมายงานใหม่ เพื่อให้ทีมของคุณสามารถมุ่งเน้นไปที่ภาพรวมที่สำคัญได้
คุณสมบัติเหล่านี้ร่วมกันขจัดความไม่มีประสิทธิภาพและช่วยให้ทีมของคุณทำงานได้อย่างชาญฉลาดยิ่งขึ้น ทำให้การสร้างสรรค์นวัตกรรมและความก้าวหน้าเกิดขึ้นได้อย่างง่ายดาย
ลงทะเบียนใช้ ClickUpฟรีวันนี้ ✅