

แบบจำลองภาษาขนาดใหญ่ (LLMs) ได้เปิดโอกาสใหม่ที่น่าตื่นเต้นสำหรับแอปพลิเคชันซอฟต์แวร์ ช่วยให้ระบบมีความชาญฉลาดและพลวัตมากกว่าที่เคยเป็นมา
ผู้เชี่ยวชาญคาดการณ์ว่า ภายในปี 2025 แอปพลิเคชันที่ใช้โมเดลเหล่านี้อาจทำให้งานดิจิทัลเกือบครึ่งหนึ่งเป็นไปโดยอัตโนมัติ
อย่างไรก็ตาม เมื่อเราปลดล็อกศักยภาพเหล่านี้ ความท้าทายก็ปรากฏขึ้น: เราจะวัดคุณภาพของผลลัพธ์ได้อย่างน่าเชื่อถือในระดับใหญ่ได้อย่างไร? การปรับตั้งค่าเพียงเล็กน้อย อาจทำให้ผลลัพธ์แตกต่างอย่างเห็นได้ชัด ความแปรปรวนนี้อาจทำให้การประเมินประสิทธิภาพของพวกเขายากขึ้น ซึ่งมีความสำคัญอย่างยิ่งเมื่อเตรียมแบบจำลองให้พร้อมใช้งานในโลกจริง
บทความนี้จะแบ่งปันข้อมูลเชิงลึกเกี่ยวกับแนวทางการประเมินระบบ LLM ที่ดีที่สุด ตั้งแต่การทดสอบก่อนการใช้งานไปจนถึงการผลิตจริง ดังนั้น มาเริ่มกันเลย!
การประเมิน LLM คืออะไร?
ตัวชี้วัดการประเมิน LLM เป็นวิธีในการตรวจสอบว่าคำสั่งของคุณ การตั้งค่าโมเดล หรือขั้นตอนการทำงานของคุณกำลังบรรลุเป้าหมายที่คุณตั้งไว้หรือไม่ ตัวชี้วัดเหล่านี้ให้ข้อมูลเชิงลึกเกี่ยวกับประสิทธิภาพของโมเดลภาษาขนาดใหญ่ของคุณ และว่ามันพร้อมใช้งานจริงในโลกแห่งความเป็นจริงหรือไม่
วันนี้ ตัวชี้วัดที่พบบ่อยที่สุดบางตัววัด การเรียกคืนบริบทในงานการเพิ่มประสิทธิภาพการค้นหา (RAG), การจับคู่ที่แน่นอนสำหรับการจำแนกประเภท, การตรวจสอบความถูกต้องของ JSON สำหรับผลลัพธ์ที่มีโครงสร้าง, และความคล้ายคลึงเชิงความหมาย สำหรับงานที่ต้องการความคิดสร้างสรรค์มากขึ้น
แต่ละตัวชี้วัดเหล่านี้รับประกันอย่างเป็นเอกลักษณ์ว่า LLM จะตรงตามมาตรฐานสำหรับกรณีการใช้งานเฉพาะของคุณ
ทำไมคุณต้องประเมิน LLM
โมเดลภาษาขนาดใหญ่ (LLMs) กำลังถูกนำไปใช้ในหลากหลายแอปพลิเคชันในปัจจุบัน การประเมินประสิทธิภาพของโมเดลจึงเป็นสิ่งสำคัญเพื่อให้แน่ใจว่าโมเดลเหล่านั้นสามารถตอบสนองมาตรฐานที่คาดหวังและให้บริการตามวัตถุประสงค์ที่ตั้งไว้ได้อย่างมีประสิทธิภาพ
ลองคิดดูแบบนี้: LLMs กำลังขับเคลื่อนทุกอย่างตั้งแต่แชทบอทสนับสนุนลูกค้าไปจนถึงเครื่องมือสร้างสรรค์ และเมื่อพวกมันพัฒนาขึ้น พวกมันก็ปรากฏในที่ต่างๆ มากขึ้น
ซึ่งหมายความว่าเราจำเป็นต้องมีวิธีที่ดีกว่าในการติดตามและประเมินผลพวกมัน—วิธีการแบบดั้งเดิมไม่สามารถรองรับงานทั้งหมดที่โมเดลเหล่านี้กำลังจัดการได้
ตัวชี้วัดการประเมินที่ดีเปรียบเสมือนการตรวจสอบคุณภาพสำหรับ LLM พวกมันแสดงให้เห็นว่าโมเดลมีความน่าเชื่อถือ แม่นยำ และมีประสิทธิภาพเพียงพอสำหรับการใช้งานในโลกจริงหรือไม่ หากไม่มีการตรวจสอบเหล่านี้ ข้อผิดพลาดอาจหลุดรอดไป นำไปสู่ประสบการณ์ที่น่าหงุดหงิดหรือแม้กระทั่งทำให้ผู้ใช้เข้าใจผิดได้
เมื่อคุณมีตัวชี้วัดการประเมินผลที่แข็งแกร่ง จะทำให้สามารถตรวจพบปัญหา ปรับปรุงแบบจำลอง และมั่นใจได้ว่าพร้อมที่จะตอบสนองความต้องการเฉพาะของผู้ใช้ได้ ด้วยวิธีนี้ คุณจะทราบว่าแพลตฟอร์ม AIที่คุณกำลังใช้งานนั้นได้มาตรฐานและสามารถให้ผลลัพธ์ที่คุณต้องการได้
📖 อ่านเพิ่มเติม: LLM กับ AI สร้างสรรค์: คู่มือฉบับละเอียด
ประเภทของการประเมิน LLM
การประเมินผลให้มุมมองที่เป็นเอกลักษณ์ในการตรวจสอบความสามารถของโมเดล แต่ละประเภทจะครอบคลุมแง่มุมคุณภาพที่หลากหลาย ช่วยให้สร้างโมเดลการนำไปใช้ที่เชื่อถือได้ ปลอดภัย และมีประสิทธิภาพ
นี่คือประเภทต่างๆ ของวิธีการประเมิน LLM:
- การประเมินภายใน มุ่งเน้นไปที่ประสิทธิภาพภายในของแบบจำลองในภารกิจทางภาษาศาสตร์หรือการเข้าใจเฉพาะทาง โดยไม่เกี่ยวข้องกับการนำไปใช้ในโลกจริง การประเมินนี้มักดำเนินการในระยะการพัฒนาของแบบจำลองเพื่อเข้าใจความสามารถหลัก
- การประเมินผลภายนอก เป็นการประเมินประสิทธิภาพของโมเดลในการนำไปใช้จริงในโลกแห่งความเป็นจริง การประเมินประเภทนี้จะตรวจสอบว่าโมเดลสามารถตอบสนองเป้าหมายเฉพาะที่กำหนดไว้ภายใต้บริบทนั้น ๆ ได้ดีเพียงใด
- การประเมินความทนทาน ทดสอบความเสถียรและความน่าเชื่อถือของแบบจำลองในสถานการณ์ที่หลากหลาย รวมถึงข้อมูลที่ไม่คาดคิดและสภาวะที่เป็นปฏิปักษ์ ระบุจุดอ่อนที่อาจเกิดขึ้น เพื่อให้มั่นใจว่าแบบจำลองทำงานได้อย่างคาดการณ์ได้
- การทดสอบประสิทธิภาพและความหน่วง ตรวจสอบการใช้ทรัพยากร ความเร็ว และความหน่วงของโมเดล เพื่อให้มั่นใจว่าโมเดลสามารถทำงานได้อย่างรวดเร็วและมีต้นทุนการคำนวณที่เหมาะสม ซึ่งมีความสำคัญอย่างยิ่งต่อความสามารถในการขยายขนาด
- การประเมินจริยธรรมและความปลอดภัย เพื่อให้แน่ใจว่าโมเดลสอดคล้องกับมาตรฐานจริยธรรมและแนวทางความปลอดภัย ซึ่งเป็นสิ่งสำคัญอย่างยิ่งในการประยุกต์ใช้ในกรณีที่มีความอ่อนไหว
การประเมินแบบจำลอง LLM กับการประเมินระบบ LLM
การประเมินแบบจำลองภาษาขนาดใหญ่ (LLMs) มีสองแนวทางหลัก: การประเมินแบบจำลอง และการประเมินระบบ แต่ละแนวทางมุ่งเน้นไปที่แง่มุมต่าง ๆ ของประสิทธิภาพของ LLM และการรู้ถึงความแตกต่างนี้มีความสำคัญอย่างยิ่งต่อการเพิ่มศักยภาพของแบบจำลองเหล่านี้ให้สูงสุด
🧠 การประเมินโมเดลจะพิจารณาทักษะทั่วไปของ LLM การประเมินประเภทนี้จะทดสอบความสามารถของโมเดลในการเข้าใจ สร้าง และทำงานกับภาษาได้อย่างถูกต้องในบริบทที่หลากหลาย เปรียบเสมือนการดูว่าโมเดลสามารถจัดการกับงานต่างๆ ได้ดีเพียงใด คล้ายกับการทดสอบความฉลาดทั่วไป
ตัวอย่างเช่น การประเมินโมเดลอาจถามว่า "โมเดลนี้มีความหลากหลายมากน้อยเพียงใด?"
🎯 การประเมินระบบ LLM วัดประสิทธิภาพของ LLM ในการทำงานภายใต้การตั้งค่าหรือวัตถุประสงค์เฉพาะ เช่น ในแชทบอทบริการลูกค้า ในกรณีนี้ จะเน้นที่ความสามารถในการทำงานเฉพาะด้านมากกว่าความสามารถโดยรวมของโมเดล เพื่อปรับปรุงประสบการณ์ของผู้ใช้
อย่างไรก็ตาม การประเมินระบบมุ่งเน้นไปที่คำถามเช่น "โมเดลนี้สามารถจัดการกับงานเฉพาะนี้สำหรับผู้ใช้ได้ดีเพียงใด?"
การประเมินแบบจำลองช่วยให้ผู้พัฒนาเข้าใจความสามารถโดยรวมและข้อจำกัดของ LLM ซึ่งช่วยในการปรับปรุงให้ดีขึ้น การประเมินระบบมุ่งเน้นไปที่ว่า LLM สามารถตอบสนองความต้องการของผู้ใช้ได้ดีเพียงใดในบริบทที่เฉพาะเจาะจง ซึ่งช่วยให้ประสบการณ์ของผู้ใช้ราบรื่นขึ้น
การประเมินเหล่านี้ร่วมกันให้ภาพรวมที่สมบูรณ์ของจุดแข็งและพื้นที่ที่ต้องปรับปรุงของ LLM ทำให้มีประสิทธิภาพมากขึ้นและใช้งานง่ายขึ้นในการใช้งานจริง
ตอนนี้ มาสำรวจตัวชี้วัดเฉพาะสำหรับการประเมิน LLM กัน
ตัวชี้วัดสำหรับการประเมิน LLM
ตัวชี้วัดการประเมินที่น่าเชื่อถือและทันสมัย ได้แก่:
1. ความสับสน
ความสับสน (Perplexity) วัดว่าโมเดลภาษาสามารถทำนายลำดับของคำได้ดีเพียงใด โดยพื้นฐานแล้ว มันบ่งบอกถึงความไม่แน่ใจของโมเดลเกี่ยวกับคำถัดไปในประโยค คะแนนความสับสนที่ต่ำหมายความว่าโมเดลมีความมั่นใจในการทำนายมากขึ้น ส่งผลให้ประสิทธิภาพดีขึ้น
📌 ตัวอย่าง: จินตนาการถึงโมเดลที่สร้างข้อความจากคำสั่ง "แมวนั่งบน" หากมันทำนายคำที่มีความน่าจะเป็นสูงเช่น "ผ้าปู" และ "พื้น" แสดงว่ามันเข้าใจบริบทได้ดี ส่งผลให้คะแนนความซับซ้อนต่ำ
ในทางกลับกัน หากมันแนะนำคำที่ไม่เกี่ยวข้อง เช่น "ยานอวกาศ" คะแนนความสับสนจะสูงขึ้น ซึ่งบ่งบอกว่าโมเดลมีปัญหาในการทำนายข้อความที่มีความหมาย
2. คะแนน BLEU
คะแนน BLEU (Bilingual Evaluation Understudy) ใช้เป็นหลักในการประเมินการแปลภาษาของเครื่องจักรและประเมินการสร้างข้อความ
มันวัดจำนวน n-grams (ลำดับต่อเนื่องของ n รายการจากตัวอย่างข้อความที่กำหนด) ในผลลัพธ์ที่ซ้อนทับกับ n-grams ในข้อความอ้างอิงหนึ่งหรือมากกว่า คะแนนมีช่วงตั้งแต่ 0 ถึง 1 โดยคะแนนที่สูงกว่าแสดงถึงประสิทธิภาพที่ดีกว่า
📌 ตัวอย่าง: หากโมเดลของคุณสร้างประโยค "สุนัขสีน้ำตาลที่ว่องไวกระโดดข้ามสุนัขขี้เกียจ" และข้อความอ้างอิงคือ "สุนัขสีน้ำตาลที่ว่องไวกระโดดข้ามสุนัขขี้เกียจ" BLEU จะเปรียบเทียบ n-grams ที่เหมือนกัน
คะแนนสูงบ่งชี้ว่าประโยคที่สร้างขึ้นมีความสอดคล้องกับข้อมูลอ้างอิงอย่างใกล้ชิด ขณะที่คะแนนต่ำอาจบ่งชี้ว่าผลลัพธ์ที่สร้างขึ้นไม่สอดคล้องกันดี
3. คะแนน F1
ตัวชี้วัดการประเมิน LLM แบบ F1 score ใช้สำหรับงานจำแนกประเภทเป็นหลัก โดยวัดความสมดุลระหว่างความแม่นยำ (ความถูกต้องของการทำนายที่เป็นบวก) และค่าความครอบคลุม (ความสามารถในการระบุตัวอย่างที่เกี่ยวข้องทั้งหมด)
มีค่าตั้งแต่ 0 ถึง 1 โดยที่คะแนน 1 หมายถึงมีความแม่นยำสมบูรณ์
📌 ตัวอย่าง: ในงานตอบคำถาม หากมีการถามโมเดลว่า "ท้องฟ้าเป็นสีอะไร?" และโมเดลตอบว่า "ท้องฟ้าเป็นสีฟ้า" (ผลบวกจริง) แต่รวมถึง "ท้องฟ้าเป็นสีเขียว" (ผลบวกเท็จ) คะแนน F1 จะพิจารณาทั้งความเกี่ยวข้องของคำตอบที่ถูกต้องและคำตอบที่ไม่ถูกต้อง
ตัวชี้วัดนี้ช่วยในการประเมินประสิทธิภาพของโมเดลอย่างสมดุล
4. ดาวตก
METEOR (Metric for Evaluation of Translation with Explicit ORdering) ก้าวไปไกลกว่าการจับคู่คำที่ตรงกัน โดยพิจารณาคำที่มีความหมายเหมือนกัน การแยกคำเป็นรากศัพท์ และการถอดความเพื่อประเมินความคล้ายคลึงระหว่างข้อความที่สร้างขึ้นกับข้อความอ้างอิง ตัวชี้วัดนี้มีเป้าหมายเพื่อให้สอดคล้องกับการตัดสินของมนุษย์มากขึ้น
📌 ตัวอย่าง: หากโมเดลของคุณสร้างประโยค "แมวนอนอยู่บนพรม" และอ้างอิงจาก "แมวนอนอยู่บนพรม" METEOR จะให้คะแนนสูงกว่า BLEU เพราะ METEOR รับรู้ว่า "feline" เป็นคำพ้องความหมายของ "cat" และ "rug" กับ "carpet" มีความหมายใกล้เคียงกัน
สิ่งนี้ทำให้ METEOR มีประโยชน์อย่างยิ่งในการจับความแตกต่างของภาษา
5. BERTScore
BERTScore ประเมินความคล้ายคลึงของข้อความ โดยอิงจากการฝังตัวตามบริบทที่ได้มาจากโมเดลอย่าง BERT (Bidirectional Encoder Representations from Transformers) โดยเน้นที่ความหมายมากกว่าการจับคู่คำที่ตรงกัน ทำให้สามารถประเมินความคล้ายคลึงเชิงความหมายได้ดีขึ้น.
📌 ตัวอย่าง: เมื่อเปรียบเทียบประโยค "รถแข่งลงถนน" กับ "ยานพาหนะวิ่งไปตามถนน" BERTScore จะวิเคราะห์ความหมายที่แท้จริงมากกว่าการเลือกใช้คำ
แม้ว่าคำจะแตกต่างกัน แต่แนวคิดโดยรวมคล้ายคลึงกัน ส่งผลให้มีคะแนน BERTScore สูง ซึ่งสะท้อนถึงประสิทธิภาพของเนื้อหาที่สร้างขึ้น
6. การประเมินโดยมนุษย์
การประเมินโดยมนุษย์ยังคงเป็นแง่มุมที่สำคัญของการประเมิน LLM ซึ่งเกี่ยวข้องกับผู้ตัดสินที่เป็นมนุษย์ในการให้คะแนนคุณภาพของ ผลลัพธ์ของโมเดลตามเกณฑ์ต่างๆ เช่น ความคล่องแคล่วและความเกี่ยวข้อง เทคนิคต่างๆ เช่น มาตราส่วนลิเคิร์ตและการทดสอบแบบ A/B สามารถนำมาใช้เพื่อรวบรวมข้อเสนอแนะ
📌 ตัวอย่าง: หลังจากที่แชทบอทบริการลูกค้าได้สร้างคำตอบแล้ว ผู้ประเมินที่เป็นมนุษย์อาจให้คะแนนแต่ละคำตอบในระดับ 1 ถึง 5 ตัวอย่างเช่น หากแชทบอทให้คำตอบที่ชัดเจนและเป็นประโยชน์ต่อคำถามของลูกค้า อาจได้รับคะแนน 5 ในขณะที่คำตอบที่คลุมเครือหรือสับสนอาจได้รับคะแนน 2
7. ตัวชี้วัดเฉพาะงาน
งาน LLM ที่แตกต่างกันต้องการเกณฑ์การประเมินที่ปรับให้เหมาะสม
สำหรับระบบสนทนา ตัวชี้วัดอาจประเมินการมีส่วนร่วมของผู้ใช้หรืออัตราการเสร็จสิ้นงาน สำหรับการสร้างโค้ด ความสำเร็จอาจวัดได้จากจำนวนครั้งที่โค้ดที่สร้างสามารถคอมไพล์หรือผ่านการทดสอบได้บ่อยเพียงใด
📌 ตัวอย่าง: ในแชทบอทสำหรับการสนับสนุนลูกค้า ระดับการมีส่วนร่วมอาจวัดได้จากระยะเวลาที่ผู้ใช้อยู่ในบทสนทนา หรือจำนวนคำถามติดตามผลที่ผู้ใช้ถาม
หากผู้ใช้ขอข้อมูลเพิ่มเติมบ่อยครั้ง แสดงว่าโมเดลสามารถดึงดูดความสนใจของพวกเขาได้สำเร็จและสามารถตอบคำถามของพวกเขาได้อย่างมีประสิทธิภาพ
8. ความทนทานและความยุติธรรม
การประเมินความทนทานของแบบจำลองเกี่ยวข้องกับการทดสอบ ว่ามันตอบสนองต่อข้อมูลที่ไม่คาดคิดหรือไม่ปกติได้ดีเพียงใด ตัวชี้วัดความยุติธรรมช่วยระบุความลำเอียงในผลลัพธ์ของแบบจำลอง ทำให้มั่นใจว่ามันทำงานอย่างเป็นธรรมต่อประชากรกลุ่มต่าง ๆ และสถานการณ์ต่าง ๆ
📌 ตัวอย่าง: เมื่อทดสอบโมเดลด้วยคำถามที่แปลกประหลาด เช่น "คุณคิดอย่างไรเกี่ยวกับยูนิคอร์น?" โมเดลควรจัดการกับคำถามนี้อย่างเหมาะสมและให้คำตอบที่เกี่ยวข้อง หากโมเดลให้คำตอบที่ไร้สาระหรือไม่เหมาะสม แสดงว่าโมเดลยังขาดความแข็งแกร่ง
การทดสอบความเป็นธรรมช่วยให้แน่ใจว่าแบบจำลองไม่ผลิตผลลัพธ์ที่มีอคติหรือเป็นอันตราย ส่งเสริมระบบ AI ที่ครอบคลุมมากขึ้น
📖 อ่านเพิ่มเติม:ความแตกต่างระหว่างแมชชีนเลิร์นนิงกับปัญญาประดิษฐ์
9. ตัวชี้วัดประสิทธิภาพ
เมื่อแบบจำลองทางภาษาเพิ่มความซับซ้อนขึ้น การวัดประสิทธิภาพของพวกเขาก็กลายเป็นสิ่งที่มีความสำคัญมากขึ้นเรื่อย ๆ โดยเฉพาะในด้านความเร็ว การใช้หน่วยความจำ และการบริโภคพลังงาน ตัวชี้วัดประสิทธิภาพช่วยในการประเมินว่าแบบจำลองมีความต้องการทรัพยากรมากเพียงใดเมื่อทำการสร้างคำตอบ
📌 ตัวอย่าง: สำหรับโมเดลภาษาขนาดใหญ่ การวัดประสิทธิภาพอาจเกี่ยวข้องกับการติดตามความเร็วในการสร้างคำตอบต่อคำถามของผู้ใช้ และปริมาณหน่วยความจำที่ใช้ในระหว่างกระบวนการนี้
หากใช้เวลานานเกินไปในการตอบสนองหรือใช้ทรัพยากรมากเกินไป อาจเป็นปัญหาสำหรับแอปพลิเคชันที่ต้องการประสิทธิภาพแบบเรียลไทม์ เช่น แชทบอทหรือบริการแปลภาษา
ตอนนี้คุณรู้แล้วว่าจะประเมินโมเดล LLM ได้อย่างไร แต่คุณจะใช้เครื่องมืออะไรในการวัดผลนี้ได้บ้าง? มาสำรวจกัน
ClickUp Brain สามารถเพิ่มประสิทธิภาพการประเมิน LLM ได้อย่างไร
ClickUp เป็นแอปสำหรับทุกเรื่องในการทำงานที่มาพร้อมกับผู้ช่วยส่วนตัวในตัวที่เรียกว่า ClickUp Brain
ClickUp Brainคือตัวเปลี่ยนเกมสำหรับการประเมินประสิทธิภาพของ LLM แล้วมันทำอะไรได้บ้าง?
มันจัดระเบียบและเน้นข้อมูลที่เกี่ยวข้องมากที่สุด ทำให้ทีมของคุณอยู่ในเส้นทางที่ถูกต้อง ด้วยคุณสมบัติที่ขับเคลื่อนด้วย AI ของ ClickUp Brain ทำให้เป็นหนึ่งในซอฟต์แวร์เครือข่ายประสาทที่ดีที่สุดที่มีอยู่ มันทำให้กระบวนการทั้งหมดราบรื่น มีประสิทธิภาพมากขึ้น และทำงานร่วมกันได้ดีกว่าที่เคย มาสำรวจความสามารถของมันไปด้วยกันเถอะ
การจัดการความรู้อย่างชาญฉลาด
เมื่อประเมินโมเดลภาษาขนาดใหญ่ (LLMs) การจัดการข้อมูลจำนวนมหาศาลอาจเป็นเรื่องที่ท้าทายอย่างมาก

ClickUp Brainสามารถจัดระเบียบและเน้นข้อมูลเมตริกและทรัพยากรที่สำคัญซึ่งปรับให้เหมาะสมเฉพาะสำหรับการประเมิน LLM แทนที่จะต้องค้นหาผ่านสเปรดชีตที่กระจัดกระจายและรายงานที่ซับซ้อน ClickUp Brain จะรวบรวมทุกอย่างไว้ในที่เดียว เมตริกประสิทธิภาพ ข้อมูลเปรียบเทียบ และผลการทดสอบสามารถเข้าถึงได้ทั้งหมดภายในอินเทอร์เฟซที่ชัดเจนและเป็นมิตรกับผู้ใช้
องค์กรนี้ช่วยให้ทีมของคุณตัดผ่านเสียงรบกวนและมุ่งเน้นไปที่ข้อมูลเชิงลึกที่มีความสำคัญจริง ๆ ทำให้การตีความแนวโน้มและรูปแบบของประสิทธิภาพง่ายขึ้น
ด้วยทุกสิ่งที่คุณต้องการในที่เดียว คุณสามารถเปลี่ยนจากการเก็บข้อมูลธรรมดาไปสู่การตัดสินใจที่มีผลกระทบและขับเคลื่อนด้วยข้อมูล เปลี่ยนข้อมูลที่ล้นเกินให้กลายเป็นข้อมูลเชิงลึกที่สามารถนำไปปฏิบัติได้
การวางแผนโครงการและการจัดการกระบวนการทำงาน
การประเมิน LLM ต้องการการวางแผนอย่างรอบคอบและการร่วมมือ และ ClickUp ทำให้การจัดการกระบวนการนี้ง่ายขึ้น
คุณสามารถมอบหมายความรับผิดชอบต่าง ๆ เช่น การรวบรวมข้อมูล การฝึกอบรมแบบจำลอง และการทดสอบประสิทธิภาพได้อย่างง่ายดาย พร้อมทั้งกำหนดลำดับความสำคัญเพื่อให้มั่นใจว่างานที่สำคัญที่สุดได้รับความสนใจก่อน นอกจากนี้ ฟิลด์ที่กำหนดเองยังช่วยให้คุณสามารถปรับแต่งกระบวนการทำงานให้เหมาะสมกับความต้องการเฉพาะของโครงการของคุณได้อีกด้วย

ด้วย ClickUp ทุกคนสามารถเห็นได้ว่าใครกำลังทำอะไรและเมื่อไหร่ ช่วยหลีกเลี่ยงความล่าช้าและทำให้มั่นใจว่างานดำเนินไปอย่างราบรื่นทั่วทั้งทีม เป็นวิธีที่ยอดเยี่ยมในการรักษาความเป็นระเบียบและให้ทุกอย่างเป็นไปตามแผนตั้งแต่ต้นจนจบ
การติดตามตัวชี้วัดผ่านแดชบอร์ดที่กำหนดเอง
ต้องการติดตามประสิทธิภาพของระบบ LLM ของคุณอย่างใกล้ชิดหรือไม่?
แดชบอร์ดของ ClickUpแสดงตัวชี้วัดประสิทธิภาพแบบเรียลไทม์ ช่วยให้คุณสามารถติดตามความคืบหน้าของโมเดลของคุณได้ทันที แดชบอร์ดเหล่านี้สามารถปรับแต่งได้อย่างสูง ช่วยให้คุณสร้างกราฟและแผนภูมิที่แสดงข้อมูลที่คุณต้องการได้อย่างแม่นยำในเวลาที่คุณต้องการ
คุณสามารถดูความแม่นยำของโมเดลของคุณพัฒนาไปในแต่ละขั้นตอนของการประเมิน หรือแยกการบริโภคทรัพยากรในแต่ละเฟสได้ ข้อมูลนี้ช่วยให้คุณสามารถระบุแนวโน้มได้อย่างรวดเร็ว ระบุพื้นที่ที่ต้องปรับปรุง และทำการปรับเปลี่ยนได้ทันที
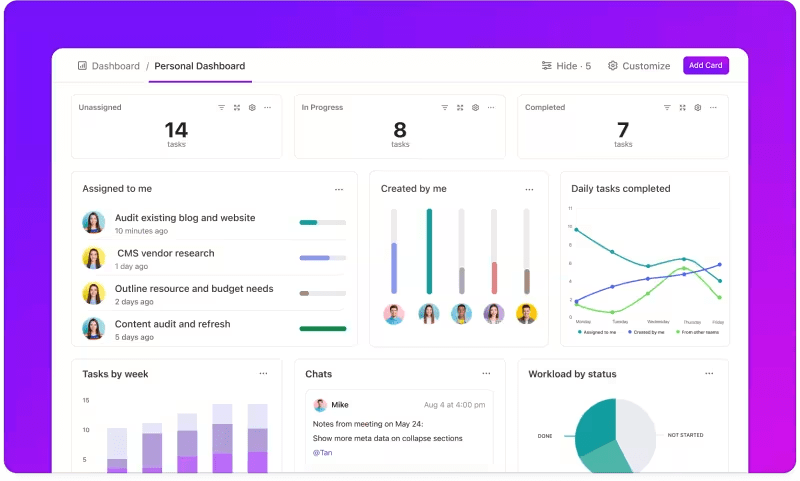
แทนที่จะรอรายงานฉบับละเอียดฉบับถัดไปแดชบอร์ดของ ClickUpช่วยให้คุณสามารถติดตามข้อมูลและตอบสนองได้อย่างรวดเร็ว ให้อำนาจทีมของคุณในการตัดสินใจโดยใช้ข้อมูลเป็นพื้นฐานโดยไม่ล่าช้า
ข้อมูลเชิงลึกอัตโนมัติ
การวิเคราะห์ข้อมูลอาจใช้เวลานาน แต่ฟีเจอร์ ClickUp Brainช่วยลดภาระด้วยการให้ข้อมูลเชิงลึกที่มีคุณค่า มันเน้นแนวโน้มที่สำคัญและแม้กระทั่งแนะนำข้อเสนอแนะตามข้อมูล ทำให้ง่ายต่อการสรุปผลที่มีความหมาย
ด้วยข้อมูลเชิงลึกอัตโนมัติของ ClickUp Brain คุณไม่จำเป็นต้องค้นหาข้อมูลดิบเพื่อหาแบบแผนด้วยตัวเองอีกต่อไป—ระบบจะค้นหาให้คุณโดยอัตโนมัติ การทำงานอัตโนมัติเช่นนี้ช่วยให้ทีมของคุณมีเวลาไปปรับปรุงประสิทธิภาพของแบบจำลองได้มากขึ้น แทนที่จะต้องเสียเวลาไปกับการวิเคราะห์ข้อมูลซ้ำๆ
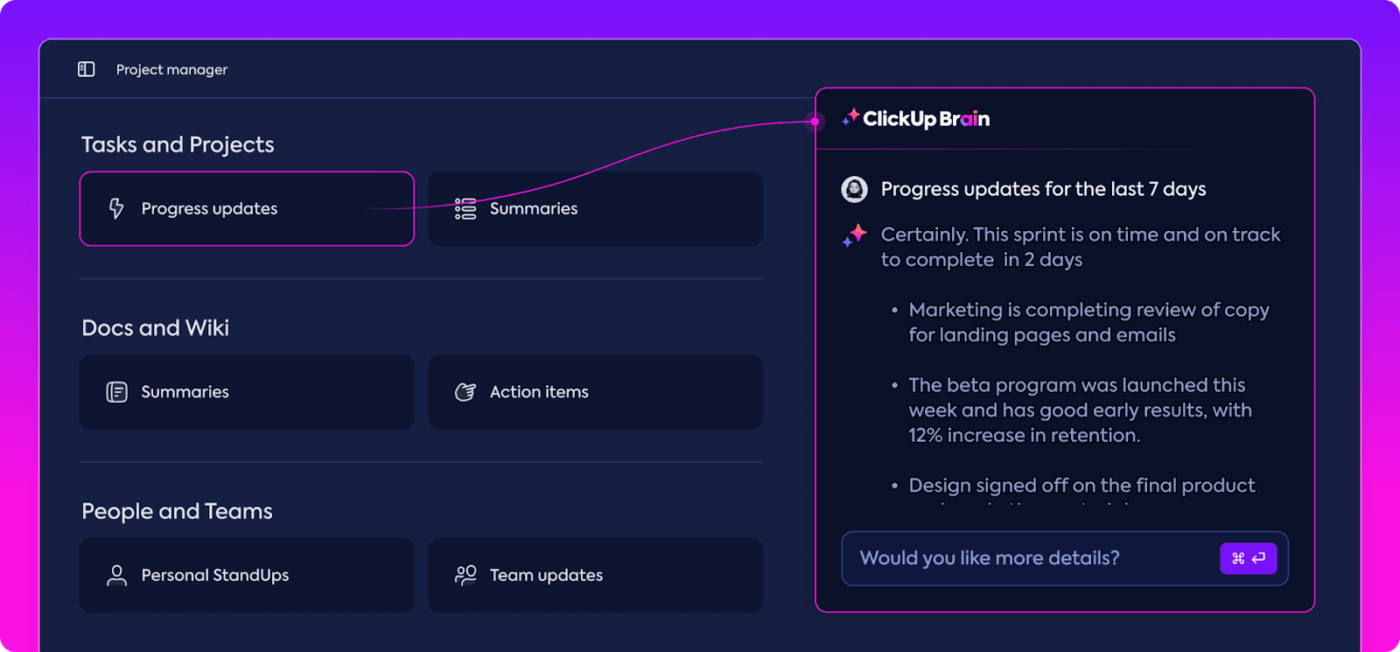
ข้อมูลเชิงลึกที่ได้สามารถนำไปใช้ได้ทันที ทำให้ทีมของคุณสามารถเห็นสิ่งที่ได้ผลและจุดที่อาจต้องการการเปลี่ยนแปลงได้ทันที ด้วยการลดเวลาที่ใช้ในการวิเคราะห์ ClickUp ช่วยให้ทีมของคุณเร่งกระบวนการประเมินผลและมุ่งเน้นไปที่การนำไปปฏิบัติ
เอกสารและการร่วมมือ
ไม่ต้องเสียเวลาค้นหาอีเมลหรือแพลตฟอร์มต่าง ๆ อีกต่อไป ทุกอย่างที่คุณต้องการอยู่ตรงหน้าคุณ พร้อมใช้งานเมื่อคุณต้องการ
ClickUp Docsเป็นศูนย์กลางที่รวบรวมทุกสิ่งที่ทีมของคุณต้องการสำหรับการประเมิน LLM อย่างราบรื่น มันจัดระเบียบเอกสารโครงการสำคัญ เช่น เกณฑ์การเปรียบเทียบ ผลการทดสอบ และบันทึกประสิทธิภาพ ให้อยู่ในที่เดียวที่เข้าถึงได้ง่าย เพื่อให้ทุกคนสามารถเข้าถึงข้อมูลล่าสุดได้อย่างรวดเร็ว
สิ่งที่ทำให้ ClickUp Docs โดดเด่นอย่างแท้จริงคือฟีเจอร์การทำงานร่วมกันแบบเรียลไทม์ การผสานรวมClickUp Chat และความคิดเห็นช่วยให้สมาชิกในทีมสามารถพูดคุยแลกเปลี่ยนความคิดเห็น ให้ข้อเสนอแนะ และแนะนำการเปลี่ยนแปลงได้โดยตรงภายในเอกสาร
ซึ่งหมายความว่าทีมของคุณสามารถพูดคุยเกี่ยวกับข้อค้นพบและทำการปรับเปลี่ยนได้ทันทีบนแพลตฟอร์ม ทำให้การสนทนาทั้งหมดมีความเกี่ยวข้องและตรงประเด็น

ทุกอย่างตั้งแต่เอกสารไปจนถึงการทำงานเป็นทีมเกิดขึ้นภายใน ClickUp Docs สร้างกระบวนการประเมินผลที่มีประสิทธิภาพ ซึ่งทุกคนสามารถดู แบ่งปัน และดำเนินการตามพัฒนาการล่าสุดได้
ผลลัพธ์? กระบวนการทำงานที่ราบรื่นและเป็นหนึ่งเดียว ช่วยให้ทีมของคุณก้าวไปสู่เป้าหมายได้อย่างชัดเจนและไร้ข้อกังวล
คุณพร้อมที่จะลองใช้ ClickUp หรือยัง? ก่อนอื่น มาดูเคล็ดลับและเทคนิคที่จะช่วยให้คุณได้รับประโยชน์สูงสุดจากการประเมิน LLM ของคุณกันก่อน
แนวทางปฏิบัติที่ดีที่สุดในการประเมิน LLM
แนวทางที่มีโครงสร้างชัดเจนในการประเมิน LLM ช่วยให้มั่นใจได้ว่าโมเดลจะตอบสนองความต้องการของคุณ สอดคล้องกับความคาดหวังของผู้ใช้ และให้ผลลัพธ์ที่มีความหมาย
การกำหนดวัตถุประสงค์ที่ชัดเจน การพิจารณาผู้ใช้งานปลายทาง และการใช้วิธีการวัดผลที่หลากหลาย จะช่วยสร้างการประเมินผลที่ครอบคลุมซึ่งเผยให้เห็นจุดแข็งและพื้นที่ที่ต้องปรับปรุง ด้านล่างนี้คือแนวทางปฏิบัติที่ดีที่สุดเพื่อเป็นแนวทางในกระบวนการของคุณ
🎯 กำหนดวัตถุประสงค์ที่ชัดเจน
ก่อนที่จะเริ่มกระบวนการประเมินผล จำเป็นอย่างยิ่งที่จะต้องทราบอย่างชัดเจนว่าคุณต้องการให้โมเดลภาษาขนาดใหญ่ (LLM) ของคุณบรรลุเป้าหมายอะไร ให้ใช้เวลาในการกำหนดภารกิจหรือเป้าหมายที่เฉพาะเจาะจงสำหรับโมเดลนี้
📌 ตัวอย่าง: หากคุณต้องการปรับปรุงประสิทธิภาพการแปลของเครื่องจักร ให้ชี้แจงระดับคุณภาพที่คุณต้องการให้ถึง การมีวัตถุประสงค์ที่ชัดเจนช่วยให้คุณมุ่งเน้นไปที่ตัวชี้วัดที่เกี่ยวข้องมากที่สุด ทำให้การประเมินของคุณสอดคล้องกับเป้าหมายเหล่านี้และวัดความสำเร็จได้อย่างถูกต้อง
👥 พิจารณาผู้ชมของคุณ
คิดถึงผู้ที่จะใช้ LLM และความต้องการของพวกเขา. การปรับการประเมินให้เหมาะกับผู้ใช้ที่คุณต้องการเป็นสิ่งสำคัญอย่างยิ่ง.
📌 ตัวอย่าง: หากโมเดลของคุณมีวัตถุประสงค์เพื่อสร้างเนื้อหาที่น่าสนใจ คุณควรให้ความสำคัญกับตัวชี้วัดเช่น ความคล่องตัวและความสอดคล้อง การเข้าใจผู้ชมของคุณช่วยปรับปรุงเกณฑ์การประเมินของคุณ ทำให้แน่ใจว่าโมเดลมอบคุณค่าที่แท้จริงในแอปพลิเคชันที่ใช้ได้จริง
📊 ใช้ตัวชี้วัดที่หลากหลาย
อย่าพึ่งพาเพียงตัวชี้วัดเดียวในการประเมิน LLM ของคุณ; การผสมผสานตัวชี้วัดหลายตัวจะช่วยให้คุณเห็นภาพรวมของประสิทธิภาพได้ชัดเจนยิ่งขึ้น แต่ละตัวชี้วัดจะสะท้อนแง่มุมที่แตกต่างกัน ดังนั้นการใช้หลายตัวจึงช่วยให้คุณระบุทั้งจุดแข็งและจุดอ่อนได้
📌 ตัวอย่าง: แม้ว่าคะแนน BLEU จะยอดเยี่ยมในการวัดคุณภาพการแปล แต่คะแนนเหล่านี้อาจไม่ครอบคลุมถึงรายละเอียดที่ซับซ้อนของการเขียนเชิงสร้างสรรค์ การนำตัวชี้วัดอย่างเช่นค่าความซับซ้อน (perplexity) สำหรับความแม่นยำในการทำนาย และแม้กระทั่งการประเมินโดยมนุษย์เพื่อดูบริบท สามารถนำไปสู่ความเข้าใจที่ครอบคลุมมากขึ้นเกี่ยวกับประสิทธิภาพของโมเดลของคุณ
เกณฑ์มาตรฐานและเครื่องมือสำหรับ LLM
การประเมินแบบจำลองภาษาขนาดใหญ่ (LLMs) มักอาศัยเกณฑ์มาตรฐานอุตสาหกรรมและเครื่องมือเฉพาะทางที่ช่วยวัดประสิทธิภาพของแบบจำลองในหลากหลายงาน
นี่คือการแยกแยะของเกณฑ์มาตรฐานและเครื่องมือที่ใช้กันอย่างแพร่หลายซึ่งช่วยให้กระบวนการประเมินมีโครงสร้างและชัดเจนขึ้น
เกณฑ์มาตรฐานสำคัญ
- GLUE (General Language Understanding Evaluation): GLUE ประเมินความสามารถของโมเดลในหลากหลายงานด้านภาษา รวมถึงการจำแนกประเภทประโยค การหาความคล้ายคลึง และการอนุมาน เป็นเกณฑ์มาตรฐานที่นิยมใช้สำหรับโมเดลที่ต้องการจัดการความเข้าใจภาษาทั่วไป
- SQuAD (Stanford Question Answering Dataset): กรอบการประเมิน SQuAD เหมาะอย่างยิ่งสำหรับการอ่านเพื่อความเข้าใจ และวัดความสามารถของแบบจำลองในการตอบคำถามตามข้อความที่อ่าน โดยทั่วไปใช้สำหรับงานเช่นการสนับสนุนลูกค้าและการค้นหาข้อมูลตามฐานความรู้ ซึ่งคำตอบที่แม่นยำเป็นสิ่งสำคัญ
- SuperGLUE: ในฐานะเวอร์ชันที่ได้รับการปรับปรุงของ GLUE, SuperGLUE ประเมินโมเดลในภารกิจที่ต้องใช้การคิดวิเคราะห์ที่ซับซ้อนมากขึ้นและความเข้าใจในบริบท. มันให้ข้อมูลเชิงลึกที่ลึกซึ้งยิ่งขึ้น โดยเฉพาะอย่างยิ่งสำหรับการนำไปใช้ที่ต้องการความเข้าใจทางภาษาขั้นสูง
เครื่องมือประเมินผลที่จำเป็น
- Hugging Face: เป็นที่นิยมอย่างแพร่หลายเนื่องจากมีคลังโมเดลขนาดใหญ่ ชุดข้อมูล และคุณสมบัติการประเมินผลที่หลากหลาย อินเทอร์เฟซที่ใช้งานง่ายช่วยให้ผู้ใช้สามารถเลือกเกณฑ์มาตรฐาน ปรับแต่งการประเมิน และติดตามประสิทธิภาพของโมเดลได้อย่างง่ายดาย ทำให้มีความยืดหยุ่นสำหรับการใช้งาน LLM ในหลากหลายรูปแบบ
- SuperAnnotate: มีความเชี่ยวชาญในการจัดการและทำเครื่องหมายข้อมูล ซึ่งมีความสำคัญอย่างยิ่งสำหรับงานการเรียนรู้แบบมีผู้สอน (supervised learning tasks). มีประโยชน์อย่างยิ่งสำหรับการปรับปรุงความแม่นยำของแบบจำลอง เนื่องจากช่วยให้ได้ข้อมูลที่มีการทำเครื่องหมายโดยมนุษย์คุณภาพสูง ซึ่งช่วยปรับปรุงประสิทธิภาพของแบบจำลองในงานที่ซับซ้อน
- AllenNLP: พัฒนาโดยสถาบัน Allen Institute for AI AllenNLP มุ่งเน้นสำหรับนักวิจัยและนักพัฒนาที่ทำงานกับโมเดล NLP ที่ปรับแต่งเอง รองรับมาตรฐานการทดสอบที่หลากหลายและให้เครื่องมือสำหรับการฝึกฝน ทดสอบ และประเมินโมเดลภาษา มอบความยืดหยุ่นสำหรับการประยุกต์ใช้ NLP ที่หลากหลาย
การใช้การผสมผสานของเกณฑ์มาตรฐานและเครื่องมือเหล่านี้มอบแนวทางที่ครอบคลุมสำหรับการประเมิน LLM. เกณฑ์มาตรฐานสามารถกำหนดมาตรฐานข้ามภารกิจได้ ในขณะที่เครื่องมือมอบโครงสร้างและความยืดหยุ่นที่จำเป็นสำหรับการติดตาม ปรับปรุง และเพิ่มประสิทธิภาพของแบบจำลองอย่างมีประสิทธิภาพ.
ร่วมกัน พวกเขาทำให้แน่ใจว่า LLMs ตรงตามมาตรฐานทางเทคนิคและต้องการการนำไปใช้ในทางปฏิบัติ
ความท้าทายในการประเมินแบบจำลอง LLM
การประเมินแบบจำลองภาษาขนาดใหญ่ (LLMs) ต้องใช้แนวทางที่มีความละเอียดอ่อน. การประเมินนี้มุ่งเน้นไปที่คุณภาพของคำตอบ และการเข้าใจถึงความสามารถในการปรับตัวของแบบจำลองตลอดจนข้อจำกัดของมันในสถานการณ์ที่หลากหลาย.
เนื่องจากโมเดลเหล่านี้ได้รับการฝึกฝนบนชุดข้อมูลที่กว้างขวาง พฤติกรรมของพวกมันจึงได้รับอิทธิพลจากปัจจัยหลากหลาย ทำให้การประเมินความแม่นยำเพียงอย่างเดียวไม่เพียงพอ
การประเมินผลที่แท้จริงหมายถึงการตรวจสอบความน่าเชื่อถือของแบบจำลอง ความสามารถในการรับมือกับคำสั่งที่ไม่ปกติ และความสม่ำเสมอของคำตอบโดยรวม กระบวนการนี้ช่วยให้เห็นภาพที่ชัดเจนยิ่งขึ้นเกี่ยวกับจุดแข็งและจุดอ่อนของแบบจำลอง และเปิดเผยพื้นที่ที่ต้องปรับปรุง
นี่คือภาพรวมที่ละเอียดขึ้นเกี่ยวกับความท้าทายทั่วไปที่เกิดขึ้นระหว่างการประเมิน LLM
1. ข้อมูลการฝึกอบรมซ้ำซ้อน
เป็นเรื่องยากที่จะทราบว่าโมเดลได้ เห็น ข้อมูลทดสอบบางส่วนแล้วหรือไม่ เนื่องจาก LLMs ได้รับการฝึกฝนบนชุดข้อมูลขนาดใหญ่มาก จึงมีโอกาสที่คำถามทดสอบบางข้อจะซ้ำกับตัวอย่างที่ใช้ในการฝึกฝน สิ่งนี้อาจทำให้โมเดลดูดีกว่าความเป็นจริง เนื่องจากอาจเพียงแค่ทำซ้ำสิ่งที่มันรู้อยู่แล้ว แทนที่จะแสดงให้เห็นถึงความเข้าใจที่แท้จริง
2. ประสิทธิภาพการทำงานไม่สม่ำเสมอ
LLM อาจมีการตอบสนองที่ไม่สามารถคาดการณ์ได้. ในเวลาหนึ่ง พวกมันอาจให้ข้อมูลเชิงลึกที่น่าทึ่ง และในเวลาต่อมา พวกมันอาจทำผิดพลาดอย่างแปลก ๆ หรือเสนอข้อมูลที่ไม่มีอยู่จริงเป็นข้อเท็จจริง (ที่เรียกว่า 'การหลอน').
ความไม่สอดคล้องนี้หมายความว่า แม้ว่าผลลัพธ์ของ LLM อาจโดดเด่นในบางด้าน แต่ในบางด้านอาจยังขาดประสิทธิภาพ ส่งผลให้การประเมินความน่าเชื่อถือและคุณภาพโดยรวมได้อย่างแม่นยำเป็นเรื่องยาก
3. ช่องโหว่จากการโจมตีแบบมีเจตนาร้าย
LLMs อาจมีความเสี่ยงต่อการโจมตีแบบต่อต้าน (adversarial attacks) ซึ่งเป็นการใช้คำสั่งหรือข้อความที่ออกแบบมาอย่างชาญฉลาดเพื่อหลอกให้ระบบสร้างผลลัพธ์ที่ผิดพลาดหรือเป็นอันตราย ช่องโหว่นี้เปิดเผยจุดอ่อนของโมเดลและอาจนำไปสู่ผลลัพธ์ที่ไม่คาดคิดหรือมีอคติ การทดสอบเพื่อค้นหาจุดอ่อนเหล่านี้ถือเป็นสิ่งสำคัญอย่างยิ่งต่อการทำความเข้าใจขอบเขตของโมเดล
กรณีศึกษาการประเมิน LLM ที่ใช้ได้จริง
ในที่สุด นี่คือสถานการณ์ทั่วไปบางประการที่การประเมิน LLM มีความแตกต่างอย่างแท้จริง:
แชทบอทสนับสนุนลูกค้า
LLMs ถูกนำมาใช้อย่างแพร่หลายในแชทบอทเพื่อจัดการกับคำถามของลูกค้า การประเมินว่าโมเดลตอบสนองได้ดีเพียงใดช่วยให้มั่นใจว่ามันให้คำตอบที่ถูกต้อง มีประโยชน์ และเกี่ยวข้องกับบริบท
การวัดความสามารถในการเข้าใจเจตนาของลูกค้า การจัดการกับคำถามที่หลากหลาย และการให้คำตอบที่เหมือนมนุษย์นั้นมีความสำคัญอย่างยิ่ง ซึ่งจะช่วยให้ธุรกิจสามารถมอบประสบการณ์ที่ราบรื่นแก่ลูกค้าได้ในขณะที่ลดความไม่พอใจของลูกค้าให้น้อยที่สุด
การสร้างเนื้อหา
หลายธุรกิจใช้ LLMs ในการสร้างเนื้อหาบล็อก, โซเชียลมีเดีย, และคำอธิบายสินค้า การประเมินคุณภาพของเนื้อหาที่สร้างขึ้นช่วยให้แน่ใจว่ามันถูกต้องตามไวยากรณ์, น่าสนใจ, และเกี่ยวข้องกับกลุ่มเป้าหมาย ตัวชี้วัดเช่นความคิดสร้างสรรค์, ความสอดคล้อง, และความเกี่ยวข้องกับหัวข้อมีความสำคัญในที่นี้เพื่อรักษาคุณภาพของเนื้อหาให้สูง
การวิเคราะห์ความรู้สึก
LLMs สามารถวิเคราะห์ความรู้สึกจากคำติชมของลูกค้า, โพสต์บนสื่อสังคมออนไลน์, หรือรีวิวสินค้าได้ การประเมินความแม่นยำของแบบจำลองในการระบุว่าข้อความใดเป็นบวก, ลบ, หรือกลางนั้นเป็นสิ่งจำเป็นอย่างยิ่ง ซึ่งช่วยให้ธุรกิจเข้าใจอารมณ์ของลูกค้า, ปรับปรุงสินค้าหรือบริการ, เพิ่มความพึงพอใจของผู้ใช้, และปรับปรุงกลยุทธ์การตลาดได้
การสร้างโค้ด
นักพัฒนาซอฟต์แวร์มักใช้ LLM เพื่อช่วยในการสร้างโค้ด การประเมินความสามารถของโมเดลในการสร้างโค้ดที่ทำงานได้และมีประสิทธิภาพเป็นสิ่งสำคัญ
สิ่งสำคัญคือต้องตรวจสอบว่าโค้ดที่สร้างขึ้นมีตรรกะที่ถูกต้อง ปราศจากข้อผิดพลาด และตรงตามข้อกำหนดของงาน ซึ่งจะช่วยลดปริมาณการเขียนโค้ดด้วยตนเองและเพิ่มประสิทธิภาพในการทำงาน
เพิ่มประสิทธิภาพการประเมิน LLM ของคุณด้วย ClickUp
การประเมิน LLMs คือการเลือกตัวชี้วัดที่เหมาะสมซึ่งสอดคล้องกับเป้าหมายของคุณ. สิ่งสำคัญคือการเข้าใจเป้าหมายเฉพาะของคุณ ไม่ว่าจะเป็นการปรับปรุงคุณภาพการแปล, การเพิ่มคุณภาพการสร้างเนื้อหา, หรือการปรับแต่งให้เหมาะกับงานเฉพาะทาง.
การเลือกตัวชี้วัดที่เหมาะสมสำหรับการประเมินประสิทธิภาพ เช่น RAG หรือตัวชี้วัดการปรับแต่งอย่างละเอียด เป็นรากฐานของการประเมินที่แม่นยำและมีความหมาย ในขณะเดียวกัน ผู้ประเมินขั้นสูงอย่าง G-Eval, Prometheus, SelfCheckGPT และ QAG ให้ข้อมูลเชิงลึกที่แม่นยำด้วยความสามารถในการให้เหตุผลที่แข็งแกร่ง
อย่างไรก็ตาม นั่นไม่ได้หมายความว่าคะแนนเหล่านี้สมบูรณ์แบบ—ยังคงมีความสำคัญที่จะต้องตรวจสอบให้แน่ใจว่าคะแนนเหล่านี้เชื่อถือได้
เมื่อคุณดำเนินการประเมินการสมัคร LLM ของคุณไปข้างหน้า ปรับกระบวนการให้เหมาะกับกรณีการใช้งานเฉพาะของคุณ ไม่มีเกณฑ์สากลที่เหมาะกับทุกสถานการณ์ การผสมผสานของเกณฑ์ต่าง ๆ พร้อมกับการให้ความสำคัญกับบริบท จะช่วยให้คุณได้ภาพที่แม่นยำขึ้นเกี่ยวกับประสิทธิภาพของแบบจำลองของคุณ
เพื่อปรับปรุงการประเมิน LLM ของคุณให้ราบรื่นขึ้น และเพิ่มประสิทธิภาพการร่วมมือในทีม ClickUp คือโซลูชันที่เหมาะที่สุดสำหรับการจัดการกระบวนการทำงานและการติดตามตัวชี้วัดที่สำคัญ
ต้องการเพิ่มประสิทธิภาพการทำงานของทีมคุณหรือไม่?ลงทะเบียนใช้ ClickUpวันนี้และสัมผัสประสบการณ์การเปลี่ยนแปลงการทำงานของคุณ!