

En kundtjänstbot som lär sig av varje interaktion. En försäljningsassistent som justerar sin strategi baserat på insikter i realtid. Det här är inte bara koncept – de är verkliga, tack vare AI-inlärningsagenter.
Men vad gör dessa agenter unika, och hur fungerar en inlärningsagent för att uppnå denna anpassningsförmåga?
Till skillnad från traditionella AI-system som fungerar med fast programmering utvecklas inlärningsagenter.
De anpassar, förbättrar och förfinar sina åtgärder över tid, vilket gör dem oumbärliga för branscher som autonoma fordon och hälso- och sjukvård, där flexibilitet och precision är oumbärliga.
Tänk på dem som AI som blir smartare med erfarenhet, precis som människor.
I den här bloggen utforskar vi de viktigaste komponenterna, processerna, typerna och tillämpningarna av inlärningsagenter inom AI. 🤖
⏰ 60-sekunderssammanfattning
Här är en snabb introduktion till inlärningsagenter inom AI:
Vad de gör: Anpassar sig genom interaktioner, t.ex. kundtjänstbotar som förfinar sina svar.
Viktiga användningsområden: Robotik, personaliserade tjänster och smarta system som hemapparater.
Kärnkomponenter:
- Lärandeelement: Samlar kunskap för att förbättra prestandan
- Prestandaelement: Utför uppgifter baserat på inlärd kunskap
- Kritiker: Utvärderar handlingar och ger feedback
- Problemgenerator: Identifierar möjligheter till vidare inlärning
Lärandemetoder:
- Övervakad inlärning: Känner igen mönster med hjälp av märkta data
- Oövervakad inlärning: Identifierar strukturer i omärkta data
- Förstärkt inlärning: Lär sig genom trial and error
Verklig påverkan: Förbättrar anpassningsförmåga, effektivitet och beslutsfattande i olika branscher.
⚙️ Bonus: Känner du dig överväldigad av AI-jargongen? Kolla in vår omfattande ordlista med AI-termer för att enkelt förstå grundläggande begrepp och avancerad terminologi.
Vad är inlärningsagenter inom AI?
Lärande agenter inom AI är system som förbättras över tid genom att lära sig av sin omgivning. De anpassar sig, fattar smartare beslut och optimerar sina åtgärder baserat på feedback och data.
Till skillnad från traditionella AI-system, som förblir fasta, utvecklas inlärningsagenter kontinuerligt. Detta gör dem oumbärliga för robotik och personliga rekommendationer, där förhållandena är oförutsägbara och ständigt föränderliga.
🔍 Visste du att? Lärande agenter fungerar i en återkopplingsloop – de uppfattar omgivningen, lär sig av återkoppling och förfinar sina handlingar. Detta är inspirerat av hur människor lär sig av erfarenhet.
Lärande agenters viktigaste komponenter
Lärande agenter består vanligtvis av flera sammankopplade komponenter som arbetar tillsammans för att säkerställa anpassningsförmåga och förbättring över tid.
Här är några viktiga komponenter i denna inlärningsprocess. 📋
Lärandeelement
Agentens huvudsakliga ansvar är att skaffa kunskap och förbättra prestandan genom att analysera data, interaktioner och feedback.
Med hjälp av AI-tekniker som övervakad, förstärkt och oövervakad inlärning anpassar och uppdaterar agenten sitt beteende för att förbättra sin funktionalitet.
📌 Exempel: En virtuell assistent som Siri lär sig användarens preferenser över tid, till exempel ofta använda kommandon eller specifika accenter, för att kunna ge mer exakta och personliga svar.
Prestandaelement
Denna komponent utför uppgifter genom att interagera med omgivningen och fatta beslut baserat på tillgänglig information. Den är i huvudsak agentens ”handlingsarm”.
📌 Exempel: I autonoma fordon bearbetar prestandadelarna trafikdata och miljöförhållanden för att fatta beslut i realtid, till exempel att stanna vid rött ljus eller undvika hinder.
Kritiker
Kritikern utvärderar de åtgärder som vidtagits av prestationselementet och ger feedback. Denna feedback hjälper inlärningselementet att identifiera vad som fungerade bra och vad som behöver förbättras.
📌 Exempel: I ett rekommendationssystem analyserar kritiken användarinteraktioner (som klick eller hopp) för att avgöra vilka förslag som var framgångsrika och hjälper inlärningselementet att förfina framtida rekommendationer.
Problemgenerator
Denna komponent uppmuntrar till utforskning genom att föreslå nya scenarier eller åtgärder som agenten kan testa.
Det driver agenten bortom sin komfortzon och säkerställer kontinuerlig förbättring. Agenten förhindrar också suboptimala resultat genom att utvidga agentens erfarenhetsområde.
📌 Exempel: I e-handels-AI kan problemgeneratorn föreslå personliga marknadsföringsstrategier eller simulera kundbeteendemönster. Detta hjälper AI att förfina sin strategi för att leverera rekommendationer som är anpassade efter olika användares preferenser.
Lärandeprocessen i lärande agenter
Lärande agenter förlitar sig främst på tre nyckelkategorier för att anpassa sig och förbättras. Dessa beskrivs nedan. 👇
1. Övervakad inlärning
Agenten lär sig från märkta datamängder, där varje indata motsvarar en specifik utdata.
Denna metod kräver en stor mängd korrekt märkta data för träning och används ofta i tillämpningar som bildigenkänning, språköversättning och bedrägeridetektering.
📌 Exempel: Ett e-postfiltreringssystem lär sig att klassificera e-postmeddelanden som skräppost eller inte baserat på historiska data. Lärandeelementet identifierar mönster mellan indata (e-postinnehåll) och utdata (klassificeringsetiketter) för att göra korrekta förutsägelser.
2. Oövervakad inlärning
Dolda mönster eller relationer i data framträder när agenten analyserar information utan explicita etiketter. Denna metod fungerar bra för att upptäcka avvikelser, skapa rekommendationssystem och optimera datakomprimering.
Det hjälper också till att identifiera insikter som kanske inte är omedelbart synliga med märkta data.
📌 Exempel: Kundsegmentering inom marknadsföring kan gruppera användare utifrån deras beteende för att utforma riktade kampanjer. Fokus ligger på att förstå strukturen och bilda kluster eller associationer.
3. Förstärkt inlärning
Till skillnad från ovanstående innebär förstärkt inlärning (RL) att agenter vidtar åtgärder i en miljö för att maximera kumulativa belöningar över tid.
Agenten lär sig genom trial and error och får feedback genom belöningar eller straff.
🔔 Kom ihåg: Valet av inlärningsmetod beror på problemet, datatillgängligheten och miljöens komplexitet. Förstärkt inlärning är avgörande för uppgifter utan direkt övervakning, eftersom den använder återkopplingsloopar för att anpassa åtgärder.
Tekniker för förstärkt inlärning
- Policyiteration: Optimerar belöningsförväntningar genom att direkt lära sig en policy som kopplar samman tillstånd med åtgärder.
- Värdeiteration: Bestämmer optimala åtgärder genom att beräkna värdet för varje tillstånd-åtgärdspar.
- Monte Carlo-metoder: Simulerar flera framtida scenarier för att förutsäga belöningar för åtgärder, särskilt användbart i dynamiska och probabilistiska miljöer.
Exempel på RL-tillämpningar i verkligheten
- Autonom körning: RL-algoritmer tränar fordon att navigera säkert, optimera rutter och anpassa sig till trafikförhållanden genom att kontinuerligt lära sig från simulerade miljöer.
- AlphaGo och spel-AI: Förstärkt inlärning gjorde det möjligt för Googles AlphaGo att besegra mänskliga mästare genom att lära sig optimala strategier för komplexa spel som Go.
- Dynamisk prissättning: E-handelsplattformar använder RL för att justera prissättningsstrategier baserat på efterfrågemönster och konkurrenters agerande för att maximera intäkterna.
🧠 Kul fakta: Lärande agenter har besegrat mänskliga mästare i spel som schack och Starcraft, vilket visar deras anpassningsförmåga och intelligens.
Q-inlärning och neurala nätverk
Q-learning är en allmänt använd RL-algoritm där agenter lär sig värdet av varje tillstånd-åtgärdspar genom utforskning och feedback. Agenten bygger en Q-tabell, en matris som tilldelar förväntade belöningar till tillstånd-åtgärdspar.
Den väljer den åtgärd som har högst Q-värde och förfinar sin tabell iterativt för att förbättra noggrannheten.
📌 Exempel: En AI-driven drönare som lär sig att leverera paket på ett effektivt sätt använder Q-learning för att utvärdera rutter. Den gör detta genom att tilldela belöningar för leveranser i tid och straff för förseningar eller kollisioner. Med tiden förfinar den sin Q-tabell för att välja de mest effektiva och säkra leveransvägarna.
Q-tabeller blir dock opraktiska i komplexa miljöer med högdimensionella tillståndsrum.
Här kommer neurala nätverk in i bilden, som approximerar Q-värden istället för att lagra dem explicit. Denna förändring gör det möjligt för förstärkt inlärning att hantera mer komplexa problem.
Deep Q-networks (DQN) tar detta ett steg längre genom att utnyttja djupinlärning för att bearbeta råa, ostrukturerade data som bilder eller sensorinmatningar. Dessa nätverk kan direkt koppla sensorisk information till åtgärder, vilket gör att man slipper omfattande feature engineering.
📌 Exempel: I självkörande bilar bearbetar DQN:er sensordata i realtid för att lära sig körstrategier, såsom filbyten eller undvikande av hinder, utan förprogrammerade regler.
Dessa avancerade metoder gör det möjligt för agenter att skala sina inlärningsförmågor till uppgifter som kräver hög datorkraft och anpassningsförmåga.
⚙️ Bonus: Lär dig hur du skapar och förfinar en AI-kunskapsbas som effektiviserar informationshanteringen, förbättrar beslutsfattandet och ökar teamets produktivitet.
Lärandeprocessen för agenter värdesätter strategier för intelligent beslutsfattande i realtid. Här är några viktiga aspekter som underlättar beslutsfattandet:
- Utforskning kontra utnyttjande: Agenter balanserar mellan att utforska nya åtgärder för att hitta bättre strategier och att utnyttja kända åtgärder för att maximera belöningarna.
- Beslutsfattande med flera agenter: I samarbets- eller konkurrenssituationer interagerar agenterna och anpassar sina strategier utifrån gemensamma mål eller motstridiga taktiker.
- Strategiska avvägningar: Agenter lär sig också att prioritera mål baserat på sammanhanget, till exempel att balansera hastighet och noggrannhet i ett leveranssystem.
🎤 Podcast-tip: Gå igenom vår lista över populära AI-podcasts för att fördjupa din förståelse för hur inlärningsagenter fungerar.
Typer av AI-agenter
Lärande agenter inom artificiell intelligens finns i olika former, var och en anpassad till specifika uppgifter och utmaningar.
Låt oss utforska deras arbetsmekanismer, unika egenskaper och exempel från verkligheten. 👀
Enkla reflexagenter
Sådana agenter reagerar direkt på stimuli baserat på fördefinierade regler. De använder en villkor-åtgärd (om-då)-mekanism för att välja åtgärder baserat på den aktuella miljön utan att ta hänsyn till historiken eller framtiden.
Egenskaper
- Fungerar på ett logikbaserat villkors-åtgärdssystem.
- Anpassar sig inte till förändringar eller lär sig av tidigare handlingar.
- Fungerar bäst i transparenta och förutsägbara miljöer.
Exempel
En termostat fungerar som en enkel reflexagent genom att slå på värmen när temperaturen sjunker under en viss tröskel och stänga av den när temperaturen stiger. Den fattar beslut enbart baserat på aktuella temperaturmätningar.
🧠 Kul fakta: Vissa experiment tilldelar inlärningsagenter simulerade behov som hunger eller törst, vilket uppmuntrar dem att utveckla målinriktade beteenden och lära sig hur man tillgodoser dessa ”behov” på ett effektivt sätt.
Modellbaserade reflexagenter
Dessa agenter har en intern modell av världen som gör att de kan överväga effekterna av sina handlingar. De drar också slutsatser om miljöns tillstånd utöver vad de omedelbart kan uppfatta.
Egenskaper
- Använder en lagrad modell av miljön för beslutsfattande.
- Uppskattar det aktuella tillståndet för att hantera delvis observerbara miljöer.
- Erbjuder större flexibilitet och anpassningsförmåga jämfört med enkla reflexagenter.
Exempel
En självkörande bil från Tesla använder en modellbaserad agent för att navigera på vägarna. Den upptäcker synliga hinder och förutsäger rörelserna hos närliggande fordon, inklusive de som befinner sig i döda vinklar, med hjälp av avancerade sensorer och realtidsdata. Detta gör att bilen kan fatta precisa och välgrundade körbeslut, vilket ökar säkerheten och effektiviteten.
🔍 Visste du att? Konceptet med inlärningsagenter efterliknar ofta beteenden som observerats hos djur, såsom inlärning genom trial-and-error eller belöningsbaserad inlärning.
Programvaruagent och virtuella assistentfunktioner
Dessa agenter arbetar i digitala miljöer och utför specifika uppgifter självständigt.
Virtuella assistenter som Siri eller Alexa bearbetar användarinmatningar med hjälp av naturlig språkbehandling (NLP) och utför åtgärder som att svara på frågor eller styra smarta enheter.
Egenskaper
- Förenklar dagliga uppgifter som schemaläggning, inställning av påminnelser eller styrning av enheter.
- Förbättras kontinuerligt med hjälp av inlärningsalgoritmer och data om användarinteraktion.
- Fungerar asynkront och svarar i realtid eller när den triggas.
Exempel
Alexa kan spela musik, ställa in påminnelser och styra smarta hem-enheter genom att tolka röstkommandon, ansluta till molnbaserade system och utföra lämpliga åtgärder.
🔍 Visste du att? Nyttobaserade agenter, som fokuserar på att maximera resultaten genom att utvärdera olika åtgärder, arbetar ofta tillsammans med inlärningsbaserade agenter inom AI. Inlärningsagenter förfinar sina strategier över tid baserat på erfarenhet, och de kan använda nyttobaserat beslutsfattande för att fatta smartare val.
Multiagent-system och tillämpningar av spelteori
Dessa system består av flera interagerande agenter som samarbetar, konkurrerar eller arbetar självständigt för att uppnå individuella eller kollektiva mål.
Dessutom styr principerna för spelteori ofta deras beteende i konkurrenssituationer.
Egenskaper
- Kräver samordning eller förhandling mellan agenterna.
- Fungerar bra i dynamiska och distribuerade miljöer.
- Simulerar eller hanterar komplexa system såsom leveranskedjor eller stadstrafik.
Exempel
I Amazons lagerautomatiseringssystem arbetar robotar (agenter) tillsammans för att plocka, sortera och transportera artiklar. Dessa robotar kommunicerar med varandra för att undvika kollisioner och säkerställa en smidig drift. Spelteorins principer hjälper till att hantera konkurrerande prioriteringar, som att balansera hastighet och resurser, för att säkerställa att systemet fungerar effektivt.
Tillämpningar av inlärningsagenter
Lärande agenter har förändrat många branscher genom att förbättra effektiviteten och beslutsfattandet.
Här är några viktiga tillämpningar. 📚
Robotik och automatisering
Lärande agenter är kärnan i modern robotik och gör det möjligt för robotar att fungera autonomt och adaptivt i dynamiska miljöer.
Till skillnad från traditionella system som kräver detaljerad programmering för varje uppgift, gör inlärningsagenter det möjligt för robotar att självförbättras genom interaktion och feedback.
Hur det fungerar
Robotar utrustade med inlärningsagenter använder tekniker som förstärkningsinlärning för att interagera med sin omgivning och utvärdera resultaten av sina handlingar. De förfinar sitt beteende över tid, med fokus på att maximera belöningar och undvika straff.
Neurala nätverk tar detta ett steg längre och gör det möjligt för robotar att bearbeta komplexa data som visuella intryck eller rumsliga layouter, vilket underlättar sofistikerat beslutsfattande.
Exempel
- Autonoma fordon: Inom jordbruket driver inlärningsagenter autonoma traktorer som navigerar på fälten, anpassar sig till varierande markförhållanden och optimerar planterings- eller skördeprocesser. De använder realtidsdata för att förbättra effektiviteten och minska svinnet.
- Industrirobotar: Inom tillverkningsindustrin finjusterar robotarmar utrustade med inlärningsagenter sina rörelser för att förbättra precision, effektivitet och säkerhet, till exempel i bilmonteringslinjer.
📖 Läs också: AI-tips som gör dig snabbare, smartare och bättre
Simulering och agentbaserade modeller
Lärande agenter driver simuleringar som erbjuder ett kostnadseffektivt och riskfritt sätt att studera komplexa system.
Dessa system replikerar dynamiken i den verkliga världen, förutsäger resultat och optimerar strategier genom att modellera agenter med distinkta beteenden och anpassningsförmåga.
Hur det fungerar
Lärande agenter i simuleringar observerar sin omgivning, testar åtgärder och justerar sina strategier för att maximera effektiviteten. De lär sig och förbättras kontinuerligt över tid, vilket gör det möjligt för dem att optimera resultaten.
Simuleringar är mycket effektiva inom supply chain management, stadsplanering och robotutveckling.
Exempel
- Trafikledning: Simulerade agenter modellerar trafikflödet i städer. Detta gör det möjligt för forskare att testa åtgärder som nya vägar eller trängselavgifter innan de implementeras.
- Epidemiologi: I pandemisimuleringar efterliknar inlärningsagenter mänskligt beteende för att bedöma spridningen av sjukdomar. Det hjälper också till att utvärdera effektiviteten av begränsningsåtgärder som social distansering.
💡 Proffstips: Optimera förbehandlingen av data i AI-maskininlärning för att förbättra inlärningsagenternas noggrannhet och effektivitet. Högkvalitativ input garanterar mer tillförlitliga beslut.
Intelligenta system
Lärande agenter driver intelligenta system genom att möjliggöra databehandling i realtid och anpassning till användarnas beteende och preferenser.
Från smarta apparater till autonoma rengöringsenheter – dessa system förändrar hur användarna interagerar med tekniken och gör vardagliga uppgifter mer effektiva och personliga.
Hur det fungerar
Enheter som Roomba använder inbyggda sensorer och inlärningsagenter för att kartlägga hemmets layout, undvika hinder och optimera städrutter. De samlar och analyserar ständigt data, till exempel områden som kräver frekvent städning eller möbelplacering, vilket förbättrar deras prestanda för varje användning.
Exempel
- Smarta hem-enheter: Termostater som Nest lär sig användarnas scheman och temperaturpreferenser. De justerar automatiskt inställningarna för att spara energi samtidigt som komforten bibehålls.
- Robotdammsugare: Roomba samlar in många datapunkter per sekund. Detta lär den att röra sig runt möbler och identifiera områden med hög trafik för effektiv rengöring.
Dessa intelligenta system belyser de praktiska tillämpningarna av inlärningsagenter i vardagen, såsom att effektivisera arbetsflöden och automatisera repetitiva uppgifter för ökad effektivitet.
🔍 Visste du att? Roomba samlar in över 230 400 datapunkter per sekund för att kartlägga ditt hem.
Internetforum och virtuella assistenter
Lärande agenter är viktiga för att förbättra onlineinteraktioner och digital assistans. De gör det möjligt för forum och virtuella assistenter att leverera personliga upplevelser.
Hur det fungerar
Lärande agenter modererar diskussioner i forum och identifierar och tar bort spam eller skadligt innehåll. Intressant nog rekommenderar de också relevanta ämnen till användare baserat på deras surfhistorik.
Virtuella AI-assistenter som Alexa och Google Assistant använder inlärningsagenter för att bearbeta naturliga språkinmatningar, vilket förbättrar deras kontextuella förståelse över tid.
Exempel
- Internetforum: Reddits modereringsbots använder inlärningsagenter för att skanna inlägg efter regelbrott eller kränkande språk. Sådan AI-baserad hygien håller online-gemenskaper säkra och engagerande.
- Virtuella assistenter: Alexa lär sig användarens preferenser, till exempel favoritlängor eller ofta använda smarta hemkommandon, för att kunna ge personlig och proaktiv hjälp.
⚙️ Bonus: Lär dig hur du använder AI på din arbetsplats för att öka produktiviteten och effektivisera arbetsuppgifter med intelligenta agenter.
Utmaningar vid utveckling av inlärningsagenter
Utvecklingen av inlärningsagenter innebär tekniska, etiska och praktiska utmaningar, inklusive algoritmdesign, beräkningskrav och implementering i verkligheten.
Låt oss titta på några viktiga utmaningar som AI-utvecklingen står inför i takt med att den utvecklas. 🚧
Balansera utforskning och utnyttjande
Lärande agenter står inför dilemmat att balansera utforskning och utnyttjande.
Även om algoritmer som epsilon-greedy kan vara till hjälp är det mycket kontextberoende att uppnå rätt balans. Dessutom kan överdriven utforskning leda till ineffektivitet, medan överdriven tillit till exploatering kan ge suboptimala lösningar.
Hantera höga beräkningskostnader
Att träna sofistikerade inlärningsagenter kräver ofta omfattande beräkningsresurser. Detta är mer tillämpligt i miljöer med komplex dynamik eller stora tillstånds- och åtgärdsutrymmen.
Kom ihåg att algoritmer som förstärkningsinlärning med neurala nätverk, till exempel Deep Q-Learning, kräver betydande processorkraft och minne. Du kommer att behöva hjälp med att göra realtidsinlärning praktiskt genomförbart för applikationer med begränsade resurser.
Övervinna skalbarhet och överföringsinlärning
Det är fortfarande en utmaning att skala inlärningsagenter så att de fungerar effektivt i stora, flerdimensionella miljöer. Transferinlärning, där agenter tillämpar kunskap från ett område till ett annat, är fortfarande i sin linda.
Detta har begränsat deras förmåga att generalisera mellan olika uppgifter eller miljöer.
📌 Exempel: En AI-agent som tränats för schack skulle ha svårt med Go på grund av de mycket olika reglerna och målen, vilket belyser utmaningen med att överföra kunskap mellan olika domäner.
Datakvalitet och tillgänglighet
Lärandeagenters prestanda beror i hög grad på kvaliteten och mångfalden hos träningsdata.
Otillräckliga eller partiska data kan leda till ofullständigt eller felaktigt lärande och resultera i suboptimala eller oetiska beslut. Dessutom kan insamling av verkliga data för träning vara kostsamt och tidskrävande.
⚙️ Bonus: Utforska AI-kurser för att förbättra din förståelse för andra agenter.
Verktyg och resurser för inlärningsagenter
Utvecklare och forskare förlitar sig på olika verktyg för att bygga och träna inlärningsagenter. Ramverk som TensorFlow, PyTorch och OpenAI Gym erbjuder grundläggande infrastruktur för implementering av maskininlärningsalgoritmer.
Dessa verktyg hjälper också till att skapa simulerade miljöer. Vissa AI-appar förenklar och förbättrar också denna process.
För traditionella maskininlärningsmetoder är verktyg som Scikit-learn fortfarande tillförlitliga och effektiva.
För hantering av AI-forsknings- och utvecklingsprojekt erbjuder ClickUp mer än bara uppgiftshantering – det fungerar som en centraliserad hubb för att organisera uppgifter, spåra framsteg och möjliggöra smidigt samarbete mellan team.
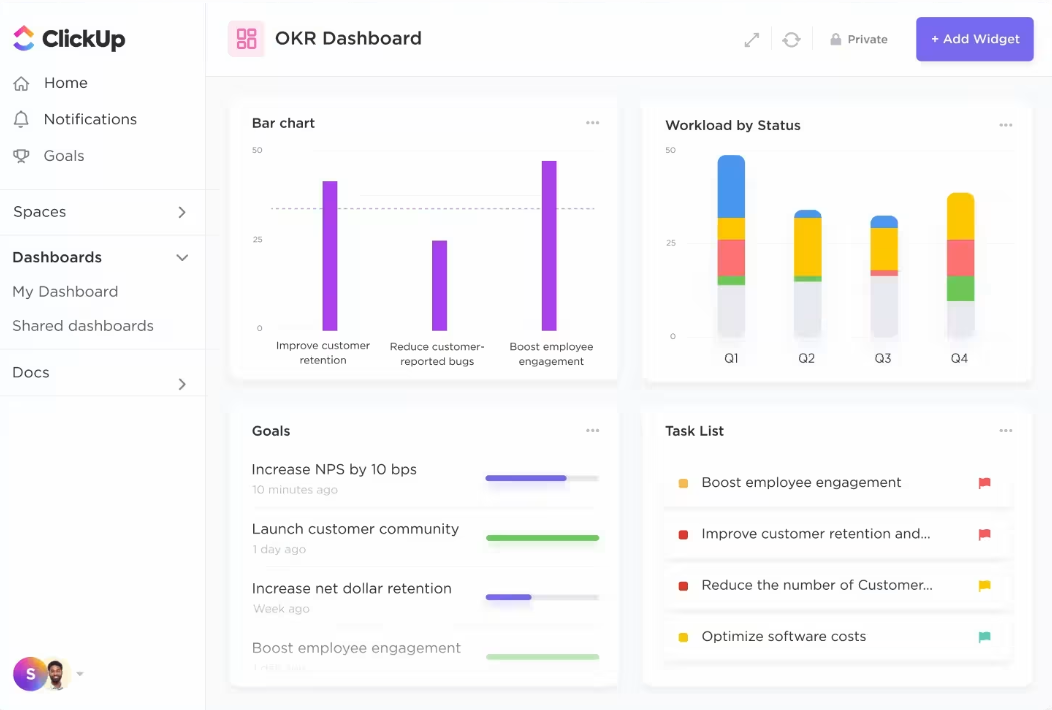
ClickUp för AI-projektledning minskar det manuella arbetet med att bedöma uppgiftsstatus och fördela arbetsuppgifter.
Istället för att manuellt kontrollera varje uppgift eller ta reda på vem som är tillgänglig, gör AI det tunga arbetet. Den kan automatiskt uppdatera framsteg, identifiera flaskhalsar och föreslå den bästa personen för varje uppgift baserat på deras arbetsbelastning och kompetens.
På så sätt lägger du mindre tid på tråkiga administrativa uppgifter och mer tid på det som är viktigt – att driva dina projekt framåt.
Här är några AI-drivna funktioner som sticker ut. 🤩
ClickUp Brain
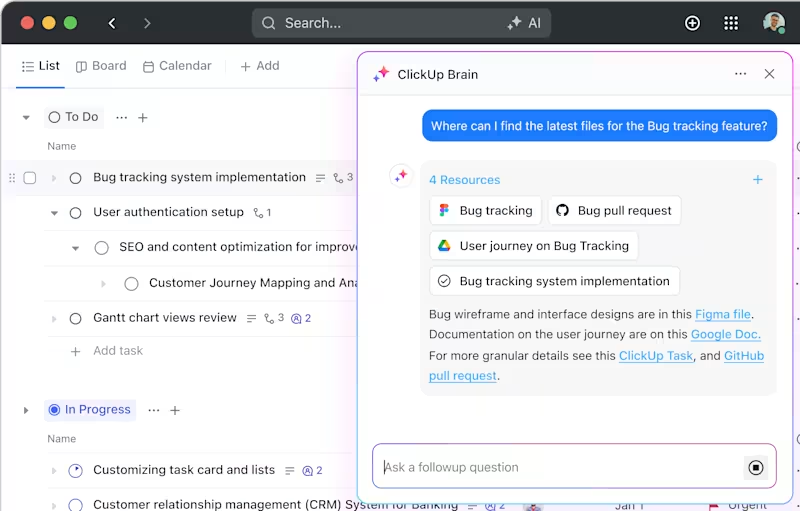
ClickUp Brain, en AI-driven assistent inbyggd i plattformen, förenklar även de mest komplexa projekten. Den delar upp omfattande studier i hanterbara uppgifter och deluppgifter, vilket hjälper dig att hålla ordning och följa planen.
Behöver du snabb tillgång till experimentella resultat eller dokumentation? Skriv bara in en fråga så hämtar ClickUp Brain allt du behöver på några sekunder. Du kan till och med ställa följdfrågor baserade på befintliga data, vilket gör att det känns som din personliga assistent.
Dessutom kopplar den automatiskt samman uppgifter med relevanta resurser, vilket sparar tid och arbete.
Låt oss säga att du genomför en studie om hur förstärkningsinlärningsagenter förbättras över tid.
Du har flera steg – litteraturgenomgång, datainsamling, experiment och analys. Med ClickUp Brain kan du be om att "dela upp denna studie i uppgifter" och det kommer automatiskt att skapa deluppgifter för varje fas.
Du kan sedan be den att hämta relevanta artiklar om Q-learning eller hämta datamängder om agenters prestanda, vilket den gör omedelbart. När du arbetar med uppgifterna kan ClickUp Brain länka specifika forskningsartiklar eller experimentresultat direkt till uppgifterna, så att allt hålls organiserat.
Oavsett om du arbetar med forskningsramverk eller vardagliga projekt, ser ClickUp Brain till att du arbetar smartare, inte hårdare.
ClickUp-automatiseringar
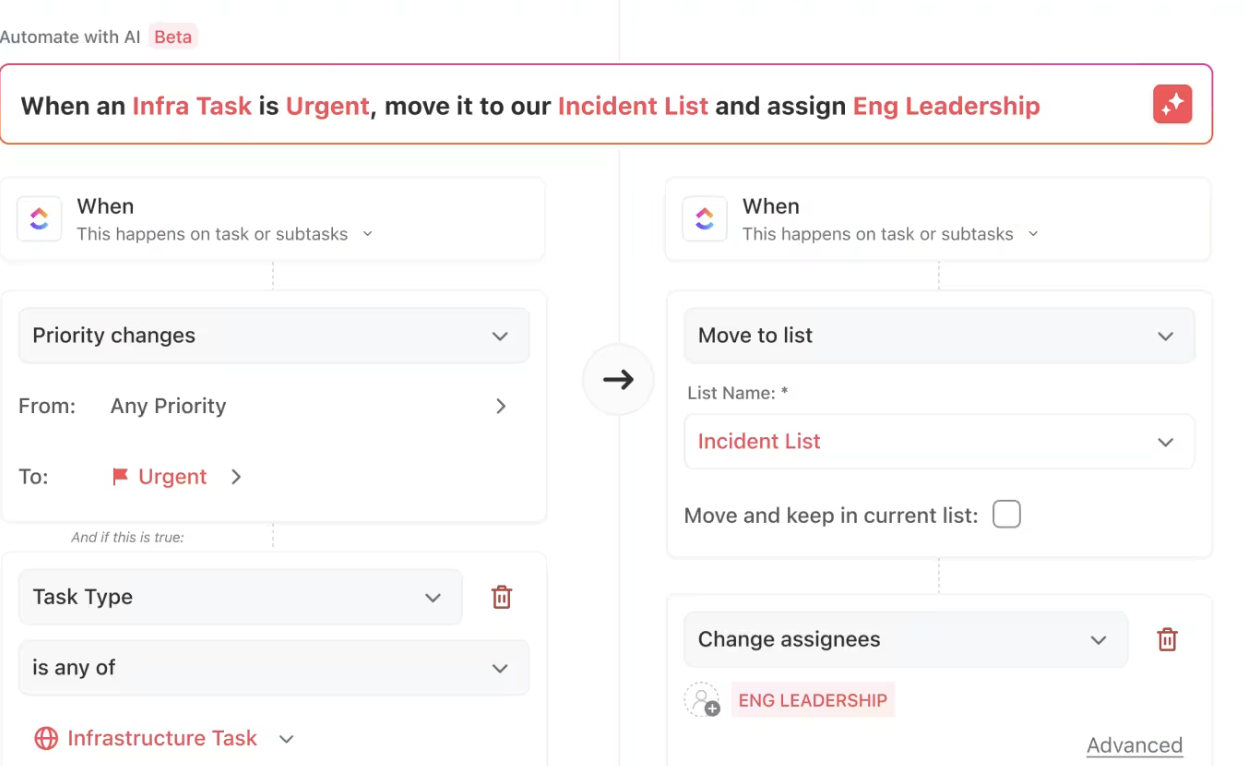
ClickUp Automations är ett enkelt men kraftfullt sätt att effektivisera ditt arbetsflöde.
Det möjliggör omedelbara uppgiftsfördelningar när förutsättningarna är uppfyllda, meddelar intressenter om milstolpar i framstegen och flaggar förseningar – allt utan manuell inblandning.
Du kan också använda kommandon i naturligt språk, vilket gör arbetsflödeshanteringen ännu enklare. Du behöver inte fördjupa dig i komplexa inställningar eller teknisk jargong – bara tala om för ClickUp vad du behöver, så skapar det automatiseringen åt dig.
Oavsett om det handlar om att "flytta uppgifter till nästa steg när de är markerade som slutförda" eller "tilldela Sarah en uppgift när prioriteten är hög", förstår ClickUp din begäran och ställer in den automatiskt.
Utveckla inlärningsagenter som en mästare med ClickUp
För att bygga AI-inlärningsagenter behöver du en expertblandning av strukturerade arbetsflöden och adaptiva verktyg. Det ökade behovet av teknisk expertis gör det hela ännu mer utmanande, särskilt med tanke på sådana uppgifts statistiska och datastödda natur.
Överväg att använda ClickUp för att effektivisera dessa projekt. Utöver ren organisation stöder detta verktyg ditt teams innovation genom att eliminera onödiga ineffektiviteter.
ClickUp Brain hjälper dig att bryta ner komplexa uppgifter, hämta relevanta resurser direkt och erbjuda AI-drivna insikter för att hålla dina projekt organiserade och på rätt spår. Samtidigt hanterar ClickUp Automations repetitiva uppgifter, som att uppdatera statusar eller tilldela nya uppgifter, så att ditt team kan fokusera på helheten.
Tillsammans eliminerar dessa funktioner ineffektivitet och gör det möjligt för ditt team att arbeta smartare, vilket underlättar innovation och framsteg.
Registrera dig gratis på ClickUp idag. ✅