

Bot zákaznického servisu, který se učí z každé interakce. Prodejní asistent, který upravuje svou strategii na základě informací v reálném čase. Nejedná se pouze o koncepty – díky učícím se agentům AI jsou tyto věci realitou.
Co však činí tyto agenty jedinečnými a jak funguje učící se agent, aby dosáhl této přizpůsobivosti?
Na rozdíl od tradičních systémů umělé inteligence, které fungují na základě pevného programování, se učící agenti vyvíjejí.
V průběhu času se přizpůsobují, zlepšují a zdokonalují své činnosti, což je činí nepostradatelnými pro odvětví, jako jsou autonomní vozidla a zdravotnictví, kde je flexibilita a přesnost nezbytná.
Představte si je jako AI, která se s rostoucími zkušenostmi stává chytřejší, stejně jako lidé.
V tomto blogu prozkoumáme klíčové komponenty, procesy, typy a aplikace učících se agentů v AI. 🤖
⏰ 60sekundové shrnutí
Zde je stručný úvod do učících se agentů v AI:
Co dělají: Přizpůsobují se prostřednictvím interakcí, např. boti zákaznického servisu vylepšují odpovědi.
Hlavní použití: Robotika, personalizované služby a inteligentní systémy, jako jsou domácí zařízení.
Základní komponenty:
- Učební prvek: Shromažďuje znalosti za účelem zlepšení výkonu.
- Výkonnostní prvek: Provádí úkoly na základě naučených znalostí.
- Kritik: Hodnotí akce a poskytuje zpětnou vazbu.
- Generátor problémů: Identifikuje příležitosti pro další učení.
Metody učení:
- Supervizované učení: Rozpoznává vzorce pomocí označených dat.
- Nekontrolované učení: Identifikuje struktury v neoznačených datech.
- Posilující učení: Učí se metodou pokusů a omylů.
Dopad v reálném světě: Zvyšuje přizpůsobivost, efektivitu a rozhodování v různých odvětvích.
⚙️ Bonus: Cítíte se zahlceni žargonem umělé inteligence? Podívejte se na náš komplexní slovníček pojmů umělé inteligence, který vám pomůže snadno porozumět základním pojmům a pokročilé terminologii.
Co jsou učící agenti v AI?
Učící se agenti v AI jsou systémy, které se v průběhu času zdokonalují tím, že se učí ze svého prostředí. Přizpůsobují se, činí chytřejší rozhodnutí a optimalizují své akce na základě zpětné vazby a dat.
Na rozdíl od tradičních systémů umělé inteligence, které zůstávají neměnné, se učící agenti neustále vyvíjejí. Díky tomu jsou nepostradatelní pro robotiku a personalizovaná doporučení, kde jsou podmínky nepředvídatelné a neustále se mění.
🔍 Věděli jste? Učící se agenti fungují v rámci zpětnovazební smyčky – vnímají prostředí, učí se ze zpětné vazby a zdokonalují své akce. To je inspirováno způsobem, jakým se lidé učí ze zkušeností.
Klíčové komponenty učících se agentů
Učící se agenti se obvykle skládají z několika propojených komponent, které spolupracují, aby zajistily přizpůsobivost a zlepšování v průběhu času.
Zde jsou některé klíčové komponenty tohoto procesu učení. 📋
Vzdělávací prvek
Hlavní úlohou agenta je získávat znalosti a zlepšovat výkonnost prostřednictvím analýzy dat, interakcí a zpětné vazby.
Pomocí technik umělé inteligence, jako je řízené, posilující a neřízené učení, agent přizpůsobuje a aktualizuje své chování, aby vylepšil svou funkčnost.
📌 Příklad: Virtuální asistent, jako je Siri, se postupem času učí preference uživatele, například často používané příkazy nebo specifické přízvuky, aby mohl poskytovat přesnější a personalizovanější odpovědi.
Výkonnostní prvek
Tato součást provádí úkoly prostřednictvím interakce s prostředím a rozhodování na základě dostupných informací. Jedná se v podstatě o „akční rameno“ agenta.
📌 Příklad: V autonomních vozidlech zpracovává výkonový prvek dopravní data a podmínky prostředí, aby mohl v reálném čase přijímat rozhodnutí, jako je zastavení na červenou nebo vyhýbání se překážkám.
Kritik
Kritik hodnotí akce provedené výkonným prvkem a poskytuje zpětnou vazbu. Tato zpětná vazba pomáhá učícímu prvku identifikovat, co fungovalo dobře a co je třeba zlepšit.
📌 Příklad: V doporučovacím systému kritik analyzuje interakce uživatelů (například kliknutí nebo přeskočení) s cílem určit, které návrhy byly úspěšné, a pomáhá učícímu prvku vylepšovat budoucí doporučení.
Generátor problémů
Tato součást podporuje zkoumání tím, že navrhuje nové scénáře nebo akce, které může agent vyzkoušet.
Agent je tak vytlačován ze své komfortní zóny, což zajišťuje jeho neustálé zdokonalování. Agent také zabraňuje suboptimálním výsledkům tím, že rozšiřuje rozsah svých zkušeností.
📌 Příklad: V oblasti eCommerce AI může generátor problémů navrhovat personalizované marketingové strategie nebo simulovat vzorce chování zákazníků. To pomáhá AI zdokonalit svůj přístup a poskytovat doporučení přizpůsobená různým preferencím uživatelů.
Proces učení v učících se agentech
Učící se agenti se při přizpůsobování a zdokonalování opírají především o tři klíčové kategorie. Ty jsou popsány níže. 👇
1. Řízené učení
Agent se učí z označených datových sad, kde každý vstup odpovídá konkrétnímu výstupu.
Tato metoda vyžaduje velké množství přesně označených dat pro trénování a je široce používána v aplikacích, jako je rozpoznávání obrazu, překlad jazyků a detekce podvodů.
📌 Příklad: Systém filtrování e-mailů se na základě historických dat učí klasifikovat e-maily jako spam nebo ne. Učící se prvek identifikuje vzorce mezi vstupy (obsah e-mailů) a výstupy (klasifikační štítky), aby mohl provádět přesné předpovědi.
2. Neřízené učení
Skryté vzorce nebo vztahy v datech se objevují, když agent analyzuje informace bez explicitních štítků. Tento přístup funguje dobře pro detekci anomálií, vytváření doporučovacích systémů a optimalizaci komprese dat.
Pomáhá také identifikovat poznatky, které nemusí být na první pohled patrné z označených dat.
📌 Příklad: Segmentace zákazníků v marketingu může seskupovat uživatele na základě jejich chování, aby bylo možné navrhnout cílené kampaně. Důraz je kladen na pochopení struktury a vytváření klastrů nebo asociací.
3. Posilující učení
Na rozdíl od výše uvedeného zahrnuje posilující učení (RL) agenty, kteří provádějí akce v prostředí s cílem maximalizovat kumulativní odměny v průběhu času.
Agent se učí metodou pokusů a omylů a získává zpětnou vazbu prostřednictvím odměn nebo trestů.
🔔 Pamatujte: Volba metody učení závisí na problému, dostupnosti dat a složitosti prostředí. Posilující učení je zásadní pro úkoly bez přímého dohledu, protože využívá zpětnovazební smyčky k přizpůsobení akcí.
Techniky posilujícího učení
- Iterace politiky: Optimalizuje očekávání odměn přímým učením politiky, která mapuje stavy na akce.
- Iterace hodnot: Určuje optimální akce výpočtem hodnoty každého páru stav-akce.
- Metody Monte Carlo: Simulují více budoucích scénářů za účelem předpovědi odměn za akce, což je užitečné zejména v dynamických a pravděpodobnostních prostředích.
Příklady reálných aplikací RL
- Autonomní řízení: Algoritmy RL učí vozidla bezpečně navigovat, optimalizovat trasy a přizpůsobovat se dopravním podmínkám prostřednictvím neustálého učení se ze simulovaných prostředí.
- AlphaGo a herní AI: Díky posilovacímu učení dokázal program AlphaGo od Googlu porazit lidské šampiony tím, že se naučil optimální strategie pro složité hry, jako je Go.
- Dynamické stanovení cen: eCommerce platformy využívají RL k úpravě cenových strategií na základě vzorců poptávky a akcí konkurence, aby maximalizovaly výnosy.
🧠 Zajímavost: Učící se agenti porazili lidské šampiony v hrách jako šachy a Starcraft, čímž prokázali svou přizpůsobivost a inteligenci.
Q-learning a přístupy neuronových sítí
Q-learning je široce používaný algoritmus RL, ve kterém agenti učí hodnotu každého páru stav-akce prostřednictvím explorace a zpětné vazby. Agent vytváří Q-tabulku, matici, která přiřazuje očekávané odměny párům stav-akce.
Vybere akci s nejvyšší hodnotou Q a iterativně vylepšuje svou tabulku, aby zvýšil přesnost.
📌 Příklad: Dron poháněný umělou inteligencí, který se učí efektivně doručovat balíčky, využívá k hodnocení tras Q-learning. Činí tak tím, že přiřazuje odměny za včasné doručení a tresty za zpoždění nebo kolize. Postupem času vylepšuje svou Q-tabulku, aby vybral nejúčinnější a nejbezpečnější trasy doručení.
Q-tabulky se však stávají nepraktickými v komplexních prostředích s vysokorozměrnými stavovými prostory.
Zde vstupují do hry neuronové sítě, které aproximují Q-hodnoty namísto jejich explicitního ukládání. Tato změna umožňuje posilujícímu učení řešit složitější problémy.
Hluboké Q-sítě (DQN) jdou ještě dál a využívají hluboké učení ke zpracování surových, nestrukturovaných dat, jako jsou obrázky nebo vstupy ze senzorů. Tyto sítě mohou přímo mapovat smyslové informace na akce, čímž obcházejí potřebu rozsáhlého feature engineeringu.
📌 Příklad: V samořídících automobilech zpracovávají DQN data ze senzorů v reálném čase, aby se naučily strategie řízení, jako je změna jízdního pruhu nebo vyhýbání se překážkám, bez předem naprogramovaných pravidel.
Tyto pokročilé metody umožňují agentům škálovat své učící schopnosti na úkoly vyžadující vysoký výpočetní výkon a přizpůsobivost.
⚙️ Bonus: Naučte se, jak vytvořit a vylepšit znalostní bázi AI, která zefektivňuje správu informací, zlepšuje rozhodování a zvyšuje produktivitu týmu.
Proces učení agentů klade důraz na vytváření strategií pro inteligentní rozhodování v reálném čase. Zde jsou klíčové aspekty, které pomáhají při rozhodování:
- Průzkum vs. využití: Agenti vyvažují průzkum nových akcí za účelem nalezení lepších strategií a využití známých akcí za účelem maximalizace odměn.
- Rozhodování s více agenty: V kolaborativním nebo kompetitivním prostředí agenti interagují a přizpůsobují strategie na základě společných cílů nebo soupeřských taktik.
- Strategické kompromisy: Agenti se také učí stanovovat priority cílů na základě kontextu, například vyvažovat rychlost a přesnost v doručovacím systému.
🎤 Upozornění na podcast: Projděte si náš seznam oblíbených podcastů o umělé inteligenci a prohlubte své znalosti o fungování učících se agentů.
Typy agentů umělé inteligence
Učící agenti v umělé inteligenci mají různé formy, z nichž každá je přizpůsobena konkrétním úkolům a výzvám.
Prozkoumejme jejich pracovní mechanismy, jedinečné vlastnosti a příklady z reálného světa. 👀
Jednoduché reflexní agenti
Tito agenti reagují přímo na podněty na základě předem definovaných pravidel. Používají mechanismus podmínky-akce (if-then) k výběru akcí na základě aktuálního prostředí, aniž by brali v úvahu historii nebo budoucnost.
Charakteristiky
- Funguje na logickém systému podmínek a akcí.
- Nepřizpůsobuje se změnám ani se neučí z minulých akcí.
- Nejlépe funguje v transparentním a předvídatelném prostředí.
Příklad
Termostat funguje jako jednoduchý reflexní agent tím, že zapíná topení, když teplota klesne pod nastavenou hranici, a vypíná ho, když teplota stoupne. Rozhoduje se čistě na základě aktuálních údajů o teplotě.
🧠 Zajímavost: Některé experimenty přiřazují učícím se agentům simulované potřeby, jako je hlad nebo žízeň, a povzbuzují je tak k rozvoji cílově orientovaného chování a k učení se, jak tyto „potřeby“ efektivně uspokojovat.
Modelové reflexní agenti
Tito agenti udržují interní model světa, který jim umožňuje zvažovat dopady svých akcí. Také odvozují stav prostředí nad rámec toho, co mohou okamžitě vnímat.
Charakteristiky
- Využívá uložený model prostředí pro rozhodování.
- Odhaduje aktuální stav pro zpracování částečně pozorovatelných prostředí.
- Nabízí větší flexibilitu a přizpůsobivost ve srovnání s jednoduchými reflexními agenty.
Příklad
Autonomní vozidlo Tesla využívá k navigaci po silnicích modelový agent. Pomocí pokročilých senzorů a dat v reálném čase detekuje viditelné překážky a předpovídá pohyb vozidel v okolí, včetně těch v mrtvých úhlech. To umožňuje vozidlu činit přesná a informovaná rozhodnutí o jízdě, což zvyšuje bezpečnost a efektivitu.
🔍 Věděli jste? Koncept učících se agentů často napodobuje chování pozorované u zvířat, jako je učení metodou pokusů a omylů nebo učení založené na odměnách.
Funkce softwarového agenta a virtuálního asistenta
Tito agenti působí v digitálním prostředí a autonomně provádějí konkrétní úkoly.
Virtuální asistenti jako Siri nebo Alexa zpracovávají uživatelské vstupy pomocí zpracování přirozeného jazyka (NLP) a provádějí akce, jako je odpovídání na dotazy nebo ovládání chytrých zařízení.
Charakteristiky
- Zjednodušuje každodenní úkoly, jako je plánování, nastavování připomínek nebo ovládání zařízení.
- Neustále se zlepšuje pomocí učících se algoritmů a dat o interakci uživatelů.
- Funguje asynchronně, reaguje v reálném čase nebo po spuštění.
Příklad
Alexa umí přehrávat hudbu, nastavovat připomenutí a ovládat chytrá domácí zařízení tím, že interpretuje hlasové příkazy, připojuje se k cloudovým systémům a provádí příslušné akce.
🔍 Věděli jste? Agenti založení na užitku, kteří se zaměřují na maximalizaci výsledků prostřednictvím hodnocení různých akcí, často spolupracují s agenty založenými na učení v oblasti umělé inteligence. Agenti pro učení v průběhu času zdokonalují své strategie na základě zkušeností a mohou využívat rozhodování založené na užitku k tomu, aby činili chytřejší rozhodnutí.
Multiagentní systémy a aplikace teorie her
Tyto systémy se skládají z více interagujících agentů, kteří spolupracují, soutěží nebo pracují nezávisle, aby dosáhli individuálních nebo kolektivních cílů.
Kromě toho jejich chování v konkurenčních scénářích často řídí principy teorie her.
Charakteristiky
- Vyžaduje koordinaci nebo vyjednávání mezi agenty.
- Funguje dobře v dynamických a distribuovaných prostředích.
- Simuluje nebo spravuje komplexní systémy, jako jsou dodavatelské řetězce nebo městská doprava.
Příklad
V automatizovaném skladovém systému Amazonu roboti (agenti) spolupracují při vychystávání, třídění a přepravě zboží. Tito roboti mezi sebou komunikují, aby se vyhnuli kolizím a zajistili hladký provoz. Principy teorie her pomáhají řídit konkurenční priority, jako je vyvážení rychlosti a zdrojů, aby byl zajištěn efektivní provoz systému.
Aplikace učících se agentů
Učící se agenti transformovali řadu odvětví tím, že zlepšili efektivitu a rozhodování.
Zde je několik klíčových aplikací. 📚
Robotika a automatizace
Učící se agenti jsou jádrem moderní robotiky a umožňují robotům autonomní a adaptivní provoz v dynamických prostředích.
Na rozdíl od tradičních systémů, které vyžadují podrobné programování pro každý úkol, umožňují učící se agenti robotům samy se zdokonalovat prostřednictvím interakce a zpětné vazby.
Jak to funguje
Roboti vybaveni učícími se agenty používají techniky jako posilující učení, aby mohli komunikovat se svým okolím a vyhodnocovat výsledky svých akcí. Postupem času zdokonalují své chování a soustředí se na maximalizaci odměn a vyhýbání se trestům.
Neuronové sítě jdou ještě dál a umožňují robotům zpracovávat komplexní data, jako jsou vizuální vstupy nebo prostorové rozvržení, což usnadňuje sofistikované rozhodování.
Příklady
- Autonomní vozidla: V zemědělství umožňují učící se agenti autonomním traktorům navigovat po polích, přizpůsobovat se měnícím se podmínkám půdy a optimalizovat procesy výsadby nebo sklizně. Využívají data v reálném čase ke zvýšení efektivity a snížení plýtvání.
- Průmyslové roboty: Ve výrobě robotická ramena vybavená učícími se agenty jemně ladí své pohyby, aby zlepšila přesnost, efektivitu a bezpečnost, například na montážních linkách automobilů.
📖 Přečtěte si také: AI triky, díky kterým budete rychlejší, chytřejší a lepší
Simulace a modely založené na agentech
Učící se agenti pohánějí simulace, které nabízejí nákladově efektivní a bezrizikový způsob studia složitých systémů.
Tyto systémy replikují dynamiku reálného světa, předpovídají výsledky a optimalizují strategie pomocí modelování agentů s odlišným chováním a adaptivními schopnostmi.
Jak to funguje
Učící se agenti v simulacích pozorují své prostředí, testují akce a upravují své strategie tak, aby maximalizovali efektivitu. Neustále se učí a v průběhu času se zlepšují, což jim umožňuje optimalizovat výsledky.
Simulace jsou velmi účinné v oblasti řízení dodavatelského řetězce, urbanistického plánování a vývoje robotiky.
Příklady
- Řízení dopravy: Simulovaní agenti modelují dopravní tok ve městech. To umožňuje výzkumníkům testovat zásahy, jako jsou nové silnice nebo zpoplatnění dopravního přetížení, před jejich implementací.
- Epidemiologie: V simulacích pandemie napodobují učící se agenti lidské chování, aby vyhodnotili šíření nemocí. Pomáhají také hodnotit účinnost opatření k omezení šíření, jako je sociální distancování.
💡 Tip pro profesionály: Optimalizujte předzpracování dat v strojovém učení AI, abyste zlepšili přesnost a efektivitu učících se agentů. Vysoce kvalitní vstupní data zajišťují spolehlivější rozhodování.
Inteligentní systémy
Učící se agenti řídí inteligentní systémy tím, že umožňují zpracování dat v reálném čase a přizpůsobení se chování a preferencím uživatelů.
Od chytrých spotřebičů po autonomní čisticí zařízení – tyto systémy mění způsob, jakým uživatelé interagují s technologiemi, a díky nim jsou každodenní úkoly efektivnější a personalizovanější.
Jak to funguje
Zařízení jako Roomba využívají vestavěné senzory a učící se agenty k mapování dispozic domácnosti, vyhýbání se překážkám a optimalizaci tras úklidu. Neustále shromažďují a analyzují data, jako jsou oblasti vyžadující častý úklid nebo umístění nábytku, a s každým použitím tak zlepšují svůj výkon.
Příklady
- Chytrá domácí zařízení: Termostaty jako Nest se učí rozvrhy uživatelů a jejich preference ohledně teploty. Automaticky upravují nastavení tak, aby šetřily energii a zároveň udržovaly pohodlí.
- Robotické vysavače: Roomba shromažďuje mnoho datových bodů za sekundu. Díky tomu se naučí pohybovat kolem nábytku a identifikovat oblasti s vysokým provozem pro efektivní úklid.
Tyto inteligentní systémy zdůrazňují praktické aplikace učících se agentů v každodenním životě, jako je zefektivnění pracovních postupů a automatizace opakujících se úkolů pro zvýšení efektivity.
🔍 Věděli jste, že... Roomba shromažďuje více než 230 400 datových bodů za sekundu, aby zmapovala váš domov.
Internetová fóra a virtuální asistenti
Učící se agenti hrají klíčovou roli při zlepšování online interakcí a digitální asistence. Umožňují fórům a virtuálním asistentům poskytovat personalizované zážitky.
Jak to funguje
Učící agenti moderují diskuse ve fórech a identifikují a odstraňují spam nebo škodlivý obsah. Zajímavé je, že také doporučují uživatelům relevantní témata na základě jejich historie prohlížení.
Virtuální asistenti AI, jako jsou Alexa a Google Assistant, používají učící se agenty ke zpracování vstupů v přirozeném jazyce, čímž postupem času zlepšují své kontextové porozumění.
Příklady
- Internetová fóra: Moderovací roboti Redditu využívají učící se agenty ke skenování příspěvků za účelem odhalení porušení pravidel nebo urážlivého jazyka. Taková hygiena založená na umělé inteligenci udržuje online komunity bezpečné a atraktivní.
- Virtuální asistenti: Alexa se učí preference uživatelů, jako jsou oblíbené seznamy skladeb nebo často používané příkazy pro chytrou domácnost, aby mohla poskytovat personalizovanou a proaktivní pomoc.
⚙️ Bonus: Naučte se, jak využívat AI na svém pracovišti k zvýšení produktivity a zefektivnění úkolů pomocí inteligentních agentů.
Výzvy při vývoji učících se agentů
Vývoj učících se agentů s sebou nese technické, etické a praktické výzvy, včetně návrhu algoritmů, výpočetních požadavků a implementace v reálném světě.
Podívejme se na některé klíčové výzvy, kterým čelí vývoj AI v průběhu svého vývoje. 🚧
Rovnováha mezi průzkumem a využíváním
Učící se agenti čelí dilematu, jak vyvážit průzkum a využití.
Ačkoli algoritmy jako epsilon-greedy mohou pomoci, dosažení správné rovnováhy je velmi závislé na kontextu. Nadměrné zkoumání může navíc vést k neefektivitě, zatímco přílišné spoléhání se na využití může vést k suboptimálním řešením.
Řízení vysokých výpočetních nákladů
Trénování sofistikovaných učících se agentů často vyžaduje rozsáhlé výpočetní zdroje. To platí zejména v prostředích s komplexní dynamikou nebo velkými prostory stavů a akcí.
Nezapomeňte, že algoritmy, jako je učení s posilováním pomocí neuronových sítí, například Deep Q-Learning, vyžadují značný výpočetní výkon a paměť. Budete potřebovat pomoc s praktickým využitím učení v reálném čase pro aplikace s omezenými zdroji.
Překonání škálovatelnosti a přenosu učení
Škálování učících se agentů tak, aby efektivně fungovali ve velkých, multidimenzionálních prostředích, zůstává náročné. Transferové učení, při kterém agenti aplikují znalosti z jedné domény do druhé, je stále ještě v plenkách.
To omezilo jejich schopnost generalizovat napříč úkoly nebo prostředími.
📌 Příklad: Agent AI vycvičený pro šachy by měl potíže s hrou Go kvůli výrazně odlišným pravidlům a cílům, což zdůrazňuje výzvu přenosu znalostí mezi doménami.
Kvalita a dostupnost dat
Výkonnost učících se agentů do značné míry závisí na kvalitě a rozmanitosti trénovacích dat.
Nedostatečná nebo zkreslená data mohou vést k neúplnému nebo chybnému učení a mít za následek suboptimální nebo neetická rozhodnutí. Navíc sběr reálných dat pro školení může být nákladný a časově náročný.
⚙️ Bonus: Prozkoumejte kurzy umělé inteligence, abyste lépe porozuměli ostatním agentům.
Nástroje a zdroje pro učící se agenty
Vývojáři a výzkumníci se při vytváření a trénování učících se agentů spoléhají na různé nástroje. Frameworky jako TensorFlow, PyTorch a OpenAI Gym nabízejí základní infrastrukturu pro implementaci algoritmů strojového učení.
Tyto nástroje také pomáhají vytvářet simulovaná prostředí. Některé aplikace AI také tento proces zjednodušují a vylepšují.
Pro tradiční přístupy k strojovému učení zůstávají nástroje jako Scikit-learn spolehlivé a efektivní.
Pro správu projektů výzkumu a vývoje v oblasti umělé inteligence nabízí ClickUp více než jen správu úkolů – funguje jako centralizované centrum pro organizaci úkolů, sledování pokroku a umožňuje hladkou spolupráci mezi týmy.
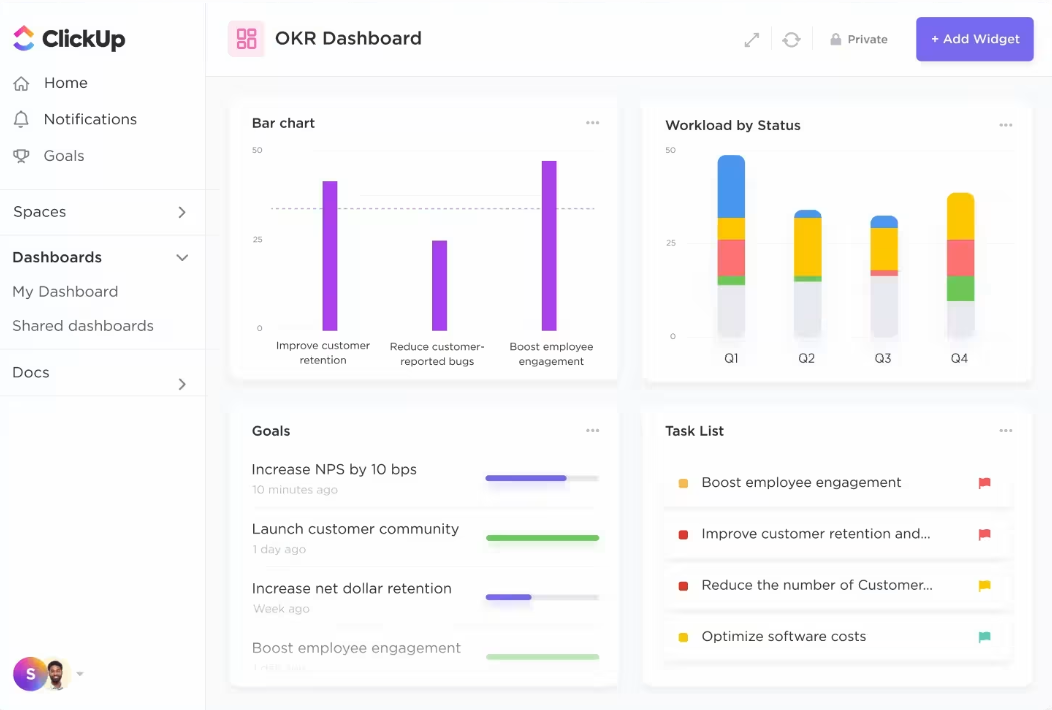
ClickUp pro řízení projektů v oblasti umělé inteligence snižuje manuální úsilí vynaložené na hodnocení stavu úkolů a přidělování povinností.
Místo ručního kontrolování každého úkolu nebo zjišťování, kdo je k dispozici, AI vykonává náročnou práci. Může automaticky aktualizovat pokrok, identifikovat překážky a navrhnout nejlepší osobu pro každý úkol na základě jejího pracovního vytížení a dovedností.
Tímto způsobem strávíte méně času nudnou administrativou a více času tím, na čem záleží – posunem vašich projektů vpřed.
Zde je několik vynikajících funkcí založených na umělé inteligenci. 🤩
ClickUp Brain
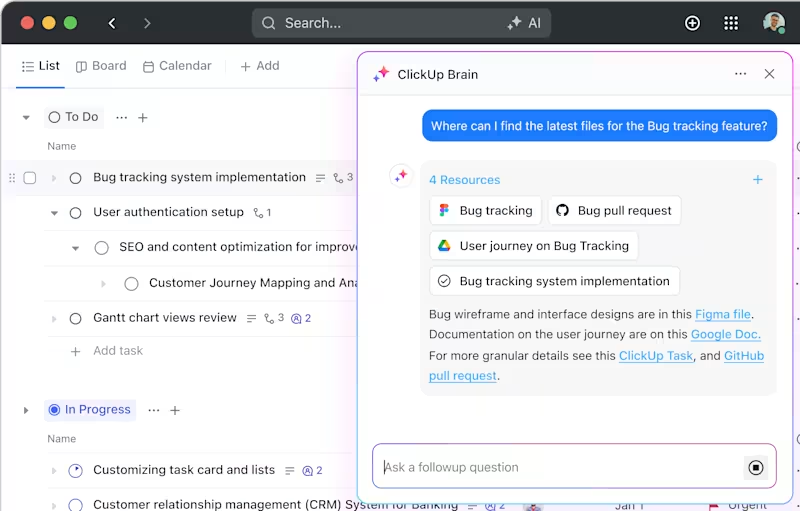
ClickUp Brain, asistent s umělou inteligencí zabudovaný do platformy, zjednodušuje i ty nejsložitější projekty. Rozkládá rozsáhlé studie na zvládnutelné úkoly a podúkoly, což vám pomáhá udržet si přehled a zůstat na správné cestě.
Potřebujete rychlý přístup k experimentálním výsledkům nebo dokumentaci? Stačí zadat dotaz a ClickUp Brain vám během několika sekund vyhledá vše, co potřebujete. Dokonce vám umožní klást doplňující otázky na základě existujících dat, takže budete mít pocit, jako byste měli osobního asistenta.
Navíc automaticky propojuje úkoly s relevantními zdroji, čímž vám šetří čas a námahu.
Řekněme, že provádíte studii o tom, jak se agenti posilujícího učení v průběhu času zlepšují.
Máte před sebou několik fází – rešerši literatury, sběr dat, experimentování a analýzu. S ClickUp Brain můžete zadat příkaz „Rozděl tuto studii na úkoly“ a program automaticky vytvoří podúkoly pro každou fázi.
Poté jej můžete požádat, aby vyhledal relevantní články o Q-learningu nebo načítal datové soubory o výkonu agentů, což provede okamžitě. Při práci na úkolech může ClickUp Brain propojit konkrétní výzkumné články nebo výsledky experimentů přímo s úkoly, takže vše zůstane přehledně uspořádané.
Ať už se zabýváte výzkumnými rámci nebo každodenními projekty, ClickUp Brain vám zajistí, že budete pracovat chytřeji, nikoli tvrději.
Automatizace ClickUp
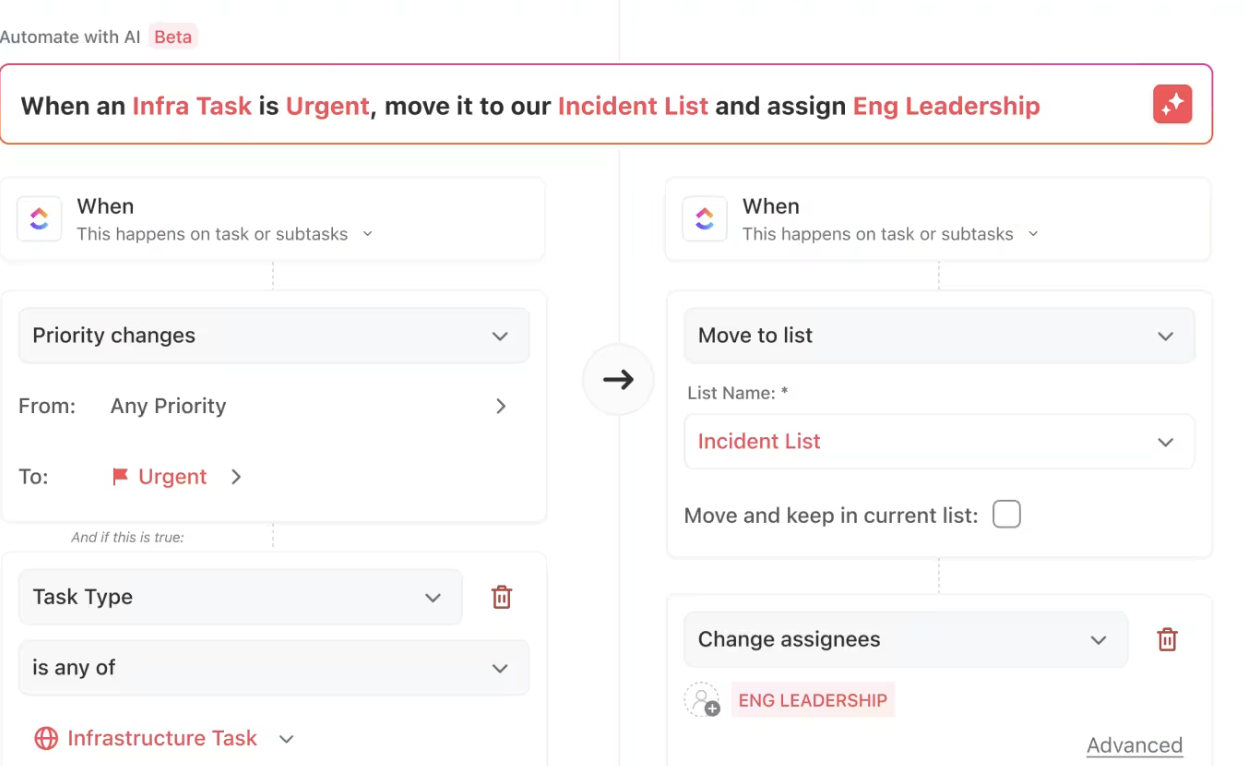
ClickUp Automations je jednoduchý, ale výkonný nástroj pro zefektivnění vašeho pracovního postupu.
Umožňuje okamžité přidělování úkolů po splnění předpokladů, informuje zúčastněné strany o milnících pokroku a upozorňuje na zpoždění – to vše bez ručního zásahu.
Můžete také používat příkazy v přirozeném jazyce, což ještě více usnadňuje správu pracovních postupů. Není třeba se zabývat složitými nastaveními nebo technickým žargonem – stačí ClickUp sdělit, co potřebujete, a on za vás vytvoří automatizaci.
Ať už jde o „přesunout úkoly do další fáze, když jsou označeny jako dokončené“ nebo „přiřadit úkol Sarah, když je priorita vysoká“, ClickUp rozumí vašemu požadavku a nastaví jej automaticky.
📖 Přečtěte si také: Jak využít AI pro zvýšení produktivity (případy použití a nástroje)
Vyvíjejte učící se agenty jako mistr s ClickUp
K vytvoření AI učících se agentů budete potřebovat odbornou kombinaci strukturovaných pracovních postupů a adaptivních nástrojů. Dodatečná poptávka po technických znalostech to činí ještě náročnějším, zejména s ohledem na statistickou a datově podloženou povahu těchto úkolů.
Zvažte použití ClickUp k zefektivnění těchto projektů. Tento nástroj podporuje nejen organizaci, ale také inovace vašeho týmu tím, že odstraňuje zbytečné neefektivnosti.
ClickUp Brain pomáhá rozložit složité úkoly, okamžitě vyhledat relevantní zdroje a nabídnout poznatky založené na umělé inteligenci, aby vaše projekty zůstaly organizované a na správné cestě. ClickUp Automations mezitím zpracovává opakující se úkoly, jako je aktualizace stavů nebo přiřazování nových úkolů, takže se váš tým může soustředit na celkový obraz.
Tyto funkce společně odstraňují neefektivitu a umožňují vašemu týmu pracovat chytřeji, díky čemuž jsou inovace a pokrok snadné.
Zaregistrujte se ještě dnes zdarma na ClickUp. ✅