

Relacionální databázi si představte jako dobře organizovaný kartotéčník, kde je každá zásuvka a složka označena a seřazena tak, aby byl přístup k ní snadný. Bez ní může být hledání správného dokumentu noční můrou.
Robustní systém pro správu relačních databází [RDBMS] je zásadní pro každou úspěšnou aplikaci. Díky efektivní organizaci a správě dat činí relační databáze správu dat intuitivní a výkonnou.
Dobře navržené relační databáze:
- Přizpůsobte se obchodním cílům bez narušení systému.
- Umožněte snadné vyhledávání dat
- Žádná redundance dat
- Zachyťte všechna potřebná data
Co ale činí systém pro správu relačních databází „relačním“ a proč je tak důležitý? Tento blogový příspěvek se zaměří na koncepty, které stojí za systémem relačních databází, a poskytne vám nástroje potřebné k jeho vytvoření.
Porozumění relačním databázím
Relacionální databáze ukládá data ve strukturovaném formátu pomocí řádků a sloupců. Je to jako dobře organizovaná databáze Excel, kde jsou data uspořádána do tabulek. Každá tabulka představuje jiný typ dat a vztahy mezi tabulkami jsou stanoveny pomocí jedinečných identifikátorů známých jako klíče.
To vám umožní efektivně vyhledávat a manipulovat s informacemi v jedné databázi nebo napříč více databázemi.
V minulosti databáze používali především vývojáři. Informace z databází získávali pomocí programovacího jazyka SQL (Structured Query Language). RDMBS se také nazývá SQL databáze.
Nereprelační databáze, neboli NoSQL databáze, naopak ukládá data, ale bez tabulek, řádků nebo klíčů, které charakterizují relační databázi. Nereprelační databáze místo toho optimalizují své úložiště na základě typu ukládaných dat.
Součásti relační databáze
Porozumění základním komponentám relační databáze je nezbytné pro efektivní správu a využívání dat. Tyto komponenty společně strukturovají, ukládají a propojují data, aby byla zajištěna jejich přesnost a efektivita.
1. Tabulky
Představte si tabulky jako základnu pro vaše data, kde každá tabulka obsahuje informace o konkrétní entitě. Můžete mít například tabulku Projekty se sloupci pro ID projektu, název, datum zahájení a stav. Každý řádek v této tabulce představuje jiný projekt, přehledně uspořádaný pro snadný přístup.
— Vytvořte tabulku projektu
CREATE TABLE Projekty (
ProjectID INT PRIMARY KEY,
ProjectName VARCHAR(100),
StartDate DATE,
Status VARCHAR(50)
);
2. Primární klíč
Primární klíče jsou jedinečné identifikátory nebo značky pro každý záznam, které nelze nechat prázdné. Zajišťují, že dotaz může jednoznačně identifikovat každý řádek v tabulce, a tabulka může mít pouze jeden primární klíč. Například v tabulce Úkoly může být primárním klíčem ID úkolu, které odlišuje každý úkol od ostatních.
— Vytvořte tabulku úkolů
Úlohy CREATE TABLE (
TaskID INT PRIMARY KEY,
TaskName VARCHAR(100),
Termín DATE
);
3. Cizí klíč
Cizí klíč je jako logické propojení, které spojuje jednu tabulku s druhou. Jedná se o pole v jedné tabulce, které vytváří odkaz na jinou tabulku odkazem na primární klíč v této tabulce. Například chcete identifikovat komentáře související s úkolem. V tabulce Komentáře se tedy ID úkolu stává cizím klíčem, který odkazuje zpět na ID úkolu v tabulce Úkoly [výše] a ukazuje, ke kterému úkolu se každý komentář vztahuje.
— Vytvořte tabulku komentářů
CREATE TABLE Komentáře (
CommentID INT PRIMARY KEY,
TaskID INT,
KomentářText TEXT,
FOREIGN KEY (TaskID) REFERENCES Tasks(TaskID)
);
4. Indexy
Indikátory zvyšují výkon dotazů tím, že umožňují rychlý přístup k řádkům na základě hodnot sloupců. Například vytvoření indikátoru ve sloupci StartDate v tabulce Projects zrychluje dotazy filtrující podle dat zahájení projektu.
— Vytvořte index ve sloupci StartDate.
CREATE INDEX idx_startdate ON Projects(StartDate);
5. Pohledy
Pohledy jsou virtuální tabulky vytvořené dotazováním dat z jedné nebo více tabulek. Zjednodušují složité dotazy tím, že prezentují data v přístupnějším formátu. Pohled může například zobrazovat souhrn stavů projektů a souvisejících úkolů.
— Vytvořte pohled pro shrnutí úkolů projektu
CREATE VIEW ProjectTaskSummary AS
SELECT p. ProjectName, t. TaskName
Z projektů p
JOIN Tasks t ON p. ProjectID = t. ProjectID;
Různé typy vztahů v relačních databázích
Pro zachování integrity dat a optimalizaci dotazů je klíčové určit, jak různé tabulky v relačních databázích vzájemně interagují. Tyto interakce jsou definovány prostřednictvím různých vztahů, z nichž každý slouží konkrétnímu účelu, aby bylo možné data efektivně organizovat a propojovat.
Porozumění těmto vztahům pomáhá navrhnout robustní schéma databáze, které přesně odráží skutečné vazby mezi různými entitami.
1. Vztah jeden k jednomu
Představte si scénář, ve kterém každý zaměstnanec [jeden] má přesně jeden identifikační průkaz zaměstnance [jeden]. V záznamech tabulky Zaměstnanci tedy každý záznam bude odpovídat jednomu záznamu v tabulce Identifikační průkazy zaměstnanců. Jedná se o vztah jedna ku jedné mezi tabulkami, kde jeden záznam přesně odpovídá druhému.
Zde je ukázkový kód, který ilustruje vztah jeden k jednomu:
— Vytvořte tabulku zaměstnanců
CREATE TABLE Zaměstnanci (
EmployeeID INT PRIMARY KEY,
Název VARCHAR(100)
);
— Vytvořte tabulku IDBadges
CREATE TABLE IDBadges (
BadgeID INT PRIMARY KEY,
EmployeeID INT UNIQUE,
FOREIGN KEY (EmployeeID) REFERENCES Employees(EmployeeID)
);
EmployeeID v tabulce IDBadges jednoznačně [UNIQUE je příkaz SQL, který neumožňuje duplicitní data nebo opakované záznamy v záznamech pod atributem] odpovídá záznamu v poli EmployeeID v tabulce Employees.
2. Vztah jeden k mnoha
Představte si projektového manažera velké organizace [jeden], který dohlíží na více projektů [mnoho].
V tomto případě má tabulka Project Managers (Projektoví manažeři) vztah jeden k mnoha s tabulkou Projects (Projekty). Projektový manažer zpracovává mnoho projektů, ale každý projekt patří pouze jednomu projektovému manažerovi.
— Vytvořte tabulku projektového manažera
CREATE TABLE ProjectManagers (
ManagerID INT PRIMARY KEY,
ManagerName VARCHAR(100)
);
— Vytvořte tabulku projektu
CREATE TABLE Projekty (
ProjectID INT PRIMARY KEY,
ProjectName VARCHAR(100),
ManagerID INT,
FOREIGN KEY (ManagerID) REFERENCES ProjectManagers(ManagerID)
);
Pole ManagerID je odkaz, který propojuje obě tabulky. V druhé tabulce však není jedinečné, což znamená, že v tabulce může být více záznamů s jedním ManagerID nebo že jeden manažer může mít více projektů.
3. Vztah mnoho-k-mnoha
Představte si scénář, ve kterém více zaměstnanců [mnoho] pracuje na různých projektech [mnoho].
K tomu byste použili spojovací tabulku, například Employee_Project_Assignments, která propojuje zaměstnance s projekty, na kterých pracují. Tato tabulka bude obsahovat cizí klíče propojující tabulku Employees a tabulku Projects.
— Vytvořte tabulku zaměstnanců
CREATE TABLE Zaměstnanci (
EmployeeID INT PRIMARY KEY,
EmployeeName VARCHAR(100)
);
— Vytvořte tabulku projektu
CREATE TABLE Projekty (
ProjectID INT PRIMARY KEY,
ProjectName VARCHAR(100)
);
— Vytvořte tabulku přidělených projektů zaměstnancům
CREATE TABLE Employee_Project_Assignments (
EmployeeID INT,
ProjectID INT,
PRIMARY KEY (EmployeeID, ProjectID),
FOREIGN KEY (EmployeeID) REFERENCES Employees(EmployeeID),
FOREIGN KEY (ProjectID) REFERENCES Projects(ProjectID)
);
Zde je Employee_Project_Assignments spojovací tabulkou, která propojuje zaměstnance a projekty.
Výhody relačních databází
Relacionální databáze změnily přístup k správě dat. Díky svým výhodám jsou ideálním řešením pro každého, kdo pracuje s velkými propojenými datovými sadami.
1. Konzistence
Představte si, že se snažíte porozumět nesouvislému souboru dat, kde tabulky a pole nedodržují pravidla názvosloví a jsou rozházené po celém souboru – matoucí, že?
Relacionální databáze vynikají tím, že se zaměřují na konzistenci. Prosazují pravidla integrity dat, která organizují data tak, aby byla všechna přesná a spolehlivá.
Pokud například vytváříte databázi zákazníků, relační databáze zajistí, že kontaktní údaje zákazníků budou správně propojeny s jejich objednávkami, čímž se zabrání nesrovnalostem nebo chybám.
— Vytvořte tabulku zákazníků
CREATE TABLE zákazníci (
customer_id INT PRIMARY KEY,
name VARCHAR(100),
email VARCHAR(100)
);
— Vytvořte tabulku objednávek s omezením cizího klíče
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_id INT,
order_date DATE,
FOREIGN KEY (customer_id) REFERENCES customers(customer_id)
);
Tento kód zabraňuje propojení objednávek s neexistujícími zákazníky, čímž zajišťuje konzistenci dat. Díky relačnímu modelu tak vždy pracujete s důvěryhodnými datovými body, což usnadňuje analýzu a reporting!
2. Normalizace
Práce s více servery a tabulkami a řešení duplicitních informací o zákaznících je únavné. Relacionální databáze v tomto ohledu představují zásadní změnu.
Normalizace organizuje vaše datové struktury do přehledných tabulek, které snižují redundanci a zefektivňují ukládání dat pomocí relačního modelu.
Představte si systém CRM (Customer Relationship Management, řízení vztahů se zákazníky). Normalizace vám pomůže oddělit údaje o zákaznících od jejich interakcí a nákupů. Pokud zákazník aktualizuje své kontaktní údaje, stačí je aktualizovat pouze jednou.
Takto ji můžete nastavit:
— Vytvořte tabulku zákazníků
CREATE TABLE zákazníci (
customer_id INT PRIMARY KEY,
name VARCHAR(100),
email VARCHAR(100),
telefon VARCHAR(20)
);
— Vytvořte tabulku objednávek
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_id INT,
order_date DATE,
total_amount DECIMAL(10, 2),
FOREIGN KEY (customer_id) REFERENCES customers(customer_id)
);
— Vytvořte tabulku interakcí se zákazníky:
CREATE TABLE customer_interactions (
interaction_id INT PRIMARY KEY,
customer_id INT,
interaction_date DATE,
interaction_type VARCHAR(50),
poznámky TEXT,
FOREIGN KEY (customer_id) REFERENCES customers(customer_id)
);
S tímto nastavením je aktualizace e-mailu zákazníka hračkou – stačí provést změnu v tabulce Zákazníci a nemá to žádný vliv na dotazy ani jiné tabulky jinde. Díky tomu je správa, dotazování a ukládání dat efektivnější a méně náchylné k chybám.
3. Škálovatelnost
S růstem vaší firmy poroste i vaše databáze zaměstnanců a zákazníků. Vývojáři softwarových systémů relačních databází navrhují relační databáze tak, aby zvládaly velké objemy dat.
Ať už spravujete prodejní záznamy startupu nebo více uživatelů technologického giganta, relační databáze se snadno přizpůsobují růstu vašeho podnikání. Indexují datový model a optimalizují datové sady, aby výkon zůstal plynulý i při růstu objemu dat.
Chcete-li například zlepšit výkon dotazů na velké tabulce objednávek, můžete vytvořit index ve sloupci order_date:
— Vytvořte index ve sloupci order_date
CREATE INDEX idx_order_date ON orders(order_date);
Tento index vytváří samostatný datový soubor, který ukládá umístění sloupce order_date a lze jej rychle vyhledat.
Vytvoření indexu urychluje provádění dotazů při spuštění filtru nebo třídění podle dotazu order_date, čímž se zrychlují transakce relační databáze.
Pomáhá také škálovat vaše relační databázové systémy s rostoucím počtem objednávek.
4. Flexibilita
Při práci s měnícími se datovými potřebami je flexibilita zásadní a relační databáze ji nabízejí.
Potřebujete přidat nová pole nebo tabulky? Do toho!
Pokud například potřebujete sledovat věrnostní body zákazníků v tabulce zákazníků vaší databáze Customer Resource Management [CRM], můžete přidat nový sloupec:
— Přidejte nový sloupec pro věrnostní body
ALTER TABLE customers ADD loyalty_points INT DEFAULT 0;
Tato přizpůsobivost zajišťuje, že váš model správy relační databáze může růst a měnit se podle potřeb vašeho projektu, aniž by to mělo vliv na stávající relační datový model, fyzické struktury úložiště, fyzický model úložiště dat nebo operace databáze.
Při zkoumání relačních databázových systémů vyniká ClickUp jako univerzální nástroj pro správu projektů, který nabízí výkonné funkce CRM a relační databáze.

Software pro správu projektů CRM od ClickUp mění způsob, jakým spravujete vztahy se zákazníky a zefektivňujete prodejní procesy. Model relační databáze zákazníků si můžete přizpůsobit podle svých představ propojením úkolů, dokumentů a obchodů a pomocí automatizace a formulářů zefektivnit pracovní postupy, automatizovat přiřazování úkolů a spouštět aktualizace stavu.
Můžete prozkoumat informace o svých zákaznících pomocí výkonnostních dashboardů, které vizualizují klíčové metriky, jako je celková hodnota zákazníka a průměrná velikost obchodu.
Kromě toho vám ClickUp CRM pomůže zjednodušit správu účtů, organizovat zákazníky, spravovat pipeline, sledovat objednávky a dokonce přidávat geografická data – vše s cílem zvýšit efektivitu a produktivitu vašeho CRM.
Přečtěte si také: Jak vytvořit databázi CRM, abyste mohli lépe sloužit svým zákazníkům
5. Výkonné možnosti dotazování
Chcete-li odhalit informace ve své relační databázi, můžete pomocí jazyka SQL provádět složité vyhledávání, spojovat více tabulek a agregovat data.
Řekněme například, že analyzujete prodejní výkonnost tím, že zjistíte celkový počet objednávek a jejich hodnotu na zákazníka. Tento dotaz spojuje tabulky zákazníků a objednávek, aby poskytl souhrn prodejní výkonnosti podle zákazníků.
Uložená procedura je jako zkratka v databázi. Uložené procedury jsou předem napsané bloky kódu SQL, které můžete spustit, kdykoli potřebujete provést složité dotazy, automatizovat úkoly nebo zpracovat opakující se procesy.
Pomocí uložených procedur zefektivníte operace, zvýšíte efektivitu a zajistíte konzistentnost a rychlost akcí v databázi. Uložené procedury jsou ideální pro ověřování dat a aktualizaci záznamů.
SQL vám umožňuje shromažďovat data z různých tabulek a vytvářet podrobné zprávy a vizualizace. Tato schopnost generovat smysluplné informace činí relační databáze nepostradatelným nástrojem pro správce databází, analytiky dat nebo vývojáře dat.
Kroky k vytvoření relační databáze
Nyní, když jsme prozkoumali a pochopili komponenty a různé typy vztahů v relačních databázích, je čas aplikovat to, co jsme se naučili. Zde je podrobný návod k vytvoření relační databáze. Pro lepší pochopení vytvoříme databázi pro řízení projektů.
Krok 1: Definujte účel
Začněte tím, že si ujasníte, co bude váš relační databázový systém dělat.
V našem příkladu vytváříme relační databázový model pro sledování vlastností projektového řízení, jako jsou úkoly, členové týmu a termíny.
Chcete, aby relační databáze:
- Spravujte více projektů současně
- Přiřazujte úkoly členům týmu a sledujte jejich pokrok.
- Sledujte termíny úkolů a stav jejich dokončení.
- Vytvářejte zprávy o postupu projektu a výkonu týmu.
Krok 2: Navrhněte schéma
Poté načrtněte strukturu své relační databáze.
Identifikujte klíčové entity [tabulky], jejich datové atributy [sloupce] a způsob, jakým spolu interagují. Tento krok zahrnuje plánování toho, jak budou vaše strukturovaná data organizována a propojena.
Entity pro řízení projektů:
- Projekty: Obsahuje podrobnosti o každém projektu.
- Úkoly: Obsahuje informace o jednotlivých úkolech.
- Členové týmu: Ukládá podrobnosti o týmu.
- Přiřazení úkolů: Propojuje úkoly s členy týmu
Zde je ukázkové schéma:
| Název tabulky | Atributy | Popis |
| Projekty | project_id (INT, PK)project_name (VARCHAR(100))start_date (DATE)end_date (DATE) | Tabulka obsahuje informace o každém projektu. |
| Úkoly | task_id (INT, PK)project_id (INT, FK)task_name (VARCHAR(100))status (VARCHAR(50))due_date (DATE) | Tabulka obsahuje podrobnosti o úkolech souvisejících s projekty. |
| Členové týmu | member_id (INT, PK)name (VARCHAR(100))role (VARCHAR(50)) | Tabulka obsahuje informace o členech týmu. |
| Úkoly | task_id (INT, FK)member_id (INT, FK)assignment_date (DATE) | Tabulka propojuje úkoly s členy týmu a termíny jejich zadání. |
Vztahy mezi těmito logickými datovými strukturami a datovými tabulkami mohou být někdy matoucí, protože většina systémů pro správu relačních databází je stále složitější.
Mnozí dávají přednost vizuálnímu znázornění vztahů, obvykle pomocí myšlenkových map a nástrojů pro návrh relačních databází.
V další části článku se budeme zabývat myšlenkovými mapami a nástroji pro návrh relačních databází.
Krok 3: Vytvořte vztahy
O typech vztahů jsme již hovořili dříve a schéma tabulky pomáhá definovat vztahy mezi tabulkami.
Cizí klíč je zásadní pro zajištění konzistence dat a umožnění složitých dotazů.
Propojují související datové body napříč tabulkami a udržují referenční integritu dat, čímž zajišťují, že každý záznam je správně propojen s ostatními.
Musíte jej však sdílet, aby bylo možné jej snadno vyhledat, jako v příkladu níže:
- Úkoly jsou spojeny s projekty prostřednictvím project_id.
- Úkoly přiřazují úkoly a členy týmu pomocí task_id a member_id.
Krok 4: Vytvořte tabulky
Proces vytváření tabulek a definování primárních a cizích klíčů jsme již podrobně probrali. V případě potřeby se můžete k těmto částem vrátit. Níže však najdete SQL dotazy pro vytvoření malé relační databáze pro správu projektů jako součást průvodce.
— Vytvořte tabulku Projekty
CREATE TABLE Projekty (
project_id INT PRIMARY KEY,
project_name VARCHAR(100),
start_date DATE,
end_date DATE
);
— Vytvořte tabulku Úkoly
Úlohy CREATE TABLE (
task_id INT PRIMARY KEY,
project_id INT,
task_name VARCHAR(100),
status VARCHAR(50),
due_date DATE,
FOREIGN KEY (project_id) REFERENCES Projects(project_id)
);
— Vytvořte tabulku členů týmu
CREATE TABLE TeamMembers (
member_id INT PRIMARY KEY,
name VARCHAR(100),
role VARCHAR(50)
);
— Vytvořte tabulku přiřazení úkolů
CREATE TABLE TaskAssignments (
task_id INT,
member_id INT,
assignment_date DATE,
FOREIGN KEY (task_id) REFERENCES Tasks(task_id),
FOREIGN KEY (member_id) REFERENCES TeamMembers(member_id),
PRIMARY KEY (task_id, member_id)
);
Krok 5: Vložení dat
Přidejte do svých tabulek skutečná data a podívejte se, jak vše funguje.
Tento krok zahrnuje testování vašeho nastavení, aby bylo zajištěno, že relační databáze fungují podle očekávání. Zahrnuje vložení podrobností o projektu, popisu úkolů, členů týmu a přiřazených úkolů do databáze SQL.
Příklad kódu SQL
— Vložit do tabulky Projekty
INSERT INTO Projekty (id_projektu, název_projektu, datum_zahájení, datum_ukončení) HODNOTY
(1, „Redesign webových stránek“, „2024-01-01“, „2024-06-30“),
(2, „Vývoj mobilních aplikací“, „2024-03-01“, „2024-12-31“);
— Vložit do tabulky Úkoly
INSERT INTO Úkoly (task_id, project_id, task_name, status, due_date) VALUES
(1, 1, „Návrhy maket“, „Probíhá“, „2024-02-15“),
(2, 1, „Front-end Development“, „Not Started“, „2024-04-30“);
— Vložit do tabulky Členové týmu
INSERT INTO TeamMembers (member_id, name, role) VALUES
(1, „Alice Johnson“, „Designérka“),
(2, „Bob Smith“, „Developer“);
— Vložit do tabulky úkolů
INSERT INTO TaskAssignments (task_id, member_id, assignment_date) VALUES
(1, 1, „2024-01-10“),
(2, 2, „2024-03-01“);
Krok 6: Dotazování dat
Jakmile jsou data uložena ve vaší relační databázi, použijte dotazy SQL k jejich načtení a analýze. Dotazy vám pomohou sledovat průběh projektu, monitorovat přidělené úkoly a generovat cenné zprávy.
Příklad dotazu SQL
— Dotaz pro vyhledání všech úkolů pro konkrétní projekt
SELECT t. task_name, t. status, t. due_date, tm. name
OD Úkoly t
JOIN TaskAssignments ta ON t. task_id = ta. task_id
JOIN TeamMembers tm ON ta. member_id = tm. member_id
WHERE t. project_id = 1;
Vytváření systémů pro správu relačních databází pomocí zobrazení tabulky ClickUp
ClickUp vyniká ve vytváření přehledných, organizovaných a kolaborativních relačních databází a tabulek pomocí svého zobrazení tabulky.
Tabulkový pohled ClickUp podporuje více než 15 typů dat, od vzorců a postupu úkolů až po náklady a hodnocení, a umožňuje vám připojit dokumenty a odkazy přímo k vašim tabulkám. Nabízí vizuální a intuitivní způsob správy relační databáze a relační datové struktury v rámci projektů.

Podrobný průvodce vytvořením systému pro správu relačních databází pomocí zobrazení tabulky ClickUp.
Krok 1: Definujte databázi
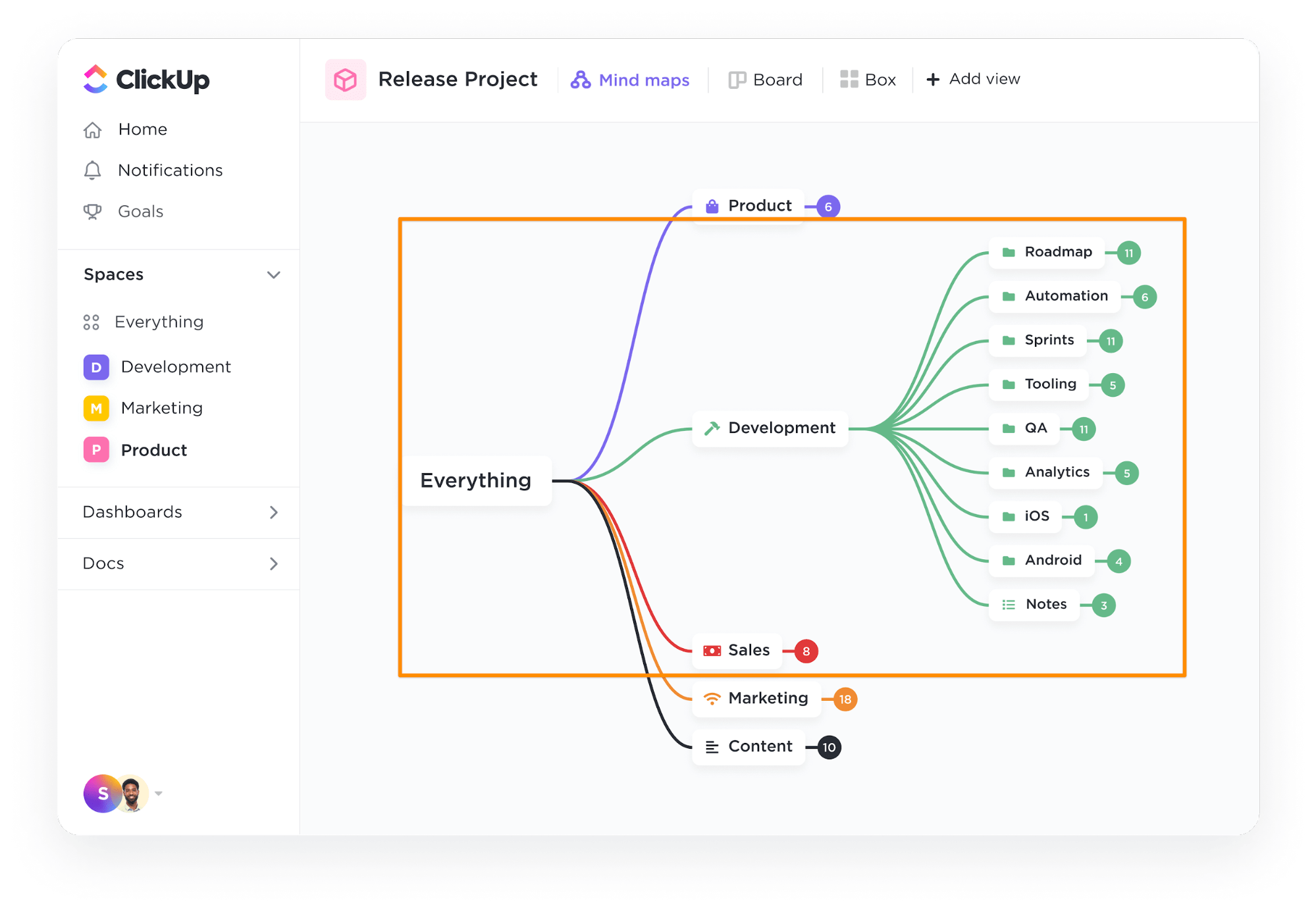
Pomocí nástroje ClickUp Mind Maps vyplňte a definujte schéma databáze, tj. jaké tabulky vytvořit a jaké budou vzájemné vztahy mezi nimi.
Krok 2: Nastavení zobrazení tabulky
Přejděte na požadovaný projekt nebo pracovní prostor v ClickUp.

Přidejte nový pohled a vyberte možnost Tabulkový pohled.
Krok 3: Vytvořte tabulky
Použijte úkoly a vlastní pole k zobrazení tabulek a sloupců.

Uspořádejte klíčové datové body v tabulkovém zobrazení.
Krok 4: Vytvořte vztahy
Použijte vlastní pole k propojení souvisejících úkolů [např. pomocí rozevíracích polí k odkazování na jiné úkoly].

Zajistěte integritu dat tím, že ověříte správnost odkazů.
Krok 5: Správa dat
Přidávejte, upravujte a odstraňujte datové záznamy přímo v tabulkovém zobrazení.

Používejte filtry a možnosti třídění k správě a analýze dat.
Krok 6: Dotazy a sestavy
Využijte pokročilé funkce filtrování a reportování ClickUp k získání přehledu o vašich relačních datech.

Připravené bezplatné šablony databází ClickUp mohou urychlit proces vytváření relačních databází a zjednodušit práci.

Šablona tabulky ClickUp shromažďuje důležité informace o zákaznících pro vaše podnikání. Jedná se o šablonu na úrovni seznamu, která používá databázi s plochými soubory.
Stačí přidat šablonu do svého prostoru a můžete ji hned používat.
Tyto šablony tabulek vám pomohou efektivně zaznamenávat a spravovat důležité údaje o zákaznících. Můžete bezpečně ukládat data a vytvářet vysoce efektivní relační databáze, které pomohou obchodníkům ve vaší organizaci.
Šablona editovatelné tabulky ClickUp je nejjednodušší přizpůsobitelná šablona pro správu složitých finančních dat. Tato šablona zefektivňuje sledování rozpočtu a plánování projektů.
Funkce jako automatický import dat, vlastní finanční vzorce, intuitivní vizuální prvky pro sledování pokroku a vlastní stavy, pole a zobrazení pro efektivní organizaci a správu finančních záznamů činí tento nástroj ideálním pro odborníky na finanční data a manažery.
S ClickUp můžete automatizovat úkoly, nastavit opakované aktualizace a plynule kontrolovat strukturu dat, čímž zajistíte přesnost a konzistenci všech dokumentů.
Vytváření obsahu může být vzhledem k množství generovaného obsahu velmi náročné. K jeho správě slouží databáze obsahu, která pomáhá efektivně organizovat a sledovat obsah, což usnadňuje jeho škálování podle rostoucích potřeb. Konsoliduje všechny informace související s obsahem, jako je stav a metriky, do standardizovaného systému, což šetří čas a zabraňuje zdvojování úsilí.
Šablona databáze blogů ClickUp je vaším nepostradatelným nástrojem pro efektivní správu obsahu blogů. Na rozdíl od jiných tabulek pro správu projektů v Excelu je velmi intuitivní a pomůže vám organizovat příspěvky, zefektivnit jejich tvorbu a sledovat pokrok od návrhu až po zveřejnění.

Tuto šablonu můžete použít k:
- Kategorizujte a podkategorizujte příspěvky na blogu pro snadný přístup a vyhledávání.
- Sledujte stav každého příspěvku od jeho vzniku až po zveřejnění pomocí vlastních stavů.
- Využijte více zobrazení, jako jsou tabulka, sledování stavu a databázový hub, k vizualizaci dat.
- Využijte kontrolní seznamy a předvyplněná pole k zefektivnění procesu vytváření blogových příspěvků.
- Analyzujte výkon blogu a spravujte analytické údaje za účelem optimalizace strategie obsahu.
Díky integrovanému sledování času, značkám a upozorněním na závislosti nebylo spravování obsahu vašeho blogu nikdy snazší.
Vybudujte si pevné základy s relačními databázemi
Systém pro správu relačních databází je více než jen nástroj pro správce databází – je základem škálovatelné a efektivní správy dat. Zvládnutí složitosti tabulek, primárních a cizích klíčů a vztahů v databázi vám umožní navrhovat robustní a flexibilní systémy.
Využitím těchto principů a nástroje ClickUp můžete zvýšit integritu dat, zefektivnit přístup a podpořit inovativní řešení.
Jste připraveni zlepšit správu svých dat? Zaregistrujte se ještě dnes na ClickUp a objevte, jak může změnit správu vaší relační databáze a zvýšit vaši produktivitu!