
ภัยพิบัติทางไอทีสามารถเกิดขึ้นได้โดยไม่มีการเตือนล่วงหน้า
จากการล่มของเซิร์ฟเวอร์ไปจนถึงการโจมตีทางไซเบอร์—หากไม่มีแผนการกู้คืนที่มั่นคง ธุรกิจของคุณอาจเผชิญกับเวลาหยุดทำงานหลายชั่วโมง ข้อมูลสูญหาย และความเสียหายทางการเงินอย่างรุนแรง โดย54% ของเหตุการณ์หยุดทำงานที่รุนแรงมีค่าใช้จ่ายมากกว่า 100,000 ดอลลาร์สหรัฐ
บล็อกนี้จะพาคุณสร้างแผนการกู้คืนระบบ IT ที่ครอบคลุมซึ่งปกป้องระบบของคุณ กำหนดวัตถุประสงค์การกู้คืนที่ชัดเจน และทำให้ทีมของคุณทราบอย่างชัดเจนว่าต้องทำอะไรเมื่อเกิดปัญหา
แผนการกู้คืนระบบจากภัยพิบัติทางไอทีคืออะไร?
หากเซิร์ฟเวอร์ของคุณล่มตอนนี้ ทีมของคุณจะรู้ทันทีว่าต้องทำอย่างไร? 🛠️
แผนการกู้คืนระบบเทคโนโลยีสารสนเทศ (IT Disaster Recovery หรือ DR) คือกลยุทธ์ที่จัดทำเป็นเอกสารสำหรับการกู้คืนระบบเทคโนโลยีสารสนเทศและข้อมูลหลังจากเกิดความขัดข้องใด ๆ ไม่ว่าจะเป็นภัยธรรมชาติหรือการโจมตีทางไซเบอร์ โดยพื้นฐานแล้ว แผนนี้เปรียบเสมือนคู่มือปฏิบัติสำหรับการนำเทคโนโลยีกลับมาใช้งานได้อีกครั้งเมื่อเกิดปัญหา
💡 DR เทียบกับการดำเนินธุรกิจอย่างต่อเนื่อง
การกู้คืนจากภัยพิบัติ (DR) มุ่งเน้นเฉพาะการฟื้นฟูโครงสร้างพื้นฐานด้านไอทีและข้อมูลของคุณ การดำเนินธุรกิจอย่างต่อเนื่อง (BC) มีขอบเขตที่กว้างกว่า โดยมีเป้าหมายเพื่อให้ธุรกิจของคุณดำเนินงานได้อย่างต่อเนื่องทั้งในระหว่างและหลังเกิดวิกฤต แม้ในกรณีที่ระบบไอทีไม่สามารถใช้งานได้ ให้คิดถึง DR ว่าเป็นส่วนสำคัญของกลยุทธ์ BC โดยรวมของคุณ
💡 DR เทียบกับการดำเนินธุรกิจอย่างต่อเนื่อง
การกู้คืนจากภัยพิบัติ (DR) มุ่งเน้นเฉพาะการฟื้นฟูโครงสร้างพื้นฐานด้านไอทีและข้อมูลของคุณ การดำเนินธุรกิจอย่างต่อเนื่อง (BC) มีขอบเขตที่กว้างกว่า โดยมีเป้าหมายเพื่อให้ธุรกิจของคุณดำเนินงานได้อย่างต่อเนื่องทั้งในระหว่างและหลังวิกฤต แม้ในกรณีที่ระบบไอทีหยุดทำงาน ให้คิดถึง DR ว่าเป็นส่วนสำคัญของกลยุทธ์ BC โดยรวมของคุณ
แผนการกู้คืนจากภัยพิบัติของคุณมีความสำคัญเพราะเวลาที่ระบบหยุดทำงานมีค่าใช้จ่ายมากกว่าแค่เงิน ทุกนาทีที่ระบบของคุณออฟไลน์สามารถทำลายความไว้วางใจของลูกค้า ทำให้การดำเนินงานหยุดชะงัก และอาจนำไปสู่ค่าปรับจากการไม่ปฏิบัติตามข้อกำหนด แผนการกู้คืนจากภัยพิบัติที่ครอบคลุมคือแผนที่นำทางสู่ความยืดหยุ่นของคุณ
แผนที่ยอดเยี่ยมครอบคลุม:
- ขั้นตอนการสำรองข้อมูล: วิธีการและสถานที่ที่คุณเก็บสำเนาของข้อมูลสำคัญเพื่อที่คุณจะสามารถกู้คืนได้
- ขั้นตอนการกู้คืนระบบ: ลำดับที่แน่นอนในการนำบริการกลับมาออนไลน์ในลำดับที่ถูกต้อง
- ความรับผิดชอบของทีม: ใครทำอะไรในระหว่างเหตุการณ์เพื่อหลีกเลี่ยงความสับสน
- โปรโตคอลการสื่อสาร: วิธีการที่คุณจะอัปเดตผู้มีส่วนได้ส่วนเสีย ตั้งแต่ทีมของคุณไปจนถึงลูกค้า
- วัตถุประสงค์การกู้คืน: เป้าหมายเฉพาะของคุณเกี่ยวกับความรวดเร็วที่ระบบต้องกลับมาทำงานและปริมาณข้อมูลที่สูญเสียได้ที่ยอมรับได้
สถานการณ์ภัยพิบัติทางไอทีที่พบบ่อยและผลกระทบ
ภัยพิบัติไม่ใช่แค่ฉากในภาพยนตร์ฮอลลีวูด; มันเกิดขึ้นกับธุรกิจทุกวัน. การเข้าใจสิ่งที่คุณกำลังปกป้องช่วยให้คุณสร้างการป้องกันที่แข็งแกร่งมากขึ้น.
ภัยธรรมชาติและความเสียหายทางกายภาพ
เหตุการณ์เช่นน้ำท่วม, ไฟไหม้, แผ่นดินไหว, และการไฟฟ้าดับครั้งใหญ่สามารถทำลายศูนย์ข้อมูลทั้งหมดได้ในเวลาเพียงไม่กี่นาที. ตัวอย่างเช่น เมื่อเกิดน้ำท่วมใหญ่ที่ศูนย์ข้อมูลในแนชวิลล์, บางบริษัทสูญเสียข้อมูลเป็นเวลาหลายสัปดาห์และต้องใช้เวลาหลายเดือนในการกู้คืน. การป้องกันที่ดีที่สุดคือความซ้ำซ้อนทางภูมิศาสตร์, ซึ่งหมายถึงการกระจายโครงสร้างพื้นฐานของคุณไปยังหลายสถานที่ทางกายภาพเพื่อให้เหตุการณ์หนึ่งไม่สามารถทำลายทุกสิ่งได้.
การโจมตีทางไซเบอร์และการรั่วไหลของข้อมูล
แรนซัมแวร์, การโจมตีแบบปฏิเสธการให้บริการแบบกระจาย (DDoS), และการละเมิดข้อมูล มีความแตกต่างจากภัยพิบัติทางกายภาพ พวกมันมักตรวจจับได้ยากกว่า สามารถแพร่กระจายอย่างเงียบๆ ผ่านระบบที่เชื่อมต่อกัน และมักจะมุ่งเป้าไปที่ระบบสำรองข้อมูลของคุณด้วย ทำให้การกู้คืนเป็นเรื่องที่ท้าทายเป็นพิเศษ ความถี่และความซับซ้อนของการโจมตีทางไซเบอร์เหล่านี้ยังคงเพิ่มขึ้นในทุกอุตสาหกรรมโดยแรนซัมแวร์ตอนนี้คิดเป็น 44%ของการละเมิดข้อมูลที่ได้รับการยืนยันทั้งหมด ทำให้เป็นภัยคุกคามอันดับต้นๆ
📖 อ่านเพิ่มเติม: 10 วิธีลดความเสี่ยงด้านความปลอดภัยทางไซเบอร์ในการบริหารโครงการ
ความล้มเหลวของฮาร์ดแวร์และการสูญเสียข้อมูล
บางครั้ง แม้แต่ระบบสำรองข้อมูลที่ผ่านการทดสอบและเชื่อถือได้มากที่สุดก็อาจล้มเหลวได้ เซิร์ฟเวอร์ล่ม ความล้มเหลวของอุปกรณ์จัดเก็บข้อมูล และอุปกรณ์เครือข่ายทำงานผิดปกติสามารถเกิดขึ้นได้โดยไม่มีการแจ้งเตือนล่วงหน้า แม้ว่าคุณจะมีระบบสำรองข้อมูลสำรอง (redundant) ก็ตาม แต่ระบบเหล่านี้อาจล้มเหลวพร้อมกันได้หากใช้ส่วนประกอบหรือแหล่งพลังงานร่วมกัน ซึ่งอาจทำให้เกิดจุดล้มเหลวเพียงจุดเดียว
👀 คุณรู้หรือไม่: ในเดือนตุลาคม 2025AWS ประสบปัญหาการหยุดให้บริการครั้งใหญ่เนื่องจากข้อผิดพลาดในระบบจัดการ DNS ภายในสำหรับ Amazon DynamoDB ทำให้การแก้ไขชื่อโดเมนล้มเหลวในภูมิภาคศูนย์ข้อมูล US-EAST-1 ข้อบกพร่องทางเทคนิคที่ "เล็กน้อย" นี้ได้ก่อให้เกิดความล้มเหลวแบบลูกโซ่ในบริการ AWS หลายสิบรายการ และทำให้แอปพลิเคชันและแพลตฟอร์มยอดนิยมหลายร้อยรายการทั่วโลกหยุดทำงาน — ตั้งแต่แอปส่งข้อความและโซเชียลมีเดีย ไปจนถึงธนาคาร เว็บไซต์เกม และอื่นๆ อีกมากมาย สำหรับหลายคน การหยุดให้บริการชั่วคราวนี้ทำให้อินเทอร์เน็ตส่วนใหญ่ "หายไป" ชั่วขณะ ซึ่งเน้นย้ำถึงความเปราะบางของโครงสร้างพื้นฐานดิจิทัลของเรา เมื่อทุกอย่างขึ้นอยู่กับผู้ให้บริการคลาวด์เพียงไม่กี่ราย
ข้อผิดพลาดของซอฟต์แวร์และการขัดข้องของบริการ
ฐานข้อมูลที่เสียหาย การอัปเดตซอฟต์แวร์ที่ล้มเหลว หรือข้อผิดพลาดในการกำหนดค่าเพียงเล็กน้อยสามารถทำให้แพลตฟอร์มทั้งหมดล่มได้ คุณอาจสังเกตเห็นว่ารหัสเพียงบรรทัดเดียวที่ตั้งค่าผิดพลาดสามารถส่งผลกระทบต่อระบบที่เชื่อมต่อกันทั้งหมด ทำให้เกิดการหยุดชะงักอย่างกว้างขวางและส่งผลกระทบเป็นวงกว้าง การจัดการการเปลี่ยนแปลงอย่างเหมาะสมและการทดสอบในสภาพแวดล้อมเฉพาะทางคือเพื่อนที่ดีที่สุดของคุณในการลดความเสี่ยงเหล่านี้ให้น้อยที่สุด
ข้อผิดพลาดของมนุษย์และการกำหนดค่าผิดพลาด
การลบข้อมูลโดยไม่ตั้งใจ การตั้งค่าที่ไม่ถูกต้อง และการเปลี่ยนแปลงโดยไม่ได้รับอนุญาต ยังคงเป็นหนึ่งในสาเหตุที่พบบ่อยที่สุดของการหยุดชะงักของระบบไอที คำสั่งที่ผิดพลาดเพียงครั้งเดียวหรือไฟล์ที่ถูกลบสามารถทำให้เกิดการหยุดชะงักของระบบและคุณภาพการให้บริการที่ลดลงเป็นเวลาหลายชั่วโมง แม้ว่าการฝึกอบรมและการควบคุมการเข้าถึงจะช่วยได้ แต่ก็ไม่สามารถกำจัดข้อผิดพลาดของมนุษย์ได้อย่างสมบูรณ์
📮ClickUp Insight:92% ของพนักงานใช้วิธีการที่ไม่สอดคล้องกันในการติดตามรายการที่ต้องดำเนินการ ซึ่งส่งผลให้เกิดการตัดสินใจที่พลาดและการดำเนินการล่าช้า
ไม่ว่าคุณจะส่งบันทึกติดตามผลหรือใช้สเปรดชีต กระบวนการมักจะกระจัดกระจายและไม่มีประสิทธิภาพ ด้วยความสามารถในการจัดการงานของ ClickUpคุณไม่ต้องกังวลเรื่องนี้อีกต่อไป สร้างงานจากการแชทความคิดเห็นใน ClickUp Task เอกสาร และอีเมลได้ด้วยการคลิกเพียงครั้งเดียว!
องค์ประกอบสำคัญของแผนการกู้คืนระบบจากภัยพิบัติทางไอที
แผนการกู้คืนระบบที่มั่นคงคือคู่มือการดำเนินการที่สมบูรณ์สำหรับการกลับมาออนไลน์ของคุณ ทุกส่วนประกอบเหล่านี้สร้างขึ้นบนพื้นฐานของกันและกันเพื่อสร้างการปกป้องที่ครอบคลุมสำหรับธุรกิจของคุณ
การประเมินความเสี่ยงและการจัดลำดับความสำคัญ
ก่อนอื่น คุณต้องรู้ว่ากำลังเผชิญกับอะไรการประเมินความเสี่ยงคือกระบวนการระบุจุดอ่อนของคุณและประเมินความน่าจะเป็นและผลกระทบของแต่ละภัยคุกคามที่อาจเกิดขึ้น คุณสามารถจัดระเบียบสิ่งนี้ในเมทริกซ์ความเสี่ยงเพื่อดูว่าภัยคุกคามใดมีความรุนแรงมากที่สุด
การประเมินของคุณควรครอบคลุม:
- ระบบสำคัญ: สิ่งที่จำเป็นต้องทำงานอยู่ตลอดเวลาเพื่อให้ธุรกิจของคุณดำเนินต่อไปได้
- ความอ่อนไหวของข้อมูล: ข้อมูลใดที่ต้องการการปกป้องในระดับสูงสุด (เช่น ข้อมูลลูกค้า)
- การพึ่งพา: ระบบหรือกระบวนการอื่นใดที่อาจล้มเหลวเมื่อแต่ละระบบล้มเหลว
📖 อ่านเพิ่มเติม: วิธีการนำการจัดการโครงสร้างพื้นฐานด้านไอทีไปปฏิบัติ
การวิเคราะห์ผลกระทบทางธุรกิจและความสำคัญ
ต่อไป ให้คำนวณต้นทุนที่แท้จริงของการหยุดทำงานการวิเคราะห์ผลกระทบทางธุรกิจ (BIA)จะช่วยให้คุณกำหนดผลกระทบทางการเงินและการดำเนินงานของการหยุดทำงานสำหรับแต่ละระบบ สิ่งนี้ช่วยให้คุณสามารถจัดประเภทระบบของคุณเป็นระดับความสำคัญเพื่อจัดลำดับความสำคัญของความพยายามในการกู้คืน
| วิกฤต | น้อยกว่าหนึ่งชั่วโมง | การประมวลผลการชำระเงิน, ฐานข้อมูลลูกค้า |
| สูง | หนึ่งถึงสี่ชั่วโมง | อีเมล, เครื่องมือสื่อสารภายใน |
| ระดับกลาง | สี่ถึงยี่สิบสี่ชั่วโมง | สภาพแวดล้อมการพัฒนา, เครื่องมือรายงาน |
| ต่ำ | 24+ ชั่วโมง | ระบบจัดเก็บข้อมูลสำรอง, เซิร์ฟเวอร์ทดสอบที่ไม่ใช่การผลิต |
วัตถุประสงค์ของ RTO และ RPO
สองคำย่อเหล่านี้คือหัวใจของกลยุทธ์การฟื้นตัวของคุณ
- วัตถุประสงค์ของระยะเวลาการกู้คืน (RTO): นี่คือระยะเวลาสูงสุดที่คุณสามารถยอมรับได้สำหรับระบบที่จะหยุดทำงาน ตอบคำถามว่า "เราต้องการให้ระบบกลับมาใช้งานได้เร็วแค่ไหน?"
- จุดเป้าหมายการกู้คืน (Recovery Point Objective - RPO): นี่คือปริมาณข้อมูลสูงสุดที่คุณสามารถสูญเสียได้ โดยวัดเป็นเวลา คำถามที่ตอบคือ "เราสามารถสูญเสียข้อมูลได้มากแค่ไหนโดยไม่ก่อให้เกิดความเสียหายร้ายแรง?"
ตัวอย่างเช่น ระบบอีเมลภายในของคุณอาจมี RTO อยู่ที่สี่ชั่วโมง แต่ฐานข้อมูลอีคอมเมิร์ซที่ติดต่อกับลูกค้าอาจมี RPO เพียง 15 นาที ซึ่งหมายความว่าคุณไม่สามารถสูญเสียข้อมูลการทำธุรกรรมได้เกิน 15 นาที
แผนการสำรองข้อมูลและการกู้คืนข้อมูล
แผนสำรองของคุณคือตาข่ายความปลอดภัยขั้นสูงสุดของคุณ. แนวทางปฏิบัติที่ดีที่สุดที่พบได้บ่อยคือกฎ 3-2-1: รักษาสำเนาของข้อมูลสำคัญของคุณไว้อย่างน้อยสามชุด, จัดเก็บไว้ในสื่อสองประเภทที่แตกต่างกัน, และเก็บสำเนาหนึ่งชุดไว้ที่นอกสถานที่.
คุณยังจะต้องเลือกระหว่างประเภทการสำรองข้อมูลที่แตกต่างกัน:
- การสำรองข้อมูลแบบเต็ม: สำเนาข้อมูลทั้งหมดโดยสมบูรณ์ ซึ่งมักจะดำเนินการเป็นรายสัปดาห์หรือรายเดือน
- การสำรองข้อมูลแบบเพิ่มเติม: สำรองเฉพาะการเปลี่ยนแปลงที่เกิดขึ้นนับตั้งแต่การสำรองข้อมูลครั้งล่าสุด (ไม่ว่าจะเป็นการสำรองข้อมูลประเภทใดก็ตาม)
- การสำรองข้อมูลแบบต่างส่วน: สำรองข้อมูลทุกการเปลี่ยนแปลงที่ทำขึ้นตั้งแต่การสำรองข้อมูลแบบเต็มครั้งล่าสุด
สิ่งที่สำคัญที่สุดคือ คุณต้องทดสอบกระบวนการกู้คืนข้อมูลสำรองของคุณเป็นประจำ การสำรองข้อมูลที่ไม่ได้รับการทดสอบเป็นเพียงความหวัง ไม่ใช่แผนการ
💟 โบนัส: จับรายละเอียดสำคัญในระหว่างเหตุการณ์ที่มีความเครียดสูงโดยใช้ฟีเจอร์พูดเป็นข้อความของ ClickUp Brain MAX MAX เพื่อให้คุณไม่พลาดข้อมูลสำคัญแม้ในยามที่ไม่สามารถพิมพ์ได้ เพียงพูดสิ่งที่คุณสังเกตเห็น แล้วให้ AI จัดการเอกสารให้เอง
แผนการสื่อสารและการอัปเดตผู้มีส่วนได้ส่วนเสีย
เมื่อเกิดภัยพิบัติขึ้นแผนการสื่อสารที่ชัดเจนคือสิ่งสำคัญที่สุด แผนของคุณต้องกำหนดลำดับการแจ้งเตือน ความถี่ในการอัปเดต และช่องทางที่คุณจะใช้สำหรับแต่ละประเภทของเหตุการณ์
กลุ่มต่าง ๆ ต้องการข้อมูลที่แตกต่างกัน:
- ทีมภายใน: ต้องการรายละเอียดทางเทคนิคและรายการดำเนินการเฉพาะ
- ลูกค้า: ต้องการทราบสถานะการให้บริการและคาดว่าจะได้รับการแก้ไขเมื่อใด
- ผู้ขาย: อาจจำเป็นต้องมีการติดต่อเพื่อขอความช่วยเหลือหรือการส่งต่อปัญหา
- หน่วยงานกำกับดูแล: อาจต้องการการแจ้งเตือนอย่างเป็นทางการขึ้นอยู่กับอุตสาหกรรมของคุณ
เครื่องมือเช่นนี้ แบบแผนการสื่อสารพร้อมใช้ จาก ClickUp สามารถช่วยคุณดำเนินการได้รวดเร็วขึ้นด้วยโปรโตคอลที่ได้รับการจัดตั้งไว้แล้วในระหว่างวิกฤต

โปรแกรมทดสอบและฝึกอบรม
แผนที่คุณไม่เคยทดสอบคือแผนที่จะล้มเหลว การทดสอบอย่างสม่ำเสมอช่วยเปิดเผยช่องว่างและจุดอ่อนก่อนที่ภัยพิบัติที่แท้จริงจะเกิดขึ้น
กำหนดการทดสอบประเภทต่างๆ ตลอดทั้งปี:
- การฝึกซ้อมบนโต๊ะ: ทีมของคุณจะจำลองสถานการณ์ภัยพิบัติบนกระดาษเพื่อตรวจสอบความสมเหตุสมผลของแผน
- การกู้คืนบางส่วน: คุณทดสอบการกู้คืนของส่วนประกอบหรือบริการที่ไม่ใช่ส่วนสำคัญ
- การทดสอบ DR แบบเต็มรูปแบบ: คุณดำเนินการย้ายระบบไปยังระบบสำรองอย่างสมบูรณ์ (การทดสอบขั้นสูงสุด)
หลังจากการทดสอบทุกครั้ง ให้อัปเดตเอกสารของคุณและฝึกอบรมสมาชิกใหม่ในทีมเกี่ยวกับขั้นตอนทันที
📖 อ่านเพิ่มเติม: วิธีพัฒนาระเบียบและนโยบายด้านไอทีที่มีประสิทธิภาพ
ขั้นตอนการสร้างแผนกู้คืนระบบจากภัยพิบัติด้านไอที
การสร้างแผนการกู้คืนระบบของคุณไม่จำเป็นต้องเป็นเรื่องที่ยุ่งยาก
นี่คือวิธีที่คุณสามารถจัดการมันได้ทีละขั้นตอน 🙌
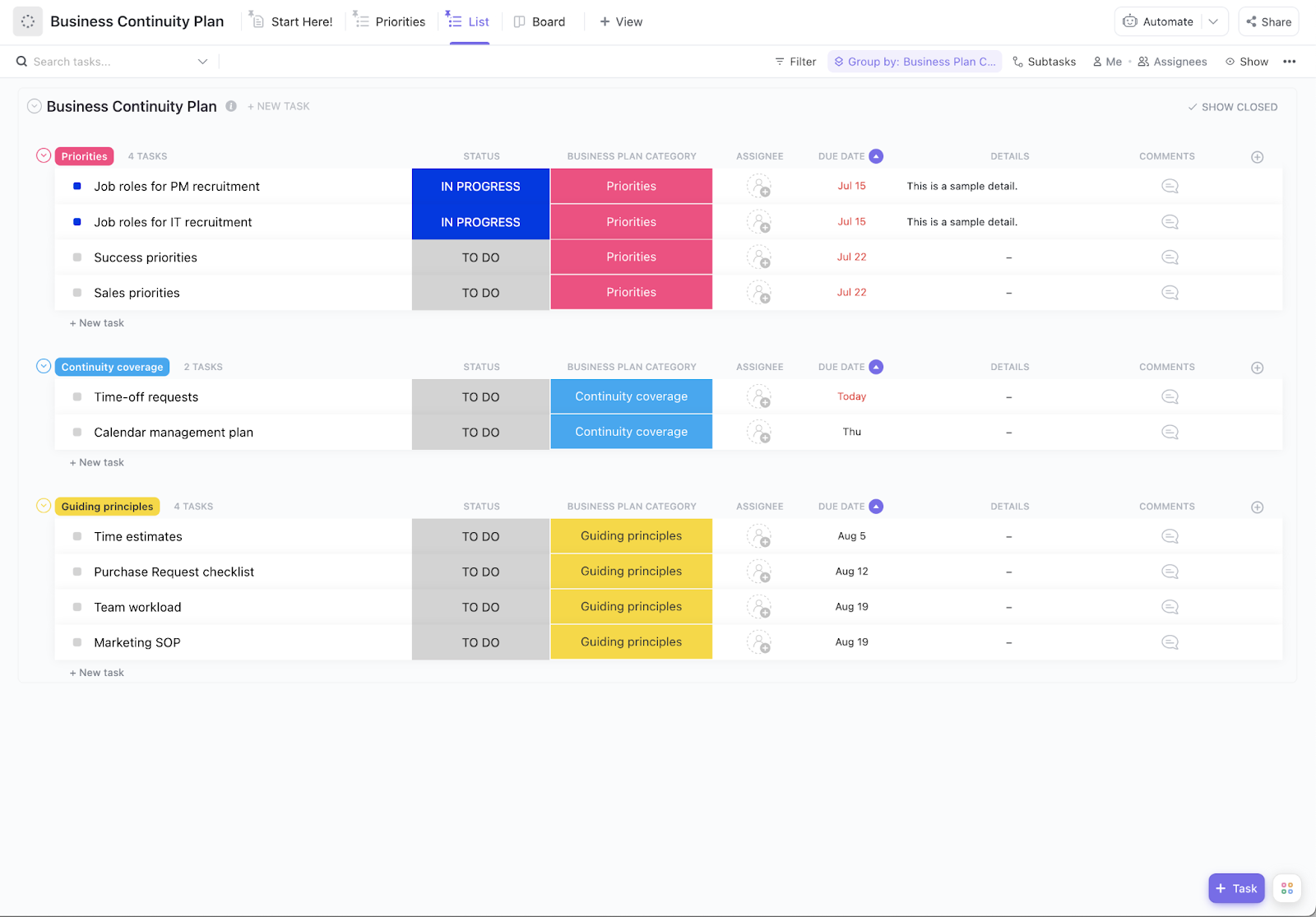
ขั้นตอนที่ 1: สร้างรายการสินทรัพย์
คุณไม่สามารถปกป้องสิ่งที่คุณไม่รู้ว่ามีอยู่ได้ เริ่มต้นด้วยการสร้างรายการสินทรัพย์ที่ระบุฮาร์ดแวร์ ซอฟต์แวร์ ที่เก็บข้อมูล และระบบที่พึ่งพาอาศัยกันทุกชิ้นในสภาพแวดล้อมของคุณ อย่าลืมรวมข้อมูลติดต่อของผู้ขาย รหัสใบอนุญาต และรายละเอียดการกำหนดค่าไว้ด้วย เพื่อความสะดวกในการอ้างอิงระหว่างการกู้คืน

เทมเพลต ClickUp ITAMรวมการจัดการเหตุการณ์ การจัดการปัญหา การจัดการการเปลี่ยนแปลง โซลูชันการจัดการสินทรัพย์อย่างง่าย และการจัดการความรู้เข้าไว้ด้วยกันเทมเพลตข้อผิดพลาดที่ทราบแล้วของ ITSMของเราช่วยให้การติดตามข้อผิดพลาดที่ทราบในระบบของคุณเป็นเรื่องง่ายสำรวจเทมเพลต ITทั้งหมดของเราทันทีที่วัตถุประสงค์ของคุณเปลี่ยนไป
ปรับแต่งกระบวนการทำงานของคุณในสไตล์ที่คุณต้องการสำหรับแต่ละขั้นตอนของ ITAM ตั้งแต่การติดตั้งและการกำหนดค่าไปจนถึงการบำรุงรักษาและการปลดระวาง
ขั้นตอนที่ 2: จัดประเภทบริการที่สำคัญ
ตอนนี้ ให้ระบุว่ามีสินทรัพย์ใดบ้างที่มีความสำคัญต่อภารกิจหลัก และสินทรัพย์ใดที่เพียงแค่มีไว้ก็ดี สร้างแผนที่การพึ่งพาบริการที่แสดงว่าระบบของคุณเชื่อมต่อและพึ่งพาซึ่งกันและกันอย่างไร ให้ความสนใจเป็นพิเศษกับบริการที่เผชิญหน้ากับลูกค้าซึ่งมีผลกระทบโดยตรงต่อรายได้หรือประสบการณ์ของผู้ใช้
🎥 ชมวิดีโอสาธิตเชิงปฏิบัติที่แสดงวิธีการสร้างแผนที่มีโครงสร้างและระดับสูงโดยใช้ฟีเจอร์อันทรงพลังของ ClickUp ตั้งแต่การตั้งเป้าหมาย การมอบหมายงาน ไปจนถึงการติดตามความคืบหน้า
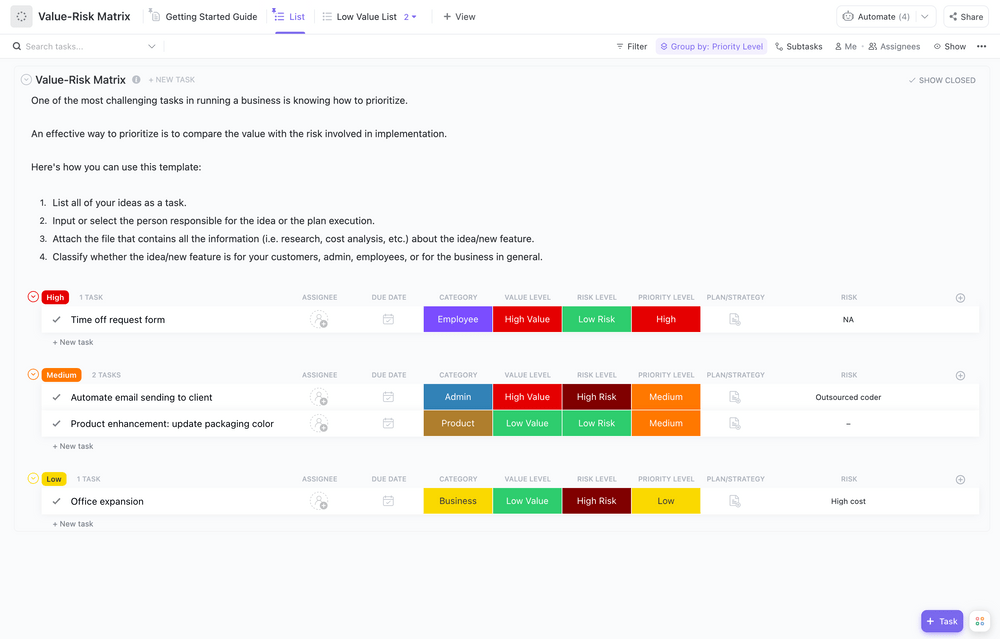
ขั้นตอนที่ 3: ประเมินความเสี่ยงและภัยคุกคาม
ประเมินความเสี่ยงและภัยคุกคามโดยการประเมินความน่าจะเป็นและผลกระทบของแต่ละประเภทของภัยคุกคามสำหรับสถานการณ์เฉพาะของคุณ ให้พิจารณาความเสี่ยงทางภูมิศาสตร์ของคุณ (คุณอยู่ในเขตแผ่นดินไหวหรือพื้นที่น้ำท่วมหรือไม่?) และภัยคุกคามที่เกี่ยวข้องกับอุตสาหกรรมของคุณ (เช่น การเปลี่ยนแปลงทางกฎหมายหรือการโจมตีทางไซเบอร์ที่มีเป้าหมาย) บันทึกทุกอย่างไว้ในทะเบียนความเสี่ยงเพื่อให้คุณสามารถติดตามได้ในระยะยาว

เทมเพลตไวท์บอร์ดการประเมินความเสี่ยงของ ClickUpสร้างมิติที่มองเห็นได้สำหรับกระบวนการประเมินความเสี่ยงของคุณ ช่วยในการประเมินความเสี่ยงและจัดหมวดหมู่ สร้างแรงบันดาลใจให้ทีมของคุณแบ่งปันข้อมูลเชิงลึกและทำงานร่วมกันในรูปแบบที่น่าสนใจและมองเห็นได้
เทมเพลตนี้ช่วยให้คุณสามารถ:
- ประเมินประเภทความเสี่ยงและผลกระทบที่อาจเกิดขึ้น
- วิเคราะห์ข้อมูลเพื่อระบุพื้นที่ที่อาจเป็นปัญหา
- กำหนดมาตรการป้องกันเพื่อลดความเสี่ยง
ด้วยคุณสมบัติที่ช่วยให้คุณสามารถวาด เขียน และเพิ่มโน้ตติดได้ แม่แบบไวท์บอร์ดการจัดการความเสี่ยงนี้เหมาะอย่างยิ่งสำหรับการประเมินความเสี่ยงของโครงการของคุณ
ขั้นตอนที่ 4: กำหนดเป้าหมาย RTO และ RPO
ทำงานร่วมกับผู้มีส่วนได้ส่วนเสียทางธุรกิจของคุณโดยตรงเพื่อกำหนดระยะเวลาที่ระบบหยุดทำงานและการสูญเสียข้อมูลที่พวกเขาสามารถยอมรับได้สำหรับแต่ละระดับของบริการที่คุณได้ระบุไว้ก่อนหน้านี้ คุณจะต้องพิจารณาความสมดุลระหว่างค่าใช้จ่ายในการกู้คืนที่รวดเร็วขึ้นกับผลกระทบต่อธุรกิจ—ไม่ใช่ทุกสิ่งที่ต้องการการกู้คืนทันทีโดยไม่มีการสูญเสียข้อมูลเลย ต้องได้รับการอนุมัติจากผู้บริหารสำหรับเป้าหมายเหล่านี้
ขั้นตอนที่ 5: กำหนดเส้นทางสำรองและเส้นทางสลับการทำงาน
เมื่อคุณได้กำหนดเป้าหมายไว้แล้ว คุณสามารถออกแบบโซลูชันทางเทคนิคของคุณได้ในตอนนี้ สร้างกลยุทธ์สำรองที่เหมาะกับ RPO ของแต่ละระบบ และวางแผนขั้นตอนการกู้คืนระบบอย่างละเอียด รวมถึงสถานที่ประมวลผลสำรองและวิธีการเข้าถึงในกรณีฉุกเฉิน ให้รวมแผนผังเครือข่ายและคู่มือการดำเนินการแบบขั้นตอนต่อขั้นตอนเพื่อให้การดำเนินการเป็นไปอย่างไม่มีข้อผิดพลาด
ขั้นตอนที่ 6: กำหนดบทบาทและการส่งต่อปัญหา
กำหนดโครงสร้างทีม DR ของคุณให้ชัดเจนพร้อมหน้าที่ความรับผิดชอบและอำนาจในการตัดสินใจ สร้างรายชื่อติดต่อที่ครอบคลุมทั้งบุคลากรหลักและสำรองสำหรับแต่ละบทบาท แม่แบบ RACI (รับผิดชอบ, รับผิดชอบ, ให้คำปรึกษา, แจ้งให้ทราบ) เป็นเครื่องมือที่ดีในการขจัดความสับสนในระหว่างเหตุการณ์ที่มีความเครียดสูง
ขั้นตอนที่ 7: จัดทำเอกสารและสื่อสารแผน
จัดทำเอกสารและสื่อสารแผนงานด้วยขั้นตอนที่ชัดเจนและเป็นลำดับขั้น ซึ่งทุกคนในทีมของคุณสามารถปฏิบัติตามได้ แม้ในสภาวะกดดัน สิ่งสำคัญคือต้องจัดเก็บเอกสารนี้ไว้ในสถานที่ที่เข้าถึงได้ง่ายและแยกออกจากโครงสร้างพื้นฐานหลักของคุณ ตรวจสอบให้แน่ใจว่าสมาชิกทุกคนในทีมทราบตำแหน่งที่แน่นอนในการค้นหาแผนงานนี้ในช่วงวิกฤต
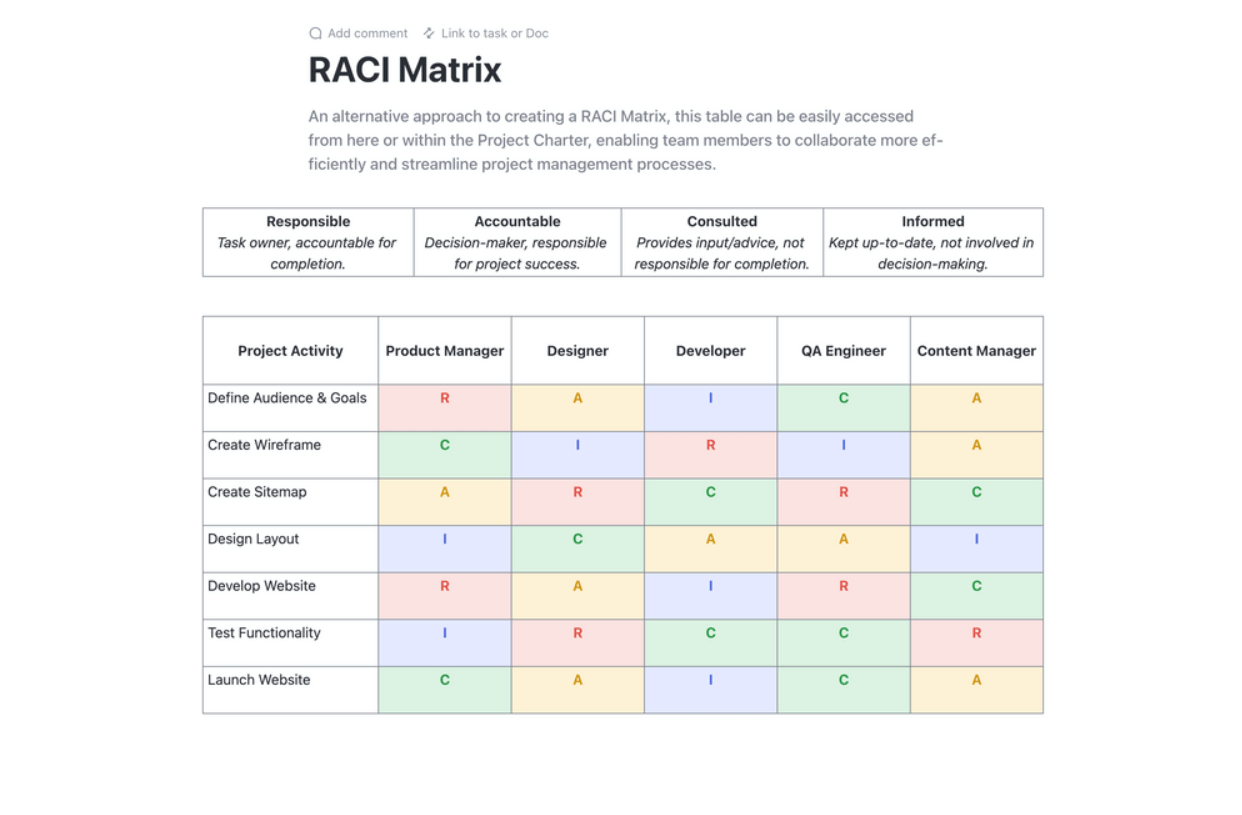
ปรับปรุงการวางแผนโครงการของคุณให้ราบรื่นด้วยเทมเพลตการวางแผน RACI ของ ClickUp เทมเพลต Doc นี้เป็นการเปลี่ยนแปลงครั้งสำคัญ มอบแผนภูมิที่ชัดเจนเพื่อกำหนดบทบาทและความรับผิดชอบของทีมที่เกี่ยวข้องกับงานโครงการ ใช้กรอบการทำงาน RACI (ผู้รับผิดชอบ, ผู้รับผิดชอบหลัก, ผู้ให้คำปรึกษา, และผู้รับทราบ) เพื่อให้ทุกคนเข้าใจตรงกัน รับประกันความรับผิดชอบและการสอดคล้องกับเป้าหมายขององค์กร
ขั้นตอนที่ 8: ทดสอบ ทบทวน และปรับปรุง
สุดท้าย กำหนดการทดสอบรายไตรมาสเพื่อตรวจสอบความถูกต้องของขั้นตอนและระบุช่องว่างที่อาจเกิดขึ้น บันทึกบทเรียนที่ได้รับจากการทดสอบแต่ละครั้งและเหตุการณ์จริงที่เกิดขึ้น และใช้ข้อมูลเหล่านี้ในการปรับปรุงแผนของคุณ สร้างระบบการติดตามการปรับปรุงอย่างเป็นระบบเพื่อให้มั่นใจว่าปัญหาที่พบได้รับการแก้ไข
🌼 คุณรู้หรือไม่: ในปี 2017 GitLabประสบปัญหาฐานข้อมูลล่มครั้งใหญ่ ระหว่างการกู้คืน พวกเขาพบว่าวิธีการสำรองข้อมูลหลายวิธีล้มเหลวโดยไม่แสดงอาการเป็นเวลาหลายวัน เหตุการณ์นี้ได้สอนบทเรียนสำคัญให้กับอุตสาหกรรมเทคโนโลยีทั้งหมด: การตรวจสอบความถูกต้องของการสำรองข้อมูลเป็นสิ่งที่ไม่สามารถต่อรองได้ การสำรองข้อมูลที่ไม่ได้รับการทดสอบไม่ถือว่าเป็นการสำรองข้อมูลที่แท้จริงเลย
🌼 คุณรู้หรือไม่: ในปี 2017 GitLabประสบปัญหาฐานข้อมูลล่มครั้งใหญ่ ระหว่างการกู้คืน พวกเขาพบว่าวิธีการสำรองข้อมูลหลายวิธีล้มเหลวโดยไม่มีสัญญาณเตือนเป็นเวลาหลายวัน เหตุการณ์นี้ได้สอนบทเรียนสำคัญให้กับอุตสาหกรรมเทคโนโลยีทั้งหมด: การตรวจสอบความถูกต้องของการสำรองข้อมูลเป็นสิ่งที่ไม่สามารถต่อรองได้ การสำรองข้อมูลที่ไม่ได้รับการทดสอบไม่ถือว่าเป็นการสำรองข้อมูลที่แท้จริงเลย
กลยุทธ์และแนวทางแก้ไขการกู้คืนจากภัยพิบัติ
ไม่ใช่ทุกองค์กรที่ต้องการแนวทาง DR แบบเดียวกัน. มาสำรวจตัวเลือกของคุณตามงบประมาณ, ความต้องการในการกู้คืน, และทรัพยากรที่มีอยู่.
วิธีการสำรองและกู้คืน
นี่คือวิธีที่ง่ายที่สุดและคุ้มค่าที่สุด. วิธีนี้เกี่ยวข้องกับการสำรองข้อมูลเป็นประจำไปยังตำแหน่งนอกสถานที่ (เช่น คลาวด์หรือศูนย์ข้อมูลสำรอง) และจากนั้นทำการกู้คืนข้อมูลด้วยตนเองเมื่อต้องการ. วิธีนี้เหมาะที่สุดสำหรับระบบที่ไม่สำคัญซึ่งสามารถทนต่อระยะเวลาการกู้คืนที่ยาวนานได้ (RTO) เนื่องจากกระบวนการกู้คืนอาจใช้เวลาหลายชั่วโมงหรืออาจนานถึงหลายวัน.
ความพร้อมใช้งานสูงและการสำรองข้อมูล
กลยุทธ์นี้มีเป้าหมายเพื่อขจัดจุดล้มเหลวเดี่ยวโดยใช้ระบบที่ทำงานพร้อมกันหลายระบบ เทคนิคต่างๆ เช่น การกระจายโหลด การจัดกลุ่มเซิร์ฟเวอร์ และการจัดเก็บข้อมูลแบบ RAID ช่วยให้มั่นใจได้ว่าหากส่วนใดส่วนหนึ่งล้มเหลว ส่วนอื่นจะเข้ามาทำงานแทนทันที แม้ว่าการตั้งค่าและการบำรุงรักษาจะมีค่าใช้จ่ายสูงกว่า แต่แนวทางนี้สามารถลดเวลาหยุดทำงานให้เหลือเพียงไม่กี่วินาทีหรือไม่กี่นาที ทำให้เหมาะอย่างยิ่งสำหรับบริการที่มีความสำคัญสูง
ตัวเลือกการจำลองและสลับระบบ
การทำซ้ำข้อมูลเกี่ยวข้องกับการคัดลอกข้อมูลในเวลาใกล้เคียงกับเรียลไทม์ไปยังไซต์สำรอง ซึ่งช่วยให้มั่นใจได้ว่าจะมีการสูญเสียข้อมูลน้อยที่สุดระหว่างเกิดภัยพิบัติ
- การจำลองข้อมูลแบบซิงโครนัส: เขียนข้อมูลไปยังทั้งไซต์หลักและไซต์รองพร้อมกัน รับประกันการสูญหายของข้อมูลเป็นศูนย์ อย่างไรก็ตาม ต้องใช้แบนด์วิดท์สูงและอาจทำให้ระบบหลักของคุณช้าลง
- การจำลองข้อมูลแบบอะซิงโครนัส: เขียนข้อมูลไปยังไซต์หลักก่อนแล้วจึงคัดลอกไปยังไซต์รองโดยมีความล่าช้าเล็กน้อย วิธีนี้มีค่าใช้จ่ายน้อยกว่าและส่งผลกระทบต่อประสิทธิภาพน้อยกว่า แต่คุณยอมรับความเสี่ยงเล็กน้อยในการสูญเสียข้อมูล
การกู้คืนจากภัยพิบัติบนคลาวด์และบริการกู้คืนจากภัยพิบัติแบบบริการ (DRaaS)
การกู้คืนจากภัยพิบัติเป็นบริการ (DRaaS) กลายเป็นตัวเลือกยอดนิยมสำหรับธุรกิจจำนวนมาก โดยเสนอการชำระเงินตามการใช้งาน การกระจายทางภูมิศาสตร์ทันที และการจัดการการกู้คืนอัตโนมัติโดยไม่จำเป็นต้องสร้างและบำรุงรักษาศูนย์ DR ทางกายภาพของคุณเอง DR บนคลาวด์ขจัดค่าใช้จ่ายด้านทุนจำนวนมากในการสร้างศูนย์ข้อมูลสำรอง ในขณะที่ให้การปรับขนาดที่รวดเร็วและความยืดหยุ่นมากกว่าวิธีการแบบศูนย์ร้อน ศูนย์อุ่น หรือศูนย์เย็นแบบดั้งเดิม
ClickUp ช่วยให้การวางแผนการกู้คืนจากภัยพิบัติด้านไอทีเป็นไปอย่างมีประสิทธิภาพได้อย่างไร
การจัดการแผนการกู้คืนระบบจากภัยพิบัติ (DR) ผ่านสเปรดชีต เอกสาร และอีเมลที่กระจัดกระจายสร้างความเสี่ยงต่อภัยพิบัติในตัวเอง
การขยายตัวของงานในลักษณะนี้ ซึ่งหมายถึงการกระจายงานไปยังเครื่องมือหลายชนิดที่ไม่เชื่อมต่อกันและไม่สามารถสื่อสารกันได้ รวมถึงการกระจายของบริบท เมื่อทีมต้องเสียเวลาหลายชั่วโมงในการค้นหาข้อมูลที่กระจัดกระจายอยู่ในแอปพลิเคชันและแพลตฟอร์มต่างๆ นำไปสู่ความสับสน ข้อมูลที่ล้าสมัย และการตอบสนองที่ล่าช้า ซึ่งทุกวินาทีมีค่า
ด้วยClickUp Converged AI Workspace—แพลตฟอร์มเดียวที่ปลอดภัยซึ่งรวมแอปงาน ข้อมูล และเวิร์กโฟลว์ทั้งหมดของคุณไว้ด้วยกัน พร้อมด้วย AI ที่เข้าใจบริบทเป็นชั้นข้อมูลอัจฉริยะ—ที่ผสานการจัดการโครงการ เอกสาร และการสื่อสารของทีมเข้าด้วยกัน หยุดการสลับแพลตฟอร์มหลายตัว และนำการวางแผนการกู้คืนระบบ การทดสอบ และการตอบสนองต่อเหตุการณ์เข้าสู่ระบบเดียวที่รวมกัน
เอกสารการกู้คืนระบบจากภัยพิบัติแบบรวมศูนย์ด้วย ClickUp Docs พร้อมความช่วยเหลือจาก AI ในตัว
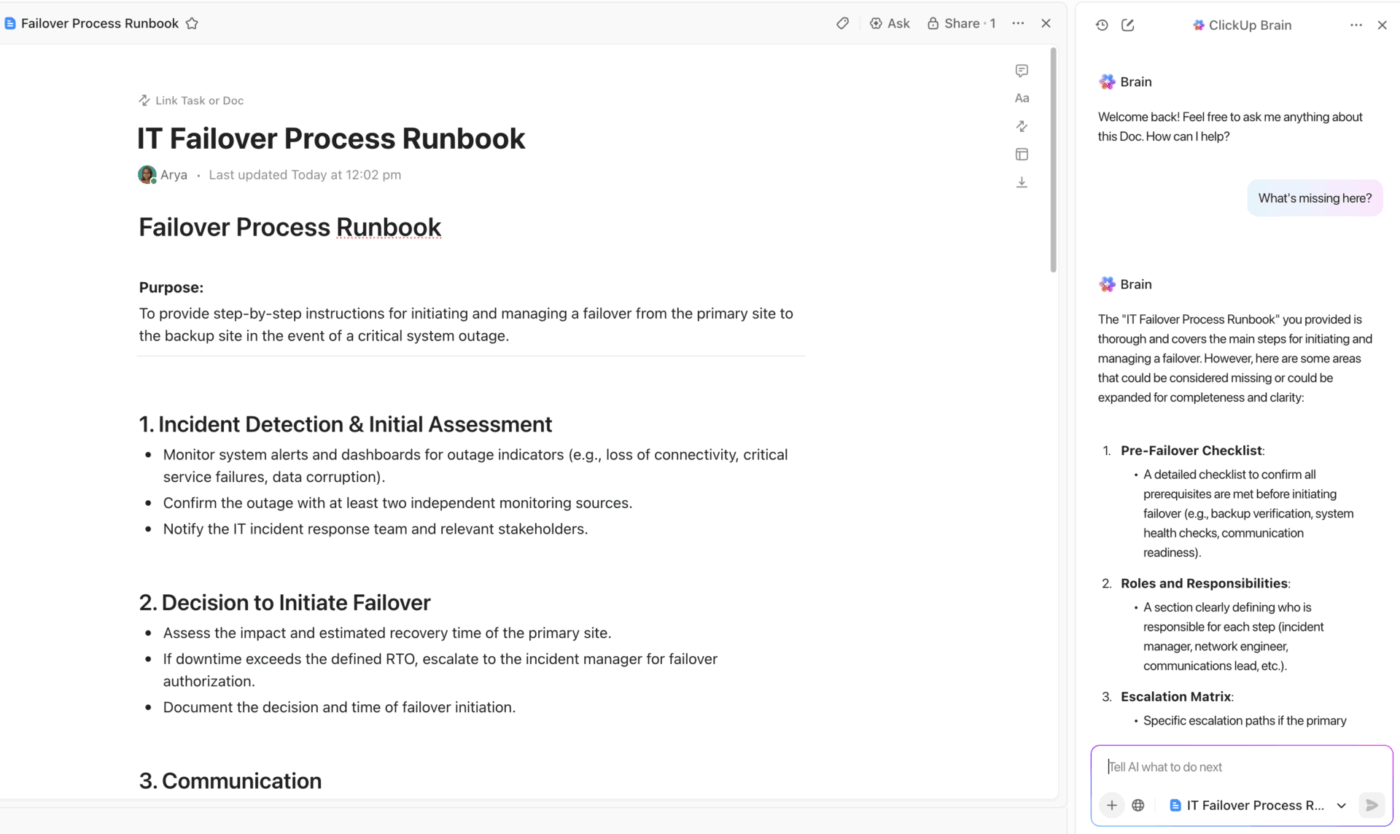
ให้ทีมของคุณมีแหล่งข้อมูลที่ถูกต้องเพียงแหล่งเดียวเสมอด้วยClickUp Docs
สร้างแผนการกู้คืนจากภัยพิบัติทั้งหมดของคุณในพื้นที่ทำงานร่วมกันที่ทุกคนสามารถมีส่วนร่วมได้แบบเรียลไทม์ระหว่างเหตุการณ์ เชื่อมโยงเอกสารกับงานและโครงการที่เกี่ยวข้องกับเหตุการณ์โดยตรงเพื่อการนำทางที่ราบรื่น และฝังแผนผังหรือคู่มือการปฏิบัติงานเพื่อให้ข้อมูลสำคัญอยู่ตรงที่คุณต้องการ
ที่ดีที่สุดคือ คุณสามารถปกป้องเอกสารของคุณเพื่อป้องกันการแก้ไขโดยไม่ได้ตั้งใจ และใช้สิทธิ์การเข้าถึง ClickUpแบบละเอียดเพื่อควบคุมว่าใครสามารถดูหรือเปลี่ยนแปลงขั้นตอนการกู้คืนข้อมูลที่ละเอียดอ่อนได้ ทุกการเปลี่ยนแปลงจะถูกติดตามในประวัติของเอกสาร ทำให้คุณมีเส้นทางการตรวจสอบที่สมบูรณ์
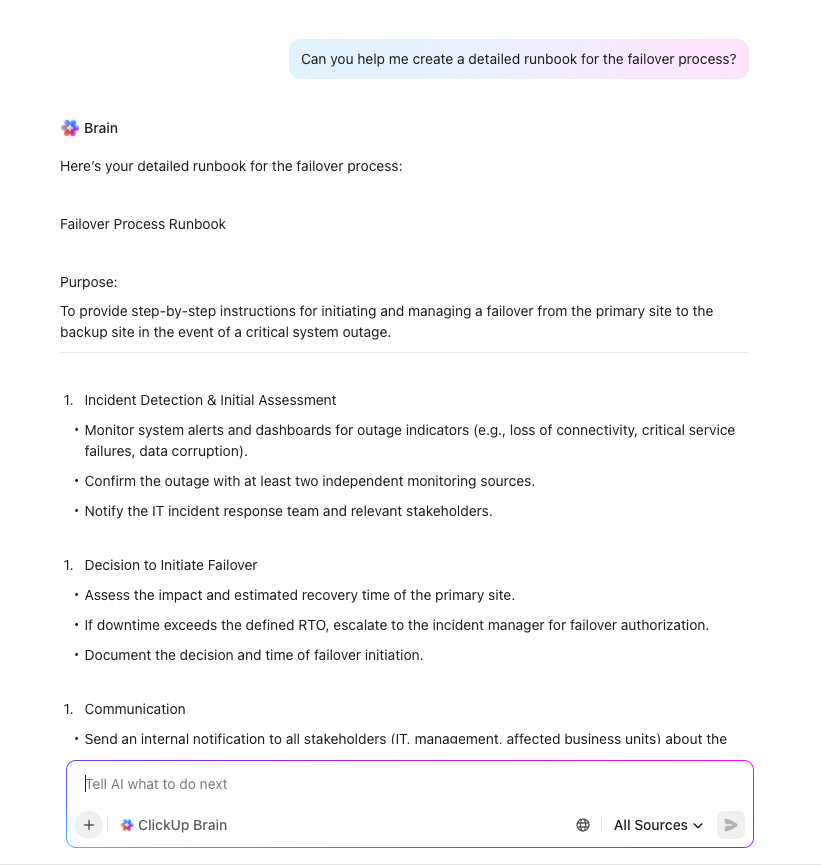
การสร้างแผนด้วยพลัง AI ด้วย ClickUp Brain
เร่งการวางแผนการกู้คืนจากภัยพิบัติและกำจัดช่องว่างที่สำคัญด้วยClickUp Brain— ผู้ช่วย AI ที่เข้าใจบริบทของคุณและเข้าใจพื้นที่ทำงานทั้งหมดของคุณ ไม่เหมือนกับเครื่องมือ AI ทั่วไป ClickUp Brain ใช้ประโยชน์จากงาน เอกสาร และกระบวนการทำงานจริงขององค์กรของคุณเพื่อมอบการสนับสนุนที่แม่นยำและนำไปปฏิบัติได้สำหรับโครงการ DR
เพียงแค่แจ้ง ClickUp Brain ด้วยคำขอ เช่น "สร้างรายการตรวจสอบการกู้คืนจากภัยพิบัติสำหรับแพลตฟอร์มอีคอมเมิร์ซของเรา" แล้วรับเทมเพลตที่ครอบคลุมและปรับแต่งให้เหมาะสมกับระบบ กระบวนการ และความต้องการด้านการปฏิบัติตามข้อกำหนดของคุณได้ทันที มันสามารถช่วยคุณในเรื่อง:
- การรับรู้บริบท: ClickUp Brain สามารถเข้าถึงโครงสร้าง เนื้อหา และสิทธิ์การเข้าถึงของพื้นที่ทำงานของคุณได้ สามารถอ้างอิงถึงงาน เอกสาร ความคิดเห็น และแม้แต่แอปที่เชื่อมต่ออยู่ เพื่อมอบคำตอบและการดำเนินการที่ปรับให้เหมาะสมกับงานจริงของคุณ ไม่ใช่แค่คำแนะนำทั่วไป
- การแก้ไขปัญหาและคำแนะนำ: แก้ไขปัญหาได้ทันที รับคำแนะนำทีละขั้นตอน หรือสอบถามแนวทางปฏิบัติที่ดีที่สุดสำหรับฟีเจอร์ใดก็ได้ของ ClickUp Brain สามารถแนะนำคุณผ่านกระบวนการที่ซับซ้อน อัตโนมัติงานที่ทำซ้ำ และช่วยแก้ไขปัญหาที่ติดขัด
- การอัตโนมัติและการเร่งกระบวนการทำงาน: ใช้ตัวแทน AI ที่สร้างไว้ล่วงหน้าหรือปรับแต่งเองเพื่อทำงานอัตโนมัติในกระบวนการหลายขั้นตอน, คัดกรองคำขอ, หรือจัดการงานที่เกิดขึ้นซ้ำ—ประหยัดเวลาได้หลายชั่วโมงทุกสัปดาห์
- ค้นหาอย่างล้ำลึก: ค้นหาข้อมูลที่ซ่อนอยู่ทุกที่ในพื้นที่ทำงานของคุณ ไม่ว่าจะเป็นงาน เอกสาร หรือเครื่องมือที่เชื่อมต่อ แม้จะเป็นข้อมูลเก่าหลายปีหรือยากต่อการค้นหาด้วยระบบค้นหาทั่วไป
- สรุปและอัปเดตแบบเรียลไทม์: สร้างการอัปเดตโครงการ สรุปการประชุม หรือรายงานความคืบหน้าได้ทันที โดยดึงข้อมูลจากพื้นที่ทำงานแบบเรียลไทม์
- การทำให้เอกสารทางเทคนิคง่ายขึ้น: แปลงเอกสารทางเทคนิคที่ซับซ้อนให้กลายเป็นขั้นตอนหรือรายการตรวจสอบที่ชัดเจนและสามารถนำไปปฏิบัติได้ ซึ่งทีมของคุณสามารถปฏิบัติตามได้แม้ภายใต้ความกดดัน
- ปัญญาประดิษฐ์หลายรูปแบบ: เลือกจากโมเดล AI ชั้นนำ (OpenAI GPT-4.1, GPT-5, Claude, Gemini และอื่น ๆ) เพื่อผลลัพธ์ที่ดีที่สุดในทุกงาน—ไม่ต้องสมัครสมาชิกแยกต่างหาก
- ปลอดภัยและตระหนักถึงสิทธิ์การเข้าถึง: Brain จะเข้าถึงข้อมูลที่คุณมีสิทธิ์ในการดูเท่านั้น โดยรักษามาตรฐานความเป็นส่วนตัวและการปฏิบัติตามข้อกำหนดอย่างเคร่งครัด
- อินเทอร์เฟซการสนทนา: ใช้ @brain ในความคิดเห็นหรือแชทเพื่อรับข้อมูลเชิงลึกตามบริบท ร่างคำตอบ หรือเรียกใช้การทำงานอัตโนมัติโดยไม่ต้องออกจากขั้นตอนการทำงานของคุณ
- คำแนะนำที่กำหนดเอง & กระบวนการทำงานที่บันทึกไว้: บันทึกและนำคำแนะนำกลับมาใช้ใหม่สำหรับความต้องการที่เกิดขึ้นซ้ำ เพื่อให้เกิดความสม่ำเสมอและประหยัดเวลาในทีมของคุณ
💡เคล็ดลับจากผู้เชี่ยวชาญ: อย่าพลาดบทเรียนจากการประชุมทบทวนเหตุการณ์ของคุณโดยเด็ดขาด ด้วยการบันทึกทุกรายละเอียดด้วยClickUp AI Notetaker ซึ่งสามารถเข้าร่วมการประชุมเสมือนจริงของคุณ บันทึกการสนทนาทั้งหมด และสร้างรายการสิ่งที่ต้องดำเนินการจากบทเรียนที่ได้เรียนรู้โดยอัตโนมัติ สิ่งนี้จะสร้างประวัติเหตุการณ์ที่สามารถค้นหาได้ เพื่อให้คุณสามารถอ้างอิงเหตุการณ์ที่ผ่านมาและการแก้ไขได้อย่างรวดเร็ว

กระบวนการทำงานสำรองข้อมูลอัตโนมัติด้วย ClickUp Automations
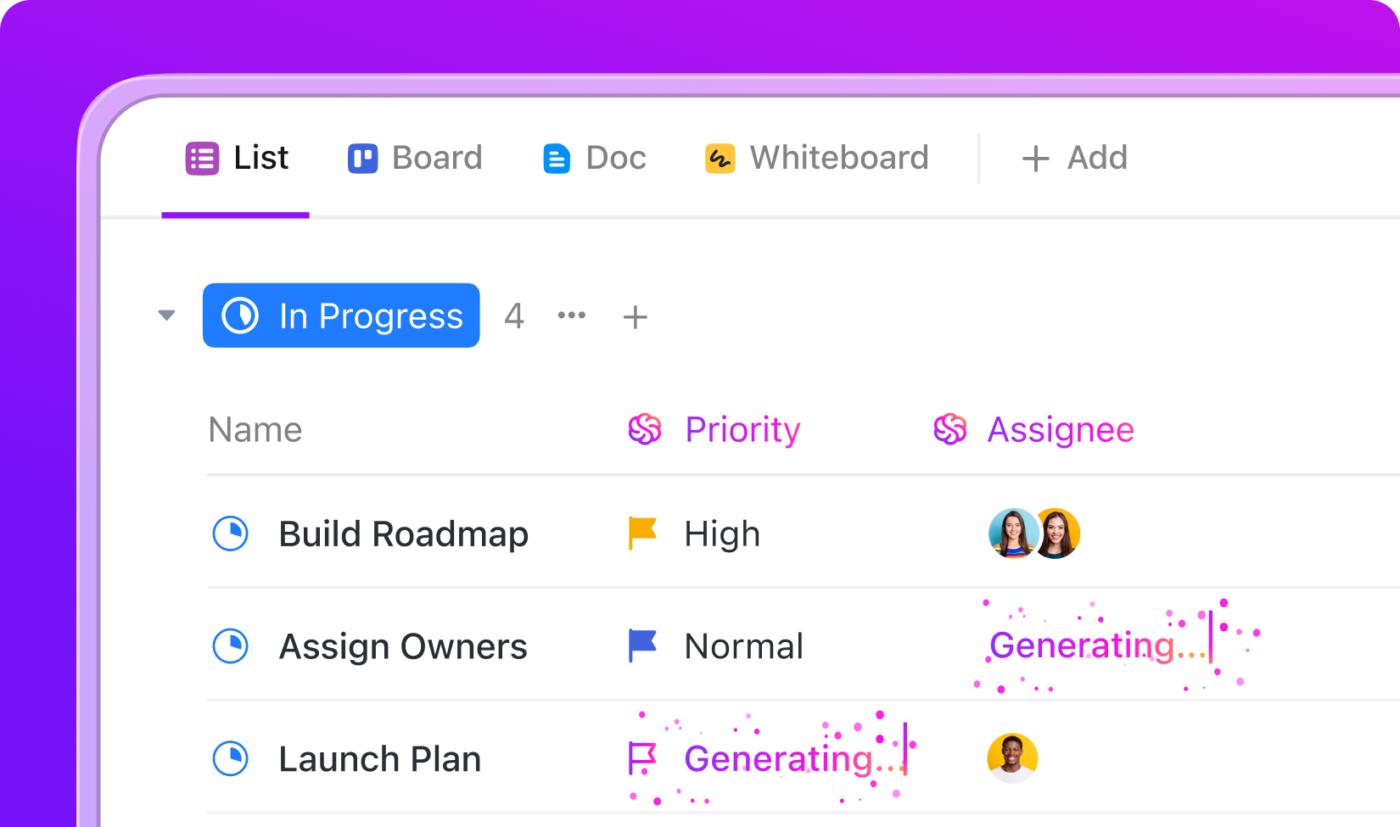
จินตนาการว่าทีมของคุณกำลังเผชิญกับปัญหาการหยุดชะงักอย่างกะทันหัน—ทุกวินาทีมีค่า และคุณไม่สามารถพลาดขั้นตอนใด ๆ ได้เลย ด้วยClickUp AI AgentsและAutomations คุณไม่ต้องรีบวิ่งวุ่นหรือพึ่งพาความจำอีกต่อไป ทันทีที่มีการประกาศเหตุการณ์ ClickUp AI จะเริ่มทำงานทันที นำทางทีมของคุณ และจัดการกับงานที่ซ้ำซากเพื่อให้คุณสามารถมุ่งเน้นไปที่การแก้ปัญหาได้
นี่คือวิธีการทำงานในสถานการณ์จริง:
- เมื่อมีผู้ใดทำเครื่องหมายงานว่า "ประกาศเป็นเหตุการณ์" ClickUp Agent จะสร้างรายการตรวจสอบขั้นตอนการตอบสนองโดยอัตโนมัติ มอบหมายให้กับบุคคลที่เหมาะสม และเริ่มจับเวลาเพื่อติดตามระยะเวลาที่ใช้ในการกู้คืน
- หากเหตุการณ์ถูกทำเครื่องหมายว่า "วิกฤต" เจ้าหน้าที่จะสามารถส่งอีเมลแจ้งเตือนไปยังทีมผู้นำของคุณได้ทันที และตั้งค่าห้องแชทพิเศษ—"ห้องสงคราม" ของคุณ—เพื่อให้ทุกคนสามารถสื่อสารได้ในที่เดียว
- ระบบ AI สามารถดึงรายงานเหตุการณ์ที่ผ่านมาและเอกสารที่เกี่ยวข้องขึ้นมาได้ ทำให้ทีมของคุณมีทุกสิ่งที่ต้องการอยู่ในปลายนิ้ว
ดูขั้นตอนการทำงานได้ที่นี่:
ด้วย ClickUp AI Agents คุณจะได้รับเพื่อนร่วมงานดิจิทัลที่เชื่อถือได้ซึ่งช่วยให้ทีมของคุณทำงานได้อย่างสงบ เป็นระเบียบ และมีประสิทธิภาพ แม้ในยามที่เผชิญกับแรงกดดัน
การติดตามแบบเรียลไทม์ด้วยแดชบอร์ด ClickUp
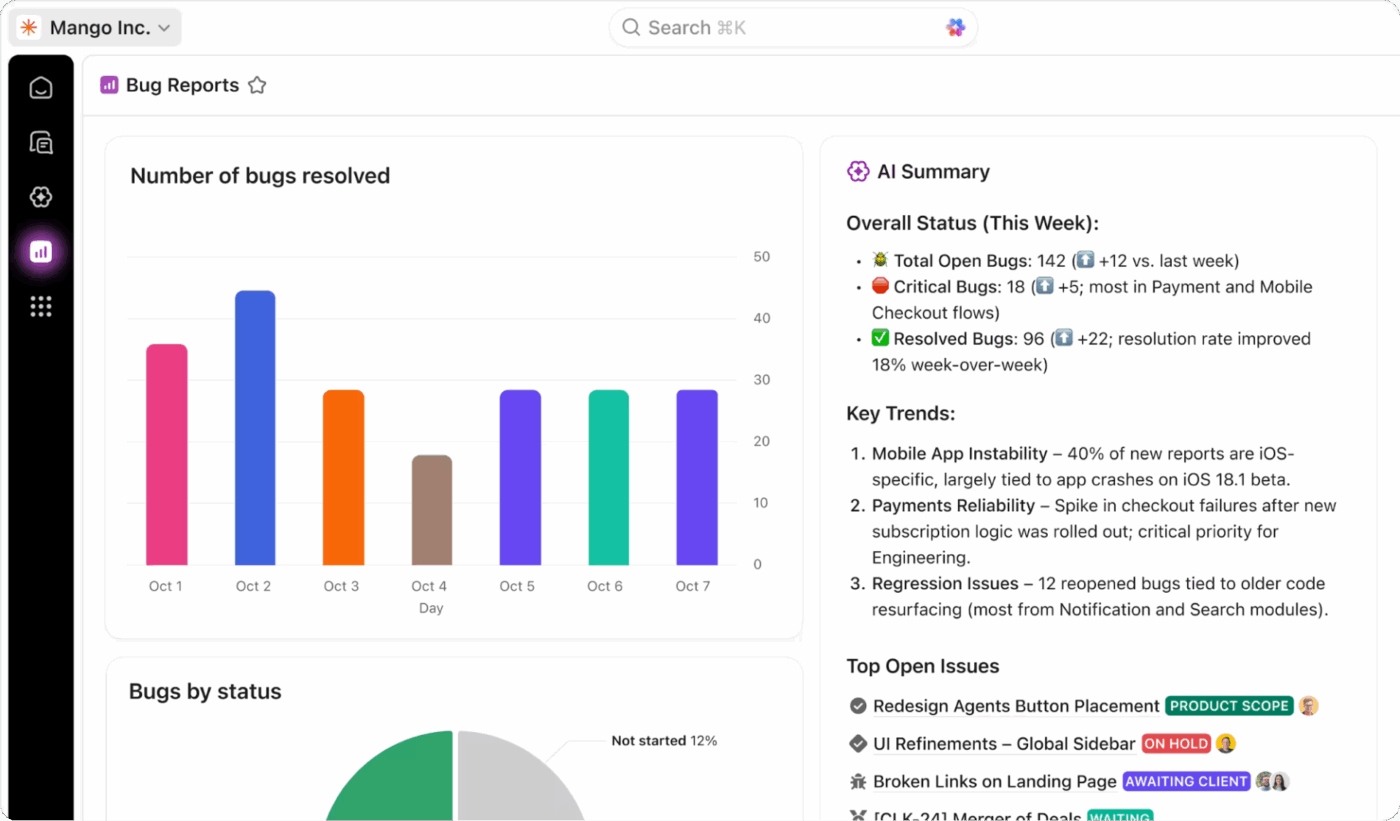
รับการมองเห็นที่ครบถ้วนเกี่ยวกับสุขภาพของโปรแกรม DR ของคุณโดยการติดตามทุกสิ่งทุกอย่างแบบเรียลไทม์ด้วยClickUp Dashboards คุณสามารถสร้างวิดเจ็ตเพื่อติดตามประสิทธิภาพของ RTO และ RPO ของคุณระหว่างการทดสอบ ติดตามอัตราการเสร็จสิ้นการทดสอบ และดูแนวโน้มของเหตุการณ์ตามเวลา
เพิ่มฟิลด์ที่กำหนดเองของ ClickUpลงในรายการงานของคุณเพื่อติดตามความสำคัญต่อระบบ สถานะการกู้คืน และผลการทดสอบ จากนั้นดึงข้อมูลทั้งหมดมาไว้ในมุมมองระดับสูงเพียงที่เดียว แดชบอร์ดเหล่านี้จะช่วยให้คุณได้รับรายงานที่พร้อมนำเสนอแก่ผู้บริหาร ซึ่งอัปเดตข้อมูลแบบเรียลไทม์จากกิจกรรมการทดสอบและการตอบสนองต่อเหตุการณ์ของทีมคุณอยู่เสมอ
📖 อ่านเพิ่มเติม: วิธีสร้างรายการตรวจสอบการประเมินความเสี่ยง
สร้างแผนการรับมือภัยพิบัติของคุณวันนี้
ทุกวันที่คุณดำเนินงานโดยไม่มีแผนการกู้คืนระบบ (DR) คือการเดิมพันที่คุณไม่สามารถเสียได้. ภัยพิบัติไม่อาจหลีกเลี่ยงได้—ไม่ว่าจะเกิดจากธรรมชาติ, ความล้มเหลวทางเทคโนโลยี, หรือความผิดพลาดของมนุษย์—แต่การเตรียมตัวของคุณคือสิ่งที่กำหนดว่ามันจะกลายเป็นความไม่สะดวกเล็กน้อยหรือภัยพิบัติใหญ่หลวง.
แผนการกู้คืนระบบที่ครอบคลุมจำเป็นต้องมีความเข้าใจในความเสี่ยงของคุณ การจัดทำเอกสารขั้นตอนที่ชัดเจน และการทดสอบอย่างสม่ำเสมอ เครื่องมือที่เหมาะสมช่วยให้กระบวนการนี้สามารถจัดการได้โดยการขจัดความวุ่นวายของเอกสารที่กระจัดกระจายและกระบวนการทำงานด้วยมือ
แม้แผนการรับมือเบื้องต้นก็ดีกว่าไม่มีอะไรเลยเมื่อเกิดภัยพิบัติ การทดสอบและปรับปรุงอย่างสม่ำเสมอจะเปลี่ยนแผนการกู้คืนระบบของคุณจากเอกสารที่เก่าเก็บให้กลายเป็นระบบที่มีชีวิตชีวาซึ่งสามารถปกป้องธุรกิจของคุณได้จริง
ก้าวแรกของคุณคือการเริ่มต้นสร้างแผนการกู้คืนระบบของคุณด้วย ClickUp วันนี้.เริ่มต้นได้ฟรีกับ ClickUpและนำการวางแผนการกู้คืนระบบ, เอกสาร, และการตอบสนองต่อเหตุการณ์ของคุณมาไว้ในแพลตฟอร์มเดียวที่รวมทุกอย่างไว้ด้วยกัน. ✨
คำถามที่พบบ่อย
คุณควรทบทวนแผนการกู้คืนระบบ (DR) ของคุณอย่างน้อยปีละสี่ครั้ง และปรับปรุงทันทีหลังจากการเปลี่ยนแปลงโครงสร้างพื้นฐานที่สำคัญหรือเหตุการณ์จริงที่เกิดขึ้น องค์กรส่วนใหญ่จะทำการปรับปรุงครั้งใหญ่และละเอียดถี่ถ้วนเป็นประจำทุกปี เพื่อนำบทเรียนที่ได้รับมาปรับใช้และรองรับเทคโนโลยีใหม่ๆ
ทีมไอที ทีมความปลอดภัย และผู้วางแผนความต่อเนื่องทางธุรกิจมักเป็นผู้นำในการวางแผนและทดสอบการกู้คืนระบบจากภัยพิบัติ (DR) อย่างไรก็ตาม พวกเขาต้องการข้อมูลที่สำคัญจากผู้นำการปฏิบัติการและผู้นำหน่วยธุรกิจเพื่อให้แน่ใจว่าแผนดังกล่าวสอดคล้องกับความต้องการและความ 우선ของธุรกิจในโลกจริง
ใช้เครื่องจับเวลาและบันทึกเวลาอย่างชัดเจนเพื่อวัดเวลาการฟื้นตัวที่แท้จริงเทียบกับเป้าหมายที่กำหนดไว้ในแต่ละการทดสอบ การบันทึกช่องว่างระหว่างเป้าหมายและประสิทธิภาพจริงในรายงานการทดสอบเป็นสิ่งสำคัญอย่างยิ่ง เพื่อเป็นแนวทางในการปรับปรุงในอนาคต
แพลตฟอร์มการจัดการโครงการเช่น ClickUp เป็นตัวเลือกที่เหมาะสำหรับการรวมเอกสารไว้ในที่เดียว, การทำงานอัตโนมัติ, และการติดตามตัวชี้วัดสำหรับโปรแกรม DR ของคุณทั้งหมด. คุณสามารถนำไปใช้ร่วมกับเครื่องมือ DR ที่เฉพาะทางซึ่งจัดการกับด้านเทคนิคของการจำลองข้อมูลและการเปลี่ยนระบบในกรณีฉุกเฉินได้.