
IT-katastrofer kan inträffa utan förvarning.
Från serverkrascher till cyberattacker – utan en gedigen återställningsplan kan ditt företag drabbas av timmar av driftstopp, förlorade data och allvarliga ekonomiska skador, där 54 % av allvarliga driftstopp kostar över 100 000 US-dollar.
Denna blogg guidar dig genom skapandet av en omfattande IT-katastrofåterställningsplan som skyddar dina system, definierar tydliga återställningsmål och säkerställer att ditt team vet exakt vad de ska göra när något går fel.
Vad är en IT-katastrofåterställningsplan?
Om dina servrar kraschade just nu, skulle ditt team veta exakt vad de skulle göra? 🛠️
En IT-katastrofåterställningsplan (DR) är din dokumenterade strategi för att återställa IT-system och data efter eventuella störningar – från naturkatastrofer till cyberattacker. Det är i huvudsak din handbok för att få tekniken online igen när något går fel.
💡 DR vs. affärskontinuitet
Katastrofåterställning (DR) fokuserar specifikt på att återställa din IT-infrastruktur och data. Affärskontinuitet (BC) är bredare och syftar till att hålla hela din verksamhet igång under och efter en kris, även om IT-systemen är nere. Tänk på DR som en viktig del av din övergripande BC-strategi.
💡 DR vs. affärskontinuitet
Katastrofåterställning (DR) fokuserar specifikt på att återställa din IT-infrastruktur och data. Affärskontinuitet (BC) är bredare och syftar till att hålla hela din verksamhet igång under och efter en kris, även om IT-systemen är nere. Tänk på DR som en viktig del av din övergripande BC-strategi.
Din katastrofåterställningsplan är viktig eftersom driftstopp kostar mer än bara pengar. Varje minut som dina system är offline kan undergräva kundernas förtroende, störa verksamheten och till och med leda till böter för bristande efterlevnad. En omfattande katastrofåterställningsplan är din väg till resiliens.
En bra plan omfattar:
- Procedurer för säkerhetskopiering av data: Hur och var du lagrar kopior av viktig information så att du kan återställa den.
- Steg för systemåterställning: Den exakta sekvensen för att återställa tjänsterna i rätt ordning
- Teamets ansvar: Vem gör vad under en incident för att undvika förvirring?
- Kommunikationsprotokoll: Hur du håller intressenterna uppdaterade, från ditt team till dina kunder.
- Återställningsmål: Dina specifika mål för hur snabbt systemen måste återställas och hur mycket dataförlust som är acceptabelt.
Vanliga IT-katastrofscenarier och konsekvenser
Katastrofer är inte bara något som händer i Hollywoodfilmer, utan något som drabbar företag varje dag. Genom att förstå vad du skyddar dig mot kan du bygga upp ett mycket starkare försvar.
Naturkatastrofer och fysiska skador
Händelser som översvämningar, bränder, jordbävningar och större strömavbrott kan förstöra hela datacenter på några minuter. När ett datacenter i Nashville drabbades av en stor översvämning förlorade vissa företag flera veckors data och stod inför månader av återställningsarbete. Det bästa skyddet mot detta är geografisk redundans, vilket innebär att man sprider sin infrastruktur över flera fysiska platser så att en enda händelse inte kan slå ut allt.
Cyberattacker och dataintrång
Ransomware, distribuerade överbelastningsattacker (DDoS) och dataintrång skiljer sig från fysiska katastrofer. De är ofta svårare att upptäcka, kan spridas tyst genom anslutna system och riktar sig ofta även mot dina säkerhetskopieringssystem, vilket gör återställningen särskilt utmanande. Frekvensen och sofistikationen hos dessa cyberattacker fortsätter att öka inom alla branscher, och ransomware förekommer nu i 44 % av alla bekräftade intrång, vilket gör dem till ett av de största hoten.
Hårdvarufel och dataförlust
Ibland går även de mest beprövade och pålitliga säkerhetskopieringssystemen sönder. Serverkrascher, lagringsfel och fel på nätverksutrustning kan inträffa utan förvarning. Även om du har redundanta (säkerhetskopierings-)system kan de ändå sluta fungera samtidigt om de delar gemensamma komponenter eller strömkällor, vilket skapar en enda felpunkt.
👀 Visste du att: Under oktober 2025 drabbades AWS av ett större avbrott när en bugg i det interna DNS-hanteringssystemet för Amazon DynamoDB orsakade att domännamnsupplösningen misslyckades i datacenterregionen US-EAST-1. Denna ”lilla” tekniska defekt utlöste ett kedjefel i dussintals AWS-tjänster och slog ut hundratals populära appar och plattformar globalt – från meddelande- och sociala appar till banker, spelsajter och mycket mer. För många människor gjorde avbrottet att stora delar av internet tillfälligt ”försvann”, vilket tydliggjorde hur sårbar vår digitala infrastruktur är när så mycket är beroende av ett fåtal molnleverantörer.
Programvarufel och avbrott i tjänster
En skadad databas, en misslyckad programuppdatering eller ett enkelt konfigurationsfel kan slå ut hela plattformar. Du kanske märker att en felkonfigurerad kodrad kan sprida sig genom anslutna system och orsaka ett omfattande avbrott med stor räckvidd. Korrekt förändringshantering och dedikerade testmiljöer är dina bästa vänner när det gäller att minimera dessa risker.
Mänskliga fel och felkonfigurationer
Oavsiktliga raderingar, felaktiga konfigurationer och obehöriga ändringar är fortfarande några av de vanligaste orsakerna till IT-avbrott. Ett enda felaktigt kommando eller en raderad fil kan orsaka timmar av driftstopp och försämrad service. Utbildning och åtkomstkontroller hjälper, men de kan inte helt eliminera mänskliga misstag.
📮ClickUp Insight: 92 % av arbetstagarna använder inkonsekventa metoder för att spåra åtgärdspunkter, vilket resulterar i missade beslut och försenad genomförande.
Oavsett om du skickar uppföljningsmeddelanden eller använder kalkylblad är processen ofta splittrad och ineffektiv. Med ClickUps funktioner för uppgiftshantering behöver du aldrig oroa dig för detta. Skapa uppgifter från chatt, ClickUp-uppgiftskommentarer, dokument och e-postmeddelanden med ett enda klick!
Viktiga komponenter i en IT-katastrofåterställningsplan
En gedigen katastrofåterställningsplan är din kompletta handbok för att komma tillbaka online. Var och en av dessa komponenter bygger på de andra för att skapa ett omfattande skydd för ditt företag.
Riskbedömning och prioritering
Först måste du veta vad du har att göra med. En riskbedömning är processen att identifiera dina sårbarheter och utvärdera sannolikheten och effekten av varje potentiellt hot. Du kan organisera detta i en riskmatris för att se vilka hot som är mest allvarliga.
Din utvärdering bör omfatta:
- Kritiska system: Vad som absolut måste fortsätta att fungera för att ditt företag ska kunna bedriva sin verksamhet
- Datakänslighet: Vilken information behöver högsta skyddsnivå (t.ex. kunddata)?
- Beroenden: Vilka andra system eller processer slutar fungera när ett system går ner?
Analys av affärspåverkan och kritikalitet
Ta sedan reda på den verkliga kostnaden för driftstopp. En affärspåverkansanalys (BIA) hjälper dig att fastställa den finansiella och operativa påverkan av ett driftstopp för varje system. Detta gör att du kan klassificera dina system i kritikalitetsnivåer för att prioritera dina återställningsinsatser.
| Kritiskt | Mindre än en timme | Betalningshantering, kunddatabaser |
| Hög | En till fyra timmar | E-post, interna kommunikationsverktyg |
| Medium | Fyra till 24 timmar | Utvecklingsmiljöer, rapporteringsverktyg |
| Låg | 24+ timmar | Arkivsystem, testservrar som inte används för produktion |
RTO- och RPO-mål
Dessa två akronymer är kärnan i din återställningsstrategi.
- Återställningstidsmål (RTO): Detta är den maximala tid som ett system får vara nere. Det svarar på frågan: ”Hur snabbt behöver vi få detta online igen?”
- Återställningsmål (RPO): Detta är den maximala mängd data du har råd att förlora, mätt i tid. Det svarar på frågan: ”Hur mycket data kan vi förlora utan att det orsakar större skada?”
Till exempel kan ditt interna e-postsystem ha en RTO på fyra timmar, men din kundinriktade e-handelsdatabas kan ha en RPO på bara 15 minuter, vilket innebär att du inte kan förlora mer än 15 minuters transaktionsdata.
Plan för säkerhetskopiering och återställning av data
Din säkerhetskopieringsplan är ditt ultimata säkerhetsnät. En vanlig bästa praxis är 3-2-1-regeln: ha minst tre kopior av dina viktiga data, lagra dem på två olika typer av media och förvara en av kopiorna utanför kontoret.
Du kan också välja mellan olika typer av säkerhetskopiering:
- Fullständiga säkerhetskopior: En komplett kopia av all data, vanligtvis utförd varje vecka eller månad.
- Inkrementella säkerhetskopior: Säkerhetskopierar endast ändringar som gjorts sedan den senaste säkerhetskopian av något slag.
- Differentiella säkerhetskopior: Säkerhetskopierar alla ändringar som gjorts sedan den senaste fullständiga säkerhetskopieringen.
Det viktigaste är att du testar din återställningsprocess för säkerhetskopior regelbundet. En otestad säkerhetskopia är bara en förhoppning, inte en plan.
💟 Bonus: Fånga upp viktiga detaljer under stressiga incidenter med hjälp av ClickUp Brain MAX:s talk-to-text-funktion, så att du aldrig missar viktig information även när det inte är praktiskt att skriva. Tala bara in dina observationer och låt AI:n sköta dokumentationen.
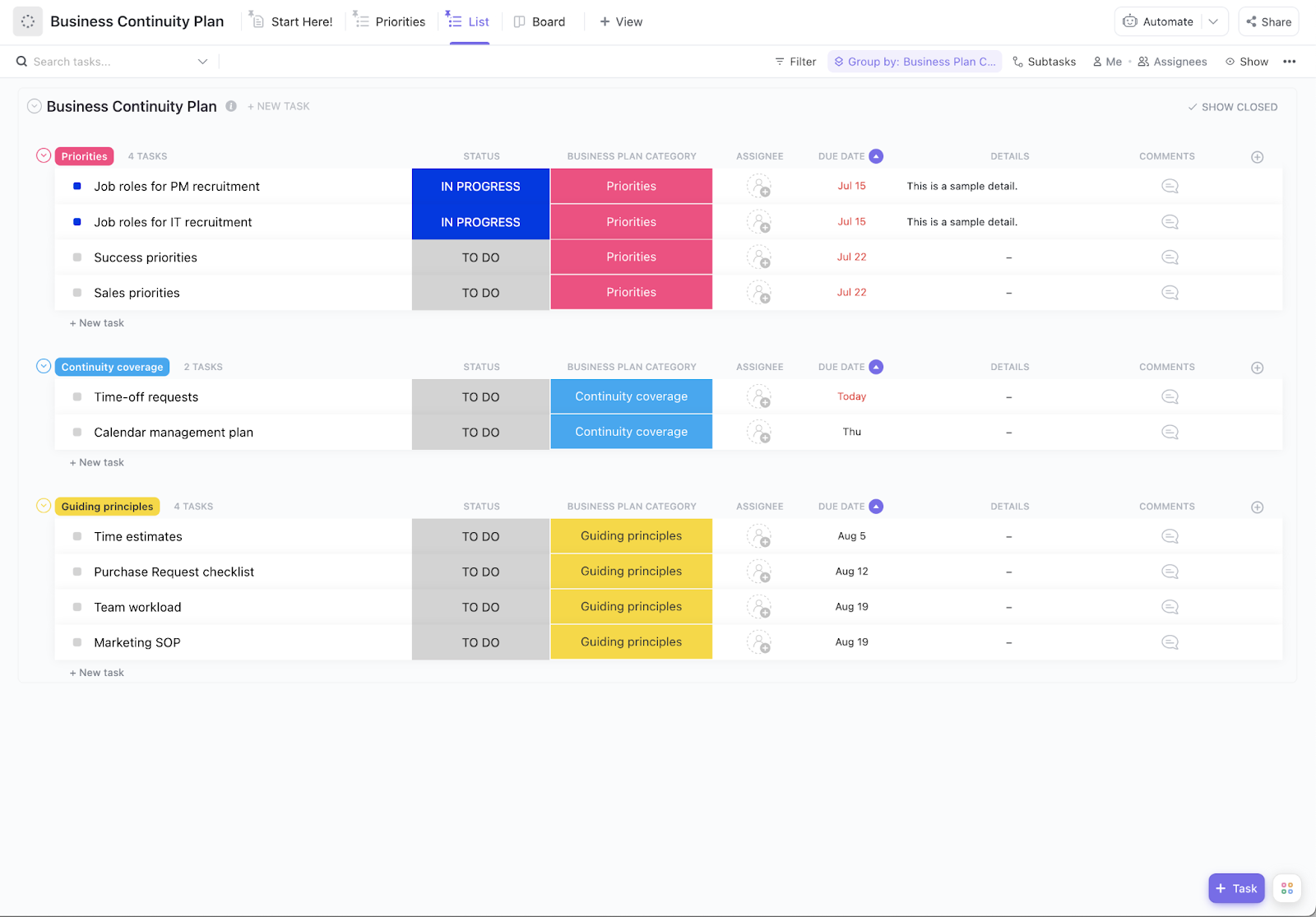
Kommunikationsplan och uppdateringar för intressenter
När en katastrof inträffar är en tydlig kommunikationsplan A och O. Din plan måste definiera meddelandekedjor, hur ofta du kommer att ge uppdateringar och vilka kanaler du kommer att använda för varje typ av incident.
Olika grupper behöver olika information:
- Interna team: Behöver tekniska detaljer och specifika åtgärdspunkter
- Kunder: Behöver veta servicestatus och när du förväntar dig att problemet ska vara löst.
- Leverantörer: Kan behöva anlitas för support eller eskaleringar.
- Tillsynsmyndigheter: Kan kräva formella anmälningar beroende på din bransch.
Verktyg som denna färdiga mall för kommunikationsplan från ClickUp kan hjälpa dig att agera snabbare med ett fastställt protokoll under en kris.

Test- och utbildningsprogram
En plan som aldrig testas är en plan som kommer att misslyckas. Regelbundna tester avslöjar luckor och svagheter innan en verklig katastrof inträffar.
Planera olika typer av tester under året:
- Tabletop-övningar: Ditt team går igenom ett katastrofscenario på papper för att kontrollera planens logik.
- Partiella failovers: Du testar återställningen av specifika, icke-kritiska komponenter eller tjänster.
- Fullständiga DR-tester: Du utför en fullständig failover till dina backup-system (det ultimata testet).
Efter varje test ska du uppdatera din dokumentation och omedelbart utbilda nya teammedlemmar i procedurerna.
Steg för att skapa en IT-katastrofåterställningsplan
Att skapa en DR-plan behöver inte vara överväldigande.
Så här kan du ta itu med det steg för steg. 🙌
Steg 1: Skapa en inventering av tillgångar
Du kan inte skydda det du inte vet att du har. Börja med att skapa en tillgångsförteckning som listar all hårdvara, mjukvara, datalagring och systemberoenden i din miljö. Se till att inkludera leverantörskontakter, licensnycklar och konfigurationsdetaljer för snabb referens under en återställning.

ClickUp ITAM-mallen kombinerar incidenthantering, problemhantering, förändringshantering, enkla lösningar för tillgångshantering och kunskapshantering. Vår ITSM-mall för kända fel förenklar hur du spårar kända fel i dina system. Utforska alla våra IT-mallar så snart ditt syfte ändras.
Anpassa dina arbetsflöden efter önskemål för varje ITAM-steg, från distribution och konfiguration till underhåll och avveckling.
Steg 2: Klassificera kritiska tjänster
Identifiera nu vilka av dessa tillgångar som är affärskritiska och vilka som bara är bra att ha. Skapa kartor över tjänsteberoenden som visar hur dina system är kopplade till varandra och är beroende av varandra. Var särskilt uppmärksam på alla kundinriktade tjänster som direkt påverkar intäkterna eller användarupplevelsen.
🎥 Titta på denna praktiska genomgång som visar hur du skapar en strukturerad plan på hög nivå med hjälp av ClickUps kraftfulla funktioner – från att sätta upp mål till att tilldela uppgifter och följa upp framsteg.
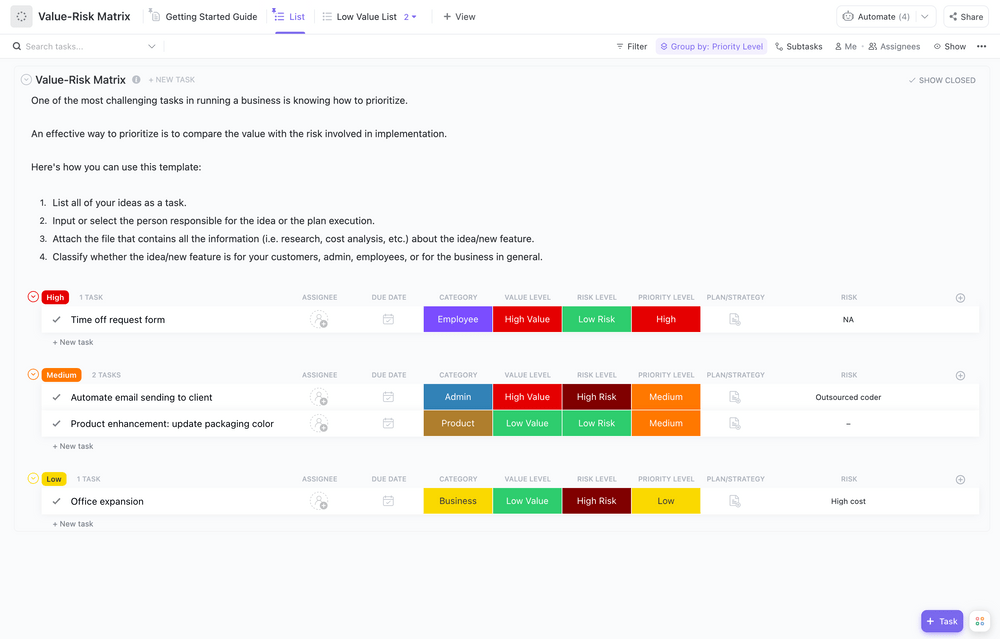
Steg 3: Bedöm risker och hot
Bedöm risker och hot genom att utvärdera sannolikheten och påverkan för varje typ av hot i din specifika situation. Beakta dina geografiska risker (befinner du dig i ett jordbävningsområde eller översvämningsområde?) och eventuella branschspecifika hot (som regeländringar eller riktade cyberattacker). Dokumentera allt i ett riskregister så att du kan följa upp det över tid.

ClickUps mall för riskbedömning på whiteboard skapar en visuell dimension för din riskbedömningsprocess. Den hjälper dig att bedöma risker och kategorisera dem, vilket inspirerar ditt team att dela med sig av insikter och samarbeta i ett engagerande och visuellt format.
Med den här mallen kan du:
- Utvärdera riskkategorier och potentiella effekter
- Analysera data för att identifiera potentiella problemområden
- Fastställ förebyggande åtgärder för att minska riskexponeringen
Med funktioner som gör det möjligt att rita, skriva och lägga till klisterlappar är denna whiteboardmall för riskhantering perfekt för att utvärdera riskerna i ditt projekt.
Steg 4: Ställ in RTO- och RPO-mål
Arbeta direkt med dina affärsintressenter för att definiera vad de anser vara acceptabla driftstopp och dataförluster för varje servicenivå som du identifierat tidigare. Du måste balansera kostnaden för snabbare återställning mot påverkan på verksamheten – inte allt kräver omedelbar återställning utan dataförlust. Få ledningens godkännande för dessa mål.
Steg 5: Definiera säkerhetskopierings- och failover-vägar
När du har fastställt dina mål kan du utforma dina tekniska lösningar. Skapa säkerhetskopieringsstrategier som är anpassade till varje systems RPO och planera detaljerade failover-procedurer, inklusive alternativa bearbetningsplatser och metoder för nödåtkomst. Inkludera nätverksdiagram och steg-för-steg-handböcker för att göra genomförandet idiotsäkert.
Steg 6: Tilldela roller och eskalering
Definiera strukturen för ditt DR-team med tydliga ansvarsområden och beslutsbefogenheter. Skapa omfattande kontaktlistor med primär och reservpersonal för varje roll. En RACI-matris (Responsible, Accountable, Consulted, Informed) är ett utmärkt verktyg för att undvika förvirring under en stressig incident.
Steg 7: Dokumentera och kommunicera planen
Dokumentera och kommunicera planen med tydliga, stegvisa procedurer som alla i ditt team kan följa, även under press. Det är viktigt att lagra denna dokumentation på en lättillgänglig plats som är separat från din primära infrastruktur. Se till att alla teammedlemmar vet exakt var de kan hitta planen under en kris.
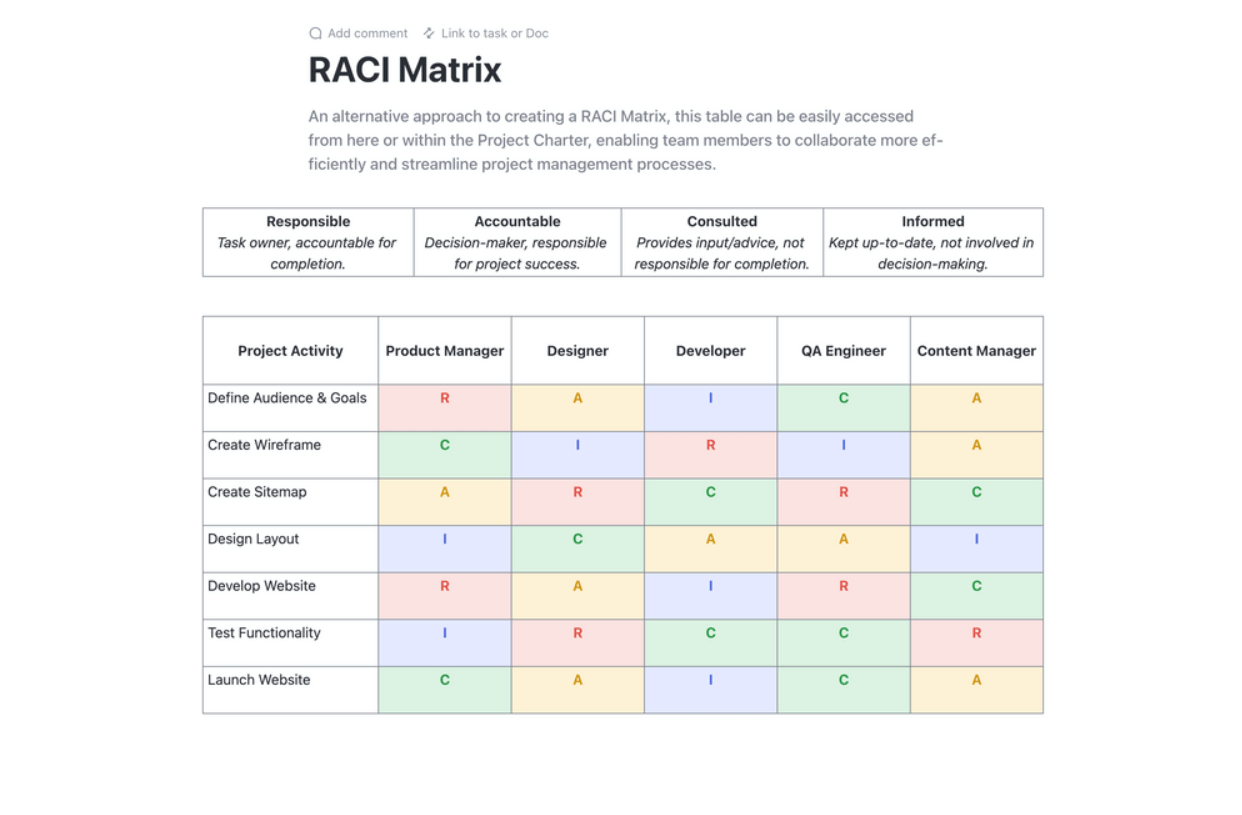
Effektivisera din projektplanering med ClickUps RACI-planeringsmall. Denna dokumentmall är banbrytande och erbjuder ett tydligt diagram för att definiera teamets roller och ansvar i relation till projektets uppgifter. Använd RACI-ramverket (Responsible, Accountable, Consulted och Informed) för att få alla på samma sida, säkerställa ansvarstagande och anpassning till organisationens mål.
Steg 8: Testa, granska och förbättra
Slutligen, planera in kvartalsvisa tester för att validera dina procedurer och identifiera eventuella brister. Dokumentera alla lärdomar från varje test och eventuella verkliga incidenter, och använd dem för att uppdatera din plan. Skapa ett systematiskt system för att spåra förbättringar så att alla problem du upptäcker blir lösta.
🌼 Visste du att: 2017 drabbades GitLab av ett större databasavbrott. Under återställningen upptäckte de att flera av deras säkerhetskopieringsmetoder hade fungerat dåligt i flera dagar utan att de märkt det. Denna incident lärde hela teknikbranschen en viktig läxa: validering av säkerhetskopior är inte förhandlingsbart. En otestad säkerhetskopia är egentligen ingen säkerhetskopia alls.
🌼 Visste du att: 2017 drabbades GitLab av ett större databasavbrott. Under återställningen upptäckte de att flera av deras säkerhetskopieringsmetoder hade fungerat dåligt i flera dagar utan att de märkt det. Denna incident lärde hela teknikbranschen en viktig läxa: validering av säkerhetskopior är inte förhandlingsbart. En otestad säkerhetskopia är egentligen ingen säkerhetskopia alls.
Strategier och lösningar för katastrofåterställning
Alla organisationer behöver inte samma DR-strategi. Låt oss utforska dina alternativ utifrån din budget, dina återställningsbehov och tillgängliga resurser.
Strategi för säkerhetskopiering och återställning
Detta är den enklaste och mest kostnadseffektiva metoden. Den innebär att man regelbundet säkerhetskopierar till en extern plats (t.ex. molnet eller ett sekundärt datacenter) och sedan manuellt återställer dem vid behov. Denna metod är bäst för icke-kritiska system som tål en längre RTO, eftersom återställningen kan ta timmar eller till och med dagar.
Hög tillgänglighet och redundans
Denna strategi syftar till att eliminera enskilda felpunkter genom att använda flera aktiva system. Tekniker som lastbalansering, serverkluster och RAID-lagring säkerställer att om en komponent slutar fungera, tar en annan omedelbart över. Även om det är dyrare att installera och underhålla, kan denna metod minimera driftstopp till bara några sekunder eller minuter, vilket gör den idealisk för kritiska tjänster.
Alternativ för replikering och failover
Replikering innebär att data kopieras i nära realtid till en sekundär plats, vilket säkerställer minimal dataförlust vid en katastrof.
- Synkron replikering: Skriver data till både den primära och sekundära webbplatsen samtidigt, vilket garanterar noll dataförlust. Det kräver dock hög bandbredd och kan göra ditt primära system långsammare.
- Asynkron replikering: Skriver först data till den primära webbplatsen och kopierar sedan data till den sekundära webbplatsen med en liten fördröjning. Det är billigare och har mindre inverkan på prestandan, men du accepterar en liten risk för dataförlust.
Molnbaserad katastrofåterställning och DRaaS
Disaster Recovery as a Service (DRaaS) har blivit ett populärt val för många företag. Det erbjuder pay-as-you-go-prissättning, omedelbar geografisk distribution och automatiserad återställningskoordination utan att du behöver bygga och underhålla egna fysiska DR-platser. Cloud DR eliminerar de enorma kapitalkostnaderna för ett reservdatacenter samtidigt som det ger snabbare skalning och större flexibilitet än traditionella hot-, warm- eller cold-site-lösningar.
Hur ClickUp effektiviserar planeringen av IT-katastrofåterställning
Att hantera en katastrofåterställningsplan i spridda kalkylblad, dokument och e-postkedjor skapar en egen katastrofrisk.
Denna typ av arbetsutbredning, fragmentering av arbetet över flera, icke sammankopplade verktyg som inte kommunicerar med varandra, och kontextutbredning, när team slösar timmar på att söka efter information som är utspridd över olika appar och plattformar, leder till förvirring, föråldrad information och långsamma svarstider när varje sekund räknas.
Med ClickUp Converged AI Workspace – en enda säker plattform där alla dina arbetsappar, data och arbetsflöden samlas tillsammans med kontextuell AI som intelligenslager – som kombinerar projektledning, dokumentation och teamkommunikation. Sluta jonglera mellan flera plattformar och samla din DR-planering, testning och incidenthantering i ett enda enhetligt system.
Centraliserad DR-dokumentation med ClickUp Docs och inbyggd AI-assistans
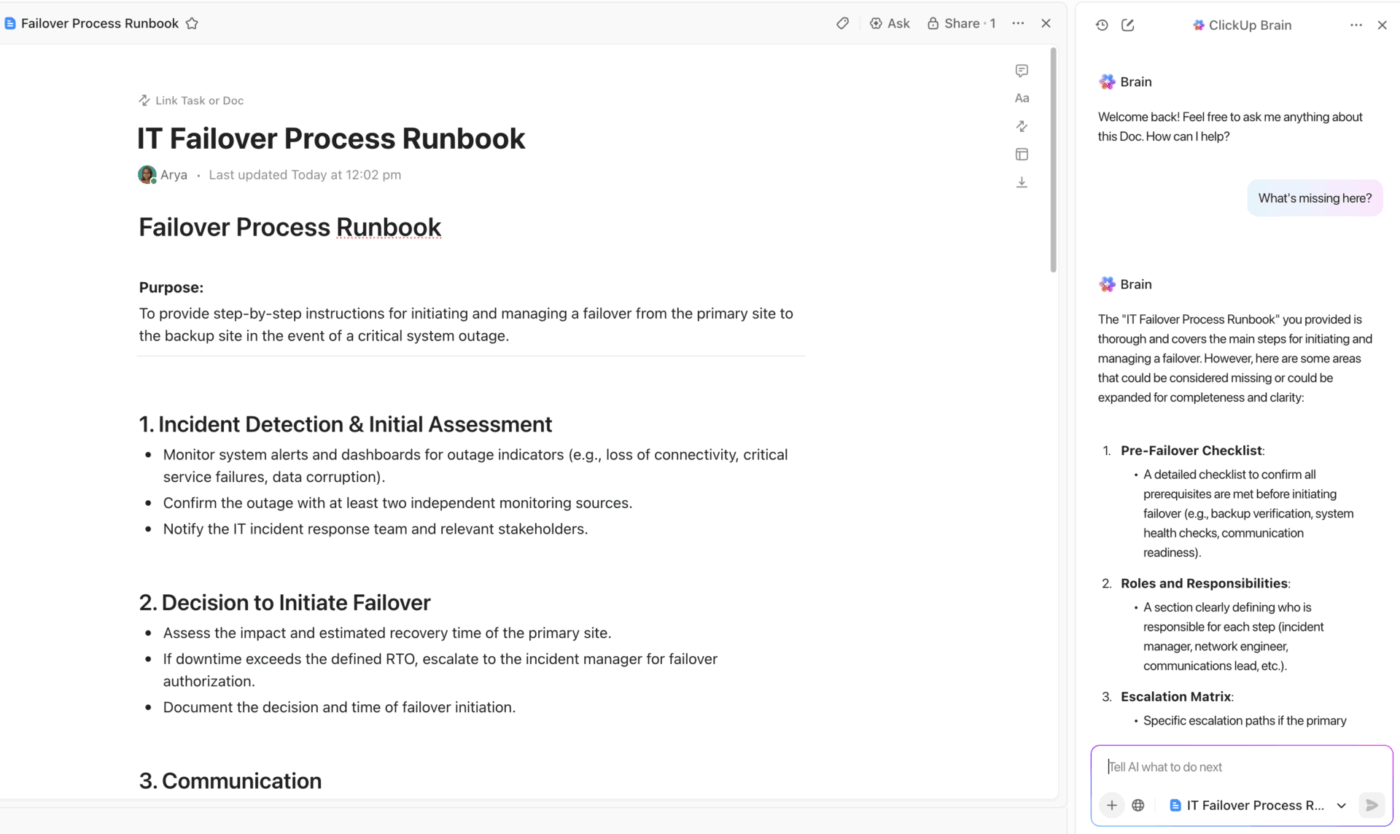
Se till att ditt team alltid har en enda källa till information med ClickUp Docs.
Skapa hela din katastrofåterställningsplan i ett samarbetsutrymme där alla kan bidra i realtid under en incident. Länka dokument direkt till incidentuppgifter och projekt för smidig navigering, och bädda in diagram eller handböcker för att ha viktig information precis där du behöver den.
Det bästa av allt är att du kan skydda dina dokument för att förhindra oavsiktliga redigeringar och använda detaljerade ClickUp-behörigheter för att kontrollera vem som kan visa eller ändra känsliga återställningsprocedurer. Varje ändring spåras i dokumentets historik, vilket ger dig en komplett revisionsspår.
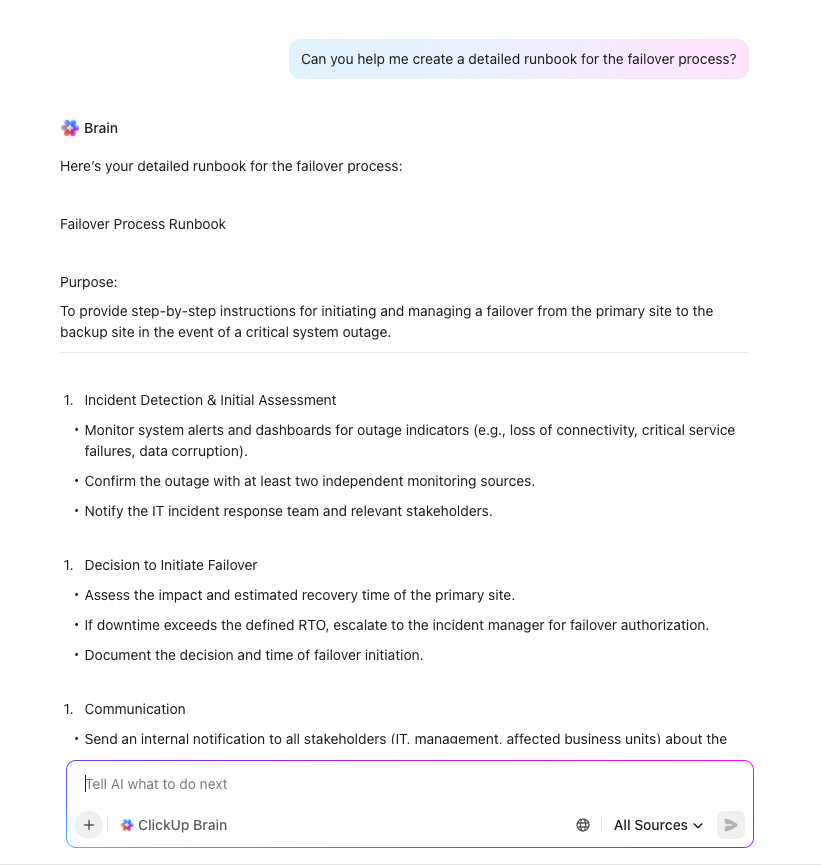
AI-driven planering med ClickUp Brain
Påskynda planeringen av katastrofåterställning och eliminera kritiska luckor med ClickUp Brain – din kontextuella AI-assistent som förstår hela din arbetsmiljö. Till skillnad från generiska AI-verktyg utnyttjar ClickUp Brain din organisations verkliga uppgifter, dokument och arbetsflöden för att leverera precis och praktisk support för DR-initiativ.
Be bara ClickUp Brain om något i stil med ”Skapa en checklista för katastrofåterställning för vår e-handelsplattform” så får du omedelbart en omfattande, skräddarsydd mall som passar dina system, processer och efterlevnadskrav. Det kan hjälpa dig med:
- Kontextuell medvetenhet: ClickUp Brain har tillgång till din arbetsplats struktur, innehåll och behörigheter. Den kan hänvisa till uppgifter, dokument, kommentarer och till och med anslutna appar, och ge svar och åtgärder som är anpassade efter ditt faktiska arbete – inte bara generella förslag.
- Felsökning och vägledning: Felsök problem direkt, få steg-för-steg-instruktioner eller fråga om bästa praxis för alla ClickUp-funktioner. Brain kan guida dig genom komplexa processer, automatisera repetitiva uppgifter och hjälpa till att lösa problem.
- Automatisering och arbetsflödesacceleration: Använd förkonfigurerade eller anpassade AI-agenter för att automatisera flerstegsarbetsflöden, prioritera förfrågningar eller hantera återkommande arbete – och spara flera timmar varje vecka.
- Djup sökning: Hitta information som är gömd någonstans i din arbetsyta, inklusive uppgifter, dokument och integrerade verktyg, även om den är flera år gammal eller svår att hitta med standard sökning.
- Sammanfattningar och uppdateringar i realtid: Skapa projektuppdateringar, mötesreferat eller lägesrapporter direkt med hjälp av data från arbetsytan.
- Förenkla teknisk dokumentation: Omvandla komplexa tekniska dokument till tydliga, praktiska procedurer eller checklistor som ditt team kan följa, även under press.
- Multimodellintelligens: Välj mellan ledande AI-modeller (OpenAI GPT-4. 1, GPT-5, Claude, Gemini och fler) för bästa resultat i alla uppgifter – inga separata prenumerationer krävs.
- Säker och behörighetsmedveten: Brain har endast åtkomst till information som du redan har behörighet att se, vilket upprätthåller strikta sekretess- och efterlevnadsstandarder.
- Konversationsgränssnitt: Använd @brain i kommentarer eller chatt för att få kontextuell information, skriva svar eller aktivera automatiseringar utan att lämna ditt arbetsflöde.
- Anpassade uppmaningar och sparade arbetsflöden: Spara och återanvänd uppmaningar för återkommande behov, vilket säkerställer konsekvens och sparar tid för hela teamet.
💡Proffstips: Missa aldrig en lektion från dina incidentgranskningsmöten genom att fånga varje detalj med ClickUp AI Notetaker. Den kan delta i dina virtuella möten, transkribera hela diskussionen och automatiskt generera en lista med åtgärdspunkter utifrån de lärdomar som dragits. Detta skapar en sökbar incidenthistorik, så att du snabbt kan referera till tidigare händelser och deras lösningar.

Automatiserade DR-arbetsflöden med ClickUp Automations
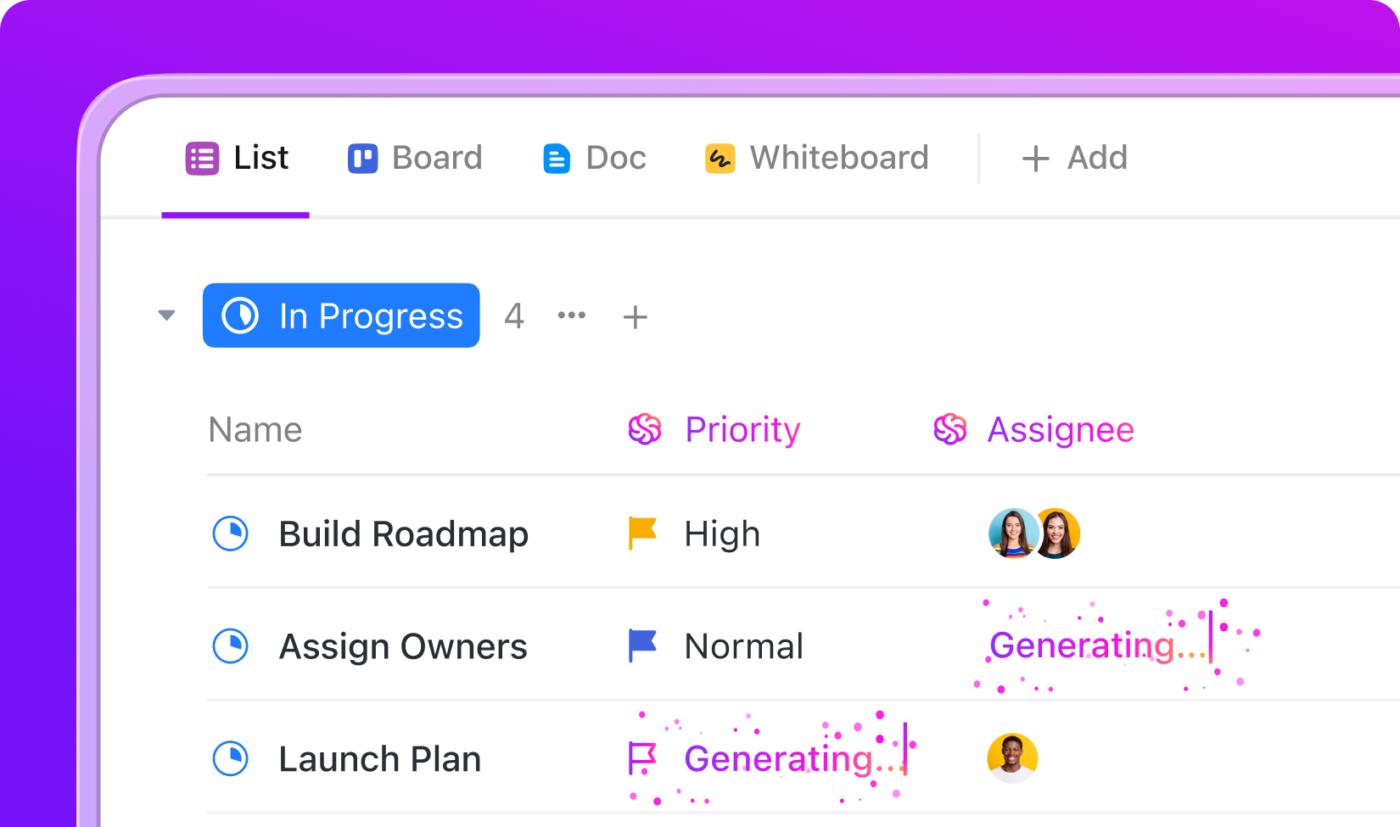
Tänk dig att ditt team drabbas av ett plötsligt avbrott – varje sekund räknas och du har inte råd att missa ett enda steg. Med ClickUp AI Agents och Automations behöver du inte stressa eller förlita dig på minnet. Så snart en incident rapporteras, aktiveras ClickUps AI och guidar ditt team och hanterar det tidskrävande arbetet så att du kan fokusera på att lösa problemet.
Så här fungerar det i ett verkligt scenario:
- När någon markerar en uppgift som ”Incident deklarerad” skapar ClickUp Agent automatiskt en checklista med åtgärder, tilldelar dem till rätt personer och startar en timer för att spåra hur lång tid återställningen tar.
- Om incidenten markeras som ”kritisk” kan en agent omedelbart skicka ett varningsmeddelande via e-post till ledningsgruppen och skapa ett särskilt chattrum – ditt ”krigsrum” – så att alla kan kommunicera på ett och samma ställe.
- AI-tekniken kan hämta tidigare incidentrapporter och relevant dokumentation, så att ditt team har allt de behöver till hands.
Se arbetsflödet här:
Med ClickUp AI Agents får du en pålitlig digital teamkamrat som hjälper ditt team att hålla sig lugnt, organiserat och effektivt – även när pressen är stor.
Realtidsspårning med ClickUp Dashboards
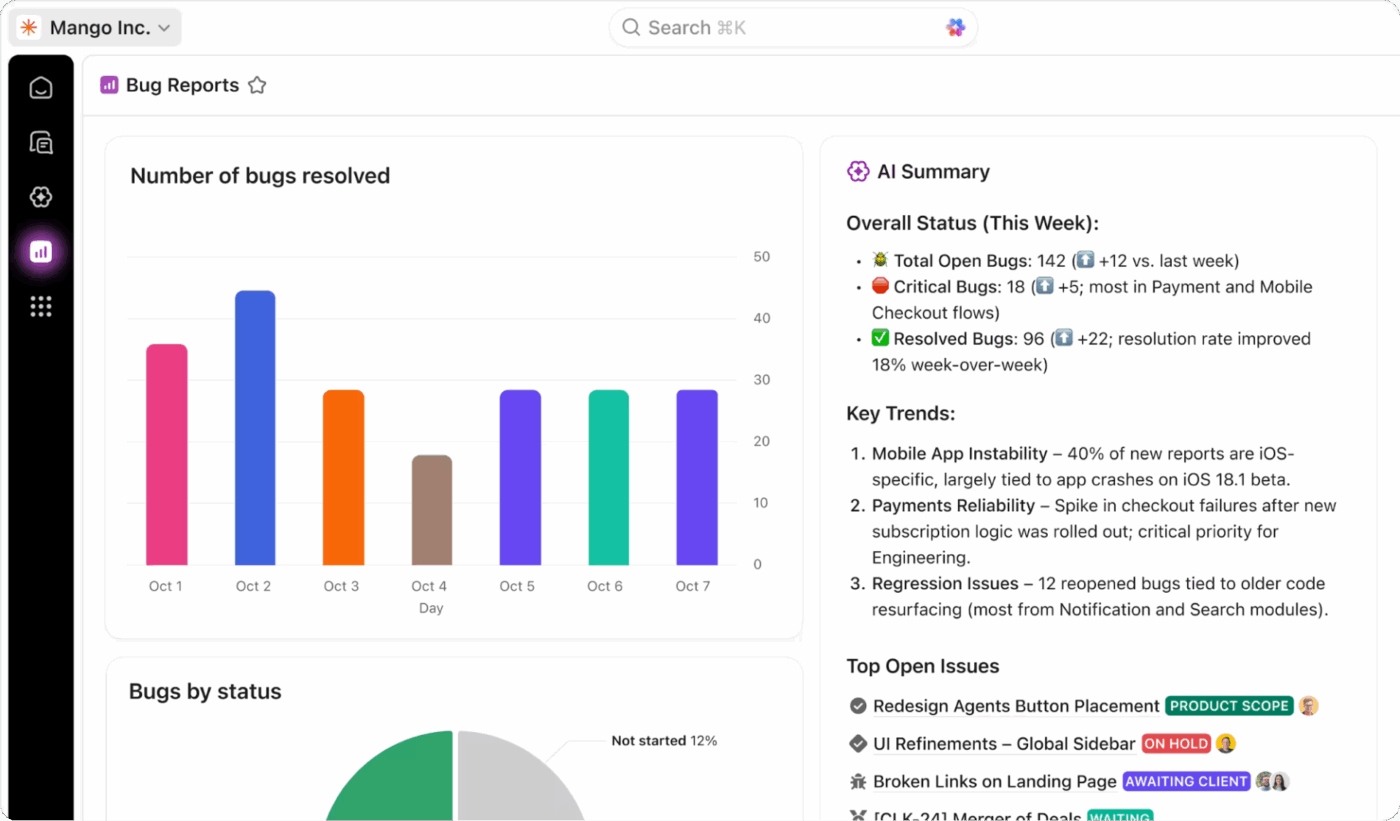
Få fullständig insyn i ditt DR-programs hälsa genom att spåra allt i realtid med ClickUp Dashboards. Du kan skapa widgets för att övervaka din RTO- och RPO-prestanda under tester, spåra testens slutförandegrad och visa incidenttrender över tid.
Lägg till ClickUp Custom Fields till dina uppgifter för att spåra systemets kritikalitet, återställningsstatus och testresultat, och samla sedan all data i en översiktlig vy. Dessa instrumentpaneler ger dig rapporter som är redo att presenteras för ledningen och som alltid är uppdaterade med realtidsdata från ditt teams test- och incidenthanteringsaktiviteter.
Skapa din DR-plan idag
Varje dag du arbetar utan en katastrofåterställningsplan är ett risktagande du inte har råd att förlora. Katastrofer är oundvikliga – oavsett om de beror på naturen, tekniska fel eller mänskliga misstag – men det är din förberedelse som avgör om de blir mindre olägenheter eller stora katastrofer.
En omfattande katastrofåterställningsplan kräver att du förstår dina risker, dokumenterar tydliga procedurer och testar dem regelbundet. Med rätt verktyg blir denna process hanterbar genom att kaoset med spridda dokument och manuella processer elimineras.
Även grundläggande beredskapsplaner är bättre än att inte ha något alls när en katastrof inträffar. Regelbundna tester och uppdateringar förvandlar din DR-plan från ett dammigt dokument till ett levande system som verkligen skyddar ditt företag.
Ta det första steget och börja bygga din DR-plan med ClickUp idag. Kom igång gratis med ClickUp och samla all din katastrofåterställningsplanering, dokumentation och incidenthantering på en enda plattform. ✨
Vanliga frågor
Du bör granska din katastrofåterställningsplan minst fyra gånger om året och uppdatera den omedelbart efter betydande infrastrukturförändringar eller verkliga incidenter. De flesta organisationer genomför en omfattande, djupgående översyn varje år för att införliva alla lärdomar och anpassa sig till ny teknik.
IT-team, säkerhetsteam och planerare för affärskontinuitet leder vanligtvis arbetet med att planera och testa katastrofåterställning. De behöver dock viktig input från drifts- och affärsenhetschefer för att säkerställa att planen överensstämmer med verkliga affärsbehov och prioriteringar.
Använd stoppur och tydliga tidsstämplar för att mäta den faktiska återställningstiden mot dina definierade mål under varje test. Det är viktigt att dokumentera eventuella skillnader mellan ditt mål och den faktiska prestandan i dina testrapporter för att kunna göra framtida förbättringar.
Projektledningsplattformar som ClickUp är idealiska för att centralisera dokumentation, automatisera arbetsflöden och spåra mätvärden för hela ditt DR-program. Du kan sedan kombinera dem med specialiserade DR-verktyg som hanterar de tekniska aspekterna av datareplikering och systemfailover.