
A legtöbb csapat úgy tekint az SQL-generálásra, mint egy varázslatra. Beír egy kérdést, és kap egy lekérdezést.
De a valóság a következő: a Snowflake Cortex Analyst csak annyira működik jól, amennyire az Ön által előbb létrehozott szemantikai modell, és ez a beállítás nem triviális feladat. A Snowflake Cortex SQL-generáláshoz való használatának elsajátításával az adatelemző csapatok most már másodpercek alatt alakíthatják át a természetes nyelvet komplex, végrehajtható lekérdezésekké.
Ez az útmutató végigvezeti Önt a tényleges megvalósítási folyamaton, a YAML szemantikai modell meghatározásától az adatraktár természetes nyelvű lekérdezéséig, hogy még a kezdés előtt megértse mind a lehetőségeket, mind az előfeltételeket.
Megvizsgáljuk azt is, hogy a Snowflake Cortex milyen területeken mutat hiányosságokat, és hogy a ClickUp hogyan tudja támogatni az SQL-generálást körülvevő szélesebb körű munkafolyamatokat.
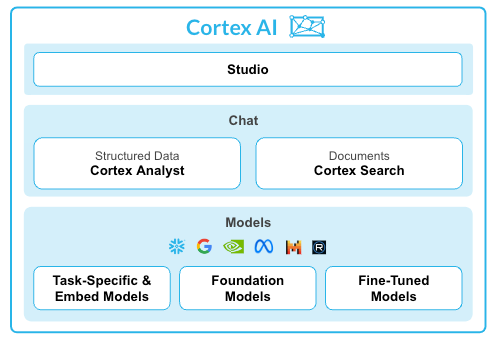
Mi az a Snowflake Cortex Analyst?
A Snowflake Cortex Analyst egy teljesen felügyelt szolgáltatás, amely lehetővé teszi, hogy beszélgetős alkalmazásokat építsen az analitikai adatai alapján.
A szolgáltatás egy speciális szöveg-SQL-átalakító ügynököt használ, amely a természetes nyelvű kérdéseket pontos, végrehajtható lekérdezésekké alakítja. Ez a szolgáltatás áthidalja a komplex adatstruktúrák és azok között a üzleti felhasználók között fennálló szakadékot, akik kódírás nélkül szeretnének válaszokat kapni.
A legfontosabb funkciók:
- Nagy pontosságú felület biztosítása a strukturált adatok kezeléséhez
- Szemantikai modellek használata az Ön üzleti logikájának és terminológiájának megértéséhez
- REST API-t kínál az egyedi alkalmazásokba vagy BI-eszközökbe való egyszerű integrációhoz
- Az adatvédelem fenntartása a kérések Snowflake biztonsági határain belüli feldolgozásával
📮 ClickUp Insight: A felmérésünkben résztvevők 88%-a használja az AI-t személyes feladataihoz, mégis több mint 50% kerüli a használatát a munkahelyén. A három fő akadály? A zökkenőmentes integráció hiánya, a tudásbeli hiányosságok vagy a biztonsági aggályok.
De mi van, ha az AI be van építve a munkaterületébe, és már eleve biztonságos? A ClickUp Brain, a ClickUp beépített AI-asszisztense ezt valósággá teszi. Érti a köznyelvi utasításokat, megoldva ezzel az AI bevezetésével kapcsolatos mindhárom aggályt, miközben összeköti a csevegést, a feladatokat, a dokumentumokat és a tudást a munkaterületen belül.
Egyetlen kattintással találjon válaszokat és betekintést!
A Snowflake Cortex SQL-generálás előfeltételei
A megfelelő beállítások nélkül a Snowflake Cortex használata frusztrációhoz vezet. Pontatlan eredményeket kaphat, időt pazarolhat a hibaelhárításra, és tévesen arra a következtetésre juthat, hogy az eszköz nem működik, miközben a valódi probléma a gyenge alapok.
Ennek elkerülése érdekében először három alapvető elemet kell biztosítania.
1. Állítsa be az adatbázist és a táblákat
Az Ön AI-je csak annyira okos, amennyire az adatok, amelyekhez hozzáfér. Ha az adatbázis-sémája olyan rejtélyes oszlopnevek labirintusa, mint például a cust_dat_v2_final, akkor mind az elemzői, mind az AI-je nehezen fogja tudni értelmezni.
Ez a zavarodottság oda vezet, hogy az AI helytelen csatlakozásokat generál, vagy a rossz oszlopokból von ki adatokat, és a csapata órákat pazarol el csak azzal, hogy megpróbálja megfejteni a sémát, mielőtt egyáltalán lekérdezést írhatna.
Először győződjön meg arról, hogy az adatraktár-szoftver tartalmazza azokat a táblákat, amelyeket a Cortex Analyst lekérdezzen. Amennyiben lehetséges, használjon egyértelmű, leíró oszlopneveket. Például a customer_lifetime_value nevű oszlop mind az emberek, mind a mesterséges intelligencia számára sokkal intuitívabb, mint a clv_01.
A beállítás folytatásához a Snowflake-szerepkörének a következő jogosultságokra lesz szüksége:
- HASZNÁLAT: Az Ön tábláit tartalmazó adatbázisban és sémában
- SELECT: Azokon a táblákon, amelyeket a Cortex Analyst lekérdezzen
- CREATE STAGE: A sémán, amely szükséges a szemantikai modellfájl feltöltéséhez
📖 Olvassa el még: Hogyan használhatja a Snowflake Cortexet üzleti intelligencia céljára
2. Készítse el a szemantikai modellfájlt
Bármely szöveg-SQL eszköz legnagyobb akadálya az, hogy az AI nem beszéli a vállalat egyedi nyelvét. Nem tudja eleve, hogy az „ARR” az „Annual Recurring Revenue” (éves ismétlődő bevétel) rövidítése, vagy hogy az ügyfelek táblája a customer_id mezőn kapcsolódik a megrendelések táblájához.
E kontextus nélkül az AI olyan SQL-kódot generálhat, amely technikailag érvényes, de logikailag hibás, így olyan válaszokat kap, amelyek helyesnek tűnnek, de veszélyesen félrevezetőek.
A megoldás a szemantikai modell. Ez egy YAML fájl, amely egyedi „fordítási rétegként” működik, és megtanítja a Cortex Analystnek az Ön vállalkozásának sajátos szókincsét és logikáját. E fájl létrehozása és karbantartása az ETL-eszközöket használó, a sémát ismerő adatelemzők és a terminológiát ismerő üzleti elemzők közötti együttműködés eredménye.
A szemantikai modellfájlnak a következő kulcsfontosságú elemeket kell tartalmaznia:
| Komponens | Cél |
| Táblázatok | Felsorolja az egyes táblákat, és egyszerű nyelven leírja azok rendeltetését |
| Oszlopok | Meghatározza az egyes oszlopok szemantikai típusát (például kategória vagy mutató), és tartalmazhat mintaértékeket is |
| Kapcsolatok | Meghatározza, hogy a táblák hogyan kapcsolódnak össze csatlakozásokon keresztül, így az AI számára nincs szükség találgatásra |
| Ellenőrzött lekérdezések | Példákat tartalmaz kérdés-SQL párokra, amelyek hatékony útmutatóként szolgálnak az LLM számára |
3. A Cortex Search Service beállítása (opcionális)
Előfordul, hogy a szükséges válaszok strukturálatlan szövegekben rejtőznek, például termékleírásokban, ügyfélszolgálati jegyekben vagy telefonbeszélgetések átirataiban. A szokásos SQL-lekérdezések nem tudnak hozzáférni ezekhez az adatokhoz, ami azt jelenti, hogy gyakran elkerüli a figyelmét a „mi” mögött rejlő „miért”.
Opcionálisan hozzáadhatja ide a Snowflake Cortex Search Service szolgáltatást is. Ez egy keresés-szolgáltatásként működő réteg, amely lehetővé teszi, hogy egyszerre lekérdezze strukturált tábláit és strukturálatlan szöveges adatait, miközben az adatelemzéshez mesterséges intelligencia ügynököket használ.
A Cortex Search beállítására akkor van szükség, ha az elemzőinek olyan kérdéseket kell feltenniük, amelyekhez az SQL generálása előtt kontextust kell kiolvasni a szövegből. Például először kereshet az összes olyan termékértékelés között, amely tartalmazza a „battery issue” kifejezést, majd generálhat egy SQL-lekérdezést, amely csak azoknak a termékeknek az értékesítési adatait összesíti.
Strukturált táblákhoz történő tiszta SQL-generáláshoz ez a szolgáltatás nem szükséges.
🧠 Érdekesség: Az 1970-es évek elején az IBM kutatói, Donald Chamberlin és Raymond Boyce létrehozták a „Structured English Query Language” nyelvet. A nevet SQL-re kellett változtatniuk, mert a „SEQUEL” már egy brit repülőgépgyártó cég védjegye volt.
Lépésről lépésre: SQL generálás a Cortex Analyst segítségével
Elvégezte az előkészítő munkát, de most egy üres képernyő előtt áll, és nem biztos a tényleges munkafolyamatban. Hogyan jut el a fejében lévő kérdéstől egy futtatható SQL-lekérdezésig? Ha a munkafolyamat kezelése nem egyértelmű, az új eszközöket gyakran nem használják, és a beállításba fektetett beruházás kárba vész.
A gyakorlati folyamat meglepően egyszerű. Nézzük meg közelebbről!
1. lépés: Adatainak előkészítése a Snowflake-ben
Mindenekelőtt a strukturált adatoknak a Snowflake-ben kell lenniük. Minden Cortex Analyst alkalmazás vagy egy táblára, vagy egy vagy több táblából álló nézetre irányul. Győződjön meg arról, hogy a táblák létre vannak hozva és kitöltve.
Ha sík fájlokból tölt be adatokat:
- Töltse fel adatfájljait (pl. CSV-fájlokat) egy Snowflake Stage-re
- Használja a COPY INTO parancsot az adatok betöltéséhez a stage-ből a táblákba
- Mielőtt továbbhaladna, ellenőrizze, hogy az adatok sikeresen betöltődtek-e
📖 Olvassa el még: Hogyan használhatja a Snowflake Cortexet vállalati elemzésekhez
2. lépés: Szemantikai modell (vagy szemantikai nézet) létrehozása
Ez a legkritikusabb beállítási lépés. A Cortex Analyst ereje abból fakad, hogy nagy nyelvi modelleket (LLM-eket) kombinál szemantikai modellekkel, egy YAML fájllal, amely az adatbázis-sémája mellett helyezkedik el, és kódolja az üzleti kontextust.
A szemantikai nézetek mostantól a Snowflake által ajánlott módszer a Cortex Analyst számára. Ezek az üzleti mutatókat, kapcsolatokat és definíciókat közvetlenül a Snowflake-ben tárolják. A régi YAML szemantikai modellfájlok továbbra is működnek, de a Snowflake az új implementációkat a szemantikai nézetek felé irányítja.
A szemantikai modellnek vagy nézetnek a következőket kell tartalmaznia:
- Táblák és oszlopok leírása: Egyszerű nyelvű magyarázatok az egyes mezők jelentéséről
- Üzleti mutatók: A számított mezők, például a bevétel, az ügyfélvesztés vagy a konverziós arány definíciói
- Szűrők és szinonimák: Alternatív kifejezések, amelyeket a felhasználók használhatnak (pl. a „törölve” kifejezés egy adott állapotértékhez rendelve)
- Ellenőrzött lekérdezések: A Snowflake Verified Query Repository (Ellenőrzött lekérdezések tárháza) a jóváhagyott kérdés-SQL párokat tárolja. Ha egy felhasználói kérdés hasonlít az egyik ilyen bejegyzéshez, a Cortex Analyst hivatkozhat rá az SQL-generálás során.
🤝 Barátkozó emlékeztető: A Snowflake azt javasolja, hogy a Snowsight munkafolyamatban az optimális teljesítmény érdekében legfeljebb 10 táblát és legfeljebb 50 kiválasztott oszlopot használjon.
3. lépés: Töltse fel a szemantikai modellt egy Snowflake-szakaszba
Ha YAML-alapú szemantikai modellt használ, azt előkészítenie kell, hogy a Cortex Analyst futásidőben hivatkozhasson rá.
- Töltse fel a .yaml fájlt egy Snowflake belső tárolóba (pl. RAW_DATA)
- Ellenőrizze a Snowsight felhasználói felületén vagy a LIST @stage_name paranccsal, hogy a fájl megjelenik-e a szakaszban.
- Jegyezze meg a szakasz elérési útját; erre fog hivatkozni az API-hívásokban vagy az alkalmazás konfigurációjában
Ha szemantikus nézetet használ, ezt a lépést a Snowflake natívan kezeli, és nincs szükség külön feltöltésre.
🔍 Tudta? Az SQL-ben a NULL nem nullát vagy üres értéket jelent. Ismeretlen vagy hiányzó adatokat jelöl, ami olyan intuitívnak nem mondható viselkedéshez vezet, mint például az olyan összehasonlítások, amelyek sem igazat, sem hamisat nem adnak vissza.
4. lépés: Küldjön el egy természetes nyelvű kérdést a REST API-n keresztül
Most kezdődik a tényleges SQL-generálás. A REST API egy adott kérdéshez SQL-lekérdezést generál a kérésben megadott szemantikai modell vagy szemantikai nézet felhasználásával.
Az API-kérés felépítése:
- üzenetek; egy tömb, amely tartalmazza a felhasználói kérdést a „user” szerepkörrel
- Hivatkozás a szemantikai modelljére vagy szemantikai nézetére
- Válassza ki a kívánt modellt (vagy hagyja az automatikus beállítást, hogy a Cortex válassza ki a legjobbat)
Többfordulós beszélgetéseket folytathat, amelyekben a korábbi lekérdezésekre épülő kiegészítő kérdéseket tehet fel.
5. lépés: Az API-válasz elemzése
A válasz minden üzenete több, különböző típusú tartalmi blokkot tartalmazhat. A type mezőben jelenleg három érték támogatott: text, suggestions és SQL.
Az egyes típusok jelentése a következő:
- SQL: A Cortex sikeresen generált egy lekérdezést; ezt fogja végrehajtani
- szöveg: Az SQL-hez tartozó természetes nyelvű magyarázat vagy válasz
- javaslatok: A javaslat tartalomtípus csak akkor szerepel a válaszban, ha a felhasználó kérdése kétértelmű volt, és a Cortex Analyst nem tudott SQL-utasítást adni az adott lekérdezéshez. Használja ezeket a kérdés pontosításához vagy finomításához
🔍 Tudta? Az SQL-kód írási sorrendje nem egyezik meg a végrehajtás sorrendjével. Annak ellenére, hogy a SELECT utasítást írja le először, az adatbázisok valójában a FROM és a WHERE utasításokat dolgozzák fel, mielőtt kiválasztanák az oszlopokat. Ez a kezdőket és a tapasztalt felhasználókat egyaránt megzavarja.
6. lépés: Futtassa a generált SQL-t a Snowflake-ben
Miután megkapta a válaszból az SQL-blokkot, futtassa azt a Snowflake virtuális adattárházán. A generált SQL-lekérdezés a Snowflake virtuális adattárházában fut, hogy létrehozza a végső kimenetet. Az adatok a Snowflake irányítási határain belül maradnak.
A végrehajtáskor tudni kell:
- A Cortex Analyst teljes mértékben integrálódik a Snowflake szerepköralapú hozzáférés-vezérlési (RBAC) szabályaival, biztosítva, hogy a generált és végrehajtott SQL-lekérdezések minden megállapított hozzáférés-vezérlési szabálynak megfeleljenek.
- Ha egy felhasználónak nincs hozzáférése egy táblához, a lekérdezés végrehajtása sikertelen lesz, ugyanúgy, mint a kézzel írt SQL esetében.
- Ebben a szakaszban a raktár számítási költségei érvényesek, függetlenül a Cortex Analyst saját használati díjaitól.
7. lépés: Finomítás és iteráció
Nem mindig garantált, hogy az első próbálkozásnál tökéletes lekérdezést kap. Így javíthatja az eredményeket idővel:
- Adjon hozzá ellenőrzött lekérdezéseket a szemantikai modelljéhez az ismétlődő kérdésekhez
- Gazdagítsa szemantikai modelljét jobb leírásokkal, szinonimákkal és szűrőkkel, amikor a Cortex félreérti egy kifejezést
- Használjon többszöri párbeszédet a folytatáshoz, például: „Most szűrje azt régió szerint”. A többszöri párbeszéd lehetővé teszi az előző lekérdezésekre épülő kiegészítő kérdések feltevését.
- Figyelje a használatot a CORTEX_ANALYST_USAGE_HISTORY és a Snowflake lekérdezési előzmények segítségével, hogy felismerje a sikertelen vagy pontatlan lekérdezésekben megjelenő mintákat
🧠 Érdekesség: Egyetlen hiányzó JOIN feltétel is hatalmas problémákat okozhat. A join feltétel kihagyása kartézi szorzatot eredményezhet, ami drámaian megnöveli a sorok számát, és esetenként a rendszer összeomlását is okozhatja.
A Snowflake Text-to-SQL pontosságának legjobb gyakorlata
A szemantikai modell minősége közvetlenül meghatározza a generált lekérdezések pontosságát. Íme a pontosságot javító bevált gyakorlatok. 🛠️
- Adjon hozzá ellenőrzött lekérdezéseket a szemantikai modelljéhez: Ez a leghatásosabb lépés, amit tehet. Számos olyan példakérdés-SQL párost vegyen fel, amelyek tükrözik, hogy a csapata valójában hogyan teszi fel a kérdéseket
- Használjon leíró oszlop- és táblaneveket: A modell jobban teljesít, ha az oszlop- és táblanevek önmagukban is érthetőek. Ha nem tudja megváltoztatni a sémát, adjon hozzá egyértelmű leírásokat a YAML-fájlhoz minden rejtélyes oszlopnévhez.
- Példaértékek hozzáadása: A kategóriás oszlopokhoz (például állapot vagy régió) példaadatok hozzáadása segít a modellnek megérteni az elérhető érvényes szűrőopciókat.
- Teszteljen szélsőséges esetekkel: A fejlesztés során szándékosan tegyen fel kétértelmű vagy trükkös kérdéseket, hogy azonosítsa, hol van szükség a szemantikai modelljében további kontextusra vagy pontosításra
- Fejlessze tovább szemantikai modelljét: Tekintsen szemantikai modelljére élő dokumentumként. A modellt folyamatosan frissíteni kell egy iteratív folyamat keretében, amelynek alapja az, hogy mely lekérdezések sikeresek és melyek sikertelenek.
ClickUp: A Snowflake Cortex egyszerűbb alternatívája
A Snowflake Cortex akkor működik jól, ha a csapatok SQL-kódot szeretnének generálni és lekérdezéseket futtatni strukturált adatokon. A csapatok meghatározzák a sémákat, leképezik a kapcsolatokat, és lekérdezéseket írnak az információk kinyeréséhez. Ez a felállás adatigényes környezetekben bizonyul hatékonynak, különösen akkor, ha az elemzés és a jelentéskészítés az elemzők feladata.
Sok csapatnak azonban nincs szüksége teljes SQL-rétegre a mindennapi operatív kérdések megválaszolásához. A termékmenedzserek, a programvezetők és az operációs csapatok gyakran gyors válaszokat szeretnének kapni az aktuális munkájukhoz kapcsolódóan.
A ClickUp egy könnyebben elérhető megoldást kínál. A csapatok egyszerű nyelven tesznek fel kérdéseket, élőben tekintik át a műszerfalakat, és a kapott információk alapján cselekszenek anélkül, hogy SQL-kódot kellene írniuk vagy szemantikai modelleket kellene építeniük.
Gyorsabb SQL-generálás és finomítás
A Snowflake Cortex arra összpontosít, hogy SQL-lekérdezéseket generáljon a raktárkörnyezetben található strukturált adatkészletekből. Ez akkor működik jól, ha az adatok már a Snowflake-ben vannak, és a sémák már le vannak térképezve.

A ClickUp Brain rugalmasabb, végrehajtásközpontú módon támogatja az SQL-generálást. A csapatok közvetlenül a munkaterületükön generálják, finomítják és tárolják az SQL-lekérdezéseket, ahol az elemzések, megbeszélések és döntések máris zajlanak.
Tegyük fel, hogy egy termékelemző a ClickUp-on belül egy megtartási elemzési feladaton dolgozik. Ahelyett, hogy másik eszközre váltana a lekérdezések írásához, a ClickUp Brain-hez fordul:
📌 Próbálja ki ezt a parancsot: Írjon egy SQL-lekérdezést, amely kiszámítja a regisztrációs kohorszok szerint csoportosított felhasználók hétnapos megtartási arányát.
A ClickUp Brain strukturált lekérdezést generál, amely tartalmazza a kohortcsoportosítást, a dátumszűrőket és a megtartási logikát. Az elemző beilleszti a lekérdezést a Snowflake-be vagy egy másik adattárházba, és azonnal futtatja.
Ez segít:
- Írjon összekapcsolásokat több táblára, például felhasználókra, megrendelésekre és eseményekre
- Konvertálja az egyszerű angol nyelvű termékkel kapcsolatos kérdéseket végrehajtásra kész SQL-logikává
- Hibás lekérdezések hibakeresése és a problémák magyarázata, például helytelen csatlakozások vagy hiányzó feltételek esetén
- Írja át a lekérdezéseket a jobb teljesítmény vagy olvashatóság érdekében
Például egy növekedési kísérlet értékelése során egy marketinges a következő kérdést teszi fel: „Írjon egy SQL-lekérdezést, amely összehasonlítja a két céloldal konverziós arányait az elmúlt 14 napban”.
A ClickUp Brain feltételes összesítés és dátumszűrők segítségével generálja a lekérdezést. A csapat futtatja azt a Snowflake-ben, és ellenőrzi a kísérlet eredményeit.
📌 Próbálja ki ezt a parancsot: Javítsa ki ezt az SQL-lekérdezést, amelyben a join duplikálja a sorokat, és magyarázza el a problémát.
A ClickUp Brain azonosítja a csatlakozási problémát, kijavítja a lekérdezést, és elmagyarázza, hogyan keletkeztek az ismétlődő sorok a helytelen csatlakozási feltételek miatt.
Cserélje le az SQL-alapú jelentéskészítést
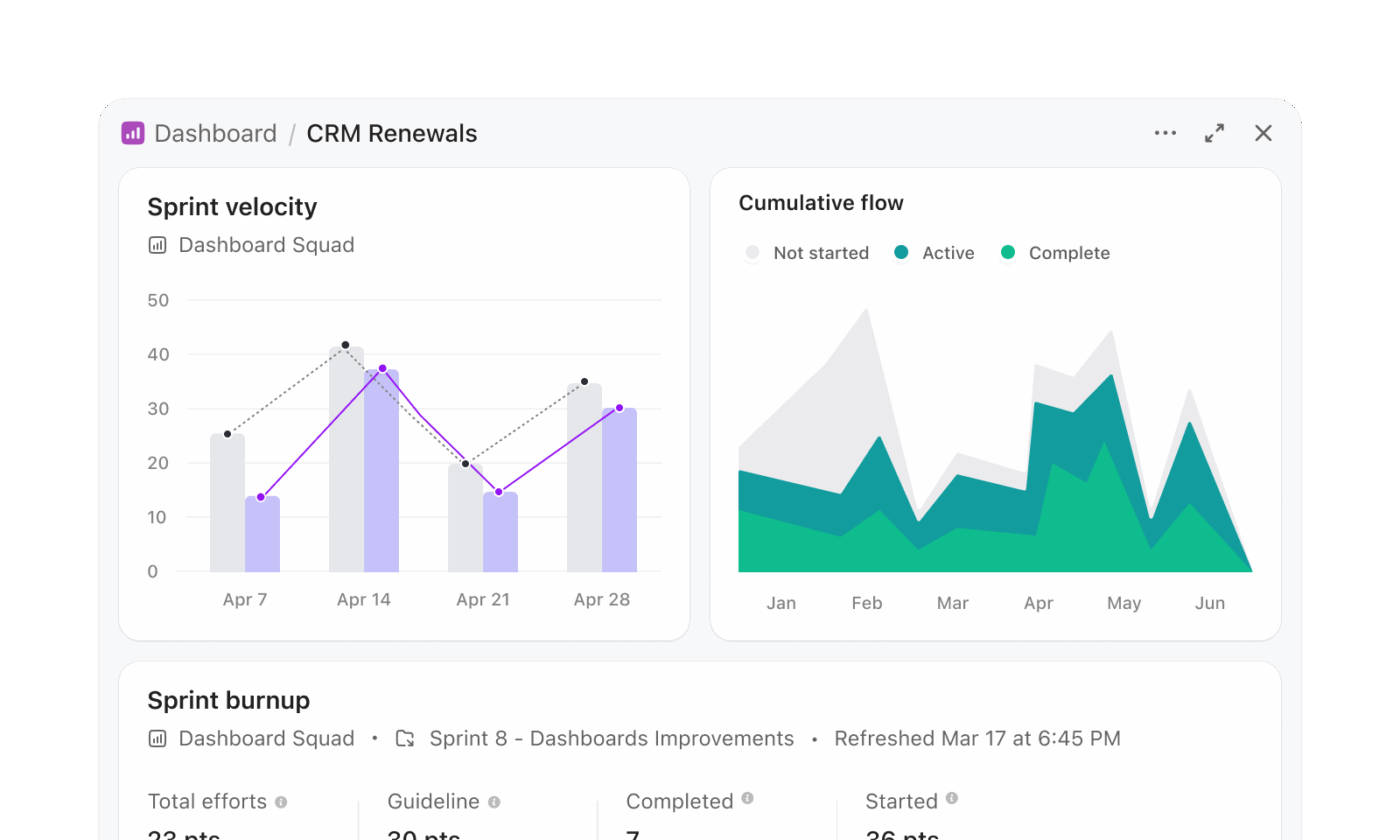
A Snowflake Cortex munkafolyamatai gyakran magukban foglalják az SQL generálását, a lekérdezések futtatását és az eredmények vizualizálását egy külön rétegben. A ClickUp Dashboards megszünteti ezt a több lépésből álló folyamatot, és az élő munkából közvetlenül nyújt betekintést.
A kiadásra való felkészültséget nyomon követő programmenedzsment-csapat lekérdezések írása nélkül is létrehozhat egy irányítópultot. Például egy kiadási irányítópult a következőket tartalmazhatja:
- Egy feladatlista-kártya, amely úgy van szűrve, hogy az összes termékcsapatnál a lejárt feladatokat mutassa
- Egy munkafolyamat-kártya, amely bemutatja a feladatok elosztását a mérnökök között
- Oszlopdiagram, amely összehasonlítja a befejezett és a függőben lévő feladatokat sprintenként
- Számítási kártya, amely nyomon követi az átlagos befejezési időt
Tegyük fel, hogy egy programvezető áttekinti ezt a műszerfalat egy kiadási megbeszélés előtt. Azonnal észreveszi, hogy a háttérszolgáltatásoknál magasabb a késleltetési arány. Megnyitja a feladatlista kártyát, és megvizsgálja, hogy pontosan mely feladatok okoznak kockázatot.
Egy valódi ClickUp-felhasználó így mesél:
A ClickUp segítségével GYORSAN átadhatjuk egymásnak a projekteket, KÖNNYEDEN ellenőrizhetjük a projektek állapotát, és felettesünk bármikor betekintést nyerhet a munkaterhelésünkbe anélkül, hogy meg kellene szakítania a munkánkat. A ClickUp használatával biztosan egy napot, ha nem többet is megtakarítottunk hetente. Az e-mailek száma JELENTŐSEN csökkent.
A ClickUp segítségével GYORSAN átadhatjuk egymásnak a projekteket, KÖNNYEDEN ellenőrizhetjük a projektek állapotát, és felettesünk bármikor betekintést nyerhet a munkaterhelésünkbe anélkül, hogy megzavarná a munkánkat. A ClickUp használatával biztosan egy napot, ha nem többet is megtakarítottunk hetente. Az e-mailek száma JELENTŐSEN csökkent.
Használja ki az információkat pipeline-ok nélkül
A Snowflake Cortex az adatokból nyert betekintések generálására összpontosít. A csapatoknak továbbra is külön kell értelmezniük az eredményeket és elindítaniuk a műveleteket.
A ClickUp AI Super Agents áthidalja ezt a szakadékot, és a betekintést cselekvéssé alakítja. Olyan AI-csapattársakként működnek, amelyek folyamatosan figyelik a munkaterület adatait, és a feltételek alapján intézkednek.
Tegyük fel, hogy egy programmenedzser több termékkezdeményezést felügyel. A Super Agent képes:
- Figyelje a feladatokat a projektek között, és észlelje, ha a késedelmes feladatok meghaladják a meghatározott küszöbértéket
- Azonosítson olyan mintákat, mint például az ismétlődő késések ugyanazon a munkafolyamat-szakaszban
- Hozzon létre egy feladatot, amely összefoglalja az érintett projekteket, és rendelje hozzá a programvezetőhöz
- Értesítse a csapatvezetőket, ha a kritikus feladatok a határidő lejárta után is megoldatlanok maradnak
Például egy kiadási ciklus során egy Super Agent észleli, hogy két csapatnál több mint 10 kiemelt fontosságú feladat nem tartotta be a határidőt. Létrehoz egy „Kiadási kockázat: határidő túllépés” nevű ClickUp-feladatot, hozzáadja az összes releváns feladatot, és kijelöli a programmenedzsert az azonnali áttekintéshez.
A csapatok közvetlenül is kommunikálhatnak a Super Agenttel: „Elemezze az összes aktív projektet, és jelölje ki a jelen sprint szállítási kockázatait”.
A Super Agent áttekinti a határidőket, a függőségeket és a feladatok állapotát, majd strukturált összefoglalót tesz közzé a munkaterületen belül.
Így állíthatja be saját Super Agentjét a ClickUpban:
Központosítsa adatfolyamait a ClickUp segítségével
A Snowflake Cortexhez hasonló szöveg-SQL eszközök hozzáférhetőbbé teszik az adatokat. Ugyanakkor a megbízható eredmények elérése továbbra is erőfeszítést igényel.
A csapatoknak tiszta sémákra, erős szemantikai modellekre és folyamatos iterációra van szükségük a kimenetek pontosságának biztosításához. Még a megfelelő lekérdezés generálása után sem ér véget a munka. Valakinek továbbra is értelmeznie kell az eredményeket, meg kell osztania a betekintéseket, és azokat döntésekké kell alakítania.
A ClickUp egy másfajta megközelítést kínál. Ahelyett, hogy elválasztaná az elemzést a végrehajtástól, a ClickUp összekapcsolja a kettőt. A csapatok ugyanazon a munkaterületen generálnak SQL-t, dokumentálják az eredményeket, együttműködnek a megállapításokban, és azok alapján cselekszenek.
A ClickUp Brain segít a lekérdezések megírásában és finomításában, míg a műszerfalak és az AI-ügynökök segítségével a csapatok nyomon követhetik az eredményeket és haladhatnak a munkával anélkül, hogy különböző eszközök között kellene váltogatniuk.
A Snowflake Cortex segít megkapni a válaszokat. A ClickUp segít azokat hasznosítani. Regisztráljon még ma a ClickUp-ra!
Gyakran ismételt kérdések
A Snowflake Cortex Analyst egy speciális szolgáltatás a tágabb értelemben vett Snowflake Cortex AI csomagon belül. A Cortex Analyst kifejezetten a szemantikai modellek segítségével történő szöveg-SQL generálásra összpontosít, míg a Cortex AI szélesebb körű LLM-funkciókat, gépi tanulási modell-következtetést és keresési képességeket tartalmaz.
Igen, a Cortex Analyst lekérdezheti a Snowflake-en keresztül kezelt Apache Iceberg táblákat. Amennyiben a táblák elérhetők a Snowflake-környezetében, és megfelelően vannak definiálva a szemantikai modellben, lekérdezéseket generálhat rájuk.
A komplex lekérdezések pontossága szinte teljes mértékben a szemantikai modell minőségétől függ. A jól definiált táblakapcsolatokkal, számos ellenőrzött lekérdezéssel és leíró metaadatokkal rendelkező modell lényegesen pontosabb eredményeket ad többtáblás csatlakozások és komplex összesítések esetén.
A Snowflake Cortex Analyst árazása a Snowflake felhasználásalapú modelljét követi, ami azt jelenti, hogy a számlázás a lekérdezések generálása során felhasznált számítási kreditek alapján történik. A legfrissebb árakról mindig a Snowflake hivatalos árazási dokumentációjában tájékozódjon.