
Většina týmů považuje generování SQL za kouzlo. Zadáte otázku a dostanete dotaz.
Realita je však taková: Snowflake Cortex Analyst funguje pouze tak dobře, jak dobrý je sémantický model, který nejprve vytvoříte, a toto nastavení není triviální. Po osvojení si používání Snowflake Cortex pro generování SQL mohou datové týmy nyní během několika sekund převádět přirozený jazyk na komplexní, spustitelné dotazy.
Tato příručka vás provede samotným procesem implementace, od definování sémantického modelu YAML až po dotazování datového skladu pomocí přirozeného jazyka, abyste před zahájením práce pochopili jak jeho možnosti, tak i předpoklady.
Podíváme se také na to, v čem Snowflake Cortex zaostává a jak může ClickUp podporovat širší pracovní postupy související s generováním SQL.
Co je Snowflake Cortex Analyst?
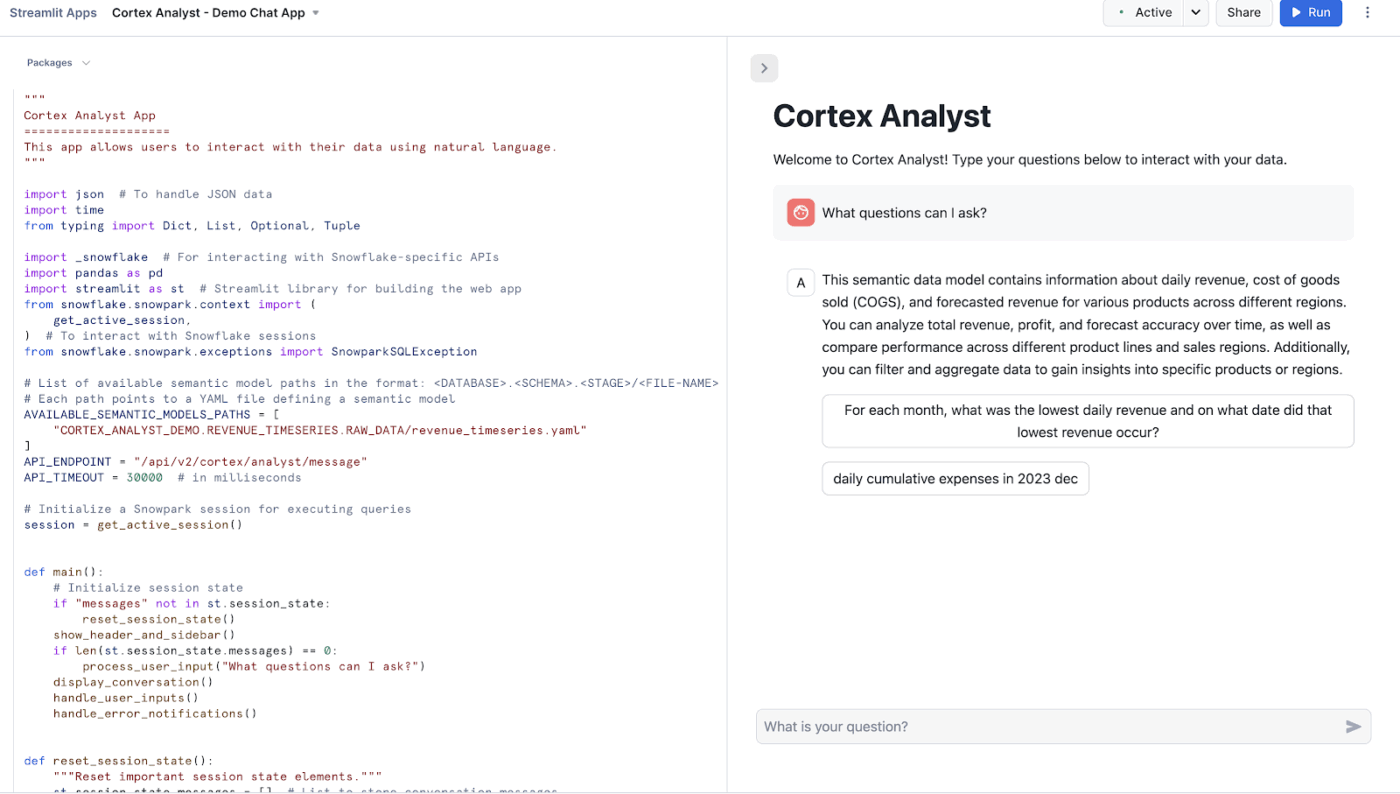
Snowflake Cortex Analyst je plně spravovaná služba, která vám umožňuje vytvářet konverzační aplikace nad vašimi analytickými daty.
Využívá specializovaného agenta pro převod textu na SQL, který přeměňuje otázky v přirozeném jazyce na přesné a spustitelné dotazy. Tato služba překlenuje propast mezi složitými datovými strukturami a obchodními uživateli, kteří potřebují odpovědi, aniž by museli psát kód.
Mezi klíčové funkce patří:
- Poskytuje vysoce přesné rozhraní pro práci se strukturovanými daty
- Využití sémantických modelů k pochopení vaší specifické obchodní logiky a terminologie
- Nabízí REST API pro snadnou integraci do vlastních aplikací nebo nástrojů BI
- Zachování ochrany osobních údajů zpracováním požadavků v rámci bezpečnostních hranic Snowflake
📮 ClickUp Insight: 88 % respondentů našeho průzkumu používá AI pro své osobní úkoly, ale více než 50 % se bojí ji používat v práci. Jaké jsou tři hlavní překážky? Nedostatek hladké integrace, mezery ve znalostech nebo obavy o bezpečnost.
Ale co když je AI zabudována přímo do vašeho pracovního prostoru a je již zabezpečená? ClickUp Brain, vestavěný AI asistent ClickUp, to promění ve skutečnost. Rozumí pokynům v běžném jazyce, řeší všechny tři obavy spojené s přijetím AI a zároveň propojuje váš chat, úkoly, dokumenty a znalosti napříč pracovním prostorem.
Najděte odpovědi a poznatky jediným kliknutím!
Předpoklady pro generování SQL pomocí Snowflake Cortex
Používání Snowflake Cortex bez správného nastavení vede k frustraci. Můžete získat nepřesné výsledky, ztrácet čas řešením problémů a mylně dojít k závěru, že nástroj nefunguje, zatímco skutečným problémem je slabý základ.
Abyste tomu předešli, musíte nejprve zajistit tři základní prvky.
1. Nastavte si databázi a tabulky
Vaše AI je jen tak chytrá, jak chytrá jsou data, ke kterým má přístup. Pokud je schéma vaší databáze bludištěm záhadných názvů sloupců, jako je cust_dat_v2_final, budou mít jak vaši analytici, tak AI potíže s tím, aby tomu porozuměli.
Tato nejednoznačnost vede k tomu, že AI generuje nesprávné spojení nebo čerpá data ze špatných sloupců, a váš tým tak ztrácí hodiny jen tím, že se snaží rozluštit schéma, než vůbec může napsat dotaz.
Nejprve se ujistěte, že váš software pro datové sklady obsahuje tabulky, které chcete, aby Cortex Analyst dotazoval. Kdykoli je to možné, používejte jasné a popisné názvy sloupců. Například sloupec s názvem customer_lifetime_value je pro lidi i AI mnohem intuitivnější než clv_01.
Chcete-li pokračovat v nastavení, bude vaše role Snowflake potřebovat následující oprávnění:
- POUŽITÍ: V databázi a schématu obsahujícím vaše tabulky
- SELECT: V tabulkách, které chcete, aby Cortex Analyst dotazoval
- CREATE STAGE: Ve schématu, které je nutné pro nahrání souboru sémantického modelu
📖 Přečtěte si také: Jak používat Snowflake Cortex pro business intelligence
2. Vytvořte soubor sémantického modelu
Největší překážkou u jakéhokoli nástroje pro převod textu na SQL je to, že umělá inteligence nerozumí specifickému jazyku vaší společnosti. Neví automaticky, že „ARR“ znamená „Annual Recurring Revenue“ (roční opakující se výnosy) nebo že tabulka zákazníků se spojuje s tabulkou objednávek na základě pole customer_id.
Bez tohoto kontextu by AI mohla generovat SQL, které je technicky platné, ale logicky nesprávné, a poskytovat vám odpovědi, které vypadají správně, ale jsou nebezpečně zavádějící.
Řešením je sémantický model. Jedná se o soubor YAML, který funguje jako vaše vlastní „překladová vrstva“ a učí Cortex Analyst specifickou slovní zásobu a logiku vašeho podnikání. Vytvoření a údržba tohoto souboru je společným úsilím datových inženýrů, kteří používají nástroje ETL k poznání schématu, a obchodních analytiků, kteří znají terminologii.
Váš soubor sémantického modelu by měl obsahovat tyto klíčové komponenty:
| Komponenta | Účel |
| Tabulky | Uvádí seznam všech tabulek s popisem jejich účelu v běžném jazyce |
| Sloupce | Definuje sémantický typ každého sloupce (například kategorii nebo metriku) a může obsahovat vzorové hodnoty |
| Vztahy | Určuje, jak se tabulky propojují pomocí spojení, čímž eliminuje jakékoli dohady ze strany AI |
| Ověřené dotazy | Obsahuje příklady dvojic otázek a SQL dotazů, které slouží jako užitečné vodítko pro LLM |
3. Nakonfigurujte službu Cortex Search Service (volitelné)
Někdy jsou odpovědi, které potřebujete, skryté v nestrukturovaném textu, jako jsou popisy produktů, žádosti o podporu nebo přepisy hovorů. Standardní dotazy SQL se k těmto datům nedostanou, což znamená, že vám často uniká „proč“ za „čím“.
Zde můžete volitelně přidat službu Snowflake Cortex Search Service. Jedná se o vrstvu typu „search-as-a-service“, která vám umožňuje současně dotazovat jak strukturované tabulky, tak nestrukturovaná textová data pomocí agentů AI pro analýzu dat.
Cortex Search byste měli nakonfigurovat, pokud vaši analytici potřebují klást otázky, které vyžadují získání kontextu z textu před generováním SQL. Můžete například nejprve vyhledat všechny recenze produktů obsahující frázi „problém s baterií“ a poté vygenerovat dotaz SQL, který agreguje údaje o prodeji pouze těchto produktů.
Pro generování čistého kódu SQL pro strukturované tabulky není tato služba nutná.
🧠 Zajímavost: Na počátku 70. let 20. století vytvořili výzkumníci IBM Donald Chamberlin a Raymond Boyce jazyk „Structured English Query Language“. Museli však název změnit na SQL, protože název „SEQUEL“ již byl chráněn jako ochranná známka britské letecké společnosti.
Podrobný průvodce generováním SQL pomocí Cortex Analyst
Přípravné práce máte za sebou, ale nyní stojíte před prázdnou obrazovkou a nejste si jisti, jak vlastně postupovat. Jak se dostat od otázky v hlavě k spustitelnému dotazu SQL? Pokud není jasné, jak postupovat, nové nástroje často zůstávají nevyužité a investice do jejich nastavení přichází vniveč.
Praktický postup je příjemně jednoduchý. Podívejme se na to blíže!
Krok č. 1: Připravte si data ve Snowflake
Především musí být vaše strukturovaná data uložena ve Snowflake. Každá aplikace Cortex Analyst je nasměrována buď na jednu tabulku, nebo na pohled složený z jedné či více tabulek. Ujistěte se, že jsou vaše tabulky vytvořeny a naplněny.
Pokud načítáte data z plochých souborů:
- Nahrajte své datové soubory (např. CSV) do Snowflake Stage
- Pomocí příkazu COPY INTO načtěte data ze stage do svých tabulek
- Než budete pokračovat, ověřte, zda se data úspěšně načtou
📖 Přečtěte si také: Jak používat Snowflake Cortex pro podnikovou analytiku
Krok č. 2: Vytvořte sémantický model (nebo sémantický pohled)
Toto je nejdůležitější krok při nastavení. Síla nástroje Cortex Analyst spočívá v kombinaci velkých jazykových modelů (LLM) se sémantickými modely, což je soubor YAML, který je umístěn vedle schématu vaší databáze a kóduje obchodní kontext.
Sémantické pohledy jsou nyní doporučenou metodou Snowflake pro Cortex Analyst. Ukládají obchodní metriky, vztahy a definice přímo do Snowflake. Starší soubory sémantických modelů YAML stále fungují, ale Snowflake směřuje nové implementace k sémantickým pohledům.
Váš sémantický model nebo pohled by měl obsahovat:
- Popisy tabulek a sloupců: Vysvětlení v běžném jazyce, co jednotlivá pole znamenají
- Obchodní metriky: Definice pro vypočítaná pole, jako jsou tržby, míra odchodu zákazníků nebo míra konverze
- Filtry a synonyma: Alternativní výrazy, které mohou uživatelé použít (např. „zrušeno“ přiřazené ke konkrétní hodnotě stavu)
- Ověřené dotazy: Úložiště ověřených dotazů Snowflake ukládá schválené páry otázek a SQL. Pokud se otázka uživatele podobá některé z těchto položek, může Cortex Analyst při generování SQL na ni odkazovat.
🤝 Přátelské připomenutí: Snowflake doporučuje pro optimální výkon v pracovním postupu Snowsight použít maximálně 10 tabulek a maximálně 50 vybraných sloupců.
Krok č. 3: Nahrajte sémantický model do Snowflake Stage
Pokud používáte sémantický model založený na YAML, je třeba jej připravit, aby na něj mohl Cortex Analyst odkazovat v době běhu.
- Nahrajte svůj soubor .yaml do interní fáze Snowflake (např. RAW_DATA)
- Ověřte, zda se soubor objeví ve fázi, a to prostřednictvím uživatelského rozhraní Snowsight nebo příkazu LIST @stage_name.
- Poznamenejte si cestu ke stage; budete na ni odkazovat ve svých voláních API nebo v konfiguraci aplikace
Pokud používáte sémantický pohled, tento krok se provádí nativně v rámci Snowflake a není nutné žádné samostatné nahrávání.
🔍 Věděli jste, že? NULL v SQL neznamená nulu ani prázdnou hodnotu. Představuje neznámá nebo chybějící data, což vede k neintuitivnímu chování, jako jsou porovnání, která nevracejí ani hodnotu true, ani false.
Krok č. 4: Odeslání dotazu v přirozeném jazyce prostřednictvím REST API
Nyní začíná samotná generace SQL. REST API vygeneruje SQL dotaz pro danou otázku pomocí sémantického modelu nebo sémantického pohledu poskytnutého v požadavku.
Strukturovejte svůj požadavek API pomocí:
- zprávy; pole obsahující otázku uživatele s rolí: „user“
- Odkaz na váš sémantický model nebo sémantický pohled
- Váš preferovaný model (nebo ponechte nastavení „auto“, aby Cortex vybral ten nejlepší)
Můžete vést vícekolové konverzace, ve kterých můžete klást navazující otázky vycházející z předchozích dotazů.
Krok č. 5: Analyzujte odpověď API
Každá zpráva v odpovědi může obsahovat více bloků obsahu různých typů. Tři hodnoty, které jsou v současné době podporovány pro pole typu, jsou: text, návrhy a SQL.
Zde je vysvětlení jednotlivých typů:
- SQL: Cortex úspěšně vygeneroval dotaz; toto je to, co budete provádět
- text: Vysvětlení nebo odpověď v přirozeném jazyce doprovázející dotaz SQL
- návrhy: Typ obsahu „návrh“ je zahrnut v odpovědi pouze v případě, že otázka uživatele byla nejednoznačná a Cortex Analyst nemohl pro daný dotaz vrátit příkaz SQL. Použijte je k upřesnění nebo zpřesnění otázky
🔍 Věděli jste, že? Pořadí, v jakém píšete SQL, není pořadí, v jakém se provádí. I když napíšete SELECT jako první, databáze ve skutečnosti zpracují FROM a WHERE ještě před výběrem sloupců. To mate jak začátečníky, tak zkušené uživatele.
Krok č. 6: Spusťte vygenerovaný kód SQL v Snowflake
Jakmile získáte blok SQL z odpovědi, spusťte jej ve svém virtuálním skladu Snowflake. Generovaný dotaz SQL se provede ve vašem virtuálním skladu Snowflake a vygeneruje konečný výstup. Data zůstávají v rámci správy Snowflake.
Klíčové informace, které je třeba znát v době provádění:
- Cortex Analyst je plně integrován s politikami řízení přístupu na základě rolí (RBAC) Snowflake, což zajišťuje, že generované a prováděné dotazy SQL dodržují všechna stanovená pravidla řízení přístupu.
- Pokud uživatel nemá přístup k tabulce, dotaz selže při provedení, stejně jako by tomu bylo u ručně psaného SQL.
- V této fázi se účtují náklady na výpočetní výkon datového skladu, které jsou oddělené od poplatků za používání služby Cortex Analyst.
Krok č. 7: Vylepšujte a opakujte
Není vždy zaručeno, že se vám podaří vytvořit dokonalý dotaz hned na první pokus. Zde je návod, jak výsledky postupem času vylepšovat:
- Přidejte ověřené dotazy do svého sémantického modelu pro otázky, které se opakovaně vyskytují
- Obohaťte svůj sémantický model o lepší popisy, synonyma a filtry, když Cortex nesprávně interpretuje nějaký termín
- Využijte vícekolovou konverzaci k navázání, například „Teď to filtruj podle regionu“ – vícekolové konverzace umožňují navazující otázky, které vycházejí z předchozích dotazů
- Sledujte využití pomocí CORTEX_ANALYST_USAGE_HISTORY a historie dotazů Snowflake, abyste odhalili vzorce v neúspěšných nebo nepřesných dotazech
🠠 Zajímavost: Jedna chybějící podmínka JOIN může způsobit obrovské problémy. Zapomenutí na podmínku JOIN může vést ke vzniku kartézského součinu, který dramaticky znásobí počet řádků a někdy způsobí selhání systému.
Osvědčené postupy pro přesnost převodu textu na SQL v Snowflake
Kvalita vašeho sémantického modelu přímo určuje přesnost dotazů, které generuje. Zde jsou osvědčené postupy, které zvyšují přesnost. 🛠️
- Přidejte ověřené dotazy do svého sémantického modelu: To je to nejúčinnější, co můžete udělat. Zahrňte spoustu příkladů dvojic otázka-SQL, které odrážejí, jak váš tým skutečně klade otázky
- Používejte popisné názvy sloupců a tabulek: Model funguje lépe, když jsou názvy sloupců a tabulek srozumitelné. Pokud nemůžete změnit schéma, přidejte do souboru YAML jasné popisy pro všechny nesrozumitelné názvy sloupců
- Zahrňte vzorové hodnoty: Přidání vzorových dat pro kategorické sloupce (jako je stav nebo region) pomáhá modelu porozumět platným dostupným možnostem filtrování
- Testujte s okrajovými případy: Během vývoje záměrně klást nejednoznačné nebo záludné otázky, abyste zjistili, kde váš sémantický model potřebuje více kontextu nebo upřesnění
- Vylepšujte svůj sémantický model: Považujte svůj sémantický model za živý dokument. Měl by být průběžně aktualizován prostřednictvím iterativního procesu založeného na tom, které dotazy jsou úspěšné a které neúspěšné
ClickUp: Jednodušší alternativa k Snowflake Cortex
Snowflake Cortex se osvědčuje v situacích, kdy týmy chtějí generovat SQL a spouštět dotazy na strukturovaných datech. Týmy definují schémata, mapují vztahy a píší dotazy za účelem získání poznatků. Takové nastavení dává smysl v prostředích s velkým objemem dat, zejména pokud za reporting odpovídají analytici.
Mnoho týmů však k zodpovězení běžných provozních otázek nepotřebuje plnohodnotnou vrstvu SQL. Produktoví manažeři, vedoucí programů a provozní týmy často chtějí rychlé odpovědi související s aktuální prací.
ClickUp nabízí přístupnější cestu. Týmy kladou otázky v běžném jazyce, prohlížejí si živé dashboardy a reagují na získané poznatky, aniž by musely psát SQL nebo vytvářet sémantické modely.
Rychlejší generování a vylepšování dotazů SQL
Snowflake Cortex se zaměřuje na generování dotazů SQL ze strukturovaných datových sad v prostředí datového skladu. To funguje dobře, pokud jsou vaše data již uložena ve Snowflake a máte zmapovaná schémata.

ClickUp Brain podporuje generování SQL flexibilnějším způsobem zaměřeným na provádění. Týmy generují, vylepšují a ukládají dotazy SQL přímo ve svém pracovním prostoru, kde již probíhají analýzy, diskuse a rozhodování.
Představte si, že produktový analytik pracuje na analýze retence v ClickUp. Místo toho, aby přepínal mezi nástroji pro psaní dotazů, zeptá se ClickUp Brain:
📌 Vyzkoušejte tento příkaz: Napište dotaz SQL pro výpočet sedmidenní retence uživatelů seskupených podle kohorty registrace.
ClickUp Brain generuje strukturovaný dotaz, který zahrnuje seskupení kohort, filtry podle data a logiku retence. Analytik vloží dotaz do Snowflake nebo jiného datového skladu a okamžitě jej spustí.
Pomáhá:
- Vytvářejte spojení mezi více tabulkami, jako jsou uživatelé, objednávky a události
- Převádějte jednoduché otázky týkající se produktů v běžné angličtině na logiku SQL připravenou k provedení
- Odstraňujte chyby v dotazech a vysvětlujte problémy, jako jsou nesprávné spojení nebo chybějící podmínky
- Přepište dotazy pro lepší výkon nebo čitelnost
Například při revizi experimentu zaměřeného na růst se marketér zeptá: „Napište dotaz SQL, který porovná míry konverze mezi dvěma vstupními stránkami za posledních 14 dní“.
ClickUp Brain generuje dotaz pomocí podmíněné agregace a filtrů podle data. Tým jej spustí v Snowflake a ověří výsledky experimentu.
📌 Vyzkoušejte tento příkaz: Opravte tento dotaz SQL, ve kterém spojení duplikuje řádky, a vysvětlete, v čem spočívá problém.
ClickUp Brain identifikuje problém se spojováním, opraví dotaz a vysvětlí, jak došlo k duplicitním řádkům v důsledku nesprávných podmínek spojování.
Nahraďte reportování založené na SQL
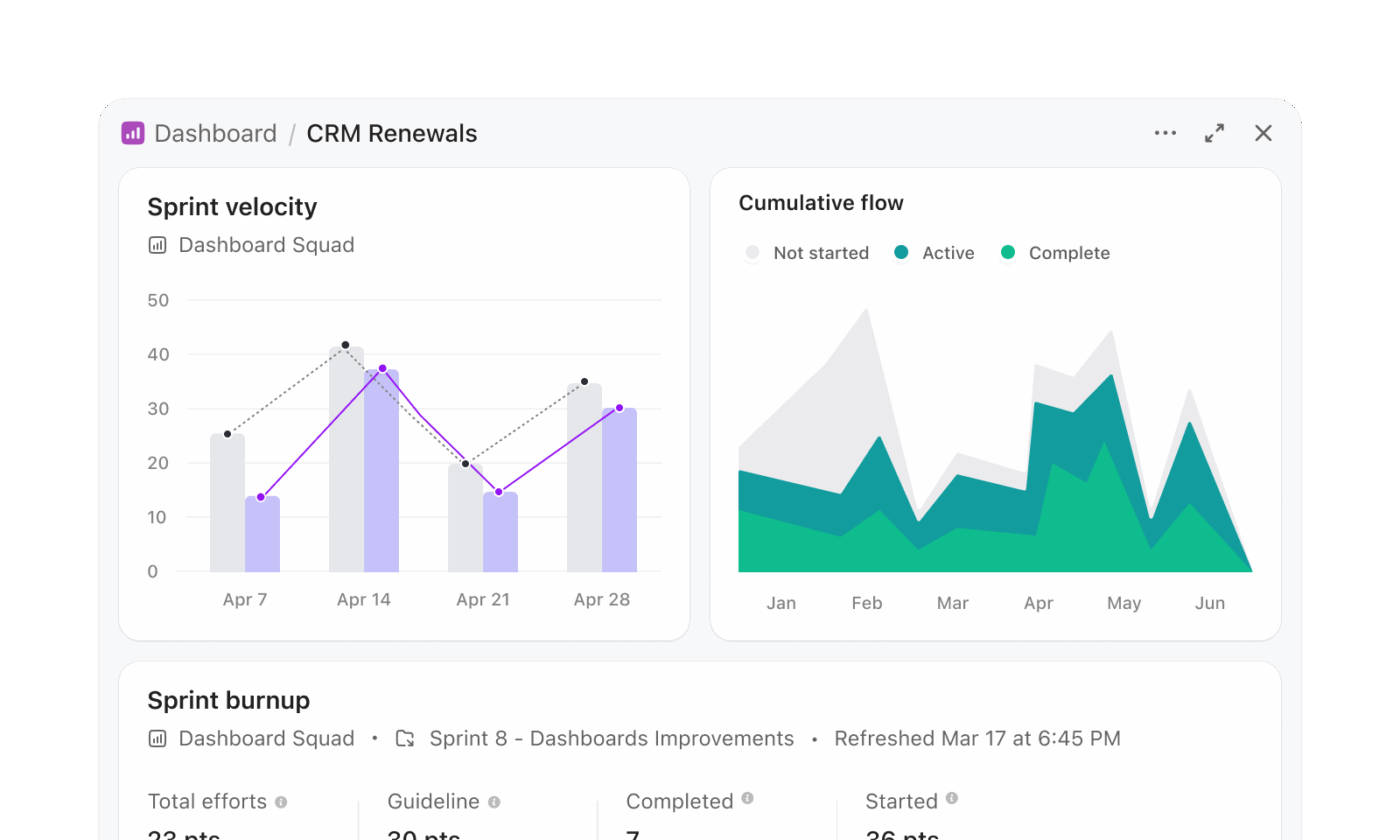
Pracovní postupy Snowflake Cortex často zahrnují generování SQL, spouštění dotazů a vizualizaci výsledků v samostatné vrstvě. Dashboardy ClickUp tento vícestupňový proces eliminují a prezentují poznatky přímo z živé práce.
Tým pro správu programu, který sleduje připravenost vydání, může vytvořit dashboard bez nutnosti psát dotazy. Dashboard vydání může například obsahovat:
- Karta se seznamem úkolů filtrovaná tak, aby zobrazovala úkoly po termínu ve všech produktových týmech
- Karta pracovního zatížení, která zobrazuje rozložení úkolů mezi inženýry
- Sloupcový graf porovnávající dokončené a nevyřízené úkoly podle sprintu
- Výpočetní karta sledující průměrnou dobu dokončení
Představme si, že vedoucí programu před schůzkou k vydání zkontroluje tento dashboard. Okamžitě si všimne, že backendové služby vykazují vyšší míru zpoždění. Otevře kartu se seznamem úkolů a zkontroluje konkrétní úkoly, které představují riziko.
Zkušenosti skutečného uživatele ClickUp:
ClickUp nám umožňuje RYCHLE si předávat projekty, SNADNO kontrolovat stav projektů a dává naší nadřízené přehled o našem pracovním vytížení kdykoli, aniž by nás musela rušit. Díky ClickUp jsme určitě ušetřili jeden den v týdnu, ne-li více. Počet e-mailů se VÝRAZNĚ snížil.
ClickUp nám umožňuje RYCHLE si předávat projekty, SNADNO kontrolovat stav projektů a dává naší nadřízené přehled o našem pracovním vytížení kdykoli, aniž by nás musela rušit. Díky ClickUp jsme určitě ušetřili jeden den v týdnu, ne-li více. Počet e-mailů se VÝRAZNĚ snížil.
Reagujte na poznatky bez nutnosti vytvářet datové potrubí
Snowflake Cortex se zaměřuje na získávání poznatků z dat. Týmy stále musí výsledky interpretovat a spouštět akce samostatně.
Super agenti ClickUp AI tuto mezeru vyplňují a proměňují poznatky v konkrétní kroky. Fungují jako AI kolegové, kteří nepřetržitě monitorují data v pracovním prostoru a na základě podmínek podnikají příslušné kroky.
Předpokládejme, že programový manažer dohlíží na několik produktových iniciativ. Super Agent může:
- Sledujte úkoly napříč projekty a zjistěte, kdy počet zpožděných úkolů překročí definovanou hranici
- Identifikujte vzorce, jako jsou opakovaná zpoždění ve stejné fázi pracovního postupu
- Vytvořte úkol, který shrne dotčené projekty, a přiřaďte jej vedoucímu programu
- Upozorněte vedoucí týmů, pokud kritické úkoly zůstávají nevyřešené i po uplynutí termínů
Například během cyklu vydávání aktualizací Super Agent zjistí, že ve dvou týmech bylo zmeškáno více než 10 úkolů s vysokou prioritou. Vytvoří úkol ClickUp s názvem „Riziko vydání: zmeškané termíny“, připojí k němu všechny relevantní úkoly a přiřadí jej programovému manažerovi k okamžitému posouzení.
Týmy mohou také přímo komunikovat se Super Agentem: „Analyzuj všechny aktivní projekty a vyznač rizika dodání pro tento sprint“.
Super Agent zkontroluje termíny, závislosti a stav úkolů a poté zveřejní strukturované shrnutí v pracovním prostoru.
Takto si v ClickUp nastavíte svého vlastního Super agenta:
Centralizujte své datové pracovní postupy pomocí ClickUp
Nástroje typu text-to-SQL, jako je Snowflake Cortex, zvyšují přístupnost dat. Získání spolehlivých výsledků však stále vyžaduje určité úsilí.
Týmy potřebují čistá schémata, silné sémantické modely a neustálé iterace, aby výstupy zůstaly přesné. Ani po vygenerování správného dotazu práce nekončí. Někdo stále musí výsledky interpretovat, sdílet poznatky a proměnit je v rozhodnutí.
ClickUp přináší odlišný přístup. Namísto oddělení analýzy od provedení ClickUp obě tyto činnosti propojuje. Týmy generují dotazy SQL, dokumentují poznatky, spolupracují na zjištěních a reagují na ně v rámci stejného pracovního prostoru.
ClickUp Brain pomáhá psát a vylepšovat dotazy, zatímco Dashboards a AI Agents pomáhají týmům sledovat výsledky a posouvat práci vpřed, aniž by musely přeskakovat mezi nástroji.
Snowflake Cortex vám pomůže získat odpovědi. ClickUp vám pomůže s nimi pracovat. Zaregistrujte se do ClickUp ještě dnes!
Často kladené otázky
Snowflake Cortex Analyst je specializovaná služba v rámci širší sady Snowflake Cortex AI. Cortex Analyst se zaměřuje konkrétně na generování text-to-SQL pomocí sémantických modelů, zatímco Cortex AI zahrnuje širší škálu funkcí LLM, inferenci modelů strojového učení a vyhledávací funkce.
Ano, Cortex Analyst může dotazovat tabulky Apache Iceberg, které jsou spravovány prostřednictvím Snowflake. Pokud jsou tabulky přístupné ve vašem prostředí Snowflake a správně definovány ve vašem sémantickém modelu, můžete na nich generovat dotazy.
Přesnost složitých dotazů závisí téměř výhradně na kvalitě vašeho sémantického modelu. Model s dobře definovanými vztahy mezi tabulkami, četnými ověřenými dotazy a popisnými metadaty bude poskytovat výrazně přesnější výsledky pro spojení více tabulek a složité agregace.
Ceny služby Snowflake Cortex Analyst se řídí modelem Snowflake založeným na spotřebě, což znamená, že vám budou účtovány náklady na základě výpočetních kreditů použitých během procesu generování dotazů. Aktuální ceny najdete vždy v oficiální cenové dokumentaci Snowflake.