
IT katastrofy mohou nastat bez varování.
Od selhání serverů po kybernetické útoky – bez spolehlivého plánu obnovy může vaše firma čelit hodinovým výpadkům, ztrátě dat a vážným finančním škodám, přičemž 54 % závažných výpadků stojí více než 100 000 USD.
Tento blog vás provede vytvořením komplexního plánu obnovy IT po havárii, který chrání vaše systémy, definuje jasné cíle obnovy a zajišťuje, že váš tým přesně ví, co dělat, když dojde k problému.
Co je plán obnovy IT po havárii?
Kdyby vaše servery právě teď selhaly, věděl by váš tým přesně, co dělat? 🛠️
Plán obnovy IT po havárii (DR) je vaší zdokumentovanou strategií pro obnovení IT systémů a dat po jakémkoli narušení – od přírodních katastrof po kybernetické útoky. Jedná se v podstatě o váš plán pro obnovení technologie, když dojde k problémům.
💡 DR vs. kontinuita podnikání
Obnova po havárii (DR) se zaměřuje konkrétně na obnovení vaší IT infrastruktury a dat. Kontinuita podnikání (BC) je širší pojem, jehož cílem je udržet celý váš podnik v provozu během krize i po ní, i když je IT mimo provoz. Považujte DR za klíčovou součást vaší celkové strategie BC.
💡 DR vs. kontinuita podnikání
Obnova po havárii (DR) se zaměřuje konkrétně na obnovení vaší IT infrastruktury a dat. Kontinuita podnikání (BC) je širší pojem, jehož cílem je udržet celý váš podnik v provozu během krize i po ní, i když je IT mimo provoz. Považujte DR za klíčovou součást vaší celkové strategie BC.
Váš plán obnovy po havárii je důležitý, protože prostoje stojí víc než jen peníze. Každá minuta, kdy jsou vaše systémy mimo provoz, může narušit důvěru zákazníků, přerušit provoz a dokonce vést k pokutám za nedodržení předpisů. Komplexní plán obnovy po havárii je vaší cestou k odolnosti.
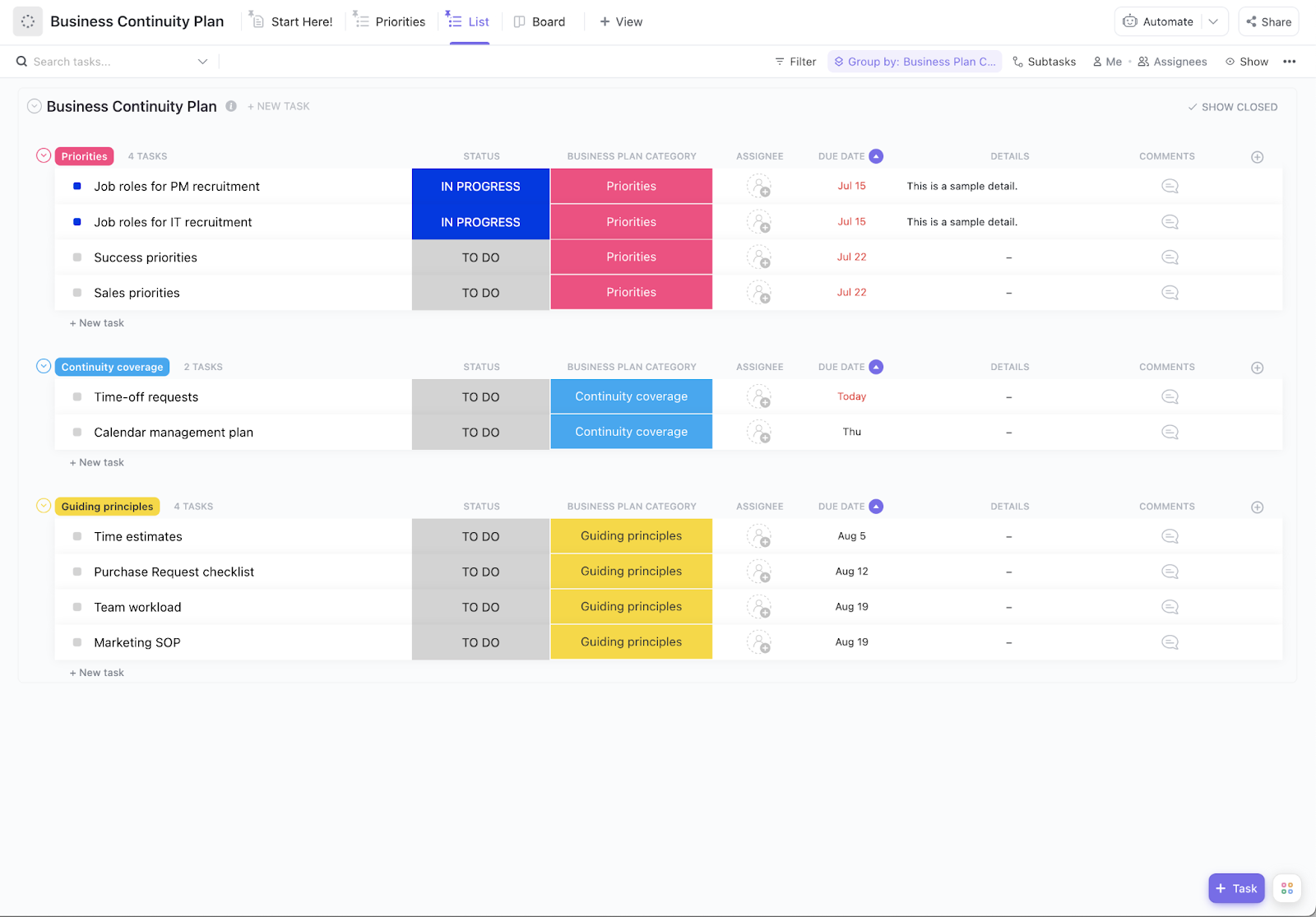
Dobrý plán zahrnuje:
- Postupy zálohování dat: Jak a kde ukládáte kopie důležitých informací, abyste je mohli obnovit
- Kroky obnovy systému: Přesný postup pro obnovení služeb ve správném pořadí
- Odpovědnosti týmu: Kdo co dělá během incidentu, aby se předešlo zmatkům
- Komunikační protokoly: Jak budete informovat zainteresované strany, od svého týmu až po zákazníky
- Cíle obnovy: Vaše konkrétní cíle ohledně toho, jak rychle musí být systémy obnoveny a jaká ztráta dat je přijatelná.
Běžné scénáře IT katastrof a jejich dopady
Katastrofy nejsou jen hollywoodské scénáře, ale každodenní realita podniků. Pochopení toho, před čím se chráníte, vám pomůže vybudovat mnohem silnější obranu.
Přírodní katastrofy a fyzické poškození
Události jako povodně, požáry, zemětřesení a rozsáhlé výpadky proudu mohou během několika minut zničit celá datová centra. Když například datové centrum v Nashvillu zasáhla velká povodeň, některé společnosti přišly o data za několik týdnů a čelily měsíčnímu zotavování. Nejlepší ochranou proti tomuto riziku je geografická redundance, což znamená rozložení infrastruktury do více fyzických lokalit, aby jedna událost nemohla zničit vše.
Kybernetické útoky a ohrožení dat
Ransomware, útoky typu Distributed Denial-of-Service (DDoS) a narušení dat se liší od fyzických katastrof. Často jsou obtížněji detekovatelné, mohou se tiše šířit prostřednictvím propojených systémů a často se zaměřují také na vaše záložní systémy, což činí obnovu obzvláště náročnou. Četnost a sofistikovanost těchto kybernetických útoků ve všech odvětvích neustále roste, přičemž ransomware nyní představuje 44 % všech potvrzených narušení, což z něj činí nejvýznamnější hrozbu.
📖 Další informace: 10 způsobů, jak snížit rizika kybernetické bezpečnosti v projektovém řízení
Poruchy hardwaru a ztráta dat
Někdy se i ty nejlépe otestované a nejspolehlivější zálohovací systémy prostě porouchají. K selhání serverů, poruchám úložišť a poruchám síťových zařízení může dojít bez varování. I když máte redundantní (záložní) systémy, mohou selhat současně, pokud sdílejí společné komponenty nebo zdroje napájení, což vytváří jediný bod selhání.
👀 Věděli jste, že: V říjnu 2025 došlo v AWS k výraznému výpadku, když chyba v interním systému správy DNS pro Amazon DynamoDB způsobila selhání překladu doménových jmen v datovém centru US-EAST-1. Tato „malá“ technická závada vyvolala kaskádový výpadek desítek služeb AWS a způsobila výpadek stovek populárních aplikací a platforem po celém světě – od aplikací pro zasílání zpráv a sociálních sítí až po banky, herní weby a další. Pro mnoho lidí tento výpadek dočasně způsobil „zmizení“ velké části internetu, což poukázalo na to, jak křehká je naše digitální infrastruktura, když tolik závisí na několika málo poskytovatelích cloudových služeb.
Chyby softwaru a přerušení služeb
Poškozená databáze, neúspěšná aktualizace softwaru nebo jednoduchá chyba v konfiguraci mohou způsobit výpadek celé platformy. Možná jste si všimli, že jedna nesprávně nakonfigurovaná řádka kódu může mít kaskádový efekt na propojené systémy a způsobit rozsáhlý výpadek s velkým dosahem. Správné řízení změn a specializovaná testovací prostředí jsou vašimi nejlepšími pomocníky při minimalizaci těchto rizik.
Lidské chyby a nesprávné konfigurace
Náhodné smazání, nesprávné konfigurace a neoprávněné změny zůstávají jednou z nejčastějších příčin výpadků IT. Jediný nesprávný příkaz nebo smazaný soubor může způsobit několikahodinový výpadek a zhoršení kvality služeb. Školení a kontrola přístupu sice pomáhají, ale lidské chyby nelze zcela vyloučit.
📮ClickUp Insight: 92 % zaměstnanců používá nekonzistentní metody ke sledování akčních položek, což vede k opomenutým rozhodnutím a zpožděnému provedení.
Ať už posíláte následné poznámky nebo používáte tabulky, proces je často roztříštěný a neefektivní. S funkcemi správy úkolů ClickUp se o to už nikdy nebudete muset starat. Vytvářejte úkoly z chatu, komentářů k úkolům ClickUp, dokumentů a e-mailů jediným kliknutím!
Klíčové součásti plánu obnovy IT po havárii
Spolehlivý plán obnovy po havárii je vaším kompletním návodem pro návrat do online provozu. Každá z těchto složek navazuje na ostatní a společně vytvářejí komplexní ochranu pro vaši firmu.
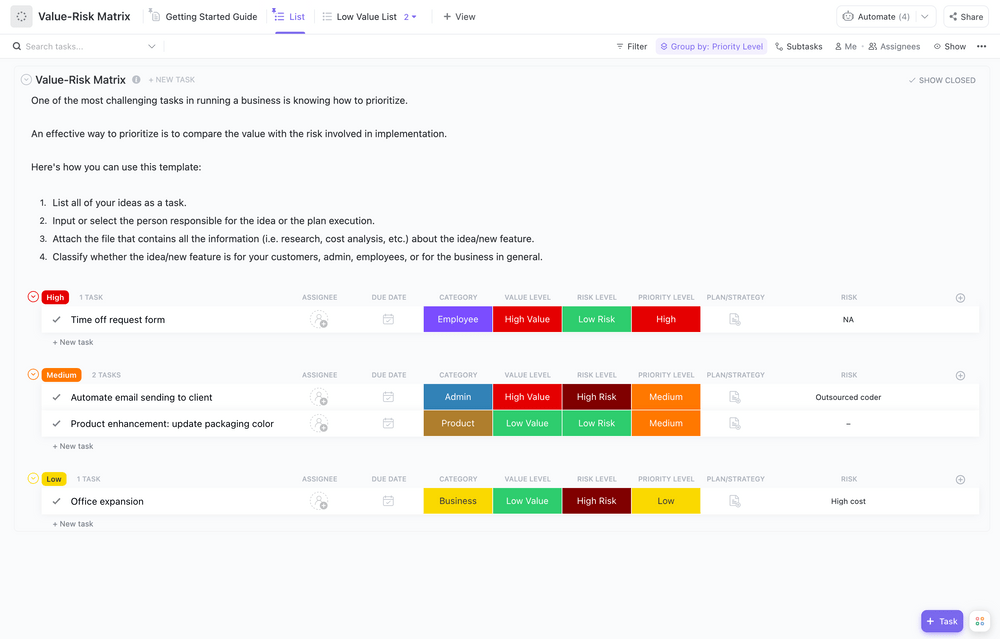
Posouzení rizik a stanovení priorit
Nejprve musíte vědět, čemu čelíte. Posouzení rizik je proces identifikace vašich zranitelných míst a vyhodnocení pravděpodobnosti a dopadu každé potenciální hrozby. Můžete to uspořádat do matice rizik, abyste zjistili, které hrozby jsou nejzávažnější.
Vaše hodnocení by mělo zahrnovat:
- Kritické systémy: Co musí bezpodmínečně zůstat v provozu, aby vaše firma mohla fungovat
- Citlivost dat: Které informace vyžadují nejvyšší úroveň ochrany (například údaje o zákaznících)?
- Závislosti: Jaké další systémy nebo procesy přestanou fungovat, když dojde k selhání některého systému?
📖 Další informace: Jak implementovat správu IT infrastruktury
Analýza dopadu na podnikání a kritičnost
Dále zjistěte skutečné náklady výpadků. Analýza dopadu na podnikání (BIA) vám pomůže určit finanční a provozní dopad výpadku pro každý systém. To vám umožní klasifikovat vaše systémy podle úrovně kritičnosti a stanovit priority vašich obnovovacích opatření.
| Kritické | Méně než jedna hodina | Zpracování plateb, databáze zákazníků |
| Vysoká | Jedna až čtyři hodiny | E-mail, interní komunikační nástroje |
| Střední | Čtyři až 24 hodin | Vývojová prostředí, nástroje pro reporting |
| Nízká | 24+ hodin | Archivační systémy, testovací servery mimo produkční prostředí |
Cíle RTO a RPO
Tyto dvě zkratky jsou jádrem vaší strategie obnovy.
- Cílová doba obnovy (RTO): Jedná se o maximální dobu, po kterou si můžete dovolit, aby byl systém mimo provoz. Odpovídá na otázku: „Jak rychle potřebujeme, aby byl systém znovu online?“
- Cíl bodu obnovy (RPO): Jedná se o maximální množství dat, které si můžete dovolit ztratit, měřené v čase. Odpovídá na otázku: „Kolik dat můžeme ztratit, aniž by to mělo závažné následky?“
Například váš interní e-mailový systém může mít RTO čtyři hodiny, ale vaše databáze e-commerce pro zákazníky může mít RPO pouze 15 minut, což znamená, že nesmíte ztratit více než 15 minut transakčních dat.
Plán zálohování a obnovy dat
Váš záložní plán je vaší nejvyšší bezpečnostní sítí. Běžnou osvědčenou praxí je pravidlo 3-2-1: uchovávejte alespoň tři kopie důležitých dat, uložte je na dva různé typy médií a jednu z těchto kopií uchovávejte mimo pracoviště.
Budete si také moci vybrat mezi různými typy zálohování:
- Úplné zálohy: Kompletní kopie všech dat, obvykle prováděná týdně nebo měsíčně.
- Přírůstkové zálohy: Zálohují pouze změny provedené od poslední zálohy jakéhokoli typu.
- Diferenciální zálohy: Zálohuje všechny změny provedené od poslední úplné zálohy.
Nejdůležitější je pravidelně testovat proces obnovy záloh. Netestovaná záloha je jen naděje, nikoli plán.
💟 Bonus: Zaznamenejte důležité podrobnosti během stresových incidentů pomocí funkce ClickUp Brain MAX „talk-to-text“, abyste nikdy nezmeškali důležité informace, i když není praktické psát. Stačí vyslovit své postřehy a dokumentaci necháte na AI.
Komunikační plán a aktualizace pro zúčastněné strany
Když dojde k havárii, jasný komunikační plán je základ. Váš plán musí definovat řetězce oznámení, jak často budete poskytovat aktualizace a jaké kanály budete používat pro každý typ incidentu.
Různé skupiny potřebují různé informace:
- Interní týmy: Potřebují technické podrobnosti a konkrétní akční body.
- Zákazníci: Potřebujete znát stav služby a kdy očekáváte její vyřešení.
- Dodavatelé: Může být nutné je zapojit pro podporu nebo eskalaci.
- Regulační orgány: V závislosti na odvětví mohou vyžadovat formální oznámení.
Nástroje, jako je tato připravená šablona komunikačního plánu od ClickUp, vám pomohou rychleji reagovat na krizové situace díky zavedenému protokolu.

Testovací a školicí program
Plán, který nikdy netestujete, je plán, který selže. Pravidelné testování odhalí mezery a slabiny ještě předtím, než dojde ke skutečné katastrofě.
Naplánujte si různé typy testů v průběhu celého roku:
- Simulační cvičení: Váš tým projde scénářem katastrofy na papíře, aby ověřil logiku plánu.
- Částečné převzetí služeb při selhání: Testujete obnovení konkrétních, nekritických komponent nebo služeb.
- Kompletní testy obnovy po havárii: Provedete kompletní převzetí služeb záložními systémy (konečný test).
Po každém testu aktualizujte dokumentaci a okamžitě proškolte nové členy týmu v postupech.
📖 Další informace: Jak vyvinout účinné IT politiky a postupy
Kroky k vytvoření plánu obnovy IT po havárii
Vytvoření plánu obnovy po havárii nemusí být nijak složité.
Zde je návod, jak na to postupovat krok za krokem. 🙌
Krok 1: Vytvořte inventář aktiv
Nemůžete chránit to, o čem nevíte, že máte. Začněte vytvořením inventáře aktiv, který obsahuje seznam veškerého hardwaru, softwaru, úložišť dat a systémových závislostí ve vašem prostředí. Nezapomeňte uvést kontakty na dodavatele, licenční klíče a podrobnosti o konfiguraci, abyste je měli po ruce pro rychlou referenci během obnovy.

Šablona ClickUp ITAM spojuje správu incidentů, správu problémů, správu změn, jednoduchá řešení správy aktiv a správu znalostí. Naše šablona ITSM Known Errors zjednodušuje sledování známých chyb ve vašich systémech. Prozkoumejte všechny naše IT šablony, jakmile se změní váš účel.
Přizpůsobte si pracovní postupy podle svých představ pro každou fázi ITAM, od nasazení a konfigurace až po údržbu a vyřazení.
Krok 2: Klasifikujte kritické služby
Nyní určete, která z těchto aktiv jsou kriticky důležitá a která jsou pouze příjemným doplňkem. Vytvořte mapy závislostí služeb, které ukazují, jak jsou vaše systémy propojeny a jak se navzájem ovlivňují. Zvláštní pozornost věnujte službám orientovaným na zákazníky, které mají přímý dopad na tržby nebo uživatelský komfort.
🎥 Podívejte se na tento praktický návod, který ukazuje, jak vytvořit strukturovaný plán na vysoké úrovni pomocí výkonných funkcí ClickUp – od stanovení cílů po přidělování úkolů a sledování pokroku.
Krok 3: Posouzení rizik a hrozeb
Posuďte rizika a hrozby vyhodnocením pravděpodobnosti a dopadu každého typu hrozby pro vaši konkrétní situaci. Zvažte geografická rizika (nacházíte se v seizmicky aktivní oblasti nebo v záplavové zóně?) a případné hrozby specifické pro vaše odvětví (například změny v předpisech nebo cílené kybernetické útoky). Vše zaznamenejte do registru rizik, abyste je mohli v průběhu času sledovat.

Šablona ClickUp Risk Assessment Whiteboard Template vytváří vizuální rozměr pro váš proces hodnocení rizik. Pomáhá při hodnocení rizik a jejich kategorizaci a inspiruje váš tým ke sdílení poznatků a spolupráci v poutavém a vizuálním formátu.
Tato šablona vám umožní:
- Vyhodnoťte kategorie rizik a potenciální dopady
- Analyzujte data a identifikujte potenciální problematické oblasti.
- Určete preventivní opatření ke snížení rizika.
Díky funkcím, které vám umožňují kreslit, psát a přidávat poznámky, je tato šablona tabule pro řízení rizik ideální pro hodnocení rizik vašeho projektu.
Krok 4: Stanovte cíle RTO a RPO
Spolupracujte přímo se zainteresovanými stranami ve vaší společnosti a definujte, co považují za přijatelnou dobu výpadku a ztrátu dat pro každou úroveň služeb, kterou jste dříve identifikovali. Budete muset vyvážit náklady na rychlejší obnovu s dopadem na podnikání – ne vše vyžaduje okamžitou obnovu bez ztráty dat. Získejte souhlas vedení s těmito cíli.
Krok 5: Definujte cesty pro zálohování a převzetí služeb při selhání
Po stanovení cílů můžete nyní navrhnout technická řešení. Vytvořte strategie zálohování přizpůsobené RPO každého systému a naplánujte podrobné postupy pro převzetí služeb při selhání, včetně alternativních zpracovatelských míst a metod nouzového přístupu. Zahrňte síťové diagramy a podrobné příručky, aby bylo provedení bezchybné.
Krok 6: Přiřaďte role a eskalaci
Definujte strukturu svého týmu pro obnovu po havárii s jasnými odpovědnostmi a rozhodovacími pravomocemi. Vytvořte komplexní seznamy kontaktů s primárními a záložními pracovníky pro každou roli. Matice RACI (Responsible, Accountable, Consulted, Informed – odpovědný, zodpovědný, konzultovaný, informovaný) je skvělým nástrojem k eliminaci zmatků během incidentů s vysokou mírou stresu.
Krok 7: Dokumentujte a sdělte plán
Zdokumentujte a sdělte plán pomocí jasných postupů krok za krokem, které může dodržet každý člen vašeho týmu, i když je pod tlakem. Je velmi důležité uložit tuto dokumentaci na snadno přístupném místě, které je oddělené od vaší primární infrastruktury. Ujistěte se, že každý člen týmu přesně ví, kde plán v případě krize najde.
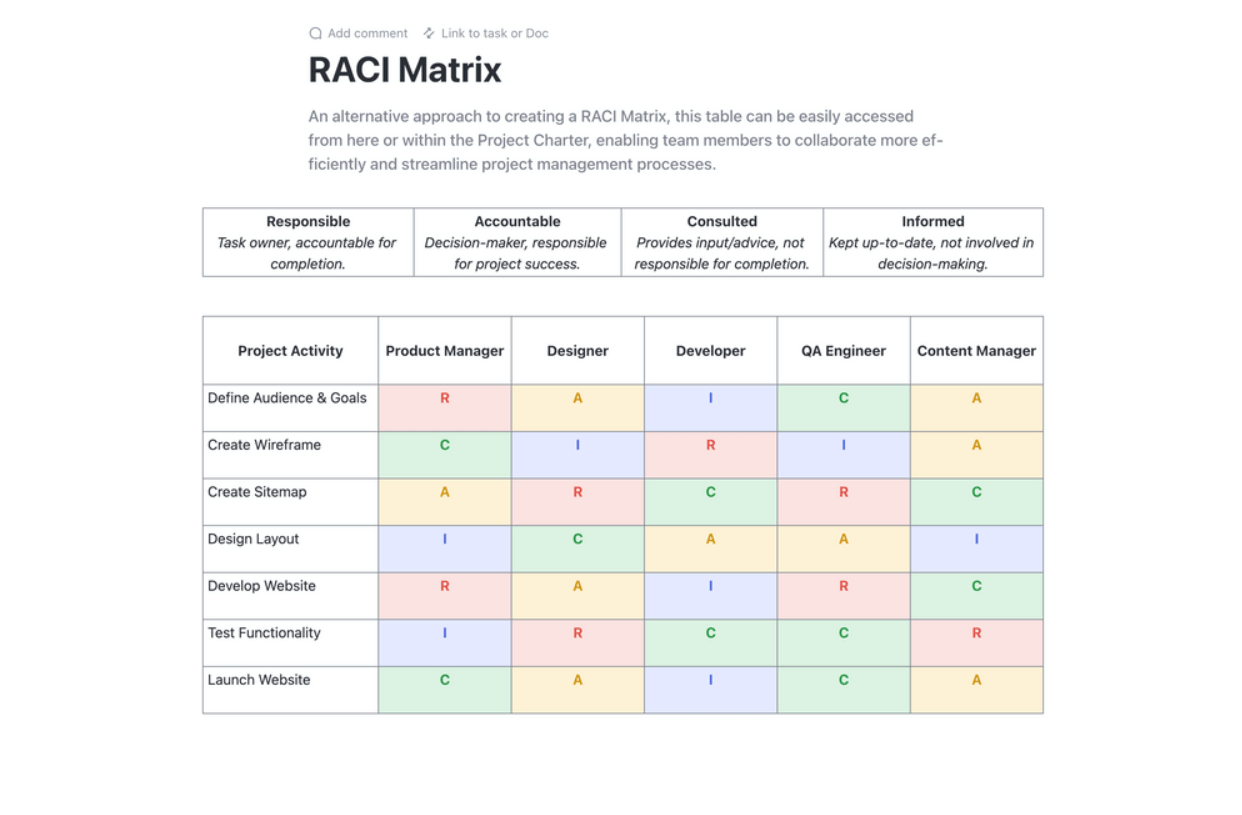
Zefektivněte plánování projektů pomocí šablony RACI Planning Template od ClickUp. Tato šablona Doc je revoluční a nabízí přehledný graf pro definování rolí a odpovědností týmu v souvislosti s úkoly projektu. Využijte rámec RACI (Responsible, Accountable, Consulted, and Informed) k tomu, aby všichni byli na stejné vlně, a zajistěte tak odpovědnost a soulad s cíli organizace.
Krok 8: Testování, kontrola a vylepšování
Nakonec naplánujte čtvrtletní testy, abyste ověřili své postupy a identifikovali případné mezery. Zaznamenejte všechny poznatky získané z každého testu a skutečných incidentů a využijte je k aktualizaci svého plánu. Vytvořte systematický systém sledování zlepšení, abyste zajistili, že všechny nalezené problémy budou vyřešeny.
🌼 Věděli jste, že: V roce 2017 došlo v GitLabu k výpadku databáze. Během obnovy zjistili, že několik jejich zálohovacích metod již několik dní nefungovalo. Tato událost byla pro celý technologický průmysl důležitou lekcí: ověření záloh je nezbytné. Neotestovaná záloha není ve skutečnosti žádnou zálohou.
🌼 Věděli jste, že: V roce 2017 došlo v GitLabu k výpadku databáze. Během obnovy zjistili, že několik jejich zálohovacích metod již několik dní nefungovalo. Tato událost byla pro celý technologický průmysl důležitou lekcí: ověření záloh je nezbytné. Neotestovaná záloha není ve skutečnosti žádnou zálohou.
Strategie a řešení pro obnovu po havárii
Ne každá organizace potřebuje stejný přístup k obnově po havárii. Prozkoumáme vaše možnosti na základě vašeho rozpočtu, potřeb v oblasti obnovy a dostupných zdrojů.
Přístup k zálohování a obnově
Jedná se o nejjednodušší a nejhospodárnější metodu. Zahrnuje pravidelné zálohování na vzdálené místo (například do cloudu nebo sekundárního datového centra) a následné ruční obnovení v případě potřeby. Tento přístup je nejvhodnější pro nekritické systémy, které mohou tolerovat delší RTO, protože obnova může trvat hodiny nebo dokonce dny.
Vysoká dostupnost a redundance
Cílem této strategie je eliminovat jednotlivé body selhání pomocí více aktivních systémů. Techniky jako vyvažování zatížení, serverové clustery a úložiště RAID zajišťují, že pokud jedna komponenta selže, okamžitě ji nahradí jiná. Ačkoli je tento přístup dražší z hlediska nastavení a údržby, může minimalizovat prostoje na pouhé sekundy nebo minuty, což je ideální pro kritické služby.
Možnosti replikace a převzetí služeb při selhání
Replikace zahrnuje kopírování dat v téměř reálném čase na sekundární místo, což zajišťuje minimální ztrátu dat během katastrofy.
- Synchronní replikace: Zapisuje data současně na primární i sekundární lokalitu, čímž zaručuje nulovou ztrátu dat. Vyžaduje však vysokou šířku pásma a může zpomalit váš primární systém.
- Asynchronní replikace: Nejprve zapíše data na primární lokalitu a poté je s mírným zpožděním zkopíruje na sekundární lokalitu. Je levnější a má menší dopad na výkon, ale přijímáte malé riziko ztráty dat.
Obnova po havárii založená na cloudu a DRaaS
Služba Disaster Recovery as a Service (DRaaS) se stala oblíbenou volbou pro mnoho podniků. Nabízí platby podle skutečného využití, okamžitou geografickou distribuci a automatizovanou koordinaci obnovy bez nutnosti budovat a udržovat vlastní fyzická místa pro obnovu po havárii. Cloudová obnova po havárii eliminuje obrovské kapitálové výdaje na záložní datové centrum a zároveň poskytuje rychlejší škálování a větší flexibilitu než tradiční přístupy typu hot, warm nebo cold site.
Jak ClickUp zefektivňuje plánování obnovy IT po havárii
Správa plánu obnovy po havárii v roztříštěných tabulkách, dokumentech a e-mailových řetězcích s sebou nese vlastní riziko havárie.
Tento druh rozptýlení práce, fragmentace práce mezi několika nesouvislými nástroji, které spolu nekomunikují, a rozptýlení kontextu, kdy týmy ztrácejí hodiny hledáním informací roztroušených po různých aplikacích a platformách, vede k záměně, zastaralým informacím a pomalým reakčním časům, když záleží na každé vteřině.
S ClickUp Converged AI Workspace – jedinou bezpečnou platformou, kde jsou všechny vaše pracovní aplikace, data a pracovní postupy spojeny s kontextovou AI jako inteligentní vrstvou – která kombinuje řízení projektů, dokumentaci a týmovou komunikaci. Přestaňte žonglovat s více platformami a sjednoťte plánování, testování a reakci na incidenty v rámci jednoho jednotného systému.
Centralizovaná dokumentace DR s ClickUp Docs a integrovanou asistencí AI
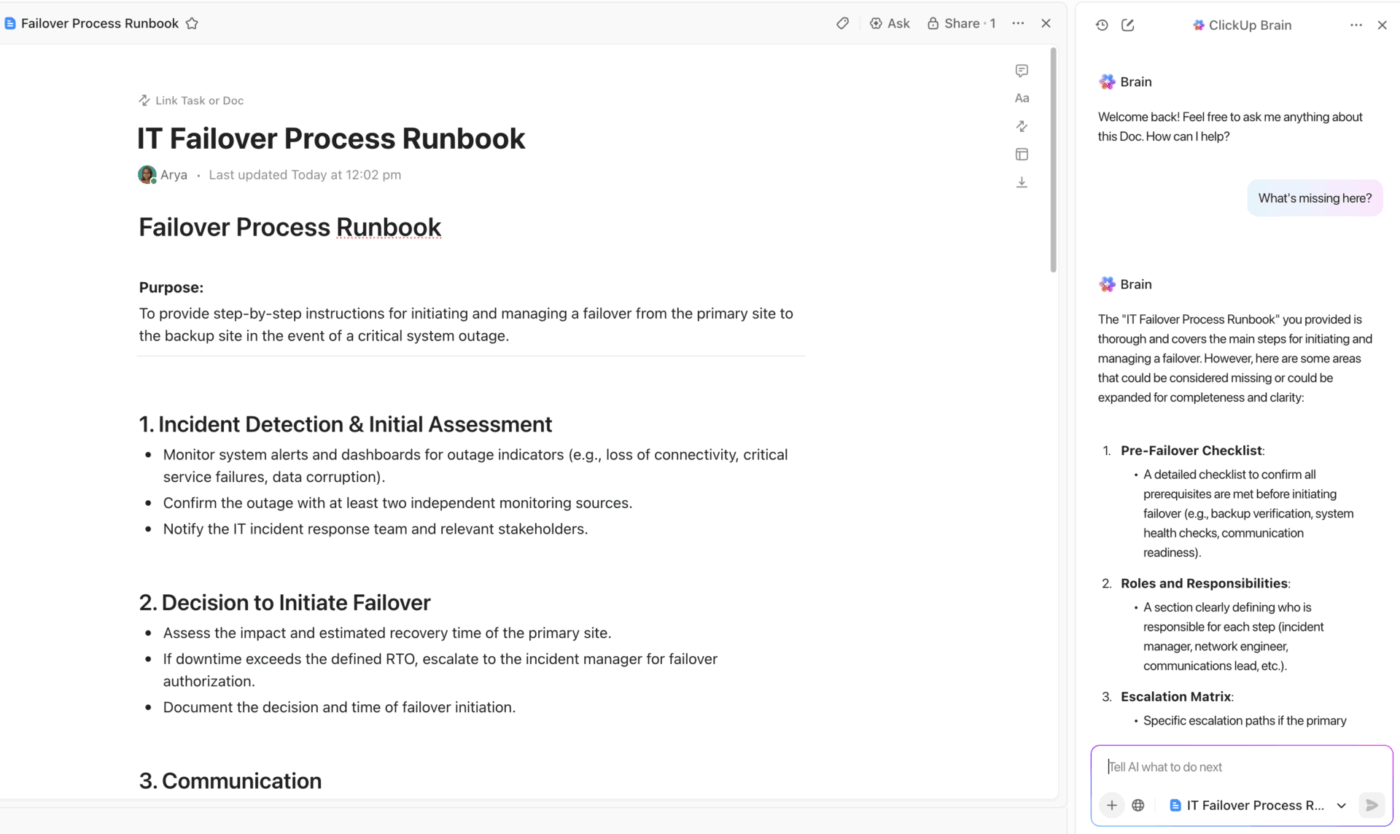
Zajistěte, aby váš tým měl vždy k dispozici jediný zdroj pravdivých informací díky ClickUp Docs.
Vytvořte celý plán obnovy po havárii ve společném prostoru, kde může každý v případě incidentu přispívat v reálném čase. Propojte dokumenty přímo s úkoly a projekty souvisejícími s incidentem, abyste mohli snadno navigovat, a vložte diagramy nebo příručky, abyste měli důležité informace vždy po ruce.
A co je nejlepší, můžete chránit své dokumenty před náhodnými úpravami a pomocí podrobných oprávnění ClickUp kontrolovat, kdo může zobrazit nebo změnit citlivé postupy obnovy. Každá změna je zaznamenána v historii dokumentu, takže máte k dispozici kompletní auditní stopu.
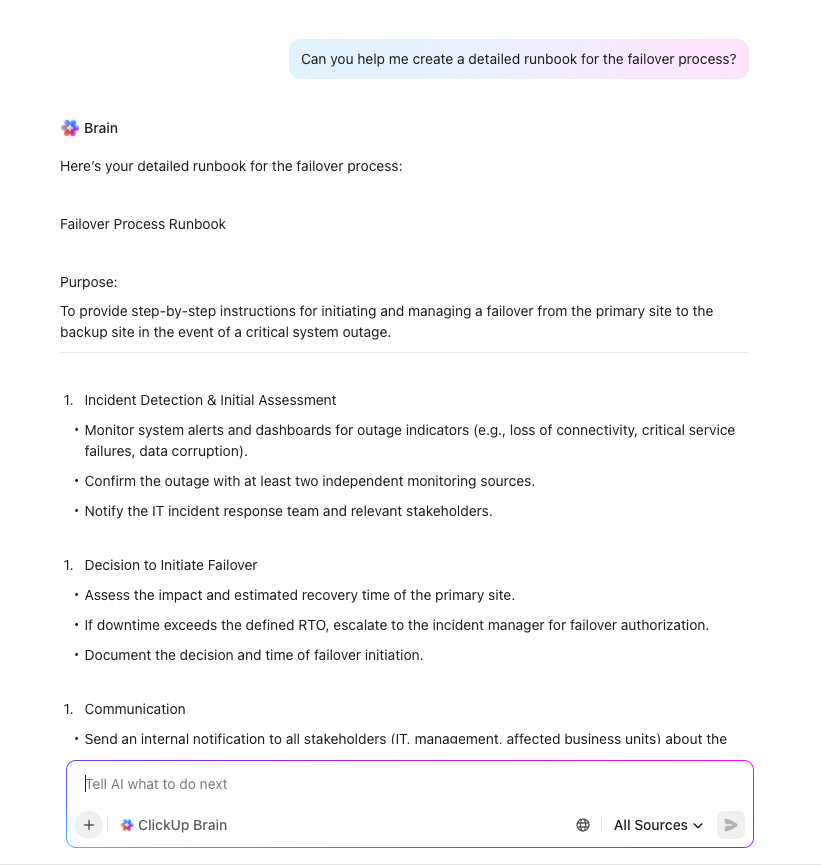
Vytváření plánů pomocí umělé inteligence s ClickUp Brain
Urychlete plánování obnovy po havárii a odstraňte kritické mezery pomocí ClickUp Brain – kontextového asistenta AI, který rozumí celému vašemu pracovnímu prostoru. Na rozdíl od generických nástrojů AI využívá ClickUp Brain skutečné úkoly, dokumenty a pracovní postupy vaší organizace, aby poskytoval přesnou a praktickou podporu pro iniciativy DR.
Stačí zadat do ClickUp Brain požadavek typu „Vytvořte kontrolní seznam pro obnovu po havárii pro naši e-commerce platformu“ a okamžitě obdržíte komplexní šablonu přizpůsobenou vašim systémům, procesům a požadavkům na dodržování předpisů. Může vám pomoci s:
- Kontextové povědomí: ClickUp Brain má přístup ke struktuře, obsahu a oprávněním vašeho pracovního prostoru. Může odkazovat na úkoly, dokumenty, komentáře a dokonce i propojené aplikace a poskytovat odpovědi a akce přizpůsobené vaší skutečné práci – nejen obecné návrhy.
- Řešení problémů a pokyny: Okamžitě řešte problémy, získejte podrobné pokyny nebo požádejte o osvědčené postupy týkající se jakékoli funkce ClickUp. Brain vás provede složitými procesy, automatizuje opakující se úkoly a pomůže vyřešit překážky.
- Automatizace a zrychlení pracovních postupů: Použijte předem připravené nebo vlastní agenty AI k automatizaci vícestupňových pracovních postupů, třídění požadavků nebo správě opakujících se úkolů – ušetříte tak každý týden několik hodin času.
- Hloubkové vyhledávání: Najděte informace ukryté kdekoli ve vašem pracovním prostoru, včetně úkolů, dokumentů a integrovaných nástrojů, i když jsou staré několik let nebo je obtížné je najít pomocí standardního vyhledávání.
- Souhrny a aktualizace v reálném čase: Okamžitě generujte aktualizace projektů, souhrny schůzek nebo zprávy o postupu prací na základě živých dat z pracovního prostoru.
- Zjednodušení technické dokumentace: Převádějte složité technické dokumenty na srozumitelné, praktické postupy nebo kontrolní seznamy, které může váš tým dodržovat i pod tlakem.
- Více modelová inteligence: Vyberte si z předních modelů umělé inteligence (OpenAI GPT-4. 1, GPT-5, Claude, Gemini a další) a dosáhněte nejlepších výsledků při jakékoli úloze – bez nutnosti samostatných předplatných.
- Bezpečné a s ohledem na oprávnění: Brain přistupuje pouze k informacím, ke kterým již máte oprávnění, a dodržuje přísné standardy ochrany soukromí a souladu s předpisy.
- Konverzační rozhraní: Použijte @brain v komentářích nebo chatu, abyste získali kontextové informace, navrhli odpovědi nebo spustili automatizace, aniž byste opustili svůj pracovní postup.
- Vlastní výzvy a uložené pracovní postupy: Ukládejte a znovu používejte výzvy pro opakující se potřeby, čímž zajistíte konzistenci a ušetříte čas celému týmu.
💡Tip pro profesionály: Nezmeškejte žádnou lekci z vašich schůzek k přezkoumání incidentů a zaznamenejte si každý detail pomocí ClickUp AI Notetaker. Může se připojit k vašim virtuálním schůzkám, přepsat celou diskusi a automaticky vygenerovat seznam akčních položek z získaných poznatků. Vytvoří se tak prohledávatelná historie incidentů, takže můžete rychle vyhledat minulé události a jejich řešení.

Automatizované pracovní postupy DR s automatizací ClickUp
Představte si, že váš tým čelí náhlému výpadku – každá vteřina se počítá a nemůžete si dovolit vynechat ani jeden krok. S AI agenty a automatizacemi ClickUp se nemusíte honit ani spoléhat na paměť. Jakmile je incident nahlášen, AI ClickUp se dá do práce, vede váš tým a postará se o rutinní práci, abyste se mohli soustředit na řešení problému.
Takto to funguje v reálném scénáři:
- Když někdo označí úkol jako „Incident Declared“ (Vyhlášení incidentu), ClickUp Agent automaticky vytvoří kontrolní seznam kroků, přiřadí je správným osobám a spustí časovač, který sleduje, jak dlouho trvá obnovení.
- Pokud je incident označen jako „kritický“, agent může okamžitě odeslat výstražný e-mail vašemu vedoucímu týmu a zřídit speciální chatovací místnost – vaši „válečnou místnost“ –, aby všichni mohli komunikovat na jednom místě.
- Umělá inteligence dokáže vyhledat zprávy o minulých incidentech a relevantní dokumentaci, takže váš tým má vše, co potřebuje, na dosah ruky.
Podívejte se na pracovní postup zde:
S ClickUp AI Agents získáte spolehlivého digitálního kolegu, který pomáhá vašemu týmu zůstat klidným, organizovaným a efektivním – i když je pod tlakem.
Sledování v reálném čase pomocí panelů ClickUp
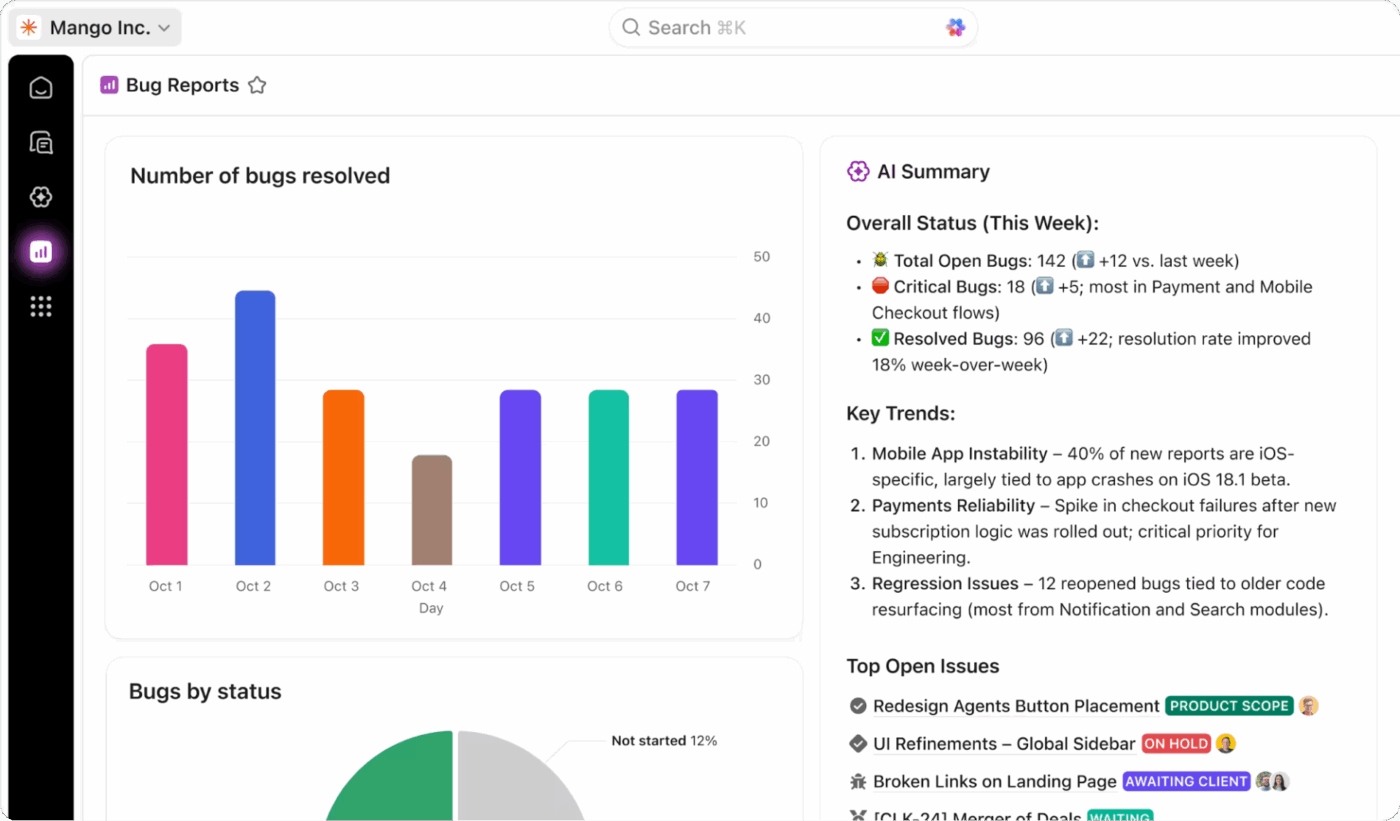
Získejte kompletní přehled o stavu svého programu obnovy po havárii díky sledování všeho v reálném čase pomocí panelů ClickUp Dashboards. Můžete vytvářet widgety pro sledování výkonu RTO a RPO během testů, sledovat míru dokončení testů a zobrazovat trendy incidentů v čase.
Přidejte do svých úkolů vlastní pole ClickUp, abyste mohli sledovat kritičnost systému, stav obnovy a výsledky testů, a poté všechna tato data shromážděte do jednoho přehledného zobrazení. Tyto dashboardy vám poskytnou přehledné reporty, které jsou vždy aktuální a obsahují data v reálném čase z testování a reakcí na incidenty vašeho týmu.
📖 Další informace: Jak vytvořit kontrolní seznam pro posouzení rizik
Vytvořte si svůj plán obnovy po havárii ještě dnes
Každý den, kdy pracujete bez plánu obnovy po havárii, je sázkou, kterou si nemůžete dovolit prohrát. Katastrofy jsou nevyhnutelné – ať už jde o přírodní katastrofy, technologické poruchy nebo lidské chyby – ale vaše příprava rozhoduje o tom, zda se stanou jen drobnými nepříjemnostmi, nebo velkými katastrofami.
Komplexní plán obnovy po havárii vyžaduje pochopení vašich rizik, zdokumentování jasných postupů a jejich pravidelné testování. Správné nástroje tento proces usnadňují tím, že eliminují chaos rozptýlených dokumentů a manuálních procesů.
I základní pohotovostní plány jsou lepší než nic, když dojde k havárii. Pravidelné testování a aktualizace promění váš plán obnovy po havárii z zaprášeného dokumentu na živý systém, který skutečně chrání vaše podnikání.
Udělejte první krok a začněte ještě dnes vytvářet svůj plán obnovy po havárii s ClickUp. Začněte s ClickUp zdarma a sjednoťte veškeré plánování obnovy po havárii, dokumentaci a reakce na incidenty na jedné jednotné platformě. ✨
Často kladené otázky
Plán obnovy po havárii byste měli revidovat alespoň čtyřikrát ročně a aktualizovat jej ihned po jakýchkoli významných změnách infrastruktury nebo skutečných incidentech. Většina organizací provádí každoročně rozsáhlou a důkladnou revizi, aby zahrnula všechny získané zkušenosti a přizpůsobila se novým technologiím.
Plánování a testování obnovy po havárii obvykle vedou týmy IT, týmy zabezpečení a plánovači kontinuity podnikání. Potřebují však důležité podněty od vedoucích provozních a obchodních jednotek, aby zajistili, že plán bude v souladu se skutečnými obchodními potřebami a prioritami.
Pomocí stopek a jasných časových značek měřte skutečné doby obnovy ve srovnání s definovanými cíli během každého testu. Je velmi důležité zdokumentovat veškeré rozdíly mezi cílovým a skutečným výkonem ve svých testovacích zprávách, aby bylo možné provést budoucí vylepšení.
Platformy pro řízení projektů, jako je ClickUp, jsou ideální pro centralizaci dokumentace, automatizaci pracovních postupů a sledování metrik pro celý váš program DR. Poté je můžete spárovat se specializovanými nástroji DR, které se starají o technické aspekty replikace dat a převzetí služeb při selhání systému.