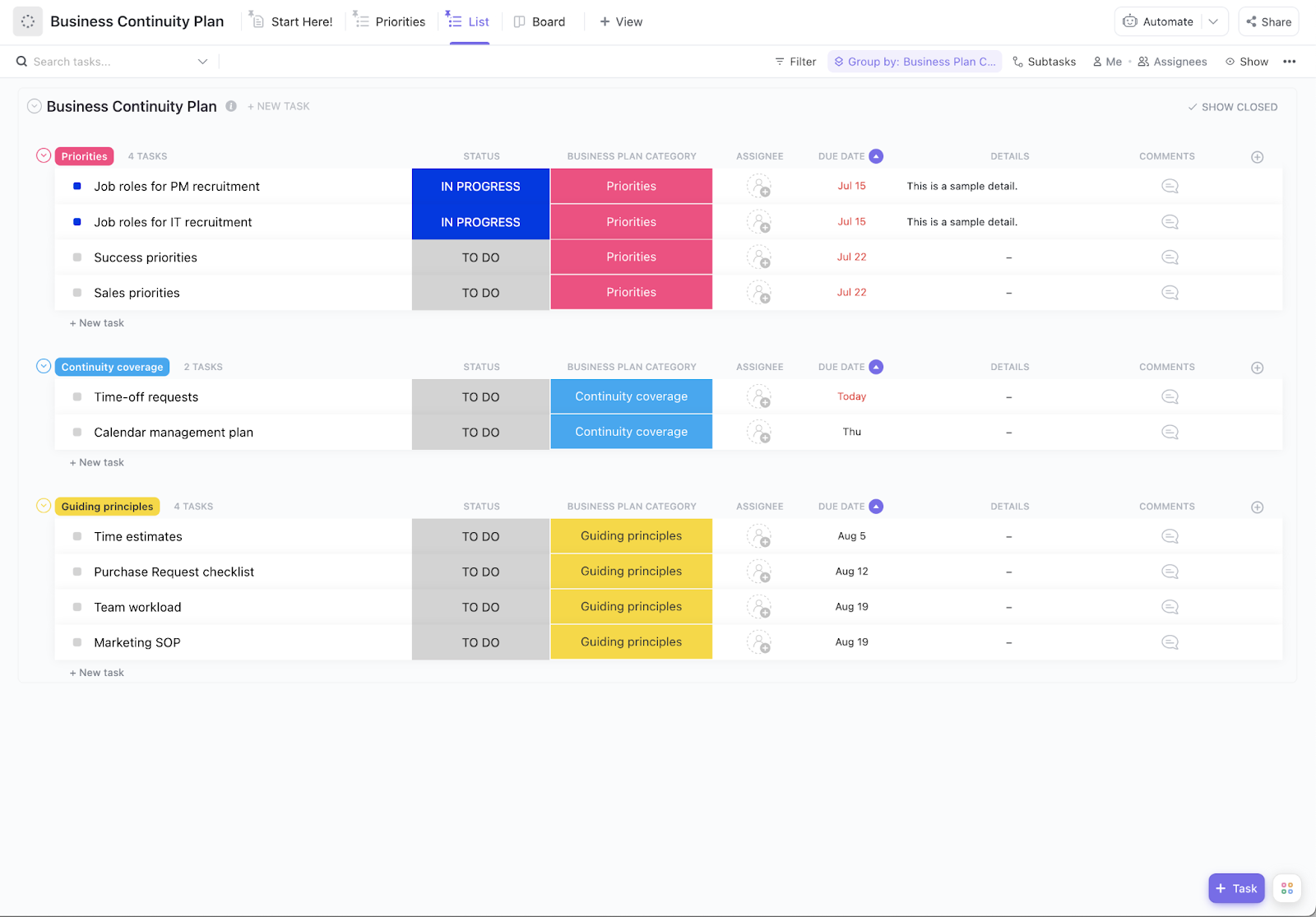

ИТ бедствия могат да възникнат без предупреждение.
От сривове на сървъри до кибератаки – без солиден план за възстановяване вашият бизнес може да се сблъска с часове прекъсване на работата, загуба на данни и сериозни финансови щети, като 54% от сериозните прекъсвания струват над 100 000 щатски долара.
Този блог ви води през процеса на изготвяне на цялостен план за възстановяване след ИТ бедствие, който защитава вашите системи, определя ясни цели за възстановяване и гарантира, че вашият екип знае точно какво да прави, когато нещо се обърка.
Какво е план за възстановяване при бедствия в ИТ?
Ако сървърите ви се сринат в този момент, екипът ви ще знае ли точно какво да направи? 🛠️
Планът за възстановяване след бедствие (DR) е вашата документирана стратегия за възстановяване на ИТ системи и данни след всяко прекъсване – от природни бедствия до кибератаки. По същество това е вашият план за действие за възстановяване на технологията, когато нещо се обърка.
💡 Възстановяване след бедствие срещу непрекъснатост на бизнеса
Възстановяването при бедствия (DR) се фокусира специално върху възстановяването на вашата ИТ инфраструктура и данни. Непрекъснатостта на бизнеса (BC) е по-широка и има за цел да поддържа цялата ви дейност оперативна по време и след криза, дори ако ИТ системите не функционират. Мислете за DR като ключова част от цялостната ви стратегия за BC.
💡 Възстановяване след бедствие срещу непрекъснатост на бизнеса
Възстановяването при бедствия (DR) се фокусира специално върху възстановяването на вашата ИТ инфраструктура и данни. Непрекъснатостта на бизнеса (BC) е по-широка и има за цел да поддържа цялата ви дейност оперативна по време и след криза, дори ако ИТ системите не функционират. Мислете за DR като ключова част от цялостната ви стратегия за BC.
Вашият план за възстановяване при бедствия е важен, защото прекъсването на работата струва повече от пари. Всяка минута, в която системите ви са изключени, може да подкопае доверието на клиентите, да наруши работата и дори да доведе до глоби за несъответствие. Всеобхватният план за възстановяване при бедствия е вашата пътна карта към устойчивостта.
Един добър план включва:
- Процедури за архивиране на данни: Как и къде съхранявате копия на критична информация, за да можете да я възстановите
- Стъпки за възстановяване на системата: Точната последователност за възстановяване на услугите в правилния ред
- Отговорности на екипа: Кой какво прави по време на инцидент, за да се избегне объркване
- Протоколи за комуникация: Как ще информирате заинтересованите страни, от вашия екип до вашите клиенти
- Цели за възстановяване: Вашите конкретни цели за това колко бързо трябва да се възстановят системите и колко загуба на данни е приемлива.
Чести сценарии за ИТ бедствия и тяхното въздействие
Бедствията не са само сценарии от Холивуд; те се случват на бизнеса всеки ден. Разбирането на това, от което се защитавате, ви помага да изградите много по-силна защита.
Природни бедствия и физически щети
Събития като наводнения, пожари, земетресения и големи прекъсвания на електрозахранването могат да унищожат цели центрове за данни за минути. Когато голямо наводнение засегна център за данни в Нашвил, например, някои компании загубиха данни за седмици и се сблъскаха с месеци на възстановяване. Най-добрата защита срещу това е географската излишност, което означава разпределяне на инфраструктурата ви на няколко физически места, така че едно събитие да не може да унищожи всичко.
Кибератаки и компрометиране на данни
Рансъмуеър, DDoS (Distributed Denial-of-Service) атаки и нарушения на сигурността на данните се различават от физическите бедствия. Те често са по-трудни за откриване, могат да се разпространяват незабелязано през свързани системи и често атакуват и вашите системи за архивиране, което прави възстановяването особено трудно. Честотата и сложността на тези кибератаки продължават да нарастват във всички отрасли, като рансъмуеърът вече съставлява 44% от всички потвърдени нарушения, което го превръща в една от най-големите заплахи.
Хардуерни повреди и загуба на данни
Понякога дори най-тестваните и надеждни системи за архивиране просто се повреждат. Сривове на сървъри, откази на устройства за съхранение и неизправности на мрежово оборудване могат да се случат без предупреждение. Дори ако разполагате с резервни (архивни) системи, те все пак могат да се повредят едновременно, ако споделят общи компоненти или източници на захранване, създавайки единна точка на отказ.
👀 Знаете ли, че: През октомври 2025 г. AWS претърпя сериозен срив, когато грешка във вътрешната система за управление на DNS за Amazon DynamoDB доведе до неуспешно разрешаване на домейн имена в региона на центъра за данни US-EAST-1. Този „малък“ технически дефект предизвика верижна повреда в десетки AWS услуги и срина стотици популярни приложения и платформи в световен мащаб – от приложения за съобщения и социални мрежи до банки, сайтове за игри и др. За много хора прекъсването временно „изтри“ голяма част от интернет, подчертавайки колко крехка е нашата цифрова инфраструктура, когато толкова много зависи от няколко доставчици на облачни услуги.
Софтуерни грешки и прекъсване на услугата
Повредена база данни, неуспешна актуализация на софтуер или проста грешка в конфигурацията могат да сринат цели платформи. Може да забележите, че една неправилно конфигурирана реда код може да се разпространи каскадно през свързаните системи, създавайки широко разпространено прекъсване с голям радиус на въздействие. Правилното управление на промените и специалните тестови среди са вашите най-добри приятели за минимизиране на тези рискове.
Човешки грешки и неправилни конфигурации
Случайното изтриване, неправилната конфигурация и неразрешените промени остават едни от най-честите причини за прекъсвания в работата на ИТ системите. Една единствена грешна команда или изтрит файл могат да доведат до часове прекъсване на работата и влошаване на качеството на услугата. Въпреки че обучението и контролът на достъпа помагат, те не могат напълно да елиминират човешките грешки.
📮ClickUp Insight: 92% от работниците използват непоследователни методи за проследяване на задачите, което води до пропуснати решения и забавено изпълнение.
Независимо дали изпращате бележки за проследяване или използвате електронни таблици, процесът често е разпръснат и неефективен. С възможностите за управление на задачи на ClickUp никога няма да се налага да се притеснявате за това. Създавайте задачи от чат, коментари към задачи в ClickUp, документи и имейли с едно кликване!
Ключови компоненти на план за възстановяване при бедствия в ИТ
Един солиден план за възстановяване след бедствие е вашият пълен наръчник за връщане в онлайн режим. Всеки от тези компоненти се основава на останалите, за да създаде цялостна защита за вашия бизнес.
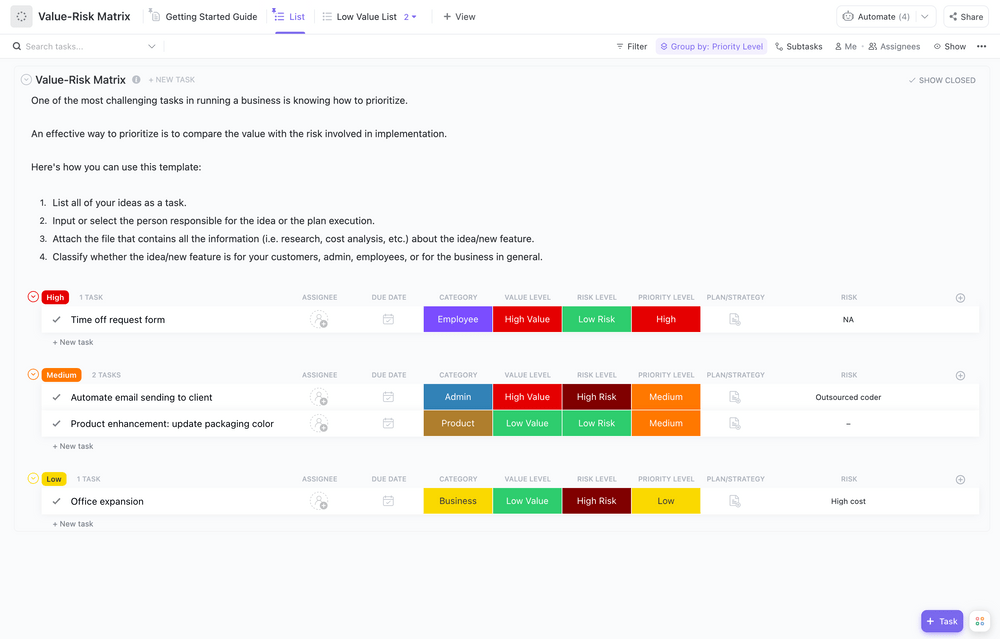
Оценка и приоритизиране на рисковете
Първо, трябва да знаете с какво се сблъсквате. Оценката на риска е процесът на идентифициране на уязвимостите ви и оценяване на вероятността и въздействието на всяка потенциална заплаха. Можете да организирате това в матрица на риска, за да видите кои заплахи са най-сериозни.
Вашата оценка трябва да обхваща:
- Критични системи: Това, което абсолютно трябва да продължи да работи, за да функционира вашият бизнес.
- Чувствителност на данните: Коя информация се нуждае от най-високо ниво на защита (например данни за клиенти)
- Зависимости: Кои други системи или процеси се прекъсват, когато дадена система откаже?
📖 Прочетете още: Как да внедрите управление на ИТ инфраструктурата
Анализ на въздействието върху бизнеса и критичност
След това изчислете реалните разходи от прекъсването на работата. Анализът на въздействието върху бизнеса (BIA) ви помага да определите финансовото и оперативното въздействие на прекъсването на работата за всяка система. Това ви позволява да класифицирате системите си по нива на критичност, за да определите приоритетите в усилията си за възстановяване.
| Критично | По-малко от един час | Обработка на плащания, клиентски бази данни |
| Високо | От един до четири часа | Имейл, инструменти за вътрешна комуникация |
| Средно | От четири до 24 часа | Развойни среди, инструменти за отчитане |
| Ниско | 24+ часа | Архивни системи, непроизводствени тестови сървъри |
Цели за RTO и RPO
Тези две абревиатури са в основата на вашата стратегия за възстановяване.
- Цел за време за възстановяване (RTO): Това е максималното време, през което можете да си позволите системата да не работи. То отговаря на въпроса: „Колко бързо трябва да възстановим работата на системата?“
- Цел за възстановяване (RPO): Това е максималното количество данни, което можете да си позволите да загубите, измерено във време. Тя отговаря на въпроса: „Колко данни можем да загубим, без да настъпи сериозна вреда?“
Например, вашата вътрешна система за електронна поща може да има RTO от четири часа, но вашата база данни за електронна търговия, насочена към клиенти, може да има RPO от само 15 минути, което означава, че не можете да загубите повече от 15 минути транзакционни данни.
План за архивиране и възстановяване на данни
Вашият резервен план е вашата крайна предпазна мрежа. Често срещана най-добра практика е правилото 3-2-1: поддържайте поне три копия на важните си данни, съхранявайте ги на два различни типа носители и дръжте едно от тези копия извън офиса.
Ще можете да избирате между различни видове архивиране:
- Пълни резервни копия: пълно копие на всички данни, обикновено се прави седмично или месечно.
- Инкрементални резервни копия: Резервни копия само на промените, направени след последната резервна копия от какъвто и да е тип.
- Диференциални резервни копия: Архивира всички промени, направени от последната пълна резервна копия.
Най-важното е да тествате редовно процеса на възстановяване на резервните копия. Нетестваното резервно копие е само надежда, а не план.
💟 Бонус: Записвайте важни подробности по време на инциденти с висока степен на стрес, като използвате функцията „говори-на-текст“ на ClickUp Brain MAX, за да не пропускате важна информация, дори когато писането не е практично. Просто изкажете наблюденията си и оставете изкуственият интелект да се погрижи за документирането.
План за комуникация и актуализации за заинтересованите страни
Когато настъпи бедствие, ясният план за комуникация е от решаващо значение. Вашият план трябва да определя веригите за уведомяване, честотата на предоставяне на актуализации и каналите, които ще използвате за всеки тип инцидент.
Различните групи се нуждаят от различна информация:
- Вътрешни екипи: Нуждаете се от технически подробности и конкретни действия
- Клиенти: Необходимо е да знаете състоянието на услугата и кога очаквате тя да бъде възстановена.
- Доставчици: Може да се наложи да се ангажират за поддръжка или ескалации.
- Регулаторни органи: В зависимост от вашия бранш може да се изискват официални уведомления.
Инструменти като този готов за употреба шаблон за комуникационен план от ClickUp могат да ви помогнат да действате по-бързо с установен протокол по време на криза.

Програма за тестване и обучение
План, който никога не тествате, е план, който ще се провали. Редовното тестване разкрива пропуски и слабости, преди да настъпи реална катастрофа.
Планирайте различни видове тестове през цялата година:
- Учения на маса: Вашият екип преминава през сценарий за бедствие на хартия, за да провери логиката на плана.
- Частични прехвърляния: Тествате възстановяването на конкретни, некритични компоненти или услуги.
- Пълни тестове за възстановяване след бедствие: Извършвате пълно прехвърляне към резервните си системи (крайният тест).
След всеки тест актуализирайте документацията си и незабавно обучете новите членове на екипа за процедурите.
📖 Прочетете още: Как да разработите ефективни ИТ политики и процедури
Стъпки за създаване на план за възстановяване при бедствия в ИТ
Изготвянето на план за възстановяване след бедствие не трябва да бъде прекалено сложно.
Ето как можете да се справите с това стъпка по стъпка. 🙌
Стъпка 1: Създайте инвентар на активите
Не можете да защитите това, за което не знаете, че имате. Започнете с изготвяне на инвентарен списък на активите, в който са изброени всички хардуерни и софтуерни компоненти, хранилища на данни и системни зависимости във вашата среда. Не забравяйте да включите контактите на доставчиците, лицензионните ключове и подробностите за конфигурацията, за да можете бързо да се ориентирате по време на възстановяването.

Шаблонът ClickUp ITAM обединява управление на инциденти, управление на проблеми, управление на промени, прости решения за управление на активи и управление на знания. Нашият шаблон ITSM Known Errors опростява проследяването на известни грешки във вашите системи. Разгледайте всички наши IT шаблони, веднага щом целта ви се промени.
Персонализирайте работните си процеси по желания от вас начин за всеки етап от ITAM, от внедряване и конфигуриране до поддръжка и извеждане от употреба.
Стъпка 2: Класифициране на критичните услуги
Сега определете кои от тези активи са от критично значение за мисията и кои са просто желателни. Създайте карти на зависимостите между услугите, които показват как вашите системи се свързват и разчитат една на друга. Обърнете специално внимание на всички услуги, насочени към клиенти, които оказват пряко влияние върху приходите или потребителското преживяване.
🎥 Гледайте това практическо ръководство, което показва как да създадете структуриран план на високо ниво, използвайки мощните функции на ClickUp – от определяне на цели до възлагане на задачи и проследяване на напредъка.
Стъпка 3: Оценете рисковете и заплахите
Оценете рисковете и заплахите, като прецените вероятността и въздействието на всеки тип заплаха за вашата конкретна ситуация. Вземете предвид географските рискове (намирате ли се в сеизмична зона или в заливна равнина?) и всички специфични за отрасъла заплахи (като промени в нормативната уредба или целенасочени кибератаки). Документирайте всичко в регистър на рисковете, за да можете да го проследявате във времето.

Шаблонът за оценка на риска на ClickUp създава визуално измерение за процеса на оценка на риска. Той помага при оценяването и категоризирането на рисковете, като вдъхновява екипа ви да споделя идеи и да сътрудничи в увлекателен и визуален формат.
Този шаблон ви позволява да:
- Оценете категориите риск и потенциалните въздействия
- Анализирайте данните, за да идентифицирате потенциални проблемни области.
- Определете превантивни мерки за намаляване на риска
С функции, които ви позволяват да рисувате, пишете и добавяте лепящи се бележки, този шаблон за бяла дъска за управление на риска е идеален за оценяване на рисковете на вашия проект.
Стъпка 4: Задайте цели за RTO и RPO
Работете директно с бизнес заинтересованите страни, за да определите какво считат за приемливо прекъсване на работата и загуба на данни за всеки ниво на обслужване, което сте идентифицирали по-рано. Трябва да балансирате разходите за по-бързо възстановяване с въздействието върху бизнеса – не всичко се нуждае от незабавно възстановяване без загуба на данни. Получете одобрение от ръководството за тези цели.
Стъпка 5: Определете пътища за архивиране и прехвърляне при отказ
След като сте определили целите си, вече можете да проектирате техническите си решения. Създайте стратегии за архивиране, съобразени с RPO на всяка система, и планирайте подробни процедури за прехвърляне при отказ, включително алтернативни места за обработка и методи за достъп в спешни случаи. Включете мрежови диаграми и постъпкови ръководства, за да направите изпълнението безупречно.
Стъпка 6: Разпределете роли и ескалация
Определете структурата на екипа си за възстановяване след бедствие с ясни отговорности и правомощия за вземане на решения. Създайте изчерпателни списъци с контакти с основния и резервния персонал за всяка роля. Матрицата RACI (отговорен, отчетен, консултиран, информиран) е чудесен инструмент за премахване на объркването по време на инцидент с висока степен на стрес.
Стъпка 7: Документирайте и комуникирайте плана
Документирайте и комуникирайте плана с ясни, постъпкови процедури, които всеки член на екипа ви може да следва, дори и под натиск. Много е важно да съхранявате тази документация на леснодостъпно място, което е отделено от основната ви инфраструктура. Уверете се, че всеки член на екипа знае точно къде да намери плана по време на криза.
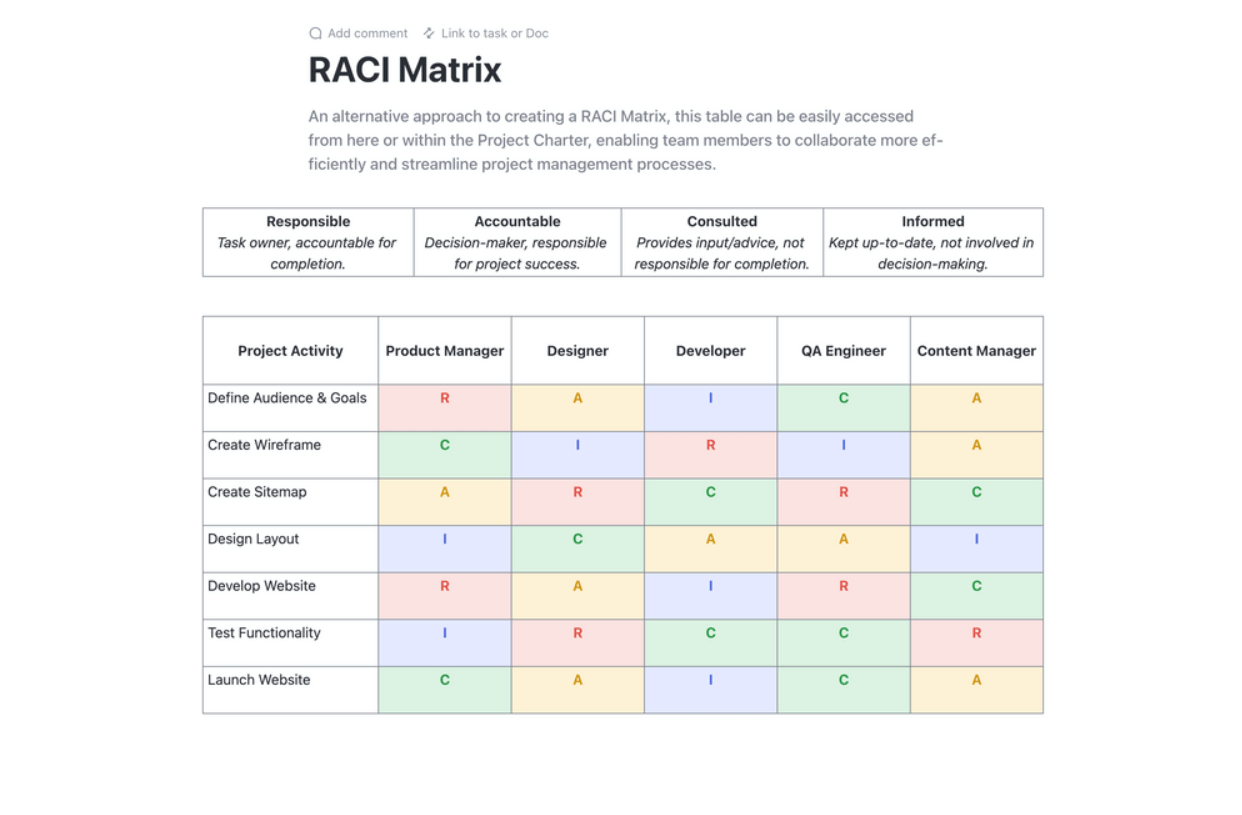
Оптимизирайте планирането на проектите си с шаблона за планиране RACI на ClickUp. Този шаблон за документи променя правилата на играта, като предлага ясна таблица за определяне на ролите и отговорностите на екипа във връзка с задачите по проекта. Възприемете рамката RACI (отговорен, отчетен, консултиран и информиран), за да синхронизирате всички, като гарантирате отчетност и съгласуваност с целите на организацията.
Стъпка 8: Тествайте, прегледайте и подобрете
Накрая, планирайте тримесечни тестове, за да проверите процедурите си и да идентифицирате евентуални пропуски. Документирайте всички поуки от всеки тест и всички реални инциденти и ги използвайте, за да актуализирате плана си. Създайте система за систематично проследяване на подобренията, за да се уверите, че всички открити проблеми се решават.
🌼 Знаете ли, че: През 2017 г. GitLab претърпя сериозен срив на базата данни. По време на възстановяването те откриха, че няколко от методите им за архивиране са се проваляли безшумно в продължение на дни. Този инцидент даде важен урок на цялата технологична индустрия: валидирането на архивирането е задължително. Нетествано архивиране всъщност не е архивиране.
🌼 Знаете ли, че: През 2017 г. GitLab претърпя сериозен срив на базата данни. По време на възстановяването те откриха, че няколко от методите им за архивиране са се проваляли безшумно в продължение на дни. Този инцидент даде важен урок на цялата технологична индустрия: валидирането на архивирането е задължително. Нетествано архивиране всъщност не е архивиране.
Стратегии и решения за възстановяване след бедствия
Не всяка организация се нуждае от един и същ подход към възстановяване при бедствия. Нека разгледаме вашите възможности въз основа на бюджета, нуждите от възстановяване и наличните ресурси.
Подход за архивиране и възстановяване
Това е най-простият и най-рентабилен метод. Той включва редовно архивиране на данни на външно място (като облак или вторичен център за данни) и ръчното им възстановяване при необходимост. Този подход е най-подходящ за некритични системи, които могат да понасят по-дълго време за възстановяване, тъй като възстановяването може да отнеме часове или дори дни.
Висока наличност и излишък
Тази стратегия има за цел да елиминира единичните точки на отказ чрез използване на множество активни системи. Техники като балансиране на натоварването, клъстериране на сървъри и RAID съхранение гарантират, че ако един компонент откаже, друг незабавно поема функциите му. Въпреки че е по-скъп за настройка и поддръжка, този подход може да сведе прекъсванията до само секунди или минути, което го прави идеален за критични услуги.
Опции за репликация и прехвърляне при отказ
Репликацията включва копиране на данни в почти реално време на вторичен сайт, което гарантира минимална загуба на данни по време на бедствие.
- Синхронно репликиране: Записва данни едновременно на първичния и вторичния сайт, гарантирайки нулева загуба на данни. Това обаче изисква висока скорост на интернет връзката и може да забави работата на първичната ви система.
- Асинхронно репликиране: първо записва данните на основния сайт, а след това ги копира на второстепенния сайт с леко закъснение. То е по-евтино и има по-малко влияние върху производителността, но приемате малък риск от загуба на данни.
Възстановяване при бедствия в облака и DRaaS
Възстановяването след бедствие като услуга (DRaaS) се превърна в популярен избор за много компании. То предлага ценообразуване на базата на реално потребление, незабавно географско разпределение и автоматизирана координация на възстановяването, без да е необходимо да изграждате и поддържате свои собствени физически DR сайтове. Cloud DR елиминира огромните капиталови разходи за резервен център за данни, като същевременно осигурява по-бързо мащабиране и по-голяма гъвкавост в сравнение с традиционните подходи с горещи, топли или студени сайтове.
Как ClickUp оптимизира планирането на възстановяване при ИТ бедствия
Управлението на план за възстановяване след бедствие чрез разпръснати електронни таблици, документи и вериги от имейли създава свой собствен риск от бедствие.
Този вид разпръскване на работата, фрагментирането на работата между множество несвързани инструменти, които не комуникират помежду си, и разпръскването на контекста, когато екипите губят часове в търсене на информация, разпръсната из различни приложения и платформи, води до объркване, остаряла информация и бавни реакции, когато всяка секунда е от значение.
С ClickUp Converged AI Workspace – единна, сигурна платформа, в която всички ваши работни приложения, данни и работни потоци съжителстват с контекстуална изкуствена интелигентност като интелигентен слой – която комбинира управление на проекти, документация и комуникация в екипа. Спрете да жонглирате с множество платформи и обединете планирането, тестването и реакцията при инциденти в една единна система.
Централизирана документация за възстановяване след бедствия с ClickUp Docs и вградена AI помощ
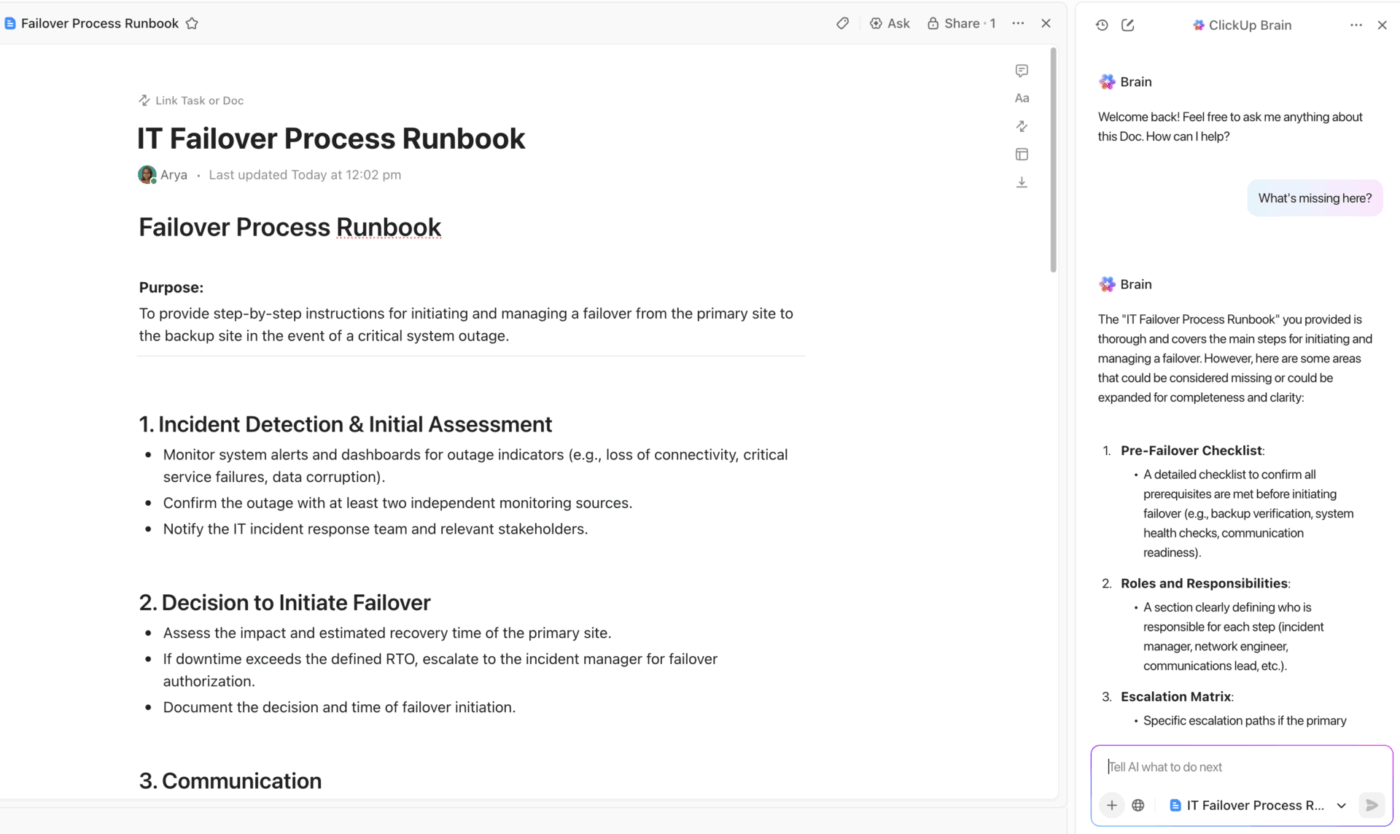
Уверете се, че вашият екип винаги разполага с единен източник на информация с ClickUp Docs.
Изградете целия си план за възстановяване при бедствия в пространство за сътрудничество, където всеки може да допринесе в реално време по време на инцидент. Свържете документи директно с задачи и проекти, свързани с инциденти, за безпроблемна навигация, и вградете диаграми или ръководства, за да съхранявате критичната информация точно там, където ви е необходима.
Най-хубавото е, че можете да защитите документите си, за да предотвратите случайно редактиране, и да използвате подробни разрешения в ClickUp, за да контролирате кой може да вижда или променя чувствителни процедури за възстановяване. Всяка промяна се проследява в историята на документа, което ви дава пълен одит.
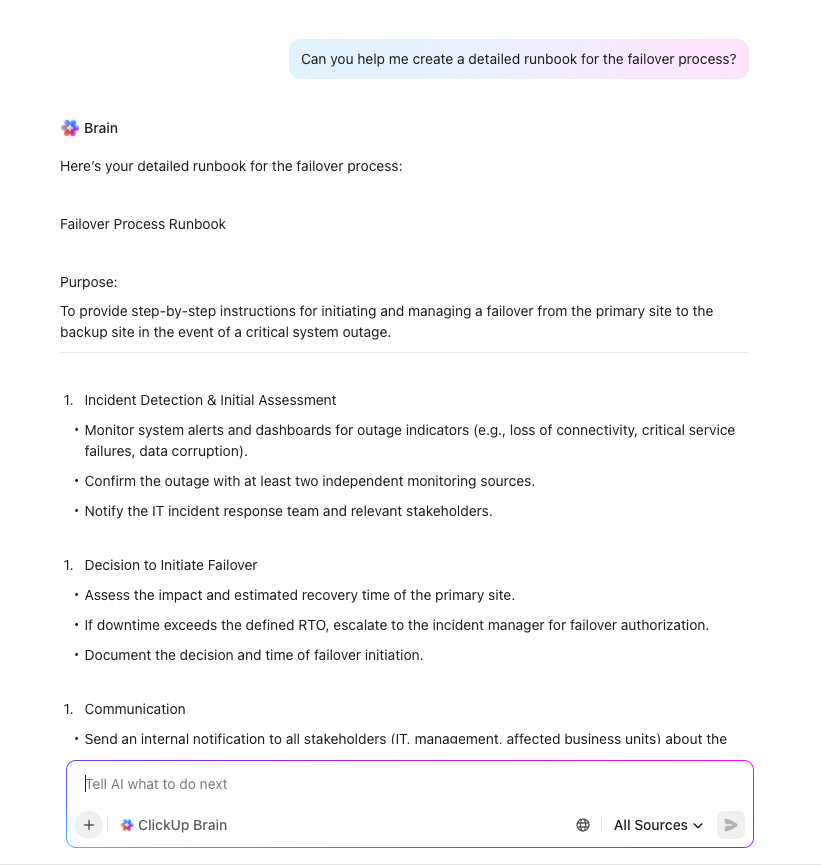
Създаване на план с помощта на изкуствен интелект с ClickUp Brain
Ускорете планирането на възстановяване при бедствия и елиминирайте критични пропуски с ClickUp Brain – вашият контекстуален AI асистент, който разбира цялото ви работно пространство. За разлика от общите AI инструменти, ClickUp Brain използва реалните задачи, документи и работни процеси на вашата организация, за да предостави прецизна и практична подкрепа за инициативи за възстановяване при бедствия.
Просто задайте на ClickUp Brain заявка от типа „Създай списък за възстановяване след бедствие за нашата платформа за електронна търговия“ и веднага ще получите изчерпателен, персонализиран шаблон, който отговаря на вашите системи, процеси и изисквания за съответствие. Той може да ви помогне с:
- Контекстуална осведоменост: ClickUp Brain има достъп до структурата, съдържанието и разрешенията на вашето работно пространство. Той може да се позовава на задачи, документи, коментари и дори свързани приложения, като предоставя отговори и действия, съобразени с вашата реална работа, а не само общи предложения.
- Отстраняване на проблеми и насоки: Отстранявайте проблеми незабавно, получавайте подробни инструкции или питайте за най-добрите практики за всяка функция на ClickUp. Brain може да ви преведе през сложни процеси, да автоматизира повтарящи се задачи и да ви помогне да разрешите пречките.
- Автоматизация и ускоряване на работния процес: Използвайте предварително създадени или персонализирани AI агенти, за да автоматизирате многоетапни работни процеси, да сортирате заявки или да управлявате повтарящи се задачи, спестявайки часове всяка седмица.
- Дълбоко търсене: Намерете информация, скрита навсякъде в работното ви пространство, включително задачи, документи и интегрирани инструменти, дори ако е отпреди години или е трудно да се намери със стандартно търсене.
- Обобщения и актуализации в реално време: Генерирайте актуализации на проекти, обобщения на срещи или доклади за напредъка незабавно, като извличате данни от работната среда в реално време.
- Опростяване на техническата документация: Преобразувайте сложни технически документи в ясни, приложими процедури или контролни списъци, които вашият екип може да следва, дори и под натиск.
- Мултимоделна интелигентност: Изберете от водещи AI модели (OpenAI GPT-4. 1, GPT-5, Claude, Gemini и др.) за най-добри резултати при всяка задача – не се изискват отделни абонаменти.
- Сигурност и съобразяване с разрешенията: Brain има достъп само до информация, за която вече имате разрешение да виждате, като поддържа строги стандарти за поверителност и съответствие.
- Разговорна интерфейс: Използвайте @brain в коментари или чат, за да получите контекстуална информация, да съставите отговори или да задействате автоматизации, без да напускате работния си процес.
- Персонализирани подсказки и запазени работни процеси: Запазете и използвайте отново подсказки за повтарящи се нужди, като по този начин гарантирате последователност и спестявате време на целия си екип.
💡Съвет от професионалист: Никога не пропускайте урок от срещите за преглед на инциденти, като записвате всеки детайл с ClickUp AI Notetaker. Той може да се присъедини към вашите виртуални срещи, да транскрибира цялата дискусия и автоматично да генерира списък с действия, които трябва да се предприемат въз основа на извлечените поуки. Това създава история на инцидентите, която може да се търси, така че можете бързо да се позовавате на минали събития и техните решения.

Автоматизирани работни процеси за възстановяване при бедствия с ClickUp Automations
Представете си, че вашият екип се сблъсква с внезапно прекъсване на работата – всяка секунда е от значение и не можете да си позволите да пропуснете нито една стъпка. С AI агентите и автоматизациите на ClickUp не е нужно да се бързате или да разчитате на паметта си. Веднага след като бъде обявен инцидент, AI на ClickUp се задейства, насочва вашия екип и се занимава с рутинната работа, за да можете да се съсредоточите върху решаването на проблема.
Ето как работи това в реална ситуация:
- Когато някой маркира задача като „Деклариран инцидент“, ClickUp Agent автоматично създава списък с стъпки за реакция, възлага ги на подходящите лица и стартира таймер, за да проследи колко време отнема възстановяването.
- Ако инцидентът е маркиран като „критичен“, агентът може незабавно да изпрати предупредителен имейл на вашия ръководен екип и да създаде специален чат – вашата „военна зала“ – така че всички да могат да комуникират на едно място.
- Изкуственият интелект може да извлече доклади за минали инциденти и съответната документация, така че вашият екип да има всичко необходимо на разположение.
Вижте работния процес тук:
С ClickUp AI Agents получавате надежден дигитален съотборник, който помага на екипа ви да остане спокоен, организиран и ефективен, дори когато натискът е голям.
Проследяване в реално време с таблата за управление на ClickUp
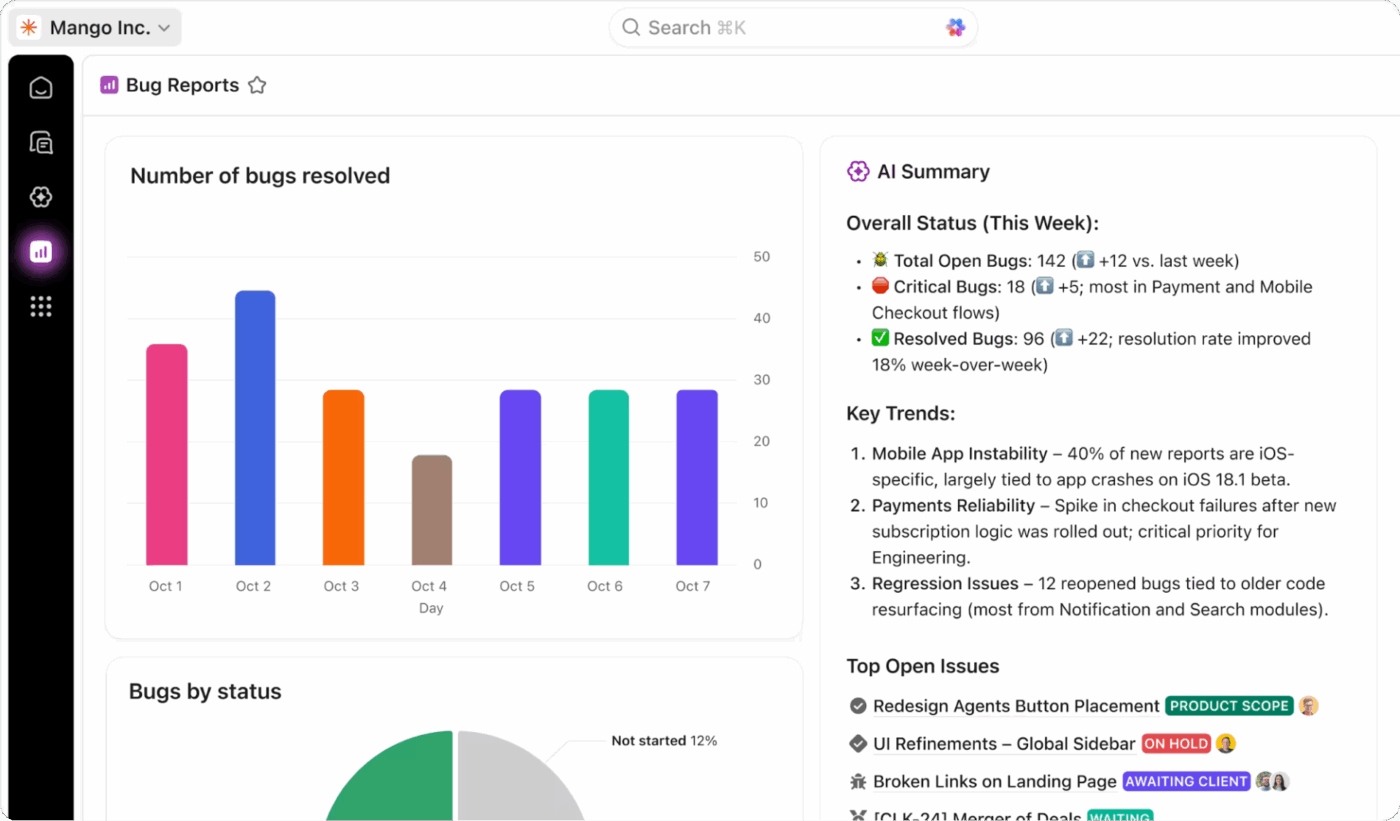
Получете пълна видимост за състоянието на програмата си за възстановяване след бедствие, като проследявате всичко в реално време с таблата за управление на ClickUp. Можете да създавате джаджи, за да наблюдавате ефективността на RTO и RPO по време на тестове, да проследявате степента на завършеност на тестовете и да преглеждате тенденциите на инцидентите във времето.
Добавете персонализирани полета ClickUp към задачите си, за да проследявате критичността на системата, състоянието на възстановяването и резултатите от тестовете, а след това съберете всички тези данни в един общ изглед. Тези табла ви предоставят готови за изпълнение отчети, които са винаги актуални с данни в реално време от тестовете и дейностите по реагиране на инциденти на вашия екип.
📖 Прочетете още: Как да създадете списък за оценка на риска
Изградете своя план за възстановяване при бедствия още днес
Всеки ден, в който работите без план за възстановяване при бедствия, е риск, който не можете да си позволите да поемете. Бедствията са неизбежни – независимо дали са причинени от природата, технологични проблеми или човешка грешка – но вашата подготовка е това, което определя дали те ще се превърнат в незначителни неудобства или в големи катастрофи.
Един цялостен план за възстановяване след бедствие изисква разбиране на рисковете, документиране на ясни процедури и редовното им тестване. Подходящите инструменти улесняват този процес, като елиминират хаоса от разпръснати документи и ръчни процеси.
Дори и най-основните планове за действие при извънредни ситуации са по-добри от липсата на такива, когато настъпи бедствие. Редовните тестове и актуализации ще превърнат плана ви за възстановяване след бедствие от прашен документ в жива система, която наистина защитава вашия бизнес.
Направете първата стъпка и започнете да изготвяте плана си за възстановяване при бедствия с ClickUp още днес. Започнете безплатно с ClickUp и обединете цялото си планиране за възстановяване при бедствия, документацията и реакцията при инциденти в една единна платформа. ✨
Често задавани въпроси
Трябва да преглеждате плана си за възстановяване след бедствие поне четири пъти годишно и да го актуализирате веднага след всяка значителна промяна в инфраструктурата или реални инциденти. Повечето организации извършват ежегодно основна, задълбочена ревизия, за да включат всички извлечени поуки и да се адаптират към новите технологии.
ИТ екипите, екипите по сигурността и планиращите непрекъснатостта на бизнеса обикновено ръководят усилията по планиране и тестване на възстановяването при бедствия. Те обаче се нуждаят от важни данни от ръководителите на операциите и бизнес единиците, за да гарантират, че планът съответства на реалните бизнес нужди и приоритети.
Използвайте хронометри и ясни времеви отметки, за да измерите действителното време за възстановяване спрямо определените цели по време на всеки тест. Много е важно да документирате всички разлики между целта и действителните резултати в тестовите си доклади, за да насочите бъдещите подобрения.
Платформите за управление на проекти като ClickUp са идеални за централизиране на документацията, автоматизиране на работните процеси и проследяване на показателите за цялата ви програма за възстановяване след бедствие. След това можете да ги съчетаете със специализирани инструменти за възстановяване след бедствие, които се занимават с техническите аспекти на репликацията на данни и прехвърлянето на системи при отказ.