

Büyük Dil Modelleri (LLM'ler), yazılım uygulamaları için heyecan verici yeni olanaklar sunmaktadır. Bu modeller, her zamankinden daha akıllı ve dinamik sistemlerin oluşturulmasını mümkün kılmaktadır.
Uzmanlar, 2025 yılına kadar bu modellerle çalışan uygulamaların tüm dijital işlerin neredeyse yarısını otomatikleştirebileceğini öngörüyor.
Ancak, bu yetenekleri ortaya çıkardıkça, bir zorluk ortaya çıkıyor: çıktılarının kalitesini büyük ölçekte nasıl güvenilir bir şekilde ölçebiliriz? Ayarlarda küçük bir değişiklik yapıldığında, aniden belirgin şekilde farklı çıktılarla karşılaşabilirsiniz. Bu değişkenlik, gerçek dünya kullanımı için bir model hazırlarken çok önemli olan performanslarını ölçmeyi zorlaştırabilir.
Bu makale, dağıtım öncesi testlerden üretime kadar en iyi LLM sistemi değerlendirme uygulamaları hakkında bilgiler paylaşacaktır. Öyleyse başlayalım!
LLM değerlendirmesi nedir?
LLM değerlendirme ölçümleri, istemlerinizin, model ayarlarınızın veya iş akışınızın belirlediğiniz hedefleri karşılayıp karşılamadığını görmenin bir yoludur. Bu ölçümler, Büyük Dil Modelinizin ne kadar iyi performans gösterdiğine ve gerçek dünyada kullanıma gerçekten hazır olup olmadığına dair içgörüler sağlar.
Günümüzde en yaygın metriklerden bazıları, geri alma ile güçlendirilmiş üretim (RAG) görevlerinde bağlam hatırlama, sınıflandırmalar için tam eşleşmeler, yapılandırılmış çıktılar için JSON doğrulama ve daha yaratıcı görevler için anlamsal benzerlik ölçer.
Bu ölçümlerin her biri, LLM'nin belirli kullanım durumunuzun standartlarını karşıladığını benzersiz bir şekilde garanti eder.
LLM'yi neden değerlendirmek gerekir?
Büyük dil modelleri (LLM'ler) artık çok çeşitli uygulamalarda kullanılmaktadır. Modellerin beklenen standartları karşıladığından ve amaçlarına etkili bir şekilde hizmet ettiğinden emin olmak için modellerin performansını değerlendirmek çok önemlidir.
Şöyle düşünün: LLM'ler, müşteri desteği sohbet robotlarından yaratıcı araçlara kadar her şeyi destekliyor ve daha da gelişirken daha fazla yerde ortaya çıkıyor.
Bu, bunları izlemek ve değerlendirmek için daha iyi yöntemlere ihtiyacımız olduğu anlamına gelir; geleneksel yöntemler, bu modellerin üstlendiği tüm görevleri yerine getiremez.
İyi değerlendirme metrikleri, LLM'ler için bir kalite kontrol gibidir. Modelin gerçek dünyada kullanım için yeterince güvenilir, doğru ve verimli olup olmadığını gösterir. Bu kontroller yapılmazsa, hatalar gözden kaçabilir ve bu da kullanıcıların hayal kırıklığına uğramasına ve hatta yanıltıcı bir deneyim yaşamasına neden olabilir.
Güçlü değerlendirme metriklerine sahip olduğunuzda, sorunları tespit etmek, modeli iyileştirmek ve modelin kullanıcıların özel ihtiyaçlarını karşılayacağından emin olmak daha kolaydır. Bu sayede, çalıştığınız AI platformunun standartlara uygun olduğunu ve ihtiyacınız olan sonuçları sağlayabileceğini bilirsiniz.
📖 Daha fazla bilgi: LLM ve Üretken Yapay Zeka: Ayrıntılı Kılavuz
LLM Değerlendirme Türleri
Değerlendirmeler, modelin yeteneklerini incelemek için benzersiz bir bakış açısı sağlar. Her tür, çeşitli kalite yönlerini ele alarak güvenilir, güvenli ve verimli bir dağıtım modeli oluşturmanıza yardımcı olur.
İşte farklı LLM değerlendirme yöntemleri:
- İçsel değerlendirme, gerçek dünya uygulamalarını içermeden belirli dilbilimsel veya anlama görevlerinde modelin iç performansına odaklanır. Genellikle, temel yetenekleri anlamak için modelin geliştirme aşamasında gerçekleştirilir
- Dışsal değerlendirme, modelin gerçek dünya uygulamalarındaki performansını değerlendirir. Bu tür değerlendirme, modelin bir bağlam içinde belirli hedefleri ne kadar iyi karşıladığını inceler
- Sağlamlık değerlendirmesi, beklenmedik girdiler ve olumsuz koşullar dahil olmak üzere çeşitli senaryolarda modelin kararlılığını ve güvenilirliğini test eder. Potansiyel zayıflıkları belirleyerek modelin öngörülebilir şekilde çalışmasını sağlar
- Verimlilik ve gecikme testi, modelin kaynak kullanımı, hızı ve gecikmesini inceler. Modelin görevleri hızlı ve makul bir hesaplama maliyetiyle gerçekleştirebilmesini sağlar, bu da ölçeklenebilirlik için çok önemlidir
- Etik ve güvenlik değerlendirmesi, modelin etik standartlara ve güvenlik kurallarına uygun olmasını sağlar. Bu, hassas uygulamalarda hayati önem taşır
LLM modeli değerlendirmeleri ve LLM sistemi değerlendirmeleri
Büyük dil modellerini (LLM) değerlendirmek iki ana yaklaşımı içerir: model değerlendirmeleri ve sistem değerlendirmeleri. Her biri LLM'nin performansının farklı yönlerine odaklanır ve bu modellerin potansiyelini en üst düzeye çıkarmak için aradaki farkı bilmek çok önemlidir.
🧠 Model değerlendirmeleri, LLM'nin genel becerilerini inceler. Bu tür değerlendirme, modeli çeşitli bağlamlarda dili doğru bir şekilde anlama, üretme ve işleme becerisi açısından test eder. Bu, modelin farklı görevleri ne kadar iyi yerine getirebildiğini görmek gibidir, neredeyse genel zeka testi gibidir.
Örneğin, model değerlendirmelerinde "Bu model ne kadar çok yönlü?" gibi sorular sorulabilir
🎯 LLM sistem değerlendirmeleri, LLM'nin müşteri hizmetleri chatbotunda olduğu gibi belirli bir kurulum veya amaç dahilinde nasıl performans gösterdiğini ölçer. Burada, modelin genel yeteneklerinden çok, kullanıcı deneyimini iyileştirmek için belirli görevleri nasıl yerine getirdiğine odaklanılır.
Ancak sistem değerlendirmeleri, "Model, kullanıcılar için bu belirli görevi ne kadar iyi yerine getiriyor?" gibi sorulara odaklanır
Model değerlendirmeleri, geliştiricilerin LLM'nin genel yeteneklerini ve sınırlarını anlamalarına yardımcı olarak iyileştirmelere yön verir. Sistem değerlendirmeleri, LLM'nin belirli bağlamlarda kullanıcı ihtiyaçlarını ne kadar iyi karşıladığına odaklanarak daha sorunsuz bir kullanıcı deneyimi sağlar.
Bu değerlendirmeler bir araya gelerek LLM'nin güçlü yönleri ve iyileştirilmesi gereken alanları hakkında eksiksiz bir tablo sunar ve gerçek uygulamalarda daha güçlü ve kullanıcı dostu olmasını sağlar.
Şimdi, LLM Değerlendirmesi için belirli metrikleri inceleyelim.
LLM Değerlendirmesi için Metrikler
Güvenilir ve popüler değerlendirme ölçütlerinden bazıları şunlardır:
1. Karmaşıklık
Perplexity, bir dil modelinin bir dizi kelimeyi ne kadar iyi tahmin ettiğini ölçer. Esasen, cümlenin bir sonraki kelimesi hakkında modelin belirsizliğini gösterir. Perplexity puanı düşükse, model tahminlerinde daha kendinden emin demektir ve bu da daha iyi performans anlamına gelir.
📌 Örnek: Bir modelin "Kedi üzerine oturdu." komutundan metin ürettiğini düşünün. "Halı" ve "zemin" gibi kelimeler için yüksek olasılık öngörürse, bağlamı iyi anlar ve sonuçta düşük bir karmaşıklık puanı alır.
Öte yandan, "uzay gemisi" gibi alakasız bir kelime önerirse, şaşkınlık puanı daha yüksek olur ve modelin mantıklı metinleri tahmin etmekte zorlandığını gösterir.
2. BLEU Puanı
BLEU (Bilingual Evaluation Understudy) puanı, öncelikle makine çevirisini değerlendirmek ve metin oluşturmayı ölçmek için kullanılır.
Çıktıda bir veya daha fazla referans metindeki n-gramların (belirli bir metin örneğinden alınan n öğenin ardışık dizileri) kaç tanesinin çakıştığını ölçer. Puan aralığı 0 ile 1 arasındadır ve puan ne kadar yüksekse performans o kadar iyidir.
📌 Örnek: Modeliniz "The quick brown fox jumps over the lazy dog" cümlesini oluşturur ve referans metin "A fast brown fox leaps over a lazy dog" ise, BLEU paylaşılan n-gramları karşılaştırır.
Yüksek puan, oluşturulan cümlenin referansla yakından eşleştiğini gösterirken, düşük puan oluşturulan çıktının iyi uyum sağlamadığını gösterebilir.
3. F1 Puanı
F1 puanı LLM değerlendirme metriği, öncelikle sınıflandırma görevleri içindir. Bu metrik, kesinlik (olumlu tahminlerin doğruluğu) ile geri çağırma (tüm ilgili örnekleri tanımlama yeteneği) arasındaki dengeyi ölçer.
0 ile 1 arasında bir aralıkta olup, 1 puan mükemmel doğruluğu gösterir.
📌 Örnek: Bir soru-cevap görevinde, modele "Gökyüzünün rengi nedir?" sorusu sorulduğunda, model "Gökyüzü mavidir" (doğru pozitif) yanıtını verir, ancak "Gökyüzü yeşildir" (yanlış pozitif) ifadesini de ekler. F1 puanı, doğru ve yanlış yanıtların alaka düzeyini dikkate alır.
Bu metrik, modelin performansının dengeli bir şekilde değerlendirilmesini sağlar.
4. METEOR
METEOR (Açık Sipariş ile Çevirinin Değerlendirilmesi için Metrik), tam kelime eşleşmesinin ötesine geçer. Oluşturulan metin ile referans metin arasındaki benzerliği değerlendirmek için eş anlamlılar, kökler ve eş anlamlılar dikkate alınır. Bu metrik, insan yargısına daha yakın bir uyum sağlamayı amaçlamaktadır.
📌 Örnek: Modeliniz "Kedi halının üzerinde dinlendi" ifadesini oluşturursa ve referans "Kedi halının üzerinde yatıyordu" ise, METEOR buna BLEU'dan daha yüksek bir puan verir, çünkü "kedi" ile "kedi" kelimelerinin eşanlamlı olduğunu ve "halı" ile "halı" kelimelerinin benzer anlamlar taşıdığını tanır.
Bu, METEOR'u dilin nüanslarını yakalamak için özellikle kullanışlı hale getirir.
5. BERTScore
BERTScore, BERT (Transformers'tan Çift Yönlü Kodlayıcı Temsilleri) gibi modellerden elde edilen bağlamsal gömmelere dayalı olarak metin benzerliğini değerlendirir. Tam kelime eşleşmelerinden çok anlam üzerine odaklanarak daha iyi bir anlamsal benzerlik değerlendirmesi sağlar.
📌 Örnek: "Araba yolda hızla gitti" ve "Araç caddede hızla ilerledi" cümlelerini karşılaştırırken, BERTScore sadece kelime seçimini değil, altta yatan anlamları da analiz eder.
Kelimeler farklı olsa da genel fikirler benzerdir ve bu da oluşturulan içeriğin etkinliğini yansıtan yüksek bir BERTScore'a yol açar.
6. İnsan Değerlendirmesi
İnsan değerlendirmesi, LLM değerlendirmesinin önemli bir parçası olmaya devam ediyor. Bu değerlendirmede, insan yargıçlar akıcılık ve alaka düzeyi gibi çeşitli kriterlere göre model çıktılarının kalitesini derecelendirir . Likert ölçekleri ve A/B testi gibi teknikler geri bildirim toplamak için kullanılabilir.
📌 Örnek: Müşteri hizmetleri sohbet robotundan yanıtlar oluşturulduktan sonra, insan değerlendiriciler her yanıtı 1 ila 5 arasında bir ölçekte derecelendirebilir. Örneğin, sohbet robotu bir müşteri sorusuna açık ve yararlı bir yanıt verirse 5 puan alabilirken, belirsiz veya kafa karıştırıcı bir yanıt 2 puan alabilir.
7. Göreve özel metrikler
Farklı LLM görevleri, özel olarak tasarlanmış değerlendirme metrikleri gerektirir.
Diyalog sistemleri için metrikler, kullanıcı etkileşimini veya görev tamamlama oranlarını değerlendirebilir. Kod oluşturma için başarı, oluşturulan kodun derlenme veya testleri geçme sıklığı ile ölçülebilir.
📌 Örnek: Bir müşteri desteği chatbotunda, etkileşim düzeyleri kullanıcıların konuşmada ne kadar süre kaldıkları veya kaç tane takip sorusu sordukları ile ölçülebilir.
Kullanıcılar sık sık ek bilgi isterse, bu, modelin kullanıcıları başarılı bir şekilde etkileşime soktuğunu ve sorgularını etkili bir şekilde yanıtladığını gösterir.
8. Sağlamlık ve adalet
Bir modelin sağlamlığını değerlendirmek, modelin beklenmedik veya olağandışı girdilere ne kadar iyi yanıt verdiğini test etmeyi içerir. Adalet ölçütleri, modelin çıktılarını inceleyerek önyargıları tespit etmeye yardımcı olur ve farklı demografik gruplar ve senaryolar arasında adil bir performans sergilemesini sağlar.
📌 Örnek: "Tek boynuzlu atlar hakkında ne düşünüyorsunuz?" gibi tuhaf bir soruyla bir modeli test ederken, model bu soruyu nazikçe ele almalı ve alakalı bir yanıt vermelidir. Bunun yerine anlamsız veya uygunsuz bir yanıt verirse, bu sağlamlık eksikliğini gösterir.
Adalet testi, modelin önyargılı veya zararlı çıktılar üretmemesini sağlayarak daha kapsayıcı bir AI sistemi oluşturur.
📖 Daha fazla bilgi: Makine Öğrenimi ve Yapay Zeka Arasındaki Farklar
9. Verimlilik ölçütleri
Dil modellerinin karmaşıklığı arttıkça, hız, bellek kullanımı ve enerji tüketimi açısından verimliliklerini ölçmek giderek daha önemli hale geliyor. Verimlilik ölçütleri, bir modelin yanıtlar üretirken ne kadar kaynak yoğun olduğunu değerlendirmeye yardımcı olur.
📌 Örnek: Büyük bir dil modeli için verimliliği ölçmek, kullanıcı sorgularına ne kadar hızlı yanıt ürettiğini ve bu süreçte ne kadar bellek kullandığını izlemeyi içerebilir.
Yanıt verme süresi çok uzun sürerse veya aşırı kaynak tüketirse, bu durum sohbet robotları veya çeviri hizmetleri gibi gerçek zamanlı performans gerektiren uygulamalar için sorun oluşturabilir.
Artık bir LLM modelini nasıl değerlendireceğinizi biliyorsunuz. Peki bunu ölçmek için hangi araçları kullanabilirsiniz? Gelin birlikte inceleyelim.
ClickUp Brain, LLM Değerlendirmesini Nasıl Geliştirebilir?
ClickUp, ClickUp Brain adlı yerleşik bir kişisel asistan içeren, iş için her şeyi içeren bir uygulamadır.
ClickUp Brain, LLM performans değerlendirmesi için çığır açan bir araçtır. Peki ne işe yarar?
En alakalı verileri düzenler ve vurgular, böylece takımınızın yolunda ilerlemesini sağlar. AI destekli özellikleriyle ClickUp Brain, piyasadaki en iyi sinir ağı yazılımlarından biridir. Tüm süreci her zamankinden daha sorunsuz, daha verimli ve daha işbirlikçi hale getirir. Özelliklerini birlikte keşfedelim.
Akıllı bilgi yönetimi
Büyük Dil Modellerini (LLM) değerlendirirken, büyük miktarda veriyi yönetmek çok zor olabilir.

ClickUp Brain, LLM değerlendirmesi için özel olarak tasarlanmış temel metrikleri ve kaynakları düzenleyebilir ve öne çıkarabilir. Dağınık elektronik tablolar ve yoğun raporları karıştırmak yerine, ClickUp Brain her şeyi tek bir yerde bir araya getirir. Performans metrikleri, karşılaştırma verileri ve test sonuçlarına, açık ve kullanıcı dostu bir arayüzden erişilebilir.
Bu organizasyon, takımınızın gereksiz bilgileri ayıklayıp gerçekten önemli olan içgörülere odaklanmasına yardımcı olarak trendleri ve performans modellerini yorumlamayı kolaylaştırır.
İhtiyacınız olan her şey tek bir yerde olduğundan, salt veri toplama aşamasından etkili, veriye dayalı karar alma aşamasına geçebilir ve bilgi yükünü eyleme geçirilebilir zekaya dönüştürebilirsiniz.
Proje planlama ve iş akışı yönetimi
LLM değerlendirmeleri dikkatli planlama ve işbirliği gerektirir ve ClickUp bu süreci kolaylaştırır.
Veri toplama, model eğitimi ve performans testi gibi sorumlulukları kolayca delege edebilir ve aynı zamanda en kritik görevlerin öncelikle ele alınmasını sağlamak için öncelikler belirleyebilirsiniz. Bunun yanı sıra, Özel Alanlar, iş akışlarını projenizin özel ihtiyaçlarına göre özelleştirmenize olanak tanır.

ClickUp ile herkes kimin neyi ne zaman yaptığını görebilir, bu da gecikmeleri önler ve görevlerin takım içinde sorunsuz bir şekilde ilerlemesini sağlar. Her şeyi baştan sona düzenli ve yolunda tutmak için harika bir yoldur.
Özel gösterge panelleri aracılığıyla metrik izleme
LLM sistemlerinizin performansını yakından takip etmek ister misiniz?
ClickUp Gösterge Panelleri, performans göstergelerini gerçek zamanlı olarak görselleştirir. Modelinizin ilerlemesini anında izlemenizi sağlar. Bu gösterge panelleri son derece özelleştirilebilir olup, ihtiyacınız olanı tam olarak istediğiniz anda sunan grafikler ve çizelgeler oluşturmanıza olanak tanır.
Modelin doğruluğunun değerlendirme aşamalarında nasıl geliştiğini izleyebilir veya her aşamadaki kaynak tüketimini ayrıntılı olarak inceleyebilirsiniz. Bu bilgiler, eğilimleri hızlı bir şekilde tespit etmenize, iyileştirme alanlarını belirlemenize ve anında ayarlamalar yapmanıza olanak tanır.
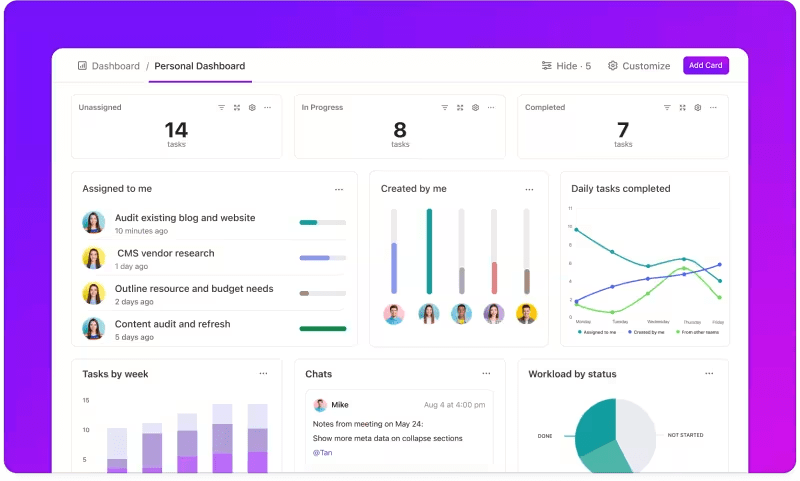
Bir sonraki ayrıntılı raporu beklemek yerine, ClickUp Gösterge Panelleri sizi bilgilendirir ve hızlı tepki vermenizi sağlar, böylece takımınız gecikmeden veriye dayalı kararlar alabilir.
Otomatik içgörüler
Veri analizi zaman alıcı olabilir, ancak ClickUp Brain özellikleri değerli içgörüler sağlayarak yükünüzü hafifletir. Önemli eğilimleri vurgular ve hatta verilere dayalı önerilerde bulunarak anlamlı sonuçlara ulaşmanızı kolaylaştırır.
ClickUp Brain'in otomatik içgörüleriyle, ham verileri manuel olarak tarayarak kalıpları aramanıza gerek kalmaz; ClickUp bunları sizin için bulur. Bu otomasyon, takımınızın tekrarlayan veri analizleriyle uğraşmak yerine model performansını iyileştirmeye odaklanmasını sağlar.
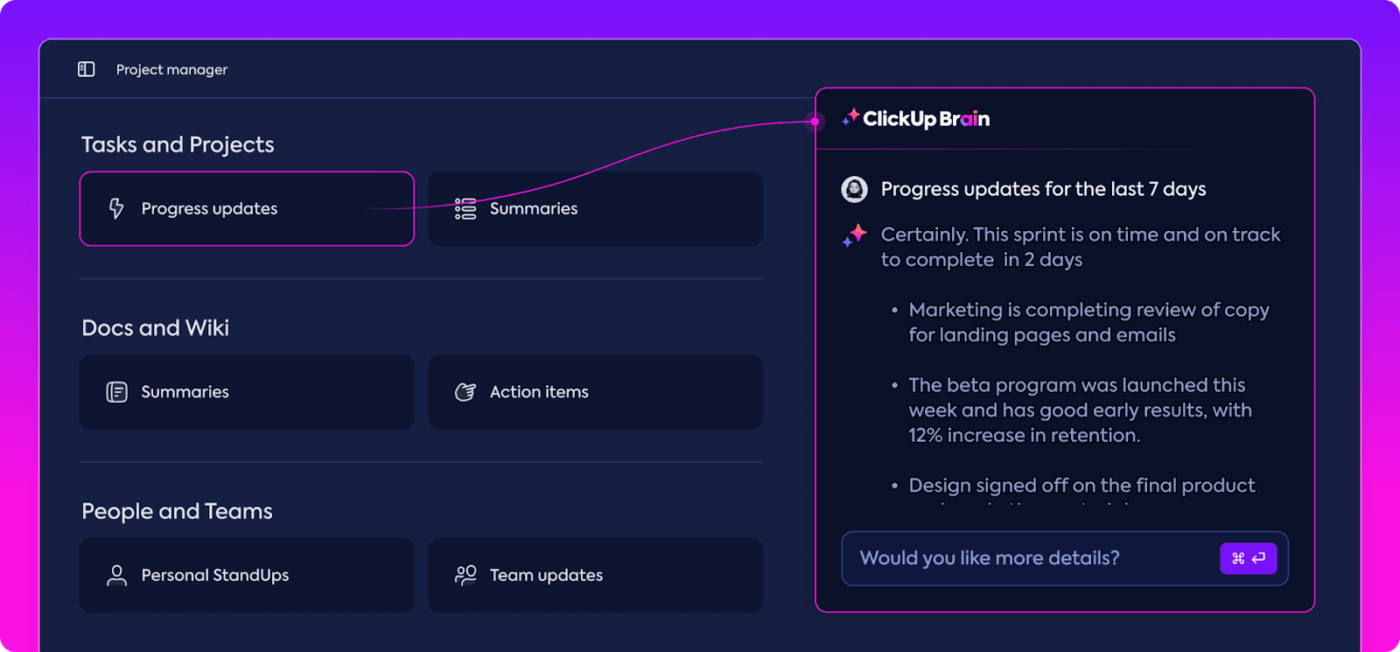
Oluşturulan içgörüler kullanıma hazırdır, böylece takımınız neyin işe yaradığını ve nerede değişiklik yapılması gerektiğini hemen görebilir. Analize harcanan zamanı azaltarak, ClickUp takımınızın değerlendirme sürecini hızlandırmasına ve uygulamaya odaklanmasına yardımcı olur.
Dokümantasyon ve işbirliği
Artık ihtiyacınız olanı bulmak için e-postaları veya birden fazla platformu aramanıza gerek yok; her şey tam orada, hazır olduğunuzda kullanabilirsiniz.
ClickUp Docs, takımınızın sorunsuz LLM değerlendirmesi için ihtiyaç duyduğu her şeyi bir araya getiren merkezi bir merkezdir. Karşılaştırma kriterleri, test sonuçları ve performans günlükleri gibi anahtar proje belgelerini tek bir erişilebilir noktada düzenler, böylece herkes en son bilgilere hızlı bir şekilde erişebilir.
ClickUp Belgeleri'ni gerçekten farklı kılan, gerçek zamanlı işbirliği özellikleridir. Entegre ClickUp Sohbet ve Yorumlar, takım üyelerinin belgeler içinde doğrudan içgörülerini tartışmasına, geri bildirimde bulunmasına ve değişiklikler önermesine olanak tanır.
Bu, takımınızın bulguları tartışıp doğrudan platformda ayarlamalar yapabileceği ve tüm tartışmaların konuyla ilgili ve yerinde olacağı anlamına gelir.

Belgelemeden ekip çalışmasına kadar her şey ClickUp Belgeleri içinde gerçekleşir ve herkesin en son gelişmeleri görebileceği, paylaşabileceği ve bunlara göre hareket edebileceği kolaylaştırılmış bir değerlendirme süreci oluşturur.
Sonuç? Takımınızın hedeflerine tam bir netlikle ilerlemesini sağlayan sorunsuz, birleşik bir iş akışı.
ClickUp'ı denemeye hazır mısınız? Öncelikle, LLM Değerlendirmenizden en iyi şekilde yararlanmak için bazı ipuçları ve püf noktaları ele alalım.
LLM Değerlendirmesinde En İyi Uygulamalar
LLM değerlendirmesine iyi yapılandırılmış bir yaklaşım, modelin ihtiyaçlarınızı karşıladığından, kullanıcı beklentileriyle uyumlu olduğundan ve anlamlı sonuçlar sağladığından emin olmanızı sağlar.
Son kullanıcıları göz önünde bulundurarak net hedefler belirlemek ve çeşitli metrikler kullanmak, güçlü ve iyileştirilmesi gereken alanları ortaya çıkaran kapsamlı bir değerlendirme oluşturmanıza yardımcı olur. Aşağıda, sürecinize rehberlik edecek bazı en iyi uygulamalar yer almaktadır.
🎯 Net hedefler belirleyin
Değerlendirme sürecine başlamadan önce, büyük dil modelinizin (LLM) tam olarak neyi başarmasını istediğinizi bilmeniz çok önemlidir. Model için belirli görevleri veya hedefleri belirlemek için zaman ayırın.
📌 Örnek: Makine çevirisinin performansını iyileştirmek istiyorsanız, ulaşmak istediğiniz kalite düzeylerini netleştirin. Net hedefler belirlemek, en alakalı metriklere odaklanmanıza yardımcı olur, değerlendirmenizin bu hedeflerle uyumlu kalmasını sağlar ve başarıyı doğru bir şekilde ölçmenizi sağlar.
👥 Hedef kitlenizi göz önünde bulundurun
LLM'yi kimlerin kullanacağını ve bunların ihtiyaçlarının neler olduğunu düşünün. Değerlendirmeyi hedef kullanıcılarınıza göre özelleştirmek çok önemlidir.
📌 Örnek: Modeliniz ilgi çekici içerik üretmek için tasarlanmışsa, akıcılık ve tutarlılık gibi metriklere özellikle dikkat etmelisiniz. Hedef kitlenizi anlamak, değerlendirme kriterlerinizi iyileştirmenize yardımcı olur ve modelin pratik uygulamalarda gerçek değer sunmasını sağlar
📊 Çeşitli metrikleri kullanın
LLM'nizi değerlendirmek için tek bir metrikle yetinmeyin; çeşitli metrikleri bir arada kullanarak performansını daha kapsamlı bir şekilde görebilirsiniz. Her metrik farklı yönleri yakalar, bu nedenle birkaçını bir arada kullanarak hem güçlü hem de zayıf yönleri belirleyebilirsiniz.
📌 Örnek: BLEU puanları çeviri kalitesini ölçmek için harika olsa da, yaratıcı yazımın tüm nüanslarını kapsamayabilir. Tahmin doğruluğu için karmaşıklık ve hatta bağlam için insan değerlendirmeleri gibi metrikleri dahil etmek, modelinizin performansını çok daha kapsamlı bir şekilde anlamanıza yardımcı olabilir
LLM Benchmarkları ve Araçları
Büyük dil modellerinin (LLM) değerlendirilmesi genellikle, çeşitli görevlerde model performansını ölçmeye yardımcı olan endüstri standardı karşılaştırma ölçütlerine ve özel araçlara dayanır.
Değerlendirme sürecine yapı ve netlik kazandıran, yaygın olarak kullanılan bazı karşılaştırma ölçütleri ve araçların bir dökümü aşağıda verilmiştir.
Anahtar Karşılaştırma Ölçütleri
- GLUE (Genel Dil Anlama Değerlendirmesi): GLUE, cümle sınıflandırma, benzerlik ve çıkarım dahil olmak üzere birden çok dil görevinde model yeteneklerini değerlendirir. Genel amaçlı dil anlamayı işlemesi gereken modeller için başvurulacak bir karşılaştırma ölçütüdür
- SQuAD (Stanford Question Answering Dataset): SQuAD değerlendirme çerçevesi, okuduğunu anlama için idealdir ve bir modelin metin pasajına dayalı soruları ne kadar iyi yanıtladığını ölçer. Genellikle, kesin yanıtların çok önemli olduğu müşteri desteği ve bilgi tabanlı arama gibi görevler için kullanılır
- SuperGLUE: GLUE'nun gelişmiş bir sürümü olan SuperGLUE, modelleri daha karmaşık akıl yürütme ve bağlamsal anlama görevleri üzerinde değerlendirir. Özellikle ileri düzey dil anlama gerektiren uygulamalar için daha derin içgörüler sağlar
Temel Değerlendirme Araçları
- Hugging Face : Kapsamlı model kitaplığı, veri kümeleri ve değerlendirme özellikleriyle oldukça popülerdir. Son derece sezgisel arayüzü, kullanıcıların kolayca karşılaştırma ölçütleri seçmesine, değerlendirmeleri özelleştirmesine ve model performansını izlemesine olanak tanır, bu da onu birçok LLM uygulaması için çok yönlü hale getirir
- SuperAnnotate: Denetimli öğrenme görevleri için çok önemli olan verilerin yönetimi ve açıklama ekleme konusunda uzmanlaşmıştır. Karmaşık görevlerde model performansını artıran, yüksek kaliteli, insan tarafından açıklama eklenmiş veriler sağladığı için model doğruluğunu iyileştirmek için özellikle kullanışlıdır
- AllenNLP: Allen Institute for AI tarafından geliştirilen AllenNLP, özel NLP modelleri üzerinde çalışan araştırmacılar ve geliştiriciler için tasarlanmıştır. Bir dizi karşılaştırma ölçütünü destekler ve dil modellerini eğitmek, test etmek ve değerlendirmek için araçlar sunarak çeşitli NLP uygulamaları için esneklik sağlar
Bu karşılaştırma ölçütleri ve araçların bir kombinasyonunu kullanmak, LLM değerlendirmesine kapsamlı bir yaklaşım sunar. Karşılaştırma ölçütleri görevler arasında standartlar belirlerken, araçlar model performansını etkili bir şekilde izlemek, iyileştirmek ve geliştirmek için gereken yapı ve esnekliği sağlar.
Birlikte, LLM'lerin hem teknik standartları hem de pratik uygulama ihtiyaçlarını karşıladığından emin olurlar.
LLM Model Değerlendirme Zorlukları
Büyük dil modellerini (LLM) değerlendirmek, incelikli bir yaklaşım gerektirir. Bu yaklaşım, yanıtların kalitesine ve modelin çeşitli senaryolardaki uyarlanabilirliğini ve sınırlarını anlamaya odaklanır.
Bu modeller kapsamlı veri kümeleri üzerinde eğitildiğinden, davranışları bir dizi faktörden etkilenir ve bu da doğruluktan daha fazlasını değerlendirmeyi gerekli kılar.
Gerçek değerlendirme, modelin güvenilirliğini, olağandışı komutlara karşı dayanıklılığını ve genel yanıt tutarlılığını incelemek anlamına gelir. Bu süreç, modelin güçlü ve zayıf yönlerini daha net bir şekilde ortaya koymaya yardımcı olur ve iyileştirilmesi gereken alanları ortaya çıkarır.
LLM değerlendirmesi sırasında ortaya çıkan bazı yaygın zorluklara daha yakından bakalım.
1. Eğitim verilerinin çakışması
Modelin test verilerinin bir kısmını *daha önce görmüş olup olmadığını bilmek zordur. LLM'ler büyük veri kümeleri üzerinde eğitildiğinden, bazı test sorularının eğitim örnekleriyle örtüşme olasılığı vardır. Bu, modelin gerçekte olduğundan daha iyi görünmesine neden olabilir, çünkü model gerçek anlamayı göstermek yerine sadece zaten bildiği şeyleri tekrarlıyor olabilir.
2. Tutarlı olmayan performans
LLM'ler öngörülemeyen yanıtlar verebilir. Bir an etkileyici içgörüler sunarken, bir sonraki an tuhaf hatalar yapabilir veya hayali bilgileri gerçekmiş gibi sunabilir (buna "halüsinasyon" denir).
Bu tutarsızlık, LLM çıktılarının bazı alanlarda mükemmel olsa da diğer alanlarda yetersiz kalabileceği ve bu nedenle genel güvenilirliğini ve kalitesini doğru bir şekilde değerlendirmek zor olabileceği anlamına gelir.
3. Karşıt güvenlik açıkları
LLM'ler, akıllıca tasarlanmış komutlarla onları hatalı veya zararlı yanıtlar vermeye yönlendiren düşmanca saldırılara maruz kalabilir. Bu güvenlik açığı, modeldeki zayıflıkları ortaya çıkarır ve beklenmedik veya önyargılı çıktılara yol açabilir. Bu düşmanca zayıflıkları test etmek, modelin sınırlarının nerede olduğunu anlamak için çok önemlidir.
Pratik LLM Değerlendirme Kullanım Örnekleri
Son olarak, LLM değerlendirmesinin gerçekten fark yarattığı birkaç yaygın durum:
Müşteri desteği chatbotları
LLM'ler, müşteri sorgularını işlemek için sohbet robotlarında yaygın olarak kullanılır. Modelin ne kadar iyi yanıt verdiğini değerlendirmek, doğru, yararlı ve bağlamsal olarak alakalı yanıtlar verdiğinden emin olmanızı sağlar.
Müşteri niyetini anlama, çeşitli soruları ele alma ve insan benzeri yanıtlar verme yeteneğini ölçmek çok önemlidir. Bu, işletmelerin sorunsuz bir müşteri deneyimi sunarken hayal kırıklığını en aza indirmesini sağlar.
İçerik oluşturma
Birçok işletme, blog içeriği, sosyal medya ve ürün açıklamaları oluşturmak için LLM'leri kullanır. Oluşturulan içeriğin kalitesini değerlendirmek, içeriğin gramer açısından doğru, ilgi çekici ve hedef kitle ile alakalı olmasını sağlar. Yüksek içerik standartlarını korumak için yaratıcılık, tutarlılık ve konuyla alakalı olma gibi metrikler burada önemlidir.
Duygu analizi
LLM'ler, müşteri geri bildirimlerinin, sosyal medya gönderilerinin veya ürün incelemelerinin duygularını analiz edebilir. Modelin bir metnin olumlu, olumsuz veya tarafsız olup olmadığını ne kadar doğru bir şekilde belirlediğini değerlendirmek çok önemlidir. Bu, işletmelerin müşteri duygularını anlamasına, ürün veya hizmetlerini iyileştirmesine, kullanıcı memnuniyetini artırmasına ve pazarlama stratejilerini geliştirmesine yardımcı olur.
Kod oluşturma
Geliştiriciler genellikle kod oluşturmaya yardımcı olmak için LLM'leri kullanır. Modelin işlevsel ve verimli kod üretme yeteneğini değerlendirmek çok önemlidir.
Oluşturulan kodun mantıklı, hatasız ve görev gereksinimlerini karşılayıp karşılamadığını kontrol etmek önemlidir. Bu, gerekli manuel kodlama miktarını azaltmaya ve verimliliği artırmaya yardımcı olur.
ClickUp ile LLM Değerlendirmenizi Optimize Edin
LLM'leri değerlendirmek, hedeflerinize uygun doğru metrikleri seçmekle ilgilidir. Anahtar, çeviri kalitesini artırmak, içerik oluşturmayı geliştirmek veya özel görevler için ince ayar yapmak gibi belirli hedeflerinizi anlamaktır.
RAG veya ince ayar metrikleri gibi performans değerlendirmesi için doğru metrikleri seçmek, doğru ve anlamlı bir değerlendirmenin temelini oluşturur. Öte yandan, G-Eval, Prometheus, SelfCheckGPT ve QAG gibi gelişmiş puanlayıcılar, güçlü akıl yürütme yetenekleri sayesinde kesin içgörüler sağlar.
Ancak bu, bu puanların mükemmel olduğu anlamına gelmez; yine de güvenilir olduklarından emin olmak önemlidir.
LLM uygulama değerlendirmenizde ilerledikçe, süreci özel kullanım durumunuza uyacak şekilde özelleştirin. Her senaryo için işe yarayan evrensel bir metrik yoktur. Metriklerin bir kombinasyonu ve bağlama odaklanma, modelinizin performansını daha doğru bir şekilde görmenizi sağlar.
LLM değerlendirmenizi kolaylaştırmak ve takım işbirliğini geliştirmek için ClickUp, iş akışlarını yönetmek ve önemli metrikleri izlemek için ideal çözümdür.
Takımınızın verimliliğini artırmak mı istiyorsunuz? Bugün ClickUp'a kaydolun ve iş akışınızı nasıl dönüştürebileceğini deneyimleyin!