
ทีมส่วนใหญ่ปฏิบัติต่อการสร้าง SQL ราวกับเป็นกลมายากล คุณพิมพ์คำถามแล้วก็ได้คำสั่งค้นหา
แต่ความจริงก็คือ Snowflake Cortex Analyst จะทำงานได้ดีเพียงใด ขึ้นอยู่กับแบบจำลองเชิงความหมายที่คุณสร้างขึ้นเป็นอันดับแรก และการตั้งค่าดังกล่าวไม่ใช่เรื่องง่าย การเรียนรู้วิธีใช้ Snowflake Cortex สำหรับการสร้าง SQL ทำให้ทีมข้อมูลสามารถแปลงภาษาธรรมชาติให้เป็นคำสั่งที่ซับซ้อนและสามารถดำเนินการได้ในเวลาเพียงไม่กี่วินาที
คู่มือนี้จะนำคุณผ่านกระบวนการนำไปใช้จริง ตั้งแต่การกำหนดแบบจำลองเชิงความหมาย YAML ของคุณ ไปจนถึงการค้นหาข้อมูลในคลังข้อมูลของคุณโดยใช้ภาษาธรรมชาติ เพื่อให้คุณเข้าใจทั้งศักยภาพและข้อกำหนดเบื้องต้นก่อนที่คุณจะเริ่มต้น
เรายังพิจารณาว่า Snowflake Cortex มีข้อจำกัดในด้านใดบ้าง และClickUpสามารถสนับสนุนกระบวนการทำงานที่กว้างขึ้นซึ่งเกี่ยวข้องกับการสร้าง SQL ได้อย่างไร
Snowflake Cortex Analyst คืออะไร?
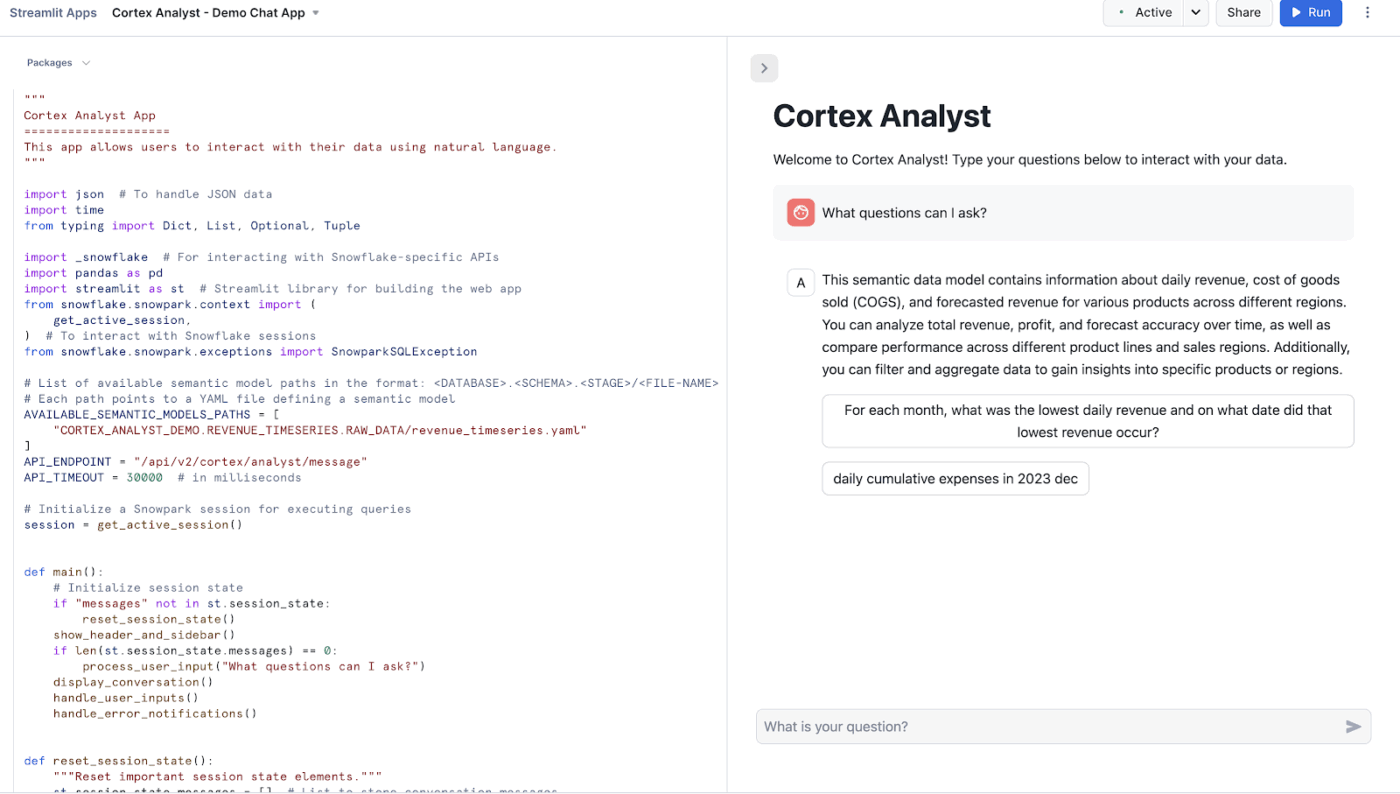
Snowflake Cortex Analyst เป็นบริการที่จัดการอย่างเต็มรูปแบบที่ช่วยให้คุณสามารถสร้างแอปพลิเคชันการสนทนาบนข้อมูลการวิเคราะห์ของคุณได้
มันใช้ตัวแทนเฉพาะทางในการแปลงข้อความเป็น SQL เพื่อเปลี่ยนคำถามภาษาธรรมชาติให้กลายเป็นคำสั่งที่แม่นยำและสามารถดำเนินการได้ บริการนี้ช่วยเชื่อมช่องว่างระหว่างโครงสร้างข้อมูลที่ซับซ้อนกับผู้ใช้ทางธุรกิจที่ต้องการคำตอบโดยไม่ต้องเขียนโค้ด
ความสามารถหลักประกอบด้วย:
- การจัดเตรียมอินเตอร์เฟซที่มีความแม่นยำสูงสำหรับการโต้ตอบกับข้อมูลที่มีโครงสร้าง
- การใช้แบบจำลองเชิงความหมายเพื่อทำความเข้าใจตรรกะทางธุรกิจและคำศัพท์เฉพาะของคุณ
- ให้บริการ REST API สำหรับการผสานรวมอย่างง่ายดายเข้ากับแอปพลิเคชันที่กำหนดเองหรือเครื่องมือ BI
- การรักษาความเป็นส่วนตัวของข้อมูลโดยการประมวลผลคำขอภายในขอบเขตความปลอดภัยของ Snowflake
📮 ClickUp Insight: 88% ของผู้ตอบแบบสำรวจของเราใช้ AI สำหรับงานส่วนตัว แต่กว่า 50% ยังลังเลที่จะใช้ในที่ทำงาน อุปสรรคหลักสามประการคือ? การขาดการผสานรวมที่ราบรื่น ช่องว่างด้านความรู้ หรือความกังวลด้านความปลอดภัย
แต่ถ้า AI ถูกฝังอยู่ในพื้นที่ทำงานของคุณแล้วและมีความปลอดภัยล่ะ? ClickUp Brain ผู้ช่วย AI ในตัวจาก ClickUp ทำให้สิ่งนี้เป็นจริงได้ มันเข้าใจคำสั่งในภาษาที่เข้าใจง่าย แก้ไขปัญหาการนำ AI มาใช้ทั้งสามข้อ พร้อมเชื่อมต่อแชท งาน เอกสาร และความรู้ของคุณทั่วทั้งพื้นที่ทำงาน
ค้นหาคำตอบและข้อมูลเชิงลึกได้เพียงคลิกเดียว!
ข้อกำหนดเบื้องต้นสำหรับการสร้าง SQL ของ Snowflake Cortex
การกระโดดเข้าสู่ Snowflake Cortex โดยไม่มีการตั้งค่าที่เหมาะสมจะนำไปสู่ความหงุดหงิด คุณอาจได้รับผลลัพธ์ที่ไม่ถูกต้อง เสียเวลาในการแก้ไขปัญหา และสรุปผิดว่าเครื่องมือมีปัญหา ทั้งที่ความจริงแล้วปัญหาอยู่ที่พื้นฐานที่ไม่มั่นคง
เพื่อหลีกเลี่ยงสิ่งนี้ คุณจำเป็นต้องมีองค์ประกอบพื้นฐานสามประการให้พร้อมก่อน
1. ตั้งค่าฐานข้อมูลและตารางของคุณ
ระบบปัญญาประดิษฐ์ของคุณฉลาดได้เพียงเท่าที่ข้อมูลที่มันสามารถเข้าถึงได้เท่านั้น หากโครงสร้างฐานข้อมูลของคุณเป็นเขาวงกตของชื่อคอลัมน์ที่เข้าใจยาก เช่น cust_dat_v2_final ทั้งนักวิเคราะห์และระบบปัญญาประดิษฐ์ของคุณจะประสบปัญหาในการทำความเข้าใจข้อมูลนั้น
ความสับสนนี้นำไปสู่การที่ AI สร้างการเชื่อมโยงที่ไม่ถูกต้องหรือดึงข้อมูลจากคอลัมน์ที่ไม่ถูกต้อง ทำให้ทีมของคุณเสียเวลาหลายชั่วโมงเพียงเพื่อพยายามถอดรหัสโครงสร้างข้อมูลก่อนที่จะสามารถเขียนคำสั่งค้นหาได้
เริ่มต้นด้วยการตรวจสอบให้แน่ใจ ว่าซอฟต์แวร์คลังข้อมูลของคุณมีตารางที่คุณต้องการให้ Cortex Analyst สอบถามข้อมูลอยู่เสมอ เมื่อเป็นไปได้ ให้ใช้ชื่อคอลัมน์ที่ชัดเจนและอธิบายได้ ตัวอย่างเช่น คอลัมน์ที่มีชื่อว่า customer_lifetime_value จะเข้าใจได้ง่ายกว่า clv_01 ทั้งสำหรับมนุษย์และ AI
เพื่อดำเนินการตั้งค่าต่อไป บทบาท Snowflake ของคุณจะต้องมีสิทธิ์ดังต่อไปนี้:
- การใช้งาน: บนฐานข้อมูลและสคีมาที่มีตารางของคุณ
- เลือก: บนตารางที่คุณต้องการให้ Cortex Analyst สอบถามข้อมูล
- สร้างสเตจ: บนสคีมา ซึ่งจำเป็นต้องใช้เพื่ออัปโหลดไฟล์โมเดลเชิงความหมายของคุณ
📖 อ่านเพิ่มเติม: วิธีใช้ Snowflake Cortex สำหรับธุรกิจอัจฉริยะ
2. สร้างไฟล์โมเดลเชิงความหมายของคุณ
อุปสรรคที่ใหญ่ที่สุดของเครื่องมือแปลงข้อความเป็น SQL คือ AI ไม่สามารถสื่อสารภาษาเฉพาะของบริษัทคุณได้ มันไม่รู้ว่า "ARR" หมายถึง "รายได้ประจำรายปี" หรือว่าการเชื่อมตารางของลูกค้าของคุณกับตารางคำสั่งซื้อของคุณใช้ฟิลด์ customer_id
หากไม่มีบริบทนี้ ระบบ AI อาจสร้าง SQL ที่ถูกต้องตามเทคนิค แต่ไม่ถูกต้องตามตรรกะ ซึ่งอาจให้คำตอบที่ดูเหมือนถูกต้อง แต่เป็นการชี้นำที่อันตราย
โมเดลเชิงความหมายคือคำตอบ มันเป็นไฟล์ YAML ที่ทำหน้าที่เป็น "ชั้นแปล" เฉพาะของคุณ สอน Cortex Analyst ให้รู้จักคำศัพท์และตรรกะเฉพาะของธุรกิจของคุณ การสร้างและบำรุงรักษาไฟล์นี้เป็นความร่วมมือระหว่างวิศวกรข้อมูลที่ใช้ เครื่องมือ ETLเพื่อทราบโครงสร้างข้อมูล และนักวิเคราะห์ธุรกิจที่รู้คำศัพท์เฉพาะ
ไฟล์โมเดลเชิงความหมายของคุณควรประกอบด้วยองค์ประกอบสำคัญดังต่อไปนี้:
| ส่วนประกอบ | วัตถุประสงค์ |
| ตาราง | แสดงรายการแต่ละตารางพร้อมคำอธิบายวัตถุประสงค์ด้วยภาษาที่เข้าใจง่าย |
| คอลัมน์ | กำหนดประเภทเชิงความหมายของแต่ละคอลัมน์ (เช่น หมวดหมู่หรือเมตริก) และสามารถรวมค่าตัวอย่างได้ |
| ความสัมพันธ์ | ระบุวิธีที่ตารางเชื่อมต่อกันผ่านการเชื่อมโยง (joins) โดยขจัดความไม่แน่นอนทั้งหมดสำหรับ AI |
| คำค้นหาที่ตรวจสอบแล้ว | ให้ตัวอย่างคำถามและคู่ SQL ที่ทำหน้าที่เป็นแนวทางที่มีประสิทธิภาพสำหรับ LLM |
3. กำหนดค่าบริการค้นหา Cortex (ไม่บังคับ)
บางครั้ง คำตอบที่คุณต้องการอาจซ่อนอยู่ในข้อความที่ไม่มีโครงสร้าง เช่น คำอธิบายสินค้า ตั๋วการสนับสนุน หรือบันทึกการโทร คำสั่ง SQL แบบมาตรฐานไม่สามารถเข้าถึงข้อมูลนี้ได้ ซึ่งหมายความว่าคุณมักพลาด 'เหตุผล' ที่อยู่เบื้องหลัง 'สิ่งที่เกิดขึ้น'
คุณสามารถเพิ่มบริการ Snowflake Cortex Search Service ได้ที่นี่ตามต้องการ เป็นบริการ ค้นหาในรูปแบบบริการ (search-as-a-service) ที่ช่วยให้คุณสามารถค้นหาข้อมูลทั้งจากตารางที่มีโครงสร้างและข้อมูลข้อความที่ไม่มีโครงสร้าง โดยใช้ ตัวแทนปัญญาประดิษฐ์ (AI agents) สำหรับการวิเคราะห์ข้อมูลพร้อมกันในเวลาเดียวกัน
คุณควรกำหนดค่า Cortex Search หากนักวิเคราะห์ของคุณต้องการถามคำถามที่ต้องการดึงบริบทจากข้อความก่อนที่จะสร้าง SQL ตัวอย่างเช่น คุณสามารถค้นหาคำวิจารณ์ผลิตภัณฑ์ทั้งหมดที่มีวลี 'ปัญหาแบตเตอรี่' ก่อน แล้วสร้างคำสั่ง SQL เพื่อรวบรวมข้อมูลการขายเฉพาะผลิตภัณฑ์เหล่านั้น
สำหรับการสร้าง SQL แบบบริสุทธิ์เพื่อใช้กับตารางที่มีโครงสร้าง บริการนี้ไม่จำเป็น
🧠 เกร็ดความรู้:ในช่วงต้นทศวรรษ 1970 นักวิจัยจาก IBM ชื่อ Donald Chamberlin และ Raymond Boyce ได้สร้าง 'Structured English Query Language' ขึ้นมา แต่พวกเขาต้องเปลี่ยนชื่อเป็น SQL เพราะ 'SEQUEL' ได้ถูกจดทะเบียนเครื่องหมายการค้าโดยบริษัทเครื่องบินของอังกฤษแล้ว
คู่มือทีละขั้นตอนในการสร้าง SQL ด้วย Cortex Analyst
คุณได้เตรียมงานล่วงหน้าไว้แล้ว แต่ตอนนี้คุณกำลังเผชิญหน้ากับหน้าจอว่างเปล่า ไม่แน่ใจเกี่ยวกับขั้นตอนการทำงานที่แท้จริง คุณจะเปลี่ยนคำถามในหัวของคุณให้กลายเป็นคำสั่ง SQL ที่สามารถนำไปใช้ได้อย่างไร? เมื่อการจัดการขั้นตอนการทำงานไม่ชัดเจน เครื่องมือใหม่ ๆ มักไม่ถูกนำมาใช้ และการลงทุนในการตั้งค่าก็สูญเปล่า
กระบวนการลงมือปฏิบัติจริงนั้นตรงไปตรงมาอย่างน่าชื่นชม มาดูรายละเอียดกันใกล้ๆ!
ขั้นตอนที่ 1: เตรียมข้อมูลของคุณใน Snowflake
ก่อนอื่น ข้อมูลที่มีโครงสร้างของคุณต้องอยู่ใน Snowflake แอปพลิเคชัน Cortex Analyst แต่ละตัวจะถูกชี้ไปที่ตารางเดียวหรือมุมมองที่ประกอบด้วยหนึ่งหรือหลายตาราง ตรวจสอบให้แน่ใจว่าตารางของคุณถูกสร้างและเติมข้อมูลเรียบร้อยแล้ว
หากคุณกำลังโหลดจากไฟล์แบน:
- อัปโหลดไฟล์ข้อมูลของคุณ (เช่น CSV) ไปยัง Snowflake Stage
- ใช้คำสั่ง COPY INTO เพื่อโหลดข้อมูลจากสเตจไปยังตารางของคุณ
- ตรวจสอบให้แน่ใจว่าข้อมูลถูกโหลดสำเร็จก่อนที่จะดำเนินการต่อ
📖 อ่านเพิ่มเติม: วิธีใช้ Snowflake Cortex สำหรับการวิเคราะห์ข้อมูลระดับองค์กร
ขั้นตอนที่ 2: สร้างแบบจำลองเชิงความหมาย (หรือมุมมองเชิงความหมาย)
นี่คือขั้นตอนการจัดตั้งที่สำคัญที่สุด. พลังของ Cortex Analyst มาจากการผสานรวมแบบจำลองภาษาขนาดใหญ่(LLMs) กับแบบจำลองเชิงความหมาย, ไฟล์ YAML ที่อยู่เคียงข้างกับโครงสร้างฐานข้อมูลของคุณ และเข้ารหัสบริบททางธุรกิจ.
มุมมองเชิงความหมาย (Semantic Views) เป็นวิธีที่แนะนำของ Snowflake สำหรับ Cortex Analyst ในขณะนี้ โดยจะจัดเก็บเมตริกทางธุรกิจ ความสัมพันธ์ และคำนิยามต่าง ๆ ไว้โดยตรงภายใน Snowflake ไฟล์โมเดลเชิงความหมายแบบ YAML เดิมยังคงใช้งานได้ แต่ Snowflake จะแนะนำให้ใช้งาน Semantic Views สำหรับการติดตั้งใหม่
แบบจำลองเชิงความหมายหรือมุมมองของคุณควรประกอบด้วย:
- คำอธิบายตารางและคอลัมน์: คำอธิบายที่เข้าใจง่ายเกี่ยวกับความหมายของแต่ละฟิลด์
- ตัวชี้วัดทางธุรกิจ: คำจำกัดความสำหรับฟิลด์ที่คำนวณได้ เช่น รายได้, อัตราการยกเลิก, หรืออัตราการเปลี่ยนแปลง
- ตัวกรองและคำพ้องความหมาย: คำที่ใช้แทนซึ่งผู้ใช้อาจใช้ (เช่น 'ยกเลิก' ที่เชื่อมโยงกับสถานะเฉพาะ)
- คำถามที่ได้รับการตรวจสอบ: คลังคำถามที่ได้รับการตรวจสอบของ Snowflake จัดเก็บคู่คำถามและ SQL ที่ได้รับการอนุมัติ เมื่อคำถามของผู้ใช้คล้ายกับรายการใดรายการหนึ่งในนั้น Cortex Analyst สามารถอ้างอิงถึงคำถามนั้นได้ระหว่างการสร้าง SQL
🤝 ขอแจ้งเตือนอย่างเป็นกันเอง: Snowflake แนะนำให้ใช้ตารางไม่เกิน 10 ตาราง และใช้คอลัมน์ที่เลือกไม่เกิน 50 คอลัมน์ เพื่อประสิทธิภาพที่ดีที่สุดในกระบวนการทำงานของ Snowsight
ขั้นตอนที่ 3: อัปโหลดโมเดลเชิงความหมายไปยังสเตจของ Snowflake
หากคุณกำลังใช้โมเดลเชิงความหมายที่ใช้ YAML เป็นพื้นฐาน โมเดลนั้นจำเป็นต้องถูกจัดเตรียมไว้ล่วงหน้าเพื่อให้ Cortex Analyst สามารถอ้างอิงได้ขณะทำงาน
- อัปโหลดไฟล์ yaml ของคุณไปยังสแตจภายในของ Snowflake (เช่น RAW_DATA)
- ยืนยันว่าไฟล์ปรากฏอยู่ในสเตจผ่าน Snowsight UI หรือคำสั่ง LIST @stage_name
- โปรดสังเกตเส้นทางของขั้นตอน; คุณจะต้องอ้างอิงถึงมันในคำขอ API หรือการตั้งค่าแอปของคุณ
หากคุณกำลังใช้มุมมองเชิงความหมาย ขั้นตอนนี้จะดำเนินการโดยอัตโนมัติภายใน Snowflake โดยไม่จำเป็นต้องอัปโหลดแยกต่างหาก
🔍 คุณรู้หรือไม่? NULL ใน SQLไม่ได้หมายถึงศูนย์หรือว่างเปล่า แต่หมายถึงข้อมูลที่ไม่ทราบหรือไม่มีอยู่ ซึ่งอาจทำให้เกิดพฤติกรรมที่ไม่คาดคิด เช่น การเปรียบเทียบที่ไม่ให้ผลลัพธ์เป็นจริงหรือเท็จ
ขั้นตอนที่ 4: ส่งคำถามภาษาธรรมชาติผ่าน REST API
ตอนนี้การสร้าง SQL จริงจะเริ่มต้นขึ้น REST API จะสร้างคำสั่ง SQL สำหรับคำถามที่กำหนดโดยใช้แบบจำลองเชิงความหมายหรือมุมมองเชิงความหมายที่มีอยู่ในคำขอ
จัดโครงสร้างคำขอ API ของคุณด้วย:
- ข้อความ; อาร์เรย์ที่ประกอบด้วยคำถามของผู้ใช้ของคุณพร้อมบทบาท: "ผู้ใช้"
- การอ้างอิงถึงแบบจำลองเชิงความหมายหรือมุมมองเชิงความหมายของคุณ
- รุ่นที่คุณต้องการ (หรือปล่อยให้เป็นอัตโนมัติเพื่อให้ Cortex เลือกให้ดีที่สุด)
คุณสามารถมีการสนทนาหลายรอบได้ โดยที่คุณสามารถถามคำถามติดตามผลที่ต่อยอดจากคำถามก่อนหน้าได้
ขั้นตอนที่ 5: แยกวิเคราะห์การตอบกลับของ API
แต่ละข้อความในคำตอบสามารถมีบล็อกเนื้อหาหลายบล็อกซึ่งมีประเภทต่างกันได้ ค่าที่รองรับในปัจจุบันสำหรับฟิลด์ประเภทคือ: ข้อความ, ข้อเสนอแนะ, และ SQL
นี่คือความหมายของแต่ละประเภท:
- SQL: Cortex สร้างคำสั่งค้นหาสำเร็จแล้ว; นี่คือสิ่งที่คุณจะดำเนินการ
- ข้อความ: คำอธิบายหรือคำตอบในภาษาธรรมชาติที่แนบมากับ SQL
- คำแนะนำ: ประเภทเนื้อหาคำแนะนำจะถูกเพิ่มในคำตอบเฉพาะเมื่อคำถามของผู้ใช้ไม่ชัดเจนและ Cortex Analyst ไม่สามารถส่งคืนคำสั่ง SQL สำหรับการสอบถามนั้นได้ ใช้สิ่งเหล่านี้เพื่อชี้แจงหรือปรับปรุงคำถาม
🔍 คุณรู้หรือไม่?ลำดับที่คุณเขียน SQLไม่ใช่ลำดับที่มันทำงาน แม้ว่าคุณจะเขียน SELECT ก่อน แต่ฐานข้อมูลจะประมวลผล FROM และ WHERE ก่อนที่จะเลือกคอลัมน์ ซึ่งทำให้ทั้งผู้เริ่มต้นและผู้ใช้ที่มีประสบการณ์สับสนได้
ขั้นตอนที่ 6: ดำเนินการ SQL ที่สร้างขึ้นใน Snowflake
เมื่อคุณได้รับบล็อก SQL จากคำตอบแล้ว ให้รันบล็อกนั้นกับคลังข้อมูลเสมือนของคุณใน Snowflake คำสั่ง SQL ที่สร้างขึ้นจะถูกดำเนินการในคลังข้อมูลเสมือนของคุณใน Snowflake เพื่อสร้างผลลัพธ์สุดท้าย ข้อมูลจะยังคงอยู่ภายในขอบเขตการกำกับดูแลของ Snowflake
สิ่งสำคัญที่ต้องทราบขณะดำเนินการ:
- Cortex Analyst ผสานการทำงานอย่างสมบูรณ์กับนโยบายการควบคุมการเข้าถึงตามบทบาท (RBAC) ของ Snowflake เพื่อให้มั่นใจว่าคำสั่ง SQL ที่สร้างและดำเนินการเป็นไปตามการควบคุมการเข้าถึงที่กำหนดไว้ทั้งหมด
- หากผู้ใช้ไม่มีสิทธิ์เข้าถึงตาราง การค้นหาข้อมูลจะล้มเหลวในขั้นตอนการดำเนินการ เช่นเดียวกับการเขียนคำสั่ง SQL ด้วยตนเอง
- ค่าใช้จ่ายในการประมวลผลของคลังข้อมูลจะถูกคิดในขั้นตอนนี้ แยกต่างหากจากค่าบริการการใช้งานของ Cortex Analyst
ขั้นตอนที่ 7: ปรับปรุงและทำซ้ำ
การได้รับคำถามที่สมบูรณ์แบบในครั้งแรกไม่ใช่สิ่งที่สามารถรับประกันได้เสมอไป นี่คือวิธีที่จะปรับปรุงผลลัพธ์ให้ดีขึ้นเมื่อเวลาผ่านไป:
- เพิ่มคำถามที่ได้รับการยืนยัน ลงในแบบจำลองเชิงความหมายของคุณสำหรับคำถามที่เกิดขึ้นซ้ำๆ
- เสริมสร้างแบบจำลองเชิงความหมายของคุณ ด้วยคำอธิบายที่ดีขึ้น คำพ้องความหมาย และตัวกรองเมื่อ Cortex ตีความคำผิด
- ใช้การสนทนาแบบหลายขั้นตอน เพื่อติดตามผล เช่น 'ตอนนี้กรองตามภูมิภาค' การสนทนาแบบหลายขั้นตอนช่วยให้สามารถถามคำถามติดตามผลที่ต่อยอดจากคำถามก่อนหน้าได้
- ตรวจสอบการใช้งาน ผ่าน CORTEX_ANALYST_USAGE_HISTORY และประวัติการสืบค้นใน Snowflake เพื่อค้นหาลักษณะของคำสั่งที่ล้มเหลวหรือไม่ถูกต้อง
🧠 ข้อเท็จจริงสนุกๆ: เงื่อนไขการเชื่อมโยง (JOIN) ที่ขาดไปเพียงหนึ่งข้อสามารถสร้างปัญหาใหญ่ได้ การลืมเงื่อนไขการเชื่อมโยงอาจทำให้เกิดผลลัพธ์แบบคาร์ทีเซียน (Cartesian product) ซึ่งเพิ่มจำนวนแถวอย่างมากและบางครั้งอาจทำให้ระบบล่มได้
แนวทางปฏิบัติที่ดีที่สุดสำหรับความแม่นยำของ Snowflake Text-to-SQL
คุณภาพของแบบจำลองเชิงความหมายของคุณเป็นตัวกำหนดความถูกต้องของคำสั่งค้นหาที่มันสร้างขึ้นโดยตรง. นี่คือแนวทางที่ดีที่สุดเพื่อปรับปรุงความถูกต้อง. 🛠️
- เพิ่มคำค้นหาที่ได้รับการยืนยันลงในแบบจำลองเชิงความหมายของคุณ: นี่คือสิ่งที่มีผลกระทบมากที่สุดที่คุณสามารถทำได้ รวมตัวอย่างคำถามและคำสั่ง SQL จำนวนมากที่สะท้อนถึงวิธีที่ทีมของคุณถามคำถามอย่างแท้จริง
- ใช้ชื่อคอลัมน์และตารางที่อธิบายได้: โมเดลจะทำงานได้ดีขึ้นเมื่อชื่อคอลัมน์และตารางสามารถอธิบายตัวเองได้ หากไม่สามารถเปลี่ยนสคีมาได้ ให้เพิ่มคำอธิบายที่ชัดเจนในไฟล์ YAML ของคุณสำหรับชื่อคอลัมน์ที่เข้าใจยาก
- รวมตัวอย่างค่า: การเพิ่มข้อมูลตัวอย่างสำหรับคอลัมน์ประเภทหมวดหมู่ (เช่น สถานะหรือภูมิภาค) ช่วยให้โมเดลเข้าใจตัวเลือกตัวกรองที่ถูกต้องที่มีอยู่
- ทดสอบด้วยกรณีขอบเขต: ในระหว่างการพัฒนา ตั้งคำถามที่คลุมเครือหรือซับซ้อนโดยเจตนาเพื่อระบุจุดที่โมเดลเชิงความหมายของคุณต้องการบริบทหรือการชี้แจงเพิ่มเติม
- ปรับปรุงโมเดลเชิงความหมายของคุณ: ให้ถือว่าโมเดลเชิงความหมายของคุณเป็นเอกสารที่มีชีวิต ควรมีการอัปเดตอย่างต่อเนื่องผ่าน กระบวนการวนซ้ำโดยพิจารณาจากคำค้นหาที่ประสบความสำเร็จและคำค้นหาที่ไม่ประสบความสำเร็จ
ClickUp: ทางเลือกที่ง่ายกว่าสำหรับ Snowflake Cortex
Snowflake Cortex ทำงานได้ดีเมื่อทีมต้องการสร้าง SQL และรันคำสั่งค้นหาข้อมูลที่มีโครงสร้าง ทีมสามารถกำหนดสคีมา, แผนผังความสัมพันธ์, และเขียนคำสั่งค้นหาเพื่อดึงข้อมูลเชิงลึก การตั้งค่าเช่นนี้เหมาะสำหรับสภาพแวดล้อมที่มีข้อมูลจำนวนมาก โดยเฉพาะอย่างยิ่งเมื่อผู้วิเคราะห์เป็นเจ้าของรายงาน
อย่างไรก็ตาม หลายทีมไม่จำเป็นต้องมีชั้น SQL เต็มรูปแบบเพื่อตอบคำถามการดำเนินงานประจำวัน ผู้จัดการผลิตภัณฑ์ ผู้นำโครงการ และทีมปฏิบัติการมักต้องการคำตอบที่รวดเร็วซึ่งเชื่อมโยงกับงานที่กำลังดำเนินการอยู่
ClickUp มอบเส้นทางที่เข้าถึงได้ง่ายกว่า ทีมสามารถถามคำถามด้วยภาษาที่เข้าใจง่าย ตรวจสอบแดชบอร์ดแบบเรียลไทม์ และดำเนินการตามข้อมูลเชิงลึกได้โดยไม่ต้องเขียน SQL หรือสร้างโมเดลเชิงความหมาย
สร้างและปรับปรุง SQL ได้เร็วขึ้น
Snowflake Cortex มุ่งเน้นการสร้างคำสั่ง SQL จากชุดข้อมูลที่มีโครงสร้างภายในสภาพแวดล้อมคลังข้อมูล ซึ่งทำงานได้ดีเมื่อข้อมูลของคุณอยู่ใน Snowflake อยู่แล้วและมีสคีมาที่วางแผนไว้

ClickUp Brainรองรับการสร้าง SQL ในรูปแบบที่ยืดหยุ่นและเน้นการดำเนินการมากขึ้น ทีมงานสามารถสร้าง ปรับแต่ง และจัดเก็บคำสั่ง SQL ได้โดยตรงภายในพื้นที่ทำงานของพวกเขา ซึ่งเป็นการรวมการวิเคราะห์ การอภิปราย และการตัดสินใจไว้ในที่เดียว
สมมติว่านักวิเคราะห์ผลิตภัณฑ์ทำงานเกี่ยวกับงานวิเคราะห์การรักษาลูกค้าภายใน ClickUp แทนที่จะเปลี่ยนไปใช้เครื่องมืออื่นเพื่อเขียนคำสั่งค้นหา พวกเขาจะถาม ClickUp Brain:
📌 ลองใช้คำสั่งนี้: เขียนคำสั่ง SQL เพื่อคำนวณการเก็บรักษาข้อมูลผู้ใช้เป็นเวลาเจ็ดวัน โดยจัดกลุ่มตามกลุ่มผู้ใช้ที่ลงทะเบียน
ClickUp Brain สร้างคำสั่งค้นหาที่มีโครงสร้างซึ่งรวมถึงการจัดกลุ่มกลุ่มตัวอย่าง, ตัวกรองวันที่, และตรรกะการเก็บรักษา. นักวิเคราะห์วางคำสั่งค้นหาลงใน Snowflake หรือคลังข้อมูลอื่น ๆ และรันทันที.
มันช่วย:
- การเขียนการเชื่อมโยงข้ามหลายตาราง เช่น ผู้ใช้, คำสั่งซื้อ, และเหตุการณ์
- แปลงคำถามเกี่ยวกับผลิตภัณฑ์ที่เป็นภาษาอังกฤษธรรมดาให้เป็นตรรกะ SQL พร้อมสำหรับการดำเนินการ
- แก้ไขปัญหาคำสั่งค้นหาที่ผิดพลาดและอธิบายปัญหา เช่น การเชื่อมข้อมูลที่ไม่ถูกต้องหรือเงื่อนไขที่ขาดหายไป
- เขียนคำสั่งค้นหาใหม่เพื่อประสิทธิภาพที่ดีขึ้นหรืออ่านง่ายขึ้น
ตัวอย่างเช่น ในระหว่างการทบทวนการทดลองการเติบโต นักการตลาดถามว่า: 'เขียนคำสั่ง SQL เพื่อเปรียบเทียบอัตราการเปลี่ยนแปลงระหว่างสองหน้า landing page ในช่วง 14 วันที่ผ่านมา'
ClickUp Brain สร้างคำค้นหาโดยใช้การรวมข้อมูลแบบมีเงื่อนไขและตัวกรองวันที่ ทีมดำเนินการใน Snowflake และตรวจสอบความถูกต้องของผลลัพธ์การทดลอง
📌 ลองใช้คำสั่งนี้: แก้ไขคำสั่ง SQL นี้ที่การเชื่อมโยงทำให้เกิดแถวซ้ำและอธิบายปัญหา
ClickUp Brain ระบุปัญหาการเชื่อมโยง แก้ไขคำค้นหา และอธิบายว่าทำไมจึงเกิดแถวซ้ำเนื่องจากเงื่อนไขการเชื่อมโยงที่ไม่ถูกต้อง
แทนที่การรายงานที่ขับเคลื่อนด้วย SQL
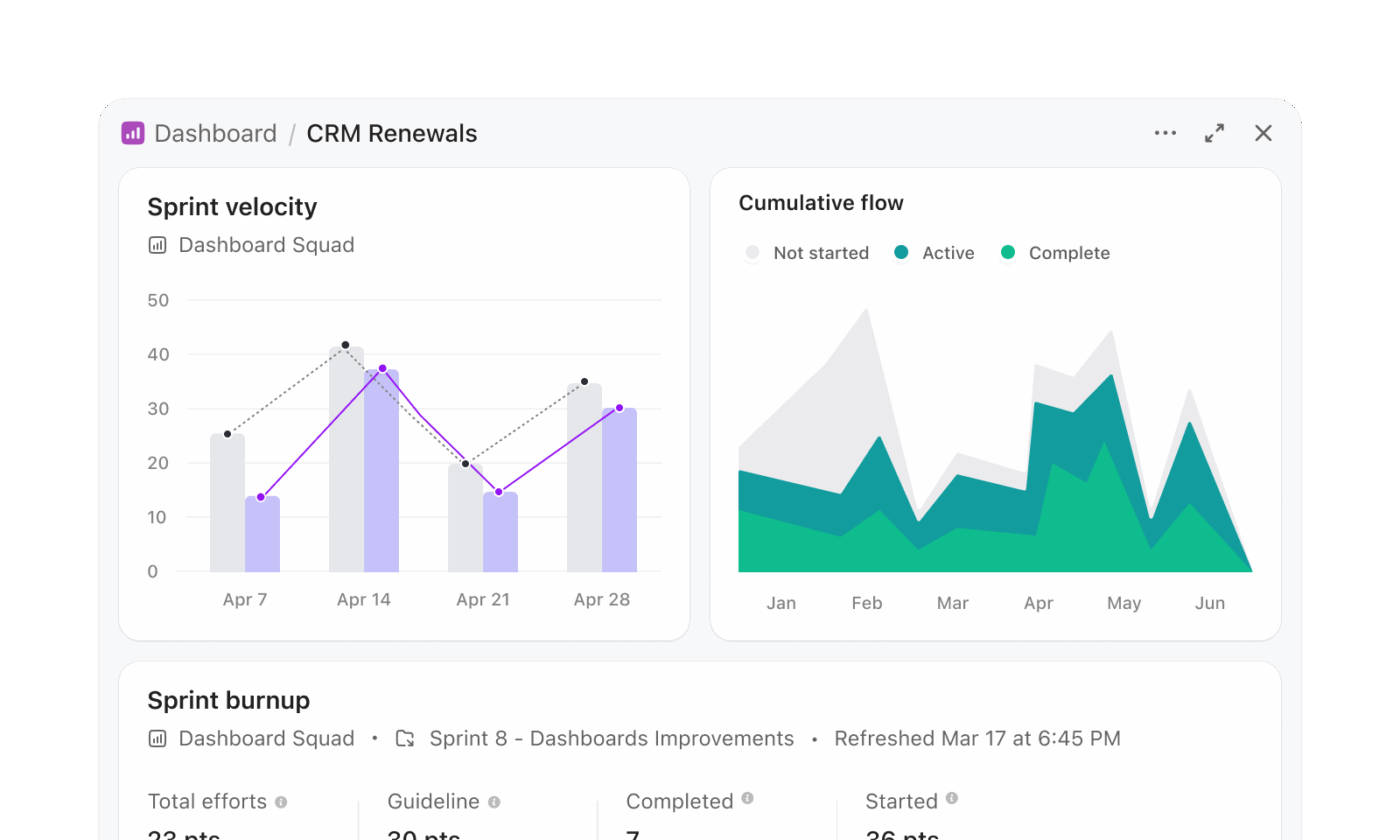
เวิร์กโฟลว์ของ Snowflake Cortex มักเกี่ยวข้องกับการสร้าง SQL, การรันคำสั่งค้นหา และการแสดงผลลัพธ์ในชั้นที่แยกต่างหากแดชบอร์ดของ ClickUpช่วยลดกระบวนการหลายขั้นตอนนั้นและนำเสนอข้อมูลเชิงลึกโดยตรงจากการทำงานสด
ทีมบริหารโครงการที่ติดตามความพร้อมในการปล่อยเวอร์ชันสามารถสร้างแดชบอร์ดได้โดยไม่ต้องเขียนคำสั่งค้นหา ตัวอย่างเช่น แดชบอร์ดการปล่อยเวอร์ชันอาจประกอบด้วย:
- บัตรรายการงาน ที่กรองเพื่อแสดงงานที่ค้างอยู่ทั้งหมดในทุกทีมผลิตภัณฑ์
- บัตรปริมาณงาน ที่แสดงการกระจายงานระหว่างวิศวกร
- แผนภูมิแท่ง เปรียบเทียบงานที่เสร็จสิ้นกับงานที่ยังค้างอยู่ตามสปรินท์
- บัตรคำนวณ ที่ติดตามเวลาเฉลี่ยในการทำงานให้เสร็จ
สมมติว่าผู้นำโปรแกรมตรวจสอบแดชบอร์ดนี้ก่อนการประชุมปล่อยเวอร์ชัน พวกเขาจะเห็นทันทีว่าบริการแบ็กเอนด์แสดงอัตราการล่าช้าสูงขึ้น พวกเขาเปิดการ์ดรายการงานและตรวจสอบงานที่ก่อให้เกิดความเสี่ยงอย่างละเอียด
ผู้ใช้ ClickUp ตัวจริงแบ่งปัน:
ClickUp ช่วยให้เราสามารถส่งต่อโปรเจ็กต์ให้กันได้อย่างรวดเร็ว ตรวจสอบสถานะของโปรเจ็กต์ได้อย่างง่ายดาย และมอบหน้าต่างให้ผู้บังคับบัญชาของเราสามารถมองเห็นปริมาณงานของเราได้ตลอดเวลาโดยไม่ต้องรบกวนเรา เราได้ประหยัดเวลาไปหนึ่งวันต่อสัปดาห์อย่างแน่นอน หากไม่มากกว่านั้น จำนวนอีเมลก็ลดลงอย่างมากอย่างเห็นได้ชัด
ClickUp ช่วยให้เราสามารถส่งต่อโปรเจกต์ให้กันได้อย่างรวดเร็ว ตรวจสอบสถานะของโปรเจกต์ได้อย่างง่ายดาย และเปิดโอกาสให้หัวหน้าสามารถติดตามปริมาณงานของเราได้ตลอดเวลาโดยไม่ต้องรบกวนเรา เราประหยัดเวลาได้หนึ่งวันต่อสัปดาห์อย่างแน่นอนจากการใช้ ClickUp หรืออาจจะมากกว่านั้น จำนวนอีเมลก็ลดลงอย่างเห็นได้ชัด
ดำเนินการตามข้อมูลเชิงลึกโดยไม่ต้องมีขั้นตอนที่ซับซ้อน
Snowflake Cortex มุ่งเน้นการสร้างข้อมูลเชิงลึกจากข้อมูล ทีมยังคงต้องตีความผลลัพธ์และกระตุ้นการดำเนินการแยกกัน
ClickUp AI Super Agentsช่วยลดช่องว่างและเปลี่ยนข้อมูลเชิงลึกให้เป็นการดำเนินการ พวกเขาทำงานเป็นเพื่อนร่วมทีม AI ที่คอยตรวจสอบข้อมูลในพื้นที่ทำงานอย่างต่อเนื่องและดำเนินการตามเงื่อนไขที่กำหนด
สมมติว่าผู้จัดการโปรแกรมดูแลโครงการผลิตภัณฑ์หลายโครงการ ซูเปอร์เอเจนต์สามารถ:
- ติดตามงานในโครงการต่างๆ และตรวจจับเมื่องานที่ล่าช้ากว่ากำหนดเกินเกณฑ์ที่กำหนดไว้
- ระบุรูปแบบ เช่น ความล่าช้าที่เกิดขึ้นซ้ำในขั้นตอนเดียวกันของกระบวนการทำงาน
- สร้างงานที่สรุปโครงการที่ได้รับผลกระทบและมอบหมายให้กับผู้นำโครงการ
- แจ้งเตือนเจ้าของทีมเมื่อมีงานสำคัญที่ยังไม่ได้รับการแก้ไขเกินกำหนดเวลา
ตัวอย่างเช่น ในระหว่างรอบการปล่อยผลิตภัณฑ์ Super Agent ตรวจพบว่ามีการพลาดกำหนดเวลาของงานที่มีความสำคัญสูงมากกว่า 10 งานในสองทีม มันสร้างงานใน ClickUpที่มีชื่อว่า 'ความเสี่ยงในการปล่อย: พลาดกำหนดเวลา' แนบงานที่เกี่ยวข้องทั้งหมด และมอบหมายให้ผู้จัดการโปรแกรมเพื่อตรวจสอบทันที
ทีมสามารถโต้ตอบโดยตรงกับซูเปอร์เอเจนต์ได้เช่นกัน: 'วิเคราะห์โครงการที่กำลังดำเนินการทั้งหมดและเน้นความเสี่ยงในการส่งมอบสำหรับสปรินท์นี้'
ซูเปอร์เอเจนต์ตรวจสอบกำหนดเวลา, ความเกี่ยวข้อง, และสถานะของงาน จากนั้นโพสต์สรุปที่มีโครงสร้างไว้ในเวิร์กสเปซ
นี่คือวิธีการตั้งค่า Super Agent ของคุณเองใน ClickUp:
รวมศูนย์กระบวนการทำงานข้อมูลของคุณด้วย ClickUp
เครื่องมือแปลงข้อความเป็น SQL เช่น Snowflake Cortex ทำให้ข้อมูลเข้าถึงได้ง่ายขึ้น ในขณะเดียวกัน การได้ผลลัพธ์ที่เชื่อถือได้ยังคงต้องใช้ความพยายาม
ทีมต้องการสคีมาที่สะอาด, แบบจำลองเชิงความหมายที่แข็งแกร่ง, และการปรับปรุงอย่างต่อเนื่องเพื่อให้ผลลัพธ์มีความถูกต้อง. แม้ว่าจะสร้างคำค้นหาที่ถูกต้องแล้ว, งานก็ยังไม่จบเพียงแค่นั้น. ยังต้องมีผู้ที่จะตีความผลลัพธ์, แบ่งปันข้อมูลเชิงลึก, และเปลี่ยนข้อมูลเหล่านั้นให้กลายเป็นการตัดสินใจ.
ClickUp นำเสนอแนวทางที่แตกต่าง แทนที่จะแยกการวิเคราะห์ออกจากกระบวนการดำเนินงาน ClickUp เชื่อมโยงทั้งสองเข้าด้วยกัน ทีมงานสามารถสร้าง SQL บันทึกข้อมูลเชิงลึก ทำงานร่วมกันในสิ่งที่ค้นพบ และดำเนินการแก้ไขทั้งหมดภายในพื้นที่ทำงานเดียวกัน
ClickUp Brain ช่วยในการเขียนและปรับปรุงคำถาม ในขณะที่แดชบอร์ดและตัวแทน AI ช่วยทีมติดตามผลลัพธ์และขับเคลื่อนงานไปข้างหน้าโดยไม่ต้องสลับไปมาระหว่างเครื่องมือต่างๆ
Snowflake Cortex ช่วยให้คุณได้รับคำตอบ ClickUp ช่วยให้คุณนำคำตอบเหล่านั้นไปใช้งานได้สมัครใช้ ClickUpวันนี้!
คำถามที่พบบ่อย
Snowflake Cortex Analyst เป็นบริการเฉพาะทางภายในชุดผลิตภัณฑ์ Snowflake Cortex AI ที่ครอบคลุม Cortex Analyst มุ่งเน้นเฉพาะการสร้างข้อความเป็น SQL โดยใช้โมเดลเชิงความหมาย ในขณะที่ Cortex AI ครอบคลุมฟังก์ชัน LLM ที่หลากหลายกว่า การอนุมานโมเดลการเรียนรู้ของเครื่อง และความสามารถในการค้นหา
ใช่ Cortex Analyst สามารถค้นหาตาราง Apache Iceberg ที่จัดการผ่าน Snowflake ได้ ตราบใดที่ตารางสามารถเข้าถึงได้ภายในสภาพแวดล้อม Snowflake ของคุณและถูกกำหนดไว้อย่างถูกต้องในแบบจำลองเชิงความหมายของคุณ คุณสามารถสร้างคำสั่งค้นหาต่อตารางเหล่านั้นได้
ความแม่นยำสำหรับคำค้นหาที่ซับซ้อนขึ้นอยู่กับคุณภาพของแบบจำลองเชิงความหมายของคุณเกือบทั้งหมด แบบจำลองที่มีความสัมพันธ์ของตารางที่ชัดเจน คำค้นหาที่ได้รับการตรวจสอบจำนวนมาก และข้อมูลเมตาที่อธิบายได้ดี จะให้ผลลัพธ์ที่มีความแม่นยำมากขึ้นอย่างมีนัยสำคัญสำหรับการรวมข้อมูลจากหลายตารางและการรวมข้อมูลที่ซับซ้อน
ราคาของ Snowflake Cortex Analyst เป็นไปตามโมเดลการคิดค่าบริการตามการใช้งานของ Snowflake ซึ่งหมายความว่าคุณจะถูกเรียกเก็บเงินตามเครดิตการประมวลผลที่ใช้ในระหว่างกระบวนการสร้างคำสั่งค้นหา สำหรับอัตราค่าบริการล่าสุด กรุณาอ้างอิงเอกสารราคาอย่างเป็นทางการของ Snowflake เสมอ