
Cyberincidenter utvecklas snabbt. Ransomware sprider sig på några minuter, AI-genererad phishing slinker förbi filter, och ett enda felsteg kan eskalera till en fullskalig säkerhetsöverträdelse innan teamen ens hunnit samordna sig om vad som händer. Pressen är påtaglig, och det är kostnaderna också.
Enligt IBM:s rapport Cost of a Data Breach Report ligger det globala genomsnittet på 4,44 miljoner dollar, och förseningar i hanteringen samt bristfällig samordning driver upp siffran ännu högre.
Mitt i kaoset behöver teamen tydlighet. En handbok för incidenthantering ger ditt team ett gemensamt manus när det blir kaotiskt. Den beskriver vem som agerar först, vilka steg som ska följas och hur man upprätthåller en tät kommunikation medan situationen utvecklas.
I det här blogginlägget lär du dig hur du skapar en incidenthanteringsguide anpassad för dagens hot. Vi utforskar verkliga scenarier, tydliga åtgärder och ClickUp, världens första konvergerade AI-arbetsyta, som ett system ditt team kan använda under press.
Vad är en handbok för incidenthantering?
En incidenthanteringsguide är en strukturerad, steg-för-steg-guide som hjälper säkerhetsteam att hantera specifika typer av cyberincidenter på ett konsekvent och effektivt sätt. Den beskriver exakt vad som ska göras när en incident inträffar, vem som ansvarar för varje åtgärd och hur man går från upptäckt till begränsning och återställning utan förvirring eller fördröjningar.
Se det som en färdig handlingsplan för verkliga scenarier som nätfiskeattacker, ransomware-infektioner eller dataintrång.
🧠 Rolig fakta: Det första datorviruset var inte skadligt. År 1971 rörde sig ett program som hette Creeper mellan datorer bara för att visa meddelandet: ”Jag är Creeper, fånga mig om du kan.” Det ledde till skapandet av det första antivirusprogrammet, som hette Reaper.
Handlingsplan för incidenthantering jämfört med plan jämfört med runbook
Människor blandar ofta ihop terminologin för säkerhetsdokumentation. Denna förvirring skapar reella problem när teamen utarbetar sina standardrutiner. Resultatet blir antingen övergripande planer som saknar konkreta åtgärder eller alltför tekniska handböcker som förvirrar ledningen.
Så här skiljer sig dessa tre dokument åt.
| Dokument | Omfattning | Detaljnivå | När den används | Vem använder den | Format |
| Planera | Strategi för hela organisationen | Övergripande riktlinjer | Innan incidenter inträffar | Ledning och juridik | Policyhandling |
| Handbok | Scenariebaserad hantering | Taktiska steg-för-steg-åtgärder | Under en specifik typ av incident | Incidenthanteringsteam | Arbetsflöde med beslutsträd |
| Handlingsplan | Enskild teknisk procedur | Detaljerade automatiserade steg | Under en specifik uppgift | Tekniska insatspersoner | Checklista eller manus |
Alla tre delarna måste samverka. En plan utan handböcker är för vag för att kunna genomföras. En handbok utan körmanualer innebär att det tekniska genomförandet blir en improvisation.
📮 ClickUp Insight: 53 % av organisationerna har ingen AI-styrning eller endast informella riktlinjer.
Och när människor inte vet vart deras data tar vägen – eller om ett verktyg kan utgöra en risk för regelefterlevnaden – tvekar de.
Om ett AI-verktyg finns utanför betrodda system eller har otydliga rutiner för datahantering räcker rädslan för ”Tänk om det här inte är säkert?” för att stoppa införandet direkt.
Så är inte fallet med ClickUps fullt reglerade, säkra miljö. ClickUp AI uppfyller kraven i GDPR, HIPAA och SOC 2 och är certifierat enligt ISO 42001, vilket garanterar att dina data är privata, skyddade och hanteras på ett ansvarsfullt sätt.
Tredjepartsleverantörer av AI får inte träna på eller lagra någon kunddata från ClickUp, och stödet för flera modeller fungerar under enhetliga behörigheter, integritetskontroller och strikta säkerhetsstandarder. Här blir AI-styrning en del av själva arbetsytan, så att teamen kan använda AI med tillförsikt, utan extra risk.
Viktiga komponenter i en handbok för incidenthantering
Alla effektiva handlingsplaner för incidenthantering har samma grundstruktur. Innan du börjar skapa den måste du veta vad den ska innehålla.
Utlösande kriterier och klassificering av incidenter
Triggers är de specifika förhållanden som aktiverar handlingsplanen. Det kan vara en SIEM-varning om onormala inloggningsmönster eller en användare som rapporterar ett misstänkt e-postmeddelande. Koppla ihop dina triggers med ett system för klassificering av incidenter så att ditt team vet hur snabbt de ska agera.
- Allvarlighetsgrad 1: Kritisk: Aktiv dataexfiltrering eller kryptering med ransomware pågår
- Allvarlighetsgrad 2: Hög: Bekräftad intrång utan aktiv spridning
- Allvarlighetsgrad 3: Medel: Misstänkt aktivitet som kräver utredning
- Allvarlighetsgrad 4: Låg: Policyöverträdelse eller mindre avvikelse
Klassificeringen avgör vilka åtgärder som ska vidtas och hur snabbt. Utan den reagerar teamen antingen överdrivet på varningar med låg prioritet eller för svagt på verkliga hot.
📖 Läs även: Sätt att förbättra cybersäkerheten inom projektledning
Roller och ansvarsområden
En handbok är värdelös om ingen vet vem som ansvarar för vad. Definiera de viktigaste rollerna som bör finnas i varje handbok.
- Incidentansvarig: Ansvarar för den övergripande hanteringen och fattar beslut om eskalering
- Teknisk ledare: Leder den praktiska utredningen och begränsningen
- Kommunikationsansvarig: Hanterar interna uppdateringar och externa meddelanden
- Juridisk kontaktperson: Ger råd om lagstadgade skyldigheter och bevarande av bevis
- Ansvarig chef: Godkänner viktiga beslut, såsom systemavstängningar
Tilldela roller efter funktion snarare än enbart efter person. Medarbetare kan ta semester eller sluta på företaget, så varje roll behöver en huvudansvarig och en ersättare.
Procedurer för upptäckt, begränsning och återställning
Detta är handbokens operativa kärna. Detektering och analys bekräftar om utlösaren är en verklig incident och samlar in initiala indikatorer på intrång.
Begränsning innebär omedelbara åtgärder för att förhindra att incidenten sprider sig. Detta inkluderar att isolera drabbade system, blockera skadliga IP-adresser och inaktivera komprometterade konton. Du måste skilja mellan kortsiktig begränsning för att stoppa skadan och långsiktig begränsning för stabilitet.
Eradikering och återställning eliminerar hotet helt genom borttagning av skadlig programvara och korrigering av sårbarheter. Denna fas återställer systemen till normal drift och inkluderar valideringstester för att säkerställa att hotet verkligen är borta.
🔍 Visste du att? Ett av de största säkerhetshot som någonsin funnits började med ett lösenordsproblem. År 2012 drabbades LinkedIn av ett massivt dataintrång, delvis på grund av att lösenorden lagrades med hjälp av föråldrade hashmetoder, vilket gjorde det enkelt att knäcka miljontals konton.
Kommunikations- och eskaleringsprotokoll
Incidenter kräver samordnad kommunikation vid sidan av den tekniska hanteringen. Intern eskalering avgör när incidentledaren ska involvera ledningsgruppen och juridisk rådgivare.
Extern kommunikation styr vem som talar med kunder, tillsynsmyndigheter eller pressen. Många regelverk har obligatoriska tidsfrister för anmälan som din handbok bör hänvisa till.
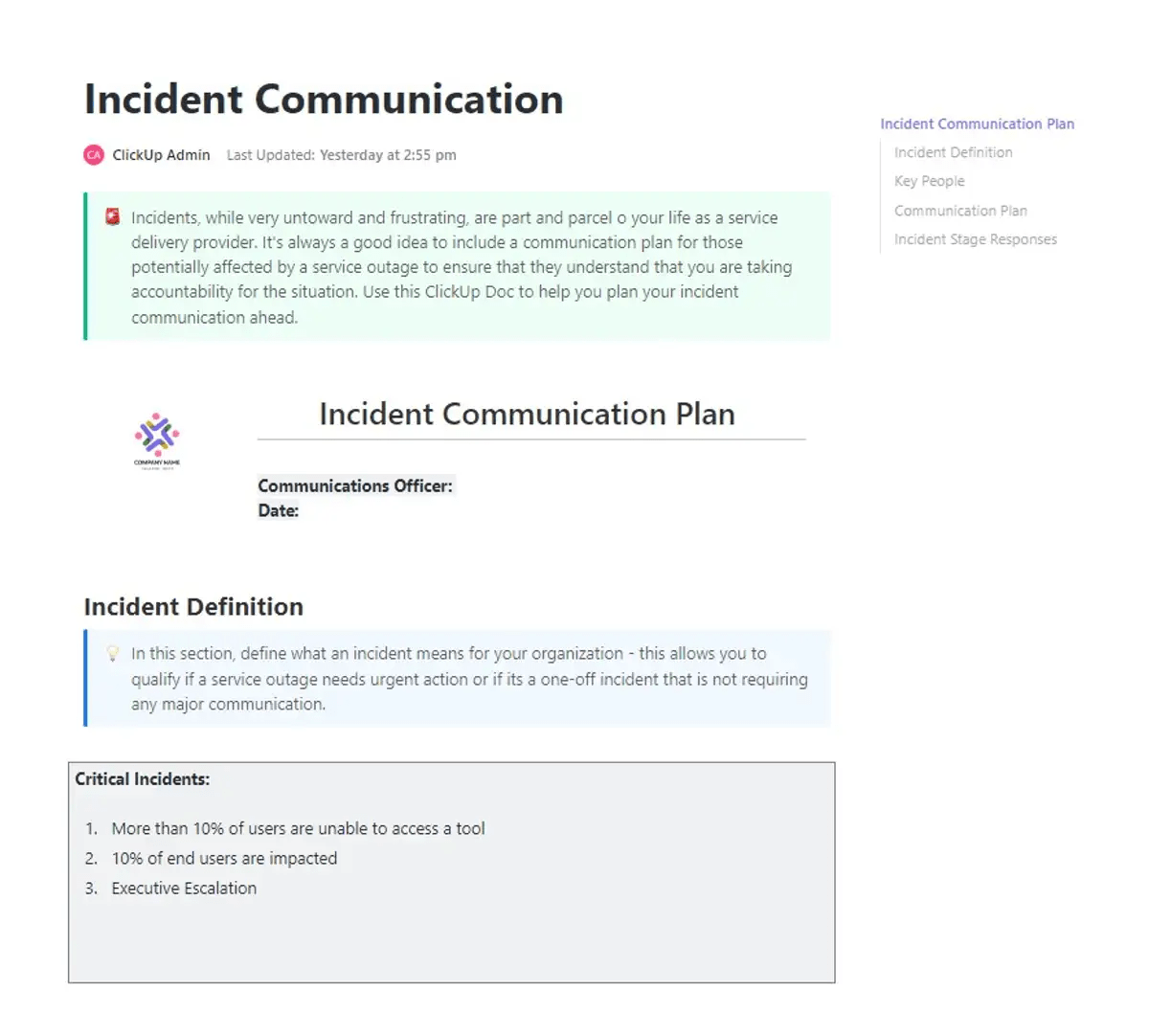
⚡ Mallarkiv: När incidenter inträffar är den största risken ofta den förvirring som följer. Försenade uppdateringar, otydligt ansvar och splittrad kommunikation kan fördröja insatstiderna och förvärra konsekvenserna. Det är precis där ClickUps mall för kommunikationsplan vid incidenter ger verkligt värde.
Denna mall ger teamen ett färdigt ramverk för att kommunicera tydligt under press. Du kan definiera roller, kartlägga kommunikationskanaler och säkerställa att rätt intressenter informeras vid rätt tidpunkt. Den centraliserar allt från kontaktpunkter till eskaleringsvägar, så att teamen kan samarbeta när det är som viktigast.
Hur man skapar en handbok för incidenthantering (steg för steg)
En säkerhetsincident utan plan är en kris. En säkerhetsincident med en handbok är en process. Så här skapar du en handbok som håller i pressade situationer. 👀
Steg 1: Definiera omfattning och mål
Innan du skriver en enda procedur bör du fastställa vad handboken omfattar och vad den inte omfattar.
Omfattningsglidning förstör användbarheten. En handbok som försöker täcka alla möjliga scenarier slutar med att inte fungera bra för något av dem, och de som hanterar incidenten slösar tid på att leta efter vägledning som antingen inte finns eller inte gäller för deras situation.
Börja med att besvara fyra frågor:
- Vilka typer av incidenter omfattas: Ransomware, dataintrång, hot från insiders, DDoS, nätfiske, kontoövertaganden, intrång i leverantörskedjan eller alla ovanstående
- Vilka system och miljöer handboken gäller: Molninfrastruktur, lokala servrar, hybridmiljöer, SaaS-plattformar, OT/ICS-system eller specifika affärsenheter med unika riskprofiler
- Så ser framgång ut: Ett mål för genomsnittlig tid till upptäckt (MTTD) på under 60 minuter, genomsnittlig tid till åtgärd (MTTR) på under fyra timmar, eller att uppnå efterlevnad av SOC 2, ISO 27001 eller HIPAA
- Vem ansvarar för handboken: En namngiven person eller ett team som ansvarar för att hålla den uppdaterad, distribuera den till rätt personer och planera in granskningar
Att definiera omfattningen låter enkelt tills man sätter sig ner för att göra det. Team fastnar ofta i detta skede eftersom informationen finns spridd över tidigare incidenter, utspridda anteckningar och intressenternas förväntningar.
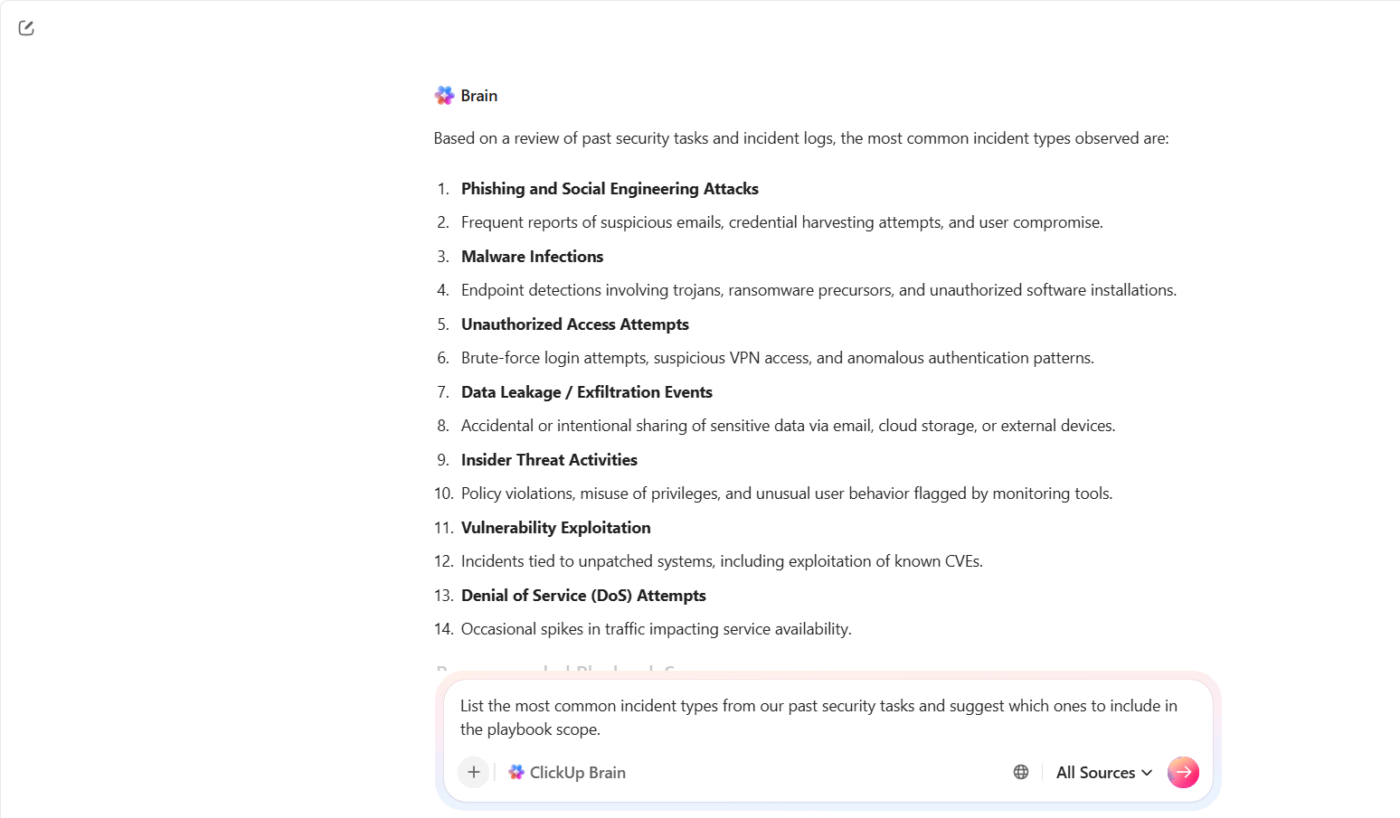
ClickUp Brain hjälper dig att sammanställa den kontexten och omvandla den till en användbar utgångspunkt. Du börjar inte från ett tomt blad. Du bygger vidare på det som ditt team redan vet.
Anta till exempel att ditt säkerhetsteam hanterade flera incidenter med nätfiske och kontoövertagande under det senaste kvartalet. Istället för att manuellt granska varje fall kan du be ClickUp Brain: ”Lista de vanligaste incidenttyperna från våra tidigare säkerhetsuppgifter och föreslå vilka som ska inkluderas i handbokens omfattning.”
Steg 2: Identifiera och klassificera incidenttyper
Alla incidenter är inte likadana. En felkonfigurerad S3-bucket och en pågående ransomware-attack kräver helt olika åtgärder, olika teammedlemmar och olika eskaleringsvägar.
Genom att skapa ett klassificeringssystem i ett tidigt skede kan incidenthanterarna fatta snabba och konsekventa beslut redan vid den första larmsignalen, utan att behöva vänta på ledningens godkännande vid varje larm.
En standardmodell med fyra svårighetsgrader fungerar så här:
- Kritisk (P1): Aktivt intrång, dataexfiltrering eller systemomfattande kompromettering – omedelbar respons krävs
- Hög (P2): Misstänkt intrång, stöld av inloggningsuppgifter eller betydande störning av tjänsten
- Medium (P3): Skadlig programvara upptäckt men begränsad, policyöverträdelse med risk för dataläckage
- Låg (P4): Misslyckade inloggningsförsök, mindre policyöverträdelser, informationsvarningar
Koppla varje incidenttyp till en allvarlighetsgrad så att incidenthanterarna kan fatta snabba beslut utan att varje ärende behöver eskaleras.
När du har definierat vad som ingår i omfattningen handlar nästa utmaning om konsekvens. Olika insatspersoner tolkar ofta samma larm på olika sätt, vilket fördröjer beslut och skapar onödiga eskaleringar.
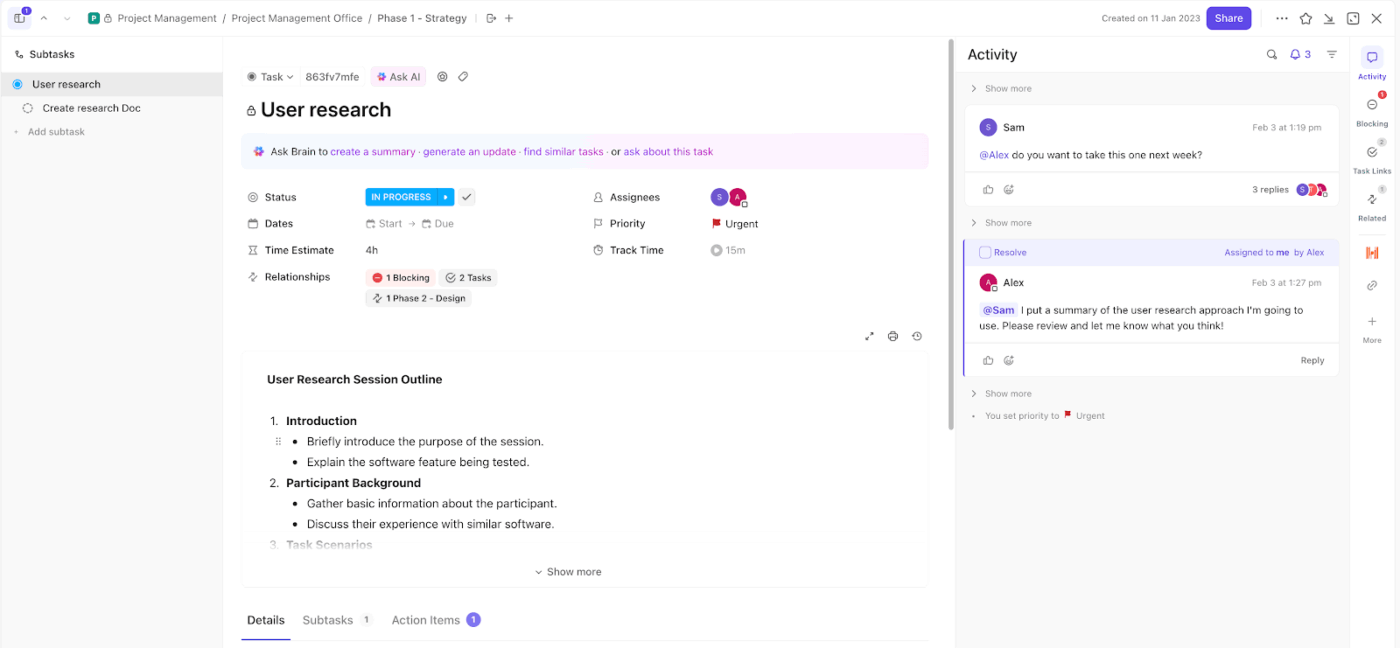
Börja med ClickUp-uppgifter som din enda enhet för genomförande. Varje incident blir en uppgift, vilket innebär att ingenting faller mellan stolarna via kanaler som inte spåras, såsom e-post eller chatt.
Anta till exempel att ditt övervakningsverktyg flaggar en potentiell stöld av inloggningsuppgifter. Du skapar en uppgift med titeln ”Möjlig kompromettering av inloggningsuppgifter – finanskonto”. Den uppgiften blir nu den centrala platsen för utredning, uppdateringar och lösning.
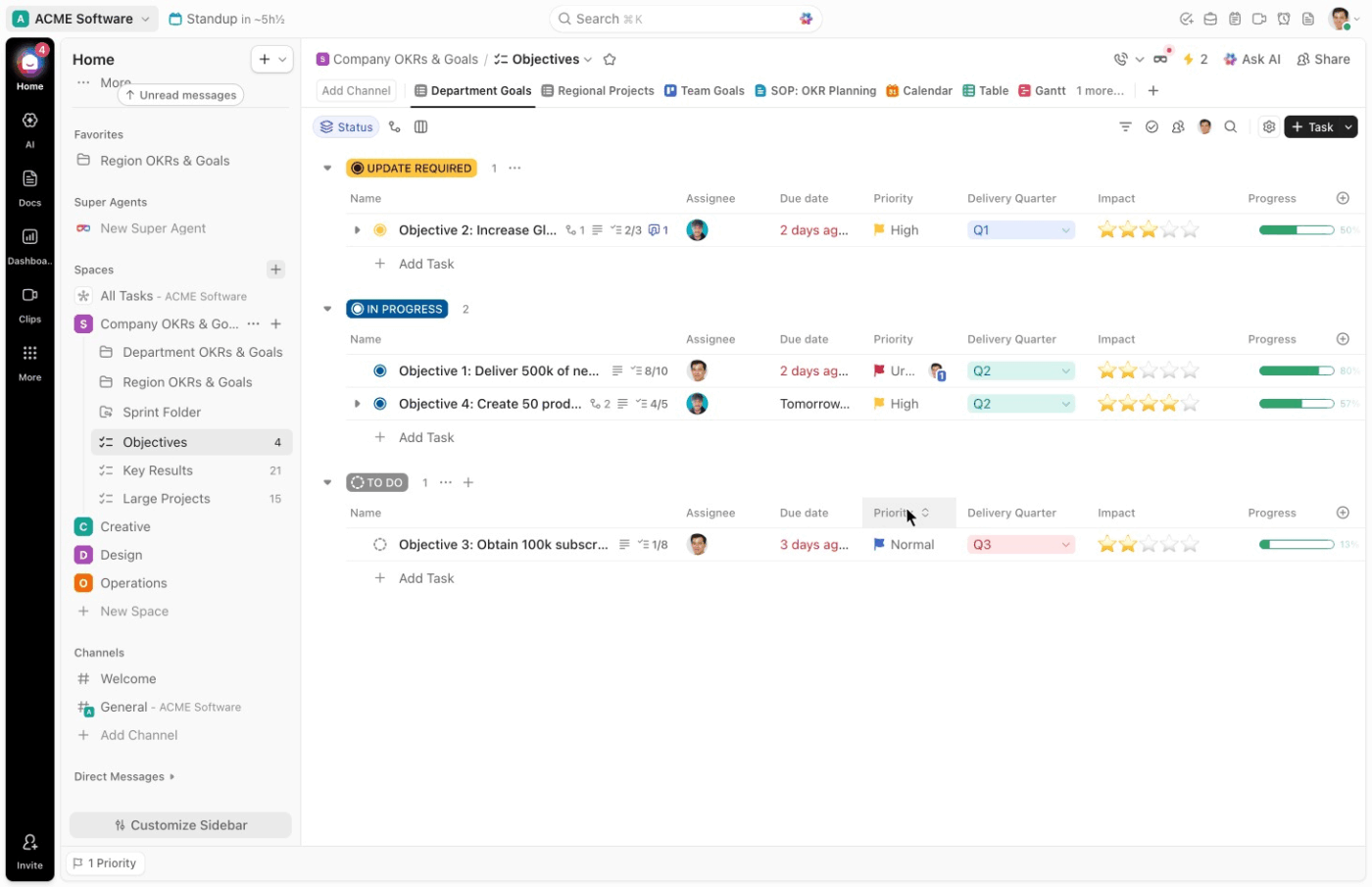
Därefter ger anpassade fält i ClickUp dig den struktur som behövs för snabb klassificering. Du kan ställa in fält som:
- Incidenttyp: Nätfiske, ransomware, DDoS, hot från insiders
- Allvarlighetsgrad: P1, P2, P3, P4
- Berörda system: Moln, lokalt, SaaS, slutpunkter
- Datakänslighet: Hög, medel, låg
Steg 3: Skriv incident-specifika hanteringsrutiner
Detta är handbokens operativa kärna.
För varje typ av incident ska du skriva en särskild procedur som är tillräckligt detaljerad för att en insatsledare ska kunna följa den under press utan att behöva improvisera. Allmänna riktlinjer ignoreras när systemen är nere.
Varje procedur bör innehålla:
- Utlösare: Den specifika varningen eller rapporten som sätter igång insatsen
- Inledande triagesteg: De första åtgärderna som en incidenthanterare vidtar inom 15 minuter, anpassade efter incidenttypen
- Checklista för bevisinsamling: Loggar, minnesdump, nätverksdata och e-postrubriker – allt som behövs innan begränsningsåtgärderna förstör det
- Åtgärder för begränsning: Konkreta, genomförbara steg
- Eskaleringskriterier: De förhållanden som utlöser eskalering till ledningen, juridisk rådgivare eller en extern leverantör av incidenthanteringstjänster
- Kommunikationsmallar: Färdiga utkast för interna uppdateringar och kundmeddelanden
En rutin för ransomware ser inte alls ut som en rutin för nätfiske. Skriv dem separat med den specificitet som varje scenario kräver.

Med ClickUp Docs kan du strukturera varje incidentprocedur så att den besvarar exakt de frågor som en incidenthanterare ställs inför i stunden. Låt oss till exempel säga att du dokumenterar ett ransomware-scenario.
Handboken kan vägleda den som hanterar incidenten på följande sätt:
- Vad som utlöste detta: ”Varning om kryptering av slutpunkt upptäckt via EDR”
- Vad som måste göras under de första 15 minuterna: Isolera den drabbade datorn, stäng av nätverksåtkomsten, bekräfta omfattningen av spridningen
- Vad måste dokumenteras före begränsning: Systemloggar, aktiva processer, senaste filändringar
- Vilka situationer kräver eskalering: Kryptering som sprider sig över flera enheter eller åtkomst till delade enheter
- Vad som behöver kommuniceras: Intern varning till säkerhetsledningen och en förberedd uppdatering till berörda team
ClickUp Docs förstärker detta ytterligare genom direkt integration i genomförandet:
- Koppla proceduren till incidentuppgifterna i ClickUp, så att de som hanterar incidenten kan öppna vägledningen precis när det är dags att agera
- Lägg till checklistor i varje avsnitt så att viktiga steg inte hoppas över under press
- Tilldela teammedlemmarna specifika åtgärder vid eskalering utan att lämna dokumentet
- Förfina instruktionerna direkt efter att problemet har lösts så att framtida insatser förbättras utan dröjsmål
Steg 4: Fastställ kommunikationsprotokoll och standarder för bevis
Två områden som ofta prioriteras bort under utvecklingen av handlingsplanen och som orsakar allvarliga problem vid en faktisk incident: hur teamet kommunicerar och hur bevis hanteras.
När det gäller kommunikation bör du definiera följande parametrar i förväg:
- Primära kanaler och reservkanaler
- Tidsplaner för meddelanden
- Krav på extern informationsgivning
- En enda källa till sanning
Handboken bör innehålla följande:
- Vad du ska samla in: Systemhändelseloggar, autentiseringsloggar, minnesavbildningar, nätverksflödesdata och skärmdumpar av angriparens aktivitet
- Hur man samlar in det: Skrivskyddad forensisk avbildning, skrivskydd och en logg över varje insamlingsåtgärd med tidsstämpel och namnet på den person som utförde den
- Var ska den förvaras: En separat, åtkomstkontrollerad miljö som är isolerad från drabbade system
- Vem har tillgång: Begränsat till namngivna utredare och godkänt av kontaktpersonen för juridik och regelefterlevnad
När en incident inträffar splittras kommunikationen ofta mellan olika verktyg. Uppdateringar hamnar i Slack, beslut fattas under telefonsamtal och viktiga detaljer försvinner i trådar som ingen återvänder till. Denna brist på struktur skapar förvirring, fördröjer eskalering och gör granskningar efter incidenten svårare än de borde vara.
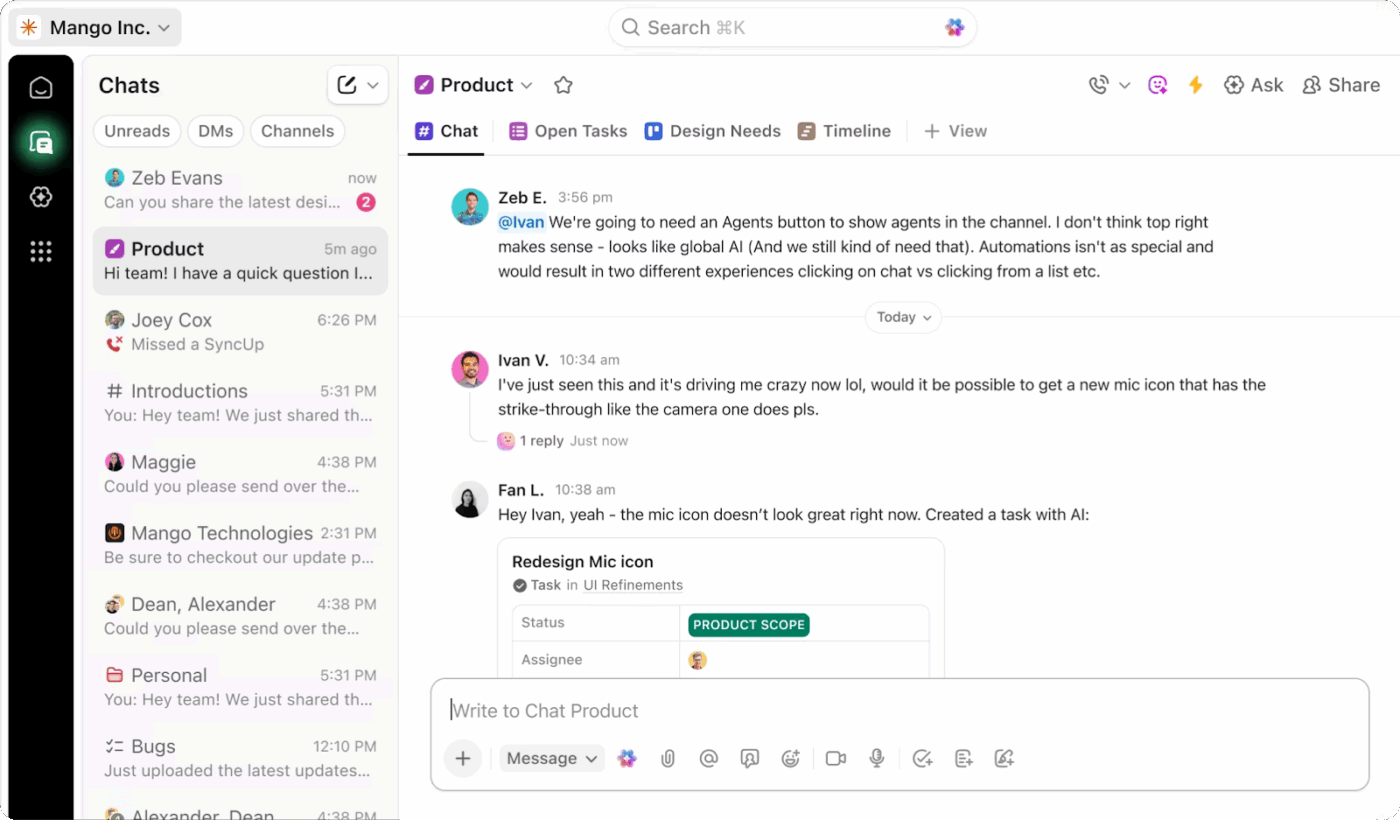
ClickUp Chat ger dig en dedikerad, kontextlänkad kanal där kommunikationen kring incidenter förblir fokuserad, synlig och lätt att följa.
Du kan ställa in den som ditt primära kommunikationslager för incidenthantering, direkt kopplat till det arbete som spåras. Den kopplingen förändrar hur teamen samordnar sig i pressade situationer.
🚀 Fördel med ClickUp: Förvandla varje incident till en lärdom med ClickUps mall för incidenthanteringsrapport.
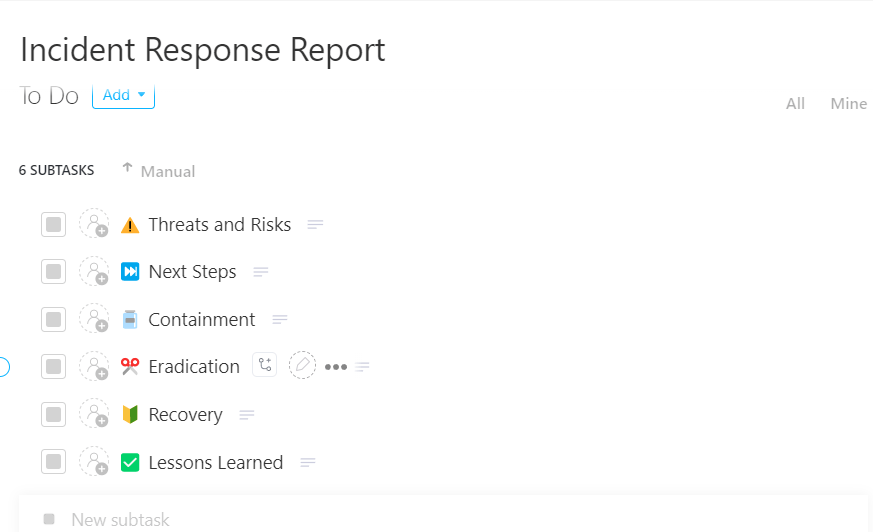
Dokumentera varje incident tydligt och utan luckor med hjälp av ClickUps mall för incidenthanteringsrapport
Den är utformad som ett färdigt, uppgiftsbaserat system som låter dig registrera, spåra och hantera incidenter från början till slut på ett och samma ställe, så att inget går förlorat mellan olika verktyg eller team.
Steg 5: Testa, integrera och skapa en granskningsrytm
En handbok som aldrig har testats är bara en samling antaganden. Innan du betraktar den som operativ bör du validera den genom strukturerade övningar och koppla den till de verktyg som ditt team använder dagligen.
För att testa, genomför övningar i ordning efter svårighetsgrad:
- Simuleringsövning: En facilitator presenterar ett simulerat scenario och teamet diskuterar besluten muntligt
- Funktionsövning: Teamet utför specifika steg i en kontrollerad miljö, till exempel att isolera en testterminal
- Fullständig simulering: Ett red team genomför ett realistiskt attackscenario medan incidenthanteringsteamet hanterar situationen i realtid
För verktygsintegration ska du koppla handboken direkt till dina SIEM-larm-ID:n, EDR-begränsningsåtgärder, ärendehanteringsflöden och överlämningsrutiner till externa IR-leverantörer. De som hanterar incidenter bör gå från larm till rutin till åtgärd utan att byta sammanhang.
Hur ClickUp hjälper till
När man genomför övningar och simuleringar upptäcker man ofta samma brist. Teamen känner till stegen i teorin, men genomförandet går långsamt eftersom inget system aktivt styr insatsen i realtid.

ClickUp AI Agents fyller den luckan. De observerar aktiviteten i uppgifter, fält och arbetsflöden och vidtar sedan åtgärder baserat på den logik du definierar. Det gör dem mycket användbara när du testar och implementerar din handbok.
Börja med att se hur detta fungerar under en simulering.
Anta att din facilitator presenterar en phishingattack som eskalerar till att inloggningsuppgifter komprometteras. Medan ditt team diskuterar nästa steg kan en AI-agent:
- Skapa en strukturerad checklista för hantering som är anpassad efter din rutin för phishing
- Föreslå nästa åtgärder baserat på uppgiftsfält som ”incidenttyp” och ”allvarlighetsgrad”
- Utarbeta en intern uppdatering med aktuella uppgiftsdetaljer
Detta gör att diskussionerna hålls förankrade i de faktiska genomförandestegen.
💡 Proffstips: För löpande underhåll bör du utforma granskningar utifrån tre utlösande faktorer:
- En årlig fullständig granskning med en simulering av alla rutiner som inte har testats under de senaste 12 månaderna
- Efter varje allvarlig incident, medan detaljerna fortfarande är färska
- En kvartalsvis kontroll av personal- och verktygsförändringar
Tilldela en namngiven ansvarig till varje steg med ClickUps funktion för flera ansvariga. Utan ansvarsskyldighet hoppar man över granskningar och handboken blir i tysthet en belastning.
Exempel på handböcker för incidenthantering efter hotkategori
Så här ser processen för att skapa en handbok ut när den tillämpas på de vanligaste typerna av hot.
Handlingsplan för hantering av ransomware-incidenter
- Utlösare: Varning från endpoint-detektering om filkrypteringsaktivitet eller ovanliga ändringar av filändelser
- Omedelbar begränsning: Isolera drabbade system från nätverket omedelbart och inaktivera delade enheter
- Viktiga åtgärder: Identifiera ransomware-varianten, fastställ omfattningen av krypteringen och bevara tekniska bevis
- Återställning: Återställ från rena säkerhetskopior efter att ha verifierat att de inte har komprometterats och åtgärda ingångspunkten
- Efter incidenten: Dokumentera händelseförloppet och granska rutinerna för säkerhetskopieringens integritet
🔍 Visste du att? En av de första hackarna var en visselblåsare. På 1980-talet avslöjade en grupp som kallades Chaos Computer Club säkerhetsbrister i banksystem för att visa på sårbarheter, snarare än att utnyttja dem för vinst.
Handlingsplan för hantering av phishing-incidenter
- Utlösare: Användare rapporterar ett misstänkt e-postmeddelande eller en sida för insamling av inloggningsuppgifter har upptäckts
- Omedelbara åtgärder: Sätt e-postmeddelandet i karantän i alla inkorgar och blockera avsändarens domän
- Viktiga åtgärder: Tvinga fram återställning av lösenord och avbryt aktiva sessioner omedelbart om inloggningsuppgifter har skickats in
- Kommunikation: Meddela berörda användare och skicka ut en varning till hela organisationen utan att orsaka panik
- Återställning: Kontrollera att ingen kvarvarande åtkomst finns kvar och uppdatera reglerna för e-postfiltrering
Handbok för obehörig åtkomst
- Utlösande faktor: Onormal inloggningsaktivitet, varning om utökade behörigheter eller åtkomst till känsliga resurser
- Omedelbar begränsning: Inaktivera det komprometterade kontot, avsluta aktiva sessioner och begränsa åtkomsten
- Viktiga åtgärder: Fastställ hur åtkomst erhölls och granska alla åtgärder som vidtagits av det komprometterade kontot
- Återställning: Återställ inloggningsuppgifterna för alla konton som kan ha påverkats och skärp åtkomstkontrollerna
- Efter incidenten: Genomför en fullständig åtkomstgranskning och uppdatera riktlinjerna för minsta möjliga behörighet
Bästa praxis för handböcker för incidenthantering
Här är de bästa metoderna som skiljer team som löser incidenter smidigt från team som fortfarande sitter i ett krigsrum sex timmar senare och bråkar om vem som ansvarar för återställningen. Få dessa rätt så blir allt annat enklare. 🔥
Beskriv vad man ska göra, inte vad man ska tänka på
De flesta handböcker är fulla av steg som ”bedöm situationens allvar” eller ”identifiera berörda parter”. Det här är inga steg. Det är påminnelser om att tänka efter.
En användbar handbok talar om för dig vilka åtgärder du ska vidta, inte bara att en åtgärd behövs. Ersätt ”utvärdera påverkan på kunden” med ”kontrollera instrumentpanelen för aktiva sessioner och klistra in siffran i incidentkanalen”. Det handlar om att vara specifik.
Separera den person som hittar lösningen från den person som hanterar incidenten
När den mest erfarna teknikern på plats samtidigt felsöker orsaken, svarar på frågor från ledningen och bestämmer vem som ska tillkallas, går alla tre sakerna snett.
Din handbok bör föreskriva en tydlig uppdelning: en person ansvarar för utredningen, en person ansvarar för incidenten. Incidentchefen fattar inga tekniska beslut. Hen delegerar, löser problem och kommunicerar. Detta kan kännas som en extra kostnad tills det första tillfället då det sparar dig två timmar.
🔍 Visste du att? Hela 91 % av de stora organisationerna har redan ändrat sina cybersäkerhetsstrategier på grund av den geopolitiska instabiliteten, vilket innebär att globala spänningar har blivit en direkt drivkraft för beslut om cyberförsvar.
Genomför efteranalysen medan folk fortfarande är irriterade
De bästa efteranalyserna görs inom 48 timmar eftersom frustrationen fortfarande är färsk. Den tekniker som tyckte att tröskeln för larm var för hög kommer att säga det på dag två.
Vid dag 10 har de gått vidare och mötet blir en artigt återgivning av en tidslinje snarare än ett ärligt samtal om vad som gick fel.
Testa handboken genom att försöka bryta den
Det enda tillförlitliga sättet att ta reda på om din handlingsplan fungerar är att använda den när inget faktiskt står i brand. Genomför en övning. Välj ett realistiskt fel-scenario, ge någon handlingsplanen utan förvarning och se var de tvekar.
Varje tvekan är en lucka. Varje fråga de ställer är ett steg som saknas. En handbok som aldrig har stresstestats är aldrig färdig.
En driftschef delar med sig av sina tankar om att använda ClickUp:
ClickUp har varit ett fantastiskt verktyg för att hålla vårt team organiserat och samordnat. Det gör det enkelt att hantera projekt, tilldela uppgifter och följa upp framsteg på ett och samma ställe. Jag uppskattar särskilt flexibiliteten – man kan anpassa arbetsflöden, skapa mallar och anpassa plattformen efter olika teamprocesser.
Det har varit till stor hjälp för att skapa repeterbara system för saker som standardrutiner, prestationsutvärderingar och projektuppföljning. Att ha uppgifter, dokument och kommunikation sammankopplade bidrar till att minska fram- och återkommande kontakter och ser till att alla är på samma sida.
Skapa och hantera handböcker för incidenthantering med ClickUp
Att hålla handböckerna uppdaterade och tillgängliga när det verkligen gäller är en enorm utmaning. De flesta team slutar med dokumentation utspridd över wikis, Google Docs och Slack-bokmärken. När en incident inträffar är ingen säker på vilken version som är aktuell eller var eskaleringsmatrisen finns.
Eliminera verktygsfloden och kontextväxlingar med ClickUp. Som en samlad arbetsyta finns din handboksdokumentation, dina hanteringsflöden och teamkommunikationen på exakt samma plats.
Oavsett om du skapar din första handbok eller samlar ihop spridd dokumentation ger ClickUp ditt team en enda plats att planera, hantera och förbättra. Registrera dig gratis idag!
Vanliga frågor (FAQ)
1. Vad är skillnaden mellan en handbok för incidenthantering och en driftshandbok?
En handbok täcker hela hanteringscykeln för en specifik typ av incident. En runbook är däremot en mer avgränsad teknisk procedur för att utföra en enskild uppgift inom ramen för den hanteringen.
2. Hur ofta bör du uppdatera din handbok för incidenthantering?
Granska och uppdatera handböckerna minst en gång per kvartal. Du bör också uppdatera dem efter varje verklig incident och efter varje simulering.
4. Kan du använda en mall för en incidenthanteringsplan som utgångspunkt?
Ja, mallar från ramverk som NIST eller CISA ger dig en beprövad struktur. ClickUp-mallar är också mycket användbara. Detta gör att du kan anpassa grunden för din miljö istället för att börja från ett tomt blad.
5. Behöver små team en handbok för incidenthantering?
Små team har förmodligen större behov av handböcker eftersom det finns mindre utrymme för fel. En enkel handbok för dina värsta hotbildscenarier är betydligt bättre än att improvisera en hantering.