

Klockan är 03:00.
Ett genomträngande larm väcker dig med ett ryck.
Du rusar upp, lockad av skenet från din datorskärm. Ett kritiskt system har kraschat. Paniken sätter in. Det här är inte en scen från en science fiction-thriller, utan ett mardrömsscenario för alla IT-proffs.
Men det är också en realitet. När den digitala världen stannar upp blir pressen enorm.
Det är här incidenthantering blir en livlina.
Incidenthantering är nyckeln till att snabbt hantera och lösa projektstörningar. Genom att hantera dessa störningar på ett effektivt sätt kan du fokusera mer på att leverera resultat och slutföra ditt projekt på ett effektivt sätt.
I den här artikeln utforskar vi incidenthanteringsprocessen och delar med oss av bästa praxis för att hjälpa dig att implementera en robust beredskapsplan. Detta säkerställer att du effektivt kan hantera eventuella framtida projektincidenter.
Förstå incidenthantering
Incidenter är störningar eller potentiella hot som påverkar tjänstens kvalitet. Exempelvis kan en affärsapplikation som kraschar eller en webbserver som går trögt och orsakar produktivitetsproblem räknas som incidenter. Dessa händelser kan variera från mindre problem som påverkar några få användare till större avbrott som påverkar globala tjänster.
Incidenthantering är processen att identifiera, prioritera och lösa IT-problem för att minimera störningar i verksamheten samtidigt som åtgärder vidtas för att förhindra att liknande incidenter inträffar i framtiden. Denna process för proaktiv incidentförebyggande är avgörande för alla organisationer, eftersom driftstopp kan leda till betydande affärsförluster. Effektiv incidenthantering gör det möjligt för teamen att prioritera och lösa problem snabbt, vilket säkerställer bättre servicekontinuitet.
När team hanterar incidenter behöver de en väl definierad plan som hjälper dem att:
- Reagera snabbt för att minimera driftstopp
- Kommunicera effektivt med kunder, intressenter, tjänsteägare och andra berörda parter.
- Samarbeta smidigt för att påskynda problemlösningen och eliminera hinder för lösningen.
- Fortsätt att förbättra genom att lära av incidenter och tillämpa dessa lärdomar för att höja servicekvaliteten och förfina processerna.
Att veta hur man skriver en incidentrapport är också viktigt i detta sammanhang. Detaljerade incidentrapporter underlättar en grundlig analys, identifierar grundorsaker och utvecklar förebyggande strategier.
Förhållandet mellan incidenthantering, ITSM och DevOps
Incidenthantering är en central del av IT-tjänstehantering (ITSM) och säkerställer att IT-tjänsterna förblir tillgängliga och tillförlitliga. Samtidigt integrerar DevOps utvecklings- och driftsteam för att förbättra samarbetet och effektiviteten.
Genom att anpassa incidenthanteringen till DevOps-projektledningsprinciperna kan organisationer hantera incidenter snabbt och effektivt. Denna anpassning främjar kontinuerlig förbättring, snabbare återställning efter incidenter och förbättrad tjänsteleverans.
Förstå incidenthanteringsprocesser
En effektiv incidenthanteringsprocess gör det möjligt för IT-team att undersöka, dokumentera och lösa serviceavbrott eller driftstopp på ett effektivt sätt.
Olika företag använder ofta olika typer av incidenthanteringsprocesser som är anpassade efter deras specifika behov. Eftersom det inte finns någon universallösning, finns det olika metoder inom olika organisationer.
Vissa team följer traditionella IT-baserade incidenthanteringsprocesser, såsom de som beskrivs i ITIL-certifieringarna (Information Technology Infrastructure Library). Andra föredrar en mer SRE- (Site Reliability Engineering) eller DevOps-orienterad approach.
ITIL:s arbetsflöde för incidenthantering fokuserar på att minska driftstopp och mildra incidenternas inverkan på medarbetarnas produktivitet. Med hjälp av mallar för incidentrapporter kan teamen skapa ett repeterbart arbetsflöde för att logga, diagnostisera och lösa incidenter samtidigt som de för omfattande register över sina aktiviteter.
ITIL-ramverket används främst av IT-team som hanterar tjänster inom företag. Dessa team anpassar ofta ITIL:s omfattande täckning av incidenter och processer efter sina behov.
ITIL är särskilt fördelaktigt för att skapa en kultur av proaktiv felsökning. Dess strukturerade processer hjälper teamen att konsekvent spåra incidenter och åtgärder, vilket förbättrar rapporteringen och analysen och i slutändan leder till mer robusta tjänster och effektiva team.
AI och maskininlärning inom incidenthantering
Integrering av AI och maskininlärning i incidenthanteringen förändrar hur team hanterar incidenter. AI-drivna verktyg kan analysera stora mängder data för att förutsäga potentiella incidenter innan de inträffar, vilket möjliggör förebyggande åtgärder.
Maskininlärningsalgoritmer kan identifiera mönster och avvikelser som mänskliga analytiker kan missa, vilket ger djupare insikter om grundorsaker och möjliga lösningar. Dessa tekniker kan också automatisera rutinuppgifter, såsom incidentloggning och initial diagnostik, vilket frigör personalresurser för mer komplex problemlösning.
Hög tillgänglighet och driftstopp i incidenthantering
Att minimera driftstopp är avgörande för en effektiv incidenthantering. Hög tillgänglighet säkerställer att systemen är driftklara och tillgängliga hela tiden, vilket minimerar risken för avbrott i tjänsten. Redundans, failover-mekanismer och lastbalansering används för att uppnå hög tillgänglighet.
Att minska driftstopp är avgörande för att upprätthålla produktiviteten och kundnöjdheten. Processerna för incidenthantering måste inkludera robusta planer för snabb respons och återställning för att minimera driftstoppens varaktighet och påverkan.
IT-incidenthanteringsprocessen i detalj
Incidenthantering innebär att effektivt identifiera, logga, kategorisera, prioritera och lösa incidenter.
Genom att förstå dessa steg kan du säkerställa en systematisk approach till incidenthantering, minimera driftstopp och förebygga framtida incidenter.
Steg i processen för hantering av IT-incidenter
1. Identifiera och logga incidenten
Incidenter kan ha olika orsaker, till exempel anställda, kunder, leverantörer eller övervakningssystem. Det första steget är att identifiera och logga incidenten. Dessa loggar, som ofta kallas incidentrapporter, innehåller vanligtvis:
- Namnet på den person som rapporterar incidenten
- Datum och tidpunkt då incidenten rapporterades
- En beskrivning av incidenten med detaljerad information om vad som inte fungerar eller är nere.
- Ett unikt identifikationsnummer tilldelas för spårningsändamål.
2. Kategorisera incidenten
Det är viktigt att tilldela varje incident en logisk och intuitiv kategori (och underkategori, om nödvändigt). Denna kategorisering underlättar analysen av data för trender och mönster, vilket är viktigt för effektiv problemhantering och förebyggande av framtida incidenter.
3. Prioritera incidenten
Varje incident måste prioriteras utifrån dess inverkan på verksamheten, antalet berörda personer, relevanta SLA:er och potentiella konsekvenser för ekonomi, säkerhet och efterlevnad.
De ansvariga teamen fastställer incidentens relativa prioritet genom att jämföra den med andra öppna incidenter. Det är god praxis att fastställa allvarlighetsgrad och prioritetsnivåer i förväg, så att incidenthanterare snabbt kan bedöma prioriteten.
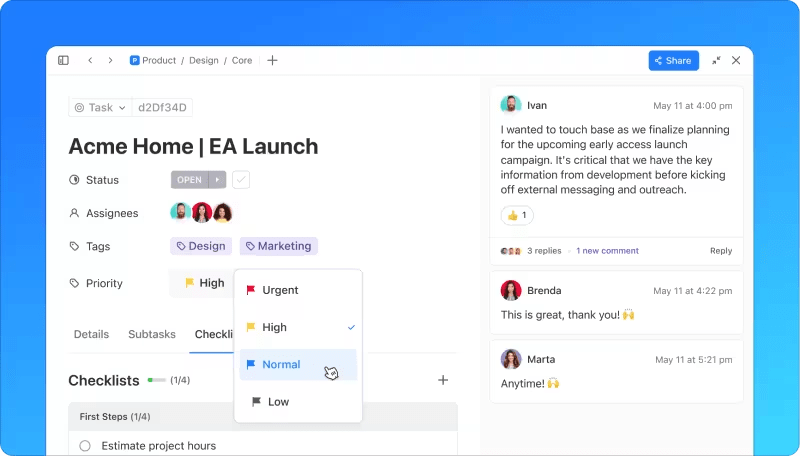
4. Hantera incidenten
Responsfasen innefattar flera viktiga åtgärder:
- Initial diagnos: Idealt sett diagnostiserar och löser supportteamet i frontlinjen incidenten. Om de inte kan det loggar de all relevant information och eskalerar den till nästa nivå i teamet.
- Eskalering: Det efterföljande teamet fortsätter diagnosprocessen. Om de inte kan lösa incidenten eskalerar de den.
- Kommunikation: Regelbundna uppdateringar delas med berörda interna och externa intressenter.
- Undersökning och diagnos: Denna fas fortsätter tills incidentens natur har identifierats. Team kan ta in externa resurser eller medlemmar från andra avdelningar för att hjälpa till med lösningen.
- Lösning och återställning: När diagnosen är ställd vidtar teamet nödvändiga åtgärder för att lösa incidenten. Återställningen omfattar den tid som krävs för att driften ska återställas fullt ut, eftersom vissa korrigeringar, till exempel buggfixar, kan behöva testas och implementeras även efter att incidenten har lösts.
- Avslutning: Om incidenten eskalerades återförs den till servicedesk för avslutning. Endast servicedeskens anställda kan avsluta incidenter, vilket säkerställer kvalitet och kundnöjdhet.
Incidenthantering för DevOps- och SRE-team
DevOps- och SRE-metoder har blivit enormt populära, särskilt med uppkomsten av alltid tillgängliga molntjänster, globalt tillgängliga webbapplikationer, mikrotjänster och SaaS-lösningar (Software-as-a-Service).
Modern programvara, som är avgörande för privat och professionellt bruk, finns sällan på en lokal server. Istället distribueras dessa applikationer vanligtvis i datacenter och betjänar tusentals eller miljoner användare över hela världen. Flexibilitet och snabbhet är avgörande för de team som ansvarar för underhållet av dessa tjänster. Varje driftstopp kan få långtgående konsekvenser och påverka flera organisationer samtidigt.
Filosofin ”du bygger det, du driver det” ger agila team den flexibilitet de behöver. Men den kan också göra ansvarsfördelningen otydlig. DevOps-team kan visserligen blomstra med mindre rigida utvecklingsprocesser, men det är viktigt att standardisera de centrala rutinerna för incidenthantering:
Delade jouransvar
Till skillnad från traditionella modeller där specifika teammedlemmar utses till jourhavande experter, använder DevOps-team vanligtvis ett roterande jourschema. Denna metod säkerställer att alla teammedlemmar är ansvariga för att hantera incidenter, inklusive sådana som kan inträffa utanför ordinarie arbetstid.
Kunskap leder till lösningar
Centralt för DevOps-filosofin är övertygelsen att de ingenjörer som utvecklat en tjänst är bäst lämpade att lösa problem när de uppstår. Denna princip betonar mentaliteten ”du bygger det, du driver det”, där de som är mest bekanta med tjänstens arkitektur och komplexitet hanterar avbrott och störningar.
Snabbhet och ansvarsskyldighet
DevOps-team måste snabbt utveckla och distribuera programvara. Men denna snabbhet medför ett extra ansvar. Vetskapen om att de måste lösa incidenter motiverar ingenjörerna att producera högkvalitativ och tillförlitlig kod.
Orsaksanalys (RCA) är också viktigt inom DevOps-incidenthantering. RCA innebär att man identifierar de bakomliggande orsakerna till incidenter, så att teamen kan implementera praktiska lösningar och förhindra att incidenterna upprepas.
Det är en proaktiv metod som tar itu med akuta problem och stärker systemet som helhet, vilket minskar risken för framtida större incidenter och förbättrar tjänsternas motståndskraft.
Genom att upprätthålla ett kontinuerligt och sammanhängande flöde i incidenthanteringsrutinerna kan DevOps-team balansera flexibilitet och struktur. Detta säkerställer att de är väl förberedda för att hantera incidenter snabbt och effektivt, vilket leder till mer tillförlitliga och robusta mjukvarutjänster.
Roller inom incidenthantering
Även om organisationer kan anpassa sina roller och ansvarsområden efter sina specifika behov, är följande några av de vanligaste rollerna i IT-incidenthanteringsteam:
- Slutanvändare/begärare: Denna person är vanligtvis den som upplever en tjänstestörning och ansvarar för att initiera incidenthanteringsprocessen genom att skicka in ett incidentärende.
- Tier 1-servicedesk: Tier 1-servicedesk är den första kontaktpunkten för förfrågare. Tekniker hanterar grundläggande problem och förfrågningar. Deras expertis omfattar vanliga problem som återställning av lösenord och anslutningsproblem som Wi-Fi-problem.
- Tier 2-servicedesk: Tekniker på denna nivå har mer avancerade färdigheter och kunskaper än tekniker på Tier 1. De hanterar mer komplexa problem och eskaleringar från Tier 1. Deras roll innebär att lösa komplicerade tekniska problem och säkerställa effektiv incidenthantering.
- Tier 3 och högre servicedesk: Denna nivå består av specialister med djup expertis inom specifika områden av IT-infrastrukturen, såsom hårdvaruunderhåll eller serversupport.
- Incidenthanterare: Incidenthanteraren övervakar incidenthanteringsprocessen, utvärderar dess effektivitet, föreslår förbättringar och säkerställer att fastställda rutiner följs.
- Processägare: Processägaren övervakar och förfinar incidenthanteringsprocessen. De analyserar, justerar och förbättrar processen för att säkerställa att den är i linje med organisationens mål och på bästa sätt stöder incidenthanteringsarbetet.
Dessa roller bidrar tillsammans till en välstrukturerad och effektiv process för identifiering och hantering av incidenter, vilket säkerställer snabb och effektiv incidenthantering samtidigt som metoden kontinuerligt förbättras.
Verktyg och resurser för effektiv incidenthantering
Genom att använda rätt verktyg och resurser för incidenthantering kan du avsevärt förbättra effektiviteten och ändamålsenligheten i incidenthanteringsprocessen.
Webbläsare, särskilt Google Chrome, är avgörande för incidenthantering. Chromes mångsidighet och kompatibilitet med olika webbaserade incidenthanteringsprogram gör det till ett oumbärligt verktyg för IT-team. Dess omfattande bibliotek med tillägg, såsom utvecklingsverktyg, buggspårare och prestandamonitorer, möjliggör diagnostik och felsökning i realtid.
Dessutom kan teamen identifiera möjliga källor till virusattacker och skadlig kod genom att hämta artefakter som cachdata, historik, nedladdningar etc. med hjälp av webbläsarforensik.
Chrome integreras också sömlöst med ClickUp, en högt rankad produktivitets- och incidenthanteringsprogramvara som används av team i både små och stora företag.
Här är några av de viktigaste fördelarna med att använda ClickUp för incidenthantering:
1. Centraliserad incidentuppföljning
ClickUp samlar all incidentrelaterad information på en enda plattform. Denna centraliserade metod säkerställer att alla incidentrapporter, uppdateringar och lösningar är tillgängliga på ett och samma ställe, vilket minskar risken för informationsförlust och säkerställer att teammedlemmarna har tillgång till den senaste informationen.
2. Samarbete i realtid
ClickUps samarbetsfunktioner underlättar smidig kommunikation mellan teammedlemmarna. Användare kan kommentera direkt på uppgifter, dela filer och uppdatera incidentstatus i realtid med ClickUp Chat-vyn. Denna funktion är till stor nytta för team som arbetar på olika platser eller i olika tidszoner, eftersom den säkerställer att alla hålls informerade och samordnade.

3. Automatiserad arbetsflödeshantering
ClickUp Automations hjälper dig att skapa automatiserade arbetsflöden som utlöser specifika åtgärder baserat på fördefinierade villkor. När en incident rapporteras kan till exempel automatiska aviseringar skickas till berörda teammedlemmar och uppgifter kan tilldelas baserat på incidenttypen. Detta minskar det manuella arbetet och påskyndar incidenthanteringen.
4. Integrerad rapportering och analys
Plattformen erbjuder robusta rapporterings- och analysverktyg som hjälper dig att övervaka incidenttrender och prestandamätvärden. Team kan skapa detaljerade rapporter om incidentprioritering, incident lösningstider, återkommande incidenter och andra viktiga prestationsindikatorer. Denna datadrivna metod hjälper dig att identifiera mönster, utvärdera effektiviteten i responsstrategier och fatta välgrundade beslut för att förbättra incidenthanteringsprocesserna.
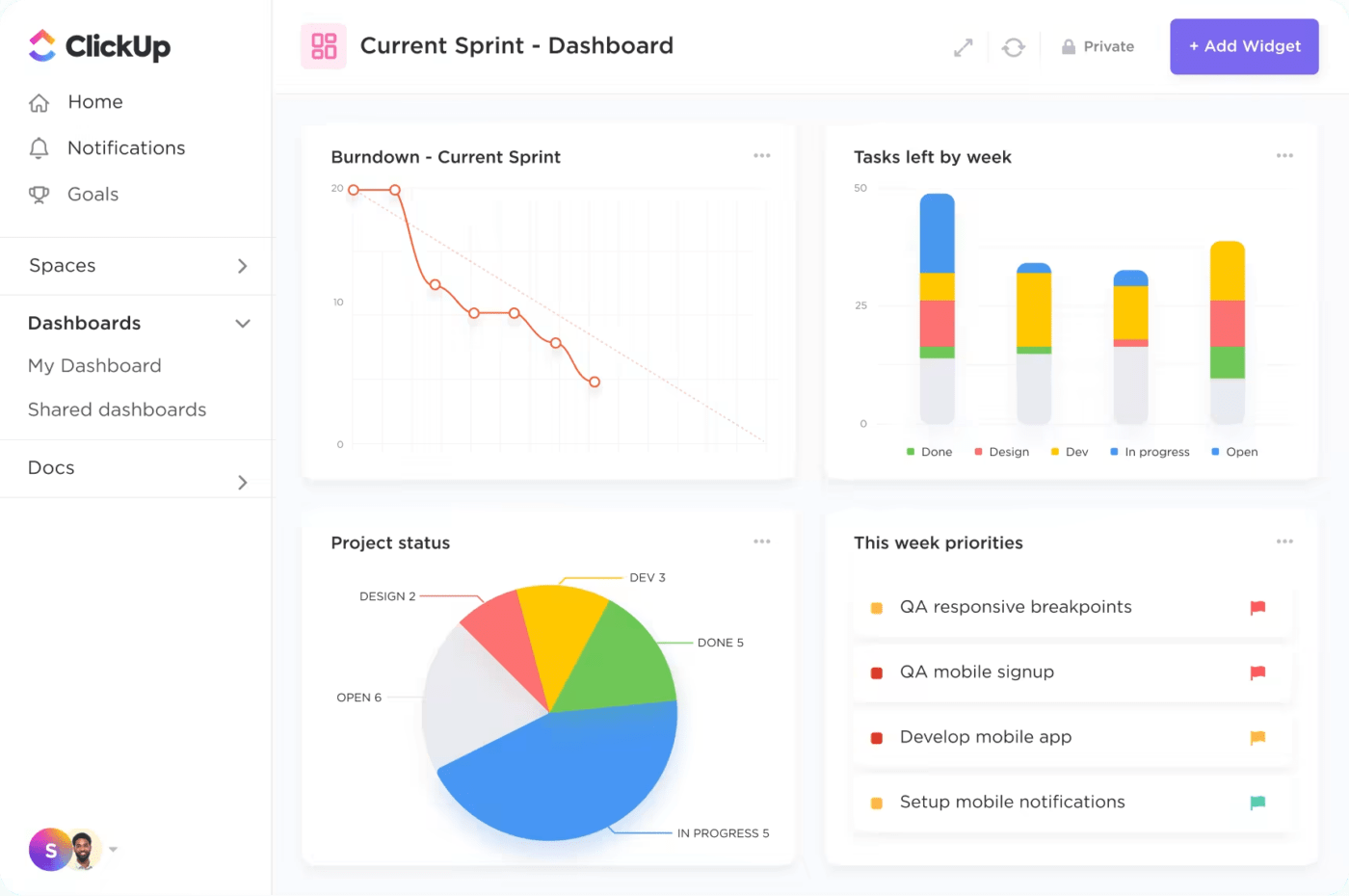
5. Anpassningsbara instrumentpaneler
Plattformen låter dig skapa anpassade instrumentpaneler som visar viktiga incidenthanteringsmått och KPI:er. ClickUp Dashboards ger en visuell översikt över pågående incidenter, väntande uppgifter och teamets prestanda, vilket gör det möjligt för chefer att snabbt bedöma det aktuella läget för incidenthanteringen och åtgärda eventuella problem.
6. Fördefinierade mallar
ClickUp erbjuder en rad anpassningsbara IT-mallars som är utformade för incidenthantering. Dessa mallar hjälper också användarna att dokumentera buggar.
Till exempel gör ClickUp IT Incident Report Template det möjligt för IT-team att dokumentera, spåra och lösa incidenter snabbt och effektivt. Detta förbättrar inte bara servicens hastighet utan hjälper också företag att identifiera långsiktiga trender som de kan ta itu med för att förbättra sin övergripande IT-infrastruktur.
Denna mall gör det enkelt att:
- Dokumentera och rapportera incidenter på ett korrekt sätt
- Spåra problemlösningen i realtid
- Identifiera mönster i rapporterade problem för proaktiv problemlösning
Den innehåller viktiga komponenter som en detaljerad beskrivning, en checklista, deluppgifter och anpassningsbara fält. Denna flexibilitet gör att mallen kan anpassas efter din organisations processer och rutiner, vilket skapar en omfattande IT-incidentrapport.
Du kan också använda ClickUps mall för incidentåtgärdsplan, som förenklar utvecklingen av omfattande incidentåtgärdsplaner (IAP) för företag.
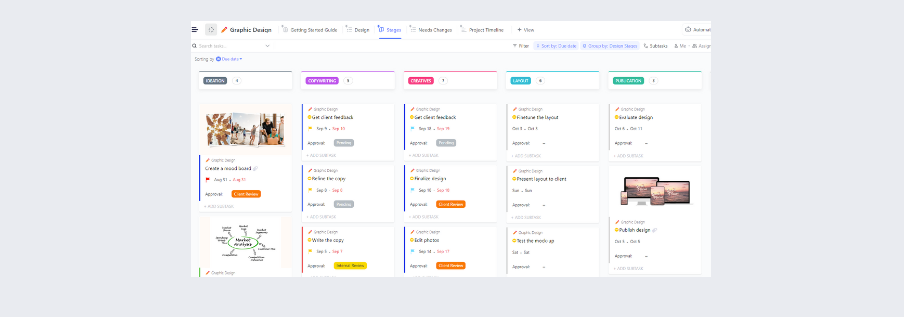
Denna mall innehåller systematiskt all viktig information och hjälper dig att skapa tillförlitliga register över incidentrelaterade aktiviteter och implementera effektiva responsstrategier.
Mallen har färgkodade avsnitt för organiserad dokumentation:
- Situationsöversikt: Ger en kortfattad översikt över incidenten och den övergripande handlingsplanen.
- Genomförandeplan: Detaljerade mål och strategier för hantering av incidenten.
- Kontaktuppgifter för incidentteamet: Listar kontaktuppgifter för personal som är involverad i hanteringen.
- Lista över incidentorganisation: Beskriver roller och ansvarsområden för teamen inom drift, planering, logistik och ekonomi.
- Incidentfördelningslista: Tilldelar specifika uppgifter till chefer och teammedlemmar.
- Karta/situationsöversikt: Innehåller grafiska representationer av incidentplatsen eller regionen.
- Godkännande av incidentplan: Samlar in information såsom namnet på den person som lämnar in planen, inlämningsdatum och erforderliga underskrifter.
Genom att använda denna mall kan företag effektivt sammanställa alla nödvändiga uppgifter för IAP-godkännande och sätta upp en välkoordinerad och grundlig incidenthantering.
Bästa praxis för incidenthantering
Effektiv incidenthantering bygger på bästa praxis som säkerställer snabb och effektiv lösning.
Ställ tydliga förväntningar med SLA:er
Servicenivåavtal (SLA) spelar en viktig roll genom att fastställa tydliga förväntningar på hur snabbt teamen ska hantera incidenter utifrån deras allvarlighetsgrad.
SLA:er definierar specifika svarstider och lösningstider, vilket hjälper till att prioritera incidenter och vägleda teamen i att hantera sin arbetsbelastning på ett effektivt sätt. Denna strukturerade metod hjälper dig att fokusera resurserna där de behövs mest, så att du kan anpassa incidenthanteringen efter företagets prioriteringar och minimera driftstopp.
Installera uppdateringar regelbundet för att förebygga incidenter
En annan viktig åtgärd är regelbunden patchning, som hjälper till att förebygga incidenter genom att åtgärda sårbarheter innan de kan utnyttjas. Det är en kontinuerlig process som åtgärdar säkerhetsbrister i programvara och system, vilket gör det svårare för angripare att utnyttja kända svagheter.
Denna praxis är en grundläggande del av ett ramverk för hantering av cybersäkerhetsrisker, eftersom den skyddar IT-infrastrukturen från nya hot och minskar risken för intrång. Utan snabba uppdateringar förblir sårbarheterna öppna och kan leda till betydande säkerhetsproblem.
Prioritera övervakning av datacenter
Datacenterhantering spelar också en viktig roll i incidenthanteringen. Korrekt hantering säkerställer att både fysiska och virtuella aspekter av datacentret underhålls väl. Detta inkluderar övervakning av miljökontroller, strömförsörjning och fysisk säkerhet.
Realtidsövervakningssystem är avgörande här, eftersom de hjälper till att upptäcka och åtgärda problem innan de eskalerar. Effektiv datacenterhantering i kombination med ett väl implementerat ramverk för hantering av cybersäkerhetsrisker möjliggör tidig problemdetektering, vilket hjälper till att undvika större störningar och upprätthålla stabiliteten i IT-driften.
Fördelar och utmaningar med incidenthantering
Incidenter kan bromsa projektets framsteg och tömma värdefulla resurser, vilket ofta orsakar betydande driftsstörningar och potentiell förlust av kritiska data. Detta understryker vikten av effektiv incidenthantering.
De viktigaste fördelarna med incidenthantering är:
1. Förbättrad incidentavledning
Incidentavledning innebär att man proaktivt identifierar och mildrar potentiella problem innan de eskalerar till allvarliga problem. Effektiva incidenthanteringssystem gör det möjligt för organisationer att implementera förebyggande åtgärder och kontinuerligt övervaka systemets prestanda, vilket minskar incidenternas frekvens och allvarlighetsgrad.
2. Effektiviserad förändringsprocess
En välhanterad förändringsprocess säkerställer att medarbetarna implementerar uppdateringar och modifieringar systematiskt, enligt fastställda rutiner. Att utnyttja standardrutiner (SOP) för förändringshantering bidrar till att standardisera rutinerna, säkerställa konsekvens och minska risken för fel.
3. Effektiv incidenthantering och avslutning
En tydligt definierad lösningsprocess säkerställer att teamen hanterar incidenter snabbt och vidtar alla nödvändiga åtgärder för att lösa problemet. När incidenten är löst avslutas den formellt med fullständig dokumentation och uppföljningsåtgärder. Denna strukturerade metod förbättrar den operativa effektiviteten och ger värdefull dokumentation för analys efter incidenten och kontinuerlig förbättring, vilket bidrar till att förfina strategierna för incidenthantering över tid.
Utmaningar inom incidenthantering
Trots fördelarna uppstår ofta flera utmaningar i incidenthanteringen.
1. Svårigheter att identifiera grundorsaker
En stor utmaning är att identifiera den bakomliggande orsaken till en incident, framför allt när det gäller komplexa problem som involverar flera systemkomponenter och ömsesidiga beroenden.
För att kunna diagnostisera den bakomliggande orsaken på ett korrekt sätt krävs en grundlig utredning och ofta även samarbete mellan olika funktioner. Standardiserade arbetsrutiner (SOP) kan vara till hjälp vid skapandet av standardiserade procedurer för analys av grundorsaker, men för att dessa procedurer ska kunna implementeras på ett effektivt sätt krävs avancerade verktyg och metoder.
Stanley Security stod inför en liknande utmaning när de hanterade sina incidenthanteringsprocesser. Som en global ledare inom säkerhetslösningar hanterar Stanley Security olika incidenter i olika system och regioner.
Tidigare förlitade sig företagets marknadsföringsteam på verktyg som Excel och e-post för intern kommunikation och uppgiftshantering. COVID-19-pandemins krav på mer integrerade och skalbara projektledningsverktyg lyfte fram behovet av att bryta ner silos och öka produktiviteten.
ClickUp tillhandahöll en enhetlig arbetsplats för globala team, vilket underlättade kommunikationen och organiseringen av dokument samt SOP:er i en världsomspännande databas. Denna samordning gjorde det möjligt för teamen att samarbeta mer effektivt och dela med sig av bästa praxis. Som ett resultat uppnådde Stanley Security en 80-procentig ökning av förbättrat teamarbete, vilket sparade över 8 timmar per vecka på möten och uppdateringar. De observerade också en 50-procentig minskning av den tid som spenderades på att skapa och dela rapporter.
2. Återkommande incidenter
En annan utmaning är att förhindra att incidenter upprepas. Detta kräver en djup förståelse för de underliggande problemen och implementering av effektiva förebyggande åtgärder. Att identifiera mönster och trender från tidigare incidenter är avgörande för att utveckla strategier för att minska framtida risker.
ClickUp hanterar denna utmaning genom att tillhandahålla integrerade rapporterings- och analysverktyg som ger insikter i incidentstatistik och prestandatrender. Denna datadrivna metod underlättar identifieringen av återkommande problem och hjälper till att utveckla riktade förebyggande strategier.

ClickUps IT- och PMO-lösning kan vara till hjälp här:
- Skapa anpassade statusar (t.ex. ”Stängd”, ”På vänt”, ”Pågående”) och fält (t.ex. ”Begärare”, ”Avdelning”) för att effektivt kategorisera och hantera incidenter.
- Spåra och övervaka incidenter i realtid, vilket säkerställer snabba uppdateringar och statuskontroller.
- Bifoga relevanta dokument, skärmdumpar eller loggar till incidenter för analys. Skapa en kunskapsbas för gemensamma incidentlösningar.
- Skapa rapporter om incidentfrekvens, lösningstid och grundorsaker för att identifiera trender och förbättra responsen.
- Anslut ClickUp till andra IT-verktyg för en helhetsbild av incidenter.
Behärska incidenthantering för optimala projektresultat
Att behärska incidenthantering handlar inte bara om att reagera på problem – det handlar om att skapa en resilient och agil miljö där avbrott hanteras snabbt och projektmål uppnås med minimal påverkan.
Genom att tillämpa dessa strategier kan ditt team undvika potentiella problem och säkerställa att dina projekt löper smidigt och framgångsrikt.
Med ClickUp får du fördelarna med en allt-i-ett-plattform som integrerar incidenthantering med projekt- och IT-driftshantering. ClickUps realtidsspårning, automatiserade arbetsflöden och samarbetsverktyg gör det möjligt för ditt team att hantera och lösa problem snabbt samtidigt som dina projekt hålls på rätt spår. Oavsett om du hanterar den dagliga driften eller navigerar i komplexa projektkrav, ger ClickUp den översikt och kontroll som krävs för exceptionella resultat.
Är du redo att förbättra din incidenthantering och dina projektresultat? Registrera dig på ClickUp idag och förvandla din incidenthantering!