
คุณแน่ใจว่ามีเอกสารนี้อยู่ คุณเห็นมันเมื่อสัปดาห์ที่แล้ว
แต่หลังจากที่คุณลองใช้ทุกคำค้นหาที่คุณคิดได้—"ผลประกอบการการตลาดไตรมาส 3," "ผลการดำเนินงานไตรมาสที่สาม," "รายงานการตลาดเดือนตุลาคม"—แถบค้นหาของบริษัทคุณก็ยังคงว่างเปล่า การค้นหาข้อมูลที่น่าหงุดหงิดนี้เป็นสัญญาณคลาสสิกของการค้นหาคำสำคัญที่ล้าสมัย
ระบบเหล่านี้จะค้นหาเฉพาะคำที่ตรงกันเท่านั้น และอาจพลาดสิ่งที่คุณตั้งใจจะสื่อ Cohere แก้ไขปัญหานี้ได้อย่างมีประสิทธิภาพด้วยการเพิ่มชั้นการค้นหาอัจฉริยะที่เชื่อมโยงระบบของคุณเข้าด้วยกัน
ดังนั้น หากคุณกำลังพยายามหาวิธีใช้ Cohere สำหรับการค้นหาในองค์กร เราได้เตรียมคำแนะนำไว้ให้คุณแล้ว คู่มือนี้จะอธิบายทุกอย่างให้คุณเข้าใจ
Cohere AI คืออะไรและทำไมจึงมีความสำคัญต่อการค้นหาข้อมูลในองค์กร?
Cohere เป็นแพลตฟอร์ม AI ที่สร้างโมเดลภาษาขนาดใหญ่ (LLMs) โดยเฉพาะสำหรับองค์กรธุรกิจสำหรับการค้นหาภายในองค์กร นี่หมายถึงการก้าวข้ามการค้นหาแบบใช้คีย์เวิร์ดไปสู่การค้นหาเชิงความหมายและอัจฉริยะที่เข้าใจเจตนา บริบท และความหมายที่แท้จริง
เครื่องมือค้นหาสำหรับองค์กรส่วนใหญ่ยังคงพึ่งพาการจับคู่คำหลักตามตัวอักษร หากคำที่ตรงกันไม่ปรากฏในชื่อเอกสารหรือเนื้อหา ผลลัพธ์มักจะพลาดไป Cohere เปลี่ยนแปลงสิ่งนี้โดยทำให้ระบบค้นหาสามารถเข้าใจสิ่งที่ผู้ใช้กำลังมองหาจริงๆ ไม่ใช่แค่สิ่งที่พวกเขาพิมพ์
ทีมที่พยายามสร้างระบบค้นหาที่ใช้ AI ด้วยตนเองมักจะใช้เวลาหลายเดือนในการรวบรวมฐานข้อมูลเวกเตอร์, ฝังท่อส่งข้อมูล, และจัดอันดับโมเดลใหม่ แม้จะทำงานทั้งหมดนั้นแล้ว การค้นหาก็มักจะมีประสิทธิภาพต่ำเพราะมันอยู่ในระบบที่แยกจากระบบที่งานจริงๆ เกิดขึ้น, ไม่เชื่อมต่อกับงาน, เอกสาร, และกระบวนการทำงาน
เครื่องมือค้นหาสำหรับองค์กรที่ทรงพลังอย่าง Cohere ใช้การเพิ่มประสิทธิภาพการค้นหาด้วยการเสริมสร้างข้อมูล (RAG)เพื่อผสานการค้นหาอัจฉริยะกับปัญญาประดิษฐ์ วิธีการนี้เปลี่ยนความรู้ภายในองค์กรของคุณให้กลายเป็นแหล่งข้อมูลที่สามารถเข้าถึงได้ทันที
ในกรณีของ Cohere เครื่องมือนี้จะแปลงเอกสารให้เป็น embeddings ซึ่งเป็นตัวแทนเชิงตัวเลขของความหมาย เมื่อมีคนค้นหาคำว่า "รายงานรายได้รายไตรมาส" ระบบจะดึงเอกสารที่มีความเกี่ยวข้องในเชิงแนวคิด เช่น "ผลประกอบการไตรมาส 4" หรือ "สรุปผลประกอบการ" แม้ว่าจะไม่มีคำค้นหาตรงตามนั้นก็ตาม
นั่นคือเหตุผลที่ Cohere มีความสำคัญสำหรับการค้นหาในองค์กร มันช่วยลดความซับซ้อนในการใช้งาน ปรับปรุงความแม่นยำของผลลัพธ์ และทำให้การค้นหาทำงานในแบบที่พนักงานคิดและถามคำถามจริงๆ ภายในระบบการทำงานสมัยใหม่
📮ClickUp Insight: พนักงานมากกว่าครึ่งหนึ่ง (57%) เสียเวลาในการค้นหาเอกสารภายในหรือฐานความรู้ของบริษัทเพื่อหาข้อมูลที่เกี่ยวข้องกับงาน
แล้วเมื่อพวกเขาทำไม่ได้ล่ะ? 1 ใน 6 คนต้องใช้วิธีแก้ปัญหาด้วยตัวเอง—ขุดค้นอีเมลเก่า บันทึก หรือภาพหน้าจอ เพียงเพื่อรวบรวมข้อมูลให้ครบถ้วน
ClickUp Brainช่วยขจัดความยุ่งยากในการค้นหาด้วยการให้คำตอบทันทีโดยใช้ปัญญาประดิษฐ์ที่ดึงข้อมูลจากทั้งพื้นที่ทำงานของคุณและแอปของบุคคลที่สามที่เชื่อมต่อไว้ เพื่อให้คุณได้รับสิ่งที่ต้องการโดยไม่ต้องเสียเวลา
คุณสมบัติหลักของ Cohere สำหรับการค้นหาในองค์กร
เมื่อคุณกำลังประเมินโซลูชันการค้นหาด้วย AI การโฆษณาเกินจริงอาจทำให้คุณยากที่จะบอกได้ว่าความสามารถใดที่แก้ปัญหาของคุณได้จริง ๆ คำสัญญาทั่วไปเกี่ยวกับ "การค้นหาที่ฉลาดขึ้น" ไม่ได้ช่วยให้ทีมวิศวกรรมและผลิตภัณฑ์ของคุณตัดสินใจอย่างมีข้อมูล
ความจริงก็คือ ระบบค้นหาที่เชื่อถือได้นั้นต้องอาศัยกระบวนการทำงานร่วมกันของโมเดล AI ที่แตกต่างกันหลายรูปแบบ
Cohere นำเสนอโมเดลหลายแบบที่คุณสามารถใช้แยกกันหรือรวมกันเพื่อสร้างสถาปัตยกรรมการค้นหาที่ซับซ้อนได้ การทำความเข้าใจคุณสมบัติหลักเหล่านี้เป็นขั้นตอนแรกในการออกแบบระบบที่ตอบสนองความต้องการเฉพาะของทีมคุณ
ฝังสำหรับการค้นหาเวกเตอร์เชิงความหมาย
ความหงุดหงิดที่ใหญ่ที่สุดกับระบบค้นหาเก่าคือความสามารถในการค้นหาข้อมูลที่เกี่ยวข้องทางแนวคิดไม่ได้ คุณค้นหาคำว่า "คู่มือการปฐมนิเทศพนักงานใหม่" แต่พลาดเอกสารที่มีชื่อว่า "รายการตรวจสอบวันแรกสำหรับพนักงานใหม่" สิ่งนี้เกิดขึ้นเพราะระบบจับคู่คำ ไม่ใช่ความหมาย
โมเดล Embedพร้อมการค้นหาแบบประสาทเทียม แก้ไขปัญหานี้โดยการแปลงข้อความให้เป็นเวกเตอร์—รายการตัวเลขยาวที่จับความหมายเชิงความหมายได้ กระบวนการนี้เรียกว่าการฝัง (embedding) ช่วยให้ระบบสามารถระบุเอกสารที่มีความคล้ายคลึงกันในเชิงแนวคิดได้ แม้ว่าเอกสารเหล่านั้นจะไม่มีคำสำคัญที่เหมือนกันก็ตาม โดยพื้นฐานแล้ว เครื่องมือค้นหาของคุณจะเข้าใจคำที่มีความหมายเหมือนกันและแนวคิดที่เกี่ยวข้องโดยอัตโนมัติ
นี่คือแง่มุมสำคัญของโมเดล Embed ของ Cohere:
- การสนับสนุนหลายรูปแบบ: เวอร์ชันล่าสุด Embed 4 สามารถประมวลผลทั้งข้อความและรูปภาพ ทำให้คุณสามารถค้นหาเนื้อหาประเภทต่างๆ ได้พร้อมกัน
- ความสามารถในการใช้หลายภาษา: คุณสามารถค้นหาข้อมูลข้ามเอกสารในภาษาต่างๆ ได้โดยไม่ต้องแปลเอกสารก่อน
- ตัวเลือกมิติ: คุณสามารถเลือกขนาดของเวกเตอร์ของคุณได้ มิติที่สูงขึ้นจะจับรายละเอียดได้มากขึ้น แต่ต้องการพื้นที่จัดเก็บและพลังการประมวลผลมากขึ้น
📖 อ่านเพิ่มเติม: กรณีการใช้งานการค้นหาข้อมูลองค์กรด้วย AI
จัดอันดับใหม่เพื่อความเกี่ยวข้องของผลลัพธ์ที่ดีขึ้น
บางครั้ง การค้นหาจะแสดงรายการเอกสารที่เกี่ยวข้อง แต่เอกสารที่สำคัญที่สุดกลับถูกฝังอยู่ในหน้าที่สอง ซึ่งทำให้ผู้ใช้ต้องเสียเวลาค้นหาและสูญเสียความเชื่อมั่นในระบบค้นหา
นี่คือปัญหาการจัดอันดับ ระบบพบข้อมูลที่ถูกต้องแล้ว แต่ไม่สามารถจัดลำดับความสำคัญได้อย่างถูกต้อง
โมเดล Rerank ของ Cohere แก้ไขปัญหานี้ด้วยกระบวนการสองขั้นตอน ขั้นแรก คุณใช้วิธีการค้นหาที่รวดเร็ว (เช่น การค้นหาเชิงความหมาย) เพื่อรวบรวมชุดเอกสารจำนวนมากที่อาจเกี่ยวข้อง จากนั้น คุณส่งรายการนั้นไปยังโมเดล Rerank ซึ่งใช้สถาปัตยกรรม cross-encoder ที่ใช้การคำนวณมากกว่าเพื่อวิเคราะห์เอกสารแต่ละฉบับเทียบกับคำค้นหาเฉพาะของคุณและจัดลำดับใหม่เพื่อความเกี่ยวข้องสูงสุด
สิ่งนี้จะมีประโยชน์อย่างยิ่งในสถานการณ์ที่มีความเสี่ยงสูงซึ่งความแม่นยำเป็นสิ่งสำคัญ เช่น เมื่อเจ้าหน้าที่ฝ่ายสนับสนุนค้นหาคำตอบที่ถูกต้องสำหรับลูกค้า หรือเมื่อสมาชิกในทีมค้นหาส่วนเฉพาะในเอกสาร แม้ว่าจะเพิ่มเวลาในการประมวลผลเล็กน้อย แต่การปรับปรุงคุณภาพของผลลัพธ์ก็มักจะคุ้มค่ากับการแลกเปลี่ยน
📖 อ่านเพิ่มเติม: ตัวอย่างและกรณีการใช้งานระบบอัตโนมัติในกระบวนการทำงาน
กรณีการใช้งานการค้นหาภายในองค์กรสำหรับทีม
ความสามารถของ AI ในระดับนามธรรมนั้นน่าสนใจ แต่จะไม่มีประโยชน์จนกว่าคุณจะนำไปใช้แก้ปัญหาทางธุรกิจในโลกจริง การนำการค้นหาองค์กรมาใช้อย่างประสบความสำเร็จเริ่มต้นจากการระบุจุดเจ็บปวดเฉพาะเหล่านี้ 👀
นี่คือตัวอย่างสถานการณ์จริงบางประการที่ทีมสามารถนำการค้นหาที่ขับเคลื่อนด้วย Cohere ไปใช้ได้:
- การค้นหาฐานความรู้: ช่วยให้พนักงานค้นหาคำตอบในเอกสารภายใน วิกิฐานความรู้ฝ่ายบริการลูกค้าและขั้นตอนการปฏิบัติงานมาตรฐาน (SOP)
- การสนับสนุนลูกค้า: ช่วยให้เจ้าหน้าที่สามารถค้นหาบทความช่วยเหลือที่เกี่ยวข้องและวิธีแก้ไขปัญหาในตั๋วที่ผ่านมาได้อย่างรวดเร็วขณะสนทนากับลูกค้า—การวิเคราะห์ของ McKinsey แสดงให้เห็นว่าประสิทธิภาพการทำงานเพิ่มขึ้น 30-45%เมื่อใช้ AI เชิงสร้างสรรค์กับกระบวนการดูแลลูกค้า
- กฎหมายและการปฏิบัติตามกฎระเบียบ: ค้นหาสัญญา นโยบาย และเอกสารกำกับดูแลนับล้านฉบับด้วยความเข้าใจเชิงความหมาย เพื่อค้นหาข้อกำหนดเฉพาะหรือบรรทัดฐานที่เคยใช้
- การวิจัยและพัฒนา: ให้วิศวกรสามารถค้นหาผลงานที่เกี่ยวข้องก่อนหน้านี้, สิทธิบัตร, และเอกสารทางเทคนิคเพื่อหลีกเลี่ยงการซ้ำซ้อนในการทำงาน
- ฝ่ายทรัพยากรบุคคลและการปฐมนิเทศ: เปิดเผยนโยบายที่เกี่ยวข้อง, เอกสารการฝึกอบรม,ตัวอย่างขั้นตอนการทำงาน, และขั้นตอนปฏิบัติสำหรับพนักงานใหม่ เพื่อให้พวกเขาสามารถค้นหาคำตอบได้ด้วยตนเอง
- การเสริมศักยภาพฝ่ายขาย: ช่วยให้พนักงานขายค้นหาตัวอย่างกรณีศึกษา ข้อมูลเชิงลึกด้านการแข่งขัน และข้อมูลผลิตภัณฑ์ที่เหมาะสม เพื่อปิดการขายได้เร็วขึ้น
จุดร่วมที่สำคัญคือ การค้นหาภายในองค์กรที่มีประสิทธิภาพจำเป็นต้องผสานรวมเข้ากับระบบการจัดการเวิร์กโฟลว์ที่มีอยู่เดิม การใช้เพียงแถบค้นหาแบบแยกเดี่ยวนั้นไม่เพียงพอ ทีมงานของคุณต้องสามารถค้นหาข้อมูลและดำเนินการได้ทันทีโดยไม่ต้องสลับเครื่องมือ
🛠️ ชุดเครื่องมือ: สร้างศูนย์กลางภายในที่ทีมของคุณจะใช้จริง ๆเทมเพลตฐานความรู้ของ ClickUpช่วยจัดระเบียบทุกอย่างตั้งแต่คู่มือการใช้งานไปจนถึง SOPs อย่างเป็นระเบียบและค้นหาได้ง่าย ทำให้ไม่มีใครต้องเดาว่าข้อมูลอยู่ที่ไหน

วิธีตั้งค่า Cohere สำหรับการค้นหาในองค์กร
การเปลี่ยนจากการประเมินการค้นหาด้วย AI ไปสู่การนำไปใช้จริงอาจรู้สึกน่ากลัว โดยเฉพาะอย่างยิ่งหากทีมของคุณยังใหม่ต่อโมเดลภาษาขนาดใหญ่
แม้ว่าความซับซ้อนของการตั้งค่าของคุณจะขึ้นอยู่กับขนาดและเทคโนโลยีที่มีอยู่ แต่ขั้นตอนหลักในการสร้างระบบค้นหาที่ขับเคลื่อนด้วย Cohere นั้นยังคงเหมือนเดิม ส่วนนี้จะนำเสนอวิธีการปฏิบัติที่เป็นรูปธรรมเพื่อเป็นแนวทางให้กับทีมเทคนิคของคุณ
ข้อกำหนดเบื้องต้นและการเข้าถึง API
ก่อนที่คุณจะเขียนโค้ดใด ๆ คุณจำเป็นต้องเตรียมเครื่องมือและการเข้าถึงให้เรียบร้อย การตั้งค่าเบื้องต้นนี้จะช่วยป้องกันปัญหาด้านความปลอดภัยและอุปสรรคที่อาจเกิดขึ้นในภายหลัง
นี่คือสิ่งที่คุณจะต้องใช้เพื่อเริ่มต้น:
- บัญชี Cohere API: ลงทะเบียนบนเว็บไซต์ Cohere เพื่อรับคีย์ API ของคุณ
- สภาพแวดล้อมการพัฒนา: ทีมส่วนใหญ่ใช้ Python แต่มี SDK ให้ใช้สำหรับภาษาอื่น ๆ
- ฐานข้อมูลเวกเตอร์: คุณจะต้องมีที่สำหรับเก็บ embeddings ของเอกสารของคุณ เช่น Pinecone, Weaviate, Qdrant หรือบริการที่มีการจัดการอย่าง Amazon OpenSearch
- เอกสารชุดข้อมูล: รวบรวมเนื้อหาที่คุณต้องการให้สามารถค้นหาได้ (เช่น PDF, ไฟล์ข้อความ, บันทึกฐานข้อมูล)
คุณยังสามารถเข้าถึงโมเดลของ Cohere ผ่าน Amazon Bedrock ได้ ซึ่งสามารถทำให้การเรียกเก็บเงินและความปลอดภัยง่ายขึ้น หากบริษัทของคุณทำงานอยู่ในระบบนิเวศของ AWS อยู่แล้ว
สร้าง embedding ด้วย Cohere Embed
ขั้นตอนต่อไปคือการแปลงเอกสารของคุณให้เป็นเวกเตอร์ที่สามารถค้นหาได้ กระบวนการนี้ประกอบด้วยการเตรียมเนื้อหาของคุณและจากนั้นให้ผ่านแบบจำลอง Cohere Embed
วิธีที่คุณเตรียมเอกสารของคุณ โดยเฉพาะวิธีที่คุณแบ่งเอกสารออกเป็นส่วนย่อย มีผลกระทบอย่างมากต่อคุณภาพการค้นหานี่เรียกว่ากลยุทธ์การแบ่งส่วนของคุณ
กลยุทธ์การแบ่งกลุ่มที่พบบ่อย ได้แก่:
- ชิ้นส่วนขนาดคงที่: วิธีที่ง่ายที่สุด แต่สามารถแบ่งประโยคหรือความคิดออกกลางคันได้อย่างไม่เหมาะสม
- การแบ่งกลุ่มเชิงความหมาย: วิธีการขั้นสูงที่คำนึงถึงโครงสร้างของเอกสาร เช่น การแบ่งที่จุดสิ้นสุดของย่อหน้าหรือส่วน
- ชิ้นส่วนที่ทับซ้อนกัน: วิธีการนี้รวมถึงข้อความที่ซ้ำกันเล็กน้อยระหว่างชิ้นส่วนเพื่อช่วยรักษาบริบทข้ามขอบเขต
เมื่อเอกสารของคุณถูกแบ่งเป็นส่วน ๆ แล้ว คุณสามารถส่งเอกสารเหล่านั้นไปยัง Embed API เป็นชุด ๆ ได้เพื่อสร้างตัวแทนเวกเตอร์ของเอกสารนั้น ๆ กระบวนการนี้มักเป็นกระบวนการที่ทำเพียงครั้งเดียวสำหรับเอกสารที่มีอยู่แล้วของคุณ และเอกสารใหม่หรือเอกสารที่ได้รับการปรับปรุงจะถูกฝังไว้เมื่อมีการสร้างขึ้น
📖 อ่านเพิ่มเติม: เครื่องมือค้นหาภายในคืออะไร? เครื่องมือที่ดีที่สุด & วิธีการทำงาน
จัดเก็บและค้นหาเวกเตอร์
เวกเตอร์ที่คุณสร้างขึ้นใหม่ต้องการที่เก็บ ฐานข้อมูลเวกเตอร์เป็นฐานข้อมูลเฉพาะทางที่ออกแบบมาเพื่อจัดเก็บและค้นหาการฝังตัวตามความคล้ายคลึงกันของพวกมัน
กระบวนการค้นหาทำงานดังนี้:
- ผู้ใช้พิมพ์คำค้นหา
- แอปพลิเคชันของคุณส่งคำค้นหาดังกล่าวไปยังโมเดล Cohere Embed เดียวกันเพื่อแปลงเป็นเวกเตอร์
- เวกเตอร์คำถามนั้นถูกส่งไปยังฐานข้อมูล ซึ่งจะค้นหาเวกเตอร์เอกสารที่คล้ายคลึงกันมากที่สุด
- ฐานข้อมูลจะคืนเอกสารที่ตรงกัน ซึ่งคุณสามารถแสดงให้ผู้ใช้ดูได้
เมื่อเลือกฐานข้อมูลเวกเตอร์ คุณจะต้องพิจารณาด้วยว่าจะใช้มาตรวัดความคล้ายคลึงแบบใด Cosine similarity เป็นที่นิยมมากที่สุดสำหรับการค้นหาแบบข้อความ แต่ยังมีตัวเลือกอื่น ๆ สำหรับกรณีการใช้งานที่แตกต่างกัน
| เมตริกความคล้ายคลึง | เหมาะที่สุดสำหรับ |
|---|---|
| ความคล้ายคลึงโคไซน์ | การค้นหาข้อความทั่วไป |
| ผลคูณจุด | เมื่อขนาดของเวกเตอร์มีความสำคัญ |
| ระยะทางยูคลิด | ข้อมูลเชิงพื้นที่หรือข้อมูลภูมิศาสตร์ |
ดำเนินการจัดอันดับใหม่เพื่อผลลัพธ์ที่ดีขึ้น
สำหรับหลายการใช้งาน ผลลัพธ์จากฐานข้อมูลเวกเตอร์ของคุณก็เพียงพอแล้ว แต่เมื่อคุณต้องการผลลัพธ์ที่ดีที่สุดในระดับสูงสุด การเพิ่มขั้นตอนการจัดอันดับใหม่ก็เป็นทางเลือกที่ชาญฉลาด
สิ่งนี้มีความสำคัญเป็นพิเศษเมื่อระบบค้นหาของคุณขับเคลื่อนระบบ RAG เนื่องจากคุณภาพของคำตอบที่สร้างขึ้นนั้นขึ้นอยู่กับคุณภาพของบริบทที่ดึงมาอย่างมาก
กระบวนการจัดอันดับใหม่มีความตรงไปตรงมา:
- ดึงชุดข้อมูลผู้สมัครเริ่มต้นที่ใหญ่ขึ้นจากฐานข้อมูลเวกเตอร์ของคุณ (เช่น ผลลัพธ์ 50 อันดับแรก)
- ส่งคำค้นหาต้นฉบับของผู้ใช้และรายการผู้สมัครนี้ไปยัง Cohere Rerank API
- API ส่งคืนรายการเอกสารชุดเดิม แต่จัดเรียงใหม่ตามคะแนนความเกี่ยวข้องที่แม่นยำยิ่งขึ้น
- แสดงผลลัพธ์ที่ดีที่สุดจากลิสต์ที่ได้รับการจัดอันดับใหม่ให้ผู้ใช้
เพื่อวัดผลกระทบของการจัดอันดับใหม่ คุณสามารถติดตามตัวชี้วัดการประเมินผลแบบออฟไลน์ เช่น nDCG (Normalized Discounted Cumulative Gain) และ MRR (Mean Reciprocal Rank)
💫 สำหรับภาพรวมในการนำความสามารถในการค้นหาขององค์กรไปใช้ โปรดชมการสาธิตนี้ที่แสดงแนวคิดหลักและข้อพิจารณาในทางปฏิบัติ:
แนวทางปฏิบัติที่ดีที่สุดสำหรับการค้นหาข้อมูลในองค์กรด้วย Cohere
การสร้างระบบค้นหาเป็นเพียงก้าวแรกเท่านั้น การรักษาและปรับปรุงคุณภาพของระบบอย่างต่อเนื่องคือสิ่งที่ทำให้โครงการประสบความสำเร็จหรือล้มเหลว หากผู้ใช้มีประสบการณ์ที่ไม่ดีเพียงไม่กี่ครั้ง พวกเขาจะสูญเสียความไว้วางใจและหยุดใช้เครื่องมือนั้น 🛠️
นี่คือบทเรียนที่ได้จากการนำระบบการค้นหาสำหรับองค์กรไปใช้อย่างประสบความสำเร็จ:
- เริ่มต้นด้วยการค้นหาแบบผสมผสาน: อย่าพึ่งพาการค้นหาเชิงความหมายเพียงอย่างเดียว ผสมผสานกับอัลกอริทึมการค้นหาคำหลักแบบดั้งเดิม เช่น BM25 เพื่อให้ได้ประโยชน์สูงสุดจากทั้งสองวิธี—การค้นหาเชิงความหมายจะค้นหาสิ่งที่เกี่ยวข้องกันในเชิงแนวคิด ในขณะที่การค้นหาคำหลักจะช่วยให้คุณพบการจับคู่ที่ตรงกันสำหรับรหัสสินค้าหรือชื่อเฉพาะ
- ลงทุนในความสะอาดและคุณภาพของข้อมูล: ผลลัพธ์การค้นหาของคุณจะดีได้เท่ากับคุณภาพของข้อมูลเท่านั้น เอกสารที่สะอาด มีโครงสร้างที่ดี พร้อมหัวข้อและย่อหน้าที่ชัดเจน จะสร้าง embeddings ที่ดีกว่ามาก
- แบ่งส่วนอย่างรอบคอบ: วิธีที่คุณแบ่งเอกสารออกเป็นส่วนๆ นั้นมีความสำคัญอย่างยิ่ง แทนที่จะใช้ขีดจำกัดจำนวนอักขระแบบสุ่ม ลองจัดแบ่งเอกสารให้สอดคล้องกับโครงสร้างเชิงตรรกะของเอกสาร เช่น ย่อหน้าหรือหัวข้อต่างๆ
- เพิ่มการกรองข้อมูลเมตา: การค้นหาเชิงความหมายมีประสิทธิภาพ แต่บางครั้งผู้ใช้ก็รู้ว่ากำลังมองหาอะไรอยู่แล้ว อนุญาตให้พวกเขาสามารถกรองผลลัพธ์ตามข้อมูลเมตา เช่น วันที่ แผนก หรือประเภทเอกสาร ก่อน ที่การค้นหาเชิงความหมายจะเริ่มทำงาน
- ติดตามและปรับปรุงอย่างต่อเนื่อง: ให้ความสนใจอย่างใกล้ชิดกับสิ่งที่ผู้ใช้ของคุณค้นหา ผลลัพธ์ที่พวกเขาคลิก และคำค้นหาที่ไม่แสดงผลลัพธ์ ข้อมูลเหล่านี้มีค่าอย่างยิ่งในการระบุช่องว่างของเนื้อหาและปรับปรุงระบบของคุณ
- จัดการกับความล้มเหลวอย่างนุ่มนวล: ไม่มีระบบค้นหาใดที่สมบูรณ์แบบ เมื่อการค้นหาให้ผลลัพธ์ที่ไม่ดี ควรมีทางเลือกที่ช่วยเหลือ เช่น แนะนำคำค้นหาทางเลือกหรือเสนอให้แจ้งผู้เชี่ยวชาญ
ข้อจำกัดของ Cohere สำหรับการค้นหาในองค์กร
แม้ว่า Cohere จะให้บริการโมเดล AI ที่ทรงพลัง แต่ก็ไม่ใช่โซลูชันแบบติดตั้งแล้วใช้งานได้ทันที (ไม่เชิงนั้น)
การสร้างโซลูชันการค้นหาสำหรับองค์กรที่พร้อมใช้งานจริงนั้นมาพร้อมกับความท้าทายที่สำคัญซึ่งทีมมักประเมินค่าต่ำเกินไป การเข้าใจข้อจำกัดเหล่านี้เป็นสิ่งสำคัญอย่างยิ่งสำหรับการตัดสินใจอย่างมีข้อมูลและหลีกเลี่ยงความประหลาดใจที่มีค่าใช้จ่ายสูงในอนาคต
ปัญหาใหญ่ที่สุดคือคุณได้รับชุดเครื่องมือ ไม่ใช่ผลิตภัณฑ์ที่เสร็จสมบูรณ์แล้ว ซึ่งทำให้ทีมของคุณต้องรับผิดชอบในการสร้างและบำรุงรักษาโครงสร้างพื้นฐานทั้งหมดที่อยู่รอบๆการค้นหาในฐานะบริการ
นี่คือข้อจำกัดสำคัญบางประการที่ควรพิจารณา:
| ความท้าทาย | ทำไมมันกลายเป็นปัญหา |
|---|---|
| ต้องการความเชี่ยวชาญเฉพาะทาง | คุณต้องการวิศวกร AI และข้อมูลที่มีประสบการณ์เพื่อสร้าง, ดำเนินการ, และบำรุงรักษาระบบ. นี่ไม่ใช่สิ่งที่ทีมส่วนใหญ่สามารถตั้งค่าหรือเป็นเจ้าของได้โดยไม่คิดมาก. |
| ต้องการการผสานระบบแบบกำหนดเอง | โมเดลเหล่านี้จะไม่เชื่อมต่อกับเครื่องมือที่คุณมีอยู่โดยอัตโนมัติ แหล่งข้อมูลทุกแหล่งจำเป็นต้องเชื่อมต่อและดูแลรักษาด้วยตนเอง |
| การบำรุงรักษาอย่างต่อเนื่องสูง | ดัชนีการค้นหาต้องได้รับการปรับปรุงอย่างต่อเนื่องเมื่อมีการเปลี่ยนแปลงเนื้อหาหรือมีการอัปเดตโมเดล ซึ่งเพิ่มภาระงานปฏิบัติการอย่างต่อเนื่อง |
| ไม่ได้เชื่อมต่อกับพื้นที่ทำงานของคุณ | ระบบ AI เข้าใจภาษา แต่ไม่ได้ทำงานอยู่ในที่ที่ทีมของคุณทำงานจริง ทำให้เกิดช่องว่างระหว่างการค้นหาและการดำเนินการ |
| การสลับบริบทเป็นสิ่งที่หลีกเลี่ยงไม่ได้ | ผู้คนค้นหาข้อมูลในที่เดียว จากนั้นเปลี่ยนเครื่องมือเพื่อดำเนินการ ซึ่งส่งผลให้ประสิทธิภาพและการยอมรับลดลง |
📖 อ่านเพิ่มเติม: แม่แบบฐานความรู้ฟรีใน Word & ClickUp
วิธีใช้ ClickUp เป็นทางเลือกสำหรับการค้นหาภายในองค์กร
ณ ตอนนี้ การแลกเปลี่ยนควรชัดเจนแล้ว
การค้นหาภายในองค์กรมีประสิทธิภาพสูง แต่การสร้างระบบขึ้นมาเองหมายถึงการต้องดูแลทั้งกระบวนการนำข้อมูลเข้า กลยุทธ์การแบ่งข้อมูล การอัปเดตข้อมูลแบบฝังตรรกะ การจัดอันดับใหม่ และงานบำรุงรักษาอย่างต่อเนื่อง ทั้งหมดนี้คือการลงทุนด้านโครงสร้างพื้นฐานระยะยาว ไม่ใช่แค่การเปิดตัวฟีเจอร์ใหม่
ในฐานะที่เป็นพื้นที่ทำงานแบบรวม AI แห่งแรกของโลกClickUpได้ขจัดชั้นการทำงานนั้นออกไปทั้งหมดด้วยการทำให้การค้นหาด้วย AI เป็นฟีเจอร์พื้นฐานในตัวพื้นที่ทำงานเอง
เรื่องนี้สำคัญเพราะปัญหาการค้นหาส่วนใหญ่ไม่ใช่ปัญหาการค้นหาจริงๆ แต่เป็นปัญหาการขยายงานที่ไม่มีประสิทธิภาพ เมื่องานกระจัดกระจายอยู่ในเครื่องมือที่แยกจากกัน ทีมงานจะถูกบังคับให้ต้องค้นหาบริบทอยู่ตลอดเวลา ผลลัพธ์คือเวลาที่สูญเสียไป ความพยายามที่ซ้ำซ้อน และการตัดสินใจที่ขาดข้อมูลครบถ้วน
ClickUp แก้ไขปัญหาที่ต้นตอโดยการรวมงาน, บริบท, และข้อมูลเชิงลึกไว้ในที่ทำงานเดียว. มาดูกันว่ามันทำงานอย่างไรในทางปฏิบัติ.
รับคำตอบที่เข้าใจบริบทจากทั่วทั้งพื้นที่ทำงานด้วย ClickUp Brain
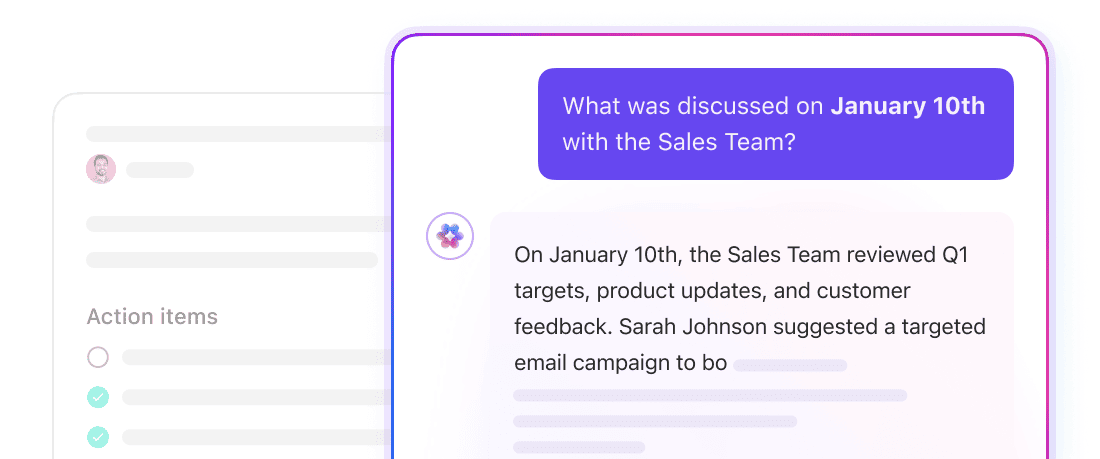
ClickUp Brainเป็นชั้น AI ที่ทำงานตามบริบทซึ่งทำงานข้ามพื้นที่ทำงานทั้งหมดของคุณ สามารถตอบคำถาม สรุปข้อมูล และแสดงงานที่เกี่ยวข้องได้ เนื่องจากสามารถเข้าถึงโครงสร้างพื้นฐานของพื้นที่ทำงานของคุณได้อยู่แล้ว:งานใน ClickUp เอกสารใน ClickUp ความคิดเห็นใน ClickUp และอื่นๆ อีกมากมาย
ไม่จำเป็นต้องกำหนดขนาดของข้อมูลหรือจัดการการฝังข้อมูลที่นี่ Brain ใช้โมเดลข้อมูลพื้นฐานของ ClickUp เพื่อทำความเข้าใจว่าข้อมูลเชื่อมโยงกันอย่างไร ถามคำถามเช่น "อะไรกำลังขัดขวางการเปิดตัว Q4?" และ Brain สามารถดึงบริบทจากงาน ความคิดเห็น และเอกสารที่เชื่อมโยงกับโครงการนั้นได้
ClickUp Brain ยังรองรับโมเดล AI หลายแบบอยู่เบื้องหลัง ทำให้คุณสามารถใช้คำขอที่แตกต่างกันกับโมเดลที่เหมาะสมที่สุดสำหรับการให้เหตุผล การสรุป หรือการสร้างเนื้อหาได้ ซึ่งช่วยหลีกเลี่ยงการจำกัดเวิร์กโฟลว์ของคุณให้อยู่ภายใต้จุดแข็งหรือข้อจำกัดของโมเดลเดียว
เมื่อคุณต้องการบริบทภายนอก Brain สามารถทำการค้นหาเว็บได้โดยตรงจากพื้นที่ทำงาน โดยจะแสดงผลลัพธ์ที่สรุปไว้โดยไม่ต้องออกจาก ClickUp หรือเปิดแท็บเบราว์เซอร์แยกต่างหาก
ค้นหา, นำทาง, และดำเนินการด้วย ClickUp Enterprise Search
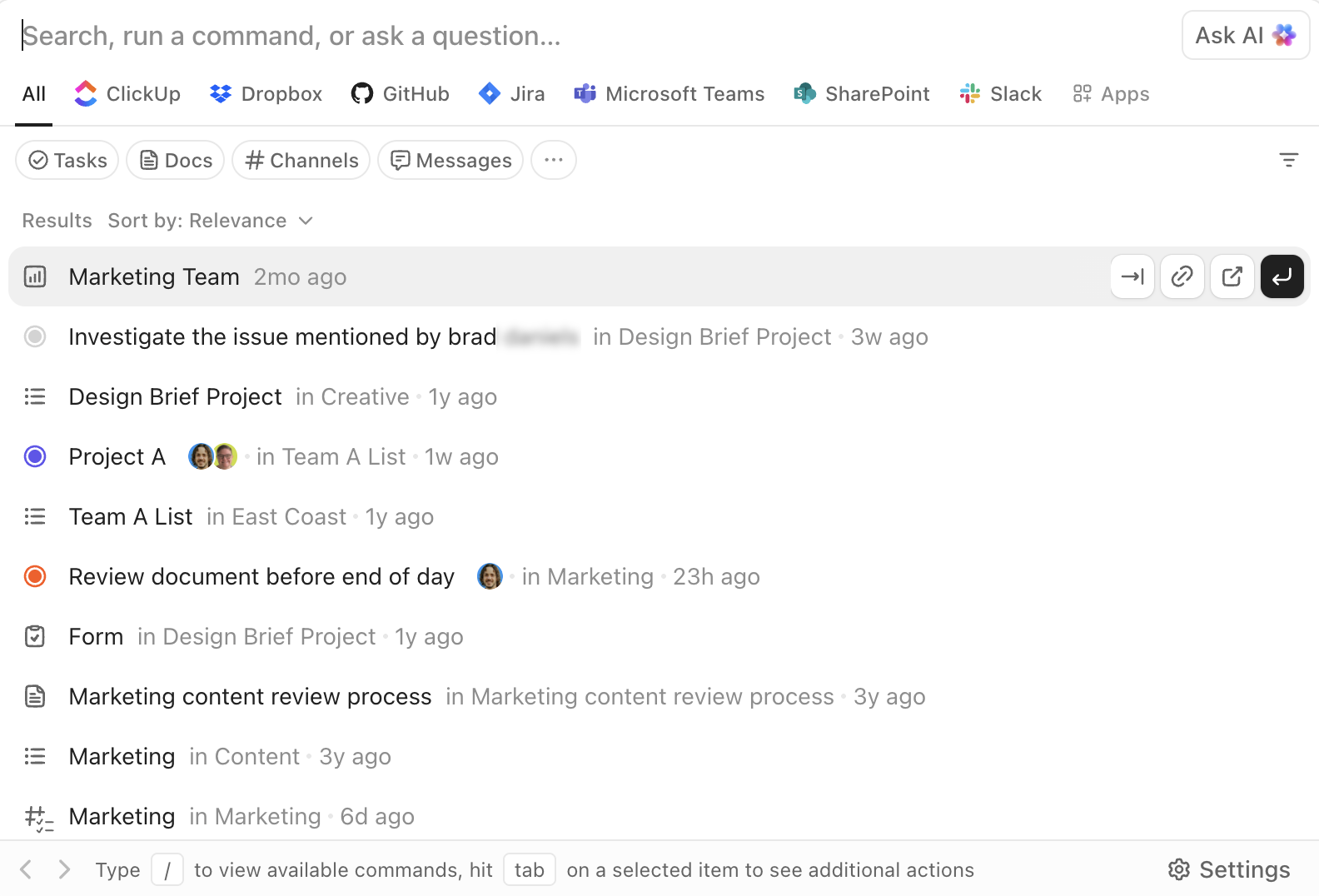
การค้นหาแบบองค์กรของ ClickUpสามารถเข้าถึงได้จากทุกที่ในพื้นที่ทำงาน ช่วยให้คุณสามารถค้นหาข้ามงาน เอกสาร ความคิดเห็น และไฟล์แนบ รวมถึงแอปของบุคคลที่สามที่เชื่อมต่อ เช่น Google Drive, Slack, GitHub และอื่นๆ ขึ้นอยู่กับการเชื่อมต่อของคุณ
แถบคำสั่ง AIเปลี่ยนการค้นหาให้กลายเป็นชั้นการดำเนินการ คุณสามารถกระโดดไปยังรายการ สร้างงาน เปลี่ยนสถานะ มอบหมายเจ้าของ หรือเปิดมุมมองเฉพาะได้โดยตรงจากอินเทอร์เฟซเดียวกัน นี่ไม่ใช่แค่ "ค้นหาและอ่าน" แต่เป็น "ค้นหาและดำเนินการ"
เนื่องจากการค้นหาถูกฝังอยู่ในส่วนติดต่อผู้ใช้ของพื้นที่ทำงาน ผลลัพธ์จึงสามารถดำเนินการได้เสมอ คุณไม่ต้องดึงข้อมูลออกมาแยกต่างหากแล้วเปลี่ยนเครื่องมือเพื่อใช้งาน ขั้นตอนการทำงานจะดำเนินต่อไปในจุดเดิม
ลดความซับซ้อนของเครื่องมือด้วย ClickUp BrainGPT
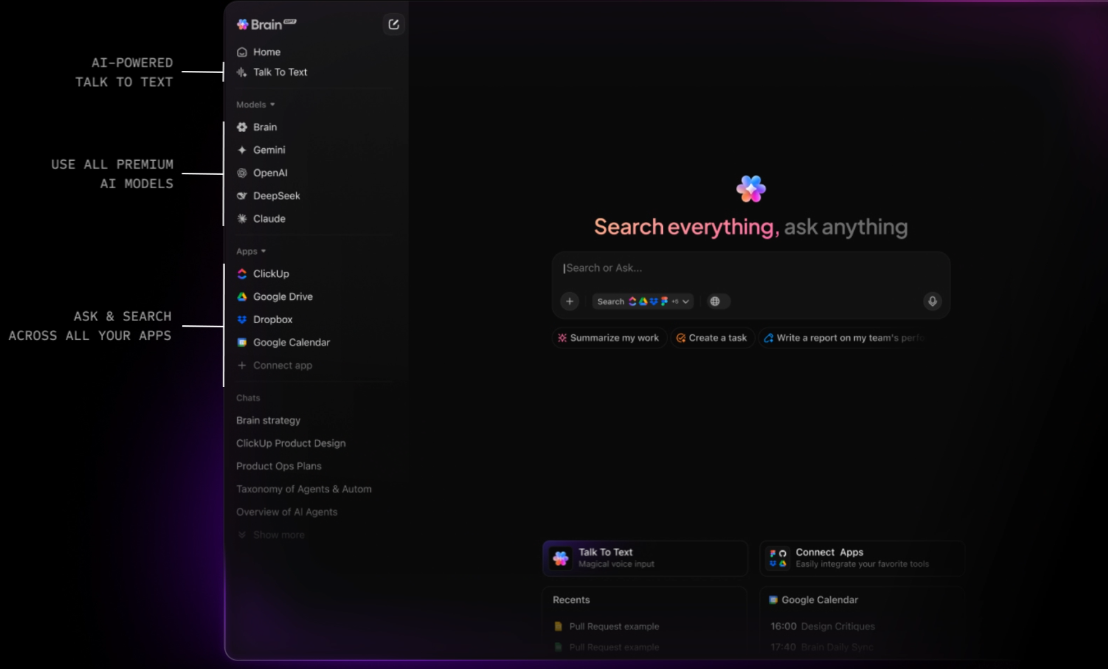
ClickUp BrainGPTขยายขีดความสามารถในการค้นหาให้เหนือกว่าเบราว์เซอร์ ด้วยแอปพลิเคชันเดสก์ท็อปแบบสแตนด์อโลนและส่วนขยายสำหรับ Chrome โดยเชื่อมต่อโดยตรงกับ Workspace ของคุณและแสดงข้อมูลเชิงบริบทเดียวกันโดยไม่ต้องเปิด ClickUp หรือแอปที่เชื่อมต่ออื่น ๆ ก่อน
จากอินเทอร์เฟซเดียว คุณสามารถค้นหางาน เอกสาร ความคิดเห็น และเครื่องมือที่เชื่อมต่อ รวมถึง Gmail และการผสานรวมอื่นๆ ฟีเจอร์Talk-to-Textที่ใช้เสียงช่วยให้คุณออกคำสั่งค้นหาหรือจับคำถามได้ทันที ซึ่งเป็นประโยชน์อย่างยิ่งสำหรับการค้นหาอย่างรวดเร็วหรือการทำงานขณะเดินทาง
แทนที่จะเพิ่มผลิตภัณฑ์ค้นหา AI อีกตัวเพื่อจัดการ Brain GPT ได้รวมการค้นพบไว้ในพื้นผิวเดียวที่เข้าใจงานของคุณอยู่แล้ว
นั่นคือการเปลี่ยนแปลงที่แท้จริง ClickUp ไม่ได้ขอให้คุณสร้างระบบค้นหาสำหรับองค์กร พื้นที่ทำงานแบบรวมศูนย์นี้ฝังระบบค้นหาไว้โดยตรงในระบบที่งานเกิดขึ้น ช่วยลดภาระโครงสร้างพื้นฐานในขณะที่ยังคงรักษาประสิทธิภาพ ความแม่นยำ และความเร็ว
📖 อ่านเพิ่มเติม: ตัวอย่างระบบบริหารจัดการความรู้ชั้นนำ
โบนัส: การเปรียบเทียบเชิงกลยุทธ์ระหว่างการปรับแต่งระบบตามความต้องการกับ AI สำหรับพื้นที่ทำงานแบบเนทีฟ
| ค่านิยมหลัก | ความยืดหยุ่นสูงสุด; การควบคุมที่เป็นกรรมสิทธิ์ | พร้อมใช้งานทันที; รู้บริบทโดยอัตโนมัติ |
| การดำเนินการ | เดือน: ต้องการทีมวิศวกรรมในการสร้างระบบท่อ | บันทึกการประชุม: สลับการใช้งานได้ด้วยการคลิกเพียงครั้งเดียวสำหรับทั้งพื้นที่ทำงาน |
| การนำเข้าข้อมูล | คู่มือ: คุณต้องสร้างและดูแลฐานข้อมูล ETL และเวกเตอร์ | อัตโนมัติ: เข้าถึงงาน เอกสาร และการแชทแบบเรียลไทม์ |
| ตรรกะการอนุญาต | ต้องทำการเข้ารหัสด้วยตนเอง (มีความเสี่ยงสูงต่อการรั่วไหลของข้อมูล) | สืบทอดมาโดยตรงจากลำดับชั้นของ ClickUp ของคุณ |
| ความลึกเชิงบริบท | เชิงความหมาย (อิงตามความหมาย) | การปฏิบัติการ (รู้ว่าใครได้รับมอบหมายให้ทำอะไร) |
| ส่วนติดต่อผู้ใช้ | คุณต้องออกแบบและสร้างแถบค้นหา/แชท | ในตัว (แถบค้นหา, เอกสาร และมุมมองงาน) |
| การดำเนินการตามขั้นตอนการทำงาน | ไม่มี: ผู้ใช้ค้นหาข้อมูล จากนั้นเปลี่ยนเครื่องมือเพื่อทำงาน | สูง: ค้นหาข้อมูลและแปลงเป็นงานได้ทันที |
| เหมาะที่สุดสำหรับ | บริษัทที่มีเทคโนโลยีสูงซึ่งพัฒนาซอฟต์แวร์ที่เป็นกรรมสิทธิ์ | ทีมที่ต้องการกำจัด "การกระจายเครื่องมือ" และดำเนินการอย่างรวดเร็ว |
การค้นหาไม่ควรเป็นอุปสรรคสำหรับคุณ!
การค้นหาเชิงความหมายไม่ใช่ตัวสร้างความแตกต่างอีกต่อไป มันเป็นเพียงมาตรฐานพื้นฐานเท่านั้น
ต้นทุนที่แท้จริงของการค้นหาในองค์กรปรากฏให้เห็นในทุกที่: เวลาของวิศวกรที่ใช้ในการสร้างและบำรุงรักษา, โครงสร้างพื้นฐานที่จำเป็นเพื่อให้มันถูกต้องแม่นยำ, และแรงเสียดทานที่เกิดขึ้นเมื่อการค้นหาอยู่นอกเครื่องมือที่งานจริงๆ เกิดขึ้น การค้นหาเอกสารที่ถูกต้องไม่มีความสำคัญมากนักหากการดำเนินการตามเอกสารนั้นยังคงต้องเปลี่ยนระบบ
นั่นคือเหตุผลว่าทำไมปัญหาไม่ใช่แค่ "การค้นหาที่ดีขึ้น" แต่เป็นการกำจัดช่องว่างระหว่างข้อมูลกับการดำเนินการ
เมื่อการค้นหาถูกฝังไว้โดยตรงในพื้นที่ทำงาน บริบทจะถูกเก็บรักษาไว้โดยอัตโนมัติ คำตอบไม่ได้ถูกดึงมาเพียงอย่างเดียว แต่สามารถนำไปใช้ได้ทันที งานสามารถอัปเดตได้ การตัดสินใจสามารถบันทึกไว้เป็นเอกสาร และงานสามารถดำเนินต่อไปได้โดยไม่ต้องสร้างการส่งต่อข้อมูลเพิ่มเติม
สำหรับทีมที่ไม่ต้องการใช้เวลาหลายเดือนในการสร้างและบำรุงรักษาโครงสร้างพื้นฐานการค้นหาแบบกำหนดเอง การทำงานในพื้นที่ทำงาน AI แบบรวมศูนย์จะเปลี่ยนสมการทั้งหมด ClickUp มอบการค้นหาที่ขับเคลื่อนด้วย AI ระดับองค์กรเป็นส่วนหนึ่งของระบบที่ทีมของคุณใช้อยู่แล้วในการวางแผน ร่วมมือ และดำเนินการ
คำถามที่พบบ่อย
Cohere มุ่งเน้นเฉพาะกรณีการใช้งานในระดับองค์กร เช่น การค้นหา โดยนำเสนอโมเดลอย่าง Embed และ Rerank ที่ออกแบบมาโดยเฉพาะสำหรับงานการค้นหาข้อมูล OpenAI ให้บริการโมเดลที่กว้างกว่าและใช้ได้กับงานทั่วไป ซึ่งสามารถปรับใช้กับการค้นหาได้แต่อาจต้องมีการปรับแต่งเพิ่มเติม
ใช่ Cohere มี API ที่ช่วยให้สามารถผสานการทำงานกับเครื่องมืออื่น ๆ ได้ อย่างไรก็ตาม การดำเนินการนี้จำเป็นต้องมีการพัฒนาและใช้ทรัพยากรด้านวิศวกรรมแบบกำหนดเอง ทางเลือกอย่าง ClickUp มีฟีเจอร์ค้นหาด้วย AI ในตัวที่สามารถใช้งานได้ทันทีโดยไม่ต้องติดตั้งหรือผสานระบบเพิ่มเติม
อุตสาหกรรมที่มีคลังเอกสารขนาดใหญ่และไม่มีโครงสร้าง เช่น อุตสาหกรรมกฎหมาย การดูแลสุขภาพ บริการทางการเงิน และเทคโนโลยี ได้รับประโยชน์สูงสุดจากการค้นหาเชิงความหมาย องค์กรใดก็ตามที่กำลังประสบปัญหาในการจัดการความรู้สามารถเห็นการปรับปรุงที่สำคัญได้