
De flesta team ser på SQL-generering som ett trolleritrick. Du skriver in en fråga och får en fråga.
Men så här ser verkligheten ut: Snowflake Cortex Analyst fungerar bara så bra som den semantiska modell du bygger först, och den konfigurationen är inte trivial. Genom att lära sig hur man använder Snowflake Cortex för SQL-generering kan datateam nu omvandla naturligt språk till komplexa, körbara frågor på några sekunder.
Den här guiden leder dig genom den faktiska implementeringsprocessen, från att definiera din semantiska YAML-modell till att göra frågor i ditt datalager med hjälp av naturligt språk, så att du förstår både kraften och förutsättningarna innan du börjar.
Vi tittar också på var Snowflake Cortex har sina brister och hur ClickUp kan stödja de bredare arbetsflödena kring SQL-generering.
Vad är Snowflake Cortex Analyst?
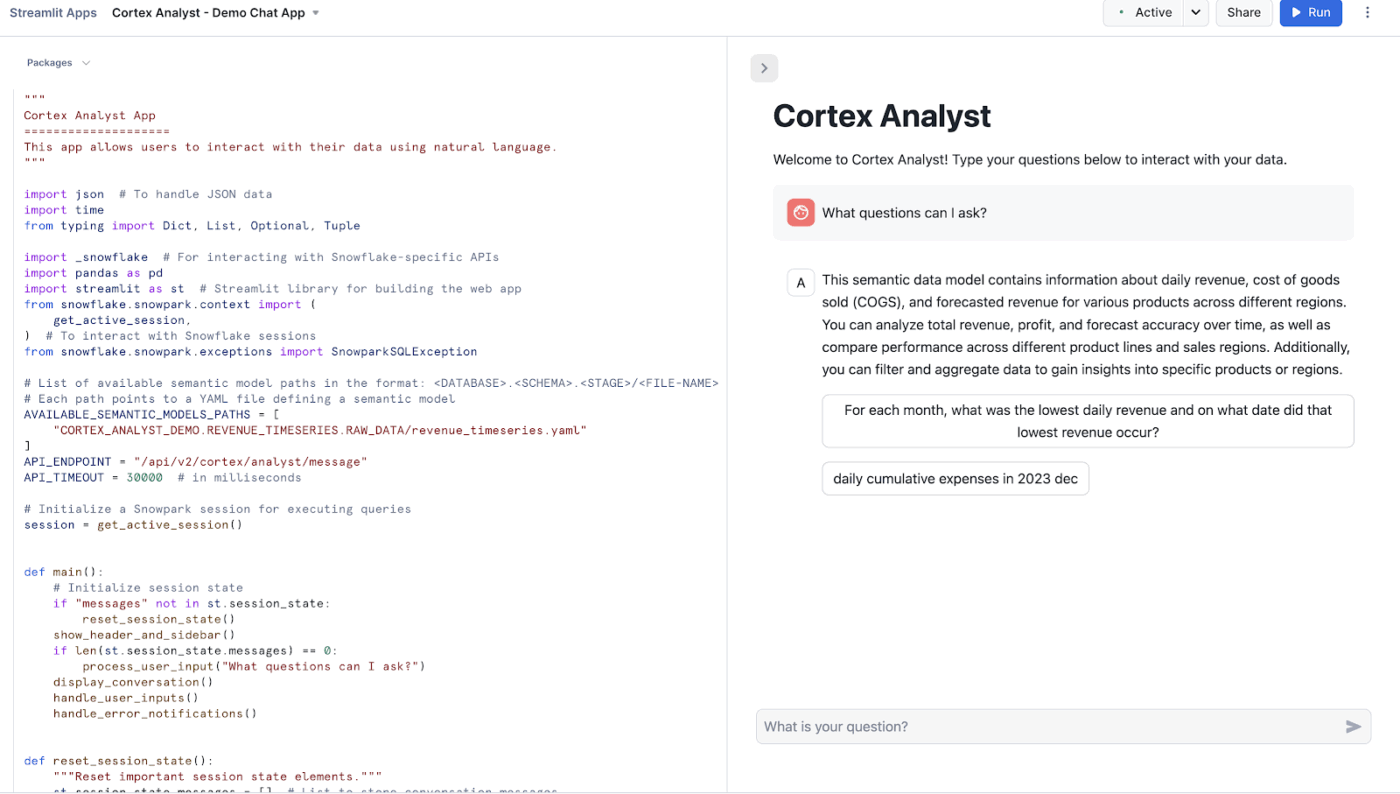
Snowflake Cortex Analyst är en helt hanterad tjänst som gör det möjligt för dig att bygga konversationsapplikationer baserade på dina analysdata.
Den använder en specialiserad text-till-SQL-agent för att omvandla frågor i naturligt språk till exakta, körbara frågor. Denna tjänst överbryggar klyftan mellan komplexa datastrukturer och affärsanvändare som behöver svar utan att skriva kod.
Viktiga funktioner inkluderar:
- Tillhandahåller ett gränssnitt med hög precision för interaktion med strukturerade data
- Använda semantiska modeller för att förstå din specifika affärslogik och terminologi
- Erbjuder ett REST-API för enkel integration i anpassade applikationer eller BI-verktyg
- Upprätthåll dataintegriteten genom att behandla förfrågningar inom Snowflakes säkerhetsgränser
📮 ClickUp Insight: 88 % av de som svarade på vår undersökning använder AI för sina personliga uppgifter, men över 50 % drar sig för att använda det på jobbet. De tre största hindren? Brist på smidig integration, kunskapsluckor eller säkerhetsfarhågor.
Men vad händer om AI är inbyggt i din arbetsyta och redan är säkert? ClickUp Brain, ClickUps inbyggda AI-assistent, gör detta till verklighet. Den förstår uppmaningar i vanligt språk och löser alla tre problem som kan uppstå vid införandet av AI samtidigt som den kopplar samman din chatt, dina uppgifter, dokument och kunskap över hela arbetsytan.
Hitta svar och insikter med ett enda klick!
Förutsättningar för Snowflake Cortex SQL-generering
Att kasta sig in i Snowflake Cortex utan rätt konfiguration leder till frustration. Du kan få felaktiga resultat, slösa tid på felsökning och felaktigt dra slutsatsen att verktyget inte fungerar när det egentliga problemet är en svag grund.
För att undvika detta måste du först se till att tre grundläggande element finns på plats.
1. Konfigurera din databas och dina tabeller
Din AI är bara så smart som de data den har tillgång till. Om ditt databasschema är en labyrint av kryptiska kolumnnamn som cust_dat_v2_final kommer både dina analytiker och AI:n att ha svårt att förstå det.
Denna förvirring leder till att AI:n genererar felaktiga sammanfogningar eller hämtar data från fel kolumner, och ditt team slösar bort timmar på att försöka tolka schemat innan de ens kan skriva en fråga.
Börja med att se till att din datalagringsprogramvara innehåller de tabeller som du vill att Cortex Analyst ska söka i. Använd tydliga, beskrivande kolumnnamn när det är möjligt. Till exempel är en kolumn med namnet customer_lifetime_value mycket mer intuitivt för både människor och AI än clv_01.
För att fortsätta med konfigurationen behöver din Snowflake-roll följande behörigheter:
- ANVÄNDNING: I databasen och schemat som innehåller dina tabeller
- SELECT: På de tabeller som du vill att Cortex Analyst ska söka i
- CREATE STAGE: I schemat, vilket krävs för att ladda upp din semantiska modellfil
2. Skapa din semantiska modellfil
Det största hindret med alla text-till-SQL-verktyg är att AI:n inte talar ditt företags unika språk. Den vet inte automatiskt att ”ARR” betyder ”Annual Recurring Revenue” eller att din kundtabell kopplas samman med din ordertabell via fältet customer_id.
Utan detta sammanhang kan AI:n generera SQL som är tekniskt giltig men logiskt felaktig, vilket ger dig svar som ser korrekta ut men som är farligt missvisande.
Den semantiska modellen är lösningen. Det är en YAML-fil som fungerar som ditt anpassade ”översättningslager” och lär Cortex Analyst det specifika vokabuläret och logiken i din verksamhet. Att bygga och underhålla denna fil är ett samarbete mellan dataingenjörer som använder ETL-verktyg för att förstå schemat och affärsanalytiker som känner till terminologin.
Din semantiska modellfil bör innehålla följande nyckelkomponenter:
| Komponent | Syfte |
| Tabeller | Visar varje tabell med en beskrivning i klartext av dess syfte |
| Kolumner | Definierar varje kolumns semantiska typ (t.ex. kategori eller mätvärde) och kan inkludera exempelvärden |
| Relationer | Anger hur tabeller kopplas samman genom sammanfogningar, vilket eliminerar gissningar för AI:n |
| Verifierade frågor | Innehåller exempel på frågor och motsvarande SQL-frågor som fungerar som kraftfulla guider för LLM |
3. Konfigurera Cortex Search Service (valfritt)
Ibland finns de svar du behöver gömda i ostrukturerad text, som produktbeskrivningar, supportärenden eller samtalsutskrifter. Vanliga SQL-frågor kan inte hantera dessa data, vilket innebär att du ofta missar ”varför” bakom ”vad”.
Du kan valfritt lägga till Snowflake Cortex Search Service här. Det är ett sök-som-tjänst-lager som gör att du kan söka i både dina strukturerade tabeller och dina ostrukturerade textdata med hjälp av AI-agenter för dataanalys samtidigt.
Du bör konfigurera Cortex Search om dina analytiker behöver ställa frågor som kräver att man hämtar sammanhang från text innan man genererar SQL. Du kan till exempel först söka efter alla produktrecensioner som innehåller frasen ”batteriproblem” och sedan generera en SQL-fråga för att sammanställa försäljningsdata endast för dessa produkter.
För ren SQL-generering mot strukturerade tabeller behövs inte den här tjänsten.
🧠 Rolig fakta: I början av 1970-talet skapade IBM-forskarna Donald Chamberlin och Raymond Boyce ”Structured English Query Language”. De var tvungna att byta namn till SQL eftersom ”SEQUEL” redan var ett registrerat varumärke hos ett brittiskt flygbolag.
Steg-för-steg-guide för att generera SQL med Cortex Analyst
Du har gjort förarbetet, men nu står du framför en tom skärm och är osäker på hur arbetsflödet egentligen ser ut. Hur går du från en fråga i huvudet till en körbar SQL-fråga? När arbetsflödeshanteringen inte är tydlig blir nya verktyg ofta oanvända, och investeringen i installationen går till spillo.
Den praktiska processen är uppfriskande enkel. Här är en närmare titt!
Steg 1: Förbered dina data i Snowflake
Innan du gör något annat måste dina strukturerade data finnas i Snowflake. Varje Cortex Analyst-applikation riktas mot antingen en enskild tabell eller en vy som består av en eller flera tabeller. Se till att dina tabeller är skapade och fyllda med data.
Om du laddar från platta filer:
- Ladda upp dina datafiler (t.ex. CSV-filer) till en Snowflake Stage
- Använd kommandot COPY INTO för att ladda data från mellanlagringen till dina tabeller
- Kontrollera att data har laddats korrekt innan du går vidare
Steg 2: Skapa en semantisk modell (eller semantisk vy)
Detta är det viktigaste steget i konfigurationen. Cortex Analyst hämtar sin kraft från kombinationen av stora språkmodeller (LLM) och semantiska modeller, en YAML-fil som finns vid sidan av ditt databasschema och kodar affärskontext.
Semantiska vyer är nu Snowflakes rekommenderade metod för Cortex Analyst. De lagrar affärsmetriker, relationer och definitioner direkt i Snowflake. Äldre YAML-filer för semantiska modeller fungerar fortfarande, men Snowflake riktar nya implementeringar mot semantiska vyer.
Din semantiska modell eller vy bör innehålla:
- Tabell- och kolumnbeskrivningar: Förklaringar i klartext om vad varje fält betyder
- Affärsmetriker: Definitioner för beräknade fält som intäkter, kundbortfall eller konverteringsgrad
- Filter och synonymer: Alternativa termer som användare kan använda (t.ex. ”avbokad” kopplat till ett specifikt statusvärde)
- Verifierade frågor: Snowflakes Verified Query Repository lagrar godkända par av frågor och SQL-koder. När en användarfråga liknar en av dessa poster kan Cortex Analyst hänvisa till den under SQL-genereringen
🤝 Vänlig påminnelse: Snowflake rekommenderar att du använder högst 10 tabeller och högst 50 valda kolumner för optimal prestanda i Snowsight-arbetsflödet.
Steg 3: Ladda upp den semantiska modellen till en Snowflake-stage
Om du använder en YAML-baserad semantisk modell måste den förberedas så att Cortex Analyst kan referera till den vid körning.
- Ladda upp din .yaml-fil till en intern Snowflake-etapp (t.ex. RAW_DATA)
- Kontrollera att filen visas i scenen via Snowsight-gränssnittet eller kommandot LIST @stage_name
- Notera stegvägen; du kommer att referera till den i dina API-anrop eller appkonfiguration
Om du använder en Semantic View hanteras detta steg direkt i Snowflake, och ingen separat uppladdning behövs.
🔍 Visste du att? NULL i SQL betyder inte noll eller tomt. Det representerar okända eller saknade data, vilket leder till ointuitivt beteende som jämförelser som varken returnerar sant eller falskt.
Steg 4: Skicka en fråga på naturligt språk via REST API
Nu börjar själva SQL-genereringen. REST-API:et genererar en SQL-fråga för en given fråga med hjälp av en semantisk modell eller semantisk vy som tillhandahålls i begäran.
Strukturera din API-förfrågan med:
- meddelanden; en matris som innehåller din användarfråga med rollen: ”användare”
- En referens till din semantiska modell eller semantiska vy
- Din föredragna modell (eller låt den stå på auto så att Cortex väljer den bästa)
Du kan föra konversationer i flera steg där du kan ställa uppföljningsfrågor som bygger vidare på tidigare frågor.
Steg 5: Analysera API-svaret
Varje meddelande i ett svar kan innehålla flera innehållsblock av olika typer. Tre värden som för närvarande stöds för fältet type är: text, suggestions och SQL.
Här är vad varje typ betyder:
- SQL: Cortex har genererat en fråga; detta är vad du kommer att köra
- text: En förklaring eller ett svar på naturligt språk som åtföljer SQL-frågan
- förslag: Innehållstypen ”förslag” ingår endast i ett svar om användarens fråga var tvetydig och Cortex Analyst inte kunde returnera ett SQL-uttryck för den frågan. Använd dessa för att förtydliga eller förfina frågan
🔍 Visste du att? Ordningen du skriver SQL i är inte samma som den körs i. Även om du skriver SELECT först, bearbetar databaser faktiskt FROM och WHERE innan de väljer kolumner. Detta förvirrar både nybörjare och erfarna användare.
Steg 6: Kör den genererade SQL-koden i Snowflake
När du har fått SQL-blocket från svaret kör du det mot ditt virtuella Snowflake-lager. Den genererade SQL-frågan körs i ditt virtuella Snowflake-lager för att generera det slutliga resultatet. Data stannar inom Snowflakes styrningsgränser.
Viktiga saker att känna till vid körning:
- Cortex Analyst integreras fullt ut med Snowflakes policyer för rollbaserad åtkomstkontroll (RBAC), vilket säkerställer att genererade och utförda SQL-frågor följer alla fastställda åtkomstkontroller
- Om en användare saknar åtkomst till en tabell kommer frågan att misslyckas vid körning, precis som det skulle göra med handskriven SQL
- I detta skede tillkommer kostnader för datalagring, utöver Cortex Analyst:s egna användningsavgifter.
Steg 7: Förfina och iterera
Det är inte alltid garanterat att du får en perfekt fråga på första försöket. Så här förbättrar du resultaten över tid:
- Lägg till verifierade frågor i din semantiska modell för frågor som återkommer ofta
- Berika din semantiska modell med bättre beskrivningar, synonymer och filter när Cortex misstolkar ett begrepp
- Använd flerrundiga konversationer för att följa upp, till exempel ”Filtrera nu efter region”. Flerrundiga konversationer möjliggör uppföljningsfrågor som bygger vidare på tidigare frågor.
- Övervaka användningen via CORTEX_ANALYST_USAGE_HISTORY och Snowflakes sökhistorik för att upptäcka mönster i misslyckade eller felaktiga sökningar
🧠 Rolig fakta: En enda saknad JOIN-villkor kan orsaka enorma problem. Om man glömmer ett JOIN-villkor kan det leda till ett kartesiskt produkt, vilket dramatiskt multiplicerar antalet rader och ibland får systemet att krascha.
Bästa praxis för noggrannhet i Snowflake Text-to-SQL
Kvaliteten på din semantiska modell avgör direkt noggrannheten hos de frågor den genererar. Här är de bästa metoderna för att förbättra noggrannheten. 🛠️
- Lägg till verifierade frågor i din semantiska modell: Det här är det mest effektiva du kan göra. Inkludera många exempel på frågor och motsvarande SQL-frågor som speglar hur ditt team faktiskt ställer frågor
- Använd beskrivande kolumn- och tabellnamn: Modellen fungerar bättre när kolumn- och tabellnamnen är självförklarande. Om du inte kan ändra schemat, lägg till tydliga beskrivningar i din YAML-fil för eventuella kryptiska kolumnnamn
- Inkludera exempelvärden: Att lägga till exempeldata för kategoriska kolumner (som status eller region) hjälper modellen att förstå vilka giltiga filteralternativ som finns tillgängliga
- Testa med gränsfall: Ställ medvetet tvetydiga eller knepiga frågor under utvecklingen för att identifiera var din semantiska modell behöver mer sammanhang eller förtydligande
- Utveckla din semantiska modell: Betrakta din semantiska modell som ett levande dokument. Den bör uppdateras kontinuerligt genom en iterativ process baserad på vilka frågor som lyckas och vilka som misslyckas
ClickUp: Ett enklare alternativ till Snowflake Cortex
Snowflake Cortex fungerar bra när team vill generera SQL och köra frågor på strukturerade data. Team definierar scheman, kartlägger relationer och skriver frågor för att extrahera insikter. Denna konfiguration är lämplig för datatunga miljöer, särskilt när analytiker ansvarar för rapporteringen.
Många team behöver dock inte ett fullständigt SQL-lager för att besvara dagliga operativa frågor. Produktchefer, programledare och driftsteam vill ofta ha snabba svar kopplade till det pågående arbetet.
ClickUp erbjuder en mer tillgänglig väg. Team ställer frågor i klarspråk, granskar realtidsdashboards och agerar på insikter utan att skriva SQL eller bygga semantiska modeller.
Skapa och finjustera SQL snabbare
Snowflake Cortex fokuserar på att generera SQL-frågor från strukturerade datamängder i en datalagringsmiljö. Det fungerar bra när dina data redan finns i Snowflake och du har scheman utformade.

ClickUp Brain stöder SQL-generering på ett mer flexibelt och exekveringsinriktat sätt. Team genererar, förfinar och lagrar SQL-frågor direkt i sin arbetsyta där analys, diskussioner och beslut redan sker.
Anta att en produktanalytiker arbetar med en analys av kundlojalitet i ClickUp. Istället för att byta verktyg för att skriva frågor frågar de ClickUp Brain:
📌 Prova följande uppmaning: Skriv en SQL-fråga för att beräkna sju dagars retention för användare grupperade efter registreringskohort.
ClickUp Brain genererar en strukturerad fråga som inkluderar kohortgruppering, datumfilter och retentionlogik. Analytikern klistrar in frågan i Snowflake eller ett annat datalager och kör den omedelbart.
Det hjälper till att:
- Skriv sammanfogningar över flera tabeller, till exempel användare, order och händelser
- Omvandla produktfrågor på vanlig engelska till SQL-logik som är redo att köras
- Felsök trasiga frågor och förklara problem, till exempel felaktiga sammanfogningar eller saknade villkor
- Skriv om frågor för bättre prestanda eller läsbarhet
Till exempel, under en granskning av ett tillväxtexperiment, frågar en marknadsförare: ”Skriv en SQL-fråga för att jämföra konverteringsgraden mellan två landningssidor under de senaste 14 dagarna”.
ClickUp Brain genererar frågan med hjälp av villkorlig aggregering och datumfilter. Teamet kör den i Snowflake och validerar experimentresultaten.
📌 Prova denna prompt: Rätta till denna SQL-fråga där join-operationen duplicerar rader och förklara problemet.
ClickUp Brain identifierar sammanfogningsproblemet, korrigerar frågan och förklarar hur dubbla rader uppstod på grund av felaktiga sammanfogningsvillkor.
Ersätt SQL-driven rapportering
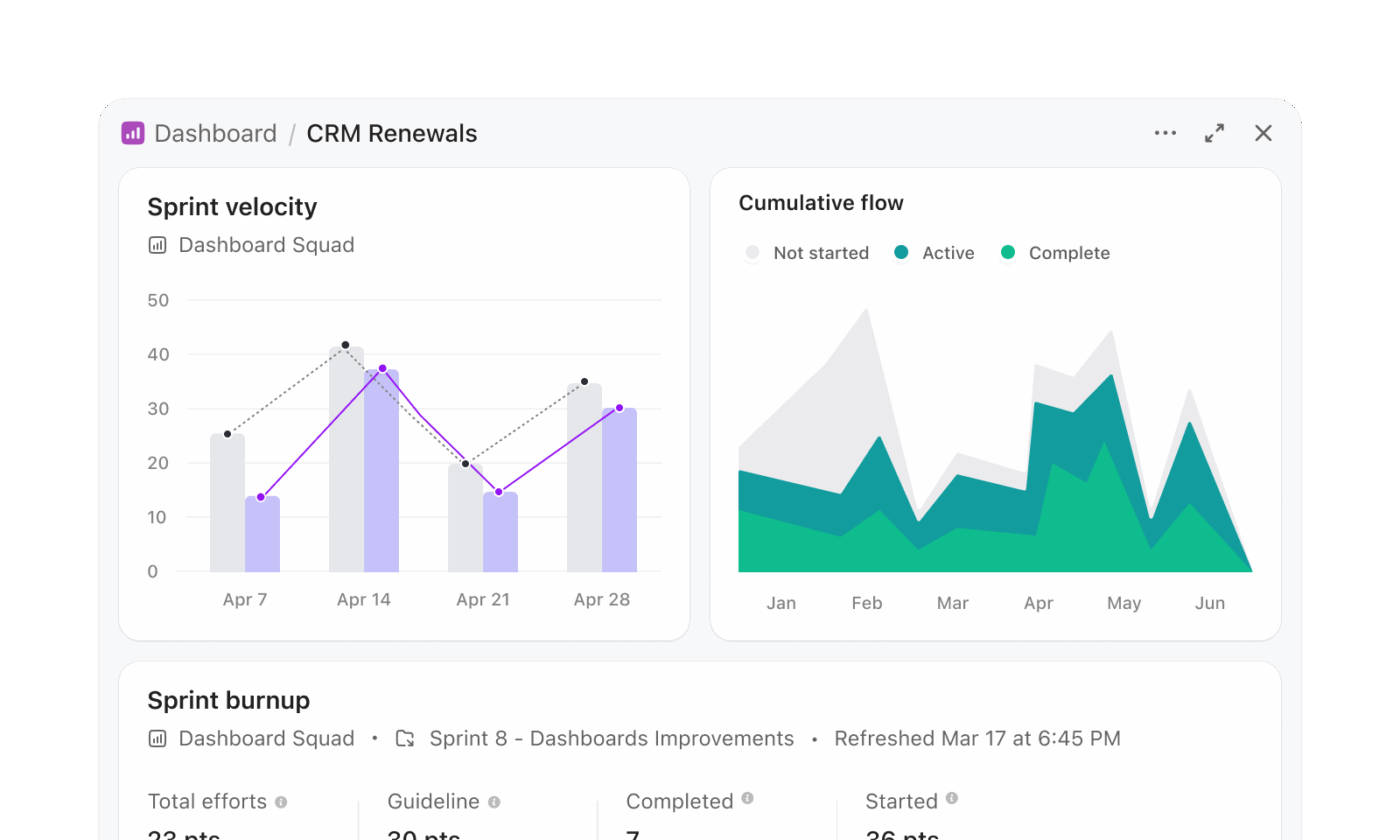
Snowflake Cortex-arbetsflöden innebär ofta att man genererar SQL, kör frågor och visualiserar resultaten i ett separat lager. ClickUp Dashboards eliminerar den flerstegsprocessen och presenterar insikter direkt från det pågående arbetet.
Ett programledningsteam som följer upp releaseberedskapen kan skapa en instrumentpanel utan att skriva frågor. En release-instrumentpanel kan till exempel innehålla:
- Ett uppgiftskort som filtrerats för att visa försenade uppgifter i alla produktteam
- Ett arbetsbelastningskort som visar uppgiftsfördelningen mellan ingenjörerna
- Ett stapeldiagram som jämför slutförda uppgifter med pågående uppgifter per sprint
- Ett beräkningskort som spårar genomsnittlig slutförandetid
Anta att en programledare granskar denna instrumentpanel inför ett release-möte. Hen ser omedelbart att backend-tjänsterna uppvisar högre fördröjningsfrekvenser. Hen öppnar kortet med uppgiftslistan och undersöker exakt vilka uppgifter som orsakar risken.
En verklig ClickUp-användare berättar:
ClickUp gör det möjligt för oss att SNABBT skicka projekt till varandra, ENKELT kontrollera projektens status och ger vår chef en inblick i vår arbetsbelastning när som helst utan att hon behöver störa oss. Vi har definitivt sparat en dag per vecka genom att använda ClickUp, om inte mer. Antalet e-postmeddelanden har MINSKAT BETYDANDE.
ClickUp gör det möjligt för oss att SNABBT skicka projekt till varandra, ENKELT kontrollera projektens status och ger vår chef en inblick i vår arbetsbelastning när som helst utan att hon behöver störa oss. Vi har definitivt sparat en dag per vecka genom att använda ClickUp, om inte mer. Antalet e-postmeddelanden har MINSKAT BETYDANDE.
Agera på insikter utan pipelines
Snowflake Cortex fokuserar på att generera insikter från data. Team måste fortfarande tolka resultaten och utlösa åtgärder separat.
ClickUp AI Super Agents överbryggar den klyftan och omvandlar insikter till handling. De fungerar som AI-teammates som kontinuerligt övervakar data i arbetsytan och vidtar åtgärder baserat på förutsättningarna.
Anta att en programchef övervakar flera produktinitiativ. En Super Agent kan:
- Övervaka uppgifter i olika projekt och upptäck när försenade uppgifter överskrider en definierad tröskel
- Identifiera mönster såsom upprepade förseningar i samma steg i arbetsflödet
- Skapa en uppgift som sammanfattar berörda projekt och tilldela den till programledaren
- Meddela teamledare när kritiska uppgifter fortfarande är olösta efter att tidsfristerna har passerat
Under en release-cykel upptäcker till exempel en Super Agent att mer än 10 uppgifter med hög prioritet har missat sina deadlines i två team. Den skapar en ClickUp-uppgift med titeln ”Release-risk: missade deadlines”, bifogar alla relevanta uppgifter och tilldelar programchefen för omedelbar granskning.
Team kan också interagera direkt med Super Agent: ”Analysera alla aktiva projekt och markera leveransrisker för denna sprint”.
Superagenten granskar deadlines, beroenden och uppgiftsstatus och publicerar sedan en strukturerad sammanfattning i arbetsytan.
Så här konfigurerar du din egen Super Agent i ClickUp:
Centralisera dina dataflöden med ClickUp
Text-till-SQL-verktyg som Snowflake Cortex gör data mer tillgängliga. Samtidigt krävs det fortfarande en del arbete för att få tillförlitliga resultat.
Team behöver tydliga scheman, starka semantiska modeller och kontinuerlig iteration för att säkerställa korrekta resultat. Arbetet slutar inte ens efter att rätt fråga har genererats. Någon måste fortfarande tolka resultaten, dela insikter och omvandla dem till beslut.
ClickUp erbjuder ett annorlunda tillvägagångssätt. Istället för att separera analys från utförande kopplar ClickUp samman båda delarna. Team genererar SQL, dokumenterar insikter, samarbetar kring resultaten och agerar på dem inom samma arbetsyta.
ClickUp Brain hjälper till att skriva och förfina frågor, medan Dashboards och AI-agenter hjälper teamen att följa upp resultat och driva arbetet framåt utan att behöva hoppa mellan olika verktyg.
Snowflake Cortex hjälper dig att få svar. ClickUp hjälper dig att göra något med dem. Registrera dig för ClickUp idag!
Vanliga frågor
Snowflake Cortex Analyst är en specialiserad tjänst inom den bredare Snowflake Cortex AI-sviten. Cortex Analyst är specifikt inriktat på text-till-SQL-generering med hjälp av semantiska modeller, medan Cortex AI omfattar ett bredare utbud av LLM-funktioner, inferens av maskininlärningsmodeller och sökfunktioner.
Ja, Cortex Analyst kan göra sökningar i Apache Iceberg-tabeller som hanteras via Snowflake. Så länge tabellerna är tillgängliga i din Snowflake-miljö och korrekt definierade i din semantiska modell kan du generera sökfrågor mot dem.
Noggrannheten för komplexa frågor beror nästan helt på kvaliteten på din semantiska modell. En modell med väldefinierade tabellrelationer, många verifierade frågor och beskrivande metadata ger betydligt mer exakta resultat för sammanfogningar av flera tabeller och komplexa aggregeringar.
Prissättningen för Snowflake Cortex Analyst följer Snowflakes konsumtionsbaserade modell, vilket innebär att du debiteras utifrån de beräkningskrediter som används under processen för generering av frågor. För de senaste priserna bör du alltid hänvisa till Snowflakes officiella prissättningsdokumentation.