
Du är säker på att dokumentet finns. Du såg det förra veckan.
Men efter att ha provat alla tänkbara kombinationer av sökord – ”marknadsföringsresultat Q3”, ”resultat tredje kvartalet”, ”marknadsföringsrapport oktober” – är ditt företags sökfält fortfarande tomt. Denna frustrerande jakt på information är ett klassiskt tecken på en föråldrad sökordsökning.
Dessa system hittar bara exakta ordmatchningar och missar det du egentligen menar. Cohere löser detta problem effektivt genom att tillhandahålla ett intelligent söklag som kopplar samman dina system.
Om du har försökt lista ut hur man använder Cohere för företagssökning har vi lösningen för dig. Den här guiden förklarar allt.
Vad är Cohere AI och varför är det viktigt för Enterprise Search?
Cohere är en AI-plattform som bygger stora språkmodeller (LLM) specifikt för företagsanvändning. För intern sökning innebär detta att man går från sökning baserad på nyckelord till semantisk, intelligent sökning som förstår avsikt, sammanhang och betydelse.
De flesta sökverktyg för företag förlitar sig fortfarande på bokstavlig sökordsmatchning. Om de exakta orden inte förekommer i dokumentets titel eller brödtext missas ofta resultatet. Cohere förändrar detta genom att göra det möjligt för söksystem att förstå vad en användare faktiskt letar efter, inte bara vad de har skrivit in.
Team som försöker bygga AI-driven sökning på egen hand brukar lägga månader på att sammanställa vektordatabaser, bädda in pipelines och omrangordna modeller. Även efter allt detta arbete presterar sökningen ofta undermåligt eftersom den finns i ett separat system från där arbetet faktiskt utförs, utan koppling till uppgifter, dokument och arbetsflöden.
Ett kraftfullt sökverktyg för företag som Cohere använder RAG (retrieval-augmented generation) för att kombinera smart sökning med AI. Denna metod förvandlar din interna kunskap till en omedelbart tillgänglig resurs.
I fallet med Cohere omvandlar verktyget dokument till inbäddningar, numeriska representationer av betydelse. När någon söker efter ”kvartalsrapport” hämtar systemet konceptuellt relevanta dokument som ”Finansiella resultat för Q4” eller ”Resultatöversikt”, även om dessa exakta nyckelord inte förekommer.
Det är därför Cohere är viktigt för företagssökning. Det minskar komplexiteten i implementeringen, förbättrar resultatens noggrannhet och möjliggör sökningar som fungerar på samma sätt som anställda faktiskt tänker och ställer frågor i moderna arbetssystem.
📮ClickUp Insight: Mer än hälften av alla anställda (57 %) slösar tid på att söka igenom interna dokument eller företagets kunskapsbas för att hitta arbetsrelaterad information.
Och när de inte kan det? 1 av 6 tar till personliga lösningar – gräver igenom gamla e-postmeddelanden, anteckningar eller skärmdumpar bara för att pussla ihop saker.
ClickUp Brain eliminerar sökningen genom att tillhandahålla omedelbara, AI-drivna svar hämtade från hela ditt arbetsområde och integrerade tredjepartsappar, så att du får det du behöver utan krångel.
Viktiga Cohere-funktioner för Enterprise Search
När du utvärderar AI-söklösningar kan marknadsföringshypen göra det svårt att avgöra vilka funktioner som faktiskt löser dina problem. Generiska löften om "smartare sökning" hjälper inte dina teknik- och produktteam att fatta välgrundade beslut.
I verkligheten är ett tillförlitligt söksystem beroende av en pipeline av olika AI-modeller som arbetar tillsammans.
Cohere erbjuder flera modeller som du kan använda separat eller kombinera för att bygga en sofistikerad sökarkitektur. Att förstå dessa kärnfunktioner är det första steget för att utforma ett system som uppfyller ditt teams specifika behov.
Bädda in för semantisk vektorsökning
Det mest frustrerande med gamla söksystem är deras oförmåga att hitta konceptuellt relaterad information. Du söker efter ”guide för nyanställda” och missar dokumentet med titeln ”Checklista för nyanställdas första dag”. Detta beror på att systemet matchar ord, inte betydelse.
Embed-modellen, med neural sökning, löser detta genom att konvertera text till vektorer – långa listor med siffror som fångar semantisk mening. Denna process, som kallas inbäddning, gör det möjligt för systemet att identifiera dokument som är konceptuellt liknande, även om de inte har några gemensamma nyckelord. I grund och botten förstår ditt sökverktyg automatiskt synonymer och relaterade idéer.
Här är de viktigaste aspekterna av Coheres inbäddningsmodell:
- Multimodal support: Den senaste versionen, Embed 4, kan bearbeta både text och bilder, vilket gör att du kan söka i olika typer av innehåll samtidigt.
- Flerspråkiga funktioner: Du kan söka efter information i dokument på olika språk utan att behöva översätta dem först.
- Dimensionsalternativ: Du kan välja storleken på dina vektorer. Högre dimensioner fångar upp fler nyanser men kräver mer lagringsutrymme och processorkraft.
📖 Läs mer: Användningsfall för AI Enterprise Search
Omrankning för förbättrad relevans i resultaten
Ibland ger en sökning en lista med relevanta dokument, men det viktigaste dokumentet ligger gömt på andra sidan. Detta tvingar användarna att söka igenom resultaten, vilket slösar tid och gör att de tappar förtroendet för söksystemet.
Detta är ett rankningsproblem. Systemet hittade rätt information men lyckades inte prioritera den korrekt.
Cohere:s omrankingsmodell löser detta med en tvåstegsprocess. Först använder du en snabb hämtningsmetod (som semantisk sökning) för att samla in en stor uppsättning potentiellt relevanta dokument. Sedan skickar du listan till omrankingsmodellen, som använder en mer beräkningsintensiv cross-encoder-arkitektur för att analysera varje dokument mot din specifika sökfråga och omordna dem för maximal relevans.
Detta är särskilt användbart i situationer där precision är avgörande, till exempel när en supportagent hittar rätt svar för en kund eller en teammedlem söker efter ett specifikt avsnitt i ett dokument. Även om det ökar bearbetningstiden något, är förbättringen av resultatets kvalitet ofta värd kompromissen.
Användningsfall för Enterprise Search för team
Abstrakta AI-funktioner är intressanta, men de blir inte användbara förrän du tillämpar dem för att lösa verkliga affärsproblem. En framgångsrik implementering av företagssökning börjar med att identifiera dessa specifika problemområden. 👀
Här är några praktiska scenarier där team kan använda Cohere-driven sökning:
- Sökning i kunskapsbasen: Hjälp anställda att hitta svar i intern dokumentation, wikis, kundtjänstens kunskapsbas och standardrutiner (SOP) .
- Kundsupport: Gör det möjligt för agenter att snabbt hitta relevanta hjälp artiklar och tidigare lösningar på ärenden medan de pratar med en kund – McKinsey-analys visar 30–45 % produktivitetsökning när generativ AI tillämpas på kundtjänstarbetsflöden.
- Juridik och efterlevnad: Sök i miljontals kontrakt, policyer och regleringsdokument med semantisk förståelse för att hitta specifika klausuler eller prejudikat.
- Forskning och utveckling: Gör det möjligt för ingenjörer att hitta relevant tidigare arbete, patent och teknisk dokumentation för att undvika dubbelarbete.
- HR och onboarding: Visa relevanta policyer, utbildningsmaterial, exempel på arbetsflöden och procedurer för nyanställda så att de själva kan hitta svaren.
- Försäljningsstöd: Hjälp säljarna att hitta rätt fallstudier, konkurrensinformation och produktinformation för att avsluta affärer snabbare.
Den röda tråden är att effektiv företagssökning måste integreras i befintlig arbetsflödeshantering. En fristående sökfält räcker inte. Ditt team måste kunna hitta information och omedelbart agera på den utan att behöva byta verktyg.
🛠️ Verktygslåda: Skapa en intern hubb som ditt team faktiskt kommer att använda. ClickUps mall för kunskapsbas håller allt – från instruktioner till SOP:er – snyggt organiserat och lätt att söka, så att ingen behöver gissa var informationen finns.

Hur man konfigurerar Cohere för Enterprise Search
Att gå från att utvärdera AI-sökning till att faktiskt implementera den kan kännas skrämmande. Särskilt om ditt team är nytt inom stora språkmodeller.
Även om komplexiteten i din installation beror på din skala och befintlig teknikstack, är de grundläggande stegen för att bygga ett Cohere-drivet söksystem desamma. Detta avsnitt innehåller en praktisk genomgång som vägledning för ditt tekniska team.
Förutsättningar och API-åtkomst
Innan du skriver någon kod måste du se till att du har rätt verktyg och åtkomst. Denna initiala konfiguration hjälper till att förhindra säkerhetsproblem och hinder senare.
Här är vad du behöver för att komma igång:
- Cohere API-konto: Registrera dig på Cohere-webbplatsen för att få dina API-nycklar.
- Utvecklingsmiljö: De flesta team använder Python, men SDK:er finns tillgängliga för andra språk.
- Vektordatabas: Du behöver ett ställe att lagra dina dokumentinbäddningar, till exempel Pinecone, Weaviate, Qdrant eller en hanterad tjänst som Amazon OpenSearch.
- Dokumentkorpus: Samla det innehåll du vill göra sökbart (t.ex. PDF-filer, textfiler, databasposter).
Du kan också få tillgång till Coheres modeller via Amazon Bedrock, vilket kan förenkla fakturering och säkerhet om ditt företag redan arbetar inom AWS-ekosystemet.
Skapa inbäddningar med Cohere Embed
Nästa steg är att konvertera dina dokument till sökbara vektorer. Denna process innebär att du förbereder ditt innehåll och sedan kör det genom Cohere Embed-modellen.
Hur du förbereder dina dokument, särskilt hur du delar upp dem i mindre delar, har en enorm inverkan på sökkvaliteten. Detta kallas din chunking-strategi.
Vanliga chunkingstrategier inkluderar:
- Fast storlek på bitar: Den enklaste metoden, men den kan dela upp meningar eller idéer på ett konstigt sätt mitt i.
- Semantisk chunking: En mer avancerad metod som respekterar dokumentstrukturen, till exempel genom att dela upp i slutet av stycken eller avsnitt.
- Överlappande block: Denna metod inkluderar en liten mängd upprepad text mellan blocken för att bevara sammanhanget över gränserna.
När dina dokument har delats upp i bitar skickar du dem till Embed API i batcher för att generera vektorrepresentationer. Detta är vanligtvis en engångsprocess för dina befintliga dokument, medan nya eller uppdaterade dokument bäddas in när de skapas.
Lagra och sök vektorer
Dina nyskapade vektorer behöver ett hem. En vektordatabas är en specialiserad databas som är utformad för att lagra och söka efter inbäddningar baserat på deras likhet.
Sökprocessen fungerar så här:
- En användare skriver in en sökfråga
- Din applikation skickar frågan till samma Cohere Embed-modell för att konvertera den till en vektor.
- Denna sökvektor skickas till databasen, som hittar de mest liknande dokumentvektorerna.
- Databasen returnerar matchande dokument, som du sedan kan visa för användaren.
När du väljer en vektordatabas bör du också överväga vilken likhetsmetrik du ska använda. Kosinuslikhet är den vanligaste metoden för textbaserad sökning, men det finns andra alternativ för olika användningsfall.
| Likhetsmått | Bäst för |
|---|---|
| Kosinuslikhet | Allmän textsökning |
| Dot Product | När vektorns storlek är viktig |
| Euklidiskt avstånd | Rumsliga eller geografiska data |
Implementera omrankning för bättre resultat
För många applikationer är resultaten från din vektordatabas tillräckligt bra. Men när du behöver det absolut bästa resultatet högst upp är det smart att lägga till ett omrankningstrin.
Detta är särskilt viktigt när din sökning driver ett RAG-system, eftersom kvaliteten på det genererade svaret i hög grad beror på kvaliteten på det hämtade sammanhanget.
Omrankingsprocessen är enkel:
- Hämta en större uppsättning initiala kandidater från din vektordatabas (t.ex. de 50 bästa resultaten).
- Skicka användarens ursprungliga sökfråga och denna lista med kandidater till Cohere Rerank API.
- API:et returnerar samma lista med dokument, men omordnade utifrån en mer precis relevanspoäng.
- Visa de bästa resultaten från den omrankade listan för användaren.
För att mäta effekten av omrankningen kan du spåra offlineutvärderingsmått, såsom nDCG (Normalized Discounted Cumulative Gain) och MRR (Mean Reciprocal Rank).
💫 För en visuell översikt över implementeringen av sökfunktioner för företag, titta på denna genomgång som visar de viktigaste begreppen och praktiska överväganden:
Bästa praxis för Cohere-driven Enterprise Search
Att bygga ett söksystem är bara det första steget. Att upprätthålla och förbättra dess kvalitet över tid är det som skiljer ett framgångsrikt projekt från ett misslyckat. Om användarna har några dåliga upplevelser kommer de att förlora förtroendet och sluta använda verktyget. 🛠️
Här är några lärdomar från framgångsrika implementeringar av företagssökning:
- Börja med hybridsökning: Förlita dig inte enbart på semantisk sökning. Kombinera den med en traditionell algoritm för sökning efter nyckelord, till exempel BM25. På så sätt får du det bästa av två världar – semantisk sökning hittar konceptuellt relaterade objekt, medan sökning efter nyckelord säkerställer att du fortfarande kan hitta exakta matchningar för produktkoder eller specifika namn.
- Investera i datahygien och kvalitet: Dina sökresultat kan bara bli så bra som dina data. Rena, välstrukturerade dokument med tydliga rubriker och stycken ger mycket bättre inbäddningar.
- Dela upp på ett genomtänkt sätt: Hur du delar upp dina dokument i delar är avgörande. Istället för att använda godtyckliga teckenbegränsningar, försök att anpassa delarna efter dokumentens logiska struktur, till exempel stycken eller avsnitt.
- Lägg till metadatafiltrering: Semantisk sökning är kraftfullt, men ibland vet användarna redan vad de letar efter. Låt dem filtrera resultaten efter metadata som datum, avdelning eller dokumenttyp innan den semantiska sökningen startar.
- Övervaka och iterera: Var uppmärksam på vad dina användare söker efter, vilka resultat de klickar på och vilka sökningar som inte ger några resultat. Dessa data är guld värda för att identifiera luckor i innehållet och förbättra ditt system.
- Hantera fel på ett elegant sätt: Inget söksystem är perfekt. När en sökning ger dåliga resultat, ge användbara alternativ, till exempel genom att föreslå alternativa sökfrågor eller erbjuda att kontakta en expert.
Begränsningar för Cohere för Enterprise Search
Cohere tillhandahåller kraftfulla AI-modeller, men det är inte en plug-and-play-lösning (inte exakt).
Att bygga en produktionsklar sökmotor för företag innebär stora utmaningar som teamen ofta underskattar. Det är viktigt att förstå dessa begränsningar för att kunna fatta välgrundade beslut och undvika kostsamma överraskningar längre fram.
Det största problemet är att du får en uppsättning verktyg, inte en färdig produkt. Detta innebär att ditt team ansvarar för att bygga och underhålla hela infrastrukturen kring sökning som en tjänst.
Här är några av de viktigaste begränsningarna att tänka på:
| Utmaning | Varför det blir ett problem |
|---|---|
| Kräver specialiserad expertis | Du behöver erfarna AI- och dataingenjörer för att bygga, driva och underhålla systemet. Detta är inte något som de flesta team kan sätta upp eller äga utan vidare. |
| Anpassade integrationer krävs | Modellerna ansluts inte automatiskt till dina befintliga verktyg. Varje datakälla måste anslutas och underhållas manuellt. |
| Högt löpande underhåll | Sökindex måste uppdateras kontinuerligt när innehållet ändras eller modellerna uppdateras, vilket medför kontinuerligt operativt arbete. |
| Inte ansluten till din arbetsyta | AI förstår språk, men den finns inte där ditt team faktiskt arbetar, vilket skapar en klyfta mellan sökning och utförande. |
| Kontextväxling är oundvikligt | Användarna hittar information på ett ställe och byter sedan verktyg för att agera på den, vilket minskar produktiviteten och användningen. |
Hur man använder ClickUp som ett alternativ till Enterprise Search
Vid det här laget bör avvägningen vara uppenbar.
Enterprise Search är kraftfullt, men att bygga det själv innebär att man måste hantera ingestionspipelines, chunkingstrategier, uppdateringar av inbäddningar, omrankingslogik och löpande underhåll. Det är ett långsiktigt infrastrukturåtagande, inte en funktionslansering.
Som världens första konvergerade AI-arbetsyta tar ClickUp bort hela det lagret genom att göra AI-driven sökning inbyggd i själva arbetsytan.
Detta är viktigt eftersom de flesta sökproblem egentligen inte är sökproblem. De är problem med spridda arbetsuppgifter . När arbetet är spritt över olika verktyg tvingas teamen ständigt leta efter sammanhang. Resultatet blir förlorad tid, dubbelarbete och beslut som fattas utan fullständig insyn.
ClickUp tacklar det problemet vid källan genom att sammanföra arbete, sammanhang och intelligens i ett enda arbetsutrymme. Låt oss bryta ner hur det fungerar i praktiken.
Få kontextmedvetna svar från hela arbetsytan med ClickUp Brain.
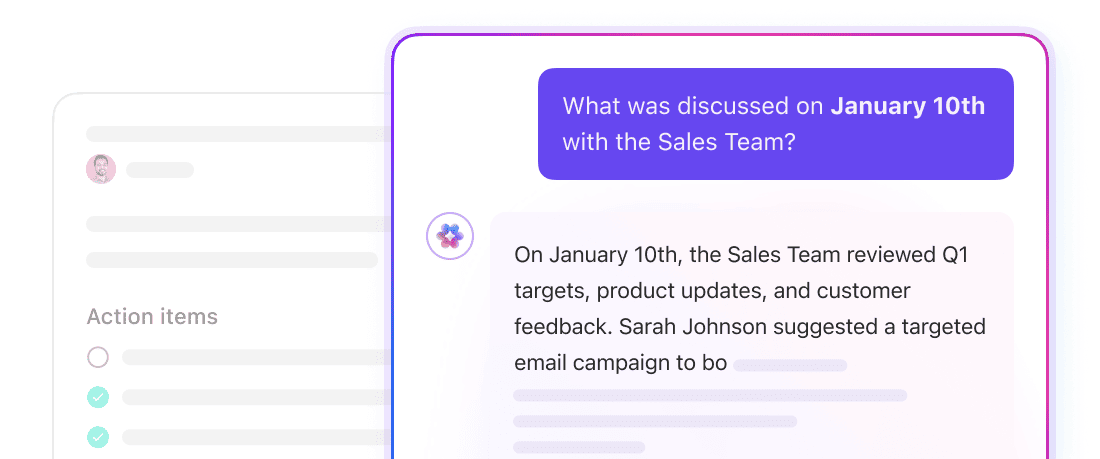
ClickUp Brain är ett kontextuellt AI-lager som fungerar i hela ditt arbetsområde. Det kan svara på frågor, sammanfatta information och visa relevant arbete eftersom det redan har tillgång till den underliggande strukturen i ditt arbetsområde: ClickUp Tasks, ClickUp Docs, ClickUp Comments och mer.
Här behöver du inte definiera chunkstorlekar eller hantera inbäddningar. Brain använder ClickUps inbyggda datamodell för att förstå hur informationen hänger ihop. Ställ en fråga som ”Vad hindrar lanseringen av Q4?” så kan Brain hämta sammanhang från uppgifter, kommentarer och dokument som är kopplade till det initiativet.
ClickUp Brain stöder också flera AI-modeller under huven, vilket gör att du kan utnyttja olika förfrågningar till den mest lämpliga modellen för resonemang, sammanfattning eller generering. Detta undviker att dina arbetsflöden låses till en enda modells styrkor eller begränsningar.
När du behöver extern kontext kan Brain utföra webbsökningar direkt från arbetsytan och visa sammanfattade resultat utan att du behöver lämna ClickUp eller öppna en separat webbläsarflik.
Sök, navigera och utför med ClickUp Enterprise Search
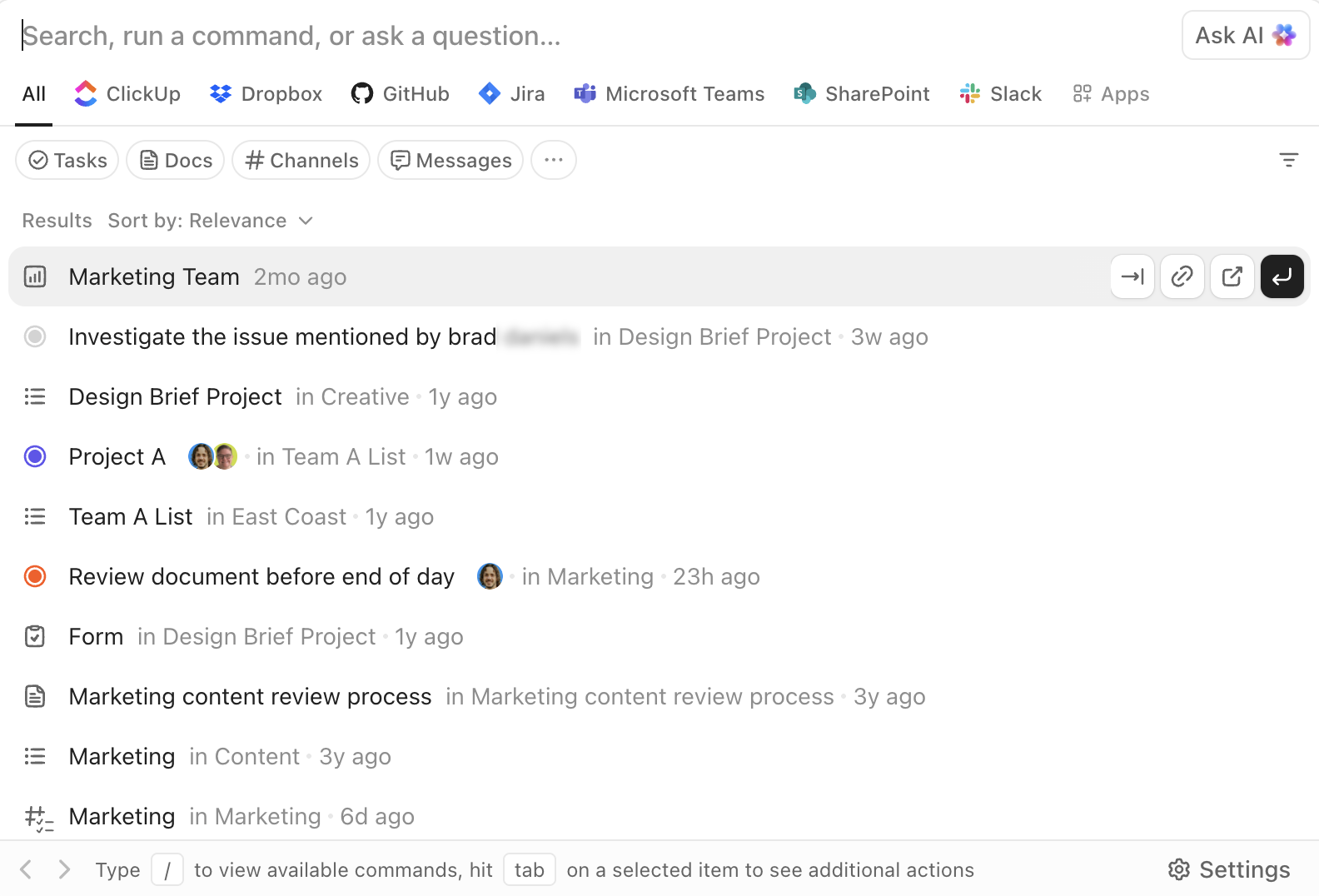
ClickUps Enterprise Search är tillgängligt från var som helst i arbetsytan. Det låter dig söka i uppgifter, dokument, kommentarer och bilagor, samt i anslutna tredjepartsappar som Google Drive, Slack, GitHub och mer, beroende på dina integrationer.
AI Command Bar förvandlar sökningen till ett exekveringslager. Du kan hoppa till objekt, skapa uppgifter, ändra status, tilldela ägare eller öppna specifika vyer direkt från samma gränssnitt. Det handlar inte bara om att "hitta och läsa", utan om att "hitta och agera".
Eftersom sökfunktionen är inbäddad i arbetsytans användargränssnitt är resultaten alltid användbara. Du hämtar inte information isolerat och byter sedan verktyg för att använda den. Arbetsflödet fortsätter på plats.
Minska antalet verktyg med ClickUp BrainGPT
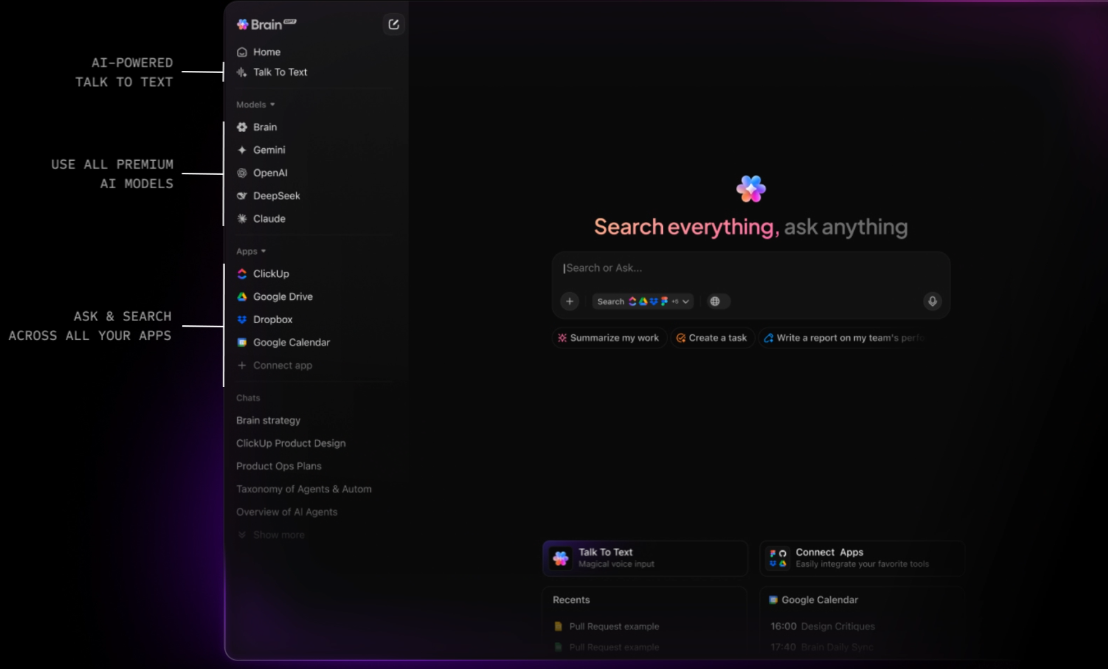
ClickUp BrainGPT utökar sökfunktionerna bortom webbläsaren och erbjuder en fristående desktop-app och Chrome-tillägg. Den ansluter direkt till ditt arbetsområde och visar samma kontextuella information utan att du först behöver öppna ClickUp eller någon av dina anslutna appar.
Från ett enda gränssnitt kan du söka efter uppgifter, dokument, kommentarer och anslutna verktyg, inklusive Gmail och andra integrationer. Med röstbaserad Talk-to-Text kan du göra sökningar eller ställa frågor direkt, vilket är särskilt användbart för snabba uppslag eller arbete på resande fot.
Istället för att lägga till ytterligare en AI-sökprodukt att hantera, konsoliderar Brain GPT upptäckterna till en yta som redan förstår ditt arbete.
Det är den verkliga förändringen. ClickUp ber dig inte att bygga en företagssökmotor. Denna konvergerade arbetsyta integrerar den direkt i det system där arbetet utförs, vilket eliminerar infrastrukturkostnaderna samtidigt som kraften, noggrannheten och hastigheten bevaras.
Bonus: Strategisk jämförelse mellan anpassad utveckling och inbyggd AI i arbetsytan
| Kärnvärde | Maximal flexibilitet; egen kontroll | Klar för användning; kontextmedveten som standard |
| Implementering | Månader: Kräver att teknikteam bygger pipelines | Minuter: Växla med ett klick för hela arbetsytan |
| Datainhämtning | Manual: Du måste bygga och underhålla ETL och vektordatabas. | Automatiskt: Realtidsåtkomst till uppgifter, dokument och chatt |
| Behörighetslogik | Måste kodas manuellt (hög risk för dataläckage) | Arvtagare från din ClickUp-hierarki |
| Kontextuell djup | Semantisk (meningsbaserad) | Operativt (vet vem som är tilldelad vad) |
| Användargränssnitt | Du måste utforma och bygga sökfältet/chatten. | Inbyggt (sökfält, dokument och uppgiftsvyer) |
| Arbetsflödesåtgärd | Inget: Användaren hittar information och byter sedan verktyg för att arbeta vidare. | Hög: Hitta information och konvertera direkt till en uppgift |
| Bäst för | Teknikintensiva företag som utvecklar egen programvara | Team som vill eliminera ”verktygsspridning” och agera snabbt |
Sökningen ska inte hindra dig!
Semantisk sökning är inte längre något som skiljer sig från mängden. Det är en självklarhet.
Den verkliga kostnaden för företagssökning syns överallt: den tid som krävs för att bygga och underhålla den, den infrastruktur som krävs för att hålla den korrekt och den friktion som uppstår när sökningen sker utanför de verktyg där arbetet faktiskt utförs. Att hitta rätt dokument spelar ingen större roll om det fortfarande krävs ett byte av system för att agera på det.
Därför handlar problemet inte bara om ”bättre sökning”. Det handlar om att eliminera klyftan mellan information och genomförande.
När sökningen är inbäddad direkt i arbetsytan bevaras kontexten som standard. Svaren hämtas inte bara, de kan användas omedelbart. Uppgifter kan uppdateras, beslut kan dokumenteras och arbetet kan fortskrida utan att ytterligare överlämningar behöver göras.
För team som inte vill spendera månader på att bygga och underhålla anpassad sökinfrastruktur förändrar arbetet i en konvergerad AI-arbetsyta ekvationen helt. ClickUp levererar AI-driven sökning i företagsklass som en del av det system som ditt team redan använder för att planera, samarbeta och utföra.
✅ Kom igång med ClickUp gratis.
Vanliga frågor
Cohere fokuserar specifikt på användningsfall inom företag, såsom sökning, och erbjuder modeller som Embed och Rerank som är specialbyggda för återhämtningsuppgifter. OpenAI tillhandahåller bredare, allmänna modeller som kan anpassas för sökning men som kan kräva mer finjustering.
Ja, Cohere tillhandahåller API:er som möjliggör integration med andra verktyg, men detta kräver anpassad utveckling och tekniska resurser. Ett alternativ som ClickUp erbjuder inbyggd AI-sökning som fungerar direkt, vilket eliminerar behovet av integrationsarbete.
Branscher med stora, ostrukturerade dokumentarkiv – såsom juridik, hälso- och sjukvård, finansiella tjänster och teknik – har störst nytta av semantisk sökning. Alla organisationer som kämpar med kunskapshantering kan se betydande förbättringar.