
Повечето екипи разглеждат генерирането на SQL като фокус. Въвеждате въпрос и получавате заявка.
Но ето как стоят нещата в действителност: Snowflake Cortex Analyst работи толкова добре, колкото семантичният модел, който създадете първо, а тази настройка не е тривиална. Като научат как да използват Snowflake Cortex за генериране на SQL, екипите за данни вече могат да преобразуват естествен език в сложни, изпълними заявки за секунди.
Това ръководство ви води през целия процес на внедряване – от дефинирането на вашия семантичен модел в YAML до извличането на данни от хранилището чрез естествен език – за да разберете както възможностите, така и предварителните условия, преди да започнете.
Ще разгледаме също така къде Snowflake Cortex има недостатъци и как ClickUp може да подкрепи по-широките работни процеси, свързани с генерирането на SQL.
Какво представлява Snowflake Cortex Analyst?
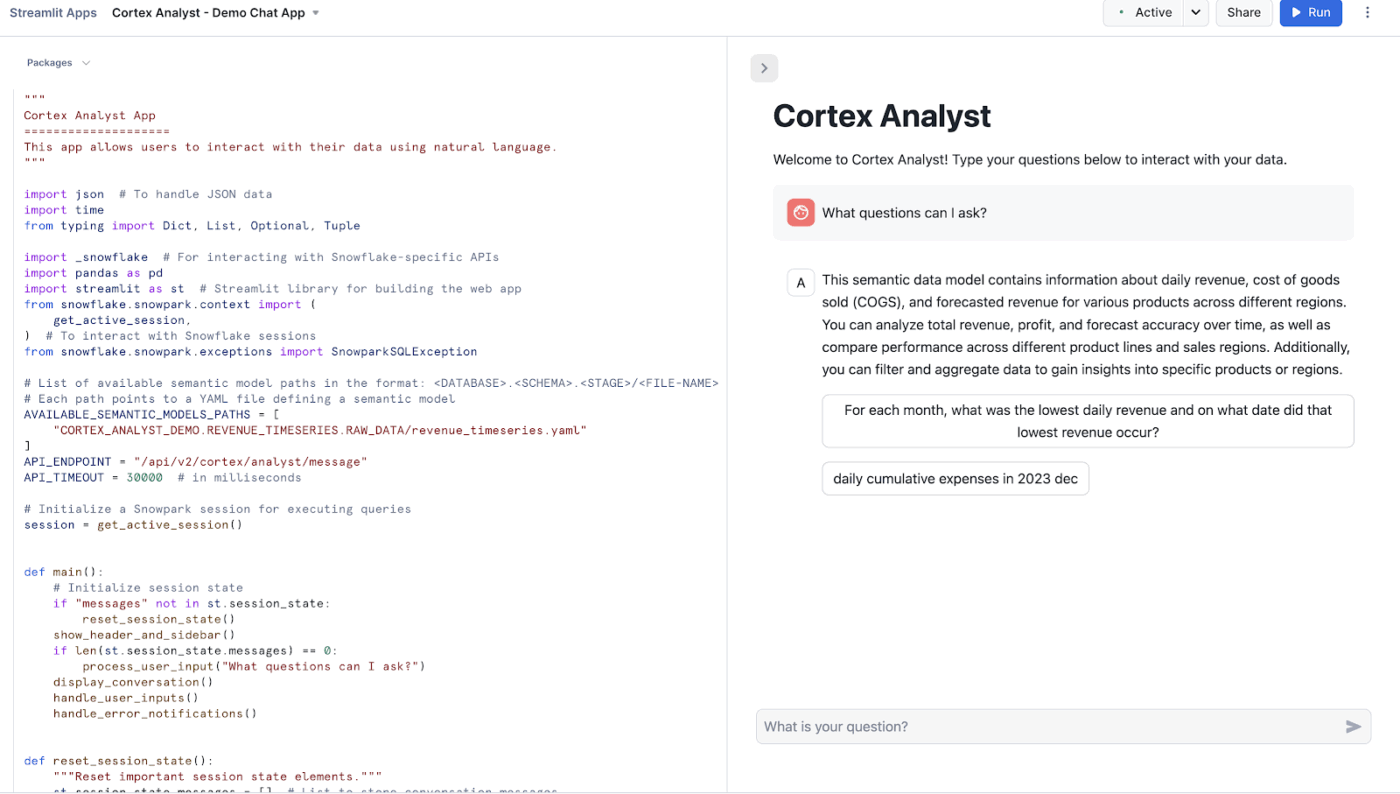
Snowflake Cortex Analyst е напълно управлявана услуга, която ви позволява да създавате приложения за разговорни взаимодействия въз основа на вашите аналитични данни.
Той използва специализиран агент за преобразуване на текст в SQL, за да превърне въпросите на естествен език в точни, изпълними заявки. Тази услуга преодолява различията между сложните структури на данни и бизнес потребителите, които се нуждаят от отговори, без да пишат код.
Основните възможности включват:
- Предоставяне на интерфейс с висока точност за взаимодействие със структурирани данни
- Използване на семантични модели за разбиране на вашата специфична бизнес логика и терминология
- Предлага REST API за лесна интеграция в персонализирани приложения или BI инструменти
- Поддържане на поверителността на данните чрез обработка на заявки в рамките на границите на сигурността на Snowflake
📮 ClickUp Insight: 88% от участниците в нашето проучване използват изкуствен интелект за личните си задачи, но над 50% се въздържат да го използват на работното място. Кои са трите основни пречки? Липса на безпроблемна интеграция, пропуски в знанията или опасения относно сигурността.
Но какво ще стане, ако изкуственият интелект е вграден във вашето работно пространство и вече е защитен? ClickUp Brain, вграденият AI асистент на ClickUp, превръща това в реалност. Той разбира команди на обикновен език, като решава и трите проблема, свързани с внедряването на AI, и същевременно свързва вашия чат, задачи, документи и знания в цялото работно пространство.
Намерете отговори и полезна информация с едно кликване!
Предпоставки за генериране на SQL с Snowflake Cortex
Започването на работа със Snowflake Cortex без подходяща настройка води до разочарование. Може да получите неточни резултати, да губите време за отстраняване на проблеми и погрешно да заключите, че инструментът не работи, когато истинският проблем е слабата основа.
За да избегнете това, първо трябва да подготвите три основни елемента.
1. Настройте базата данни и таблиците си
Вашият ИИ е толкова умен, колкото са данните, до които има достъп. Ако схемата на вашата база данни е лабиринт от загадъчни имена на колони като cust_dat_v2_final, както вашите анализатори, така и ИИ ще се затруднят да я разберат.
Тази объркване води до това, че ИИ генерира неправилни съединения или извлича данни от грешни колони, а вашият екип губи часове, просто опитвайки се да разгадае схемата, преди дори да може да напише заявка.
Започнете, като се уверите, че софтуерът за хранилище на данни съдържа таблиците, които искате Cortex Analyst да запитва. Когато е възможно, използвайте ясни, описателни имена на колони. Например, колона с име customer_lifetime_value е много по-интуитивна както за хората, така и за изкуствения интелект, отколкото clv_01.
За да продължите с настройката, вашата роля в Snowflake ще се нуждае от следните разрешения:
- УПОТРЕБА: В базата данни и схемата, съдържащи вашите таблици
- SELECT: В таблиците, които искате Cortex Analyst да запитва
- CREATE STAGE: В схемата, която е необходима за качване на файла с вашия семантичен модел
📖 Прочетете също: Как да използвате Snowflake Cortex за бизнес анализи
2. Създайте своя файл със семантичен модел
Най-голямото препятствие при всеки инструмент за преобразуване на текст в SQL е, че изкуственият интелект не говори уникалния език на вашата компания. Той по принцип не знае, че „ARR“ означава „Годишен повтарящ се приход“ или че таблицата с вашите клиенти се свързва с таблицата с поръчките ви по полето customer_id.
Без този контекст изкуственият интелект може да генерира SQL, който е технически валиден, но логически погрешен, като ви дава отговори, които изглеждат правилни, но са опасно подвеждащи.
Семантичният модел е решението. Това е YAML файл, който действа като ваш персонализиран „преводачески слой“, като учи Cortex Analyst специфичния речник и логиката на вашия бизнес. Създаването и поддържането на този файл е съвместно усилие между инженерите по данни, които използват ETL инструменти, за да познават схемата, и бизнес анализаторите, които познават терминологията.
Вашият файл със семантичен модел трябва да съдържа следните ключови компоненти:
| Компонент | Цел |
| Таблици | Изброява всяка таблица с описание на нейното предназначение на обикновен език |
| Колони | Определя семантичния тип на всяка колона (като категория или метрика) и може да включва примерни стойности |
| Връзки | Определя как таблиците се свързват чрез съединения, премахвайки всякакви догадки за изкуствения интелект |
| Проверени заявки | Предоставя примери за двойки въпроси и SQL, които служат като мощни насоки за LLM |
3. Конфигуриране на Cortex Search Service (по избор)
Понякога отговорите, от които се нуждаете, са скрити в неструктуриран текст, като описания на продукти, заявки за поддръжка или стенограми от разговори. Стандартните SQL заявки не могат да обработват тези данни, което означава, че често пропускате „защо“ зад „какво“.
По желание можете да добавите тук Snowflake Cortex Search Service. Това е слой за търсене като услуга, който ви позволява да извършвате заявки както към структурираните си таблици, така и към неструктурираните си текстови данни, като използвате AI агенти за анализ на данни едновременно.
Трябва да конфигурирате Cortex Search, ако вашите анализатори трябва да задават въпроси, които изискват извличане на контекст от текста, преди да генерират SQL. Например, първо можете да търсите всички рецензии на продукти, съдържащи фразата „проблем с батерията“, а след това да генерирате SQL заявка, за да агрегирате данните за продажбите само за тези продукти.
За генериране на чист SQL за структурирани таблици тази услуга не е необходима.
🧠 Интересен факт: В началото на 70-те години на миналия век изследователите от IBM Доналд Чембърлин и Реймънд Бойс създават „Structured English Query Language“. Те са били принудени да променят името на SQL, тъй като „SEQUEL“ вече е било запазена търговска марка на британска авиокомпания.
Стъпка по стъпка ръководство за генериране на SQL с Cortex Analyst
Извършили сте подготвителната работа, но сега сте изправени пред празен екран, без да сте сигурни какви са действителните стъпки. Как да превърнете въпроса в главата си в изпълнима SQL заявка? Когато управлението на работния процес не е ясно, новите инструменти често остават неизползвани, а инвестицията в настройката се оказва напразна.
Практическият процес е приятно прост. Ето по-подробна информация!
Стъпка 1: Подгответе данните си в Snowflake
Преди всичко, вашите структурирани данни трябва да се намират в Snowflake. Всяко приложение на Cortex Analyst е насочено към една таблица или към изглед, съставен от една или повече таблици. Уверете се, че таблиците ви са създадени и попълнени.
Ако зареждате от плоски файлове:
- Качете вашите файлове с данни (например CSV) в Snowflake Stage
- Използвайте командата COPY INTO, за да заредите данни от етапа във вашите таблици
- Уверете се, че данните са заредени успешно, преди да продължите
📖 Прочетете също: Как да използвате Snowflake Cortex за корпоративна аналитика
Стъпка #2: Създайте семантичен модел (или семантичен изглед)
Това е най-важната стъпка при настройката. Силата на Cortex Analyst идва от комбинирането на големи езикови модели (LLM) със семантични модели – YAML файл, който се намира до схемата на вашата база данни и кодира бизнес контекста.
Семантичните изгледи вече са препоръчителният метод на Snowflake за Cortex Analyst. Те съхраняват бизнес показатели, взаимоотношения и дефиниции директно в Snowflake. Старите YAML файлове със семантични модели все още работят, но Snowflake насочва новите имплементации към семантичните изгледи.
Вашият семантичен модел или изглед трябва да включва:
- Описания на таблици и колони: Обяснения на обикновен език за значението на всяко поле
- Бизнес показатели: Дефиниции за изчислени полета като приходи, отлив на клиенти или процент на конверсия
- Филтри и синоними: Алтернативни термини, които потребителите могат да използват (например „отменено“, съответстващо на конкретна стойност на статуса)
- Проверени заявки: Хранилището за проверени заявки на Snowflake съхранява одобрени двойки от въпроси и SQL. Когато въпросът на потребителя прилича на някоя от тези записи, Cortex Analyst може да я използва като референция по време на генерирането на SQL
🤝 Приятелско напомняне: Snowflake препоръчва да използвате не повече от 10 таблици и не повече от 50 избрани колони за оптимална производителност в работния процес на Snowsight.
Стъпка #3: Качете семантичния модел в Snowflake stage
Ако използвате семантичен модел на базата на YAML, той трябва да бъде подготвен, за да може Cortex Analyst да го използва по време на изпълнение.
- Качете вашия .yaml файл във вътрешен етап на Snowflake (например RAW_DATA)
- Уверете се, че файлът се появява в етапа чрез потребителския интерфейс на Snowsight или командата LIST @stage_name
- Запишете пътя на етапа; ще го използвате в API заявките си или в конфигурацията на приложението
Ако използвате Semantic View, тази стъпка се обработва вградено в Snowflake и не е необходимо отделно качване.
🔍 Знаете ли? NULL в SQL не означава нула или празно. То представлява неизвестни или липсващи данни, което води до неинтуитивно поведение, като например сравнения, които не връщат нито true, нито false.
Стъпка 4: Изпратете въпрос на естествен език чрез REST API
Сега започва самото генериране на SQL. REST API генерира SQL заявка за даден въпрос, като използва семантичен модел или семантичен изглед, предоставен в заявката.
Структурирайте заявката си към API с:
- съобщения; масив, съдържащ въпроса на потребителя с роля: „user“
- Препратка към вашия семантичен модел или семантичен изглед
- Вашият предпочитан модел (или оставете го на „авто“, за да избере Cortex най-подходящия)
Можете да водите многоетапни разговори, в които да задавате последващи въпроси, основаващи се на предишни заявки.
Стъпка #5: Анализирайте отговора на API
Всяко съобщение в отговора може да съдържа няколко блока със съдържание от различни типове. Три стойности, които понастоящем се поддържат за полето „тип“, са: текст, предложения и SQL.
Ето какво означава всеки тип:
- SQL: Cortex успешно генерира заявка; това е, което ще изпълните
- текст: Обяснение или отговор на естествен език, придружаващ SQL
- предложения: Типът съдържание „предложение“ се включва в отговора само ако въпросът на потребителя е бил двусмислен и Cortex Analyst не е могъл да върне SQL израз за този запит. Използвайте ги, за да изясните или уточните въпроса
🔍 Знаете ли? Редът, в който пишете SQL, не е редът, в който той се изпълнява. Въпреки че първо пишете SELECT, базите данни всъщност обработват FROM и WHERE, преди да подберат колоните. Това обърква както начинаещите, така и опитните потребители.
Стъпка 6: Изпълнете генерирания SQL код в Snowflake
След като получите SQL блока от отговора, изпълнете го във вашия виртуален склад Snowflake. Генерираната SQL заявка се изпълнява във вашия виртуален склад Snowflake, за да се генерира крайният резултат. Данните остават в рамките на управлението на Snowflake.
Важни неща, които трябва да знаете по време на изпълнение:
- Cortex Analyst се интегрира напълно с политиките за контрол на достъпа въз основа на роли (RBAC) на Snowflake, като гарантира, че генерираните и изпълнени SQL заявки спазват всички установени правила за контрол на достъпа
- Ако даден потребител няма достъп до таблица, заявката ще се провали при изпълнението, точно както би се случило с ръчно написан SQL код
- На този етап се прилагат разходи за изчислителна мощност на хранилището, които са отделни от таксите за използване на Cortex Analyst.
Стъпка #7: Усъвършенствайте и повтаряйте
Не винаги е гарантирано, че ще получите перфектна заявка още от първия опит. Ето как да подобрите резултатите с течение на времето:
- Добавете проверени заявки към семантичния си модел за въпроси, които се повтарят често
- Обогатете семантичния си модел с по-добри описания, синоними и филтри, когато Cortex интерпретира неправилно даден термин
- Използвайте многоетапни разговори за последващи въпроси, например „Сега филтрирай това по регион“; многоетапните разговори позволяват последващи въпроси, които надграждат предишни заявки
- Наблюдавайте използването чрез CORTEX_ANALYST_USAGE_HISTORY и историята на заявките в Snowflake, за да откривате модели в неуспешни или неточни заявки
🧠 Интересен факт: Едно пропуснато JOIN условие може да създаде огромни проблеми. Забравянето на JOIN условие може да доведе до декартово произведение, което драстично увеличава броя на редовете и понякога причинява срив на системите.
Най-добри практики за точност на Snowflake Text-to-SQL
Качеството на вашия семантичен модел пряко определя точността на заявките, които той генерира. Ето най-добрите практики, които подобряват точността. 🛠️
- Добавете проверени заявки към семантичния си модел: Това е най-ефективното нещо, което можете да направите. Включете много примери за двойки въпрос-SQL, които отразяват начина, по който вашият екип наистина задава въпроси
- Използвайте описателни имена на колони и таблици: Моделът работи по-добре, когато имената на колоните и таблиците са самоописателни. Ако не можете да промените схемата, добавете ясни описания във вашия YAML файл за всички неясни имена на колони
- Включете примерни стойности: Добавянето на примерни данни за категорични колони (като статус или регион) помага на модела да разбере валидните налични опции за филтриране
- Тествайте с крайни случаи: По време на разработката задавайте умишлено двусмислени или сложни въпроси, за да установите къде семантичният ви модел се нуждае от повече контекст или пояснения
- Работете итеративно върху семантичния си модел: Разглеждайте семантичния си модел като динамичен документ. Той трябва да се актуализира непрекъснато чрез итеративен процес, основан на това кои заявки са успешни и кои не
ClickUp: По-проста алтернатива на Snowflake Cortex
Snowflake Cortex работи добре, когато екипите искат да генерират SQL и да изпълняват заявки върху структурирани данни. Екипите дефинират схеми, картографират взаимоотношения и пишат заявки, за да извличат информация. Тази конфигурация е подходяща за среди с голям обем данни, особено когато анализаторите отговарят за отчетите.
Много екипи обаче не се нуждаят от пълен SQL слой, за да отговорят на ежедневните оперативни въпроси. Продуктовите мениджъри, ръководителите на програми и оперативните екипи често искат бързи отговори, свързани с текущата работа.
ClickUp предлага по-достъпен подход. Екипите задават въпроси на обикновен език, преглеждат табла в реално време и действат въз основа на получените данни, без да пишат SQL или да създават семантични модели.
Генерирайте и усъвършенствайте SQL по-бързо
Snowflake Cortex се фокусира върху генерирането на SQL заявки от структурирани набори от данни в среда на хранилище. Това работи добре, когато данните ви вече се намират в Snowflake и имате изготвени схеми.

ClickUp Brain поддържа генерирането на SQL по по-гъвкав начин, фокусиран върху изпълнението. Екипите генерират, усъвършенстват и съхраняват SQL заявки директно в своето работно пространство, където вече се извършват анализи, дискусии и вземане на решения.
Да предположим, че продуктов анализатор работи по задача за анализ на задържането в ClickUp. Вместо да сменя инструментите, за да напише заявки, той пита ClickUp Brain:
📌 Опитайте този подсказ: Напишете SQL заявка за изчисляване на седемдневната задържаемост на потребителите, групирани по кохорти на регистрация.
ClickUp Brain генерира структурирана заявка, която включва групиране по кохорти, филтри по дата и логика за задържане. Аналитикът поставя заявката в Snowflake или друг хранилище и я изпълнява незабавно.
Това помага:
- Напишете съединения между няколко таблици, като например потребители, поръчки и събития
- Преобразувайте въпроси за продукти, формулирани на обикновен английски, в SQL логика, готова за изпълнение
- Отстранявайте грешки в заявките и обяснявайте проблеми, като например неправилни съединения или липсващи условия
- Пренапишете заявките за по-добра производителност или четимост
Например, по време на преглед на експеримент за растеж, маркетологът пита: „Напишете SQL заявка, за да сравните процентите на конверсия между две целеви страници през последните 14 дни“.
ClickUp Brain генерира заявката, използвайки условна агрегация и филтри за дата. Екипът я изпълнява в Snowflake и проверява резултатите от експеримента.
📌 Опитайте този подсказ: Поправете тази SQL заявка, в която съединението дублира редове, и обяснете проблема.
ClickUp Brain идентифицира проблема с обединяването, коригира заявката и обяснява как са възникнали дублиращите се редове поради неправилни условия за обединяване.
Заменете отчетите, базирани на SQL
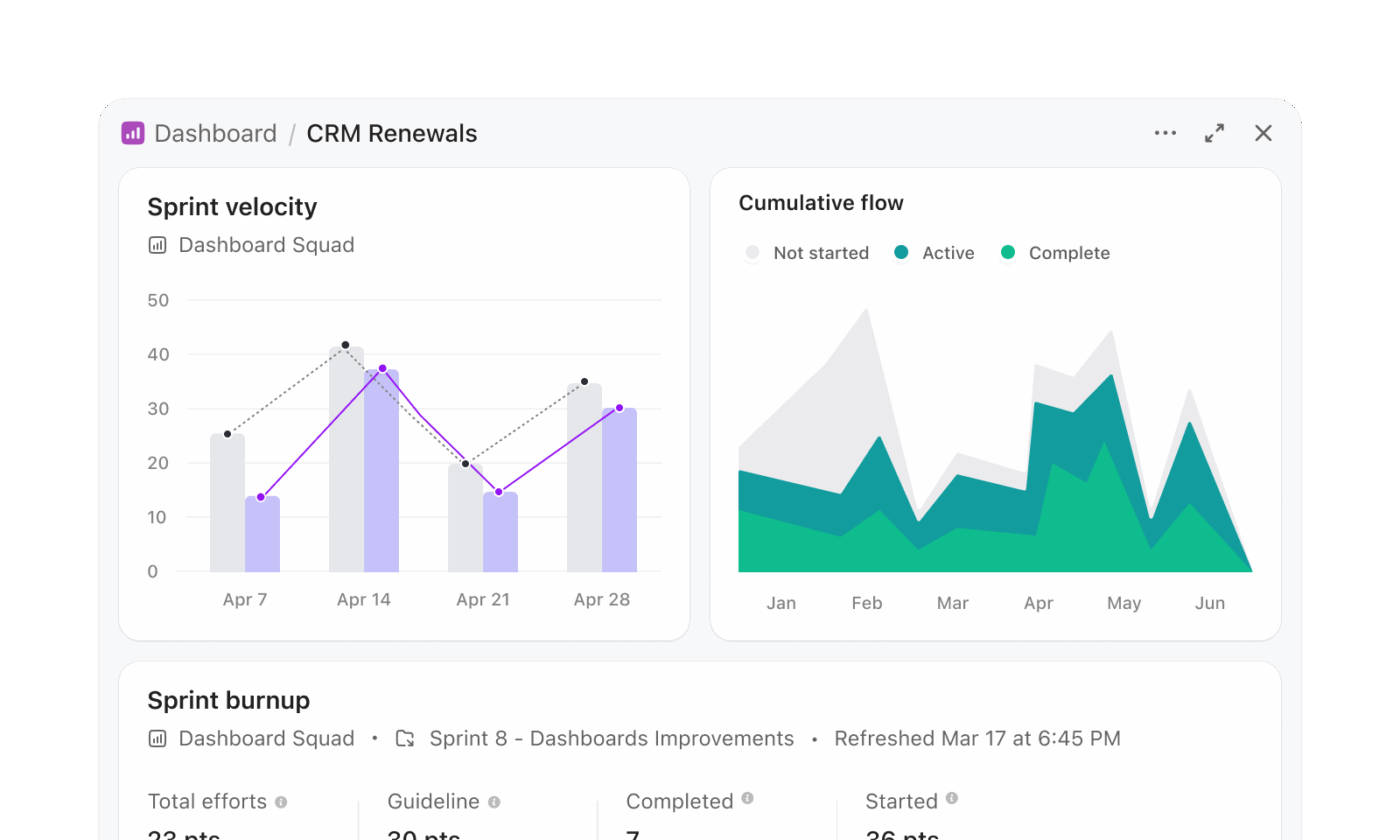
Работните процеси в Snowflake Cortex често включват генериране на SQL, изпълняване на заявки и визуализиране на резултатите в отделен слой. Таблата на ClickUp премахват този многоетапен процес и представят анализите директно от текущата работа.
Екипът за управление на програмата, който следи готовността за пускане на версии, може да създаде табло, без да пише заявки. Например, таблото за пускане на версии може да включва:
- Карта със списък със задачи, филтрирана така, че да показва просрочените задачи във всички продуктови екипи
- Карта на работната натоварване, която показва разпределението на задачите между инженерите
- Диаграма с ленти, сравняваща завършените и чакащите задачи по спринт
- Карта за изчисления, проследяваща средното време за изпълнение
Да предположим, че ръководител на програмата преглежда този дашборд преди среща за пускане на версия. Той веднага забелязва, че бекенд услугите показват по-високи нива на закъснение. Той отваря картата със списъка със задачи и проверява точно кои задачи създават риск.
Един реален потребител на ClickUp споделя:
ClickUp ни позволява БЪРЗО да си предаваме проектите, ЛЕСНО да проверяваме статуса на проектите и дава на нашия супервайзор възможност да следи натоварването ни по всяко време, без да се налага да ни прекъсва. С помощта на ClickUp със сигурност спестяваме един ден седмично, ако не и повече. Броят на имейлите е ЗНАЧИТЕЛНО намален.
ClickUp ни позволява БЪРЗО да си предаваме проектите, ЛЕСНО да проверяваме статуса на проектите и дава на нашия супервайзор възможност да следи натоварването ни по всяко време, без да се налага да ни прекъсва. С помощта на ClickUp със сигурност спестяваме един ден седмично, ако не и повече. Броят на имейлите е ЗНАЧИТЕЛНО намален.
Действайте въз основа на анализите без пипалини
Snowflake Cortex се фокусира върху извличането на информация от данните. Екипите все още трябва да интерпретират резултатите и да задействат действия поотделно.
Super Agents на ClickUp AI запълват тази празнина и превръщат прозренията в действие. Те работят като AI съотборници, които непрекъснато наблюдават данните в работната среда и предприемат действия въз основа на определени условия.
Да предположим, че един програмен мениджър отговаря за няколко продуктови инициативи. Един Super Agent може:
- Наблюдавайте задачите в различните проекти и откривайте кога просрочените задачи надхвърлят определена граница
- Идентифицирайте модели като повтарящи се закъснения в един и същ етап от работния процес
- Създайте задача, която обобщава засегнатите проекти, и я възложете на ръководителя на програмата
- Уведомявайте ръководителите на екипи, когато критични задачи остават нерешени след крайния срок
Например, по време на цикъл на пускане на версия, Super Agent открива, че повече от 10 задачи с висок приоритет са пропуснали крайните срокове в два екипа. Той създава задача в ClickUp, озаглавена „Риск при пускането: пропуснати крайни срокове“, прикачва всички съответни задачи и я възлага на програмния мениджър за незабавен преглед.
Екипите могат също така да взаимодействат директно със Super Agent: „Анализирай всички активни проекти и подчертай рисковете за изпълнението на този спринт“.
Super Agent проверява крайните срокове, зависимостите и състоянието на задачите, след което публикува структурирано обобщение в работната среда.
Ето как да настроите своя собствен Super Agent в ClickUp:
Централизирайте работните си потоци с данни с ClickUp
Инструменти за преобразуване на текст в SQL като Snowflake Cortex правят данните по-достъпни. В същото време получаването на надеждни резултати все още изисква усилия.
Екипите се нуждаят от изчистени схеми, силни семантични модели и непрекъснати итерации, за да поддържат точността на резултатите. Дори след генерирането на правилния запит работата не спира дотук. Все още е необходимо някой да интерпретира резултатите, да сподели прозренията и да ги превърне в решения.
ClickUp предлага различен подход. Вместо да разделя анализа от изпълнението, ClickUp свързва и двете. Екипите генерират SQL, документират прозрения, сътрудничат си по отношение на заключенията и действат въз основа на тях в рамките на едно и също работно пространство.
ClickUp Brain помага при писането и усъвършенстването на заявките, докато Dashboards и AI Agents помагат на екипите да проследяват резултатите и да напредват в работата си, без да се налага да преминават от един инструмент към друг.
Snowflake Cortex ви помага да получите отговори. ClickUp ви помага да направите нещо с тях. Регистрирайте се в ClickUp още днес!
Често задавани въпроси
Snowflake Cortex Analyst е специализирана услуга в рамките на по-широкия пакет Snowflake Cortex AI. Cortex Analyst е фокусиран конкретно върху генерирането на текст към SQL чрез използване на семантични модели, докато Cortex AI включва по-широк спектър от LLM функции, изводи от модели за машинно обучение и възможности за търсене.
Да, Cortex Analyst може да извършва заявки към таблици в Apache Iceberg, които се управляват чрез Snowflake. Доколкото таблиците са достъпни във вашата Snowflake среда и са правилно дефинирани във вашия семантичен модел, можете да генерирате заявки към тях.
Точността при сложни заявки зависи почти изцяло от качеството на вашия семантичен модел. Модел с добре дефинирани връзки между таблиците, многобройни проверени заявки и описателни метаданни ще дава значително по-точни резултати при обединяване на няколко таблици и сложни агрегации.
Ценообразуването на Snowflake Cortex Analyst следва модела на Snowflake, базиран на потреблението, което означава, че се таксувате въз основа на изчислителните кредити, използвани по време на процеса на генериране на заявки. За най-актуалните тарифи винаги трябва да се обръщате към официалната документация за ценообразуване на Snowflake.