
นักพัฒนาส่วนใหญ่ที่สร้างสคริปต์สรุปของ Hugging Face มักจะเจอปัญหาเดียวกัน: สรุปทำงานได้อย่างสมบูรณ์แบบในเทอร์มินัลของพวกเขา แต่แทบจะไม่เชื่อมโยงกับงานจริงที่มันควรจะสนับสนุน
คู่มือนี้จะนำคุณผ่านขั้นตอนการสร้างตัวสรุปข้อความด้วยไลบรารี Transformers ของ Hugging Face จากนั้นจะแสดงให้คุณเห็นว่าทำไมแม้การนำไปใช้ที่สมบูรณ์แบบก็อาจสร้างปัญหาได้มากกว่าที่แก้ไขเมื่อทีมของคุณต้องการสรุปที่สามารถเชื่อมโยงกับงาน โครงการ และการตัดสินใจได้จริง
การสรุปเนื้อหาคืออะไร?
ทีมกำลังจมอยู่ในข้อมูล คุณกำลังเผชิญกับเอกสารยาวเหยียด บันทึกการประชุมที่ไม่มีที่สิ้นสุด รายงานการวิจัยที่ซับซ้อน และรายงานประจำไตรมาสที่ต้องใช้เวลาหลายชั่วโมงในการประมวลผลด้วยตนเอง การรับข้อมูลที่มากเกินไปอย่างต่อเนื่องนี้ทำให้การตัดสินใจช้าลงและทำลายประสิทธิภาพการทำงาน
การสรุปข้อความคือกระบวนการที่ใช้การประมวลผลภาษาธรรมชาติ (NLP)เพื่อย่อเนื้อหาให้เหลือเพียงเวอร์ชันสั้นที่สอดคล้องกันและยังคงรักษาข้อมูลที่สำคัญที่สุดไว้ คิดว่าเป็นเหมือนสรุปสำหรับผู้บริหารทันทีสำหรับเอกสารใด ๆ เทคโนโลยีการสรุปด้วย NLP นี้โดยทั่วไปจะใช้หนึ่งในสองแนวทาง:
การสรุปแบบดึงข้อมูล: วิธีนี้ทำงานโดยการระบุและดึงประโยคที่สำคัญที่สุดโดยตรงจากข้อความต้นฉบับ เปรียบเสมือนมีปากกาไฮไลท์ที่เลือกจุดสำคัญให้คุณโดยอัตโนมัติ สรุปสุดท้ายจะเป็นการรวบรวมประโยคต้นฉบับไว้ด้วยกัน
การสรุปแบบนามธรรม: วิธีขั้นสูงนี้สร้างประโยคใหม่ทั้งหมดเพื่อจับความหมายหลักของข้อความต้นฉบับ มันจะถอดความข้อมูลใหม่ ทำให้ได้สรุปที่ลื่นไหลและเป็นธรรมชาติเหมือนมนุษย์มากขึ้น คล้ายกับวิธีที่คนอธิบายเรื่องราวที่ยาวด้วยคำพูดของตนเอง
คุณจะเห็นผลลัพธ์ของสิ่งนี้ได้ทุกที่มันถูกใช้เพื่อย่อบันทึกการประชุมให้เป็นรายการที่ต้องดำเนินการ, สรุปความคิดเห็นของลูกค้าให้เป็นแนวโน้ม, และสร้างภาพรวมอย่างรวดเร็วของเอกสารโครงการ เป้าหมายนั้นเหมือนกันเสมอ: เพื่อให้ได้ข้อมูลที่สำคัญโดยไม่ต้องอ่านทุกคำ
📮 ClickUp Insight: มืออาชีพโดยเฉลี่ยใช้เวลา30 นาทีขึ้นไปต่อวันในการค้นหาข้อมูลที่เกี่ยวข้องกับงาน นั่นคือมากกว่า 120 ชั่วโมงต่อปีที่สูญเสียไปกับการค้นหาอีเมล, กระทู้ Slack และไฟล์ที่กระจัดกระจาย ผู้ช่วย AI อัจฉริยะที่ฝังอยู่ในพื้นที่ทำงานของคุณสามารถเปลี่ยนแปลงสิ่งนี้ได้ClickUpBrain มอบข้อมูลเชิงลึกและคำตอบทันทีโดยการดึงเอกสาร, การสนทนา และรายละเอียดงานที่ถูกต้องขึ้นมาภายในไม่กี่วินาที ทำให้คุณสามารถหยุดการค้นหาและเริ่มทำงานได้
💫 ผลลัพธ์ที่แท้จริง: ทีมอย่าง QubicaAMF สามารถประหยัดเวลาได้มากกว่า 5 ชั่วโมงต่อสัปดาห์ หรือมากกว่า 250 ชั่วโมงต่อคนต่อปี ด้วยการกำจัดกระบวนการจัดการความรู้ที่ล้าสมัย โดยใช้ ClickUp
ทำไมต้องใช้ Hugging Face สำหรับการสรุปข้อความ?
การสร้างแบบจำลองสรุปข้อความแบบกำหนดเองตั้งแต่เริ่มต้นเป็นงานที่ใหญ่หลวงมาก มันต้องการชุดข้อมูลขนาดใหญ่สำหรับการฝึกฝน ทรัพยากรการคำนวณที่ทรงพลังและมีค่าใช้จ่ายสูง และทีมผู้เชี่ยวชาญด้านการเรียนรู้ของเครื่อง อุปสรรคที่สูงนี้ทำให้ทีมวิศวกรรมและผลิตภัณฑ์ส่วนใหญ่ไม่สามารถเริ่มต้นได้เลย
Hugging Face คือแพลตฟอร์มที่แก้ปัญหาดังกล่าว เป็นชุมชนโอเพ่นซอร์สและแพลตฟอร์มวิทยาศาสตร์ข้อมูลที่ให้คุณเข้าถึงโมเดลที่ผ่านการฝึกฝนมาแล้วนับพันแบบ ทำให้การสรุปผล LLM เป็นเรื่องที่เข้าถึงได้สำหรับนักพัฒนาทุกคน แทนที่จะต้องสร้างขึ้นใหม่ทั้งหมด คุณสามารถเริ่มต้นด้วยโมเดลที่ทรงพลังซึ่งได้พัฒนาไปถึง 99% แล้ว
นี่คือเหตุผลที่นักพัฒนาจำนวนมากหันมาใช้ Hugging Face: 🛠️
การเข้าถึงโมเดลที่ผ่านการฝึกอบรมล่วงหน้า:Hugging Face Hubเป็นคลังข้อมูลขนาดใหญ่ที่มีโมเดลสาธารณะมากกว่า 2 ล้านโมเดล ซึ่งได้รับการฝึกอบรมโดยบริษัทต่างๆ เช่น Google, Meta และ OpenAI คุณสามารถดาวน์โหลดและใช้จุดตรวจสอบที่ทันสมัยเหล่านี้สำหรับโครงการของคุณเองได้
API แบบท่อที่เรียบง่าย: ฟังก์ชัน pipeline เป็น API ระดับสูงที่จัดการขั้นตอนที่ซับซ้อนทั้งหมด เช่น การเตรียมข้อมูลข้อความ การอนุมานโมเดล และการจัดรูปแบบผลลัพธ์ ในโค้ดเพียงไม่กี่บรรทัด
ความหลากหลายของโมเดล: คุณไม่ได้ถูกจำกัดอยู่แค่ตัวเลือกเดียว คุณสามารถเลือกจากสถาปัตยกรรมที่หลากหลาย เช่น BART, T5 และ Pegasus ซึ่งแต่ละแบบมีจุดเด่น ขนาด และลักษณะการทำงานที่แตกต่างกัน
ความยืดหยุ่นของเฟรมเวิร์ก: ไลบรารี Transformers ทำงานร่วมกับเฟรมเวิร์กการเรียนรู้เชิงลึกที่ได้รับความนิยมสูงสุดสองตัว ได้แก่ PyTorch และ TensorFlow ได้อย่างราบรื่น คุณสามารถเลือกใช้เฟรมเวิร์กที่ทีมของคุณคุ้นเคยอยู่แล้วได้ตามความสะดวก
การสนับสนุนจากชุมชน: ด้วยเอกสารประกอบที่ครอบคลุม หลักสูตรอย่างเป็นทางการ และชุมชนนักพัฒนาที่กระตือรือร้น คุณสามารถค้นหาบทเรียนและขอความช่วยเหลือได้อย่างง่ายดายเมื่อพบปัญหา
ในขณะที่ Hugging Face เป็นเครื่องมือที่ทรงพลังอย่างยิ่งสำหรับนักพัฒนา สิ่งสำคัญที่ต้องจำไว้คือมันเป็นโซลูชันที่อิงกับโค้ด ซึ่งต้องอาศัยความเชี่ยวชาญทางเทคนิคในการนำไปใช้และดูแลรักษา วิธีนี้อาจไม่เหมาะสมเสมอไปสำหรับทีมที่ไม่มีความเชี่ยวชาญด้านเทคนิคและเพียงแค่ต้องการสรุปผลงานของตนเอง
🧐 คุณรู้หรือไม่? ไลบรารี Transformers ของ Hugging Face ทำให้การใช้โมเดล NLP ที่ทันสมัยที่สุดกลายเป็นเรื่องธรรมดาด้วยโค้ดเพียงไม่กี่บรรทัด ซึ่งเป็นเหตุผลว่าทำไมต้นแบบการสรุปเนื้อหาจึงมักเริ่มต้นที่นั่น
ฮักกิ้ง เฟイス ทรานสฟอร์เมอร์ คืออะไร?
ดังนั้นคุณได้ตัดสินใจที่จะใช้ Hugging Face แล้ว แต่เทคโนโลยีที่แท้จริงที่ทำงานอยู่คืออะไร? เทคโนโลยีหลักคือสถาปัตยกรรมที่เรียกว่า Transformer เมื่อมันถูกนำเสนอในบทความปี 2017 ที่มีชื่อว่า "Attention Is All You Need" มันได้เปลี่ยนแปลงวงการ NLP อย่างสิ้นเชิง
ก่อนที่ Transformer จะถูกพัฒนาขึ้น โมเดลต่าง ๆ มักประสบปัญหาในการเข้าใจบริบทของประโยคยาว ๆ นวัตกรรมสำคัญของ Transformer คือ กลไกการให้ความสนใจ (attention mechanism) ซึ่งช่วยให้โมเดลสามารถประเมินความสำคัญของคำต่าง ๆ ในข้อความที่ป้อนเข้ามาได้เมื่อประมวลผลคำใดคำหนึ่งโดยเฉพาะ กลไกนี้ช่วยให้โมเดลสามารถจับความสัมพันธ์ที่ซับซ้อนในระยะยาวและเข้าใจบริบทได้อย่างถูกต้อง ซึ่งมีความสำคัญอย่างยิ่งต่อการสร้างสรุปเนื้อหาที่มีความสอดคล้องกัน
ไลบรารี Hugging Face Transformers เป็นแพ็กเกจ Python ที่ทำให้คุณสามารถใช้งานโมเดลที่ซับซ้อนเหล่านี้ได้อย่างง่ายดาย คุณไม่จำเป็นต้องมีปริญญาเอกในด้านการเรียนรู้ของเครื่อง ไลบรารีนี้ได้ทำการแยกงานที่ยุ่งยากออกไปแล้ว
สามองค์ประกอบหลักที่คุณต้องรู้
- ตัวแยกโทเค็น: โมเดลไม่เข้าใจคำศัพท์; โมเดลเข้าใจตัวเลข ตัวแยกโทเค็นจะนำข้อความที่คุณป้อนเข้ามาและแปลงเป็นลำดับของโทเค็นตัวเลข—กระบวนการที่เรียกว่าการแยกโทเค็น—ซึ่งโมเดลสามารถประมวลผลได้
- โมเดล: นี่คือโครงข่ายประสาทเทียมที่ได้รับการฝึกฝนล่วงหน้าแล้ว สำหรับการสรุปเนื้อหา โมเดลเหล่านี้มักจะเป็นโมเดลแบบลำดับต่อลำดับที่มีโครงสร้างแบบเข้ารหัส-ถอดรหัส โดยตัวเข้ารหัสจะอ่านข้อความนำเข้าเพื่อสร้างตัวแทนในรูปแบบตัวเลข และตัวถอดรหัสจะใช้ตัวแทนนั้นเพื่อสร้างสรุป
- Pipelines: นี่คือวิธีที่ง่ายที่สุดในการใช้โมเดล. Pipeline จะรวมโมเดลที่ฝึกไว้ล่วงหน้าไว้กับตัวแยกคำที่เกี่ยวข้อง และจัดการทุกขั้นตอนของการเตรียมข้อมูลก่อนการป้อนข้อมูล และการประมวลผลหลังการป้อนข้อมูลให้คุณ.
สองโมเดลที่ได้รับความนิยมมากที่สุดสำหรับการสรุปคือ BART และ T5 BART (Bidirectional and Auto-Regressive Transformer) มีความเชี่ยวชาญเป็นพิเศษในการสรุปแบบสังเคราะห์ (abstractive summarization) โดยสามารถสร้างสรุปที่อ่านได้อย่างเป็นธรรมชาติมาก ๆ T5 (Text-to-Text Transfer Transformer) เป็นโมเดลที่มีความหลากหลาย สามารถจัดกรอบงาน NLP ทุกอย่างให้เป็นปัญหาแบบข้อความต่อข้อความ (text-to-text) ทำให้เป็นเครื่องมือที่ทรงพลังและเหมาะกับการใช้งานหลากหลาย
🎥 รับชมวิดีโอนี้ เพื่อเปรียบเทียบเครื่องมือสรุปเนื้อหา PDF ด้วย AI ที่ดีที่สุด และเรียนรู้ว่าเครื่องมือใดสามารถสรุปได้รวดเร็วและแม่นยำที่สุดโดยไม่สูญเสียบริบท
วิธีสร้างโปรแกรมสรุปข้อความด้วย Hugging Face
พร้อมที่จะสร้างตัวอย่างโปรแกรมสรุปเนื้อหาของคุณเองหรือยัง? สิ่งที่คุณต้องมีคือความรู้พื้นฐานเกี่ยวกับภาษา Python, โปรแกรมแก้ไขโค้ด เช่น VS Code และการเชื่อมต่ออินเทอร์เน็ตเท่านั้น กระบวนการทั้งหมดใช้เวลาเพียงสี่ขั้นตอน คุณจะได้โปรแกรมสรุปเนื้อหาที่ใช้งานได้จริงภายในไม่กี่นาที
ขั้นตอนที่ 1: ติดตั้งไลบรารีที่จำเป็น
ก่อนอื่น คุณต้องติดตั้งไลบรารีที่จำเป็นก่อน ไลบรารีหลักคือ transformers คุณยังต้องมีเฟรมเวิร์กสำหรับการเรียนรู้เชิงลึก เช่น PyTorch หรือ TensorFlow สำหรับตัวอย่างนี้เราจะใช้ PyTorch
เปิดเทอร์มินัลหรือพรอมต์คำสั่งของคุณแล้วรันคำสั่งต่อไปนี้:

บางโมเดล เช่น T5 ยังต้องการไลบรารี sentencepiece สำหรับตัวแยกโทเค็นด้วย การติดตั้งไลบรารีนี้ไว้ด้วยจะเป็นประโยชน์

💡 เคล็ดลับมืออาชีพ: สร้างสภาพแวดล้อมเสมือนของ Python ก่อนติดตั้งแพ็กเกจเหล่านี้ วิธีนี้จะช่วยให้การพึ่งพาของโครงการของคุณถูกแยกออกจากกันและป้องกันการขัดแย้งกับโครงการอื่น ๆ บนเครื่องของคุณ
ขั้นตอนที่ 2: โหลดโมเดลและตัวแยกโทเค็น
วิธีที่ง่ายที่สุดในการเริ่มต้นคือการใช้ฟังก์ชัน pipeline ซึ่งจะช่วยจัดการโหลดโมเดลและตัวแยกโทเค็นที่ถูกต้องสำหรับงานสรุปโดยอัตโนมัติ
ในสคริปต์ Python ของคุณ ให้ทำการนำเข้า pipeline และเริ่มต้นใช้งานดังนี้:

ที่นี่ เรากำลังระบุสองสิ่ง:
งานที่ต้องทำ: เราบอกกับระบบว่าเราต้องการดำเนินการ "สรุปข้อมูล"
โมเดล: เราเลือกจุดตรวจสอบโมเดลที่ผ่านการฝึกฝนล่วงหน้าแล้วจาก Hugging Face Hub facebook/bart-large-cnn เป็นตัวเลือกยอดนิยมที่ฝึกฝนบนบทความข่าวและทำงานได้ดีสำหรับการสรุปเนื้อหาทั่วไป สำหรับการทดสอบที่รวดเร็วขึ้น คุณสามารถใช้โมเดลที่เล็กกว่า เช่น t5-small
ครั้งแรกที่คุณรันโค้ดนี้ ระบบจะดาวน์โหลดน้ำหนักของแบบจำลองจาก Hub ซึ่งอาจใช้เวลาสักครู่ หลังจากนั้น แบบจำลองจะถูกเก็บไว้ในเครื่องของคุณเพื่อโหลดได้ทันที
ขั้นตอนที่ 3: สร้างฟังก์ชันสรุป
เพื่อให้โค้ดของคุณสะอาดและสามารถนำกลับมาใช้ใหม่ได้ ควรนำตรรกะการสรุปข้อมูลไปใส่ไว้ในฟังก์ชัน วิธีนี้ยังช่วยให้ง่ายต่อการทดลองใช้พารามิเตอร์ที่แตกต่างกันอีกด้วย
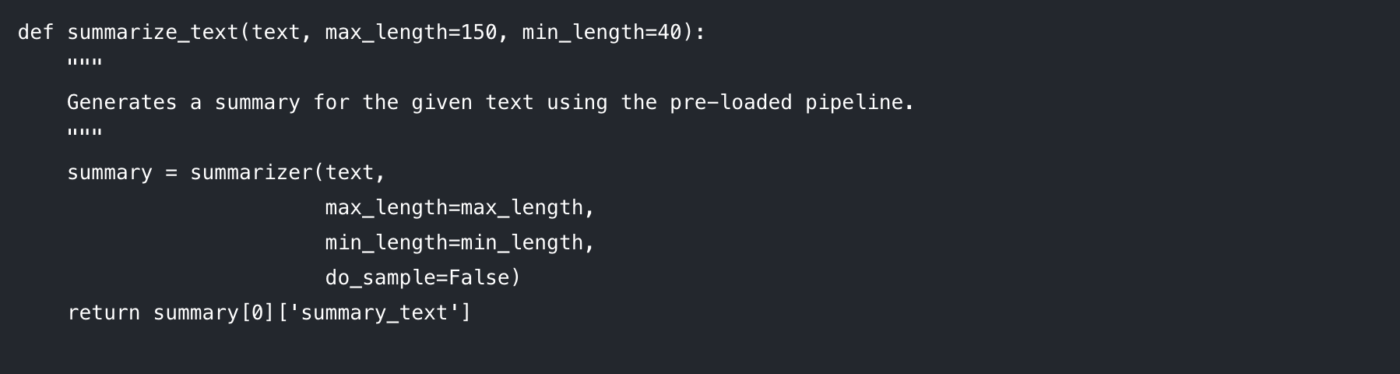
มาดูพารามิเตอร์ที่คุณสามารถควบคุมได้:
max_length: กำหนดจำนวนโทเค็นสูงสุด (โดยประมาณ คำ) สำหรับสรุปผลลัพธ์
min_length: กำหนดจำนวนโทเค็นขั้นต่ำเพื่อป้องกันไม่ให้โมเดลสร้างสรุปที่สั้นเกินไปหรือว่างเปล่า
do_sample: เมื่อตั้งค่าเป็น False โมเดลจะใช้เมธอดแบบกำหนดแน่นอน (เช่น beam search) เพื่อสร้างสรุปที่มีความน่าจะเป็นสูงสุด การตั้งค่าเป็น True จะเพิ่มความสุ่ม ซึ่งอาจให้ผลลัพธ์ที่มีความคิดสร้างสรรค์มากขึ้นแต่คาดเดาได้น้อยลง
การปรับแต่งพารามิเตอร์เหล่านี้เป็นกุญแจสำคัญในการได้คุณภาพของผลลัพธ์ตามที่คุณต้องการ
ขั้นตอนที่ 4: สร้างสรุปของคุณ
ตอนนี้มาถึงส่วนที่สนุกแล้ว ส่งข้อความของคุณไปยังฟังก์ชันและพิมพ์ผลลัพธ์ออกมา 🤩

คุณควรเห็นเวอร์ชันย่อของบทความที่พิมพ์ออกมาในคอนโซลของคุณ หากคุณพบปัญหา นี่คือวิธีแก้ไขเบื้องต้น:
ข้อความที่ป้อนยาวเกินไป: โมเดลอาจแสดงข้อผิดพลาดหากข้อความที่คุณป้อนเกินความยาวสูงสุด (มักจะเป็น 512 หรือ 1024 โทเค็น) ให้เพิ่ม truncation=True ภายในคำสั่ง summarizer() เพื่อตัดข้อความยาวโดยอัตโนมัติ
สรุปทั่วไปเกินไป: ลองเพิ่มพารามิเตอร์ num_beams (เช่น num_beams=4) วิธีนี้จะทำให้โมเดลค้นหาสรุปที่ดีขึ้นอย่างละเอียดมากขึ้น แต่จะช้าลงเล็กน้อย
แนวทางที่ใช้โค้ดนี้เป็นวิธีที่ยอดเยี่ยมสำหรับนักพัฒนาที่กำลังสร้างแอปพลิเคชันแบบกำหนดเอง แต่จะเกิดอะไรขึ้นเมื่อคุณต้องการผสานสิ่งนี้เข้ากับงานประจำวันของทีม? นั่นคือจุดที่ข้อจำกัดเริ่มปรากฏให้เห็น
ข้อจำกัดของ Hugging Face สำหรับการสรุปข้อความ
Hugging Face เป็นตัวเลือกที่ยอดเยี่ยมเมื่อคุณต้องการความยืดหยุ่นและการควบคุม แต่เมื่อคุณพยายามใช้มันสำหรับกระบวนการทำงานของทีมจริง ๆ (ไม่ใช่แค่สมุดบันทึกสาธิต) ความท้าทายที่คาดการณ์ได้จะปรากฏขึ้นอย่างรวดเร็ว
ข้อจำกัดของโทเค็นและปัญหาเอกสารยาว
โมเดลสรุปส่วนใหญ่มีข้อจำกัดความยาวอินพุตสูงสุดที่กำหนดไว้ตายตัว ตัวอย่างเช่นfacebook/bart-large-cnnถูกตั้งค่า max_position_embeddings = 1024 ซึ่งหมายความว่าเอกสารที่ยาวกว่านี้มักจะต้องถูกตัดหรือแบ่งเป็นช่วงๆ
หากคุณต้องการเพียงข้อมูลพื้นฐานเบื้องต้นอย่างรวดเร็ว คุณสามารถเปิดใช้งานการตัดข้อความในขั้นตอนของระบบและดำเนินการต่อไปได้ แต่หากคุณต้องการสรุปเอกสารยาวอย่างถูกต้องและครบถ้วน โดยทั่วไปแล้วคุณจะต้องสร้างตรรกะในการแบ่งเอกสารออกเป็นส่วน ๆ จากนั้นจึงดำเนินการสรุปอีกครั้งในขั้นตอนที่สอง หรือที่เรียกว่า "สรุปจากสรุป" เพื่อนำผลลัพธ์มารวมกัน วิธีนี้ต้องใช้การพัฒนาเพิ่มเติม และง่ายต่อการได้ผลลัพธ์ที่ไม่สอดคล้องกัน
ความเสี่ยงของการเห็นภาพหลอน (และภาษีการตรวจสอบ)
โมเดลเชิงนามธรรมอาจสร้างภาพหลอนได้บ้าง โดยสร้างข้อความที่ฟังดูน่าเชื่อถือแต่ไม่ถูกต้องตามข้อเท็จจริง สำหรับการใช้งานที่มีความสำคัญต่อธุรกิจ สิ่งนี้สร้างปัญหา: ทุกการสรุปต้องได้รับการตรวจสอบด้วยมือ ซึ่งในจุดนั้น คุณไม่ได้ประหยัดเวลาจริงๆ แต่เพียงแค่ย้ายงานไปยังส่วนอื่นของกระบวนการเท่านั้น
การขาดการรับรู้บริบท
โมเดล Hugging Face จะรู้เพียงข้อความที่คุณป้อนเข้าไปเท่านั้น มันไม่เข้าใจเป้าหมายของโครงการของคุณ ผู้ที่เกี่ยวข้อง หรือความสัมพันธ์ระหว่างเอกสารแต่ละฉบับ เนื่องจากขาดความฉลาดทางบริบทที่ระบบสมัยใหม่มีมันไม่สามารถบอกคุณได้ว่าสรุปจากการสนทนากับลูกค้าขัดแย้งกับเอกสารข้อกำหนดของโครงการหรือไม่ เพราะมันทำงานแยกออกจากกันโดยสิ้นเชิง
ค่าใช้จ่ายในการผสานรวม (ปัญหา "ไมล์สุดท้าย")
การสร้างสรุปมักจะเป็นส่วนที่ง่าย ส่วนที่ยุ่งยากจริงๆ คือสิ่งที่ตามมาหลังจากนั้น
สรุปนี้ควรอยู่ที่ไหน? ใครจะเห็นมัน? มันจะกลายเป็นงานที่สามารถดำเนินการได้อย่างไร? คุณจะเชื่อมโยงมันกับงานที่เป็นต้นเหตุได้อย่างไร?
การแก้ไขปัญหา "ไมล์สุดท้าย" หมายถึงการสร้างการผสานระบบแบบกำหนดเองและโค้ดเชื่อมต่อ ซึ่งเพิ่มงานให้กับนักพัฒนาตั้งแต่เริ่มต้น และมักสร้างขั้นตอนการทำงานที่ยุ่งยากสำหรับทุกคน
อุปสรรคทางเทคนิคและการบำรุงรักษาอย่างต่อเนื่อง
แนวทางที่ใช้ Python เป็นหลักสามารถเข้าถึงได้ส่วนใหญ่สำหรับผู้ที่สามารถเขียนโค้ดได้ ซึ่งสร้างอุปสรรคทางปฏิบัติสำหรับทีมการตลาด, ทีมขาย, และทีมปฏิบัติการ ซึ่งหมายความว่าการนำไปใช้ยังคงมีจำกัด
นอกจากนี้ยังมาพร้อมกับการบำรุงรักษาอย่างต่อเนื่อง: การจัดการการพึ่งพา, การอัปเดตไลบรารี, และการรักษาให้ทุกอย่างทำงานได้ตามที่ API และโมเดลมีการพัฒนา สิ่งที่เริ่มต้นเป็นความสำเร็จอย่างรวดเร็วอาจกลายเป็นระบบอีกระบบที่ต้องดูแลอย่างเงียบๆ
📮 ClickUp Insight:42% ของการหยุดชะงักในการทำงานเกิดจากการสลับแพลตฟอร์ม การจัดการอีเมล และการกระโดดระหว่างการประชุม แล้วจะเป็นอย่างไรถ้าคุณสามารถกำจัดสิ่งรบกวนที่มีค่าใช้จ่ายเหล่านี้ได้? ClickUp รวมเวิร์กโฟลว์ (และการแชท) ของคุณไว้ในแพลตฟอร์มเดียวที่เรียบง่าย เปิดตัวและจัดการงานของคุณจากแชท เอกสาร กระดานไวท์บอร์ด และอื่นๆ อีกมากมาย ในขณะที่ฟีเจอร์ที่ขับเคลื่อนด้วย AI จะรักษาบริบทให้เชื่อมต่อ ค้นหาได้ และจัดการได้ง่าย
ปัญหาที่ใหญ่กว่า: การขยายตัวของบริบท
แม้ว่าสคริปต์สรุปข้อมูลของคุณจะทำงานได้อย่างสมบูรณ์แบบ ทีมของคุณก็อาจเสียเวลาได้อยู่ดี เพราะผลลัพธ์ที่ได้ไม่สอดคล้องกับจุดที่งานจริงเกิดขึ้น
นั่นคือการขยายบริบทเกินความจำเป็น เมื่อทีมต้องเสียเวลาหลายชั่วโมงไปกับการค้นหาข้อมูล สลับไปมาระหว่างแอปพลิเคชันต่าง ๆ และตามหาไฟล์ที่กระจัดกระจายอยู่บนแพลตฟอร์มที่ไม่เชื่อมต่อกัน
นี่คือจุดที่เวิร์กสเปซแบบรวมศูนย์เปลี่ยนเกมการแข่งขันแทนที่จะสร้างสรุปในที่เดียวแล้วพยายาม "ย้ายไปทำงาน" ในภายหลัง ระบบแบบรวมศูนย์จะเก็บโครงการ เอกสาร และการสนทนาไว้ด้วยกัน โดยมี ClickUp Brain ฝังเป็นชั้นของปัญญาประดิษฐ์ สรุปของคุณจะเชื่อมต่อกับงานและเอกสารต่างๆ ดังนั้นขั้นตอนต่อไปจึงชัดเจน และการส่งต่อจึงเป็นไปอย่างทันที
สรุปที่นำไปสู่การปฏิบัติด้วย ClickUp
สคริปต์สรุปสามารถทำงานได้อย่างสมบูรณ์แบบและยังคงล้มเหลวในทีมของคุณในทางที่น่าหงุดหงิดอย่างหนึ่ง: สรุปนั้นจบลงที่อยู่ในที่ที่แยกจากงาน
ช่องว่างนั้นก่อให้เกิด การกระจายบริบท ซึ่งข้อมูลกระจัดกระจายอยู่ทั่วเอกสาร กระทู้แชท งาน และ "บันทึกย่อ" ในเครื่องมือที่ไม่เชื่อมต่อกัน ผู้คนใช้เวลาในการค้นหาสรุปมากกว่าการใช้สรุปนั้น สิ่งที่ได้จริงไม่ใช่แค่การสร้างสรุปเท่านั้น แต่คือการรักษาสรุปนั้นให้ เชื่อมโยงกับการตัดสินใจ เจ้าของงาน และขั้นตอนถัดไป ซึ่งเป็นจุดที่งานเกิดขึ้นจริง
นั่นคือสิ่งที่ClickUp Brainทำแตกต่างออกไป มันสรุปงาน เอกสาร และการสนทนา ภายในพื้นที่ทำงานเดียวกันกับที่โครงการของคุณอยู่ เพื่อให้ทีมของคุณสามารถเข้าใจและดำเนินการได้โดยไม่ต้องสลับเครื่องมือ

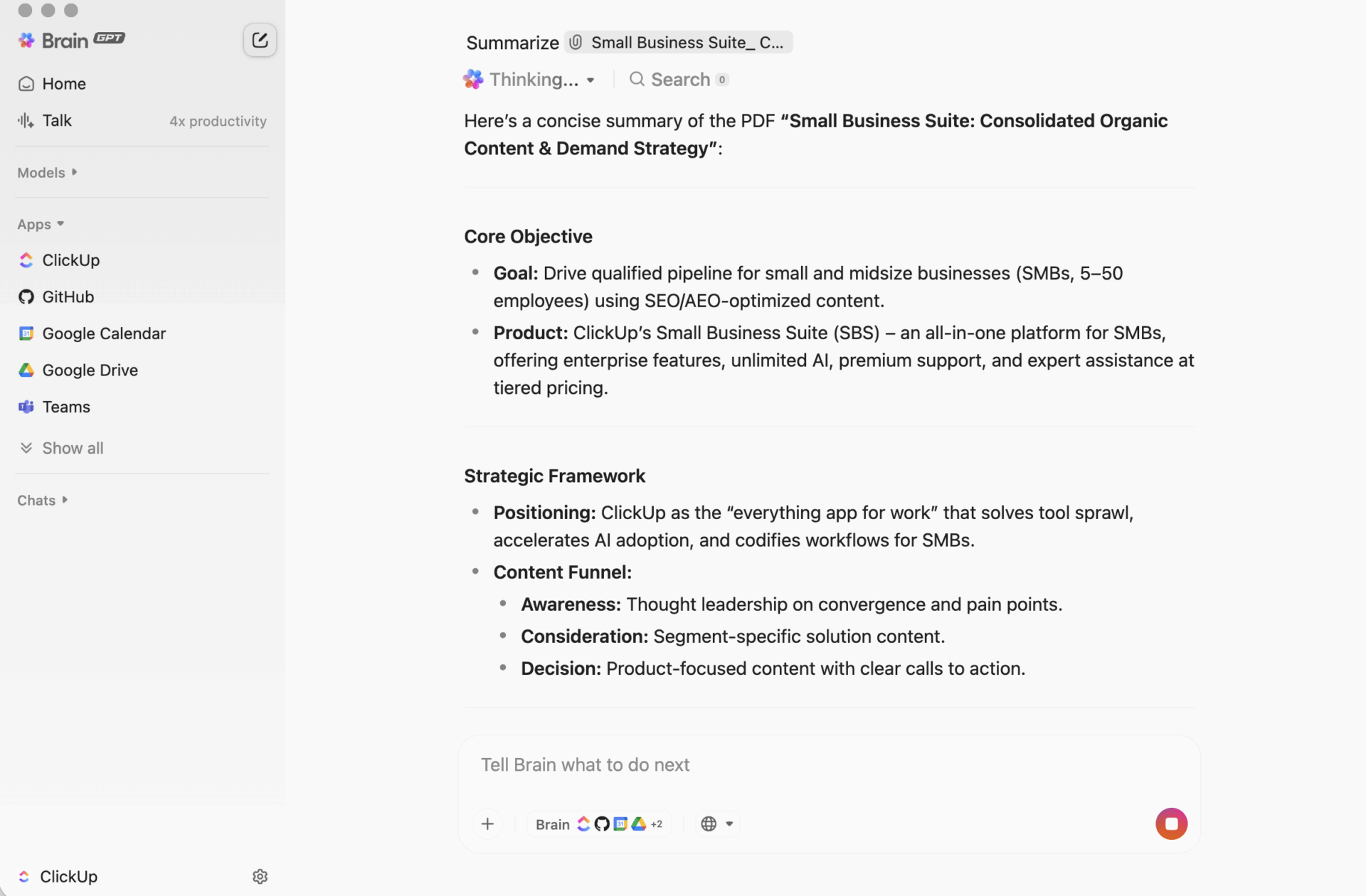
ClickUp BrainGPT: สื่อสารกับสรุปด้วยภาษาธรรมชาติ
บนเดสก์ท็อป BrainGPT คืออินเทอร์เฟซการสนทนาสำหรับ ClickUp Brain แทนที่จะเปิดสคริปต์ โน้ตบุ๊ก หรือเครื่องมือ AI ภายนอก ทีมงานของคุณสามารถขอสิ่งที่ต้องการได้ในภาษาที่เข้าใจง่ายโดยตรงใน ClickUp
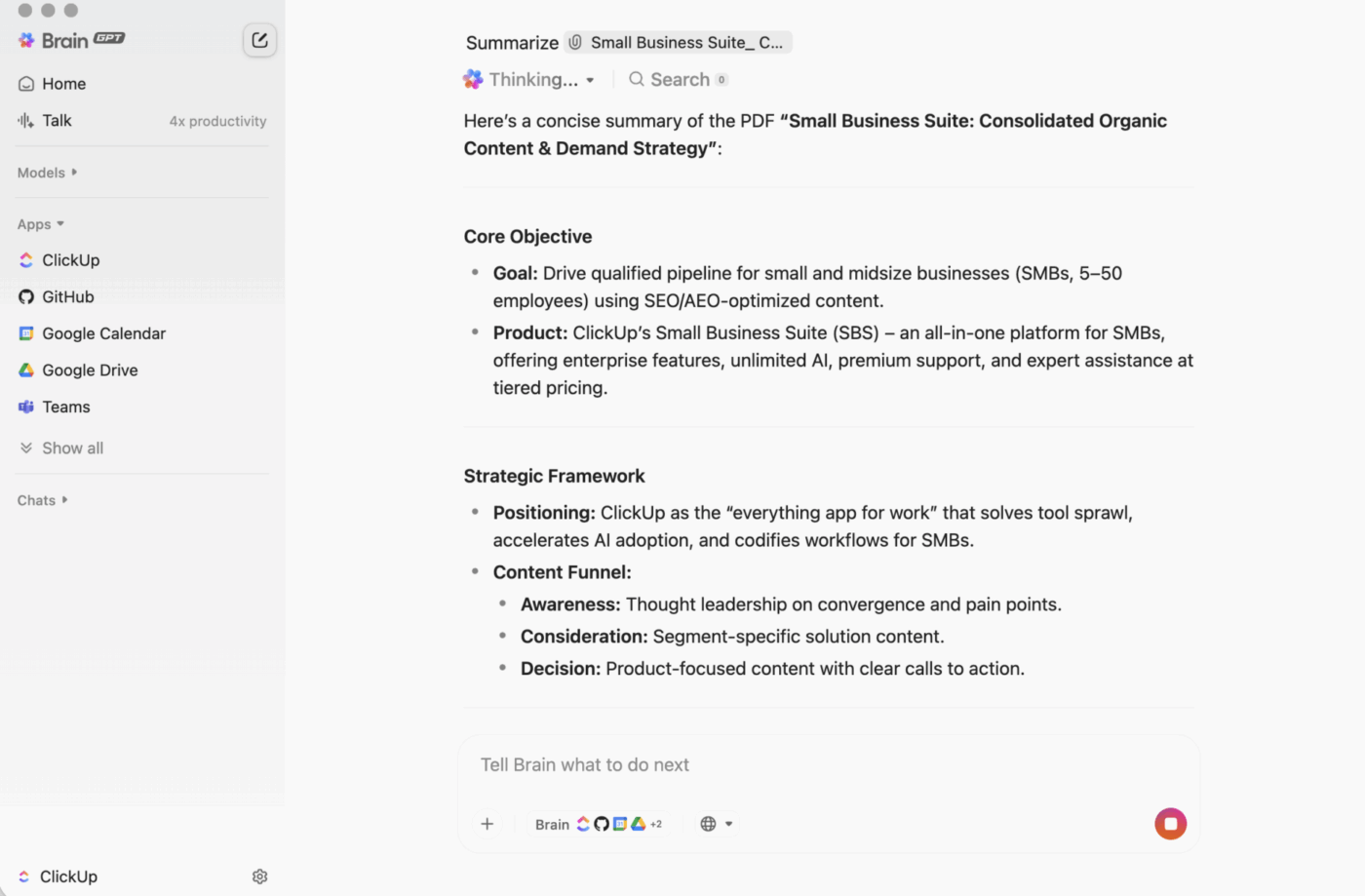
คุณสามารถพิมพ์ (หรือใช้การพูดเป็นข้อความ) เพื่อ:
- สรุป คำอธิบายงานยาว, กระทู้ความคิดเห็น, หรือเอกสาร
- ติดตามผล ด้วยคำถามเช่น "ขั้นตอนต่อไปคืออะไร?" หรือ "ใครเป็นผู้รับผิดชอบเรื่องนี้?"
- เปลี่ยนสรุปให้เป็นงานปฏิบัติ โดยการสร้างงานจากสรุปนั้น พร้อมกำหนดผู้รับผิดชอบและกำหนดเวลาส่ง
เนื่องจาก ClickUp Brain ทำงานภายในพื้นที่ทำงานของคุณ ผลลัพธ์จึงอ้างอิงจาก บริบทสด: คำอธิบายงาน ความคิดเห็น งานย่อย เอกสารที่เชื่อมโยง และโครงสร้างโครงการ คุณไม่ต้องคัดลอกข้อความไปยังเครื่องมืออื่นและหวังว่าข้อมูลสำคัญจะไม่สูญหาย
ทำไมวิธีนี้จึงดีกว่ากระบวนการสรุปผลแบบใช้โค้ดสำหรับทีมส่วนใหญ่
กระบวนการทำงานที่สร้างโดยนักพัฒนาสามารถสร้างสรุปที่แข็งแกร่งได้ แต่ปัญหาจะเกิดขึ้นหลังจากนั้น เมื่อมีคนต้องคัดลอกผลลัพธ์ไปยังที่ที่งานเกิดขึ้น จากนั้นแปลงเป็นงานที่ต้องทำ แล้วติดตามผลต่อไป
ClickUp Brain ปิดวงจรนั้น:
ไม่ต้องเขียนโค้ดใครในทีมก็สามารถสรุปเอกสาร, หัวข้อการสนทนา, หรือชุดความคิดเห็นที่ยุ่งเหยิงได้โดยไม่ต้องติดตั้งอะไรหรือเขียนโค้ด
สรุปตามบริบท ClickUp Brain สามารถรวมส่วนที่ผู้คนมักลืมได้: การตัดสินใจที่ซ่อนอยู่ในความคิดเห็น, อุปสรรคที่กล่าวถึงในคำตอบ, งานย่อยที่เปลี่ยนความหมายของคำว่า "เสร็จแล้ว"
สรุปอยู่ตรงที่งานอยู่ คุณสามารถติดตามความคืบหน้าภายในงาน เพิ่มสรุปไว้ที่ด้านบนของClickUp Docs หรือสรุปประเด็นสำคัญจากการสนทนาได้อย่างรวดเร็วโดยไม่ต้องสร้าง "เอกสารสรุป" เพิ่มเติมที่ไม่มีใครตรวจสอบ
ลดความซับซ้อนของเครื่องมือคุณไม่จำเป็นต้องใช้สคริปต์แยกต่างหาก, โน้ตบุ๊ก Jupyter, คีย์ API หรือขั้นตอนการทำงานที่มีเพียงคนเดียวเท่านั้นที่เข้าใจ เอกสาร, งาน และสรุปทั้งหมดจะอยู่ในระบบเดียวกัน
นี่คือข้อได้เปรียบในทางปฏิบัติของพื้นที่ทำงานแบบรวมศูนย์: การสรุป การดำเนินการ และการทำงานร่วมกันเกิดขึ้นพร้อมกัน แทนที่จะถูกนำมาประกอบเข้าด้วยกันภายหลัง
นี่คือข้อได้เปรียบในทางปฏิบัติของพื้นที่ทำงานแบบรวมศูนย์: การสรุป การดำเนินการ และการทำงานร่วมกันเกิดขึ้นพร้อมกัน แทนที่จะถูกนำมาประกอบเข้าด้วยกันภายหลัง
การทำงานในชีวิตจริง
นี่คือรูปแบบทั่วไปบางอย่างที่ทีมมักใช้:
- สรุปความคิดเห็นในกระทู้: เปิดงานที่มีบทสนทนายาว คลิกตัวเลือก AI แล้วรับสรุปอย่างรวดเร็วเกี่ยวกับสิ่งที่เปลี่ยนแปลงและประเด็นสำคัญ
- สรุปเอกสาร: เปิดเอกสารใน ClickUp และใช้ "Ask AI" เพื่อสร้างสรุปของหน้าเอกสารเพื่อให้ทุกคนสามารถเข้าใจเนื้อหาได้อย่างรวดเร็ว
- สกัดรายการที่ต้องดำเนินการ: นำสรุปมาและแปลงขั้นตอนถัดไปเป็นงานที่มีผู้รับผิดชอบและกำหนดวันครบกำหนดทันที เพื่อไม่ให้แรงขับเคลื่อนหยุดชะงักระหว่างการส่งต่อ
| ความสามารถ | Hugging Face (แบบใช้โค้ด) | ClickUp Brain |
|---|---|---|
| ต้องตั้งค่าก่อน | สภาพแวดล้อมของ Python, ไลบรารี, การเขียนโค้ด | ไม่มี, ในตัว |
| การรับรู้บริบท | ข้อความเท่านั้น (สิ่งที่คุณป้อนเข้าไป) | บริบทของพื้นที่ทำงานทั้งหมด (งาน, เอกสาร, ความคิดเห็น, งานย่อย) |
| การผสานการทำงานของระบบ | การส่งออก/นำเข้าด้วยตนเอง | Native: สรุปสามารถกลายเป็นงานและการอัปเดตได้ |
| ทักษะทางเทคนิคที่ต้องการ | ระดับนักพัฒนา | ทุกคนในทีม |
| การบำรุงรักษา | การบำรุงรักษาแบบจำลองและโค้ดอย่างต่อเนื่อง | การอัปเดตอัตโนมัติ |
จากสรุปสู่การดำเนินการด้วยซูเปอร์เอเจนต์
สรุปมีประโยชน์ ส่วนที่ยากคือการทำให้มั่นใจว่าสรุปเหล่านั้นนำไปสู่การดำเนินการต่อได้อย่างสม่ำเสมอ โดยเฉพาะเมื่อปริมาณงานเพิ่มขึ้น
นั่นคือจุดที่ ClickUp Super Agents เข้ามามีบทบาท พวกเขาสามารถใช้ข้อมูลที่สรุปแล้วและดำเนินการงานต่อไปตามเงื่อนไขและทริกเกอร์ต่าง ๆ ได้ภายในพื้นที่ทำงานเดียวกัน
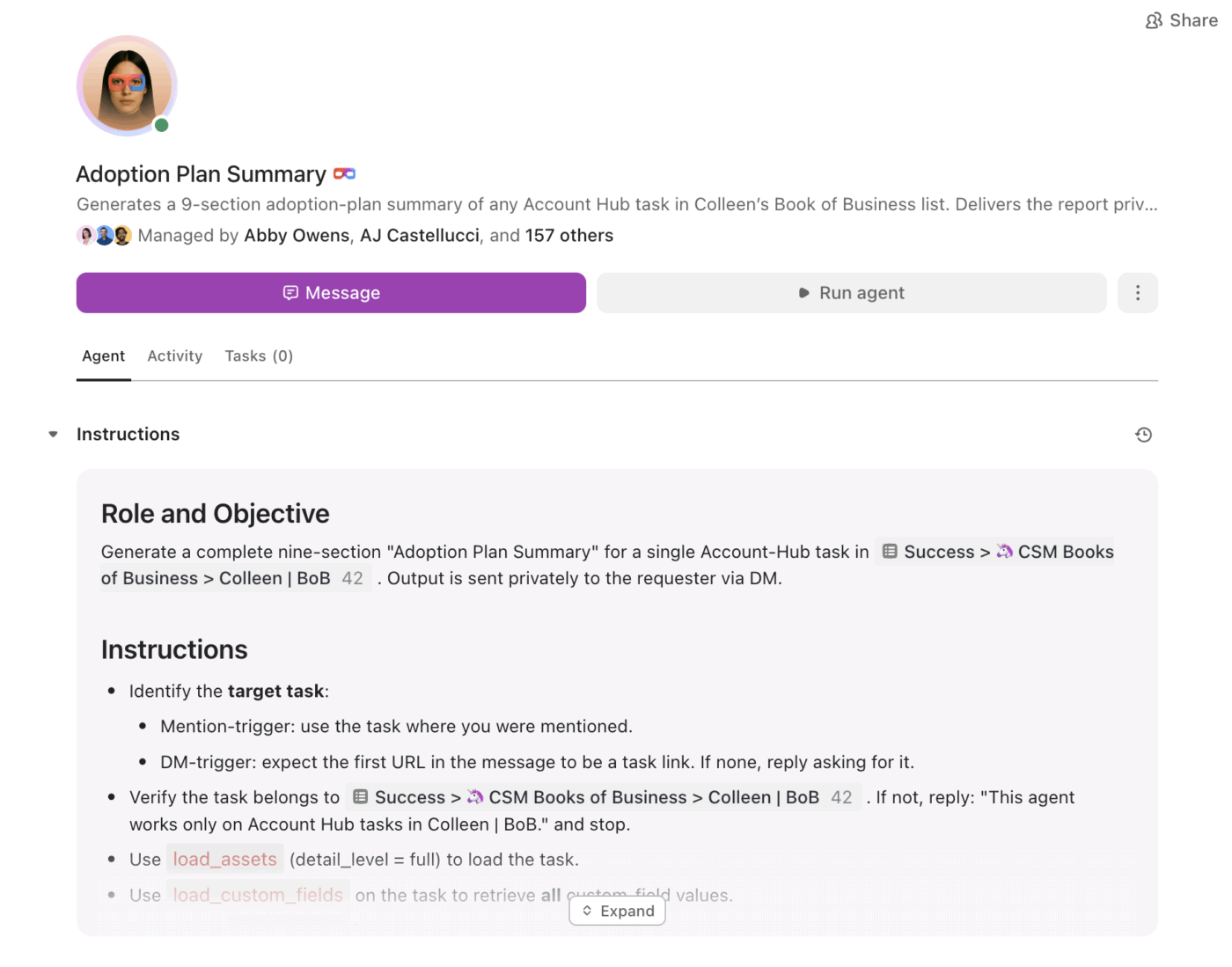
ด้วย Super Agents ทีมสามารถ:
- สรุปการเปลี่ยนแปลงตามกำหนดการ (สรุปโครงการรายสัปดาห์, สรุปสถานะรายวัน)
- สกัดรายการที่ต้องดำเนินการและมอบหมายผู้รับผิดชอบ โดยอัตโนมัติ
- ติดธงงานที่ค้าง (งานที่ติดอยู่ในขั้นตอนการตรวจสอบ, กระทู้ที่ยังไม่มีคำตอบ, ขั้นตอนถัดไปที่เลยกำหนด)
- รักษาการมองเห็นของผู้นำให้สูงอยู่เสมอ โดยไม่ต้องรายงานด้วยตนเอง
แทนที่จะเป็นเพียงข้อความสรุปที่อยู่นิ่ง ๆ ตัวแทนจะช่วยให้มั่นใจว่าสรุปนั้นกลายเป็นแผน และแผนนั้นกลายเป็นความก้าวหน้า
สรุปที่อยู่ในที่ที่การทำงานเกิดขึ้น
Hugging Face Transformers เหมาะอย่างยิ่งเมื่อคุณต้องการแอปพลิเคชันที่ปรับแต่งเองได้, กระบวนการเฉพาะทาง, หรือการควบคุมพฤติกรรมของโมเดลอย่างเต็มที่
แต่สำหรับทีมส่วนใหญ่ ปัญหาที่ใหญ่กว่าไม่ใช่ "เราจะสรุปสิ่งนี้ได้ไหม?" แต่เป็น "เราจะสรุปสิ่งนี้และเปลี่ยนให้เป็นงานได้ทันที พร้อมเจ้าของงาน กำหนดเวลา และความโปร่งใสได้หรือไม่?"
หากเป้าหมายของคุณคือ ประสิทธิภาพของทีมและการดำเนินงานอย่างรวดเร็ว ClickUp Brain จะมอบสรุปเนื้อหาในบริบทที่เหมาะสม ตรงจุดที่งานเกิดขึ้น พร้อมเส้นทางที่ชัดเจนจาก "นี่คือประเด็นสำคัญ" ไปสู่ "นี่คือสิ่งที่เราจะดำเนินการต่อไป"
พร้อมที่จะข้ามขั้นตอนการตั้งค่าและเริ่มสรุปงานของคุณในที่ที่มันอยู่จริงหรือยัง?เริ่มต้นฟรีกับ ClickUpและให้ Brain จัดการงานหนักแทนคุณ