

Jste zaplaveni daty? I ti nejzkušenější odborníci na data se snaží udržet krok s přílivem dat generovaných digitálním světem, nemluvě o snaze zefektivnit procesy. Od webové analytiky přes zákaznická data až po metriky výkonu – máte na starosti, aby tato data byla co nejpřesnější a nejaktuálnější. ✨
Pro vytvoření a údržbu databáze pro vaše podnikání je nezbytný solidní návrh databáze, ale i tak musíte vědět, jak zabránit vzájemnému ovlivňování a redundanci dat. Závislosti definují vztah mezi datovými atributy, což pomáhá ve všech ohledech, od přesnosti dat až po pokročilé analýzy.
A co je nejlepší? Na výběr je tolik různých typů závislostí. Funkční závislosti jsou však nezbytností, pokud se nemůžete dočkat, až vytvoříte databázi.
V tomto průvodci vysvětlíme, co je funkční závislost, uvedeme několik příkladů všech funkčních závislostí a nabídneme užitečné tipy, jak maximalizovat výkon relační databáze.
Co je funkční závislost?
Funkční závislost je typ závislosti, ve kterém existuje vztah mezi dvěma proměnnými. Na levé straně je determinantní atribut, známý také jako primární klíč, a na pravé straně je závislý atribut, známý také jako neklíčový atribut. Funkce nebo výsledek se bude měnit v závislosti na vztahu mezi těmito dvěma proměnnými.
Víme, že to zní trochu komplikovaně, proto vám vysvětlíme, jak funkční závislosti fungují:
- Řekněme, že používáte software pro správu zákaznické databáze ke sledování narozenin svých zákazníků. Chcete zákazníkům poslat personalizovaný e-mail v den jejich narozenin, abyste si u nich získali přízeň.
- Funkční závislost potřebujete, abyste mohli každému uživateli poslat e-mail k jeho narozeninám – koneckonců, nebylo by trochu divné poslat 300 lidem irelevantní hromadný e-mail s přáním „Všechno nejlepší k narozeninám“?
- V tomto případě závisí funkce odeslání e-mailu na proměnné narozenin zákazníka.
- Pokud chcete tento typ vztahu ve své databázi, musíte nastavit funkční závislost mezi datem narozenin zákazníka a funkcí, která odesílá e-mail v den jeho narozenin.
Funkční závislosti jsou základem normalizace databáze. Normalizací organizujete databázi – podobně jako při úklidu pokoje – tak, aby se data neopakovala.
Pravidla funkčních závislostí v systémech správy databází
Funkční závislosti se řídí několika pravidly odvození, která se také nazývají Armstrongovy axiomy.
Existují tři hlavní pravidla funkční závislosti:
- Reflexivita: Reflexivní pravidlo říká, že pokud atribut A souvisí s atributem X, pak atribut X souvisí s atributem A. Například pokud A je křestní jméno a X je příjmení, tyto dva atributy budou vždy souviset.
- Rozšíření: Pravidlo rozšíření říká, že pokud přidáte data do proměnné, což se také nazývá rozšíření, musíte toto rozšíření přidat do sady atributů. Pokud tedy rozšíříte pole křestního jména o přezdívku, bude se toto pole nyní vztahovat také k poli příjmení.
- Transitivita: Pravidlo transitivity říká, že pokud atribut A souvisí s atributem C, pak podle asociace se atribut B rovná také atributu C. Nenechte se tím zmást – transitivní závislost znamená, že někdy jedna věc může určovat druhou, která určuje třetí věc. Například pokud ve své CRM platformě generujete čárové kódy pro zákazníky na základě jejich jména a příjmení, pak jméno určuje místo zákazníka v abecedním seznamu.
Funkční závislosti promění vaše datové modely v reálné relační schéma pomocí SQL, které zachovává integritu vašich dat. V praxi můžete funkční závislosti použít ve svém systému pro správu databází (DBMS), abyste se zbavili redundance dat a nepříjemných překvapení, která narušují databáze. 👀
Plná funkční závislost versus částečná funkční závislost
Než se podíváme na různé typy funkčních závislostí, je důležité rozlišovat mezi částečnými a plně funkčními závislostmi.
Řekněme, že vkládáte data z organizačního schématu do databáze. Při plné funkční závislosti závisí atribut na jiné sadě atributů, ale ne na podsadu tohoto atributu. Řekněme, že máme kombinaci „Jméno zaměstnance“ a „ID zaměstnance“, která určuje „Umístění“.
Pokud znáte „jméno zaměstnance“ a „ID zaměstnance“, můžete určit „umístění“. Nicméně nemůžete určit „umístění“ pouze na základě těchto dvou proměnných. V tomto případě je „umístění“ plně závislé na kombinaci „jména zaměstnance“ a „ID zaměstnance“.
Částečná funkční závislost nastává, když atribut závisí pouze na části primárního klíče namísto složeného primárního klíče. Pokud například můžete zjistit datové pole „Počet odpracovaných let“ pomocí „ID zaměstnance“, máte částečnou závislost, protože „Počet odpracovaných let“ nezávisí na „Umístění“.
Může to znít jako malý rozdíl, ale má to velké důsledky pro normalizaci dat. Částečné funkční závislosti mohou vést k redundanci v databázi, což znamená, že je musíte řešit v druhé normální formě normalizačního procesu, neboli 2NF. Není to konec světa, ale rozhodně je to něco, co budete muset v budoucnu opravit. 🛠️
První, druhá a třetí normální forma v SQL
Cílem normalizace dat je odstranit z databáze všechny anomálie při vkládání, aktualizaci nebo mazání, které mohou způsobit chaos. Normalizace s funkčními závislostmi se provádí ve třech krocích.
První normální forma
První normální formu považujte za základ pro budování systému, ve kterém můžete používat funkční závislosti. Vytváří základ pro identifikaci závislostí ve druhé a třetí normální formě. Technicky řečeno, 1NF má atributy, které obsahují pouze atomické hodnoty, což zajišťuje, že se žádné skupiny neopakují.
Druhá normální forma
Po zpracování dat pomocí 1NF získáte tabulku, ve které jsou všechny atributy, které nejsou klíčové, plně funkčně závislé na primárním klíči. V 2NF odstraníte částečné závislosti rozdělením tabulek, abyste se ujistili, že každý atribut, který není klíčový, je plně závislý na primárním klíči.
Třetí normální forma
Poté, co je datová tabulka v 2NF, přejde do 3NF, jakmile jsou všechny atributy funkčně závislé pouze na primárním klíči a na ničem jiném. V 3ND odstraníte všechny tranzitivní závislosti prostřednictvím dalšího rozdělení tabulky v této fázi.
1NF připravuje půdu pro funkční závislosti, zatímco 2NF a 3NF zdokonalují způsob organizace dat restrukturalizací funkčních závislostí. Tím je zajištěno, že každý úryvek dat je uložen na nejlogičtějším místě, což snižuje redundanci a zvyšuje integritu dat.
Typy funkčních závislostí s příklady
Pokud jste připraveni začít používat funkční závislosti, máte na výběr ze čtyř možností.
Triviální
Triviální závislost je základní typ funkční závislosti, kdy atribut nebo sada atributů určuje sama sebe. Každá jednotlivá závislost je zde podmnožinou vašeho determinantu. Jinými slovy, pokud C je podmnožinou A, funkční vztah je triviální.
Může to znít trochu zřejmě, ale příkladem může být identifikace názvu knihy, když znáte jak název, tak autora. Vztah mezi těmito dvěma atributy je poměrně snadno pochopitelný, proto jsou triviální funkční závislosti nejjednodušší k pochopení.
Netriviální
Zde se věci stávají zajímavějšími. V netriviální funkční závislosti může jeden atribut určovat jiný odlišný atribut. V tomto případě je A souborem atributů, stejně jako B, ale B není podmnožinou A. Pokud B není podmnožinou A, mají netriviální vztah.
Máte netriviální vztah, pokud vytvoříte databázi knih, přiřadíte každé knize jedinečný kód a můžete vyhledat název knihy, pokud znáte kód přiřazený knize.
Vícehodnotové
U vícehodnotové závislosti se jeden atribut spojuje s několika dalšími atributy. Atributy ve vaší sadě závislých prvků na sobě nejsou vzájemně závislé. Pokud tedy atributy A a C nemají funkční závislost, je vztah mezi B, A a C vícehodnotový.
Abychom pokračovali v analogii s knihou, je to jako autor, který napsal mnoho knih. Pokud znáte jeho jméno, můžete vypsat všechny knihy, které napsal. V případě vícehodnotové funkční závislosti bude mít jeden autor více knih spojených se svým jménem.
Transitivní
Transitivní funkční závislost nastává, když jeden atribut určuje druhý a ten další. Je to něco jako řetězová reakce. Pokud vám to zní povědomě, je to proto, že tento typ funkční závislosti se řídí pravidlem transitivity.
V tomto případě, pokud A se rovná B a B se rovná C, pak A se musí rovnat C. Řekněme, že vytváříte databázi knih a vaše jedinečné kódy knih určují vydavatele a jejich žánry. Pokud znáte kód knihy, můžete zjistit, kdo je vydavatelem a jaký je její žánr.
Jak používat funkční závislosti pro správu databází
Chcete začít používat funkční závislosti? Funkční závislosti můžete používat podle svého uvážení, ale pokud potřebujete pracovat chytřeji a s menším úsilím, sáhněte po ClickUp.
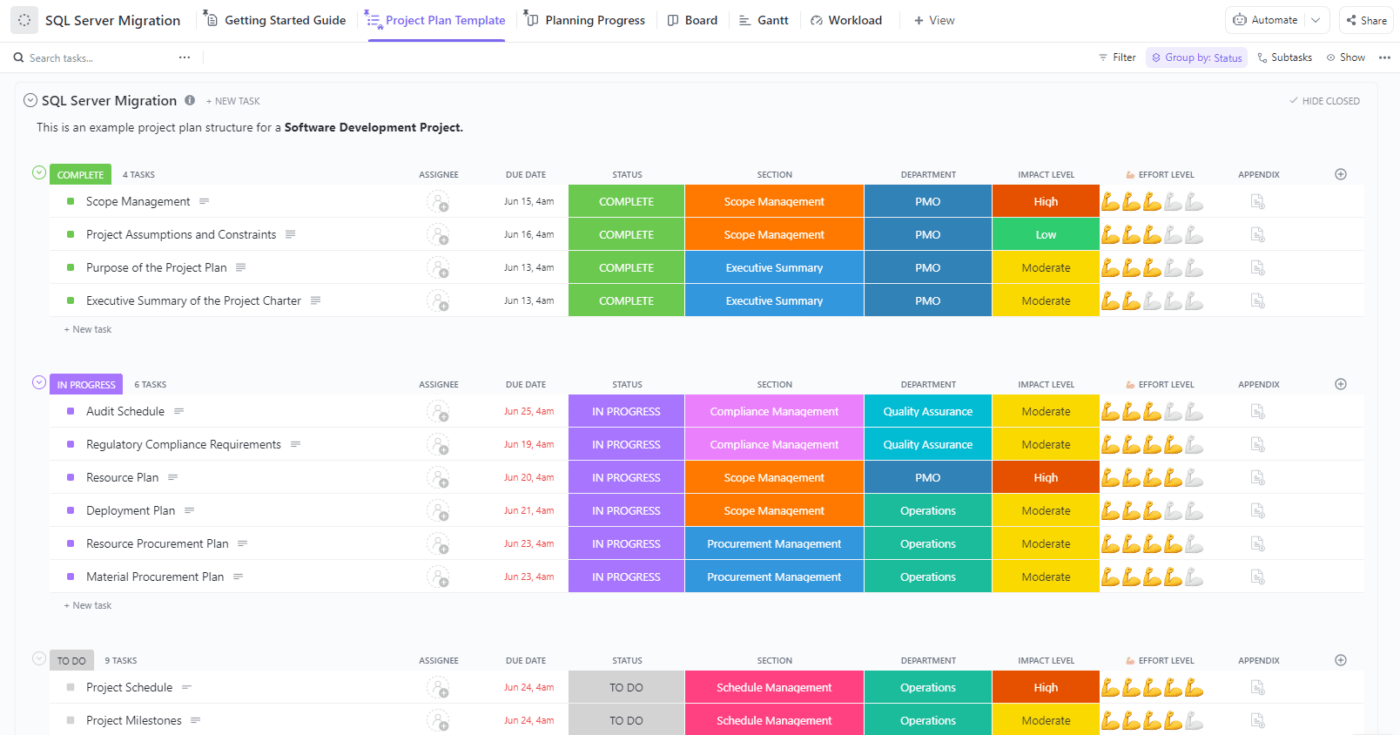
Zde je stručný přehled toho, jak vytvořit databázi v ClickUp a začlenit funkční závislosti:
Nejprve je třeba nastavit databázi v ClickUp. Můžete importovat datové listy z Excelu nebo vytvořit vlastní od začátku.
Zobrazení tabulky ClickUp umožňuje hromadnou úpravu a další vlastní zobrazení pro sledování dat prakticky čehokoli. ClickUp také vizualizuje data, abyste mohli svou databázi uzavřít v rekordním čase.
Dobrou zprávou je, že nemusíte začínat úplně od nuly. Šablony databází ClickUp usnadňují vytváření databází.
Šablona databáze ClickUp Blog je velmi užitečná pro plánování obsahu a šablona ClickUp Employee Directory je ideální pro rychlé vytvoření databáze s kontaktními údaji spolupracovníků. Jedná se také o databázi bez kódu, takže pokud chcete vytvořit databázi bez nutnosti učit se SQL, máme pro vás řešení.
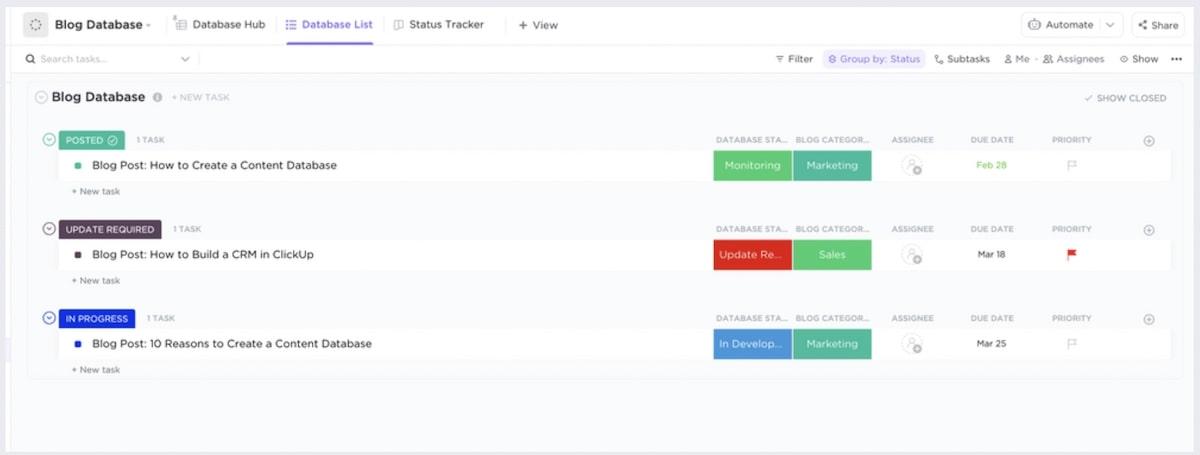
Začlenění funkčních závislostí do ClickUp
Normálně byste museli použít SQL, abyste mohli vytvořit funkční závislosti v databázi. Naštěstí rozhraní ClickUp s funkcí drag-and-drop usnadňuje vytváření vztahů mezi úkoly a dokumenty. Není na škodu, že nástroje AI v ClickUp usnadňují správu databází, i když sami nejste odborníci na databáze.
Zde je návod, jak vytvořit závislost ve vaší databázi ClickUp.
Nejprve klikněte na úkol, se kterým chcete pracovat.
Přejděte do části Vztahy > Závislost. Vyberte si z možností Čekání na, Blokování a Úkoly a přizpůsobte vztah.

V tomto případě vybereme Čekání na a vyhledáme další úkol, který bude souviset s aktuálním úkolem.
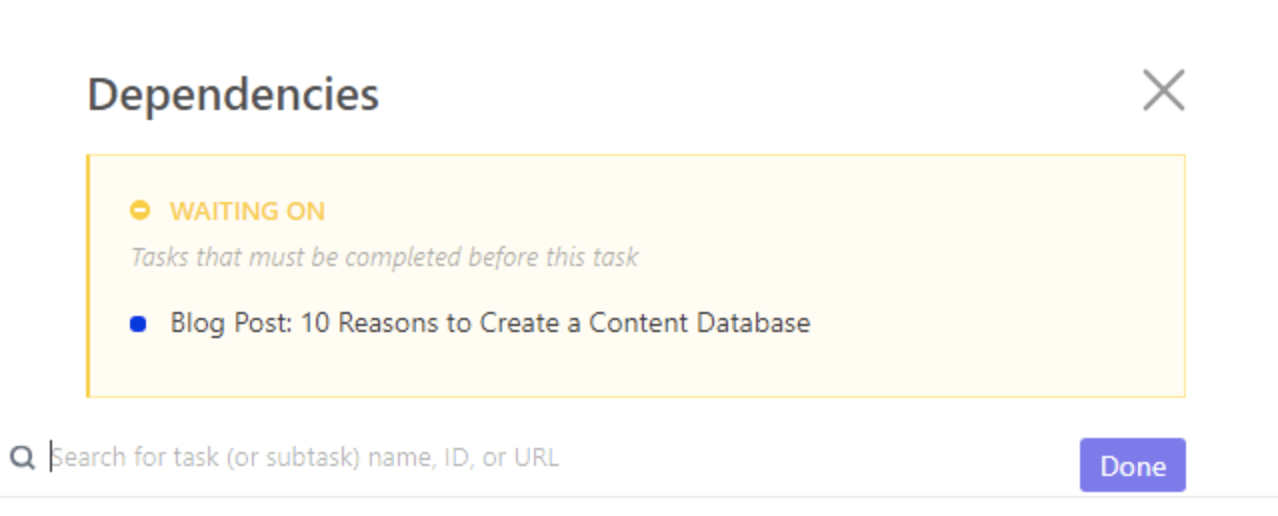
Klikněte na „Hotovo“ a máte hotovo! 🙌
Zjednodušte závislosti pomocí ClickUp
Kdo říká, že správa databází musí být složitá? Pokud rozumíte fungování funkčních závislostí, navrhnete rychlou a přesnou databázi, která pomůže vaší organizaci v dalším rozvoji.
A nemusíte to dělat sami. ClickUp je spolehlivý systém pro správu databází, který kombinuje data se šablonami, projekty, úkoly, cíli a vším ostatním.
Ušetřete více času a soustřeďte se na úkoly s vysokou přidanou hodnotou díky přechodu na skutečně komplexní platformu ClickUp.
Vyzkoušejte to sami: Vytvořte si bezplatný účet ClickUp a vytvořte lepší databázi!