
ทีมส่วนใหญ่ที่กำลังสำรวจโมเดล AI แบบโอเพนซอร์สพบว่า LLaMA ของ Meta มอบการผสมผสานที่หายากระหว่างพลังและความยืดหยุ่น แต่การตั้งค่าทางเทคนิคอาจรู้สึกเหมือนการประกอบเฟอร์นิเจอร์โดยไม่มีคำแนะนำ
คู่มือนี้จะนำคุณผ่านขั้นตอนการสร้างแชทบอท LLaMA ที่ใช้งานได้จริงตั้งแต่เริ่มต้น ครอบคลุมทุกสิ่งตั้งแต่ข้อกำหนดด้านฮาร์ดแวร์และการเข้าถึงโมเดล ไปจนถึงการออกแบบคำสั่งและการปรับใช้กลยุทธ์
มาเริ่มกันเลย!
LLaMA คืออะไรและทำไมจึงใช้สำหรับแชทบอท?
การสร้างแชทบอทด้วย API ที่เป็นกรรมสิทธิ์มักให้ความรู้สึกเหมือนคุณถูกจำกัดอยู่ในระบบของผู้อื่น ต้องเผชิญกับค่าใช้จ่ายที่ไม่แน่นอนและคำถามเกี่ยวกับความเป็นส่วนตัวของข้อมูลการถูกผูกขาดกับผู้ให้บริการรายนี้หมายความว่าคุณไม่สามารถปรับแต่งโมเดลให้ตรงกับความต้องการเฉพาะของทีมได้อย่างแท้จริง ส่งผลให้คำตอบที่ได้เป็นแบบทั่วไปและอาจนำไปสู่ปัญหาด้านการปฏิบัติตามข้อกำหนด
LLaMA (Large Language Model Meta AI) คือกลุ่มของโมเดลภาษาแบบน้ำหนักเปิดของ Meta และเป็นทางเลือกที่ทรงพลัง มันถูกออกแบบมาเพื่อทั้งการวิจัยและการใช้งานเชิงพาณิชย์ มอบการควบคุมที่โมเดลแบบปิดไม่ให้
โมเดล LLaMA มีหลายขนาด ซึ่งวัดจากจำนวนพารามิเตอร์ (เช่น 7B, 13B, 70B) พารามิเตอร์เปรียบเสมือนมาตรวัดความซับซ้อนและศักยภาพของโมเดล—โมเดลที่มีขนาดใหญ่กว่าจะมีความสามารถมากกว่า แต่ต้องใช้ทรัพยากรการคำนวณมากขึ้น
นี่คือเหตุผลที่คุณอาจใช้แชทบอท LLaMA:
- ความเป็นส่วนตัวของข้อมูล: เมื่อคุณรันโมเดลบนโครงสร้างพื้นฐานของคุณเอง ข้อมูลการสนทนาของคุณจะไม่ถูกนำออกจากสภาพแวดล้อมของคุณเลย นี่เป็นสิ่งสำคัญอย่างยิ่งสำหรับทีมที่จัดการข้อมูลที่มีความอ่อนไหว
- การปรับแต่ง: คุณสามารถปรับแต่งโมเดล LLaMA ให้เหมาะสมกับเอกสารหรือข้อมูลภายในบริษัทของคุณได้ ซึ่งช่วยให้โมเดลเข้าใจบริบทเฉพาะของคุณและให้คำตอบที่เกี่ยวข้องมากยิ่งขึ้น
- ความคาดการณ์ได้ของค่าใช้จ่าย: หลังจากติดตั้งฮาร์ดแวร์ครั้งแรกแล้ว คุณไม่ต้องกังวลเกี่ยวกับค่าธรรมเนียม API ต่อโทเค็น ค่าใช้จ่ายของคุณจะคงที่และคาดการณ์ได้
- ไม่มีข้อจำกัดด้านอัตรา: ความสามารถของแชทบอทของคุณถูกจำกัดโดยฮาร์ดแวร์ของคุณเอง ไม่ใช่โดยโควต้าของผู้ให้บริการ คุณสามารถปรับขนาดได้ตามต้องการ
ข้อแลกเปลี่ยนหลักคือความสะดวกในการควบคุม LLaMA ต้องการการตั้งค่าทางเทคนิคมากกว่า API แบบเสียบแล้วใช้ได้เลย สำหรับแชทบอทที่ใช้ในเชิงการผลิต ทีมมักจะใช้ LLaMA 2 หรือ LLaMA 3 รุ่นใหม่กว่า ซึ่งมีการให้เหตุผลที่ดีขึ้นและสามารถจัดการข้อความได้มากขึ้นในคราวเดียว
สิ่งที่คุณต้องเตรียมก่อนสร้างแชทบอท LLaMA
การกระโดดเข้าไปในโครงการพัฒนาโดยไม่มีเครื่องมือที่เหมาะสมเป็นสูตรสำเร็จของความหงุดหงิด คุณจะทำงานไปได้ครึ่งทางแล้วจึงตระหนักว่าคุณขาดฮาร์ดแวร์หรือการเข้าถึงซอฟต์แวร์ที่สำคัญ ซึ่งจะทำให้ความคืบหน้าของคุณหยุดชะงักและเสียเวลาไปหลายชั่วโมง
เพื่อหลีกเลี่ยงปัญหานี้ กรุณาเตรียมทุกอย่างที่จำเป็นไว้ล่วงหน้า นี่คือรายการตรวจสอบเพื่อให้เริ่มต้นได้อย่างราบรื่น 🛠️
ข้อกำหนดด้านฮาร์ดแวร์
| ขนาดของแบบจำลอง | หน่วยความจำวิดีโอขั้นต่ำ | ทางเลือกอื่น |
|---|---|---|
| พารามิเตอร์ 7B | 8GB | อินสแตนซ์ GPU บนคลาวด์ |
| พารามิเตอร์ 13B | 16GB | อินสแตนซ์ GPU บนคลาวด์ |
| พารามิเตอร์ 70B | หลาย GPU | การควอนไทซ์หรือคลาวด์ |
หากเครื่องคอมพิวเตอร์ของคุณไม่มีหน่วยประมวลผลกราฟิก (GPU) ที่ทรงพลังเพียงพอ คุณสามารถใช้บริการคลาวด์เช่น AWS หรือ GCP ได้ แพลตฟอร์มการอนุมานเช่น Baseten และ Replicate ก็มีการให้บริการ GPU แบบชำระเงินตามการใช้งานเช่นกัน
ข้อกำหนดทางซอฟต์แวร์
- Python 3. 8+: นี่คือภาษาการเขียนโปรแกรมมาตรฐานสำหรับโครงการการเรียนรู้ของเครื่อง
- ผู้จัดการแพ็กเกจ: คุณจะต้องใช้ pip หรือ Conda เพื่อติดตั้งไลบรารีที่จำเป็นสำหรับโปรเจกต์ของคุณ
- สภาพแวดล้อมเสมือน: นี่คือแนวทางปฏิบัติที่ดีที่สุดที่ช่วยให้การพึ่งพาของโครงการของคุณแยกออกจากโครงการ Python อื่นๆ บนเครื่องของคุณ
ข้อกำหนดการเข้าถึง
- บัญชี Hugging Face: คุณจะต้องมีบัญชีเพื่อดาวน์โหลดน้ำหนักของโมเดล LLaMA
- การอนุมัติจาก Meta: คุณต้องยอมรับข้อตกลงใบอนุญาตของ Meta เพื่อเข้าถึงโมเดล LLaMA ซึ่งโดยปกติจะได้รับการอนุมัติภายในไม่กี่ชั่วโมง
- คีย์ API: สิ่งเหล่านี้จำเป็นเฉพาะเมื่อคุณตัดสินใจใช้จุดสิ้นสุดการอนุมานที่โฮสต์แทนการรันโมเดลในเครื่อง
สำหรับคู่มือนี้ เราจะใช้วงจรการทำงานของ LangChain ซึ่งช่วยให้ง่ายขึ้นในส่วนที่ซับซ้อนหลายอย่างของการสร้างแชทบอท เช่น การจัดการคำสั่งและการบันทึกประวัติการสนทนา
{kind=link}
วิธีสร้างแชทบอทด้วย LLaMA ทีละขั้นตอน
การเชื่อมต่อชิ้นส่วนทางเทคนิคทั้งหมดของแชทบอท—ไม่ว่าจะเป็นโมเดล คำสั่งเริ่มต้น หรือหน่วยความจำ—อาจดูเป็นเรื่องที่ซับซ้อนและน่ากังวล เป็นเรื่องง่ายที่จะหลงทางในโค้ด ซึ่งนำไปสู่ข้อผิดพลาดและแชทบอทที่ไม่ทำงานตามที่คาดหวัง คู่มือแบบทีละขั้นตอนนี้จะช่วยให้คุณสามารถแบ่งกระบวนการออกเป็นส่วนย่อย ๆ ที่เข้าใจง่ายและจัดการได้
วิธีการนี้ใช้ได้ผลไม่ว่าคุณจะรันโมเดลบนเครื่องของคุณเองหรือใช้บริการโฮสต์ก็ตาม
ขั้นตอนที่ 1: ติดตั้งแพ็กเกจที่จำเป็น
ก่อนอื่น คุณต้องติดตั้งไลบรารี Python หลักก่อน. เปิดเทอร์มินัลของคุณ และรันคำสั่งนี้:
pip install langchain transformers accelerate torch
หากคุณกำลังใช้บริการโฮสต์เช่น Baseten สำหรับการอนุมาน คุณจะต้องติดตั้งชุดพัฒนาซอฟต์แวร์ (SDK) เฉพาะของมันด้วย:
pip install baseten
นี่คือสิ่งที่แต่ละแพ็กเกจเหล่านี้ทำ:
- Langchain: เฟรมเวิร์กที่ช่วยในการสร้างแอปพลิเคชันที่ใช้โมเดลภาษาขนาดใหญ่ รวมถึงการจัดการโซ่การสนทนาและความจำ
- Transformers: ไลบรารี Hugging Face สำหรับโหลดและรันโมเดล LLaMA
- เร่งความเร็ว: ไลบรารีที่ช่วยเพิ่มประสิทธิภาพในการโหลดโมเดลเข้าสู่ CPU และ GPU ของคุณ
- Torch: ไลบรารี PyTorch ซึ่งให้พลังการคำนวณเบื้องหลังสำหรับการคำนวณของโมเดล
หากคุณกำลังรันโมเดลบนเครื่องที่มี NVIDIA GPU ให้ตรวจสอบให้แน่ใจว่าคุณได้ติดตั้งและกำหนดค่า CUDA อย่างถูกต้องแล้ว การทำเช่นนี้จะช่วยให้โมเดลสามารถใช้ GPU เพื่อเพิ่มประสิทธิภาพการทำงานได้เร็วขึ้นมาก
ขั้นตอนที่ 2: เข้าถึงโมเดล LLaMA
ก่อนที่คุณจะสามารถดาวน์โหลดโมเดลได้ คุณจำเป็นต้องได้รับการเข้าถึงอย่างเป็นทางการจาก Meta ผ่านทาง Hugging Face
- สร้างบัญชีบนhuggingface.co
- ไปที่หน้าของโมเดล เช่น meta-llama/Llama-2-7b-chat-hf
- คลิก "เข้าถึงแหล่งข้อมูล" และยอมรับข้อกำหนดการใช้งานของ Meta
- ในหน้าการตั้งค่าบัญชี Hugging Face ของคุณ ให้สร้างโทเค็นการเข้าถึงใหม่
- ในเทอร์มินัลของคุณ ให้รัน huggingface-cli login และวางโทเค็นของคุณเพื่อยืนยันตัวตนของเครื่อง
การอนุมัติมักจะรวดเร็ว ตรวจสอบให้แน่ใจว่าคุณเลือกแบบจำลองที่มีคำว่า 'แชท' ในชื่อ เนื่องจากแบบจำลองเหล่านี้ได้รับการฝึกอบรมมาโดยเฉพาะสำหรับงานการสนทนา
ขั้นตอนที่ 3: โหลดโมเดล LLaMA
ตอนนี้คุณสามารถโหลดโมเดลเข้าไปในโค้ดของคุณได้แล้ว คุณมีตัวเลือกหลักสองอย่างขึ้นอยู่กับฮาร์ดแวร์ของคุณ
หากคุณมี GPU ที่ทรงพลังเพียงพอ คุณสามารถโหลดโมเดลไว้ในเครื่องได้:
หากฮาร์ดแวร์ของคุณมีข้อจำกัด คุณสามารถใช้บริการอินเฟอร์เรนซ์แบบโฮสต์ได้:
คำสั่ง device_map="auto" บอกให้ไลบรารี transformers จัดสรรโมเดลไปยัง GPU ที่มีอยู่โดยอัตโนมัติ
หากคุณยังคงประสบปัญหาหน่วยความจำไม่เพียงพอ คุณสามารถใช้เทคนิคที่เรียกว่าการควอนไทเซชัน (quantization) เพื่อลดขนาดของโมเดลได้ แม้ว่าวิธีนี้อาจทำให้ประสิทธิภาพลดลงเล็กน้อยก็ตาม
ขั้นตอนที่ 4: สร้างแม่แบบข้อความแจ้งเตือน
โมเดลแชท LLaMA ได้รับการฝึกฝนให้คาดหวังรูปแบบเฉพาะสำหรับคำสั่ง คำสั่งแบบเทมเพลตช่วยให้มั่นใจว่าข้อมูลที่คุณป้อนมีโครงสร้างที่ถูกต้อง
มาแยกแยะรูปแบบนี้กัน:
- <
>: ส่วนนี้ประกอบด้วยข้อความแจ้งเตือนของระบบ ซึ่งให้คำแนะนำหลักแก่โมเดลและกำหนดบุคลิกของมัน - [INST]: นี่คือจุดเริ่มต้นของคำถามหรือคำแนะนำของผู้ใช้
- [/INST]: สัญญาณนี้บอกให้โมเดลทราบว่าถึงเวลาที่ต้องสร้างคำตอบ
โปรดทราบว่า LLaMA เวอร์ชันต่างๆ อาจใช้แม่แบบที่แตกต่างกันเล็กน้อย ควรตรวจสอบเอกสารประกอบของโมเดลบน Hugging Face เสมอเพื่อใช้รูปแบบที่ถูกต้อง
ขั้นตอนที่ 5: ตั้งค่าโซ่แชทบอท
ต่อไป คุณจะเชื่อมต่อโมเดลและเทมเพลตคำสั่งของคุณเข้าด้วยกันเป็นสายโซ่การสนทนาโดยใช้ LangChain สายโซ่นี้จะรวมถึงหน่วยความจำเพื่อใช้ติดตามการสนทนาด้วย
LangChain มีหน่วยความจำหลายประเภท:
- ConversationBufferMemory: นี่คือตัวเลือกที่ง่ายที่สุด มันเก็บประวัติการสนทนาทั้งหมด
- สรุปความจำการสนทนา: เพื่อประหยัดพื้นที่ ตัวเลือกนี้จะสรุปส่วนที่เก่ากว่าของการสนทนาเป็นระยะ
- ConversationBufferWindowMemory: เก็บเพียงการแลกเปลี่ยนข้อความล่าสุดไม่กี่รายการไว้ในหน่วยความจำ ซึ่งมีประโยชน์ในการป้องกันไม่ให้บริบทยาวเกินไป
สำหรับการทดสอบ ConversationBufferMemory เป็นจุดเริ่มต้นที่ดี
ขั้นตอนที่ 6: ดำเนินการวนลูปของแชทบอท
สุดท้ายนี้ คุณสามารถสร้างลูปง่าย ๆ เพื่อโต้ตอบกับแชทบอทของคุณจากเทอร์มินัลได้
ในการใช้งานจริง คุณจะแทนที่ลูปนี้ด้วยจุดสิ้นสุดของ API โดยใช้เฟรมเวิร์กเช่น FastAPI หรือ Flask คุณยังสามารถสตรีมการตอบสนองของโมเดลกลับไปยังผู้ใช้ได้ ซึ่งจะทำให้แชทบอทรู้สึกเร็วขึ้นมาก
คุณยังสามารถปรับพารามิเตอร์เช่นอุณหภูมิเพื่อควบคุมความสุ่มของคำตอบได้ อุณหภูมิต่ำ (เช่น 0.2) จะทำให้ผลลัพธ์มีความแน่นอนและเป็นข้อเท็จจริงมากขึ้น ในขณะที่อุณหภูมิสูง (เช่น 0.8) จะส่งเสริมความคิดสร้างสรรค์มากขึ้น
วิธีทดสอบแชทบอท LLaMA ของคุณ
คุณได้สร้างแชทบอทที่ให้คำตอบแล้ว แต่พร้อมสำหรับผู้ใช้จริงหรือยัง? การนำบอทที่ยังไม่ผ่านการทดสอบไปใช้ อาจนำไปสู่ความล้มเหลวที่น่าอาย เช่น การให้ข้อมูลที่ไม่ถูกต้องหรือการสร้างเนื้อหาที่ไม่เหมาะสม ซึ่งอาจส่งผลเสียต่อชื่อเสียงของบริษัทของคุณ
แผนการทดสอบอย่างเป็นระบบคือทางออกสำหรับความไม่แน่นอนนี้ มันช่วยให้มั่นใจว่าแชทบอทของคุณมีความแข็งแกร่ง เชื่อถือได้ และปลอดภัย
การทดสอบการทำงาน:
- กรณีขอบเขต: ทดสอบว่าบอทจัดการกับข้อมูลนำเข้าที่ว่างเปล่า ข้อความที่ยาวมาก และอักขระพิเศษอย่างไร
- การตรวจสอบความจำ: ตรวจสอบให้แน่ใจว่าแชทบอทสามารถจดจำบริบทได้ข้ามหลายรอบในการสนทนา
- คำแนะนำในการปฏิบัติตาม: ตรวจสอบว่าบอทปฏิบัติตามกฎที่คุณกำหนดไว้ในคำแนะนำของระบบ
การประเมินคุณภาพ:
- ความเกี่ยวข้อง: คำตอบนั้นตอบคำถามของผู้ใช้จริงหรือไม่
- ความถูกต้อง: ข้อมูลที่ให้ถูกต้องหรือไม่
- ความสอดคล้อง: การสนทนาดำเนินไปอย่างมีเหตุผลหรือไม่
- ความปลอดภัย: บอทปฏิเสธที่จะตอบคำถามที่ไม่เหมาะสมหรือเป็นอันตรายหรือไม่
การทดสอบประสิทธิภาพ:
- ความหน่วง: วัดระยะเวลาที่ใช้ในการเริ่มตอบสนองของบอทและสิ้นสุดการตอบสนอง
- การใช้ทรัพยากร: ตรวจสอบปริมาณหน่วยความจำ GPU ที่โมเดลใช้ในระหว่างการอนุมาน
- การทำงานพร้อมกัน: ทดสอบประสิทธิภาพของระบบเมื่อมีผู้ใช้หลายคนโต้ตอบกับระบบในเวลาเดียวกัน
นอกจากนี้ ให้ระวังปัญหาทั่วไปของ LLM เช่น การเห็นภาพหลอน (การกล่าวข้อมูลเท็จอย่างมั่นใจ), การหลุดจากบริบท (การสูญเสียการติดตามหัวข้อในการสนทนาที่ยาว), และการซ้ำซ้อน การบันทึกการสนทนาทดสอบทั้งหมดเป็นวิธีที่ดีในการสังเกตเห็นรูปแบบและแก้ไขปัญหา ก่อนที่มันจะถึงผู้ใช้ของคุณ
กรณีการใช้งานแชทบอท LLaMA สำหรับทีม
เมื่อคุณผ่านพ้นขั้นตอนกลไกของการปรับแต่งและการใช้งาน LLaMA จะมีคุณค่ามากที่สุดเมื่อถูกนำไปใช้กับปัญหาทั่วไปของทีม ไม่ใช่การสาธิต AI ที่นามธรรม ทีมโดยทั่วไปไม่ต้องการ "แชทบอท" แต่พวกเขาต้องการการเข้าถึงความรู้ที่รวดเร็วขึ้น ลดการส่งต่องานด้วยตนเอง และลดงานที่ทำซ้ำๆ
ผู้ช่วยความรู้ภายใน
โดยการปรับแต่ง LLaMA บนเอกสารภายใน, วิกิ, และคำถามที่พบบ่อย—หรือจับคู่กับฐานความรู้ที่ใช้ RAG—ทีมสามารถถามคำถามในภาษาธรรมชาติและได้รับคำตอบที่แม่นยำและเข้าใจบริบทได้ นี่ช่วยลดความยุ่งยากในการค้นหาข้ามเครื่องมือที่กระจัดกระจายในขณะที่เก็บข้อมูลที่ละเอียดอ่อนไว้ภายในองค์กรอย่างสมบูรณ์ แทนที่จะส่งไปยัง API ของบุคคลที่สาม
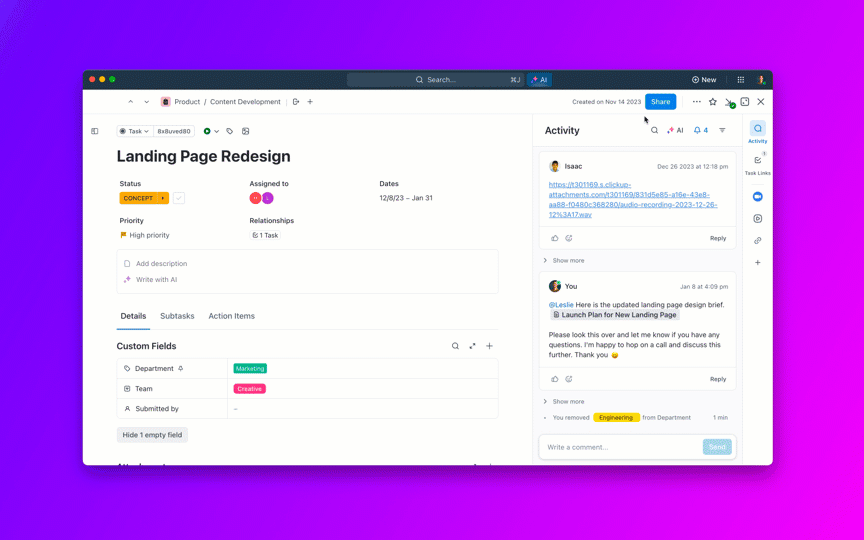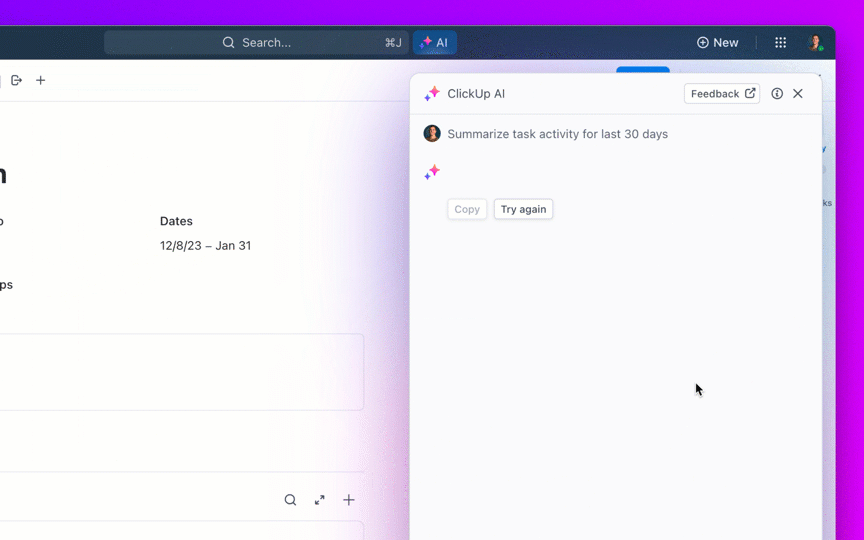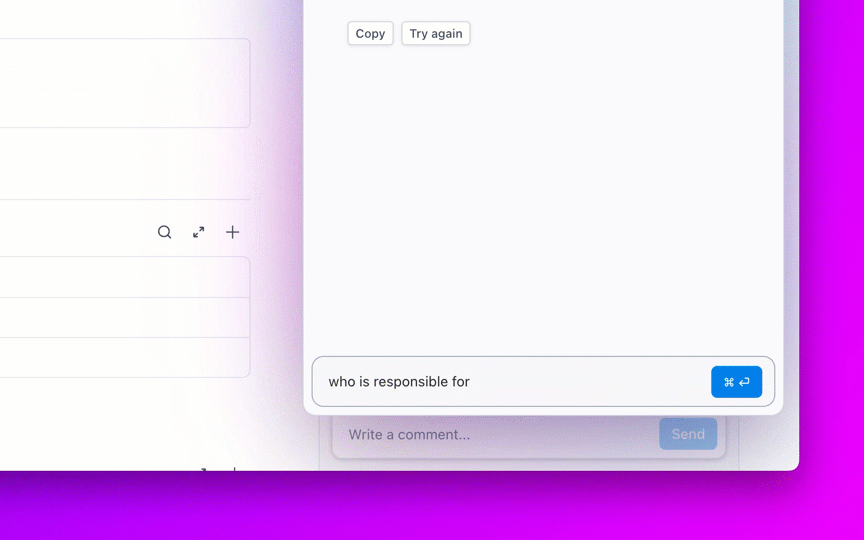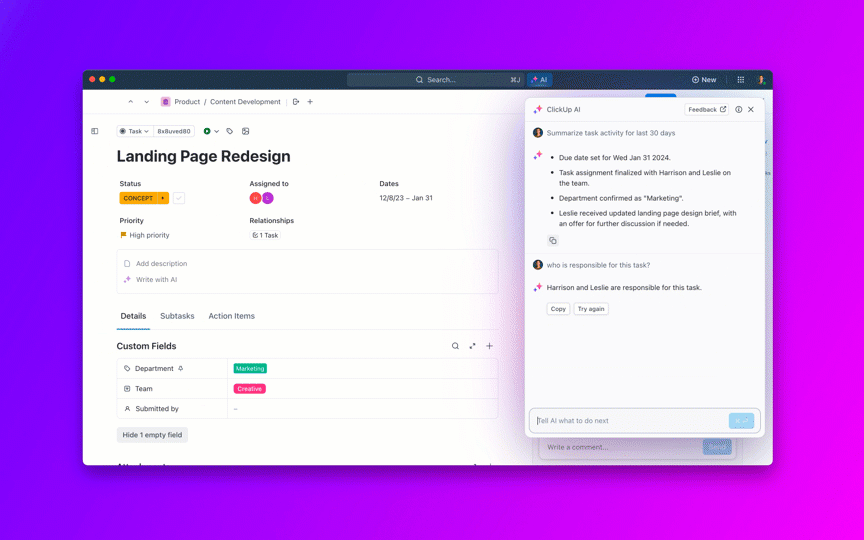
🌟การค้นหาองค์กรใน ClickUp และตัวแทนAmbient Answersที่สร้างไว้ล่วงหน้า ให้คำตอบเชิงบริบทโดยละเอียดสำหรับคำถามของคุณโดยใช้ความรู้ภายในพื้นที่ทำงาน ClickUp ของคุณ
ผู้ช่วยตรวจสอบโค้ด
เมื่อได้รับการฝึกฝนบนฐานโค้ดและคู่มือสไตล์ของคุณเอง LLaMA สามารถทำหน้าที่เป็นผู้ช่วยตรวจสอบโค้ดตามบริบทได้ แทนที่จะเป็นแนวทางปฏิบัติที่ดีที่สุดทั่วไป นักพัฒนาจะได้รับคำแนะนำที่สอดคล้องกับข้อตกลงของทีม การตัดสินใจทางสถาปัตยกรรม และรูปแบบในอดีต
🌟 ผู้ช่วยตรวจสอบโค้ดที่ใช้ LLaMA สามารถตรวจพบปัญหา แนะนำการปรับปรุง หรืออธิบายโค้ดที่ไม่คุ้นเคยได้ClickUp's Codegenก้าวไปอีกขั้นด้วยการทำงานภายในกระบวนการพัฒนา—สร้าง pull request, ใช้การ refactor, หรืออัปเดตไฟล์โดยตรงตามข้อมูลเชิงลึกที่ได้รับ ผลลัพธ์คือลดการคัดลอก-วาง และลดข้อผิดพลาดในการส่งต่อระหว่าง "การคิด" และ "การลงมือทำ"
การคัดกรองการสนับสนุนลูกค้า
LLaMA สามารถฝึกฝนเพื่อจำแนกเจตนาในการเข้าใจคำถามของลูกค้าที่เข้ามาและส่งต่อไปยังทีมหรือกระบวนการที่เหมาะสมได้ คำถามทั่วไปสามารถจัดการได้โดยอัตโนมัติ ในขณะที่กรณีพิเศษจะถูกส่งต่อไปยังเจ้าหน้าที่มนุษย์พร้อมบริบทที่เกี่ยวข้อง ซึ่งช่วยลดเวลาในการตอบสนองโดยไม่ลดทอนคุณภาพ
คุณยังสามารถสร้าง Triage Super Agent โดยใช้ภาษาธรรมชาติภายในพื้นที่ทำงาน ClickUp ของคุณได้อีกด้วย เรียนรู้เพิ่มเติม
การสรุปการประชุมและการติดตามผล
โดยใช้บันทึกการประชุมเป็นข้อมูลนำเข้า LLaMA สามารถสกัดการตัดสินใจ, รายการที่ต้องดำเนินการ, และประเด็นการหารือที่สำคัญได้ คุณค่าที่แท้จริงจะปรากฏขึ้นเมื่อผลลัพธ์เหล่านี้ถูกส่งต่อไปยังเครื่องมือจัดการงานโดยตรง ทำให้การสนทนากลายเป็นงานที่สามารถติดตามได้
🌟ClickUp's AI Meeting Notetakerไม่เพียงแต่บันทึกการประชุมเท่านั้น แต่ยังร่างสรุป สร้างรายการที่ต้องดำเนินการ และเชื่อมโยงบันทึกการประชุมกับเอกสารและงานของคุณอีกด้วย
การจัดทำร่างเอกสารและการปรับปรุงแก้ไข
ทีมสามารถใช้ LLaMA เพื่อสร้างร่างแรกของรายงาน ข้อเสนอ หรือเอกสารต่างๆ โดยอิงจากเทมเพลตที่มีอยู่และตัวอย่างที่ผ่านมา ซึ่งจะช่วยลดความพยายามในการสร้างจากศูนย์และเปลี่ยนไปเน้นที่การตรวจสอบและปรับปรุงแทน ทำให้การส่งมอบงานเร็วขึ้นโดยไม่ลดมาตรฐาน
🌟 ClickUp Brain สามารถสร้างร่างเอกสารได้อย่างรวดเร็ว พร้อมรักษาบริบทของความรู้ในที่ทำงานทั้งหมดของคุณไว้ ลองใช้วันนี้เลย
แชทบอทที่ขับเคลื่อนด้วย LLaMA จะมีประสิทธิภาพสูงสุดเมื่อถูกฝังอยู่ในกระบวนการทำงานที่มีอยู่แล้ว เช่น เอกสารประกอบ การจัดการโครงการ และการสื่อสารภายในทีม มากกว่าการใช้งานเป็นเครื่องมือเดี่ยว
นี่คือจุดที่การผสาน AI เข้ากับพื้นที่ทำงานของคุณโดยตรงสร้างความแตกต่างอย่างแท้จริง แทนที่จะสร้างเครื่องมือแยกต่างหาก คุณสามารถนำ AI ที่มีการสนทนาได้มาสู่ที่ที่ทีมของคุณทำงานอยู่แล้ว
ตัวอย่างเช่น คุณอาจสร้างบอท LLaMA แบบกำหนดเองเพื่อทำหน้าที่เป็นผู้ช่วยด้านความรู้ แต่หากบอทนี้อยู่นอกเครื่องมือจัดการโครงการของคุณ ทีมงานจะต้องสลับบริบทเพื่อถามคำถาม ซึ่งทำให้เกิดความยุ่งยากและทำให้ทุกคนทำงานช้าลง
กำจัดปัญหาการสลับบริบทนี้โดยใช้ AI ที่เป็นส่วนหนึ่งของกระบวนการทำงานของคุณอยู่แล้ว
ถามคำถามเกี่ยวกับโปรเจกต์ งาน และเอกสารของคุณได้โดยไม่ต้องออกจาก ClickUp ด้วยClickUp Brain เพียงพิมพ์ @brain ในความคิดเห็นของงานใด ๆ หรือในClickUp Chatเพื่อรับคำตอบที่เข้าใจบริบทได้ทันที ราวกับมีสมาชิกทีมที่มีความรู้สมบูรณ์แบบเกี่ยวกับพื้นที่ทำงานของคุณทั้งหมด 🤩
สิ่งนี้เปลี่ยนแชทบอทจากสิ่งใหม่ ๆ ให้กลายเป็นส่วนสำคัญของเครื่องยนต์เพิ่มประสิทธิภาพการทำงานของทีมคุณ
ข้อจำกัดของการใช้ LLaMA ในการสร้างแชทบอท
การสร้างแชทบอท LLaMA อาจเป็นสิ่งที่สร้างพลังให้กับทีม แต่บ่อยครั้งที่ทีมต้องเผชิญกับความซับซ้อนที่ซ่อนอยู่โดยไม่ทันตั้งตัว โมเดลโอเพนซอร์สที่ "ฟรี" อาจกลายเป็นทางเลือกที่มีค่าใช้จ่ายสูงกว่าและยากต่อการจัดการมากกว่าที่คาดไว้ ส่งผลให้ประสบการณ์ของผู้ใช้ไม่ดี และต้องเผชิญกับวงจรการบำรุงรักษาที่สิ้นเปลืองทรัพยากรอย่างต่อเนื่อง
สิ่งสำคัญคือต้องเข้าใจข้อจำกัดก่อนที่จะตัดสินใจ
- ความซับซ้อนทางเทคนิค: การตั้งค่าและบำรุงรักษาโมเดล LLaMA ต้องการความรู้เกี่ยวกับโครงสร้างพื้นฐานการเรียนรู้ของเครื่อง
- ข้อกำหนดด้านฮาร์ดแวร์: การใช้งานโมเดลที่มีขนาดใหญ่และมีความสามารถมากขึ้นต้องการฮาร์ดแวร์ GPU ที่มีราคาสูง และค่าใช้จ่ายในการใช้คลาวด์สามารถเพิ่มขึ้นอย่างรวดเร็ว
- ข้อจำกัดของหน้าต่างบริบท: โมเดล LLaMA มีหน่วยความจำจำกัด (4K โทเคนสำหรับ LLaMA 2) การจัดการเอกสารหรือบทสนทนาที่ยาวต้องใช้กลยุทธ์การแบ่งส่วนที่ซับซ้อน
- ไม่มีราวกั้นนิรภัยในตัว: คุณเป็นผู้รับผิดชอบในการดำเนินการกรองเนื้อหาและมาตรการความปลอดภัยด้วยตนเอง
- การบำรุงรักษาอย่างต่อเนื่อง: เมื่อมีการเปิดตัวรุ่นใหม่ คุณจะต้องอัปเดตระบบของคุณ และแบบจำลองที่ได้รับการปรับแต่งอาจต้องฝึกฝนใหม่
โมเดลที่โฮสต์เองมักมีค่าความหน่วงสูงกว่า API เชิงพาณิชย์ที่ได้รับการปรับแต่งอย่างสูง สิ่งเหล่านี้ล้วนเป็นภาระในการดำเนินงานที่โซลูชันแบบจัดการจะดูแลให้คุณ
📮ClickUp Insight: 88% ของผู้ตอบแบบสำรวจของเราใช้ AI สำหรับงานส่วนตัว แต่กว่า 50% ยังลังเลที่จะใช้ในที่ทำงาน อุปสรรคหลักสามประการคือ? การขาดการผสานรวมที่ราบรื่น ช่องว่างด้านความรู้ หรือความกังวลด้านความปลอดภัย
แต่ถ้า AI ถูกฝังอยู่ในพื้นที่ทำงานของคุณแล้วและมีความปลอดภัยล่ะ? ClickUp Brain ผู้ช่วย AI ในตัวจาก ClickUp ทำให้สิ่งนี้เป็นจริงได้ มันเข้าใจคำสั่งในภาษาที่เข้าใจง่าย แก้ไขข้อกังวลทั้งสามเกี่ยวกับการนำ AI มาใช้ พร้อมทั้งเชื่อมต่อแชท งาน เอกสาร และความรู้ของคุณทั่วทั้งพื้นที่ทำงาน ค้นหาคำตอบและข้อมูลเชิงลึกได้ด้วยการคลิกเพียงครั้งเดียว!
ทางเลือกแทน LLaMA สำหรับการสร้างแชทบอท
LLaMA เป็นเพียงหนึ่งในตัวเลือกมากมายของโมเดล AI และอาจทำให้รู้สึกสับสนเมื่อต้องตัดสินใจว่าโมเดลใดเหมาะสมกับคุณ
นี่คือวิธีการที่ภูมิทัศน์ของทางเลือกต่างๆ ถูกแบ่งออก
โมเดลโอเพนซอร์สอื่น ๆ:
- Mistral: เป็นที่รู้จักในด้านประสิทธิภาพที่แข็งแกร่งแม้จะมีขนาดโมเดลที่เล็ก ทำให้มีประสิทธิภาพ
- Falcon: มาพร้อมกับใบอนุญาตที่อนุญาตให้ใช้ได้อย่างกว้างขวางมาก ซึ่งเหมาะอย่างยิ่งสำหรับการใช้งานเชิงพาณิชย์
- MPT: ปรับปรุงให้เหมาะสมสำหรับการจัดการเอกสารและบทสนทนาที่ยาว
API เชิงพาณิชย์:
- OpenAI (GPT-4, GPT-3. 5): โดยทั่วไปถือว่าเป็นโมเดลภาษาขนาดใหญ่ที่มีความสามารถมากที่สุด และง่ายต่อการผสานรวม
- Anthropic (Claude): เป็นที่รู้จักในด้านคุณสมบัติด้านความปลอดภัยที่แข็งแกร่งและหน้าต่างบริบทขนาดใหญ่มาก
- Google (Gemini): มอบความสามารถที่หลากหลายและทรงพลังในการประมวลผลข้อมูลหลายรูปแบบ ช่วยให้สามารถเข้าใจข้อความ รูปภาพ และเสียงได้
คุณสามารถสร้างมันขึ้นมาเองได้ด้วยโมเดลโอเพนซอร์ส, จ่ายเงินสำหรับ API เชิงพาณิชย์, หรือใช้เวิร์กสเปซ AI แบบรวมที่มอบโซลูชันที่ผสานรวมไว้ล่วงหน้าพร้อมตัวแทน AI หลากหลายประเภท
📚 อ่านเพิ่มเติม:วิธีใช้แชทบอทสำหรับธุรกิจของคุณ
สร้างผู้ช่วย AI ที่ตระหนักถึงบริบทด้วย ClickUp
การสร้างแชทบอทด้วย LLaMA มอบการควบคุมที่ยอดเยี่ยมให้กับคุณเกี่ยวกับข้อมูล ค่าใช้จ่าย และการปรับแต่งตามความต้องการของคุณ แต่การควบคุมนี้มาพร้อมกับความรับผิดชอบในการดูแลโครงสร้างพื้นฐาน การบำรุงรักษา และความปลอดภัย—ซึ่งทั้งหมดนี้เป็นสิ่งที่ API ที่มีการจัดการดูแลให้คุณ เป้าหมายไม่ใช่แค่การสร้างบอทเท่านั้น—แต่คือการทำให้ทีมของคุณมีประสิทธิภาพมากขึ้น และโครงการวิศวกรรมที่ซับซ้อนอาจทำให้เสียสมาธิจากเป้าหมายนั้นได้
การเลือกที่เหมาะสมขึ้นอยู่กับทรัพยากรและลำดับความสำคัญของทีมคุณ หากคุณมีความเชี่ยวชาญด้าน ML และมีความต้องการด้านความเป็นส่วนตัวอย่างเข้มงวด LLaMA เป็นตัวเลือกที่ยอดเยี่ยม หากคุณให้ความสำคัญกับความรวดเร็วและความเรียบง่าย เครื่องมือแบบบูรณาการอาจเป็นตัวเลือกที่เหมาะสมกว่า
ด้วย ClickUp คุณจะได้รับพื้นที่ทำงาน AI แบบรวมศูนย์ที่มีงาน เอกสาร และการสนทนาทั้งหมดของคุณในที่เดียว ขับเคลื่อนด้วย AI ที่ผสานรวม ช่วยลดความสับสนของบริบทและช่วยให้ทีมทำงานได้เร็วและมีประสิทธิภาพมากขึ้น ด้วยข้อมูลที่ถูกต้องเพียงปลายนิ้วผ่าน Super Agents ที่ปรับแต่งได้และ AI ที่เข้าใจบริบท
หยุดเสียเวลาไปกับโครงสร้างพื้นฐาน และได้รับประโยชน์จากผู้ช่วย AI ที่ตระหนักถึงบริบทได้ในวันนี้ โดยไม่ต้องสร้างอะไรจากศูนย์เริ่มต้นได้ฟรีกับ ClickUp
คำถามที่พบบ่อย (FAQ)
ค่าใช้จ่ายขึ้นอยู่กับวิธีการติดตั้งของคุณโดยสมบูรณ์ และการคาดการณ์โครงการสามารถช่วยคุณประมาณค่าใช้จ่ายได้ หากคุณใช้ฮาร์ดแวร์ของคุณเอง คุณจะมีค่าใช้จ่ายล่วงหน้าสำหรับ GPU แต่ไม่มีค่าธรรมเนียมต่อคำค้นหาอย่างต่อเนื่อง ผู้ให้บริการคลาวด์จะคิดค่าบริการเป็นรายชั่วโมงตามขนาดของ GPU และแบบจำลอง
ใช่, ใบอนุญาตสำหรับ LLaMA 2 และ LLaMA 3 อนุญาตให้ใช้ในเชิงพาณิชย์ได้ อย่างไรก็ตาม คุณต้องยอมรับเงื่อนไขการใช้งานของ Meta และให้เครดิตตามที่กำหนดไว้ในผลิตภัณฑ์ของคุณ
LLaMA 3 เป็นรุ่นที่ใหม่กว่าและมีความสามารถสูงกว่า มอบทักษะการให้เหตุผลที่ดีกว่าและหน้าต่างบริบทที่กว้างขึ้น (8K โทเค็น เทียบกับ 4K สำหรับ LLaMA 2) ซึ่งหมายความว่าสามารถจัดการกับการสนทนาและเอกสารที่ยาวขึ้นได้ แต่ในขณะเดียวกันก็ต้องการทรัพยากรการคำนวณมากขึ้นในการทำงาน
แม้ว่า Python จะเป็นภาษาที่นิยมมากที่สุดสำหรับการเรียนรู้ของเครื่อง (machine learning) เนื่องจากมีไลบรารีที่หลากหลาย แต่ไม่ได้จำเป็นต้องใช้เสมอไป บางแพลตฟอร์มเริ่มมีโซลูชันแบบไม่ต้องเขียนโค้ดหรือเขียนโค้ดน้อย (no-code หรือ low-code) ที่ช่วยให้คุณสามารถปรับใช้แชทบอท LLaMA พร้อมอินเทอร์เฟซแบบกราฟิกได้