
โครงการฝึกอบรม AI มักไม่ล้มเหลวในระดับโมเดล พวกเขามักประสบปัญหาเมื่อการทดลอง เอกสารประกอบ และการอัปเดตผู้มีส่วนได้ส่วนเสียกระจัดกระจายอยู่ในเครื่องมือมากเกินไป
คู่มือนี้จะแนะนำคุณในการฝึกโมเดลด้วย Databricks DBRX ซึ่งเป็น LLMที่มีประสิทธิภาพในการคำนวณสูงกว่าโมเดลชั้นนำอื่น ๆถึงสองเท่าพร้อมทั้งจัดการงานที่เกี่ยวข้องทั้งหมดอย่างเป็นระบบในClickUp
ตั้งแต่การตั้งค่าและการปรับแต่งไปจนถึงการสร้างเอกสารและการอัปเดตข้ามทีม คุณจะเห็นว่าพื้นที่ทำงานแบบรวมศูนย์เดียวช่วยลดความสับสนและทำให้ทีมของคุณมุ่งเน้นไปที่การสร้างแทนที่จะค้นหา 🛠
DBRX คืออะไร?
DBRX เป็นโมเดลภาษาขนาดใหญ่ (LLM) ที่ทรงพลังและเปิดกว้าง ซึ่งออกแบบมาโดยเฉพาะสำหรับการฝึกอบรมและอนุมานโมเดล AI สำหรับองค์กรเนื่องจากเป็นโอเพนซอร์สภายใต้Databricks Open Model License ทีมงานของคุณจึงสามารถเข้าถึงน้ำหนักและสถาปัตยกรรมของโมเดลได้อย่างเต็มที่ ทำให้คุณสามารถตรวจสอบ แก้ไข และนำไปใช้งานได้ตามเงื่อนไขของคุณเอง
มีสองรูปแบบ: DBRX Base สำหรับการฝึกฝนล่วงหน้าอย่างลึก และ DBRX Instruct สำหรับงานที่ปฏิบัติตามคำแนะนำได้ทันที
สถาปัตยกรรม DBRX และการออกแบบแบบผสมผสานผู้เชี่ยวชาญ
DBRX แก้ไขปัญหาโดยใช้สถาปัตยกรรม Mixture-of-Experts (MoE) ซึ่งแตกต่างจากโมเดลภาษาขนาดใหญ่แบบดั้งเดิมที่ใช้พารามิเตอร์จำนวนหลายพันล้านตัวในการคำนวณทุกครั้ง DBRX จะเปิดใช้งานเพียงบางส่วนของพารามิเตอร์ทั้งหมด (เฉพาะผู้เชี่ยวชาญที่เกี่ยวข้องมากที่สุด) สำหรับแต่ละงานที่กำหนดเท่านั้น
คิดเสียว่ามันเป็นทีมของผู้เชี่ยวชาญเฉพาะทาง แทนที่ทุกคนจะทำงานกับทุกปัญหา ระบบจะทำการจัดสรรงานแต่ละอย่างไปยังผู้ที่เหมาะสมที่สุดตามเกณฑ์ที่ตรงกัน
ไม่เพียงแต่ช่วยลดเวลาในการตอบสนองเท่านั้น แต่ยังมอบประสิทธิภาพและผลลัพธ์ระดับสูงสุด พร้อมทั้งลดต้นทุนการคำนวณได้อย่างมีนัยสำคัญอีกด้วย
นี่คือภาพรวมอย่างรวดเร็วของข้อมูลจำเพาะหลัก:
- พารามิเตอร์ทั้งหมด: 132B ครอบคลุมผู้เชี่ยวชาญทั้งหมด
- พารามิเตอร์ที่ใช้งานอยู่: 36B ต่อการส่งข้อมูลไปข้างหน้าหนึ่งครั้ง
- จำนวนผู้เชี่ยวชาญ: ทั้งหมด 16 คน (การกำหนดเส้นทาง MoE Top-4) โดยมีผู้เชี่ยวชาญที่ใช้งานอยู่ 4 คนสำหรับโทเค็นใดก็ได้
- หน้าต่างบริบท: 32K โทเคน
ข้อมูลการฝึกอบรม DBRX และข้อกำหนดโทเค็น
ประสิทธิภาพของ LLM จะดีเพียงใดขึ้นอยู่กับข้อมูลที่ใช้ในการฝึกฝนเท่านั้น DBRX ได้รับการฝึกฝนล่วงหน้าบนชุดข้อมูลขนาดใหญ่ถึง 12 ล้านล้านโทเคนซึ่งได้รับการคัดสรรอย่างพิถีพิถันโดยทีม Databricks โดยใช้เครื่องมือประมวลผลข้อมูลขั้นสูงของพวกเขา นี่คือเหตุผลที่ทำให้มันมีประสิทธิภาพสูงในการทดสอบมาตรฐานอุตสาหกรรม
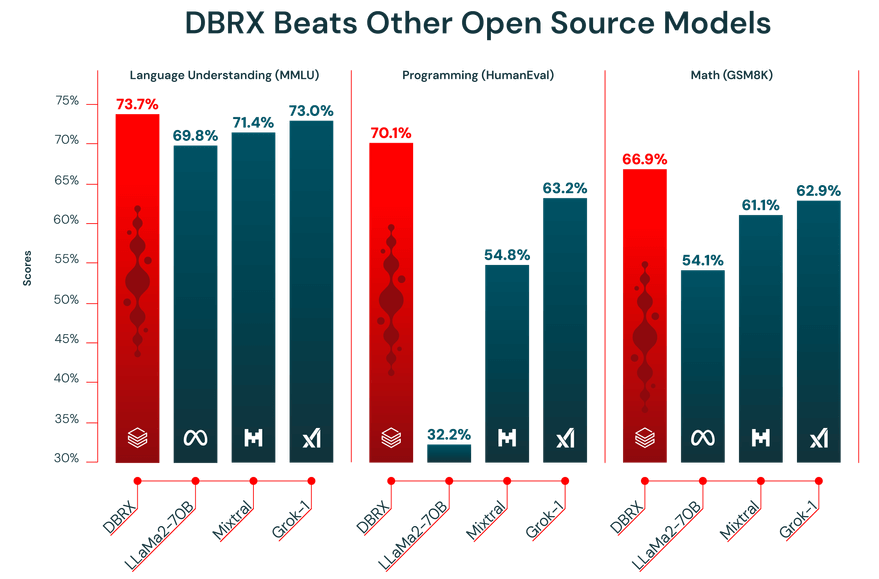
นอกจากนี้ DBRX ยังมีหน้าต่างบริบทขนาด 32,000 โทเคน ซึ่งเป็นปริมาณข้อความที่โมเดลสามารถพิจารณาได้ในเวลาเดียวกัน หน้าต่างบริบทขนาดใหญ่มีประโยชน์อย่างมากสำหรับงานที่ซับซ้อน เช่น การสรุปรายงานยาว การค้นหาข้อมูลในเอกสารทางกฎหมายที่ยาวหรือการพัฒนาระบบการค้นหาและเสริมสร้างการสร้างเนื้อหาขั้นสูง(RAG) เนื่องจากช่วยให้โมเดลสามารถรักษาบริบทได้โดยไม่ตัดหรือลืมข้อมูล
🎥 ชมวิดีโอนี้เพื่อดูว่าการประสานงานโครงการที่มีประสิทธิภาพสามารถเปลี่ยนแปลงกระบวนการฝึกอบรม AI ของคุณได้อย่างไร และขจัดปัญหาการสลับระหว่างเครื่องมือที่ไม่เชื่อมต่อกัน 👇🏽
วิธีการเข้าถึงและตั้งค่า DBRX
DBRX มีเส้นทางการเข้าถึงหลักสองเส้นทาง ซึ่งทั้งสองเส้นทางให้การเข้าถึงน้ำหนักของโมเดลอย่างเต็มที่ภายใต้ เงื่อนไขทางการค้าที่ยืดหยุ่น คุณสามารถใช้ Hugging Face เพื่อความยืดหยุ่นสูงสุด หรือเข้าถึงโดยตรงผ่าน Databricks เพื่อประสบการณ์ที่ผสานรวมมากขึ้น
เข้าถึง DBRX ผ่าน Hugging Face
สำหรับทีมที่ให้ความสำคัญกับความยืดหยุ่นและคุ้นเคยกับระบบนิเวศของ Hugging Face อยู่แล้ว การเข้าถึง DBRX ผ่าน Hub เป็นเส้นทางที่เหมาะสมที่สุด ช่วยให้คุณผสานรวมโมเดลเข้ากับเวิร์กโฟลว์ที่ใช้ transformers ที่มีอยู่เดิมได้อย่างง่ายดาย
นี่คือวิธีเริ่มต้น:
- สร้างหรือเข้าสู่ระบบบัญชี Hugging Face ของคุณ
- ไปที่บัตรโมเดล DBRX บนฮับและยอมรับข้อกำหนดของใบอนุญาต
- ติดตั้งไลบรารีของหม้อแปลงไฟฟ้าพร้อมกับสิ่งที่จำเป็นเช่น accelerate
- ใช้คลาส AutoModelForCausalLM ในสคริปต์ Python ของคุณเพื่อโหลดโมเดล DBRX
- กำหนดค่าอินเฟอร์เรนซ์พายไลน์ของคุณ โดยคำนึงว่า DBRX ต้องการหน่วยความจำ GPU (VRAM) จำนวนมากสำหรับการทำงานที่มีประสิทธิภาพ
📖 อ่านเพิ่มเติม: วิธีตั้งค่าอุณหภูมิ LLM
เข้าถึง DBRX ผ่าน Databricks
หากทีมของคุณใช้ Databricks สำหรับการวิศวกรรมข้อมูลหรือการเรียนรู้ของเครื่องอยู่แล้ว การเข้าถึง DBRX ผ่านแพลตฟอร์มเป็นวิธีที่ง่ายที่สุด มันช่วยลดความยุ่งยากในการตั้งค่าและให้คุณมีเครื่องมือทั้งหมดที่คุณต้องการสำหรับ MLOps อยู่ในที่ที่คุณทำงานอยู่แล้ว
ทำตามขั้นตอนเหล่านี้ภายในพื้นที่ทำงาน Databricks ของคุณเพื่อเริ่มต้นใช้งาน:
- ไปที่สวนโมเดลหรือส่วน Mosaic AI
- เลือก DBRX Base หรือ DBRX Instruct ตามความต้องการของคุณ
- กำหนดค่าจุดให้บริการสำหรับการเข้าถึง API หรือตั้งค่าสภาพแวดล้อมของโน้ตบุ๊กสำหรับการใช้งานแบบโต้ตอบ
- เริ่มทดสอบการอนุมานด้วยตัวอย่างคำสั่งเพื่อให้แน่ใจว่าทุกอย่างทำงานอย่างถูกต้องก่อนที่จะขยายการฝึกอบรมหรือการใช้งานโมเดล AI ของคุณ
แนวทางนี้ช่วยให้คุณเข้าถึงเครื่องมือต่างๆ ได้อย่างราบรื่น เช่น MLflow สำหรับการติดตามการทดลอง และ Unity Catalogสำหรับการกำกับดูแลโมเดล
📮 ClickUp Insight: มืออาชีพโดยเฉลี่ยใช้เวลา 30 นาทีขึ้นไปต่อวันในการค้นหาข้อมูลที่เกี่ยวข้องกับงาน—นั่นคือมากกว่า 120 ชั่วโมงต่อปีที่สูญเสียไปกับการค้นหาอีเมล, กระทู้ใน Slack และไฟล์ที่กระจัดกระจาย
ผู้ช่วย AI ที่ชาญฉลาดฝังอยู่ในที่ทำงานของคุณสามารถเปลี่ยนแปลงสิ่งนั้นได้. เข้าสู่ClickUp Brain.
มันมอบข้อมูลเชิงลึกและคำตอบทันทีโดยการค้นหาเอกสารที่เหมาะสม, การสนทนา, และรายละเอียดของงานในเวลาเพียงไม่กี่วินาที—เพื่อให้คุณสามารถหยุดการค้นหาและเริ่มทำงานได้ทันที
วิธีปรับแต่ง DBRX และฝึกโมเดล AI แบบกำหนดเอง
โมเดลสำเร็จรูป ไม่ว่าจะทรงพลังเพียงใด ก็ไม่สามารถเข้าใจความละเอียดอ่อนเฉพาะของธุรกิจของคุณได้ เนื่องจาก DBRX เป็นโอเพนซอร์ส คุณสามารถปรับแต่งมันเพื่อสร้างโมเดลที่ปรับให้เข้ากับภาษาของบริษัทคุณหรือทำงานเฉพาะที่คุณต้องการให้จัดการได้
นี่คือสามวิธีทั่วไปที่คุณสามารถทำได้:
1. ปรับแต่ง DBRX ด้วยชุดข้อมูล Hugging Face
สำหรับทีมที่เพิ่งเริ่มต้นหรือกำลังทำงานในภารกิจทั่วไป ชุดข้อมูลสาธารณะจาก Hugging Face Hub เป็นแหล่งข้อมูลที่ยอดเยี่ยม ชุดข้อมูลเหล่านี้ถูกจัดรูปแบบไว้ล่วงหน้าและโหลดได้ง่าย ซึ่งหมายความว่าคุณไม่ต้องเสียเวลาหลายชั่วโมงในการเตรียมข้อมูลของคุณ
กระบวนการนี้ค่อนข้างตรงไปตรงมา:
- ค้นหาชุดข้อมูลบนฮับที่ตรงกับงานของคุณ (เช่น การปฏิบัติตามคำแนะนำ การสรุปเนื้อหา)
- โหลดโดยใช้ไลบรารีชุดข้อมูล
- ตรวจสอบให้แน่ใจว่าข้อมูลถูกจัดรูปแบบเป็นคู่ของคำสั่งและการตอบสนอง
- กำหนดค่าสคริปต์การฝึกอบรมของคุณด้วยไฮเปอร์พารามิเตอร์ เช่น อัตราการเรียนรู้และขนาดแบตช์
- เริ่มงานฝึกอบรม โดยอย่าลืมบันทึกจุดตรวจสอบเป็นระยะ
- ประเมินโมเดลที่ปรับแต่งแล้วบนชุดข้อมูลการตรวจสอบที่แยกไว้เพื่อวัดการปรับปรุง
2. ปรับแต่ง DBRX ด้วยชุดข้อมูลท้องถิ่น
คุณมักจะได้รับผลลัพธ์ที่ดีที่สุดโดยการปรับแต่งอย่างละเอียดด้วยข้อมูลที่เป็นกรรมสิทธิ์ของคุณเอง ซึ่งช่วยให้คุณสามารถสอนโมเดลเกี่ยวกับคำศัพท์เฉพาะของบริษัท รูปแบบ และความรู้ในสาขาของคุณได้อย่างไรก็ตาม คุณต้องระลึกไว้เสมอว่ามันคุ้มค่าก็ต่อเมื่อข้อมูลของคุณสะอาดและเตรียมไว้อย่างดี และมีปริมาณเพียงพอ
ทำตามขั้นตอนต่อไปนี้เพื่อเตรียมข้อมูลภายในของคุณ:
- การรวบรวมข้อมูล: รวบรวมตัวอย่างคุณภาพสูงจากวิกิภายใน เอกสาร และฐานข้อมูลของคุณ
- การแปลงรูปแบบ: จัดโครงสร้างข้อมูลของคุณให้เป็นรูปแบบคำสั่ง-คำตอบที่สอดคล้องกัน มักจะเป็นบรรทัด JSON
- การกรองคุณภาพ: ลบตัวอย่างที่มีคุณภาพต่ำ ซ้ำ หรือไม่เกี่ยวข้องออก
- การแบ่งข้อมูลเพื่อตรวจสอบความถูกต้อง: จัดสรรข้อมูลส่วนหนึ่ง (โดยทั่วไป 10-15%) เพื่อประเมินประสิทธิภาพของโมเดล
- การตรวจสอบความเป็นส่วนตัว: ลบหรือปกปิดข้อมูลส่วนบุคคลที่สามารถระบุตัวตนได้ (PII) หรือข้อมูลที่ละเอียดอ่อน
3. ปรับแต่ง DBRX ด้วย StreamingDataset
หากชุดข้อมูลของคุณมีขนาดใหญ่เกินกว่าที่เครื่องของคุณจะรองรับได้ ไม่ต้องกังวล คุณสามารถใช้ไลบรารี Streaming Dataset ของ Databricks ได้ ไลบรารีนี้ช่วยให้คุณสามารถสตรีมข้อมูลโดยตรงจากพื้นที่จัดเก็บข้อมูลบนคลาวด์ในขณะที่โมเดลกำลังฝึกฝน แทนที่จะโหลดข้อมูลทั้งหมดเข้าสู่หน่วยความจำในคราวเดียว
นี่คือวิธีที่คุณสามารถทำได้:
- การเตรียมข้อมูล: ทำความสะอาดและจัดโครงสร้างข้อมูลการฝึกอบรมของคุณ จากนั้นจัดเก็บในรูปแบบที่สามารถสตรีมได้ เช่น JSONL หรือ CSV ในพื้นที่จัดเก็บข้อมูลบนคลาวด์
- การแปลงรูปแบบการสตรีม: แปลงชุดข้อมูลของคุณให้เป็นรูปแบบที่เหมาะกับการสตรีม เช่น Mosaic Data Shard (MDS) เพื่อให้สามารถอ่านได้อย่างมีประสิทธิภาพระหว่างการฝึกอบรม
- การตั้งค่าตัวโหลดสำหรับการฝึกอบรม: กำหนดค่าตัวโหลดสำหรับการฝึกอบรมของคุณให้ชี้ไปยังชุดข้อมูลระยะไกล และกำหนดแคชท้องถิ่นสำหรับการจัดเก็บข้อมูลชั่วคราว
- การเริ่มต้นโมเดล: เริ่มกระบวนการปรับแต่ง DBRX โดยใช้เฟรมเวิร์กการฝึกอบรมที่รองรับ StreamingDataset เช่น LLM Foundry
- การฝึกอบรมแบบสตรีมมิง: ดำเนินการฝึกอบรมในขณะที่ข้อมูลถูกสตรีมเข้ามาเป็นชุด ๆ ระหว่างการฝึกอบรม แทนที่จะโหลดข้อมูลทั้งหมดเข้าสู่หน่วยความจำ
- การบันทึกจุดและกู้คืน: กลับมาฝึกฝนได้อย่างราบรื่นหากการฝึกถูกขัดจังหวะ โดยไม่ทำซ้ำหรือข้ามข้อมูล
- การประเมินผลและการนำไปใช้: ตรวจสอบความถูกต้องของประสิทธิภาพของแบบจำลองที่ได้รับการปรับแต่งอย่างละเอียด และนำไปใช้โดยใช้ระบบให้บริการหรือระบบคำนวณที่คุณชื่นชอบ
💡เคล็ดลับมืออาชีพ: แทนที่จะสร้างแผนการฝึกอบรม DBRX จากศูนย์ ให้เริ่มต้นด้วยเทมเพลตแผนงานโครงการ AI และ Machine Learningของ ClickUp และปรับแต่งให้เหมาะกับความต้องการของทีมคุณ มันให้โครงสร้างที่ชัดเจนสำหรับการวางแผนชุดข้อมูล, ระยะการฝึกอบรม, การประเมินผล, และการนำไปใช้, ทำให้คุณสามารถมุ่งเน้นไปที่การจัดระเบียบงานของคุณแทนที่จะสร้างโครงสร้างของกระบวนการทำงาน
กรณีการใช้งาน DBRX สำหรับการฝึกอบรมแบบจำลอง AI
การมีโมเดลที่ทรงพลังเป็นสิ่งหนึ่ง แต่การรู้ว่ามันโดดเด่นที่สุดตรงไหนคืออีกสิ่งหนึ่ง
เมื่อคุณไม่มีภาพที่ชัดเจนเกี่ยวกับจุดแข็งของโมเดล มันง่ายที่จะใช้เวลาและทรัพยากรไปกับการพยายามทำให้มันทำงานในที่ที่มันไม่เหมาะสม ซึ่งนำไปสู่ผลลัพธ์ที่ต่ำกว่ามาตรฐานและความหงุดหงิด
สถาปัตยกรรมและข้อมูลการฝึกอบรมที่เป็นเอกลักษณ์ของ DBRX ทำให้เหมาะสมอย่างยิ่งสำหรับกรณีการใช้งานที่สำคัญหลายประการขององค์กร การทราบถึงจุดแข็งเหล่านี้จะช่วยให้คุณปรับโมเดลให้สอดคล้องกับวัตถุประสงค์ทางธุรกิจของคุณและเพิ่มผลตอบแทนจากการลงทุนให้สูงสุด
การสร้างข้อความและการสร้างเนื้อหา
DBRX Instruct ได้รับการปรับแต่งอย่างละเอียดเพื่อปฏิบัติตามคำแนะนำและสร้างข้อความคุณภาพสูง ทำให้เป็นเครื่องมือที่ทรงพลังสำหรับการทำงานอัตโนมัติในงานที่เกี่ยวข้องกับเนื้อหาหลากหลายประเภท หน้าต่างบริบทขนาดใหญ่เป็นข้อได้เปรียบที่สำคัญ ช่วยให้สามารถจัดการเอกสารยาวได้โดยไม่สูญเสียเนื้อหาหลัก
คุณสามารถใช้มันสำหรับ:
- เอกสารทางเทคนิค: สร้างและปรับปรุงคู่มือผลิตภัณฑ์, เอกสารอ้างอิง API, และคู่มือผู้ใช้
- เนื้อหาการตลาด: ร่างบทความบล็อก จดหมายข่าวทางอีเมล และอัปเดตบนโซเชียลมีเดีย
- การสร้างรายงาน: สรุปผลการวิเคราะห์ข้อมูลที่ซับซ้อนและสร้างบทสรุปสำหรับผู้บริหารที่กระชับ
- การแปลและการปรับให้เข้ากับท้องถิ่น: ปรับเนื้อหาที่มีอยู่ให้เหมาะสมกับตลาดและกลุ่มเป้าหมายใหม่
การสร้างโค้ดและการแก้ไขข้อผิดพลาด
ข้อมูลการฝึกอบรมส่วนใหญ่ของ DBRX ประกอบด้วยโค้ด ทำให้เป็นLLM ที่รองรับนักพัฒนาได้อย่างมีประสิทธิภาพ สามารถช่วยเร่งวงจรการพัฒนาโดยการทำซ้ำงานเขียนโค้ดให้เป็นอัตโนมัติและช่วยในการแก้ปัญหาที่ซับซ้อน
นี่คือวิธีการบางประการที่ทีมวิศวกรรมของคุณสามารถใช้ประโยชน์จากมันได้:
- การเติมโค้ดอัตโนมัติ: สร้างเนื้อหาฟังก์ชันโดยอัตโนมัติจากคอมเมนต์หรือ docstrings
- การตรวจจับข้อบกพร่อง: วิเคราะห์โค้ดสั้น ๆ เพื่อระบุข้อผิดพลาดที่อาจเกิดขึ้นหรือข้อบกพร่องทางตรรกศาสตร์
- คำอธิบายโค้ด: แปลอัลกอริทึมที่ซับซ้อนหรือโค้ดเก่าให้เข้าใจง่ายเป็นภาษาอังกฤษ
- การสร้างการทดสอบ: สร้างการทดสอบหน่วยตามลายเซ็นของฟังก์ชันและพฤติกรรมที่คาดหวัง
แอปพลิเคชัน RAG และแอปพลิเคชันที่มีบริบทยาว
การเพิ่มประสิทธิภาพการค้นหาข้อมูลเพื่อสร้างเนื้อหา (Retrieval-Augmented Generation หรือ RAG)เป็นเทคนิคที่ทรงพลังซึ่งช่วยให้การตอบสนองของโมเดลมีพื้นฐานจากข้อมูลส่วนตัวของบริษัทคุณ อย่างไรก็ตาม ระบบ RAG มักประสบปัญหาเมื่อใช้กับโมเดลที่มีหน้าต่างบริบทขนาดเล็ก ซึ่งบังคับให้ต้องแบ่งข้อมูลออกเป็นส่วนๆ อย่างเข้มงวดจนอาจสูญเสียบริบทที่สำคัญไป หน้าต่างบริบทขนาด 32K ของ DBRX จึงเป็นรากฐานที่ยอดเยี่ยมสำหรับการใช้งาน RAG ที่มีความแข็งแกร่ง
นี่ช่วยให้คุณสร้างเครื่องมือภายในที่ทรงพลัง เช่น:
- การค้นหาภายในองค์กร: สร้างแชทบอทที่ตอบคำถามของพนักงานโดยใช้ฐานความรู้ภายในองค์กรของคุณ
- การสนับสนุนลูกค้า: สร้างตัวแทนที่สร้างคำตอบสำหรับการสนับสนุนที่อ้างอิงจากเอกสารประกอบผลิตภัณฑ์ของคุณ
- การช่วยเหลือด้านการวิจัย: พัฒนาเครื่องมือที่สามารถสังเคราะห์ข้อมูลจากเอกสารวิจัยหลายร้อยหน้า
- การตรวจสอบความสอดคล้อง: ตรวจสอบข้อความทางการตลาดโดยอัตโนมัติให้สอดคล้องกับแนวทางของแบรนด์ภายในหรือเอกสารกำกับดูแล
วิธีการผสานการฝึกอบรม DBRX เข้ากับกระบวนการทำงานของทีมคุณ
โครงการฝึกอบรมโมเดล AI ที่ประสบความสำเร็จไม่ได้เกี่ยวข้องเพียงแค่โค้ดและการคำนวณเท่านั้น แต่เป็นความร่วมมือระหว่างวิศวกร ML นักวิทยาศาสตร์ข้อมูล ผู้จัดการผลิตภัณฑ์ และผู้มีส่วนได้ส่วนเสีย
เมื่อความร่วมมือนี้กระจัดกระจายอยู่ใน Jupyter notebooks, Slack channels, และเครื่องมือจัดการโครงการที่แยกต่างหาก, คุณกำลังสร้างการกระจายบริบท (context sprawl), ซึ่งเป็นสถานการณ์ที่ข้อมูลโครงการที่สำคัญกระจายอยู่ทั่วเครื่องมือมากเกินไป.
ClickUp แก้ไขปัญหานั้นให้คุณ แทนที่จะต้องสลับไปมาระหว่างเครื่องมือหลายอย่าง คุณจะได้รับพื้นที่ทำงาน AI แบบรวมศูนย์ในที่เดียว ซึ่งรวมการจัดการโครงการ เอกสาร และการสื่อสารไว้ด้วยกัน—เพื่อให้การทดลองของคุณเชื่อมโยงกันตั้งแต่การวางแผน การดำเนินการ ไปจนถึงการประเมินผล
อย่าลืมติดตามการทดลองและความก้าวหน้า
เมื่อทำการทดลองหลายครั้ง ส่วนที่ยากที่สุดไม่ใช่การฝึกโมเดล แต่เป็นการติดตามสิ่งที่เปลี่ยนแปลงไปในระหว่างกระบวนการ. เวอร์ชันของชุดข้อมูลที่ใช้คืออะไร, อัตราการเรียนรู้ใดที่ให้ผลลัพธ์ดีที่สุด, หรือการทดลองครั้งใดที่ถูกนำไปใช้จริง?
ClickUp ทำให้กระบวนการนี้ง่ายมากสำหรับคุณ คุณสามารถติดตาม การฝึกซ้อมแต่ละครั้ง แยกกันในClickUp Tasks และภายในงาน คุณสามารถใช้Custom Fieldsเพื่อบันทึก:
- เวอร์ชันของชุดข้อมูล
- พารามิเตอร์ระดับสูง
- รุ่นย่อย (DBRX Base เทียบกับ DBRX Instruct)
- สถานะการฝึกอบรม (คิว, กำลังดำเนินการ, กำลังประเมิน, ใช้งานแล้ว)
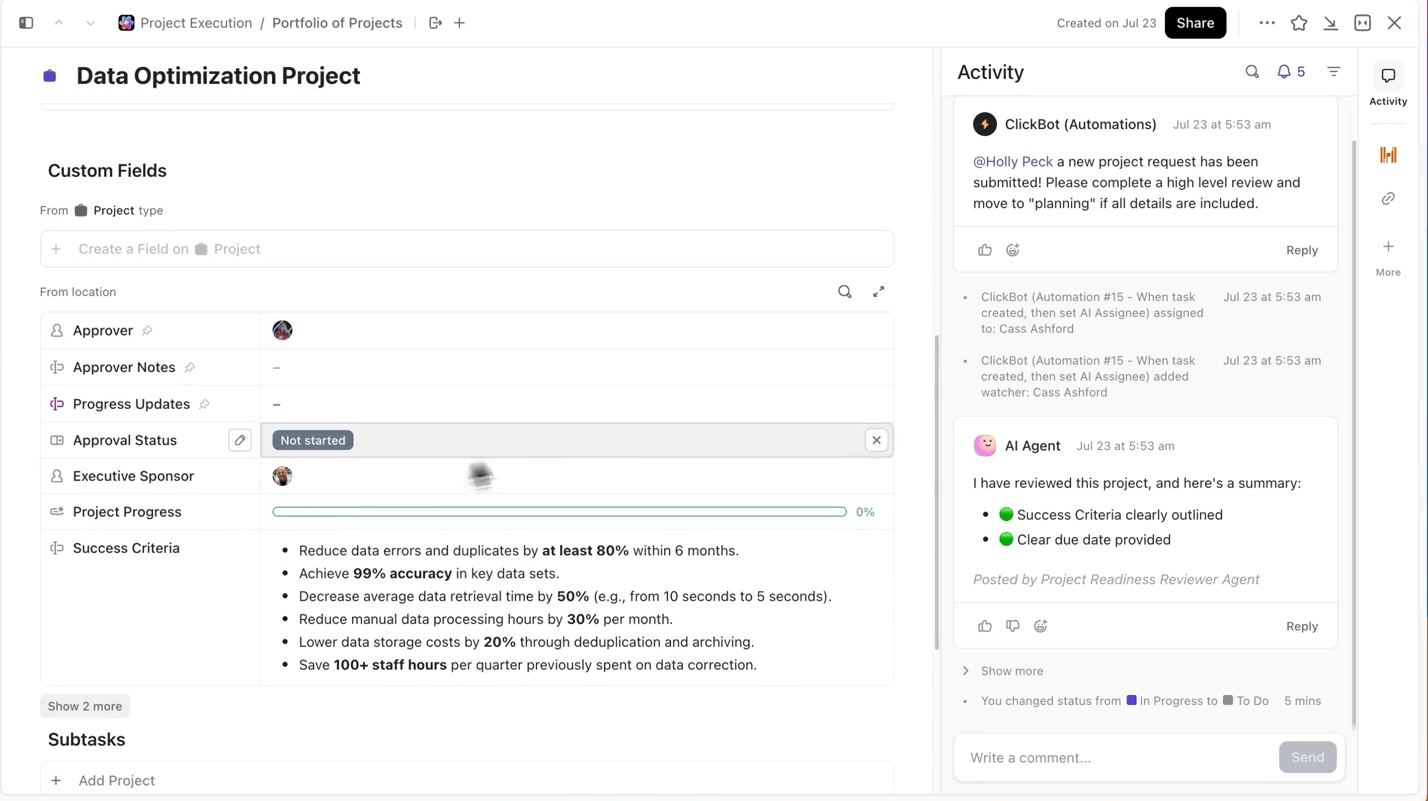
ด้วยวิธีนี้ ทุกการทดลองที่มีการบันทึกไว้จะสามารถค้นหาได้ เปรียบเทียบกับผู้อื่นได้ง่าย และสามารถทำซ้ำได้
เก็บเอกสารของแบบจำลองให้เชื่อมโยงกับงาน
คุณไม่จำเป็นต้องสลับไปมาระหว่าง Jupyter notebook, ไฟล์ README หรือกระทู้ใน Slack เพื่อทำความเข้าใจบริบทของงานทดลอง
ด้วยClickUp Docsคุณสามารถจัดระเบียบและเข้าถึงสถาปัตยกรรมโมเดล, สคริปต์เตรียมข้อมูล, หรือเมตริกการประเมินผลของคุณได้อย่างง่ายดายโดยการบันทึกไว้ในเอกสารที่สามารถค้นหาได้ และเชื่อมโยงโดยตรงกับงานทดลองที่เอกสารนั้นมาจาก

💡เคล็ดลับจากมืออาชีพ: รักษาเอกสารโครงการที่อัปเดตอยู่เสมอใน ClickUp Docs โดยระบุรายละเอียดทุกการตัดสินใจ ตั้งแต่สถาปัตยกรรมไปจนถึงการปรับใช้ เพื่อให้สมาชิกใหม่สามารถเข้าใจรายละเอียดโครงการได้อย่างรวดเร็วโดยไม่ต้องค้นหาข้อมูลเก่า
ให้ผู้มีส่วนได้ส่วนเสียสามารถมองเห็นข้อมูลได้แบบเรียลไทม์
แดชบอร์ดของ ClickUpแสดงความคืบหน้าของการทดลองและปริมาณงานของทีมแบบเรียลไทม์ ฉัน
แทนที่จะรวบรวมการอัปเดตด้วยตนเองหรือส่งอีเมล แดชบอร์ดจะอัปเดตโดยอัตโนมัติตามข้อมูลในภารกิจของคุณ ทำให้ผู้มีส่วนได้ส่วนเสียสามารถตรวจสอบได้ตลอดเวลา เห็นสถานะปัจจุบัน และไม่ต้องรบกวนคุณด้วยคำถาม "สถานะเป็นอย่างไรบ้าง?"
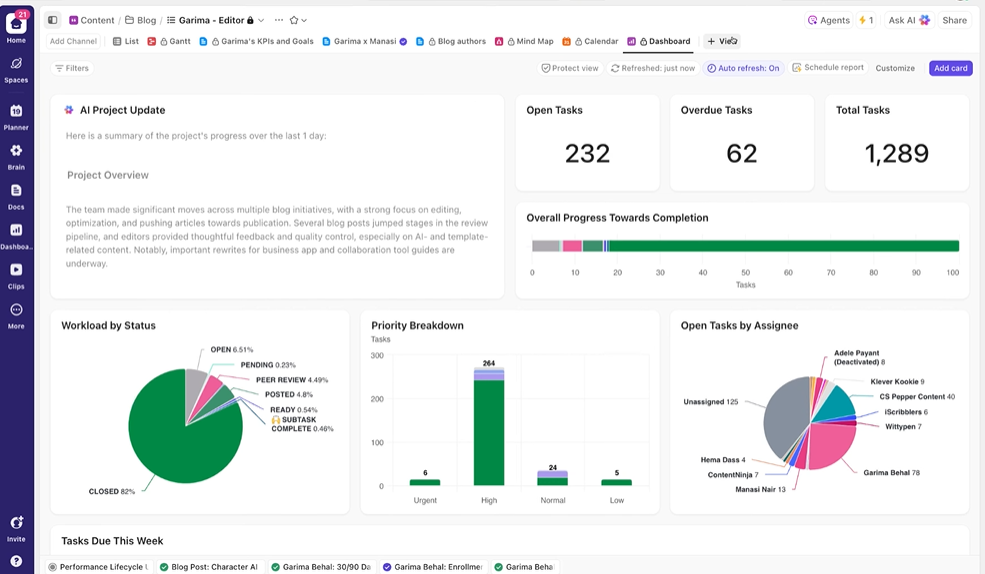
ด้วยวิธีนี้ คุณจะมุ่งเน้นไปที่การดำเนินการทดลองแทนที่จะต้องรายงานผลด้วยตนเองอยู่ตลอดเวลา
เปลี่ยน AI ให้เป็นเพื่อนคู่คิดอัจฉริยะสำหรับโปรเจกต์ของคุณ
คุณไม่จำเป็นต้องค้นหาข้อมูลการฝึกอบรมเป็นสัปดาห์เพื่อสรุปผลการทดลองที่ผ่านมา เพียงแค่กล่าวถึง @Brain ในความคิดเห็นของงานใด ๆ แล้ว ClickUp Brain จะให้ความช่วยเหลือที่คุณต้องการพร้อมบริบทครบถ้วนของโครงการที่ผ่านมาและที่กำลังดำเนินการอยู่
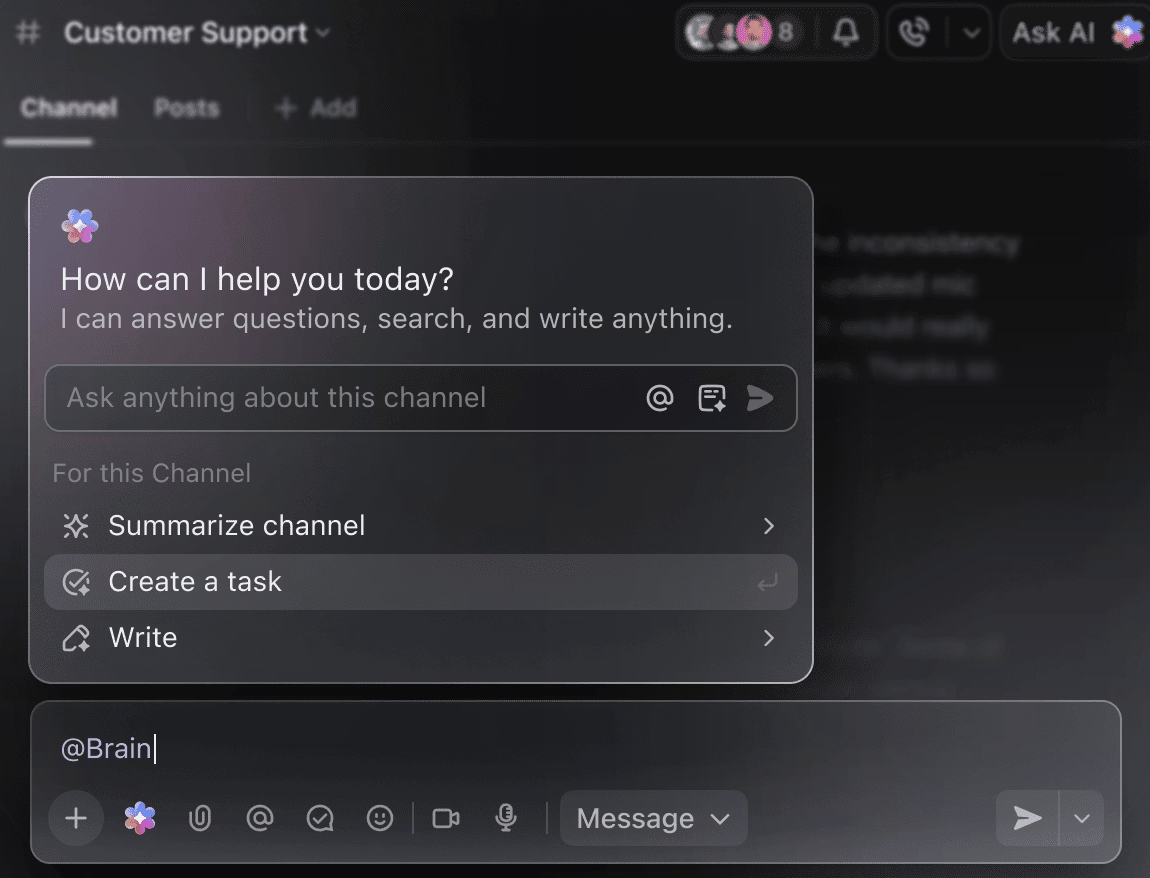
คุณสามารถขอให้ Brain 'สรุปการทดลองของสัปดาห์ที่แล้วใน 5 ข้อ' หรือ 'ร่างเอกสารที่มีผลลัพธ์ของไฮเปอร์พารามิเตอร์ล่าสุด' และรับผลลัพธ์ที่เสร็จสมบูรณ์ได้ทันที
🧠 ข้อได้เปรียบของ ClickUp:เจ้าหน้าที่ระดับซูเปอร์ของClickUp สามารถทำได้มากกว่านั้น—พวกเขาสามารถ อัตโนมัติเวิร์กโฟลว์ทั้งหมดตามตัวกระตุ้นที่คุณกำหนด ไม่ใช่แค่ตอบคำถามของคุณเท่านั้น ด้วยซูเปอร์เอเจนต์ คุณสามารถสร้างงานฝึกอบรม DBRX ใหม่โดยอัตโนมัติทุกครั้งที่มีการอัปโหลดชุดข้อมูล แจ้งเตือนทีมของคุณ และเชื่อมโยงเอกสารที่เกี่ยวข้องเมื่อการฝึกอบรมเสร็จสิ้นหรือถึงจุดตรวจสอบ รวมถึงสร้างสรุปความคืบหน้าประจำสัปดาห์และส่งไปยังผู้มีส่วนได้ส่วนเสียโดยที่คุณไม่ต้องทำอะไรเลย
ข้อผิดพลาดทั่วไปที่ควรหลีกเลี่ยง
การเริ่มต้นโครงการฝึกอบรม DBRX เป็นเรื่องที่น่าตื่นเต้น แต่มีข้อผิดพลาดทั่วไปบางประการที่อาจทำให้ความก้าวหน้าของคุณสะดุด การหลีกเลี่ยงข้อผิดพลาดเหล่านี้จะช่วยให้คุณประหยัดเวลา เงิน และความหงุดหงิดมากมาย
- การประเมินความต้องการฮาร์ดแวร์ต่ำเกินไป: DBRX เป็นเครื่องมือที่ทรงพลัง แต่ก็ใช้ทรัพยากรมากเช่นกัน การพยายามใช้งานบนฮาร์ดแวร์ที่ไม่เพียงพอจะนำไปสู่ข้อผิดพลาดจากการขาดหน่วยความจำและการฝึกฝนล้มเหลว โปรดจำไว้ว่า DBRX (132B) ต้องการ VRAM อย่างน้อย 264GB สำหรับการอนุมานแบบ 16-bit หรือประมาณ 70GB-80GB เมื่อใช้การควอนไทซ์แบบ 4-bit
- การข้ามการตรวจสอบคุณภาพข้อมูล: ข้อมูลขยะเข้า ข้อมูลขยะออก การปรับแต่งโมเดลบนชุดข้อมูลที่ยุ่งเหยิงและมีคุณภาพต่ำ จะทำให้โมเดลเรียนรู้และสร้างผลลัพธ์ที่ยุ่งเหยิงและมีคุณภาพต่ำเช่นกัน
- การเพิกเฉยต่อข้อจำกัดความยาวของบริบท: แม้ว่าหน้าต่างบริบทขนาด 32K ของ DBRX จะมีความกว้างขวาง แต่ก็ไม่ได้ไม่มีที่สิ้นสุด การป้อนข้อมูลที่เกินขีดจำกัดนี้จะส่งผลให้มีการตัดทอนโดยไม่มีการแจ้งเตือนและประสิทธิภาพการทำงานที่แย่ลง
- การใช้ Base เมื่อ Instruction เหมาะสม: DBRX Base เป็นโมเดลที่ผ่านการฝึกฝนเบื้องต้นแล้วและยังไม่ผ่านการปรับแต่งเพิ่มเติม เหมาะสำหรับการฝึกฝนในระดับใหญ่ต่อไป สำหรับงานส่วนใหญ่ที่ต้องการปฏิบัติตามคำสั่ง คุณควรเริ่มต้นด้วย DBRX Instruct ซึ่งได้รับการปรับแต่งให้เหมาะสมกับวัตถุประสงค์นั้นแล้ว
- การแยกงานฝึกอบรมออกจากงานประสานงานโครงการ: เมื่อการติดตามการทดลองของคุณอยู่ในเครื่องมือหนึ่ง และแผนโครงการของคุณอยู่ในอีกเครื่องมือหนึ่ง คุณจะสร้างไซโลข้อมูลขึ้น ใช้แพลตฟอร์มแบบบูรณาการเช่น ClickUp เพื่อรักษาการทำงานทางเทคนิคและการประสานงานโครงการของคุณให้สอดคล้องกัน
- การละเลยการประเมินก่อนการใช้งาน: แบบจำลองที่ทำงานได้ดีกับข้อมูลการฝึกอบรมของคุณอาจล้มเหลวอย่างน่าตกใจในโลกจริงควรตรวจสอบความถูกต้องของแบบจำลองที่ได้รับการปรับแต่งอย่างละเอียดบนชุดทดสอบที่แยกไว้ก่อนที่จะนำไปใช้งานจริงเสมอ
- มองข้ามความซับซ้อนในการปรับแต่ง: เนื่องจาก DBRX เป็นโมเดล Mixture-of-Experts สคริปต์การปรับแต่งมาตรฐานอาจต้องใช้ไลบรารีเฉพาะทางเช่น Megatron-LM หรือ PyTorch FSDP เพื่อจัดการการแบ่งพาร์ามิเตอร์ระหว่าง GPU หลายตัว
DBRX เทียบกับแพลตฟอร์มการฝึกอบรม AI อื่นๆ
การตัดสินใจเลือกแพลตฟอร์มฝึกอบรม AI เกี่ยวข้องกับการแลกเปลี่ยนพื้นฐาน: การควบคุมกับความสะดวกสบาย โมเดลที่เป็นกรรมสิทธิ์และใช้ได้เฉพาะผ่าน API นั้นใช้งานง่ายแต่จะผูกคุณไว้กับระบบนิเวศของผู้ให้บริการรายนั้น
แบบจำลองน้ำหนักเปิดเช่น DBRX ให้การควบคุมอย่างสมบูรณ์ แต่ต้องการความเชี่ยวชาญทางเทคนิคและโครงสร้างพื้นฐานมากขึ้น การเลือกนี้อาจทำให้คุณรู้สึกติดขัด ไม่แน่ใจว่าจะเลือกเส้นทางใดที่สนับสนุนเป้าหมายระยะยาวของคุณได้จริง—ซึ่งเป็นความท้าทายที่ทีมหลาย ๆ ทีมเผชิญในระหว่างการนำ AI มาใช้
ตารางนี้แสดงรายละเอียดความแตกต่างที่สำคัญเพื่อช่วยให้คุณตัดสินใจได้อย่างมีข้อมูล
| น้ำหนัก | เปิด (กำหนดเอง) | กรรมสิทธิ์ | เปิด (กำหนดเอง) | กรรมสิทธิ์ |
| การปรับแต่งอย่างละเอียด | การควบคุมอย่างเต็มที่ | ใช้ API เป็นพื้นฐาน | การควบคุมอย่างเต็มที่ | ใช้ API เป็นพื้นฐาน |
| โฮสต์ด้วยตนเอง | ใช่ | ไม่ | ใช่ | ไม่ |
| ใบอนุญาต | DB Open Model | ข้อกำหนดของ OpenAI | ชุมชนลามะ | คำศัพท์ทางมานุษยวิทยา |
| บริบท | 32K | 128K – 1M | 128 กิโลไบต์ | 200,000 – 1,000,000 |
DBRX เป็นตัวเลือกที่เหมาะสมเมื่อคุณต้องการควบคุมโมเดลอย่างเต็มที่ ต้องโฮสต์เองเพื่อความปลอดภัยหรือการปฏิบัติตามข้อกำหนด หรือต้องการความยืดหยุ่นของใบอนุญาตเชิงพาณิชย์แบบอนุญาตให้ใช้ได้กว้างขวาง หากคุณไม่มีโครงสร้างพื้นฐาน GPU ที่เฉพาะเจาะจง หรือคุณให้ความสำคัญกับความรวดเร็วในการออกสู่ตลาดมากกว่าการปรับแต่งอย่างลึกซึ้ง ทางเลือกที่ใช้ API อาจเหมาะสมกว่า
เริ่มต้นฝึกฝนอย่างชาญฉลาดด้วย ClickUp
DBRX มอบรากฐานที่พร้อมสำหรับองค์กรในการสร้างแอปพลิเคชัน AI ที่ปรับแต่งได้เอง พร้อมความโปร่งใสและการควบคุมที่คุณจะไม่ได้รับจากโมเดลที่เป็นกรรมสิทธิ์ สถาปัตยกรรม MoE ที่มีประสิทธิภาพช่วยลดค่าใช้จ่ายในการอนุมาน และการออกแบบที่เปิดกว้างทำให้การปรับแต่งเป็นเรื่องง่าย แต่เทคโนโลยีที่แข็งแกร่งเป็นเพียงครึ่งหนึ่งของสมการเท่านั้น
ความสำเร็จที่แท้จริงเกิดจากการปรับงานทางเทคนิคของคุณให้สอดคล้องกับกระบวนการทำงานร่วมกันของทีม การฝึกอบรมโมเดล AI เป็นงานที่ต้องอาศัยการทำงานเป็นทีม และการรักษาความสอดคล้องของการทดลอง เอกสาร และการสื่อสารกับผู้มีส่วนได้ส่วนเสียเป็นสิ่งสำคัญ เมื่อคุณนำทุกอย่างมารวมไว้ในพื้นที่ทำงานเดียวและลดการกระจายของบริบทที่ไม่จำเป็น คุณสามารถส่งมอบโมเดลที่ดีขึ้นได้เร็วขึ้น
เริ่มต้นใช้งานฟรีกับ ClickUpเพื่อประสานงานโครงการฝึกอบรม AI ของคุณในที่เดียว ✨
คำถามที่พบบ่อย
คุณสามารถติดตามการฝึกอบรมโดยใช้เครื่องมือมาตรฐานของ ML เช่น TensorBoard, Weights & Biases หรือ MLflow ได้ หากคุณกำลังฝึกอบรมภายในระบบนิเวศของ Databricks, MLflow จะถูกผสานรวมไว้โดยกำเนิดเพื่อการติดตามการทดลองอย่างราบรื่น
ใช่, DBRX สามารถรวมเข้ากับมาตรฐาน MLOps pipelines ได้. โดยการบรรจุแบบคอนเทนเนอร์ของโมเดล, คุณสามารถPLOYมันได้โดยใช้แพลตฟอร์มการจัดการการPLOYเช่น Kubeflow หรือเวิร์กโฟลว์ CI/CD ที่กำหนดเอง.
DBRX Base เป็นโมเดลพื้นฐานที่ผ่านการฝึกฝนล่วงหน้าแล้ว ซึ่งออกแบบมาสำหรับทีมที่ต้องการดำเนินการฝึกฝนล่วงหน้าเฉพาะโดเมนหรือปรับแต่งสถาปัตยกรรมเชิงลึก DBRX Instruct เป็นเวอร์ชันที่ปรับแต่งเพิ่มเติมเพื่อเน้นการปฏิบัติตามคำแนะนำ ทำให้เป็นจุดเริ่มต้นที่ดีกว่าสำหรับการพัฒนาแอปพลิเคชันส่วนใหญ่
ความแตกต่างหลักคือการควบคุม DBRX ให้คุณเข้าถึงน้ำหนักของโมเดลได้อย่างเต็มที่เพื่อการปรับแต่งอย่างละเอียดและการโฮสต์ด้วยตนเอง ในขณะที่ GPT-4 เป็นบริการที่ใช้ผ่าน API เท่านั้น
น้ำหนักของแบบจำลอง DBRX สามารถดาวน์โหลดได้ฟรีภายใต้ลิขสิทธิ์ Databricks Open Model License อย่างไรก็ตาม คุณต้องรับผิดชอบค่าใช้จ่ายของโครงสร้างพื้นฐานการคำนวณที่จำเป็นสำหรับการรันหรือปรับแต่งแบบจำลอง