

เวลา 3 โมงเช้า
เสียงสัญญาณเตือนที่ดังแหลมทำให้ตื่นขึ้นมาอย่างกะทันหัน
คุณรีบลุกขึ้นยืน ดึงตัวเองไปที่แสงสว่างจากหน้าจอคอมพิวเตอร์ ระบบสำคัญล่ม ความตื่นตระหนกเริ่มก่อตัวขึ้น นี่ไม่ใช่ฉากจากภาพยนตร์ไซไฟระทึกขวัญ แต่เป็นฝันร้ายสำหรับผู้เชี่ยวชาญด้านไอทีทุกคน
แต่มันก็เป็นความจริงเช่นกัน เมื่อโลกดิจิทัลหยุดชะงัก ความกดดันก็มหาศาล
นี่คือจุดที่การจัดการเหตุการณ์กลายเป็นเส้นชีวิต
การจัดการเหตุการณ์คือกุญแจสำคัญในการแก้ไขปัญหาการหยุดชะงักของโครงการอย่างรวดเร็ว ด้วยการจัดการการหยุดชะงักเหล่านี้อย่างมีประสิทธิภาพ คุณสามารถมุ่งเน้นไปที่การส่งมอบผลลัพธ์และทำให้โครงการของคุณเสร็จสิ้นอย่างมีประสิทธิภาพได้มากขึ้น
ในบทความนี้ เราจะสำรวจกระบวนการจัดการเหตุการณ์และแบ่งปันแนวทางปฏิบัติที่ดีที่สุดเพื่อช่วยให้คุณนำแผนสำรองที่แข็งแกร่งไปใช้ ซึ่งจะทำให้คุณสามารถจัดการกับเหตุการณ์ที่เกิดขึ้นในโครงการในอนาคตได้อย่างมีประสิทธิภาพ
การเข้าใจการจัดการเหตุการณ์
เหตุการณ์คือ การขัดข้องหรือภัยคุกคามที่อาจเกิดขึ้น ซึ่งส่งผลกระทบต่อคุณภาพการให้บริการ ตัวอย่างเช่น แอปพลิเคชันทางธุรกิจที่ล่มหรือเว็บเซิร์ฟเวอร์ที่ทำงานช้าลงจนก่อให้เกิดปัญหาด้านประสิทธิภาพการทำงาน ล้วนถือเป็นเหตุการณ์ทั้งสิ้น เหตุการณ์เหล่านี้อาจมีตั้งแต่ปัญหาเล็กน้อยที่กระทบผู้ใช้เพียงไม่กี่ราย ไปจนถึงการหยุดให้บริการโดยสิ้นเชิงซึ่งส่งผลกระทบต่อบริการในระดับโลก
การจัดการเหตุการณ์คือกระบวนการในการระบุ จัดลำดับความสำคัญ และแก้ไขปัญหาด้านไอทีเพื่อลดการหยุดชะงักของการดำเนินงานทางธุรกิจ พร้อมทั้งดำเนินมาตรการเพื่อป้องกันไม่ให้เกิดเหตุการณ์ซ้ำในอนาคต กระบวนการป้องกันเหตุการณ์เชิงรุกนี้มีความสำคัญอย่างยิ่งสำหรับทุกองค์กร เนื่องจากการหยุดให้บริการอาจนำไปสู่ความสูญเสียทางธุรกิจอย่างมีนัยสำคัญ การจัดการเหตุการณ์ที่มีประสิทธิภาพช่วยให้ทีมงานสามารถจัดลำดับความสำคัญและแก้ไขปัญหาได้อย่างรวดเร็ว ส่งผลให้สามารถให้บริการได้อย่างต่อเนื่องและมีคุณภาพยิ่งขึ้น
เมื่อต้องรับมือกับเหตุการณ์ ทีมจำเป็นต้องมีแผนที่ชัดเจนซึ่งช่วยให้พวกเขา:
- ตอบกลับโดยด่วน เพื่อลดเวลาหยุดทำงานให้น้อยที่สุด
- สื่อสารอย่างมีประสิทธิภาพ กับลูกค้า ผู้มีส่วนได้ส่วนเสีย เจ้าของบริการ และบุคคลที่เกี่ยวข้องอื่นๆ
- ร่วมมืออย่างราบรื่น เพื่อเร่งการแก้ไขปัญหาและขจัดอุปสรรคในการหาทางออก
- ปรับปรุงอย่างต่อเนื่อง โดยการเรียนรู้จากเหตุการณ์ที่เกิดขึ้นและนำบทเรียนเหล่านี้ไปประยุกต์ใช้เพื่อยกระดับคุณภาพการให้บริการและปรับปรุงกระบวนการทำงาน
การรู้วิธีเขียนรายงานเหตุการณ์ก็เป็นสิ่งสำคัญในกรอบนี้เช่นกัน รายงานเหตุการณ์ที่ละเอียดจะ ช่วยให้การวิเคราะห์อย่างถี่ถ้วนเป็นไปได้, ระบุสาเหตุที่แท้จริง, และพัฒนา стратегииป้องกันล่วงหน้า
ความสัมพันธ์ระหว่างการจัดการเหตุการณ์, ITSM, และ DevOps
การจัดการเหตุการณ์เป็นองค์ประกอบหลักของการบริหารจัดการบริการไอที (ITSM) ซึ่งช่วยให้บริการไอทีพร้อมใช้งานและเชื่อถือได้ตลอดเวลา ในขณะเดียวกัน DevOps ผสานรวมทีมพัฒนากับทีมปฏิบัติการเพื่อปรับปรุงการทำงานร่วมกันและประสิทธิภาพ
การปรับการจัดการเหตุการณ์ให้สอดคล้องกับหลักการบริหารโครงการ DevOpsสามารถช่วยให้องค์กรตอบสนองต่อเหตุการณ์ได้อย่างรวดเร็วและมีประสิทธิภาพ การปรับให้สอดคล้องนี้ส่งเสริมการปรับปรุงอย่างต่อเนื่อง การกู้คืนเหตุการณ์ที่รวดเร็วขึ้น และการส่งมอบบริการที่ดีขึ้น
การเข้าใจกระบวนการจัดการเหตุการณ์
กระบวนการจัดการเหตุการณ์ที่มีประสิทธิภาพช่วยให้ทีมไอทีสามารถตรวจสอบ บันทึก และแก้ไขปัญหาการหยุดชะงักหรือการขัดข้องของบริการได้อย่างมีประสิทธิผล
บริษัทต่างๆ มักจะนำกระบวนการจัดการเหตุการณ์ที่แตกต่างกันซึ่งปรับให้เหมาะกับความต้องการเฉพาะของตน เนื่องจากไม่มีแนวทางใดที่เหมาะกับทุกองค์กร, คุณจะพบวิธีการที่หลากหลายในองค์กรต่างๆ
บางทีมยังคงยึดถือกระบวนการจัดการเหตุการณ์ตามรูปแบบไอทีแบบดั้งเดิม เช่นเดียวกับที่ระบุไว้ในมาตรฐานการรับรอง Information Technology Infrastructure Library (ITIL) ในขณะที่บางทีมชอบแนวทางที่เน้นด้านวิศวกรรมความน่าเชื่อถือของระบบ (Site Reliability Engineering - SRE) หรือแนวทาง DevOps มากกว่า
กระบวนการจัดการเหตุการณ์ของ ITIL มุ่งเน้นที่การลดเวลาหยุดทำงานและบรรเทาผลกระทบของเหตุการณ์ต่อประสิทธิภาพการทำงานของพนักงาน โดยใช้แม่แบบรายงานเหตุการณ์ ทีมงานสามารถสร้างกระบวนการทำงานที่สามารถทำซ้ำได้เพื่อบันทึก วินิจฉัย และแก้ไขเหตุการณ์ในขณะที่รักษาบันทึกกิจกรรมอย่างครบถ้วน
กรอบการทำงาน ITIL ถูกใช้ เป็นหลักโดยทีมไอทีที่จัดการบริการภายในธุรกิจ ทีมเหล่านี้มักจะปรับแต่งการครอบคลุมที่กว้างขวางของ ITIL เกี่ยวกับเหตุการณ์และกระบวนการให้เหมาะสมกับความต้องการของพวกเขา
ITIL มีประโยชน์อย่างยิ่งในการสร้างวัฒนธรรมการแก้ไขปัญหาเชิงรุก. กระบวนการที่มีโครงสร้างชัดเจนช่วยให้ทีมสามารถติดตามเหตุการณ์และกิจกรรมต่าง ๆ ได้อย่างสม่ำเสมอ ซึ่งช่วยปรับปรุงการรายงานและการวิเคราะห์ให้ดีขึ้น และนำไปสู่การให้บริการที่แข็งแกร่งขึ้นและทีมที่มีประสิทธิภาพมากขึ้นในที่สุด.
ปัญญาประดิษฐ์และการเรียนรู้ของเครื่องในการจัดการเหตุการณ์
การผสานปัญญาประดิษฐ์และการเรียนรู้ของเครื่องเข้ากับการจัดการเหตุการณ์เปลี่ยนแปลงวิธีที่ทีมจัดการกับเหตุการณ์ เครื่องมือที่ขับเคลื่อนด้วย AI สามารถ วิเคราะห์ข้อมูลจำนวนมหาศาลเพื่อทำนายเหตุการณ์ที่อาจเกิดขึ้นก่อนที่มันจะเกิดขึ้นจริง ทำให้สามารถดำเนินการป้องกันล่วงหน้าได้
อัลกอริทึมการเรียนรู้ของเครื่องสามารถระบุรูปแบบและความผิดปกติที่นักวิเคราะห์มนุษย์อาจมองข้ามได้ มอบความเข้าใจเชิงลึกเกี่ยวกับสาเหตุที่แท้จริงและแนวทางแก้ไขที่เป็นไปได้ เทคโนโลยีเหล่านี้ยังสามารถทำงานที่เป็นกิจวัตร เช่น การบันทึกเหตุการณ์และการวินิจฉัยเบื้องต้น โดยอัตโนมัติ ทำให้ทรัพยากรมนุษย์สามารถมุ่งเน้นไปที่การแก้ปัญหาที่ซับซ้อนมากขึ้นได้
ความพร้อมใช้งานสูงและเวลาหยุดทำงานในการจัดการเหตุการณ์
การลดเวลาหยุดทำงานให้น้อยที่สุดเป็นสิ่งสำคัญสำหรับการจัดการเหตุการณ์อย่างมีประสิทธิภาพ ความพร้อมใช้งานสูง ช่วยให้ระบบสามารถทำงานและเข้าถึงได้ตลอดเวลา ลดความเสี่ยงของการหยุดให้บริการ การสำรองข้อมูล, กลไกการสลับระบบ, และการกระจายโหลดถูกนำมาใช้เพื่อให้ได้ความพร้อมใช้งานสูง
การลดเวลาหยุดทำงานเป็นสิ่งสำคัญอย่างยิ่งต่อการรักษาประสิทธิภาพการทำงานและความพึงพอใจของลูกค้า กระบวนการจัดการเหตุการณ์ต้องประกอบด้วยแผนที่แข็งแกร่งสำหรับการตอบสนองอย่างรวดเร็วและการกู้คืนเพื่อลดระยะเวลาและผลกระทบของการหยุดชะงักให้น้อยที่สุด
กระบวนการจัดการเหตุการณ์ด้านไอทีโดยละเอียด
การจัดการเหตุการณ์เกี่ยวข้องกับการระบุ, บันทึก, จัดหมวดหมู่, จัดลำดับความสำคัญ, และแก้ไขเหตุการณ์อย่างมีประสิทธิภาพ
การเข้าใจขั้นตอนเหล่านี้ช่วยให้มั่นใจได้ว่าจะมีการจัดการเหตุการณ์อย่างเป็นระบบ ลดเวลาหยุดทำงาน และป้องกันไม่ให้เกิดเหตุการณ์ซ้ำในอนาคต
ขั้นตอนในกระบวนการจัดการเหตุการณ์ด้านไอที
1. ระบุและบันทึกเหตุการณ์
เหตุการณ์สามารถเกิดขึ้นได้จากแหล่งต่าง ๆ รวมถึงพนักงาน ลูกค้า ผู้ขาย หรือระบบเฝ้าระวัง ขั้นตอนแรกคือการระบุและบันทึกเหตุการณ์ การบันทึกเหล่านี้ซึ่งมักเรียกว่าบัตรเหตุการณ์ (incident tickets) โดยทั่วไปจะประกอบด้วย:
- ชื่อของบุคคล ที่รายงานเหตุการณ์
- วันที่และเวลา ที่เหตุการณ์ถูกรายงาน
- คำอธิบายเหตุการณ์ รายละเอียดเกี่ยวกับสิ่งที่ทำงานผิดปกติหรือหยุดทำงาน
- หมายเลขประจำตัวที่ไม่ซ้ำกันจะถูก กำหนดเพื่อวัตถุประสงค์ในการติดตาม
2. จัดประเภทเหตุการณ์
การกำหนด หมวดหมู่ที่สมเหตุสมผลและเข้าใจง่าย ให้กับแต่ละเหตุการณ์เป็นสิ่งสำคัญ (และหากจำเป็น ให้มีหมวดหมู่ย่อย) การจัดหมวดหมู่นี้ช่วยให้การวิเคราะห์ข้อมูลเพื่อหาแนวโน้มและรูปแบบต่าง ๆ เป็นไปอย่างมีประสิทธิภาพ ซึ่งมีความจำเป็นอย่างยิ่งสำหรับการจัดการปัญหาอย่างมีประสิทธิผลและการป้องกันเหตุการณ์ในอนาคต
3. จัดลำดับความสำคัญของเหตุการณ์
ทุกเหตุการณ์ต้องได้รับการจัดลำดับความสำคัญ โดยพิจารณาจากผลกระทบต่อธุรกิจ จำนวนบุคคลที่ได้รับผลกระทบ SLA ที่เกี่ยวข้อง และผลกระทบที่อาจเกิดขึ้นทางการเงิน ความปลอดภัย และการปฏิบัติตามข้อกำหนด
ทีมที่รับผิดชอบจะกำหนดลำดับความสำคัญโดยเปรียบเทียบกับเหตุการณ์ที่เปิดอยู่อื่น ๆ การกำหนดระดับความรุนแรงและลำดับความสำคัญล่วงหน้าเป็นแนวทางปฏิบัติที่ดีที่สุด ซึ่งช่วยให้ผู้จัดการเหตุการณ์สามารถประเมินลำดับความสำคัญได้อย่างรวดเร็ว
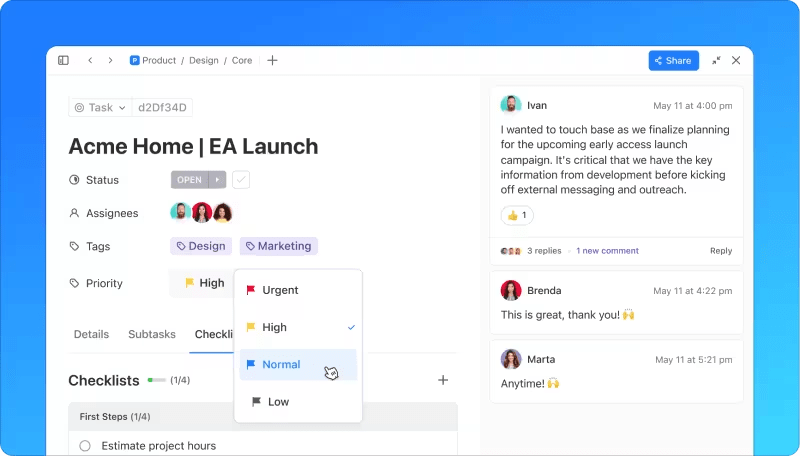
4. ตอบสนองต่อเหตุการณ์
ขั้นตอนการตอบสนองประกอบด้วยหลายการกระทำที่สำคัญ:
- การวินิจฉัยเบื้องต้น: ในอุดมคติ ทีมสนับสนุนแนวหน้าควรวินิจฉัยและแก้ไขเหตุการณ์ได้ หากไม่สามารถทำได้ พวกเขาจะบันทึกข้อมูลที่เกี่ยวข้องทั้งหมดและส่งต่อไปยังทีมระดับถัดไป
- การยกระดับ: ทีมถัดไปจะดำเนินการวินิจฉัยต่อไป หากไม่สามารถแก้ไขเหตุการณ์ได้ พวกเขาจะยกระดับไปยังขั้นตอนต่อไป
- การสื่อสาร: มีการแจ้งข้อมูลอัปเดตเป็นประจำแก่ผู้มีส่วนได้ส่วนเสียทั้งภายในและภายนอกที่ได้รับผลกระทบ
- การสืบสวนและวินิจฉัย: ระยะนี้จะดำเนินต่อไปจนกว่าจะสามารถระบุลักษณะของเหตุการณ์ได้ชัดเจน ทีมอาจนำทรัพยากรภายนอกหรือสมาชิกจากแผนกอื่น ๆ เข้ามาช่วยเหลือในการแก้ไขปัญหา
- การแก้ไขและฟื้นฟู: เมื่อได้รับการวินิจฉัยแล้ว ทีมงานจะดำเนินการตามขั้นตอนที่จำเป็นเพื่อแก้ไขเหตุการณ์ดังกล่าว การฟื้นฟูหมายถึงระยะเวลาที่จำเป็นสำหรับการดำเนินงานให้กลับมาเป็นปกติอย่างสมบูรณ์ เนื่องจากการแก้ไขบางอย่าง เช่น การอัปเดตแพตช์ข้อบกพร่อง อาจต้องผ่านการทดสอบและนำไปใช้งานจริง แม้ว่าจะได้ดำเนินการแก้ไขแล้วก็ตาม
- การปิด: หากเหตุการณ์ถูกยกระดับขึ้น จะถูกส่งกลับไปยังแผนกบริการเพื่อดำเนินการปิด พนักงานแผนกบริการเท่านั้นที่สามารถปิดเหตุการณ์ได้ เพื่อให้มั่นใจในคุณภาพและความพึงพอใจของลูกค้า
การจัดการเหตุการณ์สำหรับทีม DevOps และ SRE
แนวทาง DevOps และ SRE ได้รับความนิยมอย่างแพร่หลาย โดยเฉพาะอย่างยิ่งกับการเติบโตของบริการคลาวด์ที่พร้อมใช้งานตลอดเวลา แอปพลิเคชันเว็บที่เข้าถึงได้จากทั่วโลก ไมโครเซอร์วิส และโซลูชันซอฟต์แวร์ในรูปแบบบริการ (SaaS)
ซอฟต์แวร์สมัยใหม่ ซึ่งมีความสำคัญอย่างยิ่งต่อการใช้งานทั้งส่วนบุคคลและระดับมืออาชีพ มักไม่ได้ถูกโฮสต์บนเซิร์ฟเวอร์ภายในองค์กร แต่จะถูกนำไปใช้งานในศูนย์ข้อมูลแทน โดยให้บริการแก่ผู้ใช้หลายพันหรือหลายล้านคนทั่วโลก ความคล่องตัวและความรวดเร็วเป็นปัจจัยสำคัญสำหรับทีมที่รับผิดชอบดูแลการให้บริการเหล่านี้ การหยุดให้บริการแม้เพียงช่วงเวลาสั้น ๆ อาจส่งผลกระทบในวงกว้างต่อองค์กรจำนวนมากพร้อมกัน
ปรัชญา "คุณสร้าง คุณดูแล" มอบความยืดหยุ่นที่จำเป็นให้กับทีมที่มีความคล่องตัว แต่ก็สามารถทำให้เส้นแบ่งความรับผิดชอบไม่ชัดเจนได้เช่นกัน แม้ว่าทีม DevOps จะสามารถเติบโตได้ดีกับกระบวนการพัฒนาที่ไม่เคร่งครัด แต่การมาตรฐานการจัดการเหตุการณ์ที่สำคัญก็เป็นสิ่งจำเป็น:
ความรับผิดชอบในการรับสายฉุกเฉินร่วมกัน
ต่างจากแบบดั้งเดิมที่สมาชิกทีมเฉพาะถูกกำหนดให้เป็นผู้เชี่ยวชาญที่พร้อมให้บริการตลอดเวลา ทีม DevOps มักจะนำระบบหมุนเวียนการเป็นผู้รับผิดชอบการให้บริการมาใช้ วิธีการนี้ทำให้แน่ใจว่าสมาชิกทีมทุกคนมีความรับผิดชอบในการตอบสนองต่อเหตุการณ์ที่เกิดขึ้น รวมถึงเหตุการณ์ที่อาจเกิดขึ้นนอกเวลาทำงานปกติ
ความคุ้นเคยนำไปสู่การแก้ไข
แก่นสำคัญของแนวคิด DevOps คือความเชื่อที่ว่า วิศวกรผู้พัฒนาบริการนั้นเหมาะสมที่สุดในการแก้ไขปัญหาเมื่อเกิดขึ้น หลักการนี้เน้นย้ำแนวคิด 'คุณสร้าง คุณดูแล' ซึ่งผู้ที่คุ้นเคยกับสถาปัตยกรรมและความซับซ้อนของบริการมากที่สุดจะเป็นผู้รับผิดชอบในการแก้ไขปัญหาและหยุดชะงักต่างๆ
ความเร็วและความรับผิดชอบ
ทีม DevOps ต้องสร้างและปรับใช้ซอฟต์แวร์อย่างรวดเร็ว แต่ความเร็วนี้มาพร้อมกับความรับผิดชอบที่เพิ่มขึ้น การรู้ว่าพวกเขาจะต้องแก้ไขปัญหาต่างๆ เป็นแรงจูงใจให้วิศวกรผลิตโค้ดที่มีคุณภาพสูงและเชื่อถือได้
การวิเคราะห์หาสาเหตุที่แท้จริง (RCA) มีความสำคัญอย่างยิ่งในกระบวนการจัดการเหตุการณ์ของ DevOps RCA เกี่ยวข้องกับการระบุสาเหตุที่แท้จริงของเหตุการณ์ ช่วยให้ทีมสามารถนำไปสู่การแก้ไขปัญหาอย่างเป็นรูปธรรม และป้องกันการเกิดซ้ำ
นี่คือแนวทางเชิงรุกที่มุ่งแก้ไขปัญหาที่เกิดขึ้นทันทีและเสริมสร้างความแข็งแกร่งให้กับระบบโดยรวม ลดโอกาสการเกิดเหตุการณ์สำคัญในอนาคต และเพิ่มความสามารถในการฟื้นตัวของบริการ
ด้วยการรักษาการไหลที่ต่อเนื่องและสอดคล้องในแนวทางการจัดการเหตุการณ์ DevOps teams สามารถ บาลานซ์ความยืดหยุ่นกับโครงสร้างได้ ซึ่งทำให้พวกเขาเตรียมพร้อมอย่างดีในการรับมือกับเหตุการณ์อย่างรวดเร็วและมีประสิทธิภาพ นำไปสู่บริการซอฟต์แวร์ที่เชื่อถือได้และแข็งแกร่งยิ่งขึ้น
บทบาทในการจัดการเหตุการณ์
ในขณะที่องค์กรอาจปรับบทบาทและความรับผิดชอบของตนตามความต้องการเฉพาะของตน ต่อไปนี้คือบทบาทที่พบได้บ่อยที่สุดในทีมจัดการเหตุการณ์ด้านไอที:
- ผู้ใช้ปลายทาง/ผู้ร้องขอ: บุคคลนี้มักจะเป็นผู้ที่ประสบปัญหาการหยุดชะงักของบริการและมีหน้าที่เริ่มกระบวนการจัดการเหตุการณ์โดยการส่งคำร้องเหตุการณ์
- แผนกบริการระดับ 1: แผนกบริการระดับ 1 เป็นจุดติดต่อแรกสำหรับผู้ร้องขอ เจ้าหน้าที่เทคนิคจะจัดการกับปัญหาและคำขอพื้นฐาน ความเชี่ยวชาญของพวกเขาครอบคลุมปัญหาทั่วไป เช่น การรีเซ็ตรหัสผ่านและปัญหาการเชื่อมต่อ เช่น ปัญหา Wi-Fi
- แผนกบริการระดับ 2: ช่างเทคนิคในระดับนี้มีความสามารถและองค์ความรู้ที่ล้ำหน้ากว่าในระดับ 1 พวกเขาจัดการกับปัญหาที่ซับซ้อนมากขึ้นและรับการส่งต่อจากระดับ 1 บทบาทของพวกเขาคือการแก้ไขปัญหาทางเทคนิคที่ซับซ้อนและทำให้แน่ใจว่าการแก้ไขเหตุการณ์เป็นไปอย่างมีประสิทธิภาพ
- แผนกบริการระดับ 3 ขึ้นไป: ระดับนี้ประกอบด้วยผู้เชี่ยวชาญที่มีความเชี่ยวชาญลึกซึ้งในด้านเฉพาะของโครงสร้างพื้นฐานด้านไอที เช่น การบำรุงรักษาฮาร์ดแวร์หรือการสนับสนุนเซิร์ฟเวอร์
- ผู้จัดการเหตุการณ์: ผู้จัดการเหตุการณ์ดูแลกระบวนการจัดการเหตุการณ์ ประเมินประสิทธิภาพของกระบวนการ เสนอแนะการปรับปรุง และตรวจสอบให้มีการปฏิบัติตามขั้นตอนที่กำหนดไว้
- เจ้าของกระบวนการ: เจ้าของกระบวนการดูแลและปรับปรุงกระบวนการจัดการเหตุการณ์ พวกเขาวิเคราะห์ ปรับปรุง และพัฒนาเพื่อให้แน่ใจว่ากระบวนการสอดคล้องกับเป้าหมายขององค์กรและสนับสนุนความพยายามในการจัดการเหตุการณ์ได้อย่างมีประสิทธิภาพ
บทบาทเหล่านี้ร่วมกันมีส่วนช่วยในการสร้างกระบวนการระบุและจัดการเหตุการณ์ที่มีโครงสร้างดีและมีประสิทธิภาพ ซึ่งช่วยให้การแก้ไขปัญหาเป็นไปอย่างรวดเร็วและมีประสิทธิผล พร้อมทั้งปรับปรุงแนวทางอย่างต่อเนื่อง
อ่านเพิ่มเติม: วิธีเขียนรายงานข้อบกพร่องที่ดี (พร้อมตัวอย่างและเทมเพลต)
เครื่องมือและทรัพยากรสำหรับการจัดการเหตุการณ์อย่างมีประสิทธิภาพ
การใช้เครื่องมือและทรัพยากรการจัดการเหตุการณ์ที่เหมาะสมสามารถเพิ่มประสิทธิภาพและประสิทธิผลของกระบวนการจัดการเหตุการณ์ได้อย่างมาก
เว็บเบราว์เซอร์ โดยเฉพาะ Google Chrome มีบทบาทสำคัญในการจัดการเหตุการณ์ ความหลากหลายและความเข้ากันได้ของ Chrome กับซอฟต์แวร์จัดการเหตุการณ์บนเว็บต่างๆ ทำให้เป็นเครื่องมือที่ขาดไม่ได้สำหรับทีมไอที คลังส่วนขยายที่หลากหลาย เช่น เครื่องมือสำหรับนักพัฒนา ตัวติดตามข้อบกพร่อง และตัวตรวจสอบประสิทธิภาพ ช่วยให้สามารถวินิจฉัยและแก้ไขปัญหาแบบเรียลไทม์ได้
นอกจากนี้ การดึงข้อมูลวัตถุ เช่น ข้อมูลแคช ประวัติการเข้าชม ไฟล์ที่ดาวน์โหลด ฯลฯ ผ่าน การวิเคราะห์ทางนิติเวชของเบราว์เซอร์ ยังช่วยให้ทีมสามารถระบุแหล่งที่มาที่เป็นไปได้ของการโจมตีไวรัสและโค้ดที่เป็นอันตราย
Chrome ยังผสานการทำงานกับClickUp ได้อย่างราบรื่นซึ่งเป็นซอฟต์แวร์จัดการงานและเหตุการณ์ที่ได้รับการจัดอันดับสูง โดยทีมในบริษัทขนาดเล็กและใหญ่ใช้กัน
นี่คือประโยชน์ที่สำคัญบางประการของการใช้ ClickUp สำหรับการจัดการเหตุการณ์:
1. การติดตามเหตุการณ์แบบรวมศูนย์
ClickUp รวบรวมข้อมูลที่เกี่ยวข้องกับเหตุการณ์ทั้งหมดไว้ในแพลตฟอร์มเดียว วิธีการรวมศูนย์นี้ช่วยให้มั่นใจได้ว่ารายงานเหตุการณ์ทั้งหมด การอัปเดต และการแก้ไขปัญหาสามารถเข้าถึงได้ในที่เดียว ลดความเสี่ยงของการสูญหายของข้อมูล และทำให้มั่นใจว่าสมาชิกในทีมมีข้อมูลล่าสุดอยู่เสมอ
2. การทำงานร่วมกันแบบเรียลไทม์
คุณสมบัติการร่วมมือของ ClickUp ช่วยให้การสื่อสารระหว่างสมาชิกในทีมเป็นไปอย่างราบรื่น ผู้ใช้สามารถแสดงความคิดเห็นได้โดยตรงบนงาน แบ่งปันไฟล์ และอัปเดตสถานะของเหตุการณ์ได้ในเวลาจริงผ่านมุมมอง ClickUp Chat คุณสมบัตินี้เป็นประโยชน์สำหรับทีมที่ทำงานในสถานที่ต่าง ๆ หรือเขตเวลาที่ต่างกัน ทำให้ทุกคนได้รับข้อมูลที่ทันสมัยและสอดคล้องกัน

3. การจัดการกระบวนการทำงานอัตโนมัติ
ClickUp Automationsช่วยสร้างกระบวนการทำงานอัตโนมัติที่กระตุ้นให้เกิดการกระทำเฉพาะตามเงื่อนไขที่กำหนดไว้ล่วงหน้า ตัวอย่างเช่น เมื่อมีรายงานเหตุการณ์เกิดขึ้น ระบบสามารถส่งการแจ้งเตือนอัตโนมัติไปยังสมาชิกทีมที่เกี่ยวข้อง และมอบหมายงานตามประเภทของเหตุการณ์นั้น ๆ ได้ ซึ่งช่วยลดความพยายามในการทำงานด้วยตนเองและเร่งการแก้ไขปัญหาให้รวดเร็วขึ้น
4. การรายงานและการวิเคราะห์แบบบูรณาการ
แพลตฟอร์มนี้มอบเครื่องมือรายงานและวิเคราะห์ที่แข็งแกร่งซึ่งช่วยติดตามแนวโน้มของเหตุการณ์และตัวชี้วัดประสิทธิภาพ ทีมสามารถ สร้างรายงานละเอียดเกี่ยวกับการจัดลำดับความสำคัญของเหตุการณ์, เวลาการแก้ไข เหตุการณ์, อัตราการเกิดซ้ำ, และตัวชี้วัดประสิทธิภาพสำคัญอื่น ๆ แนวทางที่ขับเคลื่อนด้วยข้อมูลนี้ช่วยในการระบุรูปแบบ, ประเมินประสิทธิภาพของกลยุทธ์การตอบสนอง, และตัดสินใจอย่างมีข้อมูลเพื่อปรับปรุงกระบวนการจัดการเหตุการณ์
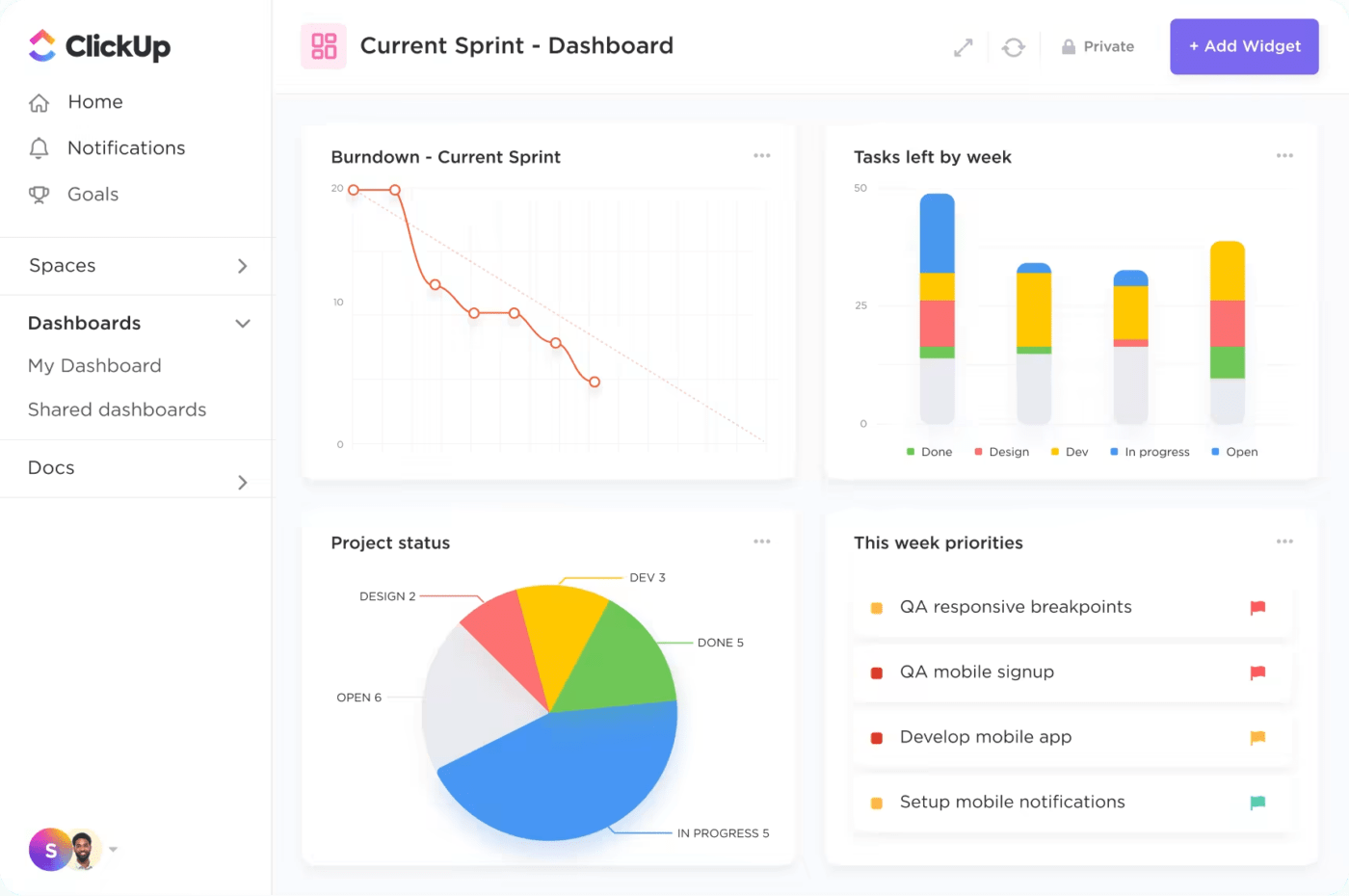
5. แผงควบคุมที่ปรับแต่งได้
แพลตฟอร์มนี้ช่วยให้คุณสามารถสร้างแดชบอร์ดที่ปรับแต่งได้ตามต้องการเพื่อแสดงตัวชี้วัดการจัดการเหตุการณ์ที่สำคัญและ KPI ต่าง ๆClickUp Dashboardsให้ภาพรวมที่ชัดเจนของเหตุการณ์ที่กำลังดำเนินอยู่ งานที่รอการดำเนินการ และประสิทธิภาพของทีม ช่วยให้ผู้จัดการสามารถประเมินสถานะปัจจุบันของการจัดการเหตุการณ์ได้อย่างรวดเร็วและแก้ไขปัญหาต่าง ๆ ได้อย่างทันท่วงที
6. แม่แบบที่สร้างไว้ล่วงหน้า
ClickUpนำเสนอเทมเพลตไอทีที่สามารถปรับแต่งได้หลากหลายsซึ่งออกแบบมาเพื่อการจัดการเหตุการณ์ เทมเพลตเหล่านี้ยังช่วยให้ผู้ใช้สามารถบันทึกข้อบกพร่องได้อีกด้วย
ตัวอย่างเช่น เทมเพลตรายงานเหตุการณ์ด้านไอทีของ ClickUp ช่วยให้ทีมไอทีสามารถบันทึก ติดตาม และแก้ไขเหตุการณ์ได้อย่างรวดเร็วและมีประสิทธิภาพ ไม่เพียงแต่ช่วยเพิ่มความเร็วในการให้บริการเท่านั้น แต่ยังช่วยให้บริษัทสามารถระบุแนวโน้มระยะยาวที่สามารถแก้ไขเพื่อปรับปรุงโครงสร้างพื้นฐานด้านไอทีโดยรวมได้อีกด้วย
เทมเพลตนี้ช่วยให้คุณทำได้ง่าย:
- บันทึกและรายงาน เหตุการณ์อย่างถูกต้อง
- ติดตามความคืบหน้าในการแก้ไขปัญหาแบบเรียลไทม์
- ระบุรูปแบบ ในปัญหาที่รายงานเพื่อแก้ไขปัญหาเชิงรุก
ประกอบด้วยองค์ประกอบที่จำเป็น เช่น คำอธิบายโดยละเอียด รายการตรวจสอบ งานย่อย และฟิลด์ที่สามารถปรับแต่งได้ ความยืดหยุ่นนี้ช่วยให้แม่แบบสามารถปรับให้เข้ากับกระบวนการและขั้นตอนขององค์กรของคุณได้ สร้างรายงานเหตุการณ์ด้านไอทีที่ครอบคลุม
คุณยังสามารถใช้เทมเพลตแผนปฏิบัติการกรณีเหตุการณ์ของ ClickUp ซึ่งช่วยให้การพัฒนาแผนปฏิบัติการกรณีเหตุการณ์ที่ครอบคลุมสำหรับธุรกิจเป็นเรื่องง่ายขึ้น
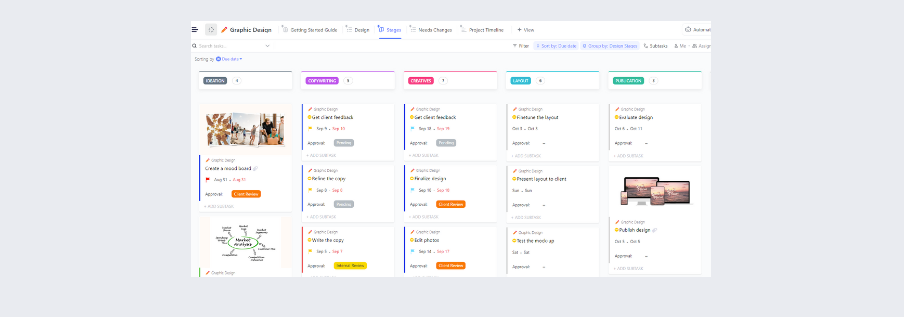
เทมเพลตนี้ได้รวบรวมข้อมูลสำคัญทั้งหมดอย่างเป็นระบบ ช่วยให้คุณจัดทำบันทึกกิจกรรมที่เกี่ยวข้องกับเหตุการณ์ได้อย่างน่าเชื่อถือ และนำไปสู่การดำเนินกลยุทธ์การตอบสนองที่มีประสิทธิภาพ
เทมเพลตนี้มีส่วนต่างๆ ที่ใช้รหัสสีเพื่อการจัดเอกสารอย่างเป็นระเบียบ:
- สรุปสถานการณ์: ให้ภาพรวมที่กระชับของเหตุการณ์และแผนการดำเนินการโดยรวม
- แผนการดำเนินการ: รายละเอียดวัตถุประสงค์และกลยุทธ์ในการจัดการเหตุการณ์
- ข้อมูลติดต่อทีมเหตุการณ์: รายการวิธีการติดต่อสำหรับบุคลากรที่เกี่ยวข้องกับการตอบสนอง
- รายการองค์กรเหตุการณ์: ระบุบทบาทและความรับผิดชอบของทีมปฏิบัติการ, วางแผน, โลจิสติกส์, และการเงิน
- รายการมอบหมายเหตุการณ์: มอบหมายงานเฉพาะให้กับหัวหน้างานและสมาชิกในทีม
- แผนที่/สรุปสถานการณ์: ประกอบด้วยภาพกราฟิกแสดงสถานที่เกิดเหตุหรือพื้นที่ที่เกี่ยวข้อง
- การอนุมัติแผนการรับมือเหตุการณ์: บันทึกข้อมูล เช่น ชื่อของผู้ที่ส่งแผน วันที่ส่ง และลายเซ็นที่จำเป็น
โดยการใช้ประโยชน์จากเทมเพลตนี้ บริษัทสามารถรวบรวมข้อมูลที่จำเป็นทั้งหมดสำหรับการอนุมัติ IAP ได้อย่างมีประสิทธิภาพ และจัดทำแผนการตอบสนองต่อเหตุการณ์ที่ประสานงานอย่างดีและครอบคลุม
แนวทางปฏิบัติที่ดีที่สุดในการจัดการเหตุการณ์
การจัดการเหตุการณ์ที่มีประสิทธิภาพอาศัยแนวทางปฏิบัติที่ดีที่สุดเพื่อให้มั่นใจในการแก้ไขปัญหาอย่างรวดเร็วและมีประสิทธิผล
กำหนดความคาดหวังที่ชัดเจนด้วย SLA
ข้อตกลงระดับการให้บริการ (SLAs) มีบทบาทสำคัญในการกำหนดความคาดหวังที่ชัดเจนเกี่ยวกับระยะเวลาที่ทีมควรดำเนินการแก้ไขเหตุการณ์ต่างๆ ตามระดับความรุนแรง
SLA กำหนดเวลาการตอบสนองและการแก้ไขปัญหาที่เฉพาะเจาะจง ซึ่งช่วยให้สามารถจัดลำดับความสำคัญของเหตุการณ์และแนะนำทีมในการจัดการปริมาณงานได้อย่างมีประสิทธิภาพ แนวทางที่มีโครงสร้างนี้ช่วยให้คุณมุ่งเน้นทรัพยากรไปยังจุดที่มีความจำเป็นมากที่สุด เพื่อให้สามารถแก้ไขปัญหาให้สอดคล้องกับลำดับความสำคัญของธุรกิจและลดเวลาหยุดทำงานให้น้อยที่สุด
ติดตั้งแพตช์อย่างสม่ำเสมอเพื่อป้องกันเหตุการณ์
การปฏิบัติที่สำคัญอีกประการหนึ่งคือการอัปเดตแพตช์อย่างสม่ำเสมอ ซึ่งช่วย ป้องกันเหตุการณ์ไม่พึงประสงค์โดยการแก้ไขช่องโหว่ก่อนที่จะถูกนำไปใช้ประโยชน์ นี่เป็นกระบวนการที่ต้องทำอย่างต่อเนื่องเพื่อแก้ไขข้อบกพร่องด้านความปลอดภัยในซอฟต์แวร์และระบบ ทำให้ผู้โจมตีเข้าถึงจุดอ่อนที่ทราบได้ยากขึ้น
การปฏิบัตินี้เป็นส่วนพื้นฐานของกรอบการบริหารความเสี่ยงทางไซเบอร์ เนื่องจากช่วยปกป้องโครงสร้างพื้นฐานด้านไอทีจาก ภัยคุกคามที่เกิดขึ้นใหม่ และลดความเสี่ยงของการละเมิดข้อมูล หากไม่มีการอัปเดตแพตช์อย่างทันท่วงที ช่องโหว่จะยังคงเปิดอยู่และอาจนำไปสู่ปัญหาด้านความปลอดภัยที่สำคัญได้
ให้ความสำคัญกับการตรวจสอบศูนย์ข้อมูล
การจัดการศูนย์ข้อมูลยังมีบทบาทสำคัญในการจัดการเหตุการณ์ การจัดการที่เหมาะสมช่วยให้มั่นใจว่าทั้ง ด้านกายภาพและเสมือนจริงของศูนย์ข้อมูลได้รับการดูแลอย่างดี ซึ่งรวมถึงการดูแลควบคุมสภาพแวดล้อม แหล่งจ่ายพลังงาน และความปลอดภัยทางกายภาพ
ระบบการตรวจสอบแบบเรียลไทม์มีความสำคัญอย่างยิ่งในที่นี้ เนื่องจากช่วยตรวจจับและแก้ไขปัญหาได้ก่อนที่ปัญหาจะลุกลาม การจัดการศูนย์ข้อมูลที่มีประสิทธิภาพ เมื่อรวมกับกรอบการจัดการความเสี่ยงทางไซเบอร์ที่ดำเนินการอย่างดี จะช่วยให้สามารถตรวจจับปัญหาได้ตั้งแต่เนิ่นๆ ช่วยหลีกเลี่ยงการหยุดชะงักครั้งใหญ่และรักษาเสถียรภาพของการดำเนินงานด้านไอที
ประโยชน์และความท้าทายของการจัดการเหตุการณ์
เหตุการณ์สามารถทำให้ความคืบหน้าของโครงการช้าลงและทำให้ทรัพยากรที่มีค่าหมดไป ซึ่งมักก่อให้เกิดการหยุดชะงักในการดำเนินงานอย่างมีนัยสำคัญและอาจสูญเสียข้อมูลสำคัญได้ นี่แสดงให้เห็นถึงความสำคัญอย่างยิ่งของการจัดการเหตุการณ์อย่างมีประสิทธิภาพ
ประโยชน์หลักของการจัดการเหตุการณ์ ได้แก่:
1. การเบี่ยงเบนเหตุการณ์ที่เพิ่มประสิทธิภาพ
การเบี่ยงเบนเหตุการณ์เกี่ยวข้องกับการ ระบุและแก้ไขปัญหาที่อาจเกิดขึ้นก่อนที่ปัญหาจะลุกลามเป็นปัญหาใหญ่ ระบบการจัดการเหตุการณ์ที่มีประสิทธิภาพช่วยให้องค์กรสามารถนำมาใช้มาตรการป้องกันและตรวจสอบประสิทธิภาพของระบบอย่างต่อเนื่อง ซึ่งช่วยลดความถี่และความรุนแรงของเหตุการณ์
2. กระบวนการเปลี่ยนแปลงที่มีประสิทธิภาพ
กระบวนการเปลี่ยนแปลงที่มีการจัดการอย่างดีช่วยให้พนักงานดำเนินการอัปเดตและปรับเปลี่ยนอย่างเป็นระบบตามขั้นตอนที่กำหนดไว้การใช้มาตรฐานการปฏิบัติงาน(SOP) สำหรับการจัดการการเปลี่ยนแปลงช่วยให้มาตรฐานการปฏิบัติงานเป็นมาตรฐานเดียวกัน ทำให้เกิดความสม่ำเสมอ และลดความเสี่ยงของการเกิดข้อผิดพลาด
3. การแก้ไขปัญหาและปิดคดีอย่างมีประสิทธิภาพ
กระบวนการแก้ไขปัญหาที่มีการกำหนดไว้อย่างชัดเจนช่วยให้ทีมสามารถจัดการกับ เหตุการณ์ได้อย่างรวดเร็ว และดำเนินการ ทุกขั้นตอนที่จำเป็นเพื่อแก้ไขปัญหา เมื่อแก้ไขปัญหาเสร็จสิ้นแล้ว เหตุการณ์จะถูกปิดอย่างเป็นทางการพร้อมเอกสารที่สมบูรณ์และการติดตามผล แนวทางที่มีโครงสร้างนี้ช่วยปรับปรุงประสิทธิภาพการดำเนินงาน และให้บันทึกที่มีคุณค่าสำหรับการวิเคราะห์หลังเหตุการณ์ และการปรับปรุงอย่างต่อเนื่อง ซึ่งช่วยให้สามารถปรับปรุงกลยุทธ์การจัดการเหตุการณ์ให้ดีขึ้นตามกาลเวลา
ความท้าทายของการจัดการเหตุการณ์
แม้จะมีประโยชน์ แต่บ่อยครั้งก็มีความท้าทายหลายประการที่เกิดขึ้นในการจัดการเหตุการณ์
1. ความยากลำบากในการระบุสาเหตุที่แท้จริง
หนึ่งในความท้าทายที่สำคัญคือการระบุสาเหตุที่แท้จริงของเหตุการณ์ โดยเฉพาะอย่างยิ่งเมื่อต้องจัดการกับปัญหาที่ซับซ้อนซึ่งเกี่ยวข้องกับองค์ประกอบของระบบหลายส่วนและความพึ่งพาอาศัยกัน
การวินิจฉัยสาเหตุที่แท้จริงอย่างถูกต้องต้องอาศัยการตรวจสอบอย่างละเอียดถี่ถ้วน และมักต้องอาศัยความร่วมมือจากหลายฝ่าย มาตรฐานการปฏิบัติงาน (SOP) สามารถช่วยในการสร้างขั้นตอนมาตรฐานสำหรับการวิเคราะห์หาสาเหตุที่แท้จริงได้ แต่การนำขั้นตอนเหล่านี้ไปใช้อย่างมีประสิทธิภาพจำเป็นต้องใช้เครื่องมือและวิธีการขั้นสูง
สแตนลีย์ ซีเคียวริตี้เผชิญกับความท้าทายที่คล้ายกันเมื่อจัดการกับกระบวนการตอบสนองต่อเหตุการณ์ ในฐานะผู้นำระดับโลกในด้านโซลูชั่นความปลอดภัย สแตนลีย์ ซีเคียวริตี้ต้องรับมือกับเหตุการณ์ต่าง ๆ ที่เกิดขึ้นในระบบและภูมิภาคต่าง ๆ
ก่อนหน้านี้ ทีมการตลาดของบริษัทพึ่งพาเครื่องมือเช่น Excel และอีเมลสำหรับการสื่อสารภายในและการจัดการงาน ความต้องการของโรคระบาด COVID-19 ที่ต้องการเครื่องมือการจัดการโครงการที่ผสานรวมและขยายขนาดได้มากขึ้น ได้เน้นย้ำถึงความจำเป็นในการทำลายการแยกส่วนและเพิ่มผลผลิต
ClickUp ได้จัดเตรียมพื้นที่ทำงานแบบรวมศูนย์สำหรับทีมทั่วโลก ช่วยให้การสื่อสารและการจัดระเบียบเอกสาร รวมถึง SOPs เป็นไปอย่างมีประสิทธิภาพในฐานข้อมูลระดับโลก การปรับให้สอดคล้องนี้ทำให้ทีมสามารถทำงานร่วมกันได้อย่างมีประสิทธิผลมากขึ้นและแบ่งปันแนวทางปฏิบัติที่ดีที่สุดได้ ส่งผลให้ Stanley Security บรรลุการปรับปรุงการทำงานเป็นทีมเพิ่มขึ้น 80% ประหยัดเวลาได้มากกว่า 8 ชั่วโมงต่อสัปดาห์จากการประชุมและการอัปเดต นอกจากนี้ยังพบว่าใช้เวลาในการสร้างและแบ่งปันรายงานลดลง 50%
2. การเกิดซ้ำของเหตุการณ์
อีกหนึ่งความท้าทายคือการป้องกันไม่ให้เกิดเหตุการณ์ซ้ำขึ้นอีก ซึ่งสิ่งนี้ต้องอาศัยความเข้าใจอย่างลึกซึ้งในปัญหาพื้นฐานและการนำมาตรการป้องกันที่มีประสิทธิภาพมาใช้ การระบุรูปแบบและแนวโน้มจากเหตุการณ์ในอดีตถือเป็นสิ่งสำคัญสำหรับการพัฒนากลยุทธ์เพื่อลดความเสี่ยงที่อาจเกิดขึ้นในอนาคต
ClickUp แก้ไขปัญหานี้ด้วยการจัดเตรียมเครื่องมือรายงานและวิเคราะห์แบบบูรณาการที่ให้ข้อมูลเชิงลึกเกี่ยวกับตัวชี้วัดเหตุการณ์และแนวโน้มของประสิทธิภาพ แนวทางที่ขับเคลื่อนด้วยข้อมูลนี้ช่วยให้สามารถระบุปัญหาที่เกิดขึ้นซ้ำได้ และช่วยในการพัฒนากลยุทธ์การป้องกันที่ตรงเป้าหมาย

โซลูชัน IT & PMO ของ ClickUpสามารถช่วยคุณได้ที่นี่:
- สร้างสถานะที่กำหนดเอง (เช่น 'ปิดแล้ว', 'รอการดำเนินการ', 'อยู่ระหว่างดำเนินการ') และฟิลด์ (เช่น 'ผู้ร้องขอ', 'แผนก') เพื่อจัดหมวดหมู่และจัดการเหตุการณ์อย่างมีประสิทธิภาพ
- ติดตามและตรวจสอบเหตุการณ์ แบบเรียลไทม์ เพื่อให้แน่ใจว่าการอัปเดตและตรวจสอบสถานะเป็นไปอย่างรวดเร็ว
- แนบเอกสารที่เกี่ยวข้อง ภาพหน้าจอ หรือบันทึกเหตุการณ์เพื่อใช้ในการวิเคราะห์ สร้างฐานความรู้สำหรับวิธีแก้ไขเหตุการณ์ที่พบบ่อย
- สร้างรายงาน เกี่ยวกับความถี่ของเหตุการณ์, ระยะเวลาการแก้ไข, และสาเหตุที่แท้จริงเพื่อระบุแนวโน้มและปรับปรุงการตอบสนอง
- เชื่อมต่อ ClickUp กับเครื่องมือไอทีอื่นๆ เพื่อมุมมองที่ครอบคลุมของเหตุการณ์
การบริหารจัดการเหตุการณ์อย่างมีประสิทธิภาพเพื่อความสำเร็จสูงสุดของโครงการ
การเชี่ยวชาญการจัดการเหตุการณ์ไม่ใช่เพียงแค่การตอบสนองต่อปัญหาเท่านั้น—แต่เป็นการสร้างสภาพแวดล้อมที่มีความยืดหยุ่นและคล่องตัว ซึ่งสามารถจัดการกับการหยุดชะงักได้อย่างรวดเร็วและบรรลุเป้าหมายของโครงการโดยมีผลกระทบน้อยที่สุด
การนำกลยุทธ์เหล่านี้ไปใช้จะช่วยให้ทีมของคุณหลีกเลี่ยงปัญหาที่อาจเกิดขึ้น และทำให้โครงการของคุณดำเนินไปอย่างราบรื่นและประสบความสำเร็จ
ด้วย ClickUp คุณจะได้รับประโยชน์จากการใช้แพลตฟอร์มครบวงจรที่ผสานการจัดการเหตุการณ์เข้ากับการจัดการโครงการและการดำเนินงานด้านไอที ClickUp มีการติดตามแบบเรียลไทม์, กระบวนการทำงานอัตโนมัติ, และเครื่องมือการทำงานร่วมกันที่ช่วยให้ทีมของคุณสามารถแก้ไขปัญหาได้อย่างรวดเร็วในขณะที่ยังคงรักษาโครงการให้อยู่ในเส้นทางที่ถูกต้อง ไม่ว่าจะเป็นการจัดการการดำเนินงานประจำวันหรือการนำทางผ่านข้อกำหนดโครงการที่ซับซ้อน ClickUp มอบการมองเห็นและการควบคุมที่จำเป็นสำหรับผลลัพธ์ที่ยอดเยี่ยม
พร้อมที่จะเพิ่มประสิทธิภาพการจัดการเหตุการณ์และความสำเร็จของโครงการของคุณหรือไม่?ลงทะเบียนกับ ClickUpวันนี้และเปลี่ยนแปลงการจัดการเหตุการณ์ของคุณ!