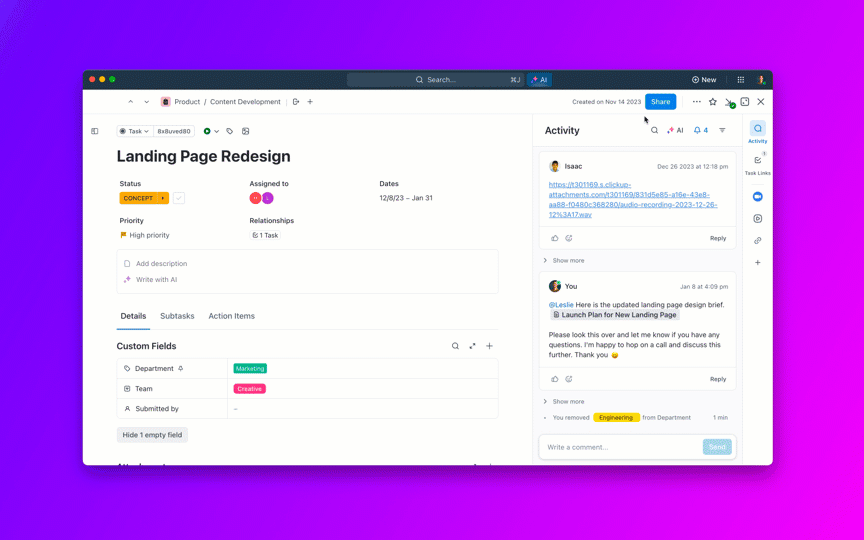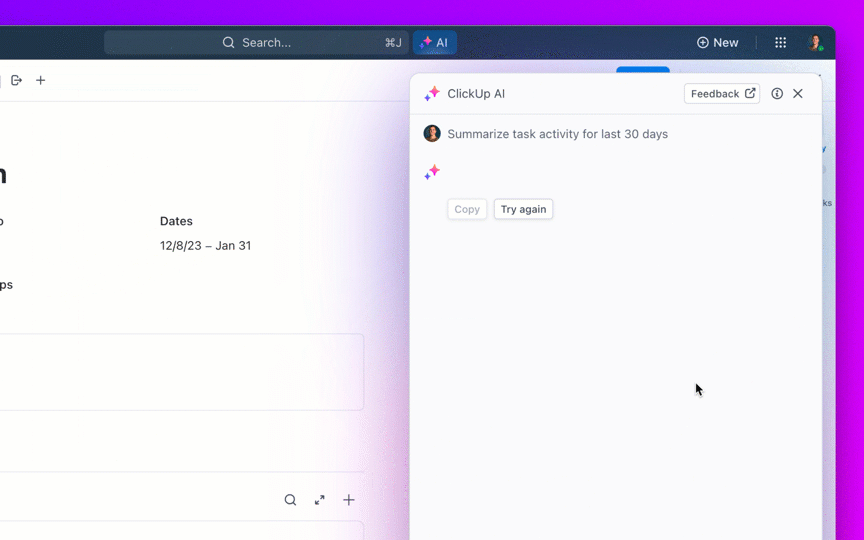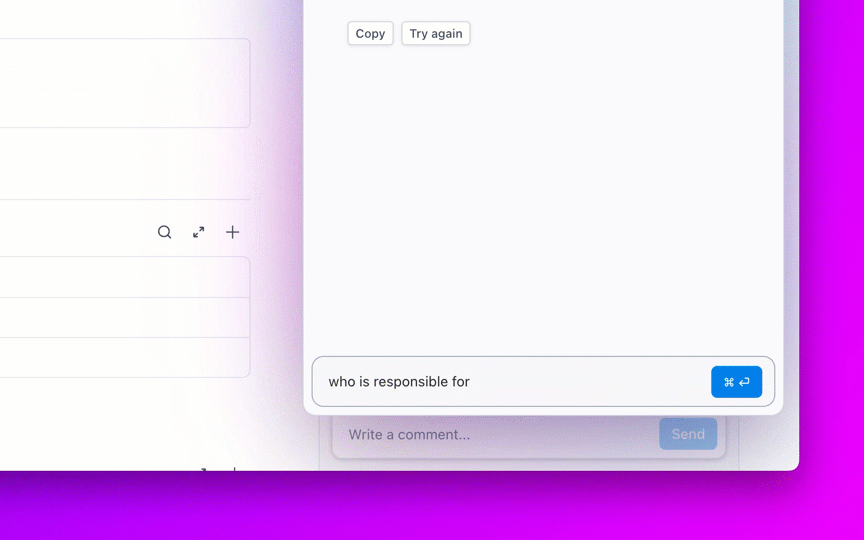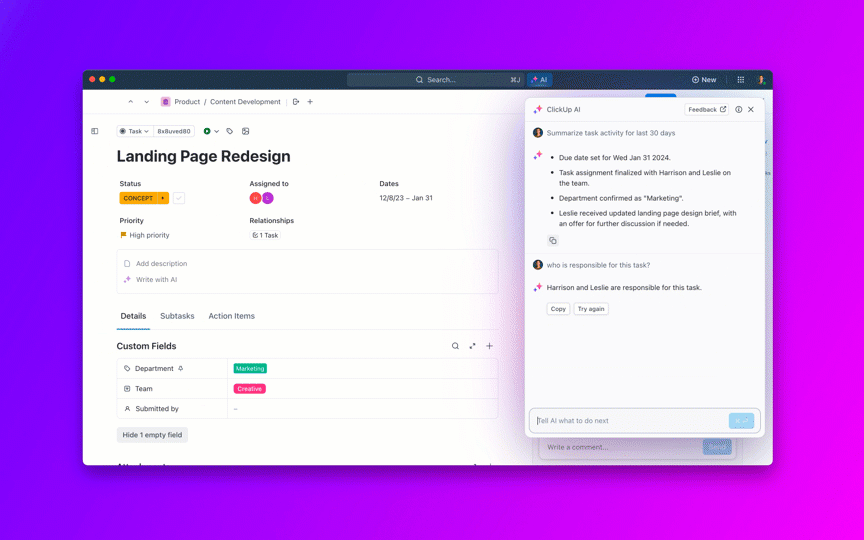

De flesta team som utforskar öppen källkods-AI-modeller upptäcker att Metas LLaMA erbjuder en sällsynt kombination av kraft och flexibilitet, men den tekniska installationen kan kännas som att montera möbler utan instruktioner.
Denna guide visar dig hur du bygger en funktionell LLaMA-chatbot från grunden och täcker allt från hårdvarukrav och modellåtkomst till promptteknik och distributionsstrategier.
Sätt igång!
Vad är LLaMA och varför ska man använda det för chatbots?
Att bygga en chatbot med proprietära API:er känns ofta som att du är låst till någon annans system, med oförutsägbara kostnader och frågor om dataintegritet. Denna leverantörsberoende innebär att du inte kan anpassa modellen efter ditt teams unika behov, vilket leder till generiska svar och potentiella problem med efterlevnad.
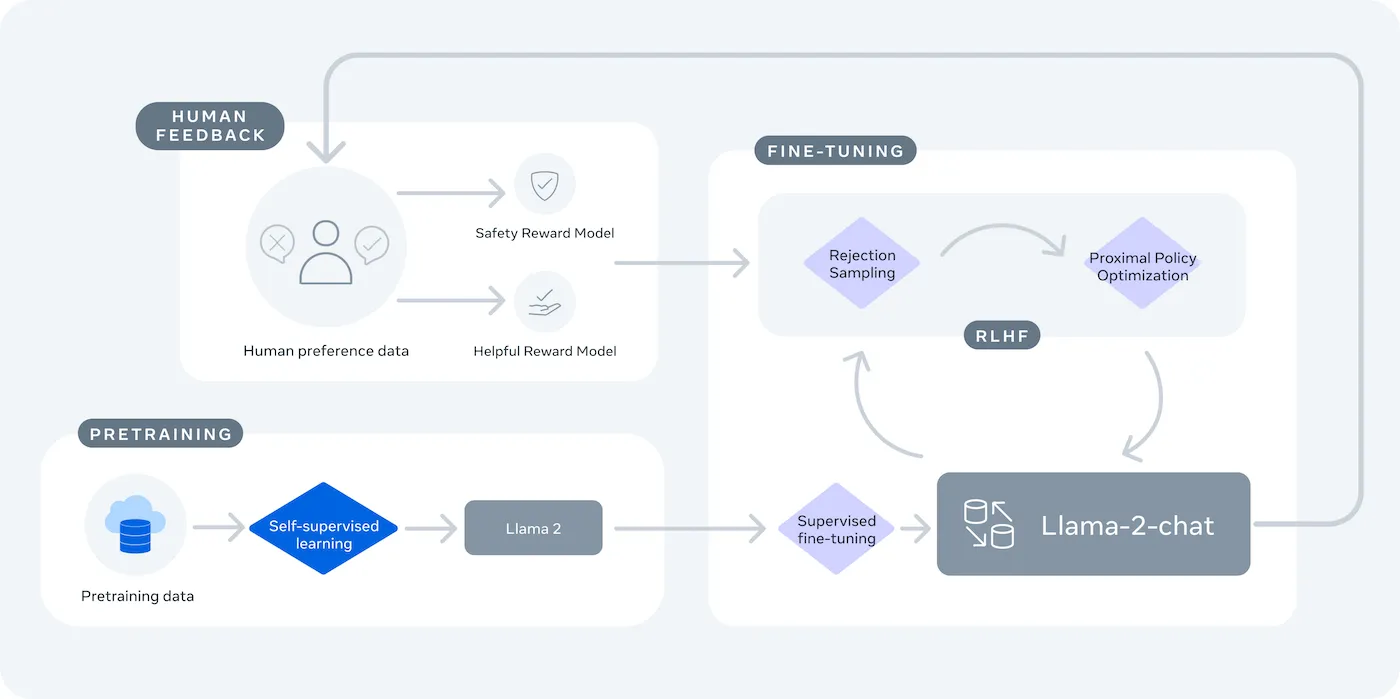
LLaMA (Large Language Model Meta AI) är Metas familj av öppna språkmodeller och erbjuder ett kraftfullt alternativ. Den är utformad för både forskning och kommersiellt bruk och ger dig den kontroll som slutna modeller inte ger.
LLaMA-modeller finns i olika storlekar, mätt i parametrar (t.ex. 7B, 13B, 70B). Tänk på parametrar som ett mått på modellens komplexitet och kraft – större modeller är mer kapabla men kräver mer beräkningsresurser.
Här är några skäl till varför du kan använda en LLaMA-chatbot:
- Dataskydd: När du kör en modell på din egen infrastruktur lämnar dina konversationsdata aldrig din miljö. Detta är avgörande för team som hanterar känslig information.
- Anpassning: Du kan finjustera en LLaMA-modell utifrån ditt företags interna dokument eller data. Detta hjälper den att förstå ditt specifika sammanhang och ge mycket mer relevanta svar.
- Kostnadsförutsägbarhet: Efter den initiala hårdvaruinstallationen behöver du inte oroa dig för API-avgifter per token. Dina kostnader blir fasta och förutsägbara.
- Inga hastighetsbegränsningar: Din chatbots kapacitet begränsas av din egen hårdvara, inte av leverantörens kvoter. Du kan skala efter behov.
Den viktigaste avvägningen är bekvämlighet mot kontroll. LLaMA kräver mer teknisk installation än ett plug-and-play-API. För produktionschattbottar använder teamen vanligtvis LLaMA 2 eller den nyare LLaMA 3, som erbjuder förbättrad resonemangsförmåga och kan hantera mer text samtidigt.
Vad du behöver innan du bygger en LLaMA-chattbot
Att kasta sig in i ett utvecklingsprojekt utan rätt verktyg är ett recept på frustration. Du kommer halvvägs och inser att du saknar en viktig del av hårdvaran eller mjukvaran, vilket hindrar din framsteg och slösar bort timmar av din tid.
För att undvika detta, samla allt du behöver i förväg. Här är en checklista för att säkerställa en smidig start. 🛠️
Hårdvarukrav
| Modellstorlek | Minsta VRAM | Alternativt alternativ |
|---|---|---|
| 7B parametrar | 8 GB | Molnbaserad GPU-instans |
| 13B parametrar | 16 GB | Molnbaserad GPU-instans |
| 70 miljarder parametrar | Flera GPU:er | Kvantisering eller moln |
Om din lokala dator inte har en tillräckligt kraftfull grafikprocessor (GPU) kan du använda molntjänster som AWS eller GCP. Inferensplattformar som Baseten och Replicate erbjuder också GPU-åtkomst med betalning per användning.
Programvarukrav
- Python 3. 8+: Detta är det vanligaste programmeringsspråket för maskininlärningsprojekt.
- Pakethanterare: Du behöver pip eller Conda för att installera de nödvändiga biblioteken för ditt projekt.
- Virtuell miljö: Detta är en bästa praxis som håller ditt projekts beroenden isolerade från andra Python-projekt på din maskin.
Åtkomstkrav
- Hugging Face-konto: Du behöver ett konto för att ladda ner LLaMA-modellvikterna.
- Meta-godkännande: Du måste acceptera Metas licensavtal för att få tillgång till LLaMA-modeller, vilket vanligtvis godkänns inom några timmar.
- API-nycklar: Dessa behövs endast om du väljer att använda en hostad inferensändpunkt istället för att köra modellen lokalt.
I den här guiden använder vi ramverket LangChain. Det förenklar många av de komplexa delarna av att bygga en chatbot, som att hantera promptar och konversationshistorik.
{kind=link}
Hur man bygger en chatbot med LLaMA steg för steg
Att koppla samman alla tekniska delar av en chatbot – modellen, prompten, minnet – kan kännas överväldigande. Det är lätt att gå vilse i koden, vilket leder till buggar och en chatbot som inte fungerar som förväntat. Denna steg-för-steg-guide delar upp processen i enkla, hanterbara delar.
Denna metod fungerar oavsett om du kör modellen på din egen maskin eller använder en hostad tjänst.
Steg 1: Installera nödvändiga paket
Först måste du installera de centrala Python-biblioteken. Öppna terminalen och kör följande kommando:
pip install langchain transformers accelerate torch
Om du använder en hostad tjänst som Baseten för inferens måste du också installera dess specifika mjukvaruutvecklingskit (SDK):
pip install baseten
Här är vad varje paket innehåller:
- Langchain: Ett ramverk som hjälper till att bygga applikationer med stora språkmodeller, inklusive hantering av konversationskedjor och minne.
- Transformers: Hugging Face-biblioteket för att ladda och köra LLaMA-modellen.
- Accelerate: Ett bibliotek som hjälper till att optimera hur modellen laddas på din CPU och GPU.
- Torch: PyTorch-biblioteket, som tillhandahåller backend-kraft för modellens beräkningar.
Om du kör modellen lokalt på en maskin med ett NVIDIA GPU, se till att du har CUDA installerat och korrekt konfigurerat. Detta gör att modellen kan använda GPU:n för mycket snabbare prestanda.
Steg 2: Få tillgång till LLaMA-modeller
Innan du kan ladda ner modellen måste du få officiell åtkomst från Meta via Hugging Face.
- Skapa ett konto på huggingface.co
- Gå till modellens sida, till exempel meta-llama/Llama-2-7b-chat-hf
- Klicka på ”Öppna arkiv” och godkänn Metas licensvillkor.
- Skapa en ny åtkomsttoken i inställningarna för ditt Hugging Face-konto.
- Kör huggingface-cli login i din terminal och klistra in din token för att autentisera din maskin.
Godkännandet går vanligtvis snabbt. Se till att du väljer en modellvariant med ”chat” i namnet, eftersom dessa har tränats specifikt för konversationsuppgifter.
Steg 3: Ladda LLaMA-modellen
Nu kan du ladda modellen i din kod. Du har två huvudalternativ beroende på din hårdvara.
Om du har en tillräckligt kraftfull GPU kan du ladda modellen lokalt:
Om din hårdvara är begränsad kan du använda en hostad inferenstjänst:
Kommandot device_map="auto" talar om för transformers-biblioteket att automatiskt distribuera modellen över alla tillgängliga GPU:er.
Om du fortfarande har ont om minne kan du använda en teknik som kallas kvantisering för att minska modellens storlek, även om detta kan minska prestandan något.
Steg 4: Skapa en promptmall
LLaMA-chattmodeller är tränade att förvänta sig ett specifikt format för promptar. En promptmall säkerställer att din inmatning är korrekt strukturerad.
Låt oss bryta ner detta format:
- <
>: Detta avsnitt innehåller systemprompten, som ger modellen dess grundläggande instruktioner och definierar dess personlighet. - [INST]: Detta markerar början på användarens fråga eller instruktion.
- [/INST]: Detta signalerar till modellen att det är dags att generera ett svar.
Tänk på att olika versioner av LLaMA kan använda något olika mallar. Kontrollera alltid modellens dokumentation på Hugging Face för att se vilket format som är korrekt.
Steg 5: Konfigurera chatbotkedjan
Därefter kopplar du din modell och promptmall till en konversationskedja med hjälp av LangChain. Denna kedja kommer också att innehålla minne för att hålla reda på konversationen.
LangChain erbjuder flera typer av minne:
- ConversationBufferMemory: Detta är det enklaste alternativet. Det lagrar hela konversationshistoriken.
- ConversationSummaryMemory: För att spara utrymme sammanfattar detta alternativ regelbundet äldre delar av konversationen.
- ConversationBufferWindowMemory: Detta sparar endast de senaste konversationerna i minnet, vilket är användbart för att förhindra att kontexten blir för lång.
För testning är ConversationBufferMemory ett bra ställe att börja på.
Steg 6: Kör chatbot-loopen
Slutligen kan du skapa en enkel loop för att interagera med din chatbot från terminalen.
I en verklig applikation skulle du ersätta denna loop med en API-ändpunkt med hjälp av ett ramverk som FastAPI eller Flask. Du kan också strömma modellens svar tillbaka till användaren, vilket gör att chatboten känns mycket snabbare.
Du kan också justera parametrar som temperatur för att kontrollera slumpmässigheten i svaren. En låg temperatur (t.ex. 0,2) gör resultatet mer deterministiskt och faktabaserat, medan en högre temperatur (t.ex. 0,8) uppmuntrar till mer kreativitet.
Hur du testar din LLaMA-chatbot
Du har byggt en chatbot som ger svar, men är den redo för riktiga användare? Att distribuera en otestad bot kan leda till pinsamma misslyckanden, som att ge felaktig information eller generera olämpligt innehåll, vilket kan skada ditt företags rykte.
En systematisk testplan är lösningen på denna osäkerhet. Den säkerställer att din chatbot är robust, pålitlig och säker.
Funktionstestning:
- Gränsfall: Testa hur boten hanterar tomma inmatningar, mycket långa meddelanden och specialtecken.
- Minnesverifiering: Se till att chatboten kommer ihåg sammanhanget över flera turer i en konversation.
- Instruktionsföljande: Kontrollera om boten följer de regler du har ställt in i systemprompten.
Kvalitetsutvärdering:
- Relevans: Svarar svaret verkligen på användarens fråga?
- Noggrannhet: Är den information som tillhandahålls korrekt?
- Sammantagning: Flödar konversationen logiskt?
- Säkerhet: Vägrar boten att svara på olämpliga eller skadliga förfrågningar?
Prestandatestning:
- Latens: Mät hur lång tid det tar för boten att börja svara och avsluta sitt svar.
- Resursanvändning: Övervaka hur mycket GPU-minne modellen använder under inferens.
- Samtidighet: Testa hur systemet fungerar när flera användare interagerar med det samtidigt.
Se också upp för vanliga LLM-problem som hallucinationer (att med säkerhet ange felaktig information), kontextförskjutning (att tappa tråden i ett långt samtal) och upprepningar. Att logga alla testsamtal är ett utmärkt sätt att upptäcka mönster och åtgärda problem innan de når dina användare.
LLaMA Chatbot Användningsfall för team
När du väl har kommit förbi finjusteringen och implementeringen blir LLaMA som mest värdefullt när det tillämpas på vardagliga teamproblem – inte abstrakta AI-demonstrationer. Team behöver vanligtvis inte en ”chatbot”, utan snabbare tillgång till kunskap, färre manuella överlämningar och mindre repetitivt arbete.
Intern kunskapsassistent
Genom att finjustera LLaMA på intern dokumentation, wikis och FAQ:er – eller koppla ihop det med en RAG-baserad kunskapsbas – kan team ställa frågor på naturligt språk och få precisa, kontextmedvetna svar. Detta eliminerar friktionen med att söka i spridda verktyg samtidigt som känslig data hålls helt internt, istället för att skickas till tredjeparts-API:er.
🌟 Enterprise Search i ClickUp och den förkonfigurerade agenten Ambient Answers ger detaljerade kontextuella svar på dina frågor med hjälp av kunskapen i ditt ClickUp-arbetsområde.
Hjälp med kodgranskning
När LLaMA tränas på din egen kodbas och dina egna stilguider kan den fungera som en kontextuell kodgranskningsassistent. Istället för generiska bästa praxis får utvecklare förslag som överensstämmer med teamets konventioner, arkitektoniska beslut och historiska mönster.
🌟 En LLaMA-baserad kodgranskningshjälpare kan upptäcka problem, föreslå förbättringar eller förklara okänd kod. ClickUps Codegen går ett steg längre genom att agera inom utvecklingsarbetsflödet – skapa pull-förfrågningar, tillämpa refaktorer eller uppdatera filer direkt som svar på dessa insikter. Resultatet blir mindre kopiering och klistrande och färre misslyckade överlämningar mellan ”tänkande” och ”görande”.
Kundsupportens prioritering
LLaMA kan tränas för att klassificera avsikter, förstå inkommande kundfrågor och vidarebefordra dem till rätt team eller arbetsflöde. Vanliga frågor kan hanteras automatiskt, medan specialfall eskaleras till mänskliga agenter med bifogad kontext, vilket minskar svarstiderna utan att kompromissa med kvaliteten.
Du kan också skapa en Triage Super Agent med hjälp av naturligt språk i ditt ClickUp-arbetsområde. Läs mer
Sammanfattning och uppföljning av möten
Med hjälp av mötesprotokoll som indata kan LLaMA extrahera beslut, åtgärdspunkter och viktiga diskussionspunkter. Det verkliga värdet uppstår när dessa resultat flödar direkt in i verktyg för uppgiftshantering, vilket förvandlar konversationer till spårbart arbete.
🌟 ClickUps AI Meeting Notetaker tar inte bara mötesanteckningar, utan skriver också sammanfattningar, genererar åtgärdspunkter och länkar mötesanteckningar till dina dokument och uppgifter.
Dokumentutkast och iteration
Team kan använda LLaMA för att generera första utkast till rapporter, förslag eller dokumentation baserat på befintliga mallar och tidigare exempel. Detta flyttar arbetet från att skapa tomma sidor till granskning och förfining, vilket påskyndar leveransen utan att sänka standarden.
🌟 ClickUp Brain kan snabbt generera utkast till dokumentation och behålla all din kunskap om arbetsplatsen i sitt sammanhang. Prova det idag.
LLaMA-drivna chatbots är mest effektiva när de är inbäddade i befintliga arbetsflöden – dokumentation, projektledning och teamkommunikation – snarare än när de fungerar som fristående verktyg.
Det är här som integrering av AI direkt i din arbetsmiljö gör hela skillnaden. Istället för att bygga ett separat verktyg kan du föra in konversations-AI till den plats där ditt team redan arbetar.
Du kan till exempel skapa en anpassad LLaMA-bot som fungerar som kunskapsassistent. Men om den finns utanför ditt projektledningsverktyg måste ditt team byta kontext för att ställa en fråga. Detta skapar friktion och saktar ner alla.
Eliminera detta kontextbyte genom att använda en AI som redan är en del av ditt arbetsflöde.
Ställ frågor om dina projekt, uppgifter och dokument utan att någonsin lämna ClickUp med hjälp av ClickUp Brain. Skriv bara @brain i valfri uppgiftskommentar eller ClickUp Chat för att få ett omedelbart, kontextmedvetet svar. Det är som att ha en teammedlem som har perfekt kunskap om hela din arbetsyta. 🤩
Detta förvandlar chatboten från en nyhet till en central del av ditt teams produktivitetsmotor.
Begränsningar vid användning av LLaMA för att bygga chatbots
Att bygga en LLaMA-chatbot kan vara givande, men teamen blir ofta överraskade av dolda komplexiteter. Den ”gratis” open source-modellen kan i slutändan bli dyrare och svårare att hantera än väntat, vilket leder till en dålig användarupplevelse och en ständig, resurskrävande underhållscykel.
Det är viktigt att förstå begränsningarna innan du bestämmer dig.
- Teknisk komplexitet: Att konfigurera och underhålla en LLaMA-modell kräver kunskap om infrastruktur för maskininlärning.
- Hårdvarukrav: För att köra de större, mer kapabla modellerna krävs dyr GPU-hårdvara, och molnkostnaderna kan snabbt bli höga.
- Begränsningar i kontextfönstret: LLaMA-modeller har ett begränsat minne ( 4K-tokens för LLaMA 2 ). Hantering av långa dokument eller konversationer kräver komplexa chunkingstrategier.
- Inga inbyggda säkerhetsåtgärder: Du ansvarar själv för att implementera dina egna innehållsfiltrerings- och säkerhetsåtgärder.
- Löpande underhåll: När nya modeller släpps måste du uppdatera dina system, och finjusterade modeller kan kräva omskolning.
Självhostade modeller har också vanligtvis högre latens än högoptimerade kommersiella API:er. Allt detta är operativa bördor som hanterade lösningar tar hand om åt dig.
📮ClickUp Insight: 88 % av våra undersökningsdeltagare använder AI för sina personliga uppgifter, men över 50 % drar sig för att använda det på jobbet. De tre största hindren? Brist på smidig integration, kunskapsluckor eller säkerhetsproblem.
Men vad händer om AI är inbyggt i din arbetsyta och redan är säkert? ClickUp Brain, ClickUps inbyggda AI-assistent, gör detta till verklighet. Den förstår uppmaningar i klarspråk och löser alla tre problem med AI-implementering samtidigt som den kopplar samman din chatt, dina uppgifter, dokument och kunskap i hela arbetsytan. Hitta svar och insikter med ett enda klick!
Alternativ till LLaMA för att bygga chatbots
LLaMA är bara ett alternativ bland en uppsjö av AI-modeller, och det kan vara svårt att avgöra vilken som är rätt för dig.
Här är en översikt över de olika alternativen.
Andra öppen källkodsmodeller:
- Mistral: Känd för sin starka prestanda även med mindre modellstorlekar, vilket gör den effektiv.
- Falcon: Levereras med en mycket tillåtande licens, vilket är utmärkt för kommersiella applikationer.
- MPT: Optimerad för hantering av långa dokument och konversationer
Kommersiella API:er:
- OpenAI (GPT-4, GPT-3. 5): Allmänt ansedda som de mest kapabla stora språkmodellerna, och de är mycket lätta att integrera.
- Anthropic (Claude): Känd för sina starka säkerhetsfunktioner och mycket stora kontextfönster.
- Google (Gemini): Erbjuder kraftfulla multimodala funktioner som gör det möjligt att förstå text, bilder och ljud.
Du kan bygga den själv med en öppen källkodsmodell, betala för ett kommersiellt API eller använda en konvergerad AI-arbetsyta som erbjuder en förintegrerad lösning med olika typer av AI-agenter.
📚 Läs också: Hur du använder en chatbot för ditt företag
Bygg kontextmedvetna AI-assistenter med ClickUp
Att bygga en chatbot med LLaMA ger dig otrolig kontroll över dina data, kostnader och anpassningar. Men den kontrollen kommer med ansvar för infrastruktur, underhåll och säkerhet – allt som hanterade API:er sköter åt dig. Målet är inte bara att bygga en bot – det är att göra ditt team mer produktivt, och ett komplext teknikprojekt kan ibland distrahera från det.
Det rätta valet beror på ditt teams resurser och prioriteringar. Om du har ML-expertis och strikta sekretesskrav är LLaMA ett fantastiskt alternativ. Om du prioriterar snabbhet och enkelhet kan ett integrerat verktyg vara ett bättre val.
Med ClickUp får du en konvergerad AI-arbetsyta med alla dina uppgifter, dokument och konversationer på ett ställe, drivet av integrerad AI. Det minskar kontextförvirringen och hjälper team att arbeta snabbare och mer effektivt, med rätt information till hands genom anpassningsbara Super Agents och kontextuell AI.
Sluta slösa tid på infrastruktur och dra nytta av en kontextmedveten AI-assistent redan idag utan att behöva bygga något från grunden. Kom igång gratis med ClickUp.
Vanliga frågor (FAQ)
Kostnaden beror helt på din distributionsmetod, och projektprognoser kan hjälpa dig att uppskatta den. Om du använder din egen hårdvara har du en initial kostnad för GPU:n, men inga löpande avgifter per sökning. Molnleverantörer tar ut en timavgift baserad på GPU och modellstorlek.
Ja, licenserna för LLaMA 2 och LLaMA 3 tillåter kommersiell användning. Du måste dock godkänna Metas användarvillkor och ange den erforderliga källhänvisningen i din produkt.
LLaMA 3 är den nyare och mer kapabla modellen, som erbjuder bättre resonemangsförmåga och ett större kontextfönster (8K tokens jämfört med 4K för LLaMA 2). Detta innebär att den kan hantera längre konversationer och dokument, men det kräver också mer beräkningsresurser för att köras.
Python är det vanligaste språket för maskininlärning tack vare sina omfattande bibliotek, men det är inte ett absolut krav. Vissa plattformar börjar erbjuda kodfria eller kodfattiga lösningar som gör det möjligt att distribuera en LLaMA-chatbot med ett grafiskt gränssnitt. /