
AI-träningsprojekt misslyckas sällan på modellnivå. De stöter på problem när experiment, dokumentation och uppdateringar från intressenter är spridda över för många verktyg.
Den här guiden visar dig hur du tränar modeller med Databricks DBRX – en LLM som är upp till dubbelt så beräknings effektiv som andra ledande modeller – samtidigt som du håller arbetet kring det organiserat i ClickUp.
Från installation och finjustering till dokumentation och teamöverskridande uppdateringar – du kommer att se hur en enda, samlad arbetsyta hjälper till att eliminera kontextförvirring och håller ditt team fokuserat på att bygga, inte söka. 🛠
Vad är DBRX?
DBRX är en kraftfull, öppen källkodsbaserad stor språkmodell (LLM) som är speciellt utformad för träning och inferens av AI-modeller för företag. Eftersom den är öppen källkod under Databricks Open Model License har ditt team full tillgång till modellens vikter och arkitektur, vilket gör att du kan inspektera, modifiera och distribuera den på dina egna villkor.
Det finns i två varianter: DBRX Base för djup förträning och DBRX Instruct för färdiga instruktionsföljande uppgifter.
DBRX-arkitektur och mix av experter-design
DBRX löser uppgifter med hjälp av en Mixture-of-Experts (MoE)-arkitektur. Till skillnad från traditionella stora språkmodeller som använder alla sina miljarder parametrar för varje enskild beräkning, aktiverar DBRX endast en bråkdel av sina totala parametrar (de mest relevanta experterna) för en given uppgift.
Tänk på det som ett team av specialiserade experter; istället för att alla arbetar med alla problem, dirigerar systemet på ett intelligent sätt varje uppgift till de mest kvalificerade matchande parametrarna.
Detta minskar inte bara svarstiden, utan ger också förstklassig prestanda och resultat samtidigt som beräkningskostnaderna minskas avsevärt.
Här är en snabb överblick över de viktigaste specifikationerna:
- Totalt antal parametrar: 132 miljarder för alla experter
- Aktiva parametrar: 36B per framåtpass
- Antal experter: Totalt 16 (MoE Top-4 routing), varav 4 är aktiva för varje given token.
- Kontextfönster: 32K tokens
DBRX-träningsdata och tokenspecifikationer
Prestandan hos en LLM är bara så bra som den data den tränats på. DBRX förtränades på en enorm dataset med 12 biljoner token som noggrant sammanställts av Databricks-teamet med hjälp av deras avancerade databehandlingsverktyg. Det är precis därför den presterade så bra i branschens benchmarktest.
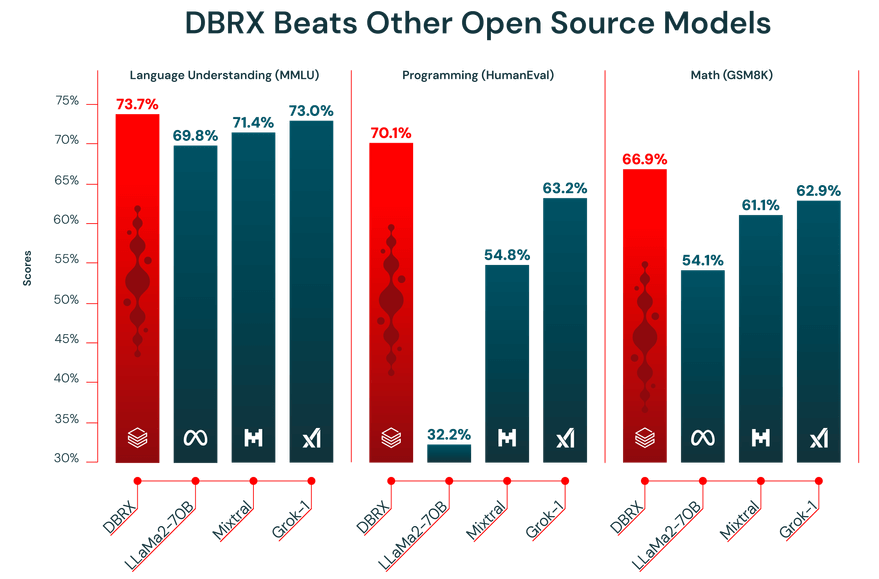
Dessutom har DBRX ett kontextfönster på 32 000 token. Detta är den mängd text som modellen kan ta hänsyn till samtidigt. Ett stort kontextfönster är mycket användbart för komplexa uppgifter som att sammanfatta långa rapporter, gräva igenom långa juridiska dokument eller bygga avancerade RAG-system (Retrieval-Augmented Generation), eftersom det gör att modellen kan behålla kontexten utan att avkorta eller glömma information.
🎥 Titta på den här videon för att se hur effektiv projektkoordinering kan förändra ditt AI-träningsflöde och eliminera friktionen mellan olika verktyg. 👇🏽
Hur du kommer åt och konfigurerar DBRX
DBRX erbjuder två huvudsakliga åtkomstvägar, som båda ger full åtkomst till modellvikterna under generösa kommersiella villkor. Du kan använda Hugging Face för maximal flexibilitet eller komma åt det direkt via Databricks för en mer integrerad upplevelse.
Få tillgång till DBRX via Hugging Face
För team som värdesätter flexibilitet och redan är bekväma med Hugging Face-ekosystemet är åtkomst till DBRX via Hub den idealiska vägen. Det gör att du kan integrera modellen i dina befintliga transformatorbaserade arbetsflöden.
Så här kommer du igång:
- Skapa eller logga in på ditt Hugging Face-konto
- Navigera till DBRX-modellkortet på Hub och acceptera licensvillkoren.
- Installera transformers-biblioteket tillsammans med nödvändiga beroenden som accelerate.
- Använd klassen AutoModelForCausalLM i ditt Python-skript för att ladda DBRX-modellen.
- Konfigurera din inferenspipeline och tänk på att DBRX kräver betydande GPU-minne (VRAM) för effektiv drift.
📖 Läs mer: Hur man konfigurerar LLM-temperatur
Få tillgång till DBRX via Databricks
Om ditt team redan använder Databricks för dataengineering eller maskininlärning är det enklast att komma åt DBRX via plattformen. Det eliminerar friktionen vid installationen och ger dig alla verktyg du behöver för MLOps precis där du redan arbetar.
Följ dessa steg i ditt Databricks-arbetsområde för att komma igång:
- Navigera till Model Garden eller Mosaic AI-sektionen.
- Välj antingen DBRX Base eller DBRX Instruct, beroende på dina behov.
- Konfigurera en serveringsändpunkt för API-åtkomst eller ställ in en anteckningsboksmiljö för interaktiv användning.
- Börja testa inferens med exempelprompter för att säkerställa att allt fungerar korrekt innan du skalar upp din AI-modellträning eller -distribution.
Denna metod ger dig smidig tillgång till verktyg som MLflow för experimentuppföljning och Unity Catalog för modellstyrning.
📮 ClickUp Insight: Den genomsnittliga yrkesverksamma person spenderar mer än 30 minuter om dagen på att söka efter arbetsrelaterad information – det är över 120 timmar om året som går förlorade på att leta igenom e-postmeddelanden, Slack-trådar och spridda filer.
En intelligent AI-assistent inbyggd i ditt arbetsutrymme kan ändra på det. Presentera ClickUp Brain.
Det ger omedelbara insikter och svar genom att visa rätt dokument, konversationer och uppgiftsdetaljer på några sekunder – så att du kan sluta söka och börja arbeta.
Hur man finjusterar DBRX och tränar anpassade AI-modeller
En färdig modell, oavsett hur kraftfull den är, kommer aldrig att förstå de unika nyanserna i din verksamhet. Eftersom DBRX är öppen källkod kan du finjustera den för att skapa en anpassad modell som talar ditt företags språk eller utför en specifik uppgift som du vill att den ska hantera.
Här är tre vanliga sätt att göra detta på:
1. Finjustera DBRX med Hugging Face-datauppsättningar
För team som just har börjat eller arbetar med vanliga uppgifter är offentliga datamängder från Hugging Face Hub en utmärkt resurs. De är förformaterade och lätta att ladda, vilket innebär att du inte behöver lägga timmar på att förbereda dina data.
Processen är ganska enkel:
- Hitta en dataset på Hub som matchar din uppgift (t.ex. instruktionsföljande, sammanfattning)
- Ladda det med hjälp av datauppsättningsbiblioteket
- Se till att data formateras i instruktions-responspar.
- Konfigurera ditt träningsskript med hyperparametrar som inlärningshastighet och batchstorlek.
- Starta träningsjobbet och se till att spara kontrollpunkter regelbundet.
- Utvärdera den finjusterade modellen på en undantagen valideringsuppsättning för att mäta förbättringen.
2. Finjustera DBRX med lokala datamängder
Du får vanligtvis bäst resultat genom att finjustera med dina egna data. Detta gör att du kan lära modellen ditt företags specifika terminologi, stil och domänkunskap. Tänk bara på att det bara lönar sig om dina data är rena och väl förberedda och har tillräcklig volym.
Följ dessa steg för att förbereda dina interna data:
- Datainsamling: Samla in högkvalitativa exempel från dina interna wikis, dokument och databaser.
- Formatkonvertering: Strukturera dina data i ett konsekvent instruktions-svar-format, ofta som JSON-rader.
- Kvalitetsfiltrering: Ta bort alla exempel av låg kvalitet, dubbletter eller irrelevanta exempel.
- Valideringsuppdelning: Avsätt en liten del av dina data (vanligtvis 10–15 %) för att utvärdera modellens prestanda.
- Sekretessgranskning: Ta bort eller maskera all personlig identifierbar information (PII) eller känslig data.
3. Finjustera DBRX med StreamingDataset
Om din dataset blir för stor för att rymmas i maskinens minne behöver du inte oroa dig, du kan använda Databricks Streaming Dataset-bibliotek. Det gör att du kan strömma data direkt från molnlagringen medan modellen tränas, istället för att ladda allt i minnet på en gång.
Så här gör du:
- Datapreparering: Rensa och strukturera dina träningsdata och lagra dem sedan i ett strömningsbart format som JSONL eller CSV i molnlagring.
- Konvertering av streamingformat: Konvertera din dataset till ett streamingvänligt format, till exempel Mosaic Data Shard (MDS), så att den kan läsas effektivt under träningen.
- Inställning av träningsladdare: Konfigurera din träningsladdare så att den pekar på den fjärranslutna datamängden och definiera en lokal cache för tillfällig datalagring.
- Modelinitialisering: Starta DBRX-finjusteringsprocessen med hjälp av ett träningsramverk som stöder StreamingDataset, till exempel LLM Foundry.
- Streamingbaserad träning: Kör träningsjobbet medan data strömmas i batcher under träningen, istället för att laddas helt i minnet.
- Kontrollpunkter och återställning: Återuppta träningen smidigt om en körning avbryts, utan att duplicera eller hoppa över data.
- Utvärdering och distribution: Validera den finjusterade modellens prestanda och distribuera den med din föredragna serverings- eller inferenskonfiguration.
💡Proffstips: Istället för att skapa en DBRX-träningsplan från grunden, börja med ClickUps mall för AI- och maskininlärningsprojekt och anpassa den efter ditt teams behov. Den ger en tydlig struktur för planering av datamängder, träningsfaser, utvärdering och distribution, så att du kan fokusera på att organisera ditt arbete istället för att strukturera ett arbetsflöde.
Användningsfall för DBRX för träning av AI-modeller
Det är en sak att ha en kraftfull modell, men det är en annan sak att veta exakt var den kommer till sin rätt.
När du inte har en tydlig bild av en modells styrkor är det lätt att lägga tid och resurser på att försöka få den att fungera där den helt enkelt inte passar. Detta leder till undermåliga resultat och frustration.
DBRX:s unika arkitektur och träningsdata gör det exceptionellt väl lämpat för flera viktiga användningsfall inom företag. Att känna till dessa styrkor hjälper dig att anpassa modellen efter dina affärsmål och maximera avkastningen på din investering.
Textgenerering och innehållsskapande
DBRX Instruct är finjusterat för att följa instruktioner och generera högkvalitativ text. Detta gör det till ett kraftfullt verktyg för att automatisera ett brett spektrum av innehållsrelaterade uppgifter. Dess stora kontextfönster är en betydande fördel, vilket gör det möjligt att hantera långa dokument utan att tappa tråden.
Du kan använda det för:
- Teknisk dokumentation: Skapa och förfina produktmanualer, API-referenser och användarhandböcker.
- Marknadsföringsinnehåll: Utkast till blogginlägg, nyhetsbrev via e-post och uppdateringar på sociala medier
- Rapportgenerering: Sammanfatta komplexa datafynd och skapa koncisa sammanfattningar.
- Översättning och lokalisering: Anpassa befintligt innehåll för nya marknader och målgrupper
Kodgenerering och felsökningsuppgifter
En betydande del av DBRX:s träningsdata innehöll kod, vilket gör det till ett kapabelt LLM-stöd för utvecklare. Det kan hjälpa till att påskynda utvecklingscykler genom att automatisera repetitiva kodningsuppgifter och hjälpa till med komplex problemlösning.
Här är några sätt som ditt teknikteam kan utnyttja det på:
- Kodkomplettering: Generera automatiskt funktionskroppar från kommentarer eller dokumentsträngar.
- Felupptäckt: Analysera kodsnuttar för att identifiera potentiella fel eller logiska brister.
- Kodförklaring: Översätt komplexa algoritmer eller äldre kod till klarspråk.
- Testgenerering: Skapa enhetstester baserade på en funktions signatur och förväntade beteende.
RAG och applikationer med lång kontext
Retrieval-Augmented Generation (RAG) är en kraftfull teknik som baserar modellens svar på ditt företags privata data. RAG-system har dock ofta svårt med modeller som har små kontextfönster, vilket tvingar fram aggressiv datadelning som kan leda till att viktig kontext går förlorad. DBRX:s 32K-kontextfönster gör det till en utmärkt grund för robusta RAG-applikationer.
Detta gör att du kan bygga kraftfulla interna verktyg, såsom:
- Företagssökning: Skapa en chattbot som svarar på anställdas frågor med hjälp av din interna kunskapsbas.
- Kundsupport: Skapa en agent som genererar supportsvar baserade på din produktdokumentation.
- Forskningsassistans: Utveckla ett verktyg som kan syntetisera information från hundratals sidor forskningsrapporter.
- Kontroll av efterlevnad: Verifiera automatiskt marknadsföringstexter mot interna varumärkesriktlinjer eller regleringsdokument.
Hur du integrerar DBRX-träning i ditt teams arbetsflöde
Ett framgångsrikt AI-modellträningsprojekt handlar om mer än bara kod och beräkningar. Det är ett samarbete mellan ML-ingenjörer, datavetare, produktchefer och intressenter.
När detta samarbete är utspritt över Jupyter-anteckningsböcker, Slack-kanaler och separata projektledningsverktyg skapas kontextutbredning, en situation där viktig projektinformation är utspridd över för många verktyg.
ClickUp löser det. Istället för att jonglera med flera verktyg får du en samlad AI-arbetsyta där projektledning, dokumentation och kommunikation samlas – så att dina experiment förblir sammankopplade från planering till genomförande och utvärdering.
Tappa aldrig bort experiment och framsteg
När man kör flera experiment är det svåraste inte att träna modellen, utan att hålla reda på vad som har förändrats under processen. Vilken version av datasetet användes, vilken inlärningshastighet fungerade bäst eller vilken körning levererades?
ClickUp gör denna process superenkel för dig. Du kan spåra varje träningsomgång separat i ClickUp Tasks, och inom uppgifterna kan du använda anpassade fält för att logga:
- Datasetversion
- Hyperparametrar
- Modellvariant (DBRX Base vs DBRX Instruct)
- Träningsstatus (i kö, körs, utvärderas, distribueras)
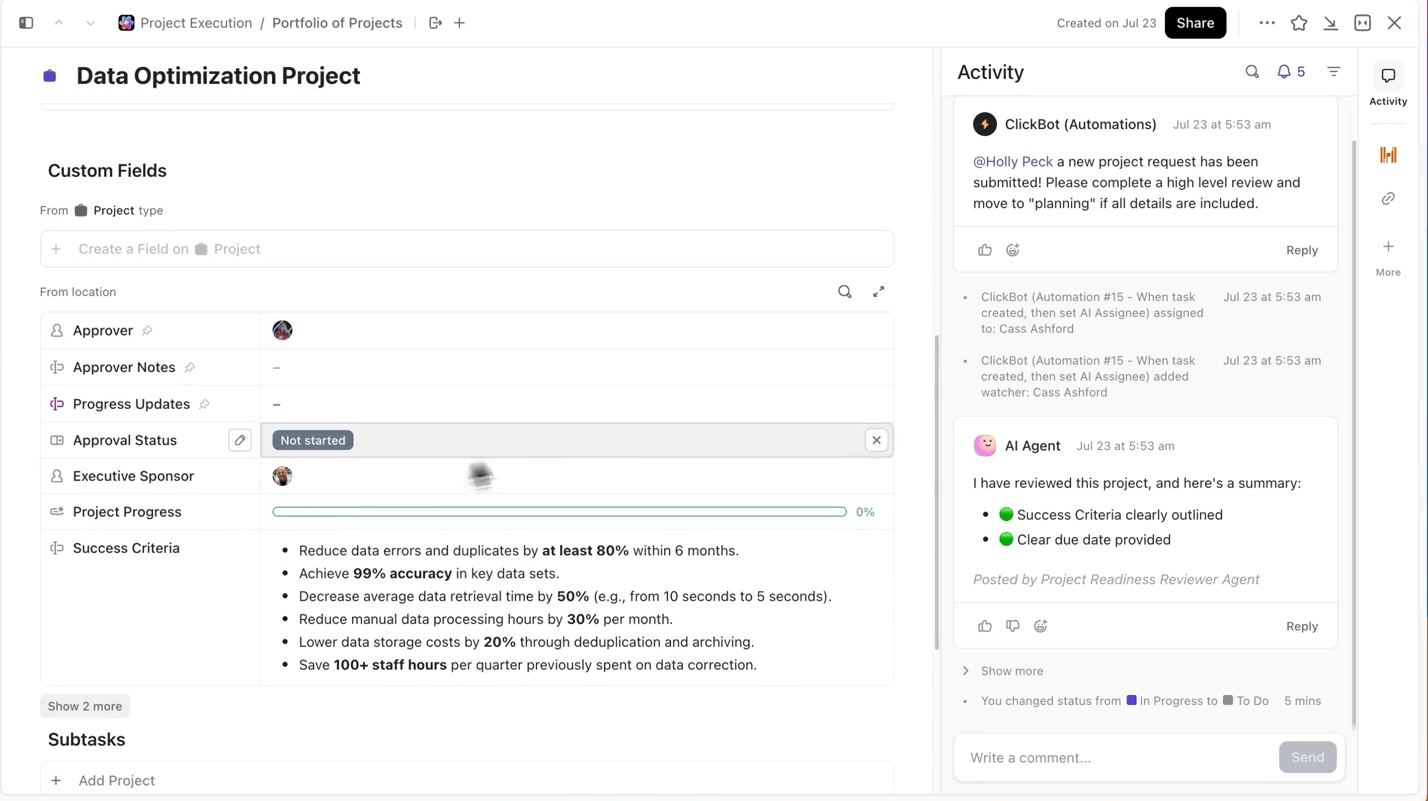
På så sätt blir varje dokumenterat experiment sökbart, lätt att jämföra med andra och reproducerbart.
Håll modelldokumentationen kopplad till arbetet
Du behöver inte hoppa mellan Jupyter-anteckningsböcker, README-filer eller Slack-trådar för att förstå sammanhanget för ett experiments uppgift.
Med ClickUp Docs kan du hålla din modellarkitektur, dina dataprepareringsskript eller dina utvärderingsmått organiserade och tillgängliga genom att dokumentera dem i ett sökbart dokument som länkar direkt till de experimentuppgifter de kommer från.

💡Proffstips: Håll en levande projektbeskrivning i ClickUp Docs som detaljerat beskriver varje beslut, från arkitektur till distribution, så att nya teammedlemmar alltid kan sätta sig in i projektdetaljerna utan att behöva gräva igenom gamla trådar.
Ge intressenterna insyn i realtid
ClickUp Dashboards visar experimentets framsteg och teamets arbetsbelastning i realtid. I
Istället för att manuellt sammanställa uppdateringar eller skicka e-postmeddelanden uppdateras instrumentpanelerna automatiskt baserat på data i dina uppgifter. På så sätt kan intressenterna när som helst kolla läget, se hur det står till och behöver aldrig störa dig med frågor om status.
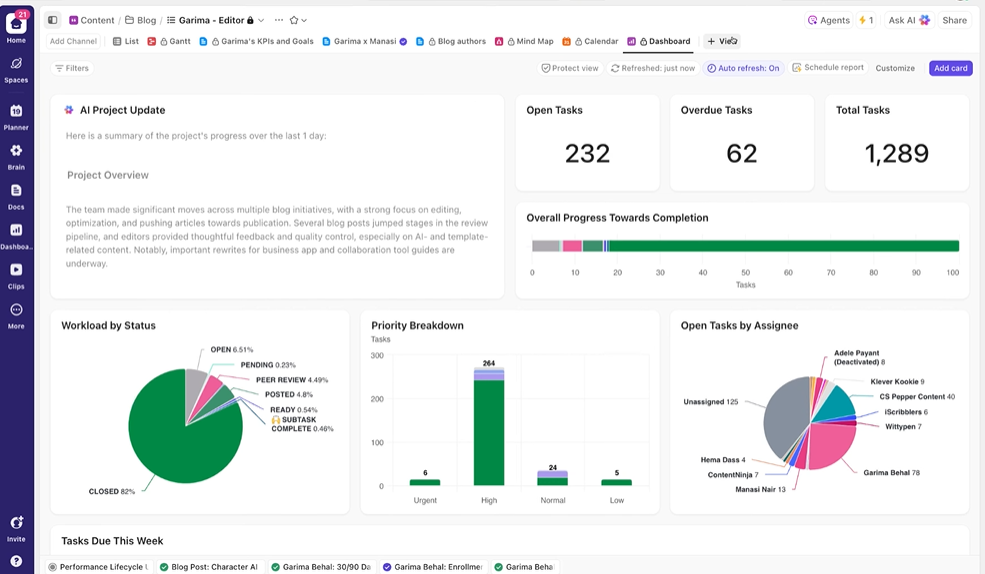
På så sätt kan du fokusera på att genomföra experiment istället för att ständigt behöva rapportera om dem manuellt.
Gör AI till din smarta projektpartner
Du behöver inte manuellt gå igenom veckor av träningsdata för att få en sammanfattning av hittills genomförda experiment. Nämn bara @Brain i en kommentar till en uppgift så ger ClickUp Brain dig den hjälp du behöver med fullständig kontext till dina tidigare och pågående projekt.
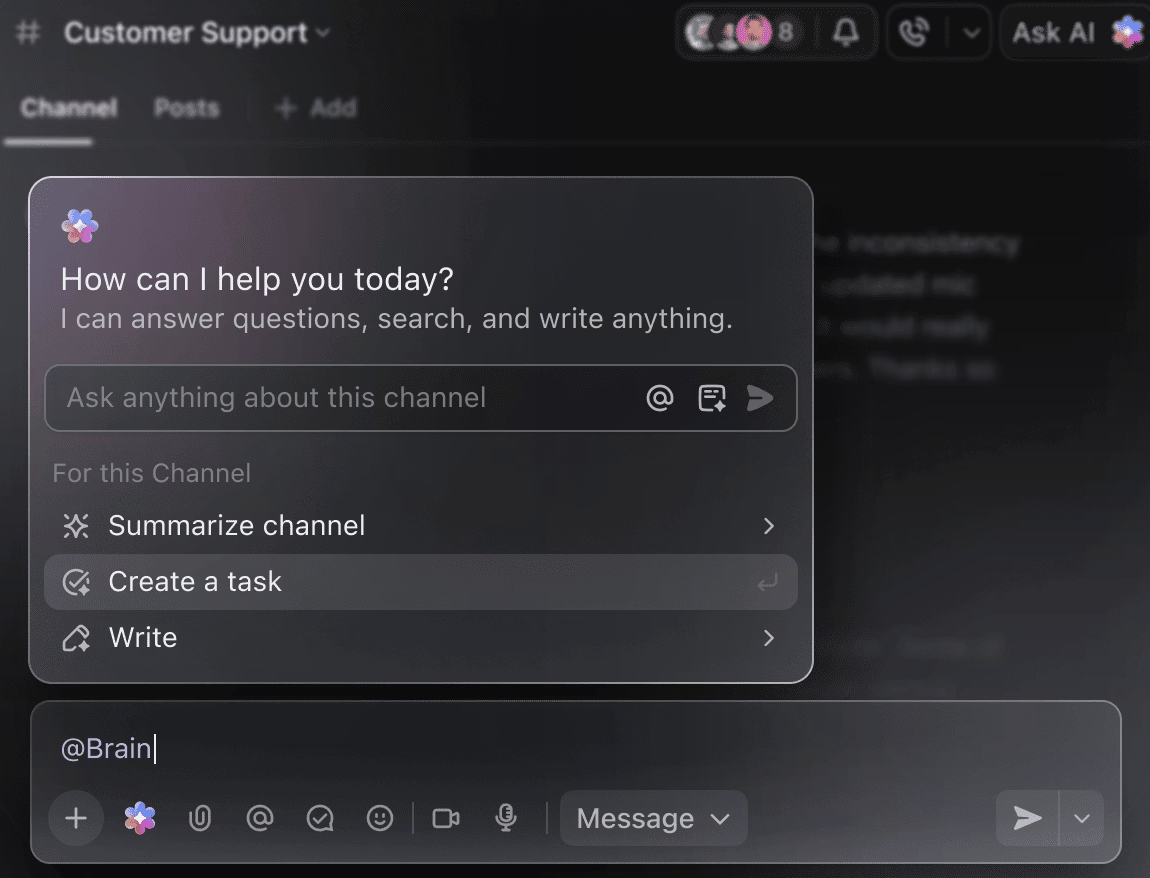
Du kan be Brain att "sammanfatta förra veckans experiment i 5 punkter" eller "skriva ett dokument med de senaste hyperparametrarna" och omedelbart få ett polerat resultat.
🧠 Fördelen med ClickUp: ClickUps superagenter tar detta ännu längre – de kan automatisera hela arbetsflöden baserat på triggers som du definierar, inte bara svara på dina frågor. Med superagenter kan du automatiskt skapa en ny DBRX-träningsuppgift varje gång en dataset laddas upp, meddela ditt team och länka relevanta dokument när träningen är klar eller når en kontrollpunkt, samt generera en veckovis sammanfattning av framstegen och skicka den till intressenterna utan att du behöver göra något.
Vanliga misstag att undvika
Att påbörja ett DBRX-träningsprojekt är spännande, men några vanliga fallgropar kan hindra dina framsteg. Genom att undvika dessa misstag sparar du tid, pengar och mycket frustration.
- Underskatta hårdvarukraven: DBRX är kraftfullt, men också stort. Att försöka köra det på otillräcklig hårdvara leder till minnesfel och misslyckade träningsjobb. Tänk på att DBRX (132B) kräver minst 264 GB VRAM för 16-bitars inferens, eller ungefär 70–80 GB vid användning av 4-bitars kvantisering.
- Att hoppa över datakvalitetskontroller: Skräp in, skräp ut. Finjustering av en rörig dataset av låg kvalitet kommer bara att lära modellen att producera röriga resultat av låg kvalitet.
- Ignorera begränsningar för kontextlängd: Även om DBRX:s kontextfönster på 32K är generöst, är det inte oändligt. Om du matar modellen med indata som överskrider denna gräns kommer det att resultera i tyst avkortning och dålig prestanda.
- Använd Base när Instruct är lämpligt: DBRX Base är en rå, förtränad modell avsedd för vidare, storskalig träning. För de flesta instruktionsföljande uppgifter bör du börja med DBRX Instruct, som redan har finjusterats för det ändamålet.
- Siloing av träningsarbete från projektkoordinering: När din experimentuppföljning finns i ett verktyg och din projektplan i ett annat skapar du informationssilos. Använd en integrerad plattform som ClickUp för att hålla ditt tekniska arbete och din projektkoordinering synkroniserade.
- Att försumma utvärdering före implementering: En modell som fungerar bra på dina träningsdata kan misslyckas spektakulärt i verkligheten. Validera alltid din finjusterade modell på en separat testuppsättning innan du implementerar den i produktionen.
- Överser komplexiteten i finjusteringen: Eftersom DBRX är en Mixture-of-Experts-modell kan standardskript för finjustering kräva specialiserade bibliotek som Megatron-LM eller PyTorch FSDP för att hantera parameterdelning över flera GPU:er.
DBRX jämfört med andra AI-träningsplattformar
Att välja en AI-träningsplattform innebär en grundläggande avvägning: kontroll kontra bekvämlighet. Proprietära, API-baserade modeller är lätta att använda men låser dig i leverantörens ekosystem.
Öppna viktmodeller som DBRX erbjuder fullständig kontroll men kräver mer teknisk expertis och infrastruktur. Detta val kan göra att du känner dig fast, osäker på vilken väg som faktiskt stöder dina långsiktiga mål – en utmaning som många team står inför när de inför AI.
Denna tabell visar de viktigaste skillnaderna för att hjälpa dig att fatta ett välgrundat beslut.
| Vikter | Öppen (anpassad) | Proprietär | Öppen (anpassad) | Proprietär |
| Finjustering | Full kontroll | API-baserad | Full kontroll | API-baserad |
| Självhosting | Ja | Nej | Ja | Nej |
| Licens | DB Open Model | OpenAI-villkor | Llama Community | Antropiska termer |
| Kontext | 32K | 128K – 1M | 128K | 200 000 – 1 miljon |
DBRX är rätt val när du behöver full kontroll över modellen, måste själv stå för värdtjänsten av säkerhets- eller efterlevnadsskäl, eller vill ha flexibiliteten som en tillåtande kommersiell licens ger. Om du inte har en dedikerad GPU-infrastruktur – eller om du värdesätter snabb marknadsintroduktion mer än djupgående anpassning – kan API-baserade alternativ vara ett bättre val.
Börja träna smartare med ClickUp
DBRX ger dig en företagsanpassad grund för att bygga anpassade AI-applikationer, med den transparens och kontroll som du inte får från proprietära modeller. Dess effektiva MoE-arkitektur håller inferenskostnaderna nere och dess öppna design gör finjusteringen enkel. Men stark teknik är bara halva ekvationen.
Verklig framgång uppnås genom att anpassa ditt tekniska arbete till ditt teams samarbetsflöde. Träning av AI-modeller är ett lagarbete, och det är avgörande att hålla experiment, dokumentation och kommunikation med intressenter synkroniserade. När du samlar allt i ett enda konvergerat arbetsutrymme och minskar kontextförvirringen kan du leverera bättre modeller snabbare.
Kom igång gratis med ClickUp för att samordna dina AI-träningsprojekt i ett arbetsutrymme. ✨
Vanliga frågor
Du kan övervaka träningen med hjälp av standardverktyg för maskininlärning som TensorBoard, Weights & Biases eller MLflow. Om du tränar inom Databricks ekosystem är MLflow integrerat för smidig spårning av experiment.
Ja, DBRX kan integreras i standardiserade MLOps-pipelines. Genom att containerisera modellen kan du distribuera den med hjälp av orkestreringsplattformar som Kubeflow eller anpassade CI/CD-arbetsflöden.
DBRX Base är den grundläggande förtränade modellen avsedd för team som vill utföra domänspecifik fortsatt förträning eller djup arkitektonisk finjustering. DBRX Instruct är en finjusterad version som är optimerad för att följa instruktioner, vilket gör den till en bättre utgångspunkt för de flesta applikationsutvecklingar.
Den största skillnaden är kontrollen. DBRX ger dig full tillgång till modellvikterna för djupgående anpassning och självhosting, medan GPT-4 är en ren API-tjänst.
DBRX-modellvikterna är tillgängliga gratis under Databricks Open Model License. Du ansvarar dock själv för kostnaderna för den datorinfrastruktur som krävs för att köra eller finjustera modellen.