

Elárasztják az adatok? Még a legtapasztaltabb adatszakértők is nehezen tudnak lépést tartani a digitális világ által generált adatáradattal, nem is beszélve a folyamatok hatékonyságának optimalizálásáról. A webes elemzésektől az ügyféladatokon át a teljesítménymutatókig, Ön felel azért, hogy ezek az adatok a lehető legpontosabbak és legfrissebbek legyenek. ✨
A vállalkozásához szükséges adatbázis létrehozásához és karbantartásához szilárd adatbázis-tervezés szükséges, de még akkor is tudnia kell, hogyan tarthatja munkáját mentesen a keresztfertőzéstől és az adatok redundanciájától. A függőségek meghatározzák az adatattribútumok közötti kapcsolatot, ami mindenben segít, az adatok pontosságától a fejlett betekintésig.
A legfontosabb? Rengeteg típusú függőség közül lehet választani. De a funkcionális függőségek elengedhetetlenek, ha alig várja, hogy adatbázist hozzon létre.
Ebben az útmutatóban elmagyarázzuk, mi is az a funkcionális függőség, bemutatunk néhány példát az összes funkcionális függőségre, és hasznos tippeket adunk a relációs adatbázis maximális kihasználásához.
Mi az a funkcionális függőség?
A funkcionális függőség egy olyan függőségtípus, amely két változó közötti kapcsolatot jelenti. A bal oldalon található a meghatározó attribútum, más néven elsődleges kulcs, a jobb oldalon pedig a függő attribútum, más néven nem kulcs attribútum. A funkció vagy eredmény a két változó közötti kapcsolattól függően változik.
Tudjuk, hogy ez kissé bonyolultnak tűnik, ezért itt van egy rövid leírás a funkcionális függőségek működéséről:
- Tegyük fel, hogy ügyfél-adatbázis szoftvert használ a vásárlói születésnapjainak nyomon követésére. Szándékában áll személyre szabott e-mailt küldeni az ügyfeleknek a születésnapjukon, hogy jóindulatot keltsen bennük.
- Funkcionális függőséget kell használnia ahhoz, hogy minden felhasználónak e-mailt küldjön a születésnapján – elvégre nem lenne kissé furcsa, ha 300 embernek küldene egy irreleváns „Boldog születésnapot” üzenetet?
- Ebben az esetben az e-mail küldésének funkciója a vásárló születésnapjának változójától függ.
- Ha ilyen típusú kapcsolatot szeretne az adatbázisában, akkor funkcionális függőséget kell beállítania az ügyfél születésnapja és az e-mailt a születésnapján elküldő funkció között.
A funkcionális függőségek alapvető fontosságúak az adatbázis normalizálásához. A normalizálás révén rendezheti az adatbázist – akárcsak egy szobát –, hogy elkerülje az adatok ismétlődését.
A funkcionális függőségek szabályai az adatbázis-kezelő rendszerekben
A funkcionális függőségek több következtetési szabályt követnek, amelyeket Armstrong-féle axiómáknak is neveznek.
A funkcionális függőségnek három fő szabálya van:
- Reflexivitás: A reflexivitási szabály szerint, ha az A attribútum kapcsolódik az X attribútumhoz, akkor az X attribútum is kapcsolódik az A attribútumhoz. Például, ha A valakinek a keresztneve, X pedig a vezetékneve, akkor ez a két attribútum mindig kapcsolódik egymáshoz.
- Bővítés: A bővítési szabály szerint, ha adatokat ad hozzá egy változóhoz (más néven bővítés), akkor azt a bővítést hozzá kell adnia az attribútumok halmazához. Tehát, ha a keresztnév mezőt egy becenévvel bővíti, akkor az a mező most már a vezetéknév mezőhöz is kapcsolódik.
- Transzitivitás: A transzitivitási szabály szerint, ha az A attribútum kapcsolódik a C attribútumhoz, akkor az asszociáció alapján a B attribútum is egyenlő a C attribútummal. Ne törje a fejét ezen – a transzitivitás azt jelenti, hogy néha egy dolog meghatározhat egy másikat, ami pedig egy harmadikat határoz meg. Például, ha a CRM platformon a vezeték- és utónév alapján generál vonalkódokat az ügyfelek számára, akkor a név határozza meg az ügyfél helyét az ábécés listában.
A funkcionális függőségek SQL segítségével alakítják adatmodelleit tényleges relációs sémává, megőrizve ezzel adatai integritását. A gyakorlatban a funkcionális függőségeket adatbázis-kezelő rendszerében (DBMS) használhatja, hogy megszabaduljon az adatduplikációktól és az adatbázisokat tönkretevő „hoppá” pillanatoktól. 👀
Teljes funkcionális függőség kontra részleges funkcionális függőség
Mielőtt megvizsgálnánk a funkcionális függőségek különböző típusait, fontos megkülönböztetni a részleges és a teljes funkcionális függőségeket.
Tegyük fel, hogy a szervezeti ábra adatait adatbázisba viszi be. Teljes funkcionális függőség esetén egy attribútum egy másik attribútumkészlettől függ, de nem annak részhalmazától. Tegyük fel, hogy van egy „Alkalmazott neve” és „Alkalmazott azonosítója” kombinációnk, amely meghatározza a „Helyet”.
Ha ismeri az „alkalmazott nevét” és „alkalmazotti azonosítóját”, akkor meghatározhatja a „helyet”. Azonban nem lehet csak ezt a két változót figyelembe venni a „hely” meghatározásához. Ebben az esetben a „hely” teljes mértékben függ az „alkalmazott neve” és „alkalmazotti azonosítója” kombinációjától.
Részleges funkcionális függőség akkor áll fenn, ha egy attribútum csak az elsődleges kulcs egy részétől függ, ahelyett, hogy az összetett elsődleges kulcstól függne. Például, ha a „Munkaviszony évei” adatmezőt az „Alkalmazotti azonosító” segítségével tudja kitalálni, akkor részleges függőség áll fenn, mert a „Munkaviszony évei” nem függ a „Helyszín” mezőtől.
Ez talán apró különbségnek tűnik, de nagy hatással van az adatok normalizálására. A részleges funkcionális függőségek redundanciákhoz vezethetnek az adatbázisban, ami azt jelenti, hogy azokat a normalizálási folyamat második normál formájában, vagyis 2NF-ben kell kezelni. Ez nem a világ vége, de mindenképpen valamit, amit később meg kell oldani. 🛠️
Az SQL első, második és harmadik normál formája
Az adatok normalizálásának célja az, hogy kiküszöbölje az adatbázisban előforduló, káros hatással járó beillesztési, frissítési vagy törlési anomáliákat. A funkcionális függőségekkel történő normalizálás három lépésből áll.
Első normál forma
Az első normál formát tekintse a funkcionális függőségek használatára alkalmas rendszer felépítésének alapjának. Ez teremti meg az alapot a második és harmadik normál formában lévő függőségek azonosításához. Technikai szempontból az 1NF olyan attribútumokkal rendelkezik, amelyek csak atomikus értékeket tartalmaznak, így biztosítva, hogy ne legyenek ismétlődő csoportok.
Második normál forma
Miután az adatokat 1NF-en futtatta át, kap egy táblázatot, amelyben az összes nem kulcsattribútum teljes mértékben funkcionálisan függ az elsődleges kulcstól. A 2NF-ben eltávolítja a részleges függőségeket a táblák felosztásával, hogy ellenőrizze, hogy minden nem kulcsattribútum teljes mértékben függ-e az elsődleges kulcstól.
Harmadik normálforma
Miután az adattábla 2NF állapotba került, 3NF állapotba lép, ha az összes attribútum csak az elsődleges kulcsra függ funkcionálisan, és semmi másra. A 3ND állapotban ebben a szakaszban további táblaszétválasztással eltávolítja az összes tranzitív függőséget.
Az 1NF megteremti a funkcionális függőségek alapját, míg a 2NF és a 3NF a funkcionális függőségek átszervezésével finomítja az adatok szervezését. Ez biztosítja, hogy minden adatdarabot a leglogikusabb helyen tároljon, csökkentve ezzel a redundanciákat és növelve az adatok integritását.
Funkcionális függőségek típusai példákkal
Ha készen áll a funkcionális függőségek használatára, négy lehetőség közül választhat.
Triviális
A triviális függőség egy alapvető típusú funkcionális függőség, amelyben egy attribútum vagy attribútumkészlet önmagát határozza meg. Minden egyes függő elem itt a meghatározó elem részhalmaza. Más szavakkal, ha C az A részhalmaza, akkor a funkcionális kapcsolat triviális.
Lehet, hogy kissé nyilvánvalónak tűnik, de egy példa erre lehet egy könyv címének azonosítása, ha ismeri mind a címet, mind a szerzőt. Elég könnyű megérteni a két attribútum közötti kapcsolatot, ezért a triviális funkcionális függőségek a legkönnyebben érthetőek.
Nem triviális
Itt kezdődik az érdekes rész. Egy nem triviális funkcionális függőségben egy attribútum meghatározhat egy másik, elkülönülő attribútumot. Ebben az esetben A egy attribútumok gyűjteménye, ahogy B is, de B nem A részhalmaza. Ha B nem A részhalmaza, akkor nem triviális kapcsolatuk van.
Nem triviális kapcsolat áll fenn, ha létrehoz egy könyvadatbázist, minden könyvnek egyedi kódot rendel hozzá, és a könyv címét a könyvhez rendelt kód alapján tudja megkeresni.
Többértékű
Többértékű függőség esetén egy attribútum több más attribútumhoz kapcsolódik. A függőségek halmazában szereplő attribútumok nem függnek egymástól. Tehát, ha az A és C attribútumok között nincs funkcionális függőség, akkor a B, A és C közötti kapcsolat többértékű.
Ha továbbra is a könyvhasonlatot használjuk, ez olyan, mint egy szerző, aki sok könyvet írt. Ha ismeri a nevét, felsorolhatja az összes könyvét. Egy többértékű funkcionális függőségben egy szerzőnek több könyve is kapcsolódik a nevéhez.
Transzitiv
A tranzitív funkcionális függőség akkor áll fenn, amikor egy attribútum egy másikat, majd egy harmadikat határoz meg. Ez egyfajta láncreakcióhoz hasonlít. Ha ez ismerősen hangzik, az azért van, mert ez a típusú funkcionális függőség a tranzitivitás szabályát követi.
Ebben az esetben, ha A egyenlő B-vel, és B egyenlő C-vel, akkor A-nak egyenlőnek kell lennie C-vel. Tegyük fel, hogy egy könyvadatbázist épít, és az egyedi könyvkódok határozzák meg a kiadókat és a műfajokat. Ha ismeri a könyvkódot, akkor kiderítheti, ki a kiadó és mi a műfaj.
Hogyan használhatók a funkcionális függőségek az adatbázis-kezeléshez?
Alig várja, hogy elkezdje használni a funkcionális függőségeket? A funkcionális függőségeket tetszése szerint használhatja, de ha kevesebb erőfeszítéssel szeretne hatékonyabban dolgozni, válassza a ClickUp-ot.
Íme egy rövid áttekintés arról, hogyan lehet adatbázist létrehozni a ClickUp-ban és funkcionális függőségeket beépíteni:
Először is be kell állítania egy adatbázist a ClickUp-ban. Importálhat adatlapokat az Excelből, vagy létrehozhat saját adatlapokat a semmiből.
A ClickUp táblázatos nézet lehetővé teszi a tömeges szerkesztést és egyéb egyéni nézeteket, hogy szinte bármiről nyomon követhesse az adatokat. A ClickUp az adatokat is vizualizálja, hogy rekordidő alatt elkészíthesse adatbázisát.
A jó hír, hogy nem kell a nulláról kezdenie. A ClickUp adatbázis-sablonjai segítségével az adatbázis létrehozása gyerekjáték.
A ClickUp Blog adatbázis sablon rendkívül hasznos a tartalom tervezéséhez, a ClickUp Alkalmazotti névjegyzék sablon pedig tökéletes a munkatársak elérhetőségeit tartalmazó adatbázis gyors létrehozásához. Ez is egy kódolás nélküli adatbázis, így ha SQL ismeretek nélkül szeretne adatbázist létrehozni, mi segítünk Önnek.
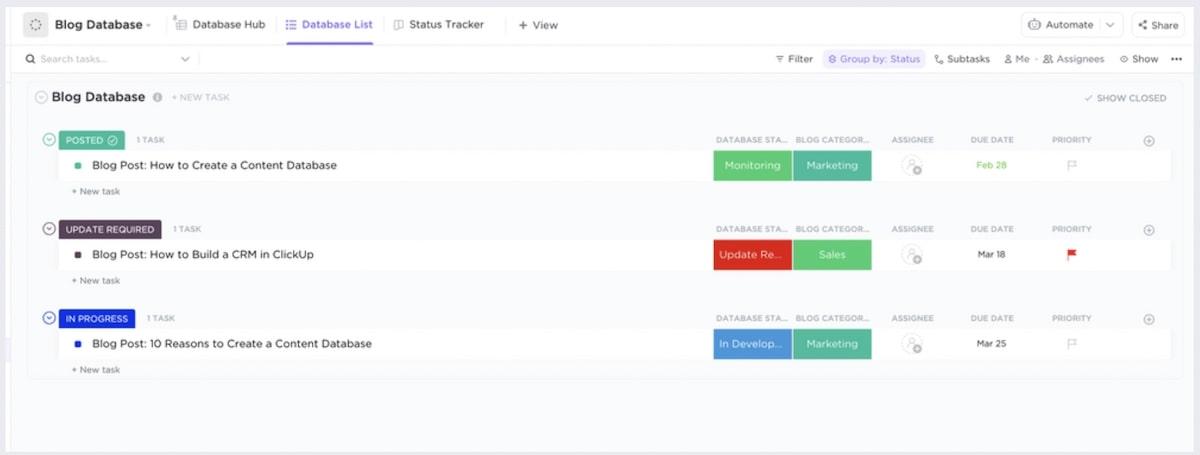
Funkcionális függőségek beépítése a ClickUp-ba
Normális esetben az adatbázisban funkcionális függőségek létrehozásához SQL-t kell használnia. Szerencsére a ClickUp drag-and-drop felülete megkönnyíti a feladatok és a dokumentumok közötti kapcsolatok létrehozását. Nem árt, hogy a ClickUp AI-eszközei az adatbázis-kezelést gyerekjátékká teszik – még akkor is, ha Ön nem adatbázis-szakértő.
Így hozhat létre függőséget a ClickUp adatbázisában.
Először kattintson a feladatra, amellyel dolgozni szeretne.
Lépjen a Kapcsolatok > Függőség menüpontra. Válasszon a Várakozás, Blokkolás és Feladatok közül a kapcsolat testreszabásához.

Ebben az esetben a Várakozás opciót választjuk, és keresünk egy másik feladatot, amely kapcsolódik a jelenlegi feladathoz.
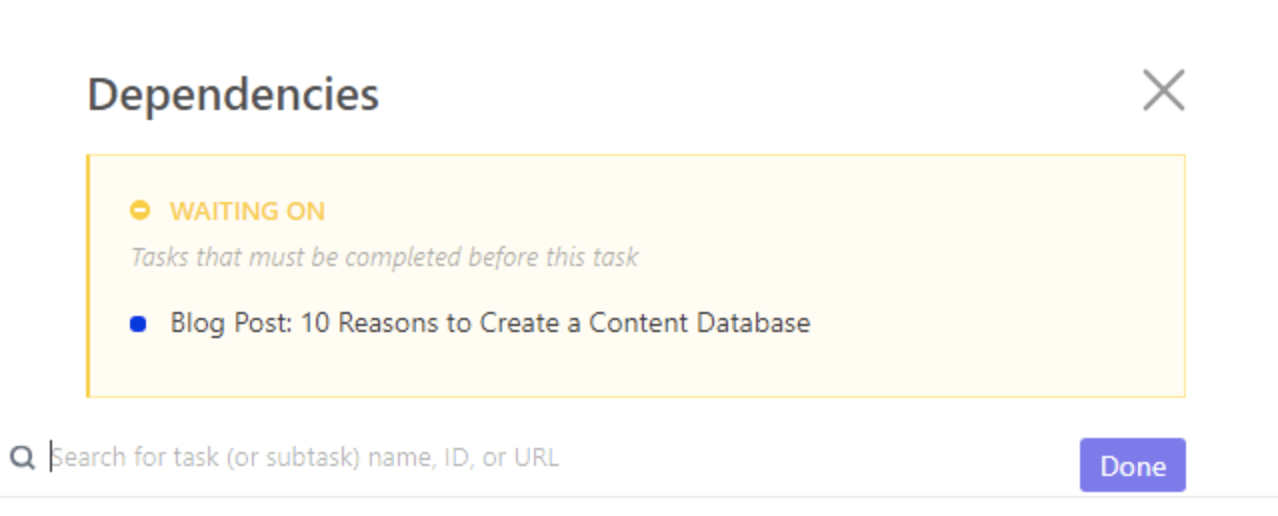
Kattintson a „Kész” gombra, és máris kész! 🙌
Egyszerűsítse a függőségeket a ClickUp segítségével
Ki mondta, hogy az adatbázis-kezelésnek bonyolultnak kell lennie? Ha megérti a funkcionális függőségek működését, akkor gyors és pontos adatbázist tervezhet, amely elősegíti szervezetének fejlődését.
Ezt sem kell egyedül megtennie. A ClickUp egy megbízható adatbázis-kezelő rendszer, amely az adatokat sablonokkal, projektekkel, feladatokkal, célokkal és minden mással ötvözi.
Takarítson meg több időt, és összpontosítson a magas értékű feladatokra azáltal, hogy áttér a ClickUp valóban mindenre kiterjedő platformjára.
Próbálja ki Ön is: hozzon létre egy ingyenes ClickUp fiókot, és építsen jobb adatbázist!