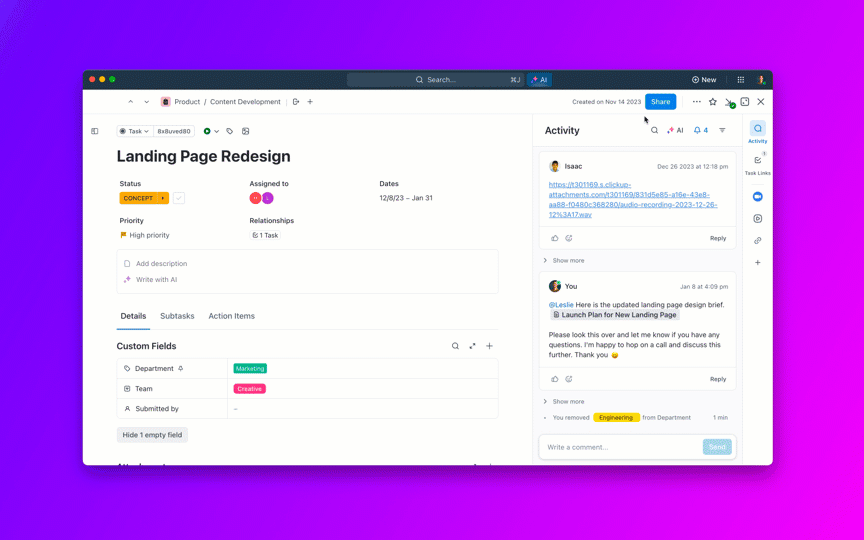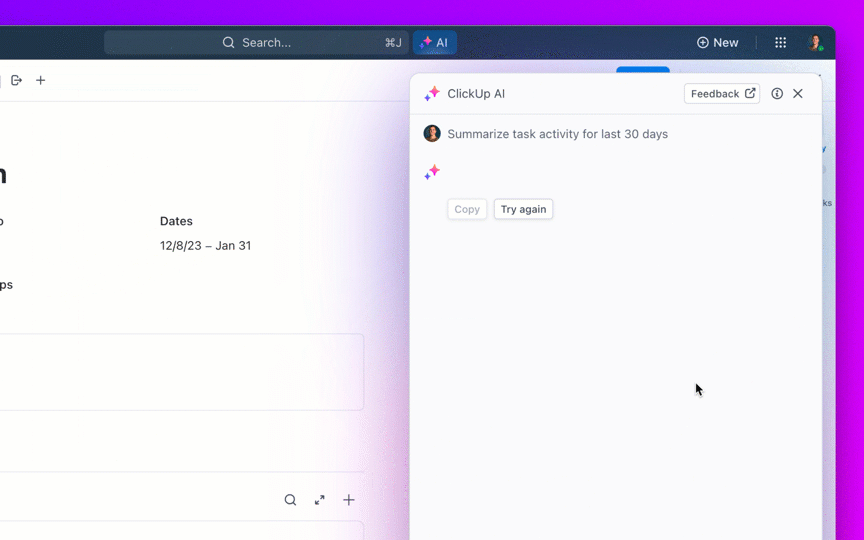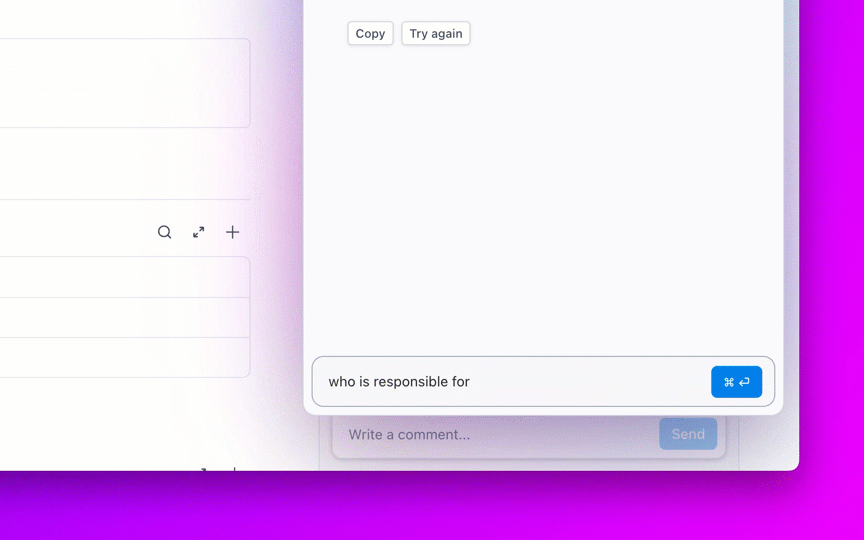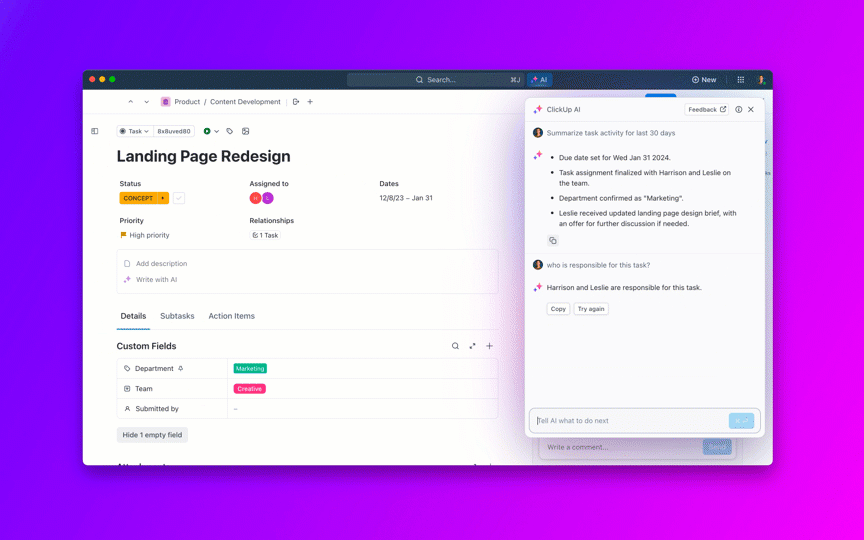

A legtöbb, nyílt forráskódú AI-modelleket kutató csapat rájön, hogy a Meta LLaMA ritka kombinációját kínálja a teljesítménynek és a rugalmasságnak, de a technikai beállítás olyan lehet, mintha bútort szerelne össze utasítások nélkül.
Ez az útmutató végigvezeti Önt egy funkcionális LLaMA chatbot felépítésén a nulláról, mindenre kiterjedően, a hardverkövetelményektől és a modellhez való hozzáférésen át a prompt-tervezésig és a telepítési stratégiákig.
Kezdjük hozzá!
Mi az a LLaMA és miért érdemes chatbotokhoz használni?
A saját API-kkal rendelkező chatbotok létrehozása gyakran olyan érzést kelt, mintha valaki más rendszerébe lenne bezárva, kiszámíthatatlan költségekkel és adatvédelmi kérdésekkel szembesülve. Ez a beszállítói függőség azt jelenti, hogy nem tudja igazán testreszabni a modellt csapata egyedi igényeinek megfelelően, ami általános válaszokhoz és potenciális megfelelési problémákhoz vezet.
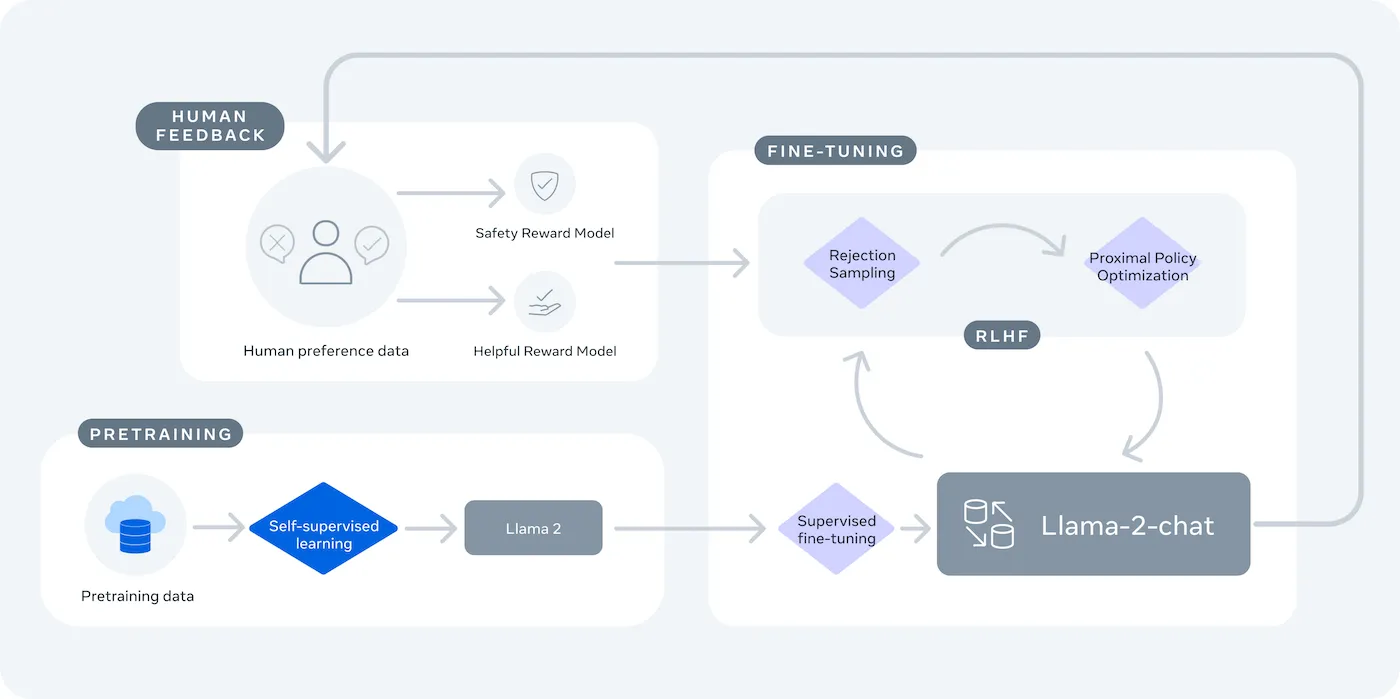
A LLaMA (Large Language Model Meta AI) a Meta nyílt súlyú nyelvi modelljeinek családja, amely hatékony alternatívát kínál. Kutatási és kereskedelmi célokra egyaránt tervezték, így olyan ellenőrzési lehetőségeket biztosít, amelyeket a zárt forráskódú modellek nem nyújtanak.
A LLaMA modellek különböző méretűek, paraméterekben mérve (pl. 7B, 13B, 70B). A paramétereket tekintsük a modell komplexitásának és teljesítményének mérésére – a nagyobb modellek többet tudnak, de több számítási erőforrást igényelnek.
Íme néhány ok, amiért érdemes LLaMA chatbotot használni:
- Adatvédelem: Ha a modellt a saját infrastruktúráján futtatja, a beszélgetési adatok soha nem hagyják el a környezetét. Ez kritikus fontosságú az érzékeny információkat kezelő csapatok számára.
- Testreszabás: Finomhangolhatja a LLaMA modellt a vállalat belső dokumentumai vagy adatai alapján. Ez segít a modellnek megérteni az Ön konkrét kontextusát, és sokkal relevánsabb válaszokat adni.
- Költségelőrejelzés: A kezdeti hardverbeállítás után nem kell aggódnia a tokenenkénti API-díjak miatt. Költségei fixek és előre jelezhetők lesznek.
- Nincs sebességkorlátozás: A chatbot kapacitását a saját hardvere korlátozza, nem pedig a gyártó kvótái. Szükség szerint méretezhető.
A fő kompromisszum a kényelem és az ellenőrzés között van. Az LLaMA több technikai beállítást igényel, mint egy plug-and-play API. A termelési chatbotokhoz a csapatok általában az LLaMA 2-t vagy az újabb LLaMA 3-at használják, amely jobb érvelési képességet kínál és egyszerre több szöveget tud kezelni.
Amit a LLaMA chatbot létrehozása előtt szükséged lesz
A megfelelő eszközök nélkül belevágni egy fejlesztési projektbe csak frusztrációhoz vezet. Félúton rájössz, hogy hiányzik egy fontos hardver vagy szoftver, ami megakadályozza a haladást és órákat veszteget el.
Hogy ezt elkerülje, előre gyűjtsön össze mindent, amire szüksége van. Íme egy ellenőrzőlista a zökkenőmentes induláshoz. 🛠️
Hardverkövetelmények
| Modellméret | Minimális VRAM | Alternatív lehetőség |
|---|---|---|
| 7 milliárd paraméter | 8 GB | Felhőalapú GPU-példány |
| 13 milliárd paraméter | 16 GB | Felhőalapú GPU-példány |
| 70 milliárd paraméter | Több GPU | Kvantálás vagy felhő |
Ha a helyi gépe nem rendelkezik elég erős grafikus processzorral (GPU), akkor használhat olyan felhőszolgáltatásokat, mint az AWS vagy a GCP. Az olyan következtető platformok, mint a Baseten és a Replicate, szintén fizetésenkénti GPU-hozzáférést kínálnak.
Szoftverkövetelmények
- Python 3. 8+: Ez a gépi tanulási projektek standard programozási nyelve.
- Csomagkezelő: A projekthez szükséges könyvtárak telepítéséhez pip vagy Conda szükséges.
- Virtuális környezet: Ez egy bevált módszer, amely elszigeteli a projekt függőségeit a gépen található egyéb Python projektektől.
Hozzáférési követelmények
- Hugging Face-fiók: A LLaMA modell súlyainak letöltéséhez fiókra lesz szüksége.
- Meta jóváhagyás: A LLaMA modellekhez való hozzáféréshez el kell fogadnia a Meta licencszerződését, amely általában néhány órán belül jóváhagyásra kerül.
- API-kulcsok: Ezek csak akkor szükségesek, ha úgy dönt, hogy a modell helyi futtatása helyett egy hosztolt következtető végpontot használ.
Ehhez az útmutatóhoz a LangChain keretrendszert fogjuk használni. Ez egyszerűsíti a chatbot létrehozásának számos bonyolult részét, például a promptok és a beszélgetési előzmények kezelését.
{kind=link}
Hogyan építsünk chatbotot a LLaMA segítségével lépésről lépésre
A chatbot összes technikai elemének – a modellnek, a promptnak, a memóriának – összekapcsolása nyomasztó feladatnak tűnhet. Könnyű eltévedni a kódban, ami hibákhoz és a chatbot vártnál rosszabb működéséhez vezethet. Ez a lépésről lépésre bemutató útmutató egyszerű, kezelhető részekre bontja a folyamatot.
Ez a megközelítés akkor is működik, ha a modellt a saját gépén futtatja, vagy ha egy hosztolt szolgáltatást használ.
1. lépés: Telepítse a szükséges csomagokat
Először telepítenie kell a Python alapvető könyvtárait. Nyissa meg a terminált, és futtassa ezt a parancsot:
pip install langchain transformers accelerate torch
Ha olyan hosztolt szolgáltatást használ, mint a Baseten az inferenciához, akkor annak speciális szoftverfejlesztő készletét (SDK) is telepítenie kell:
pip install baseten
Az egyes csomagok funkciói a következők:
- Langchain: Keretrendszer, amely segít nagy nyelvi modellekkel rendelkező alkalmazások létrehozásában, beleértve a beszélgetési láncok és a memória kezelését.
- Transformers: A Hugging Face könyvtár a LLaMA modell betöltéséhez és futtatásához.
- Accelerate: Egy könyvtár, amely segít optimalizálni a modell CPU-ra és GPU-ra való betöltését.
- Torch: A PyTorch könyvtár, amely a modell számításainak háttérszolgáltatásait biztosítja.
Ha a modellt helyileg futtatja egy NVIDIA GPU-val felszerelt gépen, győződjön meg arról, hogy a CUDA megfelelően van telepítve és konfigurálva. Ez lehetővé teszi a modell számára, hogy a GPU-t használva sokkal gyorsabb teljesítményt nyújtson.
2. lépés: Hozzáférés a LLaMA modellekhez
Mielőtt letölthetné a modellt, hivatalos hozzáférést kell szereznie a Meta-tól a Hugging Face-en keresztül.
- Hozzon létre egy fiókot a huggingface.co oldalon.
- Lépjen a modell oldalára, például meta-llama/Llama-2-7b-chat-hf
- Kattintson az „Access repository” (Hozzáférés a tárházhoz) gombra, és fogadja el a Meta licencfeltételeit.
- A Hugging Face fiókbeállításokban hozzon létre egy új hozzáférési tokent.
- A termináljában futtassa a huggingface-cli login parancsot, és illessze be a tokenjét a gép hitelesítéséhez.
A jóváhagyás általában gyors. Győződjön meg róla, hogy olyan modellváltozatot választ, amelynek neve tartalmazza a „chat” szót, mivel ezeket kifejezetten beszélgetési feladatokra képezték ki.
3. lépés: Töltse be a LLaMA modellt
Most már betöltheti a modellt a kódjába. A hardverétől függően két fő lehetőség közül választhat.
Ha rendelkezik elég erős GPU-val, akkor a modellt helyileg is betöltheti:
Ha hardvere korlátozott, használhat egy hosztolt következtető szolgáltatást:
A device_map="auto" parancs utasítja a transformers könyvtárat, hogy automatikusan ossza el a modellt az összes rendelkezésre álló GPU között.
Ha még mindig kevés a memóriája, akkor a kvantálás nevű technikával csökkentheti a modell méretét, bár ez kissé ronthatja a teljesítményét.
4. lépés: Hozzon létre egy prompt sablont
A LLaMA csevegőmodellek úgy vannak betanítva, hogy egy adott formátumú promptokat várnak. A prompt sablonok biztosítják, hogy a beviteled helyesen legyen strukturálva.
Vessünk egy pillantást erre a formátumra:
- <
>: Ez a szakasz tartalmazza a rendszer promptját, amely megadja a modell alapvető utasításait és meghatározza személyiségét. - [INST]: Ez jelzi a felhasználó kérdésének vagy utasításának kezdetét.
- [/INST]: Ez jelzi a modellnek, hogy ideje generálni a választ.
Ne feledje, hogy a LLaMA különböző verziói kissé eltérő sablonokat használhatnak. Mindig ellenőrizze a modell dokumentációját a Hugging Face-en a helyes formátumért.
5. lépés: A chatbot lánc beállítása
Ezután a LangChain segítségével összekapcsolja a modellt és a prompt sablont egy beszélgetési lánccá. Ez a lánc memóriát is tartalmaz, amely nyomon követi a beszélgetést.
A LangChain többféle memóriát kínál:
- ConversationBufferMemory: Ez a legegyszerűbb lehetőség. Az egész beszélgetési előzményeket tárolja.
- ConversationSummaryMemory: Helytakarékosság érdekében ez az opció rendszeresen összefoglalja a beszélgetés régebbi részeit.
- ConversationBufferWindowMemory: Ez csak az utolsó néhány üzenetváltást tárolja a memóriában, ami hasznos lehet a kontextus túl hosszúvá válásának megakadályozásához.
A teszteléshez a ConversationBufferMemory kiváló kiindulási pont.
6. lépés: Futtassa a chatbot hurkot
Végül létrehozhat egy egyszerű hurkot, hogy a terminálról kommunikáljon a chatbotjával.
A valós alkalmazásokban ezt a hurkot egy FastAPI vagy Flask keretrendszerrel API végponttal helyettesítené. A modell válaszát vissza is továbbíthatja a felhasználónak, ami sokkal gyorsabbá teszi a chatbot működését.
Beállíthat olyan paramétereket is, mint a hőmérséklet, hogy szabályozza a válaszok véletlenszerűségét. Alacsony hőmérséklet (pl. 0,2) esetén a kimenet determinisztikusabb és tényalapúbb lesz, míg magasabb hőmérséklet (pl. 0,8) esetén több kreativitásra ösztönöz.
Hogyan tesztelje LLaMA chatbotját
Létrehozott egy chatbotot, amely válaszokat ad, de készen áll-e a valódi felhasználókra? A teszteletlen botok telepítése kínos kudarcokhoz vezethet, például helytelen információk megadásához vagy nem megfelelő tartalom generálásához, ami károsíthatja vállalatának hírnevét.
A szisztematikus tesztelési terv a megoldás erre a bizonytalanságra. Biztosítja, hogy a chatbot robusztus, megbízható és biztonságos legyen.
Funkcionális tesztelés:
- Szélsőséges esetek: Tesztelje, hogyan kezeli a bot az üres beviteli mezőket, a nagyon hosszú üzeneteket és a speciális karaktereket.
- Memóriaellenőrzés: Gondoskodjon arról, hogy a chatbot több fordulóban is megjegyezze a beszélgetés kontextusát.
- Utasítások követése: Ellenőrizze, hogy a bot betartja-e a rendszer promptjában beállított szabályokat.
Minőségértékelés:
- Relevancia: A válasz valóban megválaszolja a felhasználó kérdését?
- Pontosság: A szolgáltatás által nyújtott információk helyesek-e?
- Koherencia: A beszélgetés logikusan folyik-e?
- Biztonság: A bot megtagadja-e a nem megfelelő vagy káros kérések megválaszolását?
Teljesítménytesztelés:
- Késleltetés: Mérje meg, mennyi időbe telik, amíg a bot elkezdi a válaszadást és befejezi a válaszát.
- Erőforrás-használat: Figyelje, hogy a modell mennyi GPU-memóriát használ a következtetés során.
- Párhuzamosság: Tesztelje, hogyan működik a rendszer, ha több felhasználó egyszerre használja.
Figyeljen az LLM-mel kapcsolatos gyakori problémákra is, mint például a hallucinációk (hamis információk magabiztos közlése), a kontextus eltolódás (hosszú beszélgetés során a téma elvesztése) és az ismétlések. Az összes tesztbeszélgetés naplózása kiváló módszer a minták felismerésére és a problémák kijavítására, mielőtt azok eljutnának a felhasználókhoz.
LLaMA chatbot használati esetek csapatok számára
Miután túljutott a finomhangolás és a telepítés mechanizmusain, a LLaMA akkor válik igazán értékessé, ha mindennapi csapatproblémákra alkalmazzák, nem pedig absztrakt AI-demókra. A csapatoknak általában nincs szükségük „chatbotra”; gyorsabb hozzáférésre van szükségük a tudáshoz, kevesebb manuális átadásra és kevesebb ismétlődő munkára.
Belső tudásasszisztens
A LLaMA belső dokumentációk, wikik és GYIK-ek alapján történő finomhangolásával – vagy RAG-alapú tudásbázissal való párosításával – a csapatok természetes nyelvű kérdéseket tehetnek fel, és pontos, kontextusérzékeny válaszokat kaphatnak. Ezzel megszűnik a szétszórt eszközökben való keresés nehézsége, miközben az érzékeny adatok teljes mértékben belsőek maradnak, és nem kerülnek továbbításra harmadik fél API-jainak.
🌟 A ClickUp vállalati keresője és az előre elkészített Ambient Answers ügynök a ClickUp munkaterületén található ismeretek felhasználásával részletes, kontextushoz illeszkedő válaszokat ad kérdéseire.
Kódfelülvizsgálati segéd
Ha a saját kódbázisán és stílusúti mutatókon alapuló képzéssel rendelkezik, az LLaMA kontextusfüggő kódfelülvizsgálati asszisztensként működhet. A fejlesztők nem általános legjobb gyakorlatokat kapnak, hanem olyan javaslatokat, amelyek összhangban vannak a csapat konvencióival, architektúrával kapcsolatos döntéseivel és korábbi mintákkal.
🌟 A LLaMA-alapú kódfelülvizsgálati segédprogram felhívhatja a figyelmet a problémákra, javasolhat javításokat vagy magyarázhatja az ismeretlen kódokat. A ClickUp Codegen egy lépéssel tovább megy, mivel a fejlesztési munkafolyamaton belül működik: pull requesteket hoz létre, refaktorokat alkalmaz vagy fájlokat frissít közvetlenül az ezekből nyert információk alapján. Az eredmény: kevesebb másolás-beillesztés és kevesebb megszakítás a „gondolkodás” és a „cselekvés” között.
Ügyfélszolgálati triázs
Az LLaMA betanítható a szándékok osztályozására, hogy megértse a beérkező ügyfélkérdéseket, és azokat a megfelelő csapatnak vagy munkafolyamatnak továbbítsa. A gyakori kérdéseket automatikusan lehet kezelni, míg a szélsőséges eseteket kontextussal ellátva továbbítják az emberi ügynököknek, így a válaszadási idő rövidül, anélkül, hogy a minőség romlana.
Vagy egyszerűen csak hozzon létre egy Triage Super Agent-et természetes nyelv használatával a ClickUp munkaterületén belül. További információk
Találkozók összefoglalása és nyomon követése
A találkozók jegyzőkönyveit bemeneti adatokként felhasználva a LLaMA képes kivonni a döntéseket, a teendőket és a legfontosabb megbeszélési pontokat. Az igazi érték akkor jelenik meg, amikor ezek az eredmények közvetlenül bekerülnek a feladatkezelő eszközökbe, így a beszélgetések nyomon követhető munkává válnak.
🌟 A ClickUp AI Meeting Notetaker nem csak jegyzeteket készít a megbeszélésekről, hanem összefoglalókat is ír, teendőket generál, és a jegyzeteket összekapcsolja a dokumentumaival és feladataival.
Dokumentumok szerkesztése és iterációja
A csapatok a LLaMA segítségével jelentések, javaslatok vagy dokumentációk első vázlatát készíthetik meg a meglévő sablonok és korábbi példák alapján. Ezáltal a munkavégzés középpontja az üres oldal létrehozásáról a felülvizsgálatra és finomításra helyeződik át, ami felgyorsítja a teljesítést anélkül, hogy csökkenne a színvonal.
🌟 A ClickUp Brain gyorsan létrehozhat dokumentációs vázlatokat, megőrizve az összes munkahelyi tudást a kontextusban. Próbálja ki még ma!
A LLaMA-alapú chatbotok akkor a leghatékonyabbak, ha beágyazódnak a meglévő munkafolyamatokba – dokumentáció, projektmenedzsment és csapatkommunikáció –, ahelyett, hogy önálló eszközként működnének.
Itt jön be a képbe az AI közvetlen integrálása a munkaterületébe. Ahelyett, hogy külön eszközt építene, a beszélgető AI-t beviheti oda, ahol a csapata máris működik.
Például létrehozhat egy egyedi LLaMA botot, amely tudásasszisztensként működik. De ha ez a projektmenedzsment eszközön kívül található, akkor a csapatának kontextust kell váltania, hogy kérdést tehessen fel neki. Ez feszültséget okoz és lassítja a munkát.
Szüntesse meg a kontextusváltást egy olyan AI használatával, amely már része a munkafolyamatának.
A ClickUp Brain segítségével kérdéseket tehet fel projektjeivel, feladataival és dokumentumaival kapcsolatban anélkül, hogy elhagyná a ClickUp alkalmazást. Csak írja be a @brain szót bármely feladat megjegyzésébe vagy a ClickUp Chatbe, és azonnal kontextusfüggő választ kap. Mintha lenne egy csapattagja, aki tökéletesen ismeri az egész munkaterületét. 🤩
Ezzel a chatbot egy újdonságból a csapat termelékenységének motorjának központi elemévé válik.
A LLaMA chatbotok építéséhez való használatának korlátai
A LLaMA chatbot létrehozása nagy lehetőségeket rejt magában, de a csapatok gyakran nem veszik észre a rejtett bonyolultságokat. A „ingyenes” nyílt forráskódú modell végül drágább és nehezebben kezelhető lehet a vártnál, ami rossz felhasználói élményhez és állandó, erőforrás-igényes karbantartási ciklushoz vezet.
Fontos, hogy megértse a korlátozásokat, mielőtt elkötelezi magát.
- Technikai komplexitás: A LLaMA modell beállítása és karbantartása gépi tanulási infrastruktúra ismereteket igényel.
- Hardverkövetelmények: A nagyobb, nagyobb teljesítményű modellek futtatásához drága GPU hardverre van szükség, és a felhőalapú költségek gyorsan meghaladhatják a várt mértéket.
- Kontextusablak korlátai: A LLaMA modellek memóriája korlátozott ( 4K tokenek a LLaMA 2 esetében ). Hosszú dokumentumok vagy beszélgetések kezelése komplex darabokra bontási stratégiákat igényel.
- Nincs beépített biztonsági korlát: Ön felelős a saját tartalomszűrés és biztonsági intézkedések megvalósításáért.
- Folyamatos karbantartás: Az új modellek megjelenésekor frissítenie kell a rendszereit, és a finomhangolt modellek újratanulást igényelhetnek.
Az önállóan üzemeltetett modellek általában nagyobb késleltetéssel működnek, mint a magasan optimalizált kereskedelmi API-k. Mindezek olyan működési terhek, amelyeket a kezelt megoldások kezelnek az Ön helyett.
📮ClickUp Insight: A felmérésünkben résztvevők 88%-a használ mesterséges intelligenciát személyes feladatokhoz, de több mint 50% nem meri használni a munkahelyén. A három fő akadály? A zökkenőmentes integráció hiánya, a tudáshiány vagy a biztonsági aggályok.
De mi van akkor, ha az AI be van építve a munkaterületébe, és már eleve biztonságos? A ClickUp Brain, a ClickUp beépített AI asszisztense ezt valósággá teszi. Megérti a parancsokat egyszerű nyelven, megoldva mindhárom AI-bevezetési problémát, miközben összekapcsolja a csevegést, a feladatokat, a dokumentumokat és a tudást a munkaterületen. Találjon válaszokat és betekintést egyetlen kattintással!
Alternatívák a LLaMA-hoz chatbotok építéséhez
A LLaMA csak egy lehetőség a rengeteg AI-modell közül, és nehéz lehet eldönteni, melyik a legmegfelelőbb az Ön számára.
Íme, hogyan alakulnak az alternatívák.
Egyéb nyílt forráskódú modellek:
- Mistral: Kisebb modellekkel is kiváló teljesítményéről ismert, ami hatékonnyá teszi.
- Falcon: Nagyon engedékeny licenccel rendelkezik, ami kiválóan alkalmas kereskedelmi alkalmazásokhoz.
- MPT: Hosszú dokumentumok és beszélgetések kezelésére optimalizálva
Kereskedelmi API-k:
- OpenAI (GPT-4, GPT-3. 5): Általánosan a legalkalmasabb nagy nyelvi modelleknek tartják őket, és nagyon könnyen integrálhatók.
- Anthropic (Claude): Erős biztonsági funkcióiról és nagyon nagy kontextusablakairól ismert.
- Google (Gemini): Hatékony multimodális képességeket kínál, amelyek lehetővé teszik a szöveg, képek és hangok megértését.
Megépítheti saját maga egy nyílt forráskódú modellel, fizethet egy kereskedelmi API-ért, vagy használhat egy konvergált AI-munkaterületet, amely előre integrált megoldást kínál különböző típusú AI-ügynökökkel.
📚 Olvassa el még: Hogyan használhatja a chatbotot az üzleti tevékenységéhez?
Készítsen kontextusérzékeny AI asszisztenseket a ClickUp segítségével
A LLaMA segítségével létrehozott chatbot hihetetlenül pontos ellenőrzést biztosít az adatok, a költségek és a testreszabás felett. Ez az ellenőrzés azonban az infrastruktúra, a karbantartás és a biztonság felelősségével jár együtt – mindezt a kezelt API-k végzik el Ön helyett. A cél nem csupán egy bot létrehozása, hanem a csapat termelékenységének növelése, és egy komplex mérnöki projekt néha elterelheti a figyelmet erről.
A megfelelő választás a csapat erőforrásaitól és prioritásaitól függ. Ha rendelkezik gépi tanulási szakértelemmel és szigorú adatvédelmi követelményekkel, akkor a LLaMA fantasztikus választás. Ha a sebességet és az egyszerűséget tartja szem előtt, akkor egy integrált eszköz lehet a megfelelőbb.
A ClickUp segítségével egy konvergált AI munkaterületet kap, ahol minden feladata, dokumentuma és beszélgetése egy helyen található, integrált AI támogatásával. Ez csökkenti a kontextus szétaprózódását, és segít a csapatoknak gyorsabban és hatékonyabban dolgozni, mivel a testreszabható Super Agents és a kontextusfüggő AI segítségével a megfelelő információk mindig kéznél vannak.
Ne pazarolja tovább az idejét az infrastruktúrára, és élvezze még ma a kontextustudatos AI-asszisztens előnyeit anélkül, hogy mindent nulláról kellene felépítenie. Kezdje el ingyen a ClickUp használatát.
Gyakran ismételt kérdések (GYIK)
A költségek teljes mértékben a telepítési módszertől függenek, és a projekt előrejelzése segíthet azok becslésében. Ha saját hardvert használ, akkor előzetes költségek merülnek fel a GPU-val kapcsolatban, de nincs folyamatos lekérdezési díj. A felhőszolgáltatók óradíjat számolnak fel a GPU és a modell mérete alapján.
Igen, az LLaMA 2 és LLaMA 3 licencének kereskedelmi felhasználása megengedett. Azonban el kell fogadnia a Meta felhasználási feltételeit, és meg kell adnia a szükséges hivatkozást a termékében.
Az LLaMA 3 az újabb és nagyobb teljesítményű modell, amely jobb érvelési képességeket és nagyobb kontextusablakot kínál (8K tokenek szemben az LLaMA 2 4K-jával). Ez azt jelenti, hogy hosszabb beszélgetéseket és dokumentumokat tud kezelni, de működéséhez több számítási erőforrásra is szükség van.
Bár a Python a leggyakrabban használt nyelv a gépi tanuláshoz kiterjedt könyvtárai miatt, nem feltétlenül szükséges. Egyes platformok már kínálnak kód nélküli vagy alacsony kódigényű megoldásokat, amelyek lehetővé teszik a LLaMA chatbot grafikus felületen történő telepítését. /